Inst
it ut
oTecnológico
y
de
Estudios Superiores
de
Monterrey
Campus Monterrey
División de Computación,
Informática y Comunicación.
Programa de Graduados en Computación,
Informática y Comunicación.
Análisis y Síntesis de unidades
aritméticas orientados al cómputo
reconfigurable.
TESIS
Presentada como requisito parcial para
obtener el grado de
Maestro en Ciencias en Ingeniería Electrónica
Especialidad en Sistemas Electrónicos
Instituto
Tecnológico y de Estudios Superiores
de Monterrey
Campus Monterrey
División de Computación,
Informàtica y Comunicación.
Programa de Graduados en Computación,
Informàtica y Comunicación.
Análisis
y
Síntesis de unidades
aritméticas orientados al cómputo
reconfigurable.
TESIS
Presentada como requisito parcial para obtener
el grado de
Maestro en Ciencias en Ingeniería Electrónica
Especialidad en Sistemas Electrónicos
Iiist~t
uto
iec~no1ogico
y
de Estudios Superiores
de Monterrey
Campus Moriterrey
DivisiOn de ComputaciOn,
Inforiiiática y ComunicaciOn.
Programa de Graduados en ComputaciOn,
Iiiformàtica y ComunicaciOn.
Lo~IlliclilbioK (id comit(~ 1c Tesis recorriendanios la aceptación de la tesis del
lug
Luis Igiiacio Marti’nez Castillo corrio requisito parcial del requerinuiento dcl gla(Io(Ic
Maestro cii Ciencias conla especialidad de
Ingenierla ElectrOnica
Al lustit lit o leeuol6gico ~ do Lstudios Superiores do Monterrey por haher preparado un pioglalila de \Iaest iIa tan niteresante v de tan alto nivel, asf como dc (lar una preparacidri
integral quo (olll
1)leiilellt a al asj)ecto toenico.
Al Coiisejo ~~?I(ioulalpara la Cieuicia v la ‘lecnologia. por haberme apoyado con una
beca (1110 1110 l)(~11iiti() coinpletar satisfactoriarneiite mis estudios do postgrado, los cuales ietiieiiaii V (loll imis sentido a los conocimieiitos adquiiridos alo largo de toda mi preparaciOn
1~r()f Si(II!il
A lii Facuiltad do IrigouiierIa i\Iecáiiica. Electrica ElectrOnica de la Universidad de
Guanajuiat o. por habeime (lado las bases quo me ayudaron a completar irna meta más en mi
Sd)IlY~\ Ii esposa. tii apovo ~ to aunorfuerdn 11110 grail fuer,.a (1110 me unotivo a Seguir para
Ieiiililiar (011 exito 11110 illot a uiids (Id nil Vi(li1. V(1110 aliora (:OrllpartimoS jililtos. TQYTA!
A lois Iladles: I ~apa v ~lanai. 110 Iengo i)alabrlIs para expresarles su cariflo. fuerda un
graIl apoVo. V ~UIl(I110desafortuna(lalllente estuvimos lejos. siempre los tengo en mi corazOn! Gracias
A rIds liernianos: \like. aliora Si me gailaste! Compartirnos juntos todos nuestros exitos,
adobauite!. fl icardito. siglie a(lelante coii tus suenos.
A lId faixiilia: Chuba. l3eatriz. Tios. Tias. Sra. Vita, Primos, Primas. Gracias por su aI)OVO. los liuieio.
A 11115 Aiiiigos Au . Joel. Marcia, Artiiro, Oscar. Lois D., Daniel Cli., Hector , Lucy,
Lotit a. Cris Jose Lois.
.\ Dli asesor: Cracias por la confianza y la amistad que me ha brindado.
.-\ lilis nlaestros: (;r11ias por SOS euisenansas. un tesoro invaluable.
Al Dr. Gustavo lorres C
(
): Dr. G, desafortiinadameute so adelanto, V ya est~ des—(allZaul(l() (Oil El. Nd) sabe ullant() be ?lgradezco do corazOn toclo SO apovo.
Resumen
C on la necesidad de procesar más información cada día. la ingeniería se ha visto en la necesidad de crear sistemas deinformación que sean capaces desatisfacer las demandas actua-les. Un enfoque t radicional es el uso de microprecesadores, sin embargo, estos tienen una limitante. las operaciones nativas que pueden manejar ya estan interconstruidas dentro de
ellos. y el hacer cualquier otra operacion distinta a una instrucción nativa implica desarrollar un que ut ilize las operaciones básicas para Ilevar a cabo dicha tarea.
Aquí es donde el cómputo reconfigurable tiene una gran ventaja. a que el hardware ahora no está fijo. si no que puede cambiar para ajustarse a la demanda de tareas que se desee realizar.
En esta tesis presenta el análisis y la síntesis de algoritmos aritméticos de punto entero y punto flot ante. con una estruct ura de pipeline para obtener un alto rendimiento y puedan ser ut i lizados dentro del cómputo reconfigurable.
El esquema de pipeline es una técnica para la implementación, en la cual se translapa la ejecucion de múltiples instrucciones para obtener un mayor reridimiento.
El alcance de está tesis esta limitado a el desarrollo de las unidades funcionales eficientes en VHDL para su implementacion utilizando teenologia de objetos de hardware en unidades parcialmente reconfigurables.
Indice General
1 Introducción 1
1.1 01 )j(‘t1V() do là tesis 2
1.2 Pipeline. 3
1.3 C6niputo reconfigurabl 6
1 .1 IeIl(leIlcias en los sistemas delcórnputo reconfigurable 6 1.0 LimitaeioIles en los sistemas actuales de cómptto reconfigurable 8 1.6 1lerranuentas utilizadas para el desarrollo 9
1 .7 OrganizaciOn do la tesis 10
2 Antecedentes 11
2.1 FPGAs 11
2.1.1 FPGAs hasados en RAM estática 13
2.2 Ilistoria do las m iquinas vectoriales 16
2.3 Perspectivas histOricas do là aritmética para computadoras 18
2.1 Procesadores (10 punto flotante 20
2.5 Algimos sistemas do cdmputo reconfigurable y aplicaciones 22
3 Algoritmos de punto entero 25
3.1 Introduccioii 25
3.2 Suma (10 punto entero 27
3.2.1 Suma~do propagaciOn do carry (Ripple carry addition) 29 3.2.2 Surna con adelantarniento de carry (Carry Lookaheaci Addition) 31
3.2.3 Implernentacion en VHDL y SIntesis 35
3.3 Resta do punto entero 39
3.3.1 Resta de propagaciOn y Resta con adelantamiento de carry 43
3.3.2 IrnplementaciOn en VHDL y SIntesis 44
3.4 MultiplicaciOn de punto entero 48
3.4.1 Algoritmo de Booth 50
3.1.2 RecodificaciOn do pares do hits 55
3.4.2.1 Implementacion porarreglos planos 58
INDICE GENERAL
3.4.4 IrnplementaciOn en VHDL y SIntesis 70
3.5 DivisiOn de punto entero 7-1
3.5.1 DivisiOn secuencial desplazar-resta sunia restaurar 77
3.5.1.1 Sobreflujo 80
3.5.2 DivisiOn SRT 81
3.5.2.1 CorrecciOn del residuo 86
3.5.2.2 FinalizaciOn 87
3.5.2.3 Operandos negativos 87
3.5.3 ImplementaciOn cii VHDL v SIntesis 88
4 Algoritmos de punto flotante 99
4.1 IntroducciOn 99
4.2 El formato de punto flotante 100
4.2.1 Exponentes polarizados 101
4.3 Definiciones de Aritmética do purito flotante nornializada 10-1
4.3.1 Sobreflujo y Bajoflujo 108
4.3.2 PrecisiOn 109
4.3.3 Aritmética do punto flotante no nornializada 110
4.3.4 Métodos de redondeo 13
4.3.4.1 Truncado 114
4.3.4.2 Redondeo basado en sumador 114
4.3.4.3 Redondeado usando là técnica de Von Neumann 116
4.3.5 Aritmética (10 mUltiple precisiOn 118
4.3.5.1 Sunia y Resta 120
4.3.5.2 MultiplicaciOn 120
4.3.5.3 DivisiOn 21
4.4 El estándar JEEE-754 23
4.4.1 Consideraciones 123
4.4.2 Formatos 2.5
4.4.3 Operaciones 128
4.4.4 Excepciones 129
4.5 Consideraciones para la implernentacion 130
4.6 Suma/Resta de punto flotante 130
4.6.1 Algoritmo 132
4.6.2 ImplementaciOn en VHDL y Sfntesis 143
4.7 MultiplicaciOn de punto flotante 148
4.7.1 Algoritmo 150
4.7.2 ImplementaciOn en VHDL y Sintesis 156
4.8 DivisiOn de punto flotarite 162
4.8.1 Algoritmo 165
INDICE GENERAL iii
5 Conclusiones 181
6 Apéndice: COdigo VHDL 183
6.1 Siimadoi Eiiteio 18.5
6.2 l~esl d(lOr Lliter() 197
6.3 ~\1ii1til)lic IdOr Eiitero 209
6.4 Divisor Entero 243
6.5 Suiiiadoi B est ador eu Piuuito flotante 277
6.6 ~\lu1tiplicadoi eu Punt o Hot ant 307
Indice de Figuras
1 Grilfica de Ia aceleraciOn total del sisterna 5
1.2 Arquitectura lupot(~tica del hardware de una estaciOn de trabajo dinámica—
iuieiut e recon figuirable. 8
2.1 Difereuutes arquitecturas de FPGAs 12
2.2 Esqueiuia simplificado (10 un FPGA 14
2.3 CLBs e Interconexiones 15
2.4 Rlo(ple lOgico configurable 15
3.1 Sunuador cmuiplet o 30
3.2 OrganizaciOn do un surriador do propagaciOn de carry 31
3.3 Esqueni itico pani el bit do carry ci 34
3.4 Diagrama (IC bloques (101 grupo do 4 bits~ 35
3.5 OperaciOn do (ada etapa rio là suma por adelantauniento de carry 36 3.6 Esqueina de.1 sumador por adelantamiento do carry 36 .3.7 SimulaciOn VHDL del sumador por adelauitamiento de carry 37
3.8 Diagrama RTL del sumador do purito entero 40
3.9 OrganizaciOn do un sumador/rostador do n hits con propagaciOn do carry... 44 3.10 Diagrama a hloques do uui sumador/restador con adelantamiento do carry.
