Análisis del rendimiento del algoritmo OptQuest para optimización en simulación
174
0
0
Texto completo
(2) PONTIFICIA UNIVERSIDAD CATOLICA DE CHILE ESCUELA DE INGENIERIA. ANÁLISIS DEL RENDIMIENTO DEL ALGORITMO OPTQUEST PARA OPTIMIZACIÓN EN SIMULACIÓN. JORGE ANTONIO FAUNDES BERKHOFF. Tesis (Proyecto) presentada(o) a la Comisión integrada por los profesores: PEDRO GAZMURI SCHLEYER JORGE VERA ANDREO MARCOS GOYCOOLEA GUZMAN CRISTIAN TEJOS NUÑEZ. Para completar las exigencias del grado de Magister en Ciencias de la Ingeniería. Santiago de Chile, Agosto, 2014.
(3) A mi familia. ii.
(4) AGRADECIMIENTOS Mis agradecimientos para mi profesor guía, Pedro Gazmuri, por su aporte al desarrollo de esta tesis. También agradezco al comité por sus comentarios que me permitieron mejorar los primeros borradores y así escribir una mejor tesis. También agradezco a mi familia por su apoyo durante mis estudios. Agradezco, además, al equipo de Simula UC por su ayuda durante el desarrollo de mi tesis y por prestarme equipamiento para realizar el estudio. Finalmente, agradezco a CONICYT por otorgarme la beca de magíster en Chile.. iii.
(5) INDICE GENERAL AGRADECIMIENTOS ....................................................................................................... iii INDICE DE TABLAS ........................................................................................................ vii INDICE DE FIGURAS ........................................................................................................ ix RESUMEN ......................................................................................................................... xiii ABSTRACT ....................................................................................................................... xiv 1. 2. 3. Introducción .................................................................................................................. 1 1.1. Simulación computacional ..................................................................................... 1. 1.2. Optimización en simulación ................................................................................... 2. 1.3. Objetivos................................................................................................................. 3. 1.4. Metodología ............................................................................................................ 5. 1.5. Estructura de la tesis ............................................................................................... 6. Metodologías actuales ................................................................................................... 7 2.1. Ranking y Selección ............................................................................................... 7. 2.2. Métodos de superficie de respuesta ........................................................................ 8. 2.3. Métodos del gradiente ............................................................................................ 8. 2.4. Búsqueda aleatoria .................................................................................................. 9. 2.5. Optimización de trayectoria muestreada .............................................................. 10. 2.6. Metaheurísticas ..................................................................................................... 11. 2.7. Optimización en la práctica .................................................................................. 12. Metaheurísticas para optimización en simulación ...................................................... 14 3.1. Definición ............................................................................................................. 14. 3.2. Simulated annealing ............................................................................................. 15. 3.3. Algoritmos genéticos ............................................................................................ 16 iv.
(6) 4. 5. 6. 7. 8. 3.4. Tabu Search .......................................................................................................... 17. 3.5. Scatter Search ....................................................................................................... 19. 3.6. Influencia de la simulación en el uso de metaheurísticas ..................................... 32. OptQuest...................................................................................................................... 34 4.1. Definición ............................................................................................................. 34. 4.2. El procedimiento de OptQuest ............................................................................. 35. 4.3. Rendimiento de OptQuest .................................................................................... 40. 4.4. OptQuest en software comerciales de simulación ................................................ 41. Problema 1: Tiempo de espera en las cajas de un supermercado................................ 46 5.1. Proceso a modelar ................................................................................................. 46. 5.2. Problema de optimización .................................................................................... 48. 5.3. Experimentos de OptQuest y resultados ............................................................... 51. Problema 2: Flujo de camiones en un centro de distribución ..................................... 86 6.1. Proceso a modelar ................................................................................................. 86. 6.2. Problema de optimización .................................................................................... 90. 6.3. Experimentos de OptQuest y resultados ............................................................... 95. Problema 3: Faena Minera ........................................................................................ 117 7.1. Proceso a modelar ............................................................................................... 117. 7.2. Problema de optimización .................................................................................. 121. 7.3. Experimentos de OptQuest y resultados ............................................................. 123. Conclusiones generales ............................................................................................. 141 8.1. Velocidad de convergencia ................................................................................. 141. 8.2. Diversidad y calidad de soluciones .................................................................... 142. 8.3. Restricciones aleatorias ...................................................................................... 143 v.
(7) 8.4. Influencia de la estructura del problema............................................................. 144. 8.5. Recomendaciones para el usuario....................................................................... 145. 8.6. Recomendaciones para desarrollos futuros ........................................................ 146. Referencias ........................................................................................................................ 149 A N E X O S ...................................................................................................................... 155 ANEXO A. ANÁLISIS FAENA MINERA CON DISTANCIA EUCLIDIANA ............ 156. vi.
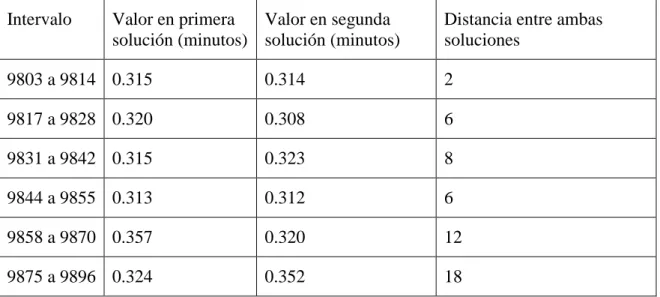
(8) INDICE DE TABLAS Tabla 2-1: Paquetes de Optimización en Simulación.......................................................... 12 Tabla 5-1: Parámetros por Sector ........................................................................................ 53 Tabla 5-2: Mejor solución cada 1,000 iteraciones para el segundo experimento ............... 65 Tabla 5-3: Detalle del recorrido del algoritmo cada 1,000 iteraciones para el segundo experimento ......................................................................................................................... 67 Tabla 5-4: Análisis de saltos entre iteraciones 4,200 a 4,300 para el segundo experimento ............................................................................................................................................. 70 Tabla 5-5: Análisis de saltos entre iteraciones 9,800 a 9,900 para el segundo experimento ............................................................................................................................................. 72 Tabla 5-6: Relación de la factibilidad con el rendimiento del algoritmo ............................ 83 Tabla 6-1: Demanda de porteo por semana ......................................................................... 90 Tabla 6-2: Funciones de grúas ............................................................................................ 91 Tabla 6-3: Funciones de chequeadores ............................................................................... 91 Tabla 6-4: Cotas para las variables de decisión. ................................................................. 96 Tabla 6-5: Cotas relajadas para las variables de decisión ................................................. 104 Tabla 6-6: Relación de la factibilidad con el rendimiento del algoritmo .......................... 111 Tabla 6-7: Comparación de la distancia entre iteraciones factibles consecutivas y entre iteraciones consecutivas .................................................................................................... 115 Tabla 7-1: Tipos de mecánicos.......................................................................................... 120 Tabla 7-2: Cotas para variables de decisión ...................................................................... 124 Tabla 7-3: Histograma acumulado de utilización de recursos con recursos máximos...... 128 Tabla 7-4: Cantidad de mecánicos por tipo para solución que asegura recursos disponibles el 90% del tiempo .............................................................................................................. 129 Tabla 7-5: Detalle del recorrido del algoritmo cada 500 iteraciones ................................ 134 vii.
(9) Tabla A-1: Detalle del recorrido del algoritmo cada 500 iteraciones ............................... 159. viii.
