INSTITUTO POLITÉCNICO NACIONAL
ESCUELA SUPERIOR DE INGENIERÍA
MECÁNICA Y ELÉCTRICA
IMPLEMENTACIÓN DE UNA RED NEURONAL EN UN
FPGA CON LENGUAJE DESCRIPTOR DE
HARDWARE
QUE PARA OBTENER EL TÍTULO DE:
INGENIERO EN COMUNICACIONES Y ELECTRÓNICA.
PRESENTAN:
PEÑA SERRATO ERNESTO ANTONIO
DÁVILA LÓPEZ JUAN FERNANDO
ASESORES:
DR. LÓPEZ CÁRDENAS RODRIGO
M. EN C. SALINAS SALINAS MARISOL
M. EN C. NOVOA COLÍN JUAN FRANCISCO
i
Dedicatoria
Ernesto Antonio Pen a Serrato
A mi familia por apoyarme durante estos años a alcanzar este objetivo, gracias. Este logro es de todos porque no ha sido fácil llegar hasta aquí y siempre les estaré agradecido por su tiempo, ayuda y comprensión.
A mis asesores por su tiempo y consejos durante el desarrollo de este trabajo, en especial al Dr. Rodrigo quien fue de gran ayuda para poder concluir este proyecto, gracias.
Juan Fernando Da vila Lo pez
iii
Índice
Dedicatoria ... i
Índice ...iii
Índice de figuras ... vii
Introducción ... ix
Objetivo general ... ix
Objetivos específicos ... ix
Justificación ... ix
Planteamiento del problema ... xi
Estructura del proyecto terminal ... xi
Capítulo 1 Marco Teórico. ... 1
1.1. Redes Neuronales Artificiales... 2
1.1.1. Principios básicos de las Redes Neuronales ... 2
1.1.2. Aplicaciones de las redes neuronales ... 3
1.1.3 Arquitecturas típicas de las redes neuronales ... 5
1.1.4. Mecanismos de Aprendizaje ... 8
1.1.5. Entrenamiento de las redes neuronales artificiales ... 11
1.1.6. El Perceptrón ... 12
1.1.7. Implementación y tecnologías emergentes ... 12
1.2. Implementación en dispositivos programables ... 13
1.2.1. Dispositivo lógico programable FPGA ... 13
1.2.2. Arquitectura genérica ... 14
1.2.3. Descripción de la arquitectura ... 14
1.2.4. Lenguaje de descripción de hardware VHDL ... 16
Capítulo 2 Algoritmos de entrenamiento Perceptrón y de Retropropagación (Backpropagation) .. 19
2.1 Introducción ... 20
2.1. Las Redes ADALINE y MADALINE ... 20
2.2. Perceptrón ... 24
2.3. Algoritmo de entrenamiento Perceptrón ... 25
2.4. Red de Retroprogación (Backpropagation) ... 26
iv
2.4.3 Dimensiones de la red. Número de capas ocultas ... 31
Capítulo 3 Implementación de Algoritmos de entrenamiento en VHDL (unidad de control y máquinas de estado finito) ... 33
3.1. Introducción ... 34
3.2. Operación única del RT ... 34
3.2. Decisión de caja de registro ASMD ... 35
3.3. Máquina de Estados Finitos ... 37
3.3.1 Representación FSM... 37
3.4.1 Descripción ASM ... 37
3.5 Modelado de Hardware en VHDL ... 38
3.3.1 ¿Qué es Síntesis? ... 39
3.3.2 Síntesis en un proceso de diseño ... 39
3.3.3 Los valores para Modelar Hardware ... 39
3.3.4 FSM, Código de desarrollo en VHDL ... 40
Capítulo 4 Diseño y descripción de la implementación de una unidad de control en hardware para ejecutar el algoritmo de entrenamiento y comparación con su equivalente en software ... 41
4.1. Introducción ... 42
4.2. Descripción del diseño de la unidad de control ... 42
4.2.1. Puertos ... 42
4.2.2. Sistema de reloj ... 42
4.2.3. Variables y registros ... 44
4.2.4. Función de activación para la red neuronal ... 45
4.2.5. Máquina de estados ... 45
4.2.6. Sintetizabilidad ... 52
4.3. Comparación con la implementación en software. ... 52
Capítulo 5 Simulación y resultados ... 55
5.1. Herramientas de simulación ... 56
5.2 Revisión de sintaxis y sintetización. ... 56
5.3 Simulación con ISE Simulator ... 58
v
5.3.1.1 Simulación de diferentes patrones de entrenamiento ... 63
5.3.2. Entrenamiento de la red de retropropagación ... 68
Capítulo 6 Conclusiones y futuras posibilidades de desarrollo ... 73
6.1. Conclusiones... 74
6.2. Futuras posibilidades de desarrollo ... 75
Bibliografía ... 77
Anexos ... 79
Especificaciones generales de la familia de FPGA Spartan-3E ... 79
Código en VHDL para la red neuronal de retropropagación ... 81
Código en VHDL para el perceptrón ... 91
Código en C++ para la red neuronal de retropropagación ... 97
vii
Índice de figuras
FIGURA 1.1 UNA NEURONA ARTIFICIAL SIMPLE ... 2
FIGURA 1.2 NEURONA BIOLÓGICA ... 3
FIGURA 1.3 RED DE UNA CAPA ... 6
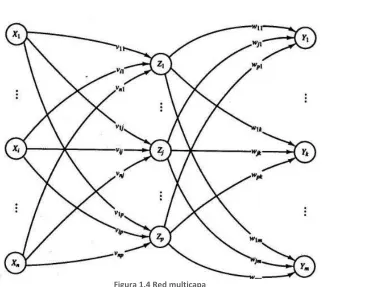
FIGURA 1.4 RED MULTICAPA ... 7
FIGURA 1.5 ARQUITECTURA DE LA FAMILIA SPARTAN-3E ... 15
FIGURA 1.6 DIAGRAMA DE INTERCONEXIÓN EN EL FPGA ... 16
FIGURA 2.1 RED DE UNA CAPA ADALINE ... 21
FIGURA 2.2RED MULTICAPA MADALINE ... 22
FIGURA 2.3 EL PERCEPTRÓN ... 24
FIGURA 2.4 ALGORITMO DE ENTRENAMIENTO RETROPROGACIÓN ... 27
FIGURA 3.1DIAGRAMA DE BLOQUES ... 35
FIGURA 3.2DIAGRAMA DE TIEMPO ... 35
FIGURA 3.3DIAGRAMA ASM ... 36
FIGURA 3.4DIAGRAMA A BLOQUES ... 36
FIGURA 3.5 MÁQUINA DE ESTADOS FINITOS Y SU EQUIVALENTE EN DIAGRAMA ASM ... 38
FIGURA 3.6 COMPONENTES DE UNA ARQUITECTURA ... 38
FIGURA 4.1 OSCILADOR DE LA TARJETA DEL FPGA ... 43
FIGURA 4.2 FLANCO DE SUBIDA DEL CICLO DE RELOJ ... 43
FIGURA 4.3 SISTEMA DE RELOJ EN VHDL ... 44
FIGURA 4.4 REGISTRO DE VARIABLE EN ESTADOS FUTURO Y PRESENTE ... 45
FIGURA 4.5 DIAGRAMA DEL PERCEPTRÓN. ... 46
FIGURA 4.6 MÁQUINA DE ESTADOS PARA EL PERCEPTRÓN ... 46
FIGURA 4.7 DIAGRAMA DE BLOQUES DE HARDWARE CAPAZ DE REALIZAR EL ENTRENAMIENTO DE UN PERCEPTRÓN. ... 47
FIGURA 4.8 DIAGRAMA DE LA RED DE RETROPROPAGACIÓN ... 48
FIGURA 4.9 MÁQUINA DE ESTADOS PARA RETROPROPAGACIÓN ... 49
FIGURA 4.10 COMPARACIÓN DE LAS CARACTERÍSTICAS DEL CÓDIGO PARA UNA MISMA FUNCIÓN ... 54
FIGURA 5.1 SINTETIZACIÓN CORRECTA ... 56
FIGURA 5.2 IMPLEMENTACIÓN CORRECTA ... 57
FIGURA 5.3 RESUMEN DE RECURSOS CONSUMIDOS Y NOTIFICACIONES ... 57
FIGURA 5.4 SIMULACIÓN ... 59
FIGURA 5.5 TRANSICIONES ... 60
FIGURA 5.6 ENTRENAMIENTO CONCLUIDO ... 61
FIGURA 5.7 RESULTADOS DE ENTRENAMIENTO EN C++... 62
FIGURA 5.8 SIMULACIÓN DEL ENTRENAMIENTO COMO COMPUERTA NOR ... 63
FIGURA 5.9 ENTRENAMIENTO COMO COMPUERTA NOR EN C++ ... 64
FIGURA 5.10 ENTRENAMIENTO COMO COMPUERTA AND EN C++ ... 64
FIGURA 5.11SIMULACIÓN DEL ENTRENAMIENTO COMO COMPUERTA AND ... 65
FIGURA 5.12 SIMULACIÓN DEL ENTRENAMIENTO COMO COMPUERTA NAND ... 66
FIGURA 5.13 ENTRENAMIENTO COMO COMPUERTA NAND EN C++ ... 67
FIGURA 5.14 SIMULACIÓN DEL ENTRENAMIENTO DE LA RED DE RETROPROPAGACIÓN COMO COMPUERTA XOR ... 69
FIGURA 5.15 ENTRENAMIENTO DE LA RED DE RETROPROPAGACIÓN COMO COMPUERTA XOR EN C++ CON 5,000 ÉPOCAS ... 70
ix
Introducción
Objetivo general
Corroborar que es posible implementar en hardware el entrenamiento de una red neural empleando lenguajes descriptores de hardware para su síntesis en un FPGA.
