i
UNIVERSIDAD TÉCNICA PARTICULAR DE LOJA
La Universidad Católica de Loja
ÁREA TÉCNICA
TÍTULO DE INGENIERO EN SISTEMAS INFORMÁTICOS Y
COMPUTACIÓN
Análisis de Grafos en paralelo mediante Graphx
TRABAJO DE TITULACIÓN
AUTOR: Rodríguez Bautista, Daniel Ignacio.
DIRECTOR: López Vargas, Jorge Afranio, Ing.
LOJA
–
ECUADOR
Esta versión digital, ha sido acreditada bajo la licencia Creative Commons 4.0, CC BY-NY-SA: Reconocimiento-No comercial-Compartir igual; la cual permite copiar, distribuir y comunicar públicamente la obra, mientras se reconozca la autoría original, no se utilice con fines comerciales y se permiten obras derivadas, siempre que mantenga la misma licencia al ser divulgada. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.es
ii APROBACIÓN DEL DIRECTOR DEL TRABAJO DE TITULACIÓN
Ingeniero.
Jorge Afranio López Vargas.
DOCENTE DE LA TITULACIÓN
De mi consideración:
El presente trabajo de fin de titulación: Análisis de grafos en paralelo mediante GraphX, realizado por Daniel Ignacio Rodríguez Bautista, ha sido revisado y orientado durante su ejecución, por cuanto se aprueba la presentación del mismo.
Loja, marzo del 2016.
f)………
iii DECLARACIÓN DE AUTORÍA Y CESIÓN DE DERECHOS
―Yo, Daniel Ignacio Rodríguez Bautista, declaro ser autor del presente trabajo de titulación: ‗Análisis de grafos en paralelo mediante GraphX‘, de la Titulación de
Sistemas Informáticos y Computación, siendo el Ing. Jorge Afranio López Vargas director del presente trabajo; y eximo expresamente a la Universidad Técnica Particular de Loja y a sus representantes legales de posibles reclamos o acciones legales. Además certifico que las ideas, conceptos, procedimientos y resultados vertidos en el presente trabajo investigativo, son de mi exclusiva responsabilidad.
Adicionalmente declaro conocer y aceptar la disposición del Art. 88 del Estatuto Orgánico de la Universidad Técnica Particular de Loja que en su parte pertinente
textualmente dice: ―Forman parte del patrimonio de la Universidad la propiedad intelectual de investigaciones, trabajos científicos o técnicos y tesis de grado o trabajos de titulación que se realicen con el apoyo financiero, académico o institucional
(operativo) de la Universidad‖.
f)………..
iv DEDICATORIA
El presente trabajo va dedicado primeramente a Dios porque él es mi mentor principal,
y cada logro en mi vida se lo debo primeramente a él.
En segundo lugar se lo dedico a mis padres y a mi hermano menor quienes siempre
desearon verme realizar mis sueños, para quienes mi éxito se constituye en una gran
alegría, a ellos dedico este logro y los resultados positivos que repercutan en
consecuencia.
A Irene, quien ha sido mi inspiración y quien siempre me ha levantado el ánimo, le
dedico este trabajo con mucho cariño y ansioso de poder disfrutar con ella también del
fruto de mi esfuerzo.
A toda la gente que siempre creyó en mí, y a los que no creían en mí pero luego se
v AGRADECIMIENTO
Mi agradecimiento primeramente al Altísimo, a mi Señor Jesús que es de quien viene
la sabiduría y el conocimiento, y es quien me ha capacitado durante todo mi proceso y
en todas las áreas de mi vida.
En segundo lugar a mis padres y también a mi hermano, por su confianza en mí y por
su apoyo incondicional en el aspecto moral, psicológico, económico, espiritual, etc.
Además porque fueron quienes me formaron con valores cristianos y morales lo cual
me ha llevado al éxito en todo, y siempre están orando por mí lo cual es el mayor
respaldo que una persona pueda tener, aunque no los tenga cerca.
También quiero darle las gracias a Irene, quien ha sido un pilar fundamental para yo
poder salir adelante, ha suplido muchas necesidades en mí y me ha dado siempre su
apoyo, recordándome siempre quién soy, y quién está conmigo, diciéndome siempre
que soy capaz y estando a mi lado en las buenas y en las malas.
Finalmente quiero darle las gracias a mi director de tesis, a quien admiro y respeto, y
cuya actitud y frontalidad me llevaron muchas veces a reflexionar sobre mis errores y
me enseñaron a ser mucho mejor de lo que podría estar siendo hasta determinados
momentos; siempre me llevó a hacer más allá de lo que creía que podía hacer. Y a
todos mis demás familiares, hermanos en Cristo y amigos, buenos y malos, todos
fueron parte de mi formación, unos más que otros, pero son quienes complementan mi
vi ÍNDICE DE CONTENIDOS
APROBACIÓN DEL DIRECTOR DEL TRABAJO DE TITULACIÓN ... ii
DECLARACIÓN DE AUTORÍA Y CESIÓN DE DERECHOS ... iii
DEDICATORIA ... iv
AGRADECIMIENTO ... v
ÍNDICE DE CONTENIDOS ... vi
RESUMEN ... 1
ABSTRACT ... 2
INTRODUCCIÓN ... 3
CAPÍTULO 1: ESTADO DEL ARTE ... 5
1.1 Introducción ... 6
1.2 Big Data. ... 6
1.2.1 Movimiento NoSQL. ... 8
1.2.2 ¿Qué tipo de datos se debe explorar? ... 9
1.3 Análisis de Redes Sociales (SNA: Social Network Analysis). ... 10
1.3.1 Niveles de análisis. ... 12
1.4 Procesamiento de grafos. ... 13
1.4.1 Grafos Dirigidos ... 14
1.4.2 Grafos Conexos y Componentes ... 15
1.4.3 Herramientas para el Procesamiento de Grafos. ... 15
1.4.3.1 Apache Giraph ... 15
1.4.3.2 GraphLab PowerGraph ... 16
1.4.3.3 PowerLyra ... 16
CAPÍTULO 2: CONCEPTOS BÁSICOS ... 18
2.1Bases de datos orientadas a grafos ... 19
2.1.1 Ventajas y desventajas de una BDOG... 20
2.1.2 Modelos de datos en Grafo. ... 21
2.2Computación Paralela ... 23
2.2.1 Clasificación de los sistemas paralelos. ... 23
2.2.2 Clúster. ... 27
2.3Spark. ... 29
2.3.1 Resilient Distributed Dataset. ... 29
2.3.2 Spark SQL. ... 30
2.3.3 Spark Streaming. ... 31
2.3.4 Machine Learning Library (MLlib). ... 31
vii
2.4Tecnologías asociadas ... 34
2.4.1 Scala. ... 35
2.4.2 SBT (Simple Build Tools). ... 35
2.4.3 JDK (Java Development Kit). ... 36
2.4.4 Apache Maven. ... 36
CAPÍTULO 3: INSTALACIÓN, CONFIGURACIÓN Y DESPLIEGUE DE SPARK-GRAPHX ... 37
3.1 Instalación de Spark ... 38
3.2 Spark Standalone Clúster ... 39
3.3 Hadoop YARN. ... 44
3.3.1 Spark sobre YARN. ... 48
3.4 Análisis de grafos con GraphX ... 49
CAPÍTULO 4: MÉTRICAS DEL SNA – GRAPHX ... 51
4.1 Métricas del SNA ... 52
4.1.1 Centralidad de Grado (Degree Centrality). ... 52
4.1.2 Centralidad de Intermediación (Betweenness Centrality). ... 52
4.1.3 Centralidad de Cercanía (Closeness Centrality). ... 53
4.1.4 Centralidad Vector Propio. ... 53
4.1.5 Coeficiente de agrupamiento. ... 53
4.1.6 Densidad. ... 53
4.2 SNA – GraphX... 54
4.2.1 Casos de aplicación. ... 55
CONCLUSIONES ... 57
RECOMENDACIONES ... 59
BIBLIOGRAFÍA ... 61
ANEXOS ... 63
ANEXO A: INSTALACIÓN DE SBT. ... 64
ANEXO B: INSTALACIÓN DE SCALA. ... 65
ANEXO C: INSTALACIÓN DE MAVEN. ... 66
ANEXO D: INSTALACIÓN DE JDK. ... 67
ANEXO E: APLICACIÓN DE EJEMPLO – GRAPHX. ... 72
ANEXO F: CAPTURAS GRAPHX ... 73
ANEXO G: DESPLIEGUE DE GRAPHX SOBRE STANDALONE-CLUSTER ... 75
1 RESUMEN
El manejo de información expresada en grafos es una de las tendencias actuales,
gracias a la popularidad de redes sociales online, diariamente se genera grandes
volúmenes de los datos, lo que provoca que las técnicas tradicionales de
procesamiento se vean limitadas. Dentro del procesamiento de grandes volúmenes de
datos o Big Data ha empezado a surgir una alternativa a Map/Reduce llamada Spark,
que cuenta con una librería para el procesamiento distribuido de grafos. El presente
proyecto de fin de titulación busca explorar las capacidades de procesamiento de
grafos en paralelo, de una de las tecnologías más actuales de clustering computing
llamada Spark, específicamente de su librería para el procesamiento de grafos en
paralelo denominada ―GraphX‖.