~[ODO indica Si es suma o resta 45
3.11 Esquema del restador por adelantamiento do carry 45 3.12 SimulaciOn Vl-IDL do là resta por adelantaniento do carry 46
3.13 Diagrania RTL (101 restador (10 punto entero 49
3.11 Des uuuetodos de multiplicacióui: (a) normal. (h) con recodiflcaciOn de Booth, 52 3.15 Algoritmo (10 Booth para un multiplicador negativo 54
3.16 GeneraciOn (101 multiplicador 55
3.17 Algoritmo do suma/desplazamionto para là rocodificaciOn por pares de Bits. 59 3.18 Esquemático para soleccionar Ia versiOn apropiada del multiplicando 60
3. 19 MOdulo para recodiflcar un arreglo. 61
3.20 Estructura (10 un arroglo do recodiflcaciOii por pares do hits para liii multipli—
(‘ador do 7 >< 6 63
3.21 Tnt ercoiiexiOn entre niOduio1 i y unOdulo 1.2 64
vi INDICE DE FIGURAS
3.22 Ejomplo para multiplicaciOui 65
3.23 Ejemplo do multiplicaciOn usarido recodificacion do paies (!e bits 65 3.24 MultiplicaciOn unostrandos los suiniandos eu los pIo(lulctos I)?1r(i~iles 67 3.25 Vectores do entrada do là rnultiplicaciOn (Ic J)Uflt() eultei() 71
3.26 Resultados do là multiplicaciOn do punto entero 72 3.27 Diagraina RTL del multiplicador (10 punto euitero 75 3.28 Diagrarna RTL (10 una do las otapas del muiltiplicador 76 3.29 Ejemplo do divisiOn binaria utilizando ci método do 1 il)iz v papel. 79 3.30 Tabla. de entradas y salidas do Ia simulaciOn (101 divisor 89 3.31 Vectoros de entrada de là divisiOn do punto ontero 90 3.32 Vectores do entrada y resultados do la divisiOn (10 punto entero 91
3.33 Rosultados do là divisiOn do pinto entero 92
3.34 Resultados de là divisiOn de pinto ontero 93
3.35 Diagrama RTL del divisor do punto ontero 96
3.36 Diagrama RTL do là etapa comUn (101 divisor 97
4.1 Formato de punto flotante do 32 hits 101
4.2 Ejeniplo de normalizaciOn binaria 101
4.3 Ejeniplos do là suma (10 punto flotanto no norinalizada: (a) suima unenor a
uno; (b) suma mayor o igual a uno 12
4.4 Truncado do los dIgitos de bajoflujo 115
4.5 Procedimiento do rodondeo:(a) valor verdadero aproxi[nado por arriba; (h)
valor verdadero aproximado por dohajo 116
4.6 Redondeo de los (Ilgitos do bajoflujo 117
4.7 Redondeo do von Neumman parà dIgitos do bajofinjo 119 4.8 Formato do punto flotante para un operando (10 32 hits 119 4.9 Operando de doble procisiOn para punto flotante 120
4.10 DIgitos de guardia usados en ciredondoo 124
4.11 Formatos IEEE do precisiOn sencilla y doble precisiOn 127 4.12 OrganizaciOn do los registros paraiii surnador/rostador do punto flotante. . 132
4.13 Algoritino de suma/resta en pinto flotante. Rovisar si hay oporauidcs (1110
sean cero 133
4.14 Algoritrno do suma/resta en punto flotante. Alinoar fracciones y su uiar /rostar
fracciones 134
INDICE DE FIGURAS vii
4.21 (a) Siuiiia do puult o Hot ante coui postnorurializacion (desplazamiento a la izquierda) (0) B cst a (Ic puuito fiot aiite 0011 postllorriullizacidn (desplazamiento a là
dere-(110) 142
-1.22 Diagu~uuia(10 1 ieiulpo del suruiador restador do pinto flotante 145 4.23 Diagrauna de tienlpo del sumador restador (10 punto flotante 146 1.21 Diagrauuia RTL del suirnador restador do punto flotanto 149
-1.25 OrgaiuzaciOn (10 los registros para urn multiplicador (10 pinto flotante 151
4.26 Algorit uiio (Ic iuuult iplicaciOn cii pinto fiotante. DetecciOn do operandos cero
v (let~ruuuinaciOii(101 signo (101 producto 152
4.27 Algorit mo de multiplicación eru pinto flotante. Suma do exponentes 153 .1.28 Algoritino de inultiplicacion en puulto flotante. MultiplicaciOn do fracciones.. 154 1.29 Algoritiuio de uuuilt iplicacion en pinto flotante. PostnorrnalizaciOn 155 4.3(1 Fjeniplo do unuitiplicaciOuido pinto flotanto sin postnormalizaciOn 156 4.311 Ejernplo do multiphoaciOn en punto flotante con normalizaciOn 157
4.32 Entradas al nnultiplicador (10 pinto flotarite 159
4.33 Salidas (101 iunultiplicadordo pinto flotanto 160
.1.31 Diagrauuia RTL de la nuultiplicaciOn rio pinto flotante 163 4.35 OrganizaciOn de los registros para urna divisiOn en punto flotanto 166 4.36 Asignanuento de registros para. la divisiOn en punto flotanto 166 4.37 .Algoritnuo do division Ni pinto flotarite. DetocciOn do oporandos igual a cero
v Deterininacidn del signo (101 cociente. 167 4.38 Algoritmo (10 division on punto flotanto. AlineaciOn (101 dividendo 169
4.39 Algorit mo de division on punto flotante. Resta do los exponentes 170 4.40 Algoritiuio (10 divisiOn en punto flotanto. DivisiOn do fracciones 171 4.41 Ejeuiiplo (10 rlivisioui (‘Ii puIltO flotarite 173
4.42 Entiadas al divisor (10 pinto flotauito 175
lndice de Tablas
2. 1 CarateiIstias (le las teciiologias cle los FPGAs 13
2.2 Rvsiiiiieiì de alguiios (‘hips (IC plinto fiotante 20
3.1 labIa ile \eidad pal’a hi suma binaria 30
3.2 ~Iu1tip1icadores recodificados a través del algoritrno de Booth 54
3.3 labia (IC recodificaciOn del muitiplicador usando el algoritmo de Booth 54
3.4 \Iultipli(’a(’iOIi utilizando recodificaciOn de pares de bits 57
Capítulo 1
Intro ducción
Con el advenimiento de Ia necesidad de procesar más información cada dia para un sin fin de aplicaciones la ingenierla se ha visto en la necesidad de crear sistemas de inforniación que scan capaces de sat isfacer las demandas actuales, para esto, han surgido un sin fin de enfoques (Ilferentes. que tratan de solucionar este problema. Un enfoque tradicional es el uso de microprocesadores estos dispositivos han aumentado su potencia computacional de una forma sorprendente. de manera que pueden realizar una gran cantidad de operaciones. Sin
embargo, estos tienen una linitante. las operaciones nativas que pueden manejar ya estan interconstruidas dentro de ellos, v el hacer cualquier otra operacion distinta a una instrucciOn nativa imphca desarrollar un algoritmo que utilize las operaciones básicas para lievar a cabo (liclia tarea.
Ahora bien, si los dispositivos contaran con là capacidad de cambiar sus instrucciones nativas. estos podrian superar a cualquier circuito que no trajera dichas instrucciones
inter-construidas.
Aqui es donde el cómputo reconfigurable tiene una gran ventaja, ya que corno se vera más adelante, el hardware ahora no esta. fijo. si no ciue puede carnbiar para ajustarse a la
demanda de t areas que se desee realizar.
En esta tesis se tratará el análisis y síntesis de algoritmos aritméticos de punto entero y punto flotante. con una estructura de pipeline para obtener un alto rendimiento y puedan ser utilizaiidos dentro del computo reconfigurable. Las razones para irnplementar estos —
aigoritinos son las siguientes:
La investigaciOn sobre las diferentes técnicas de implementación de la aritmética de
algoritmos.
