I
nstituto
P
olitécnico
N
acional
Escuela Superior de Ingeniería Mecánica y Eléctrica
EVALUACIÓN DEL DESEMPEÑO DE UNA RED DE
DATOS MULTIMEDIA CON TRÁFICO IP
T E S I S
PARA OBTENER EL TITULO DE:
INGENIERO EN COMUNICACIONES
Y ELECTRÓNICA
P R E S E N T A N
ARACELI NAVARRETE PÉREZ
SERGIO ALCÁNTARA GONZÁLEZ
Agradecimientos
Agradecimientos.
Quisiéramos expresar nuestros más sinceros agradecimientos a todas las personas
que de alguna forma contribuyeron al desarrollo de esta tesis y al logro de uno más de
nuestros objetivos.
A nuestros padres que fueron el apoyo y el impulso fundamental durante todo
nuestro desarrollo profesional.
A nuestros hermanos, por la compañía y el apoyo que nos brindan. Sabemos que
contamos con ustedes siempre.
A nuestros amigos, por su confianza y lealtad.
A esa persona especial que cada uno tenemos a nuestro lado y que constituyen una
parte esencial de nuestras vidas.
A los profesores de la E.S.I.M.E, que trascendieron en nuestro desarrollo, gracias
por abrirnos las puertas al conocimiento.
Al IPN por darnos la oportunidad de formar parte de esta gran institución.
Y a nuestro asesor Eric Gómez Gómez por su apoyo en la realización de este
trabajo.
A r a ce li Na v a r r e t e Pé r e z .
Índice de contenido.
Introducción. ... 1
Objetivo. ... 6
Alcances. ... 7
Planteamiento. ... 8
Organización de la Tesis. ... 9
1.
Convergencia De Redes. ... 11
1.1.
Introducción. ... 11
1.2.
Protocolo de internet (IP). ... 12
1.3.
Calidad de Servicio. ... 15
1.4.
Servicios Diferenciados e Integrados. ... 19
1.4.1.
Servicio de Mejor Esfuerzo. ... 20
1.4.2.
Servicios Integrados. ... 20
1.4.3.
Servicios Diferenciados. ... 21
2.
Políticas de Servicio y Gestión de Buffers. ... 24
2.1.
Introducción. ... 24
2.2.
Políticas de servicio. ... 24
2.3.
Gestión Del Buffer. ... 34
2.3.1.
Modelo Del Planificador... 35
2.3.2.
Componentes y Propiedades de un Planificador. ... 36
3.
Metodología. ... 39
3.1.
Generalidades. ... 39
3.2.
Elección del método de análisis. ... 42
3.3.
Simulador de redes Ns-2. ... 43
Índice de Contenido
4.1.
Introducción. ... 47
4.2.
Redes Y Servicios De Red. ... 50
4.3.
Fuentes de las Multimedias. ... 57
4.4.
Fuentes y Terminales Destino. ... 59
4.5.
Aplicaciones de Redes de Comunicaciones Multimedia. ... 62
4.5.1.
Video Streaming para Múltiples Usuarios. ... 62
4.5.2.
Videoconferencia. ... 65
5.
Desarrollo. ... 69
5.1.
Evaluación del desempeño de RED, Drop-Tail y SFQ como
algoritmos de planificación y gestores de buffer’s. ... 69
5.1.1.
Parámetros de evaluación. ... 69
5.1.2.
Escenarios de simulación. ... 69
5.1.3.
Descripción de la topología. ... 70
5.2.
Evaluación de la tasa de pérdidas, jitter y throughput en una red
multimedia implementando FIFO como algoritmo de gestión... 71
5.2.1.
Evaluación Jitter. ... 72
5.2.2.
Evaluación Throughput. ... 74
5.2.3.
Tasa De Pérdidas. ... 76
5.3.
Evaluación de la tasa de pérdidas, jitter y throughput en una red
multimedia implementando RED como algoritmo de gestión. ... 78
5.3.1.
Evaluación Jitter. ... 78
5.3.2.
Evaluación Throughput. ... 80
5.3.3.
Tasa De Pérdidas. ... 83
5.4.
Evaluación de la tasa de pérdidas, jitter y throughput en una red
multimedia implementando SFQ como algoritmo de gestión. ... 85
5.4.1.
Evaluación de Jitter. ... 85
5.4.2.
Evaluación Throughput. ... 87
5.4.3.
Tasa De Pérdidas. ... 90
Conclusiones ... 92
Trabajos Futuros ... 95
Índice de Figuras
Índice de Figuras.
Figura 1. Probabilidad de que un paquete sea descartado por el algoritmo RED. ... 28
Figura 2. Modelo del planificador. ... 36
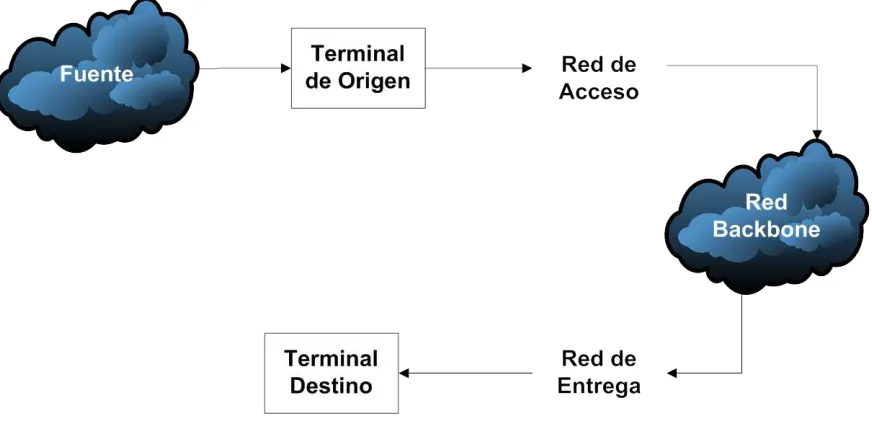
Figura 3. Componentes de una Red de Comunicaciones Multimedia ... 48
Figura 4. RSVP y multicast. (Adaptado de Peterson y Davie, 2000) ... 56
Figura 5. Red de Comunicaciones Multimedia. (ATM = Asynchronous Transfer Mode).
... 64
Figura 6. Topología de red. ... 70
Figura 7. Gráfica y tabla de los resultados del valor de jitter utilizando una cola de 25 y
FIFO. ... 72
Figura 8. Gráfica y tabla de los resultados del valor de jitter utilizando una cola de 50 y
FIFO. ... 72
Figura 9. Gráfica y tabla de los resultados del valor de jitter utilizando una cola de 100
y FIFO. ... 73
Figura10. Throughput de tráfico CBR, Video y FTP, con una cola 25 y FIFO. ... 74
Figura11. Throughput de tráfico CBR, Video y FTP, con una de cola 50 y FIFO. ... 75
Figura 12. Throughput de tráfico CBR, Video y FTP, con una de cola 100 y FIFO... 75
Figura 13. Tasa de pérdidas para tráfico mixto y 3 tamaños de cola aplicando
Drop-Tail. ... 77
Figura 14. Gráfica y tabla de los resultados del valor de jitter utilizando una cola de 25,
y RED. ... 78
Figura 15. Gráfica y tabla de los resultados del valor de jitter utilizando una cola de 50,
y RED. ... 79
Figura 16. Gráfica y tabla de los resultados del valor de jitter utilizando una cola de
100, y RED. ... 79
Figura 17. Throughput de tráfico CBR, Video y FTP, con un cola 25 y RED. ... 81
Figura 18. Throughput de tráfico CBR, Video y FTP, con un cola 50 y RED. ... 81
Figura 19. Throughput de tráfico CBR, Video y FTP, con un cola 100 y RED. ... 82
Figura 20. Tasa de pérdidas para tráfico mixto y 3 tamaños de cola aplicando RED. ... 84
Figura 21. Gráfica y tabla de los resultados del valor de jitter utilizando una cola de 25
y SFQ. ... 85
Figura 22. Gráfica y tabla de los resultados del valor de jitter utilizando una cola de 50
y SFQ. ... 86
Figura 23. Gráfica y tabla de los resultados del valor de jitter utilizando una cola de
100 y SFQ. ... 87
Figura 24. Throughput de tráfico CBR, Video y FTP, con una cola 25 y SFQ. ... 88
Figura 25. Throughput de tráfico CBR, Video y FTP, con una cola 50 y SFQ. ... 89
Índice de Figuras
Índice de Tablas.