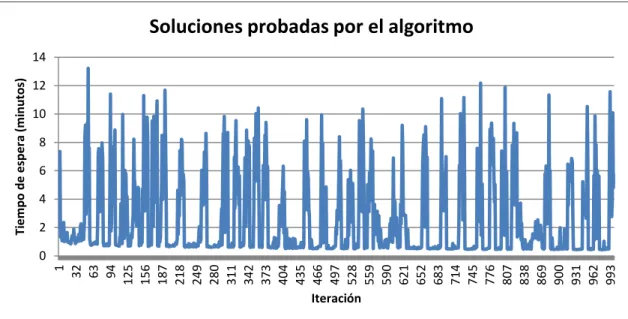
(10) INDICE DE FIGURAS Figura 3-1: Combinaciones lineales en Scatter Search. ...................................................... 20 Figura 3-2: Conexión de soluciones en Path Relinking. ..................................................... 32 Figura 4-1: OptQuest como caja negra. .............................................................................. 35 Figura 4-2: Función de penalidad........................................................................................ 38 Figura 4-3: Menú principal de OptQuest ............................................................................ 41 Figura 4-4: Opciones para variables de decisión ................................................................ 43 Figura 4-5: Opciones generales de OptQuest ...................................................................... 44 Figura 5-1: Diagrama de flujo supermercado ..................................................................... 47 Figura 5-2: Tasa de llegada de clientes por cada hora durante el día.................................. 48 Figura 5-3: Evolución de la mejor solución encontrada para el primer experimento ......... 52 Figura 5-4: Cajas abiertas por hora y sector para “mejor” solución ................................... 55 Figura 5-5: Soluciones probadas por el algoritmo en el primer experimento ..................... 56 Figura 5-6: Distancia entre iteraciones consecutivas primer experimento ......................... 57 Figura 5-7: Relación entre distancia y valor de la función objetivo para el primer experimento ......................................................................................................................... 59 Figura 5-8: Relación entre distancia y tiempo de espera para el grupo de iteraciones entre la 905 y 935 del primer experimento ...................................................................................... 60 Figura 5-9: Distancia de las mejores 100 soluciones encontradas respecto a la mejor solución encontrada para el primer experimento ............................................................................... 62 Figura 5-10: Evolución de la mejor solución encontrada para el segundo experimento .... 64 Figura 5-11: Soluciones probadas entre las iteraciones 4,000 y 5,000 para el segundo experimento ......................................................................................................................... 66 Figura 5-12: Soluciones probadas entre las iteraciones 9,000 y 10,0000 para el segundo experimento ......................................................................................................................... 66 ix.
(11) Figura 5-13: Relación entre distancia y valor de la función objetivo para las iteraciones 4,200 a 4,300 del segundo experimento ........................................................................................ 69 Figura 5-14: Relación entre distancia y valor de la función objetivo para las iteraciones 9,800 a 9,900 del segundo experimento ........................................................................................ 71 Figura 5-15: Distancia de las mejores 100 soluciones encontradas respecto a la mejor solución encontrada para el segundo experimento .............................................................. 73 Figura 5-16: Iteraciones donde el algoritmo encontró una nueva mejor solución para el segundo experimento........................................................................................................... 74 Figura 5-17: Evolución de la mejor solución encontrada para el tercer experimento......... 78 Figura 5-18: Soluciones probadas por el algoritmo para el tercer experimento ................. 79 Figura 5-19: Distancia entre iteraciones consecutivas para el tercer experimento ............. 80 Figura 5-20: Valor del tiempo de espera para el tercer experimento .................................. 81 Figura 5-21: Iteraciones donde el algoritmo probó soluciones factibles para el tercer experimento ......................................................................................................................... 82 Figura 5-22: Cantidad de cajas abiertas por hora y sector para “mejor” escenario problema inverso ................................................................................................................................. 85 Figura 6-1: Diagrama de flujo de acarreo ........................................................................... 87 Figura 6-2: Diagrama de flujo porteo .................................................................................. 88 Figura 6-3: Evolución de la mejor solución encontrada ..................................................... 98 Figura 6-4: Soluciones probadas por el algoritmo ............................................................ 100 Figura 6-5: Distancia entre iteraciones consecutivas ........................................................ 101 Figura 6-6: Relación entre distancia y valor de la función objetivo ................................. 102 Figura 6-7: Distancia de las mejores 100 soluciones encontradas respecto a la mejor solución encontrada ......................................................................................................................... 103 Figura 6-8: Distancia entre iteraciones consecutivas para el experimento con cotas relajadas ........................................................................................................................................... 106 x.
(12) Figura 6-9: Evolución de la mejor solución encontrada para el experimento con cotas relajadas ............................................................................................................................. 107 Figura 6-10: Distancia de las mejores 50 soluciones encontradas respecto a la mejor solución encontrada para el experimento con cotas relajadas ......................................................... 108 Figura 6-11: Cumplimiento de la demanda para el experimento con cotas estrictas ........ 109 Figura 6-12: Iteraciones donde el algoritmo encontró una solución factible para el experimento con cotas relajadas ........................................................................................ 110 Figura 6-13: Iteraciones donde la mejor solución encontrada por el algoritmo cambió para el experimento de cotas estrictas ....................................................................................... 112 Figura 6-14: Iteraciones donde se encontraron soluciones factibles para el experimento de cotas relajadas ................................................................................................................... 113 Figura 6-15: Iteraciones donde mejoró el valor de la mejor solución para el experimento de cotas relajadas ................................................................................................................... 114 Figura 7-1: Diagrama de flujo faena minera ..................................................................... 118 Figura 7-2: Evolución de la mejor solución encontrada ................................................... 126 Figura 7-3: Relación entre ganancia e ingresos ................................................................ 127 Figura 7-4: Solución de ingreso máximo .......................................................................... 128 Figura 7-5: Soluciones probadas por el algoritmo en el primer experimento ................... 130 Figura 7-6: Distancia entre iteraciones consecutivas ........................................................ 131 Figura 7-7: Relación entre distancia y valor de la función objetivo para el primer experimento ....................................................................................................................... 132 Figura 7-8: Distancia de las mejores 100 soluciones encontradas respecto a la mejor solución encontrada ......................................................................................................................... 133 Figura 7-9: Iteraciones donde el algoritmo encontró una nueva mejor solución .............. 135 Figura 7-10: Ingresos por faena ........................................................................................ 136 Figura 7-11: Costos asociados a mecánicos ...................................................................... 136 xi.
(13) Figura 7-12: Costos asociados a inventario....................................................................... 137 Figura A-1: Distancia euclidiana entre iteraciones consecutivas ...................................... 156 Figura A-2: Relación entre valor de la función objetivo y distancia entre iteraciones consecutivas ...................................................................................................................... 157 Figura A-3: Distancia entre las 100 mejores soluciones encontradas respecto a la mejor solución encontrada ........................................................................................................... 158. xii.
(14) RESUMEN La simulación computacional es una herramienta que permite modelar sistemas complejos que son difíciles de representar fielmente mediante técnicas matemáticas tradicionales. En este contexto, se han desarrollado diversas herramientas de optimización en simulación, ocupando distintos enfoques: algoritmos basados en técnicas tradicionales, algoritmos basados en conceptos de búsqueda aleatoria y metaheurísticas, que son la base de la gran mayoría de los software comerciales de optimización en simulación. En este trabajo se presenta un estudio detallado del rendimiento del algoritmo comercial OptQuest aplicado a problemas reales de optimización en simulación. El objetivo de esto es encontrar debilidades y fortalezas del algoritmo, para luego proponer recomendaciones para los usuarios de OptQuest y para desarrollos científicos futuros como la elaboración de nuevos algoritmos basados en los principios de OptQuest o la realización de mejoras en el motor actual de OptQuest. La metodología de esta tesis consiste en aplicar el algoritmo a tres problemas reales de optimización en simulación: asignación de horarios de trabajo en un supermercado para minimizar el tiempo de espera en las cajas de un supermercado; definición de dotación de trabajadores en un centro de distribución para mejorar los tiempos de los procesos que ocurren dentro de éste; definición de dotación de mecánicos e inventario de repuestos en una faena minera para maximizar las ganancias. Los resultados obtenidos muestran que OptQuest mejora de forma rápida, alcanzando buenas soluciones en pocas iteraciones. A pesar de esto, también se observó que el algoritmo no logra ocupar la diversidad entre las soluciones probadas de forma eficiente para mejorar la búsqueda. Por otro lado, el algoritmo presenta dificultades al enfrentar problemas con restricciones aleatorias ya que encuentra pocas soluciones factibles durante la búsqueda. Entre las recomendaciones se plantea el uso de buenas soluciones en la población inicial para aumentar la velocidad de convergencia y métodos alternativos de diversidad que buscan generar soluciones diversas de buena calidad. Palabras Claves: Simulación, Optimización en Simulación, OptQuest, Scatter Search, Tabu Search, Metaheurísticas, Algoritmos Evolutivos. xiii.