2 ABSTRACT
The management information expressed in graph is one of the current trends, thanks to
the popularity of online social networks daily large volumes of data are generated,
which causes traditional processing techniques look limited. Within the processing of
large volumes of data or big data it has begun to emerge an alternative to Map/Reduce
called Spark , which has a library for distributed processing graph. This project seeks to
explore the capabilities degree of processing graphs in parallel, one of the latest
clustering computing technologies called Spark, specifically its library for parallel graph
processing called ―GraphX‖.
3 INTRODUCCIÓN
El tema desarrollado para este trabajo de fin de titulación consiste en la
implementación de una de las herramientas de Big Data, una librería de Apache Spark
llamada Graphx para el procesamiento de grafos en paralelo.
Este trabajo de titulación pretende instalar, configurar y determinar qué métricas del
SNA se pueden aplicar usando Spark-Graphx, sobre más de una plataforma.
A través de los capítulos se tendrá un acercamiento a lo que es Big Data, qué
procesos sigue y en dónde se ubica el presente tema de tesis. Además se podrá
conocer en detalle los aspectos más relevantes de Spark – Graphx, los componentes
que requiere para construirse la implementación de un clúster para el procesamiento
de grafos en paralelo y algunas recomendaciones y mejores prácticas para su uso.
La importancia de este trabajo radica en el hecho de que actualmente la información
crece desmesuradamente, y las herramientas conocidas para su tratamiento empiezan
a verse limitadas; es por ello que surge la necesidad de buscar nuevas alternativas,
nuevas soluciones, y herramientas como ésta dan respuesta a muchas necesidades
que las tecnologías tradicionales no.
La solución al problema planteado se dio gracias a una investigación intensiva,
revisión bibliográfica, ejecutando un sin número de pruebas hasta llegar a la solución
definitiva.
Todo lo conseguido hasta el momento se ha documentado para a partir de allí poder
continuar con la investigación. Cabe señalar que la solución detallada se puede
4 Objetivo general
Explorar las capacidades de procesamiento de grafos en paralelo de GraphX.
Objetivos específicos
Implementar Spark y su librería para el procesamiento de grafos en paralelo
GraphX (multiplataforma, en Linux y Mac OS); para poder establecer una
instalación y configuración limpia de esta tecnología, determinar ventajas y
desventajas de su instalación en cada plataforma, y por último, observar su
comportamiento realizando algunas iteraciones, con variaciones en el hardware
asignado para el clúster y los datasets a analizar.
Implementar un cluster manager para realizar el procesamiento en paralelo.
Construir un grafo en GraphX y determinar qué métricas del SNA se pueden
6 1.1 Introducción
Es importante saber lo que el mundo está haciendo con respecto al análisis de datos
expresados en grafo, para de esta manera poder tener clara la perspectiva desde la
cual se abordará el presente tema de tesis.
Existe una variedad de técnicas y herramientas para realizar este trabajo, cada una
con su particularidad, pero con el transcurso del tiempo la información ha ido
creciendo mucho más rápido de lo que estas técnicas y herramientas han ido
evolucionando, y el coste de implementación de grandes infraestructuras para realizar
este tipo de procesamiento también se ha incrementado.
Sin embargo, en los últimos años la ciencia ha ido reaccionando más rápido a los
estímulos provocados por Big Data y ha desarrollado herramientas que no solo
optimizan el procesamiento, sino también la utilización de hardware.
En esta sección se verán algunos aspectos referentes al origen del procesamiento de
grafos, el concepto que lo engloba y algunas herramientas útiles para realizar esta
tarea.
1.2 Big Data.
Big Data es un concepto que está muy de moda y que a lo largo del tiempo se ha ido
expandiendo. Básicamente consiste en la manipulación de grandes cantidades de
información, lo que implica una alta demanda de hardware e infraestructura
tecnológica. Este fenómeno ha ocasionado que las herramientas convencionales de
gestión de datos (como las bases de datos relacionales) se vean cada vez más
limitadas a la hora de gestionar estas gigantescas cantidades de información
(petabytes de información), que cada día se genera a mayor velocidad y en mayores
cantidades; esto ha generado la búsqueda de nuevas alternativas, nuevas maneras de
7 de NoSQL, que es un movimiento del cual se hablará más adelante, que ofrece varias
alternativas para el almacenamiento de los datos; a más de eso, en la actualidad se
han desarrollado diversas herramientas para el procesamiento de dicha información.
El Grupo TRC1 (Grupo TRC, s.f.) sostiene que Big Data:
Es una definición utilizada en tecnología para referirse a la información o grupo de datos que por su elevado volumen, diversidad y complejidad no pueden ser almacenados ni visualizados con herramientas tradicionales. Las dimensiones de estos datos obligan a las empresas a buscar soluciones tecnológicas para gestionarlos, pues un buen manejo del Big Data puede representar nuevas métodos para la toma de decisiones y oportunidades de negocio.
Las principales técnicas de Big Data comprenden la captura y análisis de la información, estructurada, semi-estructurada y no estructurada, la misma que se produce por medio de las redes sociales, páginas web, dispositivos móviles, correos electrónicos, videos, notas de voz, archivos de texto, etc., luego la minería de datos (para su análisis), y la visualización de la información.
Existen tres conceptos clave relacionados con Big Data:
Volumen.
Variedad.
Velocidad.
Volumen.- Se refiere al tamaño de la información. ―En el año 2012, la cantidad de información en el universo digital llegó a 2.8 zettabytes (ZB); según un informe de la consultora IDC Digital Universe para el año 2020 se podrían alcanzar los 40 ZB de datos generados por personas y dispositivos.‖ (IDATHA, 2014)
Variedad.- ―Estructurados o no, los datos pueden provenir de diversas fuentes y formas. Imágenes, videos, tweets, etiquetas RFID, historias clínicas, sensores de movimiento, etcétera.‖ (IDATHA, 2014)
Velocidad.-―La velocidad en el acceso y el flujo de datos es el gran reto que plantea Big Data no solo hoy, sino también —y sobre todo— de cara al futuro.‖ (Lantares, s.f.)
1
8 1.2.1 Movimiento NoSQL.
Las bases de datos NoSQL (Not only SQL) ―son sistemas de almacenamiento de información que no cumplen con el esquema entidad-relación tradicional, es decir, no imponen una estructura de datos en forma de tablas y relaciones entre ellas.‖ (Nasca, 2014)
Las bases de datos relacionales tradicionales permiten definir la estructura de un esquema que demanda reglas rígidas que garantizan ACID:
- Atomicy. - Consistency. - Isolation. - Durability.
Pero ―las aplicaciones web modernas presentan desafíos muy distintos a los que presentan los sistemas empresariales tradicionales (ej. sistemas bancarios):
- Datos a escala web.
- Alta frecuencia de lecturas y escrituras.
- Cambios de esquemas de datos frecuentes.‖ (Ipiña, 2012)
Las principales características de los sistemas NoSQL son:
Estructura dinámica: ―Los datos no tienen una definición de atributos fija, es decir, cada registro puede contener información con diferente forma cada vez, pudiendo así almacenar solo los atributos que interesen en cada uno de ellos.‖
(Nasca, 2014)
Tolerancia a fallos y redundancia.
Alta velocidad: ―Estos sistemas realizan operaciones directamente en memoria y solo vuelcan datos al disco cada cierto tiempo. Esto permite que las operaciones de escritura sean realmente rápidas.‖ (Nasca, 2014)
Los diferentes tipos de bases de datos NoSQL son:
Key-Value (Clave-Valor).
Documental (Basada en documentos).
Orientada a Columnas.
Orientadas a Grafos.
