Bases de Datos M´etrico-Temporales
Anabella De Battista , Andr´es Pascal
Departamento de Sistemas de Informaci´on
Universidad Tecnol´ogica Nacional
Fac. Reg. Concepci´on del Uruguay
Entre R´ıos, Argentina
{debattistaa, pascalj}@frcu.utn.edu.ar
Norma Edith Herrera
Departamento de Inform´atica
Universidad Nacional de San Luis
San Luis, Argentina
Gilberto Gutierrez
Facultad de Ciencias Empresariales
Universidad del Bio-Bio
Chill´an, Chile
Contexto
El presente trabajo se desarrolla en el ´ambito del Gru-po de Investigaci´on en Bases de Datos (Proy. Nro 25-D040) perteneciente al Departamento de Sistemas de la Universidad Tecnol´ogica Nacional, Facultad Regio-nal Concepci´on del Uruguay, cuyo objetivo principal es el estudio de m´etodos de acceso, procesamiento de consultas y aplicaciones de bases de datos no tradi-cionales.
Resumen
Las bases de datos m´etrico-temporales constituyen un nuevo modelo de bases de datos orientado al proce-samiento de consultas por similitud en un intervalo o instante de tiempo. Este modelo est´a basado en la combinaci´on de espacios m´etricos con bases de da-tos temporales. Para resolver eficientemente consul-tas m´etrico-temporales, se han propuesto varios ´ındi-ces cuyas evaluaciones emp´ıricas demuestran que son competitivos. En este trabajo estamos interesado en el dise˜no de ´ındices eficientes para el procesamiento de consultas m´etricos temporales.
Palabras claves: Espacios M´etricos, Bases de Da-tos Temporales, Bases de DaDa-tos M´etrico-Temporales, ´Indices
1. INTRODUCCI ´ON
Las operaciones de b´usquedas en una base de datos requieren de alg´un soporte y organizaci´on especial a nivel f´ısico. En el caso de las bases de datos cl´asicas, la organizaci´on de la informa-ci´on se basa en el concepto de b´usqueda exac-ta sobre datos estructurados. Esto significa que la informaci´on se organiza en registros con campos completamente comparables. Una b´usqueda en la base retorna todos aquellos registros cuyos cam-pos coinciden con los aportados en la consulta (b´usqueda exacta). Otra caracter´ıstica importante de las bases de datos cl´asicas es que capturan s´olo un estado de la realidad modelizada, usualmente el m´as reciente. Por medio de las transacciones, la base de datos evoluciona de un estado al siguiente descartando el estado previo.
exacta carece de inter´es y tercero resulta de in-ter´es mantener todos los estados de la base de da-tos y no s´olo el m´as reciente a fin de poder con-sultar el instante o intervalo de tiempo de vigen-cia de dichos objetos. Como soluci´on a esta pro-blem´atica surgen modelos que permiten procesar esta clase de datos. Entre estos nuevos modelos encontramos los siguientes:
Espacios m´etricos [1, 2, 6, 8, 9, 10, 5, 17, 12, 13], que permiten almacenar objetos no estructu-rados y realizar b´usquedas por similitud sobre los mismos. Un espacio m´etrico es un par(U, d) don-deUes un universo de objetos yd:U×U →R+ es una funci´on de distancia definida entre los ele-mentos de U que mide la similitud entre ellos. Una de las consultas t´ıpicas en este nuevo modelo de bases de datos es la b´usqueda por rango, deno-tado por(q, r)d, que consiste en recuperar los
ob-jetos de la base de datos que se encuentren como m´aximo a distanciarde un elementoqdado.
Bases de datos temporales [16, 11], que incor-poran al tiempo como una dimensi´on, por lo que permiten asociar tiempos a los datos almacena-dos. Existen tres clases de bases de datos tempo-rales en funci´on de la forma en que manejan el tiempo: de tiempo transaccional (transaction ti-me), donde el tiempo se registra de acuerdo al or-den en que se procesan las transacciones; de tiem-po vigente, que almacenan el momento en que el hecho ocurri´o en la realidad (puede no coin-cidir con el momento de su registro) y bitempo-rales, que integran la dimensi´on transaccional y la dimensi´on vigente a trav´es del versionado de los estados, es decir, cada estado se modifica para actualizar el conocimiento de la realidad pasada, presente o futura, pero esas modificaciones se rea-lizan generando nuevas versiones de los mismos estados.