Tabla 1. Mecanismos de control Basados en Velocidad ... 25
Tabla 2. Definición de los Parámetros en RED. ... 27
Tabla 3. Requerimientos de QoS para diferentes aplicaciones. ... 35
Tabla 4. Algunos de los simuladores existentes. ... 42
Tabla 5. Tabla descriptiva del archivo de traza resultado de la simulación. ... 45
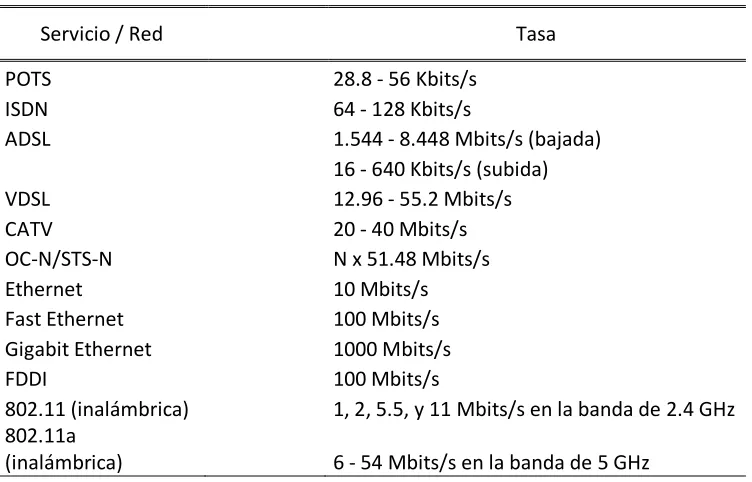
Tabla 6. Redes y Servicios de Red... 52
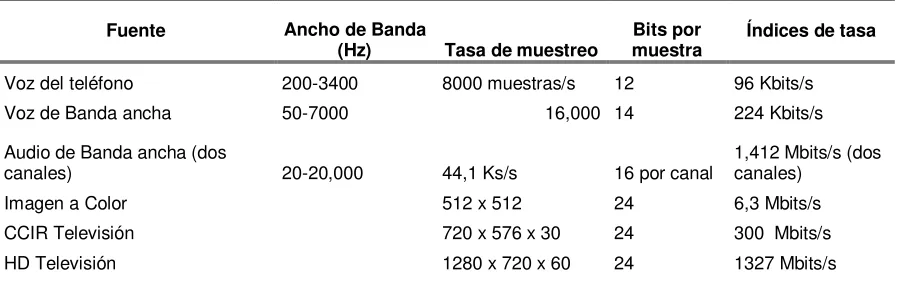
Tabla 7. Fuentes multimedia e índices de tasa típicos sin comprimir. ... 57
Tabla 8. Estándares del codificador de voz de banda ancha. ... 58
Introducción.
La tecnología de la información está cambiando la economía del mundo, la sociedad
y la vida diaria. El desarrollo de redes de comunicación hace posible que el usuario
transfiera información en forma de voz, video, correo electrónico o e-mail y archivos de
datos. Los siguientes casos pueden ser identificados en la evolución de las redes de
comunicación que proveen los servicios que el usuario necesita:
- Redes telefónicas.
- Redes de computadoras.
- Redes de televisión por cable.
- Redes inalámbricas.
Estas redes son muy diferentes; sin embargo, actualmente son capaces de ofrecer
servicios que eran exclusivos del campo de acción de otras redes con los logros de la
tecnología digital. Debido al enorme potencial económico y sus beneficios, la
convergencia de redes está en camino, en la cual la comunicación tradicional y los nuevos
servicios de comunicación como servicio de voz, datos y video, se espera que puedan ser
entregados sobre diferentes infraestructuras de red, pero esto no significa que sólo una
tecnología de red surgirá para sustituir a las demás. En su lugar, estas tecnologías serán
desplegadas durante mucho tiempo por razones económicas ya que se han hecho
grandes inversiones. Por lo tanto, el principal reto es cómo interconectar esta red
heterogénea de modo que pueda extenderse para proveer un amplio rango de calidad de
Introducción
Jamás el término de “autopistas de la información”, tuvo tanto sentido como en la
actualidad. El vertiginoso crecimiento de Internet y por tanto, del tráfico de datos que
circula por ella hace necesaria la construcción de nuevas autopistas, más rápidas,
seguras y extensas.
En el ámbito tecnológico, la palabra “convergencia” suena cada día con más fuerza.
Convergencia de datos, voz e imágenes en movimiento en un mismo medio, en una única
red, rápida y segura, que permita ofrecer a los usuarios una comunicación más eficiente.
El Protocolo de Internet, IP, es el lenguaje con que se comunica la Red, aparece ahora
también como el elemento integrador capaz de hacer posible la convergencia de todas las
necesidades de comunicación.
Las redes IP son abiertas, flexibles, robustas y estandarizadas; y constituyen la
única base posible sobre la que se apoyan la continua innovación y el desarrollo de
aplicaciones de valor agregado. Entre las ventajas que presenta IP, destaca la posibilidad
de integrar diversos servicios en una única red, una mejor interoperabilidad entre equipos
y la posibilidad de ofrecer nuevos servicios, entre los que podemos destacar los servicios
de multimedia.
En las eventuales congestiones de enlaces que son parte del recorrido del tráfico
entre dos equipos (host, o terminal) de distintas redes, cada paquete de información
compite por un poco de ancho de banda disponible para poder alcanzar su destino.
Típicamente, las redes operan en la base de entrega del mejor esfuerzo, donde todo el
tráfico tiene igual prioridad de ser entregado a tiempo, cuando ocurre la congestión, todo
este tráfico tiene la misma probabilidad de ser descartado.
En ciertos tipos de datos que circulan por las redes hoy en día, por ejemplo tráficos
información, que exista un gran ancho de banda disponible, y que los retrasos en los
envíos de estos paquetes de datos sean mínimos. Es por ello que surge la necesidad de
aplicar Calidad de Servicio (QoS) en el nivel del transporte de datos, métodos de
diferenciación de tráficos particulares con el fin de otorgar preferencia a estos datos
sensibles.
Se entiende por “Calidad de Servicio” a la capacidad de una red para sostener un
comportamiento adecuado del tráfico que transita por ella, cumpliendo a su vez con los
requerimientos de ciertos parámetros relevantes para el usuario final. Esto puede
entenderse también como el cumplimiento de un conjunto de requisitos estipulados en un
contrato (SLA: Service Level Agreement) entre un ISP (Internet Service Provider,
proveedor de servicios de Internet) y sus clientes.
Al contar con QoS, es posible asegurar una correcta entrega de la información
necesaria o crítica, para ámbitos empresariales o institucionales, dando preferencia a
aplicaciones de desempeño crítico, donde se comparten simultáneamente los recursos de
red con otras aplicaciones no críticas. QoS hace la diferencia, al prometer un uso eficiente
de los recursos ante la situación de congestión, seleccionando un tráfico específico de la
red, priorizándolo según su importancia relativa, y utilizando métodos de control y evasión
de congestión para darles un tratamiento preferencial. Implementando QoS en una red,
hace al rendimiento de la red más predecible, y a la utilización de ancho de banda más
eficiente.
Bajos niveles de calidad son fáciles de implementar usando mecanismos simples de
gestión, por ejemplo, controlando periódicamente el nivel de carga de una red y
aumentando los recursos de la red antes de que estén congestionados. Este esquema
podría servir para proporcionar un servicio predictivo. La calidad de servicio siempre se va
Introducción
pueda ofrecer cada subred. Por ello se necesitan mecanismos globales que gestionen la
calidad y negocien con las subredes la calidad de servicio individualmente.
La gestión de calidad de servicio en cada subred vendrá determinada por el modelo
de servicio, que podrá ser de servicios integrados o diferenciados, este modelo
determinará cómo se gestionan los recursos en la subred y la relación con el resto de las
subredes.