9 1.2.2 ¿Qué tipo de datos se debe explorar?
―Muchas organizaciones se enfrentan a la pregunta sobre ¿qué información es la que se debe analizar?, sin embargo, el cuestionamiento debería estar enfocado hacia ¿qué problema es el que se está tratando de resolver?‖ (IBM, 2012)
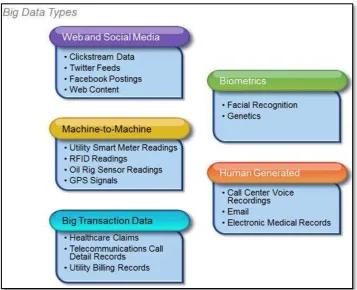
[image:17.595.118.476.256.546.2]Existen muchos tipos de datos que se pueden analizar, la figura 1 muestra una clasificación que ayudará a comprender de mejor manera la representación de los datos.
Figura 1. Clasificación de los tipos de datos. Fuente: Recuperado de: https://goo.gl/RSQfLm
Web and Social Media: Información obtenida de las redes sociales, como Twitter, Facebook, Instagram, entre otras, y páginas web en general.
Biometrics: Información biométrica como huellas digitales, escaneo de retina, reconocimiento facial, etc.
10 directamente, ya sea para transmitir o recibir señales percibidas por sensores o medidores.
Big Transaction Data: Este tipo de información se refiere a registros de facturación, registros de llamadas telefónicas, y todo tipo de datos transaccionales en general.
Human Generated: Es la información que generamos los seres humanos, como documentos, archivos de video, notas de voz, mensajes de texto, etc. (IBM, 2012)
1.3 Análisis de Redes Sociales (SNA: Social Network Analysis).
El análisis de redes sociales es un tema que, a pesar de no ser tan reciente, sigue estando en auge. Su objetivo se enfoca en el análisis de actores y sus relaciones con otros actores. Cada actor está representado como un nodo perteneciente a un grafo, que tiene uno o más vínculos con otros nodos.
De acuerdo a lo que sostiene Luis Sanz Menéndez (Menéndez, 2003) ―El análisis de redes sociales ARS (social network analysis), también denominado análisis estructural, se ha desarrollado como herramienta de medición y análisis de las estructuras sociales que emergen de las relaciones entre actores sociales diversos (individuos, organizaciones, naciones, etc.)‖. Éste se apoya en métricas que se pueden aplicar sobre un grafo (ver capítulo 4), para determinar la manera en que los actores se relacionan e interactúan, cómo se comunican, cuál es el flujo de la información, qué tan agrupados están; a nivel de nodos, conocer cuál su ubicación dentro de la red, determinar qué tan bien posicionado está con respecto a los demás, etc.
De acuerdo al INSNA (International Network for Social Network Analysis):
11 uno pudiera alejarse lo suficiente de ella, la vida humana se convertiría en modelo puro‖. (INSNA, s.f.)
Ahora, es importante definir ¿qué es una red social? De acuerdo a lo que sostiene Mauricio Monsalve Moreno (Moreno, 2008) de la Universidad de Chile, ―Una red social es un conjunto de actores vinculados entre sí. Con esto hemos definido un grafo, pues tenemos los vértices y las aristas o, como le llaman los sociólogos, actores y vínculos.‖.
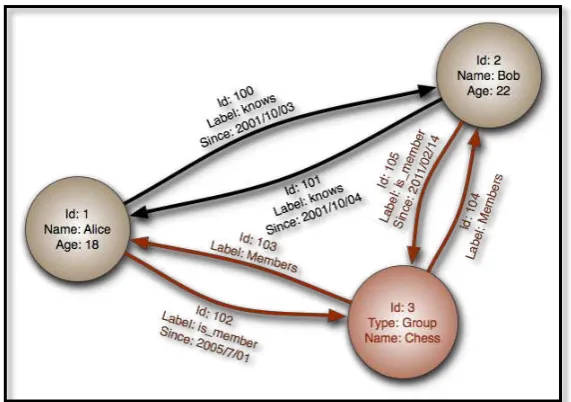
La Figura 2 ilustra una pequeña red social en la que varios individuos se relacionan entre sí por una relación de ―amistad‖. Los vínculos pueden ser de cualquier tipo, ya sea de trabajo, amor, consanguineidad, etc.
Figura 2. Red Social.
Fuente: Recuperado de: http://goo.gl/oV6ANW.
La pregunta es ¿por qué es necesario analizar o investigar las redes sociales? Hay varias razones, entre ellas destaca el interés por:
1. El estudio de La Web, que concierne directamente a la gente de ciencia de la computación.
2. El estudio de cómo se hace y mide la ciencia (scientometrics, epistemometria), que es de interés para gran parte de la comunidad científica.
3. Las ciencias sociales, ya que el análisis de redes sociales se utiliza activamente en sociología, antropología, ciencia política, gestión organizacional, medios de comunicación (social media analysis), etc.
12 5. El modelamiento, la simulación y el diseño de algoritmos, habilidades y conocimientos clave que han hecho que el análisis de redes sociales escale en tamaño. (Menéndez, 2003)
Existe una variedad de software para realizar esta tarea. Es importante mencionar que sin la existencia del software no sería posible completar muchos de estos avances tecnológicos. Entre los programas más destacados están:
Egonet.
Netdraw.
Visone.
Dynet.
NetMiner.
Pajek.
Siena.
Visone.
Estos programas se utilizan para representar y analizar gráficas que se crean en base
a una serie de datos previamente almacenados.
1.3.1 Niveles de análisis.
En el SNA existen distintos niveles de análisis, dependiendo de dónde se
focalice la atención dentro de la estructura de la red. Existen tres niveles de
análisis dentro del SNA: I) el análisis de redes egocéntricas, II) el análisis
focalizado en subgrupos de actores y III) el análisis focalizado en la estructura
total de la red.
13 que ocupa, cómo se adapta a los cambios y en qué medida éstas relaciones impulsan o restringen sus intereses.
Análisis de subgrupos de actores: En este nivel se analiza tres tipos de relaciones:
o Redes diádicas, en las que se analiza un par de nodos y la intensidad y duración de sus vínculos,
o Relaciones tríadicas, que involucran a tres actores interrelacionados,
o Clústeres, que representan subgrupos dentro de la red. El análisis de este tipo de relaciones proporciona pautas claves sobre la lógica de agrupamiento de las redes y es útil para determinar la existencia de patrones de cooperación o de competencia.
Análisis de la estructura total de la red: ―En este nivel, el énfasis está puesto en la estructura general de la Red (el nivel macro), considerando las particularidades morfológicas que adopta, la existencia, rol e interacción de subgrupos (clústeres), la distribución de las relaciones entre los actores involucrados, la distancia geodésica entre los actores, entre otros.‖ (Aguirre, 2011)
1.4 Procesamiento de grafos.
[image:21.595.159.440.571.668.2]“Graph analysis is the true killer app of Big Data” (Research, 2011)
Figura 3. Arquitectura para la implementación de un motor de procesamiento de grafos. Fuente: Ian Robinson, Jim Webber & Emil Eifrem. Graph Databases 2nd Edition.
Los grafos están en casi todo, por ejemplo en las redes sociales (Facebook, Twitter),
14 (Wikipedia, Google). Por ejemplo, es muy común que Facebook muestre ―personas
que quizás conozca‖; generalmente aciertan y presentan amigos con los que
seguramente hace mucho no se tenía contacto, la pregunta es ¿cómo supo Facebook
que son sus conocidos? Pues por la estructura de datos que manejan, es decir, en
grafos, sobre la cual se ha ejecutado un procesamiento.
Debido a que se habla de millones o miles de millones de datos, se puede deducir que
no existe un solo computador capaz de realizar dicho procesamiento, y es ahí donde
nace la necesidad de ―distribuir‖ (paralelizar) el trabajo, para que la información sea
analizada por lotes. Para ello han surgido muchas tecnologías, cada una con su
particularidad y características que las hace a unas más convenientes que otras,
según sea la necesidad.
Con el pasar de los años la el crecimiento de la información se ha acelerado
considerablemente, la información no solo crece, sino que crece a una velocidad
impresionante, los datos generados por diversos tipos de fuentes (en especial por los
humanos) se generan a millones por segundo; es por esto que las herramientas
tradicionales de procesamiento de información se han visto limitadas, y cada vez se
está buscando optimizar los tiempos de respuesta y el uso de hardware. Algunas de
estas herramientas se verán más adelante.
