Análisis de migración de datos para acceso a una biblioteca digital a través de dispositivos móviles
84
0
0
Texto completo
(2) Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey Programa de Graduados en Electrónica, Computación, Información y Comunicaciones Los miembros del comité de tesis recomendamos que la presente propuesta de Gimer Amilcar Cervera Evia sea aceptada para desarrollar el proyecto de tesis que es requisito parcial para obtener el grado académico de Maestro en Ciencias en Tecnologı́a Informática.. Comité de Tesis. Dr. David Garza Salazar Asesor Principal. M.C. Martha Sordia Sinodal. Dr. Juan Arturo Nolazco Sinodal. Ph. D. David Garza Salazar Director del Programa de Posgrado en Electrónica, Computación,Información y Comunicaciones Mayo 2004.
(3) ANÁLISIS DE MIGRACIÓN DE DATOS PARA ACCESO A UNA BIBLIOTECA DIGITAL A TRAVÉS DE DISPOSITIVOS MÓVILES. POR:. GIMER AMILCAR CERVERA EVIA. TESIS. Presentada al Programa de Graduados en Electrónica, Computación Informacón y Comunicaciones Este trabajo es requisito parcial para obtener el grado de Maestro en Ciencias con Especialidad en Tecnologı́a Informática. INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE MONTERREY CAMPUS MONTERREY. I.
(4) Dedicatoria. A Dios, mi guı́a y mi luz.. A mis padres, Gimer y Caricia.. A mi Mamá Grande y a mi hermana Valentina.. A todos mis queridos amigos.. II.
(5) Agradecimientos. Al Dr. David Garza Salazar, por todo su apoyo y valiosa asesorı́a para realizar este documento.. A mis sinodales la M.C Martha Sordia Salinas y el Dr. Juán Arturo Nolazco por todos sus comentarios y aportaciones a este trabajo.. A todos los profesores que tuve a lo largo de la Maestrı́a por sus conocimientos y amistad que me brindaron.. A mis compañeros de trabajo en el Centro de Investigación en Informática (CII) y a Isabel por todo su apoyo durante mi periodo como Becario de Docencia.. Y muchas gracias a tı́, que eres mi amigo y estas leyendo este trabajo. Por tu amistad, por estar conmigo y por tus palabras de aliento.. “I get high with a little help from my friends” Lennon-McCartney. III.
(6) Índice general 1. Introducción 2. Antecedentes 2.1. Cómputo Móvil . . . . . . . . . . . . . . . 2.2. Retos y Problemática del Cómputo Móvil 2.3. Aplicaciones de la Computación Móvil . . 2.4. Bibliotecas Digitales . . . . . . . . . . . . 2.4.1. Sistema Phronesis . . . . . . . . . 2.5. PDLib - Personal Digital Library . . . . . 2.5.1. Objetivo y Metas de PDLib . . . . 2.6. Trabajos relacionados . . . . . . . . . . . 2.7. Definición del Problema . . . . . . . . . . 2.7.1. Objetivo y solución propuesta . . . 2.8. Conclusiones . . . . . . . . . . . . . . . .. 1. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. 4 4 5 5 7 7 9 10 10 14 15 15. 3. Modelo Propuesto y Polı́ticas de Migración de Datos 3.1. Modelo Base . . . . . . . . . . . . . . . . . . . . . . . . 3.1.1. Arquitecturas Cliente-Servidor Flexibles . . . . . 3.1.2. Organización de los Servidores de Cache . . . . . 3.2. Polı́ticas de migración . . . . . . . . . . . . . . . . . . . 3.2.1. Proceso de migración . . . . . . . . . . . . . . . . 3.3. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. 16 17 18 19 22 23 26. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Transmitida. . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. 27 27 27 28 29 29 32 32 34 41 46 48 51. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. 4. Experimentos y Análisis de Resultados 4.1. Entorno Experimental . . . . . . . . . . . . . . . . . . . . . . 4.1.1. Network Simulator 2 . . . . . . . . . . . . . . . . . . . 4.1.2. Otras Herramientas . . . . . . . . . . . . . . . . . . . 4.1.3. Proceso de Simulación . . . . . . . . . . . . . . . . . . 4.1.4. Caracterı́sticas de los Experimentos . . . . . . . . . . 4.2. Experimentos . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.2.1. Definición de parámetros y variables importantes . . . 4.2.2. Descripción de los experimentos . . . . . . . . . . . . 4.2.3. Variación del evento en que se Realiza la Migración . . 4.2.4. Migración a un Nodo más Cercano . . . . . . . . . . . 4.2.5. Análisis de la Variación en la Cantidad de Información 4.3. Discusión y Conclusiones . . . . . . . . . . . . . . . . . . . .. 5. Conclusiones y Trabajo Futuro 54 5.1. Trabajo Futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56. IV.
(7) A. Componentes e Instalación del A.1. Requerimientos de Software . A.2. Componentes a Instalar . . . A.3. Guı́a de instalación . . . . . . A.4. URL´s Importantes . . . . .. NS2 . . . . . . . . . . . . . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. 58 58 58 59 59. B. Ejemplo de las Tablas de Resultados. 60. C. Código de las Simulaciones. 62. V.
(8) Índice de figuras 2.1. Sistema Phronesis basado en seis servidores (tomado de [11]). . . . . . . . . . . . . . . . . . . . . 8 2.2. Integración de servicios de cómputo móvil y Bibliotecas Digitales. . . . . . . . . . . . . . . . . . . 9 2.3. Sistema CODA (Illustración diseñada por Gaich Muramatsu tomada de [27].) . . . . . . . . . . . 11 3.1. 3.2. 3.3. 3.4. 3.5.. Extended client-server model(tomado de [19]). . . . . . . . . . . . . . . . . . . . Transacción en una arquitectura cliente-servidor flexible(tomado de [19]). . . . . Organización de de los servidores de cache en el proyecto AWC(tomado de [22]). Ubicación del Cache: cerca del consumidor ó cerca del proveedor(tomada de [6]). Aplicación de las polı́ticas de migración. . . . . . . . . . . . . . . . . . . . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. 4.1. NS2 Enviroment (tomado de [28]). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.2. Estructura del proceso de simulación. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.3. Topologı́a de las simulaciones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.4. Comparación del mejor y peor caso para cada PT. . . . . . . . . . . . . . . . . . . . . . . . . . . 4.5. Simulación con un patrón de transmisión constante, Ei = 2M B. . . . . . . . . . . . . . . . . . . 4.6. Eventos con datos aleatorios, Ei = R donde 1MB <= R <= 20MB, Na = 0 y TI = 497MB. . . . 4.7. Migración de 100MB siguiendo los patrones de transmisión: creciente y decreciente. . . . . . . . . 4.8. Comparación del Tiempo acumulado con y sin migración. . . . . . . . . . . . . . . . . . . . . . . 4.9. Migración de 50MB variando Na en cada experimento, PT = constante, Ei = 4MB y TI = 200MB. 4.10. Migración de 100MB variando Na en cada experimento, PT = constante, Ei = 8MB y TI = 400MB 4.11. Comparación del PG entre migrar al nodo 3 y al nodo 7, variando el Na,Ei = 4M B y TC=50MB. 4.12. Migración de 5MB, 10MB y 30MB, PT = constante, Ei = 50KB y TI = 2.5MB . . . . . . . . . . 4.13. Migración de 10MB variando Na, PT = constante, Ei = 50KB y TI = 2.5MB . . . . . . . . . . . 4.14. Migrando 50, 100 y 150 MB al nodo 7 y siguiendo un PT Constante. . . . . . . . . . . . . . . . .. VI. 17 18 20 21 23 28 29 30 35 37 39 40 42 43 45 48 49 50 51.
