INSTITUTO POLITÉCNICO NACIONAL
ESCUELA SUPERIOR DE INGENIERÍA MECÁNICA Y ELÉCTRICA
“
APLICACIÓN WEB PARA EL MANEJO DE
SUSTANCIAS Y RESIDUOS QUÍMICOS
”
T E S I S
Q U E P A R A O B T E N E R E L T Í T U L O D E : INGENIERO EN COMUNICACIONES Y ELECTRÓNICA
P R E S E N T A N
Gallardo Martínez Erick
Silva Sohn Servando So Yong
ASESORES:
M. en C.Felipe Durán Federico M. en C. Zavala Mejía Genaro
ESCUELA SUPERIOR DE INGENIERIA MECANICA
y
ELECTRICA
UNIDAD PROFESIONAL" ADOLFO LOPEZ MATEOS"
REPORTE TECNICO
QUE PARA OBTENER EL TITULO DE INGENIERO EN COMUNICACIONES Y ELECTRÓNICA
POR LA OPCION DE TITULACION CURRICULAR
DEBERA(N) DESARROLLAR C. ERICK GALLARDO MARTÍNEZ
C. SERVANDO SO YONG SILVA SOHN
"APLICACIÓN WEB PARA EL MANEJO I?E SUSTANCIAS Y RESIDUOS QUÍMICOS"
DISEÑAR E IMPLEMENTAR UNA APLICACIÓN WEB LA CUAL CONTENGA UNA BASE DE DATOS DEL INSTITUTO POLITÉCNICO NACIONAL PARA APOYAR LOS MATERIALES QUÍMICOS Y RESIDUOS QUE NO SE UTILICEN EN CIERTOS LABORATORIOS REASIGNÁNDOLOS A OTROS LABORATORIOS PARA SU APROVECHAMIENTO.
• ANALIZAR Y ESTRUCTURAR EL DISEÑO DE LA APLICACIÓN WEB y BASE DE DATOS • DISEÑAR Y ELABORAR LA APLICACIÓN WEB Y LA BASE DE DATOS EN BASE A LOS
PLANTEADO EN LA RPOPUESTA DE SOLUCIÓN PARA FINES DE PRUEBA Y AFINACIÓN
MÉXICO D.F. A 16 DE NOVIEMBRE DE 2011
ASESORES
FELIPE DURAN
2
Objetivo
Diseñar e implementar una aplicación WEB la cual contenga una base de datos del Instituto Politécnico Nacional para aprovechar los materiales químicos y residuos que no se utilicen en ciertos laboratorios reasignándolos a otros laboratorios para su aprovechamiento.
Objetivos Particulares
Analizar y estructurar el diseño de la aplicación WEB y base de datos.
Diseñar y elaborar la aplicación WEB y la base de datos en base a lo
planteado en la propuesta de solución para fines de prueba y afinación.
Instalar el servidor WEB donde se alojará la información y portal.
Lanzar la prueba o piloto del servicio en una unidad académica (UPIBI).
3
Justificación
Actualmente con los múltiples problemas ambientales que han sido provocados por el abuso de los recursos naturales por parte del hombre ha planteado la necesidad de crear la llamada “conciencia ecológica” o “conciencia verde”.
Las acciones usualmente enfocadas a cuidar el medio ambiente es la reutilización de los materiales, y esto es precisamente el enfoque que se le quiere dar a nuestro proyecto, en lugar de tirar los residuos químicos por la cañería sería mejor ponerlos a disposición de otros laboratorios que puedan darle algún uso útil.
Además, derramar sustancias químicas al drenaje ocasiona deterioro en las tuberías teniendo que dar mayor mantenimiento preventivo y/o correctivo a las instalaciones lo cual ocasiona gastos adicionales, sin tomar en cuenta la contaminación que pueda ocasionar al sistema fluvial nacional.
La ingeniería de comunicaciones y electrónica ha desarrollado herramientas que permiten la comunicación e interacción a distancia entre personas y organizaciones. Entre estas herramientas se encuentran las bases de datos, redes de computadoras e internet.
4
Resumen Ejecutivo
La evolución de la tecnología ha modificado drásticamente los sistemas de información en los últimos años. Anteriormente, una base de datos tenía que estar guardada en un medio de almacenamiento y para tener acceso a ella, había que tener este último físicamente para poder leerlo con algún dispositivo y posteriormente agregar más información. Con la revolución en la última década de los servicios de internet y la alta difusión que los proveedores de este servicio han tenido, hoy en día es posible acceder a bases de datos que se encuentran en servidores al otro lado del mundo, desde la comodidad de nuestros hogares, o en general desde cualquier lugar donde exista una conexión a internet.
El concepto de aplicación WEB es diferente al de una página WEB por el hecho de que esta aplicación tiene la posibilidad de realizar operaciones avanzadas, y trabajar en conjunto con bases de datos. Para esto, se requiere un servidor que mantenga el sitio, y realice los procesos en la base de datos y los almacene para que posteriormente puedan ser accedidos de manera remota desde una computadora por medio de internet.
A medida que avanza la tecnología el internet se ha vuelto una herramienta bastante importante dado que este tipo de aplicaciones pueden ser utilizadas de manera remota, con tan solo acceder a una determinada IP. Con el paso de los años la tendencia es más que clara; poco a poco todos los servicios y programas que utilizamos hoy en día se verán trasladados a servidores WEB a los cuales podremos acceder de manera remota sin siquiera tener la aplicación instalada. A este tipo de computación a la que nos dirigimos se le denomina “Cloud Computing”, o computación en nube, haciendo referencia a que siempre se pueden acceder a los datos que se encuentran “arriba”, en la “nube” como una metáfora de internet.
Con este nuevo paradigma, grandes empresas como Google y Microsoft, han decidido ofrecer nuevos servicios utilizando el cómputo en nube para satisfacer varias necesidades. Uno de los servicios más prestados en la actualidad es el servicio de almacenamiento de información mediante una base de datos que puede ser utilizada para cientos de objetivos mediante una aplicación WEB. La mayoría de los sitios de internet incluyen una base de datos de sus clientes, siendo esta la manera más básica del uso de bases de datos.
Sin embargo, otras empresas han decidido ir un paso adelante con la aplicación de base de datos, y le han dado distintos usos como el servicio de compra y ventas en un sitio WEB, páginas de intercambios de distintos materiales, venta de archivos digitales multimedia (videos, música, libros, etc.) y hasta las más recientes redes sociales que han crecido de manera acelerada en la última década.
5
lo posible todo tipo de sustancias y residuos químicos que por alguna razón no son útiles para otros.
Por medio de un sistema de datos, se pretende realizar poco a poco un gran centro de información donde los profesores, investigadores, estudiantes y profesionistas puedan acceder a ofertar y demandar toda aquella sustancia, materia, reactivo o residuo químico que requiera de otro lugar, o que desee poner a disposición para ser aprovechado por alguien más. De igual manera, se creará una base de datos de todas aquellas personas que trabajan en este medio, con la información del lugar y laboratorio donde trabajan, la institución a la que pertenecen, su área, y datos personales para contactarse en caso de necesario.
Dentro de los servicios que cumplen con estas funciones, se destacan 2 lenguajes de programación orientados a diseño y creación de páginas WEB orientadas a ser interpretadas del lado del servidor. Por un lado se encuentra el Pre-procesador de hipertexto (PHP), creado en 1994 y categorizado como software libre. Por otro lado se encuentran las Páginas de Servidor Activo (ASP), tecnología creada por Microsoft y que requiere de Licencia.
Dado el conocimiento de lenguajes de programación como Visual C# y las ventajas que ofrece, se ha elegido la tecnología ASP de Microsoft para realizar la aplicación WEB en conjunto con Microsoft SQL Server 2008 para trabajar con bases de datos. Para el servidor se utilizará el sistema operativo Windows Server 2003 o en su defecto la versión más reciente 2008.
