“S
ISTEMA DE RECONOCIMIENTO DEL LOCUTOR
BASADO EN MODELADO NO PARAMÉTRICO
”
T
E
S
I
S
Q
UE PARA OBTENER EL GRADO DE
“M
AESTRO EN
C
IENCIAS EN
I
NGENIERÍA
E
LECTRÓNICA
”
P
RESENTA
:
I
NG
.
J
UAN
P
ABLO
R
ODRÍGUEZ
R
ODRÍGUEZ
A
SESOR
:
D
R
.
F
RANCISCO
G
ALLEGOS
F
UNES
México D. F. Junio del 2008
INSTITUTO POLITECNICO NACIONAL
Si una pe rso na e s pe rse ve ra nte , a unq ue se a dura de
e nte ndimie nto , se ha rá inte lig e nte ; y a unq ue se a dé b il se
tra nsfo rma rá e n fue rte .
D
EDICATORIA
A mis padres, por su apoyo, tolerancia, amor, así como
sus consejos durante este camino llamado educación.
A mis tías, por su gran apoyo y paciencia durante este
largo camino.
A mis hermanas, por su confianza y apoyo al emprender
este proyecto.
A
G RADEC IMIENTO S
A toda mi familia, por la colaboración para este
proyecto.
A mi asesor: Dr. Francisco Gallegos Funes, por su
apoyo y orientación para la realización de este proyecto.
A todos los profesores de la SEPI que me compartieron
sus conocimientos.
A mis compañeros de la SEPI, en especial a Dante y
Tadeo por su amistad y haber formado un gran equipo.
Al IPN y al pueblo de México, por su apoyo al ofrecerme
una educación laica y gratuita.
i
Í
NDICE GENERAL
PA G I N A
RE S U M E N iii
AB S T R A C T iv
ÍN D I C E D E F I G U R A S Y T A B L A S
F i g u r a s v
T a b la s vii
NO M E N C L A T U R A viii
CA P Í T U L O I “IN T R O D U C C I Ó N”
1.1 Introducción 1
1.2 Objetivos específicos 1
1.3 Justificación 1
1.4 Alcance 2
1.5 Metodología 2
1.6 Contenido de la tesis 3
1.7 Referencias 3
CA P Í T U L O II “ES T A D O D E L A R T E”
2.1 Introducción 4
2.2 Aparato fonador y su modelo 4
2.3 Características de la señal de voz 6
2.3.1 Características espectrales de la señal de voz y ventaneo 6
2.4 Estimación espectral de potencia 7
2.4.1 Codificación lineal predictiva de la señal de voz (LPC) 8
2.4.2 Análisis cepstrum de la señal de voz 11
2.5 Clasificadores de parámetros 12
2.5.1 Método de estimación no supervisada: Cuantificación vectorial 13
2.5.1.1 Medidas de distorsión 13
2.5.1.1 Diseño del codebook 14
2.6 Detectores de activación de voz 15
2.6.1 Ruido blanco 16
2.6.2 Aplicación de la sustracción espectral para la eliminación de ruido blanco 17
2.7 Conclusiones 18
2.8 Bibliografía 18
CA P Í T U L O III “MÉ T O D O P R O P U E S T O”
3.1 Introducción 19
3.2 Propuesta del sistema 19
3.2.1 Diagrama a bloques del sistema 19
3.2.2 Bloque de adquisición 20
3.2.3 Bloque de preprocesado 20
3.2.3.1. Filtro No.1 “Pasa Bajas” 21
3.2.3.2 Pre-énfasis, Normalización y eliminación de CD en la señal de voz 22
3.2.3.3 Detector de activación de voz 22
3.2.3.3.1 Entropía de una señal 22
ii
3.2.3.4 Estimación del espectro del ruido 24
3.2.3.5 Filtro No.2 “Sustracción espectral” 24
3.2.3.6 Segmentación de la señal de voz y ventaneo 26
3.2.4 Bloque de clasificación 27
3.2.4.1 Extracción de las características 27
3.2.4.2 Cuantificación vectorial. 28
3.2.4.3 Construcción del libro de códigos 28
3.2.4.4 Algoritmo de identificación 29
3.2.4.5 Salida del sistema 29
3.3 Conclusiones 30
3.4 Bibliografía 30
CA P Í T U L O IV “RE S U L T A D O S E X P E R I M E N T A L E S”
4.1 Introducción 31
4.2 Bloque de adquisición 31
4.2.1 Corpus de las voces 31
4.3 Bloque de preprocesado 32
4.3.1 Filtro No.1 “Filtro pasa bajas” 32
4.3.2 Pre-énfasis, Normalización y eliminación de CD en la señal de voz 33
4.3.3 Detector de activación de voz (VAD) 33
4.3.4 Estimación del espectro del ruido 36
4.3.5 Filtro No:2 “Sustracción espectral” 37
4.3.6 Segmentación de la señal de voz y ventaneo 41
4.4 Bloque de clasificación 41
4.4.1 Extracción de las características de la voz (LPC-Cepstrum) 41
4.4.2 Cuantificación vectorial de los coeficientes LPC-Cepstrum 44
4.4.3 Algoritmo de identificación 45
4.4.3.1. Resultados del reconocimiento 46
4.5 Discusión de resultados 49
4.6 Conclusiones 49
4.7 Bibliografía 50
CA P Í T U L O V “RE S U L T A D O S E X P E R I M E N T A L E S”
5.1 Introducción 51
5.2 Conclusiones Generales 51
5.3 Sugerencias para trabajos futuros 51
iii
R
ESUMEN
Las técnicas biométricas permiten el reconocimiento de una persona
por medio de características únicas como la voz. El método de reconocimiento de personas a través de su voz se diferencia de los sistemas tradicionales que utilizan números PIN (Personal Identification Number), certificados digitales, firmas digitales, etc.; para poder determinar la identidad de un usuario.
Sin embargo, los sistemas de reconocimiento del locutor tienen dificultades como la variabilidad acústica que puede ser el resultado de cambios en el entorno, la posición y tipo de micrófono, la variabilidad introducida por el propio hablante debido a cambios en el estado físico o emocional.
En este trabajo se propone un sistema de identificación de hablantes dependiente del texto (dígitos del 0 al 9) capaz de identificar a un locutor entre un conjunto de locutores conocidos. Este trabajo pone un especial énfasis en las etapas de filtrado, detección y segmentación de la señal de voz debido a que estos bloques son cruciales para obtener una buena eficiencia del sistema de identificación.
A
BSTRACT
The biometric techniques allow the recognition of a person through of unique features like the voice. The method of recognizing of people through of voice differs from traditional systems that use PINs (Personal Identification Number), digital certificates, digital signatures, etc; to can determine the identity of a user.
However, the speaker recognition systems have difficulties such as the acoustic variability that can result from changes in the environment, the position and type of microphone, and the variability introduced by the speaker due to changes in the emotional or physical state.
This thesis proposes a system to identify speakers attached to the text (digits 0 through 9) able to identify a speaker among a group of broadcasters known. This work puts a special emphasis in the stages of filtering, detection and segmentation of the voice signal because these blocks are crucial to achieve a better efficiency of the identification system.
Í
ND IC E D E FIG URA S Y TA BLA S
F
IG URA S
DE S C R I P C I Ó N P A G I N A
F i g u r a 2 . 1 .
C o r t e e s q u e m á t i c o d e l a p a r a t o f o n a d o r h u m a n o . 5
F i g u r a 2 . 2 .
M o d e l o d e l t r a c t o v o c a l . 5
F i g u r a 2 . 3 .
