Integración del Servicio de Minería de Datos al Sistema Multiagente JITIK Edición Única
107
0
0
Texto completo
(2) Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey División de Computación, Información y Comunicaciones Programa de Graduados. Los miembros del comité de tesis recomendamos que la presente tesis de José Marı́a Sánchez Castellanos Barraza sea aceptada como requisito parcial para obtener el grado académico de Maestro en Ciencias, especialidad en: Sistemas Inteligentes. Comité de tesis:. Dr. José Luis Aguirre Cervantes Asesor de la tesis. Dr. Ramón Brena Pinero. Dr. Leonardo Garrido Luna. Sinodal. Sinodal. Dr. David Garza Salazar Director del Programa de Graduados. Mayo de 2004.
(3) Le dedico el presente trabajo a mis papás, mis hermanos y a Lilly..
(4) iv.
(5) Reconocimientos Mi más sincero reconocimiento a mi asesor Dr. José Luis Aguirre, a mis sinodales Dr. Ramón Brena y Dr. Leonardo Garrido, a los miembros del Centro de Sistemas Inteligentes del ITESM y a mis compañeros de maestrı́a.. José Marı́a Sánchez Castellanos Barraza Instituto Tecnológico y de Estudios Superiores de Monterrey Mayo 2004. v.
(6) Integración del Servicio de Minerı́a de Datos al Sistema Multiagente JITIK. José Marı́a Sánchez Castellanos Barraza, M.C. Instituto Tecnológico y de Estudios Superiores de Monterrey, 2004. Asesor de la tesis: Dr. José Luis Aguirre Cervantes. El documento presenta una descripción del trabajo de Tesis realizado para obtener el grado de Maestrı́a en Ciencias en Sistemas Inteligentes. JITIK (Just In Time Information and Knowledge) es un sistema de flujo de información y conocimiento basado en la tecnologı́a de agentes inteligentes. El objetivo de este sistema es apoyar la administración del conocimiento de una organización, encargándose de clasificar y distribuir la información y el conocimiento generados en fuentes relacionadas al sistema, según la relevancia que tenga para los intereses de sus usuarios. En esta tesis se presenta el desarrollo de un agente capaz de aplicar algoritmos de minerı́a de datos a bases de datos indicadas, y determinar si el conocimiento adquirido es relevante a las áreas de interés del sistema, para lo cual consulta una ontologı́a en que se definen estas áreas. Si el conocimiento obtenido está relacionado con dicha ontologı́a, el agente de minerı́a considera que es relevante y lo notifica, cosa que no hace en caso contrario. Con esto se agrega un nuevo servicio a JITIK, el cual le permite extraer información y conocimiento en bases de datos y determinar si le pueden ser relevantes. Por lo anterior se presentan fundamentos teóricos referentes a agentes y minerı́a de datos, ası́ como la comparación de éste trabajo con otros que abordan temas como la aplicación de minerı́a de datos y la distribución de sus resultados con agentes. Además se presentan pruebas del funcionamiento del servicio de minerı́a de datos realizadas sobre bases de datos y los resultados obtenidos..
(7) Índice general. Reconocimientos. V. Resumen. VI. Índice de figuras. XI. Capı́tulo 1. Introducción 1.1. Contexto de la Tesis . . . 1.2. Definición del Problema . 1.3. Trabajo Propuesto . . . . 1.4. Descripción del documento. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. 1 1 3 4 5. Capı́tulo 2. Marco Teórico 2.1. Agentes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2. Sistemas Multiagentes y Comunicación entre Agentes. . . . . . . . . . 2.3. JADE (Java Agent DEvelopment Framework). . . . . . . . . . . . . . 2.4. Distribución de Conocimiento . . . . . . . . . . . . . . . . . . . . . . . 2.5. JITIK y el Flujo de Conocimiento. . . . . . . . . . . . . . . . . . . . . 2.6. Minerı́a de Datos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.6.1. Algoritmo A priori . . . . . . . . . . . . . . . . . . . . . . . . . 2.7. Trabajos Relacionados. . . . . . . . . . . . . . . . . . . . . . . . . . . 2.7.1. Minerı́a de Datos en Rejillas de Información de la NASA . . . . 2.7.2. SCOPES. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.7.3. Automatización del Proceso de Minerı́a de Datos con Agentes . 2.7.4. PArallel Data Mining Agents (PADMA) . . . . . . . . . . . . . 2.7.5. Minerı́a de Datos con Búsqueda de Patrones de Comportamiento. 7 7 8 10 12 13 18 21 22 23 24 25 28 30. Capı́tulo 3. Integración del Servicio de Minerı́a de Datos a 3.1. Ubicación del Minero en JITIK . . . . . . . . . . . . . . . 3.2. Selección de la Herramienta de Minerı́a de Datos . . . . . . 3.3. Selección del Algoritmo para Extraer Patrones . . . . . . . 3.4. Desarrollo del Agente . . . . . . . . . . . . . . . . . . . . .. 33 33 35 36 38. vii. JITIK . . . . . . . . . . . . . . . . . . . .. . . . .. . . . ..
(8) 3.4.1. Análisis de la Aplicación . . . . . . . . . . . . . . 3.4.2. Diseño de la Aplicación . . . . . . . . . . . . . . . 3.4.3. Realización de la Aplicación . . . . . . . . . . . . 3.5. Uso del Servicio de Minerı́a de Datos en una Jerarquı́a de 3.5.1. Uso de los Nodos de la Organización . . . . . . . 3.5.2. Uso de los Nodos de la Organización con el agente 3.6. Implementación . . . . . . . . . . . . . . . . . . . . . . . 3.6.1. Agente de Minerı́a de Datos. . . . . . . . . . . . 3.6.2. Agente de Sitio. . . . . . . . . . . . . . . . . . . 3.7. Ejecuciones en Red . . . . . . . . . . . . . . . . . . . . . 3.7.1. Ejecución en Red 1 . . . . . . . . . . . . . . . . . 3.7.2. Ejecución en Red 2 . . . . . . . . . . . . . . . . . 3.7.3. Conclusiones . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . Organización . . . . . . . . de Sitio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 38 40 42 53 53 54 56 56 58 60 60 60 60. Capı́tulo 4. Pruebas 63 4.1. Objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63 4.1.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63 4.1.2. Diseño de las Pruebas . . . . . . . . . . . . . . . . . . . . . . . 64 4.1.3. Prueba 1: Atributos Definidos como Clases . . . . . . . . . . . . 65 4.1.4. Prueba 2: Atributos Definidos como Propiedades . . . . . . . . . 67 4.1.5. Prueba 3: Atributos Definidos como Instancias . . . . . . . . . . 70 4.1.6. Análisis de Resultados . . . . . . . . . . . . . . . . . . . . . . . 72 4.2. Trabajos Relacionados . . . . . . . . . . . . . . . . . . . . . . . . . . . 73 4.2.1. Minerı́a de Datos en Rejillas de Información de la NASA . . . . 73 4.2.2. SCOPES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74 4.2.3. Propuesta de Automatización del Proceso de Minerı́a de Datos con Agentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74 4.2.4. Parallel Data Mining Agentes (PADMA) . . . . . . . . . . . . . 75 4.2.5. Minerı́a de Datos con Búsqueda de Patrónes de Comportamiento 75 Capı́tulo 5. Conclusiones 5.1. Respecto a los Resultados . . . . . . . . . . . . . . . . . . . . . . . . . 5.2. Respecto a la Aplicabilidad y Generalidad . . . . . . . . . . . . . . . . 5.3. Aportaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.4. Trabajo Futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.4.1. Otros Criterios para Considerar que una Regla Puede ser Relevante. 5.4.2. Explotación de Otros Algoritmos de la Herramienta de Minerı́a de Datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.4.3. Selección de los Datos y Depuración de Resultados . . . . . . . 5.4.4. Tesaurus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . viii. 77 77 78 79 80 80 81 82 82.
(9) Apéndice A. Definición de las Bases de Datos A.1. Base de Datos de Tumores Primarios . . . . . . . . . . . . . . . . . . . A.2. Base de Datos de Decesos por el Corazón . . . . . . . . . . . . . . . . .. 85 85 86. Apéndice B. Instrucciones para Usuarios B.1. Requisitos y Ejecución del Sistema . . . . . . . . . . . . . . . . . . . . B.2. Agregar una Nueva Base de Datos . . . . . . . . . . . . . . . . . . . . . B.3. Formato arff para Bases de Datos . . . . . . . . . . . . . . . . . . . . .. 87 87 89 90. Bibliografı́a. 93. ix.
(10) x.
