U
NIVERSIDAD
T
ÉCNICA
P
ARTICULAR
D
E
L
OJA
La Universidad Católica De Loja
ÁREA TÉCNICA
TITULACIÓN DE INGENIERO EN SISTEMAS INFORMÁTICOS Y
COMPUTACIÓN
Servicios Web para Visualización de Datos Enlazados. Piloto datos
Universitarios.
TRABAJO DE FIN DE TITULACIÓN.
Autor: Montoya Montoya, Víctor Hugo
Director: Piedra Pullaguari, Nelson Oswaldo, Ing
LOJA
–
ECUADOR
ii
APROBACIÓN DEL DIRECTOR DEL TRABAJO DE FIN DE TITULACIÓN
Ingeniero.
Nelson Oswaldo Piedra Pullaguari.
DIRECTOR DEL TRABAJO DE FIN DE TITULACIÓN
De mi consideración:
El presente trabajo de fin de titulación: Servicios Web para Visualización de Datos Enlazados. Piloto datos Universitarios, realizado por: Montoya Montoya Víctor Hugo, ha sido orientado revisado durante su ejecución, por cuanto se aprueba la presentación del mismo.
Loja, Abril de 2015
iii
DECLARACIÓN DE AUTORÍA Y CESIÓN DE DERECHOS
“Yo Montoya Montoya Víctor Hugo declaro ser autor del presente trabajo de fin de titulación: Servicios Web para Visualización de Datos Enlazados. Piloto datos Universitarios, de la Titulación de Sistemas Informáticos y Computación, siendo Ing. Piedra Pullaguari Nelson Oswaldo director del presente trabajo; y eximo expresamente a la Universidad Técnica Particular de Loja y a sus representantes legales de posibles reclamos o acciones legales. Además certifico que las ideas, conceptos, procedimientos y resultados vertidos en el
presente trabajo investigativo, son de mi exclusiva responsabilidad”.
Adicionalmente declaro conocer y aceptar la disposición del Art. 88 del Estatuto Orgánico de la Universidad Técnica Particular de Loja que en su parte pertinente textualmente dice:
“Forman parte del patrimonio de la Universidad la propiedad intelectual de investigaciones, trabajos científicos o técnicos y tesis de grado o trabajos de titulación que se realicen con el apoyo financiero, académico o institucional (operativo) de la Universidad”
f)……….
Autor: Montoya Montoya Víctor Hugo. Cédula: 0705509990.
iv
DEDICATORIA
El presente trabajo se lo dedico a Dios primeramente, por acompañarme, por bendecir mi vida e iluminar cada paso que he dado para llegar alcanzar una de mis metas académicas, especialmente a mis padres Telmo Montoya y Narcisa Montoya por ser el pilar fundamental durante todos los días de mi vida, quienes me han brindado todo su apoyo incondicional, confianza y motivarme para seguir adelante siendo ellos mi principal ejemplo de perseverancia, constancia, respeto, humildad y fuerza incansable.
A mi hermana Patricia, mis sobrinas Naherly y Antonella, que con sus palabras de aliento han sido una gran fuente de inspiración y en especial a la persona que ha estado a mi lado en ésta etapa de mi vida, Lady.
A mis tíos, primos y familiares más cercanos que de una u otra forma supieron llegar con palabras emotivas y sabios consejos.
A todos mis amigos leales, sinceros, por compartir muchas experiencias, anécdotas, alegrías y tristezas en el proceso de formación y aprendizaje.
v
AGRADECIMIENTO
Dejo constancia de mi sincero agradecimiento primeramente a Dios, a la Virgen del Cisne, al Divino Niño Jesús y a San Antonio, quienes intercedieron por mí en momentos más difíciles de mi vida, a mis padres Telmo Montoya y Narcisa Montoya, a mi hermana, y a mis sobrinas, nuevamente gracias por todo su apoyo incondicional, por la confianza depositada en mí y por toda la paciencia que han tenido para compartir conmigo este sueño hecho realidad.
A mi director de tesis Ing. Nelson Oswaldo Piedra Pullaguari, por los conocimientos compartidos, por su acertada dirección y consejo durante todo el desarrollo del trabajo de fin de titulación, en especial a la Ing. Irma Elizabeth Cadme Samaniego, quien al igual me guió y compartió sus sabios conocimientos en el desarrollo del presente proyecto.
A la Universidad Técnica Particular de Loja, a la Titulación de Sistemas Informáticos y Computación y todo el Laboratorio De Tecnologías Avanzadas en la Web y Sistemas Basados en el Conocimiento por permitirme hacer uso de su tecnología para la construcción y culminación del presente proyecto, formándome como profesional para así servir a la sociedad.
Gracias al apoyo de todos ustedes, ahora es posible alcanzar un ideal más en mi vida.
VI
ÍNDICE DE CONTENIDOS
APROBACIÓN DEL DIRECTOR DEL TRABAJO DE FIN DE TITULACIÓN ... ii
DECLARACIÓN DE AUTORÍA Y CESIÓN DE DERECHOS ... iii
DEDICATORIA ... iv
AGRADECIMIENTO ... v
ÍNDICE DE CONTENIDOS ... VI ÍNDICE DE TABLAS ... VIII ÍNDICE DE FIGURAS ... VIII ÍNDICE DE ANEXOS ... IX RESUMEN ... 1
ABSTRACT ... 2
INTRODUCCIÓN ... 3
PROBLEMÁTICA ... 5
OBJETIVOS ... 6
JUSTIFICACIÓN ... 7
CAPÍTULO 1 ... 8
ESTADO DEL ARTE... 8
1.1. Prólogo. ... 9
1.2. Marco conceptual. ... 9
1.2.1. Web Semántica. ... 9
1.2.2. LinkedData. ... 13
1.2.3. Patrones de visualización. ... 16
1.3. Servicios y herramientas... 17
1.3.1. NetBeans 7.3.1. ... 17
1.3.2. JSON. ... 18
1.3.3. GlassFish. ... 18
1.3.4. Xampp. ... 18
1.3.5. Open Link Virtuoso. ... 18
1.3.6. Mysql. ... 19
1.3.7. Jena. ... 19
1.4. Visualización de datos ... 20
1.5. Trabajos relacionados ... 22
1.5.1. Herramientas de procesamiento. ... 22
1.5.2. Herramientas de visualización. ... 24
1.6. Proyectos de visualización ... 29
1.6.1. Rich Blocks, Poor Blocks. ... 29
VII
1.6.3. LOTRProject. ... 30
1.6.4. U.S.Gun Deaths. ... 31
1.7. Análisis ... 31
CAPÍTULO 2 ... 32
PROBLEMÁTICA Y ANÁLISIS ... 32
2.1. Problemática actual ... 33
2.2. Análisis ... 33
2.2.1. Especificaciones. ... 33
2.2.2. Funcionalidades del sistema. ... 34
CAPÍTULO 3 ... 36
DISEÑO DE LA SOLUCIÓN ... 36
3.1. Diseño ... 37
3.1.1. Base de Datos. ... 39
3.1.2. Ontología. ... 41
3.1.3. Relación entre Base de Datos y Ontología. ... 43
3.1.4. Arquitectura. ... 44
3.1.5. Diagrama de Clases. ... 47
CAPÍTULO 4 ... 49
DESARROLLO DE LA SOLUCIÓN ... 49
4.1. Proceso de desarrollo de software ... 50
4.1.1. Fases de desarrollo. ... 50
4.2. Metodología ... 51
4.3. Prototipos ... 52
4.3.1. Google FusionTables. ... 52
4.3.2. Google Chart. ... 56
4.3.3. Google Maps. ... 57
4.4. Implementación ... 59
4.4.1. Clases. ... 59
4.4.2. Preparación de los datos. ... 60
4.4.3. Servicios Web. ... 65
CAPÍTULO 5 ... 69
VALIDACIÓN Y PRUEBAS ... 69
5.1. Validación ... 70
5.1.1. Pruebas de funcionalidad. ... 70
5.1.2. Casos de prueba. ... 72
DISCUSIÓN ... 75
CONCLUSIONES ... 76
RECOMENDACIONES ... 78
VIII
ANEXOS ... 82
ÍNDICE DE TABLAS Tabla 1: Web Documentos vs Web Datos. ... 15
Tabla 2: Herramientas de visualización... 28