Obtener un alto renclirniento mediante la utilización de esquernas con pipeline [1].
Realizarlos niodularmente utilizando un procedimiento similar a la prograrnacion —
orientada a objetos, es decir utilizar objetos en hardware
[5].
2 CAPíTULO 1. INTRODUCCION
En las primeras aproximaciones para obteuieu’ ésta tesis. so i’ealizaroii (Iif(’Ientes est udios para obtener a partir (Id cOmputo reconfigurable. un sisteina do alto reuidiinionto, l)ehido a là relativa baja velocidad de los FPGAs [9]so peuisO ciue nIl esquema (IC pipelineilaria mejor
resultado.
El esquema de pipeline es una técuica para là impleruientacioii. en hi cuai so t raslapa là
ejeduciOn de multiples instrucciones para. obtener liii mayor u’endinieiito. En nuestros (has. elpipeline es Ia tOcmca dave para la iinplementaci(ui do procesadores (IC alto (lesCilIpeflO.
Sc puede hacer una analogla del pipeline con una lInea (IC ensanuhle: (‘ada etapa dci
pipeline cornpleta una parte de la operacidu. Es decir, là operaci n so (loscolnpone en tareas más pequeñas, en donde cada una de ellas requiere una fracciOn del tienipo para realizar là operaciOn completa. Cada umia de estas etapas so be conoce conio segmento. Las etapas
están conectadas, cada una a la siguiente, para formar un esquema seunejarite a una iinea de producciOn en donde los datos entran por mi extrerno, se procesan a trav~’sde las etapas, y salen por ci otro extremo.
La productividad o efectividad delpipeline está deternnna(la por là rapidez con là quo los resultados salgan del mismo. Ya quelas etapas están conectadas entre sf, todos los Segnientos deben estar listos para operar al mismo tiempo. El tiempo requerido para (lesplazariiii clato.
por uiia etapa a lo largo del pipeline se be conoce como cicio de nuiquina. Esta (Iuracióui esta determinada por ci tiempo que necesita là etapa rnas lenta i~~iraoperar (va que todas las etapas funcionan simultaneamente).
El alcance (Ic esta tesis esta limitado a el desarrollo de las unidades funcionaies eficientes en VHDL para su implementaciOri utilizando tecnologia do ohjetos de hardware en unidades
parcialmente reconfigurables.
1.1
Objetivo de la tesis.
Dentro de esta tesis, se pretenden abarcar los objetivos que nos ayudarán a formarlas bases
del sistema de cOmputo reconfigurable de aplicaciones rnñltiples (SCREAM).
ElahoraciOn de unidades funcionales artitméticas, utilizanclo CS~l1dfflàS(IC pipeline para
una mayor vebocidad.
Generación de cOdigo VHDL modular, (IC manera que Se puedan crear objetos dc Hardware que pueclan ser cargados/descargados dentro do un FPGA, do una nianora eficiente y rápida.
Deiitro de los objetivos, todos estos lievan a forniar parte de un esquehlla nuis aniplio
hacia la investigaciOn del cOmputo reconfigurable. El prirnero de ellos nos (là las bases para
1.2. P IPEL INE 3
Coui rosjo(’l o a! seguiido puinto. [lOSda là flexibiliclad (IC poder crear sistemas mas efi—
(‘iehltes. (sto SC roliere a (1110 110 05 necesario caiuihiar totalmente là configuraciOn de urn
sistoiiia para (‘aunhiar slu funcionannento: uui ejemplo (IC esto, puede ser Ia divisiOn de punto
(III (‘10 Y là (IiV15i( hi (11’ plult0 flot ante. corno so vera en los siguientcs capit,ulos. ba divisiOn de
pulhito euitoro 05 1111 siihcouuipoiieiite (10 là (livisión cle purito flotante. Con esto, el tiempo dc
r0(’ohlfiguuIa(’iOhi so reduce significativaniente proporcionando urn mejor rendimiento.
1.2
Pipeline.
En Un ~sqiivuuia(10 pipeline eioh jetivo del diseno. es quc las operaciones equilibren ba duraciOn do las et apas (101 pipeline. Si (staS están perfectamente equibibràdas. entonces el tiempo de oporaciui (10 los (latos so puede defmir como:
Bajo estas (‘ondiclones. la mejora de velocidad se debe a las etapas del pipeline. Sin em-bargo. generaimente estas etapas 110 se encuentran adecuadamente baianceadas; adernás, là segment anOn inplica sicmpre abgmin costo en tiempo debido a la lOgica. involucrada para la siiicrouiizaciOui (10 los registros en cada etapa.
El pipeline colisigue una reducciOn en ei tiempo dc operación de los datos. Esto se puede
lograr decrement,aiido Ia duración del reloj (cambiando de tecnologIa de impbernentaciOn) o (lisnunuvondo el nuimero ole ciclos por operaciOn (cambiando el algoritmo), o haciendo ambas. Normalinouite là niavor reduccion so da en elrnirnero de cicbos por operaciOn.
Si se (losea saber eb rcndimniento (~iCtendran est,as operaciones, será necesario definir eb
sigiuionte termnnìo: CEO, cicbos (Ic reboj por operaciOn, es là car tidad de cicios necesarios
i~n’ realizar una operaciOn. Podernos definir là aceleraciOn que so obteiidrá en ci pipeline cOhliO:
Aeelerac’ion del pipeline
4 CAPÍTULO I. INTRODUCCION
Despejando là EcuaciOn 1.2 y cobocánclola en là Ecmiacidmi 1.1 resiilta:
En los objtetivos iniciales dcl provecto SCREAM, so plant(‘0 qiie el sist i’uuia doheria. do
tener un rendimiento dc al menos 10 veces el desemuipeno que teuI(1u’ia uiuia IIià(jlUI1à vectorial
corivencional, realizando operaciones vectoriabes (que aproveclian el pipeline). ~1à 1u10el sis—
tema SCREAM puede trabajar COUlO) un coprocesador do là (‘ounpult adora audit riona. anibos sistemas pueden funcionar indepcndientemnentc. cuando ci coprocesadoi’ uiocesito intormar a là computadora dc algun requerimiento o necesidad. el sistomna anfitriOui (quo es donde reside ci coprocesador)preguntara las uecesidades do su hucsped realizando las fuuiciones quo be indique.
Utilizando là Ley dc .A.mdahl v ci sistenia trahajando en parabelo con ol procesador central dc la computadora se pueden considcrar los siguientes casos:
Cuando ci sistema funciona rinicamente con là parte vectorial. ci reuidiinieiito estará dado por là EcuaciOn 1.3.
en dondeFraccmejorada cs ci porcentajc del cOdigo que puede correr’ en là forina vectorial v
Aceleramientomejorada es là aceberaciOn que tiene là parte vectorial.
En base a là EcuaciOn 1.3, so puecle ver en Ia Figura 1.1 que para tenor uuii aceboramiemito
global dc 10. sc necesita que Ia. parte vectorial tenga un aceierainieuito (IC más ole 10 veces y que cl problema a resolver contenga más de 90% (be cOdigo vectorizable.
Cuando ci sistema funciona en paralelo con el procesador principal, el rendimiento so
puede calcular segñn las Siguientes condiciones:
Cuando cl sisterna dc cOrnputo vectorial ternnnc más rapido ciue ci anifitridn
Cuando cl sistema anfitrión espere al vectorial para ci resubtado. La aceleraciOn resulta del tiempo quc tarda en realizar là operaciOn una munidad vectorial.
1.2. PIPELINE.
6 CAPÍTULO I. INTRO D
UCCION
1.3
COmputo reconfigurable.
El cdrnputo reconfigurable os là habilida(l de modifinar là arqiiit oct ura (101 /1,(iI’du(Lre (IC Till sisterna de cdniputo en tiennipo real.
*Hardware fijo
Las computadoras actuales SOil sisteinas (10 h,urdii’are hjo hasados en rnicroprocesadores. Mientras el procesador sea uuiás poderoso. (101)0 realizar uuias funcioncs que solo la aplicacidn que esta corriendo en ci monnieuito. Con cada nuova gonoraciOii do micro— procesadores, cl rendimiento (IC las apiicaciones se increunenta marginalunonte. En muchos casos, là aplicacion tiene quc ser reescrita para tomar ventaja (10 Ia nueva arquitectulra. Tradicionalmnente los sistemas de hardwarefijo caen clentro (le tres (‘ategorias: LOgica (GateArrays, etc.), Controladores embebidos (microcontroladores. ASICs. etc.) v Comnputadoras (microprocesadores, etc.).
*Hardware reconfigurable
Los sisternas ole cOmputo reconfigurabbo son aquellas plataformas cuva arquitectura puede ser nnodificada porsoftwarepara realizar una aplicaciOn. Para obtener cl maximo rendimiento, un algoritmo dehe colocarse en hardware. So ohtieii~~i rendimientos excelentes cuando se convierte cl algoritmo a hardware dentro (Ic 1111 sisterna dc cOmputo reconfigurable.El hardwarereconfigurabbe puede ser ciasificado en tres categorlas: 1. Logica (FPGAs)
2. Control embebido (Coprocesadores reconfigurables, FPGAs conectados a los sisternas tradicionales)
3. Computadoras (platafornias (IC cOrnputo completainente recouifigurables (rue usan —
FPGAs en un sistema diseñado para cOmputo de propdsito general).