(11) Índice de figuras. 2.1. GUI de la plataforma para el desarrollo de agentes JADE. . . . . . . . 2.2. En esta figura se muestran los agentes con que el minero debe entablar comunicación. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.3. Arquitectura de JITIK antes de incorporar el servicio de minerı́a de datos. 2.4. La figura muestra el uso del agente de ontologı́as, el cual administra las ontologı́as de JITIK. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.5. árbol de la ontologı́a creado con el editor de ontologias “Oiled”. . . . . 2.6. árbol de la ontologı́a creado con el editor de ontologias “Oiled”. . . . . 2.7. Arquitectura PDMA (PArallel Data Mining Agents) . . . . . . . . . . 3.1. 3.2. 3.3. 3.4. 3.5.. Visión general del agente de minerı́a de Datos. . . . . . . . . . . . . . . Ubicación del Agente de Minerı́a de Datos en la Arquitectura de JITIK. Arquitectura del Agente de Minerı́a de Datos. . . . . . . . . . . . . . . Partición del sistema de minerı́a de datos en esféras de responsabilidad. Partición del sistema de minerı́a de datos en los agentes de la aplicación y los recursos del sistema. . . . . . . . . . . . . . . . . . . . . . . . . . 3.6. El agente minero utiliza la herramienta de minerı́a de datos Weka para extraer conocimiento. . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.7. Información extraı́da del archivo de resultados de la minerı́a de datos. 3.8. Contenido de los mensajes que el agente de minerı́a de datos envı́a al agente de sitio. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.9. Ejemplo del contenido de los mensajes enviados por el agente minero. . 3.10. Ejemplo de la definición del contenido de los mensajes que el agente minero envı́a al agente de sitio. . . . . . . . . . . . . . . . . . . . . . . 3.11. El minero consulta las ontologı́as en que fué definido un atributo obtenido en la minerı́a de datos. . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.12. Envı́o de mensajes al agente de sitio. . . . . . . . . . . . . . . . . . . . 3.13. Árbol de ontologı́a con los nodos de las áreas de Interés. . . . . . . . . 3.14. Ontologı́a de una organización donde se aprecian algunas instancias definidas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.15. Bloques utilizados en las 3 capas del diseño del agente minero. . . . . . xi. 12 14 16 17 18 19 29 34 35 35 39 40 42 43 44 45 47 48 50 52 55 56.
(12) 3.16. Interace del agente de minerı́a de datos. . . . . . . . . . . . . . . . . . 3.17. Bloques utilizados por el agente de sitio. . . . . . . . . . . . . . . . . . 3.18. Figura que muestra las caracterı́sticas de una prueba en red en la que se activo al agente minero y de sitio en una computadora y al agente de ontologı́as en otra diferente. . . . . . . . . . . . . . . . . . . . . . . . . 3.19. Figura que muestra las caracterı́sticas de una prueba en red en la que se activo al agente minero en una computadora y a los agentes de sitio y ontologı́as en otra diferente. . . . . . . . . . . . . . . . . . . . . . . . .. 58 59. 61. 62. 5.1. La herramienta de minerı́a de datos Weka incluye una gran variedad de algoritmos para extracción de conocimiento, de los cuales el minero utiliza hasta el momento solamente el algoritmo a priori, que sirve para hallar reglas de asociación entre los diferentes atributos de una base de datos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 81. B.1. Interfaz gráfica del agente minero . . . . . . . . . . . . . . . . . . . . .. 88. xii.
(13) Capı́tulo 1. Introducción El presente documento muestra el trabajo realizado para construir un agente capaz de obtener conocimiento en bases de datos identificadas como importantes para los usuarios del sistema JITIK (Just In Time Information and Knowledge), y definir a qué áreas dentro de una ontologı́a de intereses, perteneciente al mismo sistema, les resulta relevante este conocimiento.. 1.1.. Contexto de la Tesis. Las organizaciones por naturaleza no son entidades estáticas, son dinámicas y en ellas se genera una gran cantidad de información. Esta información puede ser interpretada y utilizada dentro de la misma organización. En las décadas recientes, una gran cantidad de organizaciones han dedicado un número muy importante de recursos en la construcción y mantenimiento de grandes bases de datos, incluyendo el desarrollo de grandes data ware houses. Debido a su gran tamaño, éstos conjuntos de datos no pueden ser analizados sin el uso de técnicas especializadas, como la minerı́a de datos, por lo que en muchos casos son devaluados, desaprovechados[8], y considerados como una carga debido a los recursos necesarios para mantenerlos. Sin embargo, para las organizaciones puede ser benéfico aprovechar los grandes volúmenes de datos, ya que en ellos puede hallarse conocimiento relevante para resolver un gran número de problemas. La minerı́a de datos se enfoca a la adquisición de conocimiento en bases de datos, que debido a lo descrito anteriormente, es uno de los campos más crecientes en la industria de la computación[8]. Existen muchas tecnologı́as y herramientas disponibles para aplicar minerı́a de datos[8], a las cuales se ha incorporado recientemente el uso de agentes, lo cual resulta innovador, ya que la minerı́a de datos es un proceso iterativo que requiere la intervención directa de un experto, sin embargo se están realizando esfuerzos para que este 1.
(14) proceso se realice en forma automática con sistemas basados en agentes, ya que estos ofrecen una arquitectura adecuada para resolver el problema, que requiere modularidad para que sus diferentes etapas tengan la independencia suficiente, pero al mismo tiempo la capacidad para interactuar entre si. Por otra parte, en organizaciones de gran tamaño es complicado que el conocimiento y la información lleguen a la persona que los necesita, debido a problemas organizacionales o culturales, como pueden ser rigidez, exceso de niveles, burocracia, entre otros[32]. De igual forma si se abruma a un usuario con todo tipo de información, éste perderá el interés en la fuente que se la suministre, ya que estará obligado a invertir buena parte de su tiempo en encontrar lo referente a sus temas de interés, para después leerlo, por lo cual es necesario decidir eficientemente cuál información debe ser notificada. Lo anterior puede solucionarse creando sistemas de información descentralizados, que evitan el excesivo tráfico de información en una red; además en el momento en que un servidor de un sistema descentralizado falla, el mismo sistema ofrece otras alternativas para no interrumpir el aprovechamiento de sus recursos. Sin embargo los sistemas descentralizados tienen otro tipo de inconvenientes, como la ineficiencia en el flujo de conocimiento, ya que este puede ser generado a diversos niveles, provocando que algún otro nivel o sector del sistema quede inadvertido. JITIK ofrece un conjunto de herramientas basadas en agentes cuyo objetivo es distribuir justo a tiempo la información y el conocimiento desarrollado en organizaciones a los usuarios o departamentos interesados en éste, por lo que permite evitar problemas como los antes mencionados. Para lograr esto utiliza la tecnologı́a de sistemas multiagentes, ya que ésta propone interesantes oportunidades para crear sistemas computacionales más flexibles y robustos que los tradicionales. Unido a lo anterior, el software de agentes ofrece una plataforma de tecnologı́a ideal para permitir a los usuarios de una red acceder a los recursos de la misma, personalizar servicios, y combinar el conocimiento que se genere en el sistema, conservando la privacidad y permitiendo la interacción de los usuarios[23]. Para cumplir con su objetivo, JITIK cuenta con varios tipos de agentes, como los personales (que sirven como interfaz entre el usuario y el sistema), el de sitio (que es el agente central, con el cual los demás agentes mantienen comunicación y que se encarga de distribuir el conocimiento a los agentes personales ), el de ontologı́a (encargado de resolver consultas realizadas por otros agentes de JITIK sobre las ontologı́as que modelan el conocimiento del sistema), entre otros. 2.
(15) Una caracterı́stica de JITIK es que sus agentes personales como de servicios se comunican directamente con su respectivo Agente de Sitio. Los agentes de sitio intercambian mensajes para ofrecer en forma transparente a sus usuarios los servicios con que cuenta el sistema. A continuación se describe el problema planteado.. 1.2.. Definición del Problema. JITIK es un sistema multiagente descentralizado que distribuye la información y conocimiento adecuados en el momento adecuado a las personas adecuadas. En ese contexto es relevante contar con una servicio que mantenga informado al usuario sobre los patrones que se pueden extraer de las bases de datos del sistema y que estén relacionados con sus áreas de interés, permitiéndole estar al tanto en forma automática de la nueva información y conocimiento que se generen, sin importar el nivel en que se encuentre dentro de la organización y dejando atrás otros factores que dificultan el flujo de conocimiento. JITIK se basa en la tecnologı́a de agentes inteligentes, por lo que es preciso satisfacer la problemática antes mencionada elaborando un agente, que además de descubrir nuevo conocimiento tenga la capacidad de interactuar con los demás agentes de JITIK, de forma que el agente propuesto pueda utilizar los servicios de distribución de conocimiento que se hallan definidos en el sistema, como lo es el uso de ontologı́as y el importante trabajo que desarrolla el agente de sitio para distribuir el conocimiento a los usuarios. El problema que se propone resolver esta tesis es adquirir conocimiento en bases de datos y determinar si éste conocimiento está relacionado con la ontologı́a de áreas de interés del sistema JITIK , en cuyo caso se considerará que puede ser relevante para algún usuario y que debe notificársele. El siguiente ejemplo hipotético servirá para aclarar la problemática y funcionalidad del servicio que se le agregara a JITIK con el agente de minerı́a de datos: supongamos que al ejecutar al agente minero sobre la base de datos de un hospital descubre que cuando el resultado de un electrocardiograma y la duración de una prueba fı́sica en particular son normales, un paciente no tenderá a tener más de 120mg/dl de azúcar en la sangre. Bajo esta situación, el agente de minerı́a de datos encontrará que lo referente a resultados de un electrocardiograma está relacionado con el tema “corazón”, que ha sido definido como interesante a JITIK, por lo que notificará la regla al agente de sitio. El agente de sitio determinará otros temas que están relacionados con “corazón”, para informar a los agentes personales el patrón descubierto y las áreas a que resulta intere3.
