Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey
Monterrey, Nuevo León a
en los sucesivo LA OBRA, en virtud de lo cual autorizo a el Instituto Tecnológico
y de Estudios Superiores de Monterrey (EL INSTITUTO) para que efectúe la
divulgación, publicación, comunicación pública, distribución y reproducción, así
como la digitalización de la misma, con fines académicos o propios al objeto de
EL INSTITUTO.
El Instituto se compromete a respetar en todo momento mi autoría y a
otorgarme el crédito correspondiente en todas las actividades mencionadas
anteriormente de la obra.
De la misma manera, desligo de toda responsabilidad a EL INSTITUTO
por cualquier violación a los derechos de autor y propiedad intelectual que
cometa el suscrito frente a terceros.
Nombre y Firma AUTOR (A)
de 200
Lic. Arturo Azuara Flores:
Director de Asesoría Legal del Sistema
Por medio de la presente hago constar que soy autor y titular de la obra
Alternativa de Herramientas Estadísticas para el Desarrollo de
Proyectos Seis Sigma con Datos No Normales-Edición Única
Title
Alternativa de Herramientas Estadísticas para el Desarrollo
de Proyectos Seis Sigma con Datos No Normales-Edición
Única
Authors
Marcia Ortega Infante
Affiliation
ITESM-Campus Monterrey
Issue Date
2006-05-01
Item type
Tesis
Rights
Open Access
Downloaded
19-Jan-2017 10:18:06
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE MONTERREY
CAMPUS MONTERREY
DIVISIÓN DE INGENIERÍA Y ARQUITECTURA
PROGRAMA DE GRADUADOS EN INGENIERÍA
Alternativa de Herramientas Estadísticas para el Desarrollo de
Proyectos Seis Sigma con Datos No Normales
TESIS
PRESENTADA COMO REQUISITO PARCIAL PARA OBTENER
EL GRADO ACADÉMICO DE:
MAESTRA EN CIENCIAS
ESPECIALIDAD EN SISTEMAS DE CALIDAD Y PRODUCTIVIDAD
POR:
MARCIA ORTEGA INFANTE
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE MONTERREY
CAMPUS MONTERREY
DIVISIÓN DE INGENIERÍA Y ARQUITECTURA
PROGRAMA DE GRADUADOS EN INGENIERÍA
Los miembros del Comité de Tesis recomendamos que el presente Proyecto de Tesis presentado por la Ing. Marcia Ortega Infante sea aceptado como requisito parcial para obtener el grado académico de:
Maestra en Ciencias
Especialidad en Sistemas de Calidad y Productividad
Comité de Tesis:
María del Carmen Temblador Pérez, M. C. Asesora
Alberto Hernández Luna, Ph. D. Erika Guadalupe Acosta Silva, M.C. Sinodal Sinodal
Aprobado:
Federico Viramontes Brown, Ph. D. Director del Programa de Graduados en Ingeniería
DEDICATORIA
A mis papás, Mayda y Guillermo,
mi ejemplo, mi fuerza, mi fuente inagotable de amor.
A mi hermana, Mariana,
mi inspiración, mi alegría, mi amor.
A mis abuelos, Guadalupe y Baldemar,
mi apoyo, mis amigos incondicionales.
A mis padrinos, Irma Ruth y Jorge Luis y a mis primas, Krysthel y Alejandra,
AGRADECIMIENTOS
A mi familia, especialmente a mis padres, por quienes soy lo que soy, a quienes debo todo. Por su amor y fe en mí.
A mi asesora, Maricarmen Temblador, por su apoyo incondicional en la realización de esta tesis, por ser un ejemplo a seguir en lo profesional y en lo personal, pero sobre todo, por su amistad.
A mis sinodales, Alberto Hernández y Erika Acosta, por sus consejos y sus comentarios oportunos y relevantes para esta tesis.
A los profesores y directivos del Departamento de Ingeniería Industrial y de Sistemas y del Centro de Calidad y Manufactura del Tecnológico de Monterrey, Campus Monterrey, por su apoyo a lo largo de mis estudios de posgrado.
RESUMEN
La metodología Seis Sigma es uno de lo programas de calidad más
implementados alrededor del mundo por organizaciones reconocidas internacionalmente. A lo largo de las cinco fases que integran su modelo genérico DMAIC (Definir, Medir, Analizar, Mejorar y Controlar), se utiliza una gran variedad de herramientas estadísticas.
Al hablar de las etapas MAIC, encontramos que los procedimientos estadísticos tradicionales implementados en éstas tienen como requisito básico la normalidad de los datos. Cuando los datos de los procesos bajo estudio no son normales, existen técnicas que permiten su ajuste o normalización. Sin embargo, hay ocasiones en las que ninguna de estas técnicas cumple su objetivo y los datos permanecen no normales. Cuando se presenta una situación como ésta, es necesario el uso de procedimientos estadísticos no paramétricos, insensibles al supuesto de normalidad, dándole validez a los resultados obtenidos y otorgando al investigador evidencia suficiente para la toma de decisiones.
En el Capítulo 1 de este documento se plantea la definición del problema, las hipótesis de la investigación, así como la justificación de la misma.
En el Capítulo 2 se presentan los antecedentes tanto de Seis Sigma, como de la Estadística No Paramétrica.
A lo largo del Capítulo 3 se presentan algunas de las herramientas estadísticas no paramétricas equivalentes a los procedimientos paramétricos comúnmente utilizados en las fases MAIC.
En el Capítulo 4 se muestra la aplicación de algunas de las herramientas no paramétricas expuestas en el capítulo anterior, en la problemática de una empresa de la localidad. Se desarrollan las mismas pruebas con su contraparte paramétrica, con el fin de comparar los resultados obtenidos.
Finalmente, en el Capítulo 5 se concluye acerca de la investigación realizada.