Las computadoras reconfigurables tornan ventaja del paralelisunno nmuenntras roducen ci overhead(be las operaciones de carga/almacenamiento. salto y (lecodificacion do instrucciones
1.4
Tendencias en los sistemas del cOrnputo
reconfigu-rable.
1.4 TENDENCIAS EN LOS SISTEMAS DEL COMPUTO RECONFIGURABLE. 7
Los invest igadores haii (Iesarrollado uina gran variedad de sisternàs experimenitales, (lesde ~)oqui(’ilos (‘((Ii algiulios (:ulaIit OS FPGAS luasta sistennas (:011 varios cientos ole ellos. Las me— todologías(10 ~ (10 (‘5105 sistenias Cäeii clentro de tres clases: Diseflo directo del hurdu’ar’o douitro dei l”PCA. sienido ésta ba iuias couhiiii, otra cs cl uso de sintesis dc HDLs
I ant o en (IesnripniOli ost ructuiral (:01110 (Ic comportarniento, y là dltima el uso dc lenguajes
(10 (‘ IIli)uIt0 estauidar a 1 raves (IC cOunlI)iiadoreS especiaies.
)S prO(’OSOs (10 ilitegracioni suubiiiicroiiica han permitido arquitecturas dc procesadores
oxi rouiadauunonto (‘ouluplo]as ciue àlguna vez àparccieron en los rruairnfrarnes, pero ahora —
ostun (101010 (10 uui solo chip. La impiernentaciOn completa dc operadorcs, datapaths anchos,
graIl (‘aIlti(Jad (10 registros v (:acIieS. \~tecnicas avanzadas para obtener paralelisnio a niveb iistruccioui (Id (:OdigO estan apareciendo como là fibtiuna moda dc los procesadores. Là relaciOni cost o boneficio tamhieii so ha mejoràdo. Es decir que sc tiene un rnejor rendirniento por (‘ada (lolar invortido en el cosW (IC una computadora que lo que se tenfa hace 10 aflos.
Las counpiitadoras recoiifnguirahles, ilO necesitan sufrir las bimitaciones de los CPUs con— veuiciouiales. quo dobon iuiaultonor ci modelos del programador en un solo thread o hilo de oporacionos secuieuiciaios predefinidas en uni solo espacio dc datos. Aunque ci mayor cain—
hio ~ ol dosarrolbo do las coniputadoras reconfiguirabbes, dehe clarse en ci desarrolbo dc herramiontas v arquitecturas parui (IUC sri programaciOn sea más práctica.
Deuit.ro (101 area (10 las aplicaciones. là penalizacióri (IC realizar un proceso en software,
siouuipre ha sido de uiuia a dos veces en térrninos ole orden con respecto a la velocidad del unisnio proceso roalizado por hardware. El cOmputo reconfigurable debe dc teller là veuitaja sobre las iuiplounentaciones que utilizan softwarev esquernas fijos dc hardware parajustificar 511 existeuioia 3] 4].
Otra parte ninny iuuportantc para ci desarrollo del cdmputo reconfigurabbe cs la mejora dc las arquitecturas (id hardware(IC los FPGAs. Las estructuras predefinidas dc interconexiOn pueden ser urna seria restricciOn a las herrarnientas de sIntesis del codigo. Si sc iricrernenta tainhien là cai)aeidad ole los FPCAs sc logrará que las connputadoras reconfigurables sean (:apaces (10 corror aplicaciones en una unenor cantidad dc chips, v por consiguiente tener un nienor cost o. quo las llevará. a ser competitivas en el nniercado. Una smntesis más eficiente al inounenito ole estar corriondo alguna apiio:acidn, pue(Ie incrementar grandemente cl poder dc las computadoras roconfigurables v asI misino, perinitendo que las instrucciones sc reprogra— men (linalnic’aunonte sin là I)eIialiZaCiOll del tiempo de reconfiguracion, iliejorarla tarnbién ci rendiinieuito.
8
Figura 1.2: Arquitectura hipotética del hardwarede una estacion de trahajo di námicamente reconfigurable.
configurables cercanamente unidos a los CPUs y a la memoria, qua se programan bajo là
demanda para servir a las aplicaciones. Los CPUs por Si misnios incluen unidades fun— cionales programables (FPFIJs - Field Programmable Functional Units) para instruccionos
de aplicaciOn especIfica dinárnicamente programadas
131.
1.5
Limitaciones en los sistemas actuales de córnputo
re--configurable.
Aunque las inaquinas reconfigurahies tienen un alto rendirniento, todas alias exhihen alguiias
limitaciones comunes.
1. Bajo ancho de banda e interfaz de alta latencia. Dado qua las coInI)utadorr~s reconfigurables actuales son un periferico de la computadora anfitriona, sa encuentrau~ conectadas a los buses de los periféricos, los cuales siempre están limitados con respect 0
1.6. HERRAMIENTAS UTILIZADAS PARA EL DESARROLLO. 9
cación con elprocesador limita la aceleración y previene una cooperacion cercana entre
la unidad auifit rionay las unidades lógicas.
2. Alto costo de reconflguracidn. Dado quo el costo dereconfiguracion (con respecto a
tienipo) os altoeu toclaslasteenologlas de logica reconfigurable (aunque estoestá
cam-biando eonlasfamilias parcialmente recon.figurables), el tiempo dereconfiguraciOndebe
ser amortizaclo pot tuna gran cantidad do datos procesadospara justificar el tiempo de
reeonfiguraciOn. Generalmente, osto signiflca que unasola configuratiOn debe
mante-nerse a través do la aplic:aciOn. aunque diferentes pordones do ésta se puedan acelerar
~ otros tiposdc lOgica especializada. Este costo tambiéu impide el uso de computfr
cloras reconfigurables procluctivamente en sistemas multitareas o detiempocompartido.
La cercana integratiOn do la lOgica reconfigurable dentro de un microprocesador base,
puede decrenientar siguiflcativamente Ia latencia de comunicaciOn entre las unidades
fun-nonales fijas y la ksgica reconfigurable. Sinuilarmente, cuando el procesador y la lOgica
renmfigurable conipartenelmismo Sterna, existe un mayorancho debanda disponible para
el procesarnientoutilizandolOgica reconfigurable.
1.6
Herramientas utilizadas para el desarrollo.
En esta teals so ntihzaron varias herramientas computacionales que facilitan el diseflode las
uniclades reconfigurables.
QuickVhDL (Mentor Graphics): SeutilizO este paquete para realizar las simulaciones
inicialesdel VHDL paracomprobar Si’funcionamiento.
FPGA Compiler(Synopsys): Para realizar las compilaciones del VHDL Sintetizable y
generar losarchivos compatiblespara generar FPGAs.
XACT (Xilinx): Para realizarmedicionesde tiempo dentro del FPGA.
ModelSIM (Models Inc.): lJtilizado paralas simulacionesposteriores delVHDL.
Leonardo Spectrum(Exemplar): Sintetizador de VHDL orientado a FPGAs y ASIC8.
Todos losdiseüos do las unidades funcionales se orientaron a FPGAs de XILINX, en el
caso dc esta teds parael model VX, 40125XVPG559 de manera que hubieran sufrientes
10 CAPÍTULO 1. INTRODUCCIÓN
1.7
Organización de la tesis.
Esta tesis se divide en 5 capftulos, doiide este es nib iiitrodiici~nial dv~aiio1lo. El Capititlo 2 habla sobre los antecedentes de tecnologias que so conjillit au pain el desaiiollo de este
proyecto. El tercer y duarto capftulo tratan (10 in teorla v (‘1 (losarrollo (10 las unidades funcionales enteras y do punto flotante respectivaniente, los (uales so inipleuuient an enVH1) L y se observan sirnulaciones do las unidades. El tiltirno capit iilo liabla do las (on(llisioIlOS le
esta tesis, contribuciones y futuras ivestigaciones quoso pueden lla(or doest e proyo(to. Po r
Capítulo 2
Antecedent es
El presente trabajo es una investigación dentro del area del cómputo recorifigurable y la
iInI)leIIieIitacidIi de unidades aritméticas (inc se adaptan a esta area.
Couio aiitecedcntes se encuentran aplicaciones del cOmputo reconfigurable como procesa—
inient o de iIllngenes. l)t’lsqueda (‘Ii textos. procesadores parcial y totalmente reconflgllrables,
etc.12—8] \ (leIlt 10 (Id area de là iniplementaciOn de là aritmética, toda se enfoca a imple— 111(111 aciOfles \J~SIde los algoritinos. fiO—19].
2.1
FPGAs.
Los arreglos idgicos prograinables o FPGAs (Field Programmable Gate Array) se conocen COfllO (lispoSitiVOs programables. Estos d~spositivosson unos cirduitos de proposito general (me ~ pueden configurar para una gran varieda~dde aplicaciones. Los primeros dispositi-vos programables (luc fueron ampliamente usados, son los liamados PROM (Programmable
Read Only Memory). Estos circuitos, que solo eran programables uria vez, venian en dos configiiraciones: 1) Un Cliii) programado (en la mascara) por el fabricante, y 2) Un chip programado por el usuario. Estos circuitos prograniabics por ci usuario derivaron en dos tipos, los EPROM (Erasable Programmable Read Only Memory) y los EEPROM (Electrically
Erasable Proqrarnmabie Read Only Memory).