Una de las razones principales por las cuales se ha decidido realizar este proyecto, es que además de ser un proyecto con un enfoque “ecológico”, existen un sinfín de instituciones y personas que podrían participar. En un inicio, la aplicación podría aplicarse a una institución en particular, pero posteriormente más empresas o instituciones podrían irse añadiendo, y finalmente convertirse en un estándar de la disposición de residuos, que si bien no parece ser un proceso difícil, en realidad es laborioso, tardado, costoso y complicado por las amplias situaciones que se pueden llegar a dar.
Para la realización de este proyecto, nos apoyamos en técnicas de diseño de páginas WEB, así como el planteamiento y generación de bases de datos. Adicionalmente se utilizaron procesos de ingeniería de software enfocados a la creación de aplicaciones WEB.
El proyecto consta en general de cuatro partes básicas:
Estudio de las necesidades de laboratorios químicos y la manipulación y
desecho de sustancias y residuos químicos
Diseño y creación de un sitio WEB de manera superficial aun sin manejar bases
6
Creación y vinculación de bases de datos a la página WEB para formar la aplicación
Instalación de servidor WEB y montaje del sitio en una IP con su respectivo dominio
Parametrización y Optimización de operaciones y seguridad de acuerdo a las necesidades que vayan surgiendo mediante el uso de la plataforma.
Para la correcta realización de este proyecto, se ha decidido que se forme un equipo interdisciplinario, juntando así la Escuela Superior de Ingeniería Mecánica y Eléctrica ESIME con un profesor y alumna de la Unidad Profesional Interdisciplinaria de Biotecnología UPIBI, quienes nos apoyarán con los puntos de planteamiento de necesidades y Parametrización y optimización de acuerdo a las necesidades obtenidas en los estudios.
En relación de los puntos de diseño y programación del sitio WEB, existen varias alterativas en el mercado para la correcta realización de los mismos. Los programas seleccionados fueron: Adobe Dreamweaver CS5 y Microsoft Visual Studio 2010 en conjunto con Microsoft SQL Server 2008.
La razón de utilizar Adobe Dreamweaver CS5 es que este programa es mucho más completo y flexible en cuanto a diseño de páginas WEB, permitiéndonos crear plantillas y diseños de manera dinámica y más fácil en comparación de tal manera que se trabajare el resto del desarrollo en Visual Studio. Por otro lado, MS Visual Studio se utilizó para realizar la programación en ASP y la conexión de bases de datos en SQL Server 2008 con los formularios del sitio WEB. MS Visual Studio tiene la propiedad de ser extremadamente amigable con el usuario al momento de trabajar con idiomas como C# bajo la plataforma .NET de Microsoft.
Se ha decidido utilizar las últimas versiones del software para aprovechar las últimas tecnologías pero a la vez teniendo en cuenta que sea posible la retro-compatibilidad con versiones más antiguas del mismo.
7
Introducción
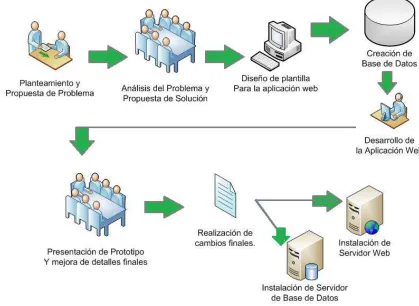
Para desarrollar este proyecto se siguió la siguiente metodología:
Se realizó una investigación previa por parte de la unidad académica UPIBI la cual identificó el problema del mal uso y desecho de sustancias y residuos químicos. De aquí se planteó una propuesta general de solución la cual era realizar un sitio WEB para poder realizar cierto intercambio de las sustancias y residuos que ya no se utilizan dentro de todas las unidades académicas y centros de investigación del Instituto Politécnico Nacional.
Una vez que nos fue planteada la solución, se decidió que lo más adecuado era realizar una aplicación WEB, en vez de un simple sitio WEB. Esta aplicación trabajará con bases de datos y se podrá acceder a él desde cualquier dispositivo con acceso a Internet.
Con la información recopilada se procedió a elaborar un plan de trabajo y juntas para realizar cambios y mejoras de los planes y posteriormente desarrollar la solución y realizar la etapa de pruebas (piloto).
La presente Tesis está estructurada de la siguiente manera:
Antes del capítulo 1 se presentan todos los antecedentes de las aplicaciones WEB y los sistemas de información. Posteriormente se realizó el Estado del Arte para investigar acerca de aplicaciones que tuvieran propósitos similares, así como el lugar donde radican y que alcance tienen.
En el capítulo 1 se presentan los puntos más básicos y relevantes de las bases de datos. Se explican los modelos de datos, los lenguajes de bases de datos y la estructura de un sistema de bases de datos. El capítulo 1 también menaje brevemente la arquitectura de las aplicaciones y conceptos básicos acerca de Microsoft SQL y el sistema Operativo Windows Server 2008.
En el capítulo 2 se estudian cuáles son los procesos de la ingeniería de software. Se detallan los modelos del proceso de software y la iteración de procesos, así como se elige el proceso a utilizar en nuestro proyecto en las conclusiones.
En el capítulo 3 se muestra la identificación del problema y la propuesta general de solución. De igual manera se muestra un diseño previo de la aplicación WEB así como se explican las facilidades y dificultades analizadas previas al desarrollo de la aplicación WEB.