ÍNDICE
Resumen
ii
Índice iii
Capítulo 1: Introducción
1.1 Planteamiento del problema 01
1.2 Objetivos 02
1.3 Hipótesis 03
1.4 Preguntas de Investigación 03
1.5 Justificación 04
1.5.1 Magnitud y trascendencia 04
1.5.2 Valor metodológico 05
1.6 Método de Investigación 06
1.6.1 Tipo de estudio 06
1.6.2 Alcance del estudio 06
1.6.3 Pasos para elaborar la investigación 07
1.6.4 Selección de la muestra 07
1.6.5 Recolección de datos 07
1.6.6 Análisis de datos 08
1.7 Alcance y Limitaciones 08
1.7.1 Características de la muestra 08
1.7.2 Área geográfica para el estudio 08
1.7.3 Limitaciones ni definidas por el investigador 08
Capítulo 2: Antecedentes
2.1 Antecedentes 09
2.2 Seis Sigma 10
2.2.1 Metodología DMAIC 12
2.3 La Estadística 16 2.3.1 La Estadística Paramétrica y la Estadística No Paramétrica 16
2.3.2 Limitaciones de la Estadística No Paramétrica 17
2.3.3 Ventajas de la Estadística No Paramétrica 18
Capítulo 3: Procedimientos Estadísticos No Paramétricos
3.1 Conceptos Básicos 20
3.1.1 Niveles de Medición 20
3.1.2 Variables Continuas y Discretas 21
3.1.3 Estadístico contra Parámetro 21
3.1.4 Pruebas de Hipótesis 21
3.2 Procedimientos No Paramétricos 23
3.2.2 Medición 27
3.2.2.1 Capacidad del Sistema de Medición:
Análisis de Dos Factores 27
3.2.2.2 Capacidad del Proceso: Curvas de Pearson 29
3.2.3 Análisis 33
3.2.3.1 Prueba de Ranks Con Signo de Wilcoxon 33
3.2.3.2 La Prueba Chi Cuadrada 34
3.2.3.3 Prueba de la χ2 para Tablas r x c 36
3.2.3.4 Prueba de Bondad de Ajuste Kolmogorov – Smirnov 37
3.2.3.5 Prueba de Bondad de Ajuste de la χ2 39
3.2.3.6 Prueba de Bondad de Ajuste Anderson – Darling 40
3.2.4 Mejora 41
3.2.4.1 Prueba U de Mann – Whitney 41
3.2.4.2 La Prueba Kruskal – Wallis 42
3.2.4.3 Análisis de un Factor para Alternativas
en Forma Curva 43
3.2.4.4 La Prueba de Levene 45
3.2.4.5 La Prueba de Siegel – Tukey 46
3.2.4.6 La Prueba de Moses 48
3.2.4.7 La Prueba de Rangos Cuadrados 50
3.2.4.8 Prueba de Rangos Cuadrados con
Signo de Wilcoxon para Muestras Pareadas 51
3.2.4.9 Prueba Q de Cochran 53
3.2.4.10 Coeficiente de Correlación de Spearman 55
3.2.5 Control 56
3.2.5.1 Gráficas de Control EWMA 56
3.3 Síntesis del Capítulo 58
Capítulo 4: Aplicación
4.1 Definición 61
4.1.1 Introducción a la Problemática 61
4.1.2 Definición 61
4.2 Medición con Procedimientos No Paramétricos 62
4.2.1 Proceso 62
4.2.2 Pruebas de Normalidad 64
4.2.3 Capacidad del Proceso en la Variable Brillo 67
4.3 Análisis con Procedimientos No Paramétricos 68
4.3.1 Gráficas de Dispersión 68
4.3.2 Correlación 70
4.3.3 Comparación de Medianas de la Variable Brillo 72
4.3.4 Gráfico de Control EWMA 73
4.3.5 Comparación de Kilogramos Rechazados en
Puntos Dentro y Fuera de Control en la Variable Brillo 76 4.3.6 Comparación de Kilogramos Rechazados en Puntos
Fuera de Control para la Variable Brillo en la Cara
Superior y Cara Inferior 77
4.3.7 Comparación de Kilogramos Rechazados
a Diferentes Temperaturas 78
4.3.8 Comparación de Kilogramos Rechazados
a Diferentes Viscosidades 79
4.3.9 Comparación de la Interacción entre las Variables
Temperatura, Viscosidad y Kilogramos Rechazados 80
4.3.10 Resultados Obtenidos 81
4.4 Medición con Procedimientos Paramétricos 82
4.4.1 Capacidad del Proceso en la Variable Brillo 82
4.5 Análisis con Procedimientos Paramétricos 83
4.5.1 Comparación de Medianas de la Variable Brillo 83
4.5.2 Gráfico de Control X – R 86
4.5.3 Comparación de Kilogramos Rechazados en
Puntos Dentro y Fuera de Control en la Variable Brillo 89 4.5.4 Comparación de Kilogramos Rechazados en Puntos
Fuera de Control para la Variable Brillo en la Cara
Superior y Cara Inferior 92
4.5.5 Comparación de Kilogramos Rechazados
a Diferentes Temperaturas 93
4.5.6 Comparación de Kilogramos Rechazados
a Diferentes Viscosidades 95
4.5.7 Resultados Obtenidos 96
Capítulo 5: Conclusiones
5.1 De la Investigación 99
5.2 Del Contenido 99 5.3 De la Aplicabilidad de la Herramienta 100
5.4 De Futuras Investigaciones 101
Referencias
102
Lista
de
Figuras
104
Lista
de
Tablas
105
Anexos
106
CAPÍTULO 1
INTRODUCCIÓN
En la década de los 80’s, época en la que inició el boom de la calidad, Philip
Crosby popularizó el concepto de Cero Defectos como orientación para el
control de calidad (Cantú, 1999). Este enfoque tiene la particular característica de establecer como meta resultados perfectos, que carezcan de errores en su totalidad.
Este concepto no difiere tanto al enfoque Seis Sigma. Ésta es una metodología integrada por herramientas estadísticas que permite llevar a cabo, de forma sostenida y eficiente, el proceso de solución de problemas, transformando un problema real en uno estadístico, y finalmente, las soluciones estadísticas a soluciones reales, a través del desarrollo de proyectos.
Aunque el término Seis Sigma surgió también en los años 80 como una importante aportación de Motorola, actualmente hay una continua búsqueda por adaptar este enfoque a las necesidades emergentes de las organizaciones. Debido a la naturaleza de la metodología Seis Sigma (cimentada en conceptos relativos a la normalidad de los datos), los análisis estadísticos concernientes a cada proyecto se realizan teniendo como base una distribución normal. Pero, ¿qué sucede cuando un analista encuentra que los datos arrojados por sus procesos no se ajustan a esta distribución? Es entonces cuando se presenta la necesidad de utilizar los fundamentos de la estadística no paramétrica.
Debido a lo anterior, el principal objetivo de esta tesis es recopilar las herramientas estadísticas básicas que permitan desarrollar proyectos Seis Sigma cuando los datos del proceso bajo estudio no cumplen con el criterio básico de normalidad.
1.1 Planteamiento
del
Problema
La forma más común de ver a la metodología Seis Sigma es a través de su objetivo de eliminar los defectos y la variación de los procesos por medio de las herramientas estadísticas adecuadas.
El desempeño estándar de un proceso actualmente gira alrededor de 3 sigmas, es decir, partiendo de la media del proceso, sus límites de especificación se encuentran a ± 3 desviaciones estándar. El área que se encuentra fuera de estos límites corresponde a aquellas partes defectuosas que no cumplen la especificación proporcionada por el cliente. Un proceso Seis Sigma equivaldría a tener 6 desviaciones estándar de cada lado de la media a los mismos límites de especificación, lo que se traduce en una menor variación, incrementando así la confiabilidad de los procesos.
Como resultado, entonces, encontramos que generalmente se relaciona esta metodología con procesos normales. Pero, ¿qué sucede cuando, al realizar la recolección y análisis de datos para el desarrollo de un proyecto, se detecta que los datos de los procesos bajo estudio no se ajustan a esta distribución?
La bibliografía acerca de la implementación del modelo DMAIC dentro de Seis Sigma para datos que se distribuyen normalmente es vasta; sin embargo, cuando
se trata de lidiar con datos no normales, la información acerca de los
procedimientos estadísticos disponibles y aplicables comienza a escasear.
Con lo anterior, ahora se puede definir el problema en una pregunta:
“¿Cuáles son algunas de las herramientas estadísticas no paramétricas que debe contener el modelo DMAIC, cuando se manejan procesos con datos no normales, para que su implementación sea exitosa?”.
1.2 Objetivos
•
Objetivo General
Determinar y mostrar el uso de algunas de las herramientas estadísticas no paramétricas que equivalen a las herramientas paramétricas estándar en el modelo DMAIC, cuando los procesos bajo análisis arrojan datos no normales.
•
Objetivos Específicos
o Definir en cada una de las etapas del modelo DMAIC, dentro del Seis
Sigma, las posibles herramientas a utilizar cuando los datos bajo análisis no son normales.
o Determinar en qué casos es necesaria la aplicación de métodos
estadísticos no paramétricos cuando se desarrolla un proyecto Seis Sigma.
o Proponer qué pruebas estadísticas no paramétricas son las adecuadas
para cada caso.
o Evaluar la factibilidad, cuando aplique, de su uso mediante la aplicación
en una empresa manufacturera de la localidad.
1.3 Hipótesis
Como resultado de la identificación y planteamiento del problema y del establecimiento de los objetivos de esta tesis, se obtuvo la siguiente hipótesis:
“Es posible identificar y describir el procedimiento de las herramientas estadísticas no paramétricas más comunes equivalentes a las existentes en el modelo DMAIC, para hacerlo utilizable en procesos con datos no normales”.
La hipótesis será validada a lo largo de la realización de esta tesis mediante la investigación y análisis de literatura especializada en el tema. Algunas de ellas se validarán a través de su aplicación en la problemática de una empresa, obteniendo de esta manera evidencia suficiente, tanto teórica como práctica, que permita finalmente aceptarla o rechazarla.