Un aspecto importante para gestionar la calidad de servicio es la señalización, es
decir, los mensajes que se envían a los distintos componentes de la red para gestionar los
recursos. Estos mensajes son necesarios para poder garantizar esta calidad de servicio
pero al costo de consumir recursos. En este sentido, si se aumenta la señalización entre
elementos se puede sobrecargar la red. Una alternativa es que se administre la red para
que sólo determinados dispositivos críticos participen en la señalización y el control de
admisión. En cambio, obtener una alta calidad de servicio, como puede ser el servicio
garantizado, es más complejo de solucionar. En general, hay que sobredimensionar los
recursos de la red y tenerlos asignados para poder garantizar este nivel de servicio. En
este sentido, se puede medir la calidad de servicio que ofrece la red en función de la
eficiencia de recursos que usa, este compromiso entre calidad y eficiencia es un aspecto
muy importante en el diseño de las redes en tiempo real. Normalmente, la calidad de
servicio es expresada por medio de parámetros que se negocian. Las necesidades
dependerán del tipo de aplicación y pueden variar durante la transmisión.
Durante el ciclo de vida de un sistema, el cuál comprende el diseño, la adquisición,
la explotación y la ampliación del mismo, es común que se lleven a cabo una o varias
evaluaciones de las prestaciones que ofrece dicho sistema, durante las cuales hay que
marcha, o bien detectar que componentes del sistema es necesario cambiar para
maximizar el aumento de prestaciones.
Dichas evaluaciones deben realizarse de forma objetiva, utilizando los parámetros
relevantes del sistema, cuyos efectos puedan ser medidos y analizados a lo largo del
tiempo o bien que puedan ser comparados con otros sistemas. Al realizar estas
evaluaciones también es necesario contar con algunas expectativas sobre el uso del
sistema. La simulación permite una solución práctica y económica para realizar dichas
Objetivo
Objetivo.
Evaluar el desempeño en la calidad de servicio (Qos) de una red de datos con
tráfico multimedia, tomando como criterio de evaluación la influencia de algoritmos de
gestión de buffers y de planificación de paquetes tales como Red, Drop-Tail (FIFO) y SFQ
Alcances.
EL presente trabajo de investigación abarca la implementación y comparación de
algoritmos de planificación (RED, FIFO y SFQ), evaluando su desempeño mediante la
obtención de parámetros como tasa de pérdidas, throughput y jitter sobre una red con
Planteamiento
Planteamiento.
Se parte de la suposición de que aumentar el tamaño del buffer, la cual es una
solución muy básica al congestionamiento en una red, no soluciona el problema de la
congestión en un punto nodal en una red multimedia ni de la pérdida de paquetes, por el
contrario a largo plazo el problema se hace mayor.
Se propone utilizar algoritmos de planificación para optimizar el desempeño de los
Organización de la Tesis.
A continuación se describe la estructura de la organización de esta Tesis:
Capítulo 1 Convergencia de Redes: en este capítulo se menciona la evolución de
las comunicaciones hacia la integración de servicios de voz, datos y video sobre una
misma red (Red Multimedia), gracias a tecnologías tales como el Protocolo de Internet
(IP) y la aplicación de Calidad de Servicio (QoS) entre otros elementos.
Capítulo 2 Políticas de Servicio y Gestión de Buffers: en este capítulo se brindan las
definiciones teóricas sobre Políticas de Servicio, diferencias entre un algoritmo de
planificación y uno de gestión de buffers y las descripciones sobre el funcionamiento de
algunos de estos.
Capítulo 3 Metodología: en este capítulo se describe el análisis aplicado para
determinar conforme a las necesidades y posibilidades, el método que mejor se adapte
para el cumplimiento del objetivo de esta tesis. Se muestra una tabla comparativa con los
diferentes simuladores existentes hoy en día y finalmente la descripción del seleccionado
(ns-2).
Capítulo-4 Comunicaciones Multimedia: Representaciones, Fuente, Redes y
Aplicaciones: en este capítulo se describe la teoría referente a las redes Multimedia,
evolución, aplicación, funcionamiento, video conferencias, entre otras consideraciones.
Capítulo 5 Desarrollo: en este último capítulo se muestran los resultados obtenidos
de la evaluación de la tasa de pérdidas, jitter y throughput en una red Multimedia
implementando Drop-Tail, RED y SFQ como algoritmos de gestión, así como el análisis
Organización de la Tesis
Finalmente, se da a conocer la conclusión a la que se llegó, así como
1. Convergencia De Redes.
1.1. Introducción.
Tradicionalmente, los servicios de telefonía y datos han estado soportados por
redes basadas en distintas tecnologías tales como:
– Redes telefónicas básicas que emplean técnicas de conmutación de circuitos para
el transporte de tráfico de voz.
– Redes que emplean técnicas de conmutación de paquetes para el tráfico de datos.
Esta diferenciación entre los tráficos de voz y datos suponía que era necesario tener
dos infraestructuras diferentes. El desarrollo y maduración de las técnicas de transmisión
de voz sobre redes de paquetes ha permitido el uso de una única infraestructura para la
transmisión de datos, voz y video conocida como “convergencia de redes” o
“convergencia de voz y datos”.
La convergencia de redes es ya una realidad. La era de las arquitecturas de red
complejas distinguidas por el servicio prestado esta finalizando para dar paso a una única
red polivalente, mas fácil de gestionar, de menores costes y capaz de soportar, con la
calidad requerida, todas las necesidades de comunicación de las empresas de forma
unificada.
El término convergencia, conocido también como redes multiservicio, o
comunicaciones IP, hace referencia a la integración de soluciones de datos, voz y vídeo
en una única plataforma de red (basada en IP). Como por ejemplo la voz sobre IP (VoIP)
que representa la conversión del tráfico de voz en datos que se transportan sobre una red
Convergencia de Redes
Esta convergencia de servicios de voz, datos y vídeo en una sola red implica
ventajas como:
– Un menor coste de capital (no se duplican las infraestructuras de voz y datos).
– Procedimientos simplificados de soporte, configuración y escalabilidad.
– Una mayor integración entre distintas ubicaciones.
– Permite la unificación de los medios de comunicación modernos (correo
electrónico, fax y correo de voz) en una sola aplicación.
1.2. Protocolo de internet (IP).
El Protocolo de Internet (IP, por sus siglas en inglés Internet Protocol) es un
protocolo orientado a no conexión usado tanto por el origen como por el destino para la
comunicación de datos a través de una red de paquetes conmutados.
En IP, las redes constituyentes están interconectadas mediante conmutadores de
paquetes especiales denominados gateways o routers. Los dispositivos de enrutamiento
IP dirigen la transferencia de paquetes IP en la Internet. Al tomar la decisión de
enrutamiento, los paquetes se encolan en una memoria temporal en espera de ser
retransmitidos sobre la siguiente red. Por lo que, los paquetes de los distintos usuarios se
colocan dinámicamente en estas memorias temporales. Las memorias subyacentes son
las encargadas de transferir los paquetes entre los dispositivos de enrutamiento.
El Protocolo de Internet está específicamente limitado a proporcionar las funciones
Router (Enrutador). Dispositivo hardware para interconexión de redes de computadoras que opera en la capa tres del modelo OSI.
necesarias para enviar un paquete de bits (un datagrama de Internet) desde un origen a
un destino a través de un sistema de redes interconectadas. No existen mecanismos para
aumentar la fiabilidad de datos entre los extremos del control de flujo, de la secuencia o
de otros servicios que se encuentran normalmente en otros protocolos
extremo-a-extremo, por lo que, al no garantizar nada sobre la recepción del paquete, éste podría
llegar dañado, en otro orden con respecto a otros paquetes, duplicado o simplemente no
llegar. Si se necesita fiabilidad, ésta es proporcionada por los protocolos de la
sus redes de soporte para proporcionar varios tipos de calidad de servicio
Este es utilizado por protocolos extremo-a-extremo en un entorno de Internet. El
cual utiliza a su vez protocolos de red locales para llevar el datagrama de Internet al
próximo gateway o host destino.