(9) Índice de cuadros 4.1. Tiempo de transmisión para cada patrón de transmisión (PT) accesando al nodo 0 y 7 sin migración. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.2. Patrón de Transmisión Constante en donde Ei = 2MB, Na = 0 y TI = 100MB . . . . . . . . . . 4.3. Patrón de Transmisión Aleatorio en donde Na = 0 y TI = 497MB. . . . . . . . . . . . . . . . . . 4.4. Patrón de Transmisión Creciente en donde Na = 0 y TI = 510MB . . . . . . . . . . . . . . . . . 4.5. Patrón de Transmisión Decreciente en donde Na = 0 y TI = 510MB . . . . . . . . . . . . . . . . 4.6. Resumen de los tiempo de sesión para patrón de transmisión en donde Na=0 . . . . . . . . . . . 4.7. Resumen del TPE con y sin migración para cada patrón de transmisión, Na = 0 . . . . . . . . . 4.8. Resumen del escenario A, usando un PT = Constante, en donde Ei = 4MB, TI = 200MB, TC = 50MB y n=50 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.9. Comportamiento del punto de equilibrio en el escenario A, migrando 50MB y Ei = 4MB . . . . . 4.10. Comportamiento del punto de equilibrio en el escenario B, migrando 100MB y Ei = 8MB . . . . 4.11. Resumen del escenario B siguiento un PT constante, en donde Ei = 8MB, TI=400MB, TC=100MB y n=50 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.12. Tiempo de sesión para cada PT Migrando 50MB al nodo 3, Na = 0 y n=50 . . . . . . . . . . . . 4.13. Tiempo de sesión para cada PT Migrando 100MB al nodo 3, Na = 0 y n=50 . . . . . . . . . . . 4.14. Resumen del TPE y TPDM para cada PT Migrando 50MB al nodo 3, Na = 0 . . . . . . . . . . 4.15. Resumen del TPE y TPDM para cada PT Migrando 100MB al nodo 3, Na = 0 . . . . . . . . . . 4.16. Resumen variando Na antes de migrar al Nodo 3, Ei = 4MB, TI = 200MB y TC = 50MB . . . 4.17. Resumen variando Na antes de migrar al Nodo 3, Ei = 8MB, TI = 400MB y TC = 100MB . . . 4.18. Patrón de Transmisión Constante, Ei = 50KB en donde Na = 0 y TI =2.5MB . . . . . . . . . . 4.19. Resumen siguiendo PT constante, en donde Ei = 50KB, TI=2.5MB, TC=10MB y n=50 . . . .. VII. 35 36 38 39 40 41 41 44 44 45 45 46 46 47 47 48 48 50 50.
(10) Capı́tulo 1. Introducción A través de la historia se puede constatar que la información es uno de los recursos más preciados por el ser humano y en la actualidad con los avances tecnológicos que existen el acceso a la información se ha vuelto una necesidad para cualquier persona. Hoy en dı́a, el acceso a los recursos y a la información disponible no se limita a usuarios que están fı́sicamente en un solo lugar, con el desarrollo de la tecnologı́a inalámbrica ahora los usuarios pueden y quieren accesar información desde cualquier lugar y en cualquier momento. Sin embargo, para lograr este objetivo es necesario enfrentar retos y restricciones que no se encuentran en el cómputo tradicional, por ejemplo, en la tecnologı́a inalámbrica los dispositivos cuentan con una capacidad de alamacenamiento limitada, dependen del tiempo de duración de la baterı́a, tienen un ancho de banda muy limitado, etc. ocasionando distracciones innecesarias para los usuarios. Por otra parte existe mucha información en internet(WWW) pero una buena parte de esta información esta desorganizada y no proviene de fuentes muy confiables. Las Bibliotecas Digitales contienen documentos en diferentes formatos digitales validados y organizados de tal forma que los usuarios pueden hacer búsquedas, enviar documentos, y/o recuperación de documentos previamente validados en su contenido. Para proveer de estos servicios a los usuarios de cómputo móvil es necesario considerar las restricciones que la tecnologı́a inalámbrica tiene en la actualidad y tomar en cuenta que en una Biblioteca Digital existe una gran cantidad de información que no podrı́a ser almacenada en un dispositivo móvil y que puede ser accesada más de una vez por uno o más usuarios. Otro aspecto importante, es la movilidad impredecible de los usuarios, que ocasiona que estos se alejen muy rápidamente del lugar al que están accesando y como consecuencia aumentar el consumo de energı́a y el tráfico en la red [31]. Una solución a estos problemas, es mover la información que los usuarios necesitan de manera que un Mobil Host(MH) pueda accesar a un nodo más cercano al que originalmente contiene la información que solicita. Sin embargo, nos enfrentamos a una serie de problemas que surgen cuando se desea mover la información, por ejemplo: ¿A dónde se debe migrar la información?, ¿En dónde se encuentra el usuario?, ¿Cuál es el servidor más cercano al usuario?, ¿Cuáles son las variables que influyen en la decisión de migrar?, ¿Cuáles son las polı́ticas para decidir migrar?. En consecuencia, los principales problemas a los que nos enfrentamos para lograr que la migración de información en un ambiente móvil traiga beneficios a los usuarios son: Definir a donde se debe migrar la información. Conocer la ubicación del usuario. Definir polı́ticas para la decidir cuando es conveniente migrar. Conocer las variables que influyen en la decisión de migrar. Establecer un proceso de migración.. 1.
(11) El objetivo de este trabajo es establecer polı́ticas que nos ayuden a decidir cuando se debe realizar la migración de datos, con el propósito de que el usuario obtenga beneficios. Estas polı́ticas están basadas en el análisis de las principales variables que influyen para que la migración sea recomendable. Adicionalmente se propone un modelo para que sea factible mover la información entre los servidores de cache y tener lo más cerca posible la información que el usuario accesa con mayor frecuencia. La importancia de analizar variables y las condiciones que influen en el proceso de migración, es entender bajo que condiciones es conveniente migrar, ya que a pesar de resolver el problema de la comunicación entre los servidores para conocer el nodo más cercano al usuario, no es garantı́a que mover la información sea conveniente para el usurio, es decir el usuario debe obtener beneficios al migrar la información a pesar del costo que implica llevar a cabo la migración y los accesos que ha realizado antes de que se muevan los datos. Especı́ficamente cuando se lleve a cabo la migración el MH debe obtener: Reducción en el tiempo de completar una transacción. Ganancia en el tiempo de completar el conjunto de tareas que va a llevar a cabo. Para conocer cuales son las variables que influyen para conseguir este objetivo nos basamos en algunas ideas propuestas en trabajos relacionados y en los experimentos que se llevaron a cabo. En este trabajo se describen diferentes experimentos basados en simulaciones de migración de información, en donde se pueden conocer los beneficios que puede obtener el usuario cuando se lleva a cabo la migración de datos siempre y cuando el tiempo que se invierte en la migración de datos y los accesos que el MH realiza antes de migrar puedan ser amortizado por la ganancia de tiempo que el usuario obtiene al accesar al nodo a donde se movió la información. Para esto se establecieron polı́ticas bajo las cuales se minimiza el riesgo de llevar a cabo una migración que no traiga beneficios para el usuario. Un servidor decide migrar cuando el tiempo de completar un conjunto de accesos al nodo al que se movió la información, es menor que el tiempo que le hubiera tomado accesar esta información sin que se lleve a cabo la migración. En los experimentos que se llevaron a cabo se analizan las variables que influyen para que se pueda reducir el tiempo de completar un conjunto de tareas accesando al nodo al cual se migró la información. Las principales variables que se analizaron para conocer el impacto que tienen en la migración de datos son: La cantidad de información que se tiene en cache. La cantidad de información que se transmite en cada acceso. El tiempo de migración, el cual depende de la cantidad de información en cache, las condiciones de la red, el tráfico y la distancia a la que se encuentre el nodo al cual se moverán los datos. El efecto de la distancia del nodo al cual se desea migrar. El patrón que sigue la información que es transmitida. Se llevaron a cabo experimentos variando el comportamiento de la información que es transmitida en cada acceso. El instante en el que se decide migrar. Realizando experimentos modificando estas variables, se pudieron observar diferentes situaciones en las cuales la migración es recomendable, además, se pudo conocer cual serı́a el beneficio que obtiene el usuario cuando se mueven los datos. Otro aspecto importante es identificar el momento en el que el usuario comienza a ver resultados positivos es decir, si la migración es en beneficio del usuario, debe existir un punto a partir del cual el usuario empieza a ganar tiempo. Poder estimar este momento es importante para decidir si es conveniente migrar. En base a los resultados obtenidos podemos concluir que es recomendable migrar cuanto antes con el objetivo de amortizar el costo de migración lo más pronto posible. Sin embargo, tomando en consideración que el usuario 2.
(12) podrı́a realizar cierta cantidad de accesos antes de migrar es necesario que la ganancia obtenida en los accesos posteriores a la migración permitan amortizar el tiempo invertido en la migración y en los accesos previos. También se pudo observar que se obtiene un mejor rendimiento en los accesos que el MH realiza al nodo a donde migró la información a medida que la distancia a la que se encuentra del nodo que originalmente tenı́a la información se incrementa. Esto nos da indicios de que se puede migrar una cantidad de información mayor a medida que el MH se va alejando ya que la ganancia que se obtiene al accesar al nuevo nodo ayudarı́a a compensar con mayor rapidez el tiempo que se invirtió al mover la información. En resumen, las principales aportaciones que se presentan en este trabajo son: El análisis experimental de las principales variables que influyen en la decisión de migrar la información. Un modelo que sirve de base para la migración de información. Las polı́ticas de migración. El algoritmo que nos indica el proceso de migración. Formalización de diferentes conceptos que son aplicados a la migración de datos. En los siguientes capı́tulos se describirá con más detalle los experimentos y las polı́ticas que se proponen. El resto del trabajo está organizado de la siguiente manera: En el capı́tulo dos se analizarán algunos problemas, restricciones y aplicaciones de la tecnologı́a móvil que existen actualmente. También se describirán algunos temas relacionados con este trabajo como lo son: Bibliotecas Digitales y trabajos relacionados con servidores de cache y migración de información. En el capı́tulo tres se describen de los objetivos de este trabajo, el modelo base y la arquitectura que soporta a este modelo, las polı́ticas de migración y se identifican las variables más importantes que influyen en la migración de datos del modelo que se propone. El capı́tulo cuatro consiste en una descripción de los experimentos que se llevaron a cabo para analizar las variables que influyen en la migración de datos. En este capı́tulo se describen las herramientas en las que se llevaron a cabo las simulaciones y el procedimiento que se siguió en los experimentos. El principal objetivo de este capı́tulo es llevar a cabo simulaciones modificando el valor de las variables que se han identificado como las más importantes en la migración de información y observar bajo que condiciones la migración de información es conveniente para los usuarios. El último capı́tulo está dedicado a las conclusiones, trabajo futuro y los puntos más importantes de este trabajo.. 3.
