FACULTAD DE MEDICINA UNIVERSIDAD DE CANTABRIA
GRADO EN MEDICINA
TRABAJO FIN DE GRADO
Evolución del papel de la Genética en Medicina: del
estudio de la herencia a la genómica personalizada.
Evolution of the role of Genetics in Medicine: from the
study of inheritance to personalized genomics.
Autora:
Dª. María del Pilar Velarde Náñez
Directora:
Dra. Matxalen Llosa Blas
1
Índice
I. Resumen
II. Introducción
III. Los comienzos de la Genética y su aplicación en medicina
III.1- El trabajo de Gregor Mendel
III.2- Errores congénitos del metabolismo III.3- Infiriendo la estructura física de los genes III.4- Genética de poblaciones
III.5- Genética bioquímica y molecular III.6- Estudiando el ADN
III.7- Evolución de la citogenética
IV. La revolución del ADN recombinante y las técnicas de
manipulación del genoma
IV.1- Tecnología del ADN recombinante
IV.1.1- Enzimas de restricción y ligación IV.1.2- Reacción en Cadena de la Polimerasa
IV.1.3- Creación e introducción del ADN recombinante en las células
IV.2- Edición genómica y CRISPR/Cas9 IV.3- Aplicaciones en medicina
IV.3.1- Terapia génica
V. La genómica y la post-genómica
V.1- Técnicas de secuenciación de ADN V.2- El Proyecto Genoma Humano
V.3- Principales aplicaciones en medicina
V.4- Variabilidad genética humana y medicina personalizada
VI. Presente de la Genética en medicina
VI.1- Aplicaciones en el diagnóstico VI.2- Aplicaciones en el tratamiento VI.3- Aplicaciones en investigación VI.4- Medicina preventiva
VII. Debate ético
VII.1- Manipulación del genoma embrionario
VII.2- Diagnóstico precoz y prevención de enfermedades
VII.3- El problema de los Kits genéticos directos al consumidor y la interpretación de la información genética
VII.4- Privacidad genética
VII.5- Desigualdad social e infrarrepresentación en los estudios VII.6- Patentes de genes
VIII. El futuro de la Genética en medicina
VIII.1- Predecir la predisposición a tener una condición genética desde el nacimiento
2
VIII.3- Detectar cualquier variación genética en cualquier célula VIII.4- Medicina personalizada
VIII.5- Investigación
IX. Conclusiones
X. Bibliografía
XI. Agradecimientos
3
I. Resumen
El objetivo de este trabajo es realizar una revisión histórica y un reflexión sobre la evolución de la Genética y su aplicación en Medicina; desde sus comienzos hace poco más de un siglo, cuando su uso se centraba sobretodo en el estudio de la herencia y el análisis de cariotipos, hasta la actualidad, en la que disponemos de nuevas tecnologías que no solo permiten conocer la información recogida en los genes, sino también modificarla. Además, se pretende deliberar sobre las profundas implicaciones sociales, éticas y legales de estas nuevas tecnologías y sugerir el posible futuro de esta disciplina.
El comienzo de la Genética como disciplina científica se remonta a finales del siglo XIX, con el trabajo de Gregor Mendel, y poco después la investigación de Archibald Garrod sobre genética bioquímica demostró su utilidad en medicina. Desde entonces la investigación y el desarrollo de nuevas técnicas la han transformado en disciplina con gran impacto en diversas ramas de la práctica médica.
Su empleo para predecir la herencia de enfermedades y detectar marcadores genéticos creó campos con múltiples aplicaciones en medicina como la citogenética o la Genética de poblaciones. Más adelante revoluciones tecnológicas como el ADN recombinante y las técnicas de secuenciación marcaron un cambio de paradigma, propiciando iniciativas de impacto mundial como el Proyecto Genoma Humano, y permitiendo el desarrollo de innovaciones médicas como la terapia génica o la medicina personalizada.
Actualmente la Genética es una herramienta esencial en algunas especialidades médicas, interviniendo en el diagnóstico y tratamiento de enfermedades, facilitando la investigación y ayudando en campos como la medicina preventiva. También tiene un importante impacto social y es sometida frecuentemente a estudio para asegurar la aplicación ética de sus descubrimientos.
Es muy posible que, en el futuro, la Genética acabe convirtiéndose en una herramienta indispensable en el ejercicio de la medicina.
Palabras clave: genética, medicina, historia, evolución.
Summary
The beginning of genetics as a scientific discipline dates back to the late nineteenth century, with the work of Gregor Mendel, and shortly after that Archibald Garrod´s research on biochemical genetics demonstrated its uses in medicine. Since then, research and development of new techniques have turned it into a very important branch of molecular biology.
Its use to predict the inheritance of diseases and detect genetic markers has created specialties with multiple applications in medicine such as cytogenetics or population genetics. Later technological advancements such as recombinant DNA and sequencing techniques caused a shift, driving initiatives with global repercussions like the Human
4
Genome Project and prompting the development of medical innovations such as gene therapy or personalized medicine.
Currently, genetics is an essential tool in some medical specialties, taking part in the diagnosis and treatment of diseases, facilitating research and helping in specialties such as preventive medicine. It also has an important social impact and is frequently studied to ensure its findings are used following ethical rules.
In the future, genetics might end up becoming an essential tool in medical practice. Key words: genetics, medicine, history, evolution.
II. Introducción
La rápida evolución de la Genética en poco más de un siglo no solo la ha convertido en una rama muy importante de la ciencia, sino que también la ha transformado en una herramienta de gran utilidad en múltiples apartados de la asistencia médica. Los avances realizados han demostrado que este campo de la ciencia no atañe solo a especialistas en enfermedades raras o congénitas, sino que influye en un amplio abanico de competencias médicas incluyendo salud pública, investigación y medicina clínica.
A pesar del creciente uso de métodos genéticos de diagnóstico, la inclusión cada vez mayor de medicina personalizada y de precisión en la práctica clínica y el apoyo tanto de la Sociedad Europea de Genética Humana como de la Asociación Española de Genética Humana (que ha hecho múltiples intentos de incluirla en el catálogo de especialidades[5][6]), España es el único país de la Unión Europea sin una especialidad de Genética Clínica[7]. Además, la integración de la Genética en los programas de estudio de las facultades de medicina españolas es escasa.
En este trabajo, hago un recorrido por la historia de la Genética, explicando cómo ha influido en el desarrollo de la Medicina desde comienzos del siglo pasado hasta ahora, las aplicaciones de las diversas técnicas descubiertas, y el conocimiento que ha aportado a diversos campos de la práctica clínica. A continuación, comento algunos aspectos éticos y dificultades morales asociadas a al estudio y aplicación de la Genética a la Medicina. Finalmente, indico algunas posibilidades del futuro de esta disciplina.
III. Los comienzos de la Genética y su aplicación en
medicina
III.1- El trabajo de Gregor Mendel
La Genética comenzó en el siglo XIX como una ciencia centrada en estudiar la herencia de características procedentes de los progenitores con el trabajo de Gregor Mendel, que realizó una serie de experimentos que aún hoy constituyen el paradigma del
5
análisis genético[8]. Los hitos más relevantes de esta etapa de dicha especialidad están recogidos en la línea temporal
representada en la Figura 1.
Mendel adoptó como método de estudio el análisis de poblaciones, en lugar de analizar individuos particulares, y sus principios de Herencia mendeliana siguen usándose para explicar los mecanismos básicos de transmisión de rasgos[9].
