ESCUELA SUPERIOR DE INGENIERÍA Y ARQUITECTURA
UNIDAD ZACATENCO
SECCIÓN DE ESTUDIOS DE POSGRADO E INVESTIGACIÓN
DETECCIÓN DE DAÑO EN EDIFICIOS UTILIZANDO REDES
NEURONALES
TESIS PRESENTADA POR: TONATIUH JAIME PÉREZ FLORES
PARA OBTENER EL GRADO DE: MAESTRO EN INGENIERÍA CIVIL
ASESORES DE TESIS:
DR. RAMSÉS RODRÍGUEZ ROCHA DR. EDUARDO GÓMEZ RAMÍREZ
Agradecimientos
A mis padres, hermanas y hermanos
Por haberme apoyado en esta y todas las etapas de mi vida y por enseñarme el valor del trabajo y del esfuerzo.
Por qué si no me hubieran dado su ejemplo no hubiera llegado a este punto tan importante en mi vida.
Por brindarme su comprensión, cariño y apoyo en todos esos momentos que la vida nos tiene preparados.
A mis amigos
Por demostrarme que hay personas con las que podemos contar ya sea en las buenas como en las malas, por qué me brindaron su amistad, comprensión y apoyo para salir adelante en esta etapa que hoy concluye y espero siempre disponer de su amistad.
A mis Asesores
Por el apoyo, comprensión, y consejo al llevar a cabo este trabajo, por enseñarme que la vida es más de lo que había conocido y abrirme un panorama más amplio en el mundo del conocimiento.
A Jessica
Por apoyarme en la última etapa de este trabajo y demostrarme que hay personas muy valiosas, con valores, creencias y pensamientos hermosos.
En general
A todas esas personas que día con día hacen un esfuerzo de la manera más humilde y honrada por llevar el sustento a sus familias, aquellas que aún con las pobres
condiciones que la vida les puso en sus caminos siguen adelante esforzándose para que sus familias tengan más oportunidades.
“Dar ejemplo no es la principal manera de influir sobre los demás, es la única manera”.
RESUMEN
En este trabajo se presenta una propuesta de metodología para determinar daño por sismo en edificios, utilizando una Red Neuronal Artificial Polinomial (RNAP), para esto se consideró daño como la pérdida de rigidez.
Con base en la ecuación dinámica se realizaron múltiples simulaciones de un edificio sujeto a carga sísmica con el registro del sismo que ocurrió en México de 1985, para obtener la respuesta dinámica teórica del edificio de referencia sin daño y después obtener la respuesta dinámica teórica del edificio para varios casos de daño. Estas respuestas se tomaron como entrada a la RNAP para que después del proceso de entrenamiento, aprendizaje y predicción, la RNAP determinara los pesos que caracterizan la dinámica de las respuestas. Así cuando la red obtuvo dichos pesos, se utilizó una métrica que al comparar las diferencias absolutas entre los pesos de un modelo sin daño y uno con daño, se pudo caracterizar el daño para su localización.
ABSTRACT
In this paper propose a methodology to determine earthquake damage in buildings by the use of a Polynomial Artificial Neural Network (PANN). Damage was considered as loss of stiffness.
Based on the dynamic equation, multiple simulations of a building subject to seismic load were performed using the earthquake record that occurred in Mexico in 1985 to obtain the theoretical dynamic response of the building without damage and then the response to several cases of damage. Those answers were taken as input data to the PANN so that after the training process of learning and predicting, the PANN would determine the weights that characterize the dynamic response. So when the network obtained these weights, a metric was used to compare the absolute differences between the weights a model without damage and one with it to characterize the damage.
CONTENIDO
RESUMEN ... 2
ABSTRACT ... 3
INTRODUCCIÓN ... 5
Antecedentes ... 6
Problema ... 9
Objetivo ... 9
Justificación ... 9
Metodología ... 10
Alcances ... 10
CAPITULO I.- Red Neuronal Artificial (RNA) ... 11
1.1.- Generalidades de una RNA ... 12
1.2.- Ventajas y Desventajas de los modelos polinomiales ... 16
1.3.- Red Neuronal Artificial Polinomial (RNAP) ... 17
CAPITULO II- Metodología para la detección de daño utilizando una RNAP ... 22
2.1.- Ecuación de Movimiento ... 23
2.2.- Series de Tiempo ... 24
2.3.- Propuesta de Metodología para la detección de daño utilizando una RNAP ... 26
CAPITULO III.- Ejemplos Numéricos ... 27
3.1.- Edificio dos niveles ... 28
3.2.- Edificios de dos niveles para identificar una relación de daño ... 48
CONCLUSIONES Y RECOMENDACIONES ... 51
TRABAJO A FUTURO ... 52
REFERENCIAS ... 53
INTRODUCCIÓN
La detección de daño en elementos estructurales de edificios a partir de datos obtenidos de monitoreo corresponde a un proceso de inversión que se basa en la relación entre los parámetros modales y las propiedades estructurales. Si hay cambios en las propiedades estructurales, los parámetros modales cambiarán en consecuencia. Así la ubicación y niveles de gravedad del daño pueden ser determinados por el análisis de los cambios en los parámetros modales.
Esta relación requiere la aplicación rigurosa de algoritmos matemáticos para llevar a cabo el análisis inverso.
Por estas razones y debido a las ventajas que se tienen, se ha experimentado con las Redes Neuronales Artificiales (RNA), basadas en un proceso de entrenamiento, aprendizaje y prueba de diferentes patrones, que guardan relación con el comportamiento de algún modelo cuando se afectan sus propiedades.
Además, existe una gran variedad de modelos de RNA con características específicas para su mejor aprovechamiento en cuanto a la resolución de un problema.
Antecedentes
Dentro de la rama de Ingeniería civil se han realizado estudios importantes para la detección del daño estructural utilizando diferentes tipos de Redes Neuronales Artificiales (RNA), sin embargo aun cuando se ha estudiado y obtenido resultados importantes, el tema es muy amplio y resulta ser una herramienta pionera que aún debe de seguir siendo de interés para los investigadores ya sea en esta rama o en otras.
Algunos trabajos de importancia utilizando RNA para ayudar en la detección de daño en estructuras civiles, se encuentran los siguientes:
Wong et al. (1996) presentaron una red neuronal para identificar el daño en línea, los datos de la respuesta son procesados por plantillas de redes neuronales para la identificación estructural que se basan en la historia de respuestas de modelos que han sido afectados en sus propiedades y el de referencia (sin daño). Así estas respuestas como la cinemática, el esfuerzo y las deformaciones plásticas, son analizadas mediante la red neuronal principal para hacer una comparación de la respuesta identificada en línea con las que se encuentran en la memoria de las plantillas. Se concluyó que el trabajo computacional debe ser eficiente y debe contar con memoria robusta, ya que de no ser así, los registros de la respuesta serán limitados. Por otra parte cuando existe ruido la identificación del daño en línea es susceptible a falsas alarmas de detección.
Existe una metodología para implementar una red neuronal de tipo backpropagation
usando el Neural Network Toolbox de Matlab para identificar niveles de daño a partir de registros de desplazamientos y periodos de vibración de una estructura tridimensional, obtenidos analíticamente mediante un análisis de elementos finitos (Hernández, 2001). Se entrenaron cuatro redes neuronales para identificar escenarios analíticos de daño en tres modelos estructurales. Concluyeron que las redes neuronales del tipo backpropagation
pueden emplearse satisfactoriamente en la detección de daños en estructuras a partir de cambios en las propiedades vibracionales, tanto la magnitud como la localización del daño pueden determinarse siempre y cuando la red sea correctamente entrenada. Las aproximaciones dependen del rango de datos de entrenamiento y de la distribución de los mismos, se obtuvieron mejores resultados cuando se realizaron reducciones elevadas en el módulo de elasticidad que cuando se tienen pequeñas reducciones. También los resultados fueron más precisos con modelos de daño simple que múltiple.