El protocolo de Internet implementa dos funciones básicas: direccionamiento y
fragmentación.
Los módulos de Internet usan las direcciones que se encuentran en el encabezado
del paquete IP para transmitir los datagramas hacia sus destinos. La selección de un
camino para la transmisión se llama enrutamiento. Estos mismos módulos usan campos
en el encabezado del paquete de IP para fragmentar y reensamblar los datagramas
cuando sea necesario para su transmisión a través de redes con una trama de menor
tamaño.
El modelo de operación se presenta cuando un módulo de Internet reside en cada
host y en cada gateway involucrado en la comunicación. Estos módulos comparten reglas
Convergencia de Redes
comunes para interpretar los campos de dirección, fragmentar y ensamblar datagramas.
Además, estos módulos (especialmente en los gateway) tienen procedimientos para
tomar decisiones de enrutamiento y otras funciones.
El protocolo de Internet utiliza cuatro mecanismos para prestar su servicio: TOS
(“Type of Service”), TTL (“Time To Live”), Opciones y Suma de Control de Encabezado
(“Checksum”).
TOS se utiliza para indicar la calidad del servicio deseado y es un conjunto abstracto
o generalizado de parámetros que caracterizan las elecciones de servicio presentes en
las redes que forman Internet. Esta indicación de tipo de servicio será usada por los
gateways para seleccionar los parámetros de transmisión efectivos para una red en
particular, la red que se utilizará para el siguiente salto, o el siguiente gateway al enrutar
un datagrama.
TTL es una indicación de un límite superior en el periodo de vida de un datagrama
de Internet. Se fija por el remitente del datagrama y se reduce en los puntos a lo largo de
la ruta donde se procesa. Si el tiempo de vida se reduce a cero antes de que el
datagrama llegue a su destino, el datagrama de Internet es destruido.
Las Opciones proporcionan funciones de control necesarias o útiles en algunas
situaciones pero innecesarias para las comunicaciones más comunes. Las opciones
incluyen recursos para marcas de tiempo, seguridad y enrutamiento especial.
El Checksum proporciona una verificación de que la información utilizada al
procesar el datagrama ha sido transmitida correctamente. Pero los datos pueden contener
Checksum. Es la suma de la cantidad de bits o bytes en una transmisión o un archivo que permite conocer si hubo alguna pérdida o
errores y si el checksum falla, el datagrama de Internet es descartado inmediatamente por
la entidad que detecta el error.
En el enrutamiento de mensajes desde un módulo de Internet a otro, los datagramas
pueden necesitar atravesar una red cuyo tamaño máximo de paquete es menor que el
tamaño del datagrama. Para evitar este inconveniente se proporciona un mecanismo de
fragmentación en el protocolo de Internet.
1.3. Calidad de Servicio.
La Calidad de Servicio (QoS, Quality of Service) es el efecto colectivo del
desempeño de un servicio, el cual determina el grado de satisfacción a la aplicación de un
usuario. Para que en una red pueda ofrecer el manejo de QoS extremo-a-extremo
(end2end), es necesario que todos los nodos o puntos de interconexión por los que viaje
el paquete de información, posean mecanismos de QoS que ofrezcan un desempeño
adecuado a la aplicación en cuestión. Estos puntos de interconexión a través de los
cuales viaja la información pueden ser enrutadores, conmutadores, incluso los puntos de
acceso al servicio (SAPs, Service Access Points) entre las capas del modelo de
comunicación que se use. Cuando se establece una conexión con un nivel de QoS
especificado, los parámetros de éste se traducen y negocian entre los diferentes
subsistemas involucrados. Solamente cuando todos los subsistemas han llegado a
acuerdos y pueden otorgar garantías respecto a los parámetros especificados, será que
se satisfagan los requerimientos de QoS de extremo a extremo.
Para garantizar la QoS se requiere de la participación de un conjunto de elementos,
Convergencia de Redes
1. Aplicaciones.- Dentro de este grupo se maneja la señalización necesaria para
hacer la negociación de parámetros con la red.
2. Acceso LAN.- En este otro grupo se define el tipo de arquitectura de red,
protocolos, mecanismos de calendarización y control de tráfico que se empleará, así
como control de admisión.
3. Acceso WAN.- Es la arquitectura de transporte de información que ofrece la
capacidad de mantener el mínimo de retardo y pérdidas de información, por medio de
mecanismos de diferenciación y control de tráfico.
Cuando inició la era de las comunicaciones, el objetivo más importante fue
conseguir que los paquetes llegaran a sus destinos, y el acceso confiable a la red se
convirtió en la principal preocupación en términos de QoS. Sin embargo, con un
incremento en la demanda del ancho de banda y el soporte simultáneo para diversos tipos
de servicio en la misma red de telecomunicaciones, la QoS se convierte en un factor
dominante en la evolución de las Redes de Nueva Generación (RNG) [1].
Aunque QoS está actualmente bajo fuertes discusiones entre los usuarios, es vista
de diversas formas por éstos, debido a que existen varios problemas ambiguos sobre
calidad de servicio [1]. Un servicio se advierte para ser de cierta calidad si puede
mantener constantemente el mismo nivel de calidad para un sistema dado y una
aplicación particular. Los usuarios de la red pretenden tener acceso a un mayor ancho de
banda para cualquier aplicación tan barato como sea posible. Sin embargo, los
proveedores de la red intentan maximizar la eficacia de la red y resolver las necesidades
específicas de QoS de los usuarios de la red al mismo tiempo. Debido a que cada usuario
tiene una definición distinta de QoS [6], enfocaremos nuestra atención sobre el punto de
del transporte de la red, procurando aumentar el volumen de datos entregados mientras
que se mantiene constante el comportamiento característico de ésta [2]. Desde que existe
el concepto de QoS, los siguientes parámetros son comúnmente utilizados para la
descripción del funcionamiento de la red:
- Rendimiento o ancho de banda: está definido por el número de bits que pueden
ser transmitidos con éxito sobre la red, en cierto período de tiempo. Generalmente el
rendimiento de las redes aumenta proporcionalmente a su carga. Después de cierta
carga, el rendimiento deja de aumentar; en la mayoría de los casos, puede incluso
comenzar a disminuir. Hay un parámetro asociado con el nombre de goodput para un
transporte confiable, como el TCP en el Internet, el cual retransmite el paquete si sucede
la pérdida de este. El goodput se define como el ancho de banda entregado al receptor,
con excepción de los paquetes duplicados.
- Retardo o latencia: está dado por el tiempo en que el mensaje viaja de su fuente al
destino en la red, que tiene tres componentes. El primero, es el retardo de propagación de
la velocidad de la luz, que ocurre porque nada puede viajar más rápido que la luz. En
segundo lugar, el retardo de la transmisión, que es la cantidad de tiempo necesario para
transmitir una unidad de datos. Tercero, puede ser el retardo de las colas o línea de
espera dentro de la red, puesto que los conmutadores de paquetes generalmente
necesitan almacenar los paquetes por un cierto tiempo antes de transmitirlos por un
enlace de salida. Observe que en la literatura, el término “switch” es utilizado por las redes
ATM, mientras que el término “router” se utiliza en el contexto del Internet, sin embargo,
en esta tesis sin distinción se refieren a los elementos de conmutación en las redes de
conmutación de paquetes.
Goodput. Eficiencia en el uso de los enlaces en una red.
Convergencia de Redes
- Probabilidad de pérdida: es una medida de la probabilidad de que el tráfico se
pierda. Hay un número de situaciones que da lugar a la pérdida del tráfico. Por ejemplo,
un paquete puede llegar a un buffer lleno y puede ser involucrado en una colisión, o al
establecer una solicitud de llamada puede llegar a un switch ocupado completamente sin
servicio de espera.
- Utilización del Sistema: es medido como la fracción de tiempo en la cual los
recursos están ocupados sirviendo a una solicitud, que esta dado por la razón del tiempo
ocupado y el tiempo total transcurrido en un cierto periodo. El período en el cual un
recurso no está siendo ocupado es llamado tiempo ocioso. Se tiene un fuerte interés en
que la carga esté balanceada, de modo que ningún enlace se utilice más que otro. Claro,
esto no siempre es posible.