8
9
ÍNDICE
Resumen ejecutivo 4
Introducción 7
Glosario técnico 13 Antecedentes 16 Estado del arte 21
C A P Í T U L O 1: Marco Teórico
1.1 Bases de datos 23
1.2 Aplicaciones de los sistemas de bases de datos 23
1.3 Modelos de los datos 24
1.3.1 Modelo Entidad-Relación 24
1.3.2 Modelo Relacional 25
1.3.3 Otros modelos de datos 26
1.4 Lenguajes de bases de datos 26
1.4.1 Lenguaje de definición de datos 26
1.4.2 Lenguaje de manipulación de datos 27
1.5 Estructura de un sistema de bases de datos 27
1.5.1 Gestor de almacenamiento 28
1.5.2 Procesador de consultas 28
1.6 Arquitectura de aplicaciones 29
1.7 SQL 31
1.7.1 Estructura básica de SQL 31
1.8 Windows server 2008 32
1.8.1 Características 32
1.8.2 Ediciones 32
1.9 Internet Information Services (IIS) 33
1.9.1 Windows Server 2008 y IIS 33
1.10 Conclusiones del capitulo 35
C A P Í T U L O 2: Marco Teórico
2.1 Procesos del software 36
2.2 Modelos del proceso del software 37
2.2.1 El modelo en cascada 38
2.2.2 Desarrollo evolutivo 39
2.2.3 Ingeniería del software basada en componentes 41
2.3 Iteración de procesos 42
2.3.1 Entrega incremental 43
2.3.2 Desarrollo en espiral 44
10
C A P Í T U L O 3: Análisis de condiciones actuales
3.1 Identificación del problema 48
3.2 Propuesta general de solución 48
3.3 Diseño preliminar a detalle 51
3.4 Facilidades y dificultades previas al desarrollo de la solución 62
3.5 Conclusiones del capitulo 64
C A P Í T U L O 4: Desarrollo Técnico
4.1 Diferencias entre lenguajes/plataforma para el desarrollo de aplicaciones WEB
65
4.2 Elección de lenguajes/plataformas para el desarrollo de aplicaciones WEB
66
4.3 Análisis y diseño de modelos entidad-relación 67
4.4 Análisis y diseño de la estructura del sitio WEB (mapa del sitio) 69
4.5 Desarrollo 70
4.5.1 Diseño de la hoja de estilo (CSS) en adobe Dreamweaver CS5 71
4.5.2 Creación y diseño de la plantilla principal en Visual Studio 2010 72
4.5.3 Desarrollo de la aplicación WEB en ASP.NET con Visual Studio 2010
74
4.5.4 Creación de bases de datos y vinculación a la aplicación 82
4.6 Instalación y puesta en marcha
4.6.1 Instalación de Internet Information Services (IIS) 86
4.6.2 Montaje de una aplicación ASP.NET en un servidor WEB 89
Evaluación Económica 99
Conclusiones 103
11
INDICE DE FIGURAS
C A P Í T U L O 1
1.1. Ejemplo de Diagrama Entidad-Relación 25
1.2. Estructura del Sistema 29
1.3. Arquitectura de dos y tres capas 30
C A P Í T U L O 2
2.1 El ciclo de vida del Software 38
2.2 Desarrollo Evolutivo 40
2.3 Ingeniería de Software basada en Componentes (CBSE) 42
2.4 Entrega Incremental 43
2.5 Modelo en Espiral de Boehm para el proceso de Software 45
C A P Í T U L O 3
3.1 Diseño preliminar de la página de inicio 51
3.2 Diseño preliminar de la sección de búsqueda 52
3.3 Diseño preliminar de los resultados de la búsqueda 52
3.4 Diseño preliminar de la sección oferta/demanda 53
3.5 Diseño preliminar del proceso de oferta/demanda 54
3.6 Diseño preliminar al no existir resultados encontrados 55
3.7 Diseño preliminar del inicio de sesion 55
3.8 Diseño preliminar de la etapa de registro de usuarios 56
3.9 Diseño preliminar del ingreso de una oferta/demanda 57
3.10 Diseño preliminar de la confirmación de nueva oferta/demanda 58
3.11 Diseño preliminar del cierre de sesión 58
3.12 Diseño preliminar de la actualización de datos 59
3.13 Diseño preliminar de la sección de eventos 60
3.14 Diseño preliminar de la sección de enlaces 60
3.15 Diseño preliminar de la sección de asesoria 61
3.16 Diseño preliminar de la sección de noticias 61
C A P Í T U L O 4
4.1 Modelo Entidad-Relación previo al desarrollo de la base de datos 67
4.2 Modelo Entidad-Relación una vez creada la base de datos en SQL Server 2008
68
4.3 Diagrama de flujo del desarrollo de una aplicación WEB 70
4.4 Hoja de estilo cascada en Dreamweaver CS5 71
4.5 Hoja de estilo cascada en Dreamweaver CS5 72
4.6 Código aspx.cs de plantilla maestra “Site Master” 73
4.7 Vista Diseño de la plantilla “Site Master” 73
12
4.9 Vista Diseño de la sección de Búsqueda de Residuos y Sustancias 75
4.10 Vista Diseño de la sección de Ofertas y Demandas 76
4.11 Vista Diseño de la Sección de Enlaces 77
4.12 Vista Diseño de la Sección “Conócenos” 78
4.13 Vista Diseño de la Sección Eventos y Noticias 79
4.14 Vista Diseño de la Sección Inicio de Sesión 80
4.15 Vista Diseño de la Sección Registro de Usuario 81
4.16 Definición de atributos y tipos de datos de la tabla Usuarios 82
4.17 Definición de atributos y tipos de datos de la tabla Formulario 83
4.18 Código aspx.cs para realizar la conexión con la base de datos 83
4.19 Exportación de los archivos para su posterior publicación 85
4.20 Carpeta con los archivos exportados desde VS 2010 85
4.21 Ventana de programas y características del panel de control 86
4.22 Ventana del Administrador del Servidor 87
4.23 Ventana del Asistente para agregar funciones 88
4.24 Proceso de selección de funciones del servidor 89
4.25 Ventana del administrador de Servicios de Administración de Internet
90
4.26 Página principal de Default WEB site 91
4.27 Opciones de configuración al crear un sitio WEB 92
4.28 Página principal del sitio WEB “TesisIntercambio” 93
4.29 Vista contenido del Sitio WEB “TesisIntercambio” 94
4.30 Sitio WEB visto en un navegador 95
4.31 Grupos de aplicaciones 96
4.32 Configuración básica del grupo de aplicaciones 97
13
GLOSARIO TÉCNICO
.NET
Framework Componente de software que provee un extenso conjunto de soluciones predefinidas para necesidades generales de la programación de aplicaciones, y administra la ejecución de los programas escritos específicamente con la plataforma.
Adobe
Dreamweaver Aplicación en forma de estudio enfocada a la construcción y edición de sitios y aplicaciones WEB.
ADP Access Data Project.
ASLR Address Space Load Randomization
ASP Active Server Pages
AWE Address Windowing Extensions
Back-up Copia de seguridad
Base de datos Conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente para su posterior uso.
C# Es un lenguaje de programación orientado a objetos desarrollado y
estandarizado por Microsoft como parte de su plataforma .NET
CAS Numero de identificador único para las sustancias químicas.
CASE Computer Aided Software Engineering. CBSE Component-based software Engineering. Cintas
Magnéticas Medio de almacenamiento de información que se graba en pistas sobre una banda plástica con un material magnetizado. Cluster Conjuntos de computadoras construidos mediante la utilización de componentes de hardware comunes y que se comportan como si fuesen una única computadora.
COTS Commercial off-the-shelf
CPU Central Processing Unit
CPR Se refiere al Código de Peligrosidad de los Residuos.
CSS Cascading Style Sheets
DDL Data Definition Language
Disco Duro Dispositivo de almacenamiento de datos no volátil que emplea un sistema de grabación magnética para almacenar datos digitales.
DML Data Manipulation Language
DNSSEC DNS Security Extensions
FTP File Transfer Protocol
GB Gigabyte; Un GB igual a 1024MB.
Hardware Corresponde a todas las partes físicas y tangibles de una computadora.
HTML HyperText Markup Language
HTTP Hypertext Transfer Protocol
HTTPS Hypertext Transfer Protocol Secure
IBM International Business Machines
IIS Internet Information Services
Internet
14
Iteración Se refiere a la acción de repetir una serie de pasos un cierto número de veces.
JAVA Lenguaje de programación orientado a objetos, desarrollado por Sun Microsystems a principios de los años 90
Javascript Lenguaje de scripting orientado a objetos, basado en prototipos, liviano, utilizado para acceder a objetos en aplicaciones.
JDBC Java Database Connectivity
LOB Line of Business
Macromedia
flash Es una aplicación en forma de estudio que trabaja sobre "fotogramas", destinado a la producción y entrega de contenido interactivo.
MB Megabyte; un MB es igual a 1024KiloBytes.
Microsoft Empresa multinacional dedicada al sector de la informática. Microsoft SQL
Server Un sistema para la gestión de bases de datos producido por Microsoft basado en el modelo relacional. Microsoft
Visual Studio Un entorno operativos Windows. de desarrollo integrado (IDE) para sistemas Modelo
Relacional Modelo de datos basado en la lógica de predicados y en la teoría de conjuntos.
modem Dispositivo que sirve para enviar una señal
llamada moduladora mediante otra señal llamada portadora.
MySQL Sistema de gestión de base de datos relacional, multi-hilo y multiusuario.
Netscape
Navigator Netscape fue el primer navegador comercial. NNTP Network News Transport Protocol
NTFS Sistema de archivos de Windows NT incluido en las versiones de Windows 2000, Windows XP, Windows Server 2003, Windows Server 2008, Windows Vista y Windows 7.
OBDC Object Data Base Conector
Oracle Sistema de gestión de base de datos relacional
Perl Lenguaje de programación que toma características del lenguaje C, del lenguaje interpretado shell (sh), AWK, sed, Lisp y, en un grado inferior, de muchos otros lenguajes de programación.