Objetivos específicos
Implementar el algoritmo de entrenamiento del perceptrón Implementar el algoritmo de retropropagación de errores
Programar los algoritmos en un FPGA Xilinx con el lenguaje descriptor de hardware VHDL Demostrar las ventajas y el alto rendimiento de la implementación en hardware.
Justificación
Las redes neuronales tienden a un procesamiento de información perteneciente a la inteligencia artificial que busca emular el comportamiento del sistema nervioso. Se basa en las múltiples interconexiones que se generan entre sus elementos básicos, denominados neuronas. De esta forma, según esta interacción pueden formar diferentes tipos de arreglos para cumplir una tarea específica.
El hecho de contar con dispositivos lógicos programables de gran tamaño y la incorporación en ellos de poderosos bloques funcionales para el procesamiento digital, como es el caso de las nuevas familias de FPGA, han dado lugar a nuevos diseños lógicos, destacando el procesamiento hardware reconfigurable. Los FPGA han dejado de ser únicamente dispositivos para el diseño de Circuitos Integrados de Aplicación Especifica (ASICs) y, han pasado a ser verdaderas plataformas de procesamiento digital de señales.
x
– Neurociencia Computacional y Cognición Computacional: Comunicación Neuronal; Aprendizaje y Memoria. Procesos y Estructuras Cognitivas/Perceptivas.
– Aplicación de la Computación Neuronal en Dominios Biomédicos, Clínicos y Medioambientales
La implementación hardware es un aspecto determinante objeto de este trabajo. Esto por dos razones, la primera reside en el hecho de que las redes neuronales de tamaño considerable en general, y de forma particular las competitivas, necesitan tiempos prolongados para su entrenamiento.
SOTFWARE
HARDWARE
Flexibles Eficientes
Programas con licencia FPGA (acelera las fases de ejecución)
Economicos Chips (VLSI Digital)
Biochips VLSI analógico Opto-Electrónicos Portabilidad
No dependen de una computadora Ahorro de energia
IMPLEMENTACIONES
Las redes neuronales de manera inherente tienen un procesamiento masivamente paralelo, característica que no es posible explotar en una implementación software, que es secuencial por naturaleza. Así que acelerar el proceso de aprendizaje y aprovechar el paralelismo inherente de las redes neuronales es una doble motivación para sus implementaciones hardware,
xi
Planteamiento del problema
Si bien la mayoría de redes neuronales artificiales están diseñadas en software y dependen
para ello de un ordenador para su entrenamiento y adaptación, en este trabajo se tiene como objetivo demostrar el mayor aprovechamiento de la implementación en hardware del algoritmo de entrenamiento de retropropagación (Backpropagation), por esto la importancia y la vigencia de las implementaciones en hardware que planteamos radica en aprovechar las ventajas propias de las redes neuronales artificiales en específico del entrenamiento de retropropagación, para las aplicaciones que requieren un alto desempeño de ejecución, velocidad y factibilidad que nos ofrece programarla en un FPGA con Lenguaje Descriptor de Hardware, sin depender de un
ordenador para sus etapas de entrenamiento y ejecución.
Los FPGA son dispositivos programables con una alta capacidad de integración. Estos dispositivos están diseñados para implementaciones en hardware, en comparación con un sistema basado en microprocesador, todo el procesamiento realizado por la red neuronal será en paralelo y no secuencial.
Las redes neuronales se implementan tanto en hardware como en software. Ambos tipos de desarrollo presentan un campo de acción definido, el cual depende de los requerimientos específicos de la aplicación; por lo cual, debe ser analizada para realizar una correcta elección
Estructura del proyecto terminal
En este trabajo se analiza la implementación de redes neuronales con lenguajes descriptores de hardware las cuales puedan realizar su entrenamiento dentro de un FPGA para observar las ventajas que ofrece la implementación de redes neuronales en hardware sobre la implementación en software.
En el capítulo 1 se mencionan las bases teóricas del área que comprende el estudio de las redes neuronales artificiales, sus principios de operación, sus analogías, arquitecturas básicas y tipos de entrenamiento.
En el capítulo 2 se profundiza de manera más concreta a las bases de los algoritmos de entrenamiento y reglas de aprendizaje de algunos tipos básicos de redes neuronales, en especial a 2, el perceptrón y la red de retropropagación del error.
En el capítulo 3 se mencionan algunas de las características del lenguaje descriptor de
hardware VHDL, así como la forma en la que sus características se acoplan a la implementación de los algoritmos de entrenamiento de redes neuronales.
En el capítulo 4 se explica la manera en la que se logró la implementación de los algoritmos de entrenamiento por medio del diseño de una unidad de control descrita en VHDL, así como su comparación con su equivalente implementación en software con C++.
En el capítulo 5 se muestran los resultados de las simulaciones obtenidas de los algoritmos de entrenamiento implementados en VHDL y se comparan los resultados con su equivalente programa de entrenamiento en software con C++.
1
Marco Teórico.
2
1.1. Redes Neuronales Artificiales
1.1.1. Principios básicos de las Redes Neuronales
Una red neuronal artificial es un sistema que procesa información cuenta con ciertas características de desempeño con las redes neuronales biológicas en común. Las redes neuronales artificiales han sido desarrolladas como modelos matemáticos de la cognición humana, en común basado en los siguientes supuestos:
El procesamiento de información se lleva a cabo en muchos elementos simplemente llamados neuronas.
Las señales son enviadas a las neuronas a través de conexiones.
Cada conexión tiene un peso asociado, el cual, en una red neural típica, multiplica la señal transmitida.
Cada neurona aplica una función de activación (usualmente no lineal) a la entrada de su red para determinar su señal de salida,
Una red neural está caracterizada por el patrón de conexión entre las neuronas (llamado arquitectura), el método para determinar el peso de las conexiones (llamado entrenamiento, aprendizaje o algoritmo) y la función de activación.
Una red neuronal consiste en un gran número de elementos simples de procesamiento llamados neuronas, unidades, células o nodos. Cada neurona está conectada a otras neuronas por medios directos de comunicación, enlaces a los cuales se les asocia un peso. El peso representa la información que la red utiliza para resolver un problema. Las redes neurales pueden ser aplicadas a la resolución de varios problemas tales como reconocer datos o patrones, agrupando patrones similares, realizando mapeos generales desde los patrones de entrada a los de salida, agrupando patrones similares o encontrando soluciones a problemas delimitados de optimización.
Cada neurona cuenta con un estado interno, llamado nivel de activación, el cual es recibido en la entrada por una función. Usualmente, una neurona envía su nivel de activación como una señal a una o varias neuronas, por ejemplo, consideremos la neurona Y de la Figura 1.1 que recibe las entradas X1, X2 y X3 en la neurona Y y sus pesos respectivos en las conexiones son W1, W2 y W3. [1]
3
Marco Teórico.
Hay una analogía cercana entre las estructuras de las redes neurales artificiales y las biológicas. Una neurona biológica tiene tres tipos de componentes: Dendritas, axón y núcleo. Las diferentes dendritas reciben señales de otras neuronas. Las señales son impulsos eléctricos que son transmitidos a lo largo de la brecha sináptica por medio de procesos químicos. La acción de los químicos modifica la señal en una manera similar a la que el peso de la conexión de una red neural artificial lo hace. [1]
El núcleo de la neurona suma las señales entrantes. Cuando se reciben suficientes señales la neurona se dispara, eso significa que transmite una señal sobre el axón a las otras neuronas. Se puede resumir que las características las neuronas biológicas fueron sugeridas para las redes neurales artificiales a partir de:
El elemento procesador recibe varias señales
Las señales son modificadas por una ganancia de la conexión
El elemento procesador suma las entradas modificadas por sus respectivas ganancias Bajo circunstancias apropiadas la neurona transmite una sola salida
La salida de una neurona puede ir hacia varias otras neuronas
En la Figura 1.2 se puede observar un ejemplo de una neurona biológica.