El siguiente paso en ci desarrollo de este campo fué el adveniiniento de los dispositi-vos idgicos prograniables PLD (Programmable Logic Devices). Estos se construyeron para
implementar circuitos lógicos sirnples. Los PLD inclulan un arreglo de compuertas AND coiiectadas a un arreglo (IC cornpuertas OR. Los PALs (Proqramrnable Array Logic) es un tipo ComüIl (IC PLD consistente en Un piano programable de compuertas AND seguido por un plano fijo (IC compuertas OR. Otros circuitos muv comunes que ofrecen un poco de más flexibilidad que los PALs, y a~lmismo tiernpo se pueden reprogramar varias veces se conO— cen como GALs (Generic Array Loqic). Estos circuitos fueron diseñados para remplazar a
peqilenas cantidades de lOgica. La ventaja de estos ñltimos. es que permiten Ia reprograma~
ciOii en varias ocasiones.
12
Figura 2.1: Diferentes arquitecturas de FPGAs.
Los MPGAs (Mask Programmable Gate Array) fueron desarrollados para manejar una gran cantidad de circuitos lOgicos. Un MPGA COfflTlfl consiste en una fila (IC transistores que puede ser interconectada para irnplementar la logica deseada. El usuario especifica las conecciones entre las filas. AsI permitiendo la irnpleinentaciOri (IC compuertas lOgicas hi~isicns y Ia habilidad de interconectar las compuertas. Como en estos circuitos se ocupahan capas de metal definidas por ci fabricante, se incurria en un tiempo v costo significativo pam là producciOn de estos circuitos.
En 1985, XILINX introdujo los FPGAs. La interconexiOn entre todos los element.os del circuito se diseño de manera que pueda ser programable por el usuario.
Hay cuatro categorias principales de FPGAs usados comercialemente (Ver Figura 2.1): Arreglo simbtrico.
Basado en filas.
Mar de compuertas (sea of gates).
PLD herarquico (tainbibn ilamado CPLD - Complex Programmable Logic Device).
2.1. FPGAS. 13
Tabla 2.1: Características de las tecnologías de los FPGAs.
Celdas de RAM estática: En estos FPGAs, las conexiories programables se realizan lit ilizafld() transistores (le paso. compuertas de transmisiOn, o multiplexores que son coiitrolador por las celdas de RAM estática. La ventaja de esta tecnologIa es que perlllite ~uia. reconfiguraciOn rapida. Sn mayor desventaja es ci tamaño del chip re-(Illerido j~’~là tecnologia de RAM.
Ant ifusible: Un antifusible es un estado de alta impedancia, y puede ser programado a Un est ado de baja unpedancia 0 estado con fusible. Es una tecnohogIa más ecoriOmica
(hid là de RAM estatitca. v estos dispositivos solo pueden ser programados una vez.
Iransistores EPROM/EEPROM: Este mbtodo es ci mismo utilizado en las memorias E(E)PRO\1. La ventaja (Ic esta tecnologfa es quc puede ser reprograinada sin ahna-cenaimento extemno (Ic la configuraciOn, COillO serIa el caso de los FPGAs hasados en
RAM.
Dependiendo de là aplicacidn, una tecnologIa de FPGA puede teller las caracterfsticas deseables ~ esa aplicación. La Tabla 2.1 inuestra las caracteristicas de las tecnologIas de prograniacion nieiicionadas anteriormente.
2.1.1 FPGAs basados en RAM estática.
Los FPGAs ~T0\~CCIi los heneficios de un VLSI, Inientras evitan los costos NRE , retrasO
de tiempo v el riesgo inherente a là prodi.iccion (IC un arreglo basado en mascaras. Los FPGAs se coiifiguran cargando datos a las celdas intemnas de memoria. Este FPGA puede ser prograniado un mimero iliinitado (IC veces y soportall relojes de sistema de más de 80
MHz.
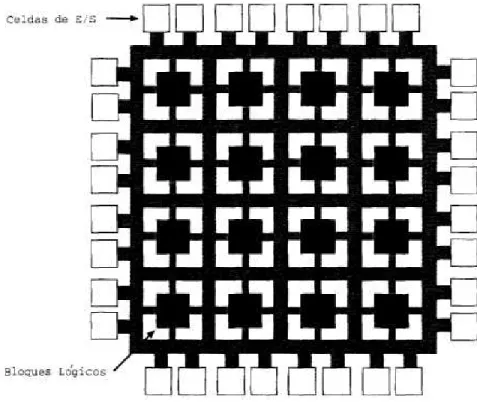
El FPGA tiene principalnlente tres elementos configurables: bloqiies iogicos conflgUr~ bles (CLBs - Configurable Logic Blocks), hioques de Entrada/Salicia (JOBs - Input/OutPut
14
Figura 2.2: Esquema simplificado de un FPGA.
La conflguraciOn propietaria se establece programando las ccldas de memoria internas que
determinan la funciOn logicay las conexiones internas implementadas en el FPGA.
En là Figura 2.3 se mucstra a un FPGA con urn arreglo bidimiensional de bloques de lOgica quc se pueden interconectar por alambres dc conexiOn. Todas las (:OIleXiOIieS intermias se componen de segmentos de metal con puntos dc rutCo programables para implemeiitar là ruta. deseada. Una ahundancia de diferentcs recursos para muteo provec liIlà concxiOn
interna eficientc. Hay cuatro tipos principales de interconcxiOn, tres se distinguicn por là longitud relativa de sus segmentos: lineas dc longitud sencilla, lincas (IC doble longitud y
lincas largas. Adicionalmcnte, existen buffers de seflalizaciOn rapida, redcs (le bajo skewque
son frecuentcmente utihizadas para rclojcs y señales de control.
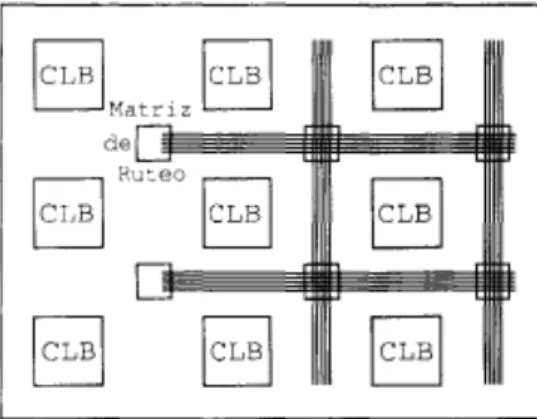
El principio de los CLBs se rnucstra en là Figura 2.4. Cada CLB tienc un par (Ic flip-.
flops y dosgencradorcs die funcioncs independicrites de 4 entradas. Estos gencradores tiemieri
una excelente flexibilidad ya quc là mayorIa dc las funciones combinatorias lOgicas requiereri menos de cuatro cntradas. En un FPGA, los CLBs realizari là mayor parte de là lOgica. La flcxibilidad y la simetrIa dic là arquitcctura de los CLBs facilita là coiocaciOn y ci ruteo die
2.1. FPGAS. 15
Figura 2.3: CLBs e Interconexiones.
16 CAPITULO 2. ANTECEDENTES
2.2
Historia de las máquinas vectoriales.
Las primeras máquinas vectoriales fueron el STAR-lOU de CDC y la ASC de TI, las dos salieron a! mercado en 1972. Ambas eran mäquinas vectoriales memoria-memoria. TenIan unidades escalares relativamente lentas -la STAR utilizó las mismas unidades para escalares y vectores- haciendo la longitud de las operaciones escalares extremadamente profunda. Estas
dos computadoras tenIan una alta penalización para iniciar cada operaciOn y trabajaban sobre vectores de varios cientos de miles de elementos.
Seymour Cray, quien trabajO en la 6600 y en la 7600 de CDC, fundO Cray Research Inc. e introdujo la CRAY-1 en 1976. Esta máquina utilizaba una arquitectura con registros vectoriales para disminuir significativamente las penalizaciones de arranque. También tenía un soporte eficiente para un stread no unitario e inventO el encadenamiento de unidades.
