El Estándar XML Topic Maps 1,0 como elemento de transición hacia una Web semántica
83
0
0
Texto completo
(2) Dictamen.. Hago constar que el presente trabajo fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del tutor. Firma del jefe del Laboratorio.
(3) PENSAMIENTO.
(4) Estar contentos con lo que poseemos es la más segura y mejor de las riquezas.. Marco Tulio Cicerón.
(5) DEDICATORIA.
(6) Dedico todo el esfuerzo realizado en este trabajo:. A mi papá. A mi mamá. A mi hermana..
(7) AGRADECIMIENTOS.
(8) “Uno puede devolver un préstamo de oro, pero está en deuda de por vida con aquellos que son amables”. Agradezco especialmente al Lic. Julio César Báez Vergara, por la ayuda brindada pese a su estado de salud.. A mi madre, por su apoyo y amor infinito.. A mi padre, por estar siempre presente.. A mi hermana, quien ha compartido conmigo los momentos alegres y tristes sin dudarlo.. A Yosleiby, por su preocupación.. A mi tutor el Ing. Dannis Rivero Cañizares, por el tiempo invertido.. A mis abuelos y abuelas presentes o no, por la educación, paciencia y ayuda incondicional.. A mis tíos y tías, por ayudarme en todo lo que han podido..
(9) A Rubersy y Midiala, por facilitarme algunas cosas.. A Guillermo, que nunca esta ocupado para ayudar a un amigo.. A Osley, por ser mí amigo y hermano.. A Leslie, por esos impulsos que me dio inconcientemente en la etapa final de este trabajo y.... A todos mis profesores, por la enseñanza brindada.. A mis amigos, por los momentos compartidos y conocimientos intercambiados.. A mi familia, que forma parte de este logro.. A todos muchas gracias Yorday..
(10) RESUMEN. El Centro de Documentación e Información CientíficoTécnica (CDICT) de la Universidad Central de Las Villas en su ambición por transitar por los cánones de la Library 2,0 se ha dado a la tarea de desarrollar una investigación exploratoria para desarrollar una Web semántica utilizando el estándar Extensible Markup Language Topic Maps (XTM) 1,0. El presente trabajo consiste en el desarrollo de un sistema computacional cuyo fin es posibilitar la navegación por una estructura semántica de recursos de información que se crea con la información almacenada en una de las bases de datos del CDICT. La solidez del sistema se encuentra en la utilización del paquete de código libre Topic Maps for Java (TM4J), que realiza una correcta implementación del estándar XTM 1,0 y esta desarrollado en el lenguaje de programación Java. El sistema se compone por dos aplicaciones, una aplicación Escritorio que permite la construcción de la estructura semántica con la información recuperada de la base de datos “Seriada” y la otra Web con la posibilidad de navegar por la información. Mediante la implementación de ambas aplicaciones se logra la navegación por la estructura semántica, lo que garantiza un mayor significado de la información en la Web por la que se navega..
(11) ABSTRACT. The Documentation and Scientific and Technical Information Center (CDICT) of the Central University of Las Villas in its wishes to transit on Library 2.0 has been engaged with an exploratory investigation to develop a semantic web using the Standard Extensible Markup Language Topic Maps (XTM) 1,0. The current work pretends to create a computational system to facilitate surfing through a information resources semantic structure created with stored information in one of the databases belonging to the CDICT. The system’s solidity lies on the usage of the free code package Topic Maps for Java (TM4J), which makes the right implementation for the standard XTM 1,0 and, at the same time is developed in Java language. Thus, the system is composed of two applications: 1Desktop application, which enables the construction of the semantic structure with the retrieved information from the database “Seriada”; 2 Web application, which enables to go through all the information. Through the implementation of both applications we achieve the navigation of the semantic structure that guarantees more structured information retrieved from the previous analysed structure..