Figura 1.2 Neurona biológica
1.1.2. Aplicaciones de las redes neuronales
Las características especiales de los sistemas de computación neuronal modernos permiten que sea utilizada esta nueva técnica de cálculo en una extensa variedad de aplicaciones. [10]
4
Análisis y Proceso de señales Reconocimiento de Imágenes Control de Procesos
Filtrado de ruido Robótica
Procesado del Lenguaje Diagnósticos médicos Otros
Conversión Texto a Voz: uno de los principales promotores de la computación neuronal en esta área es Terrence Sejnowski. La conversión texto-voz consiste en cambiar los símbolos gráficos de un texto en lenguaje hablado. El sistema de computación neuronal presentado por Sejnowski y Rosemberg, el sistema llamado NetTalk, convierte texto en fonemas y con la ayuda de un sintetizador de voz (Dectalk) genera voz a partir de un texto escrito.
La ventaja que ofrece la computación neuronal frente a las tecnologías tradicionales en la conversión texto-voz es la propiedad de eliminar la necesidad de programar un complejo conjunto de reglas de pronunciación en el ordenador. A pesar de que el sistema NetTalk ofrece un buen comportamiento, la computación neuronal para este tipo de aplicación abre posibilidades de investigación y expectativas de desarrollo comercial.
Procesado Natural del Lenguaje: incluye el estudio de cómo se construyen las reglas del lenguaje. Los científicos del conocimiento Rumelhart y McClelland han integrado una red neuronal de proceso natural del lenguaje. El sistema realizado ha aprendido el tiempo verbal pass tense de los verbos en Inglés. Las características propias de la computación neuronal como la capacidad de generalizar a partir de datos incompletos y la capacidad de abstraer, permiten al sistema generar buenos pronósticos para verbos nuevos o verbos desconocidos.
Compresión de Imágenes: la compresión de imágenes es la transformación de los datos de una imagen a una representación diferente que requiera menos memoria o que se pueda reconstruir una imagen imperceptible. Cottrel, Munro y Zisper de la Universidad de San Diego y Pisttburgh han diseñado un sistema de compresión de imágenes utilizando una red neuronal con un factor de compresión de 8:1.
Reconocimiento de Caracteres: es el proceso de interpretación visual y de clasificación de símbolos. Los investigadores de Nestor, Inc. han desarrollado un sistema de computación neuronal que tras el entrenamiento con un conjunto de tipos de caracteres de letras, es capaz de interpretar un tipo de carácter o letra que no haya visto con anterioridad.
Reconocimiento de Patrones en Imágenes: una aplicación típica es la clasificación de objetivos detectados por un sonar. Existen varias ANN basadas en Retropropagación cuyo comportamiento es comparable con el de los operadores humanos. Otra aplicación normal es la inspección industrial.
5
Marco Teórico.
Este tipo de problema ha sido abordado con éxito por Hopfield y el resultado de su trabajo ha sido el desarrollo de una ANN que ofrece buenos resultados para problemas combinatorios.
Procesado de la Señal: en este tipo de aplicación existen tres clases diferentes de procesado de la señal que han sido objeto de las ANN como son la predicción, el modelado de un sistema y el filtrado de ruido.
Predicción: en el mundo real existen muchos fenómenos de los que conocemos su comportamiento a través de una serie temporal de datos o valores
Modelado de Sistemas: los sistemas lineales son caracterizados por la función de transferencia que no es más que una expresión analítica entre la variable de salida y una variable independiente y sus derivadas. Las ANN también son capaces de aprender una función de transferencia y comportarse correctamente como el sistema lineal que está modelando.
Filtro de Ruido: las ANN también pueden ser utilizadas para eliminar el ruido de una señal. Estas redes son capaces de mantener en un alto grado las estructuras y valores de los filtros tradicionales.
Modelos Económicos y Financieros: una de las aplicaciones más importantes del modelado y pronóstico es la creación de pronósticos económicos como por ejemplo los precios de existencias, la producción de las cosechas, el interés de las cuentas, el volumen de las ventas etc. Las redes neuronales están ofreciendo mejores resultados en los pronósticos financieros que los métodos convencionales.
Servo Control: un problema difícil en el control de un complejo sistema de servomecanismo es encontrar un método de cálculo computacional aceptable para compensar las variaciones físicas que se producen en el sistema. Entre los inconvenientes destaca la imposibilidad en algunos casos de medir con exactitud las variaciones producidas y el excesivo tiempo de cálculo requerido para la obtención de la solución matemática. Existen diferentes redes neuronales que han sido entrenadas para reproducir o predecir el error que se produce en la posición final de un robot. Este error se combina con la posición deseada para proveer una posición adaptativa de corrección y mejorar la exactitud de la posición final. [10]
1.1.3 Arquitecturas típicas de las redes neuronales
6
1.1.3.1. Redes de una capa
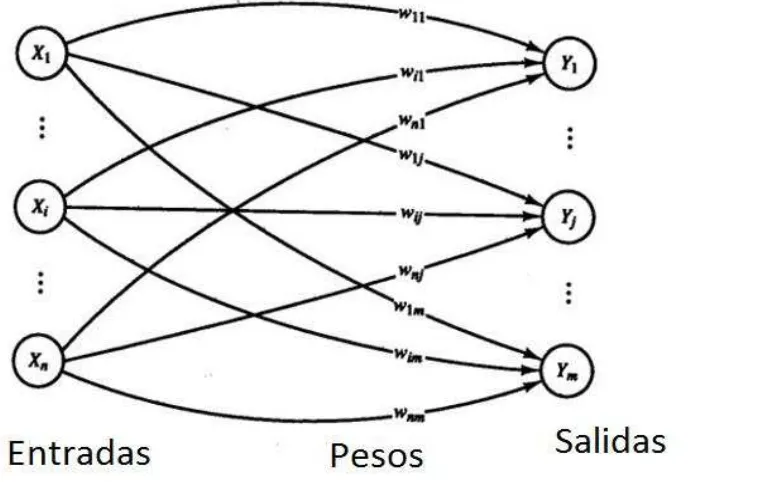
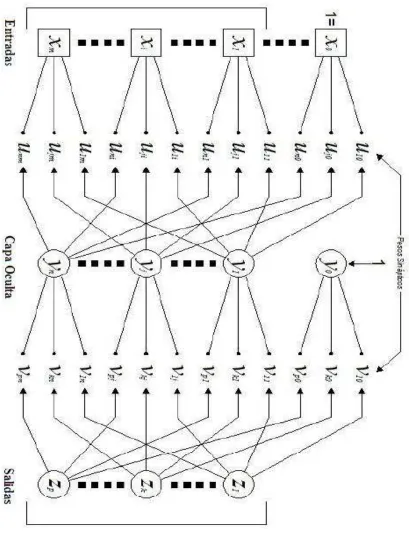
[image:21.612.138.521.208.449.2]Una red de una capa tiene una capa de pesos, una de conexiones y una de salidas. Usualmente, las unidades pueden ser distinguidas como unidades de entrada, las cuales reciben señales del mundo exterior y como unidades de salida, de las cuales, la respuesta de la red puede ser leída. En la típica red de una capa, las unidades de entrada están totalmente conectadas a las unidades de salida pero no están conectadas a otras unidades de entrada, tampoco las unidades de salida están conectadas a otras unidades de salida como se muestra en la Figura 1.3.[1]
Figura 1.3 Red de una capa
1.1.3.2 Redes multicapa
Es una red con más de una capa y nodos entre las unidades de entrada y salida. Las redes multicapa pueden resolver problemas más complejos que las redes de una capa pero el entrenamiento de estás es más difícil. Sin embargo ocasionalmente el entrenamiento de una red multicapa puede ser más exitoso para resolver un problema complejo ya que es posible que una red monocapa no podría ser entrenada correctamente. [1]
Las redes multicapa son aquellas que disponen de conjuntos de neuronas agrupadas en varios niveles o capas. Normalmente, todas las neuronas de una capa reciben señales de entrada de otra capa anterior, más cercana a la entrada de la red. A estas conexiones se les denomina conexiones hacia adelante o feedforrward.
7
[image:22.612.146.525.91.378.2]Marco Teórico.