Más importante, la CRAY-1 era también là máquina escalar más rápida del mundo en esa.
epoca. Esta combinaciOn de excelente rendimiento escalar y vectorial fué probablemente el factor más significativo que contribuyo al exito de la CRAY-i Muchas maquinas vectoriales
posteriores están basadas en là arquitectura de esta primera mäquina vectorial con éxito comercial
En 1981, CDC comenzO a construir la CYBER 205. Esta máquina tenfa là misma arqui-tectura básica de là STAR, pero ofrecIa mejores rendimientos, asI como expandibilidad de la unidad vectorial con hasta cuatro conjuntos para cálcuio vectorial, cada uno con varias unidades funcionales y un canal ancho de load/storeque proporcionaba varias palabras por ciclo de reloj El rendimiento pico de là CYBER 205 excedia enormemente a! rendimiento de là CRAY 1 Sin embargo, en problemas reales, la diferencia de rendimiento era mucho menor, debido al buen balanceo entero/vectorial de la CRAY
La máquma STAR de CDC y su descendiente, CYBER 205, fueron maqumas vectoriales memoria-memoria Para mantener el hardware sencillo y soportar los requerimientos de ancho de banda elevado (hasta tres accesos a memorma por FLOP), estas máquinas no ma-rnpulaban con eficacia los streadsno unitarios Unstread no unitario tiene pobre rendimiento en estas maqumas debido a las transferencias de datos memoria-memoria las cuales necesitan agrupar (y despues separar) los elementos no adyacentes en los vectores
En 1983, Cray construyo la primera CRAY X-MP. Con una ciclo de reloj mejorado
(9 6ns contra a los 12 5ns de là CRAY 1), un mejor soporte del encadenamiento y varios canales de acceso a memoria Esta maquina mantuvo a Cray Research Inc en el liderato de las supercomputadoras La CRAY 2, un nuevo diseño completamente configurable hasta cuatro procesadores, se introdujo más tarde Tiene un reloj mucho mas rapido que el X-MP, pero también muchos segmentos. La CRAY 2 no tiene encadenamiento y además tiene una enorma latencia en là memoria principal, y sOlo tiene un canal de memoria por procesador. En general, sOlo es más rápida que la CRAY X-MP en problemas que requieren de su gran cantidad de memoria principal.
2.2. HISTORIA DE LAS MAQUINAS VECTORIALES. 17
la SX/2 de NEC. Estas maquinas han probado estar cercanas a là CRAY X-MP. La CRAY favorecfo el uso de varios procesadores, ofreciendo primero una versiOn de dos procesadores y más tarde una máquina con cuatro. En contraste, las tres máquinas japonesas tenIan capacidades vectoriales expandibles. En 1988, Cray introdujo la Y-MP, ésta permitfa hasta ocho procesadores y disminufa la duraciOn del cicio de reloj a 6ns. Con sus 8 procesadores, là Y-MP es, generalmente, la computadora vectorial más rápida. Aunque en là actualidad las maquirlas MPP han remplazado a las vectoriales, una combinaciOn de ambas como la Fujitsu VPP700/56 se encuentra entre las máquinas más rápidas del mundo. A finales de 1989 Cray Research se separO en dos compañfas, ambas dedicadas a la construcción de supercomputadoras.
A principios de los ochentas, CDC creO un grupo ilamado ETA para construir una nueva supercomputadora, là ETA-lU, capaz de 10 GFlops. Esta máquina apareciO a finales de los ochentas, utilizaba una tecnologfa CMOSde baja temperatura en una configuraciOn de hasta 10 procesadores. Cada procesador conservaba là arquitectura memoria-memoria basada en el CYBER 205. Aunque la ETA 10 consiguiO una gran rendimiento pico, su rendimiento escalar no era comparable con las CRAYs. En 1989, CDC cerro ETA y saliO del rnercado de supercomputadoras.
En 1986, IBM introdujo là arquitectura vectorial System/370 y su primera
implernenta-ción en la 3090 Vector Facility. Esta arquitectura mejora là del System/370 con 171 instruc-ciones vectoriales. La 3090/VF está basada en el CPU 390. De forma distinta a muchas otras máquinas vectoriales, là 3090/VF canaliza sus vectores a través del cache.
En los ochentas tambiOn vieron la llegada de máquinas vectoriales de menor escala, lla-madas mini-supercomputadoras. Su precio era aproximadamente el 10% del costo de una supercomputadora, estas máquinas decayeron rapidamente. Aunque muchas compañias en-traron al mercado, las dos que han tenido más exito son Convex y Alliant. Convex comenzO con una máquina vectorial uniprocesador (C-i) y a finales die los ochentas ofrece una ma-quinas multiprocesadores de baja escala (C-2); utilizando là capacidad del softwarede Cray. Alliant se ha concentrado mas en los aspectos de multiprocesadores. Construyeron una máquina de ocho procesadores, cada uno de los cua.les ofrecfa una capacidad vectorial.
IBM desarrollo el modelo 7030, là cual se considera como là primera computadora que aprovecha el pipeline, Esta computadora era un desarrollo posterior a la IBM 704 y su objetivo era ser al menos 100 veces másrápida que esta. Esta computadora tenía unpipeline de 4 etapas.
En la actualidad casI todos los procesadores de alto rendimiento (CISC y RISC), desde là familia INTEL hasta los ALPHA utilizan el pipeline para poder mejora.r ampliarnentesu
18 CAPITULO 2. ANTECEDENTES
2.3
Perspectivas históricas de la aritmética para
corn-put adoras.
Las primeras computadoras utilizaban punto fijo en lugar de punto fiotante. En el artículo
“Preliminary Discussion of the Logical Design of an Electronic Computer Instrument” de Burks, Goldstine y von Neumman dice:
Parece que hay dos propdsitos importantes en un sistema decimal de punto flotante, los cuales surgen del hecho de que el nu’mero de digitos de una palabra sea una constante fijada por consideraciones de diseño para cada máquina en particular. El primer propdsito es mantener en una suma o producto tantos dIgitos significativos como sea posible y segundo es liberar al operador humane de la carga de estimar e insertar en un problema “factores de escala” que son constantes multiplicativas que sirven para mantener a los nu’meros dentro de los límites de la maquina.
Por supuesto, no negamos el hecho de que el tiempo humano se emplea en or-ganizar la introduccidn de factores de escala aconsejables. Solarnente implicamos que el tiempo consumido asI es un porcentaje muy pequeño de todo el tiempo que emplearemos en preparar un problema interesante para nuestra máquina. La primera ventaja del punto flotante es, pensamos, algo ilusorio. Con el fin de
-tener un punto flotante se debe malgastar capacidad de mernoria que en cualquier otro case se podria usar para obtener más digitos per palabra. For tanto, no nos parece nada claro silas modestas ventajas de un punto binario flotante compensa la pérdida de capacidad de memoria y la complejidad creciente de los circuitos aritméticos y de control.
Este artIculo da la posibilidad de ver las cosas desde ha perspectiva de los primeros disc-fladores de computadoras, que pensaban que ahorrar tiempo de computadora y de memoria, que era más imp ortante que ahorrar tiempo de programaciOn.
Habiando de aritmética de punto fiotante, aunque ci estandar IEEE es ampliamente utilizado, hay otros tres importantes sistemas en uso: ci IBM/370, ci DEC VAX y el Cray. Brevemente se explicaran estos formatos. El formato de las VAX es ci mäs cercano ai IEEE. Su formato de precisiOn simple (formato F) es parecido al formato de precision senciila del IEEE, ya que tiene un bit de signo, 8 de exponente y 23 para la fracción. Sin embargo, no tiene un bit de retenciOn, que hace que se rcdondee hacia arriba en los casos a mitad en iugar de ai par. El VAX tiene un rango de exponentes iigcramentc diferentes a! de Ia IEEE: emin es -128 en iugar de -126 como en ci IEEE y emax es 126 en lugar de 127. Las diferencias principales entre los formatos de VAX e IEEE son la faita de vaiores especiales y el desbordamiento a cero. El VAX tiene un operando reservado, pero no funciona como un
2.3. PERSPECTIVAS HISTORICAS DE LA ARITMETICA PARA COMPUTADORAS.19
como éste era muy pequeño para muchas aplicaciones, se decidió añadir el formato G; que al igual que el estándar de la IEEE, este formato tiene 11 bits de exponente. El VAX también tiene adicionalmente un formato H, que es de 128 bits.
El formato de punto flotante de las IBM/370 utiliza la base 16 en vez del sistema binario. Esto significa que no puede utilizar un bit oculto. En precisiOn sencilla tiene 7 bits de exponente y 24 bits (6 dIgitos hexadecimales) de fracción. Por lo tanto, el nümero mayor que puede representar es 1627 =
24x27
= 229 comparado con el 228 del IEEE. Sin embargo, un
nümero que está normalizado en ci sentido hexadecimal sOlo necesita tener un digito distinto de cero al principio. Cuando se interpreta en binario, los tres bits más significativos podrían ser cero. Por tanto, hay potencialmente menos de 24 bits significativos. La razón para utilizar la base más alta, fué minimizar la caritidad de desplazamientos requeridos cuando se suman números en punto flotante. Sin embargo, esto es menos importante en las máquinas actuales, donde el tiempo de suma en punto flotante es fijo, habitualmente, independientemente de los operandos. Otra diferencia entre la aritmética del 370 y la del IEEE es que el primero no tiene dIgitos de redondeo ni stickybits, lo que significa que trunca en vez de redondear. Por lo tanto, después de muchas operaciones, el resultado sistemáticamente será demasiado pequeño. De forma distinta a la aritmética del VAX y del IEEE, cualquier patrOn de bits es un nilmero valido. For lo tanto, las rutinas de las librerias deben establecer convenios sobre qué devoiver en caso de errores. For ejemplo la iibrerfa de Fortran de IBM al hacer la operaciOn
regresa un 2.