Durante el proceso de negociación de QoS pueden suceder una serie de pasos.
Primero, los parámetros de QoS son mapeados o traducidos de una capa a otra.
Segundo, cada capa o subsistema deberá determinar si puede dar soporte al servicio
requerido (entrando en juego los algoritmos de control de admisión); de ser así, deberán
reservarse ciertos recursos para la sesión, solo hasta que todos los subsistemas hayan
aceptado los parámetros de QoS, porque de otra forma la sesión será rechazada.
Otro acrónimo relacionado con la QoS es CoS (“Classes of Service”, Clases de
Servicio). CoS implica que los diferentes servicios se categorizarán en clases diferentes,
las cuales, a su vez, serán tratadas individualmente. De modo que, antes de proveer una
mayor calidad de servicio a un cliente, aplicación o protocolo, se debe clasificar el tráfico,
y luego determinar la forma de manejo de las distintas clases de tráfico que se mueven
Los métodos más usuales para realizar la diferenciación y clasificación de tráfico
tienen como base alguno de los siguientes aspectos:
- Protocolo: Protocolos de red y transporte tales como IP, TCP, UDP, IPX
(“Extended IP”,IP Extendido), etc.
- Puerto del protocolo: Para protocolos de aplicación tales como Telnet, SAPs
(“Service Acces Point”, Punto de Acceso al Servicio) de IPX, etc.
- Dirección del Host: Origen y destino.
- Interfaz del dispositivo fuente: Interfaz sobre la cual el tráfico entra a un dispositivo
particular, conocida también como interfaz de ingreso.
Se realizá esta diferenciación para clasificar el tráfico y este se pueda apegar a los
mecanismos que implementan las políticas definidas por el administrador de la red.
1.4. Servicios Diferenciados e Integrados.
Durante los últimos años han surgido variados métodos para establecer QoS en
equipamientos de redes. Algoritmos avanzados de manejos de cola, modeladores de
tráfico (traffic shaping), y mecanismos de filtrado mediante listas de acceso (access-list),
han hecho que el proceso de elegir una estrategia de QoS sea más delicado. Cada red
puede tomar ventaja de distintos aspectos en implementaciones de QoS para obtener una
Traffic Shaping. Técnica que básicamente regula el ancho de banda asignando prioridad a ciertas cosas aplicando una serie de
reglas.
Telnet. Sistema que permite conectarse a un host o servidor en donde el ordenador cliente hace de terminal virtual del ordenador
servidor. En otras palabras, Telnet es un protocolo que permite acceder mediante una red a otra máquina y manejarla, siempre en
Convergencia de Redes
mayor eficiencia, ya sea para redes de pequeñas corporaciones, empresas o proveedores
de servicios de Internet.
Existen tres modelos en los que se divide el despliegue de calidad de servicio:
servicio del mejor esfuerzo, servicios integrados y servicios diferenciados.
1.4.1. Servicio de Mejor Esfuerzo.
Se le llama servicio de mejor esfuerzo (Best Effort) al que la red provee cuando
hace todo lo posible para intentar entregar el paquete a su destino, donde no hay garantía
de que esto ocurra. Una aplicación enviará datos en cualquier cantidad, cuando lo
necesite, sin pedir permiso o notificar a la red. Éste es el modelo utilizado por las
aplicaciones de Ftp y Http. Obviamente, no es el modelo apropiado para aplicaciones
sensibles al retardo o variaciones de ancho de banda, las cuales necesitan de un
tratamiento especial.
1.4.2. Servicios Integrados.
Para proporcionar diferentes niveles de QoS, el IETF ha desarrollado el modelo de
servicios integrados (IntServ: Integrated Services), que requiere sean reservados recursos
como el ancho de banda y la memoria temporal para un flujo de datos dado y así asegurar
que la aplicación recibe su QoS solicitada. El modelo de Servicios Integrados provee a las
aplicaciones de un nivel garantizado de servicio, negociando parámetros de red, de
extremo a extremo. La aplicación solicita el nivel de servicio necesario para ella con el fin
necesarios antes de que la aplicación comience a operar. Estas reservaciones se
mantienen en pie hasta que la aplicación termina o hasta que el ancho de banda
requerido por ésta sobrepase el límite reservado para dicha aplicación.
El modelo requiere la utilización de clasificadores de paquetes para identificar que
recibirán un cierto nivel de servicio, también requiere de un gestor de salida de paquetes
para tratar el envío de diferentes flujos de paquetes de manera que se asegura que se
satisfacen los compromisos de QoS. El control de admisión también consiste en
determinar si un dispositivo de enrutamiento tiene los recursos necesarios para aceptar un
flujo nuevo.
El modelo IntServ se basa en el Protocolo de Reservación de Recursos (RSVP)
para señalizar y reservar la QoS deseada para cada flujo en la red. Debido a que la
información de estados para cada reserva necesita ser mantenida por cada enrutador a lo
largo de la ruta, la escalabilidad para cientos de miles de flujos a través de una red
central, típicos de una red óptica, se convierte en un problema.
1.4.3. Servicios Diferenciados.
Debido a las cuestiones de escalabilidad y complejidad asociadas al modelo de
servicios integrados, IETF ha introducido otro modelo de servicios llamado modelo de
servicios diferenciados, DS (differentiated Services), que esta pensado para que sea más
simple y más escalable. La escalabilidad se alcanza de dos maneras: Primero el servicio
por flujo se reemplaza por un servicio por agregados; Segundo, el procesamiento
complejo se mueve del núcleo de la red a los extremos. Este modelo incluye un conjunto
Convergencia de Redes
o protocolos con determinadas prioridades sobre el resto del tráfico en la red. DiffServ
cuenta con los enrutadores de bordes para realizar la clasificación de los distintos tipos de
paquetes que circulan por la red. El tráfico de red puede ser clasificado por dirección de
red, protocolo, puertos, interfaz de ingreso o cualquier tipo de clasificación que pueda ser
alcanzada mediante el uso de listas de acceso, en su variante para la implementación de
QoS. Al utilizar el modelo DiffServ se obtienen varias ventajas. Los enrutadores operan
más rápido, ya que se limita la complejidad de la clasificación y el encolado. Se minimizan
el tráfico de señalización y el almacenamiento. En DiffServ, se definen clases de servicio,
cada flujo particular de datos es agrupado en un tipo de clase, donde son tratados
idénticamente. Los enrutadores internos sólo están interesados del comportamiento por
salto (PHB: Per Hop Behavior), marcado en la cabecera del paquete. Esta arquitectura
permite a DiffServ rendir mucho mejor en ambientes de bajo ancho de banda, y provee de
un mayor potencial que una arquitectura IntServ.
Originalmente, para el protocolo IPv4 se diseñó el campo ToS (Type of Service)
para capacitar el marcado de paquetes con un nivel de servicio requerido. Esta definición
no se utilizó mayormente debido a la ambigüedad de su significado, por lo que más tarde
se convirtió en el denominado campo DSCP (Differentiated Services Code Point). Este
campo sí tuvo una aceptación global y se asumió una interpretación estándar que permitió
a las redes planificar metodologías basándose en ésta. Tal fue el éxito de esta nueva
definición, que fue incluida para ofrecer las mismas ventajas en el protocolo IPv6 en el
denominado campo TC (Traffic Class).
Una vez que existe la capacidad de marcar los paquetes utilizando DSCP, es
necesario proveer del tratamiento apropiado para cada una de estas clases. La colección
de paquetes con el mismo valor DSCP circulando hacia una dirección determinada, es
pertenecer al mismo BA. El PHB se refiere a la programación, encolamiento, limitación y
modelamiento del comportamiento de un nodo, basado en el BA perteneciente del
Políticas de servicio y Gestión de Buffers
2. Políticas de Servicio y Gestión de Buffers.
2.1. Introducción.
La clasificación del tráfico, como sabemos, es una de las ventajas de algunas
tecnologías de redes, que a su vez permite la integración de todo tipo de QoS. Sin
embargo, esto puede ser también una importante fuente de problemas por la posibilidad
de que existan flujos de entrada en los conmutadores que generen situaciones de
injusticia con respecto a los recursos de otras fuentes de datos. La posibilidad de que se
presente éste mal comportamiento, de unas fuentes exigentes con respecto a otras que lo
son menos, puede acabar generando situaciones de inanición y también de congestión.