8
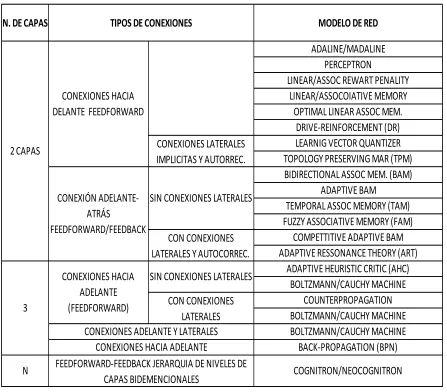
Tabla 1-1 Redes neuronales multicapa más conocidas
1.1.4. Mecanismos de Aprendizaje
El aprendizaje es el proceso por el cual una red neuronal modifica sus pesos en respuesta a la información de entrada. Los cambios que se producen durante el proceso de aprendizaje se reducen a la destrucción, modificación y creación de conexiones entre neuronas. En los sistemas biológicos existe una continua creación y destrucción de conexiones. En los modelos de redes neuronales artificiales, la creación de una nueva conexión implica que el peso de la misma pasa a tener un valor distinto de cero. De la misma forma, una conexión se destruye cuando un peso pasa a ser cero.
Durante el proceso de aprendizaje, los pesos de las conexiones en la red sufren modificaciones, por lo tanto se puede afirmar que este proceso ha terminado (la red ha aprendido) y cuando los valores de los pesos permanecen estables (dwij /dt=0).
N. DE CAPAS
ADAPTIVE BAM
TIPOS DE CONEXIONES MODELO DE RED
ADALINE/MADALINE PERCEPTRON
LINEAR/ASSOC REWART PENALITY LINEAR/ASSOCOIATIVE MEMORY
OPTIMAL LINEAR ASSOC MEM. DRIVE-REINFORCEMENT (DR) LEARNIG VECTOR QUANTIZER TOPOLOGY PRESERVING MAR (TPM) BIDIRECTIONAL ASSOC MEM. (BAM) 2 CAPAS
SIN CONEXIONES LATERALES
CON CONEXIONES LATERALES
COUNTERPROPAGATION BOLTZMANN/CAUCHY MACHINE CONEXIONES HACIA
DELANTE FEEDFORWARD
CONEXIONES LATERALES IMPLICITAS Y AUTORREC.
SIN CONEXIONES LATERALES
CON CONEXIONES LATERALES Y AUTOCORREC. CONEXIÓN
ADELANTE-ATRÁS
FEEDFORWARD/FEEDBACK
TEMPORAL ASSOC MEMORY (TAM) FUZZY ASSOCIATIVE MEMORY (FAM)
COMPETTITIVE ADAPTIVE BAM ADAPTIVE RESSONANCE THEORY (ART)
ADAPTIVE HEURISTIC CRITIC (AHC)
COGNITRON/NEOCOGNITRON N 3 CONEXIONES HACIA ADELANTE (FEEDFORWARD)
CONEXIONES ADELANTE Y LATERALES CONEXIONES HACIA ADELANTE
FEEDFORWARD-FEEDBACK JERARQUIA DE NIVELES DE CAPAS BIDEMENCIONALES
9
Marco Teórico.
Un aspecto importante respecto al aprendizaje en redes neuronales es conocer cómo se modifican los valores en los pesos; es decir, cuales son los criterios que se rigen para cambiar el valor asignado a las conexiones cuando se pretende que la red aprenda nueva información.
Estos criterios determinan lo que se conoce como la regla de aprendizaje de la red. De forma general, suelen generar dos tipos de reglas: habitualmente se le conoce como aprendizaje supervisado y aprendizaje no supervisado.
Es por ello que una de las clasificaciones por las que se realizan las redes neuronales obedece al tipo de aprendizaje utilizado por dichas redes. Así se pueden distinguir:
Redes Neuronales con aprendizaje supervisado. Redes Neuronales con aprendizaje no supervisado.
La diferencia fundamental entre ambos tipos estriba en la existencia o no de un agente externo (supervisor) que controle el proceso de aprendizaje en la red.
Otro criterio que se puede utilizar para diferenciar las reglas de aprendizaje se basa en considerar si la red puede aprender durante su funcionamiento habitual o si el aprendizaje supone la desconexión de la red; es decir su inhabilitación hasta que el proceso termine. En el primer caso, se trataría de un aprendizaje ON LINE, mientras que el segundo se conoce como aprendizaje OFF LINE.
Cuando el aprendizaje es OFF LINE se distingue entre una frase de aprendizaje o de entrenamiento y una fase de operación o funcionamiento, existiendo un conjunto de datos de entrenamiento y un conjunto de datos de prueba que serán utilizados en la correspondiente fase. En las redes con Aprendizaje OFF LINE, los pesos de las conexiones permanecen fijos después que termina la etapa de entrenamiento de la red. Debido a su carácter estático, estos sistemas no presentan problemas de estabilidad en su funcionamiento.
10
Tabla 1-2 Tipos de redes con aprendizaje supervisado más conocidas
[image:25.612.86.526.396.649.2]
Tabla 1-3 Tipos de redes con aprendizaje no supervisado más conocidas
CAUCHY MACHINE
MODELO DE RED
OFF LINE
APRENDIZAJE POR
CORRECCIÓN DE ERROR
ON LINE
APRENDIZAJE POR
REFUERZO
APRENDIZAJE
ESTOCASTICO
OFF LINE
COUNTERPROPAGATION
LINEAR REWART PENALTY
ASSOCIATIVE REWART PENALTY
ADAPTIVE HEURISTIC CRITIC (AHC)
BOLTZMANN MACHINE
TIPO DE APRENDIZAJE SUPERVIZADO
ADALINE/MADALINE
PERCEPTRON
BACK-PROPAGATION (BPN)
APRENDIZAJE HEBBIANO OFF LINE ON LINE APRENDIZAJE COMPETITIVO /COOPERATIVO ADAPTIVE BAM LEARNING VECTOR QUANTIZERCOGNITRON/NECOGNITRON TOPOLOGY PRESERVING MAP ADAPTIVE RESONANCE THEORY
SHUNTING GROSSBERG BIDIRECTIONAL ASSOC MEM. (BAM) OFF LINE
ON LINE
DRIVE-REINFORCEMENT FUZZY ASSOCIATIVE MEMORY (FAM)
ADDITIVE GROSSBERG
TIPO DE APRENDIZAJE NO SUPERVIZADO MODELO DE RED
HOPFIELD LEARNING MATRIX
11
Marco Teórico.
1.1.5. Entrenamiento de las redes neuronales artificiales
Una de las principales características de las RNA es su capacidad de aprendizaje. El entrenamiento de RNA muestra algunos paralelismos con el desarrollo intelectual de los seres humanos. No obstante aun cuando parece que se ha conseguido entender el proceso de aprendizaje conviene ser moderado porque el aprendizaje de las RNA está limitado.
El objetivo del entrenamiento de una RNA es conseguir una aplicación determinada, para un conjunto de entradas produzca el conjunto de salidas deseadas o mínimamente consistentes. El proceso de entrenamiento consiste en aplicación de diferentes conjuntos o vectores de entrada para que se ajusten los pesos de las interconexiones según un procedimiento predeterminado. Durante la sesión de entrenamiento los pesos convergen gradualmente hacia los valores que hacen que cada entrada produzca el vector de salida deseado.
Los algoritmos de entrenamiento o los procedimientos de ajuste de los valores de las conexiones de las RNA se pueden clasificar en dos grupos: Supervisado y No Supervisado.
Entrenamiento Supervisado: Estos algoritmos requieren el emparejamiento de cada vector de entrada con su correspondiente vector de salida. El entrenamiento consiste en presentar un vector de entrada a la red, calcular la salida de la red, compararla con la salida deseada, y el error o diferencia resultante se utiliza para realimentar a la red y cambiar los pesos de acuerdo con el algoritmo que tiende a minimizar el error.
Las parejas de vectores del conjunto de entrenamiento se aplican secuencialmente y de forma cíclica. Se calcula el error y el ajuste de los pesos por cada pareja hasta que el error para el conjunto de entrenamiento entero sea un valor pequeño y aceptable.
Entrenamiento No Supervisado: Los sistemas neuronales con entrenamiento supervisado han tenido éxito en muchas aplicaciones y sin embargo tienen muchas críticas debido a que desde el punto de vista biológico no son muy lógicos. Resulta difícil creer que existe un mecanismo en el cerebro que compare las salidas deseadas con las salidas reales. En el caso de que exista, ¿de dónde provienen las salidas deseadas?