Carreño et al. (2003) desarrollaron un programa de evaluación estructural después de un terremoto ayudándose de un sistema experto neuro-difuso para facilitar dicha evaluación. Éste modelo utiliza tres capas: la capa de entrada, donde las neuronas están agrupadas en cuatro grupos como elementos estructurales, no estructurales, condiciones no estructurales, y condiciones preexistentes. La capa intermedia donde se obtiene un índice de daño, a partir de la primera capa, y del cual se puede definir, en la última capa o de salida, el daño en el edificio utilizando reglas de lógica difusa con la evaluación de los elementos estructurales y no estructurales. Para así prescribir la habitabilidad del edificio, y también si así lo dictamina la posible restauración o reforzamiento. Siendo este trabajo de gran utilidad para los ingenieros evaluadores de mucha y de poca experiencia, cuando sucede un sismo de gran importancia.
Utilizando una Red Neuronal Artificial Polinomial (RNAP), Ángeles y Gómez (2005) realizan la predicción de la Salida de Aceleración de un edificio real, utilizan la RNAP para identificar el comportamiento no lineal y para predecir en línea la salida de aceleraciones de un edificio real instrumentado, la red se entrena con sólo los dos primeros ciclos de movimientos, obteniendo resultados alentadores derivados del análisis.
Un modelo de red neuronal para correlacionar el daño en un marco rígido 2D de concreto reforzado con sus características dinámicas y utilizar tales correlaciones para evaluar el estado de salud de edificios fue presentado por Kanwar et al. (2007). Donde representan el daño por la disminución de la rigidez y obteniendo sus resultados a partir de un Índice de daño establecido como la relación de la rigidez después del daño y la rigidez en el estado no dañado. La arquitectura de la red neuronal está basada en el ensayo y error, para minimizar el error y obtener una convergencia rápida, la red utiliza para el entrenamiento tres capas ocultas con capas de entrada y salida. La capa de entrada tiene tres neuronas que representan los parámetros de entrada, que son: la altura de las plantas, el coeficiente del modo de forma y la frecuencia fundamental. Observaron que el índice de daño es proporcional a la rigidez a flexión y que para cada planta la frecuencia se reduce con el aumento del daño y que esta reducción en la frecuencia aumenta aún más el índice de daño en cada planta.
local puede ser mejor identificado, así como cuando existen múltiples daños en las sub-estructuras.
Kumar et al. (2010) propusieron una red neuronal para la detección de daños basada en los cambios en una función de transferencia, considerada para que la parte de vibración forzada en el sistema vibre linealmente después de que la estructura ha sido dañada considerando que el edificio esta instrumentado durante un sismo. Mostraron que la precisión de la detección de daño aumenta con el aumento en el número de combinaciones de daños.
Un método para la detección de daño que se basa en el uso de redes neuronales para calcular la energía de onda de las señales de aceleración de la estructura fue presentado por Reda (2010). Sugiriendo y utilizando la energía como una función de onda para clasificar el estado de daño de la estructura, utilizando los patrones de daño de la Sociedad Americana de Ingenieros Civiles (ASCE) como referencia para detectar el daño. El modelo de red fue capaz de detectar y cuantificar con éxito los daños de la estructura de referencia ASSE con una sensibilidad razonable, y el método neuronal de onda destinado a establecer relaciones subyacentes entre la dinámica estructural, reconoció cambios relacionados al daño en la estructura.
Problema
Las revisiones que se hacen a los edificios después de un evento sísmico de gran importancia, están basadas principalmente en técnicas de observación visual y por tanto la revisión de los componentes estructurales de un edificio se complica ya que en ocasiones los daños no están visibles y también es difícil saber que tanto han sido afectados los elementos estructurales y por tanto existe incertidumbre en la detección de daño.
Objetivo
Proponer una metodología de localización de daño no destructiva basada en mediciones dinámicas utilizando una Red Neuronal Artificial Polinomial (RNAP).
Justificación
Con base en la experiencia mexicana en materia de sismos, convencionalmente se realizan evaluaciones visuales y/o destructivas a los edificios para conocer su estado de integridad y qué tanto han sido afectados sus elementos estructurales después de un sismo. Por lo que, este trabajo puede ser de utilidad para la evaluación de manera no destructiva del estado de los elementos estructurales de un edificio después de un evento sísmico, ya que la RNAP tiene ventajas cuando se lleva a cabo un procesamiento de señales, una de ellas es que son los modelos más utilizados para aproximar funciones de manera empírica.
Metodología
Para cumplir con el objetivo se llevó acabo la siguiente metodología:
1.- Definir casos de estudio de edificios a cortante y modelar.
2.- Resolver numéricamente la ecuación de movimiento lineal para múltiples grados de libertad, utilizando un modelo de masas y resortes para obtener la respuesta dinámica teórica por piso del modelo sujeto a varios casos de daño.
3.- Utilizar las respuestas por piso del modelo como entradas a la RNAP para el proceso de entrenamiento, aprendizaje y prueba.
4.- Calcular con la RNAP los pesos por cada piso de un modelo de referencia y los pesos del modelo sujeto a varios casos de daño.
5.- Realizar un análisis comparando los pesos del modelo sin daño con los pesos del modelo sujeto a varios casos de daño, utilizando para esto una métrica basada en la suma de la diferencia absoluta de los pesos.
6.- Asociar las mayores diferencias de pesos a la ubicación del daño.
Alcances
- Las conclusiones de esta tesis se limitan a modelos de edificios de cortante sujetos al registro del sismo de México de 1985.
- Los modelos estudiados son de 2 a 3 niveles.
- El estudio se limita a casos numéricos.
CAPITULO I
Red Neuronal Artificial (RNA)
CAPITULO I.- Red Neuronal Artificial (RNA)
1.1.- Generalidades de una Red Neuronal Artificial
Las RNA son redes de elementos simples (usualmente adaptativos) interconectadas masivamente en paralelo y con organización jerárquica, las cuales intentan interactuar con los objetos del mundo real del mismo modo que lo hace el sistema nervioso biológico (Matich Damián J., 2001).
Entre sus principales características se encuentran las siguientes:
- Consisten de unidades de procesamiento que intercambian datos o información. - Se utilizan para reconocer patrones, incluyendo imágenes, manuscritos y secuencias
de tiempo.
- Tienen capacidad de aprender y mejorar su funcionamiento.
Se puede hacer una clasificación general de ellas en dos tipos:
- Modelo tipo Biológico: Es el que trata de simular neuronas biológicas, así como las funciones auditivas o funciones básicas de la visión.
- Modelo dirigido a la aplicación: Donde la arquitectura está fuertemente ligada a las necesidades de las aplicaciones para la que es diseñada y no tiene por qué guardar similitud con los sistemas biológicos.
Sin embargo de la clasificación anterior se pueden derivar bastantes tipos de RNA, debido a sus diferentes propósitos.
Las ventajas principales de las redes neuronales pueden ser las siguientes:
- Aprendizaje Adaptativo: Capacidad de aprender a realizar tareas basadas en un entrenamiento inicial.
- Auto-Organización: Pueden crear su propia organización o representación de la información que reciben mediante una etapa de aprendizaje.
- Tolerancia a Fallos: La destrucción parcial de una red produce una degradación de su estructura, sin embargo algunas capacidades de la red se pueden retener.
- Operación en tiempo real: Los cómputos neuronales pueden ser realizados en paralelo, para esto se diseñan y fabrican maquinas con hardware especial para obtener esta capacidad.