(15) ABSTRACT Computer simulation is a tool used to model complex systems that are difficult to represent faithfully with traditional mathematical techniques. In this context, many simulation optimization tools, based on different approaches, have been developed: algorithms based on traditional techniques, algorithms based on concepts of random search and metaheuristics, which are the base of most commercial simulation optimization software. This work presents a detailed study of the performance of commercial algorithm OptQuest applied to real simulation optimization problems. The objective of this is to find strengths and weaknesses of the algorithm to propose recommendations for OptQuest users and for future research such as be the development of new algorithms based on OptQuest or the improvement of OptQuest’s current engine. The methodology of this work consists of applying the algorithm to three real simulation problems: allocation of work shifts in a supermarket to minimize the waiting time in the shopping queues; allocation of workers in a distribution center to improve the times of processes performed inside the center; allocation of workers and parts inventory in a mine site to maximize financial earnings. The obtained results show that OptQuest improves quickly, reaching good solutions in a small number of iterations. Despite this, results show that the algorithm doesn’t use the diversity between tried solutions in an efficient way to improve the search. Also, OptQuest has trouble with constraints that include random variables, finding a small amount of feasible solutions during the search. For the recommendations we propose the use of good quality solutions in the initial population to accelerate the convergence speed and alternative diversity methods that aim to generate diverse good quality solutions.. Keywords: Simulation, Simulation Optimization, OptQuest, Scatter Search, Tabu Search, Metaheuristics, Evolutionary Algorithms. xiv.
(16) 1. 1 1.1. INTRODUCCIÓN Simulación computacional La simulación computacional es una de las principales técnicas de análisis en gestión. de operaciones. Law y Kelton (1999) la definen como una técnica que busca imitar el funcionamiento de un sistema del mundo real dentro de un computador. Henderson y Nelson (2006), por su parte, definen la simulación computacional estocástica como el análisis de procesos estocásticos mediante la generación de trayectorias de muestras (sample paths) de dichos procesos. Esta herramienta permite modelar sistemas complejos de formas que son muy difíciles (o incluso imposibles) de realizar mediante técnicas matemáticas tradicionales. Por esto, la simulación tiene diversas aplicaciones. Henderson y Nelson (2006) enumeran las siguientes: a). Finanzas: Evaluación de derivados financieros y de riesgo de portafolios.. b). Modelación de rendimiento de computadores: Análisis de fallas en chips, evaluar protocolos para servidores web, etc.. c). Industria de servicios: Call centers, hospitales, envíos a domicilio, etc.. d). Manufactura: Diseño de centros de trabajo, estimación de tiempos de ciclo, etc.. e). Transporte y logística: Diseño de transporte público, modelación de centros de distribución, etc. Existen diversos software que permiten desarrollar modelos computacionales de. simulación, lo que ha ayudado a la expansión de esta herramienta. La mayoría de estos se basan en un tipo de simulación llamada simulación por eventos discretos, en la que se modelan sistemas que cambian de estado en instantes de tiempo definidos (llamados eventos). Existen otros tipos de simulación como, por ejemplo, la simulación continua, donde los estados cambian de forma continua a lo largo del tiempo..
(17) 2. 1.2. Optimización en simulación Los modelos de simulación permiten representar sistemas muy complejos y por lo. tanto son una gran herramienta para tomar decisiones. Por ejemplo, si se tiene un modelo que simula el funcionamiento de las cajas de un supermercado, se puede estimar el tiempo que esperan los clientes antes de ser atendidos. Además, se puede evaluar cómo varía este tiempo al aumentar o disminuir la cantidad de trabajadores que atienden las cajas. Así, el modelo de simulación permite comparar distintos escenarios de funcionamiento del supermercado. Luego, la extensión natural de esto es intentar encontrar la dotación óptima de trabajadores sujeta a ciertas condiciones de presupuesto y nivel de servicio. Para esto, se ocupa la optimización en simulación. La definición general de un problema de optimización en simulación es la de encontrar un set de parámetros que minimice cierta función objetivo que debe ser estimada (Fu, Glover et al, 2005). Este problema se plantea de la siguiente manera: min 𝑔(𝑥) = 𝐸(𝐺(𝑥, 𝑤)) 𝑠. 𝑎. 𝑥 ∈ 𝑋,. (1.1). donde 𝑥 representa el vector de parámetros de input, 𝑋 representa el conjunto de restricciones del problema, 𝑤 corresponde a un vector de variables aleatorias y 𝐺(𝑥, 𝑤) es una función escalar. En el ejemplo del supermercado, 𝐺(𝑥, 𝑤) puede definirse como el tiempo de espera de los clientes cuando los tiempos de atención toman los valores aleatorios dados por 𝑤 y los parámetros de input (en este caso, cantidad de trabajadores) toman los valores dados por 𝑥. Es importante destacar que el conjunto 𝑋 ⊆ ℝ𝑛 puede incluir restricciones donde alguna función deba ser estimada, es decir, restricciones del siguiente tipo: ℎ(𝑥) = 𝐸(𝐻(𝑥, 𝑤)) ≤ 𝑑.. (1.2). Los problemas de optimización en simulación presentan diversas dificultades. Azadivar (1999) y Prudius (2007) enumeran las siguientes:.
(18) 3. a). No existe una expresión analítica para la función objetivo o para las funciones ocupadas en las restricciones. Esto dificulta el uso de herramientas matemáticas tradicionales.. b). La función objetivo debe ser estimada. Esto implica que el esfuerzo computacional usado para evaluar ésta es mayor que en un problema de optimización determinística. Debido a estas dificultades, existen distintos enfoques y metodologías para realizar. optimización en simulación, desde métodos basados en procedimientos tradicionales (por ejemplo, métodos del gradiente) hasta métodos basados en heurísticas. Existen también distintos software comerciales dedicados a la optimización en simulación. Uno de estos es el paquete de optimización OptQuest, basado en las metaheurísticas Scatter Search y Tabu Search, que se encuentra integrado en diversos software de simulación computacional y que es el foco de este estudio. 1.3. Objetivos El objetivo principal de esta tesis es realizar un estudio detallado del comportamiento. del algoritmo OptQuest en problemas reales de optimización en simulación mediante la experimentación computacional. A partir de este estudio se desea encontrar fortalezas y debilidades del algoritmo, para así formular recomendaciones para los usuarios de OptQuest (que permitan mejorar la aplicación del algoritmo) y, también, recomendaciones para desarrollos científicos futuros, entre los que se incluyen la creación de nuevos algoritmos de optimización en simulación basados en principios de OptQuest y la posibilidad de inspirar mejoras en el motor de funcionamiento actual del algoritmo. En particular, en el análisis se plantea y busca responder preguntas como las siguientes:.
(19) 4. a). ¿Se puede obtener información acerca del funcionamiento del algoritmo mediante la experimentación computacional?. b). ¿Logra el algoritmo OptQuest generar diversidad en las soluciones probadas? En caso que sí lo logre, ¿se ocupa esta diversidad de forma eficiente para mejorar la búsqueda de buenas soluciones?. c). ¿Con qué velocidad encuentra buenas soluciones el algoritmo? ¿Se atasca el algoritmo en “óptimos” locales?. d). ¿Es posible evaluar la calidad de las soluciones encontradas por OptQuest? En este caso, ¿qué tan buenas son las soluciones encontradas por el algoritmo?. e). ¿Qué efectos tiene la estructura del problema sobre los resultados obtenidos por OptQuest? Por ejemplo, ¿qué efectos tiene considerar problemas con restricciones que dependan de variables aleatorias? ¿Qué efectos tiene la sensibilidad de la función objetivo respecto a cambios en las variables de decisión sobre la búsqueda? Así, mediante la búsqueda de respuestas a preguntas como las anteriores se intenta. observar posibles aspectos donde el desempeño del algoritmo pueda ser mejorado, además de aspectos positivos que deban ser mantenidos al considerar desarrollos futuros. Respecto a la relevancia de este estudio, como se verá más adelante (capítulo 4), actualmente no existen estudios que analicen de forma detallada el rendimiento de OptQuest. Esto se debe principalmente a que no se conocen todos los detalles del funcionamiento del algoritmo (ya que este es un software comercial). Luego, la literatura de OptQuest se limita principalmente a estudios prácticos que no analizan qué pasa en el interior del algoritmo o a estudios comparativos que hacen competir a OptQuest con otros algoritmos de optimización en simulación, por lo que no existe conocimiento acerca de las principales fortalezas y debilidades del algoritmo. Así, este estudio busca llenar un vacío que existe actualmente en la literatura de optimización en simulación y que, además, es muy relevante ya que OptQuest es uno de los principales software comerciales de optimización en simulación en la actualidad. Esto pues el algoritmo se encuentra integrado en diversos software de elaboración de modelos de.