(13) Capı́tulo 2. Antecedentes En este capı́tulo se describen aspectos generales del cómputo móvil, la problemática que acualmente se presenta en este ambiente, Bibliotecas Digitales y proyectos relacionados con este trabajo.. 2.1.. Cómputo Móvil. El cómputo móvil es un nuevo paradigma que surge a partir de las redes de datos inalámbricas y de disposivos portatiles, en los cuales los usuarios pueden tener acceso a información a pesar de su localización fı́sica o su movilidad. El cómputo móvil está basado en el desarrollo de Sistemas Distribuidos y en la arquitectura clienteservidor, en donde los clientes móviles realizan funciones diferentes a las de los clientes que se encuentran fijos. Básicamente, el cómputo móvil se distingue por los siguientes dos puntos [19]: La movilidad de los usuarios Las restricciones de los recursos móviles. La movilidad de los usuarios implica que estos se puedan conectar muy rápidamente a diferentes redes con caracterı́sticas heterogeneas, diferentes sistemas operativos y protocolos de red y además permanecer conectados mientras están en movimiento [8]. Por otra parte existen muchos tipos de clientes móviles, que según Baruch [4] pueden ser considerados: El inalámbrico fijo , que serı́a el usado en casas y oficinas. El inalámbrico móvil que incluye los equipos inalámbricos motorizados, como los teléfonos de vehı́culos. El inalámbrico portátil que serı́a de los equipos funcionando con baterı́as, o que se encuentran afuera de la oficina, de la casa, o de un vehı́culo por ejemplo: teléfonos celulares, PDA´s, Laptops, etc. El inalámbrico IR (Infrarrojo) que engloba a las herramientas transportando datos vı́a radiaciones infrarrojas. En respuesta a tal diversidad en la actualidad existen muchos proyecto e Institutos trabajando para enfrentar los retos que son implı́citos en la tecnologı́a inalambrica. Los sistemas de hoy en dı́a están enfocados a llevar la información al lugar en donde se encuentre el usuario sin importar las condiciones o la infraestructura tecnológica con las que cuenta. Otro punto importante que se debe considerar es la cantidad de información que hoy en dı́a existe ası́ como la variedad de formatos en la que se presentan. Un usuario de cómputo tradicional puede accesar desde su casa u oficina a gran cantidad información en Internet en formato de audio, video o texto y compartir esa información con otros usuarios. Los usuarios móviles tienen el mismo interés de accesar a toda la información que se encuentre disponible en www y por las caracterı́sticas de esta tecnologı́a lo pueden hacer desde cualquier parte. En las siguientes secciones de este capı́tulo se describirán con mayor detalle la problemática que se enfrenta en este ambiente móvil, ası́ como trabajos y proyectos relacionados para minimizar los problemas que los usuarios móviles enfretan. 4.
(14) 2.2.. Retos y Problemática del Cómputo Móvil. En el cómputo móvil se pueden encontrar problemas y restricciones que no son muy comunes en el cómputo tradicional, por ejemplo: Duración de la baterı́a [31, 15]. Capacidad de almacenamiento [5]. Heterogeneidad en las redes a las que se conectan los dispositivos móviles [31]. Ancho de Banda [8]. La conservación del ancho de banda es uno de los puntos más importantes en la tecnologı́a inalámbrica. Las conexiones frecuentemente son muy limitadas, intermitentes y con altos costos. Además, mientras aumenta la distancia a la que un MH accesa información el consumo de energı́a se incrementa [31]. En [32] se agrupan estas restricciones en cuatro puntos: Los recursos con los que cuentan los dispositivos móviles son relativamente pobres comparados con los que se emplean en el cómputo tradicional. Esto se debe a que las restricciones de tamaño, peso y diseño, afectan directamente a la velocidad de procesamiento, capacidad de almacenamiento y al tiempo de vida de la baterı́a, y a pesar de que hay grandes esfuerzos por crear dispositivos que ofrezcan mejor rendimiento, aún está muy por debajo de lo que el cómputo tradicional puede ofrecer. La móvilidad es inherentemente más peligrosa e impredecible. Los dispositivos móviles como laptops, PDA´s , celulares, etc. son más vulnerables a ser robados u olvidados por los usuarios en cualquier parte, lo que no sucederı́a con PC´s de escritorio en una oficina. Además los usuarios se mueven aleatoriamente de un lugar a otro. La conectividad es altamente variable en rendimiento y confiabilidad. Es debido a la heterogeneidad que existe en las redes disponibles, por ejemplo: en un campus se puede tener acceso a una wireless LAN de alta velocidad, pero en cualquier otro edificio podrı́an tener tan solo modems para conectarse lo que llevarı́a a los dispositivos a tener que adaptarse a las condiciones de la red a la que están conectados. La energı́a es finita. Esto es debido a que dispositivos como: Laptops, PDA´s , TabletPC, etc. dependen de las baterı́as para ser completamente móviles, con la restricción del tiempo que tarda una baterı́a sin que tenga que ser recargada. Esto implica una preocupación más para el usuario ya que debe estar pendiente de tener a la mano lugares en donde cargar de nuevo la baterı́a, que por supuesto, no tendrı́a en una PC. Los dispositivos deben ser capaces de manejar una desconexión por falta de energı́a y que esto sea transparente para los usuarios.. 2.3.. Aplicaciones de la Computación Móvil. A pesar de las restricciones que se presentaron en la sección anterior la tecnologı́a móvil ha tenido un gran impacto en muchas áreas y provee a los usuarios de un gran número de servicios que la tecnologı́a de cómputo convencional no ofrece. Algunas de las áreas en donde del cómputo móvil es de gran ayuda son: Medicina. La computación móvil permite al médico o institución mantener contacto con un paciente cuyo estado requiere continua vigilancia. Y esto no se limita al envı́o o recepción de mensajes (hablados o escritos), sino que incluye también el monitoreo constante de signos vitales crı́ticos que pueden anticipar una emergencia. Compra y venta desde dispositivos móviles. En la actualidad los usuarios móviles pueden comprar y vender productos desde cualquier dispositivo inalámbrico sin importar en donde se encuentren.. 5.
(15) Servicio a clientes. La asesorı́a, servicio técnico y consultorı́a es una área en donde la computación móvil es vital. La consulta a bancos de información, bases de datos inteligentes, recopilación de información actualizada y consulta de especialistas, es sólo una pequeña muestra de todo lo que puede impactar esta tecnologı́a, sin mencionar la posibilidad de contacto permanente con el cliente. Grupos de trabajo. La globalización y expansión de empresas hace que sea cada vez más común atacar proyectos con el personal adecuado, el cual no siempre trabaja bajo un mismo techo y, en ocasiones, ni siquiera en la misma ciudad o paı́s. Acceso a Información. En la actualidad existe mucha información en formato digital distribuido en la red, como es el caso de las Bibliotecas Digitales, en donde los usuarios pueden accesar a información de fuentes confiables en diferentes formátos digitale de audio, vı́deo, PDF, etc. Este último punto es el que tiene mayor interés para este trabajo, ya que en la actualidad uno de los principales retos a los que nos enfrentamos es accesar información en cualquier momento y desde cualquier parte, Information Anywhere, Anytime [5]. A continuación se presentan unos escenarios en donde se puede apreciar la importancia que tiene para los usuarios el accesos a la información. Escenario1 Vania es psicóloga y labora en una importante clı́nica de México. Su trabajo le exije viajar frecuentemente a diferentes ciudades de EU. Ella sabe que siempre puede necesitar casos relacionados con los pacientes que visita, tener a la mano miles de artı́culos, libros, etc. ası́ como información del hospital en el que se encuentre. Su PDA le permite: Acceso inalámbrico desde: su auto, el hospital, el hotel, etc. a casos clı́nicos que ha llevado. No importa la ciudad en la que se encuentre ya que la información que consulta con mayor frecuencia siempre está accesible. Realizar búsquedas en una Biblioteca Digital Personal en donde se encuentran artı́culos, libros o cualquier información relacionada. Frecuentemente esta revisando su correo electrónico. Escenario2 En el Hospital San José del ITESM, todos los doctores cuentan con un PDA que les permite: Visitar a los pacientes y mediante el dispositivo inalámbrico tener acceso al expediente y modificarlo de ser necesario. Frecuentemente son enviados a cursos en otras ciudades o paı́ses y en su PDA pueden accesar a una Biblioteca Digital, en donde pueden obtener artı́culos, publicaciones, etc. El acceso a los expedientes lo pueden hacer mediante su teléfono celular y escuchar la información mas importante, ası́ como grabar mensajes y anotaciones. En los escenarios anteriores los usuarios accesaban desde sus dispostivos móviles a información que se encuentra en Bibliotecas Digitales, esta manera de organizar la información brinda muchas ventjas para los usuarios, en la siguiente sección se describe la importancia y las principales caracterı́sticas que las Bibliotecas Digitales ofrecen.. 6.