Entre 1856 y 1865 estudió los patrones de herencia de ciertas características en plantas de guisante común (Pisum
sativum) y observó que los caracteres se
transmiten a través de unidades que se redistribuyen en cada generación (genes), de forma que el descendiente recibe un elemento de cada progenitor y, por tanto, debe tener un par de elementos como mínimo. Además, dedujo que los rasgos recesivos debían ser transmitidos de los progenitores originales a la primera generación, y de ésta a la segunda. También se dio cuenta de que siempre había una relación tres a uno entre los rasgos dominantes y los recesivos que aparecían en esta segunda generación, lo cual indicaba que los patrones de herencia se regían por normas estadísticas sencillas. En base a esto, postuló las reglas de Herencia mendeliana, según las cuales los patrones de herencia pueden explicarse y mediante reglas y ratios estadísticos. Predijo que toda la descendencia de progenitores que difieren en una característica es igual, y al cruzar individuos de esa generación (por tanto con el mismo genotipo) los rasgos que parecen haber desaparecido resurgen. Más tarde se observó que esto no siempre es así, ya que los fenómenos de penetrancia, expresión fenotípica y ligamiento al sexo, entre otros, no lo cumplen, pero estos datos se
6
Es particularmente destacable de su experimentos la forma metódica que tuvo de comprobar sus hipótesis y la aplicación de modelos matemáticos para el estudio de herencia biológica, creando un sistema para desarrollar predicciones estadísticas sobre la herencia de características que influyó mucho en la biología en general[9]. Las Leyes de Mendel pueden usarse para predecir cómo se transmitirán los genes de una generación a la siguiente, permitiendo determinar todas las combinaciones potenciales de descendientes de una pareja de genotipo conocido, o deducir el genotipo de una pareja mediante el estudio de sus descendientes. Si bien no todos los patrones de herencia coinciden con lo que describió Mendel, sus modelos permiten tener una base con la que comparar desviaciones para estudiarlas.
En 1866 dio dos lecturas sobre su trabajo y lo publicó con el título "Versuche über
Pflanzen-Hybriden" (Experimentos de hibridación en plantas) en Verhandlungen des Naturforschenden Vereins zu Brünn (Boletín de la Sociedad de Ciencias Naturales de
Brno), una revista científica poco conocida. Debido a esto pasó desapercibido, dándosele más importancia a otras teorías de la época que postulaban que las características en la descendencia son una mezcla de las de los progenitores[9].
Su trabajo no fue redescubierto hasta principios del siglo XX, cuando los botánicos Hugo de Vries, Carl Correns y Erich von Tschermak lo encontraron casi simultáneamente y por separado. Los tres estaban llevando a cabo experimentos similares a los suyos sobre hibridación de plantas que les llevaron a los mismos resultados: la conclusión de que los rasgos heredados dependían de dos partículas de información provenientes de los padres que se transmitían a la descendencia. Después de esto, la comunidad científica comenzó a emplear los principios mendelianos en diversos modelos animales para tratar de determinar qué moléculas estaban involucradas en los procesos de transmisión de la herencia.
III.2- Errores congénitos del metabolismo
Poco después del redescubrimiento del trabajo de Mendel, en 1902, Sir Archibald Garrod aplicó sus principios al estudio de la alcaptonuria, una enfermedad metabólica cuya naturaleza congénita ya había señalado en 1899 y en la que, con ayuda del biólogo y genetista William Bateson, había observado cierta tendencia a aparecer más frecuentemente en hijos de matrimonios con relaciones de consanguinidad (primos hermanos). Garrod dedujo que la enfermedad seguía un patrón de factor recesivo como el descrito por Mendel, y comprendió que las unidades de transmisión descritas por el monje podrían estar implicadas en las enfermedades asociadas a procesos bioquímicos, a los que llamó Errores congénitos del metabolismo; entre ellas, algunas poco graves como el albinismo o la pentosuria, y otras más graves como la cistinuria o la porfiria[10].
En su libro Inborn Errors of Metabolism (Errores innatos del metabolismo), Garrod explicó que los procesos bioquímicos en el hombre se alteran debido a defectos metabólicos que provocan la acumulación y eliminación por orina de sustancias químicas que han sido transformadas al alterarse la ruta, conclusión a la que había llegado mediante el análisis de las sustancias presentes en la orina de individuos con alcaptonuria. También recogió su observación de que estos cuadros se comportaban como si estuvieran provocados por un factor mendeliano recesivo[10].
7
Su colaboración con Bateson, que había observado el carácter hereditario de la enfermedad, estableció por primera vez la idea de que la alteración de un gen heredable de forma mendeliana provocaba un cambio en una enzima, de forma que el paso metabólico mediado por esa enzima no puede llevarse a cabo y la ruta se bloquea, produciendo una incapacidad innata para realizar el proceso metabólico[10]. Esto le llevó a la conclusión de que los errores genéticos asociados al cuadro detenían la cadena metabólica en un punto específico, causando la falta de una enzima concreta para cada enfermedad. Ambos investigadores procedieron a realizar el análisis genético de otras alteraciones del metabolismo (albinismo, cistinuria y pentosuria), descubriendo mecanismos similares de asociación entre bioquímica y genética.
Si bien su trabajo tampoco tuvo mucho impacto inmediatamente, más tarde serviría como fundamento para la rama de la Genética Bioquímica, que estudia la relación entre la bioquímica y la genética. Sus observaciones fueron el primer ejemplo de aplicación de la Genética a la medicina[9] y cómo puede ayudar a estudiar enfermedades, implicando una relación directa entre los genes, las unidades hereditarias y los enzimas.
La alcaptonuria fue la primera enfermedad genética hereditaria descrita[11] y el primer caso conocido de una alteración en un gen que producía una alteración en una ruta metabólica, pero con el tiempo se describieron otras enfermedades metabólicas asociadas a cambios genéticos, como el albinismo. Conocer la relación entre estas enfermedades y su genética permite comprender el mecanismo de enfermedad, determinar posibles tratamientos para ellas, y predecir cómo afectarán los patrones de herencia a los descendientes de los afectados.
III.3- Infiriendo la estructura física de los genes
En la década de 1910, los experimentos de Thomas Hunt Morgan y sus colaboradores de la Universidad de Columbia sobre la genética de las moscas del vinagre (Drosophila
melanogaster) mostraron que los factores hereditarios se disponen de forma lineal en
zonas concretas de los cromosomas. En base a esto se estableció el modelo mendeliano de la Genética clásica: los factores hereditarios o genes son la unidad básica de la herencia, tanto funcional como estructuralmente, y se encuentran lineal y ordenadamente dispuestos en los cromosomas, cercanos unos a otros.
Otra consecuencia de este descubrimiento fue la descripción del fenómeno de ligamiento genético: cuanto más cerca físicamente están los genes codificantes dentro de un cromosoma, menor frecuencia hay de sucesos de recombinación, y más tienden a heredarse con la misma combinación que había en los cromosomas de los progenitores). Esto influye en la herencia de rasgos, al determinar cuales se heredan en bloque, y cambia las probabilidades estadísticas de recombinación establecidas por la ley de segregación independiente de Mendel. En 1911 Alfred Sturtevant se basó en este fenómeno para determinar las distancias entre genes a partir de sus frecuencias de recombinación, lo cual permitió deducir no solo en qué cromosoma se halla un gen concreto, sino en qué región específica del cromosoma está.
Este proceso se conoce como Mapeo genético y consiste en el uso de marcadores moleculares para deducir la posición de un gen respecto a dicho marcador,
8
determinando el orden en que se coloca en la secuencia y rastreando indirectamente la transmisión de los genes a los que están ligados. Los marcadores son secuencias de nucleótidos polimórficas (ya sean genes o secuencias sin función concreta) cuya ubicación física en el cromosoma se conoce y cuya herencia, es decir de qué progenitor proviene, puede distinguirse claramente. Los mapas pueden ser genéticos, si definen la distancia entre genes con unidades de frecuencia recombinación (tienen la ventaja de que puede identificar la posición relativa de los genes en función a su efecto fenotípico), o físicos si la definen por número de nucleótidos entre genes, aunque esta segunda clase se desarrolló después.