(20) 5. simulación y que, como muestran distintos estudios, ha demostrado ser competitivo en la resolución de distintos problemas de optimización. 1.4. Metodología La metodología de este estudio corresponde a aplicar el algoritmo en tres problemas. reales de optimización en simulación de distintas industrias: a). Asignación de horarios de trabajo en un supermercado.. b). Definición de dotación de trabajadores por función en un centro de distribución.. c). Definición de dotación de mecánicos e inventario de repuestos en una faena minera. Estos tres problemas fueron escogidos por las siguientes razones. Primero, los tres. problemas presentan alta complejidad, ya sea en la cantidad de variables de decisión o en la complejidad de las funciones a evaluar, que son imposibles de abordar mediante métodos de optimización tradicionales. Segundo, los tres problemas provienen de industrias diversas, abracando problemas de colas (problema 1), centros de distribución (problema 2) y operación minera (problema 3). En tercer lugar, y como se detalla en las secciones respectivas a cada problema, se consideran estructuras diferentes: el problema 1 considera variables binarias y restricciones no aleatorias, el problema 2 considera variables enteras con restricciones aleatorias y no aleatorias y el problema 3 considera variables mixtas (es decir, tanto enteras como continuas). Además, la función objetivo de los problemas 1 y 3 no es altamente sensible a cambios en las variables de decisión, mientras que la función objetivo del problema 2 es muy sensible a cambios en las variables de decisión. Así, los tres problemas considerados permiten representar problemas reales de optimización en simulación y también permiten estudiar distintas estructuras y sus efectos sobre el rendimiento del algoritmo. Para cada uno de estos problemas se estudian distintos indicadores, buscando responder las preguntas planteadas en la sección anterior. Entre estos se consideran los porcentajes de mejora de la mejor solución obtenida cada cierto número de iteraciones, la distancia entre soluciones probadas por el algoritmo, la cantidad de soluciones factibles encontradas durante la búsqueda (indicador particularmente relevante al considerar.
(21) 6. restricciones que dependan de variables aleatorias), entre otros. Además, para estudiar el efecto de ciertos factores (por ejemplo, tamaño del espacio factible o soluciones iniciales), algunos problemas consideran la realización de más de un tipo de experimento, lo que permite estudiar el desempeño del algoritmo cuando no cambia el problema a resolver pero sí el espacio factible o las condiciones iniciales de la búsqueda. Finalmente, dado que los tres problemas a estudiar son de alta complejidad, no se conocen los valores óptimos de ellos, lo que suele ocurrir en problemas reales de optimización en simulación. Sin embargo, para contrarrestar esto, para cada problema se corrió la mayor cantidad de iteraciones que fuesen factibles en términos de restricciones de tiempo, para que así el algoritmo encontrará las mejores soluciones posibles. Además, para cada problema se generan posibles cotas o, alternativamente, buenas soluciones que permiten evaluar la calidad de las soluciones encontradas por el algoritmo. 1.5. Estructura de la tesis El resto de la tesis se organiza de la siguiente manera. El capítulo 2 presenta una. revisión de los principales métodos ocupados actualmente para la optimización en simulación. El capítulo 3 realiza una revisión detallada de las metaheurísticas principales ocupadas para la optimización en simulación, con especial énfasis en Scatter Search. El capítulo 4 muestra una detallada descripción del funcionamiento de OptQuest, desde los fundamentos teóricos hasta las opciones prácticas presentes en la integración de este algoritmo en el software de simulación Arena. Los capítulos 5, 6 y 7 presentan y analizan los resultados obtenidos en los tres problemas estudiados. Se detalla primero el problema a resolver y luego se muestran los resultados obtenidos con OptQuest. Finalmente, el capítulo 8 entrega las principales conclusiones del trabajo realizado..
(22) 7. 2. METODOLOGÍAS ACTUALES La literatura de optimización en simulación muestra una gran variedad de. metodologías que pueden ser separadas en los siguientes grupos (Fu, Glover et al, 2005): a). Ranking y selección (Ranking and selection). b). Métodos de superficie de respuesta (Response surface methods). c). Métodos del gradiente (Gradient based search methods). d). Búsqueda aleatoria (Random search). e). Optimización de trayectoria muestreada (Sample path optimization). f). Metaheurísticas. A continuación se describen brevemente estos métodos.. 2.1. Ranking y Selección Estos métodos se ocupan cuando se quiere comparar un grupo finito (y fijo) de. distintas alternativas. Kim y Nelson (2006) definen distintos objetivos para estos métodos: encontrar la mejor alternativa según valor esperado, comparar todas las alternativas contra un estándar, elegir el sistema con mayor probabilidad de ser el mejor y escoger el sistema con mayor probabilidad de éxito. La formulación tradicional de Ranking y Selección busca responder al primer objetivo, es decir, encontrar la mejor alternativa según valor esperado. Para esto, existen dos alternativas: selección de subconjuntos y zona de indiferencia. La primera busca encontrar un subconjunto de las alternativas donde se encuentre la mejor alternativa mientras que la segunda busca encontrar la mejor alternativa dentro de cierto rango de indiferencia respecto al óptimo. Es decir, si se tienen 𝑘 alternativas donde la alternativa 𝑗 es la mejor, entonces el primer método busca encontrar un conjunto 𝐼 tal que 𝑗 ∈ 𝐼 y el segundo método busca encontrar una alternativa 𝑖 ∗ tal que 𝜇𝑖 ∗ − 𝜇𝑗 ≤ 𝛿, donde 𝜇𝑖 es el valor esperado del output de la alternativa 𝑖 y 𝛿 es el rango de indiferencia..
(23) 8. Los métodos de Ranking y Selección se suelen ocupar en conjunto con los demás métodos de optimización en simulación para verificar que la alternativa señalada como la mejor por el método de optimización sea al menos la mejor de todas las alternativas probadas. 2.2. Métodos de superficie de respuesta Los métodos de superficie de respuesta buscan encontrar una relación funcional. aproximada entre los parámetros de input y la función objetivo. Para esto, los métodos más ocupados son regresión y redes neuronales (Barton, 2006). Las primeras relaciones funcionales ocupadas tienen la siguiente forma: 𝑛. 𝑛. 𝑛. 𝑔(𝑥) = 𝛽0 + ∑ 𝛽𝑗 𝑥𝑗 + ∑ ∑ 𝛽𝑖𝑘 𝑥𝑖 𝑥𝑘 + 𝜀, 𝑗=1. (2.1). 𝑖=1 𝑘=1. donde 𝑥 = (𝑥1 , … , 𝑥𝑛 ) es el vector de parámetros de input y 𝛽𝑗 , 𝛽𝑖𝑘 son los parámetros del modelo de aproximación y se estiman mediante métodos de mínimos cuadrados. 𝜀 es el error de la estimación y sigue una distribución normal de esperanza 0 y varianza 𝜎 2 . Después de encontrada la relación funcional, la optimización se realiza ocupando métodos de optimización determinística. 2.3. Métodos del gradiente Este método está basado en los métodos del gradiente de optimización determinística.. En estos métodos, dada una solución, se hace un movimiento en la dirección indicada por el gradiente. En problemas de optimización en simulación no se conoce una forma analítica de la función objetivo y por tanto no se conoce el gradiente, lo que presenta una dificultad para este método (Azadivar, 1999). La adaptación del método del gradiente tradicional al contexto de la optimización en simulación es llamada aproximación estocástica (stochastic approximation) y consiste en un método iterativo que toma la siguiente forma (Fu, 2006):.