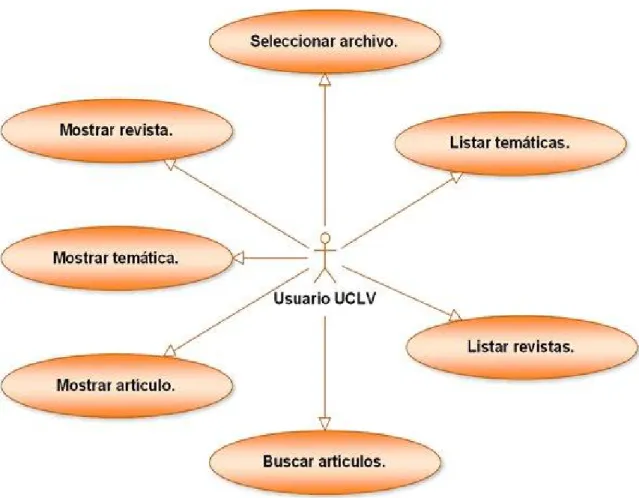
(12) TABLA DE CONTENIDOS INTRODUCCION ........................................................................................................................... 1 CAPITULO 1: ANALISIS Y ELEMENTOS FUNDAMENTALES DE LA WEB SEMANTICA..... 5 1.1.. La universidad en el mundo cambiante y globalizado............................................................. 5. 1.1.1. La universidad y la sociedad de la información y el conocimiento.......................................... 6 1.2.. De la Web tradicional a la Web semántica. ............................................................................ 7. 1.2.1. La Web hoy........................................................................................................................... 8 1.2.2. La Web semántica. .............................................................................................................. 12 1.3.. De la Web actual a la Web semántica................................................................................... 14. 1.3.1. La Web semántica hoy......................................................................................................... 16 CAPITULO 2: DISEÑO E IMPLEMENTACION DE LOS SISTEMAS BTSM 1,0 y STMS 1,0. ... 18 2.1.. El estándar XML Topic Maps 1.0. ....................................................................................... 18. 2.1.1. Características generales del estándar XTM 1,0. .................................................................. 18 2.1.2. Componentes del modelo..................................................................................................... 20 2.1.3. Entornos de aplicación......................................................................................................... 22 2.2.. Análisis del paquete Topic Maps for Java (TM4J)................................................................ 22. 2.2.1. Arquitectura básica.............................................................................................................. 22 2.2.2. Cómo crear la estructura semántica en memoria................................................................... 25 2.2.3. Cómo construir el fichero “.xtm” a partir de una estructura semántica. ................................. 26 2.2.4. Cómo importar un fichero “.xtm” a memoria. ...................................................................... 28 2.2.5. Cómo consultar una estructura semántica............................................................................. 28 2.3.. Recuperación de la información de la base de datos “Seriada”. ............................................ 29. 2.3.1. Transformación hacia XTM 1,0. .......................................................................................... 29 2.4.. Análisis del diseño e implementación de la aplicación BTMS 1,0. ....................................... 31. 2.4.1. Descripción de los casos de uso generales del sistema BTMS 1,0......................................... 31 2.5.. Análisis del diseño e implementación de la aplicación STMS 1,0......................................... 35.
(13) 2.5.1. Descripción de los casos de uso generales del sistema STMS 1,0. ........................................ 36 2.5.2. Boceto estructural de los espacios del diseño. ...................................................................... 40 2.5.3. Modelo de despliegue. ......................................................................................................... 40 2.6. Herramientas que se utilizaron en la fase de implementación de los sistemas BTMS 1,0 y SMTS 1,0. .................................................................................................................................. 41 2.7.. Conclusiones parciales......................................................................................................... 43. CAPITULO 3: GUIA DEL NAVEGADOR.................................................................................... 44 3.1.. Características generales del BTMS 1,0. .............................................................................. 44. 3.1.1. Requerimientos mínimos. .................................................................................................... 44 3.1.2. Descripción del funcionamiento........................................................................................... 44 3.2.. Características generales del STMS 1,0................................................................................ 49. 3.2.1. Requerimientos mínimos. .................................................................................................... 49 3.2.2. Instalación. .......................................................................................................................... 50 3.2.3. Descripción de funcionamiento............................................................................................ 50 CONCLUSIONES ......................................................................................................................... 57 RECOMENDACIONES................................................................................................................. 58 BIBLIOGRAFIA............................................................................................................................ 59 ANEXOS ....................................................................................................................................... 62.
(14) LISTA DE FIGURAS Fig. 1.1 La Web vista por una persona………………………………………………………………10 Fig. 1.2 La Web vista por el programador……………………………………………………...……10 Fig. 1.3 La Web actual vs La Web semántica................................................................................…..12 Fig. 1.4 De la Web actual a la Web semántica………………………………………….……………14 Fig. 2.1 Arquitectura básica del TM4J………………………………………………………….……22 Fig. 2.2 Exportando un archivo “.xtm” en TM4J…………………………………………….………26 Fig. 2.3 Base de datos “Seriada”………………………………………………………………….….29 Fig. 2.4 Casos de uso de la aplicación BTMS 1,0…………………………………………….……..30 Fig. 2.5 Casos de uso de la aplicación SMTS 1,0……………………………………………....……34 Fig. 2.6 Boceto estructural del sistema STMS 1,0……………………………………………….…..39 Fig. 2.7 Modelo de despliegue…………………………………………………………….…..….….40 Fig. 3.1 Aplicación BTMS 1,0 dividida en secciones……………………………………………..…44 Fig. 3.2 Menú Aplicación desplegado……………………………………………………………..…44 Fig. 3.3 Menú Base Datos desplegado…………………………………………………………….…45 Fig. 3.4 Configuración de usuario y contraseña……………………………………….……….…….45 Fig. 3.5 Menú dividir desplegado………………………………………………………………..…..46 Fig. 3.6 Configuración de los grupos………………………………………………..…………….…46 Fig. 3.7 Mostrar los resultados obtenidos………………………………………………………..…..48 Fig. 3.8 Pagina principal del STMS 1,0…………………………………………………….…..……49 Fig. 3.9 Formulario de búsqueda de artículos……………………………………………..……..…..50 Fig. 3.10 Resultado de la búsqueda de una palabra clave………………………………………..…..51 Fig. 3.11 Resultado de mostrar un articulo………………………………………………………..….51 Fig. 3.12 Lista de temáticas…………………………………………………………………...…..….52 Fig. 3.13 Lista de revistas pertenecientes a la temática Humanidades…………………………….....53 Fig. 3.14 Lista de revistas………………………………………………………………….…...….…54 Fig. 3.15 Resultado de mostrar una revista……………………………………………….………..…55.