1.4 Preguntas de Investigación
Ahora bien, considerando la problemática, los objetivos y la hipótesis de esta tesis, las preguntas que servirán como guía de la investigación son:
• ¿Cuáles son los orígenes de la calidad?
• ¿Cuáles son los principios que rigen la metodología Seis Sigma?
• ¿Cuál es su aportación a la calidad?
• ¿Quiénes participan en esta metodología?
• ¿Qué pasos/procedimientos se sigue en esta metodología?
• ¿En qué consiste el proceso DMAIC?
• ¿En qué parte de la metodología se aplica el análisis estadístico? ¿Qué resultados se esperan en cada etapa o fase del desarrollo de un proyecto Seis Sigma?
• ¿Qué pruebas estadísticas son necesarias antes de iniciar un proyecto Seis Sigma?
• ¿Qué pruebas estadísticas son necesarias durante el desarrollo de un
proyecto Seis Sigma?
• ¿Qué relación existe entre la metodología Seis Sigma y la Estadística No Paramétrica?
• ¿En qué casos es necesario el uso de la Estadística No Paramétrica?
• ¿Existen pruebas básicas en la Estadística No Paramétrica?
• ¿Cuáles son útiles y aplicables para un proyecto Seis Sigma?
1.5 Justificación
Seis Sigma es una metodología que involucra el uso de herramientas estadísticas como parte elemental en su aplicación. Es muy común el hecho de relacionarla estrechamente con procedimientos estadísticos que tienen como supuesto primordial la normalidad de los datos bajo análisis. Esto puede suceder debido a que la metodología en sí está desarrollada a partir los fundamentos de la distribución normal, ya que se engloba conceptos como media, desviaciones estándar y áreas defectuosas bajo la curva. Por otro lado, gran parte del entrenamiento para convertirse en un experto en Seis Sigma se enfoca de manera exclusiva en la estadística paramétrica, utilizando métodos válidos únicamente para datos normales.
Inconvenientemente, los procesos no siempre se ajustan a una distribución normal; de hecho, es bastante común que éstos sigan distribuciones diferentes (Azzimonti, 2000). La mayoría de los procesos, especialmente aquellos que tienen que ver con la confiabilidad y ciclos de vida, no se distribuyen normalmente. En días pasados se pensaba que había algo mal con los procesos que no seguían esta distribución o incluso que estaban fuera de control. Actualmente los estadísticos y profesionales de la calidad reconocen que la distribución normal es utilizada debido a su simplicidad y a su buena definición; sin embargo gran parte de los proyectos en pro de la calidad involucran procesos con datos no normales (Padnis, 2006). Entre éstos se encuentran tiempos de ciclo, llamadas por hora, tiempo de espera del cliente, perpendicularidad, encogimiento, etc.
De este modo, si el analista detecta que los datos que está manejando no son normales, se topa con la escasez de información que le permita conocer las opciones en cuanto a procedimientos estadísticos se refiere. Cuando se presenta una situación como ésta, la estadística no paramétrica brinda al investigador las herramientas adecuadas para el tratamiento de dichos datos.
Es en este punto que radica la importancia de investigar, recopilar y desarrollar las herramientas estadísticas no paramétricas básicas, que sean útiles al analista en caso de encontrarse con procesos no normales durante el desarrollo de un proyecto de mejora Seis Sigma.
1.5.1
Magnitud y trascendencia
Actualmente uno de los principales retos a los que se enfrentan las organizaciones es la competencia en un mundo cada vez más global e interdependiente. La calidad, más que un valor agregado, es ahora una exigencia del cliente y una ventaja competitiva para el proveedor que puede otorgarla.
Si a esto se le agrega la aceleración del desarrollo y renovación de la tecnología, la urgencia de una mejora continua y de la eficiencia de los procesos es
evidente. Debido a esta situación, las empresas se han percatado de la enorme necesidad de realizar un cambio en su estilo de manejarse. Una de las respuestas que ha traído muy buenos resultados ha sido la metodología Seis Sigma, debido a tres características principales:
• Seis Sigma está enfocado en el cliente.
• Los proyectos Seis Sigma producen importantes retornos sobre la inversión. En un artículo del “Harvard Business Review”, Sasser y Reichheld señalan que las compañías pueden ampliar sus ganancias en casi un 100% si retienen sólo un 5% más de sus clientes gracias al logro un alto grado de calidad.
• Seis Sigma cambia el modo que opera la organización, al conocer y aprender nuevos enfoques en la forma de resolver problemas y tomar decisiones.
Por otra parte, el llamado “costo de la calidad” es un concepto que también expone la magnitud y trascendencia de la aplicación de proyectos Seis Sigma (PPG Consultores, 2003). Mientras que los directivos de las empresas pueden llegar a pensar que invertir en la mejora de la calidad en los procesos representa un costo, la realidad es que el gasto mayor se da a partir de la ausencia de la calidad (fallas internas o externas). Cuando un proceso se encuentra controlado a seis desviaciones estándar, como lo propone la metodología, se presume que los costos de calidad, como porcentaje de las ventas, disminuyen considerablemente como se observa en la Tabla 1.1:
Nivel de
Calidad DPMO
Nivel Sigma
Costo Calidad
30.90% 690,000 1 NA 69.20% 308,000 2 NA 93.30% 66,800 3 25-40% 99.40% 6,210 4 15-25% 99.98% 320 5 5-15% 100.00% 3.4 6 <1%
Tab la 1.1: El Costo de Calidad Extraída de PPG Consultores, 2003
Con los argumentos anteriores, es posible percatarse de la importancia de la correcta implementación de Seis Sigma en las organizaciones. Pues bien, si el desarrollo de estos proyectos de mejora es hoy en día trascendental para las empresas que manejan Seis Sigma, por consecuencia, lo es también la aplicación de los procedimientos no paramétricos adecuados a lo largo de la metodología
MAIC, cuando se tienen datos no normales.
1.5.2
Valor metodológico
[image:16.612.221.418.394.511.2]aportación se presenta en forma de una guía, considerada de gran utilidad para los analistas que se enfrentan a esta situación en el desarrollo de los proyectos de mejora. La información obtenida con esta investigación brinda orientación en un tema sobre el cual no existe literatura extensa ni condensada en un solo documento. Por tanto, cabe la posibilidad de que esta tesis dé pie al surgimiento de nuevas investigaciones y sirva como base para otras similares.
1.6 Método de Investigación
1.6.1 Tipo de estudio
El enfoque de esta investigación es mixto, es decir, una combinación de cualitativo y cuantitativo. Al inicio y durante la mayor parte de la realización de esta tesis, la naturaleza del estudio fue cualitativo debido a que se utilizó la recolección de datos en forma de investigación bibliográfica, sin involucrar la medición numérica (Hernández, 2002), para contestar las preguntas de investigación enfocadas a la aplicación del Seis Sigma y al uso de la estadística no paramétrica en conjunto, desde un punto de vista teórico.
Por otra parte, se utilizó el enfoque cuantitativo al aplicar el procedimiento resultante de la investigación teórica, con datos reales en una empresa, para probar la hipótesis de que el modelo MAIC en Seis Sigma sí puede ser adaptado
para procesos no normales, con base a la medición numérica y el análisis
estadístico (Salkind, 1998).
1.6.2
Alcance del estudio
Esta investigación comenzó como un estudio exploratorio, debido a que el
problema de investigación examinado ha sido poco estudiado (Hernández, 2002). Si bien es cierto que existe una cantidad importante de literatura respecto a Seis Sigma y la estadística no paramétrica por separado, cuando se trata de la conjunción de ambos elementos, la información se reduce considerablemente. Por otra parte, esta investigación también tuvo una naturaleza descriptiva, ya que se busca identificar las propiedades y características esenciales que deben tener los procedimientos estadísticos no paramétricos para que su aplicabilidad pueda ser validada en una empresa. Esta investigación incluye la recopilación y desarrollo de las herramientas básicas que pueden ser de gran ayuda a los miembros de un equipo Seis Sigma cuando los procesos que están analizando presentan datos no normales.