PHP PHP Hypertext Pre-processor. Lenguaje de
programación interpretado, diseñado originalmente para la creación de páginas WEB dinámicas.
RAM Random-access memory
RTM Release to manufacturing
SGBD Sistema de gestión de base de datos SMB2 Server Message Block 2
SMTP Simple Mail Transfer Protocol
software Comprende el conjunto de los componentes lógicos necesarios que hacen posible la realización de tareas específicas.
SQL Lenguaje declarativo de acceso a bases de datos relacionales que
15
Super-Clave Conjunto de uno o más atributos que, tomados colectivamente, permiten identificar de forma única una entidad en el conjunto de entidades.
TB TeraByte.
Tupla Conjunto de elementos de distinto tipo que se guardan de forma consecutiva en memoria.
UDDI Universal Description, Discovery and Integration
VBA Visual Basic for Applications
Visual Basic El lenguaje de programación es un dialecto de BASIC, con importantes agregados.
W3c World Wide WEB Consortium
WEB World Wide WEB
WHEA Windows Hardware Error Architecture Windows
server Windows Server es una marca que abarca una línea de productos servidor de Microsoft Corporation.
www World Wide WEB
16
ANTECEDENTES
El diseño WEB original fue evolucionando y ha pasado por distintas generaciones, principalmente debido a mejoras en la tecnología, hardware y software. Estos cambios han generado a día de hoy 4 generaciones del diseño WEB.
Primera generación de diseño WEB
El primer diseño WEB de una página se realizó en 1993, la página WEB tenía el nombre Mosaic, y en menos de un año había recibido 2 millones de visitantes. El navegador WEB era capaz de mostrar tanto imágenes como textos, aunque con una limitación muy alta a la hora de diagramar la información de la página WEB. El diseño WEB de estas páginas era lineal y estaba orientado para científicos que eran los usuarios que compartían su información alrededor de todo el mundo mediante estas páginas WEB. La tecnología de los navegadores WEB era limitada y no disponía de la capacidad de transmitir información gráfica para la comunicación visual.
Las principales características de esta primera generación de diseño WEB eran las velocidades de transmisión de datos, ya que era conexión vía MODEM, lo que limitaba el peso de las páginas WEB. Otro detalle era el uso de monitores monocromáticos. Respecto al diseño WEB en particular, la estructuración era bastante desordenada con imágenes dispuestas horizontalmente y líneas de texto separadoras.
Debido a este caos en el diseño WEB, un año más tarde se estableció un consorcio para establecer unas normas y pautas para el futuro desarrollo de la WEB, el W3C. Se comenzaron entonces a desarrollar unos estándares de lenguaje HTML para una unificación del diseño WEB que trajo consigo la aparición de una serie de navegadores WEB con el constante desarrollo de nuevas funcionalidades y progresos en este ámbito.
Segunda generación de diseño WEB
El diseño WEB de esta generación está basado en los conceptos de la primera salvo por que empieza a utilizar iconos en lugar de algunas palabras, las páginas WEB comienzan a poseer imágenes de fondo, aparece el diseño y uso de botones con relieve para la navegabilidad, el uso de publicidad en lugar de cabeceras, la estructuración de texto de forma jerárquica mediante menús o listados, propiedades del código HTML Standard definido.
17
a usar tablas para la organización de los contenidos, posicionamiento de los elementos y generación de diseño similar a libros o revistas.
En esta generación está la aparición de monitores y tarjetas gráficas con mayores resoluciones y definición de color, lo cual generó la consecuente mejora en la calidad del diseño WEB.
Pero apareció un problema, la diferencia en la adaptación de estándares de los 2 principales navegadores: Internet Explorer y Netscape Navigator.
Tercera Generación del diseño WEB
En la tercera generación, el diseño WEB sigue teniendo muchas restricciones con el uso del lenguaje para los dos navegadores WEB. El diseño WEB se orienta en esta generación a los diseñadores, los cuales tienen mucho más dinamismo al aparecer el plug-in de Macromedia Flash, el cual revolucionaría la concepción de diseño WEB.
Es una era de enfocar las páginas WEB según el objetivo de las mismas: vender productos o servicios, comunidades, información, noticias. Para esta especialización del diseño WEB de acuerdo al objetivo de las páginas se necesita ayudar al usuario a encontrar la información, generando una navegabilidad estructurada e intuitiva.
La gran mayoría de páginas WEB que aparecen en esta generación son de publicidad y venta de productos y servicios, con lo que es este el diseño más utilizado. Conseguir acercarles al producto, que deseen ver más páginas del sitio WEB.
Cuarta Generación de diseño WEB
En la cuarta generación, el diseño WEB ya está enfocado totalmente a la multimedia, integrando en las páginas WEB los elementos multimedia de última generación. Con usuarios de todos los tipos, cualquiera tiene una página WEB a día de hoy y la variedad de diseño es enorme debido a todas las posibilidades que ofrecen las últimas tecnologías para los programadores. A esto le podemos añadir que las últimas versiones de los navegadores soportan muchas más prestaciones y elementos en las páginas WEB.
Quinta Generación de diseño WEB
18
Concepto de bases de datos
Las bases de datos son una herramienta de vital importancia para el desarrollo de la actividad profesional. Existen dos colectivos que a menudo son el mismo especialmente beneficiados por las bases de datos. Por una parte, los investigadores y, por otra, los profesionales. Se podría considerar como base de datos cualquier recopilación organizada de información sobre la que haya habido análisis documental y que disponga de un sistema de búsqueda específica. Partiendo de esta idea, se podrían incluir los catálogos bibliotecarios. Sin embargo, en este trabajo se ha optado por emplear como criterio el seleccionar sólo aquellas bases formadas principalmente por descripciones de documentos impresos o electrónicos de libre acceso procedentes de revistas y artículos en Ciencia de la Información.
Historia de los sistemas de bases de datos
El uso de sistemas de bases de datos automatizadas, se desarrolló a partir de la necesidad de almacenar grandes cantidades de datos, para su posterior consulta, producidas por las nuevas industrias que creaban gran cantidad de información.
Herman Hollerit (1860-1929) fue denominado el primer ingeniero estadístico de la historia, ya que invento una computadora llamada “Máquina Automática Perforadora de Tarjetas. Para hacer el censo de Estados Unidos en 1880 se tardaron 7 años para obtener resultados, pero Herman Hollerit en 1884 creo la máquina perforadora, con la cual, en el censo de 1890 dio resultados en 2 años y medio, donde se podía obtener datos importantes como número de nacimientos, población infantil y número de familias. La máquina uso sistemas mecánicos para procesar la información de las tarjetas y para tabular los resultados.
A diferencia con la máquina de Babbage, que utilizaba unas tarjetas similares, estas se centraban en dar instrucciones a la máquina. En el invento de Herman Hollerit, cada perforación en las tarjetas representaba un número y cada dos perforaciones una letra, cada tarjeta tenía capacidad para 80 variables. La máquina estaba compuesta por una perforadora automática y una lectora, la cual por medio de un sistema eléctrico leía los orificios de las tarjetas, esta tenía unas agujas que buscaban los orificios y al tocar el plano inferior de mercurio enviaba por medio del contacto eléctrico los datos a la unidad.
Este invento disparo el desarrollo de la tecnología, la industria de los computadores, abriendo así nuevas perspectivas y posibilidades hacia el futuro.
Historia de los sistemas de bases de datos-Década de 1950
19
ejemplo el aumento de salario. Consistía en leer una cinta o más y pasar los datos a otra, y también se podían pasar desde las tarjetas perforadas. Simulando un sistema de Back-up, que consiste en hacer una copia de seguridad o copia de respaldo, para guardar en un medio extraíble la información importante. La nueva cinta a la que se transfiere la información pasa a ser una cinta maestra. Estas cintas solo se podían leer secuencial y de manera ordenada.