E s t r u c t u r a e s p e c t r a l e n u n i n t e r v a l o d e t i e m p o d e 3 0 m s p a r a s e ñ a l e s d e v o z m a s c u l i n a
( a ) c u a n d o s e p r o n u n c i a u n a v o c a l / a / y ( b ) u n a c o n s o n a n t e / t / .
6
F i g u r a 2 . 4 .
E s t r u c t u r a d e l f i l t r o a p l i c a d o p a r a l a e t a p a d e p r e - é n f a s i s . 7
F i g u r a 2 . 5 .
D i a g r a m a a b l o q u e d e l m o d e l o d e p r e d i c c i ó n l i n e a l , a ) E c u a c i ó n 2 . 1 1 ,
b ) E c u a c i ó n 2 . 1 2 .
1 0
F i g u r a 2 . 6 .
R e s u l t a d o d e a p l i c a r e l a n á l i s i s C e p s t r a l a u n s e g m e n t o d e v o z d e 3 0 m s .
1 2
F i g u r a 2 . 7 .
D i a g r a m a a b l o q u e s d e u n c l a s i f i c a d o r d e p a r á m e t r o s . 1 3
F i g u r a 2 . 8 .
( a ) R u i d o b l a n c o , ( b ) s u a u t o c o r r e l a c i ó n , y ( c ) s u p o t e n c i a e s p e c t r a l .
1 6
F i g u r a 3 . 1 .
E s q u e m a g e n e r a l d e l s i s t e m a d e l r e c o n o c i m i e n t o d e l l o c u t o r p r o p u e s t o .
1 9
F i g u r a 3 . 2 .
B l o q u e d e p r e p r o c e s a d o . 2 0
F i g u r a 3 . 3 .
E j e m p l o d e u n a f u e n t e s i n m e m o r i a , e n l a t e o r í a d e l a i n f o r m a c i ó n . 2 2
F i g u r a 3 . 4 .
D i a g r a m a a b l o q u e s d e l m é t o d o d e s u s t r a c c i ó n e s p e c t r a l n o l i n e a l . 2 5
F i g u r a 3 . 5 .
B l o q u e d e c l a s i f i c a c i ó n . 2 7
F i g u r a 3 . 6 .
C o m p a r a c i ó n d e l a s e n v o l v e n t e s e s p e c t r a l e s m e d i a n t e l o s m é t o d o s L P C , L P C - C e p s t r u m , y F F T c e p s t r u m .
2 8
F i g u r a 3 . 7
. E t a p a d e r e c o n o c i m i e n t o d e l o c u t o r p o r c u a n t i f i c a c i ó n v e c t o r i a l . 2 9
F i g u r a 4 . 1 .
R e s p u e s t a a ) F i g u r a d e m e r i t o d e l f i l t r o i d e a l d e s e a d o b ) F i g u r a d e m e r i t o o b t e n i d a m e d i a n t e e l m é t o d o d e m u e s t r e o e n
f r e c u e n c i a , u t i l i z a n d o e l a l g o r i t m o d e P a r k s - M c C l e l l a n .
3 3
F i g u r a 4 . 2 .
a ) S e ñ a l c a p t u r a d a y p r o c e s a d a e n e l d o m i n i o d e l t i e m p o , y b ) E s p e c t r o g r a m a s d e l a s e ñ a l c a p t u r a d a y p r o c e s a d a .
3 4
F i g u r a 4 . 3 .
a ) S e g m e n t o d e v o z d e 2 5 m s y b ) s u e s p e c t r o g r a m a . 3 5
F i g u r a 4 . 4 .
P r o b a b i l i d a d d e l a b a n d a d e f r e c u e n c i a ω, p a r a e l e s p e c t r o g r a m a m o s t r a d o e n l a f i g u r a 4 . 3 . b.
3 5
F i g u r a 4 . 5 .
a ) F u n c i ó n d e e n t r o p í a , b ) F u n c i ó n d e e n e r g í a , c ) V A D p o r e n e r g í a p a r a S N R = 1 0 0 , y d ) V A D p o r e n t r o p í a p a r a S N R = 1 0 0 d B .
3 6
F i g u r a 4 . 6 .
a ) F u n c i ó n d e e n t r o p í a , b ) F u n c i ó n d e e n e r g í a , c ) V A D p o r e n e r g í a p a r a S N R = 1 0 d B , y d ) V A D p o r e n t r o p í a p a r a S N R = 1 0 d B .
3 7
F i g u r a 4 . 7 .
a ) V A D p o r e n t r o p í a p a r a S N R = 1 0 d B , b ) M a g n i t u d e s p e c t r a l p a r a u n
s e g m e n t o d e 2 5 m s , y c ) max
( )
N( )
f 2 M muestras3 8
F i g u r a
4 . 8 . a ) F u n c i ó n SNR f( ), y b ) F u n c i ó n N
( )
f 2 NL.3 8
F i g u r a 4 . 9 .
a ) P r o c e s o d e v e n t a n e o y t r a s l a p e e n l a s u s t r a c c i ó n e s p e c t r a l . b ) E s p e c t r o g r a m a d e u n s e g m e n t o d e 2 5 m s . v e n t a n e a d o , y
c ) E s p e c t r o e n f a s e p a r a e l s e g m e n t o m o s t r a d o e n b ) .
3 9
F i g u r a 4 . 1 0 .
E f e c t o d e f i l t r a r e l e s p e c t r o e n p o t e n c i a c o n e l f i l t r o r e c u r s i v o d a d o p o r l a e c u a c i ó n 3 . 1 5 p a r a u n f a c t o r d e ρ = 0 . 7 5
4 0
F i g u r a 4 . 1 2 .
P r o c e s o d e l s u b b l o q u e a t e n u a c i ó n e n l a s u s t r a c c i ó n e s p e c t r a l . 4 1
Figura 4.13.
R e s u l t a d o o b t e n i d o s a l a p l i c a r l a e t a p a d e l a s u s t r a c c i ó n e s p e c t r a l , a ) p a r a S N R = 0 d B ,
b ) p a r a S N R = 1 0 d B , c ) p a r a S N R = 2 5 d B , y d ) p a r a S N R = 7 5 d B
4 2
Figura 4.14.
a ) S e g m e n t o d e v o z v e n t a n e a d o c o n u n t r a s l a p e d e 5 0 % , b ) C o m p a r a c i ó n e n t r e c o e f i c i e n t e s o b t e n i d o s e n e l a n á l i s i s L P C y
L P C C d e o r d e n 2 0 ,
c ) E n v o l v e n t e e s p e c t r a l o b t e n i d a m e d i a n t e e l a n á l i s i s L P C C , d ) E r r o r r e s i d u a l d e e s t i m a c i ó n .
4 3
Figura 4.15.
a ) S e c u e n c i a d e e n t r e n a m i e n t o p a r a 1 0 0 v e c t o r e s d e c a r a c t e r í s t i c a s p a r a u n u s u a r i o , l o s c u a l e s e s t á n f o r m a d o s p o r l o s
c o e f i c i e n t e s L P C C p a r a c a d a u n o d e l o s s e g m e n t o s a n a l i z a d o s d e u n a m u e s t r a d e s e ñ a l d e v o z d e e n t r a d a , y
b ) E s p a c i o c u a n t i f i c a d o m e d i a n t e e l a l g o r i t m o L G B p a r a u n l i b r o d e c ó d i g o s ( c o d e b o o k ) d e 6 b i t s .
4 5
Figura 4.16.
G r á f i c o q u e m u e s t r a l o s r e s u l t a d o s p a r a l a p r u e b a N o . 1 y l a p r u e b a N o . 2
4 7
Figura 4.17.