Tabla 3: Relación Ontología - Base Datos. ... 43
Tabla 4: Fases de desarrollo. ... 52
Tabla 5: Descripción de SW para recuperar afiliaciones. ... 65
Tabla 6: Descripción de SW para recuperar publicaciones. ... 67
Tabla 7: Casos de prueba. ... 71
ÍNDICE DE FIGURAS Figura 1: Evolución de la web. ... 10
Figura 2: Infraestructura de la Web Semántica. ... 11
Figura 3: Web de documentos enlazados. ... 14
Figura 4: Web de datos enlazados. ... 14
Figura 5: Estadística de muertes por cólera. ... 20
Figura 6: Data Wrangler. ... 23
Figura 7: Google Refine. ... 23
Figura 8: Mr. Data Converter. ... 24
Figura 9: Google FusionTables. ... 25
Figura 10: TableauPublic. ... 25
Figura 11: ManyEyes. ... 26
Figura 12: CartoDB. ... 27
Figura 13: Google Chart. ... 27
Figura 14: Visualización de ingresos y rentas en America. ... 29
Figura 15: Tendencias de la gripe en Australia. ... 30
Figura 16: Visualización de información y genealogía de un personaje. ... 30
Figura 17: Muertes por armas de fuego en el 2013. ... 31
Figura 18: Diagrama de casos de uso. ... 34
Figura 19: Interfaz de visualización de publicaciones. ... 37
Figura 20: Interfaz de organizaciones con publicaciones. ... 37
Figura 21: Detalles de una organización en el mapa de visualización. ... 38
Figura 22: Visualización de publicaciones en gráfico de barras. ... 38
Figura 23: Visualización de publicaciones en diagramas circulares. ... 39
Figura 24: Visualización de publicaciones en gráficos de dispersión. ... 39
Figura 25: Diagrama ER del prototipo de visualización. ... 41
Figura 26: Ontología del prototipo de visualización de publicaciones. ... 42
Figura 27: Arquitectura del sistema. ... 45
Figura 28: Datos de publicaciones en Scopus. ... 46
Figura 29: JSON para intercambio de datos. ... 47
Figura 30: Diagrama de Clases. ... 48
Figura 31: Estructura simplificada de procesos. ... 51
Figura 32: Activación Api FusionTables. ... 53
Figura 33: Obtención de credenciales. ... 53
Figura 34: Creación de tabla. ... 54
IX
Figura 36: Id de tabla. ... 55
Figura 37: Visualización de datos. ... 55
Figura 38: Modelo Drow Table. ... 56
Figura 39: Modelo Core Chart y Column Chart. ... 56
Figura 40: Modelo Geo Chart. ... 57
Figura 41: Modelo Map. ... 57
Figura 42: Modelo App Movil en SO Adroid. ... 58
Figura 43: Modelo visualizar información del punto... 58
Figura 44: Clase Servicio. ... 60
Figura 45: Consulta SQL publicacionesscopusecuador. ... 61
Figura 46: Tabla CSV de resultados. ... 61
Figura 47: Archivo CSV cargado en Google Refine. ... 62
Figura 48: Prefijos añadidos a los datos. ... 62
Figura 49: Datos con prefijos y propiedades. ... 62
Figura 50: Funcionalidad para generar RDF. ... 63
Figura 51: Archivo RDF. ... 63
Figura 52: Archivo cargado en servidor Apolo... 63
Figura 53: IRI de almacenamiento del grafo. ... 64
Figura 54: Consultas SPARQL usando el grafo. ... 64
Figura 55: Salida del SW para recuperar afiliaciones. ... 66
Figura 56: Resultado del SW para recuperar afiliaciones. ... 66
Figura 57: Salida del SW para recuperar publicaciones. ... 68
Figura 58: Resultado del SW para recuperar publicaciones. ... 68
Figura 59: Mapa de publicaciones cargado. ... 72
Figura 60: Número de publicaciones de la afiliación. ... 72
Figura 61: Número de publicaciones por afiliación. ... 73
Figura 62: Diagrama de árbol de afiliaciones según publicación. ... 73
Figura 63: Línea de tiempo de publicaciones. ... 73
Figura 64: Tabla de publicaciones. ... 74
Figura 65: Actualizar RDF. ... 74
ÍNDICE DE ANEXOS Anexo 1: GLOSARIO DE TÉRMINOS ... 82
Anexo 2: ESPECIFICACIÓN DE REQUERIMIENTOS ... 83
Anexo 3: DIAGRAMA DE CLASES ... 90
1
RESUMENDiseño, modelado e implementación de un patrón de visualización mediante un servicio web que permita estructurar la data sobre publicaciones científicas compilada por el Laboratorio De Tecnologías Avanzadas en la Web y Sistemas Basados en el Conocimiento de la UTPL, con esto se logra agilizar el proceso de consumo de los datos semánticos sobre las publicaciones, afiliaciones, autores y posteriormente presentar los mismos mediante visualizaciones para facilitar la inferencia de información a partir de las representaciones gráficas que se hayan generado en la aplicación.
Esta investigación constituye un paso importante para nuevos proyectos de desarrollo en la UTPL y más aún al encontrarse orientada a recursos de investigación tanto en el consumo de datos como la visualización de los mismos.
2
ABSTRACTDesign, modeling and implementation of a display pattern on a web service that allows structuring the data on scientific publications compiled by the Laboratory Technologies Advanced Web and Knowledge Based Systems for UTPL, with this improve the process of consumption semantic data about publications and subsequently present the data by views to facilitate inference of information from the graphic representations stemming of this in the application.
This research is an important step for development’s new projects in the UTPL and even
more to be oriented resources research both in data consumption as the display of same.
3
INTRODUCCIÓN
“La Web es el fenómeno más importante de Internet, demostrado por
su crecimiento exponencial y su diversidad. Por su volumen y riqueza
de datos, los buscadores de páginas se han convertido en una de las
herramientas principales.
La Web tiene actualmente al menos unos cuatro mil millones de
páginas estáticas y un número cientos de veces mayor de páginas
dinámicas (aquellas que sólo se crean producto de un clic o de una
consulta en un sitio Web).” (Baeza-Yates, 2004)
Actualmente existe una vasta cantidad de datos para ser consumidos en internet, información sobre casi cualquier tema, materia, asunto, etc. Puede ser encontrada mediante buscadores, sistemas recomendadores y otras herramientas, por eso es necesario saber cuánta de esta información es lo suficientemente relevante para ser analizada e interpretada.
De ahí que nace otro concepto de la web llamado Web Semántica planteado por (Berners-Lee, Hendler, & Lassila, 2001):
“La Web Semántica no es una web separada sino una extensión de la
actual, en la cual la información tiene un significado bien definido,
habilitando a las computadoras y las personas a trabajar en cooperación.”
Por tanto, los datos disponibles en la web semántica deben ser publicados en formato que pueda ser interpretado por una computadora, lo que la hace más accesible a ser procesada e inferida, generando conocimiento más amplio, detallado y preciso.