Historia de los sistemas de bases de datos-Década de 1960
El uso de los discos en ese momento fue un adelanto muy efectivo, ya que por medio de este soporte se podía consultar la información directamente, esto ayudo a ahorrar tiempo. No era necesario saber exactamente donde estaban los datos en los discos, ya que en milisegundos era recuperable la información. A diferencia de las cintas magnéticas, ya no era necesaria una secuencia, y este tipo de soporte empiezo a ser ambiguo.
Los discos dieron inicio a las Bases de Datos, de red y jerárquicas, pues los programadores con su habilidad de manipulación de estructuras junto con las ventajas de los discos era posible guardar estructuras de datos como listas y árboles.
Historia de los sistemas de bases de datos-Década de 1970
Edgar Frank Codd (23 de agosto de 1923 – 18 de abril de 2003), en un artículo
"Un modelo relacional de datos para grandes bancos de datos compartidos" ("A Relational Model of Data for Large Shared Data Banks") en 1970, definió el modelo relacional y publicó una serie de reglas para la evaluación de administradores de sistemas de datos (DBSM) relacionales y así nacieron las bases de datos relacionales.
A partir de los aportes de Codd el multimillonario Larry Ellison desarrollo la base de datos Oracle, el cual es un sistema de administración de base de datos, que se destaca por sus transacciones, estabilidad, escalabilidad y multiplataforma.
Inicialmente no se usó el modelo relacional debido a que tenía inconvenientes por el rendimiento, ya que no podían ser competitivas con las bases de datos jerárquicas y de red. Ésta tendencia cambio por un proyecto de IBM el cual desarrolló técnicas para la construcción de un sistema de bases de datos relacionales eficientes, llamado System R.
Historia de los sistemas de bases de datos-Década de 1980
Las bases de datos relacionales con su sistema de tablas, filas y columnas, pudieron competir con las bases de datos jerárquicas y de red, ya que su nivel de programación era bajo y su uso muy sencillo.
20
Historia de los sistemas de bases de datos-Principios década de los 90
Para el manejo de bases de datos se creó el lenguaje SQL, que es un lenguaje programado para consultas. SQL es un lenguaje de alto nivel estructurado que analiza grandes cantidades de información el cual permite especificar diversos tipos de operaciones frente a la misma información, a diferencia de las bases de datos de los 80 que eran diseñadas para las aplicaciones de procesamiento de transacciones. Los grandes distribuidores de bases de datos incursionaron con la venta de bases de datos orientada a objetos.
Historia de los sistemas de bases de datos-Finales de la década de los 90
El boom de esta década fue la aparición de la WWW “Word Wide WEB‿ ya que por éste medio se facilitaba la consulta a las bases de datos. Actualmente tienen una amplia capacidad de almacenamiento de información, también una de las ventajas es el servicio de siete días a la semana las veinticuatro horas del día, sin interrupciones a menos que haya planificaciones de mantenimiento de las plataformas o el software.
Historia de los sistemas de bases de datos-Siglo XXI
En la actualidad existe gran cantidad de alternativas en línea que permiten hacer búsquedas orientadas a necesidades específicas de los usuarios, una de las tendencias más amplias son las bases de datos que cumplan con el protocolo Open Archives
Initiative – Protocol for Metadata Harvesting (OAI-PMH) los cuales permiten el
almacenamiento de gran cantidad de artículos que permiten un mayor acceso en el ámbito científico y general.
21
ESTADO DEL ARTE
El manejo y desecho correcto de sustancias y residuos químicos es un tema ampliamente debatido y concurrido entre organizaciones que se dedican a la industria química o que tienen que ver en algún aspecto con ella como lo son las Instituciones Educativas Públicas y Privadas que entre sus grandes laboratorios y la enorme cantidad de estudiantes y docentes que las frecuentan.
El problema principal radica en que en muchos lugares se manejan grandes cantidades de químicos los cuales en muchas ocasiones quedan guardados en almacenes durante mucho tiempo y finalmente terminan siendo tirados a la basura. En el mejor de los casos, este tipo de sustancias se utilizan para un proceso simple o para un objeto educativo y finalmente terminan siendo descartadas de manera impropia y sin categorizarse ni haber registro de ello.
En este caso, se podría pensar que existen métodos para aprovechar al máximo el uso de estas sustancias, así como sistemas que se dedican de manera independiente a ello, pero no es así. En los mejores casos, existen instituciones que se dedican al correcto manejo correcto de las sustancias, pero todas estas terminan sin ser utilizadas normalmente, y no existe una re-ubicación de estas para que sean aprovechados en otros lugares. Por lo mismo, las Instituciones Educativas son una excelente opción para iniciar este proceso.
En México no existe como tal un sistema que permita el intercambio de sustancias y residuos químicos hasta la fecha. Por lo menos no que esté documentado y que sea fácil acceder a él de manera pública. Algunas instituciones educativas grandes como la UNAM, el ITESM, el IPN o la UAM contratan empresas que se encargan de desechar los residuos de manera apropiada, pero intercambios incluso entre sus propias unidades académicas son procesos espontáneos y que probablemente no tienen algún registro oficial en un sistema dedicado.
Es raro pensar que en países desarrollados como Estados Unidos de América o en algunas regiones de Europa no existan sistemas como el que se quiere aplicar hoy en día, sin embargo, al realizar la investigación no logramos encontrar algún sistema o aplicación WEB dedicado única y exclusivamente al intercambio de sustancias y residuos químicos tanto de manera interna (en una misma institución) como de manera abierta.
22
Por más raro que parezca, la BORSI tiene presencia en áreas donde son necesarias y no en países primer-mundistas y realiza un trabajo bastante completo en su área correspondiente ofreciendo una solución interesante para las industrias.
Por último, cabe recalcar que existe una empresa llamada Quiminet, la cual tiene su oficina matriz en México D.F pero se extiende a países como Estados Unidos, Canadá, España, regiones de Centroamérica, el Caribe y el Resto del mundo, así como tiene oficinas en la región del Mercosur y la región Andina en Sur-América.
Quiminet ofrece la facilidad de realizar solicitudes y ofertas de un sinfín de productos de origen químico, como lo son:
Empaques, envases y embalajes
Plásticos
Industria Alimenticia
Minería
Industria Farmacéutica
Pinturas
Transporte y Logística
Eléctrica
Textil
Naturista
23
C A P Í T U L O 1
1.1. Bases de datos
Un sistema gestor de bases de datos (SGBD) se conforma de una colección de datos interrelacionados y un conjunto de programas para acceder a dichos datos. La colección de datos, normalmente se les denomina base de datos, contienen información relevante. El objetivo principal de un SGBD es proporcionar una forma de almacenar y recuperar la información de una base de datos de manera que sea práctica como eficiente.
Los sistemas de bases de datos se diseñan para gestionar grandes cantidades de información. La administración de los datos significa la definición de estructuras para almacenar la información como la provisión de herramientas para la manipulación de la información. Además, los sistemas de bases de datos deben proporcionar fiabilidad en la información almacenada, a pesar de las fallas del sistema o los intentos de acceso no autorizados. Si los datos van a ser compartidos entre varios usuarios, el sistema debe evitar posibles resultados anómalos.
Dado que la información es muy importante en la mayoría de las organizaciones, los científicos informáticos han desarrollado un amplio conjunto de conceptos y técnicas para la gestión de los datos.