Bases de datos m´etrico-temporales [3, 4, 15], que permiten almacenar objetos no estructu-rados con tiempos de vigencia asociados y realizar consultas por similitud y por tiempo en forma simult´anea. Formalmente un Espa-cio M´etrico-Temporal es un par (U,d), donde
U =O ×N ×N, y la funci´on d es de la
for-ma d : O ×O → R+
. Cada elemento u ∈ U es una triupla(obj, ti, tf), dondeobj es un objeto
(por ejemplo, una imagen, sonido, cadena, etc) y
[ti, tf]es el intervalo de vigencia deobj. La
fun-ci´on de distancia d, que mide la similitud entre dos objetos, cumple con las propiedades de una m´etrica (positividad, simetr´ıa y desigualdad trian-gular). Como un ejemplo de aplicaci´on podemos mencionar una base de datos de rostros de delin-cuentes y cada foto tiene una intervalo de vigen-cia asovigen-ciado, que representa el intervalo de tiem-po en que el delincuente ten´ıa el aspecto repre-sentado en esa foto; en este caso ser´ıa de inter´es, dada una foto y un intervalo de tiempo, poder re-cuperar de la base todos aquellos rostros pareci-dos al dado en el intervalo de tiempo especifica-do. Formalmente una consulta m´etrico-temporal se define como una 4-upla (q, r, tiq, tf q)d, tal que
(q, r, tiq, tf q)d = {o/(o, tio, tf o) ∈ X∧d(q, o) ≤
r∧(tio ≤tf q)∧(tiq ≤tf o)}
Una forma trivial de resolver una consulta m´etrico-temporal, sin realizar un barrido secuen-cial sobre todos los elementos de la bases de da-tos, es construir un ´ındice m´etrico agreg´andole a cada objeto el intervalo de tiempo de vigencia del mismo. Luego, ante una consulta (q, r, tiq, tf q)d
primero se utiliza el ´ındice m´etrico para descar-ta aquellos objetos obj que est´an a distancia ma-yor que r de q; posteriormente se realiza un ba-rrido secuencial sobre el conjunto de elementos no descartados por el paso anterior a fin de de-terminar cu´ales objetos son realmente respuesta a la consulta, es decir, cu´ales tienen un intervalo de vigencia que se superpone con[tiq, tf q].
La desventaja que tiene esta soluci´on trivial es que no se usa la componente temporal para mejo-rar el filtrado en el ´ındice; en este proceso s´olo se aprovecha la componente m´etrica. Una mejor es-trategia es que durante el proceso de b´usqueda se utilice tanto la componente m´etrica como la com-ponente temporal para descartar elementos.
ele-u1 u10 u5 u13 u3 u12
u11 u7 u15 u14 u4 u6 u2 u9 u8 0 5 6 7
4
u5 u11
6 5 4 3 2 0
[image:3.595.62.291.92.183.2]7 7 3 4 5 3 6
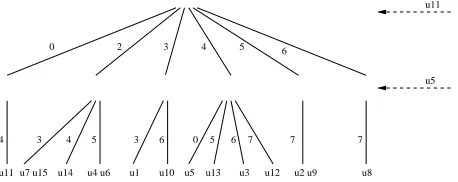
Figura 1:Un ejemplo de un FHQT sobre un conjunto de 15 elementos
mento p (pivote) que puede ser elegido arbitra-riamente, o mediante alg´un procedimiento de se-lecci´on de pivotes [7], del universoU. Para cada distanciaise crea el conjuntoCiformado por
to-dos aquellos elementos de la base de datos que est´an a distanciai dep. Luego, para cada Ci no
vac´ıo se crea un hijo del nodo correspondiente a p, con r´otuloi, y se construye recursivamente un FHQT teniendo en cuenta que todos los sub´arbo-les del mismo nivel usar´an el mismo pivote como ra´ız. Este proceso recursivo se contin´ua hasta lo-grar que todas las hojas est´en en un mismo ni-vel y tengan menos de b elementos, siendo b un valor fijado previamente. La figura 1 muestra un ejemplo de un FHQT conjunto de 15 elementos en los que se ha elegido u11 como pivote en el primer nivel yu5 como pivote del segundo nivel. Ante una consulta(q, r)d, se comienza por la ra´ız
y se descartan todas aquellas ramas con r´otulo i tal que i /∈ [d(p, q)−r, d(p, q) + r] siendo p el pivote utilizado en la ra´ız. La b´usqueda contin´ua recursivamente en todos aquellos sub´arboles no descartados, utilizando el mismo criterio.