Pero, ¿cuál es la importancia de analizar esos ―petabytes‖ de datos? La respuesta
radica en que los resultados obtenidos del análisis de estos datos pueden ayudar a
predecir el comportamiento de las personas, la tendencia de los usuarios o su
inclinación con respecto a diferentes tipos de productos, identificar oportunidades de
negocio, sirven de soporte en la toma de decisiones, etc.
1.4.1 Grafos Dirigidos
Stanley Wasserman y Katherine Faust (Stanley Wasserman, 2013, págs. 148, 149)
15 Una relación direccional se puede representar mediante un grafo dirigido. El
grafo dirigido consiste en un conjunto de nodos que representan a los actores
de una red, un conjunto de arcos dirigidos entre pares de nodos, que
representan lazos dirigidos entre los actores. La diferencia entre un grafo y un
grafo dirigido es que en un grafo dirigido se especifica la dirección de las
líneas. Los lazos dirigidos entre pares de actores se representan como líneas
en las que se especifica la orientación de la relación.
1.4.2 Grafos Conexos y Componentes
Una característica importante de un grafo a tener en cuenta, es si está conectado o no.
Un grafo está conectado si hay un camino entre cada par de nodos del grafo.
Es decir, en un grafo conexo todos los pares de nodos son accesibles. Si un
grafo no es conexo, entonces es disconexo o inconexo. Consideremos el
ejemplo de las comunicaciones entre empleados de una organización. Si el
grafo que representa las comunicaciones entre los empleados es conectado,
entonces los mensajes pueden viajar desde cualquier empleado hasta todos y
cada uno de los demás empleados a través de canales de comunicación por
pares. Pero si el grafo que representa esta red es disconexo, entonces algún
par de personas no pueden enviar o recibir mensajes entre ellos usando los
canales de comunicación. (Stanley Wasserman, 2013)
1.4.3 Herramientas para el Procesamiento de Grafos.
1.4.3.1 Apache Giraph
De acuerdo al sitio oficial de Giraph (The Apache Software Foundation, 2014):
Apache Giraph es un sistema de procesamiento de grafos interactivo
construido para una alta escalabilidad, pero se limita a un Hadoop Map/Reduce
16 grafo de la red social formado por los usuarios y sus conexiones. Giraph se
originó como la contraparte de código abierto para Pregel, la arquitectura de
procesamiento gráfico desarrollado en Google. Ambos sistemas se inspiran en
el modelo paralelo síncrona a granel de la computación distribuida introducido
por Leslie Valiant. Giraph añade varias características más allá del modelo
básico Pregel, incluyendo cómputo principal, agregadores fragmentados,
entrada de borde orientada, fuera del núcleo de la computación, y más. Con un
ciclo de desarrollo estable y una creciente comunidad de usuarios en todo el
mundo, Giraph es una elección natural para liberar el potencial de los conjuntos
de datos estructurados en una escala masiva.
1.4.3.2 GraphLab PowerGraph
GraphLab es otro de los proyectos de gran alcance para el análisis de grafos
en paralelo.
El proyecto GraphLab PowerGraph consiste en una API de núcleo y una
colección de herramientas de aprendizaje automático y minería de datos de
alto rendimiento. La API está escrito en C++ y construido en el top de las
tecnologías estándar de clúster y de computación en la nube. La comunicación
entre procesos se lleva a cabo a través de TCP-IP y MPI se utiliza para poner
en marcha y gestionar programas GraphLab PowerGraph. Cada proceso es
multiproceso para aprovechar al máximo los recursos disponibles en varios
núcleos de los nodos del clúster. Apoya la lectura y la escritura en tanto Posix y
sistemas de archivos HDFS. (Dato-Code, s.f.)
1.4.3.3 PowerLyra
PowerLyra se basa en la última base de código de GraphLab PowerGraph y
puede soportar sin problemas todos los kits de herramientas GraphLab.
17 particionamiento para lograr un rendimiento óptimo mediante el
aprovechamiento de las propiedades del grafo de entrada.2
PowerLyra integra Nuevas funciones:
Motor de computación híbrido: Explota la localidad de vértices de
bajo grado y el paralelismo de los vértices de alto grado.
Algoritmo de particionamiento híbrido: Diferencia los algoritmos de
partición para diferentes tipos de vértices.
Estrategia de programación diversa: Proporcionar los dos motores de
cálculo síncronas y asíncronas.
API compatible: Soporta sin problemas todos los kits de herramientas
GraphLab. (Chen, 2015)
2
19 2.1 Bases de datos orientadas a grafos
Las bases de datos orientadas a grafos (BDOG) son un tipo de almacenamiento
NoSQL (ver sección 1.2.1), pensado para el almacenamiento de grandes cantidades
de datos y están optimizadas para el procesamiento eficiente de grandes conjuntos de
datos interrelacionados.
Las BDOG, a diferencia de las bases de datos relacionales, almacenan los datos como
nodos (vértices) y aristas (relaciones) entre ellos, es decir, cada dato es un nodo único
que tiene atributos propios, y las relaciones a su vez tienen también atributos, esto
[image:27.595.154.440.315.516.2]facilita el análisis de las grandes cantidades de información.
Figura 4. GraphDatabase PropertyGraph.
Fuente: Recuperado de: https://goo.gl/OPMKNo.
Las consultas en una BDOG siempre empiezan en un nodo específico, a partir del cual
se exploran sus relaciones con otros nodos, de manera que para cada consulta no
será necesario recorrer todo el grafo sino solo el tamaño de la parte del grafo que
necesite recorrer para satisfacer la consulta, lo que acelera el tiempo de respuesta de
las mismas. Entre las más populares están:
- Neo4j.
20 - InfoGrid.
- HyperGraphDB. - Trinity.
- *dex.
Los componentes de una BDOG son:
- Grafo: La Red en sí.
- Nodos: Todos los actores miembros de la Red. - Relaciones: Los vínculos entre los actores.
- Propiedades: Atributos de los actores; las relaciones también pueden tener sus propios atributos.
2.1.1 Ventajas y desventajas de una BDOG.
Ian Robinson, Jim Webber y Emil Eifrem (Ian Robinson, 2015) afirman que:
Una razón importante para el uso de bases de datos con grafos es su mayor rendimiento, en comparación con las bases de datos relacionales y otras NoSQL. A diferencia de las bases de datos relacionales, cuyos rendimientos se deterioran en las consultas intensivas y con un procesamiento de datos muy alto; las bases de datos con grafos ofrecen un rendimiento que tiende a permanecer constante, así como el crecimiento de los datos. Esto se debe a que las consultas se realizan de manera gráfica, recorriendo entre las relaciones (aristas) que posea la base. Como resultado, el tiempo de ejecución de esta consulta es proporcional solo al tamaño de la parte grafica que tenga que recorrer para satisfacer esta consulta, en lugar del tamaño global del grafo.
Además de esto,
Existen otras cualidades por las que muchas empresas muestran su interés por implementar este tipo de tecnologías:
- Instalación simple. - Opensource.
21 - Rapidez para conectar los datos. En las bases de datos relacionales, el frecuente uso de joins hace que las búsquedas sean lentas. (Maribel Tirados, 2014)
No obstante, el uso de este tipo de tecnologías también conlleva ciertos riesgos o desventajas, que hacen que también muchas empresas se detengan a pensar en si es conveniente o no implementarlas. Tales desventajas consideran aspectos como:
- La tecnología no está lo suficientemente madura para algunas empresas: Debido a que es algo relativamente reciente, se puede considerar que no es totalmente confiable para el uso pleno en producción.
- Requiere un cambio conceptual para los desarrolladores, lo que implica una curva de aprendizaje.
- Problemas de compatibilidad: Las bases de datos relacionales generalmente comparten ciertos estándares, como por ejemplo el lenguaje de consultas; por su parte, las bases de datos en Grafo generalmente tienen sus propias APIs y sus propios lenguajes. (Nasca, 2014)
2.1.2 Modelos de datos en Grafo.
Existen varios modelos de datos expresados en grafo, entre ellos están:
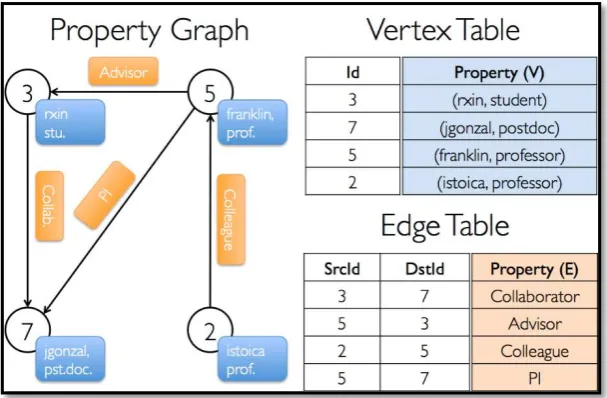
Property Graph: Este término denota un grafo multi – relacional en donde sus nodos tienen cualquier número de atributos al igual que sus aristas. Este modelo facilita la
especificación de múltiples relaciones entre dos nodos (por ejemplo, compañero de
trabajo, amigo).