(16) 2.4.. Bibliotecas Digitales. En la actualidad existen miles de lugares a los que se puede accesar via internet para conseguir información, esta puede ser en diferente formatos digitales como son: audio, video y texo, o una combinación de estos. Sin embargo esta información no siempre es confiable muchas veces procede de fuentes poco seguras, es decir no se tiene la certeza de que algún organismo internacional como la IEEE o ACM han validado un artı́culo o documento de investigación. Además, la gran mayorı́a de los sitios permiten a los usuarios un número limitado de servicios, por ejemplo, generalmente el usuario solo puede descargar el documento, y casi siempre la información se encuentra desorganizada lo que ocasiona que sea más dificil accesarla. Una forma de garantizar el acceso a documentos confiables y de manera rápida y organizada, es mediante las Bibliotecas Digitales, que ofrecen diferentes servicios y una forma segura y eficiente de obtener información. Una Biblioteca Digital puede conceptualizarse como una colección organizada de documentos en diversos formatos digitales para los cuales existen servicios tales como envı́o, clasificación, búsqueda, recuperación y administración [11]. Adicionalmente, una biblioteca digital facilita el desarrollo de actividades de estudio e investigación colaborativa entre usuarios distribuidos geográficamente. Idealmente, una biblioteca digital debe proporcionar mecanismos de almacenamiento, búsqueda y recuperación de documentos completos. Existen varios retos tecnológicos asociados a la realización de bibliotecas digitales. Entre los retos más sobresalientes se pueden mencionar [11]: Creación digital de documentos. Los archivos que son parte de una biblioteca digital se almacenan en diferentes formatos digitales. En caso de no estar en algún formato electrónico es necesario convertirlo a un formato digital. Clasificación e indexamiento. Los documentos digitales que son parte de una colección se deben clasificar, almacenar e indexar para mejorar la eficiencia del proceso de recuperación. Búsqueda y recuperación. La información almacenada en la biblioteca digital debe ser accesible a los usuarios de una manera eficiente, lo que implica que la biblioteca debe incluir una técnicas de búsqueda avanzada y de recuperación. Distribución. Los archivos electrónicos que se almacenan en la biblioteca digital deben estar disponibles a los usuarios remotos de manera rápida y segura. Administración y control de acceso. Para evitar el acceso no autorizado a los documentos, una biblioteca digital debe incorporar mecanismos para restringir el acceso a usuarios no autorizados. Personalización. Las bibliotecas digitales deben satisfacer las necesidades de información especı́ficas y preferencias de usuarios individuales y comunidades de usuarios. Un ejemplo de una Biblioteca Digital es el Sistema Phronesis [11], en la siguiente sección se describen algunas caracterı́sticas de este proyecto.. 2.4.1.. Sistema Phronesis. Phronesis es un proyecto que inció en 1988, con el apoyo del Programa Red de Desarrollo e Investigación en Informática del CONACYT y el ITESM-Campus Monterrey, y tiene como objetivo realizar investigación y desarrollo de tecnologı́as que puedan ser utilizadas para crear Bibliotecas Digitales distribuidas [12]. Las Bibliotecas Phronesis cuentan con capacidad de búsqueda booleana y por relevancia. Cuando un usuario efectúa una búsqueda y obtiene resultados, Phronesis ofrece la facilidad de visualizar los metadatos del documento o transferir el documento de la biblioteca a la computadora local del usuario. Algunas caracterı́sticas importantes del sistema Phronesis son [11]: Indexamiento y búsquedas en texto completo o en los metadatos de los documentos que se encuentren en la biblioteca digital. 7.
(17) Figura 2.1: Sistema Phronesis basado en seis servidores (tomado de [11]).. Control de acceso a los usuarios. Búsquedas de documentos escritos en inglés y español; Interfaz de usuario basada en WWW. Búsquedas en documentos y en metadatos en formato de Texto, PostScript, HTML, PDF y RTF Soporte para almacenar cualquier tipo de documento digital. búsquedas simultáneas en varios repositorios de la Biblioteca. El componente clave del sistema es el servidor Phronesis que se utiliza para la creación de una colección de la biblioteca digital. Se pueden instalar varios servidores Phronesis en Internet, permitiendo ası́ crear una biblioteca digital distribuida. Cada servidor es autónomo y se administra localmente, en una misma computadora pueden residir más de un servidor Phronesis (es decir, más de una colección). La figura 2.1 es un ejemplo de un sistema phronesis con 6 servidores. La arquitectura del Sistema Phronesis se basa en el modelo cliente-servidor. El cliente es un navegador de WWW donde los usuarios pueden buscar, recuperar y enviar documentos, ası́ como también, ver una la lista completa de los documentos existentes en la biblioteca. Los usuarios con pueden realizar las tareas de administración de la colección vı́a WWW. El servidor es el componente clave del sistema y realiza las siguientes tareas: administración y control de acceso, almacenamiento fı́sico de documentos, indexamiento, búsqueda y recuperación local y distribuida y navegación. Una caracterı́stica importante de una biblioteca digital es que posee información sobre diversos temas en su colección, esto a su vez nos representa un problema, ya que en ocasiones se dificulta encontrar la información que se necesita. En consecuencia, el sistema Phronesis posee una serie de servicios de búsqueda que facilitan la localización de documentos. Algunos de estos sevicios son [11]:. 8.
(18) Figura 2.2: Integración de servicios de cómputo móvil y Bibliotecas Digitales.. Búsquedas sencillas - A través de frases los usuarios tienen la posibilidad de efectuar busquedas en el texto completo de los documentos, metadatos o inclusive en ambas. Búsquedas avanzadas- en este tipo de búsqueda el buscador permite especificar las búsquedas más a detalle. Phronesis ofrece búsquedas por tı́tulo, tema, autor, descripción, etc. Navegación - en este servicio podemos listar documentos agrupados por autores, fechas, tipo de documento y tı́tulos. Actualmente los usuarios pueden accesar a Internet desde una gran variedad de dispositivos móviles y tienen el mismo interés de los usuarios de cómputo tradicional por accesar los servicios que se disponen en una Biblioteca Digital, por lo que la adaptación de los servicios que los sistemas ofrecen a la tecnologı́a inalámbrica es uno de los principales retos que se presentan hoy en dı́a. En la siguiente sección se describe el Proyecto PDLIb [12] cuya finalidad es proveer los servicios que las Bibliotecas Digitales ofrecen hoy en dı́a a los usurios de dispositivos móviles.. 2.5.. PDLib - Personal Digital Library. PDLib [12] es un proyecto desarrollado en el Instituto Tecnologico de Estudios Superiores de Monterrey Campus Monterrey (ITESM), en el Centro de Investigación en Informática(CII), con el propósito de investigar en el área de cómputo móvil y Bibliotecas Digitales. Ası́, PDLib (Personal Digital Library) se propone como una arquitectura de software que permita al usuario móvil accesar servicios de una Biblioteca Digital [12]. Con este proyecto se pretende que un usuario móvil pueda tener una biblioteca digital personal en cualquier dispositivo móvil como PDA´s ó Tablets PC´s, en otras palabras PDLib pretende integrar los servicios que las Bibliotecas Digitales ofrecen actualmente al cómputo móvil como se puede apreciar en la figura 2.2. PDLib ofrecerá los servicios de envió, búsqueda y recuperación de documentos adaptados para el ambiente móvil [12]. PDLib se basará en una arquitectura distribuida del Sistema Phronesis para ofrecer los servicios a los usuarios móviles. Es importante comentar que el usuario móvil tendrá la visión de una biblioteca digital en su PDA pero en realidad la biblioteca digital estará soportada por servidores Phronesis disponibles en Internet.. 9.