1.2. Aplicaciones de los sistemas de bases de datos
Las bases de datos son ampliamente usadas en diferentes áreas. Las siguientes son algunas de sus aplicaciones más representativas y comunes en la actualidad:
Bancos. Para almacenar la información de los clientes, cuentas,
préstamos, y transacciones bancarias.
Aéreo líneas. Para reservaciones e información de planificación. Las
líneas aéreas fueron de los primeros en usar las bases de datos de forma distribuida geográficamente (los terminales situados en todo el mundo accedían al sistema de bases de datos centralizado a través de las líneas telefónicas y otras redes de datos).
Universidades. Para la información de los estudiantes, calificaciones,
matriculas de las asignaturas y cursos.
Tarjetas de crédito. Para compras con tarjeta de crédito y generación
mensual de estados de cuentas.
Telecomunicaciones. Para guardar un registro de las llamadas realizadas,
generación mensual de facturas y para almacenar información sobre las redes de comunicaciones.
Finanzas. Para almacenar información sobre grandes empresas, ventas y
24
Ventas. Para información de clientes, productos y compras.
Producción. Para la gestión de la cadena de producción y para el
seguimiento de la producción de elementos en las factorías, inventario en almacenes y pedidos de elementos.
Recursos humanos. Para información sobre los empleados, salarios,
impuestos, beneficios, y para la generación de las nóminas.
Las bases de datos forman una parte esencial de casi todas las empresas actuales. A lo largo de las últimas cuatro décadas del siglo veinte, el uso de las bases de datos se extendió en empresas de todo tipo de giros comerciales.
El acceso a internet para las masas a finales de la década de 1990 aumento significativamente el acceso directo del usuario a las bases de datos. Las organizaciones convirtieron muchas de sus interfaces telefónicas a las bases de datos en interfaces WEB, y pusieron disponibles en línea muchos servicios.
Así, aunque las interfaces WEB ocultan el acceso a las bases de datos, y la mayoría de la gente ni siquiera se da cuenta de que están interactuando con una base de datos, el acceso a las bases de datos forma una parte esencial de las actividades de casi todas las personas actualmente.
1.3. Modelos de los datos
Bajo la estructura de la base de datos se encuentra el modelo de datos: una colección de herramientas conceptuales para describir los datos, las relaciones, la semántica y restricciones de consistencia. Los diferentes modelos de datos que se han propuesto se clasifican en tres grupos diferentes: modelos lógicos basados en objetos, modelos lógicos basados en registros y modelos físicos.
1.3.1 Modelo entidad-relación
El modelo de datos de entidad-relación (E-R) está basado en una percepción del mundo real que consta de una colección de objetos básicos, llamados entidades, y de relaciones entre estos objetos. Una entidad es una “cosa” u “objeto” en el mundo real que es distinguible de otros objetos.
Las entidades se describen en una base de datos mediante un conjunto de atributos. Los atributos son cualidades o características de las entidades. Por ejemplo, los atributos numero-cuenta y saldo describen una cuenta particular de un banco y pueden ser atributos del conjunto de entidades cuenta.
Una relación es una asociación entre una o varias entidades. Por ejemplo, una relación impositor asocia un cliente con cada cuenta que tiene.
25
Rectángulos, que representan los conjuntos de entidades.
Elipses, que representan atributos.
Rombos, que representan relaciones entre conjuntos de entidades.
Líneas, que unen los atributos con los conjuntos de entidades y los conjuntos de entidades con las relaciones.
Figura 1.1. Ejemplo de diagrama Entidad-Relación.Elaboración propia sobre la base de Silberschatz, Korth y Sudarshan, Fundamentos de bases de datos.
1.3.2 Modelo relacional
En el modelo relacional se utiliza un grupo de tablas para representar los datos y relaciones entre ellos. Cada tabla está compuesta por varias columnas, y cada columna tiene un nombre único e irrepetible.
El modelo relacional es un modelo basado en registros. Los modelos basados en registros se denominan así porque la base de datos se estructura en registros de formato fijo de varios tipos. Cada tabla contiene registros que pueden ser de varios tipos. Cada tipo de registro define un número fijo de campos, o atributos. Las columnas de la tabla corresponden a los atributos del registro.
El modelo de datos relacional es el modelo de datos más usado, y una amplia mayoría de sistemas de bases de datos actuales se basan en el modelo relacional.
26
1.3.3 Otros modelos de datos
El modelo de datos orientado a objetos es otro modelo de datos que está recibiendo una atención creciente. El modelo orientado a objetos se puede observar como una extensión del modelo E-R con las nociones de encapsulación, métodos (funciones) e identidad de objeto, muy típico en la programación orientada a objetos.
El modelo de datos relacional orientado a objetos combina las características del modelo de datos orientado a objetos y el modelo de datos relacional.
Los modelos de datos semi-estructurados permiten la especificación de datos donde los elementos de datos individuales del mismo tipo pueden tener diferentes conjuntos de atributos. A diferencia de los modelos de datos mencionados anteriormente, en los que cada elemento de datos de un tipo particular debe tener el mismo conjunto de atributos.
Históricamente, existen otros dos modelos de datos, el modelo de datos de red y el modelo de datos jerárquico, ambos precedieron al modelo de datos relacional. Estos modelos estuvieron ligados fuertemente a la implementación subyacente y complicaban la tarea del modelado de datos. Como resultado se usan muy poco actualmente, excepto en el código de bases de datos antiguo que aún está en servicio en algunos lugares.
1.4. Lenguajes de bases de datos
Un sistema de bases de datos proporciona un lenguaje de definición de datos para especificar el esquema de la base de datos y un lenguaje de manipulación de datos para expresar las consultas a la base de datos y modificaciones. En la práctica, los lenguajes de definición y manipulación de datos no son dos lenguajes separados; en su lugar simplemente forman parte de un único lenguaje de bases de datos, tal como SQL Server de Microsoft.
1.4.1 Lenguaje de definición de datos
Un esquema de base de datos se especifica mediante un conjunto de definiciones expresadas mediante un lenguaje especial llamado lenguaje de definición de datos (LDD).
Se define el almacenamiento y los métodos de acceso usados por el sistema de bases de datos por un conjunto de instrucciones en un tipo especial de LDD denominado lenguaje de almacenamiento y definición de datos. Estas instrucciones definen los detalles de implementación de los esquemas de base de datos, que se ocultan usualmente a los usuarios.
27
tales restricciones. Los sistemas de base de datos comprueban estas restricciones cada vez que se actualiza la base de datos.
1.4.2 Lenguaje de manipulación de datos
La manipulación de datos cumple las siguientes tareas:
La recuperación de información almacenada en la base de datos.
La inserción de información nueva en la base de datos.
El borrado de información de la base de datos.
La modificación de información almacenada en la base de datos.
Reporte de parámetros y propiedades de la base de datos.
Un lenguaje de manipulación de datos (LMD) es un lenguaje que permite a los usuarios acceder y/o manipular los datos organizados mediante el modelo de datos apropiado. Hay dos tipos de LMD básicamente:
LMDs procedimentales. Requieren que el usuario especifique que datos se
necesitan y como obtener esos datos.
LMDs declarativos (también conocidos como LMDs no procedimentales).
Requieren que el usuario especifique que datos se necesitan sin especificar como obtener esos datos.
Los LMDs declarativos son más fáciles de aprender y usar que los LMDs procedimentales. Sin embargo, como el usuario no especifica cómo conseguir los datos, el sistema de bases de datos tiene que determinar un medio eficiente de acceder a los datos. El componente LMD del lenguaje SQL es no procedimental.
1.5. Estructura de un sistema de bases de datos
Un sistema de base de datos se divide en módulos que se encargan de cada una de las funciones del sistema completo. Los componentes funcionales de un sistema de base de datos se pueden dividir a grandes rasgos en los componentes de administrador de almacenamiento y procesador de consultas.