El modelo de Grafo-Propiedad Etiquetada tiene ciertas características
sobresalientes:
Un Grafo-Propiedad marcado se compone de nodos, relaciones, propiedades y etiquetas.
22 Los nodos pueden ser etiquetados con una o más etiquetas. Grupo de etiquetas nodos juntos, e indicar las funciones que desempeñan en el conjunto de datos.
Relaciones conectan los nodos y estructuran el gráfico. Una relación siempre tiene una dirección, un solo nombre, y un nodo de inicio y fin de nodos no hay colgando relaciones. Juntos, la dirección y el nombre de una relación añaden claridad semántica a la estructuración de nodos.
Al igual que los nodos, las relaciones también pueden tener propiedades. La posibilidad de agregar propiedades a las relaciones es particularmente útil para proporcionar metadatos adicionales para gráfica algoritmos, añadiendo semántica adicional a las relaciones (incluyendo la calidad y peso), y para limitar las consultas en tiempo de ejecución. (Ian Robinson, 2015)
[image:30.595.145.449.359.558.2]Un ejemplo de este modelo se muestra en la figura 5.
Figura 5. Property Graph.
Fuente: Recuperado de: http://goo.gl/dCQykB
RDF: Es un modelo estándar para el intercambio de información en la web; esta estructura enlazada forma un grafo dirigido y marcado en donde las aristas representan las relaciones entre dos recursos (nodos o vértices).
23 2.2 Computación Paralela
La computación paralela surgió por la necesidad de resolver problemas de gran magnitud, los cuales empezaban a escaparse del alcance de las computadoras. Gracias a ella es posible realizar grandes tareas de manera muy rápida y eficiente.
La computación paralela o ―procesamiento en paralelo‖ consiste en la división o
distribución de la ejecución de un programa, en diferentes lotes que serán analizados al mismo tiempo por diferentes procesadores. Esto se hace con el fin de acelerar el tiempo de procesamiento.
En la computación paralela lo más importante es la comunicación, ya que los procesadores necesitan intercambiar información entre sí. Ésta se puede dar de dos formas:
Se cuenta con una sola memoria a la cual pueden acceder todos los procesadores (memoria compartida), dicho de otra manera, se cuenta con un solo computador que tiene varios procesadores que comparten la memoria y los dispositivos de entrada y salida; estos procesadores pueden acceder a todos los módulos de memoria directamente.
La otra manera se da teniendo dos o más computadoras (clúster), cada una con su memoria, con sus dispositivos de entrada y salida y con su procesador, las cuales se comunican entre sí por medio de una red de computadoras.
La computación paralela se divide en tres partes: La primera consiste en dividir la tarea en partes pequeñas, la segunda consiste en asignar las tareas a los diferentes procesadores para que sean ejecutadas y la tercera parte tiene que ver con la comunicación, si no hay comunicación las tareas no pueden ser procesadas al mismo tiempo por los procesadores, de esta manera todo lo que está conectado coopera.
2.2.1 Clasificación de los sistemas paralelos.
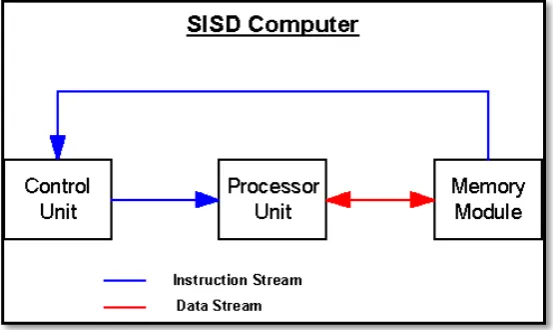
En el año de 1966 Michael J. Flynn estableció una clasificación general de los sistemas paralelos, basada en el flujo de instrucciones y el flujo de datos que en ellos se maneja.
La clasificación de Flynn es la siguiente:
24 instrucción sobre un único flujo de datos. Este modelo secuencial es el propuesto por Von Neuman en el que en cualquier instante se puede estar ejecutando una sola instrucción.
Figura 6. Modelo SISD.
FUENTE: Recuperado de: http://goo.gl/PY1D4i.
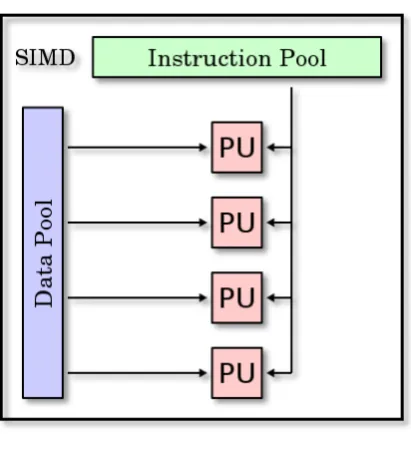
SIMD: Single Instruction Multiple Data (única instrucción, múltiples datos).
25
Figura 7. Modelo SIMD.
Fuente: Recuperado de: http://goo.gl/PY1D4i.
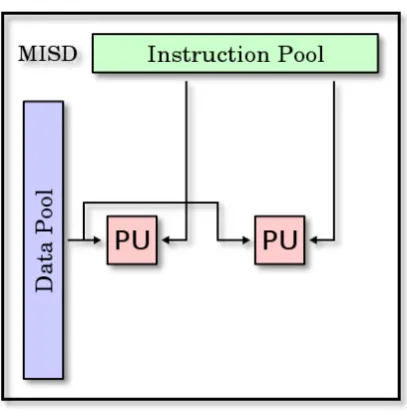
MISD: Multiple Instruction Single Data (mútiples instrucciones, datos únicos).
En este modelo de sistemas se ejecutan varios flujos de instrucciones al mismo tiempo, actuando todos ellos sobre el mismo conjunto de datos. Jose Aguilar y E. Leiss concluyen que “la idea es descomponer las
unidades de procesamiento en fases, en donde cada una se encarga de una parte de las operaciones a realizar. De esta manera, parte de los datos pueden ser procesados en la fase 1 mientras otros son
26
Figura 8. Modelo MISD.
Fuente: Recuperado de: http://goo.gl/PY1D4i.
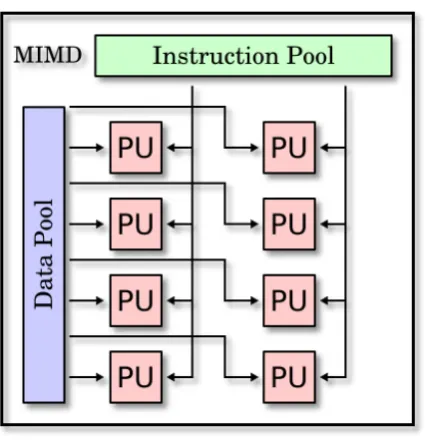
MIMD: Multiple Instructions Multiple Data (múltiples instrucciones, múltiples datos).
En este modelo de sistemas se tienen varias unidades de proceso, cada una con un conjunto de datos asociado y ejecutando un flujo de instrucciones distinto.
27
Figura 9. Modelo MIMD.
Fuente: Recuperado de: http://goo.gl/PY1D4i.
En el análisis de grafos en paralelo el modelo que se usa es el SIMD, ya que existe un
conjunto de datos separados por lotes, sobre los cuales se ejecuta la misma
instrucción al mismo tiempo.
2.2.2 Clúster.
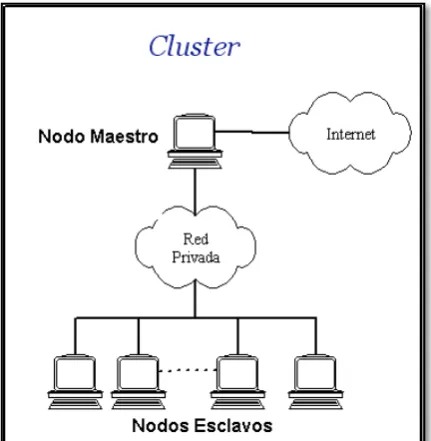
Un clúster es un tipo de arquitectura paralela distribuida, que consiste de un conjunto
de computadores interconectados operando de forma conjunta como un único
computador, cuyas prestaciones son mucho más altas que las de cualquier ordenador.