4
El presente trabajo se lo ha clasificado por capítulos de la siguiente manera:
En el Capítulo 1, se definen conceptos básicos en el Estado del Arte, sobre Web Semántica, LinkedData, patrones de visualización y se define las herramientas a utilizar, además se hace referencia a trabajos relacionados.
En el Capítulo 2, se analiza la problemática actual y se especifican las funcionalidades del sistema.
En el Capítulo 3 y 4, se realiza el diseño y desarrollo de la solución, definiendo ontologías, base de datos y prototipos.
En el Capítulo 5, se realiza las respectivas pruebas de validación de la solución implementada.
5
PROBLEMÁTICA
La gran cantidad de información disponible sobre publicaciones científicas suele ser un hecho bastante reconfortante al llevar a cabo una investigación, pero así como existe un gran volumen de datos sobre publicaciones, papers, documentos científicos, entre otros, también se necesitan de métodos rápidos para inferir la información a partir de un conjunto de datos.
En este punto se observa una estrecha relación entre los datos y las diferentes formas en que pueden mostrarse gráficamente, pues la información que proporciona un gráfico permite deducir a simple vista frecuencias, tendencias, concentraciones, comportamientos, etc.
Actualmente existen distintas herramientas y tecnologías para visualizar la información de acuerdo a una estructura y modelar las mismas en distintas formas (gráficos, barras, tablas de datos, infografías) para que el consumo de los datos sea más fácil, ordenado y preciso.
A partir de estas tecnologías se pueden obtener representaciones visuales de información bastante detalladas, en el caso de publicaciones científicas se las puede representar mediante mapas, tablas, gráficas pudiendo definirse las representaciones según autores, afiliaciones, países, temáticas entre otros rasgos de las mismas; pero para cada tecnología de visualización se requiere que los datos sean modelados en base a un formato y es aquí cuando surge un problema: no existe un patrón de visualización que a través de un servicio web permita representar publicaciones científicas mediante un modelo estándar.
6
OBJETIVOSGeneral:
x
Diseñar y desarrollar un patrón de visualización de datos e implementar el mismo en un servicio web que permita estructurar la data sobre un modelo de publicaciones científicas y posteriormente realizar consultas sobre esta información ya estructurada.
Específicos:
x
Implementar distintas formas de visualización para los datos referentes a las publicaciones de una organización/afiliación, esto para realizar inferencias más precisas, rápidas y eficaces sobre la información mostrada.
x
Construir una aplicación web que permita mostrar un mapa sobre las organizaciones/afiliaciones que actualmente ostentan algunas publicaciones.
x
7
JUSTIFICACIÓN
La aplicación de la web semántica para la búsqueda e inferencia de información ha cobrado importancia en los últimos años, adaptándose a los nuevos modelos de generación y transmisión de información, el volumen de la información disponible en la web aumenta y su conocimiento también se amplía de manera significativa gracias a estas nuevas estructuras, debido a eso los usuarios necesitan disponer de formas más versátiles, precisas y detalladas de visualizar la información.
9
1.1. Prólogo.Los datos en la web se han convertido en un potencial considerable para varios sectores
entre ellos el sector educativo, permitiendo que los datos educativos se conecten con más
datos relacionados.
El presente trabajo tiene por objetivo analizar, investigar y recopilar información con
respecto a herramientas, tecnologías y métodos que permitan diseñar y desarrollar un
patrón de visualización de datos que se implementara en un Servicios Web para
Visualización de Datos Enlazados, que permita extraer datos a partir de una base de
conocimientos SPARQL, exportarlas al formato JSON y de esta forma poder ser
presentados al usuario final acorde a la tecnología para la que fue construida el servicio web.
Palabras Claves: Servicio Web, JSON, Google Chart, Google FusionTables, Google Maps,
RDF, SPARQL, Linked Data, Jena, Web Semántica, Visualización, Tripletas.
1.2. Marco conceptual.
Siendo este un proyecto de desarrollo e investigación existen algunos conceptos estrechamente relacionados a este trabajo que necesitan ser revisados para llegar a familiarizarnos con los mismos, que se describen en este apartado:
x
Herramientas para el desarrollo de interfaces y sistemas, ya que para implementar los requerimientos del usuario se deberá seleccionar la herramienta más idónea.
x
Web semántica y datos enlazados, puesto que cabe la posibilidad de trabajar con información de tipo semántica y datos
x
Servicios y formatos de datos, necesarios para la implementación de servicios web.
1.2.1. Web Semántica.
10
[image:19.595.91.532.98.385.2]La evolución de la web se puede apreciar en la siguiente figura:
Figura 1: Evolución de la web. Fuente: Tomado de (Morales, 2014)
La web semántica nace como una extensión de la web actual para solucionar algunos de los problemas que la misma tiene como son (Grupo de Concepción de Sistemas de Información, 2011):
x
El acceso a los datos es limitado:
Los documentos están indexados en texto: Cuenca puede ser una ciudad de Ecuador o de España, como un apellido de una persona, o también una cuenca hidrográfica.
La búsqueda es a lo que tenga un alto índice de coincidencia, la decisión de pertenencia e integración de lo relevante queda a cargo del usuario.
Los datos no están accesibles, los datos se encuentran en las páginas lo que complica su procesamiento
x
La web está orientada a personas y no hay mucha ayuda para ellas:
La web puede ser vista como una colección de páginas que deben ser interpretadas necesariamente por personas.
Al indicar que la información debe tener un significado bien definido se afirma de relaciones con significados entre conceptos para que otorguen un alto grado de automatización, esto debido a que actualmente existen cosas que no podemos hacer de forma automática en la
11
de Tim Berners-Lee”, obtendremos varios resultados, la mayoría de ellos no tendrán nada que ver con lo que estamos buscando, y nos vemos en la necesidad de utilizar “técnicas de búsqueda” como utilizar sinónimos (sinonimia), o inclusive buscamos utilizando palabras en otro idioma (multilingüismo), en otras palabras realizamos una búsqueda sintáctica1, siendo
este un proceso tedioso y largo, de allí la necesidad de evolucionar en la WS.
La infraestructura de tecnologías y lenguajes necesarios para la implementación de la WS se esquematiza en una torre de siete capas según Tim Berners-Lee, como se muestra a en la Figura a continuación:
Figura 2: Infraestructura de la Web Semántica.
Fuente: Tomado de http://jimenosky.files.wordpress.com/2008/10/web-semantica.png
La arquitectura de la Web Semántica está estructurada por niveles que establecen una jerarquía entre los mismos:
x Nivel de recursos: Identificación de recursos Uniformes, (URIs), su importancia está en que se puede señalar a cualquier documento o recurso de cualquier tipo en el universo de la información (Berners-Lee, 1996).
x Nivel sintáctico: Definición de lenguajes de etiquetado para añadir semántica a las páginas web, mediante las tecnologías XML y XMLSchema.
x Nivel de Descripción de Recursos: Descripción de recursos de la web, utilizando para ello el estándar RDF.
x Nivel de Ontologías: El conocimiento es consensuado y reutilizable a través del uso de ontologías.
1Búsqueda sintáctica es un procedimiento de búsqueda donde el resultado son varios documentos
12
x Resto de niveles: La lógica nos ayuda a inferir conocimiento basado en ontologías y la seguridad nos da un cierto grado de confianza con el uso de firmas digitales. A continuación se describe el rol de cada una de las capas de la arquitectura de la Web Semántica:
x Capa Unicode: Es un estándar que permite la codificación de texto, que garantiza que la información no contenga símbolos extraños.
x Capa URI: Son cadenas de caracteres que identifican inequívocamente un recurso físico o abstracto.
x Capa XML + NS + Xmlschema: Es la capa más técnica de la Web Semántica ya que posibilita la comunicación entre agentes.
x Capa RDF + RDFSCHEMA: Define un lenguaje universal con el que podemos expresar diferentes ideas en la Web Semántica.
x Capa Ontología: Sirve para clasificar la información agregando clases y propiedades a los recursos.
x Capa Lógica: Se especifican reglas de inferencias para las ontologías.
x Capa de Pruebas: Se intercambiarán “pruebas” escritas en el lenguaje unificador de la Web Semántica.
x Capa de Confianza: Especifica que antes de que no se compruebe la veracidad de las fuentes de información los agentes no ejecuten alguna acción.
x Capa de Firma digital: Las firmas digitales nos sirven para que los computadores y los agentes estén seguros que la información proviene de una fuente confiable.