(19) 2.5.1.. Objetivo y Metas de PDLib. El objetivo de este proyecto como se define en el propuesta presentada por el equipo de desarrollo de PDLib es: “Definir una arquitectura y servicios de biblioteca digital para ambientes de cómputo móvil. La arquitectura y los servicios serán basados e incorporados en el Sistema Phronesis [11]. Mediante el cual se realizarán contribuciones a las áreas de bibliotecas digitales, cómputo móvil y reconocimiento de voz los cuáles son temas de interés en la comunidad de ciencias de la computación”. Algunas de las metas especı́ficas del proyecto son [12]: Fomentar el desarrollo de investigación en el área de bibliotecas digitales, cómputo móvil y reconocimiento de voz. Desarrollar una nueva arquitectura del Sistema Phronesis para incorporación fácilmente los servicios que actualmente existen para dispositivos móviles. Definir servicios que se adapten al ambiente móvil y explorar que nuevos servicios se pueden desarrollar en este ambiente. Continuar fomentando un ambiente abierto de desarrollo de bibliotecas digitales mediante la creación de servicios y herramientas para el acceso a bibliotecas digitales en un ambiente móvil Adaptar el Sistema Phronesis para ofrecer servcios de bibliotecas digitales en ambientes móviles. El presente trabajo pretende aportar ideas para llevar a cabo los objetivos de PDLib, ya que como se ha mencionado en este capı́tulo, en el cómputo inalámbrico se presentan problemas y restricciones diferentes a los del cómputo tradicional. Por lo que los servicios que se pretenden incorporar a este ambiente móvil de trabajo requieren estar soportados por una infraestructura técnológica que permita llevar a cabo estas metas. A continuación se describen algunos proyectos relacionados con este trabajo cuya finalidad es proveer a los usuarios móviles de una infraestructura que le permita accesar y disponer fácilmente de la información que necesita.. 2.6.. Trabajos relacionados. Sistemas de Archivos Distribuidos Por mucho tiempo los sistemas de archivos distribuidos han sido una forma de compartir y accesar información que se encuentra distribuida en varios puntos. Un sistema de archivos distribuidos almacena archivos en una o más computadoras, llamadas servidores, en donde aparecen como archivos almacenados en el mismo equipo y los hace accesibles a otras computadoras, llamadas clientes . Existen muchas ventajas de usar servidores de archivos, por ejemplo: Los archivos están disponibles a todos los clientes que puedan acceder a un servidor. Compartir los archivos en un servidor es más fácil que distribuir copias de los archivos en los clientes. Los respaldos y la seguridad de la información son más fáciles de controlar. Los servidores pueden ofrecer una gran cantidad de espacio para almacenar información, la cual podrı́a ser improbable de tener en cada uno de los clientes. La utilidad de sistemas de archivos distribuidos es muy clara cuando se piensa en un grupo de usuarios accesando la misma información, sin embargo esta idea puede extenderse también se pueden compartir aplicaciones de software y tener más cerca la información. En cualquier caso la administración de la información es más fácil. A continuación se describen algunos proyectos encaminados a resolver la problemática que se presenta en los sistemas distribuidos como son: CODA [27, 32] y Aura [26]. Estos proyectos están orientados a compartir archivos en una red con una gran cantidad de usuarios, administrar la desconexión de los usuarios y/o la información que se encuentra en cache, además, agregan caracterı́sticas para los usuarios móviles. En las siguientes secciones se describirán las principales caracterı́sticas de estos sistemas. 10.
(20) Figura 2.3: Sistema CODA (Illustración diseñada por Gaich Muramatsu tomada de [27].). CODA Coda [27, 32] es un sistema de archivos distribuidos desarrollado por un grupo de investigadores en Carnegie Mellon University. Coda surgió en respuesta a las necesidades del CMU, en un principio en esta Universidad se contaba con el sistema AFS(Andrew File System) [33]. Este sistema de archivos distribuido permite una cooperación entre diferentes computadores (clientes y servidores) para compartir eficientemente los recursos a través de una red local o de área amplia. AFS está basado en un sistema de archivos distribuidos desarrollado originalmente en el Centro de Información Tecnológica de la Universidad de Carnegie-Mellon y al final de los ochentas soportó miles de clientes en el campus de la CMU, sin embargo el número de usuarios se incremento de tal forma que los retrasos en la red y los fallos del servidor ocurrı́an en cualquier lugar cada dı́a. Coda funciona actualmente en plataformas como Linux, NetBSD y FreeBSD y una gran parte del sistema corre en Windows 95 y continúa desarrollandose para poder ejecutarse desde Windows NT. Coda es unos de los sistemas de archivos distribuidos más populares que existen hoy en dı́a y que pretende incorporar los servicios que ofrece a la cómputo móvil. Este sistema hace que los archivos estén disponibles a un conjunto de nodos clientes como si éstos formarán parte de su árbol de directorios, pero manteniendo el control de los datos de los archivos en los servidores, la figura 2.3 es un ejemplo de la arquitectura de este sistema. Coda contiene algunas caracterı́sticas que le hacen destacar: soporta funcionamiento desconectado, o sea acceso completo a una parte almacenada de los archivos en el caso de que ocurran desconexiones voluntarias o involuntarias de la red o del servidor. Cuando los clientes vuelvan a estar conectados, Coda reintegrará los cambios que se han realizado mientras se trabajaba desconectado. Además Coda tiene un sistema de replicación para fallos del servidor, ésto significa que los datos son almacenados y obtenidos en cualquier servidor dentro de un grupo de servidores y Coda continuará funcionando con sólo un subconjunto de esos servidores disponibles. Si aparecen diferencias entre servidores, debidas a particiones de red, Coda resolverá estas diferencias automáticamente en la mayor extensión posible y ayudará a los usuarios a reparar aquéllo que no se puede reparar de manera automática. Coda está organizado de manera muy diferente a NFS [25] a los directorios compartidos de Windows/Samba. Otras de las caracterı́sticas importantes de este sistema de archivos es la incorporación a la tecnologı́a móvil. Algunas de las caracterı́sticas más importantes de este sistema son: Operaciones en modo desconectado para clientes móviles 11.
(21) • Reintegración de datos para clientes desconectados. • Adaptación al ancho de banda. Manejo de Errores • Replicación de lectura/escritura al servidor. • Manejo de errores en la red. • Manejo de la desconexión de los clientes. Rendimiento y Escalabilidad • Del lado del cliente cuenta un persistente cache de archivos, directorios y atributos para un alto rendimiento. • Arquitectura write-back Seguridad • Uso de Kerberos en la identificación • Listas de Control de Acceso (ACL´s) Disponibilidad del Código Fuente El origen del funcionamiento desconectado en Coda es una de las caracterı́sticas originales del proyecto: proveer un sistema de archivos con capacidad de recuperación ante fallos de red.. Aura Los recursos más preciados en un sistema computacional ya no son el procesador, la memoria, el espacio en disco o la red. Hoy en dı́a la atención principal es al usuario. Los sistemas actuales distraen a los usuarios de muchas formas explı́citas o implı́citas y ası́ reduciendo la efectividad de los sistemas. El proyecto Aura [26] fundamentalmente rediseña los sistemas para resolver este problema. El objetivo de Aura [26] es proveer a cada usuario un Aura o espectro de servicios computacionales y de información que persistan sin importar la localización de los usuarios. Para lograr este objetivo se necesitan esfuerzos en cada nivel: desde el hardware y la capa de red, pasando por los sistemas operativos y el middleware, hasta las interfaces con los usuarios y las aplicaciones. Aura [26] diseñará, implementará y evaluará sistemas a gran escala para evaluar si cumplen con el concepto de “un aura de información personal” que abarcará todo lo que se pueda llevar puesto, los dispositivos de mano como handhelds, desktop y la infraestructura computacional. El proyecto Aura pretende conseguir dos importantes objetivos: Maximizar el uso de los recursos disponibles. Minimizar las distracciones del usuario. Esto es debido a la heterogeneidad que existe en los recursos disponibles y el tiempo que el usuario invierte en administrar estos recursos. El sistema Aura actuará como un proxy que determinará cuales son los dispositivos adecuados y el software necesario para completar las tareas que el usuario móvil desea llevar a cabo. La arquitectura del sistema Aura está compuesto por cuatro componentes: El Administrador de Tareas(Task Manager ). También llamado Prism, es un componente que aplica el concepto de Aura, minimizando las distracciones del usuario ocasionados por los cambios que ocurren en: las tareas, el contexto, el ambiente y hacia donde se mueve el usuario.. 12.