1.6.3
Pasos para elaborar la investigación
A grandes rasgos, los pasos para la elaboración de esta tesis fueron los siguientes:
• Se realizó una revisión bibliográfica de fuentes primarias y secundarias, para recolectar información que pudiera contestar las preguntas de investigación y dar un soporte teórico a las herramientas estadísticas más adecuadas para cada situación, que a fin de cuentas, es el entregable de esta tesis.
• Se hizo un análisis de la información recolectada, para hacer uso de la
literatura realmente útil y relevante para los objetivos de investigación y, por consecuencia, desechar lo inservible.
• Con todo lo anterior, se determinaron los elementos teóricos y prácticos que debe contener la descripción de las herramientas estadísticas para la aplicación de Seis Sigma a proyectos que involucren procesos con datos no normales.
• Se revisó, integró y estructuró la información.
• Se elaboró el reporte de herramientas no paramétricas adecuadas para cada situación.
• Se buscó, evaluó y seleccionó un proyecto de mejora adecuado para validar la aplicabilidad del procedimiento ya elaborado.
• Se aplicaron los procedimientos investigados al proyecto.
• Se interpretaron los resultados obtenidos.
• Se elaboraron las conclusiones.
1.6.4
Selección de la muestra
Se utilizaron datos de un proceso que cumpliera con el requisito de la existencia de procesos con datos no normales y se evaluó la factibilidad de aplicación de las herramientas investigadas. Por otra parte, la muestra de los datos que se analizaron estadísticamente se tomó de manera directa de los procesos de manufactura de una organización de la localidad.
La cantidad de datos a ser analizados corresponde a 302, obtenidos de 35 muestras con un promedio de 9 lecturas en cada muestra, correspondientes a 5 días de trabajo.
1.6.5
Recolección de datos
1.6.6
Análisis de datos
El análisis de la muestra se llevó a cabo a través de la aplicación de las herramientas estadísticas no paramétricas adecuadas para cada caso, de acuerdo a la información obtenida de la investigación literaria, que se presenta posteriormente en el marco teórico de esta tesis. Asimismo, se aplicaron las herramientas paramétricas estándar para comparar los resultados obtenidos, así como la validez de su implementación.
1.7 Alcance y Limitaciones
1.7.1 Características de la muestra
Se buscó específicamente que la muestra seleccionada para el estudio en el proyecto de mejora cumpliera con la característica de no normalidad, ya que ésta es un requisito básico para la aplicabilidad de los procedimientos y herramientas estadísticas propuestos.
1.7.2
Área geográfica para el estudio
El estudio fue realizado con datos recolectados a partir de los procesos de manufactura de una empresa de Monterrey, Nuevo León, México.
1.7.3
Limitaciones no definidas por el investigador
Por cuestiones de tiempo, la validación de la aplicabilidad de los procedimientos estadísticos puede llegar a ser sólo analítica, ya que la implementación real podría tomarse incluso como material para otras tesis, o bien, para la continuación de ésta. Además, debido a la confidencialidad acordada con la organización involucrada, se omiten algunos de los datos relacionados a sus procesos.
CAPÍTULO 2
ANTECEDENTES
Desde su nacimiento, el programa de calidad Seis Sigma ha tenido como cimiento el uso de diferentes métodos estadísticos para el análisis de información y la optimización de procesos. Debido a que su concepción se basa principalmente en parámetros referentes a la curva normal, Seis Sigma se ha visto
estrechamente vinculado a la Estadística Paramétrica. A causa de esto, la
mayoría de las personas involucradas con proyectos de esta naturaleza esperan que los datos arrojados por la medición de sus procesos se ajusten a la distribución normal, siendo que esto no sucede en todos los casos. Cuando una situación como ésta se presenta es necesario el uso de la Estadística No Paramétrica. Algunas de las herramientas estadísticas no paramétricas útiles para este caso se muestran a lo largo del Capítulo 3.
2.1 Antecedentes
La metodología Seis Sigma se inicia en los años 80's como una estrategia de
negocios y de mejora de calidad, introducida por Motorola, adoptándose y
difundiéndose posteriormente por otras organizaciones de clase mundial como
G.E., Sony, Polaroid, FeDex, Dupont, Toshiba, Ford y Black & Decker, entre otros.
Su origen en Motorola se da cuando Mikel Harry comienza a influenciar a la organización para que se estudie la variación en los procesos, es decir, la desviación estándar. Esta iniciativa se convirtió en el centro del esfuerzo para mejorar la calidad en la empresa, capturando la atención de Bob Galvin, ejecutivo de Motorola. Con el apoyo de Galvin, se hizo énfasis, no sólo en el análisis de la variación, sino también en la mejora continua, estableciendo como meta obtener 3.4 defectos por millón en los procesos.
Anteriormente, Motorola había utilizado herramientas de los grandes gurúes de la calidad, como Juran, e implantado aplicaciones del Control Estadístico del Proceso (SPC). Esto propició el desarrollo de una nueva metodología tomando lo mejor de aquellos conceptos, pero ahora con un enfoque completo hacia la satisfacción del cliente. Esta metodología fue llamada después Seis Sigma. El
impulso hacia esta metodología se incrementó cuando Motorola ganó el
Malcolm Baldridge Nacional Quality Award en 1988.
GE se entera del éxito de esta nueva estrategia, dando lugar al mayor cambio iniciado en esta organización.
La forma en que Seis Sigma se convirtió de un programa de calidad en manufactura, a un sistema para reducir fallas en el diseño y comercialización de productos se logró por dos razones significativas: la formación de equipos de trabajo como los Master Black Belts, Black Belts y Green Belts; además de la inclusión de la metodología de selección y desarrollo de proyectos como el
DMAIC (Snee, 2001).
En el modelo DMAIC (Definir, Medir, Analizar, Mejorar y Controlar), todas las etapas utilizan herramientas estadísticas, pero son las de medición, análisis, mejora y control las que involucran el uso de métodos estadísticos con requerimientos de normalidad. Cuando dicho requerimiento no se cumple, hace su entrada la
Estadística No Paramétrica. Generalmente en los proyectos Seis Sigma, se analizan modelos estadísticos que implican distribuciones tanto continuas como discretas, con ciertos supuestos básicos para la aplicación de estas técnicas (el supuesto de normalidad, por ejemplo). El principal uso de estos modelos es la estimación de parámetros desconocidos de la población que se está estudiando, para poder hacer pruebas de validación y de hipótesis planteadas. A esta metodología de trabajo se le denomina Estadística Paramétrica. Mientras los supuestos usados en la paramétrica especifican la distribución original, hay otros casos en la práctica donde no se puede hacer esto. Se requiere entonces de otra metodología de trabajo, la Estadística No Paramétrica (Azzimonti, 2000).
En las secciones posteriores de esta tesis, se hace una mención más extensa de los conceptos mencionados anteriormente.
2.2 Seis
Sigma
Desde principios de la década de 1980 a 1990, surgió la conciencia de la necesidad de productos de buena calidad: las normas que las que las empresas seguían ya no eran aceptables. Fue así como la satisfacción del cliente, la confiabilidad, la productividad, los costos y la rentabilidad comenzaron a ser directamente dependientes a la calidad de los productos y servicios.
A la par de esta tendencia, surgió también un movimiento que incluía teorías, metodologías y herramientas para lograr lo demandado por los clientes, basados en conceptos previos y nuevos referentes al control de la calidad. Entre ellos se encontraba la metodología Seis Sigma. Pero ¿qué diferencia a Seis Sigma de todas las demás metodologías y herramientas?
Desarrollada en 1987 por Motorola como una iniciativa de negocios, Seis Sigma tiene el principal objetivo de reducir el número de defectos en un proceso para lograr la satisfacción del cliente, basándose en el hecho de que la variación es el principal enemigo de la productividad en cualquier organización.