(15) LISTA DE TABLAS Tabla 2.1 Descripción del caso de uso “Especificar usuario y contraseña”…………………31 Tabla 2.2 Eventos del caso de uso “Especificar usuario y contraseña”……………………..31 Tabla 2.3 Descripción del caso de uso “Especificar partición”……………………………..32 Tabla 2.4 Eventos del caso de uso “Especificar partición”……………………………….…32 Tabla 2.5 Descripción del caso de uso “Construir archivos”………………………………..33 Tabla 2.6 Eventos del caso de uso “Construir archivos”……………………………………33 Tabla 2.7 Descripción del caso de uso “Seleccionar archivo”………………………………35 Tabla 2.8 Eventos del caso de uso “Seleccionar archivo”…………………………………..35 Tabla 2.9 Descripción del caso de uso “Listar temáticas”…………………………………..36 Tabla 2.10 Eventos del caso de uso “Listar temáticas”……………………………………..36 Tabla 2.11 Descripción del caso de uso “Buscar artículos”………………………….……...37 Tabla 2.12 Eventos del caso de uso “Buscar artículos”…………………………………..…37 Tabla 2.13 Descripción del caso de uso “Mostrar revista”………………………………….38 Tabla 2.14 Eventos del caso de uso “Mostrar revista”………………………………………38.
(16) Introducción. INTRODUCCION El desarrollo de la Web y el aumento en las necesidades de información de sus usuarios ha impuesto la necesidad de disponer de una red en la que cualquier usuario pueda encontrar respuestas a sus preguntas de forma más rápida y sencilla gracias a una información mejor definida, y disponer de sitios estandarizados donde se les provea de información mejor entendible por los ordenadores los sistemas informáticos. Al dotar a la web de más significado y, por lo tanto, de más semántica, se pueden obtener soluciones a problemas habituales en la búsqueda de información gracias a la utilización de una infraestructura común, mediante el cual es posible compartir, procesar y transferir información de forma sencilla. Esta web extendida y basada en el significado, se apoya en estándares que solucionan los problemas ocasionados por una web carente de estandarización y viciada de sitios con errores en sus códigos en la que en ocasiones el acceso a la información se convierte en una tarea difícil y frustrante. Las necesidades de los usuarios no solo estriban en la información en sí, sino también en la forma de obtenerla, por tanto, urge a la biblioteca universitaria brindar acceso a estos recursos, muchos de los cuales ni siquiera están disponibles en forma impresa. Ya no se trata sólo de describir su contenido, forma y ubicación, hay que informar sobre su accesibilidad y forma de distribución y precisamente en esto estriba los conceptos elementales de la Web Semántica. Las universidades y sus bibliotecas no escapan, por supuesto, a las transformaciones globales en el área de la informatización. El desarrollo de la tecnología, las demandas cada vez más exigentes de los usuarios, las restricciones presupuestarias y el aumento exponencial de la cantidad de recursos de información, de manera tal que ninguna organización puede mantenerlos físicamente, constituyen para las bibliotecas universitarias un complejo desafío, sin embargo el desarrollo de las bibliotecas no ha estado alejado del mismo desarrollo de la web. Hoy día el funcionamiento de una biblioteca se enmarca en la utilización de plataformas web y herramientas informáticas, eso ha dado lugar a un nuevo modelo de biblioteca conocido como Library 2,0. El Centro de Documentación e Información CientíficoTécnica (CDICT) de nuestra universidad no está ajeno de todas estas transformaciones y poco a poco ha venido.
(17) Introducción desarrollando un papel protagónico como centro de acceso a la información y el conocimiento. Uno de los principales elementos que ha ayudado en gran medida tal desempeño es la creación de grupos investigativos especializados en el desarrollo de servicios que se sustentan en las tecnologías de la Web 2,0, en este contexto se enmarca nuestro trabajo que persigue la representación con cierto grado de semántica de una base de datos aplicando el estándar XML Topic Maps 1,0 y así dar los primeros pasos en la evolución de la Web Universitaria hacia una Web Semántica y por ende el desarrollo del CDICT dentro de los cánones de la Library 2.0.. Hipótesis de investigación. Es posible representar la información disponible en las bases de datos correspondientes a los servicios de información de la Biblioteca Universitaria, a través del estándar Topic Map. Proveyendo de semántica la información allí disponible y haciéndola más entendible a los sistemas y herramientas informáticas.. Para dar cumplimiento a la hipótesis de investigación se proponen los objetivos del trabajo.. Objetivo general. Desarrollar una herramienta computacional, que permita la extracción de la información de la base de datos del servicio “Seriada” y representarla aplicando el estándar XML Topic Maps 1,0 para añadirle semántica a la información e implementar una herramienta web que sirva para explorar los posibles usos de esta filosofía de trabajo. Objetivos específicos. 1. Evaluar cual es la mejor vía para la aplicación del estándar XML Topic Maps 1,0.. 2. Establecer cuál de los softwares libres que se utilizan para representar el estándar XML Topic Maps 1,0 se ajusta más a las especificaciones de nuestro problema..