G r á f i c o q u e m u e s t r a l a e f i c i e n c i a o b t e n i d a p a r a c a d a u s u a r i o
r e g i s t r a d o e n e l s i s t e m a .
4 8
Figura A.1.
E s t r u c t u r a d e l a i n t e r f a z g r a f i c a d e u s u a r i o . 5 3
Figura A.2.
E j e m p l o d e l a i n t e r f a z g r a f i c a d e u s u a r i o p r o g r a m a d a . 5 3
Figura A.3.
D i a g r a m a d e f l u j o d e l p r o g r a m a U s u a r i o _ N u e v o . m . 5 4 Figura
A.4.
I n t e r f a z g r á f i c a p a r a l a c a p t u r a d e u n n u e v o u s u a r i o . 5 4
Figura A.5.
D i a g r a m a d e f l u j o d e l a f u n c i ó n D i s p l a y . m. 5 5 Figura
A.6.
M e n s a j e s d e s p l e g a d o s p o r e l p r o g r a m a D i s p l a y . m. a ) G r a b a c i ó n t e r m i n a d a .
b ) U s u a r i o e x i s t e n t e .
5 6
Figura A.7.
D i a g r a m a d e f l u j o d e l a f u n c i ó n U s e r . m 5 7
Figura
A.8. D i a g r a m a d e f l u j o d e l a f u n c i ó n I n p u t . m
5 9
Figura A.9.
D i a g r a m a d e f l u j o d e l a f u n c i ó n C a p S e n . m 6 0 Figura
A.10.
D i a g r a m a d e f l u j o d e l a f u n c i ó n P r e _ p r o . m 6 1 Figura
A.11.
D i a g r a m a d e f l u j o d e l a f u n c i ó n V A D. m 6 2
Figura A.12.
D i a g r a m a d e f l u j o d e l a f u n c i ó n S S. m 6 3
Figura A.13.
T
A BLA SDE S C R I P C I Ó N P A G I N A
T a b l a 2 . 1 .
C a r a c t e r í s t i c a s d e l a v e n t a n a d e H a m m i n g . 7
T a b l a 2 . 2 .
A l g o r i t m o d e L e v i s o n - D u r b i n 1 1
T a b l a 2 . 3 .
A l g o r i t m o d e k- m e a n s . 1 5
T a b l a 2 . 2 .
A l g o r i t m o L B G . 1 6
T a b l a 4 . 1 .
E s p e c i f i c a c i o n e s d e c a p t u r a d e l a s m u e s t r a d e v o z 3 1
T a b l a 4 . 2 .
R e n d i m i e n t o g e n e r a l d e l s i s t e m a d e r e c o n o c i m i e n t o p a r a l o s n ú m e r o s 0 a l 9 p r o n u n c i a d o s 1 0 v e c e s c o n s e c u t i v a m e n t e .
4 6
T a b l a 4 . 3 .
R e n d i m i e n t o g e n e r a l d e l s i s t e m a p a r a l o s 1 0 u s u a r i o s r e g i s t r a d o s c u a n d o p r o n u n c i a n 1 0 n ú m e r o s a l a z a r .
4 7
T a b l a 4 . 4 .
R e n d i m i e n t o d e l r e c o n o c i m i e n t o p o r u s u a r i o p a r a 1 0 n ú m e r o s p r o n u n c i a d o s a l a z a r .
4 8
T a b l a 4 . 5 .
R e s u l t a d o s d e l s i s t e m a a l e v a l u a r 3 u s u a r i o s n o p e r t e n e c i e n t e s a l a b a s e d e d a t o s .
[image:13.595.81.516.106.348.2]SÍ M B O L O DE S C R I P C I Ó N
( )
ω
S
MO D E L O D E P R O D U C C I Ó N D E V O Z( )
ω
G
MO D E L O P A R A L A F U E N T E D EG E N E R A C I Ó N D E V O Z
( ) ( )
H
z
H
ω
,
MO D E L O P A R A L A S C A R E C T E R I S T I C A SD E R E S O N A N C I A Y A N T I R E S O N A N C I A P A R A E L A P A R A T O F O N A D O R
( )
z
A
FI L T R O I N V E R S Ot
x
SE Ñ A L D E V O Z A C T U A L E N E L A N A L I S I SL P C
ˆ
tx
SE Ñ A L E S T I M A D A E N E L A N A L I S I S L P Ct
ε
ER R O R R E S I D U A L E N E L A N A L I S I S L P Ci
α
CO E F I C I E N T E S D E P R E D I C C I Ó N L I N E A Li
c
CO E F I C I E N T E S CE P S T R U M( )
q x
OP E R A D O R D E C U A N T I Z A C I Ó NZ
CO D E B O O K O L I B R O D E C O D I G O( )
,
d x z
ME D I C I Ó N D E D I S T O R S I Ó N( )
n
k
τ
FU N C I Ó N D E C O V A R I A N Z A D E L R U I D OB L A N C O
( )
ˆ
bX f
P A R A E L M E T O D O D E L A S U S T R A C C I Ó N ES T I M A C I Ó N D E L A S E Ñ A L F I L T R A D AE S P E C T R A L
( )
bY f
SE Ñ A L O R I G I N A L P A R A E L M E T O D O D E L A S U S T R A C C I Ó N E S P E C T R A L( )
bN f
PE N A L M E T O D O D E L A S U S T R A C C I Ó N R O M E D I O D E L E S P E C T R O D E L R U I D OE S P E C T R A L
α
PA R Á M E T R O D E C O N T R O L P A R A L AC A N T I D A D D E R U I D O S U S T R A I D O
n
y
EC U A C I Ó N D E D I F E R E N C I A S P A R AF I L T R O S F I R
( )
H x
FU N C I Ó N D E E N T R O P Í A( )
x
P x
D I S T R I B U C I Ó N D E P R O B A B I L I D A D( )
(
2)
,
H Y
ω
t
ME N E L D O M I N I O D E L E S P E C T R O D E E D I C I Ó N D E L A E N T R O P Í A D E F I N I D AE N E R G Í A
( )
(
2)
,
P Y
ω
t
PR O B A B I L I D A D D E L A B A N D A D E F R E C U E N C I Aω
( )
2NL
N f ES T I M A D O R N O L I N E A L D E L E S P E C T R O D E L R U I D O
( )
2N f
ES P E C T R O D E L A S E Ñ A L D E R U I D O( )
(
SNR f
)
α
FA C T O R D E S U S T R A C C I Ó ND E P E N D I E N T E D E L A SN R E N E L M E T O D O D E S U S T R A C C I Ó N E S P E C T R A L
N O L I N E A L
( )
(
)
sd N f
DE S V I A C I Ó N E S T A N D A R D E L E S P E C T R OL
NÚ M E R O D E C O D E B O O K O L I B R O S D E C O D I G Ofs
Com
CO S T O C O M P U T A C I O N A L P A R A U NC O D E B O O K O L I B R O D E C O D I G O S
fs
M
RE Q U E R I M I E N T O D E A L M A C E N A J E P A R AU N C O D E B O O K O L I B R O D E C O D I G O S
[ ]
N
H
k
TR A N S F O R M A D A D E FO U R I E R E NT I E M P O D I S C R E T O
[ ]
N
h
n
RE S P U E S T A A L I M P U L S O D E L AT R A N S F O R M A D A D E FO U R I E R I N V E R S A
( )
log
η
⋅
Ω
UM B R A L P A R A L A E T A P A D E D E T E C C I Ó ND E A C T I V A C I Ó N D E V O Z ( V A D )
( )
,LP
Y f t FI L T R O P A S A B A J O A P L I C A D O A U N
S E G M E N T O
t
D E L E S P E C T R O D E L A S E Ñ A L D E V O Zγ
FA C T O R D E A T E N U A C I Ó N E N E LS
SSiisissttteeemmmaaadddeeerrreeecccooonnnoooccciiimmmiiieeennntttooodddeeellllllooocccuuutttooorrrbbbaaasssaaadddoooeeennnmmmooodddeeelllaaadddooonnnooopppaaarrraaammmééétttrrriiicccooo
1
-C
APÍTULO
1
I
NTRO DUC C IÓ N
1.1
I
NTRODUCCIÓN.