El término Seis Sigma tiene su origen en la estadística a partir de un proceso capaz de abarcar seis sigmas en la curva normal. Sigma (σ) es la letra griega que se utiliza para representar la desviación estándar, una medida de dispersión en una distribución. Por tanto, un proceso que comprenda seis sigmas, es decir, seis desviaciones estándar, puede tener 3.4 defectos por millón de oportunidades. Esto equivale a un nivel de calidad de 99.99966%, que se aproxima de forma considerable al ideal de cero defectos.
En esencia, entonces, la sigma refleja la capacidad de un proceso y tiene la propiedad de relacionarse de manera directa con características como defectos por unidad, partes por millón y la probabilidad de falla o error. Por lo anterior, el seis sigma en sí se ha convertido en la meta para muchas organizaciones, ya que provee un métrico uniforme para medir el desempeño. La comparación clásica de la diferencia del nivel 6σ se muestra en la Tabla 2.1:
Capacidad del Proceso
Defectos por Millón de Oportunidades
(DPMO)
6 3.4 5 233 4 6,210 3 66,807 2 308,537
Tab la 2.1: Niveles Sigma con un desplazamiento de ± 1.5σ Extraída de Stamatis, D.H., 2002
Otra forma de apreciar y entender el efecto de moverse del estándar histórico de 3σ, al estándar actual de la mayoría de las organizaciones de 4σ y, finalmente, al nuevo estándar de 6σ, se presenta en la Tabla 2.2:
Sigma Tiempo Dinero
3σ 3.5 meses por cada 100 años.
Por cada $1000 millones de activos, hay una deuda de $2.7 millones.
4σ 2.5 días por cada 100 años.
Por cada $1000 millones de activos, hay una deuda de $63,000.
5σ 30 minutos por cada 100 años.
Por cada $1000 millones de activos, hay una deuda de $570.
6σ 6 segundos por cada 100 años.
Por cada $1000 millones de activos, hay una deuda de $2.
Sin embargo, y por conveniente que esto es, Seis Sigma no se enfoca solamente en lo que se refiere a los métricos de desempeño de la organización, sino que exige además un cambio de paradigma total en sus funciones, involucrando el compromiso de la dirección y la responsabilidad y aceptación de la propiedad del proceso de quienes forman parte de los mismos. Por tanto, Seis Sigma tiene una metodología específica para identificar, medir, analizar, mejorar y controlar los procesos, a partir del trabajo en equipo.
La utilidad de la metodología Seis Sigma radica en que puede ser aplicada no solamente a procesos de manufactura, que es el ambiente del que proviene, sino también a procesos transaccionales y de servicios.
2.2.1 Metodología DMAIC
La metodología DMAIC* es el modelo genérico de Seis Sigma∗. Es un acrónimo cuyas siglas en inglés significan Definir, Medir, Análisis, Mejorar y Controlar, representando cada una de las fases que se siguen en un proyecto de mejora.
Fig ura 2.1: Modelo General DMAIC
• De finir
Se identifican los posibles proyectos Seis Sigma evaluados por la alta dirección. En esta fase se especifica la misión del proyecto, se selecciona el equipo de trabajo, se asignan roles, se determinan objetivos, metas y roles, así como el alcance del mismo.
Herramientas:
o QFD: Traducir los requerimientos del cliente (VOC) a CTQ’s (Critical to Quality).
o Diagrama de Pareto: Identificar la principal problemática a atacar.
o AMEF: Identificar parámetros que no desea el cliente o fallas
potenciales.
o Benchmarking: Comparar lo que hacen otras empresas contra la propia.
o Mapa del proceso: Identificar procesos principales.
o SIPOC: Identificar proveedores, entradas, procesos, salidas y clientes. o VOP: Identificar los requerimientos principales del proceso.
o Planeación Operativa: Identificar áreas de oportunidad que se transformen en proyectos Seis Sigma.
∗ Términos acuñados por Motorola.
Resultados:
o Equipo integrado.
o Requerimientos del cliente y del proceso.
o Oportunidades de triunfo.
o Planteamiento del problema.
o Proyecto clarificado.
• Me dir
Se basa en la caracterización del proceso. En ésta se identifican los requisitos clave de los clientes, las características clave del producto (o variables de salida) y los parámetros (variables de entrada) que afectan al funcionamiento del proceso. A partir de esta caracterización se define el sistema de medición y se mide la capacidad del proceso.
Herramientas:
o Gráficos de Control: Verificar si el proceso se encuentra bajo control.
o Cp y Cpk: Conocer la capacidad del proceso.
o MSA= Atributos y Gage R&R: Conocer la capacidad del sistema de
medición.
o DPMO: Medición de los defectos por millón de oportunidades.
o Diagrama Causa – Efecto (Ishikawa) y Matriz Causa – Efecto: Encontrar las causas raíz de un problema determinado.
o Baseline: Determinar el estado actual del proceso y su nivel sigma. o Series de tiempo: Comprender el comportamiento de datos de los
procesos a través del tiempo en intervalos uniformes.
Resultados:
o Indicadores del proceso, de entradas y de salidas.
o Identificación de las posibles variables que afectan al métrico primario.
o Representación del proceso para obtener un punto de partida válido.
• Analizar
El equipo analiza los datos obtenidos en la fase anterior. Se desarrollan y comprueban hipótesis sobre posibles relaciones causa-efecto utilizando diversas herramientas estadísticas. De esta forma el equipo identifica las variables clave de entrada que afectan a las variables de respuesta del proceso.
Herramientas:
o Pruebas de Hipótesis: Verificar la relación entre los efectos.
o Análisis de Regresión: Identificar las relaciones entre las variables de entrada y las de salida.
o ANOVA: Verificar la igualdad de medias de los procesos. o Diagrama de Ishikawa: Identificar las causas raíz.
Resultados:
o Análisis de datos. o Causas raíz validadas.
o Fuentes de variación.
o Identificación de variables a mejorar. o Identificación de variables a discriminar.
o Comprobación de la relación causal entre las variables críticas y el
métrico primario.
• Me jo rar
El equipo de trabajo trata de determinar la relación causa-efecto para predecir, mejorar y optimizar el funcionamiento del proceso. Por último se determina el rango operacional de los parámetros o variables de entrada del proceso.
Herramientas:
o Diseño de Experimentos y Superficies de Respuesta: Optimizar las
salidas a través del uso de los niveles adecuados de las entradas.
o EVOP: Alcanzar el óptimo mediante cambios paulatinos. o Regresión: Desaclopar variables para simplificar su control.
o Simulación: Encontrar el óptimo mediante la representación de condiciones reales del proceso.
o Series de tiempo: Comprender el comportamiento de los datos para
predecir eventos futuros.
Resultados:
o Soluciones.
o Documentación de cambios necesarios.
o Niveles óptimos de operación.
o Comprobación de los cambios propuestos.
• C o ntro lar
Se diseñan y documentan los controles necesarios para asegurar que lo conseguido mediante el proyecto se mantenga una vez que se hayan implantado los cambios.
Herramientas:
o Planes de Control: Determinar planes de contingencia.
o Gráficos de Control y Control Estadístico del Proceso: Monitorear la
estabilidad del proceso y comprobar las mejoras.
o Planes de Mantenimiento Preventivo y Predictivo: Evitar adoptar la filosofía de “apagar incendios”.
o Poka Yoke: Procesos a “prueba de errores”.
o Auditorías: Asegurarse de que las soluciones se han puesto en marcha
y se han mantenido.
o Planes de transición: Organizar los esfuerzos para mantener la mejora.
Resultados:
o Planes de control.
o Planes de transición. o Evidencia de la mejora. o Reportes de auditorías.
o Normas y procedimientos.
2.2.2 Equipos de Trabajo
En la actualidad, y de forma creciente, las organizaciones están implementando equipos de trabajo para alcanzar los beneficios del esfuerzo colectivas. La metodología Seis Sigma no es ajena a esta tendencia, sino, por el contrario, es promotora del trabajo en equipo, y éste forma parte esencial de sus procedimientos.