La Web Semántica tiene los siguientes componentes:
Ontologías: Una de las definiciones más aceptadas de ontología es la dada por T. Gruber :
“Ontología es una especificación formal y explícita de una conceptualización compartida. Ésta debe ser formal por que debe ser entendible por un computador, explicita porque, se refiere a su descripción en términos de conceptos, atributos y relaciones, y conceptualización debido a que es un modelo abstracto de un fenómeno del mundo que se desea representar, además se menciona conceptos, relaciones, atributos, funciones, instancias y axiomas como los componentes de una ontología para representar el conocimiento”. (Castillo Morales, 2005).
XML (Extensible MarkupLanguage): Para (Castillo Morales, 2005) xml: “Es un lenguaje
13
relación con los metadatos, los cuales son datos estructurados que describen el significado de los recursos como el contenido, la calidad y la condición de los mismos, facilitando de esta manera la formulación de preguntas más concretas a los motores de búsqueda pero para lograr este tipo de metadatos es necesario aplicar RDF”.
XML Schema: “Es una extensión del XML que permite proporcionar y dictar ciertas
restricciones sobre el contenido de los recursos o contenidos disponibles definiendo la sintaxis con respecto al orden, tipos de datos y formatos dentro de un documento XML”. (Castillo Morales, 2005)
OWL (Web OntologyLanguaje): El autor (Castillo Morales, 2005) define OWL como el
Lenguaje utilizado para la descripción semántica de recursos en la web usando ontologías las mismas que tienen como objetivo proporcionar un modelo en RDF codificado en XML además se encargan de definir los términos utilizados para describir y representar un área de conocimiento, son utilizadas por los usuarios, base de datos y las aplicaciones que necesitan compartir información específica, el OWL es una extensión del RDF, por lo que este posee todas sus características y otras adicionales como son la aplicación de operaciones lógicas, además atribuye a las relaciones ciertas propiedades como la cardinalidad, simetría, transitividad o relaciones inversas.
1.2.2. LinkedData.
Según (Bizer, Heath, & Berners-Lee, 2011) se define a Linked Data como:
“Un conjunto de mejores prácticas para publicar y conectar datos estructurados en la Web. Estas prácticas han sido adoptadas por un creciente número de proveedores de datos sobre
los últimos tres años, dando lugar a la creación de un espacio global de datos que contiene
14
Una web de documentos enlazados sería de la siguiente forma:
Figura 3: Web de documentos enlazados. Fuente: Tomado de (Heath, 2009)
En la figura anterior los enlaces son de documento a documento, un link lleva a una página web, un repositorio, un archivo u algún otro objeto y dichos links no se encuentran clasificados según algún tipo definido, sino que cada enlace simplemente lleva a un objeto y permite realizar una especialización del mismo, no explica las características que posee dicho objeto, ni su naturaleza o las relaciones que tendría con otros objetos del mismo tipo. Mediante la web de documentos enlazados se pueden acceder a los objetos en sí y no desglosarse las propiedades, relaciones o la naturaleza del mismo.
En cambio la web de datos enlazados presenta la siguiente estructura:
Figura 4: Web de datos enlazados. Fuente: Tomado de (Heath, 2009)
Como se puede observar en la figura anterior existen 2 factores muy importantes a tener en cuenta:
x
Los enlaces son entre cosas dentro de las cosas, es decir conceptos dentro de algún objeto u otro concepto.
x
Existe una clasificación de enlaces para hacer mucho más detallada la especificación de contenidos.
15
basándose en una característica específica, un contexto en particular o tomando en cuenta la naturaleza del mismo.
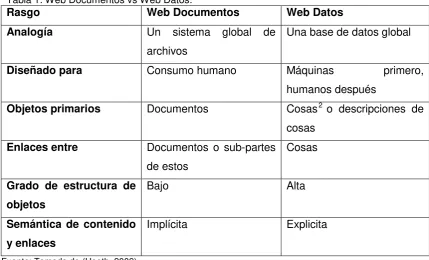
[image:24.595.114.544.205.465.2]Con esas descripciones se puede establecer diferencias entre la Web de Documentos Enlazados y la Web de Datos Enlazados, en la siguiente tabla se exponen los rasgos de cada una:
Tabla 1: Web Documentos vs Web Datos.
Rasgo Web Documentos Web Datos
Analogía Un sistema global de
archivos
Una base de datos global
Diseñado para Consumo humano Máquinas primero,
humanos después
Objetos primarios Documentos Cosas2 o descripciones de
cosas
Enlaces entre Documentos o sub-partes de estos
Cosas
Grado de estructura de objetos
Bajo Alta
Semántica de contenido y enlaces
Implícita Explicita
Fuente: Tomado de (Heath, 2009)
En resumen Linked Data es sobre usar la web para crear links clasificados entre datos de diferentes fuentes, dichas fuentes pueden ser bastantes diversas como dos bases de datos mantenidas por dos organizaciones en diferentes localizaciones geográficas o simples sistemas heterogéneos dentro de una sola organización. Linked Data es una forma de publicar datos en la web que:
x
Reduce la redundancia.
x
Fomenta la reutilización.
x
Maximiza su interconexión (real y potencial).
x
Activa el efecto de red3 para añadir valores a los datos.
2Cosas vendría a ser cualquier concepto, objeto o entidad descrita mediante datos clasificados. 3
16
1.2.3. Patrones de visualización.“Los patrones para la visualización de datos se utilizan fundamentalmente para: Aprovechar la gran capacidad humana de extraer patrones a partir de imágenes. Ayudar al usuario a
comprender más rápidamente patrones descubiertos automáticamente por un sistema de
KDD.”(Hernández-Orallo, 2013)
Los patrones de visualización son importantes porque permiten ver cosas que pueden pasar desapercibidas a simple vista, puesto que los datos contienen información y al representarlos gráficamente se obtienen respuestas más rápidas; una buena visualización permite enriquecer los datos de una investigación, porque permite realizar un análisis de las representaciones gráficas y se pueden deducir relaciones de causa-efecto, tendencias, probabilidades, influencias, entre otros avances que serían difíciles de obtener mediante representaciones convencionales de datos como tablas y conjuntos de datos.
Un punto importante de las visualizaciones es que al representar mediante colores ciertos datos permiten llegar a una comprensión más rápida de la información que se presenta, puesto que es mucho es más impactante presentar la información mediante imágenes a color debido a que son bastante más agradables y enriquecedoras de observar, por ejemplo si se presentará un informe mediante gráficas de líneas, de pastel o de barras con distintos colores para representar las alzas, bajas o los productos en sí mismo, la gente encontrará más fácil, agradable y hasta sencillo de entender la información que se presenta, cosa que sería difícil de conseguir si se presentará tablas y tablas de números, subjetivamente se le suele dar más crédito a la información, si la misma se encuentra representada en bonito envoltorio visual.
Básicamente, se puede encontrar cuatro formas de visualizar información:
a) Representación mediante Mapas. Mapas geográficos, mapas, infográficos cartogramas, etc. Vemos esos mapas casi todos los días en nuestra búsqueda por la web o ver las noticias en la televisión, representaciones de este tipo se las puede encontrar en Flu Trends, la actividad gripal en el mundo mediante un mapa que muestra las zonas más afectadas por esta enfermedad.