(16) sante, cumpliendo con esto el trabajo del sistema de minerı́a de datos. Posteriormente y según el funcionamiento de JITIK, los agentes personales eligirán los patrones que sean interesantes a su usuario, para de esta forma mantenerlos al tanto de la nueva regla. El papel de JITIK en el ejemplo anterior será, entre otras cosas, descubrir la nueva información que se genere y hacerla llegar a las personas que les sea útil, lo cual permitirá al hospital conocer las noticias que surgen referentes a sus áreas de interés. El sistema de minerı́a de datos deberá descubrir los patrones generados la base de datos indicada y determinar si éstos pueden ser útiles para los usuarios. Se utilizarán técnicas de minerı́a de datos para descubrir la nueva información generada en las bases de datos interesantes a JITIK, ya que estas permiten analizar y explorar grandes volúmenes de datos en busca de reglas o patrones, lo cual solucionarı́a el problema.. 1.3.. Trabajo Propuesto. El objetivo de esta tesis es crear un agente capaz de aplicar técnicas de minerı́a de datos y analizar los resultados de esta minerı́a para verificar si cumplen con rasgos particulares que le permitan clasificarlas como útiles o no para el sistema, y notificarlas únicamente en caso que sı́ lo sean. La implementación de este agente se realizará en JITIK, con el fin de extraer conocimiento de bases de datos que se consideren relevantes. De esta manera se nutrirá al usuario con nuevo conocimiento relacionado con las áreas e intereses que él mismo indique en el sistema. Como hipótesis se plantea que la realización de un agente que aplique técnicas de adquisición de conocimiento en bases de datos y que utilice ontologı́as para determinar la relación de éste conocimiento con áreas de interés, puede extraer conocimiento útil para el sistema y determinar si hay usuarios interesados en el mismo. Se considera que lo anterior le ayudará a JITIK a mantener informados a los usuarios sobre el conocimiento contenido en bases de datos que esté relacionado con sus temas de interés. Para demostrar el funcionamiento de la solución propuesta se realizarán pruebas sobre bases de datos reales que resulten lo más adecuadas posible. El trabajo propuesto tiene limitaciones, ya que no se pretende automatizar el proceso de minerı́a de datos, (que según autores importantes no se puede automatizar, principalmente por ser interactivo[19]) si no crear un mecanismo que extraiga conocimiento de bases de datos e identifique si éste conocimiento puede ser relevante para los usuarios del sistema. También se recomienda analizar en qué momento serı́a más útil activar el servicio de minerı́a y sobre qué bases de datos, ya que para encontrar 4.
(17) nuevos patrones es necesario que existan un número considerable de nuevos registros.. 1.4.. Descripción del documento. El resto del documento está organizado de la siguiente manera: En el Capı́tulo 2 (Marco Teórico) se ofrece una visión general de los temas relacionados con el trabajo que se realizo, ası́ como un panorama del estado actual de la minerı́a de datos y distribución de conocimiento con agentes, presentando trabajos realizados en que se abarca algún problema similar a los tratados en esta tesis. En el Capı́tulo 3 (Integración del Servicio de Minerı́a de Datos a JITIK) se describe la ubicación del agente de minerı́a de datos en el sistema JITIK, la herramienta que se utilizó para aplicar las técnicas de minerı́a, el algoritmo elegido para hallar patrones en las bases de datos, ası́ como el diseño del agente y el servicio incorporado a JITIK. Ası́ mismo se describen las decisiones importantes hechas en lo referente a la implementación. El Capı́tulo 4 (Pruebas) describe casos en que es aplicado el servicio de minerı́a a bases de datos reales, mostrando los resultados que se obtienen. El Capı́tulo 5 (Conclusiones) comenta respecto a la aplicabilidad y generalidad del servicio de minerı́a, su capacidad de expansión y algunas propuestas para trabajo futuro.. 5.
(18) 6.
(19) Capı́tulo 2. Marco Teórico En el presente capı́tulo se analizarán algunos temas relacionados con el trabajo que se realizó, como lo son distribución de conocimiento, sistemas multiagentes, el sistema JITIK, la herramienta para desarrollo de agentes JADE y técnicas de minerı́a de datos.. 2.1.. Agentes.. El concepto de agente fue introducido como resultado de la activa investigación de la Inteligencia Artificial Distribuida[12]. Un agente puede ser definido como una entidad independiente y completa en sı́ misma, implementada en hardware, software, o una mezcla de ambas, que es situada en un ambiente y que tiene la capacidad de realizar acciones autónomas que la lleven a lograr sus metas. A esta definición se le añade la propiedad de comunicación, potenciada por la aparición de lenguajes de comunicación entre agentesLos agentes difieren del software tradicional en el hecho que son personalizados, autónomos o semiautónomos y se ejecutan en forma continua[22]. Las siguientes capacidades pueden ser esperadas de un agente inteligente[34]: Reactividad. Los agentes inteligentes tienen la capacidad de percibir el ambiente y reaccionar en el momento adecuado a sus cambios, con el objeto de satisfacer sus necesidades, que son definidas según su diseño. Proactividad. Los agentes inteligentes tienen la capacidad de exhibir comportamientos orientados a metas, tomando la iniciativa con el objetivo de satisfacer sus necesidades. Habilidad Social. Los agentes inteligentes tienen la capacidad de interactuar con otros agentes (y en ocasiones con humanos) para satisfacer sus necesidades. Un agente inteligente debe tener cierto nivel de racionalidad, es decir llevar a cabo la acción más satisfactoria ante una situación determinada, de la cual toma información con sensores o alguna otra forma que le permite percibir lo que sucede en su 7.
(20) entorno[25]. Para saber cuál es la acción más satisfactoria el agente necesita tener una forma de medir los resultados de sus acciones. Los agentes implementados en software reciben en ocasiones el nombre de softbots, y pueden presentarse en una mayor variedad de dominios que los agentes implementados en hardware. Para efectos del trabajo de tesis descrito en este documento, el agente es implementado en software debido al entorno de acción de JITIK. Existen principalmente dos tipos de agentes, según la forma como se construya. Estos pueden ser de arquitectura reactiva, como lo son los agentes reactivos y agentes con representación del mundo; y arquitectura deliberativa, como los agentes basados en metas o los basados en utilidad. Los agentes de arquitectura reactiva utilizan razonamiento explı́cito sobre los efectos producidos por acciones de bajo nivel, mientras que los agentes de arquitectura deliberativa expresan su comportamiento y ambiente en términos de conocimiento representado simbólicamente utilizando mecanismos deductivos para tomar decisiones. El agente de minerı́a de datos utiliza ambos tipos de razonamiento, reactivo para aplicar técnicas de minerı́a a las bases de datos, ya que reaccionará directamente después de recibir la notificación de iniciar el servicio de minerı́a sobre una base de datos en particular; y deliberativo para identificar las clases interesadas en el conocimiento extraı́do, ya que primero deberá verificar las clases relacionadas con los resultados. Los agentes pueden agruparse en sistemas multiagentes, formando arquitecturas en forma conveniente para la realización de una tarea en particular.. 2.2.. Sistemas Multiagentes y Comunicación entre Agentes.. Un Sistema Multiagente es aquel en que varios agentes interactúan entre sı́, persiguiendo un conjunto de metas o realizando un grupo de tareas[11]. Un patrón determinante en la interacción en sistemas multiagente es la coordinación orientada a metas o a tareas, tanto en situaciones cooperativas como competitivas. En el caso de cooperación, todos los agentes tratan de combinar sus esfuerzos para lograr en grupo lo que individualmente no pueden[11]. Los sistemas multiagente ofrecen modularidad. Si el dominio de un problema es particularmente complejo o impredecible, la forma más razonable de enfrentarlo es dividirlo en un número de componentes modulares (cada componente modelado en un 8.