28
El procesador de consultas es importante porque ayuda al sistema de base de datos a simplificar y facilitar el acceso a los datos. Las vistas de alto nivel ayudan a conseguir este objetivo. Es trabajo del sistema de base de datos el traducir las actualizaciones y las consultas escritas en un lenguaje no procedimental, en el nivel lógico, en una secuencia de operaciones en el nivel físico.
1.5.1 Gestor de almacenamiento
Un gestor de almacenamiento es un módulo de programa que proporciona la interfaz entre los datos de bajo nivel en la base de datos, los programas de aplicación y consultas emitidas al sistema. Es también responsable de la interacción con el gestor de archivos. Los datos en bruto se almacenan en disco duro usando un sistema de archivos, que está disponible habitualmente en un sistema operativo convencional. Los componentes del gestor de almacenamiento incluyen los siguientes elementos
:
Gestor de Autorización e integridad, comprueba que se satisfagan las restricciones de integridad y la autorización de los usuarios para acceder a los datos.
Gestor de transacciones, asegura que la base de datos quede en un estado consistente (correcto) a pesar de los fallos del sistema, y que las ejecuciones de transacciones concurrentes ocurran sin conflictos.
Gestor de Archivos, gestiona la reserva de espacio de almacenamiento de disco y las estructuras de datos usadas para representar la información almacenada en disco.
Gestor de memoria intermedia, responsable de traer los datos del disco duro a la memoria RAM y decidir qué datos almacenar en memoria caché. El gestor de memoria intermedia es una parte crítica del sistema de bases de datos, ya que permite que la base de datos maneje tamaños de datos que son mucho mayores que el tamaño de la memoria RAM instalada.
El Gestor de almacenamiento implementa varias estructuras de datos como parte de la implementación física del sistema:
Archivos de Datos, almacena la base de datos en sí.
Diccionario de datos, almacena metadatos acerca de la estructura de la base de datos, en particular, el esquema de la base de datos.
Índices, proporcionan acceso rápido a elementos de datos que tienen valores particulares.
1.5.2 Procesador de consultas
Los componentes del procesador de consultas incluyen:
29
Compilador del LMD, traduce las instrucciones del LMD en un lenguaje de consultas a un plan de evaluación que consiste en instrucciones de bajo nivel que entiende el motor de evaluación de consultas.
[image:30.612.109.509.181.577.2] Motor de evaluación de consultas, ejecuta las instrucciones de bajo nivel generadas por el compilador LMD.
Figura 1.2. Estructura del sistema. (Silberschatz, Korth y Sudarshan, 2002)
1.6. Arquitectura de Aplicaciones
30
remotos de la base de datos, y las máquinas servidor, en las que se ejecuta el sistema de bases de datos.
[image:31.612.138.510.208.444.2]Las aplicaciones de bases de datos se dividen usualmente en dos o tres partes, como se ilustra en la figura 1.3. En una arquitectura de dos capas, la aplicación se divide en un componente que reside en la máquina cliente, que llama a la función del sistema de bases de datos en la máquina servidor mediante instrucciones del lenguaje de consultas. Los estándares de interfaces de programas de aplicación como OBDC y JDBC se usan para la interacción entre el cliente y el servidor.
Figura 1.3. Arquitectura de 2 y 3 capas. Elaboración propia sobre la base de Silberschatz, Korth y Sudarshan, Fundamentos de bases de datos.
En cambio, en una arquitectura de tres capas, la máquina cliente actúa simplemente como interfaz y no contiene ninguna llamada directa a la base de datos. En su lugar, el cliente se comunica con un servidor de aplicaciones, usualmente mediante una interfaz de formularios. El servidor de aplicaciones, a su vez, se comunica con el sistema de bases de datos para acceder a los datos.
31
1.7. SQL
El lenguaje Sequel ha evolucionado desde los principios de la década de los 70s y su nombre ha pasado a ser SQL (Structured Query Language; Lenguaje estructurado de consultas).
El lenguaje SQL tiene varios componentes:
Lenguaje de definición de datos (LDD). El LDD de SQL proporciona órdenes para la definición de esquemas de relación, borrado de relaciones, creación de índices y modificación de esquemas de relación.
Lenguaje interactivo de manipulación de datos (LMD). El LMD de SQL incluye un lenguaje de consultas, basado tanto en el álgebra relacional como en el cálculo relacional de tuplas. Incluye también órdenes para insertar, borrar y modificar tuplas de la base de datos.
Definición de vistas. El LDD de SQL incluye órdenes para la definición de vistas.
Control de transacciones. SQL incluye órdenes para la especificación del comienzo y final de transacciones.
SQL incorporado y SQL dinámico. SQL dinámico e incorporado define cómo se pueden incorporar las instrucciones SQL en lenguajes de programación de propósito general, tales como C, C++, Java.
Integridad. El LDD de SQL incluye órdenes para la especificación de las restricciones de integridad que deben satisfacer los datos almacenados en la base de datos. Las actualizaciones que violen las restricciones de integridad se rechazan.
Autorización. El LDD de SQL incluye órdenes para especificar derechos de acceso para las relaciones y vistas.
1.7.1 Estructura básica de SQL
Una base de datos relacional consiste en un conjunto de relaciones, a cada una de las cuales se le asigna un nombre único. Cada relación tiene una estructura similar. SQL permite el uso de valores nulos para indicar que el valor o bien es desconocido, o no existe. Se fijan criterios que permiten al usuario especificar a qué atributos no se puede asignar el valor nulo.
La estructura básica de una expresión SQL consiste en tres cláusulas: select, from y where.
La cláusula select corresponde a la operación proyección del álgebra relacional.
Se usa para listar los atributos deseados del resultado de una consulta.
32
La cláusula where corresponde al predicado selección del álgebra relacional. Es
un predicado que engloba a los atributos de las relaciones que aparecen en la cláusula from.
1.8 Windows Server 2008
Windows Server 2008 es el nombre de un sistema operativo diseñado para servidores de Microsoft. Es el sucesor de Windows Server 2003, distribuido al público casi cinco años antes. Al igual que Windows Vista, Windows Server 2008 se basa en el núcleo Windows NT 6.0. Posteriormente se lanzó una segunda versión, denominada Windows Server 2008 R2.
1.8.1 Características
Hay algunas diferencias con respecto a la arquitectura del nuevo Windows Server 2008, que pueden cambiar drásticamente la manera en que se usa este sistema operativo. Estos cambios afectan a la manera en que se gestiona el sistema hasta el punto de que se puede llegar a controlar el hardware de forma más efectiva, se puede controlar mucho mejor de forma remota y cambiar de forma radical la política de seguridad. Entre las mejoras que se incluyen, están:
Nuevo proceso de reparación de sistemas NTFS: proceso en segundo
plano que repara los archivos dañados.
Creación de sesiones de usuario en paralelo: reduce tiempos de espera
en los Terminal Services y en la creación de sesiones de usuario a gran escala.
Cierre adecuado de Servicios.
Sistema de archivos SMB2: de 30 a 40 veces más rápido el acceso a los
servidores multimedia.
Address Space Load Randomization (ASLR): protección
contra malware en la carga de controladores en memoria.
Windows Hardware Error Architecture (WHEA): protocolo mejorado y
estandarizado de reporte de errores.
Virtualización de Windows Server: mejoras en el rendimiento de la
virtualización.
PowerShell: inclusión de una consola mejorada con soporte GUI para
administración.
Server Core: el núcleo del sistema se ha renovado con muchas y nuevas
mejoras.
1.8.2 Ediciones
33
negocios (LOB). Por ende no está optimizado para su uso como servidor de archivos o servidor de medios. Windows Server 2008 está disponible en distintas ediciones, similar a Windows Server 2003.