(18) Introducción 3. Diseñar e implementar el sistema necesario para la construcción de los archivos que tendrán la información extraída de la base de datos después de aplicarle el estándar XML Topic Maps 1,0.. 4. Diseñar e implementar el sistema necesario para la navegación por la información que se almacena en los archivos antes creados.. Valor práctico. El valor práctico del trabajo realizado estriba en su originalidad toda vez que es parte de una investigación exploratoria y de más alcance que tiene como finalidad la migración de la Web de la Biblioteca Universitaria hacia una Web semántica. Esta migración permitirá disponer de herramientas y servicios que beneficien la recuperación de la información disponible en la red y el fortalecimiento del modelo de Library 2.0 iniciado en la Universidad.. Descripción de los capítulos. El presente trabajo se encuentra dividido en tres capítulos. El primero aborda el tema de la Sociedad del Conocimiento hoy día y el desarrollo de la Web Semántica y sus posibilidades de resolver problemas cotidianos automáticamente. También hace referencias a técnicas usadas para incorporarle el significado necesario a la información. En el segundo se mencionan aspectos generales del diseño e implementación de las herramientas Build Topic Maps Seriada versión 1,0 (BTMS 1,0) y Search Topic Maps Seriada versión 1,0 (STMS 1,0). Por último en el tercer capítulo se presenta la guía del navegador donde se explica el funcionamiento de los dos sistemas antes mencionados.. Descripción de anexos. En los anexos uno y dos se muestran los diagramas de clases de las aplicaciones BTMS 1,0 y STMS 1,0 respectivamente, donde se especifican las clases, atributos, métodos y las relaciones entre las clases. Los diagramas de clases son utilizados durante el proceso de análisis y diseño de los sistemas, donde se crea el diseño conceptual de la información que se manejará en el sistema. Para facilitar la navegación por STMS 1,0 se muestra en el anexo.
(19) Introducción tres el diagrama de navegación que refleja el flujo de interacción dentro de la interfaz de usuario. El cuarto anexo describe una Document Type Declaration (DTD) con la sintaxis para serializar e intercambiar documentos topic maps conformes a la especificación XTM..
(20) Capítulo1: Análisis y elementos fundamentales de la Web semántica.. CAPITULO 1: ANALISIS Y ELEMENTOS FUNDAMENTALES DE LA WEB SEMANTICA. Las sociedades contemporáneas se enfrentan al reto de proyectarse y adaptarse a un proceso de cambio que viene avanzando muy rápidamente hacia la construcción de Sociedades del Conocimiento. Este proceso es dinamizado esencialmente por el desarrollo de nuevas tendencias en la generación, difusión y utilización del conocimiento, y está demandando la revisión y adecuación de muchas de las empresas y organizaciones sociales y la creación de otras nuevas con capacidad para asumir y orientar el cambio. Una Sociedad del Conocimiento es una sociedad con capacidad para generar, apropiar, y utilizar el conocimiento para atender las necesidades de su desarrollo y así construir su propio futuro, convirtiendo la creación y transferencia del conocimiento en herramienta de la sociedad para su propio beneficio. Jugando un papel preponderante en este entorno se encuentran las Universidades y por ende sus bibliotecas que están llamadas a ser las locomotoras del cambio en sus centros, para ello están avocadas a cambios tanto estructurales como de cultura de la profesión toda vez que se supone un accionar totalmente novedoso. Con el desarrollo de la Web y el planteamiento de nuevas inquietudes a resolver se han venido desarrollando una serie de softwares y estándares que han dado paso a una nueva estructura de la Web.. 1.1.. La universidad en el mundo cambiante y globalizado.. En el contexto descrito anteriormente están insertadas las universidades que han de ir adaptándose a estas realidades caracterizadas por un cambio incesante e inesperado, y por una creciente globalización, el paradigma clásico de una universidad tradicional y casi inmutable no resulta muy congruente con las nuevas realidades y demandas sociales, y científicas, tanto actuales como futuras. Por otra parte, si consideramos que, cada vez más, importantes investigaciones coinciden en afirmar que «ninguna sociedad actual es superior a sus universidades », resulta evidente que un instrumento esencial del progreso y el desarrollo.
(21) Capítulo1: Análisis y elementos fundamentales de la Web semántica. es la universidad. En efecto, no hay países realmente avanzados que no cuenten con un eficaz sistema universitario y, dentro de él, con unas sólidas y permanentes investigaciones. Estas categóricas afirmaciones adquieren especial importancia para el caso de Iberoamérica, donde, por la acumulación de diversos factores, muchas de sus universidades más importantes están evidenciando, hoy día, serias y continúas limitaciones para poder modificar rápida y profundamente sus modelos, estructuras y procedimientos obsoletos, con la finalidad de responder funcional y oportunamente a las nuevas y exigentes demandas. Los sistemas de educación superior, dice la Declaración Mundial (París, octubre de 1998), deberían aumentar su capacidad para vivir en medio de la incertidumbre, para transformarse y provocar el cambio… La incertidumbre no debe conducirnos a la perplejidad, sino a la disposición para el cambio y a la ampliación y renovación incesante del conocimiento. Si el siglo XX fue el siglo de la búsqueda de certezas científicas y del desarrollo acelerado de las diferentes disciplinas del conocimiento humano, el presente siglo está llamado a ser el siglo de la incertidumbre y la interdisciplinariedad. Por consiguiente, si la universidad es un instrumento tan decisivo para las sociedades, resulta inaplazable poder transformar profundamente tanto sus instituciones individuales como sus sistemas, redes o conjuntos universitarios. No obstante, no sería justo dejar de reconocer que, especialmente durante los últimos veinte años, diversas universidades de esta área han acometido cambios e intervenciones para mejorar su condición, pero, en general, con resultados de escasa trascendencia.. 1.1.1. La universidad y la sociedad de la información y el conocimiento. Resulta evidente el papel crucial que deberá desempeñar la universidad para lograr que las respectivas sociedades tradicionales avancen hacia la conformación, en primer lugar, de la sociedad de la información y, en último término, idealmente, hacia la sociedad del conocimiento. Para avanzar hacia tales objetivos, (Tünnermann, 2000) señala: «La médula del problema radica en que nos encontramos en una etapa de transición y por lo mismo crítica, entre la educación superior elitista y la educación superior masiva..