(24) 9. ̂𝑔(𝑥𝑛 )), 𝑥𝑛+1 = ΠX (𝑥𝑛 − 𝑎𝑛 ∇. (2.2). ̂𝑔(𝑥𝑛 ) es una estimación del gradiente de 𝑔 en el punto 𝑥𝑛 , Π𝑋 es la proyección donde ∇ dentro de la región factible 𝑋 y 𝑎𝑛 denota cuánto hay que moverse en la dirección del gradiente. Para asegurar convergencia casi seguramente (es decir, con probabilidad 1), la secuencia 𝑎𝑛 debe cumplir las siguientes condiciones: ∑ 𝑎𝑛 = ∞, ∑ 𝑎𝑛2 < ∞. 𝑛. (2.3). 𝑛. Naturalmente, uno de los pasos más importantes (y computacionalmente exigentes) de este método es la estimación del gradiente. Fu (2006) enumera y detalla los siguientes métodos: a). Diferencias finitas. b). Perturbaciones simultáneas. c). Estimación directa Los métodos 1 y 2 estiman el gradiente de forma indirecta ocupando simulación para. estimar los valores de la función objetivo en vecindades del punto actual y luego ocupando las definiciones de derivada para calcular el gradiente. El método 3 busca estimar el gradiente mediante el uso de técnicas de teoría de probabilidad avanzadas, para lo que se requiere mayor conocimiento del problema específico que se está optimizando. 2.4. Búsqueda aleatoria Los métodos de búsqueda aleatoria tienen su origen en optimización de problemas. discretos determinísticos. De forma similar a los métodos del gradiente, estos métodos se mueven de forma iterativa a través del espacio factible pero, a diferencia de los métodos del gradiente, los nuevos puntos son seleccionados de forma aleatoria según cierta estrategia de muestreo. Andradóttir (2006) define la siguiente estructura general para un algoritmo de búsqueda aleatoria:.
(25) 10. Paso 1.. Elegir una estrategia de muestreo inicial 𝑆0 y definir 𝑘 = 0.. Paso 2.. Seleccionar un punto 𝑥𝑘 según la estrategia 𝑆𝑘 .. Paso 3.. Estimar 𝑔(𝑥𝑘 ) mediante simulación.. Paso 4.. Ocupar los resultados obtenidos para determinar la nueva mejor solución 𝑥𝑘∗ , determinar una nueva estrategia de muestreo 𝑆𝑘+1 hacer 𝑘 = 𝑘 + 1 y volver al paso 2. Es importante destacar que en cada iteración se pueden generar conjuntos de puntos. en vez de puntos individuales de acuerdo a la estrategia de muestreo ocupada. Por ejemplo, una estrategia de muestreo puede ser escoger uno o más vecinos del punto actual de manera aleatoria. Se puede mostrar que, bajo ciertas condiciones, los algoritmos de búsqueda aleatoria convergen con probabilidad 1. Solis (1981) encuentra condiciones de convergencia para un algoritmo cualquiera de búsqueda aleatoria aplicado a problemas determinísticos. Primero, ∗ ) el método debe ser decreciente (es decir, 𝑔(𝑥𝑛+1 ≤ 𝑔(𝑥𝑛∗ ) ∀𝑛) y, segundo, todo. subconjunto de 𝑋 es visitado con probabilidad 1 durante la búsqueda. Andradóttir (1999) muestra que este resultado se mantiene en el caso de optimización en simulación si el espacio es finito y además se puede asegurar que las estimaciones de la función objetivo son fuertemente consistentes, es decir, cada punto es evaluado infinitas veces con probabilidad 1 a lo largo de la búsqueda. Para el caso en que es infinito pero contable, Andradóttir (2006) muestra ciertas condiciones similares a las anteriores que también aseguran convergencia con probabilidad 1. 2.5. Optimización de trayectoria muestreada La idea detrás de la optimización de trayectoria muestreada es la siguiente, según la. descripción hecha en Gurkan, Ozge et al (1994). Se considera un proceso estocástico {𝐹𝑛 (𝑥)}𝑛=1…∞ (es decir, para cada 𝑛 la función 𝐹𝑛 es una variable aleatoria con parámetros de input 𝑥) que converge a una función determinística 𝐹∞ (𝑥) casi seguramente y se quiere encontrar min 𝐹∞ (𝑥). Además, se supone que no se conoce la forma de 𝐹∞ (𝑥) pero que se 𝑥. pueden obtener muestras de 𝐹𝑛 (𝑥) para valores fijos de 𝑥 y 𝑛..
(26) 11. Así, el método de optimización de trayectoria muestreada consiste en optimizar la función 𝐹𝑛 (𝑥) para cierto 𝑛 fijo y luego tomar el valor 𝑥𝑛∗ como estimador del óptimo 𝑥 ∗ de 𝐹∞ (𝑥). Ahora, ¿cómo se aplica este concepto al problema de optimización en simulación? Fu, Glover et al (2005) dan la siguiente definición para la serie {𝐹𝑛 (𝑥)}𝑛=1…∞ : 𝑛. 1 𝐹𝑛 (𝑥) = ∑ 𝑔̂𝑖 (𝑥), 𝑛. (2.4). 𝑖=1. donde 𝑔̂𝑖 (𝑥) es la estimación del valor de la función objetivo según los resultados obtenidos en la réplica 𝑖 de la simulación. Así, por la ley de los grandes números se tiene que 𝐹𝑛 (𝑥) → 𝐹∞ (𝑥) = 𝐸(𝐺(𝑥, 𝑤)) = 𝑔(𝑥). 𝑐.𝑠.. (2.5). Una de las ventajas de este método es que la función 𝐹𝑛 es determinística y por lo tanto permite ocupar los métodos tradicionales de optimización determinística para la resolución del problema. 2.6. Metaheurísticas Fu, Glover et al (2005) definen una metaheurística como un método que guía a otros. procedimientos (por ejemplo, una heurística) para evitar que estos se atasquen en óptimos locales. Las metaheurísticas más destacadas para la optimización en simulación son las siguientes: a). Algoritmo de recocido simulado (simulated annealing). b). Algoritmos genéticos. c). Búsqueda tabú (Tabu Search). d). Búsqueda dispersa (Scatter Search). Una descripción detallada del uso de metaheurísticas para optimización en simulación. se encuentra en la sección 3 de este estudio..
(27) 12. 2.7. Optimización en la práctica Como suele ocurrir en muchas áreas de la ciencia, las aplicaciones prácticas de la. optimización en simulación no se condicen con los estudios teóricos de esta. Fu (2002) realiza un análisis crítico de la relación entre el uso de simulación (y optimización) en la práctica y los estudios académicos. El aumento de potencia y memoria de los computadores en los últimos años han permitido que los algoritmos de optimización sean utilizables en la práctica (Fu, Glover et al 2005). Sin embargo, no todas las herramientas de optimización en simulación son ocupadas. La tabla 2-1 (Fu, 2002) muestra distintos software de optimización en simulación y la herramienta que ocupan. Tabla 2-1: Paquetes de Optimización en Simulación.. Paquete de Optimización. Plataforma de Simulación. Estrategias Principales de Búsqueda. AutoStat. AutoMod. Algoritmos genéticos. Evolutionary Optimizer. Extend. Algoritmos genéticos. OptQuest. Arena, Crystal Ball, SIMUL8, Simio, et al. RISKOptimizer. @RISK. Algoritmos genéticos. Optimizer. WITNESS. Simulated Annealing, Tabu Search. ProModel, Scatter Search, Tabu Search. Los 5 software presentes en la tabla 2-1 ocupan metaheurísticas como la base de su estrategia de búsqueda. Es decir, sólo 1 de los 6 grupos de optimización en simulación identificados en la sección anterior es ocupado en software de optimización en simulación. La principal razón para esto es que las metaheurísticas tienen la ventaja de ser fácilmente adaptables y no requieren mayor conocimiento matemático para su implementación, a diferencia de los otros métodos. En particular, Fu (2002) critica el hecho que los software.