- Fácil inserción dentro de la tecnología existente: Se pueden obtener chips especializados para redes neuronales que mejoran su capacidad en ciertas tareas.
Principalmente las RNA se componen de tres elementos, tres capas o tres niveles que son:
- Capa Oculta: No tiene contacto con el exterior, puede tener un número elevado de capas y pueden estar interconectadas de distintas maneras, lo que determinara la tipología de la red.
- Capa de Salida: Transfiere información de la red hacia el exterior.
- Decisión: La salida de la red es directa o indirectamente la solución al problema o la decisión a tomar, por lo tanto la red puede hallar una regla de decisión a través de un conjunto de datos.
Las RNA contienen una serie de Funciones necesarias para su funcionamiento, las cuales se describen a continuación:
- Función de Entrada: Utiliza una entrada global (muchos valores como si fuera uno) y para hacerlo necesita de una función para hacer la combinación de esos valores, para lo cual necesita de un operador adecuado que combine las entradas con su respectivo peso.
- Función de Activación: Una neurona puede estar activa o inactiva, por lo cual tiene un estado de activación y eso lo hace a través de una función de activación que calcula el estado de actividad de la neurona, transformando la entrada global en un valor de activación.
- Función de Salida: Por lo que el resultado de esta función es la salida de la neurona, esta función determina qué valor se transfiere a las neuronas vinculadas. Si la función de activación está por debajo del umbral determinado, ninguna salida se pasa a la neurona subsiguiente.
Las RNA tiene mecanismos de aprendizaje, es decir, lleva acabo una adaptación de los pesos, ya que el aprendizaje es el proceso por el cual la red modifica sus pesos en respuesta a una información de entrada debida a que solo los pesos sobre cada una de las conexiones puede cambiar, mientras que las funciones de cada neurona no pueden (Matich Damián J., 2001). Lo que significa que en los modelos de redes, la creación de una nueva conexión implica que el peso de la misma pase a tener un valor distinto de cero, de la misma manera que una conexión se destruye cuando su peso pasa a ser cero.
Peso nuevo = peso viejo + cambio de peso
Existen 2 tipos de Aprendizaje:
Aprendizaje Supervisado y el aprendizaje no supervisado.
El primero se refiere a que un supervisor controla la salida de la red y en caso de no coincidir con la salida deseada se modifican los pesos de las conexiones y se subdivide en 3 tipos de aprendizaje supervisado:
2.- Por refuerzo: Se ajustan los peso basándose en un mecanismo de probabilidad, ya que se basa en la idea de no disponer de un ejemplo completo del comportamiento deseado y por tanto el supervisor sólo indica una señal de refuerzo si la salida no se ajusta a la deseada.
3.- Estocástico: Consiste en realizar cambios aleatorios en valores de los pesos de las conexiones de la red y evaluar su efecto a partir del objetivo deseado y de distribuciones de probabilidad.
En cuanto al aprendizaje no supervisado no se requiere de la influencia externa para ajustar los pesos de las conexiones entre las neuronas y deben relacionar las características, regularidades, correlaciones o categorías que se puedan establecer entre los datos que se presentan en su entrada y se subdivide en dos tipos:
1.- Hebbiano: Pretende medir la familiaridad o extraer características de los datos de entrada. Se basa en que dos neuronas toman el mismo estado simultáneamente (ambas pueden estar activas o inactivas) y el peso de la conexión se incrementa en ambas.
2.- Aprendizaje Competitivo y Comparativo: Se orienta a la clasificación de los datos de entrada, si se determina que un patrón nuevo pertenece a una clase reconocida previamente, entonces la inclusión de este nuevo patrón a esta clase matizará la representación de la misma y si se determinó que el patrón no pertenece a ninguna clase reconocida, entonces la estructura y pesos serán ajustados para reconocer la nueva clase.
También es necesario explicar que hay más parámetros que intervienen en el proceso de análisis con RNA como los siguientes:
Detención del proceso de aprendizaje: Se tiene que establecer una condición de detención, normalmente cuando el cálculo del error está por debajo de un determinado umbral.
Codificación de los datos de entrada: Se deben hallar valores apropiados para representar las características simbólicas (alto, bajo, adecuado, etc.) y para esto existen dos tipos de codificación.
- Atributos Numéricos: Es en donde un atributo numérico puede tomar valor dentro de un cierto intervalo (tiempo, peso, etc.)
- Atributo Simbólico: Si los pesos son dados por un cierto número de términos semejantes a: alto o bajo.
Validación de la RNA: Después del entrenamiento de los pesos en las conexiones quedan fijos y se debe comprobar si la RNA puede resolver nuevos problemas, por tanto requiere de otro conjunto de datos denominado “conjunto de validación o testeo”.
Algunas de las Topologías de RNA son:
Red Multicapa: Disponen de un conjunto de neuronas agrupadas en varios niveles o capas.
Conexiones hacia adelante o Feedforward: Cuando todas las neuronas de una capa reciben señales de entrada desde otra capa anterior y envía señales de salida a otra capa posterior.
Conexiones hacia atrás o Feedback: Cuando se puede conectar la salida de una capa a la entrada de otras capas anteriores.
Red Hopfield: Es recurrente y completamente interconectada para reconocer patrones. Después de que el aprendizaje haya llegado a su fin, la red debe ser capaz de dar una salida correcta para cada patrón de entrada dado, aun cuando sea ruidoso.
Red Heteroasociativa: Asocia información de entrada con diferente información de salida, precisan al menos de dos capas, una para captar y retener la información de entrada y otra para mantener la salida con la información asociada.
Red Autoasociativa: Asocia una información de entrada con el ejemplar más parecido de los almacenados conocidos por la red. Puede utilizar sólo una capa para conseguir su funcionalidad.
1.2.- Ventajas y Desventajas de los Modelos Polinomiales
Una función polinomial tiene una forma de manera general como la siguiente:
1
1 1 0
( ) n n n n ...
p t a t a t a t a (1.2.1)
La cual representa a un polinomio como la combinación lineal de ciertos elementos del polinomio como
1, , ,...,t t2 tn
.En general cualquier función polinomial tiene el grado menor o igual a n.
El conjunto de polinomios de grado menor o igual a n forma un espacio vectorial por lo que los polinomios pueden ser añadidos, pueden ser multiplicados por un escalar y todas las propiedades de los espacios vectoriales se mantienen.
El conjunto de funciones
1, , ,...,t t2 tn
forman una base de un espacio vectorial, cualquier polinomio de grado menor o igual a n puede ser escrito como una combinación lineal de estas funciones.Un polinomio con grado 0 es simplemente una constante, con grado 1 la función es lineal, con grado 2 la función es cuadrática, con grado de 3 la función es cúbica y así sucesivamente. Históricamente, los modelos polinomiales son los modelos más utilizados para aproximar funciones de manera empírica (Luna Sánchez J. C., 2011). Esto es principalmente por las siguientes razones:
- Los modelos polinomiales tienen una forma simple. - Sus propiedades son bien conocidas.
- Tienen flexibilidad moderada de sus formas.
- Los modelos polinomiales son una familia cerrada. Esto quiere decir que los modelos polinomiales no dependen de métricas.
- Son fáciles de manejar en sistemas computacionales.
Por otro lado, los modelos polinomiales cuentan con las siguientes limitaciones:
- Son pobres para propiedades de interpolación. Los polinomios de grados superiores tienen oscilaciones para aproximaciones de valores exactos.
- Son pobres para propiedades de extrapolación. Los polinomios pueden dar buenos resultados para valores dentro del rango de los datos, sin embargo para valores fuera del rango de los datos suelen alejarse rápidamente.