En 1660 se registró que un testigo que fue capaz de identificar a un acusado por su voz durante el juicio para determinar las circunstancias de la muerte de Charles I. Investigaciones sobre el reconocimiento del locutor no se hizo hasta dos siglos después. Sin embargo, cuando la telefonía hizo posible el reconocimiento del locutor, independientemente del sitio donde la grabación era hecha, el tema tomo un nuevo papel en el quehacer científico. Después, con el descubrimiento de espectrogramas de sonido en 1940 también se incluyó la capacidad sensorial de la visión para lograr el reconociendo del locutor [1].
En 1960 el profesor sueco, Gunnar Fant, publicó un modelo describiendo los componentes fisiológicos de la producción de habla. Sus resultados están basados en el análisis de radiografías en individuos haciendo ciertos sonidos fonéticos. Los resultados de estos modelos se usaron para entender los componentes biológicos del habla, un concepto crucial en el reconocimiento de voz. Esta área fue tomada verdaderamente en cuenta por la comunidad científica cuando en 1966 un tribunal judicial de los Estados Unidos admitió como testimonio el reconocimiento del locutor en base a espectrogramas [2].
En paralelo con los métodos auditivos y visuales, los métodos automatizados para el reconocimiento del locutor han estado en constante desarrollo con diversos investigadores como Atal, Sadaoki Furui, Kohonen, Markel, Gray, Matsui, Naik, Rosenberg, Schalkwyk, entre otros [3]. También debido a los avances en materia computacional para la aplicación de temas estadísticos, probabilísticos y de reconocimiento de patrones los métodos automatizados han tenido un progreso extraordinario, volviéndose cada vez más precisos y complejos.
Dentro de las grandes ventajas de los sistemas automatizados de reconocimiento del hablante es que el coste del “hardware” necesario es mínimo y la adquisición de la señal de voz es muy sencilla y cómoda para el usuario.
1.2
O
BJETIVOS ESPECÍFICOS.
• Desarrollar el filtro por sustracción espectral para la eliminación del ruido blanco.
• Implementar un detector de actividad de voz robusto basado en
características de entropía.
• Desarrollar una base de datos de 30 grabaciones por digito de cada usuario.
• Extraer las características de cada usuario mediante el uso de los parámetros LPC-Cepstrum.
S
SSiisissttteeemmmaaadddeeerrreeecccooonnnoooccciiimmmiiieeennntttooodddeeellllllooocccuuutttooorrrbbbaaasssaaadddoooeeennnmmmooodddeeelllaaadddooonnnooopppaaarrraaammmééétttrrriiicccooo
2
-• Implementar el sistema en base al método de reconocimiento por mínimadistorsión.
1.3
J
USTIFICACIÓN.
La implementación actual de sistemas de reconocimiento del locutor utiliza la voz como la herramienta para verificar la identidad de un usuario. En un futuro próximo, estos servicios incluirán:
• Id ent i f ica ció n de sex o . En el caso de que la aplicación trate de
averiguar si la locución ha sido realizada por un hombre o una mujer.
• Ve r if ic ac i on de la e da d de l hab l ant e . Cuando la aplicación trate de clasificar por grupos de edad.
• Id ent i f ica ció n de l es tad o de sa lud de pac i e ntes . Cuando se
desean detectar patología, relacionada con las disfunciones del tracto vocal, utilizando la voz del paciente.
• Id ent i f icac ión de l le ngua je. Cuando la aplicación determina
algunos aspectos sociológicos del hablante, como su pertenencia a un grupo social de personas, a una región o país.
• I n t e l ig en c ia a r t if ic i a l. Cuando es necesario que un robot reconozca a un usuario así como sus órdenes.
• Id ent i f ica ció n de l es tad o de á n imo de l ha b la nte . Cuando la
aplicación consiste en determinar si el hablante tiene cierto grado de enfado, o si está deprimido, estresado, relajado, etc.
• I d ent i f ica ci ó n y ve r i f ic ac i ón de hab l ant e s . Hay varias áreas de aplicación para el reconocimiento de hablantes, por ejemplo en la identificación de sospechosos en los casos de acústica forense, o el control de accesos a edificios o a cuentas bancarias.
Por lo tanto, algunos sistemas de reconocimiento del locutor están siendo implementados en la actualidad por diversas compañías como: SeMarket, Verbio, AT&T, ITT, France Telecom, Bellcore, Texas Instruments, Siemens y Unisys solo por mencionar algunos.
Sin embargo, a pesar de existir diversos sistemas de reconocimiento comerciales, existen pocas investigaciones en México a nivel de instituciones de educación que expliquen la metodología y los bloques mínimos necesarios para realizarlos.
1.4 A
LCANCEEl enfoque de esta tesis teórico y experimental, con el objetivo de realizar un sistema funcional, capaz de reconocer la identidad de usuarios a través de la pronunciación de palabras aisladas (Dígitos del 0 al 9) mediante un modelo del locutor no paramétrico como lo es la cuantificación vectorial, en un ambiente contaminado de ruido blanco tipo gaussiano con una relación señal a ruido no menor a 10.
1.5. M
ETODOLOGÍA.
S
SSiisissttteeemmmaaadddeeerrreeecccooonnnoooccciiimmmiiieeennntttooodddeeellllllooocccuuutttooorrrbbbaaasssaaadddoooeeennnmmmooodddeeelllaaadddooonnnooopppaaarrraaammmééétttrrriiicccooo
3
-1.6. C
ONTENIDO DE LA TESISEsta tesis está dividida en cuatro Capítulos:
• Capítulo 1: Este capítulo da una visión general sobre los orígenes y la importancia en la actualidad de los sistemas de reconocimiento del hablante así como los objetivos y alcances de la tesis propuesta.
• Capítulo 2: En este capítulo se presenta una revisión de la literatura en diversos temas como: Aparato fonador, características y modelado de la señal de voz, detectores de activación de voz, técnicas clásicas para la eliminación de ruido blanco y métodos de cuantificación vectorial así como de reconocimiento de patrones.
• Capítulo 3: Este capítulo muestra la metodología propuesta para desarrollar el sistema de reconocimiento del hablante.
• Capitulo 4: Este capítulo presenta los resultados obtenidos por el método propuesto, así como las pruebas realizadas para caracterizar el sistema. • Capítulo 5: Las conclusiones y sugerencias para futuros trabajos son
mostrados en este capítulo.
1.7.
R
EFERENCIAS[ 1 ] Sa d a o ki Fu ru i, “ Dig it a l Sp e e c h Pro c e ssin g Sy n th e sis a n d Re c o g n itio n ”,
Ed ito ria l Bo a rd , To ky o In stitu te o f Te c h n o lo g y , To ky o Ja p a n , 2 0 0 1 . [ 2 ] L.R. Ra b in e r, Biin g - Hw a n g Ju a n g ,”Fu n d a m e n t a ls o f Sp e e c h
Re c o g n itio n ”, Pe a rso n Ed u c a tio n , 1 e d itio n , 1 9 9 3 .