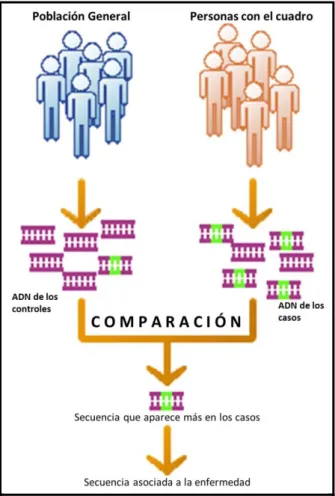
En medicina, el Mapeo genético se ha usado clásicamente para determinar las causas genéticas de enfermedades hereditarias monogénicas (fibrosis quística, distrofia muscular de Duchenne). Más recientemente, este mapeo también se ha utilizado para definir genes y alelos de susceptibilidad en desórdenes multifactoriales, en los que intervienen varios genes (asma, enfermedades cardiacas, diabetes, cáncer, afecciones psiquiátricas).
En los cuadros de transmisión familiar, actualmente el mapa genético se crea aislando el ADN de muestras de sangre o tejido obtenidas de miembros afectados de la familia y estudiándolo en busca de patrones que se heredan con la enfermedad, y que por tanto se pueden usar como marcadores de esta. Esto permite el segundo uso de los mapas genéticos en medicina: determinar el patrón de herencia de un gen y predecir a qué individuos afectará.
Es importante tener en cuenta que los marcadores no identifican necesariamente al gen responsable de la enfermedad, sino que informan sobre su presencia y posición dentro del cromosoma. El marcador puede ser el gen que produce el cuadro, pero es más frecuente que sea simplemente una secuencia que está ligada al gen causante, y por eso aparece en todos los miembros de la familia afectados. Por ello, siempre hay cierto margen de error que se basa en la probabilidad de recombinación entre el marcador y el gen en cuestión.
El mapeo genético es también la técnica base de la estrategia de clonación posicional, que ha ayudado a identificar muchos genes asociados a enfermedades monogénicas (por ejemplo, la fibrosis quística), facilitando la creación de métodos de diagnóstico y tratamiento y la adquisición de nuevos conocimientos sobre la enfermedad.
III.4- Genética de poblaciones
La Genética lleva usando conceptos de estadística para analizar los resultados de sus experimentos desde su creación, cuando Gregor Mendel aplicó reglas matemáticas para explicar los resultados de sus experimentos. Pero, al principio, la comunidad científica no estaba muy segura de cómo aplicar los descubrimientos sobre la herencia de caracteres (según los cuales los rasgos de un individuo derivan de la herencia genética obtenida de los progenitores) a la teoría de evolución de Darwin (según la cual una especie va adquiriendo sus características con el tiempo).
Los descubrimientos sobre la naturaleza física de los genes durante la década de 1910 condujeron, entre otras cosas, a la creación de la Genética de poblaciones, una rama
9
de la Genética que se centra en estudiar y comparar la variación entre individuos aplicando conceptos de bioestadística a las leyes de Mendel para desarrollar modelos estadísticos que expliquen la asociación entre genética y evolución.
Su desarrollo consiguió crear una visión matemática de la distribución de alelos y genotipos en las poblaciones, y con el tiempo las aportaciones de científicos como Ronald Fisher o Sewall Wright permitieron que, en 1930, la aplicación de modelos basados en razonamientos estadísticos llevaran a la síntesis neodarwiniana moderna, según la cual las especies tienen tanto transmisión de características entre generaciones (Genética Mendeliana) como adquisición de rasgos dependiendo de su entorno (evolución por selección natural).
En su libro The Genetical Theory of Natural Selection (La Teoría Genética de la Selección Natural), Fisher observó que la variación continua de las características de una especie podía deberse al efecto combinado de muchos cambios pequeños en los genes, así como que la selección natural podía influir en la frecuencia alélica de una población, induciendo su evolución. Por otro lado, Sewall sugirió en 1932 que en poblaciones pequeñas y aisladas la endogamia y la deriva genética podían acabar produciendo una población de características diferentes al resto de la especie.
Los modelos de Genética de poblaciones permitieron deducir que la incidencia de las enfermedades autosómicas recesivas es inversamente proporcional a los niveles de variabilidad genética de una población. A su vez esa variabilidad depende de diversos parámetros (selección natural, endogamia, mutaciones, deriva genética por aislamiento geográfico, factores sociales, "cuellos de botella") que influyen sobre las frecuencias alélicas, en cada población[12].
Esto significa que hay diferencias importantes en la frecuencia con la que ciertos alelos aparecen en las poblaciones humanas (fibrosis quística en poblaciones caucásicas, anemia falciforme en regiones africanas, enfermedad de Tay-schs en judíos asquenazíes, distrofia miotónica en europeos), lo cual significa que ciertas enfermedades tienden a aparecer más en algunas regiones o razas, dato que se debe tener en cuenta a la hora de hacer una historia clínica y predecir la probabilidad de tener descendencia afectada.
Otra utilidad de la Genética de poblaciones es explicar ciertas enfermedades según el entorno en que se perpetúan. El ejemplo más conocido de esto es la alta prevalencia de anemia falciforme en las regiones africanas con alta incidencia de malaria, al evitar la forma alterada de los hematíes la infección por el parásito, lo cual hizo un efecto de selección natural sobre los individuos heterocigotos para la mutación que causaba la anemia en homocigosis[17]. Otros ejemplos son la mayor tendencia a desarrollar mutaciones en áreas con mayor exposición a agentes mutagénicos, lo cual permite detectarlos y eliminarlos, o la mayor incidencia de enfermedades raras de herencia recesiva en las familias con muchos matrimonios de consanguineidad.
III.5- Genética bioquímica y molecular
Si bien el trabajo de Archibald Garrod sobre los errores congénitos del metabolismo demostró que había una relación entre genes y procesos enzimáticos, el mecanismo
10
que establece esa relación no se comprendió hasta los años 40, con los experimentos realizados por George Wells Beadle y Edward Lawrie Tatum sobre el moho del pan
Neurospora crassa. Estos investigadores observaron que los genes producen enzimas
que actúan directa o indirectamente en la cadena metabólica de síntesis de proteínas, de forma que, si se produce una mutación en el gen, la cadena metabólica de síntesis se bloquea en ese punto y el producto final no se genera.
Este trabajo permitió establecer claramente la relación entre la estructura molecular de un gen y su actividad bioquímica, ya que las mutaciones en los genes inducen su inactivación y, con ello, bloquean la cadena enzimática. A partir de esto se creó el concepto "Un gen, una enzima" (un gen específico codifica para una proteína específica[18]), que si bien resultó no ser del todo correcto, sirvió para confirmar la influencia de la genética en bioquímica.
En 1949 se demostró que la anemia falciforme se transmite por herencia de forma autosómica recesiva al analizar los resultados estadísticos obtenidos de observar a los descendientes de individuos afectados, estableciendo que los individuos enfermos eran homocigotos y los heterocigotos eran sanos. Basándose en estos resultados, otro grupo de investigadores descubrió que los heterocigotos tenían dos tipos de hemoglobinas y, tras observar que los que tenían anemia falciforme solo tenían uno de los tipos de hemoglobina y los sanos tenían la otra, dedujeron que la hemoglobina alterada de los enfermos estaba asociada a la anemia. Finalmente, en 1956 se descubrió mediante técnicas de secuenciación de proteínas que la única diferencia entre ambas hemoglobinas era un aminoácido concreto en una posición determinada, demostrando que una alteración en un gen con herencia autosómica recesiva en la especie humana producía una alteración en la secuencia de aminoácidos de una proteína (hemoglobina), de forma que la relación entre los genes y las enzimas era de tipo informacional: un gen llevaba información o codificaba para una enzima.