- Tienen propiedades asintóticas. Por su naturaleza, los polinomios tienen una respuesta finita para un número de valores finito y tendrán una naturaleza infinita para un número infinito de valores, por lo tanto, Los modelos polinomiales no pueden modelar fenómenos asintóticos de una manera aceptable.
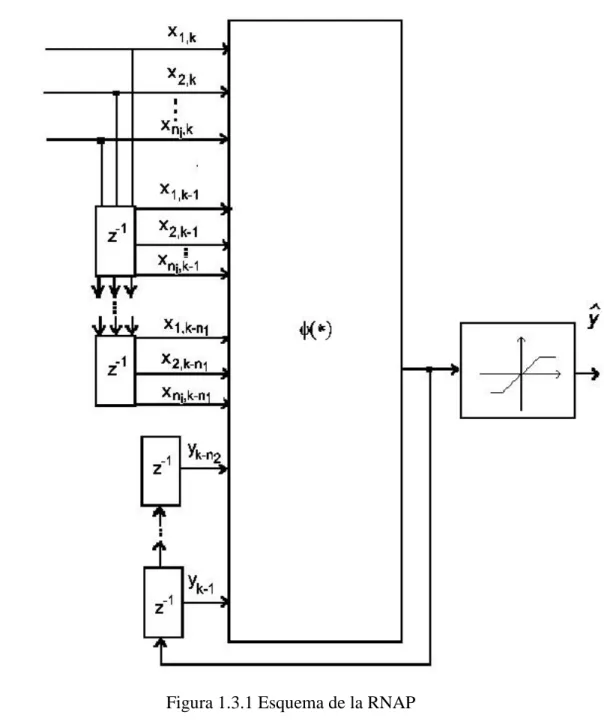
1.3.- Red Neuronal Artificial Polinomial (RNAP)
En esta sección se describirá la estructura del modelo de Red Neuronal Artificial Polinomial que por un lado se deriva de un modelo particular del modelo NARMAX (
Non-LinearAutoregressive Moving Average with eXogenous inputs) y por otro lado implementa
su propia propuesta en el uso de los modelos polinomiales. El modelo está basado en el trabajo realizado por Gómez (1999).
El modelo de RNAP propuesto puede ser descrito como:
max min 2 1
)]
...,
,
,
...,
,
...,
,
,
,
...,
,
,
(
[
ˆ
2 1 , 1 , 2 1 , 1 , , 2 , 1
n k k k n k n k k k n k k ky
y
y
x
x
x
x
x
x
y
i i
(1.3.1) donde
y
ˆ
k
es la estimación de una función, es decir la salida de la red,
x y,
es una función no lineal,x
i
X
son las entradas donde i1,...,ni y ni es el número de entradas,y
k j
Y
son los valores anteriores de la salida, n1 es el número de retardos de la entrada, para j = 1,…, n2, n2 es el número de retardos de la salida, X y Ysonconjuntos compactos de .
La función no lineal o función de activación está dada por:
min min max min max max max min
g g g gg (1.3.2)
Dónde
maxes el límite máximo y
mines el límite mínimo.Para mejor manejo y simplificación se hace un cambio de variable, quedando de la siguiente manera:
k k n k k k k n
g
g
g
g
nV
g
x
1,,
x
2,,...,
x
,,...,
y
1,
y
2,...,
y
1,
2,
3,...,
2
1
(1.3.3)
2 1n n
n n
nv i i (1.3.4)
Por lo que la función no lineal
g
p pertenece a una familia de polinomios Pque se pueden representar de la siguiente forma: ) ,..., , ( ),..., ,..., , ( ) ,..., , ( ) ,..., , ( ) ( : ) ( ) ,..., , ( 2 1 2 1 2 2 1 1 2 1 0 2 1 v v v v v n p n n n n p g g g g g g g g g g g g g g g g g a a a a
(1.3.5)El subíndice p es el máximo de las expresiones polinomiales y
a
i(
g1,
g2,...,
gnv)
sonpolinomios homogéneos de grado total
i
, para i0,...,p.Cada polinomio homogéneo se puede representar de la siguiente manera:
p n N p p p p p n n N n n N n n n n n n v p v v v v v v v v v v g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g g w w w w w w w w w w w w w w w w w , 2 1 2 , 1 1 , 2 1 p 3 , 3 2 3 2 3 2 3 2 2 3 1 6 , 3 3 2 1 5 , 3 2 2 1 4 , 3 3 2 1 3 , 3 2 2 1 2 , 3 3 1 , 3 2 1 3 2 , 2 3 2 2 2 1 3 1 3 , 2 2 1 2 , 2 2 1 , 2 2 1 2 , 1 2 2 , 1 1 1 , 1 2 1 1 0 2 1 0 ... ) ,..., , ( a ... ... ... ... ... ) ,..., , ( a ... ... ... ... ) ,..., , ( a ... ) ,..., , ( a ) ,..., , ( a 1 3 2 1 2 1 (1.3.6)
Dóndewijes el peso asociado a cada neurona, w0 es umbral de entrada o input bias de la red, el cual es un factor que es calculado con aproximaciones, a1(g)es un polinomio que corresponde únicamente a la ponderación lineal de las entradas y de a2(g)aap(g)se representan los términos de modulación entre las entradas correspondientes y las relaciones de potenciación.
El valor Ni corresponde al número de términos de cada polinomio homogéneo:
1
1
1
0 1 2 3
1 0 1
1, , ,
v v v
n n n s v
i s i
N N n N i N i
(1.3.7)3 2 1
2 2 1
1
0 0 0 1 1
...
v v v v
p
n n s n s n s
p
s s s i
p
N
i
(1.3.8)La dimensión
N
de cada familia
P puede obtenerse de la siguiente manera:0 p
i i
N
N
(1.3.9)Aprendizaje de Redes Neuronales Artificiales Polinomiales
Para introducir los conceptos de aprendizaje en RNAP, primero es necesario definir algunos términos que son utilizados:
Definición I
El error de aproximación de RNAP se define como:
n
n n k k k n k k k n
n y y y y y y
n y
n y
err , g 1 g 1 , 1, 2,..,
2 1 ^ 1 2
(1.3.10)Dónde ynes la salida deseada,
gk p y n es el número de puntos.Definición II
El error óptimo se define como:
n g
n
n
g
n
n n
g
n
y
err
y
err
y
err
opt
p *,
,
min
,
(1.3.11)
Definición III
La RNAP
g
p aprende uniformemente la salida deseada con precisión demagnitud
si:
err
ny
n,
g
err
y
n,
n* g
0
0
P
(1.3.12)Después de describir estos conceptos ahora el problema del aprendizaje de RNAP consiste en obtener la estructura de p
g que verifica esta desigualdad (1.3.12).Con la arquitectura anterior la RNAP puede calcular los pesos por medio de un algoritmo de mínimos cuadrados recursivos durante su entrenamiento.
CAPITULO II
METODOLOGÍA PARA LA
DETECCIÓN DE DAÑO
UTILIZANDO UNA RNAP
CAPITULO II.- Metodología para la Detección de Daño utilizando una RNAP
2.1.- Ecuación de movimiento
En edificios es usualmente aceptable suponer que las masas están concentradas en los niveles de los pisos y que las fuerzas de inercia son solo laterales (Bazán y Meli 2008).
Entonces para estructuras civiles, la ecuación de movimiento para un sistema lineal de múltiples grados de libertad (SMGDL) sometido a una excitación en la base, bajo la premisa de que la masa no varía es la siguiente:
Mx¨ + Cx˙ + Kx = −Mx¨g (2.1.1)
Dónde el SMGDL tiene las propiedades matriciales de masa [M], amortiguamiento viscoso [C], rigidez [K] y la fuerza excitadora se obtiene de la multiplicación de la masa por la aceleración en el terreno Mx¨g (Chopra A. K., 1995).