(22) Observador del Contexto(Context Observer ).Provee información del contexto fı́sico y reporta los eventos relevantes al Administrador de tareas. Administrador del Ambiente(Enviroment Management). Funcionad como la puerta de acceso al ambiente en el que se encuentra el usuario. Facilitadores (Suppliers). Proveen los servicios abstractos que componen las tareas que el usuario va a realizar, por ejemplo: editar texto, solicitar un archivo, etc. Aura es un proyecto que se enfoca en estudiar el comportamiento del usuario y mover la información y los recursos que el usuario solicita con el propósito de envolver al usuario en un Aura de servicios disponibles en cualquier momento. Servidores de Cache y Migración de Información Las redes de alta velocidad y la tecnologı́a multimedia introducen nuevos servicios como el video bajo demanda o la tele-educación, en donde mucha información de diversos tipos es transmitida bajo demanda. En este tipo de servicios los servidores de cache y los servidores de almacenamiento juegan importantes roles. Antes, un solo servidor que pudiera soportar a multiples usuarios o proveer de varios servicios era suficiente, sin embargo ahora esto solamente es eficiente si los servidores comparten información entre sı́ para proveer servicios a multiples usuarios y ası́ los datos que frecuentemente son accesados pueden ser replicados en diferentes servidores. Los servidores de cache guardan la información que es accesada con mayor frecuencia reduciendo el costo de transmisión y la latencia que ocasiona que multiples usuarios estén accesando a un solo servidor de almacenamiento. En este trabajo se aportan ideas para organizar la relación que existe entre los servidores de cache y de almacenamiento con el propósito de minimizar el costo de almacenamiento y transmisión de información para satisfacer las necesidades de los usuarios. La tecnica de cache ha sido adoptada ampliamente para reducir el tiempo de respuesta de los servicios en WWW debido al crecimiento de usuarios y sitios disponibles en Internet [7]. Los servidores Proxy fueron inicialmente desarrollados para permitir acceso al WWW, protegiendo a los usuarios de ataques. Pero estos son útiles para reducir la latencia en la red cuando son usados como servidores de cache. Estos servidores replican los objetos más populares en la WWW y los almacenan en hosts cercanos a los usuarios. El beneficio de usar cache se encuentra cuando los objetos que se han almacenado son accesados en repetidas ocasiones [16]. Cuando un objeto es almacenado en cache desde la primera petición, el siguiente acceso a dicho objeto será realizado a la copia local del objeto. De hecho, la mayorı́a de los Web Browsers usan el disco local para almacenar una pequeña cantidad de objetos que son accesados frecuentemente. La implementación de los servidores de cache para reducir la latencia en la WWW ha sido desarrollada de manera exitosa. El proyecto Squid [7] es una prueba de ello, este proyecto consiste de un servidor proxy de alto rendimiento que funciona como un servidor de cache para clientes web, soportando servicios como FTP, gopher, entre otros. Squid consiste de un programa en el servidor principal, un DNS, algunos programas opcionales para reescribrir peticiones y evaluar autentificaciones, además de algunas herramientas de administración de los clientes. Squid es un software gratuito desarrollo para correr bajo plataformas Unix Existen muchos otros proyectos relacionados con los servidores de cache, por ejemplo en [20] se clasifican los dispositivos de almacenamiento de la siguiente forma : servidores de almacenamiento (storage servers), servidores de cache (cache servers) y almacenamiento local (buffer locales). Los servidores de almacenamiento son usados para almacenar información por un largo periodo de tiempo, mientras que los servidores de cache son usados por periodos más cortos.. 13.
(23) La organización y administración de los servidores de cache también es un punto importante de estudio existen trabajos como [34] y [40] enfocados a la arquitectura de los servidores cache con el propósito de reducir la comunicación entre los servidores y mejorar el tiempo de respuesta. Un proyecto que tiene mucha relevacia para este trabajo es el proyecto AWC [22, 39] (Adaptive Web Caching) en el que se organizan los servidores de cache en grupos con el objetivo de mejorar la comunicación entre los servidores de cache, este trabajo será comentado con más detalle en el siguiente capı́tulo ya que aporta ideas muy interesantes a nuestro trabajo. Otro tipo de trabajo se enfoca a la información que debe ser almacenada en un servidor de cache. En [38] los autores estudian metodos de remplazo del cache usando propiedades de la localización de los datos. Por ejemplo, ellos consideran que de acuerdo a las regiones la información va tomando mayor relevancia, por ejemplo la información relacionada con el clima en la ciudad de Monterrey no es de gran relevancia si un usuario móvil se encuentra en alguna ciudad de Europa. En [17] se describe un trabajo basado en recopilar la información que se encuentre en el cache de los dispositivos móviles y enviarlos al servidor, el método que se propone se llama: ”CINDEX Cache-Index Forwarding per Document for the WWW”, con el propósito de eliminar migración o actualización de información innecesaria. En [10] se estudian varias estratégias de invalidación del cache, ya que el objetivo de este trabajo es estudiar el efecto de las desconexiones y la movilidad de los clientes en la información que se tiene en cache del lado del cliente y del servidor. De igual forma en [2] se presenta un nuevo esquema de mantenimiento de cache llamado: AS (Asynchronous Scheme), el objetivo de este esqueme es validar el cache de los dispositivos cuando estos se reconectan almacenando en cache información de los MH aun y cuando estos se mueven a otra área de registro. Este esquema es usado en el sistema de archivos CODA. En el Tecnológico de Monterrey existen trabajos de Tesis relacionados con el acceso a Bibliotecas Digitales mediante servidores de cache. En [23], Karla Martinez basó su trabajo en este tema. El principal aporte de su trabajo de investigación está orientado al diseño de un Modelo de Servidor Caché para Sistemas Distribuidos, especı́ficamente para Bibliotecas Digitales, teniendo como objetivo minimizar el tiempo de acceso a los documentos de la biblioteca, por medio de la réplica parcial y temporal de documentos que son accesados con mayor frecuencia. Este proyecto no considera el acceso a una Biblioteca Digital a través de servidores de cache por dispositivos inalámbricos. Por otra parte en [3], Aldo Ramirez trabajó en desarrollar un modelo para accesar a una Biblioteca Digital mediante dispositivos móviles pero sin tomar en cuenta servidores de cache. Nuestro trabajo pretenderá aportar ideas para integrar estas posibilidades, es decir accesar a Bibliotecas Digitales mediante dispositivos móviles usando servidores de cache. Este trabajo pretende analizar cuales son las principales variables que influyen en la migración de información y entender bajo que condiciones un usuario realmente recibe beneficios a pesar del tiempo que se invierte en la migración de datos y los accesos que haya realizado antes de mover la información.. 2.7.. Definición del Problema. La integración de los servicios de una Biblioteca Digita a un ambiente móvil genera muchos aspectos que considerar como por ejemplo: la capacidad de almacenamiento de los dispositivos, el tamaño de la pantalla de visualización, etc. Una de las problemáticas en esta integración es el acceso eficiente a la información por parte de usuarios móviles. La migración de información ofrece la oportunidad de que el usuario móvil siempre pueda accesar al servidor más cercano a el resolviendo algunos de los problemas a los que se enfrentan los usuarios móviles. Sin embargo la migración de información nos lleva a considerar una serie de restricciones que son consecuencia de la movilidad de los usuarios y lás caracterı́sticas de los dispositivos móviles. Los principales problema a los que nos enfrentamos para lograr que la migración de información en un ambiente móvil traiga beneficios a los usuarios son:. 14.
(24) Definir a donde se debe migrar la información. Conocer la ubicación del usuario. Definir polı́ticas para la decidir cuando es conveniente migrar. Conocer las variables que influyen en la decisión de migrar. Establecer un proceso de migración. En este trabajo definiremos un modelo y polı́ticas de migración que nos ayuden a resolver algunos de estos problemas y lograr que la migración de datos sea conveniente para el usuario.. 2.7.1.. Objetivo y solución propuesta. El objetivo de este trabajo es establecer polı́ticas que nos ayuden a decidir cuando se debe realizar la migración de datos, con el propósito de que el usuario obtenga beneficios. Estas polı́ticas están basadas en el análisis de las principales variables que influyen para que la migración sea recomendable. Adicionalmente se propone un modelo para que sea factible mover la información entre los servidores de cache y tener lo más cerca posible la información que el usuario accesa con mayor frecuencia.. 2.8.. Conclusiones. El cómputo móvil es un área con muchos retos y mucho futuro por delante. Existen muchos trabajos y proyectos en esta área enfocados principalmente a minimizar las restricciones que la tecnologı́a móvil tiene actualmente, la idea es proveer a los usuarios de los servicios que necesite, accesar y compartir la información que solicite rápidamente y en cualquier momento sin importar su localización. Uno de los objetivos de este trabajo es brindar un esquema en donde la información pueda moverse a un lugar cercano siguiendo al usuario, pensando que este pueda accesarla fácilmenten y en cualquier momento. En el siguiente capı́tulo se describiran con más detalles los objetivos de este trabajo.. 15.