La aritmetica de las Cray es interesante, porque esta creada con una orientación a!
rendimiento mas alto posibie en punto flotante Tiene un campo de exponentes de 15 bits y
un campo fraccionario de 48 bits La suma en las computadoras Cray no tiene un digito de
guardia, y la multiplicacion es menos precisa aun que Ia suma Fensando en la multiplicacion
como una surna de p numeros, cada uno de logitud 2p bits, lo que las computadoras Cray
hacen es suprimir los bits de orden inferior de cada sumando Asi, analizar las caracteristicas
exactas del error de la operacion de muitiplicar no es fácil Los reciprocos se calcuian
utihzando la iteracion, y la division de a por b se hace multiplicando a por 1/b Los errores
en ia multiplicación y el caicuio de los reciprocos se combinan para hacer no fiables los tres
ultimos bits de una operación de division
20 CAPITULO 2. ANTECEDENTES
Tabla 2.2: Resumen de algunos chips de punto flotante.
SP = Precisión sencilla.
2.4
Procesadores de punto flotante.
Dentro del mercado comercial existen varios chips que realizan operaciones de punto flotante. En esta sección se mencionan algunos que cumplen con el estandar IEEE y que integran en un solo chip las operaciones básicas de suma, resta, multiplicaciOn y divisiOn. Todos utilizan un ciclo de aproximadamente 4Ons. y sus algoritmos internosson bastante diferentes.
Algunas cosas en comün que tienen estos circuitos son que realizan sumas y multipli-caciones en paralelo, y no implementan ni la precisiOn extendida ni la operaciOn resto del estandar IEEE 754.
En la Tabla 1.1 se dá un resumen de los tres circuitos. Se puede observar que mientra.s se tiene un nümero más alto de transistores, se tiene un mimero menor de ciclos.
El Chip MIPS tiene el menor nümero de transistores de los tres. Esto se refleja en el hecho de que es el ilnico chip de los que se mencionan aqui que no tiene pipeline. Además, las operaciones de multiplicaciOn y suma no son completamente independientes porque corn-parten el sumador con propagaciOn del carry que realiza el redondeo final (asI como el redondeo logico). Además, en el R3010 se utiliza una mezcla de transmisiOn, CLA, y se-lecciOn de carry. El multiplicador tiene un arreglo lo suficientemente grande para que la salida pueda conectarse de nuevo a la entrada sin necesidad de reloj. Tambien utiliza la recodificaciOn de Booth de base 4. Este chip puede hacer una multiplicaciOn y una divisiOn en paralelo. El divisor utiliza el metodo SRT de base 4 con dfgitos de cociente -2, -1, 0, 1 y 2. El R3010 pone de manifiesto que, para los chips que utilizan un multiplicador de 0(n), un divisor SRT puede operar lo suficientemente rápido para conseguir una relaciOn razonable entre multiplicacion y division
El Weitek 3364 tiene unidades independientes de suma, multiplicación y divisiOn, y a! igual que el MIPS, utiliza también la divisiOn SRT en base 4. Sin embargo, las operaciones de suma y multiplicaciOn en el chip utilizan pipeline. Las tres etapas de la suma son:
2.4. PROCESADORES DE PUNTO FLOTANTE. 21
2. Sumar seguido por desplazamiento (o viceversa).
3. Redondeo final.
Las etapas 1 y 3 emplean sOlo medio ciclo, permitiendo que la operaciOn completa se haga en dos ciclos, aün cuando el pipeline sea de tres etapas. El multiplicador utiliza la recodificaciOn de Booth base 8, lo que significa que debe calcular +3 por el multiplicador. Las tres etapas del pipelinedel multiplicador son:
1. Calcular el multiplicador.
2. Pasar a través del arreglo
3. Redondeo y suma final con propagación de carry.
Cuando se utiliza la doble precisiOn, se realiza dos veces la operaciOn. Y al igual que en la suma, la latencia de la operaciOn es de dos ciclos. De forma contraria al chip MIPS, este tiene rafz cuadrada por hardware, que utiliza el hardwarede la divisiOn. La relación de multiplicación de doble precision a divisiOn es 2:17. La gran disparidad entre multiplicacion y divisiOn se debe al hecho que la multiplicaciOn utiliza la recodificaciOn de Booth en base 8, mientras que la divisiOn utiliza un método de base 4. En el MIPS ainbas operaciones utilizan la misma base.
Una caracterfstica notable del TI 8847 es que hace la divisiOn por iteraciOn, pero significa que la multiplicaciOn y la divisiOn no se pueden realizar en paralelo corno en los otros dos chips. La suma utiliza pipeline de dos etapas.
1. Comparar exponentes, desplazar fracciones y sumar fracciones
2. NormalizaciOn y el redondeo.
La multiplicaciOn utiliza un árbol binario de sumadores de dIgitos con signo y tiene uria segmentaciOn de tres etapas.
1. Se pasa a través del arreglo usando la mitad de los bits.
2. Pasa la otra mitad
3. Convierte los dIgitos con signo a complemento dos.
Como sOlo hay un arreglo para la muitiplicaciOri, una nueva operaciOn solo puede iniciarse en ciclos alternos. Sin embargo, alentando ci reloj, los dos pasos a través del arreglo pueden hacerse en un solo ciclo. El surnador del TI8847 utiliza un algoritmo de seleccion de carry.
Estos tres chips ilustran las difereiit.es tendencias realizadas por disenadores con restric-ciones similares. Una de las cosas rnás interesantes sobre estos es la diversidad de algoritmos. Cada uno utiliza un algoritnio diferentes de suma. asf comO la multiplicaciOn. Lo que Si es
22 CAPITULO 2. ANTECEDENTES
2.5
Algunos sistemas de cómputo reconfigurable y
apli-caciones.
El Splash-2
[2,
3] es una computadora reconfigurable de gran escala, la cual contiene 256 FPGAs XC4O1O [9]conectados a una estaciOn de trabajo. Soporta dos modelos de programa-ción de la arquitectura, uno es un modelo SIMD (single instruction multiple data) donde unswitch crossbar propaga las instrucciones a todos los FPGAs PE (processing elements) en paralelo, y el otro modelo es un arreglo sistólico, donde un path de datos linear de 36 bits enlaza a los PE en una cadena linear. Las aplicaciones se programan en arquitecturas de comportamiento usando VHDL, utilizando declaraciones de entidades correspondientes a los PEs. Los procesos se sincronizan al sistema utilizando instrucciones de espera. La comunica-ción entre los procesadores se realiza mediante señales. Herramientas comerciales de síntesis transladan el VHDL al FPGA. También se utiliza una extension del C enfocado a paralelismo de datos. Algunas de las aplicaciones incluyen los siguientes resultados: Biisqueda de texto a velocidades del orden de los 50 MB/s, büsquedas en bases de datos genéticas con rendi— mientos superiores en varios Ordenes de velocidad a las supercomputadoras convencionales y procesamiento de video en tiempo real[3].
El proyecto PAM (Programmable Active Memory) fué el antecesor de la computadora DECPERle-1, un arreglo de 24 XC3090 con SRAM conectados a la memoria principal de una estaciOn de trabajo mediante un bus de 100 MB/s. Las aplicaciones se han desarrollado usando desde la vista del programador un arreglo bidimensional de bloques de lógica síncrona. Más recientemente, se ha usado el C++, pero no como una entrada de procedimiento de la sIntesis, si no como un HDL estructural para definir directamente la logica en el arreglo. PAM ha sido programada como un mapeador de visiOn en dos dimensiones, un sistema para resolver ecuaciones de calorimetría a 40 BIPS(billones de instrucciones por segundo), un sintetizador de sonido de 256 canales. PAM se utiliza en ci CERN como un calorimetro de Hadron, donde es la unica solucion a los requerimientos de dicho centro con respecto a ancho de banda y latencia [3].
PRISM-IT (Processor Reconfiguration through Instruction Set Metamorphosis) es un CPU fijo con unidades funcionales reconfigurables. Su compilador de C identifica las oportunidades parar sintetizar nuevas operaciones para añadirlas al juego de instrucciones del CPU, que están compiladas dentro de un FPGA y se cargan dinámicamente cuando hay demanda de elias. La aceleración a nivel operacional esta entre 6 y 83 veces, pero cuando se corren aplicaciones, ia aceleraciOn real es más baja [3].
El Nano Processores un microprocesador de 8 bits reconfigurable que ocupa solamente 40 bloques iOgicos dentro de un FPGA. Sn poder se ye aumentado con instrucciones de aplicación especIfica y programadas dentro del mismo FPGA [3].
2.5. ALGUNOS SISTEMAS DE COMPUTO RECONFIGURABLE YAPLICACIONES.23
necesitan y estos recursos pueden ser reutilizados para implementar un nümero arbitrario de funciones. DISC mejora la densidad del FPGA cambiando fIsicamente los módulos de las instrucciones a espacio disponible dentro del FPGA j6J.
Dentro de las aplicaciones a nivel general que pueden realizar las máquinas que utilizan el cOmputo reconfigurable, se pueden comentar las siguientes:
1. Operaciones binarias. La lógica reconfigurable puede realizar operaciones binarias muy eficientemente y con un excelente paralelismo. Cuando las aplicaciones requieren la evaluaciOn de operaciones binarias grandes y regulares, las máquinas reconfigurables puede ofrecer una ventaja significativa sobre los procesadores disponibles.