17
c) Representación de Múltiples variables. Se trata de una bastante amplia clase de los patrones utilizados para visualizar los datos con muchas variables, por ejemplo, el consumo anual per cápita de Coca-Cola con relación al sexo, peso y altura de los consumidores, ManyEyes es un claro ejemplo de este tipo de aplicaciones puesto que permite representar un gran conjunto de datos y hacer análisis sobre los mismos.
d) Representación a través de Redes. Se utiliza para visualizar las dependencias, las conexiones y jerarquías, como ejemplos de estas tenemos las herramientas de representación de redes sociales como LinkedIn InMaps .
Además los patrones de visualización permiten resolver un problema derivado de la gran cantidad de datos semánticos, puesto que la visualización, exploración y uso de estos datos, en especial para usuarios no expertos y sin experiencia en tecnologías de la Web Semántica, es bastante difícil y complejo.
Aplicando técnicas de visualización de información se puede explorar cantidades de datos e interactuar con ellos, así como obtener una perspectiva mayor sobre los principales tipos, relaciones y propiedades de los conjuntos de datos. (Brunetti, Auer, & García)
1.3. Servicios y herramientas
Para el desarrollo de la aplicación se investigó distintas herramientas y entornos de desarrollo, y se seleccionó los que se utilizara en base a los siguientes aspectos:
x
Facilidad de uso
x
Documentación disponible (tutoriales, foros, videos, etc.)
x
Complejidad en el aprendizaje
x
Mejores funcionalidades
x
Flexibilidad en la implementación
x
Familiaridad con el lenguaje
1.3.1. NetBeans 7.3.1.
Según (Sun Microsystems, 2014), “NetBeans es un proyecto de código abierto de gran éxito con una gran base de usuarios, una comunidad en constante crecimiento, y con cerca de 100 socios en todo el mundo. Además fundó el proyecto de código abierto NetBeans en junio de 2000 y continúa siendo el patrocinador principal de los proyectos.
18
1.3.2. JSON.Para (Standard ECMA-404, 2013) “JSON (JavaScript ObjectNotation - Notación de Objetos de JavaScript) es un formato ligero de intercambio de datos. Leerlo y escribirlo es simple para humanos, mientras que para las máquinas es simple interpretarlo y generarlo. Está basado en un subconjunto del Lenguaje de Programación JavaScript, así mismo se lo considera como un formato de texto que es completamente independiente del lenguaje pero utiliza convenciones que son ampliamente conocidos por los programadores de la familia de lenguajes C, incluyendo C, C++, C#, Java, JavaScript, Perl, Python, y muchos otros”.
1.3.3. GlassFish.
Según (Sun Microsystems, 2010), “GlassFish es un servidor de aplicaciones desarrollado por Sun Microsystems con asistencia gratuita a la comunidad. Es uno delos mejores servidores de aplicaciones de código abierto, manteniendo una arquitectura modular y
extensible proporcionado fiabilidad y rendimiento con menor complejidad para las empresas”.
1.3.4. Xampp.
Para (Apache Friends, 2013), XAMPP es un servidor independiente de plataforma, software libre, que consiste principalmente en la base de datos MySQL, el servidor web Apache y los intérpretes para lenguajes de script: PHP y Perl. El nombre proviene del acrónimo de X (para cualquiera de los diferentes sistemas operativos), Apache, MySQL, PHP, Perl.
El programa está liberado bajo la licencia GNU y actúa como un servidor web libre, fácil de usar y capaz de interpretar páginas dinámicas. Actualmente XAMPP está disponible para Microsoft Windows, GNU/Linux, Solaris y MacOS X.
1.3.5. Open Link Virtuoso.
Para (OpenLink Software, 2012), Virtuoso es un Data Store híbrido que combina las funcionalidades de los RDBMS, ORDBMS, bases de datos virtuales, RDF, XML y aplicaciones web (W3C, 2011). Entre las características más relevantes podemos citar las siguientes, en base a lo que se menciona en (OpenLink Software, 2009).
• Posee licencia GLP para el producto conocido como OpenLinkVirtuoso y también posee licencia pagada para otras versiones del producto.
• Posee un diccionario de datos en donde se almacena toda la información de los objetos de los usuarios.
19
• Trabaja nivel de privilegios y roles, como mecanismos de seguridad.
• Su motor de datos provee conexiones a fuentes XML, ODBC, JDBC, ADO.NET y OLE DB.
1.3.6. Mysql.
Según (Sun Microsystems, 2010), MySQL es un sistema de gestión de bases de datos relacional, multihilo y multiusuario con más de seis millones de instalaciones. MySQL AB desde enero de 2008 una subsidiaria de Sun Microsystems y ésta a su vez de Oracle Corporation desde abril de 2009 desarrolla MySQL como software libre en un esquema de licenciamiento dual.
Por un lado se ofrece bajo la GNU GPL para cualquier uso compatible con esta licencia, pero para aquellas empresas que quieran incorporarlo en productos privativos deben comprar a la empresa una licencia específica que les permita este uso. Está desarrollado en su mayor parte en ANSI C.
1.3.7. Jena.
Según (Garcia, 2012), Jena es un framework desarrollado en java para construir aplicaciones para la web semántica, provee un ambiente de programación para RDF, RDFS y OWL, además provee un motor de inferencias basado en reglas, lo que la convierte en un modelo ideal para cualquier proceso automatizado de creación de contenidos destinados a ser usados en canales de información.
Entre sus características más importantes podemos citar las siguientes según (Reynolds, 2010).
• Posee un API para RDF, la misma que soporta la creación, manipulación y consulta de grafos RDF.
• Permite realizar lectura y escritura de documentos en formato RDF/XML, N3 y NTriples.
• Posee un API para OWL
• Almacenamiento persistente y en memoria.
20
1.4. Visualización de datos¿Por qué emplear una visualización para mostrar datos?
Una visualización nos permite inferir a partir de un conjunto de datos y de forma mucho más eficiente y eficaz la causa, el efecto, la preferencia o algún otro conocimiento sobre un hecho particular, que si fuera presentado en otro formato (tablas, informes, reportes) sería bastante más difícil de inferir (Iliinsky & Steele, 2011).
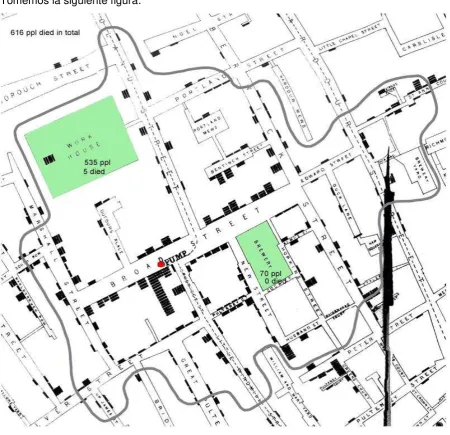
[image:29.595.85.536.238.673.2]Tomemos la siguiente figura:
Figura 5: Estadística de muertes por cólera.
Fuente: Tomado de http://www.targetprocess.com/articles/information-visualization/
21
Con este antecedente se puede concluir que una visualización permite inferir rápidamente y de forma bastante aproximada información útil y bastante acertada.