(25) Capı́tulo 3. Modelo Propuesto y Polı́ticas de Migración de Datos Como se mencionó en el capı́tulo anterior, los dispositivos móviles presentan restricciones que no se tienen en el cómputo tradicional como por ejemplo: Limitaciones en la capacidad de almacenamiento [5]. Fuentes de energı́a [31]. Ancho de banda [8]. Heterogeneidad en las redes a las que se conectan los dispositivos móviles [31]. Además, con fines comerciales los dispositivos móviles son diseñados cada vez más pequeños, ligeros y con llamativos diseños, con el proposito de ser más atractivos para los compradores. Sin embargo esto va creando mayores expectativas a los usuarios, los cuales desean dispositivos con mayores capacidades de almacenamiento, mayor tiempo de vida de la bateria, que puedan obtener información sin interrupciones y conectarse desde lugares poco usuales (la playa, mientras viaja en un tren de una ciudad a otra, etc) donde la infraestructura tecnológica es muy limitada, además los usuarios se mueven de manera impredecible por lo que la información que se encuentra cercana a él podrı́a estar muy distante. Esto nos conduce a idear nuevas soluciones para satisfacer la necesidad de los usuarios de accesar información desde cualquier parte y en todo momento. Es importante considerar que los sistemas y modelos que se enfoquen a la tencologı́a inalámbrica deben tener caracterı́sticas especiales para este entorno y minimizar estas restricciones. Por ejemplo, en [8] se plantean los siguientes patrones que se deben seguir en el diseño de un modelo en un ambiente inalámbrico: Mı́nima dependencia entre el host y el servidor. Dada la relación informal que existe entre los usuarios móviles y los servidores a los que se conectan, las aplicaciones deben ser diseñadas con el mı́nimo acoplamiento entre el mobil host y el servidor. Transparencia en la conexión. El frecuente handoff y las desconexiones resultan en cambios en la conexión entre el usuario móvil y el servidor, posiblemente en el medio de una sesión de una aplicación. Una aplicación en un ambiente móvil debe ser capáz de manejar multiples desconexiones, cada una usando diferentes protocolos. En caso de una desconexión por completo el sistema debe de poder realizar operaciones de desconexión para la aplicación en forma automática. Interacción indirecta. El proceso de entrada de datos y retroalimentación (input/feedback) de la información debe ser hecho lo más cercano posible al mobile host para minimizar el proceso de interacción directa con la lenta y poco confiable conexión inalámbrica. 16.
(26) Figura 3.1: Extended client-server model(tomado de [19]).. Protocolos adaptables de comunicación. Debido a que los hosts se pueden comunicar a redes heterogeneas y con diferentes anchos de banda, los protocolos necesitan adaptarse para proveer máxima usabilidad y facilitar la comunicación. Partición de las aplicaciones. Esto ocurre debido que los dispositivos inalámbricos frecuentemente operan desconectados o con conexiones muy débiles, las aplicaciones deben ser diseñadas para que algunos de sus componentes puedan migrar y correr en el host móvil. Siguiendo estos patrones, en este trabajo se plantea un modelo de servidores de cache en los cuales la información que tiene mayor demanda se mueve automáticamente al servidor que ofrece mejor tiempo de respuesta a las peticiones de un usuario móvil. El modelo podrı́a extenderse para migrar datos con diferentes caracterı́sticas como son: audio, video y datos muy variables. Para este trabajo nos centraremos en el caso particular de acceso a una biblioteca Digital, en donde los datos que son accesados son [23]: Documentos Digitales Busquedas Patrones de busquedas Para los usuarios que accesen a una biblioteca será más conveniente mover esa información a un servidor que se encuentre más cercano a los usuarios. Esto reducirı́a la conectividad al servidor en donde originalmente se encuentre la información y además de reducir el tiempo que los usuarios tardan en conectarse.. 3.1.. Modelo Base. En el cómputo móvil el modelo tradicional Cliente-Servidor se ve afectado por la movilidad de los usuarios a diferencia de un sistema tradicional Cliente-Servidor. Un Servidor es una computadora de escritorio que contiene una copia de una o más bases de datos, y el Cliente es capaz de accesar a la información que se encuentra en cualquier servidor con el que pueda establecer comunicación. Los sistemas tradicionales asumen que la localización y la comunicación entre los clientes y los servidores no cambian. Como resultado, la funcionalidad entre los clientes y los servidores está dividida de manera estática [19]. Por el contrario, en un ámbiente móvil la distinción entre Cliente-Servidor puede ser un poco difusa, en este entorno se tiene en realidad una extensión del modelo Cliente-Servidor, como se muestra en la figura 3.1. Por ejemplo, debido a las limitaciones de los clientes muchas de las operaciones que se ejecutan en el cliente son realizadas por el servidor que tiene muchos más recursos, por otra parte, en algunas ocasiones debido a los problemas de conectividad los clientes tienen que emular la función de un servidor. Ası́, para los clientes 17.
(27) Figura 3.2: Transacción en una arquitectura cliente-servidor flexible(tomado de [19]).. podemos definir dos arquitecturas [19]:. Thin Client Arquitecture. En esta arquitectura las aplicaciones se corren del lado del servidor, el cual se encarga de adaptar y optimizar los resultados para los clientes. Por ejemplo: Las páginas web se optimizan para ser desplegadas en dispositivos móviles como PDA´s ó teléfonos celulares. Full Client Arquitecture. En este caso el cliente emula la funcionalidad de un servidor y ası́ es capaz de minimizar la incertidumbre que ocasiona la comunicación y conectividad entre la red inalámbrica y la convencional. En esta propuesta se esperarı́a que cuando un cliente móvil realiza una búsqueda en una Biblioteca Digital, las transacciones se ejecuten del lado del servidor en donde el servidor de la Biblioteca es el encargado de interactuar con otros repositorios, optimizar los resultados y devolverlos a los usuarios, mientras que los clientes solo contarı́an con una interfaz de usuario en donde pueden ver los resultados de las peticiones que realizaron(Thin Client Arquitecture).. 3.1.1.. Arquitecturas Cliente-Servidor Flexibles. Las arquitecturas cliente-servidor flexibles generalizan las arquitecturas de clientes ligeros y completos, debido a que los roles de los clientes y los servidores y las aplicaciones lógicas pueden ser reacomodadas y ejecutadas en un host móvil o estacionario. En esta arquitectura, la distinción entre clientes y servidores no está bien definida con el propósito de conseguir rendimiento y disponibilidad, un ejemplo es la figura 3.2, en donde se puede observar como una transacción puede llevarse a cabo de lado del cliente o del servidor [19]. Además, la conexión entre los clientes y servidores puede ser establecida dinámicamente durante la ejecución de aplicaciones. Una de estas arquitecturas es conocida como: Movilidad Virtual de los Servidores (Virtual Mobility of servers) [19]. En un sistema de información inalámbrico, los servidores de datos está conectados vı́a redes convencionales para proveer servicios de información a los usuarios. La replicación (o partición) de información puede ayudar a reducir la latencia de operaciones remotas y balancear la carga de trabajo de los servidores en un ambiente de multiples redes distribuidas. La movilidad de los usuarios puede resultar en un largo camino en terminos de comunicación en una red convencional, es decir la distancia de red entre el cliente y el servidor se puede ir incrementando muy rápidamente debido a la movilidad que permiten los dispositivos inalámbricos [19]. Como consecuencia el tráfico y la latencia se van incrementando cuando el cliente desea completar una transacción con el servidor. Si el cliente. 18.
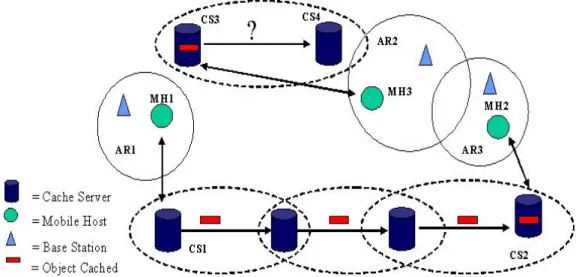
(28) pudiera conectarse a un sitio mas cercano el tráfico y la latencia en la red puede reducirse, mejorando ası́, la continua interacción entre el cliente y el servidor. Ası́ la movilidad de los clientes introducen el concepto de: Movilidad Virtual de los servidores. En base a esta arquitectura flexible de cliente-servidor, el modelo que se propone está basado en la movilidad virtual de la información de tal forma que el cliente móvil, obtenga la información que necesite desde un servidor que esté mas cercano a él, reduciendo el tráfico y la latencia que ocasiona conectarse a un servidor muy lejano.. 3.1.2.. Organización de los Servidores de Cache. En este trabajo se propone un esquema en el cual la infomación que un usuario móvil accesa frecuentemente vaya migrando de un servidor de cache a otro con el objetivo de que esté lo más cerca posible y siempre accesible para los usuarios. El propósito de mover la información es solucionar algunas de las restricciones que la tecnlogı́a inalámbrica presenta, por ejemplo: Se reduce la carga de trabajo para el servidor donde originalmente se encuentran los datos que accesa el usuario. Ahorro de energı́a. El accceso a un servidor que se encuentra muy lejano es uno de los mayores consumidores de energı́a para los dispositivos móviles. Se tiene rápido acceso a una cantidad de información que serı́a muy dificil de almacenar en un dispositivo móvil. Otro de los objetivos de este trabajo es que esto se lleve a cabo de manera transparente al usuario y que la migración de los datos sea siempre al servidor que ofrezca las mejores condiciones para que los dispositivos establezcan una conexión con él. Para esto el servidor que orignalmente contiene la información a migrar debe conocer la ubicación de los MH que le están haciendo peticiones y saber a donde puede migrar. Por otra parte, se podrı́a cuestionar que tan conveniente es mover la información y cuáles son las varibles que influyen para determinar cuándo se debe migrar. Para que un servidor pueda saber la ubicación de los MH que están accesando a él y saber a donde migrar la información, nos basaremos en un un modelo de servidores de cache organizados en grupos de multicast. El proyecto Adaptive Web Caching (AWC) [22, 39], propone un esquema basado en IP Multicast que nos ayuda a resolver el problema de la comunicación entre los servidores. El IP Multicast se distingue principalmente por dos funciones: es la forma más eficiente para enviar los mismos datos a multiples receptores y se puede usar como una forma para descubrir la red por ejemplo: un host que desee hacer una busqueda, puede hacer un multicast a un grupo cuando no sabe exactamente por quien preguntar. Este modelo es la base que permitirá a los servidores de cache migrar la información de un servidor a otro de manera que la información vaya siguiendo al usuario y que esto se realice de manera transparente al usuario móvil. La figura ??, es un ejemplo de como se organizan los servidores para formar grupos. Algunas de las principales caracterı́sticas de la organización de los grupos que propone el proyecto AWC son: Grupos traslapados. Para garantizar la comunicación entre los grupos, un servidor puede pertenecer a más de un grupo. Los grupos son autoconfigurables. Los grupos se ajustan por si solos de acuerdo a los cambios en la topologı́a, la carga de trabajo y el incremento de los usuarios. Protocolo CGMP - El proyecto AWC propone el protocolo CGMP (Cache Group Management Protocol) para administrar los grupos de servidores de cache, es decir mediante este protocolo se decide cómo añadir 19.