La arquitectura básica de un clúster computacional consta de un ―máster‖ que
encabeza las operaciones y las distribuye a los ―nodos‖ con los cuales se comunica
28
Figura 10. Arquitectura de un cúster.
Fuente: Clústers de alto rendimiento. Disponible en: http://goo.gl/j7tgJ1
Los clústeres tienen una clasificación:
o Alto rendimiento: Estos clústers se utilizan para ejecutar programas paralelizables que requieren de gran capacidad computacional de
forma intensiva. Son de especial interés para la comunidad científica o
industrias que tengan que resolver complejos problemas o
simulaciones.
o Alta disponibilidad: Los clústers de alta disponibilidad tienen como propósito principal brindar la máxima disponibilidad de los servicios que
ofrecen. Esto se consigue mediante software que monitoriza
constantemente el clúster, detecta fallos y permite recuperarse frente a
los mismos.
o Balanceo de carga: Este tipo de clúster permite distribuir las peticiones de servicio entrantes hacia un conjunto de equipos que las
29 como un servidor web o un servidor de correo electrónico, con altas
cargas de trabajo y de tráfico de red. (Esteban, 2010)
2.3 Spark.
Spark es un framework de computación paralela de código abierto, desarrollado en la
universidad de U.C. Berkeley como un proyecto de fin de carrera.
Como se mencionó anteriormente, los datos que en la actualidad se pretende analizar
pueden ser muy grandes, más de lo que podría soportar una sola máquina, y es ahí
donde Spark interviene almacenando y analizando los datos a través de múltiples
máquinas que forman parte de un clúster.
Spark se adapta muy bien al manejo de datos expresados en grafo ya que
almacena los datos en la memoria (RAM) de cada nodo del clúster, a diferencia
de Hadoop, que almacena los datos en disco. Mientras Hadoop puede manejar
el acceso secuencial de datos, Spark puede manejar órdenes de acceso
arbitrario requerido por un sistema de grafos, que tiene que recorrer el grafo a
partir de un nodo específico.
Además de que difieren con respecto a ―en dónde se procesan los datos
durante el cálculo‖ (RAM vs disco), el API del Spark es mucho más fácil de
trabajar que la API de Hadoop Map/Reduce.
La gente empezó a usar Spark para los grafos hace mucho tiempo, incluso con
el módulo Bagel (predecesor), pero ahora con GraphX tenemos una forma
estandarizada para hacerlo, y por supuesto que proporciona una biblioteca de
algoritmos útiles también. (Malak, 2015)
2.3.1 Resilient Distributed Dataset.
El concepto central en Apache Spark es el conjunto de Datos Distribuido
30 reparte a través de las máquinas en un clúster. Facilita dos tipos de
operaciones: la transformación y la acción. Una transformación es una
operación como filter(), map(), o union() en un RDD que produce otro RDD.
Una acción es una operación como count(), first(), taken(n), o colect() que
desencadena un cálculo, devuelve un valor de nuevo al Maestro, o escribe a un
sistema de almacenamiento estable. Las transformaciones son evaluadas
lentamente, en el sentido de que no se ejecutan hasta que una acción lo
justifique. El Master/Driver de Spark recuerda las transformaciones aplicadas a
un RDD, así que si se pierde una partición (por ejemplo se da de baja a un
nodo), la partición puede ser fácilmente reconstruida en alguna otra máquina
en el clúster. Es por eso que se llama "resistente". (Kuntamukkala, s.f.)
Spark está basado en Hadoop Map/Reduce y tiene en sí cuatro librerías: Spark SQL, Spark Streaming, MLlib, Graphx. Recientemente se ha agregado Spark R que es una integración de R con Spark.
2.3.2 Spark SQL.
Spark SQL es un módulo de Spark para trabajar con datos estructurados, que
proporciona una forma común para acceder a una variedad de fuentes de
datos, incluyendo Avro, ORC, JSON, JDBC o Hive3. Se puede utilizar en Java,
Scala, Python y R. (Apache Spark, 2015)
Data Frames:
Una trama de datos es una colección distribuida de datos organizados
en columnas con nombre. Es conceptualmente equivalente a una tabla
en una base de datos relacional o una trama de datos en R/Python,
pero con optimizaciones más enriquecidas. Las tramas de datos se
pueden construir a partir de una amplia gama de fuentes, tales como:
31 archivos estructurados de datos, bases de datos externas, o RDDs
existentes. (Apache Spark, 2015)
Data Source: Spark SQL admite operaciones en una variedad de fuentes de
datos a través de la interfaz de trama de datos. Una trama de datos puede ser
operado como RDD normal y también puede ser registrado como una tabla
temporal. El registro de una trama de datos en forma de tabla le permite
ejecutar consultas SQL sobre sus datos.
2.3.3 Spark Streaming.
Spark Streaming es una extensión del núcleo del API de Spark que permite un
flujo de procesamiento escalable, de alto rendimiento, con tolerancia a fallos y
en tiempo real. Los datos pueden ser extraídos de muchas fuentes, como
Kafka, Flume, Twitter, ZeroMQ, Kinesis, o sockets TCP, y pueden ser
procesados usando algoritmos complejos expresadas con funciones de alto
nivel como map, reduce y join. Por último, los datos procesados pueden ser
insertados a los sistemas de archivos y bases de datos; de hecho, se puede
aplicar algoritmos de aprendizaje automático y procesamiento de grafos de
Spark en los flujos de datos. (Apache Spark, 2015)
Figura 11. Funcionamiento de Spark Streaming.
Fuente: Recuperado de: http://goo.gl/a5la0T.
32 MLlib es la biblioteca de aprendizaje automático escalable de Spark que consiste en
algoritmos y utilidades de aprendizaje en común, incluidas la clasificación, regresión,
clústering, filtrado colaborativo, la reducción de dimensiones, así como primitivas de
optimización subyacentes. MLlib está en constante desarrollo activo, por lo que la API
puede cambiar en futuras versiones.
2.3.5 GraphX.
Michael S. Malak, en su libro ―GraphX in Action‖(Malak, 2015)afirma que:
GraphX no es una base de datos, por lo que no puede actualizar ni eliminar
datos de los nodos como sí lo podría hacer Neo4j o alguna de las bases de
datos antes mencionadas, sino que es una librería de Spark para el
procesamiento de grafos en paralelo, capaz de competir en rendimiento con los
sistemas más rápidos, mientras que conserva la flexibilidad de Spark, la
tolerancia a fallos, y la facilidad de uso.
Graphx tiene varios algoritmos, como son:
PageRank: PageRank mide la importancia de cada vértice en un grafo, en el
supuesto de un borde de u a v representa la importancia de v para u. Por
ejemplo, si un usuario de Twitter es seguido por muchos otros, el usuario será
altamente calificado.
Connected Components: Un componente conectado corresponde a un grafo
o sub grafo en el que existe un camino entre cualquier par de nodos. Este
algoritmo determina el grado de conectividad que tiene un grafo; sirve para
detectar comunidades aisladas y el grado de cohesión de esas comunidades.
Triangle Counting: Un vértice es parte de un triángulo cuando tiene dos
vértices adyacentes con un borde entre ellos. GraphX implementa un algoritmo
33 triángulos que pasan a través de cada vértice, proporcionando una medida de
la agrupación.
GraphX tiene también una cualidad que lo hace muy eficiente a la hora de repartir la
carga de trabajo, y es la manera en que particiona el grafo:
El enfoque tradicional de particionamiento que usan otros motores de procesamiento
consiste en repartir los vértices entre los nodos del clúster, a este enfoque se le llama
corte de borde (Edge-cut) como se ilustra en la figura 12, el problema de este tipo de
particionamiento es que existen vértices de alto grado (high-degree vertex) que suelen
[image:41.595.221.376.309.499.2]generar cuellos de botella.
Figura 12. Corte de borde.
Fuente: Recuperado de: https://goo.gl/x1zmxK
Un vértice de alto grado es un vértice que tiene muchas relaciones tanto de entrada
como de salida, observe la figura 13.
[image:41.595.208.389.586.736.2]34
Fuente: Michael S. Malak. Spark GraphX in Action.