Las variables x¨, x˙ y x representan los vectores de desplazamiento, velocidad y la aceleración respectivamente.
Así al resolver esta ecuación (Bazán y Meli, 2008), se pueden obtener parámetros modales a partir de parámetros estructurales de un modelo. Como los periodos, frecuencias y modos de vibrar, y lo que es aún más importante para el análisis inverso para la detección de daño, se pueden calcular los registros dinámicos teóricos por piso del modelo en términos de desplazamientos, velocidades, aceleraciones absolutas y aceleraciones relativas, que definen el comportamiento estructural bajo cargas sísmicas y para utilizarlos como herramienta en el análisis para la localización del daño.
2.2.- Series de Tiempo
Una serie de tiempo se define como un conjunto de valores numéricos de un fenómeno que da un valor periódico de respuesta (George P. y William M. 1970).
El objetivo del análisis de una serie de tiempo es el conocimiento de su patrón de comportamiento para así poder prever su evolución en el futuro cercano, suponiendo por supuesto que las condiciones no variarán significativamente.
Hay diversos ejemplos de ellas en todas las áreas del conocimiento.
Ejemplos de éstas pueden ser la población de un país en donde se hace un censo cada cierto número de años, el índice semanal de la bolsa de valores en un mercado financiero, los valores diarios de temperatura en una ciudad, el costo de algún producto de gran impacto en la sociedad, etc.
Si se cuenta con una serie de tiempo y con una herramienta de predicción, se pueden dar pronósticos más aproximados y tomar mejores decisiones, ya sea en el gobierno, en una empresa, en un centro de investigación o incluso evitar riesgos en la economía familiar, sea cual sea el caso de estudio de la serie de tiempo.
El objetivo principal es obtener una función de predicción tal que la media cuadrática de las desviaciones, que es la diferencia del valor actual con el valor de la predicción, sea la menor posible por cada tiempo futuro.
Para esto es necesario que las técnicas de predicción estén adaptadas a modelos que más se asemejen a las entradas de las series de tiempo a tratar. Por esto existen diversos modelos utilizados en la predicción de series como los siguientes:
- Modelos determinísticos - Modelos estocásticos
En cuanto a los modelos determinísticos parte de la idea de utilizar un modelo matemático para describir el comportamiento de un fenómeno físico, por lo que a veces puede adaptarse un modelo basado en leyes físicas, las cuales permiten calcular el valor de alguna cantidad dependiente del tiempo de manera muy exacta. Sin embargo es difícil poder modelar cualquier fenómeno con ecuaciones diferenciales, ya que sus incógnitas se vuelven dependientes de otras variables, por lo que se tiene un problema de simplificación y aunque se tuviera la ecuación diferencial correcta, puede ser muy compleja y difícil de resolver.
Existen series de tiempo con un comportamiento estocástico, por lo que no se puede predecir con facilidad eventos futuros con los modelos determinísticos, por lo que se opta por utilizar modelos estocásticos lineales como no lineales para la predicción de este tipo de series de tiempo.
Dentro de esos modelos existe una gran variedad, algunos se describen a continuación:
ARIMA: (Autoregressive Integrated Moving Average) Se utiliza para hacer una predicción óptima con promedio variable, y se le conoce como procesos autorregresivos con promedio variable integrado. Para aproximar una predicción con estos procesos es necesario adaptar un modelo particular para la serie de tiempo que se está analizando.
ARMAX: (Autoregressive Moving Average with eXogenous inputs) Este modelo tiene grandes similitudes con el anterior y otros no mencionados, dos de las más importantes son las siguientes: 1) tienen un conjunto de valores aleatorios zt en la secuencia de los datos de la serie de tiempo y 2) cuenta con un valor de errorat.
o Con la intención de tener algún cierto control en el comportamiento de la serie, es
o usual añadir entradas ajenas o exógenas a la serie.
NARMAX: (Non-Linear Autoregressive Moving Average with eXogenous inputs)
En el caso de referirse a modelos no lineales, cuando es un caso discreto y estocástico como se ha visto en los anteriores modelos, así como el modelo ARMAX, el modelo NARMAX también cuenta con entradas exógenas con la variante de ser un modelo no lineal.Por lo que dependiendo los objetivos y uso que vaya a tener el modelo propuesto se puede adaptar sustituyendo los valores o abreviándolos. Dependiendo las adaptaciones que se lleven a cabo, la función f(.)
tendrá diferentes nombres y usos, entre los que se encuentran el modelo bilineal, o un modelo polinomial e incluso adaptarlo a un modelo lineal, y es esto lo que hace que el modelo NARMAX sea un modelo muy versátil y utilizado en la actualidad.
Redes neuronales artificiales: Una red neuronal consiste típicamente en diversos nodos arreglados en capas y que operan en paralelo. Los pesos, que son los que definen la fuerza con la que están conectados cada uno de los nodos se adaptan durante su mismo uso para permitir un rendimiento aceptable. Por tanto las redes neuronales se pueden diferenciar por:
- La arquitectura de su red.
- Las características especiales con las que cuente el nodo. - Las reglas de aprendizaje.
2.3 Propuesta de metodología para la detección de daño utilizando una RNAP
En este trabajo se propone la siguiente metodología:
1.- Definir casos de estudio de edificios de cortante.
2.- Modelar numéricamente con base en la ecuación dinámica lineal (ec.2.1.1) para osciladores de múltiples grados de libertad edificios sujetos a carga sísmica, con la posibilidad de manipular la ubicación y magnitud de daño, reduciendo el porcentaje de rigidez de los elementos columna para simular el daño.
3.- Calcular la respuesta dinámica teórica por piso en términos de aceleraciones absolutas de un modelo de referencia (sin daño) y después generar la respuesta para el modelo sujeto a distintos casos de daño.
4.- Calcular los pesos por piso del modelo de referencia, así como los pesos de los distintos casos de daño con la RNAP utilizando como entradas de la misma la respuesta dinámica teórica de los casos de estudio.
5.- Una vez que la RNAP obtiene los pesos que caracterizan la respuesta dinámica de los diferentes casos de estudio, se utiliza una métrica basada en la suma de la diferencia absoluta de los pesos para analizar una posible relación de daño entre los pesos del modelo de referencia y los modelos con distintos casos de daño.
CAPITULO III
EJEMPLOS NUMÉRICOS
En éste capítulo se muestran y explican los experimentos realizados con la metodología expuesta en el capítulo anterior, mostrando los experimentos más representativos de la investigación mostrando que la RNAP fue capaz de detectar el daño simulado en los experimentos, e incluso para algunos experimentos también fue capaz de mostrar la localización del daño.
CAPITULO III.- Ejemplos Numéricos
Cabe mencionar que para los experimentos realizados en este trabajo se llevó a cabo la metodología descrita en el capítulo anterior.
3.1 Modelo de dos niveles.
Se modeló numéricamente un edificio de dos grados de libertad a partir del principio de masas y rigideces (Figura 3.1.1). El cual no ha sufrido cambios en las rigideces para simular el daño.
Figura 3.1.1 Modelo de masas y rigideces.
El modelo simulado tiene como características las siguientes: M1 = 600 tons2/cm, M2 = 300 tons2/cm, K1 = 1800 ton/cm, K2 = 900 ton/cm, se utilizó el cinco por ciento de amortiguamiento y la ecuación de movimiento lineal se resolvió por el Método de Interpolación Lineal. Debido a la simplificación de la modelación no se tomara en cuenta el material y se supondrá el modelo como un edificio de cortante.