Los sistemas no supervisados son modelos de aprendizaje más lógicos en los sistemas biológicos. Desarrollados por Kohonen en 1984 y otros investigadores, estos sistemas de aprendizaje no supervisado no requieren de un vector de salidas deseadas y por tanto no se realizan comparaciones entre las salidas reales y salidas esperadas. El conjunto de
12
1.1.6. El Perceptrón
El Perceptrón [3] fue la primera red neuronal artificial. Era computacionalmente factible sobre el hardware de aquella época, estaba basada en modelos biológicos y era capaz de aprender. Desafortunadamente también sufría de importantes debilidades: la inhabilidad de aprender a realizar una importante clasificación de tareas. Sin embargo, comentar sobre eta red puede contribuir a entender cercanamente redes relacionadas las cuales son inmensamente prácticas.
Rosenblatt propuso varias variaciones del Perceptrón pero la más sencilla consiste de tres
apas. La p i e a es u a e t ada eti a . Está o e tada a u a segu da apa, o puesta de lo
ue él lla o u idades de aso ia ió , las uales a túa o o dete to es de a a te es, esta capa finalmente se conecta a una capa de salida. Las unidades (neuronas) en su modelo producen una salida que es una suma la cual tiene un umbral con un peso, de sus entradas. [3]
1.1.7. Implementación y tecnologías emergentes
El resurgimiento de la computación neuronal en los últimos años se ha producido por el desarrollo teórico de nuevos modelos matemáticos del comportamiento del cerebro y por el desarrollo de nuevas tecnologías que ya están siendo utilizadas en una gran variedad de aplicaciones comerciales.
Entre los avances o desarrollos tecnológicos que permiten la realización de la computación neuronal destacan los programas de simulación software, los aceleradores en los chips de silicio y los procesadores ópticos hardware.
Simuladores Software: constituyen una de las formas más versátiles con las que se pueden implementar redes neuronales. Estos programas constituyen todo un sistema de desarrollo para prototipos de Redes Neuronales. Estos programas se utilizan para diseñar, construir, entrenar y probar Redes neuronales artificiales para resolver problemas complejos y problemas del mundo real.
Los primeros simuladores software se ejecutaban en ordenadores grandes con demasiados recursos pero el avance de los ordenadores personales en capacidad de procesado y capacidad de memoria hace posible que exista una serie de simuladores software de grandes prestaciones que corren sobre ordenadores personales. Entre otros paquetes software se incluye Neural Works, Neuralyst, Explore Net y Kwowledge Net.
Aceleradores Hardware: la naturaleza paralela de la computación neuronal se presta a realizar diseños concretos y a medida de dispositivos físicos, aceleradores hardware, que aceleren la ejecución de los cálculos. Los aceleradores hardware para los sistemas de computación neuronal son dispositivos físicos constituidos por diferentes procesadores interconectados que ayudan a la compilación y ejecución del comportamiento de las ANN. Una de las ventajas de los aceleradores hardware diseñados específicamente para la computación neuronal es el aumento
13
Marco Teórico.
Robert Hecht-Nielsen desarrolló el acelerador Mark III hardware que constaba de 8100 procesadores y trabajaba como un periférico de un VAX. La mayoría de las casas comerciales dedicadas al diseño de las ANN han desarrollado diferentes tarjetas basadas en los diferentes procesadores existentes, diseñadas para trabajar en el entorno de un ordenador personal PC y presentando un progresivo ratio de actualizaciones e interconexiones por segundo.
Chips de Silicio: Otro de los campos de la investigación en el mundo de las ANN al margen de los simuladores software y aceleradores hardware, es la integración de todos los componentes de computación neuronal en un chip de silicio. Un ejemplo concreto es el chip Electronic Neural Network (EEN) de la compañía AT&T que contiene 256 transistores-neuronas y más de 100.000 resistencias-sinapsis. Actualmente este chip se está utilizado para aplicaciones de compresión del ancho de banda de imágenes de vídeo para poder ser transmitidas por una línea telefónica. Existen muchas compañías y centros de investigación que están trabajando en el desarrollo de circuitos integrados diseñados para computación neuronal. La mayoría de las aplicaciones de estos chips son la simulación de procesos sensitivos como; visión de imágenes y la audición de sonidos.
1.2. Implementación en dispositivos programables
1.2.1. Dispositivo lógico programable FPGA
Un Dispositivo Lógico Programable (Programmable Logic Device, PLD) es un chip de propósito general para la implementación de circuitos lógicos. Contiene un conjunto de elementos lógicos agrupados de diversas maneras. Puede ser visto o o u a aja eg a ue o tie e
compuertas lógicas e interruptores programables, los cuales permiten a las compuertas conectarse entre sí para formar cualquier circuito lógico requerido [5].
Se clasifican según el grado de complejidad y cantidad de recursos lógicos presentes en el dispositivo. Así, existen SPLD (Simple PLD), dentro de los cuales están los PLA (Programmable Logic Array), PAL (Programmable Array Logic), PLA/PAL Registradas (Registered PLA/PAL), GAL (Generic
PAL); CPLD (Complex PLD); FPGA (Field-Programmable Gate Array) [5].
14
1.2.2. Arquitectura genérica
Básicamente, un FPGA contiene bloques lógicos, recursos de interconexión y unidades de entrada y salida [5].
Los bloques lógicos están conformados por tablas de verdad (Look-Up Table, LUT), la cual es un circuito programable que permite implementar cualquier función lógica de un número determinado de entradas, por flip-flops y multiplexores.
Para controlar las conexiones necesarias entre los bloques lógicos los recursos de interconexión y las unidades de entrada-salida se programan dichas conexiones mediante técnicas de programación con la tecnología de celdas SRAM.
Adicionalmente puede contar con elementos adicionales y bloques dedicados como memorias, PLL, multiplicadores, MAC, DSP, microprocesadores; todo esto según el FPGA.
1.2.3. Descripción de la arquitectura
La arquitectura de la familia Spartan-3E se compone de cinco elementos funcionales y fundamentales programables. [5]
• Blo ues lógi os o figu a les CLB contienen flexibles tablas de consulta (LUT) que implementan la lógica más elementos de almacenamiento utilizados como flip-flops. CLBs realizar una amplia variedad de funciones lógicas, así como almacenado de datos.
• Bloques de Entradas / Salidas (IOBs) que controlan el flujo de datos entre los pines de E / S y lógica interna del dispositivo. Cada IOB apoya el flujo bidireccional de datos más 3 estados de operación. Soportan una gran variedad de señales, entre ellos cuatro de alto rendimiento diferencial.
Doble velocidad de datos (DDR) de los registros:
• Bloques RAM proporciona almacenamiento de datos en forma de bloques de doble puerto 18-Kbit.
• Los bloques multiplicadores aceptan dos números binarios de 18 bits y calculan el producto.
• Administrador de Reloj Digital (DCM) provee bloques de auto-calibración, soluciones
15
Marco Teórico.
Estos elementos están organizados como se muestra en la ilustración 1. Un anillo IOBs rodea de una serie regular de CLB. Cada dispositivo tiene dos columnas bloques RAM, excepto para el XC3S100E, que tiene una columna. Cada columna RAM se compone de varios bloques RAM 18-Kbit.Cada bloque de RAM está asociado con un multiplicador. Las MCD se colocan en el centro con dos en la parte superior y dos en la parte inferior del dispositivo. La XC3S100E tiene sólo un DCM en la parte superior e inferior, mientras el XC3S1200E y el XC3S1600E añade dos MCDs a cada extremo.
[image:30.612.86.527.261.644.2]La familia Spartan-3E Figura 1.5 cuenta con una amplia red de registros que interconectar los cinco elementos funcionales, la transmisión de señales entre ellos. Cada elemento funcional tiene asociado una matriz de conmutación que permite múltiples conexiones de enrutamiento Figura 1.6[12]
16
Figura 1.6 Diagrama de interconexión en el FPGA
1.2.4. Lenguaje de descripción de hardware VHDL
Es un Lenguaje de Descripción de Hardware (HDL: Hardware Description Language) que describe el comportamiento de un circuito o sistema electrónico cuyo circuito o sistema físico (real) puede ser implementado en el dispositivo respectivo.
Es utilizado principalmente, junto con Verilog, para implementar circuitos en FPGA’s, CPLD´s y en el campo de los ASIC’s, siendo este diseño portable y reusable.
Cabe mencionar que las sentencias VHDL son inherentemente concurrentes, es decir, se ejecutan simultáneamente. Solamente las que se encuentren dentro de procesos, funciones o procesos son ejecutados de manera secuencial.
17
Marco Teórico.