De ahí que la forma de presentar la información o los datos es muy importante puesto que según (Gorny, 2013):
x “La visualización permite ver cosas que por lo general pasarían
desapercibidas. Cualquier dato contiene información, pero si no hay datos visuales se pueden perder tendencias, patrones de comportamiento o preferencias que se pueden derivar.
x La visualización da respuestas rápidas. Al mirar un gráfico se pueden obtener las tendencias del mismo al instante. Cuánto tiempo se tardaría en concluir lo mismo al analizar las filas de una tabla.
x Una buena visualización da vía libre para recopilar datos para una
investigación, también para investigar algunas relaciones curiosas de causa-efecto. Esto es bastante importante para la investigación y el trabajo de estudio, como el periodismo.
x Si el volumen de datos crece exponencialmente la visualización ayuda a
aprovechar no sólo el volumen sino la diversidad de la información.
x Es visualmente más atractivo presentar los resultados de un informe mediante
gráficos, presentar sólo números lleva a una desestimación de la información presentada. Subjetivamente, le damos más crédito a la información si tiene una presentación atractiva. “
x La interacción entre el usuario y los sistemas avanzados de visualización
puede ser tan inmersiva como los juegos, mediante la visualización se pueden inferir conclusiones y en base a las mismas avanzar hacia otras respuestas sobre un problema. (Otjacques, Stefas, Corni, & Feltz)
22
Con este antecedente y teniendo una base de datos sobre publicaciones científicas realizadas por diferentes autores de distintas organizaciones indexadas en Scopus la misma que es provista por el laboratorio de Tecnologías Avanzadas de la Web y Sistemas basados en el Conocimiento se ha decidido implementar un sistema de visualización de publicaciones que permita consumir dicha información de forma más eficiente, ágil y dinámica.
1.5. Trabajos relacionados
Según (State Secretariat for Telecommunications and the Information Society, 2013), menciona que para la visualización y manipulación de datos existen distintas herramientas como de procesamiento, de análisis estadístico y de visualización, ofreciendo distintas funcionalidades según las necesidades de los usuarios, de las cuales sólo se utilizarán las herramientas de procesamiento y herramientas de visualización.
1.5.1. Herramientas de procesamiento.
Han sido diseñadas para la depuración y transformación de los datos, son extremadamente útiles cuando se necesita limpiar y refinar datos desordenados y convertirlos en formatos adecuados, puesto que existen ocasiones en donde una base de datos bastante extensa contiene errores tipográficos, inexactitudes (fechas en distintos formatos, espacios añadidos, celdas vacías, entre otros) y para corregir dichos errores una manipulación manual es bastante problemática y extensa. (McGhee, 2011)
Mediante estas herramientas se mejora la calidad de la información y permite que los datos sean más completos y fáciles de reutilizar.
Entre las herramientas se tiene:
x Data Wrangler.
23
Figura 6: Data Wrangler.
Fuente: Tomado de http://vis.stanford.edu/wrangler/
x Google Refine.
Herramienta gratuita y bastante útil para entender la estructura y la calidad de los datos, permitiendo corregir ciertos errores comunes en los datos. (Cabo)
Figura 7: Google Refine.
Fuente: Tomado de http://code.google.com/p/google-refine/
x Mr. Data Converter.
24
Figura 8: Mr. Data Converter.
Fuente: Tomado de http://shancarter.com/data_converter/
1.5.2. Herramientas de visualización.
Actualmente las herramientas para visualización de información ya no ofrecen sólo representaciones mediante tablas y gráficos sino que también ofrecen diagramas de árboles, mapas, nubes de palabras, entre otras formas de representación. (Intel, 2013)
Entre dichas herramientas se menciona:
x Google Fusion Tables.
25
Figura 9: Google FusionTables.
Fuente: Tomado http://www.google.com/fusiontables/
x TableauPublic.
[image:34.595.162.466.487.739.2]Herramienta gratuita para la visualización de datos a través de gráficos que combina una interfaz gráfica atractiva, rápida y eficiente con elementos tradicionales de herramientas de inteligencia de negocios. (Aldhous, 2013)
Figura 10: TableauPublic.
26
x ManyEyes.
Aplicación web que permite al usuario crear, compartir y discutir la representación gráfica de datos descargados por los usuarios. (Viégas, Wattenberg, Ham, Kriss, & McKeon)
Figura 11: ManyEyes.
Fuente: Tomado de (Viégas, Wattenberg, Ham, Kriss, & McKeon)
x CartoDB.
27
Figura 12: CartoDB.
Fuente: Tomado de (State Secretariat for Telecommunications and the Information Society, 2013)
x Google Chart.
Permite la creación de imágenes gráficas como PNG. Su funcionamiento se basa en las peticiones HTTP a una URL específica (http://chart.apis.google.com).
Figura 13: Google Chart.
Fuente: Tomado de https://developers.google.com/chart/
28
Tabla 2: Herramientas de visualización.
HERRAMIENTA TIPO TECNOLOGÍA CARACTERÍSTICAS LICENCIA DataWrangler Aplicación web HTML Limpieza de datos. x
x
Conversión de datos.
Open Source
Google Refine Aplicación de escritorio
Java Ordenar y limpiar los datos. x
x
Transformar datos de un formato a otro.
BSD
Mr. Data Converter Librería JavaScript Conversión de datos recogidos en x
Excel.
x
Conversión en Otros formatos como HTML; JSON y XML.
MIT
Google Fusion Tables Aplicación Web / API
JavaScript Flash
x
Organizar y administrar datos.
x
Visualizar y publicar datos.
Open Source
TableauPublic Aplicación de escritorio
Windows JavaScript
x
Visualizar datos mediante gráficas. Open Source
ManyEyes Aplicación web Java Flash
x
Crear y compartir datos.
x
Representar gráficas de datos.
Open Source
CartoDB Aplicación web JavaScript, PostgreSQL
x
Diseñar y desarrollar mapas en tiempo real.
Comercial
Google Chart Librería JavaScript Representar gráficamente los datos x
x
Crear imágenes gráficas como PNG.
Open Source
29
1.6. Proyectos de visualizaciónExisten algunos prototipos de visualización de datos que han sido implementados a partir de diversas tecnologías:
1.6.1. Rich Blocks, Poor Blocks.
Este proyecto muestra un mapa interactivo de los Estados Unidos de ingresos y rentas en cada ciudad, los datos provienen del American Comunity Survey, y como se muestra en la siguiente figura cada vecindario está etiquetado acorde a un espectro de color en la leyenda de mapas. Se puede realizar búsquedas por una dirección específica, ciudad o estado.
Figura 14: Visualización de ingresos y rentas en America. Fuente: Tomado de (https://www.richblockspoorblocks.com/)
1.6.2. Google Flu Trends.
30
Figura 15: Tendencias de la gripe en Australia.
Fuente: Tomado de (http://www.google.org/flutrends/au/#AU-WA)
1.6.3. LOTRProject.
Este proyecto establece un censo imaginario del mundo de J.R.R Tolkien, la Tierra Media; se puede encontrar la genealogía e información de 923 personajes de las obras de Tolkien. Se puede navegar mediante varias etiquetas o usar un buscador para encontrar caracteres específicos.
31
1.6.4. U.S.Gun Deaths.Esta visualización muestra la información sobre personas que fueron asesinadas por armas de fuego en 2013 o el 2010, la gráfica está basado en datos provistos por los Reportes de Crimen Unificado del FBI y la Organización Mundial de la Salud. Los arcos muestran datos sobre víctima como su fecha de nacimiento, su fecha de deceso y un pronóstico sobre cuán largo hubiera podido vivir, al apuntar con el ratón un arco se muestra más información sobre la víctima.
Figura 17: Muertes por armas de fuego en el 2013. Fuente: Tomado de (http://guns.periscopic.com/?year=2013)
1.7. Análisis
En base a los trabajos relacionados se puede observar que existen una gama bastante amplia de herramientas para la visualización de datos, las que difieren en varios puntos como la tecnología utilizada, las características implementadas, etc.; dependiendo de las necesidades del usuario se pueden clasificar las mismas en tres tipos: de procesamiento, de análisis estadístico y de visualización.