(22) Capítulo1: Análisis y elementos fundamentales de la Web semántica. Las actuales estructuras académicas responden a la educación superior elitista; por lo mismo, les es imposible, sin una profunda transformación, hacer frente al fenómeno de masificación. Son, en general, demasiado rígidas, poco diversificadas, y carentes de adecuados canales de comunicación entre sus distintas modalidades y con el mundo de la producción y del trabajo. La homogeneidad de sus programas no les permite atender la amplia gama de habilidades, intereses y motivaciones de una población estudiantil cada vez más extensa y heterogénea; su excesiva compartimentalización contradice la naturaleza esencialmente interdisciplinaria del conocimiento moderno; su apego a los sistemas formales les impide servir con eficacia los propósitos de la educación permanente». Naturalmente, en cada uno de los casos, las estrategias requeridas tendrán grandes diferencias, y las de mayor complejidad corresponderán principalmente a las sociedades que acusen un escaso desarrollo y dispongan todavía de unas instituciones y sistemas educativos de insuficiente consolidación. Por ello, la UNESCO, en su reciente declaración mundial sobre la educación superior, reconoce su importancia estratégica en la sociedad contemporánea y concluye que: «La propia educación superior ha de emprender su transformación y la renovación más radical que jamás haya tenido por delante».. 1.2.. De la Web tradicional a la Web semántica.. Una vez que se ha expuesto los basamentos esenciales de la Library 2.0 y toda vez que ella se materializa sobre la Internet detengámonos en el análisis del origen y el desarrollo de esta plataforma. La aparición de la WWW se puede situar en 1989 (Abrams 1998, Connolly 2000), cuando Tim BernersLee presentó su proyecto de “World Wide Web” (BernersLee 1989) en el CERN (Suiza), con las características esenciales que perduran en nuestros días. El propio BernersLee completó en 1990 el primer servidor Web y el primer cliente, y un año más tarde publicó el primer borrador de las especificaciones de HTML y HTTP. El lanzamiento en 1993 de Mosaic, el primer navegador de dominio público, compatible con Unix, Windows, y Macintosh, por el National Center for Supercomputing Applications (NCSA), marca el momento en que la WWW se da a conocer al mundo, extendiéndose.
(23) Capítulo1: Análisis y elementos fundamentales de la Web semántica. primero en universidades y laboratorios, y en cuestión de meses al público en general, iniciando el que sería su vertiginoso crecimiento. Los primeros usuarios acogieron con entusiasmo la facilidad con que se podían integrar texto y gráficos y saltar de un punto a otro del mundo en una misma interfaz, y la extrema sencillez para contribuir contenidos a una Web mundial. Por estas mismas fechas se define la interfaz CGI para la generación dinámica de páginas Web, con lo que se consigue ofrecer información actualizada en tiempo real, enlazar con bases de datos, o tener en cuenta entradas del usuario, y más aún, servir como punto de acceso y plataforma para la ejecución de aplicaciones distribuidas. En 1994 miembros del equipo que creó Mosaic desarrollan Netscape, un navegador con sensibles mejoras que contribuye a impulsar la propagación de la web. Este mismo año se celebra el primer congreso internacional de la WWW, y unos meses más tarde se constituye el consorcio W3C, que desde entonces y presidido por Tim BernersLee, se ha hecho cargo de estandarizar las principales tecnologías Web. En 1995 Sun lanza oficialmente la primera versión del lenguaje Java, y un año más tarde Netscape presenta JavaScript. Estos lenguajes y otros posteriores permiten que las propias páginas Web contengan programas enteros, dando opción a una mayor autonomía respecto del servidor, mayor eficiencia, capacidad dinámica y capacidad de interacción.. 1.2.1. La Web hoy. Es sumamente difícil medir el tamaño de la Web, pero se estima que hoy día alberga un volumen de información equivalente a entre 14 y 28 millones de libros (Bergman 2001). Como dato comparativo, la asociación American Research Libraries, que agrupa unas 100 bibliotecas en EE.UU., tiene catalogados unos 3.7 millones de libros. La biblioteca de la Universidad de Harvard, la mayor de EE.UU., contiene en torno a 15 millones de libros. Estas cifras incluyen sólo lo que se ha dado en denominar la Web superficial, formada por los documentos estáticos accesibles en la Web. Se ha calculado que la llamada Web profunda, constituida por las bases de datos cuyos contenidos, no directamente accesibles, se hacen visibles mediante páginas generadas dinámicamente, puede contener un tamaño de información varios cientos de veces mayor, y de mucha mejor calidad, que la Web.