Como una forma de identificar a determinados miembros dentro de la organización que cumplen funciones específicas en la metodología de Seis Sigma, e inspirados en las artes marciales como filosofía de mejora, se asignan diferentes niveles de cinturones para aquéllos que lideran y están involucrados de alguna forma en los proyectos.
De esta manera, los Black Belt son personas que se dedican a tiempo completo a detectar oportunidades de cambio y a conseguir que logren resultados. El Black Belt es responsable de liderar, entrenar y cuidar de los miembros de su equipo. Debe poseer conocimientos tanto en materia de calidad, como en temas relativos a estadística, resolución de problemas y toma de decisiones.
El Green Belt está formado en la metodología Seis Sigma como apoyo a las tareas del Black Belt. Sus funciones fundamentales consisten en aplicar los nuevos conceptos y herramientas de Seis Sigma a las actividades del día a día de la organización.
El Master Black Belt desempeña un rol de entrenador, mentor y consultor para los
Black Belts que trabajan en los diversos proyectos. Debe poseer amplia experiencia en el campo de Seis Sigma y en las operaciones de producción, administrativas y de servicios de la organización.
2.3 La Estadística
Actualmente, las organizaciones, en su lucha constante por el liderazgo, tienen la tarea de esforzarse por mejorar constantemente la calidad de sus productos y servicios, con el objetivo de competir exitosamente en el mercado local y mundial. Los ingenieros juegan un papel fundamental en este afán por el mejoramiento de la calidad, ya que son ellos quienes tienen como responsabilidad diseñar y desarrollar nuevos productos y procesos de fabricación, así como el perfeccionamiento de los ya existentes.
Los recursos estadísticos son una herramienta básica en estas actividades debido a que proporcionan métodos descriptivos y analíticos para conocer y manejar la variabilidad de los datos observados dentro de los procesos de interés. La
Estadística trata de la recolección, presentación, análisis y uso de datos para la toma de decisiones, solución de problemas y diseño de productos y procesos (Montgomery, 2002).
2.3.1
La Estadísica Paramétrica y la Estadística No Paramétrica
La estadística es un campo dentro de las matemáticas, que involucra la agrupación, clasificación y análisis de datos. La estadística puede ser dividida en dos áreas generales, la estadística descriptiva y la estadística inferencial.
La estadística descriptiva emplea métodos y procedimientos para presentar y organizar datos, mientras que en la estadística inferencial los datos son utilizados para hacer predicciones y derivar conclusiones acerca de una población mediante la selección de una muestra. Ambas ramas de la estadística poseen procedimientos paramétricos y no paramétricos.
El propósito de la estadística es proporcionar las herramientas necesarias para darle objetividad a las conclusiones de los analistas; de esta manera, es posible separar la ciencia de la opinión (Conover, 1980). Las leyes de la probabilidad son aplicadas a ciertos modelos de experimentación con el objetivo de determinar cuáles son las oportunidades de ocurrencia de todos los resultados posibles.
A pesar de que en ocasiones es difícil describir un modelo teórico apropiado para cada experimento, la mayor dificultad se da cuando, después de que el modelo ha sido definido, se desean determinar las probabilidades asociadas a dicho modelo. Por tanto, existen modelos para los cuales nunca se han encontrado soluciones probabilísticas. Ante esta circunstancia los estadísticos han modificado ligeramente los modelos, con el objetivo de encontrar las probabilidades deseadas, procurando que el cambio sea lo suficientemente pequeño para obtener resultados válidos. De esta forma, se encuentran soluciones exactas a problemas aproximados. A esta parte de la Estadística, se le llama Estadística Paramétrica, e incluye pruebas tan conocidas como la prueba T o la pruebaF.
En la década de 1930 a 1940, surgió un enfoque diferente para lidiar con este tipo de problemas. Éste involucraba métodos simples para encontrar las probabilidades deseadas, o al menos una buena aproximación de estas probabilidades, haciendo pocas o ninguna modificación al modelo original. Con esto era posible encontrar soluciones aproximadas a problemas exactos, lo contrario a la estadística paramétrica. A esta rama de la estadística se le conoce desde entonces como Estadística No Paramétrica.
La mayoría de los procedimientos relativos a pruebas de hipótesis y construcción de intervalos de confianza utilizados en diversos ámbitos, especialmente en ingeniería, parten del supuesto de que las muestras aleatorias con las que se trabajan provienen de poblaciones normales. Estos procedimientos son conocidos como métodos paramétricos, ya que se basan en una distribución paramétrica
particular, en este caso, la normal.
De igual manera, existen los llamados métodos no paramétricos, también
conocidos como métodos de distribución libre. Generalmente, el único supuesto en el que éstos se basan es el de continuidad, es decir, que la distribución de la población de la proceden es continua.
Una de las ventajas de estos procedimientos es que no es necesario que los datos sean cuantitativos, sino que pueden ser datos categóricos o datos en forma de rank, además su aplicación es rápida y sencilla.
Si es posible aplicar ambos métodos (paramétricos y no paramétricos) en un problema específico, se optaría por utilizar un método paramétrico eficiente
(Montgomery, 2002). Sin embargo, los supuestos necesarios para que este tipo de procedimientos sean válidos en ocasiones pueden ser difíciles o imposibles de satisfacer, situación que es muy frecuente en la práctica. Por ejemplo, en caso de que los datos estén en forma de ranks, es improbable que éstos cumplan el supuesto de normalidad. Muchos métodos no paramétricos incluyen el análisis de ranks y, por tanto, se ajustan a este tipo de problemas.
Una diferencia importante entre ambos tipos de estadística, que no puede dejarse de mencionar, es que la paramétrica se enfoca en el valor de los datos como tal, mientras que la no paramétrica considera el orden de éstos (por ello se otorga el nombre de estadísticos de orden). De esta forma, mientras la primera utiliza como medidas la media y la varianza, la segunda hace uso de la mediana
y ranking de los datos.
2.3.2
Limitaciones de la Estadística No Paramétrica
distribución poblacional para cual se está empleando dicha prueba (Sheskin, 2004).
De la misma manera, se hace énfasis en la descripción de las pruebas no paramétricas como pruebas de “distribuciones libres”, debido a que no se hace ninguna suposición acerca de los parámetros de la población. Sin embargo, es importante señalar que en realidad las pruebas no paramétricas también hacen ciertas suposiciones.
Como una regla general, las pruebas de inferencia estadística que evalúan datos categóricos o nominales y ordinales o ordenados, se categorizan como no paramétricas, mientras que aquellas que evalúan datos en forma de intervalo o proporción se conocen como paramétricas.
Los autores concuerdan en que mientras no haya ninguna razón para creer que una o más de las suposiciones de las pruebas paramétricas no han sido cumplidas y cuando el nivel de medición de un grupo de datos está en forma de intervalo o proporción, éste debe ser evaluado con la prueba paramétrica apropiada. Sin embargo, si una o más de las suposiciones son violadas, algunas fuentes (no todas) mencionan que es prudente transformar los datos a un formato compatible para el análisis con la prueba no paramétrica adecuada (Sheskin, 2004).
Sin embargo, existe cierta negativa por parte de algunos autores en hacer esta transformación, ya que los datos en forma de intervalo o proporción contienen más información que los otros formatos. Debido a lo anterior, se cree más prudente emplear la prueba paramétrica apropiada aun cuando existe la duda del cumplimiento de los supuestos. Estos autores argumentan que las pruebas paramétricas son robustas, es decir, pueden proveer información razonablemente confiable acerca de la población, a pesar de lo anteriormente mencionado. Generalmente cuando una prueba paramétrica es empleada bajo estas condiciones se hacen ciertos ajustes en lo que se refiere a la evaluación del estadístico de prueba para mejorar su confiabilidad.