C
APÍTULO
2
E
STADO DEL ARTE
2.1
I
NTRODUCCIÓNEn este capítulo se presentan los conceptos básicos para la elaboración de esta tesis como son: el aparato fonador, las características y modelado de la señal de voz, los detectores de activación de voz, características del ruido blanco, filtrado de señales de voz contaminadas con ruido blanco, clasificadores de parámetros y el método de cuantificación vectorial.
2.2
A
PARATO FONADOR Y SU MODELO.
La generación del habla del ser humano es producida voluntariamente a partir de movimientos de la estructura anatómica de su sistema de producción
de voz, este proceso está conformado por tres etapas que son: F u e n t e d e
g e n e r a c ió n , a r t i c u l a c ió n d e l t r a c t o v o c a l y r a d ia c i ó n d e l o s l a b i o s y e l o r i f i c i o n a s a l [1].
Las componentes principales del aparato fonador son: los pulmones, la traquea, la laringe, la cavidad de la faringe, la cavidad oral y bucal, y la cavidad nasal (Ver figura 2.1). Los parámetros principales del sistema articulatorio son las cuerdas vocales, el paladar, la lengua, los dientes, los labios y las mandíbulas. Los distintos sonidos se producen al pasar el aire emitido por los pulmones, a través de todo el sistema de producción, en una determinada posición de cada parámetro articulatorio.
Estos parámetros son dependientes del sonido articulado clasificándose en sonidos sonoros (voiced), donde el aire es obstruido por el propio aparato fonador haciendo que las cuerdas vocales vibren, y sonidos
sordos ( u n v o i c e ) que no provocan la vibración de las cuerdas vocales y el aire
pasa a través del tracto vocal sin impedimentos.
Los sonidos sonoros pueden ser modelados por un generador de pulsos u ondas asimétricas triangulares, las cuales son repetidos durante un determinado periodo fundamental y su valor pico dependerá de la intensidad con la que fue pronunciada, mientras los sonidos sordos son modelados por un generador de ruido blanco cuya energía promedio la determinará la intensidad de la palabra pronunciada [2]. Debido a la relación entre sistemas eléctricos y sistemas acústicos la articulación puede ser modelada por una interconexión de varios circuitos simples resonantes o antiresonantes en paralelo o en cascada que pueden ser implementados a través de múltiples etapas de filtros digitales. Finalmente la radiación puede ser modelada como un pistón el cual impulsa el sonido generado por la fuente.
El tracto vocal manifiesta un número muy grande de resonancias, sin embargo se considera solo las tres o cuatro primeras toman el nombre de
f o r ma n te s y cubren un intervalo de frecuencias entre 100 y 3500 Hz, debido a
que las resonancias de alta frecuencia son atenuadas por la característica en frecuencia del tracto, que tiende a atenuar como un filtro pasa bajo con una caída de aproximadamente de -12dB por octava [3].
voz mostrada en la figura 2.2. Específicamente, este involucra
completamente la separación de la fuente de generación
G
( )
ω
, de laarticulación (resonancia y antiresonancia) H
( )
ω , y representa el modelo deproducción para la señal de voz
S
( )
ω
, como una conexión en cascada decada circuito eléctrico equivalente sin interacción mutua tal que, [4]
S
( )
ω
=
G
( ) ( )
ω
H
ω
( 2 . 1 )F i g u r a 2 . 1 . C o r t e e s q u e m á t i c o d e l a p a r a t o f o n a d o r h u m a n o .
La fuente de sonido es aproximada por pulsos y un generador de ruido blanco, y la articulación del tracto vocal es un filtro con polos y ceros
característicos. Por consiguiente, las características espectrales de
G
( )
ω
esplana, y
H
( )
ω
es un filtro digital que tiene coeficientes variables en el tiempo,que incluyen las características de la envolvente espectral de la fuente y las características de radiación, además de las características del tracto vocal.
F i g u r a 2 . 2 . M o d e l o d e l t r a c t o v o c a l .
[image:20.595.206.383.161.412.2]Espectro Espectro
Señal de voz Señal de voz
D en si da d es pe ct ra l [ dB ] D en si da d es pe ct ra l [ dB ] Frecuencia (Khz) Frecuencia (Khz) Envolvente espectral Estructura fina Estructura fina Envolvente espectral
filtro digital
H
( )
ω
pueden ser vistas como características casi constantes enperiodos breves de tiempo, como de 10-30 ms de longitud, por lo que esta señal puede ser vista como un proceso aleatorio estacionario en un sentido general.
2.3
C
ARACTERÍSTICAS DE LA SEÑAL DE VOZ.
La señal de voz tiene un rango dinámico amplio puesto que durante la generación de sonidos no sonoros su amplitud es muy pequeña y para sonidos sonoros su amplitud puede exceder los 50dB, además su ley de distribución de probabilidad es del tipo normal tanto para hombres como para mujeres. La media y la desviación estándar para voces masculinas está comprendida en 125 y 20.5 Hz respectivamente. Para voces femeninas es regularmente el doble que para voces masculinas, claro que estos valores se ven afectados en presencia de ambientes altamente ruidosos [5].
2.3.1
C
ARACTERÍSTICAS ESPECTRALES DE LA VOZ Y VENTANEO.
La densidad espectral de potencia en periodos cortos de tiempo es el
producto de dos elementos: l a e n v o lv e n te e s p e c tr a l, la cual cambia
lentamente en función de la frecuencia, esta muestra las características del
tracto vocal así como las características de radiación y la es tr uc tu ra fin a , que
cambia rápidamente, la cual es generada por patrones periódicos como son los sonidos sonoros tal como se muestra en la figura 2.3 [1].
Para obtener los N segmentos de periodos
τ
de la señal de voz esnecesario multiplicarla por una ventana adecuada. Al realizar este procedimiento se producirán dos efectos, el primero es atenuar gradualmente la amplitud en los extremos del segmento para evitar cambios abruptos; el segundo produce la convolución de la transformada de Fourier de la ventana y el espectro de la voz. Por lo que la ventana debe tener dos características: una alta resolución en frecuencia y una fuerte atenuación de los lóbulos laterales. La función de ventana de Hamming cumple de la mejor manera las dos condiciones antes mencionadas [1]. Las características de la ventana de Hamming se presentan en la tabla 2.1.
( a ) ( b )
T a b l a 2 . 1 . C a r a c t e r í s t i c a s d e l a v e n t a n a d e H a m m i n g .
Ventana S e c u e n c i a te mp o ra l
A nc hu ra a p ro x i m a d a d e l l ó b u l o p r i n c i p a l
P i c o s e c u n d a r i o
( d B )
H a m m i n g
0.54-0.46cos
2
N-1
π
⎛
⎞
⎜
⎟
⎝
⎠
8 /N
π
- 4 3La multiplicación de la señal de voz por la ventana reduce la fluctuación espectral debido a la variación y posición de excitación del tono (pitch) dentro del intervalo de interés. Esto es útil para producir espectro estable durante el análisis de sonidos sonoros ofreciendo claramente el periodo del tono. Debido a que la operación de multiplicación, decrece la efectividad del análisis en el segmento empleado por lo que es necesario traslapar cada uno de los segmentos a lo largo de la señal de voz para facilitar el trazado del espectro variante en el tiempo. El valor típico para el traslape es del 10-50% del tamaño del segmento. Otro método comúnmente empleado para reducir los efectos de la ventana es utilizar una etapa de pre-énfasis de la señal antes del análisis LPC. Esta etapa consiste en un filtro
FIR de primer orden, en donde la constante a toma valores dentro del
intervalo de [0.9, 1] [6]. La figura 2.4 muestra el filtro aplicado en la etapa de pre-énfasis.