(28) 13. ocupen la simulación como una caja negra en vez de intentar una mayor integración entre la optimización y la simulación. Otra desconexión entre la teoría y la práctica es que estos software de optimización en simulación no le indican al usuario si efectivamente se alcanzó la solución óptima del problema (Fu, 2002). Esto se contrasta con los esfuerzos académicos por demostrar convergencia de gran parte de los métodos señalados en la sección 2.2. En efecto, prácticamente no existen estudios en la literatura que analicen la convergencia de los paquetes de optimización en simulación. Los estudios de estos programas se enfocan principalmente en aplicaciones de estos software en áreas específicas o en comparaciones experimentales entre los rendimientos de los software contra otros software o contra las metaheurísticas más populares (principalmente algoritmos genéticos). Fu (2002) y Olafsson (2006) destacan la falta de estudios en esta materia y otros estudios, como Pasupathy y Henderson (2006) se centran en la idea de definir un conjunto de problemas que se pueda ocupar para probar cualquier algoritmo de optimización en simulación y así tener métricas comunes para identificar la calidad de estos..
(29) 14. 3 3.1. METAHEURÍSTICAS PARA OPTIMIZACIÓN EN SIMULACIÓN Definición La literatura de optimización en simulación abarca diversos métodos como se mostró. en el capítulo 2. Sin embargo, los software comerciales de optimización en simulación ocupan, en su mayoría, sólo uno de estos métodos: metaheurísticas (April, Glover et al, 2003). Debido a esto, es relevante estudiar a fondo el uso de metaheurísticas para optimización en simulación para así poder mejorar los algoritmos comerciales. Además, un mayor conocimiento de las metaheurísticas también permitiría encontrar resultados teóricos de convergencia y eficiencia de estos software de optimización en simulación, tarea aún pendiente en la literatura (Olafsson, 2006). Una metaheurística se define formalmente como un proceso iterativo de generación de soluciones que guía a una heurística subordinada mediante la combinación inteligente de conceptos de exploración y explotación del espacio de búsqueda para encontrar soluciones cercanas al óptimo de manera eficiente (Osman, 1996). El origen de éstas se remonta a la década de 1980 y se diseñaron para atacar problemas donde los métodos tradicionales no eran efectivos ni eficientes como, por ejemplo, los problemas determinísticos de optimización combinatorial (Olafsson, 2006). Una de las principales ventajas de estos métodos es que son muy generales, por lo que se pueden aplicar sin problemas a cualquier tipo de problemas, lo que explica por qué son usadas por la mayoría de los software comerciales de optimización en simulación. La estructura general de una metaheurística, según Olafsson (2006), es la siguiente:.
(30) 15. Paso 1.. Generar solución inicial 𝑥0 y hacer 𝑘 = 0.. Paso 2.. Identificar la vecindad 𝑉(𝑥𝑘 ) de 𝑥𝑘 .. Paso 3.. Seleccionar una solución candidata 𝑥𝑐 ∈ 𝑉(𝑥𝑘 ).. Paso 4.. Decidir si aceptar 𝑥𝑐 y hacer 𝑥𝑘+1 = 𝑥𝑐 o si rechazar 𝑥𝑐 y hacer 𝑥𝑘+1 = 𝑥𝑘 .. Paso 5.. Si no se ha alcanzado el criterio de término del algoritmo hacer 𝑘 = 𝑘 + 1 y volver al paso 2. Si bien esta estructura indica que en cada iteración se escoge un punto 𝑥𝑘 , el método. se puede generalizar fácilmente ocupando conjuntos 𝑋𝑘 en cada iteración. Algoritmos como Tabu Search y simulated annealing ocupan la versión con puntos individuales mientras que otros algoritmos como Scatter Search y los algoritmos genéticos ocupan la versión con conjuntos (también llamados poblaciones). Las cuatro metaheurísticas más importantes para optimización en simulación fueron mencionadas en la sección 2.6 y corresponden a: a). Simulated Annealing. b). Algoritmos genéticos. c). Tabu Search. d). Scatter Search A continuación se definen estos cuatro métodos, poniendo especial énfasis en Tabu. y Scatter Search, ya que el funcionamiento de OptQuest se basa en elementos de estos dos algoritmos. 3.2. Simulated annealing Simulated annealing es una de las metaheurísticas más antiguas y está inspirada en. los métodos de recocido de metales. Su principal característica es la forma en que decide si aceptar a la solución candidata 𝑥𝑐 . Fleischer (1995) define la probabilidad de pasar de una solución 𝑥𝑖 a una solución 𝑥𝑗 durante la iteración 𝑘 de la siguiente manera:.
(31) 16. 𝑔(𝑥𝑖 ) − 𝑔(𝑥𝑗 ) 𝑃𝑖𝑗 exp ( ), 𝑑𝑝𝑖𝑗 (𝑡𝑘 ) = { 𝑡𝑘 1,. 𝑔(𝑥𝑖 ) < 𝑔(𝑥𝑗 ). ,. (3.1). 𝑔(𝑥𝑖 ) ≥ 𝑔(𝑥𝑗 ). donde 𝑃𝑖𝑗 es la probabilidad de generar la solución 𝑥𝑗 si se está parado en la solución 𝑥𝑖 y 𝑡𝑘 es una secuencia de parámetros que simula la temperatura del proceso de recocido de metales. La idea principal tras esta formulación es que en cada iteración del algoritmo existe la posibilidad de moverse a una solución peor a la solución actual, pero que esta probabilidad disminuye mientras avanza el número de iteraciones. Así, el algoritmo busca evitar atascarse en óptimos locales. Naturalmente, la definición de la secuencia 𝑡𝑘 es uno de los pasos más importantes para la definición de la metaheurística. Mitra, Romeo et al (1985) demuestran que si la función objetivo es acotada, entonces simulated annealing converge casi seguramente al óptimo ocupando la siguiente definición para 𝑡𝑘 : 𝑡𝑘 =. 𝛾 , log(𝑐 + 𝑘 + 1). (3.2). donde 𝑐 ≥ 1 y 𝛾 cumplen ciertas condiciones específicas para el problema.. 3.3. Algoritmos genéticos A diferencia de simulated annealing, los algoritmos genéticos son basados en. subconjuntos (o poblaciones), es decir, volviendo a la formulación general de una metaheurística descrita en la sección 3.1, el algoritmo parte con una población inicial de puntos 𝑋0 y en cada iteración genera nuevas soluciones candidatas (denotadas por el conjunto 𝑋𝑐 ) a entrar a la población. La idea principal de este tipo de algoritmos es mantener una población de soluciones que evoluciona a lo largo de las iteraciones mediante técnicas que buscan la supervivencia de las mejores soluciones (Osman, 1996). Los métodos de generación de nuevos puntos se basan en la noción que cada solución tiene un “código genético” que se puede modificar mediante distintas operaciones, siendo las más comunes las mutaciones y los cruces. Una.
(32) 17. mutación corresponde a una pequeña modificación de una solución mientras que un cruce corresponde a mezclar dos soluciones. Srinivas y Patnaik (1994) realizan una completa revisión de los distintos tipos de cruces y mutaciones presentes en la literatura. Una de las consideraciones principales de los algoritmos genéticos es decidir qué soluciones “sobreviven” de una iteración a la siguiente. En general, los algoritmos genéticos introducen cierta aleatoriedad en esta etapa en vez de sólo seleccionar las mejores soluciones (Olafsson, 2006). Un método popular es la estrategia de la ruleta donde un punto 𝑥 es escogido con cierta probabilidad 𝑝(𝑥), definida como sigue, 𝑝(𝑥) =. 𝑔(𝑥) . ∑𝑦 𝑔(𝑦). (3.3). Así, cada solución puede ser escogida pero las mejores soluciones tienen mayor probabilidad de sobrevivir. Finalmente, existen diversos estudios acerca de la convergencia de algoritmos genéticos para problemas de optimización discretos. Rudolph (1994) demuestra, ocupando cadenas de Markov, la convergencia de los algoritmos genéticos clásicos (o canónicos). Además, Olafsson (2006) detalla distintos resultados acerca de la velocidad de convergencia, mostrando cotas sobre la probabilidad de haber alcanzado el óptimo pasado cierto número de iteraciones del algoritmo. 3.4. Tabu Search Tabu Search es un algoritmo de búsqueda introducido por Fred Glover (1989, 1990).. Al igual que simulated annealing se basa en puntos individuales y no en poblaciones. Su principal característica es que introduce los conceptos de memoria adaptativa (es decir, que miran más que solo una iteración hacia atrás) a los métodos de metaheurísticas (Fu, Glover et al, 2005). Para esto, se define un conjunto (o lista) de soluciones llamado lista tabú que se actualiza en cada iteración y que consiste principalmente en puntos que fueron visitados recientemente. Así, en cada iteración del algoritmo se define un conjunto 𝐿𝑘 de puntos tabú y la solución candidata corresponde al mejor vecino que no sea tabú, es decir,.