2.3.3
Ventajas de la Estadística No Paramétrica
A pesar de tener ciertas limitaciones, es importante resaltar las ventajas que tienen los métodos no paramétricos sobre los paramétricos. Hollander y Wolfe (1999) las sintetizan en una lista:
Los procedimientos no paramétricos requieren pocas suposiciones acerca de las poblaciones de las cuales proceden los datos bajo análisis. De manera particular, es posible dejar a un lado la suposición de normalidad de los datos.
Estos métodos son capaces de proveer con exactitud p-valores e intervalos de confianza para diferentes pruebas de hipótesis, así como tasas de error para comparaciones múltiples, entre otras.
Las pruebas no paramétricas son a menudo más fáciles de aplicar y entender que sus contrapartes paramétricas.
Aunque a primera vista pareciera que estos procedimientos sacrifican
mucha información contenida en las muestras, investigaciones teóricas han demostrado que éste no es el caso, sino por el contrario, cuando los datos no son normales, su eficiencia puede ser igual o mayor que las pruebas paramétricas.
Las técnicas no paramétricas son relativamente insensibles a observaciones alejadas del centro de los datos. Esto es, que al usar parámetros como el rango (R), cualquier variación en los datos afecta el resultado, mientras que en la estadística no paramétrica, se utiliza la posición del dato (ranking), insensibilizando así el resultado ante observaciones alejadas del centro de los datos (mediana).
Éstas son aplicables en muchas situaciones donde los procedimientos de la teoría normal no pueden ser utilizados.
Son la alternativa ideal a utilizar cuando los datos no pueden ser
CAPÍTULO 3
PROCEDIMIENTOS ESTADÍSTICOS
NO PARAMÉTRICOS
3.1 Conceptos
Básicos
3.1.1
Niveles de Medición
La información cuantificada con propósitos de análisis es clasificada respecto al nivel de medición que presentan los datos. Existen diferentes niveles de medición, los cuales contienen diferentes cantidades de información de lo que sea que se está midiendo (Sheskin, 2004).
Stevens (1946) desarrolló un sistema de clasificación de niveles de medición, el más usado en las disciplinas científicas. Las categorías existentes se presentan a continuación:
a) Nominal/Categórico: En este tipo de nivel de medición, los números se utilizan para identificar categorías mutuamente excluyentes, pero no pueden ser manipulados de forma matemática. Por ejemplo, la matrícula de un vehículo, cuyo único propósito es la identificación y por ende no puede ser utilizada en una operación aritmética.
b) Ordinal: En este caso, los números representan un orden específico, pero no proporcionan ninguna información acerca de las diferencias entre órdenes adyacentes. Por ejemplo, el orden de llegada en una carrera, que no indica la distancia de diferencia entre primero, segundo y tercer lugar.
c) Intervalo: Una escala en intervalo considera el orden relativo de las mediciones pero también considera el hecho de que una diferencia en escala entre dos medidas, corresponde a la misma diferencia en la
cantidad del atributo medido. Por ejemplo, si se hablara del IQ
d) Proporción: El concepto de nivel de medición tipo proporción es igual al del intervalo, pero además se caracteriza por tener un punto cero. Debido a lo anterior, es posible hacer aseveraciones significativas acerca del atributo o variable medido. Por ejemplo, la mayoría de las medidas físicas (estatura, peso) tienen este tipo de nivel: tienen un punto cero y se pueden hacer afirmaciones sobre el peso de alguien en forma de proporción (una persona pesa el doble que otra).
3.1.2
Variables Continuas y Discretas
Cuando se hacen mediciones acerca de personas u objetos, se asume que existirá cierta variabilidad, es decir, que lo que estamos cuantificando o midiendo no tendrá siempre el mismo valor para todos los sujetos estudiados. Es por esto que cuando algo es medido, comúnmente es llamado variable.
Las variables se clasifican en continuas y discretas. Una variable continua es aquella que puede asumir cualquier valor dentro de un rango que define los límites de dicha variable, por ejemplo, la temperatura ambiental. Por otro lado, una variable discreta es que aquella que sólo puede tomar un número limitado de valores, por ejemplo, el valor de una de las caras de un dado, que sólo puede asumir valores enteros entre 1 y el 6.
3.1.3
Estadístico contra Parámetro
Un estadístico se refiere a la característica de una muestra, mientras que un
parámetro se refiere a la característica de una población. Un estadístico puede ser utilizado tanto para propósitos descriptivos como inferenciales. En la estadística inferencial un estadístico se emplea para hacer suposiciones acerca de su parámetro correspondiente dentro de una población, de la cual se ha extraído una muestra aleatoria.
3.1.4
Pruebas de Hipótesis
La inferencia estadística tiene muchas formas. La forma que ha tenido mayor aplicación, difusión y atención por parte de los usuarios de los métodos no paramétricos es la llamada prueba de hipótesis (Conover, 1980).
La prueba de hipótesis es el proceso de inferir, a partir de una muestra, si un enunciado acerca de una población debe ser aceptado o rechazado. Dicho enunciado es lo que se llama hipótesis. En cada caso la hipótesis es probada a partir de evidencia contenida en la muestra. Ésta es rechazada si la evidencia existente nos revela con cierto grado de confianza que la hipótesis es falsa. Si, por el contrario, la evidencia muestra que la hipótesis es verdadera, ésta se acepta. El procedimiento general para realizar una prueba de hipótesis es el siguiente:
a) Las hipótesis son establecidas en términos de la población. b) Se selecciona un estadístico de prueba.
c) Se establece una regla en cuanto a los valores posibles del estadístico de prueba, para decidir se si se acepta o rechaza la hipótesis.
d) Se evalúa dicho estadístico contra la evidencia que arroje la muestra aleatoria extraída de la población, y se toma la decisión.
Existen dos tipos de hipótesis, la nula y la alternativa. La hipótesis nula (H0) es la
hipótesis que afirma una verdad establecida, y en caso de ser cierta, no es necesario ejecutar acción alguna. Por otro lado, la hipótesis alternativa (H1) es la
que se desea sea la sustituta de la hipótesis nula y, cuando es verdadera, es necesario efectuar cambios.
De la misma manera, hay dos tipos de errores que pueden ser cometidos en al momento de llevara cabo una prueba de hipótesis, el Error tipo I y Error tipo II, su definición se presenta en la Tabla 3.1:
Naturaleza Se acepta H0 Se rechaza H0
H0 es verdadera No existe error Error tipo I
H0 es falsa Error tipo II No existe error
Tab la 3.1: Errores Tipo I y Tipo II
Por otra parte, el nivel de significancia es la probabilidad de cometer el error tipo I, y se denota por α. A la probabilidad de cometer el error tipo II se le conoce como β.
Existen dos tipos de pruebas de hipótesis, la prueba bilateral y la prueba unilateral. La hipótesis nula es la misma para ambos casos, y se representa como:
0 0
:
θ
=
θ
H
En la prueba bilateral, la hipótesis alternativa es:
0 1
:
θ
≠
θ
H
En la prueba unilateral, hay dos opciones de hipótesis alternativa:
0 1
:
θ
>
θ
H
ó0 1
:
θ
<
θ
Una forma de reportar los resultados de una prueba de hipótesis es enunciando que la hipótesis nula se rechazó o no en un nivel de significancia determinado. Este enunciado puede ser inadecuado, ya que no le da al analista ninguna idea acerca de cuánto se acercó el estadístico de prueba a la zona de rechazo.
Para evitar esto, se utiliza el p-value o p-valor. Éste es la probabilidad de que el estadístico de prueba tome un valor que es al menos tan extremo como el valor observado del estadístico cuando la hipótesis nula es verdadera (Montgomery, 2002).
3.2 Procedimientos No Paramétricos
3.2.1
Procedimientos Paramétricos vs No Paramétricos
En la Sección 2.2.1 se describieron cada una de las etapas de la metodología
DMAIC (Definir, Medir, Analizar, Mejorar, Controlar) como corazón de Seis Sigma, tanto su definición, como una breve explicación las herramientas utilizadas.