Server Core está disponible en las ediciones WEB, Standard, Enterprise y Datacenter, aunque no es posible usarla en la edición Itanium. Server Core es simplemente una opción de instalación alterna soportada y en sí no es una edición propiamente dicha.
1.9 Internet Information Services (IIS)
Internet Information Services o IIS es un servidor WEB y un conjunto de servicios para el sistema operativo Microsoft Windows. Los servicios que ofrece son: FTP, SMTP, NNTP y HTTP/HTTPS.
Este servicio convierte a una PC en un servidor WEB para Internet o una intranet, es decir que en las computadoras que tienen este servicio instalado se pueden publicar páginas WEB tanto local como remotamente. Los servicios de Internet Information Services proporcionan las herramientas y funciones necesarias para administrar de forma sencilla un servidor WEB seguro.
El servidor WEB se basa en varios módulos que le dan capacidad para procesar distintos tipos de páginas. Por ejemplo, Microsoft incluye los de Active Server Pages (ASP) y ASP.NET. También pueden ser incluidos los de otros fabricantes, como PHP o Perl.
1.9.1
Windows Server 2008 y IISWindows Server 2008 proporciona los servicios de Internet Information Server (IIS) 7.0 que permiten incorporar en una empresa las siguientes tecnologías de Internet:
Un servidor de aplicaciones WEB (no solo de documentos WEB) que
permite utilizar diferentes mecanismos de autenticación de usuarios
remotos, ejecutar CGI (Common Gateway Interface) y filtros ISAPI
(Internet Server Application Programming Interface), aplicaciones .NET,
etc.
Conjuntamente con ASP.NET, es una plataforma completa para ofrecer
servicios WEB basados en estándares como XML (Extensible Markup
Languaje) y SOAP (Simple Object Access Protocol). También es posible
instalar un servidor UDDI (Universal Description, Discovery and
Integration) para disponer de un servicio de directorio de servicios WEB.
34
(eXtensible HyperText Markup Language), Javascript, CSS (Cascading Style Sheets), etc.
Un servidor FTP que permite la transferencia de archivos desde y hacia
cualquier ordenador conectado a la red.
Herramientas de administración que proporcionan la infraestructura
para administrar un servidor WEB que ejecuta ISS 7 (como la Consola de
35
1.10 Conclusiones del capítulo
Debido a que el uso de las bases de datos está implícito en un sinfín de acciones que realizamos en nuestras actividades diarias, incluso sin darnos cuenta de ello. Es por eso que es de gran importancia saber las principales aplicaciones que se le pueden dar a las bases de datos.
Las bases de datos pueden tener arquitecturas de 2 capas o 3 capas, en una arquitectura de 2 capas la máquina del cliente tiene interacción directa con el sistema de bases de datos. Mientras que en una arquitectura de 3 capas la máquina del cliente se debe conectar con un servidor de aplicaciones y este a su vez con el sistema de bases de datos. La arquitectura de 3 capas es la más usada en las aplicaciones.
Actualmente el modelo más utilizado por las bases de datos es el modelo relacional debido a su simplicidad comparado con otros modelos que facilita la tarea a los programadores. Una práctica común es hacer el diseño de la base de datos en el modelo entidad-relación y posteriormente traducirlo al modelo relacional.
Por otro lado, el lenguaje SQL nos permite realizar operaciones en una base de datos como búsquedas, borrado, inserción y actualización de los registros por medio de una sintaxis sencilla.
En el área de los sistemas operativos (SO) orientados a servidores, se analizó que estos contienen características y funciones que difícilmente se podrán encontrar en sistemas operativos orientados a usuarios domésticos, entre estas funciones exclusivas de los SO para servidores se encuentra el soporte a múltiples procesadores, soporte a grandes cantidades de memoria RAM, servidores DNS, protocolo DHCP, servidores WEB, servidores FTP, entre otras características.
36
C A P Í T U L O 2
2.1 Procesos del software
El proceso del software es un “conjunto de actividades que conducen a la creación de un producto software. Estas actividades pueden consistir en el desarrollo
de software desde cero en un lenguaje de programación estándar como Java o C”
(Sommerville 2008). Sin embargo, cada vez más, se desarrolla nuevo software ampliando y modificando los sistemas existentes y configurando e integrando software comercial o componentes del sistema.
Los procesos de software son complejos, intelectuales y creativos, y por ende dependen de las personas que toman juicios y decisiones. Debido a la necesidad de juzgar y crear, los intentos para automatizar estos procesos han tenido un éxito
limitado. Las herramientas de ingeniería del software asistida por computadora (CASE)
pueden ayudar a algunas actividades del proceso, pero no existe posibilidad alguna de una automatización mayor en el diseño creativo del software realizado con el proceso del software.
La principal razón por la cual las herramientas CASE y su eficacia están limitadas se haya en la inmensa diversidad de procesos del software ya que no existe un proceso ideal, y muchas organizaciones han desarrollado su propio enfoque para el desarrollo del software. Los procesos han evolucionado para explotar las capacidades de las personas de una organización, así como las características específicas de los sistemas que se están desarrollando. Para algunos sistemas, como los sistemas críticos, se requiere un proceso de desarrollo muy estructurado. Para sistemas de negocio, con requerimientos rápidamente cambiantes, un proceso flexible y ágil probablemente sea más efectivo.
Aun existiendo muchos procesos del software, las siguientes actividades fundamentales son comunes para todos ellos:
1. Especificación del software. Se debe definir la función del software y las restricciones en su operación.
2. Diseño e implementación del software. Se debe producir software que cumpla su especificación.
3. Validación del software. Se debe validar el software para asegurar que hace lo que el cliente desea.
4. Evolución del software. El software debe evolucionar para cubrir las necesidades cambiantes del cliente.
“Aunque no existe un proceso del software ideal, en las organizaciones existen
37
hecho, muchas organizaciones aún no aprovechan los métodos de la ingeniería del
software en el desarrollo de su software” (Somerville 2008).
Cabe mencionar que los procesos del software se pueden mejorar por la estandarización del proceso donde la diversidad de los procesos del software en una organización sea reducida. Esto puede conducir a mejorar la comunicación, reducir el tiempo de formación, y hace al proceso automatizado más económico. La estandarización también es un primer paso importante para introducir nuevos métodos y técnicas de ingeniería del software.
2.2 Modelos del proceso del software
Ian Somerville dice que: “Un modelo de procesos del software es una representación abstracta de un proceso del software. Cada modelo de proceso representa un proceso desde una perspectiva particular, y así proporciona sólo información parcial sobre ese proceso”.
Los modelos del proceso del software no son descripciones definitivas de los procesos del software. Más bien, son “abstracciones de los procesos que se pueden utilizar para explicar diferentes enfoques para el desarrollo de software. Puede pensarse en ellos como marcos de trabajo del proceso que pueden ser extendidos y adaptados para crear procesos más específicos de ingeniería del software (Sommerville 2008).
Los modelos de procesos que se incluyen son:
1. El modelo/enfoque en cascada. Considera las actividades fundamentales del proceso de especificación, desarrollo, validación y evolución, y los representa como fases separadas del proceso, tales como la especificación de requerimientos, el diseño del software, la implementación, las pruebas, etcétera. 2. Desarrollo evolutivo o iterativo. Este enfoque entrelaza las actividades de
especificación, desarrollo y validación. Un sistema inicial se desarrolla rápidamente a partir de especificaciones abstractas. Este se refina basándose en las peticiones del cliente para producir un sistema que satisfaga sus necesidades.
3. Ingeniería del software basada en componentes (CBSE). Este enfoque se basa en la existencia de un número significativo de componentes reutilizables. El proceso de desarrollo del sistema se enfoca en integrar estos componentes en el sistema más que en desarrollarlos desde cero.