(21) agente) que se especialicen en resolver un aspecto especı́fico del problema. Esta separación permite a cada agente utilizar el paradigma más apropiado para resolver su propia situación[23]. Las caracterı́sticas de los Sistemas Multiagentes son: (1) Cada Agente tiene conocimiento o capacidades insuficientes para resolver los problemas, por lo cual, tiene una visión limitada. (2) No hay un control global del sistema. (3) Los datos son descentralizados. (4) La computación es ası́ncrona. Para el correcto funcionamiento de un sistema multiagente es necesario diseñar agentes capaces de interactuar y coordinarse entre si, lo que permite que tareas complejas puedan dividirse en módulos y resolverse en conjunto. Para lograr esta coordinación es necesario contar con una forma de comunicación. La comunicación entre agentes es un requisito necesario para que un agente se considere inteligente. La compartición del conocimiento debe incluir la capacidad de los agentes de entender el conocimiento compartido. Al proceso de compartir dicho conocimiento se le llama conversación, que a menudo sigue una serie de patrones preestablecidos. Estos patrones se definen como secuencias de intercambio de mensajes, a las que también se les llama protocolos de comunicación. Existen varios protocolos de comunicación entre agentes, entre los cuales puede encontrarse FIPA, el cual es un estandard para la ı́nter operación de software de agentes heterogéneos, producido por “The Foundation for Intelligent Physical Agents”[15]. Utilizar los protocolos FIPA presenta ventajas, ya que los actos comunicativos son claros y concisos, además que por haber nacido en un ámbito industrial se espera que tenga mayor repercusión en los próximos años que otros protocolos como KQML (Knowlege Manipulation Query Language). El trabajo de estandarización de la organización FIPA se encuentra en la dirección de permitir una fácil operación entre sistemas de agentes, pues más allá de ser un lenguaje, especifica las claves necesarias para la administración de un sistema de agentes y de la ontologı́a necesaria para la interacción entre sistemas[33]. El lenguaje de comunicación entre agentes (ACL, Agent Communication Language) se caracteriza por ser un lenguaje declarativo basado en el intercambio de actos comunicativos de alto nivel. Estos permiten al receptor del mensaje interpretar su contenido, posibilitando de este modo el intercambio de conocimiento entre agentes en tiempo real y su cooperación en la resolución conjunta de problemas. Existen métodos para el diseño y elaboración de sistemas multiagente, como el Sistema de Agentes Dinámico[6], GAIA[35], MaSE[27], la metodologı́a de la herramienta Zeus, entre otras. Para el diseño del servicio de minerı́a se utiliza la metodologı́a de Zeus, ya que ofrece una guı́a adecuada para plantear el problema, descomponerlo en partes y plantear su solución con agentes. 9.
(22) La metodologı́a de Zeus consiste de las siguientes etapas [24]: 1. Análisis del dominio. El propósito de esta etapa es modelar y entender el problema de la aplicación, para lo que se recomienda realizar un análisis de roles, donde los roles de los agentes y de los modelos proveen un vocabulario para describir los sistemas multiagente. En éste análisis, cada rol de agente describe una posición y un grupo de responsabilidades en el rol del modelo. El objetivo de utilizar modelado de roles es pensar en el problema en términos de los roles necesarios y las responsabilidades asociadas a cada rol. Para identificar los roles que deben ser desempeñados por cada agente, se recomiendan las siguientes métricas: Prueba de esfera de responsabilidad. Se deriva del hecho de que los agentes deben ser autónomos, por ejemplo, responsables de controlar sus recursos y proveer servicios. Prueba de punto de interacción. El objetivo de ésta prueba es identificar los recursos con que los agentes interactuarán. 2. Diseño de los agentes. Al momento en que el proceso de diseño inicia, el desarrollador debe conocer los agentes que estarán presentes y las responsabilidades que estos cumplirán. Esta etapa involucra el paso de los roles identificados durante la etapa anterior a los problemas a nivel de agentes que éstos representan. 3. Realización de los agentes. El objetivo de ésta etapa es realizar la implementación de los diseños conceptuales creados durante las etapas anteriores. 4. Soporte de ejecución. Esta etapa considera la ejecución de los agentes, su prueba y optimización.. 2.3.. JADE (Java Agent DEvelopment Framework).. Debido a la evolución y crecimiento que han tenido los sistemas de agentes, se han desarrollado plataformas especializadas para su creación, como la que tiene por nombre Jade. El sistema multiagente JITIK ha sido desarrollado con la plataforma JADE, que es un software creado en el lenguaje de programación Java y que se especializa en el desarrollo de agentes; en ésta plataforma se desarrollará también el servicio de minerı́a de datos. La meta de JADE es la de facilitar la construcción de sistemas multiagente, de acuerdo a los estándares establecidos por FIPA, apoyándose en un grupo de servicios, entre los cuales se encuentran el de “Yellow Pages” (que permite a los agentes conocer 10.
(23) los servicios que ofrecen los demás agentes que se hallen en el contenedor), transporte de mensajes (lo cual permite enviar mensajes de una forma más sencilla), servicio de “parsing” y el de bibliotecas de protocolos de FIPA, que permite a los agentes utilizar este protocolo de comunicación. Los mensajes que son enviados por un agente desarrollado en JADE pueden contener varios parámetros, como lo son el contenido, el tipo de mensaje, el destinatario, entre otros, además de permitirle al usuario definir nuevos parámetros, que pueden utilizarse entre otras cosas para indicar el tipo de agente que está enviando el mensaje. Esta plataforma utiliza un modelo de agente y una implementación en Java que ofrecen una buena eficiencia en su ejecución y en el reuso de software. El modelo de agente es más primitivo que los modelos ofrecidos por otras herramientas[33], lo cual permite que sea implementado desde las etapas más básicas del diseño. JADE intenta optimizar el desempeño de un sistema de agentes distribuido[33], para lo que es implementado con el leguaje de programación Java. Consta básicamente de un grupo de clases que pueden ser utilizadas para crear agentes, contiene herramientas para depurar código y una interfase de desarrollo, además cumple con las especificaciones de FIPA. Gracias a su implementación en Java, la plataforma de agente JADE utiliza la máquina virtual de este lenguaje, lo cual la hace multiplataforma y puede estar distribuida en computadoras que no tengan necesariamente el mismo sistema operativo y la configuración puede ser controlada mediante una interfaz gráfica para el usuario, además de poder ser modificada incluso al trasladar agentes de una computadora a otra, según se requiera. La plataforma JADE provee una interfaz gráfica para el usuario (GUI) para la administración remota, el monitoreo y el control de los estados de los agentes. En la Figura 2.1 se muestra la GUI, donde pueden apreciarse los iconos de las funciones principales que pueden ser desarrolladas desde la interfase, como lo son iniciar un nuevo agente, finalizar un agente previamente iniciado, clonar o crear una copia de un agente, entre otras; ası́ mismo puede observarse el árbol que muestra las plataformas que han sido activadas. El cuerpo de un agente realizado con librerı́as de JADE tiene bloques con función especı́fica. Uno de estos bloques es el Setup, en el cual se especifican las inicializaciones del agente, es decir, el estado inicial de este antes de realizar sus tareas. Otro bloque importante es el Action o de acción, en el cual se especifican las tareas que realizará el agente durante su ejecución. Ası́ mismo pueden definirse bloques de diferentes tipos de 11.
(24) Figura 2.1: GUI de la plataforma para el desarrollo de agentes JADE.. comportamientos. Los comportamientos de JADE son a fin de cuentas métodos que se activarán al llamarlos, y cuyo objetivo es definir lo que el agente debe hacer en un momento dado. Hay varios tipos de comportamientos, cada uno con caracterı́sticas particulares, como lo son el comportamiento SimpleBehaviour, que se ejecuta una ocasión, y después evalúa su estado (terminado o no terminado), especificado en el método “done”; otro comportamiento es el OneShotBehaviour, que se ejecuta solamente una ocasión, a diferencia del CyclicBehaviour que se ejecuta en repetidas ocasiones. Existen más comportamientos, que pueden ser consultados en la documentación respectiva de la plataforma JADE.. 2.4.. Distribución de Conocimiento. La administración del conocimiento (“Knowledge Management”) es la forma en que las organizaciones crean, capturan y utilizan el conocimiento para lograr sus objetivos. Es considerada como parte clave para usar el ”expertise”de una organización en la creación de una ventaja competitiva sustentable para el ambiente que existirá en el futuro del negocio. El conocimiento debe ser distribuido activamente a aquellos miembros de la organización que puedan hacer uso de él. La rapidez con que el conocimiento sea distribuido es cada vez más crucial para la competitividad de una compañı́a[14]. Para respaldar este proceso es necesario contar con un sistema capaz de decidir quién debe ser informado 12.
(25) sobre una nueva pieza de conocimiento en particular. En la referencia [7] se propone un proceso de ocho etapas para la administración del conocimiento: identificar, recolectar, seleccionar, mostrar, compartir, aplicar, crear y vender. En este contexto, el agente de minerı́a se halla dentro de las etapas de recolectar, seleccionar y compartir. El objetivo de recolectar conocimiento es adquirir el conocimiento existente, habilidades, teorı́as, y experiencia necesarias para crear las competencias y conocimiento que se identifiquen como necesarios en la organización. Para recolectar el conocimiento de la organización hay que identificar las fuentes de conocimiento que se tengan disponibles, las cuales pueden ser bases de datos, publicaciones, expertos, inteligencia competitiva, activos de la organización, etc. Para motivos del trabajo descrito en el presente documento se seleccionó como fuente de conocimiento a las bases de datos. La etapa de selección se encarga de decidir cuál conocimiento es importante para los fines de la organización; funciona como un filtro para evitar que los usuarios tengan acceso a conocimiento irrelevante, innecesario o confidencial. La etapa de compartir y distribuir retribuye a los usuarios el conocimiento del sistema y lo hace accesible a ellos. La fuerza laboral informa sobre sus necesidades e intereses personales al sistema, el cuál se encarga automáticamente de hacer llegar conocimiento a sus “subscriptores” [7]. El servicio de minerı́a de datos está involucrado con las etapas de recolectar, ya que adquiere el conocimiento contenido en bases de datos; seleccionar, debido a que notifica solamente el conocimiento relevante a los usuarios de JITIK; y compartir, ya que distribuye los resultados a los usuarios. Para lograr lo anterior, el agente minero utiliza los servicios de los agentes de sitio y de ontologı́a, ya existentes en el sistema JITIK, según se muestra en la figura 2.2.. 2.5.. JITIK y el Flujo de Conocimiento.. En organizaciones grandes y distribuidas, es muy difı́cil tener a todos sus miembros informados de los eventos, polı́ticas, compromisos, etc., ası́ como compartir el valioso conocimiento que se genera a través de la práctica[5]. Incluso los medios electrónicos disponibles, tales como el “e-mail” son insuficientes para satisfacer cabalmente las necesidades de difusión de información, pues el e-mail no permite ajustar de manera flexible el conjunto de destinatarios de un mensaje. Por ejemplo, si se quieren mandar avisos a los alumnos de dos carrera en particular que estén próximos a graduarse, seguramente no habrá “listas de correo” que se adapten exactamente a esta situación, por lo que será necesario repartir el aviso a todos los 13.