En muchas tecnologías de redes, el control de congestión se sigue confiando a
protocolos de extremo-a-extremo como TCP. Lo que permite disponer de routers y
conmutadores muy sencillos, sin embargo, al no llevar un tratamiento adecuado del tráfico
en todos los extremos de la comunicación, pueden surgir situaciones críticas, debido a
que los flujos con buen comportamiento podrían ser afectados por flujos más ambiciosos
que consumieran todos los recursos de la red. Además, los extremos de la comunicación
deberán implementar algoritmos de control homogéneos, para evitar que aquellos
usuarios que empleen algoritmos de control más estrictos puedan autogenerar situaciones
de rechazo respecto a aquellas fuentes de tráfico con un control menos riguroso.
2.2. Políticas de servicio.
Las políticas de servicio se utilizan para seleccionar los paquetes a transmitir en una
Las políticas de planificación pueden ser clasificadas en work-conserving y
non-work-conserving. Una política es de work-conserving si nunca deja el enlace de salida en
estado de inactividad mientras haya paquetes en la cola. Al contrario, una política
non-work-conserving puede dejar el enlace de salida en estado de inactividad incluso si la cola
no está vacía. La tabla 1 presenta la clasificación de algunas de las políticas de
planificación más conocidas [3]. Por otro lado, las políticas de work-conserving tienden a
incrementar las ráfagas de tráfico, mientras que las políticas non-work-conserving pueden
ser usadas para limitar el tráfico a ráfagas sin embargo los planificadores
non-work-conserving tienen mayor promedio de retraso de paquetes que sus contrapartes
work-conserving, pero pueden ser usados en aplicaciones en donde los tiempos de respuesta
son más importantes que los retrasos. En términos generales, las políticas
work-conserving son más fáciles de implementar y requieren una gestión de buffers más
sencilla.
Las redes de comunicación multimedia suelen usar mecanismos basados en
velocidad. Este planteamiento puede clasificarse según lo que se observa en la siguiente
tabla.
Servicios work-conserving Servicios non-work-conserving
FIFO
Random Early Detection Weighted Fair Queueing Stochastic Fairness Queuing Entre otros…
Jitter Earliest - Due - Date Stop - and - Go
[image:33.612.94.509.501.616.2]Hierarchical Round - Robin
Tabla 1. Mecanismos de control Basados en Velocidad
A continuación se describen algunos de los esquemas de planificación
work-conserving y non-work-conserving.
Políticas de servicio y Gestión de Buffers
a) FIFO (también llamado Drop–Tail). Es el tipo más simple de encolamiento, se
basa en el siguiente concepto: el primer paquete en entrar a la interfaz, es el
primero en salir. El esquema de Drop -Tail es la técnica tradicional para manejar la
longitud de la cola en los routers, en dicho algoritmo se fija una longitud máxima a
las colas, y los paquetes se aceptan en éstas hasta que alcanzan la longitud
máxima, después los paquetes entrantes se rechazan o descartan, hasta que la
cola disminuye [4]. El nombre surge del hecho de que el paquete que ha llegado
recientemente (es decir, el que está al final de la cola) es descartado cuando la
cola está llena. FIFO ha servido por años al Internet, pero presenta dos
desventajas: una corresponde al lock - out o bloqueo (donde una conexión
monopoliza el enlace) y la otra sería la sincronización global de las ventanas de
TCP [5].
Es adecuado para interfaces de baja velocidad, sin embargo, no para bajas, ya
que FIFO es capaz de manejar cantidades limitadas de ráfagas de datos. No tiene
mecanismos de diferenciación de paquetes.
b) RED (Random Early Detection). Este algoritmo al igual que FIFO también sirve
los paquetes en el orden de llegada, pero la gestión del buffer es mucho más
sofisticada que en drop-tail y previene que se presenten los problemas de: lock-out
y sincronización global de las ventanas de TCP. RED se propone como una
alternativa de solución para evitar la congestión descartando aleatoriamente los
paquetes de flujos arbitrarios [6].
El algoritmo RED está diseñado para utilizarse conjuntamente con TCP, que
detecta la congestión por medio de tiempos de espera (o de algunos otros medios
Early ”, del acrónimo RED, sugiere que el router descarte los paquetes que tuvo
anteriormente para indicar a la fuente que disminuya su ventana de congestión
antes de lo normal. Es decir, el router descarta algunos paquetes antes de que el
espacio del buffer se ocupe completamente para prevenir que se presente la
congestión (retrasando el flujo de la fuente anterior), con la expectativa de no tener
que eliminar ráfagas de tráfico posteriormente.
La forma en cómo RED decide cuándo y a qué paquete descartar puede
demostrarse con una cola FIFO. En vez de esperar a que la cola se llene
completamente y descartar cada paquete que llega como en Drop Tail, RED
descarta sólo los paquetes que llegan con cierta probabilidad siempre que la
longitud de la cola exceda el nivel acordado. Además, RED distingue entre la
congestión transitoria y la congestión persistente en la red. Los parámetros usados
en el algoritmo son definidos en la tabla 2.
Parámetro Definición
S Tiempo típico de transmisión Tamaño normal de la cola Tiempo actual
Inicio del tiempo ocioso de la cola Longitud promedio de la cola
Probabilidad de marcar/descartar el paquete
[image:35.612.149.437.429.605.2]Umbral mínimo para la cola Umbral máximo para la cola Peso de la cola
Tabla 2. Definición de los Parámetros en RED.
Para tratar de evitar la congestión, RED realiza dos operaciones principales: uno
corresponde al cálculo del tamaño promedio de la cola y el otro a la toma de
Políticas de servicio y Gestión de Buffers
El algoritmo RED calcula el tamaño promedio de la cola usando un filtro pasa
bajas con una distribución exponencial (“ Exponential Weighted Moving Average ”,
EWMA). Entonces, a corto plazo el incremento del tamaño promedio de la cola
que resulta de una ráfaga de tráfico o de una congestión transitoria no
provoca un incremento significativo en el . El tamaño promedio de la cola se
calcula para cada paquete que llega, si la cola no está vacía,
, de lo contrario, .
RED decide qué paquete será descartado con ayuda de dos parámetros:
(umbral mínimo) y (umbral máximo). Cada que llega un paquete al router,
RED calcula el nuevo tamaño promedio de la cola y lo compara con y
. Determina el tamaño promedio de la cola bajo el cual ningún paquete
será descartado , mi-entras especifica el tamaño promedio
de la cola sobre el cual todos los paquetes deberán descartarse . Si
el tamaño promedio de la cola está entre los dos umbrales
, el paquete entrante es descartado con una probabilidad que varía
[image:36.612.154.491.517.670.2]linealmente entre 0 y , como se representa en la figura 1.
Similar a Drop -Tail, RED es incapaz de penalizar los flujos irresponsables ya que
después de cierto tiempo impone la misma tasa de pérdida a todos los flujos sin
importar su ancho de banda. Un flujo irresponsable es el que falla al reducir su
carga ofrecida al router en respuesta a un aumento en la tasa de pérdida. El
porcentaje de paquetes perdidos de cada flujo en un período de tiempo es casi
igual, así que los usuarios irresponsables aún pueden ocupar una gran proporción
del ancho de banda del enlace y privarlo de flujos responsables como TCP. Por lo
tanto, se requiere adicionar mecanismos al algoritmo RED para prevenir que el
tráfico no adaptativo gane ancho de banda a expensas del tráfico adaptativo.
c) FQ (Fair Queuing). Una de las disciplinas de servicio de paquetes en los puntos
nodales de la red, es PS (Processor Sharing) que emplea colas FIFO separadas
para cada sesión que comparte un enlace. En PS todas las sesiones en espera
reciben igual tamaño de ancho de banda, independientemente del tamaño de los
paquetes que tengan: PS es una disciplina ideal cuando el servidor es capaz de
servir N sesiones simultáneas.