(24) Capítulo1: Análisis y elementos fundamentales de la Web semántica. superficial, y crece a un ritmo aún mayor que ésta (O’Neill 2003). Se estima que el tamaño de la Web profunda ha superado ya al volumen total de información impresa existente en todo el planeta. Hoy casi todo está representado de una u otra forma en la Web, y con la ayuda de un buen buscador, podemos encontrar información sobre casi cualquier cosa que necesitemos. La Web está cerca de convertirse en una enciclopedia universal del conocimiento humano. Por otra parte la Web nos permite realizar diferentes actividades de nuestra vida diaria con una comodidad, economía y eficiencia sin precedentes: sin movernos de casa podemos comprar todo tipo de productos y servicios, gestionar una cuenta bancaria, buscar un restaurante, consultar la cartelera, leer la prensa, localizar a una persona, matricularnos en la universidad, acceder a un callejero, o trabajar desde nuestro domicilio. No obstante, en este panorama tan favorable hay espacio para mejoras. Por ejemplo, el enorme tamaño que ha alcanzado la Web, a la vez que es una de las claves de su éxito, hace que algunas tareas (por ejemplo encontrar la planificación óptima con transporte, alojamiento, etc., entre todas las posibles para un viaje bajo ciertas condiciones), requieran un tiempo excesivo para una persona o resulten sencillamente inabarcables. Desarrollar programas que realicen estas tareas en nuestro lugar es enormemente complicado, ya que es muy difícil reproducir, y más costoso aún mantener, en una máquina la capacidad de una persona para comprender los contenidos de la Web tal y como están codificados actualmente. La asombrosa eficacia de los buscadores actuales tiene también sus límites. Por ejemplo, si queremos conocer la historia de Netscape, los resultados de una consulta como “Netscape history”, nos informan sobre las herramientas de históricos de este navegador, pero no nos dicen nada sobre el origen y evolución de Netscape. Igualmente, para averiguar qué organismo se ocupa de estandarizar CGI, o en qué fecha apareció la primera versión de Java, necesitaremos realizar varias consultas y leer varios documentos y artículos hasta llegar indirectamente a la respuesta buscada. Si introducimos la palabra “Ketchup” para buscar información sobre el grupo de música del mismo nombre, obtendremos enlaces a restaurantes, recetas, fabricantes, distribuidores y clubes de aficionados al condimento, y.
(25) Capítulo1: Análisis y elementos fundamentales de la Web semántica. finalmente lo que buscábamos (posiblemente ni siquiera esto si el grupo fuese menos popular). Con los continuos cambios de la Web y los algoritmos de los buscadores, los resultados de estas pruebas pueden variar de un día para otro. Si buscamos un “artículo sobre García Márquez”, encontraremos decenas de artículos de García Márquez, pero ninguno que trate sobre este autor. Si preguntamos sobre estándares XML para la enseñanza (“XML education”), la mayor parte de los resultados se referirán a la enseñanza de XML. Todos estos ejemplos son el síntoma de una causa común: la falta de capacidad de las representaciones en que se basa la Web actual para expresar significados. Los contenidos y servicios en la Web se presentan en formatos (p.e. HTML) e interfaces (p.e. formularios) comprensibles por personas, pero no por máquinas. La Fig. 1.1 ejemplifica esta situación con una versión simplificada de una página de información meteorológica. Mientras que la presentación de los datos en el navegador es inmediatamente comprendida por una persona, es muy difícil para el ordenador entender cuál es la temperatura, el estado del cielo, y demás semántica del documento, al estar entremezclada con las etiquetas de formato (Véase Fig. 1.2)..
(26) Capítulo1: Análisis y elementos fundamentales de la Web semántica.. Fig. 1.1 La Web vista por una persona.. <html><head><title>Yahoo! Weather Harare (Zimbabwe) Forecast </title></head><body><table width=100%><tr bgcolor=CCCCFF><td> <b>Harare Today</b></td></tr> <tr><td>at 1:00 pm CAT</td></tr> <tr><td><table width=100%><tr align=center><td rowspan=2 bgcolor=FFCC66>Currently:<br><b><font size=+2>21º;C</font> </b></td><td rowspan=2 bgcolor=EEEEEE><img src=thunderstorm.gif> <br>Thunderstorms</td> <td bgcolor=FF9966>Hi: <b>27</b></td></tr> <tr align=center><td bgcolor=FFFF99>Lo: <b>18</b></td></tr> </table><p><center><img src=cscale.gif></center><p><table width=100%><tr><td><b>Appar Temp:</b></td><td>21°;</td><td> <b>Dewpoint:</b></td><td>16°;</td></tr><tr><td><b>Barometer: </b></td><td>1017 mb; falling</td><td><b>Wind:</b></td><td>SE/10 mph </td></tr><tr><td><b>Humidity:</b></td><td>73%</td><td><b> Visibility:</b></td><td>6 mi</td></tr></table></td></tr></table> </body></html>. Fig. 1.2 La Web vista por el ordenador..