Las de visualización serían las más versátiles puesto que permiten representar datos de una manera más significativa, clara y eficiente; el usuario puede inferir conclusiones rápidamente mediante el simple hecho de observar las gráficas, como en Google Chart, al observar la gráfica se puede concluir que la información está mejor organizada mediante gráficas estadísticas, para su mejor interpretación.
32
CAPÍTULO 233
2.1. Problemática actualEn la actualidad existen varias tecnologías para presentar la información de manera visual, cada una de ellas implica el uso de ciertos estándares, modelos de datos o técnicas, complicando así el uso sobre una misma data de distintas formas de visualización, sean estos mapas, graficas, tablas, modelos, entre otros; el usar cada una de estas requiere que la estructura de los datos se mantenga acorde a cada forma.
Existen algunas tecnologías para representar datos de forma visual como: google chart, google maps, google fusión tables que permiten visualizar la información desde diferentes enfoques y formas y de acuerdo a las necesidades del usuario; pero la versatilidad de las mismas genera distintas maneras de consumir los datos, generando un problema: para visualizar la misma información en distintas representaciones se deben estructurar los datos acorde a las tecnologías empleadas, no existe una estructura definida y común que librerías de representación visual (como las de javascript) puedan usar.
Esto conlleva a que las representaciones sobre un mismo conjunto de datos lleguen a ser limitados en algunos casos, debido a que al no tener predefinido un modelo de datos mediante el cual estructurar la información para cada tecnología se limite el empleo de las mismas en las representaciones.
2.2. Análisis
Para resolver la problemática descrita anteriormente se necesita establecer un modelo de datos mediante el cual estructurar la data concerniente a publicaciones científicas y posteriormente consumir dicho modelo en varias visualizaciones para probar la validez del mismo.
Una vez diseñado el modelo se implementará el mismo en un servicio web, que permita obtener la data respecto a una publicación en base a una consulta, dicha data se encontrará ya estructurada según el modelo de datos definido; también se hará el análisis, diseño e implementación de un sistema que mediante el uso de este servicio web y por ende del modelo de datos muestra distintas formas de visualización sobre publicaciones científicas.
2.2.1. Especificaciones.
El sistema necesitará implementar las siguientes especificaciones:
34
<<extends>>
<<extends>>
b) Búsqueda de organización dentro del mapa: su función es hacer una búsqueda más rápida y eficiente de una afiliación en específico.
c) Obtención de información de cada nodo: presentar información de la afiliación seleccionada como: Ciudad, Provincia donde se encuentra la misma y su respectivo número de publicaciones que ha realizado.
d) Visualización de datos en las gráficas: su función es mostrar detalles sobre las afiliaciones que se encuentran registradas en el repositorio dentro de una gráfica y en otra grafica su número de publicaciones que mantienen cada una de ellas.
e) Comparación visual de indicadores: la función de la comparación visual de indicadores es mostrar visualmente los resultados de un conjunto de datos a través de gráficas, para así dar una idea al usuario de las tendencias de la información mostrada. f) Visualización de información en tabla: su función es presentar información más
detallada sobre las publicaciones que ha realizado la afiliación donde su contenido constara el título, descripción, autor y colaborador de su respectiva afiliación.
2.2.2. Funcionalidades del sistema.
Una vez obtenidos los requerimientos de usuario se definieron los casos de uso:
35
En base a este diagrama se han definido las funcionalidades del sistema:
a) Visualización de datos en el mapa: muestra los puntos geográficos en el mapa de acuerdo a la ciudad donde se encuentra la afiliación registrada, cuya funcionalidad es mostrar información en cada punto del mapa.
b) Visualizar publicaciones: permite la visualización del número de publicaciones por afiliaciones.
c) Visualizador de información en árbol: permite la visualización de las afiliaciones que se encuentran registradas, donde su color y tamaño hacen que se diferencien unas de otras de acuerdo a su número de publicaciones.
d) Visualizar datos en línea de tiempo: permite la visualización de una lista de las publicaciones de la afiliación seleccionada con su respetivo: título, fecha en la que fue publicada y su respectivo creador.
e) Visualizar tabla de datos: permite la visualización de las publicaciones de la afiliación seleccionada con su respetivo: título, descripción, autor y colaborador de la misma. f) Actualiza RDF: permite actualizar el rdf con nuevos datos para que la aplicación
36
CAPÍTULO 337
3.1. DiseñoLa idea consiste en que un usuario al ingresar a la aplicación pueda visualizar los datos de las publicaciones en un mapa, de esta manera se puede inferir rápidamente los distintos puntos, lugares o países que han realizado publicaciones o artículos científicos, como se muestra en la figura:
Figura 19: Interfaz de visualización de publicaciones. Fuente: Autor
Al momento de seleccionar una localización deben mostrarse las organizaciones en las cuales existen publicaciones:
38
Y al seleccionar alguna de ellas deben mostrarse algunos detalles como:
x
Nombre de la organización
x
Localización
x
Número de publicaciones
Tal como se muestra en la siguiente figura:
Figura 21: Detalles de una organización en el mapa de visualización. Fuente: Autor
Además de los detalles se debe apoyar la visualización de la información mediante la representación gráfica con distintos diseños como:
x
Gráficos de barras, permitirán visualizar rápidamente la variación en el número de publicaciones a partir distintas métricas como el tiempo, la región, el tipo de organización, entre otras.
39
x
Diagramas circulares, se usarán para representar los porcentajes de publicaciones realizadas ya sea por autores, organizaciones, lugares, u otros parámetros que se definan para
Figura 23: Visualización de publicaciones en diagramas circulares. Fuente: Autor
x
Gráficos de dispersión, permiten inferir rápidamente la variabilidad en la naturaleza, el contexto, la frecuencia de las publicaciones.
Figura 24: Visualización de publicaciones en gráficos de dispersión. Fuente: Autor
3.1.1. Base de Datos.
Existen 3 entidades que deben ser representadas mediante un diagrama de entidad-relación para determinar los valores y métricas de cada uno de ellos con el fin de mostrar posteriormente la información en la visualización.
Las entidades son:
x
Autor: propiamente dicho el autor de la publicación. En este contexto se deberá disponer de los siguiente datos del mismo:
a) Nombre b) Apellido c) Iniciales d) Identificador
40
x
Afiliación: entidad a la cual se encuentra relacionado un autor o una publicación, contará con los siguientes parámetros:
a) Identificador b) URL
c) Nombre d) Ciudad e) País
f) Total de publicaciones
x
Publicación: sería el artículo escrito por un autor determinado y que se encuentra afiliado a una organización. Deberá contar con los siguientes parámetros.
a) Identificador b) URL
c) Creador d) Citas e) Keywords f) Descripción g) Taggs
Posteriormente los parámetros y valores pueden aumentar o disminuir conforme se construya la base de datos, puesto que deben establecerse relaciones, modelos y entidades nuevas para abarcar la nueva información que se vaya adquiriendo conforme se desarrolla el proyecto.
41
Figura 25: Diagrama ER del prototipo de visualización.
Fuente: Documentación Técnica del Departamento General de Investigación y Transferencia de Tecnología.
3.1.2. Ontología.
Se ha construido una ontología para delimitar o definir el conjunto de datos que se procesarán y almacenarán.