Damos a continuaci´on una breve rese˜na de los ´ındices m´etricos-temporales que se basan en el FHQT:
FHQT-Temporal [15]. Este ´ındice es una adapta-ci´on del Fixed Height Queries Tree (FHQT) en la que se agrega un intervalo de tiempo en ca-da nodo del ´arbol. Este intervalo representa el per´ıodo m´aximo de vigencia para todos los ob-jetos del sub´arbol cuya ra´ız es dicho nodo. En cada nodo hoja, este intervalo es el per´ıodo total de vigencia de los objetos que contiene. Para ca-da nodo interior, el intervalo se calcula tomando el tiempo inicial m´ınimo, y el tiempo final m´axi-mo de sus hijos. Cuando se realiza una consulta
m´etrico-temporal se procede de la siguiente ma-nera: en cada nivel del ´arbol se filtran los sub´arbo-les hijos por el intervalo de tiempo de la consulta y luego de acuerdo a la distancia entre la consul-ta y el pivote. Al llegar al ´ultimo nivel, se realiza una b´usqueda secuencial sobre las hojas que no fueron descartadas seleccionando los objetos que cumplen con las condiciones temporales y de si-militud.
Historical-FHQT [4]. Consiste en una lista de instantes v´alidos donde cada uno contiene un FHQT correspondiente a todos los objetos vigen-tes en dicho instante. Esta estructura es eficiente en bases de datos m´etrico-temporales en las que los objetos tienen vigencia en un solo instante de tiempo. Los FHQT tienen distintas profundidades en funci´on de la cantidad de elementos que de-ban indexar. La cantidad de pivotes utilizada en un ´arbol se calcula como ⌈log2(|oi|)⌉ donde |oi|
es la cantidad de objetos vigentes en el instantei. De esta manera se evita que haya ´arboles con ma-yor profundidad de la necesaria, con el fin de que la estructura no tenga un costo excesivo en alma-cenamiento. Las consultas m´etrico-temporales se efect´uan de la siguiente manera: en primer lugar se seleccionan los instantes incluidos en el inter-valo de consulta. Luego se realizan consultas por similitud usando cada uno de los FHQT corres-pondientes, y finalmente se unen los conjuntos re-sultantes.
los conjuntos resultantes y se compara cada ele-mento de ese conjunto con la consulta. .
2. L´INEAS DE INVESTIGACI ´ON Y DESARROLLO
Nuestra principal l´ınea de estudio e inves-tigaci´on es el desarrollo de ´ındices m´etrico-temporales eficientes. El trabajo en curso se pue-de resumir en los siguientes puntos:
• Se sabe que la dimensionalidad de un espa-cio m´etrico afecta el desempe˜no de los ´ındices [10]. En bases de datos m´etrico-temporales podr´ıa suceder que la dimensi´on de un conjunto de ele-mentos en el instanteisea distinta a la dimensi´on del conjunto de elementos en otro instantej y en ese caso las decisiones tomadas con respecto a la construcci´on del ´ındice deber´ıan variar de un ins-tante a otro. Por esta raz´on, un aspecto interesante a estudiar es el concepto de dimensionalidad apli-cado a bases de datos m´etrico-temporales con el fin de encontrar una definici´on que se adecue a es-te nuevo modelo de bases de datos y que permita comprender mejor el desempe˜no de los ´ındices.
• En base al punto anterior, se puede dise˜nar un ´ındice h´ıbrido que permita tener distintos ´ındices m´etricos en distintos instantes de tiempo, seg´un sea la dimensionalidad del conjunto de elementos almacenados en cada instante.
• Los ´ındices desarrollados hasta el momento se basan en el supuesto de que la memoria princi-pal tiene capacidad suficiente como para mante-ner tanto el ´ındice como la base de datos. Si esto no es as´ı, la cantidad de accesos a memoria secun-daria realizados durante el proceso de b´usqueda es un factor cr´ıtico en la performance del ´ındice [18]. Nos proponemos explorar t´ecnicas de pagi-nado que sean aplicables a los ´ındices m´etrico-temporales a fin de lograr que los mismos resulten eficientes tambi´en en memoria secundaria.
• Otro aspecto interesante a estudiar es el refe-rido al espacio necesario para mantener el ´ındice, dado que esto decide si el ´ındice se mantendr´a en
memoria principal o en memoria secundaria. Una forma de reducir el espacio utilizado es tratar de reutilizar sub´arboles: si un sub´arbol del instantei est´a tambi´en en el instantej (conj > i), enton-ces el instantej deber´ıa reutilizar el sub´arbol del instantei en lugar de crearlo de nuevo. Esto im-plica dise˜nar un algoritmo que permita detectar sub´arboles isomorfos.