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000 -200
-150 -100 -50 0 50 100 150 200
t(seg)
a
c
e
le
ra
c
ió
n
Ü
(c
m
/s
2)
Figura 3.1.2 Registro acelerográfico del Sismo 1985 de la Ciudad de México.
Resolviendo la ecuación lineal de movimiento, se obtiene el registro de aceleraciones por cada nivel del modelo al que llamaremos respuesta dinámica teórica del modelo.
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000 -400 -300 -200 -100 0 100 200 300 400 t(seg) a c e le ra c ió n Ü (c m /s 2)
Figura 3.1.3 Respuesta dinámica teórica del modelo de referencia primer nivel.
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000 -400 -300 -200 -100 0 100 200 300 t(seg) a c e le ra c ió n Ü (c m /s 2)
El daño en el modelo se simuló, degradando la rigidez en los elementos columna, empezando con un modelo original, al que llamaremos Modelo de Referencia (sin daño) y después se simuló el mismo modelo con daño cambiando su porcentaje de rigidez, y haciendo combinaciones de daño.
En la Tabla 3.1.1 se muestran las propiedades del Modelo con diferentes combinaciones de daño, que son las siguientes:
CASO 1.- No hay cambios en la rigidez.
CASO 2.- La rigidez del primer entrepiso se redujo al 10% CASO 3.- La rigidez del segundo entrepiso se redujo al 10%
CASO 4.- La rigidez del primer y segundo entrepiso se redujo al 10%
Tabla 3.1.1 Propiedades del Modelo con diferentes casos de daño y degradación de rigidez al 10 %.
k,m
CASO 1 CASO 2 CASO 3 CASO 4
m2(tons2/cm) 300 300 300 300
k2 (ton/cm) 900 900 810 810
m1(tons2/cm) 600 600 600 600
k1 (ton/cm) 1800 1620 1800 1620
De manera análoga se muestran las propiedades del Modelo cuando aumentamos la degradación de rigidez al 20, 30, 40 y 50% en los casos de daño respectivamente y que se muestran los valores en las tablas 3.1.2, 3.1.3, 3.1.4 y 3.1.5.
Tabla 3.1.2 Propiedades del Modelo con diferentes casos de daño y degradación de rigidez al 20 %.
k,m
CASO 1 CASO 2 CASO 3 CASO 4
m2(tons2/cm) 300 300 300 300
k2 (ton/cm) 900 900 765 765
m1(tons2/cm) 600 600 600 600
Tabla 3.1.3 Propiedades del Modelo con diferentes casos de daño y degradación de rigidez al 30 %.
k,m
CASO 1 CASO 2 CASO 3 CASO 4
m2(tons2/cm) 300 300 300 300
k2 (ton/cm) 900 900 630 630
m1(tons2/cm) 600 600 600 600
k1 (ton/cm) 1800 1260 1800 1260
Tabla 3.1.4 Propiedades del Modelo con diferentes casos de daño y degradación de rigidez al 40 %.
k,m
CASO 1 CASO 2 CASO 3 CASO 4
m2(tons2/cm) 300 300 300 300
k2 (ton/cm) 900 900 540 540
m1(tons2/cm) 600 600 600 600
k1 (ton/cm) 1800 1080 1800 1080
Tabla 3.1.5 Propiedades del Modelo con diferentes casos de daño y degradación de rigidez al 50 %.
k,m
CASO 1 CASO 2 CASO 3 CASO 4
m2(tons2/cm) 300 300 300 300
k2 (ton/cm) 900 900 450 450
m1(tons2/cm) 600 600 600 600
Después de obtener las respuestas dinámicas teóricas del modelo de referencia y del modelo sujeto a variaciones de daño, estas respuestas se introdujeron a la RNAP para su entrenamiento.
Cuando se utiliza una serie de tiempo como entrada de la RNAP esta señal es discretizada, en valores de entrenamiento (n_test), valores de prueba (n_test) y valores transitorios, para que así la RNAP pueda entrenar, aprender, y predecir una serie optima cercana a la serie original de entrada.
Los valores de entrenamiento son los utilizados por la RNAP para relacionar el comportamiento de dicha serie entre sus valores anteriores y sus valores futuros.
Los valores de prueba son utilizados para que la RNAP experimente una vez finalizado el proceso de entrenamiento de la serie y saber cuál es la precisión del entrenamiento y aprendizaje.
Los valores transitorios son los valores de la serie de tiempo que la RNAP no utiliza para el entrenamiento, ni para la prueba ya que se consideran no significativos para estos procesos y que dependiendo de la serie que se éste procesando, estos valores pueden variar desde ser nulos cuando todos los valores de la serie son significativos para el entrenamiento y prueba, hasta un número mucho mayor si es que hay valores de la serie que no tienen un peso significativo para los fines del experimento realizado.
En las siguientes Figuras se muestran los resultados de los experimentos teniendo como datos de entrada de la RNAP los siguientes valores:
Se utilizaron 17000 valores para el entrenamiento, 900 valores para la prueba, 50 números transitorios, una potencia de dos y dos valores previos para el entrenamiento de la RNAP.
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 x 104 -400 -300 -200 -100 0 100 200 300 400 t(seg) a c e le ra c ió n Ü (c m /s 2)
Figura 3.1.5 Señales consecutivas del modelo de referencia (sin daño-sin daño).
En la Figura 3.1.6 se muestran los resultados del entrenamiento de la RNAP comparados sobre poniéndolos con la respuesta original. Se puede notar que las series o señales son tan similares que parece que en la figura se mostrará sólo una serie.
0 2000 4000 6000 8000 10000 12000 14000 16000 18000 -0.2 0 0.2 0.4 0.6 0.8 1 1.2
Número de muestras
R e a l v s . E n tr e n a m ie n to Entrenamieto Real
En la Figura 3.1.7 se muestra un acercamiento de la Figura 3.1.6 para un rango de 1673 y 1685 muestras de la serie para mostrar que el entrenamiento de la RNAP es muy adecuado.
1.674 1.676 1.678 1.68 1.682 1.684 x 104 0.48 0.485 0.49 0.495 0.5 0.505
Número de muestras
R e a l v s . E n tr e n a m ie n to Entrenamiento Real
Figura 3.1.7 Acercamiento de la Figura 3.1.6 del entrenamiento de la RNAP.
Así también en la Figura 3.1.8 se muestran los resultados de la prueba también comparados sobre poniéndolos con la respuesta original. Donde también se puede notar que las series o señales son tan similares que parece que en la figura se mostrará sólo una serie.
0 100 200 300 400 500 600 700 800 900 0.46 0.47 0.48 0.49 0.5 0.51 0.52 0.53
Número de muestras
R e a l v s . P ru e b a Prueba Real
En la Figura 3.1.9 se muestra un acercamiento de la Figura 3.1.8 para un rango entre las 250 y 400 muestras de prueba para mostrar que la predicción de la RNAP es muy adecuada.
250 300 350 400
0.486 0.488 0.49 0.492 0.494 0.496 0.498 0.5 0.502 0.504 0.506
Número de muestras
R e a l v s . P ru e b a Prueba Real
Figura 3.1.9 Acercamiento de la Figura 3.1.8 en la fase de prueba de la RNAP.
En la Figura 3.1.10 se muestra la evolución de los pesos con respecto al tiempo. Se observó que hay un periodo de estabilización entre las 6000 y 11000 muestras y a continuación se observa un periodo de oscilación hasta la muestra 15000, para terminar otra vez con un periodo de estabilización.