2. Aritméticas. Cuando se requieren hacer operaciones aritméticas que no se proveen en los ALU/FPU estándar, o cuando las operaciones aritméticas permiten un paralelismo sustancial a nivel de bits, hay un amplio campo para especializar la logica reconfigurable de manera que se puede obtener un mayor rendimiento.
3. EncriptaciOn/Decriptación/Compresion de datos. Estas aplicaciones requieren el uso de secuencias simples de aritmética y operaciones logicas a grandes secuencias de datos. Estas operaciones no son nativas a los procesadores tipicos. M~quinas
especializadas pueden proveer el operador adecuado y hacer uso del pa.ralelismo en Ia aplicaciOn para obtener un alto rendimiento.
4. Identificación de secuencias y cadenas. Reconociendo la estructura natural de la aplicaciOn y especializando la computadora reconfigurable para tomar ventaja de dicha estructura, los investigadores han podido tener muy alto rendirniento a tin bajo costo.
5. Ordenamiento. Las tareas de ordenamiento dan un paralelisrno de grab fino.
-Explotando este paralelismo, se puede realizar el ordenamiento de grandes tareas efi-cientemente con redes para ordenamiento construidas utilizando lOgica reconfigtirable. 6. Simulación de sistemas fisicos. La simulaciOn de fenómenos fIsicos requiere la evaluaciOn repetida de variables de estado usando cOmputos rnuy regulares, general-mente con una precision limitada. Las máquinas de cómputo especializado para evaluar sistemas particulares de ecuaciones pueden tener una ventaja significativa sobre los procesadores de propósito general.
7. Procesamiento de video e imágenes El grano fino y paralelismo a nivel bit disponi-ble en la mayorIa de las aplicaciones de procesainiento do imagenes hacen muy factidisponi-ble
Capítulo 3
Algoritmos de punto entero
3.1
Introducción.
Como se viO en el Capítulo 1, una de las partes más importantes, además de la aplicaciOn del cOmputo reconfigurable en esta tesis, es là impiementación de las unidades vectoriales, y es por eso que es necesario dar una introducciOn a los sistemas numéricos que se utilizan en las computadoras, al mismo tiempo, mostrar los algoritmos más importantes para el desarrollo de estas funciones. Priinero se manejarán los nilmeros de punto entero y en el siguiente capItulo se hará la extensiOn hacia ci punto flotante.
En términos generales los nümeros de punto fijo se tratan de dos formas, como enteros con signo o sin signo. En un mirnero entero sin signo, todos los bits se usan para expresar el valor absoluto del nümero. Por su parte, en los nilmeros enteros con signo, el hit mäs a là izquierda representa el signo y el resto de los bits representan là magnitud del entero. De manera general, los nümeros positivos se representan en complemento-2, esto Cs que el primer bit es cero y el resto de los dIgitos representan la magnitud. Los ni~merosiiegativos que se representan en complemento-2 tienen ci bit de signo en 1. Más especificamente, un nt~imeronegativo se representa por ci complemento-2 de su correspondiente ntirnero positivo. El complemento-2 de un nilmero se obtiene invirtiendo cada uno de los dfgitos binarios y añadiendo un 1 al bit de más bajo orden. Por ejemplo, los nümeros +26 y -26 se representan para un operando de 16 bits.
Este tipo de representaciOn numérica se puede considerar como l.a fracciOn de más bajo orden de un nilmero en ci cual ci bit de signo se puede extender indefinidaniente hacia là izquierda. Cuando un nümero es positivo, todos los hits a là izquierda del 1 mäs significativo se pueden considerar como 0. Por ci contrario, cuando ci iiürnero es negativo, todos los bits a la izquierda dci 0 más significativo son 1.
El máximo nümero positivo consiste de un carnpo entero con l’s y Un l)it de signo 0, y
26 CAPJ’TULO 3. ALGORITMOS DE PUNTO ENTERO
ci nümero negativo con su máximo valor absoluto consiste de un campo entero con D’s y un bit de signo 1.
Los mimeros en ci formato mencionado anteriormente no solamente pueden ser tratados como enteros. El punto de la rafz1 se supone que se encuentra en cuaiquier posiciOn del nilmero. Cualquiera que sea esta posiciOn debe ser fija para ci programador, quien tiene la responsabilidad de especificar su posiciOn y tenerla en cuenta. El punto de la raIz (o punto binario) se asume que se encuentra inmediatamente después del bit de más bajo orden. Esta representaciOn de nümeros se llama en las computadoras como formato entero o punto fijo.
Un nümero con un base y con signo puede ser positivo o negativo, pero no ambos. Considérese ci siguiente nümero con base r,
donde ci bit de signo an_i asume ci valor.
Dc esta forma, para una base 2, ci bit de signo a~_i=0 6 1. El resto de los dIgitos de A especifican la magnitud (cuando ~ 0) o, là magnitud en complemento-2 (cuando ~ 1).
Para nümeros positivos enteros, ci bit de signo a~_i~0 y los dIgitos restantes a~_
2 a1a0
contienen là magnitud. La magnitud del mimero
se denota como
Asf que un ni.imero entero positivo se puede representar como
(3.1)
y su m~gnitudtiene ci valor
Cuando r = 2, ésta es la suma familiar de n dIgitos binarios cuando a~_1=0. Por ejemplo,
Si n = 8, la magnitud de A= 0 11 0 11 0 1 es
‘El término plinto de la rafz se refiere a Ia base del sistema numérico utilizado ya sea, decimal, octal,
3.2. SUMADEPUNTOENTERO. 27
y se puede evaiuar como sigue:
Para nümeros negativos enteros, a~_~=1 y ci nilmero está representado por notaciOn de complemento-2. Vamos a definir
(A)+1
que sea la versiOn negativa del nümero A, ci cual sedefiniO por là EcuàciOn 3.1. Entonces
(A)~,
tiene un digito de signo con ci valor r-1. La representaciOn en complemento-r esEn esta notaciOn (A)+, = — A . Parà r = 2, n = 8, A y
(A)+1
definidas comoentonces
El rango de los enteros asociados con la representaciOn de punto fijo está determiniado por ci nilmero de bits n que se usan. El ilmite superior sc dctermina por ci entero positivo más grande contenido en un mimero de ii bits incluyendo la posiciOn de signo (2~1— 1) en
decimal, ci ilmite inferior de igual forma se determina por ci nümero m isnegativo contenido en un nümero den bits 1. El sobreflujo (overflow)ocurre citanido un nilniero positivo excede ci iImite superior, de igual forma un “bajoflujo” (undei:flow) ocurre cuando un nüinero negativo sobrepasa là cota inferior. Para ci complemento-2, existe lilt ilnico 0, ci cual es un vector de
(00 ••0)2.
3.2
Suma de punto entero.
30 CAPITULO 3. ALGORITMOS DE PUNTO ENTERO
Tabla 3.1: Tabla de Verdad para la suma binaria.
Figura 3.1: Sumador completo.
La tabla de verdad para las funciones de suma y carry de salida para sumar dos bits de igual peso a, yb2 en los vectores
y
se muestra en la Tabla 3 1 Nótese que en cada etapa el algoritmo de la suma debe ser capaz de manejar ci bit del carry de entradac~ de la etapa precedente de bajo orden. El carryde salida de la i-ésima etapa se denomina c2. Las ecuaciones boleanas para la suma y el carry del sumador completo son
Para realizar operaciones en paralelo, hay que propagar los carrys en una configuraciOii como se ye en la Figura 3.2. Los sumadores completos se conectan de tal forma que el carry de salida del sumador ies Ia entrada para el sumador i+ 1, para 0 <i < n— 2. La entrada
del carrydel sumador0 es conectada a un 0 lOgico para realizar la suma, y la salida de carry del sumador n1 puede ser utilizada para detección de sobreflujo. Debido a que ci carry se
28 CAPITULO 3. ALGORITMOS DE P UNTO ENTERO
Los sumadores de alta velocidad son escenciales, no solo para la suma si no también, para Ia resta, muitiplicaciOn, y la division. Aquf solo se mostrarán sumadores paralelos de dos operandos.
Las reglas de la suma binaria se presentan a continuación:
con una salida de carryen la siguiente columna a la izquierda, esto es:
La suma de 1 + 1 requiere un vector de 2 bits 1 0 para representar el valor de 2. Usando la regla anterior, la suma de 0 1 y 1 1 será calculada como:
El resultado de la suma es 0 0 y el carry de salida es 1.
Como se puede notar, la suma de vectores de bits es una operación similar a la de realizar la suma en papel con nümeros decimales. Los pares de bits se van añadiendo empezando del más bajo orden (a la derecha) y los acumulados (carrys) se van propagando hacia la izquierda. Si
y
son dos nümeros binarios a sumarse, entonces una suma de n bits se realizará en ci tiempo que sea necesario para que la señal de carry se propague a la posiciOn ri — 1, sumado al
retraso de generar n— 1 bits. La propagaciOn del carry puede ser acelerada de varias formas,
la más sencilla es utilizar lOgica de alta velocidad, otra forma es generar carrys utilizando lOgica de busqueda hacia adelante, la cual no dependa de la seflal de carry que se envfa de etapa en etapa del sumado. Esta técnica se vera en otra secciOn.