19
Algoritmos de entrenamiento Perceptrón y de Retropropagación (Backpropagation)
Capítulo 2
Algoritmos de
entrenamiento Perceptrón y de
Retropropagación
20
2.1 Introducción
En este capítulo examinaremos un grupo de redes neuronales que tienen una arquitectura similar. Este es el grupo de las redes con conexiones hacia adelante, las cuales se caracterizan por arquitecturas en niveles y conexiones estrictamente hacia adelante entre neuronas. Estas redes son todas buenas clasificadoras de patrones y utilizan aprendizaje supervisado.
En este grupo se incluyen el Perceptrón, las redes ADALINE y MADALINE y la red Backpropagation. El Perceptrón y las redes ADALINE y MADALINE tiene un importante interés histórico y han abierto el camino para el desarrollo de otras redes neuronales. Por otro lado, la red Back-Propagation es probablemente una de las más utilizadas hoy en día. [13]
2.1. Las Redes ADALINE y MADALINE
21
[image:36.612.98.520.87.568.2]Algoritmos de entrenamiento Perceptrón y de Retropropagación (Backpropagation)
22
23
Algoritmos de entrenamiento Perceptrón y de Retropropagación (Backpropagation)
[image:38.612.109.509.238.657.2]ADALINE y MADALINE utilizan la denominada regla Delta de Hidrow-Hoff o regla del mínimo error cuadrado medio (LMS), basada en la búsqueda del mínimo de una expresión del error entre la salida deseada y la salida lineal obtenida antes de aplicarle la función de activación escalón (frente a la salida binaria utilizada en el caso del Perceptrón). Debido a esta nueva forma de evaluar error, estas redes pueden procesar información analógica, tanto de entrada como de salida, utilizando una función de activación lineal o sigmoidal.
24
2.2. Perceptrón
Perceptrón formado por varias neuronas de lineales para recibir las entradas a la red y una entrada de salida, es capaz de decidir cuando una entrada presentada a lared pertenece a una de las dos clases que es capaz de reconocer.
La única neurona de salida del Perceptrón realiza la suma ponderada de las entradas, resta el umbral y pasa el resultado a una función de transferencia de tipo escalón.
Figura 2.3 El Perceptrón
La regla de decisión es pertenecer +1 si el patron presentado pertenece a la clase A, o -1 si el patrón pertenece a la clase B. La salida dependerá de la entrada neta (suma de las entradas x1 ponderadas) y del valor umbral 0.
25
Algoritmos de entrenamiento Perceptrón y de Retropropagación (Backpropagation)
El algoritmo de aprendizaje del perceptrón es de tipo supervizado, lo cual requiere que sus resultados sean evaluados y se realicen las oportunas modificaciones del sistema si fuera necesario.
Se pueden usar Perceptrones como maquinas de universales de aprendizaje. Desgraciadamente , no puede aprender a realizar todo tipo de clasificaciones: en realidad solo puede aprender clasificaciones faciles (problemas de orden 1). Esa limitación se debe a que un Perceptrón usa un separador lineal como celula de decición, con lo cual no es posible realizar sino una sola separación lineal (por medio de un hiperplano).
2.3. Algoritmo de entrenamiento Perceptrón
El proceso de entrenamiento, el Perceptrón se expone a un conjunto de patrones de entrada, y los pesos de la red son ajustados de forma que al final del entrenamiento se obtengan las salidas esperadas para cada uno de esos patrones de entrada.
A continuación veremos el algoritmo de convergencia de ajuste de pesos para realizar el aprendizaje de un Perceptrón (aprendizaje por corrección de error) con N elementos procesales de entrada y un único elemento procesal de salida:
1.- Inicialización de los pesos y del umbral:
Inicialmente se asignan valores aleatorios a cada uno de los pesos (wi)de las conexiones y
al umbral (-w0=0).
2.- Presentación de un nuevo par (Entrada, Salida esperada):
Presentar un nuevo patrón de entrada Xp = (x1, x2,…, xN) junto con la salida esperada
d(t).
3.- Calculo de la salida actual:
Y(t) = f[∑i wi (t) xi(t) - 0]
26
4.- Adaptación de los pesos:
wi(t+1)= wi (t)+α[d(t)-y(t)]xi(t) (0≤i≤N)
Donde d(t) representa la salida deseada, y será 1 si el patrón pertenece a la clase A, y -1 es la clase B. En estas ecuaciones, αes un factor de ganancia en el rango 0.0 a 1.0. [13]
2.4. Red de Retroprogación (Backpropagation)
En 1986, Rumelhart, Hinton y Williams, formalizaron un método para que una red neuronal aprendiera la asociación que existe entre los patrones de entrada y las clases correspondientes, utilizando varios niveles de neuronas.
El método backpropagation (propagación del error hacia atrás), basado en la generalización de la regla delta, a pesar de sus limitaciones, ha ampliado de forma considerable el rango de aplicaciones de las redes neuronales.
El funcionamiento de la red backpropagation (BPN) consiste en el aprendizaje de un conjunto predefinido de pares de entradas-salidas dados como ejemplo: primero se aplica un patrón de entrada como estímulo para la primera capa de las neuronas de la red, se va propagando a través de todas las capas superiores hasta generar una salida, se compara el resultado en las neuronas de salida con la salida que se desea obtener y se calcula un valor de error para cada neurona de salida. A continuación, estos errores se transmiten hacia atrás, partiendo de la capa de salida hacia todas las neuronas de la capa intermedia que contribuyan directamente a la salida.
Este proceso se repite, capa por capa, hasta que todas las neuronas de la red hayan recibido un error que describa su aportación relativa al error total. Basándose en el valor del error recibido, se reajustan los pesos de conexión de cada neurona, de manera que en la siguiente vez que se presente el mismo patrón, la salida esté más cercana a la deseada [16][18][19].
27
Algoritmos de entrenamiento Perceptrón y de Retropropagación (Backpropagation)
Figura 2.4 Algoritmo de Entrenamiento Retroprogación
2.4.1 Regla Delta generalizada
La regla por Widrow en 1960 (regla delta) a sido extendida con redes con capas intermedias (regla Delta Generalizada) con conexiones hacia adelante (feedforward) y cuyas células tienen funciones de activación continuas (lineales o sigmoidales), dando lugar al algoritmo de retropropagación (backpropagation). Estas funciones continuas son no decresientes y derivables. [13]
La función sigmoidal pertenece a este tipo de funciones, a diferencia de la función escalón que se utiliza para el Perceptrón, ya que esta última no es derivable en el punto que se encuentra la discontinuidad.
28
de la superficie del error. Por ello, realimenta el error del sistema para realizar la modificación de los pesos en un valor proporcional al gradiente de dicha función de error.
El método que sigue la regla generalizada para ajustar los pesos es exactamente el mismo que el de la regla utilizada en el Perceptrón y ADALINE; es decir, los pesos se actualizan de forma proporcional a la delta, o diferencia e t e la salida deseada la o te ida δ= sal. Deseada – sal. obtenida). [13]
2.4.3 Estructura y Aprendizaje de la Red Backpropagation
En una red Backpropagation existe una capa de entrada con N neuronas y una capa de salida con M neuronas y al menos una capa oculta de neuronas internas. Cada neurona de una capa (excepto las de entrada) recibe entradas de todas las neuronas de la capa anterior y envía su salida a todas las neuronas de la capa posterior (excepto las de salida). No hay conexiones hacia atrás feedback ni laterales entre las neuronas de la misma capa.
La aplicación del algoritmo tiene dos fases, una hacia delante y otra hacia atrás. Durante la primera fase el patrón de entrada es presentado a la red y propagado a través de las capas hasta llegar a la capa de salida. Obtenidos los valores de salida de la red, se inicia la segunda fase, comparándose éstos valores con la salida esperada para así obtener el error. Se ajustan los pesos de la última capa proporcionalmente al error. Se pasa a la capa anterior con una retropopagación del error, ajustando los pesos y continuando con este proceso hasta llegar a la primera capa. De esta manera se han modificado los pesos de las conexiones de la red para cada patrón de aprendizaje del problema, del que conocíamos su valor de entrada y la salida deseada que debería generar la red ante dicho patrón.
La técnica Backpropagation requiere el uso de neuronas cuya función de activación sea continua, y por lo tanto, diferenciable. Generalmente, la función utilizada será del tipo sigmoidal.
2.4.2 Pasos para aplicar el Algoritmo de Entrenamiento
1. Inicializar los pesos de la red con valores pequeños aleatorios.
2. Presentar un patrón de entrada y especificar la salida deseada que debe generar la red.
3. Calcular la salida actual de la red.
29
Algoritmos de entrenamiento Perceptrón y de Retropropagación (Backpropagation)
Se calculan las entradas netas para las neuronas ocultas procedentes de las neuronas de entrada. Para una neurona j oculta:
Ecuación 1
En donde el índice h se refiere a magnitudes de la capa oculta; el subíndice p, al p-ésimo vector de entrenamiento, y j a la j-ésima neurona oculta. El término θ puede ser opcional, pues actúa como una entrada más.