Dentro de la etapa de Definición, como puede observarse, sólo se aplica
estadística descriptiva, que no requiere de la normalidad de los datos, por lo que los procedimientos no paramétricos presentados en los siguientes apartados se enfocarán específicamente en las etapas MAIC.
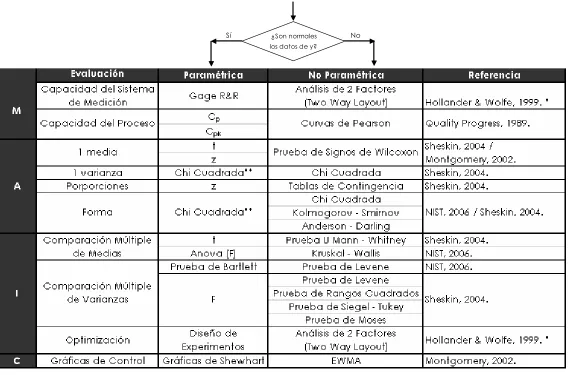
Teniendo como base diversas fuentes consultadas especializadas en estadística, y como resultado de esta tesis, en la Tabla 3.2, se presenta una propuesta que incluye los sustitutos o equivalentes no paramétricos para algunos de los procedimientos paramétricos utilizados en las fases MAIC. Se incluye también la fase de Definición, con algunas de las herramientas de estadística descriptiva empleadas, así como una guía a grandes rasgos, para verificar que los datos no pueden ser normalizados, y por tanto, tomar la decisión de utilizar herramientas no paramétricas.
Capítulo 3: Procedimientos Estadísticos No Paramétricos 26
Tab la 3.2: Procedimientos Paramétricos vs Procedimientos No Paramétricos Propuestos (Continuación)∗**
∗ Debido a que la prueba Gage R&R es considerada como un ANOVA de dos factores, su
equivalente no paramétrico es el Análisis de 2 Factores, o Two-Way Layout.
** Algunos autores, como Sheskin, consideran la Prueba Chi Cuadrada como no paramétrica,
mientras que otros, como Montgomery, la consideran un procedimiento paramétrico.
Sí ¿Son normales
los datos de y?
[image:37.612.25.593.53.428.2]En los siguientes apartados del documento, se desarrollan las herramientas no paramétricas que se sugieren como equivalentes a las pruebas tradicionales de las etapas MAIC, estas son:
Medición
o MSA- Análisis de 2 factores (Two Way Layout). o MSA-Friedman, Kendall y Babington-Smith.
o MSA-Comparaciones Múltiples de Tratamientos Basados en el
Procedimiento de Friedman.
o Capacidad del Proceso – Curvas de Pearson.
Análisis
o Pruebas de Hipótesis para Mediana – Wilcoxon.
o Pruebas de Hipótesis para Medianas – Mann – Whitney, Kruskal – Wallis, Análisis de un Factor para Alternativas con Forma Curva.
o Prueba de Hipótesis para Medianas con Muestras Dependientes –
Rangos con Signo Wilcoxon.
o Pruebas de Hipótesis para Varianza – Chi Cuadrada.
o Pruebas de Hipótesis para Varianzas – Levene, Siegel–Tukey,
Moses, Rangos Cuadrados.
o Pruebas para Proporciones - Cochran, Tablas de Contingencia.
o Pruebas de Forma: Chi Cuadrada, Anderson–Darling,
Kolmogorov–Smirnov.
Mejora
o Pruebas de Hipótesis para Medianas – Mann–Whitney, Kruskal–
Wallis, Análisis de un Factor para Alternativas con Forma Curva.
o Pruebas de Hipótesis para Varianzas – Levene, Siegel–Tukey,
Moses, Rangos Cuadrados.
o Pruebas para Proporciones - Cochran, Tablas de Contingencia. o Coeficiente de Correlación – Spearman.
Control
o Gráficos de Control – EWMA.
La presentación de estas herramientas incluye el planteamiento de las hipótesis nula y alternativa, los supuestos bajo los cuales opera, sus requisitos, el procedimiento general para llevar a cabo la prueba y finalmente, la interpretación de los resultados.
3.2.2
Medición
3.2.2.1Capacidad del Sistema de Medición: Análisis de 2 Factores (Two Way Layout)
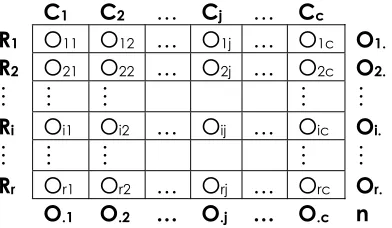
El Análisis de 2 Factores se refiere al análisis estadístico de datos recolectados generalmente bajo un diseño de experimentos que involucran dos factores, a dos o más niveles. Este tipo de estudio es útil para analizar la capacidad de un sistema de medición, ya que se enfoca en los efectos o medianas de los diferentes niveles de uno de estos factores, llamados tratamientos y de los niveles de un segundo factor, llamado bloque. Lo anterior puede ser representado en la Tabla 3.3:
Tratamientos
Bloques 1 2 … k
1 x11 x12 … x1k
2 x21 x22 … x2k
… … … … …
N xn1 xn2 … xnk
Tab la 3.3: Modelo General de Tratamientos y Bloques Adaptada de Hollander y Wolfe 1999
La hipótesis nula básica para este tipo de análisis es la igualdad de los efectos (medianas) de los k tratamientos dentro de cada uno de los bloques.
• Suposiciones
o Los N datos
{
, i = 1,…, n y j = 1,…, son mutuamenteindependientes.
)
,...,
(
x
11x
knk
}
o Las funciones de distribución Fij tienen la relación expresada en la Ecuación
3.1:
∞ < < ∞ − −
−
=F u u
u
Fij( ) (
β
iτ
j), (3.1)donde F es una función de distribución continua con mediana
desconocida θ, βi es el efecto aditivo desconocido del bloque i, y τi es el
efecto aditivo del tratamiento j.
Hipótesis nula
k
H0 :
τ
1 =τ
2 =L=τ
Hipótesis alternativa
:
1
H
Al menos hay un parτ
i≠
τ
j,tal quei
≠
j
.3.2.2.1.1 Prueba de Friedman, Kendall – Babington Smith
• Procedimiento
Dada una muestra de N datos, agrupados en la forma n bloques y k tratamientos: 1. Ordenar de menor a mayor las k observaciones de forma separada dentro de
cada uno de los n bloques.
2. Asignarle a la observación más pequeña el rank 1, a la segunda el rank 2 y así sucesivamente.
3. Realizar la sumatoria de los ranks de cada bloque, como se muestra en la
Ecuación 3.2:
∑
= = n
i ij
j r
R 1
(3.2)
donde rij es el rank de xij dentro del bloque i.
4. Calcular el rank promedio de cada bloque, utilizando la Ecuación 3.3:
n
R
R
.j=
j (3.3)5. Calcular el estadístico de prueba S de Friedman, dado por la Ecuación3.4:
∑
= ⋅⎟
⎠
⎞
⎜
⎝
⎛
−
+
+
=
kj j
k
R
k
k
n
S
1
2
2
1
)
1
(
12
(3.4)
• Interpretación de los Resultados
Rechazar la hipótesis nula si el estadístico de prueba S de Friedman es mayor o igual al valor crítico de tablas sα en su respectivo nivel de significancia.
3.2.2.1.2 Comparaciones Múltiples de Tratamientos Basadas en el Procedimiento de Friedman
Este procedimiento de comparación múltiple, se basa en el modelo de Friedman
desarrollado en el apartado anterior, y tiene el objetivo de dar al analista evidencia para tomar decisiones en base a las diferencias individuales entre pares de tratamientos (τi, τj), para i < j.
Es empleado para datos agrupados en la forma de n bloques y k tratamientos, como se muestra en la Tabla 3.3, con un dato por celda. Su uso es válido después