F i g u r a 2 . 4 . E s t r u c t u r a d e l f i l t r o a p l i c a d o p a r a l a e t a p a d e p r e - é n f a s i s .
2.4
E
STIMACIÓN ESPECTRAL DE POTENCIA.
La potencia espectral es la transformada de Fourier de la secuencia de autocorrelación. Sin embargo, la potencia espectral es equivalente a estimar la autocorrelación. La autocorrelación de un proceso ergodico es dada por [7],
1
(
) ( )
*( )
lim
2
1
N x N n Nx n
k x n
r k
N
→∞ =
⎧
+
⎫
=
⎨
+
⎬
⎩
∑
⎭
( 2 . 2 )donde
x n
( )
es conocida para todas las n, la estimación de la potenciaespectral es, en teoría, la transformada de Fourier de la secuencia de
autocorrelación
r k
x( )
dada por (2.2). Sin embargo, esto trae dos problemas.estimación
( )
j xP e
ω de un número finito de mediciones dex n
( )
contaminadascon ruido, sin embargo, la estimación de la potencia espectral puede ser facilitada si se conoce la generación del proceso.
La aproximación para la estimación del espectro puede ser generalmente catalogado dentro de dos clases. El primero incluye métodos clásicos o métodos no paramétricos los cuales obtienen un estimado de la
secuencia de autocorrelación
r k
x( )
del conjunto de datos obtenidos. Elespectro de potencia es después estimado mediante la transformada de Fourier de la secuencia de autocorrelación, sin embargo, este tipo de análisis no está diseñado para incorporar información acerca del proceso que están
modelando [2]. La segunda clase incluye los métodos no clásicos o
aproximaciones paramétricas, que están basados en el uso de un modelo del proceso para obtener el espectro de potencia. Por ejemplo, es conocido que
( )
x n
es un proceso autoregresivo de orden N, entonces los valores medidosde
x n
( )
pueden ser usados para estimar los parámetros de un modelo de solopolos,
a
ˆ
p( )
k
, para después, a su vez, ser usados para estimar la potenciaespectral como:
( )
( )
20
1
ˆ
j x p j p kP e
a
k e
ω ω − ==
∑
( 2 . 3 )
Un proceso autoregresivo,
x n
( )
,
puede ser representado como la salidade un filtro de solo polos que es conducido por un generador variable de ruido
blanco. La potencia espectral de un proceso autoregresivo de orden p que
esta dado por:
( )
( )
( )
2 2 10
1
j x p j p kb
P e
a
k e
ω ω − ==
+
∑
( 2 . 4 )
Por lo tanto, como
b
( )
0
y
a
p( )
k
pueden ser determinados de los datosde
x n
( )
,
entonces la estimación de la potencia espectral pude ser finalmenteestimada como [7]:
( )
( )
( )
2 2 1ˆ 0
ˆ
1
j x p j p kb
P e
a
k e
ω ω − =
=
+
∑
( 2 . 5 )
2.4.1
C
ODIFICACIÓN LINEAL PREDICTIVA DE LA SEÑAL DE VOZ(LPC).
para representar las características de la señal de voz, así como su espectro con un número muy reducido de parámetros, además de no requerir mucho tiempo de procesamiento [1].
Si asumimos la siguiente combinación lineal entre las características
actuales de la señal de voz
x
t en el dominio del tiempo y lasp
características previas como [1],
x
t+
α
1x
t−1+ +
...
α
px
t p−=
ε
t ( 2 .6 )Donde
ε
t es la variable estadísticamente no correlacionada que tiene unaesperanza matemática igual a 0 y una varianza
σ
2.Esta ecuación lineal de diferencias que representa los valores de
muestras presentes
x
t que son linealmente pronosticados usando valores demuestras previas. Es decir, el valor del predictor lineal
x
ˆ
t para representarx
testa dado por,
1
ˆ
p t i t ii
x
α
x
−=
= −
∑
( 2 .7 )Combinando las ecuaciones (2.6) y (2.7) se obtiene,
x
t− =
x
ˆ
tε
t( 2 .8)
Por lo tanto consideremos la ecuación (2.6) como el modelo de predicción
lineal para los coeficientes de predicción lineal
{ }
α
i .ε
t es nombrado como elerror residual.
Si definimos el filtro de predicción lineal como,
( )
p i i i i
F z
α
z
−=
= −
∑
( 2 . 9 )y
X z
ˆ
( )
⇔
x
ˆ
t,X z
( )
⇔
x
t en función de la variable complejaz
, de esta manerala ecuación (2.7) puede ser expresada como,
X z
ˆ
( )
=
F z X z
( ) ( )
(2 . 10)De las ecuaciones (2.7) y (2.8) el modelo de predicción lineal en términos de la variable compleja, puede ser escrito como [1]:
X z
( )
(
1
−
F z
( )
)
=
E z
( )
(
2 . 11)X z A z
( ) ( )
=
E z
( )
(2 .12)
donde
E z
( )
↔
ε
ty
( )
1
1
( )
p i i i i
A z
α
z
−F z
=
F(z) X(z) X(z) E(z) A(z) X(z) E(z)
El diagrama a bloques de este procedimiento se muestra en la figura 2.5.
a )
b )
F i g u r a 2 . 5 . D i a g r a m a a b l o q u e d e l m o d e l o d e p r e d i c c i ó n l i n e a l , a ) E c u a c i ó n 2 . 1 1 , b ) E c u a c i ó n 2 . 1 2 .
El análisis LPC es el proceso de aplicar un modelo predictivo lineal a la
señal de voz, minimizando la salida
σ
2 debido al ajuste de los coeficientes{ }
α
i . Por lo tanto, la señal de voz puede ser pronosticada y suscaracterísticas espectrales pueden ser extraídas por los coeficientes del predictor lineal de la siguiente manera:
Aplicando el método del error cuadrático medio en la ecuación (2.8)
para determinar los coeficientes
{ }
1:
i i p
α
= , tal que la suma al cuadrado del errort
ε
entre los valores de las muestras dex
t y los valores del predictor linealx
ˆ
tbajo un determinado periodo
[ ]
t
0,
t
1 sea minimizado.Para obtener los coeficientes de predicción
{ }
α
i deN
muestras de voz{ } {
x
t=
x x
0, ,...
1x
N−1}
,
deben resolversep
ecuaciones simultáneas. Existen dosformas para ello, el m é t o d o d e c o v a r i a n z a y el m é t o d o d e a u t o c o r r e l a c ió n,
aunque el último método es más eficiente debido a que es tres veces más
rápido en relación al primero por solo requerir 2
p
multiplicaciones yp
divisiones.
El método de autocorrelación define el periodo de análisis en
t
o= −∞
y1
t
= ∞
, y establecex
0=
0
para0
< ≤
t
N
. Aunque teóricamente el errorε
t esminimizado para un intervalo infinito, resultados equivalentes se obtienen
para una minimización bajo el intervalo real
[
0,
N
−
1
]
establecido por [1],1 0 N t t t
r
x x
τ τ
τ
− − +=
=
∑
( 2 . 1 3 )
Por esta razón
x
t es truncado a cero parat
<
0
yt
≥
N
para podermultiplicarla por una ventana de longitud finita, como lo es la ventana de Hamming.
0 1 p-1 1 1
0 1 2 2
1
p-1 0 1
r ... r
r .