En realidad, el servidor envía un paquete cada vez. Se propone un algoritmo de
aproximación a paquetes de PS llamado FQ (Fair Queueing) con asignación justa
del ancho de banda y protección contra las fuentes mal intencionadas. Además,
para los servidores que se ajustan o aproximan a la disciplina de servicio PS, las
fuentes pueden medir más eficientemente el estado de la red. De este modo
queremos destacar que PS es una disciplina de servicio que permite el diseño y la
implementación de algoritmos de congestión muy robustos.
Los algoritmos FQ (Fair Queueing) aportan atractivas ventajas y han sido
Políticas de servicio y Gestión de Buffers
para la asignación justa de ancho de banda. Sin embargo, su costo de
implementación completa en la red puede ser no aceptable para aplicaciones de
alta velocidad ya que, aparte de la complejidad de programación, requieren que el
mecanismo FQ mantenga información de estado, gestione los buffers de entrada,
realice planificación de los paquetes y, todo ello, sobre la base de la separación de
los flujos.
No obstante, varias investigaciones han demostrado que las propuestas de control
de congestión extremo a extremo pueden ser mejoradas de una forma substancial
si en los routers se aplican técnicas de asignación justa del ancho de banda
disponible en la red ya que, además de proteger unas fuentes de otras, permiten
que en la red puedan coexistir diversas políticas de control de congestión. Del
mismo modo, estas investigaciones también reconocen que la asignación justa de
ancho de banda juega un papel necesario, aunque a veces no favorable, en el
control de congestión. Así, la mayor parte de propuestas en este campo parten de
dos premisas importantes, por un lado los mecanismos de asignación justa del
ancho de banda son necesarios, y por otro, la complejidad de estos mecanismos
es un factor importante para su adopción en las redes.
Lo que parece claro, en cualquier propuesta que realicemos en este sentido, será
mucho más compleja de implementar que el clásico encolamiento FIFO que ha
sido el más utilizado. Como es sabido, en FIFO los paquetes son servidos en el
orden de llegada, y los buffers son gestionados siguiendo una sencilla estrategia
drop-tail, según la cual, los paquetes entrantes son descartados cuando el buffer
está lleno. Pero FIFO carece de la justicia que se buscó con FQ y sus variantes, y
con mecanismos de abandono por flujos como FRED (Flow Random Early
diversos flujos por separado, de forma que, para cada paquete que llega, hay que
clasificarlo en su flujo correspondiente, actualizar las variables de estado de cada
flujo y realizar operaciones (encolar_paquete, descartar_paquete, priorizar_flujo,
etc.) en función del estado de cada flujo.
d) PQ (Priority Queueing). El encolamiento de Prioridad PQ consiste en un conjunto
de colas, clasificadas desde alta a baja prioridad. Cada paquete es asignado a una
de estas colas, las cuales son servidas en estricto orden de prioridad. Las colas de
mayor prioridad son siempre atendidas primero, luego la siguiente de menor
prioridad y así. Si una cola de menor prioridad está siendo atendida, y un paquete
ingresa a una cola de mayor prioridad, ésta es atendida inmediatamente. Este
mecanismo se ajusta a condiciones donde existe un tráfico importante, pero puede
causar la total falta de atención de colas de menor prioridad (starvation).
e) CQ (Custom Queuing). Para evadir la rigidez de PQ, se opta por utilizar
Encolamiento Personalizado CQ. Permite al administrador priorizar el tráfico sin
los efectos laterales de inanición de las colas de baja prioridad, especificando el
número de paquetes o bytes que deben ser atendidos para cada cola. Se pueden
crear hasta 16 colas para categorizar el tráfico, donde cada cola es atendida al
estilo Round-Robin. CQ ofrece un mecanismo más refinado de encolamiento, pero
no asegura una prioridad absoluta como PQ. Se utiliza CQ para proveer a tráficos
particulares de un ancho de banda garantizado en un punto de posible congestión,
asegurando para este tráfico una porción fija del ancho de banda y permitiendo al
Políticas de servicio y Gestión de Buffers
f) WFQ (Weighted Fair Queueing). WFQ, es un método automatizado que provee
una justa asignación de ancho de banda para todo el tráfico de la red, utilizado
habitualmente para enlaces de velocidades menores a 2048 [Mbps]. WFQ ordena
el tráfico en flujos, utilizando una combinación de parámetros. Por ejemplo, para
una conversación TCP/IP, se utiliza como filtro el protocolo IP, dirección IP fuente,
dirección IP destino, puerto de origen, etc. Una vez distinguidos estos flujos, el
enrutador determina cuáles son de uso intensivo o sensibles al retardo,
priorizándolos y asegurando que los flujos de alto volumen sean empujados al final
de la cola, y los volúmenes bajos, sensibles al retardo, sean empujados al principio
de la cola. WFQ es apropiado en situaciones donde se desea proveer un tiempo
de respuesta consistente ante usuarios que generen altas y bajas cargas en la red,
ya que WFQ se adapta a las condiciones cambiantes del tráfico en ésta. Sin
embargo, la carga que significa para el procesador en los equipos de
enrutamiento, hace de esta metodología poco escalable, al requerir recursos
adicionales en la clasificación y manipulación dinámica de las colas.
g) Class-Based WFQ. WFQ tiene algunas limitaciones de escalamiento, ya que la
implementación del algoritmo se ve afectada a medida que el tráfico por enlace
aumenta; colapsa debido a la cantidad numerosa de flujos que analizar. CBWFQ
fue desarrollada para evitar estas limitaciones, tomando el algoritmo de WFQ y
expandiéndolo, permitiendo la creación de clases definidas por el usuario, que
permiten un mayor control sobre las colas de tráfico y asignación del ancho de
banda. Algunas veces es necesario garantizar una determinada tasa de
transmisión para cierto tipo de tráfico, lo cual no es posible mediante WFQ, pero sí
determinadas según protocolo ACL, valor DSCP, o interfaz de ingreso. Cada clase
posee una cola separada, y todos los paquetes que cumplen el criterio definido
para una clase en particular son asignados a dicha cola. Una vez que se
establecen los criterios para las clases, es posible determinar cómo los paquetes
pertenecientes a dicha clase serán manejados. Si una clase no utiliza su porción
de ancho de banda, otras pueden hacerlo. Se pueden configurar específicamente
el ancho de banda y límite de paquetes máximos (o profundidad de cola) para
cada clase. El peso asignado a la cola de la clase es determinado mediante el
ancho de banda asignado a dicha clase.
h) Low Latency Queuing. El Encolamiento de Baja Latencia (LLQ: Low-Latency
Queueing) es una mezcla entre Priority Queueing y Class-Based Weighted-Fair
Queueing. Es actualmente el método de encolamiento recomendado para Voz
sobre IP (VoIP) y Telefonía IP, que también trabajará apropiadamente con tráfico
de videoconferencias. LLQ consta de colas de prioridad personalizadas, basadas
en clases de tráfico, en conjunto con una cola de prioridad, la cual tiene
preferencia absoluta sobre las otras colas. Si existe tráfico en la cola de prioridad,
ésta es atendida antes que las otras colas de prioridad personalizadas. Si la cola
de prioridad no está encolando paquetes, se procede a atender las otras colas
según su prioridad. Debido a este comportamiento es necesario configurar un
ancho de banda límite reservado para la cola de prioridad, evitando la inanición del
resto de las colas. La cola de prioridad que posee LLQ provee de un máximo
retardo garantizado para los paquetes entrantes en esta cola, el cual es calculado
Políticas de servicio y Gestión de Buffers
i) Stochastic Fairness Queueing. Ya que el planificador de WFQ necesita
mantener la información del estado del flujo, se han hecho intentos para reducir la
complejidad de la implementación. Un esquema importante cuyo propósito es
aproximar el FQ, en un costo de implementación mucho menor, es el Stochastic
Fairness Queueing. SFQ clasifica los paquetes en un número más pequeño de
colas que el FQ por una modificación en la función, así que la cantidad de
variables de estado en SFQ es considerablemente reducida mientras su
funcionamiento puede aproximarse al del WFQ original.