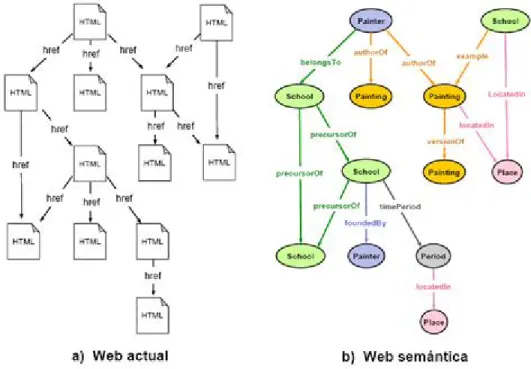
(27) Capítulo1: Análisis y elementos fundamentales de la Web semántica. En estas condiciones es poco viable automatizar tareas mediante software en substitución del humano. Un programa puede llevar al usuario hasta lugares en la Web, generar, transportar, transformar y ofrecer la información a las personas, pero la máquina sencillamente no sabe lo que esta información significa, y por tanto su capacidad de actuación autónoma es muy limitada. Esta misma limitación expresiva hace que la noción de semántica que manejan los buscadores Web se limite a palabras clave con pesos, pero planas e inconexas, lo que no permite reconocer ni solicitar significados más elaborados.. 1.2.2. La Web semántica. La Web semántica (BernersLee 2001) propone superar las limitaciones de la Web actual mediante la introducción de descripciones explícitas del significado, la estructura interna y la estructura global de los contenidos y servicios disponibles en la WWW. Frente a la semántica implícita, el crecimiento caótico de recursos, y la ausencia de una organización clara de la Web actual, la Web semántica aboga por clasificar, dotar de estructura y anotar los recursos con semántica explícita procesable por máquinas. La Fig. 1.3 ilustra esta propuesta. Actualmente la Web se asemeja a un grafo formado por nodos del mismo tipo, y arcos (hiperenlaces) igualmente indiferenciados. Por ejemplo, no se hace distinción entre la página personal de un profesor y el portal de una tienda online, como tampoco se distinguen explícitamente los enlaces a las asignaturas que imparte un profesor de los enlaces a sus publicaciones. Por el contrario en la Web semántica cada nodo (recurso) tiene un tipo (profesor, tienda, pintor, libro), y los arcos representan relaciones explícitamente diferenciadas (pintor – obra, profesor – departamento, libro – editorial)..
(28) Capítulo1: Análisis y elementos fundamentales de la Web semántica.. Fig. 1.3 La Web actual vs la Web semántica.. La Web semántica mantiene los principios que han hecho un éxito de la Web actual, como son los principios de descentralización, compartición, compatibilidad, máxima facilidad de acceso y contribución, o la apertura al crecimiento y uso no previstos de antemano. En este contexto un problema clave es alcanzar un entendimiento entre las partes que han de intervenir en la construcción y explotación de la Web: usuarios, desarrolladores y programas de muy diverso perfil. La Web semántica rescata la noción de ontología del campo de la Inteligencia Artificial como vehículo para cumplir este objetivo. Gruber define ontología como “a formal explicit specification of a shared conceptualization” (Gruber 1993). Una ontología es una jerarquía de conceptos con atributos y relaciones, que define una terminología consensuada para definir redes semánticas de unidades de información interrelacionadas. Una ontología proporciona un vocabulario de clases y relaciones para describir un dominio, poniendo el acento en la compartición del conocimiento y el consenso en la representación de éste. Por ejemplo, una ontología sobre arte podría incluir clases como Pintor, Cuadro, Estilo o Museo, y relaciones como autor de un cuadro, pintores pertenecientes a un estilo artístico u obras localizadas en un museo..
(29) Capítulo1: Análisis y elementos fundamentales de la Web semántica. La idea es que la Web semántica esté formada (al menos en parte) por una red de nodos tipificados e interconectados mediante clases y relaciones definidas por una ontología compartida por sus distintos autores. Por ejemplo, una vez establecida una ontología sobre cuadros y pintura, un museo virtual puede organizar sus contenidos definiendo instancias de pintores, cuadros, etc., interrelacionándolas y publicándolas en la Web semántica. La adopción de ontologías comunes es clave para que todos los que participen de la Web semántica, contribuyendo o consumiendo recursos, puedan trabajar de forma autónoma con la garantía de que las piezas encajen. Así por ejemplo varios museos podrían colaborar para dar lugar a un gran metamuseo que integre los contenidos de todos ellos. Un programa que navegue por una red como ésta puede reconocer las distintas unidades de información, obtener datos específicos o razonar sobre relaciones complejas. A partir de aquí sí podemos distinguir entre un cuadro pintado por un artista y un retrato de un artista. Por último, la Web no solamente proporciona acceso a contenidos sino que también ofrece interacción y servicios (comprar un libro, reservar una plaza en un vuelo, hacer una transferencia bancaria, simular una hipoteca). Los servicios Web semánticos son una línea importante de la Web semántica, que propone describir no sólo información sino definir ontologías de funcionalidad y procedimientos para describir servicios Web: sus entradas y salidas, las condiciones necesarias para que se puedan ejecutar, los efectos que producen, o los pasos a seguir cuando se trata de un servicio compuesto. Estas descripciones procesables por máquinas permitirían automatizar el descubrimiento, la composición, y la ejecución de servicios, así como la comunicación entre unos y otros.. 1.3.. De la Web actual a la Web semántica.. Llegados a este punto una pregunta importante a responder es cómo encaja la Web semántica con la actual, es decir cómo accederá el usuario a la Web semántica, y sobre todo, cómo hacer la transición de la Web actual a la Web semántica. Para que la Web semántica pueda realizarse es importante que guarde, al menos al principio, una compatibilidad con la tecnología actual. Es deseable por ejemplo mantener HTML (u otros lenguajes compatibles con los navegadores actuales) como vehículo de comunicación con el usuario. La asociación entre las instancias de la Web semántica y el código HTML se puede establecer de distintas.