Se calculan las salidas de las neuronas ocultas:
Ecuación 2
Se realizan los mismos cálculos para obtener las salidas de las neuronas de salida:
Paso 4 . Calcular los términos de error para todas las neuronas.
Si la neurona k es una neurona de la capa de salida, el valor de la delta es: δ
Ecuación 3
La función f debe ser derivable. En general disponemos de dos formas de función de salida:
30
Para una función lineal, tenemos:
mientras que la derivada de una función sigmoidal es:
por lo que los términos de error para las neuronas de salida quedan:
Si la neurona j no es de salida, entonces la derivada parcial del error no puede ser evaluada directamente, por tanto se obtiene el desarrollo a partir de valores que son conocidos y otros que pueden ser evaluados.
La expresión obtenida en este caso es:
donde observamos que el error en las capas ocultas depende de todos los términos de error de la capa de salida. De aquí surge el término propagación hacia atrás.
Paso 5. Actualización de los pesos: para ello utilizamos un algoritmo recursivo, comenzando por las neuronas de salida y trabajando hacia atrás hasta llegar a la capa de entrada, ajustando los pesos de la siguiente forma:
Para los pesos de las neuronas de la capa de salida:
31
Algoritmos de entrenamiento Perceptrón y de Retropropagación (Backpropagation)
En ambos casos, para acelerar el proceso de aprendizaje se puede añadir un término momento.
Paso 6. El proceso se repite hasta que el término de error
resulta aceptablemente pequeño para cada uno de los patrones aprendidos [4][5].
2.4.3 Dimensiones de la red. Número de capas ocultas
No se pueden dar reglas concretas para determinar el número de neuronas o número de capas de una red para resolver un problema concreto.
33
Implementación de Algoritmos de entrenamiento en VHDL (unidad de control y máquinas de estado finito)
Capítulo 3
Implementación de
Algoritmos de entrenamiento en
VHDL (unidad de control y
34
3.1. Introducción
Un FSMD (máquina de estado finito con ruta de datos) combina una FSM y circuitos secuenciales. Los FSM, que algunas veces se conoce como una ruta de acceso de control, examinan los mandatos externos y el estado, y genera las señales de control para especificar la operación regular de circuitos secuenciales, que se conocen colectivamente como una ruta de datos. La FSMD es utilizada para poner en práctica los sistemas descritos por RT (registro transferencia) metodología, en la que las operaciones se especifican como manipulación de datos y la transferencia de una colección de registros. [22]
3.2. Operación única del RT
La operación específica un RT (registro transferencia) es la manipulación de datos y la transferencia de un solo registro de destino. Está representado por la notación
Donde rdest está el registro de destino, rsrc1,r src2, y rsrcn son la fuente registra, y f ( .)
especifica la operación que se va a realizar. La notación indica que el contenido de la fuente los registros son alimentados a la f (.). La cual se realiza mediante un circuito combinatorio, y el resultado se pasa a la entrada del registro de destino y se almacena en el registro de destino en el siguiente flanco de reloj. Las siguientes operaciones son varias formas de representar RT:
Una constante 0 es almacenado en la r1 registro
El contenido del registro r1 se vuelve a escribir.
35
Implementación de Algoritmos de entrenamiento en VHDL (unidad de control y máquinas de estado finito)
Figura 3.1Diagrama de Bloques
Figura 3.2Diagrama de tiempo
El registro r2 se mueve a la derecha tres posiciones y, a continuación,
volver a escribir el contenido.
El contenido del registro r1 es transferido al registro r2.
El contenido del registro i se incrementa en 1 y el resultado se escribe en en i.
La suma de la s1, s2, y s3 registra se escribe en el d.
El cuadrado se escribe en el registro y.
La operación de RT se puede implementar mediante la construcción de un circuito combinatorio para la función y la conexión de la entrada y salida de los registros f (.).
En el diagrama de bloques se muestra que para mayor claridad, se utiliza el registro y los siguientes sufijos para representar la entrada y la salida de un registro. Se tiene en cuenta que cada operación de RT está sincronizada por el reloj. El resultado de la función f (.) no se almacena para registrar el destino hasta el siguiente flanco ascendente del reloj.
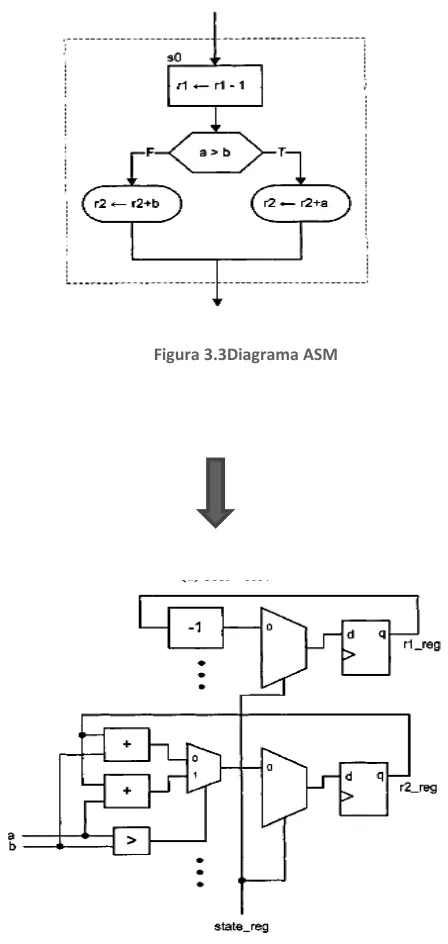
3.2. Decisión de caja de registro ASMD
La aparición de un gráfico ASMD es similar a la de un diagrama de flujo normal. La principal diferencia es que la operación de RT en un gráfico ASMD es controlado por un reloj incorporado señal y el registro de destino se actualiza cuando se cierra la FSMD el bloque ASMD actual, pero no dentro del bloque.
36
Figura 3.3Diagrama ASM
[image:51.612.183.407.75.547.2]
Figura 3.4Diagrama a bloques
El + r-1 r operación en realidad significa que:
r_next <= r_reg – 1;
r_reg <= r_next en el borde de subida del reloj (es decir, cuando se cierra el
37
Implementación de Algoritmos de entrenamiento en VHDL (unidad de control y máquinas de estado finito)
3.3. Máquina de Estados Finitos
Un FSM (máquina de estados finitos) se utiliza para modelar un sistema que transita entre un número finito de estados internos. Las transiciones dependen de la entrada del estado y externa actual. A diferencia de un circuito secuencial regular, las transiciones de estado de la FSM, que no presentan un sencillo y repetitivo patrón. Su lógica siguiente estado por lo general se construye a partir de cero y, a veces se conoce como Lógica "al azar". Esto es diferente de la lógica siguiente estado de un circuito secuencial regular, que se compone principalmente de los componentes "estructurados", como incrementos y palancas de cambio.
se proporciona un resumen de las características básicas y la representación de FSM y discutir la obtención de códigos de HDL. En la práctica, la aplicación principal de un FSM es la de actuar como el controlador de un sistema digital de gran tamaño, que examina los comandos externos y el estado y activa las señales de control adecuadas para controlar el funcionamiento de una ruta de datos, el cual por lo general se compone de componentes secuenciales regulares.
3.3.1 Representación FSM
El FSM se suele especificar mediante un diagrama de estado abstracto o carta ASM (estado algorítmico diagrama de la máquina), tanto la captura de la entrada del FSM, la producción, los estados y las transiciones en una representación gráfica. Las dos representaciones proporcionan la misma información. La representación FSM es más compacta y mejor para aplicaciones sencillas. La representación gráfica ASM es algo así como un diagrama de flujo y es más descriptivo para aplicaciones con una transición compleja condiciones y acciones.
Un diagrama de estado se compone de nodos, que representan los estados y están dibujados como círculos y arcos de transición anotados. Una expresión lógica se expresa en términos de señales de entrada se asocia con cada arco de transición y representa una condición específica. El arco se toma cuando el correspondiente expresión se evalúa verdadero.
Los valores de salida Moore se colocan en el interior del círculo, ya que dependen sólo del estado actual. Los valores de salida Mealy se asocian con las condiciones de arcos
3.4.1 Descripción ASM
Un diagrama ASM se compone de una red de bloques de ASM. Un bloque de ASM se compone de una caja de estado y una red opcional de las casillas de decisión o salidas condicionales.