2.3. Gestión Del Buffer.
Mientras que las políticas de servicio desempeñan un papel importante en los
requerimientos de QoS para la red, esta es solamente eficaz si hay suficientes buffers
para almacenar los paquetes entrantes. Las velocidades actuales de conexión se
encuentran en el orden de gigabits por segundo, así que la cantidad de memoria
requerida para almacenar el tráfico durante periodos transitorios de congestión puede ser
muy grande y exceder la cantidad de memoria de los routers. Por lo tanto, los paquetes
que llegan durante los periodos de congestión serán descartados. En consecuencia, han
sido propuestos diferentes esquemas de gestión de buffers en función de diversas
compensaciones entre funcionamiento y complejidad [4] [3] [7].
Los routers pueden manejar sus buffers formando diferentes colas. Por un lado el
planificador mantiene una cola común para todas las conexiones, que normalmente
proveen la misma calidad de servicio para todo el tráfico. Por otro lado, el planificador
distintos anchos de banda y limitar el retardo entre las distintas conexiones. Con una cola
intermedia y manteniendo la estructura del buffer por clases, el planificador sirve todos los
paquetes de las conexiones de una clase con la misma garantía de calidad de servicio.
De esta manera, el planificador puede proporcionar diferentes niveles de calidad de
servicio entre las distintas clases, mientras que las conexiones dentro de una clase
comparten la misma calidad de servicio. La clase de servicio, por lo tanto, nos permite
balancear la complejidad y el funcionamiento entre una garantía del servicio por conexión
y una garantía compartida del servicio única.
2.3.1. Modelo Del Planificador.
Los algoritmos de planificación son componentes importantes en la provisión de
calidad garantizada de parámetros de servicio tales como delay, delay jitter, tasa de
pérdida de paquetes o troughtput, por mencionar algunos.
Para muchas aplicaciones, es importante que cierta calidad de servicio QoS sea
conocida, debido al crecimiento acelerado. Algunas aplicaciones están atendiendo
cambios sustanciales en la infraestructura de la red actual. Especialmente la emergencia
de aplicaciones con diferentes parámetros como: troughout, loss rate, delay, jitter o delay
jitter, dichos requerimientos marcan la necesidad por una red capaz de soportar diferentes
niveles de servicios, contrario a un nivel de servicio best effort. La tabla 3 muestra
requerimientos típicos de QoS para algunas clases de servicio:
Clase Aplicación
Nrt-VBR non-real-time variable bit rate ABR available bite rate
UBR unspecified bit rate CBR constant bit rate
Rt-VBR real time variable bit rate
Políticas de servicio y Gestión de Buffers
Para conocer los amplios requerimientos de QoS de las aplicaciones, pueden ser
usados los algoritmos de tráfico de scheduling. Como lo muestra la figura 2, la función de
un algoritmo de scheduling es seleccionar la sesión del siguiente paquete a ser
transmitido de tal manera que el planificador controla el orden en que se van a transmitir
los paquetes y determinar cómo van a interactuar estos en las diferentes conexiones. Este
[image:44.612.200.446.259.373.2]proceso de selección está basado en los requerimientos de QoS para cada sesión.
Figura 2. Modelo del planificador.
2.3.2. Componentes y Propiedades de un Planificador.
En el diseño de los esquemas de planificación es deseable para contar con
características tales como: eficiencia del enlace, retardo, aislamiento, imparcialidad,
throughput, degradación, entre otros. Dependiendo del requerimiento específico, algunos
de estos parámetros pueden ser más importantes que otros, y la elección de los mismos
estará en función de los requerimientos de QoS.
a) Utilización eficiente del enlace. El algoritmo debe de utilizar el enlace
eficientemente. Esto implica que el planificador no debería asignar un periodo de
transmisión para una sesión con un enlace actualmente dañado puesto que la
b) Límite de retardo. El algoritmo debe ser apto para proveer límites de retardo
garantizados para sesiones individuales con el fin de apoyar a las aplicaciones
sensibles a retardos.
c) Imparcialidad. El algoritmo debe de redistribuir los recursos disponibles
imparcialmente a través de las sesiones. Deberá proveer imparcialidad entre
sesiones libres de errores y sesiones propensas a errores.
d) Throughput. El algoritmo debe proveer throughputs garantizados para sesiones
libres de errores y garantizar throughputs de términos largos para todas las
sesiones.
e) Implementación de complejidad. Un algoritmo de baja complejidad es necesario en
redes de alta velocidad en las cuales las decisiones de scheduling tienen que ser
tomadas rápidamente.
f) Degradación suave de servicio. Una sesión que ha recibido un servicio excesivo a
expensas de sesiones cuyos enlaces fueron defectuosos debe experimentar una
degradación suave del servicio al abandonar el exceso de servicio para revestir
sesiones cuyos enlaces están ahora en buen estado.
g) Aislamiento. El algoritmo debe de aislar una sesión de los efectos dañinos o del
mal comportamiento de otras sesiones. Las garantías de QoS para una sesión
deben ser mantenidas aún en la presencia de sesiones cuyas demandas exceden
Políticas de servicio y Gestión de Buffers
h) Consumo de energía. El algoritmo debe de tener en cuenta la necesidad de
prolongar la vida útil de una batería tratándose de una estación móvil.
i) Terminación de sesión retardo/ancho de banda. Para la mayoría de los
planificadores, el retardo está firmemente ligado con las tasas reservadas, esto es,
una tasa reservada más alta provee un menor retardo. Sin embargo, algunas
aplicaciones de gran ancho de banda, como exploradores web, pueden tolerar
relativamente retardos largos.
Escalabilidad. El algoritmo debe operar eficientemente al tiempo que crece el
3. Metodología.
3.1. Generalidades.
Para la evaluación de los métodos y parámetros planteados en el desarrollo de este
trabajo se hace necesaria la utilización de alguna herramienta de medición que se ajuste
a nuestras necesidades, a continuación se plantean nuestras opciones y se elige la más
adecuada para lograr nuestro objetivo.
La evaluación del desempeño es útil cuando se pretende optimizar el
funcionamiento de los sistemas con el fin de proveer un servicio más eficiente de la red a
los usuarios [8].
Para este propósito, existen tres técnicas para la evaluación:
- Medición.
- Modelado Analítico.
- Simulación.
Las mediciones son ampliamente recomendadas cuando se cuenta con la
infraestructura necesaria para efectuar la medición. Este método de evaluación es más
preciso, es menos flexible y más costoso con respecto a los métodos por simulación y
modelado analítico. El modelado analítico resulta conveniente cuando se pretende hacer
abstracciones de fenómenos físicos, construyendo, inicialmente un modelo matemático
que se aproxime al fenómeno de estudio en cuestión. Por último, la simulación incorpora
Metodología
relación al modelado analítico y es una buena solución cuando no se tiene la
infraestructura necesaria para efectuar mediciones.
Los tipos de simulaciones conocidos son: Emulación, Simulación Monte Carlo,
Simulación trace-driven y Simulación de eventos discretos.
Una simulación estática o sin variable en el tiempo es llamada simulación Monte
Carlo. Este tipo de simulación se utiliza para fenómenos de modelo probabilístico que no
cambian sus características con el tiempo. A diferencia de las simulaciones dinámicas que
requieren la generación de números pseudo-aleatorios. Las simulaciones Monte Carlo
también son usadas para evaluar expresiones no-probabilísticas usando métodos
probabilísticos.
Una simulación trace-driven se maneja generalmente por un archivo de traza. Este
tipo de simulación se utiliza usualmente en el análisis o valoración de los algoritmos de
administración de recursos. Análisis de caché, algoritmos de planificación y algoritmos
para dinámicas de asignación de recursos de la red son algunos ejemplos de casos
donde simulaciones trace-driven han sido usadas satisfactoriamente.
Una simulación utilizando un modelo de estado discreto del sistema es llamada
simulación de eventos discretos. Contrariamente a la simulación de eventos continuos,
que es aquella en la que el estado del sistema toma valores continuos. Los modelos de
estado continuo son usados en simulaciones químicas, donde el estado del sistema es
descrito por la concentración de una substancia química. En sistemas computacionales,
se utilizan modelos de eventos discretos cuando el estado del sistema es descrito por el