(33) 18. 𝑥𝑐 = argmin 𝑔(𝑥). ̅̅̅̅ 𝑥∈𝑉(𝑥𝑘 )∩𝐿 𝑘. (3.4). Luego, la solución candidata es elegida como la próxima solución del algoritmo, es decir, 𝑥𝑘+1 = 𝑥𝑐 , sin importar si 𝑔(𝑥𝑐 ) es mejor o peor que 𝑔(𝑥𝑘 ). El objetivo de esto es evitar que el algoritmo se atasque en óptimos locales. Además, el punto 𝑥𝑘 se agrega a la nueva lista tabú 𝐿𝑘+1 lo que evita que el algoritmo vuelva inmediatamente al punto anterior en la próxima iteración. La forma de definir la lista tabú es uno de los pasos más importantes del algoritmo. En general, la lista contiene a los últimos 𝑛 puntos visitados por el algoritmo, es decir, 𝐿𝑘 = {𝑥𝑘−1 , … , 𝑥𝑘−𝑛 }. Sin embargo, existen otras formas de definir esta lista, detalladas en Glover y Laguna (1999). Estas variaciones incluyen, por ejemplo, el uso del concepto de frecuencia, que consiste en mirar cuántas veces se ha probado una misma solución (o soluciones con alguna característica particular) durante una corrida del algoritmo. Al igual que para simulated annealing y los algoritmos genéticos, existen diversos estudios en la literatura acerca de la convergencia de Tabu Search para problemas de optimización determinísticos. En particular, Hanafi (2001) y Glover y Hanafi (2002) definen una variación del algoritmo que converge en una cantidad finita de pasos bajo ciertos supuestos. Respecto a la aplicación de este algoritmo a la optimización en simulación, Olafsson (2006) destaca ciertas dificultades que ocurren debido al ruido en las estimaciones. Primero, la elección del candidato 𝑥𝑘 depende de los valores estimados y, por lo tanto, puede ser errónea si es que el ruido en las estimaciones es muy alto. Además, el ruido también es relevante en la actualización de la lista tabú, ya que las estimaciones por ruido pueden llevar a que una buena solución sea mal evaluada y luego incluida a la lista tabú. En estos casos se desearía que el algoritmo vuelva a esta solución para corregir el error por lo que el concepto de lista tabú pierde cierto atractivo. Por otro lado, Fu, Glover et al (2005) y Glover, Kelly et al (2000) destacan la utilidad de ciertos conceptos asociados a Tabu Search para la optimización en simulación. En particular, se destacan los conceptos de frecuencia y recency. El primer concepto hace.
(34) 19. referencia a la memoria de largo plazo y busca evitar visitar soluciones que tengan atributos que hayan aparecido mucho durante la búsqueda. El segundo concepto hace referencia a la memoria de corto plazo y busca evitar visitar soluciones que tengan atributos similares a soluciones que hayan sido visitadas recientemente. Como se verá más adelante, el algoritmo comercial OptQuest ocupa estos conceptos. 3.5. 3.5.1. Scatter Search. Introducción Scatter Search (SS) es una metaheurística creada por F. Glover en 1977. Al igual que. los algoritmos genéticos, SS es un método evolutivo, es decir, opera sobre un conjunto de puntos que se modifica a lo largo de las iteraciones del algoritmo. La idea principal tras el funcionamiento de este algoritmo es que se puede obtener información acerca de las mejores soluciones del problema de optimización mediante la combinación de “buenas” soluciones. Glover (1998) indica los siguientes tres principios como la base de SS: a). Información útil acerca de la forma de las mejores soluciones está típicamente contenida en una colección diversa de “buenas” soluciones.. b). Cuando se combinan soluciones como estrategia para explotar esta información, es importante extrapolar fuera de la región contenida entre las soluciones a combinar.. c). Tomar en cuenta múltiples soluciones de forma simultánea para realizar combinaciones mejora la oportunidad de explotar la información contenida en la colección de “buenas” soluciones. Ahora, los principios anteriores plantean ciertas dudas: ¿Qué es una colección de. “buenas” soluciones? ¿Qué tipo de información acerca de las soluciones óptimas se puede obtener? ¿Cómo se combinan soluciones? Scatter Search, como algoritmo evolutivo, opera sobre un conjunto de soluciones llamado conjunto de referencia (o RefSet, del inglés reference set). Este conjunto es actualizado al final de cada iteración y la idea es que contenga soluciones de buena calidad.
(35) 20. (medida según el valor de la función objetivo) pero que también presente diversidad entre estas soluciones, donde la diversidad se mide según la distancia entre las soluciones (la métrica a ocupar depende del problema que se esté optimizando). A esta mezcla entre calidad y diversidad es a lo que se refieren los principios al hablar colección de “buenas” soluciones (Fu, Glover et al, 2005). Este enfoque en la diversidad es una de las principales características de SS y su objetivo es evitar que el algoritmo se concentre en una sola región, probando soluciones de gran parte del espacio factible para así evitar que el algoritmo se atasque en óptimos locales. Otra de las características principales de SS es su método para combinar soluciones. Como se describe en Glover, Laguna et al (2000), éste consiste en realizar combinaciones lineales, tanto convexas como no convexas, entre las soluciones del RefSet para generar nuevos puntos, como se muestra en la figura 3-1 (Glover, Laguna et al, 2000). Aquí, el RefSet está compuesto inicialmente por los puntos 𝐴, 𝐵 y 𝐶, con los que se generan los puntos 1 y 2, que permiten eventualmente generar los puntos 3 y 4.. Figura 3-1: Combinaciones lineales en Scatter Search.. Esta forma de combinar soluciones es uno de los principales diferenciadores de SS respecto a los algoritmos genéticos, ya que estos últimos se basan en métodos.
(36) 21. completamente aleatorios para combinar soluciones. Otra diferencia entre SS y los algoritmos genéticos es el tamaño de la población. Mientras los algoritmos genéticos suelen ocupar poblaciones de 100 o más soluciones, el RefSet de Scatter Search suele tener 20 o menos soluciones (Glover, Laguna et al, 2000). Esto se hace para evitar tener un número demasiado alto de posibles combinaciones a realizar. Finalmente, ¿qué tipo de información se puede explotar mediante combinaciones de soluciones? Glover (1998) hace referencia a que se puede explotar la información contenida en dos tipos de variables: consistentes y fuertemente determinadas. Una variable se dice consistente si es que toma un solo valor en gran parte de las soluciones del conjunto de referencia. Por otro lado, una variable se dice fuertemente determinada si es que se observa que el alterar el valor de esta variable produce fuertes empeoramientos en el valor de la función objetivo.. 3.5.2. El procedimiento de Scatter Search A continuación se describe el procedimiento de Scatter Search, basándose en los. conceptos y principios descritos en la sección 3.5.1 y en las descripciones hechas en Glover (1998), Glover, Laguna et al (2000) y Martí, Laguna et al (2003). Primero, se describen cinco métodos generales, cuyas definiciones detalladas se presentan en las secciones a continuación, que se ocupan en la implementación del algoritmo:.
(37) 22. a). Método de diversificación: Genera soluciones diversas a partir de una solución o de una semilla aleatoria.. b). Método de mejora: Transforma una solución en una (o más) soluciones de mejor calidad, medida según el valor de la función objetivo.. c). Método de actualización del conjunto de referencia: Construye y actualiza el conjunto de referencia a partir de una población de soluciones.. d). Método de generación de subconjuntos: Genera subconjuntos del conjunto de referencia.. e). Método de combinación de soluciones: Combina soluciones de subconjuntos del conjunto de referencia. Con esto, el procedimiento general de Scatter Search es el siguiente:.