III.6- Estudiando el ADN
En 1944, Oswald Avery, Colin MacLeod y Maclyn McCarty publicaron un estudio demostrando que la información genética se encuentra recogida en el ADN, y no en las propias proteínas como se pensaba hasta ese momento[19]. Esto cambió el interés de la comunidad científica por esta molécula, que había sido escaso hasta ese momento, y propició el avance de la Genética al identificar la molécula principal de los procesos que estudiaba. A partir de entonces, se profundiza en el estudio de la relación entre los genes y las proteínas, la influencia de la secuencia de nucleótidos en la ordenación lineal de los aminoácidos proteicos, y el impacto de la herencia en ambas.
En 1953, James D. Watson y Francis Crick, apoyándose en el trabajo de difracción de rayos X de Rosalind Franklin y Maurice Wilkins junto con datos de composición de bases de Erwin Chargaff, describen la estructura molecular del ADN, descubriendo así cómo el material hereditario podía ser duplicado o replicado. Un año más tarde, inspirado por los seminarios de Sanger sobre secuenciación de proteínas, Crick formuló la teoría de que el orden de los nucleótidos en el ADN determinaba la secuencia de aminoácidos en las proteínas, lo cual influía en su forma y en su función.
11
La citogenética es la rama de la Genética que estudia la estructura, función y características de los cromosomas. Su comienzo se sitúa a mediados del siglo XIX, pero fue en el siglo XX, con el auge de la Genética y el descubrimiento de que los cromosomas contenían los genes, cuando empezó a cobrar importancia. Durante la primera mitad del siglo, la pregunta principal era cuántos cromosomas había en las células humanas, y para responderla fue necesario desarrollar técnicas de visualización de dichas estructuras en células individuales. Por un tiempo se pensó que eran 48 debido al trabajo de Hans von Winiwarter en 1912, pero en 1955 el Tjio y Levan por un lado y Moorhead y su equipo por otro demostraron que eran 46.
Por otro lado, aunque los procesos de no disyunción cromosómica fueron observados por primera vez en 1908, no fue hasta mediados de la década de 1910 cuando se comenzó a comprender su asociación con ciertas enfermedades de origen genético, y no fue hasta 1959 que se observaron las primeras alteraciones en células humanas. Ese año se describió la primera patología citogenética humana en ser descubierta: la trisomía del cromosoma 21, también conocida como síndrome de Down, que es la alteración numérica más frecuente en la población mundial. La alteración estructural más frecuente es el síndrome de Cri du Chat (deleción en el cromosoma 5), que fue la primera patología definida como un síndrome de aberración estructural.
Entre finales de los 60 y principios de los 70 se observó que los cromosomas teñidos con ciertos colorantes, entre ellos los colorantes Giemsa, presentaban un patrón de bandas específico de cada uno, que ayudaba a identificarlo y a determinar si había alteraciones grandes en su estructura. Esta técnica se empleó para desarrollar el Cariotipo, que representa el patrón cromosómico característico de una especie según las particularidades de sus cromosomas, y que en clínica suele expresarse como un cariograma (representación visual de los cromosomas en metafase, ordenados según su morfología y tamaño). En la actualidad el Cariotipo permite predecir la transmisión de rasgos a la descendencia y diagnosticar y pronosticar el curso de diversos tipos de cáncer.
Hacia finales de los años 70 las técnicas de citogenética se habían desarrollado lo suficiente como para resultar de suma utilidad en la descripción de anomalías cromosómicas. En las congénitas esto permitía diagnosticar precozmente y determinar la naturaleza del defecto cromosómico en los estudios prenatales, mientras que en las adquiridas (células cancerosas) facilitaba la comprensión de la relación entre diversas translocaciones recurrentes y neoplasias hematológicas.
A lo largo de los 80 la técnica se fue perfeccionando y se descubrió que el bandeo permitía distinguir anomalías cromosómicas imposibles de observar con técnicas de coloración homogénea, por ejemplo las inversiones. En esta década se describieron también otras técnicas de marcaje de cromosomas como la Hibridación in situ con sondas fluorescentes (FiSH por sus siglas en inglés), en la que se crean híbridos moleculares de ADN y ARN para determinar la secuencia de ácidos nucleicos. Esto permite asignar genes o marcadores a los cromosomas individuales, de forma que si un cromosoma es identificable mediante su patrón de bandas o cualquier otra característica de su estructura se puede determinar si un gen se encuentra en él gracias a la sonda, así como qué región cromosómica ocupa.
12
La combinación de la técnica FISH con métodos de separación de cromosomas permitió crear sondas de ADN específicas para cada par cromosómico[22]. Estas técnicas de coloreado con fluorocromos ("pintado cromosómico") permitieron desarrollar métodos de comparación de genomas para detectar los patológicos (hibridización genómica comparativa o CGH, Arry-CGH, SKY), facilitando la detección de anomalías cromosómicas en cuadros oncológicos y hematológicos, aunque no siendo tan útiles a la hora de detectar anomalías equilibradas (translocaciones recíprocas, inversiones).
Las anomalías estructurales adquiridas ocurren con frecuencia en células cancerosas de un individuo originalmente sano. El primer ejemplo descrito fue el Cromosoma Filadelfia, una translocación asociada a la leucemia mieloide crónica descubierta en 1960, aunque la estructura exacta (parte del cromosoma 9 y parte del 22 intercambian sus posiciones) se describió en el 73. En neoplasias hematológicas y tumores sólidos la presencia de determinadas alteraciones cromosómicas aporta información con importante valor diagnóstico y pronóstico[23], con lo que los resultados citogenéticos no solo dirigen al diagnóstico a partir de las translocaciones cromosómicas presentes en las células malignas, sino que permiten la caracterización precisa de las leucemias, y aportan información esencial para determinar el pronóstico del cuadro y la susceptibilidad al tratamiento (la presencia de factores de mal pronóstico puede alterar la actitud terapéutica). Por ejemplo, la t(8;21)(q22;q22) indica buen pronóstico en la leucemia aguda no linfoblástica M2, mientras que la monosomía del cromosoma 7 o la detección de cariotipos complejos se relacionan con un pronóstico desfavorable. Cada vez es más frecuente que los protocolos clínicos incluyan en las decisiones terapéuticas el análisis genético de las células neoplásicas[24], ya que este, aparte de aportar conocimiento de la alteración cromosómica, permite seguir la evolución de la enfermedad y valorar la respuesta a tratamiento. Por ejemplo, en las neoplasias hematológicas, el análisis citogenético convencional se ha incorporado a los laboratorios de Genética como una técnica de rutina, que complementa al diagnóstico morfológico e inmunofenotípico.
La caracterización de los genes localizados en los puntos de rotura implicados en las alteraciones cromosómicas asociadas específicamente a un tipo de cáncer ha permitido conocer la significación clínica de muchos marcadores citogenéticos y está ayudando a descubrir los mecanismos etiológicos de algunas neoplasias[20], al ser un paso previo a la localización de los genes implicados en la génesis tumoral.
En investigación, la citogenética ayudó a explicar los mecanismos asociados a patologías genéticas de deficiencia en la reparación del ADN como la anemia de Fanconi y la ataxiatelangiectasia.
Otros campos en los que son útiles estas técnicas son evaluación de parejas con antecedentes de infertilidad o abortos, diagnóstico de anomalías genéticas en personas con fenotipos alterados, y ayuda en las técnicas de reproducción asistida mediante diagnóstico genético preimplantatorio.