(29) Figura 3.3: Organización de de los servidores de cache en el proyecto AWC(tomado de [22]).. o eliminar un elemento en un grupo de servidores. La funcionalidad básica del CGMP es el mantenimiento y la creación de los grupos. Balanceo de la carga de trabajo. Los grupos tienen un tamaño adecuado y se intersectan mediante un solo servidor. Esto es con el objetivo de evitar el incremento del tráfico en la red y la carga extra de trabajo causados por la comunicación entre los miembros de un grupo. Cada integrante conoce el estado del cache y cómo está formado el grupo, ya que periódicamente cada uno realiza un multicast para conocer quiénes conforman el grupo en el que se encuentra y cuales son los grupos más cercanos. En base a este trabajo, la migración de datos puede ser llevada a cabo entre servidores que estén organizados en grupos como lo que se presenta en el proyecto AWC, por lo que supondremos que el problema de la comunicación entre los servidores estarı́a resuelto. Esta organización nos permitirı́a que los servidores sepan a donde migrar y en donde se encuentra el MH que realiza las peticiones. Sin embargo el hecho de que los servidores esten bajo esta estructura no nos garantiza que la migración de dato sea en beneficio de los usuario móviles, por lo que uno de los principales objetivos de este trabajo es analizar las variables que tienen mayor importancia en la migración de datos.. Arquitectura del Cache Como se ha mencionado a lo largo de este trabajo uno de los principales objetivos es que la información esté lo más cerca posible de los usuarios móviles, es decir, que el MH accese al servidor de cache más cercano a él. Para lograr esto debemos tener en cuenta las posibles arquitecturas que existen para diseñar redes con servidores de cache. Las arquitecturas el cache puede estar: Cerca del Consumidor o Cerca del proveedor como se muestra en la figura 3.4. La ubicación del cache se puede clasificar de la siguiente forma [24]:. 20.
(30) Figura 3.4: Ubicación del Cache: cerca del consumidor ó cerca del proveedor(tomada de [6]).. Consumer dedicated - Este tipo de cache está muy cerca del consumidor, de hecho podrı́a decirse que está atado al consumidor. Por ejemplo: Microsoft Internet Explorer y el Netscape Navigator son ejemplos de navegadores web que mantienen en el cache del dispotivo las páginas y URL´s que frecuentemente accesa el usuario. Consumer Shared - En esta arquitectura el cache se ubica aparte del consumidor pero muy cercano a el. Es decir, los servidores de cache están cerca de los usuarios con el propósito de que los usuarios accesen a el y mejoren el rendimiento de las solicitudes que realizan. El proyecto Squid [7] es un ejemplo de esta arquitectura. Reverse Proxy Caching y Transparent Caching - Estas dos arquitecturas se mantienen cerca del proveedor, la única diferencia entre estas dos, es que en Reverse Proxy Caching el consumidor debe ser configurado mientras que en la arquitectura Transparent Caching no es necesario. Ambas se centran en mejorar el rendimiento del proveedor. Ambos son muy útiles en servicios que demandan tiempo de respuesta y en servicios multimedia como: audio y video. Para este trabajo consideraremos solamente el cache en los servidores, el cache en los disposivos y otros aspectos como reemplazo, actualización y administración del cache no serán considerados para este modelo, y podrı́an ser considerados como trabajo futuro. Para este trabajo consideraremos que la arquitectura más adecuada es la del tipo Consumer Shared, ya que esta úbica a los servidores de cache cerca de los consumidores, lo que favorece a los usuarios móviles ya que como se mencionó anteriormente la movilidad de los usuarios puede resultar en un largo camino en terminos de comunicación en una red convencional [19], es decir la distancia de red entre el cliente y el servidor que originalmente contiene la información que el usuario solicita, se puede ir incrementando muy rápidamente debido a la movilidad que permiten los dispositivos inalámbricos. Otro punto importante sobre la información que se quiere tener en cache cuando accesamos a una Biblioteca Digital, es considerar esta información como estática. Esto quiere decir que los datos que se migran entre servidores de cache no cambian frecuentemente, por ejemplo, los documentos de una bibioteca digital como:. 21.
Figure
![Figura 2.1: Sistema Phronesis basado en seis servidores (tomado de [11]).](https://thumb-us.123doks.com/thumbv2/123dok_es/2301799.515768/17.918.202.741.118.466/figura-sistema-phronesis-basado-en-seis-servidores-tomado.webp)

![Figura 2.3: Sistema CODA (Illustraci´ on dise˜ nada por Gaich Muramatsu tomada de [27].)](https://thumb-us.123doks.com/thumbv2/123dok_es/2301799.515768/20.918.313.636.115.424/figura-sistema-coda-illustraci-dise-gaich-muramatsu-tomada.webp)
![Figura 3.1: Extended client-server model(tomado de [19]).](https://thumb-us.123doks.com/thumbv2/123dok_es/2301799.515768/26.918.283.668.116.284/figura-extended-client-server-model-tomado-de.webp)
+7
![Figura 3.2: Transacci´ on en una arquitectura cliente-servidor flexible(tomado de [19]).](https://thumb-us.123doks.com/thumbv2/123dok_es/2301799.515768/27.918.259.685.115.338/figura-transacci-on-arquitectura-cliente-servidor-flexible-tomado.webp)
![Figura 3.3: Organizaci´ on de de los servidores de cache en el proyecto AWC(tomado de [22]).](https://thumb-us.123doks.com/thumbv2/123dok_es/2301799.515768/29.918.207.746.122.445/figura-organizaci-on-servidores-cache-proyecto-awc-tomado.webp)
![Figura 3.4: Ubicaci´ on del Cache: cerca del consumidor ´ o cerca del proveedor(tomada de [6]).](https://thumb-us.123doks.com/thumbv2/123dok_es/2301799.515768/30.918.209.735.129.432/figura-ubicaci-cache-cerca-consumidor-cerca-proveedor-tomada.webp)
![Figura 4.1: NS2 Enviroment (tomado de [28]).](https://thumb-us.123doks.com/thumbv2/123dok_es/2301799.515768/37.918.294.652.382.597/figura-ns-enviroment-tomado-de.webp)

Documento similar
"No porque las dos, que vinieron de Valencia, no merecieran ese favor, pues eran entrambas de tan grande espíritu […] La razón porque no vió Coronas para ellas, sería
dente: algunas decían que doña Leonor, "con muy grand rescelo e miedo que avía del rey don Pedro que nueva- mente regnaba, e de la reyna doña María, su madre del dicho rey,
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
Ciaurriz quien, durante su primer arlo de estancia en Loyola 40 , catalogó sus fondos siguiendo la división previa a la que nos hemos referido; y si esta labor fue de
Las manifestaciones musicales y su organización institucional a lo largo de los siglos XVI al XVIII son aspectos poco conocidos de la cultura alicantina. Analizar el alcance y
A partir de los resultados de este análisis en los que la entrevistadora es la protagonista frente a los entrevistados, la información política veraz, que se supone que
La moral especial (o institucional, la M de G ARZÓN ) parece ofrecer de- masiados pretextos; terminaría por justificar cualquier tipo de acción requerida por ra- zones
Para recibir todos los números de referencia en un solo correo electrónico, es necesario que las solicitudes estén cumplimentadas y sean todos los datos válidos, incluido el