También mediante una ontología se pueden definir:
x
relaciones entre entidades x
propiedades x
atributos x
etiquetas x
42
43
Se emplearon los siguientes prefijos en la ontología:
x foaf: http://xmlns.com/foaf/0.1/ x org: http://www.w3.org/ns/org# x dce: http://purl.org/dc/elements/1.1/ x rdfs: http://www.w3.org/2000/01/rdf-schema# x schema: http://schema.org/ x geo: http://www.w3.org/2003/01/geo/wgs84_pos# x place: http://purl.org/ontology/places/ x swpo: http://sw-portal.deri.org/ontologies/swportal# x bibo: http://purl.org/ontology/bibo/ x dcterms: http://purl.org/dc/terms/ x vivo: http://vivoweb.org/ontology/core#
3.1.3. Relación entre Base de Datos y Ontología.
Mediante la ontología se han definido los datos que el sistema utilizará para mostrar las visualizaciones. Estos datos se corresponden con algunos de las tablas de la Base de Datos como son:
x Organization: esta tabla almacena toda la información concerniente a la organización o afiliación a la que están relacionadas las publicaciones científicas.
x Person: dentro de esta se encuentra el nombre correspondiente al autor de un artículo científico.
x Publication: tal como su nombre lo indica, almacena los datos concernientes a los detalles de una publicación como son: título, descripción, páginas, entre otros.
x Authorship: esta tabla sirve de nexo entre el/los autor/autores y el artículo científico. La siguiente tabla describe los campos que se consideraron necesarios recoger de la base de datos para modelarlos dentro de la ontología:
Tabla 3: Relación Ontología - Base Datos.
TABLA CAMPO DESCRIPCIÓN
Organization
affiliationId Identificador de la Organización o Afiliación. affiliationName Nombre de la Organización o Afiliación.
affiliationUrl Dirección Url del sitio de la Organización o Afiliación.
affiliationLat
Latitud de la ciudad de la Organización o Afiliación.
affiliationLong Longitud de la ciudad de la Organización o Afiliación.
affiliationCity Ciudad donde se encuentra la Latitud de la ciudad de la Organización o Afiliación.
44
Person
author_id Identificador del autor o colaborador de la publicación.
authorName
Nombre completo del autor o colaborador de la publicación.
authorGivenName Primer nombre del autor de la publicación. authorSurname Apellido del autor de la publicación
Publication
pubId Identificador de la publicación. pubTitle Título de la publicación.
pubPrismUrl Dirección Url del sitio donde se encuentra alojada la publicación. pubCreator Nombre del creador de la publicación. pubPrismPublicationName Nombre descriptivo de la publicación. pubPrismIssn Código único de cada publicación. pubPrismVolume Volumen del artículo publicado.
pubPageRange Número de páginas del artículo publicado. pubCoverDate Fecha de creación de la publicación. pubDescription Descripción de la publicación. pubSubtypeDescription Tipo de artículo publicado.
Authorship author_id Identificador del autor con su respectiva publicación. Fuente: Autor.
3.1.4. Arquitectura.
45
Figura 27: Arquitectura del sistema.
Fuente: Documentación Técnica del Departamento General de Investigación y Transferencia de Tecnología.
El sistema consumirá las funcionalidades mediante servicios web alojados que harán consultas a distintas bases de datos alojadas en algunos servidores.
46
47
Como se describe en la arquitectura los datos a ser consultados serán una compilación de publicaciones de Scopus y se encontrarán alojados en un servidor.
[image:56.595.191.423.156.465.2]El formato que se empleará para el intercambio de datos en los servicios web será JSON, el mismo que estará definido de la siguiente manera:
Figura 29: JSON para intercambio de datos. Fuente: Autor
3.1.5. Diagrama de Clases.
48
Figura 30: Diagrama de Clases. Fuente: Autor
En dicho diagrama se pueden observar las clases implementadas dentro del sistema, a continuación se describe cada una:
x
Afiliación: almacena los datos respecto a una universidad.
x
Publicación: guarda datos concernientes a una publicación.
x
Autor: se encarga de almacenar información con respecto a un autor.
x
Consultas: se encarga de la consulta de los datos referentes a publicaciones, autores y afiliaciones.
x
Conexión: establece la conexión hacia la bases de datos.
x
Conversor: convierte los datos a tripletas con sus respectivas propiedades.
x
Vocabulario: almacena las formas de conversión de los datos en tripletas.
x
49
CAPÍTULO 450
4.1. Proceso de desarrollo de softwareTodo el ciclo de vida del sistema será llevado a cabo mediante un desarrollo iterativo e incremental que se realizará en 4 fases:
x
Requerimiento
x
Análisis e implementación
x
Prueba
x
Evaluación
Esto permitirá que al término de cada fase se obtenga un registro de la misma que servirá para alimentar la siguiente fase.
4.1.1. Fases de desarrollo.
Dentro de las fases de desarrollo tenemos:
a) Requerimiento: en esta fase determinaremos los requerimientos que se implementarán en el sistema.
b) Análisis e implementación: basados en los requerimientos obtenidos a partir de la fase anterior se determinarán las funcionalidades que debe tener el sistema, se establecerán modelos para el mismo, interfaces, servicios web, comportamientos entre otros.
c) Prueba: se llevarán a cabo pruebas sobre el sistema modelado, esto con el fin de probar la validez del mismo y si los requerimientos han sido implementados siguiendo las directrices dadas por el usuario.
51
4.2. Metodología [image:60.595.93.528.159.483.2]Para llevar a cabo el análisis, diseño y modelado del sistema se utilizará la metodología de desarrollo ágil XP:
Figura 31: Estructura simplificada de procesos. Fuente: Tomado de (Serena, 2007)
Esta metodología permite obtener resultados rápidos de forma eficiente, puesto que se centra en el desarrollo del producto y la retroalimentación que se obtiene a partir de los cambios implementados y sobre los que se han realizado pruebas unitarias.
Se pueden encontrar 3 fases de esta metodología:
x
Planificación
x
Iteración
x
52
Mediante esta metodología habrá entregables por cada fase realizada: Tabla 4: Fases de desarrollo.
Fase Tareas Documentos
Planificación
a) Identificar objetos y las relaciones que existen entre ellos.
b) Identificar los casos de uso del sistema mostrando los actores involucrados.
c) Presentar en caso de que se pueda, una prototipación rápida de las interfaces del sistema.
x
Modelo de Casos de Uso
x
Especificación de Requerimientos
x
Especificación de Casos de Uso
Iteración
a) Exponer todos los elementos de la estructura interna del sistema y su distribución, si fuera necesario emplear el diagrama de componentes.
b) Especificar el comportamiento a través del diagrama de secuencia.
c) Terminar el modelo propuesto, implementando los detalles del mismo en el diagrama de clases.
d) Verificar si el diseño satisface todos los requisitos identificados.
e) Escribir/Generar el código.
x
Diagrama de clases
x
Código Generado
Liberación
a) Comprobar el correcto desempeño de las funcionalidades que se han implementado
b) Realizar pruebas.
x
Pruebas
Fuente: Autor
4.3. Prototipos
4.3.1. Google FusionTables.
Para este prototipo se siguieron una serie de lineamientos:
1) Activación del API.
53
Figura 32: Activación Api FusionTables.
Fuente: Tomado http://www.google.com/fusiontables/
2) Obtención del API KEY.
a) Ingresamos a Credenciales.
b) Generamos un api key de acceso pública.
c) Se genera un apykey para usar en aplicaciones de servidor. d) Se genera un api key para usar en aplicaciones cliente.
Figura 33: Obtención de credenciales.
Fuente: Tomado http://www.google.com/fusiontables/
3) Creación de tabla
54
Figura 34: Creación de tabla.
Fuente: Tomado http://www.google.com/fusiontables/
4) Importación de datos.
Generamos un archivo con extensión .csv de nuestra base de datos y luego lo importamos en nuestra tabla de google fusion.
Figura 35: Importación de tabla.
[image:63.595.99.526.467.699.2]