13
IV. La revolución del ADN recombinante y las
técnicas de manipulación del genoma
El ADN recombinante es una molécula de ADN creada en el laboratorio mediante técnicas de recombinación genética que unen secuencias obtenidas de fuentes distintas (otras especies, moléculas de ADN creadas mediante síntesis química...). Mediante estas técnicas de edición del genoma podemos modificar el ADN de un organismo para inducir la expresión de rasgos nuevos o alterar los ya existentes añadiendo, quitando o alterando la localización de los genes. Esto requiere la combinación de tecnologías de manipulación del ADN con métodos de introducción del ADN en los organismos diana. Los hitos más importantes del rápido desarrollo de estas tecnologías y su integración en la práctica médica se reflejan en la línea temporal representada en la Figura 2.
IV.1- Tecnología del ADN
recombinante
El concepto de "transformación genética", es decir que el material genético de un organismo se transmita a otro y lo altere fenotípicamente, surgió por primera vez en 1928, con los experimentos de Frederick Griffith. Al principio la falta de herramientas que permitieran la alteración precisa del genoma limitaba mucho la utilidad de las técnicas de manipulación, pero tras el descubrimiento de las endonucleasas de restricción, y con ayuda de las nuevas tecnologías de mapeo y secuenciación rápida de genes, la tecnología del ADN recombinante fue
desarrollándose y facilitando los avances
de la ingeniería genética.
IV.1.1- Enzimas de restricción y
ligación
Figura 2. Principales hitos en las técnicas de manipulación del genoma
14
Las endonucleasas de restricción son enzimas capaces de reconocer una secuencia de nucleótidos (la diana de restricción) en la cadena de ADN y cortarla en ese punto. Su descubrimiento marcó el inicio del desarrollo de las técnicas de ADN recombinante al ofrecer una herramienta que permitía encontrar y aislar secuencias concretas de ADN, ofreciendo precisión al manipular el ADN.
Su existencia se postuló a principios de los años cincuenta, cuando el estudio de los virus bacteriófagos[41] puso de manifiesto que las bacterias tenían un mecanismo de defensa contra la inserción de nuevas secuencias de ADN, y, tras años de investigación, la primera Endonucleasa de restricción se aisló en 1970[48][49]. Por otro lado, en la década de los sesenta, se demostró que el proceso dependía de enzimas que cortaban el ADN viral[44][45] y se descubrió la ADN-ligasa responsable de unir moléculas de ADN[46]. Además la investigación sobre los mecanismos de aparición de resistencias a antibióticos llevó al descubrimiento de los plásmidos, pequeñas moléculas de ADN que se encuentran en el interior de las bacterias y se replican por separado del resto del ADN y que, más tarde, empezarían a usarse como vectores para transferir eficientemente genes a las bacterias[47].
Estos componentes, las enzimas de restricción como "tijeras" para cortar las hebras de ADN, la ADN-ligasa como "pegamento" para unirlas y los plásmidos como vectores para introducir la secuencia en la diana, son la base de la tecnología del ADN recombinante. En 1972 la combinación de los tres permitió la síntesis de la primera molécula de ADN recombinante, que se creó in vitro y se introdujo en una E. coli, dándole las características de la secuencia introducida. Un año más tarde se creó el primer organismo transgénico (que contiene y replica información genética procedente de otra especie), gracias al descubrimiento de un vector adecuado para introducir genes en células de mamíferos. Esto demostró que la tecnología se podía aplicar a cualquier secuencia de ADN independientemente de las especies involucradas[50].
En 1977 el uso de la E. coli para producir somatostatina humana estableció esta bacteria como el organismo de preferencia para producir proteínas recombinantes[31] y en 1983 se autorizó el uso del primer tratamiento creado
mediante esta tecnología, la insulina humana genéticamente modificada[32], que fue sintetizada por primera vez en 1978 y sustituyó a la insulina animal empleada hasta ese momento. Desde entonces el continuo desarrollo y descubrimiento de nuevas técnicas ha permitido alcanzar altos niveles de precisión a la hora de manipular el genoma.
IV.1.2- Reacción en Cadena de la Polimerasa
La Reacción en cadena de la polimerasa (PCR, de Polymerase Chain Reaction) es una técnica de biología molecular que permite replicar repetidamente un fragmento de ADN para conseguir un gran número de copias a partir de una cantidad muy pequeña de este fragmento. No requiere una célula viva para llevarse a cabo ni la manipulación de secuencias de ADN, ya que puede hacerse
15
La primera ADN-polimerasa se identificó en 1957[51], y durante los años sesenta se desarrollaron diversas técnicas necesarias para crear oligonucleótidos sintéticos (usados como cebadores para la polimerasa). En 1976 se describió la polimerasa Taq de la bacteria Thermus aquaticus[52], cuya capacidad de mantenerse estable a las altas temperaturas necesarias para desnaturalizar la cadena de ADN permitió la automatización de las técnicas de replicación al evitar tener que añadir polimerasas en cada ciclo[53]. Todos estos descubrimientos aportaron las bases para que, entre 1983 y 1986, Kary Mullis y sus colegas presentaran varias publicaciones describiendo la Reacción en cadena de la polimerasa[54][55]. Esto revolucionó las técnicas existentes para crear ADN recombinante, al ofrecer una forma rápida de identificar y amplificar una secuencia específica de ADN a cuyos extremos, además, se podían añadir, mediante oligonucleótidos diseñados a tal fin, las secuencias adecuadas para permitir su inserción en vectores de clonado.
Su principal aplicación directa en medicina es como herramienta para el diagnóstico, incluyendo detección de mutaciones causantes de enfermedades genéticas, sobretodo en el análisis prenatal y en el diagnóstico preimplantacional, y análisis del genotipo de células cancerígenas tanto para tipificar sus oncogenes y poder diseñar un tratamiento adecuado contra ellos, como para diagnosticar la neoplasia en sí.
Otro uso en el campo de las enfermedades infecciosas es la detección de agentes infecciosos y la determinación de su virulencia en función de su genotipo, así como valorar las resistencias a antibióticos, facilitando el tratamiento. La técnica puede identificar microorganismos de difícil cultivo, como Micobacterium
tuberculosis, y virus, como el VIH[56], facilitando el diagnóstico precoz de la infección y la valoración de la efectividad del tratamiento empleados. También se usa para detectar agentes infecciosos en las donaciones de sangre y estudiar la propagación una epidemia en medicina preventiva.
IV.1.3- Creación e introducción del ADN recombinante en las células
Para crear ADN recombinante primero se escoge la secuencia que se quiere transmitir o manipular, por ejemplo para producir grandes cantidades de la proteína codificada por el gen en cuestión, y se obtiene una copia de la molécula, ya sea mediante síntesis química o extrayéndola del organismo de origen. A continuación se emplean las endonucleasas o enzimas de restricción para cortar el fragmento de ADN, que luego se inserta mediante una ADN-ligasa en el vector de clonación, por ejemplo un plásmido o un virus.
Una vez creada la molécula de ADN recombinante deseada, hay que introducirla en el organismo huésped al que se va a transmitir, que puede ser desde una bacteria que queremos transformar en una bio-factoría hasta un ser humano que queremos curar mediante modificación genética de sus células. En el primer caso
es una elección frecuente la bacteria Escherichia coli, ya que al haber sido uno de los primeros organismos en usarse se conocen bien sus características[26]; su
principal inconveniente es que no tiene mecanismos de modificación post-traduccional, por lo que hay algunas proteínas eucariotas que no puede producir
16
correctamente[33]. Otros organismos que sí cumplen esa función son levaduras o células de organismos pluricelulares, pero su manejo es más complejo.
Esta introducción del material genético en las células diana puede realizarse mediante diversas técnicas de biología molecular, siendo la más comúnmente empleada la Transformación. El método consiste en modificar la permeabilidad de la envuelta celular para facilitar la entrada del ADN modificado, que además contiene un marcador que permite distinguir las células transformadas de las no transformadas. Otras técnicas son la Transformación no bacteriana, en la que se usan otros métodos para introducir el ADN (por ejemplo inyectarlo directamente en el núcleo de la célula eucariota) o la Introducción mediada por virus.