(26) Figura 2.2: En esta figura se muestran los agentes con que el minero debe entablar comunicación.. alumnos de una carrera (suponiendo que se cuenta con listas de correo), y después a los de la otra carrera, sin diferenciar si podrı́an o no graduarse, por lo que el mensaje serı́a recibido por muchos alumnos a los que no deberı́a llegar[5]. En ocasiones, el conocimiento y la información no llega a la persona que la necesita debido a problemas organizacionales o culturales, como lo son rigidez, exceso de niveles, burocracia, prejuicios, entre otros; el resultado de esto es que la distribución de conocimiento e información en organizaciones grandes y distribuidas no es un problema sencillo[32]. El trabajo de investigación se realizará dentro de JITIK, el cual es un sistema descentralizado basado en la tecnologı́a de sistemas multiagente. JITIK es un sistema de agentes cooperativos que nace del proyecto CORREARICA, cuyo objetivo era apoyar el trabajo realizado por los investigadores de México o por instituciones distribuidas geográfica o lógicamente, proporcionando un conjunto de herramientas que les permitieran mantener un eficiente flujo de información y conocimiento[5]. El proyecto CORREA (COoRdinación de Recursos de Educación e investigación mediante Agentes), que después se convertirı́a en JITIK, originalmente estaba planteado como un proyecto para facilitar la coordinación de los campus del sistema ITESM, pero que, dada la participación de CORREA en la REDII del CONACyT, se reorientó a desarrollar herramientas informáticas avanzadas para la coordinación de los grupos de investigación en computación del paı́s[1]. El propósito de este proyecto fue entonces construir herramientas basadas en la comunicación entre agentes que brinden servicios de apoyo a la interacción e integración de los grupos de investigadores en computación. 14.
(27) Actualmente se ha definido la acción de JITIK como una herramienta para la administración del conocimiento que le da a éste un flujo adecuado, para lo cual se le están incorporando nuevos servicios con el objetivo de cubrir ampliamente las necesidades de los usuarios. Debido a la computarización de los negocios, las compañı́as se han enfocado a automatizar sus tareas, usualmente con software que cumple especialmente con este propósito. Las actividades como registro de inventario, transacciones, direccionamiento de las relaciones de negocios han tendido a ser automatizadas. Ya que esta automatización ha sido inicializada a nivel de divisiones individuales, es común que las diferentes bases de datos en las organizaciones contengan solamente información parcial. Esta es una situación infortunada ya que la duplicación y el mantenimiento separado de datos puede llevar a inconsistencias, y como resultado de esto, a acciones erróneas y no coordinadas entre sı́[14]. El objetivo de JITIK, dentro de sus funciones como administrador del conocimiento, es prever este tipo de problemas, dándole a la información y conocimiento un flujo adecuado. Un ejemplo de la aplicación de JITIK en una empresa puede apreciarse en el campo de la Inteligencia Competitiva. En el marco de un mercado global, es importante que los gerentes estén conscientes de lo que estén haciendo los competidores en la misma industria en el mundo. Los gerentes de un área especı́fica o gerentes generales en situaciones particulares necesitan obtener información relacionada con sus actividades. JITIK puede suministrar información especı́fica sobre un punto en particular referente a los competidores, distribuyéndola a cada persona de acuerdo con las áreas, responsabilidades o preferencias que estas hayan expresado en la especificación del usuario del sistema. La información puede ser obtenida de fuentes externas, utilizando las facilidades de monitoreo de JITIK[32]. La arquitectura de JITIK, que se muestra en la figura 2.3, contempla varios agentes, entre los que están el agente de sitio, el de ontologı́as, el monitor y el agente puente, estos dos últimos encargados de proveer un servicio particular al sistema. Con el trabajo de esta tesis se incorporará un nuevo servicio y con ello un nuevo agente, encargado de extraer conocimiento de bases de datos y descubrir si es interesante a los usuarios de JITIK. Excluyendo a los agentes de sitio y de ontologı́a, los demás agentes de JITIK tienen un objetivo particular que no está relacionado con el servicio de minerı́a. El agente principal de JITIK es el de sitio, con el cual entablan comunicación los demás agentes, además de ser el encargado de distribuir el conocimiento a los agentes personales, que son a su vez la interfase del sistema con el usuario, según se comenta en 15.
(28) la siguiente sección. El agente de ontologı́a se encarga de resolver consultas realizadas por los demás agentes, referentes precisamente a la ontologı́a de JITIK, lo cual también se describe más adelante.. Figura 2.3: Arquitectura de JITIK antes de incorporar el servicio de minerı́a de datos.. Agente de Sitio El “sitio” es el agente central de cada célula de JITIK[9]. Cumple diversas funciones, como servir de intermediario entre los agentes de los usuarios (llamados agentes personales) y los agentes que ofrecen los demás servicios. El agente de sitio es también el encargado de enviar los mensajes a los agentes personales, lo cual hace con diversos mecanismos que hacen llegar la información a diferentes usuarios, dependiendo del tipo de mensaje que esté enviando, teniendo de esta forma mensajes de área (que son enviados a los agentes personales de los usuarios interesados en un área en particular), personales (que son enviados de un usuario a otro), entre otros. El agente de sitio será también el encargado de hacer llegar los mensajes del servicio de minerı́a de datos.. Agente de Ontologı́as JITIK cuenta con un agente encargado de administrar las ontologı́as, cuyo nombre es precisamente “agente de ontologı́as”[10]. El objetivo de este agente es ofrecer un servicio de información sobre las ontologı́as que se hallen definidas en JITIK, permitiendo que los demás agentes tengan acceso a ellas por medio de consultas. De esta forma un agente puede, entre otras cosas, obtener conocimiento especı́fico sobre la organización.. 16.
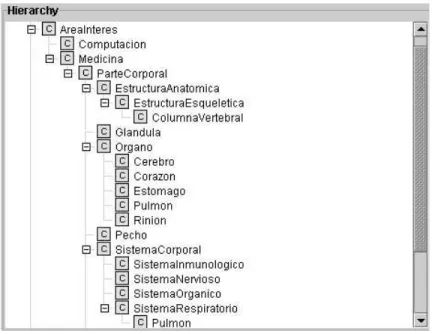
(29) El agente de ontologı́a proporciona información especı́fica sobre las ontologı́as que tenga registradas, por lo que toda la información referente a la organización que un agente necesite saber debe hallarse definida. Además, esta información debe ser accesible por medio de consultas, ya que es de esta forma que los demás agentes se comunican con el de ontologı́a; por lo tanto, si un agente requiere saber las superclases de una clase en particular, o cualquier otro hecho, deberá hacer la consulta pertinente al agente de ontologı́a, lo cual se ilustra en la figura 2.4.. Ontologı́a de JITIK JITIK cuenta hasta el momento con dos jerarquı́as dentro de su ontologı́a, la de áreas de interés y la de la organización, lo cual se comenta a continuación.. Figura 2.4: La figura muestra el uso del agente de ontologı́as, el cual administra las ontologı́as de JITIK.. Una parte prevista actualmente en la ontologı́a de JITIK es la de áreas de interés, donde se definen las áreas que pueden ser relevantes para la organización, ası́ como los usuarios que se interesan en algún área particular y los conceptos que corresponden a cada área. Un ejemplo de jerarquı́a de áreas de interés se muestra en la figura 2.5, donde se definen clases del dominio medico. Otra parte de la ontologı́a de JITIK es referente a la organización, y representa la estructura de la misma, según se aprecia en la figura 2.6. Los nodos correspondientes a esta ontologı́a deben ser definidos de forma que representen la parte conveniente del conocimiento de la organización en que el sistema se haga operar. Esta jerarquı́a tienen como objetivo permitir a los agentes determinar a que usuarios se les debe hacer llegar información referente a la organización. 17.