3. RESULTADOS OBTENIDOS/ESPERADOS
Se espera contar con ´ındice eficiente m´etrico-temporal en memoria secundaria que sea eficien-te tanto en los tiempos de respuesta como en el espacio ocupado por el mismo.
4. FORMACI ´ON DE RECURSOS HUMANOS
El trabajo desarrollado hasta el momento for-ma parte del desarrollo de dos Tesis de Maestr´ıa en Ciencias de la Computaci´on, una de ellas fue defendida y aprobada en marzo del corriente a˜no. Se cuenta con el asesoramiento del Dr. Gilberto Guti´errez, de la Universidad del Bio Bio, Chile. El grupo cuenta adem´as con dos alumnos beca-rios que se est´an iniciando en las tem´aticas desa-rrolladas por el grupo.
REFERENCIAS
[1] R. Baeza-Yates. Searching: an algorithmic tour. In A. Kent and J. Williams, editors, Encyclopedia of Computer Science and Te-chnology, volume 37, pages 331–359. Mar-cel Dekker Inc., 1997.
[2] R. Baeza-Yates, W. Cunto, U. Manber, and S. Wu. Proximity matching using fixed-queries trees. In Proc. 5th Combinatorial Pattern Matching (CPM’94), LNCS 807, pages 198–212, 1994.
la Computaci´on, Buenos Aires, Argentina, 2006.
[4] De Battista, A. Pascal, G. Gutierrez, and N. Herrera. Un nuevo ´ındice m´etrico-temporal: el historical fhqt. In Actas del XIII Congreso Argentino de Ciencias de la Computaci´on, Corrientes, Agentina, 2007.
[5] S. Brin. Near neighbor search in large me-tric spaces. In Proc. 21st Conference on Very Large Databases (VLDB’95), pages 574– 584, 1995.
[6] W. Burkhard and R. Keller. Some approa-ches to best-match file searching. Comm. of the ACM, 16(4):230–236, 1973.
[7] B. Bustos, G. Navarro, and E. Ch´avez. Pi-vot selection techniques for proximity sear-ching in metric spaces. In Proc. of the XXI Conference of the Chilean Computer Scien-ce Society (SCCC’01), pages 33–40. IEEE CS Press, 2001.
[8] E. Ch´avez and K. Figueroa. Faster proxi-mity searching in metric data. In Procee-dings of MICAI 2004. LNCS 2972, Springer, Cd. de M´exico, M´exico, 2004.
[9] E. Ch´avez, J. Marroqu´ın, and G. Navarro. Fixed queries array: A fast and economi-cal data structure for proximity searching. Multimedia Tools and Applications (MTAP), 14(2):113–135, 2001.
[10] E. Ch´avez, G. Navarro, R. Baeza-Yates, and J.L. Marroqu´ın. Searching in metric spa-ces. ACM Computing Surveys, 33(3):273– 321, September 2001.
[11] C. S. Jensen. A consensus glossary of tem-poral database concepts. ACM SIGMOD Re-cord, 23(1):52–54, 1994.
[12] I. Kalantari and G. McDonald. A data struc-ture and an algorithm for the nearest point problem. IEEE Transactions on Software Engineering, 9(5):631–634, 1983.
[13] G. ˜Navarro. Searching in metric spaces by spatial approximation. In Proc. String Processing and Information Retrieval (SPI-RE’99), pages 141–148. IEEE CS Press, 1999.
[14] A. Pascal, A. De Battista, G. Gutierrez, and N. Herrera. Indice metrico-temporal event-fhqt. In Actas del XIIII Congreso Argentino de Ciencias de la Computaci´on, La Rioja, Argentina, 2008.
[15] A. Pascal, De Battista, G. Gutierrez, and N. Herrera. Procesamiento de consultas m´etrico-temporales. In XXIII Conferen-cia Latinoamericana de Inform´atica, pages 133–144, San Jos´e de Costa Rica, 2007.
[16] B. Salzberg and V. J. Tsotras. A comparison of access methods for temporal data. ACM Computing Surveys, 31(2), 1999.
[17] J. Uhlmann. Satisfying general proxi-mity/similarity queries with metric trees. In-formation Processing Letters, 40:175–179, 1991.