. . . . . . . r . .
r ... r p p
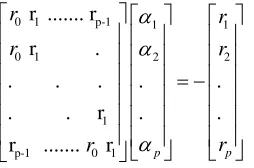
r r r r r r α α α ⎡ ⎤ ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥= −⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎣ ⎦ ⎢ ⎥⎣ ⎦ ⎣ ⎦
( 2.14)
El término del lado izquierdo de la ecuación (2.14) tiene la forma de una matriz tipo Toeplitz. La ecuación (2.14) es también llamada ecuación normal o ecuación Yule-Walker [7] y es resuelta eficientemente por el método recursivo Levinson-Durbin [1]. Este algoritmo es mostrado en la tabla 2.2.
T a b l a 2 . 2 “ A l g o r i t m o d e L e v i s o n - D u r b i n ”
2.4.2
A
NÁLISISC
EPSTRUM DE LA SEÑAL DE VOZ.
El análisis Cepstrum es una transformación homomorfica que convierte una convolución en una suma con el objetivo de separada de la envolvente espectral dada por la característica del aparato fonador de la estructura fina producida por la fuente de generación [8]. El parámetro independiente para el Cepstrum es llamado quefrency y está en el dominio del tiempo por derivarse de la transformada inversa de Fourier.
Cuando
S
( )
ω
es calculado por la transformada de Fourier de unasecuencia de muestras para un periodo corto de tiempo (20-40ms) de la señal de voz, ésta presenta picos afilados con intervalos iguales a lo largo del eje
de frecuencia. Ahora, el logaritmo de la amplitud de la señal de voz
S
( )
ω
está dado por,
log
S
( )
ω
=
log
G
( )
ω
+
log
H
( )
ω
(2 .15)P a s o _ 1 : I n i c i a l i z a c i ó n.
( )
( )
( )
0 0 1 11 1 0 2 11 0 1
E r r a E E E κ κ = = = = −
P a s o _ 2 : C o n
m
≥
2,
La siguiente recursión es desarrollada.( )
( )
( )( )
( )
( )( )
( )
( ) ( )( )( )
( )
( )
1 1 1 1, para 1 1
2 1 1
Si ,entoces incrementar a e ir al paso . Si , entonces parar.
m
i qm r m ai m r m i i
qm ii m
Em iii amm m
iv aim ai m mam i m i = 1, ..., m - 1
v E E m
m m
vi m < M m m + 1 i
m = M
[image:26.595.239.366.72.156.2]El cepstrum es la transformada inversa de Fourier del logaritmo de
( )
S
ω
dado por [1],
( )
1( )
1( )
1( )
log
log
log
c
τ
=
F
−S
ω
=
F
−G
ω
+
F
−H
ω
( 2 . 1 6 )La primera función del lado derecho de (2.16) muestra la formación de un pico en la región de alta quefrency, y la segunda función representa la concentración en baja quefrency en la región de entre 0 a 4ms (Ver figura
2.6). El periodo fundamental de la fuente
g t
( )
puede ser obtenida del pico enla región de alta quefrency. Por otro lado, la transformada de Fourier de los elementos de baja quefrency produce el logaritmo de la envolvente espectral. El proceso de separar de los elementos cepstrales en estos dos factores es llamado liftering.
Respuesta del tracto vocal Fuente de generación
Quefrency
C
oe
fic
ie
nt
es
C
ep
st
ru
m
F i g u r a 2 . 6 . R e s u l t a d o d e a p l i c a r e l a n á l i s i s C e p s t r a l a u n s e g m e n t o d e v o z d e 3 0 m s .
2.5
C
LASIFICADORES DE PATRONES.
La estadística bayesiana, es la base del reconocimiento de patrones estadísticos se basa en la suposición de que los problemas de decisión pueden ser caracterizados en términos probabilísticos y que todas las probabilidades necesarias son conocidas, desafortunadamente en la práctica no sucede así. Estos algunas veces deben ser estimados de datos de
entrenamiento. Esta estimación puede ser dividida en p a r a m é t r ic a y no
p a r a mé tr ic a [4].
Cuando los datos observados solo toman valores discretos de un
conjunto finito de
N
valores como es el caso de la discretización de la señalde voz, la estimación es asumida como no paramétrica. Así no se asume ningún modelo probabilístico y su función de probabilidad es estimada directamente de los datos de entrenamiento.
En el reconocimiento de parámetros, el conjunto de las muestras de datos, que son utilizados para estimar los parámetros del reconocedor, es referido como el c o n j u n t o d e e n t r e n a mi e n t o. En contraste, el c o n j u n t o d e p r u e b a es referido a un conjunto independiente de muestras de datos, los
cuales son usados para evaluar el rendimiento del reconocedor.
El objetivo de esta sección es dar a conocer el segundo método por ser el que se aplica en la tesis.
En el entrenamiento n o s u p e r v is a d o, la información acerca de la clase
de la muestra de datos es desconocida, por lo que se dice que se trata de una observación incompleta. Una manera de implementar este tipo de clasificadores es mediante el método de vector de cuantización el cual será
descrito más adelante. En la figura 2.7 se muestra el diagrama a bloques de
un clasificador de parámetros, en éste, se muestra el bloque de la extracción de las características de la señal de voz dada por los coeficientes LPC-Cepstrum y el bloque de clasificación que en este caso será implementado
con la técnica n o p a r a me t r ic a mediante la cuantificación vectorial.
Patrón
Extracción
de características
Vector de
Caracteristicas
Clasificación
ClaseF i g u r a 2 . 7 . D i a g r a m a a b l o q u e s d e u n c l a s i f i c a d o r d e p a r á m e t r o s .
2.5.1
M
ÉTODO ESTIMACIÓN NO SUPERVISADA:
C
UANTIFICACIÓNVECTORIAL
.
Las técnicas de parametrización de la señal de voz se realizan tomando una secuencia de ventanas temporales, cada una de las cuales se representa
por un número de parámetros P. Entonces, la información de cada ventana se
representa por un vector de observación de P posiciones.
Cuando se almacenan estos parámetros lo que generalmente se hace es cuantificar cada parámetro con un determinado número de bits, este proceso se denomina cuantificación escalar y no es la manera más eficiente para almacenar la información, además, implica la ocurrencia uniforme de las ventanas de información. Una forma más conveniente es realizar una cuantificación vectorial [9].
Un vector de cuantización es definido por un libro de códigos (cod eb oo k), que es un conjunto fijo de vectores prototipo o vectores de
reproducción. Cada uno de esos vectores prototipo es también referido como
código de palabras (codeword). Para implementar el proceso de cuantización,
el vector de entrada es comparado con cada codeword dentro del codebook usando alguna medida de distorsión. El vector de entrada es entonces remplazado por el índice del codeword que proporcione menor distorsión. Por lo tanto, para describir este proceso necesitamos:
1. Una medida de distorsión.
2. La generación de cada codeword en el codebook.
2.5.1.1
M
EDIDAS DE DISTORSIÓN.