(30) Figura 2.5: árbol de la ontologı́a creado con el editor de ontologias “Oiled”.. Descripción del Uso de la Ontologı́a Cualquier agente que requiera hacer uso de la ontologı́a deberá contener los métodos que definan tanto las consultas a utilizar como el código adecuado para recuperar el contenido de las respuestas, agregando de esta forma una capa para el manejo de las ontologı́as. Es conveniente definir lo anterior en comportamientos, de forma que el agente los pueda seleccionar según lo requiera, ya que en muchas ocasiones será necesario hacer varias consultas en forma consecutiva antes de obtener la información que se busca.. 2.6.. Minerı́a de Datos.. El descubrimiento de conocimiento y la minerı́a de datos pueden generalizar, inducir y transformar casos, o porciones de casos, en reglas útiles. Capturar conocimiento requiere capturar información sobre cada componente del sistema, y posiblemente sobre cómo estos interactúan[7]. Uno de los conceptos más recientes y excitantes sobre el descubrimiento de nuevo conocimiento es la fusión de técnicas de los campos de la estadı́stica, análisis exploratorio de datos, procesamiento analı́tico en lı́nea, modelado causal, y aprendizaje automático[3]. De acuerdo con autores importantes como Fayyad, Piatetsky-Shapiro, y Smyth , el descubrimiento de conocimiento en bases de datos (Knowledge Discovery in 18.
(31) Figura 2.6: árbol de la ontologı́a creado con el editor de ontologias “Oiled”.. Databases, KDD) es el proceso de identificar patrones de datos válidos, novedosos, potencialmente útiles y ultimadamente inentendibles, ya que en ocasiones no son de fácil interpretación o se llega al caso en que se descubren patrones que no se pueden entender. KDD es un proceso multi etapas que envuelve la selección de datos, su preprocesamiento, transformación, minerı́a y su interpretación/evaluación. El proceso KDD es interactivo e iterativo con decisiones del usuario. La Minerı́a de Datos es el corazón de los procesos KDD, es el acondicionamiento de los modelos o la determinación de la forma de los patrones de los datos observados. Las metas primarias de la Minerı́a de Datos son la descripción y predicción del dominio de los datos que se encuentren disponibles. La Minerı́a de Datos puede verse como un proceso de alto nivel consistente de cuatro procesos principales[19]: Identificar el Problema Transformar los datos en resultados utilizables Actuar sobre los resultados Medir los resultados. 19.
(32) La minerı́a de datos ofrece técnicas que permiten descubrir patrones, información y conocimiento contenidos en bases de datos[19], lo cual es una de las tareas claves dentro del trabajo que debe realizar el agente que se desarrollará en esta tesis. La minerı́a de datos desarrolla las siguientes tareas: Clasificación: Consiste en examinar las caracterı́sticas de un nuevo objeto y asignarlo a una clase predefinida de objetos. Estimación: se utiliza para determinar el valor de alguna variable continua. Predicción: la tarea de predicción consiste en clasificar una variable según el comportamiento que se estima tendrá en un futuro; Agrupación Afin o Reglas de Asociación: determina que cosas deben ir juntas; Agrupación o Clustering: es la tarea de segmentar un grupo diverso dentro de subgrupos similares o clusters; Descripción y Visualización: es utilizada en las ocasiones en que el objetivo de la minerı́a de datos es describir el comportamiento de una base de datos complicada.. Las primeras dos tareas son ejemplos de minerı́a de datos directa, como lo puede ser también la tercera. En minerı́a de datos directa la meta es usar los datos disponibles para crear un modelo que describa una variable de interés en particular en términos del resto de las variables de los datos. Las últimas tres tareas son ejemplos de Minerı́a de Datos indirecta, en la cual no hay una variable como objetivo; la meta es establecer alguna relación no trivial entre diferentes variables. Para el presente trabajo de tesis se utiliza el algoritmo a priori, que pertenece al grupo de agrupación afı́n y reglas de asociación. En minerı́a de datos se considera en general que tener más datos es mejor. Además es importante verificar que los datos cumplan los requisitos para resolver el problema. Para el caso de este trabajo, se pretende hallar resultados sobre cualquier tema que sea relevante para los usuarios, por lo que es adecuado utilizar reglas de minerı́a de datos indirecta considerándose como completos a aquellos que contengan toda la información requerida para obtener los resultados correctos. Existen un buen número de herramientas para aplicar minerı́a de datos, entre las que está Weka, que es desarrollada por la Universidad de Waikato, Nueva Zelanda, y tiene como objetivo poner al servicio de la investigación la implementación de un gran número de algoritmos para analizar bases de datos, como son los clasificadores ZeroR, 20.
(33) Bayesiano simple, tablas de decisión, árboles de decisión, algoritmo a priori, entre otros. De igual manera Weka permite al usuario probar sus propios algoritmos, para lo que implementa programas que miden la confiabilidad de los resultados, como lo son matriz de confusión, validación cruzada, probabilidades, entre otros. Hay además varios métodos de Minerı́a de Datos: árboles y reglas de Decisión. Regresión no Lineal y Reglas de Clasificación. Métodos Basados en Ejemplos. Modelos de Dependencia Probabilı́stica Gráfica. Métodos Relacionados al Aprendizaje. A continuación se explicará el funcionamiento del algoritmo a priori, ya que es utilizado por el agente de minerı́a de datos.. 2.6.1.. Algoritmo A priori. El algoritmo a pirori [29] surgió considerando el problema de obtener reglas de asociación en bases de datos de gran tamaño[28], y es fundamentalmente diferente de los algoritmos conocidos. Este algoritmo ofrece como resultado las probabilidades a priori halladas en una base de datos, lo cual indica la probabilidad de que se de un hecho dado que se han dado otros hechos. Este algoritmo se basa en que si un grupo de atributos A no tiene el soporte adecuado, cualquier superconjunto de A tampoco lo tendrá, y por consecuencia, cualquier esfuerzo por calcular el soporte de alguno de esos superconjuntos es en vano. Otros algoritmos para descubrir grandes conjuntos de elementos requieren hacer multiples pasadas en la base de datos. En la primer pasada se contabiliza el soporte para elementos individuales y se determina cual es grande (p.e. el que tiene el soporte mı́nimo). En las pasadas siguientes, se inicia con un grupo de conjuntos que en la pasada anterior se determinó podrı́an ser considerados como grandes. Este grupo se usa para generar nuevos conjuntos de elementos potencialmente grandes, llamados conjuntos candidatos, y se contabiliza el soporte actual de cada uno de esos conjuntos candidatos durante la pasada sobre la base de datos. El algoritmo a priori difiere fundamentalmente de los algoritmos AIS (Asociation Intem Sets, es un algoritmo que encuentra todas las reglas de asociación significativas entre los elementos de una base de datos)[30] y SETM (llamado también Set Minning, 21.
(34) es un algoritmo que puede ser expresado como consultas del lenguaje estándar de bases de datos SQL)[17] en términos de qué conjuntos son contados en una pasada y en la forma en que los candidatos son generados. En AIS y SETM los conjuntos candidatos son generados “al vuelo”, según los datos son leı́dos. Especı́ficamente, después de leer una transacción se determina cual de los conjuntos hallados como grandes en la pasada anterior están presentes en la actual transacción. Los nuevos conjuntos candidatos son generados extendiendo estos conjuntos grandes con otros elementos de la transacción. Sin embargo, como se puede ver, la desventaja es que para obtener los resultados se generan y cuentan muchos conjuntos candidatos que finalmente serán pequeños, y por lo tanto no relevantes[28]. El algoritmo a priori genera los conjuntos de candidatos que serán contados en una pasada utilizando solo los conjuntos determinados como grandes en la pasada previa, sin considerar las transacciones en la base de datos. La intuición básica es que cualquier subconjunto de un conjunto grande debe ser grande. De esta forma, los conjuntos candidatos teniendo k elementos pueden ser generados reuniendo grandes conjuntos con k-1 elementos, y borrando aquellos que contienen cualquier subconjunto que no sea grande. Este procedimiento resulta en la generación de un número de conjuntos candidatos mucho menor que los otros algoritmos. La herramienta de minerı́a de datos Weka incluye, además de otros algoritmos, una implementación del algoritmo a priori con el fin de obtener reglas de asociación. Esta implementación ofrece por default las 10 mejores reglas que tengan confidencia mı́nima de 0.9[16].. 2.7.. Trabajos Relacionados.. Anteriormente han sido realizados sistemas en los que fue necesario proponer soluciones a problemas similares a los que se abarcan en la integración del agente minero a JITIK. Esta sección muestra trabajos en que se abordó una temática similar a la de la tesis. Los trabajos mencionados a continuación permitirán tener una idea más clara sobre aplicaciones para las que se han desarrollado sistemas que pretenden automatizar algunas etapas del proceso de adquisición de conocimiento en bases de datos y cómo se han hecho, ası́ como la aportación que los sistemas de agentes han hecho al área.. 22.