IV.2- Edición genómica y CRISPR/Cas9
A finales de los años noventa se comenzó a experimentar con métodos para el corte selectivo del ADN de gran tamaño (como los cromosomas eucariotas), siendo la primera tecnología desarrollada las nucleasas con dedos de zinc (ZFN)[40], al principio de los años 2000. Estas enzimas reconocen combinaciones de 3 pares de bases de forma específica, pero es un proceso complicado que no siempre funciona[62]. La siguiente técnica que se creó fueron las TALENs, nucleasas sintéticas más sencillas de manipular y específicas que las ZFNs, pero que seguían requiriendo la creación de proteínas específicas para el ADN diana. Debido a la dificultad en el empleo de estas técnicas, el descubrimiento, a principios de la siguiente década, del método CRISPR/Cas9 significó una revolución en el campode la manipulación genética[58]. A diferencia de los sistemas anteriores, el método CRISPR/Cas9 solo requiere una molécula de ARN complementaria a la secuencia diana para dirigir a la nucleasa a un punto específico del
genoma[57], lo cual es mucho más sencillo que diseñar de novo una proteína con distinta especificidad de unión al ADN. Esto no solo convierte la técnica en un método de edición del genoma preciso y eficiente, sino también en el más sencillo y barato
que hay en la
actualidad[36].
La técnica consiste en emplear una nucleasa específica de la secuencia de la propia bacteria para seleccionar un punto concreto y cortarla, como
17
Primero se sintetiza una molécula de ARN guía complementario a la secuencia de ADN que se quiere modificar al que se asocia la enzima Cas9 (u otras enzimas similares). Esta molécula reconoce la secuencia diana en el genoma y se hibrida con ella, provocando que la enzima introduzca un corte de doble cadena en la región deseada. A continuación, se activan los mecanismos celulares de reparación del ADN, lo que conlleva la introducción de pequeñas inserciones y deleciones que inactivan la secuencia codificante. Si, en lugar de dejar que la secuencia se repare sin más, se añade un ADN externo con la homología adecuada, se aprovecha el mecanismo de reparación para integrar esa nueva secuencia de bases en el lugar donde la nucleasa ha introducido el corte[36][59].
La utilidad de las Cas (nucleasas asociadas a secuencias CRISPR) como herramientas de manipulación del genoma se comenzó a descubrir en 2012 y 2013. Durante estos años se publicaron varios artículos que demostraban que Cas9 podía programarse para cortar sitios concretos del ADN tanto in vitro como en las células, resultando en una técnica mucho más específica y sencilla de usar[39]. Poco después de su descubrimiento algunos predecían que acabaría sustituyendo por completo a las técnicas existentes en el momento[40], lo cual no ha resultado ser del todo cierto, al menos de momento. La investigación sobre este método de manipulación del genoma ha ofrecido múltiples posibles aplicaciones en medicina y en 2015 se utilizó por primera vez en embriones humanos. Sin embargo, al ser una tecnología relativamente nueva, todavía no hay muchos usos directos, siendo la mayoría de las aplicaciones en medicina aún experimentales. En 2016 se llevaron a cabo varios ensayos clínicos para valorar su uso en el tratamiento de enfermedades genéticas congénitas como la cardiomiopatía hipertrófica[63] y se realizó el primer uso terapéutico cuando unos investigadores introdujeron células modificadas mediante la técnica en un paciente con cáncer de pulmón[42]. También se está investigando su empleo en cuadros como la anemia falciforme[64], y se han llevado a cabo múltiples ensayos clínicos para emplearla en el tratamiento de diversos cuadros aunque, con algunas excepciones, todavía no se han aprobado pruebas en humanos. En la siguiente sección (Apartado IV.3.2) se comentan algunos de los ensayos que sí se están realizando en humanos.
IV.3- Aplicaciones en medicina
Las técnicas de manipulación del ADN se pueden emplear para prevenir y tratar muchos procesos, y en la actualidad se siguen investigando sus usos tanto en el tratamiento de enfermedades de herencia mendeliana como para manejar cuadros más complejos. También han ayudado en la creación de muchos productos farmacéuticos y pruebas de laboratorio, porque la capacidad para crear proteínas recombinantes en sistemas microbianos ha facilitado la producción de grandes cantidades de la proteína purificada, lo cual permite su obtención de forma mucho más eficaz y segura que los antiguos métodos de purificación a partir de plantas o tejidos animales[25][26]. Además, las proteínas recombinantes se usan como reactivos en experimentos de laboratorio.
Su uso más extendido es en investigación genética[26], donde permiten estudiar los genes, determinar su secuencia, identificar su función y analizar su expresión. Este conocimiento es indispensable en la comprensión de las enfermedades genéticas, así
18
como en el diseño de modelos de estudio, la creación de pruebas de diagnóstico y el desarrollo de tratamientos.
Las tecnologías de manipulación genética se han usado también para crear los principales test de diagnóstico de infección por VIH. El test de anticuerpos emplea una proteína de VIH recombinante con los test de ELISA o Western blot para detectar si hay anticuerpos contra el virus en la sangre del paciente, mientras que el test de ADN mediante PCR con retrotranscriptasa (RT-PCR) se desarrolló empleando técnicas de clonación molecular y análisis de secuencias del genoma del VIH.
La creación de microorganismos modificados genéticamente para generar productos farmacológicos como hormonas, componentes del sistema inmune o enzima, usadas en enfermedades genéticas debidas a déficits enzimáticos, ha significado un avance importante en el tratamiento de muchas enfermedades. Un ejemplo es la Insulina humana recombinante para tratar la diabetes mellitus, que fue el primer producto recombinante en comercializarse[25] (antes se empleaba la derivada de animales). Otro es la Hormona del crecimiento humano recombinante para el tratamiento de pacientes con desórdenes de crecimiento, que sustituyó por completo a la obtenida de cadáveres y, con ello, eliminó el riesgo que conllevaba de causar prionopatía[34]. En hematología ha permitido el desarrollo del Factor de coagulación VIII recombinante para tratamiento de la hemofilia, que redujo el gasto de sangre donada permitiendo su uso en otros pacientes[35], y la Eritropoyetina para la anemia, por ejemplo para pacientes con insuficiencia renal crónica. También se ha empleado para desarrollar vacunas, por ejemplo la de la hepatitis B, que previamente carecía de vacuna al no poder cultivarse el virus in vitro.
IV.3.1- Terapia génica
La terapia génica es el conjunto de técnicas terapéuticas que emplean métodos de edición y transferencia del material genético para introducir secuencias concretas de ácidos nucleicos en el genoma de las células de un paciente. La estrategia más común consiste en implantar una copia del gen sano para sustituir la función del gen defectuoso, restableciendo un proceso que ha quedado abolido, pero también hay terapias que inducen funciones completamente nuevas o que inhiben la función de genes que causan de forma activa la enfermedad.
Los tipos de terapia génica varían en el material genético que se transfiere (el gen que se quiere introducir), el método de transferencia (el vector, que puede ser viral o no viral, debe transmitir el material genético a las células apropiadas y tener acceso al tejido correspondiente) y la célula diana cuyo genoma se quiere modificar (el proceso puede realizarse en las células ex vivo para luego reintroducirlas en el paciente o in vivo empleando métodos que permitan la llegada de la cadena a la célula diana, como se muestra en la Figura 4). Actualmente solo está permitida la terapia génica en células somáticas, habiéndose prohibido su uso en células germinales por limitaciones técnicas y motivos éticos.