Un vértice de alto grado por ende toma más tiempo al computar, por lo que GraphX
emplea un enfoque llamado corte de vértice (Vertex-cut), en el que los vértices son
[image:42.595.217.374.201.392.2]particionados y propagados a través de los nodos del clúster.
Figura 14. Corte de vértice.
Fuente: Recuperado de: https://goo.gl/x1zmxK
La figura 15 muestra cómo quedaría la tabla de particionamiento de un grafo utilizando
ambos enfoques.
Figura 15. Tabla de un corte de vértice de GraphX.
Fuente: Recuperado de: https://goo.gl/x1zmxK
[image:42.595.122.474.504.640.2]35 Para poder compilar Spark en cualquier computador, es necesario instalar algunas
herramientas previamente. Tales herramientas se abordarán a lo largo de esta
sección.
2.4.1 Scala.
El nombre Scala significa "lenguaje escalable." El lenguaje se llama así porque fue
diseñado para crecer con las demandas de sus usuarios. Puede aplicar Scala a una
amplia gama de tareas de programación, desde escribir pequeños scripts para la
construcción de grandes sistemas.
Técnicamente, Scala es una mezcla de conceptos orientados a objetos y la
programación funcional en un lenguaje de tipos estáticos. Sus construcciones
orientadas a objetos hacen que sea fácil de estructurar sistemas más grandes y
adaptarlos a las nuevas exigencias. La combinación de ambos estilos en Scala
permite expresar nuevos tipos de patrones de programación y abstracciones de
componentes. También conduce a un estilo de programación legible y conciso.
(Martin Odersky, 2008)
Scala es también el lenguaje de programación en el que fue construido Spark, por lo
tanto se ha usado para la implementación de GraphX.
2.4.2 SBT (Simple Build Tools).
SBT es una herramienta de código abierto para la construcción de proyectos en Scala
y Java, algo similar a Maven (ver sección 2.4.4), y está escrito precisamente en Scala.
Ha sido desarrollada por Mark Harrah y su primera versión estable se lanzó el 20 de
marzo de 2015.
SBT puede ser ejecutado tanto en MacOS como en Linux. Su instalación es un
36 2.4.3 JDK (Java Development Kit).
Java Platform, Standard Edition (Java SE) le permite desarrollar y desplegar
aplicaciones Java en equipos de sobremesa y servidores, así como en los
exigentes entornos integrados de hoy. Java ofrece la rica interfaz de usuario,
rendimiento, versatilidad, portabilidad y seguridad que las aplicaciones de hoy
en día requieren.
La Plataforma Java, Standard Edition 8 (Java SE 8) es el último lanzamiento y
el más importante. Contiene nuevas funciones y mejoras en muchas áreas
funcionales. Java SE 8 ofrece una mayor productividad de los desarrolladores
de aplicaciones y significativos aumentos de rendimiento mediante la reducción
de código repetitivo, la mejora de las colecciones y las anotaciones, los
modelos de programación paralela más simples y un uso más eficiente de los
procesadores modernos, multi-core. (ORACLE, 2015)
2.4.4 Apache Maven.
De acuerdo a la página oficial de Apache:
Apache Maven es una herramienta de gestión de proyectos de software,
basada en el concepto de un modelo de objetos del proyecto (POM); Maven
puede gestionar la construcción de un proyecto, generación de informes y
documentación de una pieza central de la información. (The Apache Software
37 CAPÍTULO 3: INSTALACIÓN, CONFIGURACIÓN Y DESPLIEGUE DE
38 3.1 Instalación de Spark
Para poder ejecutar Spark es necesario instalar varios componentes adicionales, la
omisión de cualquiera de ellos puede impedir el levantamiento del framework.
El trabajo detallado en este documento se realizó sobre Ubuntu 14 y Mac OS. La
instalación en Linux y Mac varía en un mínimo porcentaje en la sintaxis de los
comandos (en Mac se debe agregar ―./‖ antes de los comandos especificados), por lo
demás los componentes requeridos para su correcta compilación son exactamente los
mismos, los cuales se detallan a continuación:
- SBT. - Scala. - JDK. - Maven.
La instalación de cada uno de ellos se detallará en la sección de Anexos.
Una vez instalado todo, es necesario descargar la última versión de Spark (estable)
desde la página oficial para luego descomprimirlo. Una vez descomprimido se debe
acceder a una terminal y navegar hasta el directorio donde se descomprimió Spark y
escribir el siguiente comando:
ó
Con este comando se compila Spark, este proceso toma alrededor de 30 a 40 minutos
aproximadamente, luego de eso se procede a escribir el siguiente comando:
mvn -DskipTests clean package
sbt/sbt-assembly
39 Con este comando se empezará a levantar el Shell de Spark para empezar a escribir
código en Scala.
Nota: Es posible escribir también aplicaciones en Java y Python ya que Spark tiene una integración con estos lenguajes de programación, aunque GraphX aún no está
[image:47.595.134.462.214.379.2]soportado en Python; y, algo a tener en cuenta, es que Spark fue escrito en Scala.
Figura 16. Levantamiento del shell de Spark.
Fuente: El Autor.
Lo primero que se hizo fue una familiarización con el entorno de desarrollo y el
lenguaje de programación, uno de los primeros ejercicios aplicados fue el de ―SparkPi‖
que viene incluido en el directorio de Spark4, este algoritmo se aplicó sobre una
instalación de un clúster privado denominado ―Standalone‖ cuya implementación se
describirá en la siguiente sección.
3.2 Spark Standalone Clúster
Spark ofrece un modo simple para implementar un clúster privado, este modo se
denomina Standalone. La arquitectura de Standalone se describe en la figura 17.
4
40
Figura 17. Arquitectura de Standalone Cluster.
Fuente: Recuperado de: http://goo.gl/77Uw8y.
Para construirlo se debe modificar ciertos archivos de configuración ubicados dentro
del directorio de Spark, como se verá más adelante.
Para que sea posible la comunicación entre el nodo máster y los nodos esclavos es
necesario tener instalado ―OpenSSH Server‖ en el nodo Máster y que todos los nodos
estén conectados a la misma red, en la misma VLAN.
También es necesario que cada nodo del clúster cuente con una versión compilada de
Spark (revisar la sección 3.1) y que los datasets a analizar estén replicados en cada
uno de los nodos.
Para configurar este tipo de clúster se debe seguir los siguientes pasos:
1. Acceder al directorio donde se descomprimió Spark e ingresar a la carpeta ―conf‖
en la que se modificarán tres archivos:
a. El primer archivo a modificar es ―spark-env.sh.template‖ el cual se debe
copiar y renombrar a ―spark-env.sh‖. Al final de este archivo se debe
agregar las siguientes líneas:
export SPARK_MASTER_IP='IP del Master'
export SPARK_MASTER_PORT='Puerto por donde escucha el Master'
41 Un ejemplo de cómo quedaría este archivo sería:
b. El segundo archivo a modificar se llama ―slaves.template‖ que deberá quedar como ―slaves‖. En este archivo irán todas las direcciones IP de
nuestros nodos esclavos, con los cuales el nodo máster se comunicará vía
SSH.
c. El tercer archivo a modificar se llama ―spark-defaults.conf.template‖ que debe quedar como ―spark-defaults.conf‖. Este archivo tiene varias líneas
que están comentadas (con el signo # al inicio de cada línea), al final debe
[image:49.595.101.494.416.536.2]quedar de la siguiente manera:
Figura 18. Archivo spark.desaults.conf.
Fuente: El Autor.
Como se observa en la Figura 18, las únicas líneas descomentadas son
―spark.master‖, que contiene la dirección IP y el puerto por donde escuchará el
máster, y ―spark.executor.memory‖ (agregada posteriormente) que es la que le
indica a Spark qué cantidad de memoria RAM se utilizará de cada nodo esclavo. export SPARK_MASTER_IP='172.16.88.107'
export SPARK_MASTER_PORT='7077'
42 2. Una vez realizadas estas configuraciones, se procede a levantar el clúster
mediante algunos scripts que se detallan a continuación:
a. sbin/start-master.sh: Este comando sirve para levantar el Máster de nuestro clúster.
b. sbin/start-slaves.sh: Con este comando se levantan todos los nodos esclavos cuyas direcciones IP se encuentren en el archivo ―slaves‖.
c. sbin/start-all.sh: Con este comando se levanta todo, tanto el máster como los esclavos.
Una vez iniciado el máster se creará una URL mediante la cual podremos
conectar otros nodos al Máster (mediante otro método que se explica en el punto
[image:50.595.105.510.421.645.2]3). Esta URL por defecto es http://localhost:8080 cuya interfaz se muestra en la
figura 19.