(35) 2.7.1.. Minerı́a de Datos en Rejillas de Información de la NASA. El documento en cuestión [26] describe el desarrollo de un sistema de minerı́a de datos para operar en “NASA Information Power Grid (IPG)”. Los agentes de minerı́a son posicionados a uno o más procesadores en el “IPG”. Estos agentes crecen adquiriendo nuevas operaciones “just in time”. El objetivo de este sistema es minar datos sensados en forma remota por un satélite, que es caracterizado por su potencial volúmen de datos. Escenario El usuario debe especificar lo que será minado, ası́ como la forma en que será minado y dónde. El cómo se especifica mostrando el nombre de las localidades de la rejilla de un grupo de datos asociados al minero IPG. Estos son comunicados al agente minero a través de la rejilla. El usuario especifica la forma en que los datos serán minados indicando un plan que enlista la secuencia de las operaciones que serán aplicadas a los datos, ası́ como todos los parámetros requeridos. El usuario especifica dónde tomará lugar la minerı́a aclarando los procesadores IPG en los culaes el agente de minerı́a de datos será posicionado. Con los requisitos anteriores especificados, el usuario invocará al minero, el cual enviará a los agentes de minerı́a a los procesadores IPG designados. En esos procesadores, cada agente adquirirá los datos a ser minados, los minará y enviará los resultados de regreso al usuario.. Arquitectura de la minerı́a de datos IPG Para iniciar la operación de minerı́a, un agente minero y el plan de minerı́a asociado son posicionados a un procesador IPG. Estos agentes mineros crecerán a través de la adquisición de las operaciones de minerı́a requeridas para ejecutar el plan. Está previsto que estos agentes mineros utilicen operaciones de minerı́a de múltiples sitios del IPG. Algunos serán adquiridos de sitios de repositorios públicos que contienen un conjunto estándar de operaciones de minerı́a. Se desea que una vez que el sistema de minerı́a es adecuadamente operacional, los usuarios contribuyan con nuevas operaciones a éste repositorio de minerı́a. Las operaciones propietarias de minerı́a pueden ser adquiridas de grupos privados de operaciones de minerı́a o de compañı́as que en un futuro las vendan. Debido a la multitud de recursos para operaciones de minerı́a, se consideró que el enfoque de adquisición de operaciones “just in time” representa una razonable estrategia inicial de diseño para el minero IPG. El agente también realiza adquisición de datos “just in time”. Táles datos deben 23.
(36) ser adquiridos de repositorios basados en IPG, ası́ como de varios repositorios de datos de la NASA que proveen acceso FTP a los contenedores de datos. Utilizando distribución de datos “just in time”, los requerimientos de almacenamiento del sitio principal de minerı́a son minimizados. La arquitectura de minerı́a del IPG soporta paralelismo desigualmente granulado. Un enfoque alternativo podrá soportar paralelismo finamente granulado, en el cual una porción del plan de minerı́a podrá ser realizado en un procesador, y los resultados parciales ser enviados a otro procesador para realizar trabajo adicional. Este enfoque actualmente no está soportado, debido al alto volúmen de datos involucrado y el sobre flujo de transmisión de datos a través de la rejilla. Trabajo futuro El sistema ha sido utilizado para generar una multitud de agentes en el procesador Ames 512 SGI de la NASA, se requiere trabajo adicional para que los agentes operen en forma autónoma en el ambiente IPG, según se describió en la sección referente a la arquitectura. También es requerido mayor trabajo para permitir al usuario monitorear el progreso de las multitudes de agentes que se hallen operando en un grupo de procesadores en el IPG. Finalmente se requerirá mayor trabajo para permitir de forma oportunista a los agentes de minerı́a reservar una porción del conjunto de datos que serán minados, de forma que los agentes puedan colaborar en el minado de datos correspondientes a múltiples años, siendo cada agentes capaz de reservar el próximo año no minado disponible.. 2.7.2.. SCOPES.. Un trabajo que involucra agentes basados en el descubrimiento de conocimiento y comunicación es el llamado SCOPES[13], el cuál se describe en los siguientes párrafos. SCOPES (Semiotic/Semantic Coordination for Parallel Exploration Spaces), es una arquitectura escalable de agentes diseñada para soportar fuentes de conocimiento heterogéneas, interoperables y autónomas, para lo cual tiene una capa o nivel de dialogo y adquisición de conocimiento; además tiene una capa de comunicación, entre otras que son de menor relevancia para el presente trabajo de tesis. La semántica de interoperabilidad entre fuentes heterogéneas de información requiere integración de datos, lo cual generalmente significa una estandarización en la definición de datos y estructuras como el uso de un esquema conceptual a través de una colección de fuentes de datos. El esquema conceptual especifica las definiciones de campo y registro, estructuras y reglas para dar de alta los datos. Las reglas para realizar los mapeos en sistemas de fuentes heterogéneas de conocimiento tı́picamente 24.
(37) existen en una capa separada antes de los componentes de las bases de datos. Usando mapeo y transformaciones, la fuente de datos se convierte en una forma compatible con un equivalente semántico. SCOPES define reglas de interacción para comunicarse. Estas reglas no son una interacción de semántica como en el caso de los agentes de ontologı́as[6] , son referentes a las reglas de comunicación de SCP (Semantic Cooperation Protocols). Estos protocolos son extendidos no solamente a la capa que define las reglas de interacción, si no también a las demás capas de la arquitectura.. 2.7.3.. Automatización del Proceso de Minerı́a de Datos con Agentes. En las siguientes lı́neas se comenta una propuesta de tesis doctoral realizada por Gilberto Lorenzo Martı́nez Luna, cuyo objetivo es plantear un sistema para automatizar el proceso de minerı́a de datos utilizando agentes, lo cual se relaciona con el interés que tiene el agente minero descrito en el presente documento de tesis por aplicar técnicas de minerı́a de datos en forma automática. El objetivo de la propuesta “Automatización del Proceso de Minerı́a de Datos con Agentes” es construir un Sistema de software para realizar Minerı́a de Datos, capaz de realizar planeación al desarrollar la minerı́a y si es necesario modificar su ambiente de trabajo, ya sea al adecuar el esquema de bases de datos a una estructura de datos que facilite la minerı́a solicitada, cambiar los parámetros que le permitan generar conclusiones (localizar registros y analizarlos), entre otras efectaciones a su entorno; todo esto bajo una arquitectura de agentes de software[21]. El autor de la propuesta comenta que es deseable que los programas que realizan los análisis, tengan cierto nivel de autonomı́a en cuanto a tomar decisiones que ayuden a realizar los análisis en tiempos más cortos (o aseguren dar una respuesta), que tengan una capacidad de modificar los parámetros que ayuden a regresar respuestas no vacı́as. También, es deseable que estos programas tengan memoria para recordar (aprendizaje) análisis que fracasan en su cometido, y mejor consuman recursos (tiempo, acceso a disco, procesador, memoria) en explorar nuevas alternativas que incrementen su eficiencia. El autor hace notar que tal vez además de modificar los parámetros que le definen sus búsquedas, sea también necesario cambiar las estructuras que almacenan los datos, las cuales faciliten los procesos de búsqueda y recuperación de datos (bases de datos multidimensionales o cubos, bajo el esquema estrella), habilidad que de alguna forma debe incorporarse a estos programas. Estas caracterı́sticas son las que distinguen a los 25.
(38) programas que se llaman agentes de software y que es la tecnologı́a que puede ayudar a automatizar este proceso.. Un escenario de trabajo para Automatizar la Minerı́a de Datos Sea un esquema de base de datos que defina un cubo de datos a trabajar con información escolar.. Generación +A~ no Matrı́cula *Clave Escuela *Nivel (01 = Secundarı́a, 02 = Medio, 03 = Profesional, 04 = Especialidad, 05 = Maestrı́a, 06 = Doctorado, 07 = Diplomado, 08 = Otro, 00 = Todos) *Clave *Area *Carrera Tiempo *A~ no *Semestre (01, 02) *Parcial (01, 02, 03, 00=De semestre) Ingreso *Clave Egreso *Clave Sexo 26.
(39) *Clave (01, 02, 00) Materias *Clave Evaluación *llavegeneración *llavematricula *llaveescuela *llavetiempo *llaveingreso *llaveegreso *llavesexo *llavematerias *valor Algunas de las preguntas planteadas a resolver son: > En que materias los alumnos de una institución en particular tienen un bajo desempe~ no ? Nos desplazamos por todas las generaciones por todas las matrı́culas por todas las escuelas por todo el tiempo de evaluaciones por todas las formas de ingreso por todas las formas de egreso. 27.