19 El concepto de terapia génica comenzó a desarrollarse en los años setenta después de que Friedmann y Roblin publicaran en 1972 un artículo sugiriendo el uso de técnicas de manipulación
de ADN para sustituir las secuencias defectuosas por secuencias sanas[73], siguiendo las ideas propuestas por otros investigadores.
En las décadas siguientes se investigó sobre estas nociones, haciéndose innovaciones como el diseño de vectores que empleaban retrovirus para insertar genes en el material genético. El primer uso exitoso con intención terapéutica fue un ensayo clínico, financiado por los Institutos Nacionales de Salud de Estados Unidos, que comenzó en 1990 y consistía en un tratamiento para la deficiencia de adenosina desaminasa propuesto por William French Anderson que empleaba vectores retrovirales para insertar copias del gen que codifica para la proteína[25].
A lo largo de esta década se realizaron también estudios sobre su aplicabilidad en cáncer y enfermedades hematopoyéticas. A finales de los años noventa se produjo un nuevo éxito terapéutico con el tratamiento de un grupo de niños con una inmunodeficiencia ligada al cromosoma X (XSCID) que mostraron clara mejora de los síntomas tras el tratamiento[74], siendo destacable que la cura era permanente porque las células modificadas permanecían en los pacientes de forma estable. Debido a falta de conocimiento sobre el comportamiento del vector retroviral en aquel momento, dos de ellos acabaron desarrollando leucemia aguda a causa de la terapia al activarse un oncogén como resultado de la inserción del retrovirus[75].
A partir del 2000 la investigación sobre técnicas de terapia génica empezó a acelerarse, haciéndose estudios sobre su aplicación en enfermedades monogénicas, degenerativas, hematológicas y tumorales. En 2006 un estudio de los Institutos Nacionales de Salud estadounidenses fue el primero en demostrar que esta clase de terapia podía ser efectiva en el tratamiento de neoplasias[76]. A finales de esa década y principios de la siguiente se estaban realizando múltiples ensayos sobre su uso en enfermedades de muy diversas especialidades médicas, y había resultados alentadores en muchos de ellos. A mediados de 2012
20
la Agencia Europea del Medicamento recomendó por primera vez la aprobación de un tratamiento basado en terapia génica, en concreto de un fármaco para la deficiencia de lipoproteín lipasa[77].
El número de ensayos con resultados positivos, de curación o, al menos, mejora de los síntomas, ha seguido creciendo, y actualmente se están realizando decenas de ensayos[25] que se aplican no solo a procesos de carácter monogénico, sino también a procesos de etiopatogenia multifactoral como infección por VIH, cáncer, aterosclerosis, enfermedades autoinmunes, enfermedades hematológicas.
Debido a que son técnicas de reciente descubrimiento, sus usos están aún siendo investigados y la mayoría de aplicaciones se limitan a pruebas en ensayos clínicos. Una de estas aplicaciones es el tratamiento de enfermedades hereditarias monogénicas, sobretodo deficiencias enzimáticas en las que se puede sustituir el gen deficitario, y adquiridas, en las que en teoría la introducción de ciertos genes podría revertir o ralentizar el proceso de desarrollo de enfermedades como la diabetes, la ateroesclerosis[79] o la cirrosis[80]. Otros usos intentados son el tratamiento de enfermedades infecciosas, como la hepatitis o el SIDA, y de tumores, sobre todo en procesos sin un tratamiento eficaz o en los que el tratamiento convencional ha fracasado. También tiene aplicaciones en el diagnóstico, como el marcaje genético de células específicas para saber si una recaída tras un tumor se debe a la misma línea celular del tumor original.
Algunos tratamientos que se han empezado a aprobar en la práctica clínica son Strimvelis para la deficiencia de adenosina deaminasa en Europa y Tisagenlecleucel para leucemia aguda linfoblástica.
La incorporación de las nuevas tecnologías de edición genética a la terapia génica, especialmente el CRISPR/Cas9, ha ampliado mucho las posibilidades terapéuticas. Si bien, debido a su reciente desarrollo, la mayoría aún están en fase de investigación, algunos ensayos ya han llegado a su fase de aplicación en humanos, e incluso hay tratamientos que se han comercializado.
Uno de estos tratamientos es Luxturna[43], una terapia génica que introduce una variante normal del gen mutado en las células de la retina para contrarrestar los efectos de la mutación y que ha sido aprobado por la FDA estadounidense para el manejo de enfermedades retinianas como la amaurosis congénita de Leber, un grupo de patologías en las que se está investigando mucho con CRISPR/Cas9. Otro tratamiento que ya se está probando en humanos es CTX001, una técnica que consiste en modificar las células madre hematopoyéticas para inducir la formación de hemoglobina fetal con la esperanza de que al reintroducirlas en el paciente esta hemoglobina contrarreste la enfermedad causada por la hemoglobina adulta patológica[38], y que también ha sido aprobada recientemente para pruebas en humanos por la FDA estadounidense[42].
21
Por otro lado, se está investigando el uso de estas terapias en enfermedades degenerativas neurológicas como la enfermedad de Alzheimer, la enfermedad de Huntington o la distrofia muscular de Duchenne. Estas dos últimas, al ser enfermedades asociada a un gen concreto, son buenas candidatas a tratamiento por modificación genética[38][43].
Contra la infección por VIH se han sugerido tanto mecanismos que usan CRISPR/Cas9 para inducir resistencia a la infección en las células inmunes[65] como sistemas que paralizan la extensión de la infección al evitar la inserción del genoma viral en las células[66]. También se han investigado terapias contra el virus del papiloma humano (HPV) basadas en la disrupción de la secuencia genómica vírica[67], lo cual ayudaría en la prevención del cáncer de cuello uterino. Otras terapia tumoral que se está investigando son tratamientos para las neoplasias de pulmón y esófago (ambos se asocian a la expresión de PD-1 en la superficie celular, con lo que se está investigando una técnica de CRISPR-Cas9 para parar esta expresión)y para la leucemia linfoblástica aguda[43].
También se ha investigado el uso de tratamientos basados en la tecnología CRISPR/Cas9 en la diabetes mellitus tipo 1[38] y la malaria (se han sugerido tanto métodos para erradicar la población de mosquitos Anopheles[68] como para hacerlos resistentes a la enfermedad[69]). Otro uso sugerido es como antibiótico contra especies multi-resistentes[70], usándolos contra los genes que provocan la resistencia, pero habría que encontrar una forma de administrar las enzimas a las bacterias.
En aplicaciones no terapéuticas podría usarse para detectar cambios en la expresión genética que puedan resultar relevantes durante el tratamiento (por ejemplo desarrollo de resistencia a fármacos)[71] o para crear modelos celulares o animales de enfermedad más similares a los humanos.
Por otro lado, no se deben olvidar las técnicas de modificación genética originales, que aún tienen aplicaciones en medicina. Las TALENs se han usado para desarrollar la terapia CAR-T, consistente en modificar linfocitos T obtenidos de los pacientes para que ataquen las células tumorales. Este tratamiento se emplea sobre todo en tratamiento de neoplasias hematológicas como la leucemia y las pruebas con él comenzaron en 2015[42].
V. La genómica y la post-genómica
La genómica es un campo científico relativamente nuevo que forma parte tanto de la biología molecular como de la Genética, diferenciándose de la Genética tradicional en que no estudia los genes individualmente, sino que analiza el funcionamiento del genoma como una unidad, valorando las interacciones entre las unidades genéticas y el resto de factores que influyen en la salud. Emplea técnicas moleculares para obtener la secuencia y analizar mediante programas informáticos la información conseguida sobre los distintos genes y la variación que presentan los individuos de una especie.
22
Una de las subdisciplinas de este campo es la Genómica estructural, que compara la estructura física del genoma de distintos seres vivos. Otra es la Genómica funcional, que estudia la función del genoma y sus
mecanismos de funcionamiento.