Figura 19. Web UI Spark Standalone. Fuente: El Autor.
43 IP = la dirección IP del Máster; PORT = el puerto por donde escucha el Máster.
En este caso el comando sería:
Cada vez que se agrega un nodo al clúster se debe actualizar la Web UI en el
[image:51.595.108.516.289.508.2]nodo máster para que aparezcan los nuevos nodos agregados (véase figura 17).
Figura 20. Nuevo nodo agregado. Fuente: El Autor.
4. Ahora, el primer ejemplo para probar el clúster será el antes mencionado, SparkPi, que se lo podrá ejecutar mediante el siguiente comando:
bin/spark-class org.apache.spark.deploy.worker.Worker spark://IP:PORT
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \ --deploy-mode client \
--master spark://172.168.88.107:7077 \
/home/daniel/Descargas/spark-1.2.2/examples/target/scala-2.10/spark-examples-1.2.0-hadoop1.0.4.jar 10
44 Nota: Reemplazar con sus datos la dirección del máster, el puerto y el directorio en donde tiene su archivo .jar compilado.
Hasta ahora se ha visto cómo levantar Spark y cómo ejecutar instrucciones en
paralelo, sobre un clúster (Standalone). En la siguiente sección se entrará más en
materia, ya no ejecutando algoritmos pre-compilados solamente, sino que se
empezará a hondar en el tema central de este trabajo, la implementación de GraphX,
las métricas que se pueden aplicar sobre un grafo y los tiempos de respuesta.
3.3 Hadoop YARN.
Hadoop YARN es el cluster manager de Hadoop5, que brinda mayor seguridad y una
mejor administración de recursos con respecto a Standalone.
Spark se puede ejecutar sobre un clúster YARN, por lo tanto Spark se desliga de cualquier responsabilidad con respecto a la administración del clúster y su labor se limita exclusivamente a la ejecución de los algoritmos que provee, mientras que la administración del clúster y de los recursos la lleva por completo YARN.
Hadoop YARN da solución al inconveniente que se tenía con Standalone, en el que había que replicar los datasets en todos los nodos para poder procesar la data; YARN cuenta con un Resource Manager que es el que se encarga de distribuir los recursos a todos los nodos del clúster.
La arquitectura de YARN consta de un Resource Manager, Node Manager, Application Master and Container, como se muestra en la figura 21.
5
45 Figura 21. Arquitectura de YARN.
Fuente: Recuperado de: http://goo.gl/77Uw8y.
[image:53.595.129.464.71.333.2]Hadoop permite realizar una instalación y configuración de clústers de dos tipos: Single Node (con un solo nodo) y Multi Node (con más de un nodo). Además, Spark se puede ejecutar sobre YARN de dos maneras: yarn-client mode y yarn-cluster mode. La tabla 1 muestra comparativa de cómo trabaja Spark sobre YARN en ambos modos y sobre Standalone.
Tabla 1. Comparativa entre Spark sobre YARN y Standalone Cluster.
Mode YARN Client Mode YARN Cluster Mode Spark Standalone
Driver runs in Client ApplicationMaster Client
Requests resources ApplicationMaster ApplicationMaster Client
Starts executor processes YARN NodeManager YARN NodeManager Spark Worker Persistent services YARN ResourceManager
and NodeManagers
YARN ResourceManager and NodeManagers
Spark Master and Workers
Supports Spark Shell Yes No Yes
Nota: Como se puede observar en la tabla 1, solo el modo Yarn-Client soporta el Shell de Spark.
[image:53.595.80.558.522.651.2]46 instalación revisar el Anexo H, ya que en esta sección solo se abordará aspectos generales sobre el tema.
Antes de descargar e instalar Hadoop es necesario tener instalado ciertos componentes:
- Java. - SSH server.
Además se debe tener establecidas las variables de entorno para Java.
Luego es necesario descargar Hadoop desde su sitio oficial. Para este trabajo se utilizó Hadoop 2.6. Una vez descargado, descomprimirlo en el lugar de su preferencia (recordar la ruta en donde se descomprimió).
Para configurar el clúster YARN (single-node) es necesario acceder vía terminal al
directorio en donde se descomprimió Hadoop, luego ir a la carpeta ―etc/hadoop‖. Dentro de ella se encuentran varios archivos, de los cuales se debe modificar:
hadoop-env.sh.
mapred-env.sh.
yarn-env.sh.
core-site.xml.
hdfs-site.xml.
mapred-site.xml.
yarn-site.xml.
El detalle de esas configuraciones se detallará en el Anexo H.
Una vez configurados esos archivos, es necesario crear los directorios en donde se almacenarán la información del datanode y namenode. De la siguiente manera:
Finalmente se procede a dar formato al HDFS6 para el almacenamiento de datos
(datanode) y metadatos (namenode). Para ello se debe acceder vía terminal al directorio donde se encuentra Hadoop, y escribir el comando:
6
Hadoop Distributed File System, para más información visite: https://goo.gl/OFaPKv.
$ hdfs namenode -format
$ mkdir -p /home/users/aqua/hadoop/namenode
47 Una vez terminado ese proceso se puede empezar a levantar el clúster YARN utilizando los siguientes comandos:
Para verificar que Hadoop está corriendo es necesario ejecutar el comando ―jps‖ (java process monitor), cuyo resultado debe mostrar lo siguiente:
Debe cerciorarse de que todos estos procesos estén corriendo, caso contrario el clúster YARN no funcionará correctamente.
Hadoop ofrece algunas herramientas basadas en la web para monitorear HDFS, MapReduce, y tareas en un modo Single-Node:
HDFS Administrator: http://localhost:50070.
$ ./start-dfs.sh
$ ./start-yarn.sh
$ jps
7379 DataNode
7459 SecondaryNameNode
7316 NameNode
[image:55.595.102.487.466.671.2]7636 NodeManager
7562 ResourceManager
7676 Jps
48 ResourceManager Administrator: http://localhost:8088.
Figura 23. Administrador Web del Resource Manager.
Fuente: Recuperado de: http://goo.gl/XkGwsr.
3.3.1 Spark sobre YARN.
Una vez configurado y levantado el clúster YARN, es posible ejecutar Spark sobre él. En el presente trabajo como se indicó anteriormente, se configuró un clúster single-node.
Lo primero que hay que hacer es descargar una versión de Spark pre-compilada para la versión de Hadoop que se haya instalado (Hadoop 2.6 en este caso).
Figura 24. Descarga de Spark pre-compilado para Hadoop. Fuente: Recuperado de: http://spark.apache.org/downloads.html.
49 Acceder vía terminal hasta la carpeta donde se descomprimió Spark y ejecutar el comando:
Hecho esto se levantará el Shell de Spark sobre el clúster en YARN. Es importante recordar que el Spark-Shell solo está disponible en el modo Yarn-Client.
3.4 Análisis de grafos con GraphX
En esta sección se describe el logro de uno de los objetivos principales de este trabajo
de fin de titulación, que es determinar qué es lo que se puede hacer en GraphX, qué
métricas del SNA están implementadas en esta librería y observar cómo se comporta
al trabajar en plataformas como Linux y MAC, con ciertas variaciones en hardware
también.
En la sección 3.2 se revisó la configuración de un clúster privado (Standalone), ahora
sobre ese clúster se efectuará un análisis de datos almacenados en grafo utilizando
algunos datasets de diferentes características para la experimentación.
En el SNA (Social Network Analysis) existen varias métricas que se aplican a un grafo,
estas métricas se abordarán en detalle en el capítulo 4. GraphX tiene implementadas
algunas de esas métricas, por ejemplo, el PageRank corresponde a una métrica de
centralidad del SNA, en este caso de aplicación se ejecutó este algoritmo sobre una
data que fue procesada en paralelo. En el Anexo G se detalla un caso práctico que
sirve de ilustración para conocer cómo se puede desplegar GraphX.
Para poner en marcha GraphX es necesario tener una versión compilada de Spark en
cualquiera de sus versiones, y tener implementado un cluster manager, ya sea con
Spark Standalone, Yarn o Mesos.
50 En cuanto a los datasets, no son otra cosa que archivos de texto plano que contienen
la información a procesar; uno de ellos contiene la información de todos los nodos, el
otro contiene exclusivamente las relaciones –desde, hacia–. Lo que hace el código
descrito en el Anexo E, es un join entre la información de ambos archivos para poder