(38) 23. Paso 1.. Definir el tamaño del RefSet (en general se suele ocupar un tamaño de 20 soluciones).. Paso 2.. A partir de una semilla aleatoria, ocupar el método de diversificación para crear una solución y luego aplicar el método de mejora a esta. Repetir este paso hasta construir una población inicial 10 veces más grande que el tamaño deseado del RefSet.. Paso 3.. Crear el conjunto de referencia ocupando el método de actualización del conjunto de referencia.. Paso 4.. Generar subconjuntos del conjunto de referencia ocupando el método de generación de subconjuntos.. Paso 5.. Para cada subconjunto creado en el paso anterior, aplicar el método de combinación de soluciones y luego aplicar el método de mejora a las soluciones generadas.. Paso 6.. Ocupar el método de actualización del conjunto de referencia para actualizar el RefSet con las soluciones agregadas en el paso 5.. Paso 7.. Si el RefSet cambió en el paso 6, volver al paso 4. En caso contrario, generar soluciones diversas ocupando el método de diversificación, actualizar nuevamente el RefSet con el método de actualización del conjunto de referencia y volver al paso 4. El algoritmo termina al alcanzar cierto número máximo de iteraciones (definido por el usuario). En las siguientes secciones se describen los cinco métodos ocupados por el. procedimiento de SS, basándose en las definiciones y ejemplos dados en Glover (1998), Glover, Laguna et al (2000), Marti, Laguna et al (2003), Sánchez y Laguna (2003) y Marti, Glover et al (2011).. 3.5.3. Método de diversificación El método de diversificación se ocupa para generar una colección de soluciones. diversas ocupando una solución arbitraria (o una semilla) como input. Este método se ocupa.
(39) 24. principalmente para generar la población diversa inicial, aunque algunas versiones del algoritmo también lo ocupan para agregar diversidad cuando el RefSet se estabiliza (por ejemplo, la formulación de Glover (1998)). La aplicación exacta del método de diversidad depende del tipo de problema a optimizar, pero para ilustrar su funcionamiento se describirá una versión del método de diversidad para problemas binarios. Dada una solución 𝑥 ∈ {0,1}𝑛 , se busca crear un grupo de soluciones diversas. El método que se describe a continuación crea dos soluciones 𝑥′ y 𝑥′′ para cada valor de ℎ ∈ {1, … , 𝑛 − 1}: ′ 𝑥1+𝑘⋅ℎ = 1 − 𝑥1+𝑘⋅ℎ ,. 𝑥𝑖′ = 0,. 𝑛 𝑘 = 0,1, … , [ ] ℎ. 𝑛 ∀𝑖 ≠ 1 + 𝑘 ⋅ ℎ, 𝑘 ∈ {0,1, … , [ ]} ℎ 𝑥𝑖′′ = 1 − 𝑥𝑖′ ,. 𝑖 = 1, … 𝑛.. (3.5). (3.6) (3.7). Por ejemplo, considerando 𝑛 = 5 y 𝑥 = (0,0,0,0,0) se construyen las siguientes soluciones. Para ℎ = 1 se obtienen 𝑥 ′ = (1,1,1,1,1) y 𝑥 ′′ = 𝑥. Para ℎ = 2 se obtienen 𝑥 ′ = (1,0,1,0,1) y 𝑥 ′′ = (0,1,0,1,0). Para ℎ = 3 se obtienen 𝑥 ′ = (1,0,0,1,0) y. 𝑥 ′′ =. (0,1,1,0,1). Finalmente, para ℎ = 4 se obtienen 𝑥 ′ = (1,0,0,0,1) y. 𝑥 ′′ =. (0,1,1,1,0). Así, a partir de una solución inicial 𝑥 se obtienen 7 nuevas soluciones diversas. Es importante destacar que el método de diversidad no es un método aleatorio, lo que diferencia el enfoque de Scatter Search con el enfoque de los algoritmos genéticos. El objetivo de la diversidad es producir soluciones que difieran de las demás de forma significativa y que ofrezcan alternativas productivas en el contexto del problema considerado. En cambio, la diversidad en algoritmos genéticos sólo busca crear soluciones que tengan alguna diferencia..
(40) 25. 3.5.4. Método de mejora El método de mejora toma una solución (que puede o no ser factible) y mediante el. uso de una heurística lo transforma en una solución de mayor calidad según la función objetivo. Esta solución mejorada puede ser infactible, aunque en general se espera que no lo sea. Este método es el único de los cinco métodos del algoritmo que no es estrictamente requerido en un procedimiento de Scatter Search, aunque es necesario para obtener soluciones de alta calidad. La heurística ocupada para el método de mejora depende del problema a estudiar. Un método destacado en la literatura de optimización en simulación es el método de Nelder Mead (Barton e Ivey, 1996). Éste consiste en tomar un conjunto de 𝑁 + 1 soluciones 𝑥1 , … , 𝑥𝑁+1 (donde 𝑁 es el número de variables de decisión) tales que. 𝑔(𝑥1 ) ≤ ⋯ ≤. 𝑔(𝑥𝑁+1 ) y luego reflejar la peor de estas sobre la región formada por las demás soluciones, obteniendo así una nueva solución 𝑥𝐶 . Luego, el conjunto de 𝑁 + 1 puntos se modifica dependiendo de la relación de orden de esta nueva solución con las anteriores, es decir, se realizan distintas modificaciones para cada uno de los siguientes casos: 𝑔(𝑥𝐶 ) < 𝑔(𝑥1 ), 𝑔(𝑥1 ) ≤ 𝑔(𝑥𝐶 ) ≤ 𝑔(𝑥𝑁 ), 𝑔(𝑥𝑁 ) < 𝑔(𝑥𝐶 ) ≤ 𝑔(𝑥𝑁+1 ) y 𝑔(𝑥𝑁+1 ) < 𝑔(𝑥𝐶 ). Este proceso se repite hasta que los valores de la función objetivo en los 𝑁 + 1 puntos sean similares. Este método se suele ocupar ya que, como ocupa sólo la relación de orden entre distintas soluciones, es relativamente insensible a los ruidos debido a la estimación de los valores de la función objetivo, suponiendo que éstas se realizan con una cantidad de iteraciones que asegure un error relativo bajo. Herrera, Lozano et al (2006) y Hvattum, Duarte et al (2013) muestran aplicaciones efectivas del método Nelder Mead dentro del procedimiento de Scatter Search.. 3.5.5. Método de actualización del conjunto de referencia El método de actualización del conjunto de referencia se ocupa en distintas etapas. del algoritmo. Primero se ocupa para crear el RefSet inicial a partir de una población de puntos diversos. Luego, se ocupa al final de cada iteración para decidir qué nuevos puntos ingresan al conjunto de referencia. Algunas versiones del algoritmo ocupan este método al.
Figure



+7





Documento similar
RESUMEN En la presente investigación construimos un algoritmo para la optimización del tiempo de ejecución en la situación de problemas de programación lineal, este algoritmo
En la comparación de la entropía del algoritmo original Rijndael con la modificación de este capitulo 4.4.1 se encontró que existe una diferencia en los tamaños de archivos entre
Análisis y discusión de resultados La imagen hiperespectral que se utiliza en el presente estudio fue obtenida por el sensor AVIRIS de NASA Jet Propulsion
Para cumplir la finalidad del estudio se desarrolla un modelo cuya implementación incluye el uso del Algoritmo PSO (Optimización por Enjambre de Partículas), dicho modelo simula
En base a los porcentajes de Mejora entre Indicadores Actuales y Futuros, se calcula los Costos Esperados por cada Indicador de Gestión y se hallan los Beneficios Cuantitativos
10021380 UNIVERSIDAD NACIONAL DE INGENIER?A FACULTAD DE INGENIER?A INDUSTRIAL Y DE SISTEMAS "ALGORITMO GEN?TICO EN JAVA PARA LA OPTIMIZACI?N DEL DISE?O DE RESORTES HELICOIDALES
En el presente documento se desarrollará un análisis del algoritmo RSA de cifrado público y del algoritmo de factorización prima de Shor, planteando este último como una solución
Es decir, para cada solución obtenida por Foto Japón y el Manual, se encuentra la distancia euclidiana entre cada par de puntos según la secuencia en que aparezcan los lugares a