Esenciales en este proceso son las diversas técnicas bioquímicas de secuenciación de ácidos nucleicos, procesos que determinan el orden en el que se disponen los nucleótidos de una hebra de ADN. Su evolución ha jugado un papel muy importante en el desarrollo de la biología molecular y la genética. En la
Figura 5 se esquematiza la línea temporal
de los avances en este campo y el desarrollo de sus aplicaciones a la Medicina.
V.1- Técnicas de secuenciación
del ADN
La secuenciación de ADN se convirtió en un punto de interés entre los biólogos moleculares en los años cincuenta, a raíz de la publicación de su estructura en 1953 por parte de James Watson y Francis Crick y de la descripción de la secuencia de aminoácidos de la insulina en 1955 por Frederick Sanger. La investigación de Sanger sobre técnicas de secuenciación de proteínas inspiró a Francis Crick quien, basándose en sus experimentos, publicó en 1958 una teoría en la que exponía la idea de que la secuencia de aminoácidos en las proteínas, que determinaba su función, dependía de la secuencia de nucleótidos en el ADN[82].
Interesada por este concepto, la comunidad científica comenzó a investigar cómo determinar el orden de las bases en las moléculas de ADN, y en 1965 se publicó la primera secuencia de una molécula de ARN[88]. Más tarde, en 1972, el equipo de Walter Fiers logró la primera secuenciación de un gen
23
bacteriófago MS2[89].
Sin embargo, el acontecimiento más importante de esta etapa de la Genética fue el desarrollo, entre 1975 y 1977, de un método de secuenciación de ADN por el equipo de Frederick Sanger[90], proceso que culminó con la publicación de la primera secuencia del genoma completo de un organismo, el del bacteriófago lambda[91]. La Secuenciación de Sanger, o secuenciación por terminación de la cadena, es un método enzimático que consiste en copiar repetidas veces el trozo de ADN que nos interesa mediante la ADN polimerasa y, al mismo tiempo, añadir nucleótidos alterados de tal forma que al usarlos la enzima detiene la síntesis de la cadena y marca su final[92]. Estos fragmentos de longitudes distintas pueden separarse luego mediante electroforesis en gel según su tamaño, permitiendo así dilucidar la secuencia según los fragmentos obtenidos al conocer el nucleótido alterado que se ha añadido.
Al mismo tiempo que se presentó la secuenciación de Sanger, otro grupo de investigadores publicó la Secuenciación de Maxam-Gilbert o secuenciación química, en la que se rompe la molécula con varios métodos de forma que se escinda la cadena en una zona con un nucleótido específico[93]. Al principio tenía la ventaja de que no era necesario sintetizar la molécula de ADN, lo que la hacía preferible a la técnica de Sanger, pero con el tiempo el refinamiento del método de Sanger y la complejidad de la secuenciación de Maxam-Gilbert acabó haciendo que la primera se empleara más. La secuenciación de Sanger continuó siendo el método de referencia empleado para la secuenciación y análisis de ADN hasta la creación de las técnicas de segunda generacióna principios de los 2000, casi de 30 años después.
La tecnología de secuenciación se fue desarrollando con el tiempo, y a finales de los años setenta la automatización de la técnica y el desarrollo de mejoras como el marcaje fluorescente o la electroforesis capilar incrementaron la velocidad de secuenciación y la cantidad de información que producía, bajando su precio y aumentando su eficacia[83]. Esto propició a su vez la creación de los primeros bancos de datos y herramientas de análisis capaces de manejar tal cantidad de información, como GenBank o Applied Biosystems en 1982.
Durante los años ochenta se presentaron nuevas técnicas que optimizaron la secuenciación genética y se profundizó en el estudio de los genes y su variación en relación con diversas enfermedades. En 1984 Kary Mullis describió la Reacción en cadena de la polimerasa (PCR), método que permite amplificar secuencias específicas de ADN, y se logra secuenciar el ADN del virus de Epstein-Barr, lo cual es relevante porque, a diferencia de con las secuenciaciones anteriores, no se disponía de información genética previa de este virus. En 1986 se sugiere por primera vez el término de genómica para referirse a la rama de la Genética que estudia la secuencia completa del genoma para analizar sus funciones.
El siguiente gran paso en la historia de la secuenciación fue el comienzo, en 1990, del Proyecto Genoma Humano. Esta iniciativa impulsó el desarrollo de nuevas técnicas, al presentar un reto que requirió la optimización de los métodos empleados hasta entonces y la creación de nuevas herramientas capaces de responder a las necesidades de los investigadores para mapear el genoma completo. En 1995 se secuencia por
24
primera vez el genoma completo de un organismo no viral, el Haemophilus
influenzae[94].
Tras la publicación de la secuencia del genoma humano, las técnicas continuaron avanzando, lo cual permitió la secuenciación del material genético de cientos de organismos y el uso de la tecnología de secuenciación en el laboratorio. En 2005 la presentación comercial de las técnicas de nueva generación, plataformas de secuenciación masiva que se caracterizan por poder secuenciar grandes cantidades de ADN en poco tiempo, revolucionó de nuevo el campo de la investigación en Genética y Biología molecular[87]. Su rápida evolución, gran rendimiento y alta precisión han significado un gran avance, al facilitar su uso por la comunidad científica para estudiar con más detalle la secuencia genética.
El punto fuerte de los métodos de segunda generación es su capacidad para descifrar la secuencia a gran escala, ya sea de moléculas grandes o de grandes cantidades de secuencias cortas, aumentando la velocidad y reduciendo el precio. Así, mientras que los métodos de primera generación tardaron años en secuenciar el genoma humano entero, los métodos actuales pueden hacerlo en días, y cada vez de forma más rápida. Esto se debe a que realizan la secuenciación de forma simultánea (en paralelo) y cada reacción ocupa poco espacio, permitiendo que se hagan muchas en una superficie pequeña. Las secuencias largas se analizan fragmentándolas mediante enzimas de restricción o de forma mecánica para leer la secuencia de los pedazos y luego reconstruirla como si fuera un puzle.
TÉCNICA PARES DE
BASES TIEMPO VENTAJAS DESVENTAJAS
1ª Gen e ra ci ó n Secuenciación de Sanger Didesoxinucleótidos trifosfato 1000 horas Preciso
Secuencia cadenas largas
Alto precio Mayor complejidad de la técnica Secuenciación de Maxam-Gilbert
Fragmentación química 500 horas
No necesita sintetizar la cadena complementaria a la secuencia diana Mayor complejidad de la técnica Uso de productos peligrosos 2 ª Gen er ac ió n 454 Life
Sciences Pirosecuenciación 400-600 horas
Rápido
Secuencia cadenas largas Alto precio
SOLiD Secuenciación por ligasa 100 semanas Bajo precio
Secuencia un número bajo de bp
Lento
Ion Torrent Secuenciación mediante
semiconductor 400 horas Rápido Bajo precio Secuencia un número bajo de pb SOLEXA Secuenciación por polimerasa con terminadores reversibles
300-500 días Bajo precio Secuencia cadenas largas
Costoso de adquirir y mantener Requiere grandes cantidades de ADN 3 ª Gen e ra ci ó n Polimerasa PacBio SMRT (Single Molecule,
Real time) 5000-8000 horas
Rápido
Secuencia cadenas muy largas
Baja precisión Requiere grandes cantidades de ADN
Helicos GAS SMFS (Single Molecule
Fluorescent Sequencing) 10 kb días
Preparación simple de las muestras
Secuencia un número bajo de pb
Lento



![Tabla 1. Comparación de las técnicas de secuenciación [165][166][167][168][169]](https://thumb-us.123doks.com/thumbv2/123dok_es/6783789.270319/25.892.61.835.660.1150/tabla-comparación-técnicas-secuenciación.webp)