0 2000 4000 6000 8000 10000 12000 14000 16000 18000
-0.5 0 0.5
0 2000 4000 6000 8000 10000 12000 14000 16000 18000
-2 0 2
0 2000 4000 6000 8000 10000 12000 14000 16000 18000
0 2 4
0 2000 4000 6000 8000 10000 12000 14000 16000 18000
-0.5 0 0.5
0 2000 4000 6000 8000 10000 12000 14000 16000 18000
-1 0 1
0 2000 4000 6000 8000 10000 12000 14000 16000 18000
-1 0 1
Número de muestras
En la Figura 3.1.11 se muestran los resultados obtenidos del análisis utilizando la suma de la diferencia absoluta y cuando la rigidez se degrado 10 %, obteniendo una suma de la diferencia absoluta para el primer y segundo nivel respectivamente de 0.1479 y 0.0961 cuando el daño está en el primer nivel (caso dos) y una suma de la diferencia absoluta para el primer y segundo nivel respectivamente de 0.0545 y 0.2745 cuando el daño está en el segundo nivel (caso tres). Estos resultados muestran que la métrica es mayor en el nivel dañado. Así mismo para el caso cuatro la métrica nos supone el daño en el segundo nivel.
Figura 3.1.11 Magnitud de los pesos en los diferentes casos de estudio con 10% de daño.
Figura 3.1.12 Magnitud de los pesos en los diferentes casos de estudio con 20% de daño.
En la Figura 3.1.13 se muestran los resultados obtenidos del análisis utilizando la suma de la diferencia absoluta y cuando la rigidez se degrado 30 %, obteniendo una suma de la diferencia absoluta para el primer y segundo nivel respectivamente de 0.2893 y 0.2055 cuando el daño está en el primer nivel (caso dos) y una suma de la diferencia absoluta para el primer y segundo nivel respectivamente de 0.0506 y 0.2445 cuando el daño está en el segundo nivel (caso tres). Estos resultados muestran que la métrica es mayor en el nivel dañado. Además para el caso cuatro se puede notar que la relación en cuanto a la localización del daño cambio al aumentar la degradación de rigidez, arrojándonos como resultado que el valor de la métrica mayor se encuentra en el primer nivel y no en el segundo como en los experimentos anteriores.
En la Figura 3.1.14 se muestran los resultados obtenidos del análisis utilizando la diferencia absoluta y cuando la rigidez se degrado 40 %, obteniendo una suma de la diferencia absoluta para el primer y segundo nivel respectivamente de 0.2994 y 0.1914 cuando el daño está en el primer nivel (caso dos) y una suma de la diferencia absoluta para el primer y segundo nivel respectivamente de 0.1855 y 0.2683 cuando el daño está en el segundo nivel (caso tres). Estos resultados muestran que la métrica es mayor en el nivel dañado. Se nota que para el caso cuatro la localización del daño se encuentra en el primer nivel usando la lógica de la métrica utilizada, siendo igual al experimento anterior.
Figura 3.1.14 Magnitud de los pesos en los diferentes casos de estudio con 40% de daño.
Figura 3.1.15 Relación de las magnitudes de las sumas del error cuadrático de los pesos cunado se aumenta el daño en 10%, 20%, 30% y 40%.
En las siguientes figuras se muestra la aportación de los pesos, así como su magnitud cada vez que se aumentó el daño.
En la Figura 3.1.16 se muestra la magnitud de la diferencia los pesos del modelo de referencia (sin daño-sin daño) y los pesos para los casos de daño del primer nivel cuando el daño se simula en este mismo primer nivel cada vez que se aumenta la degradación de la rigidez en 10%, 20%, 30% y 40% respectivamente. Se nota que hay una relación de comportamiento cuando se aumenta el daño y que el peso cinco es el más representativo.
En la Figura 3.1.17 se muestra la magnitud la diferencia los pesos del modelo de referencia (sin daño-sin daño) y los de los otros casos de daño del segundo nivel cuando el daño se incrementa en el primer nivel en los diferentes porcentajes de daño. Se puede observar que los valores son mayores en los pesos del 1er nivel y que podría existir una relación en cuanto el incremento de daño de no ser por que el peso cinco es mayor cuando se degrada el 30% que el mismo peso cuando se degrada la rigidez en 40%.
Figura 3.1.17 Magnitud de los pesos del segundo nivel cuando el daño se simula en el primer nivel.
Así mismo se muestra en la Figura 3.1.18 la magnitud de la diferencia de los pesos del primer nivel cuando el daño esta en el 2º nivel, observándose primeramente que el peso cinco es el mas representativo y que la relación entre el aumento de daño y los pesos no es muy clara o contundente.
Figura 3.1.18 Magnitud de los pesos del primer nivel cuando se aumenta el daño en el segundo nivel.
Figura 3.1.19 Magnitud de los pesos del segundo nivel cuando se aumenta el daño en este nivel.
Resultado de los análisis de los pesos que calcula la RNAP, se aumentó más el daño degradando la rigidez en 50%, sin embargo al aumentar más el porcentaje de degradación de rigidez los resultados no fueron adecuados para localización y magnitud de daño como se muestra en la siguiente figura.
Figura 3.1.20 Magnitud de los pesos en los diferentes casos de estudio con 50% de daño.
Del análisis anterior se concluye que al aumentar el número de valores de entrenamiento la RNAP tiene un mejor entrenamiento debido a que los errores de entrenamiento y prueba respectivamente son más pequeños y se nota una mejor predicción. También se concluyó que los pesos que la RNAP calcula no tienen la relación suficiente con la localización del daño, ya que se obtuvieron resultados favorables para los casos dos y tres para 10, 20, 30 y 40% de degradación de rigidez, pero cuando se aumentó la degradación al 50% la localización del daño según la métrica no correspondió a la simulación del daño y en el caso cuatro para todas las variaciones de daño no mostro un comportamiento adecuado para suponer correcta la localización de daño.
Por lo tanto se trabajaron experimentos en paralelo con ciertas variaciones, que se exponen a continuación:
1.- Se realizaron combinaciones haciendo variar los valores previos y cuál de estas reflejaría el menor error de entrenamiento y error de prueba (Tabla 3.1.6). Como se puede observar los valores de los errores de prueba (e_test) y error de entrenamiento (e_training) varían muy poco aunque se aumente el número de valores previos (pre_val) y no puede ser un parámetro que mejore en abundancia los resultados.
Tabla. 3.1.9 Pruebas variando el número de valores previos.
Pre_val # Cn e_test e_training
2 6 2.1416E-06 2.8914E-07
3 10 2.1327E-06 2.8157E-07
4 15 1.9915E-06 2.2955E-07
5 21 1.9248E-06 2.334E-07
6 28 1.8037E-06 2.291E-07
7 36 1.7583E-06 2.2128E-07
8 45 1.6757E-06 2.085E-07
9 55 1.6336E-06 2.0013E-07
10 66 1.5527E-06 1.8984E-06
20 231 1.2611E-06 1.4811E-07
2.- Se realizaron combinaciones cambiando los valores de las variables “max_pow” y la
variable “ration”, ya que están directamente relacionadas con la potencia de los polinomios
Tabla. 3.1.7 Prueba cambiando las variables max_pow y ration.
3.- Se realizó un experimento del comportamiento de la RNAP cuando se varían los números transitorios (que son los valores de la serie real que no son representativos para el entrenamiento de la RNAP) con variaciones de 100 en 100, obteniendo los pesos en dos puntos de la señal y haciendo su diferencia para verificar cual número de transitorios pudiera ser el ideal para empezar con el entrenamiento, se realizaron experimentos sin daño y con daño.
Para ejemplificar el experimento desde 100 a 3500 transitorio, en la Tabla 3.1.8 se muestran los valores de los pesos y la diferencia absoluta entre ellos cuando se tienen solo 100 entradas de números transitorios. Así como en la Tabla 3.1.9 se muestran los valores obtenidos cuando se tienen 3500 números transitorios.
Tabla. 3.1.8 Experimento con 100 transitorios.