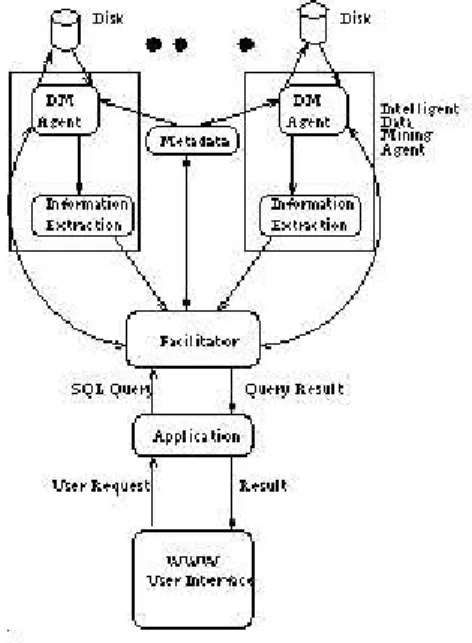
(40) por todos los tipos de sexo por todas las materias Finalmente comparamos que el valor de la evaluación sea menor a un valor predefinido. Para responder la pregunta anterior serı́a necesario dar una valor que defina qué es un bajo desempeño y en qué rango se definirı́a (meses, evaluaciones, semestral o anual). Podrı́a ser tomar una materia y comparar contra todas. Entre las consultas que pudieran ser tratadas con este agente están las siguientes: ¿En que materias los alumnos de licenciatura de una institución en particular provenientes de vocacional tienen un menor desempeño que los alumnos provenientes de otras escuela ajenas a la Universidad (preparatoria, cetis, conalep, entre otros)? Aquı́ serı́a necesario comparar lapsos iguales de tiempo de los alumnos de Licenciatura contra sus entancias a nivel medio, tanto en escuelas de la institución como de otra institución. Calcular los porcentajes de las escuelas en la que los alumnos de licenciatura tienen un mejor desempeño que en vocacional. Para esto serı́a necesario comparar las evaluaciones en lapsos iguales de tiempo de los alumnos de Licenciatura contra sus entancias a nivel medio y checar que han mejorado (mayor valor su calificación en Licenciatura que en Nivel Medio). Calcular los porcentajes de las escuelas en la que los alumnos de licenciatura de una institución disminuyen su desempeño al que tenı́an en vocacional. Aquı́ serı́a necesario comparar las evaluaciones en lapsos iguales de tiempo de los alumnos de Licenciatura contra sus entancias a nivel medio y checar que han disminuido (menor valor su calificación en Licenciatura que en Nivel Medio). Respecto a los alumnos que presentan examen y tienen una alta calificación, ¿ésta se refleja en su estancia en la escuela(es garantı́a de que será un buen alumno?. ¿Qué banda de evaluación de alumnos que presentan examen y tienen una alta probabilidad de terminar sus estudios?.. 2.7.4.. PArallel Data Mining Agents (PADMA). El acceso eficiente a datos y la escalabilidad de algoritmos para la extracción de patrones juegan un rol crı́tico en los sistemas de minerı́a de datos a gran escala. Lo anterior demanda un método efectivo entre las bases de datos y las tecnologı́as de extracción de conocimiento. Haciendo las operaciones de extracción de conocimiento en 28.
(41) forma paralela se produce una velocidad significante, haciendo además la tecnologı́a de minerı́a de datos más efectiva. El proyecto comentado en este espacio del documento desarrolla un sistema de minerı́a de datos distribuido basado en agentes, el cual logra ofrecer un buen tiempo de respuesta en las operaciones de minerı́a de datos y operaciones de acceso. En este trabajo se utilizo la arquitectura PDMA mostrada en la figura 2.7.. Figura 2.7: Arquitectura PDMA (PArallel Data Mining Agents). Esta arquitectura desarrolla un sistema flexible que será explotada por agentes que hacen minerı́a de datos. Aún cuando PDMA no es especializado para ningún dominio de minerı́a de datos, la implementación utiliza agentes especializados en clasificación de texto sin estructura. Los componentes de PDMA son: Agentes de minerı́a de datos. Facilitador, el cual coordina a los agentes. Interfase de usuario basada en Web. Los agentes mineros son responsables de acceder a datos y extraer información importante de alto nivel. Estos agentes se especializan en realizar actividades en dominios 29.
(42) de interés y tienen la capacidad de compartir su información y actuar en paralelo, coordinados por el facilitador. Este último se encarga también de presentar información sobre la interfase del usuario y proveer retroalimentación a los agentes proveniente del usuario. La interfase de usuario le muestra datos a los usuarios y captura sus instrucciones. El presente trabajo muestra la utilidad de aplicar agentes a la minerı́a de datos. Los agentes ofrecen ventajas como la capacidad de buscar información, debido a su modularidad y transportabilidad, además de poder especializarse en resolver un problema especı́fico y apoyarse con otros agentes para resolver los diversos problemas que se presenten durante la adquisición de conocimiento.. 2.7.5.. Minerı́a de Datos con Búsqueda de Patrones de Comportamiento. Uno de los puntos importantes del trabajo descrito en este documento de tesis es la presentación de resultados relevantes a los usuarios. El trabajo que lleva por tı́tulo Minerı́a de Datos con Búsqueda de Patrones de Comportamiento, comentado en esta sección, actúa en un ambiente distribuido (aunque no basado en agentes), al igual que el agente minero, y consta de tres actividades básicas similares a las que realiza este mismo agente, y que incluyen la interpretación y presentación de resultados relevantes a los usuarios. En el Laboratorio de Sistemas de Información del Centro de Información en Computación (CIC) del Instituto Politécnico Nacional (IPN), se desarrolló una herramienta que forma parte del proyecto ANASIN, con la cual la minerı́a de datos se realiza utilizando la técnica que construye cubos de n-dimensiones conocida como generalización y sumarización en cubos de datos , que es implantada en una base de datos relacional. La generalización de los datos se puede desarrollar en los niveles que se considere necesario usar y ası́ realizar análisis a diferentes niveles de conceptos. En los cubos formados se definen regiones de interés en las cuales se buscan patrones de comportamiento; al término de las búsquedas los resultados se muestran en reportes de tipo texto y gráficas [20]. En este proceso de minerı́a se pueden distinguir dos tipos de programas: los que extraen la región de interés de la base de minerı́a, llamados extractores; y los programas que realizan la búsqueda de patrones, llamados mineros. Tanto la actividad de extracción como la de búsqueda de patrones pueden consumir demasiado tiempo, por lo cual se delegan a programas que las realizan en forma autónoma y nocturna y ası́ aprovechar los recursos computacionales[20]. 30.
(43) La herramienta desarrollada en el laboratorio, llamada Módulo de Minerı́a de Datos - ANASIN, tiene el modelo de trabajo Cliente/Servidor, donde se distinguen tres actividades básicas: 1. Solicitudes de minerı́a, realizadas en una estación de trabajo o cliente. 2. El proceso de minerı́a o generación de región y búsqueda de un patrón determinado en el servidor. 3. La visualización de resultados en el cliente. ANASIN comprende un conjunto de herramientas y métodos para recolectar, integrar y analizar datos en una organización distribuida. Por ejemplo, el usuario puede manejar una gran cantidad de variables en una gran base de datos, pero sólo le pueden interesar tres variables cuya intersección es el valor de interés a analizar, esto da como resultado un cubo de datos con tres dimensiones, más una dimensión que puede contener los valores en los que se realizará la búsqueda del patrón. De una base de datos el usuario puede elegir la relación venta(producto, cliente, tiempo). Aquı́ define como primer eje al producto, como segundo eje al cliente y como tercer eje al tiempo. La intersección es la venta de un producto para un cliente en un momento definido en el tiempo [20]. El trabajo en cuestión presenta los resultados en forma gráfica, considerando que las variables analizadas son elegidas por el mismo usuario, lo cual evita presentar resultados que no sean considerados relevantes para su propósito particular. Esta herramienta se utiliza como apoyo en varios proyectos que se han planeado, entre los cuales se pueden mencionar: uso de agentes para la minerı́a de datos, uso de agentes para la minerı́a distribuida, uso de agentes para la minerı́a en texto, generación de nuevos agentes.. 31.
(44) 32.
Figure




+7




Outline
Miner´ıa de Datos
Automatizaci´on del Proceso de Miner´ıa de Datos con Agentes
Miner´ıa de Datos con B´usqueda de Patrones de Comportamiento
Realizaci´on de la Aplicaci´on
Uso del Servicio de Miner´ıa de Datos en una Jerarqu´ıa de Organizaci´on
Agente de Sitio
Miner´ıa de Datos con B´usqueda de Patr´ones de Comportamiento
Documento similar
1) La Dedicatoria a la dama culta, doña Escolástica Polyanthea de Calepino, señora de Trilingüe y Babilonia. 2) El Prólogo al lector de lenguaje culto: apenado por el avan- ce de
Como medida de precaución, puesto que talidomida se encuentra en el semen, todos los pacientes varones deben usar preservativos durante el tratamiento, durante la interrupción
•cero que suplo con arreglo á lo que dice el autor en el Prólogo de su obra impresa: «Ya estaba estendida esta Noticia, año de 1750; y pareció forzo- so detener su impresión
que hasta que llegue el tiempo en que su regia planta ; | pise el hispano suelo... que hasta que el
Ciaurriz quien, durante su primer arlo de estancia en Loyola 40 , catalogó sus fondos siguiendo la división previa a la que nos hemos referido; y si esta labor fue de
اهعضوو يداصتق�لا اهطاشنو ةينارمعلا اهتمهاسم :رئازجلاب ةيسلدنأ�لا ةيلاجلا« ،ينوديعس نيدلا رصان 10 ، ، 2 ط ،رئازجلاب يسلدنأ�لا دوجولاو يربي�لا ريثأاتلا
Estos planes de recolo- cación deben garantizar a las personas despedi- das un servicio continuado durante un periodo mínimo de seis meses que incluya medidas de formación
El contar con el financiamiento institucional a través de las cátedras ha significado para los grupos de profesores, el poder centrarse en estudios sobre áreas de interés