38
por lo general se coloca después de un cuadro de decisión. Indica que la señal de salida de lista se puede activar sólo cuando se cumple la condición correspondiente en el cuadro de decisión. [22]
Figura 3.5 Máquina de estados finitos y su equivalente en diagrama ASM
3.5 Modelado de Hardware en VHDL
Un modelo de hardware en VHDL se describe en dos partes, la declaración de la entidad y la
[image:53.612.110.443.122.374.2]arquitectura asociada parte del cuerpo. [21]
Figura 3.6 Componentes de una arquitectura
La declaración de la entidad da un nombre al modelo que se está desarrollado y también declara sus señales de interfaz externos (llamados puertos): sus nombres, modos (in, out, inout, buffer) y sus tipos.
ENTIDAD
39
Implementación de Algoritmos de entrenamiento en VHDL (unidad de control y máquinas de estado finito)
3.3.1 ¿Qué es Síntesis?
La síntesis es el proceso de construir una lista de conexiones a nivel de compuertas de un modelo de un circuito descrito en VHDL. Un programa de síntesis genera un net list RTL (FF, ALU,
multiplexor, interconectados por medio de cables). Por lo tanto, el constructor módulo de RTL es necesario y el propósito de este constructor es la construcción de cada uno de los bloques de RTL requeridos a partir de una biblioteca de componentes predefinidos (de destino especificado por el usuario de tecnología).
Después de producir una lista de conexiones a nivel de puertas, un optimizador de la lógica lee en este net list y optimiza el circuito de la zona y el momento especificado por el usuario
limitaciones.
3.3.2 Síntesis en un proceso de diseño
Un circuito puede ser descrito de muchas maneras diferentes, no todos los cuales pueden ser sintetizables. Esto es debido al hecho de que VHDL fue diseñado principalmente como lenguaje de simulación y no para la síntesis.
No hay ningún subconjunto estandarizado de VHDL para síntesis.
No hay objeto directo en VHDL que significa un cerrojo o un flip-flop, Por lo tanto, cada sistema de síntesis proporcionan diferentes mecanismos para modelar un flip-flop o un latch.
3.3.3 Los valores para Modelar Hardware
VHDL proporciona dos clases de objetos de datos, de señales y variables, que puede ser utilizado para modelar los titulares básicos de valor en el hardware.
Los valores titulares básicos en el hardware son:
•Alambre
• Flip-flop (un dispositivo activado por flancos)
• Latch (un dispositivo sensible al nivel)
40
Reglas generales para la inferencia latch
Regla 1: Una variable se le asigna en una sentencia condicional (iforcase).
Regla 2: La variable no se le asigna en todas las ramas de la condicional declaración.
Regla 3: El valor de las variables necesita ser salvados entre múltiples invocaciones del proceso.
Las tres condiciones deben cumplirse antes de que una variable se deduzca como un Latch.
3.3.4 FSM, Código de desarrollo en VHDL
El procedimiento de desarrollo de código para una FSM es similar a la de un circuito secuencial regular. En primer lugar, separar el registro de estado y luego derivar el código de la lógica del estado siguiente y la lógica combinacional de salida. La principal diferencia es la lógica del estado siguiente. Para una FSM, el código de la lógica del estado siguiente sigue el flujo de un diagrama de estado o diagrama ASM.
41
Diseño y descripción de la implementación de una unidad de control en hardware para ejecutar el algoritmo de entrenamiento y comparación con su equivalente en software
Capítulo 4
Diseño y descripción de
la implementación de una unidad
de control en
hardware
para
ejecutar el algoritmo de
entrenamiento y comparación con
42
4.1. Introducción
Como se ha establecido en el objetivo, se busca mostrar las ventajas de la implementación de redes neuronales en software incluyendo dentro del mismo FPGA el algoritmo de entrenamiento, así se obtiene un modelo más parecido al de las redes neuronales biológicas las cuales tienen un alto nivel de paralelismo y respuestas muy rápidas a diferencia de la implementación de una red neuronal en software, que pierde esta característica de paralelismo y sumado a esto una respuesta más lenta al ser códigos que se ejecutan de manera secuencial.
En este capítulo se describe la implementación del algoritmo de entrenamiento en VHDL haciendo uso de una unidad de control así como los factores que influyen en su diseño y los puntos considerados en su modelado teniendo en cuenta que se busca programar una arquitectura sintetizable e implementable en hardware.
Se realiza también en esta sección una comparación de la implementación en software de los mismos algoritmos de entrenamiento de redes neuronales (perceptrón y retropropagación), programados en C++ con Visual Studio 2012 para resaltar la importancia de las diferencias entre las implementaciones en hardware y software.
4.2. Descripción del diseño de la unidad de control
4.2.1. Puertos
Las unidades de control requieren de puertos por los cuales se comuniquen, con el resto del hardware, en los puertos se han incluido entrada y salida de datos, reloj y reset.
4.2.2. Sistema de reloj
43
Diseño y descripción de la implementación de una unidad de control en hardware para ejecutar el algoritmo de entrenamiento y comparación con su equivalente en software
Figura 4.1 Oscilador de la tarjeta del FPGA
[image:58.612.127.462.70.284.2]Es importante notar que dentro del sistema de reloj que se desarrolló para la unidad de control, se hace uso de los flancos de subida para actualizar el valor de las variables, como se mencionó en el capítulo 3, es necesario trabajar las variables con 2 estados, uno futuro y uno actual ya que si se intenta usar la variable normal como usualmente se hace en lenguajes como C, es muy probable tener errores y advertencias de fallas por latch (enclavamiento o retroalimentación).
Figura 4.2 Flanco de subida del ciclo de reloj
Dentro de esta misma sección de reloj se define como es que el sistema se comportará ante un reset, lo que se estableció es que la máquina de estados se regrese al primer estado y los valores de las variables se restablezcan a sus valores iniciales para repetir el proceso de entrenamiento.
44
Figura 4.3 Sistema de reloj en VHDL
4.2.3. Variables y registros
VHDL cuenta con una gran variedad de tipos de variables disponibles para almacenar datos. Para el caso de las redes neuronales es necesario contar con variables enteras con signo y variables de punto flotante con signo. Las variables enteras con signo son parte de la librería básica de VHDL por lo que no es necesario desarrollar una librería propia para hacer uso de ellas, en el caso de las variables de punto flotante no es así. VHDL no tiene en sus librerías básicas soporte para variables de punto flotante ni de punto fijo por lo que es necesario, por ejemplo para el caso de una red neuronal de retropropagación, desarrollar o implementar una librería de punto flotante ya que el uso de este tipo de variable es necesario. Actualmente hay disponibles librerías para el uso de punto flotante y fijo en VHDL, estas se pueden conseguir en el sitio http://www.vhdl.org. Es importante mencionar que no todas las operaciones con punto flotante son sintetizables por lo que se tiene que realizar un estudio profundo de las características con las que cuenta esta librería para ajustarla a las necesidades del proyecto en el cuál se implementará
45
Diseño y descripción de la implementación de una unidad de control en hardware para ejecutar el algoritmo de entrenamiento y comparación con su equivalente en software
Figura 4.4 Registro de variable en estados futuro y presente
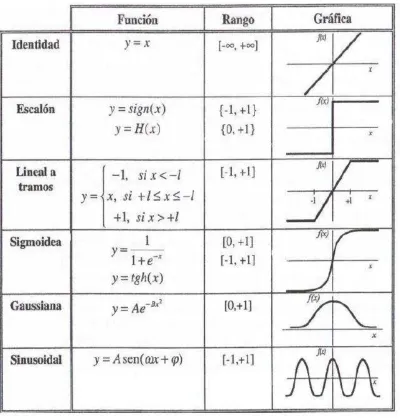
4.2.4. Función de activación para la red neuronal
Como se estudió en el Capítulo 2, las diferentes arquitecturas de redes neuronales requieren de diferentes funciones de activación. En el caso de un perceptrón se puede utilizar una función escalón, en el caso de una red de retropropagación se necesita una función de activación derivable como la sigmoidal. Dentro de la arquitectura principal de entrenamiento se debe definir una sección que evalúe la función de activación y relacionarla con la máquina de estados.
4.2.5. Máquina de estados
4.2.5.1. Máquina de estados para realizar el entrenamiento
Dentro de las opciones que ofrece VHDL para realizar un proceso, la más adecuada para este caso es la implementación de una máquina de estados ya que cuando se define bien como trabajará la transición de estados y como se comportarán las variables involucradas en este proceso, la sintetización se logra sin problemas por lo que se obtiene una arquitectura implementable en hardware. Mostrar gráficamente una máquina de estados es poco práctico en este caso ya que cuenta con varias operaciones internas en cada estado por lo que se muestran diagramas de flujo generalizados para hacer más simple la visualización de cómo se implementan los algoritmos.