100 tran Cn(pesos) pto 9001 pto 15000 Diferencia 1 9.18E-04 7.27E-04 1.91E-04
maxpow 2 0.0012 0.0175 1.63E-02
4 3 0.0073 -0.0086 1.59E-02
ration 4 -1.0253 -0.8411 1.84E-01
2 5 -0.3324 -0.7946 4.62E-01
Tabla. 3.1.9 Experimento con 3500 transitorios.
3500 tran Cn(pesos) pto 9001 pto 12500 Diferencia 1 9.18E-04 8.92E-04 2.61E-05 maxpow 2 1.26E-03 3.11E-03 1.85E-03 4 3 7.31E-03 5.91E-03 1.40E-03 ration 4 -1.03E+00 -1.04E+00 9.71E-03 2 5 -3.32E-01 -3.37E-01 4.96E-03 6 2.33E+00 2.34E+00 1.28E-02 7 3.28E-01 3.48E-01 1.97E-02 8 1.14E-01 1.20E-01 5.58E-03 9 -1.09E-01 -1.16E-01 7.44E-03 10 -3.05E-01 -3.21E-01 1.52E-02 11 -5.65E-01 -5.79E-01 1.33E-02 12 1.64E-01 1.64E-01 8.35E-05 13 4.41E-01 4.46E-01 4.82E-03 14 2.75E-01 2.79E-01 4.65E-03 15 -3.25E-01 -3.23E-01 2.67E-03 Suma 1.04E-01
De esta prueba se obtuvieron graficas similares a la de la Figura 3.1.21 donde se observan dos picos cercanos a los 500 y 1000 transitorios respectivamente, lo que significo después de un análisis que existían máximos que eran significativos y que probablemente podíamos tomarlos como referencia para iniciar ahí el entrenamiento para el aprendizaje de la RNAP, y que después de los 3000 números transitorios ya no son significativos puesto que la respuesta está en su fase más intensa.
Lo que se pretendió con estos experimentos es entender mejor el entrenamiento de la RNAP, así como determinar cuál es el mejor modo de fijar las variables dentro de la RNAP y que al hacer esto, los resultados sean más precisos.
Sin embargo al final de la investigación cuando se depuro el entrenamiento y aprendizaje de los parámetros que la RNAP utiliza para la predicción de las respuestas dinámicas, se realizaron experimentos para verificar si en verdad existía una relación de daño con el modelo matemático con el cual se obtenían las respuestas, ya que los pesos obtenidos con este modelo no reflejaron relación alguna con la magnitud y localización del daño.
3.2. Edificios de 2 para identificar una relación de daño
Se tomaron modelos de 2 niveles y analizando la norma se buscó identificar alguna relación de daño, se ejemplificara estos experimentos con el siguiente modelo; m1=0.40775
/cm s
ton 2 , k1=200 ton/cm, m2=0.40775 tons2/cm , k2=200 ton/cm, cuando se degrada la rigidez en los siguientes porcentajes; 0.25, 0.50 y 0.75.
En la Figura 3.2.1 se muestra la variación del error de las respuestas de cada piso respectivamente, calculado como la norma. En la figura el número uno representa el error de los dos pisos del modelo de referencia (sin daño), en seguida el número dos representa el error de las respuestas de los pisos cuando se degrada en 25% la rigidez, de esta forma tres y cuatro representan los errores de las respuestas cuando dañamos en 50% y 75 % respectivamente. Se puede observar que la magnitud del error es mayor para el piso 2 aún cuando el daño está en el piso 1.
En la Figura 3.2.2 se muestra la variación del error del piso 1, se observa que primero incrementa cuando se aumenta el daño hasta en 50 % pero luego disminuye cuando el daño es de 75% y el error en el piso 2 incrementa conforme aumenta el daño.
Figura 3.2.2 Error de las respuestas de piso 1 y 2, con daño en 2.
En la Figura 3.2.3 se comparan los errores de las respuestas del mismo piso 1, cuando el daño está en uno y cuando el daño está en 2. Se observa una tendencia de incremento del error para el piso 1 cuando el daño está en 1, pero el error aumenta y disminuye en el caso del piso 2 cuando se aumenta el daño.
Como en el caso anterior en la Figura 3.2.4 se muestra la tendencia del piso 2 cuando el daño está en el piso1 y cuando está en el piso 2, observándose una tendencia a aumentar cuando el daño está en el piso 2 y se aumenta el daño, pero no cuando el daño está en el piso 1.
Figura 3.2.4 Errores de las respuestas del piso 2, cuando el daño está en uno y cuando el daño está en 2.
CONCLUSIONES Y RECOMENDACIONES
Se presentan a continuación las conclusiones más relevantes:
La detección de daño en edificios como en otras obras civiles a través de los años en México ha tomado más importancia debido a la alta sismicidad que ocurre periódicamente y esto afecta directamente en las propiedades estructurales de los edificios, por lo que después de los eventos sísmicos se realizan revisiones para saber el estado de integridad de los elementos estructurales de los edificios, pero los métodos para realizar dichas revisiones aún no son totalmente adecuadas, por estas razones en este trabajo se propone una nueva metodología que ayude a realizar evaluaciones para la detección de daño, concluyendo que aún se deben hacer mejoras a su procedimiento para que la metodología sea adecuada.
En algunos experimentos se muestra cómo se localizó el daño para los casos dos y tres cuando se incrementaba el porcentaje de daño, sin embargo cuando se incrementó al 50% la localización de daño no fue adecuada. Por lo que se concluyó que utilizando el modelo lineal de la ecuación de movimiento los pesos calculados por la RNAP no tienen suficiente relación con la localización del daño.
En todos los experimentos, los errores de entrenamiento y de prueba resultaron muy adecuados, y por esa razón la predicción que hace la RNAP se puede suponer como efectiva. Para ejemplificar en el caso del experimento se la sección anterior, los errores de entrenamiento oscilan entre 1.85E-06 y 2.7169E-06 y los de prueba entre 2.1943E-07 y 3.6801E-07. Observándose que son valores muy pequeños y que podrían equivaler a cero para fines ingenieriles.
La RNAP tiene un mejor aprendizaje cuando se le aporta una mayor cantidad de datos de entrada.
Fijando un umbral para los máximos y mínimos de salida se puede tener mejores resultados y menores errores de predicción.
Cuando se aumenta la potencia de los polinomios homogéneos se puede determinar una mejor aproximación en la predicción, sin embargo la potencia 2 es aceptable y se obtienen buenos resultados.
Resulta una mejor aproximación de predicción cuando se utilizan exponentes fraccionarios.
RECOMENDACIONES
Verificar que el modelo para simular el daño contenga suficientes patrones relacionados con el daño, tanto en magnitud como en localización.
Utilizar los errores de entrenamiento y de prueba para la detección de daño.
La RNAP ha sido utilizada para predecir dinámicas no lineales, y se han obtenido
resultados favorables, por lo que podría realizarse la metodología aquí propuesta utilizando modelos no lineales para la obtención de las respuestas dinámica.
TRABAJO A FUTURO
Aplicar la metodología propuesta a modelos experimentales de laboratorio.
Utilizar modelos matemáticos no lineales para simular el daño.
Realizar experimentos para que la RNAP realice el procesamiento en tiempo real.
Tomar como base la metodología propuesta en esta tesis, tomando en cuenta las conclusiones y recomendaciones para así tener una metodología de detección de daño no destructiva y aplicada en tiempo real.
Será adecuado que los datos experimentales con los que se comparen los numéricos, se conozcan los parámetros estructurales y los daños que ya ha sufrido el edificio por algún sismo pasado.
Si es posible, comparar los resultados con algún otro método de detección de daño, para su validación.