Debido a que la minimización de la distorsión es el objetivo central del método del vector de cuantización, es necesario definirla. Si asumimos que
(
1,
2,...,
)
t d d
x
=
x x
x
∈
R
es un vectord
-dimensional cuyos componentes{
x
k,1
≤ ≤
k
d
}
son valores reales. Para obtener el vector de cuantización, elvector x es mapeado o cuantizado como otro vector
z
d
-dimensional de
z
=
q x
( )
( 2 . 1 7 )donde
q
( )
es el operador de cuantización. Típicamente,z
es un vector finito{
j,1
}
Z
=
z
≤ ≤
j
M
, dondez
j es también un vectord
-dimensional. El conjuntoZ
es referido como el codebook,M
es el tamaño del codebook, yz
j es elj
-ésimo codeword. El tamaño
M
del codebook es llamado número de particioneso niveles dentro del codebook. Para diseñar un codebook, el espacio
d
-dimensional del vector aleatorio x debe ser particionado en
M
regiones oceldas
{
C
i,1
≤ ≤
i
M
}
, y cada celdaC
i es asociada con el vectorz
i ocodeword tal que [9],
q x
( )
=
z
isi x
∈
C
i (2 .18)Cuando x es cuantizado como
z
, es inevitable un error de cuantización.Se define la medida de distorsión
d x y
( )
,
entrex
yz
para medir la calidad decuantización. Utilizando esta medida de distorsión, (2.18) puede ser reformulada como,
q x
( )
=
z
isi y solo si =argmin d
i
(
x, z
k)
(2 .19)La medición de distorsión Euclidiana es la más común, ésta asume que la distorsión aportada por cuantizar los diferentes parámetros es igual. Por lo
tanto, la medición de distorsión
d x y
( )
,
puede ser definida de la siguientemanera [9],
( ) (
) (
)
(
)
21
,
d t
i i
d x z
x
z
x
z
x
z
=
=
−
−
=
∑
−
(2 .20)La distorsión definida en (2.20) es llamada error de suma cuadrática. En general, un peso diferente puede ser introducido para observar mejor la distorsión. Una elección para el peso es usar la inversa de la matriz de
covarianza de
z
. Esta medida de distorsión es conocida como distancia deM a h a l a n o b i s y está definida por [9],
( ) (
)
1(
)
,
td x z
=
x
−
z
∑
−x
−
z
( 2.21)
2.5.1.2
D
ISEÑO DEL CODEBOOK.
Una de las partes más importantes de método de cuantificación vectorial es el diseño del codebook. El objetivo de esta técnica es minimizar
el promedio de la distorsión global sobre todos los
M
niveles del vector deecuación (2.19) y la segunda condición es que cada codeword
i
z
es elegidopara minimizar la distorsión promedio en la célula
i
C
.Un procedimiento que cumple estas dos condiciones es conocido como
el algoritmo k - me a n s o la generalización del algoritmo de L lo y d [9]. La idea
básica del algoritmo k - m e a n s es particionar el conjunto de vectores de
entrenamiento en
M
agrupamientos, 1
(
)
i
C
≤ ≤
i
M
tomando en cuenta lascondiciones de optimización. El algoritmo es descrito en la tabla 2.3.
El algoritmo de k - m e a n s puede proporcionar diversas soluciones, la
inicialización es crítica para la eventual convergencia del codebook. Un algoritmo que asegura la convergencia es conocido como el algoritmo LBG.
T a b l a 2 . 3 . A l g o r i t m o d e k- m e a n s .
El algoritmo LBG primeramente calcula un vector del codebook, entonces usa el algoritmo de particionado en el codeword para obtener el codebook inicial de dos vectores, y continúa el proceso de división hasta
obtener el codebook de
M
vectores deseado. Este procedimiento esformalmente implementado por el algoritmo mostrado en la tabla 2.4 [9].
2.6
D
ETECTORES DE ACTIVACIÓN DE VOZ.
En el reconocimiento del locutor es importante calcular los modelos y realizar el test sobre las partes de señal que corresponden a la voz, descartando las pausas, silencios entre palabras, etc. De otra forma, las tasas de reconocimiento y verificación se degradan.
En el cálculo de los modelos de cada locutor, la no eliminación de las tramas de silencio supone que el número de parámetros no se dedican a modelar al locutor, si no a modelar el ruido de los silencios de voz que no
lleva información de la identidad de la persona.
P a s o _ 1 : In i c i a l iz a c i ó n. Escoger un método adecuado para obtener el
vector de cuantización inicial el cual requerir ser optimizado.
P a s o _ 2 : C la s i f i c a c i ó n p o r e l m é t o d o d e l v e c i n o m á s c e r c a n o.
Clasificar cada vector de entrenamiento
{ }
x
k dentro de cada una delas
i
C
celdas para escoger el más cercano codeword(
)
( )
(
, , , para todo)
i i i j
z x∈C si d x z ≤d x z j≠i . Esta clasificación es
llamada clasificación de mínima distancia.
P a s o _ 3 : A c t u a l i z a c i ó n d e l c o d e b o o k. Actualizar el codeword de cada
célula para calcular el centroide de los vectores de entrenamiento en cada célula de acuerdo a,
(
)
(
)
1
ˆ arg min , ,ˆ ,1
i
i i i i
x C
zi
z d x z z cent C i M
T ∈
=
∑
= ≤ ≤P a s o _ 4 : R e i t e r a c i ó n. Repetir los pasos 2 y 3 hasta que la nueva
distorsión global d en la actual iteración sea menor a un cierto
T a b l a 2 . 4 . A l g o r i t m o L B G .
Un detector de actividad de voz (VAD) es un algoritmo utilizado para detectar regiones de actividad o inactividad de voz [8]. Los VAD producen una decisión binaria para un segmento de voz dado indicando la presencia o ausencia de voz. Sin embargo esto no es un problema trivial. Resulta tanto más complicado cuanto más ruidoso sea el entorno en que se realiza la captación de voz. Dado que la complejidad computacional del módulo VAD se añade a la de los procesos de reconocimiento, interesa que el algoritmo sea sencillo y robusto. Debido a esto, se opta por utilizar un módulo VAD basado en la e n t r o p í a d e l a m a g n i t u d d e l e s p e c t r o [10].
2.6.1
R
UIDO BLANCO.
El ruido puede ser definido como cualquier señal no deseada que interfiere con la comunicación, mediciones o procesamientos de una información producida por una señal deseada. El ruido esta presente en diversos grados en ambientes variados. El éxito de un método para procesar el ruido radica en la habilidad para caracterizarlo y modelarlo.
El ruido blanco es definido como un proceso de ruido no correlacionado con igual potencia en todas las frecuencias (Ver figura 2.8). Un ruido que
tiene la misma potencia en el rango
±∞
Hz necesariamente tiene que tenerpotencia infinita, y eso es, sin embargo, un concepto solo teórico. La
definición de este proceso es del tipo estacionario gaussiano
n t
( )
conx
=
0
y función de covarianza
( )
( )
2
nN
k
τ
=
δ
t
[11].F i g u r a 2 . 8 . ( a ) R u i d o b l a n c o , ( b ) s u a u t o c o r r e l a c i ó n , y ( c ) s u p o t e n c i a e s p e c t r a l .
P a s o _ 1 : In i c i a l iz a c i ó n. Se establece M=1 (Número de particiones o
celdas). Se encuentra el centroide de todos los datos de entrenamiento de acuerdo con la siguiente ecuación
(
)
(
)
1
ˆ
arg min
,
,
ˆ
,1
i
i i i i
x C zi
z
d x z
z
cent C
i
M
T
∈=
∑
=
≤ ≤
.P a s o _ 2 : Se g me n ta c ió n. Segmentar M en 2 particiones (2M) para
particionar cada codeword debemos encontrar dos puntos que estén lejanos uno del otro usando un método heurístico, y utilizar estos dos puntos como los nuevos centrodes para los dos nuevos
codebook. Finalmente se establecerá M=2M.
P a s o _ 3 : E t a p a k - m e a n s. Se utiliza el algoritmo interactivo k-means
descrito anteriormente para establecer los mejores centroides para el nuevo codebook.
P a s o _ 4 : T e r mi n a c i ó n. Si M es igual al tamaño del codebook