(30) Capítulo1: Análisis y elementos fundamentales de la Web semántica. maneras (Véase Fig. 1.4). Una consiste en conservar los documentos actuales, y crear las instancias asociadas anotando su correspondencia con los documentos. Esta posibilidad es la más viable cuando se parte de un gran volumen de material antiguo. Otra es generar dinámicamente páginas Web a partir de las ontologías y sus instancias. Esta última opción puede resultar factible cuando los documentos antiguos ya se estaban generando automáticamente a partir, por ejemplo, de una base de datos.. Fig. 1.4. De la Web actual a la Web semántica.. La transición de la Web actual a la Web semántica puede implicar un coste altísimo si tenemos en cuenta el volumen de contenidos que ya forman parte de la Web. Crear y poblar ontologías supone un esfuerzo extra que puede resultar tedioso cuando se agregan nuevos contenidos, pero directamente prohibitivo por lo que respecta a integrar los miles de gigabytes de contenidos antiguos. Las estrategias más viables combinan una pequeña parte de trabajo manual con la automatización del resto del proceso. Las técnicas para la automatización incluyen, entre otras, el mapeo de la estructura de bases de datos a ontologías, el aprovechamiento, previa conversión, de los metadatos y estándares de clasificación presentes en la Web (y fuera de ella), y la extracción automática de metadatos a partir de texto y recursos multimedia. Otra dificultad importante a la hora de realizar la Web semántica en la práctica es la de consensuar ontologías en una comunidad por poco amplia que sea. Converger a una representación común es una labor más compleja de lo que puede parecer, ya que típicamente cada parte del sistema conlleva peculiaridades necesarias, y un punto de vista.
(31) Capítulo1: Análisis y elementos fundamentales de la Web semántica. propio que a menudo necesitan incidir en la propia ontología. La representación del mundo no es neutra respecto al uso que se le va a dar: tanto un dietista como un biólogo tienen conocimiento sobre las plantas, pero su representación de esa materia es muy distinta, y probablemente no sería adecuado imponer la misma representación para ambas perspectivas. Las vías para salvar esta dificultad consisten en compartir ontologías para las áreas comunes en que puede tener lugar una interacción o intercambio de información entre las partes, y establecer formas de compatibilidad con las ontologías locales, mediante extensión y especialización de las ontologías genéricas, o por mapeo y exportación entre ontologías.. 1.3.1. La Web semántica hoy. Los resultados alcanzados hasta ahora hacia la realización de la Web semántica son muy preliminares si se mira desde la óptica más ambiciosa, la de la adopción universal de la Web semántica. Se ha avanzado mucho con las herramientas, los estándares y la infraestructura necesarios para el despliegue de la Web semántica, y se han desarrollado proyectos y experiencias piloto para poner a prueba las herramientas y las ideas. En este punto, el desarrollo de aplicaciones reales basadas en esta tecnología se ha identificado como una realización necesaria para que la Web semántica prospere (Haustein 2002). Existe un gran interés desde el entorno corporativo, el sector público y el mundo académico por hacer de la Web semántica una realidad, ya que se piensa que puede ser una pieza importante para el progreso de la sociedad de la información. Las grandes agencias de financiación pública (programas marco EUIST en Europa, DARPA en EE.UU.) incluyen áreas prioritarias específicas dedicadas a la Web semántica, y están invirtiendo grandes presupuestos en proyectos de investigación y desarrollo en este campo (la última llamada del VI Programa Marco ha destinado más de 60.000 millones de euros al área “Semanticbased Knowledge Systems” para los próximos cuatro años). Las principales empresas (IBM, Microsoft, Sun, Oracle, BEA, SAP, HP…) están participando activamente en el desarrollo de los estándares y tecnologías. La Web semántica se ha convertido en un área de investigación de moda en los centros de investigación de todo el mundo, entre ellos el MIT, la Universidad de Stanford, la.
(32) Capítulo1: Análisis y elementos fundamentales de la Web semántica. Universidad de Maryland, la Universidad de Innsbruck (Austria), la Universidad de Karlsruhe (Alemania), la Universidad de Manchester, la Open University en el Reino Unido, por citar tan sólo algunos de los grupos más destacados. También en la Universidad Autónoma de Madrid se están llevando a cabo proyectos en esta área. En pocos años se ha consolidado una comunidad investigadora considerable, de cuyo reflejo cabe destacar un gran congreso internacional que se celebra con carácter anual (International Semantic Web Conference), y revistas como el Journal of Web Semantics, o el área The Semantic Web de Electronic Transactions on Artificial Intelligence (ETAI). Es muy de destacar así mismo el apoyo y el importante papel del W3C en el proyecto de la Web semántica, con la creación de grandes y muy activos grupos de trabajo para el desarrollo de esta área, y muy en especial liderando el esfuerzo de estandarización de lenguajes y tecnologías específicas para la web semántica. Aún queda mucho trabajo por hacer. Se necesita crear más y mejor tecnología e infraestructura, y más aún, desarrollar aplicaciones reales que pongan en práctica los principios de la Web semántica, que pueblen la Web con ontologías, y que hagan que la Web semántica adquiera la masa crítica imprescindible para hacerse realidad. En espera de que se alcance esta meta y al margen de ese debate, se han desarrollado ideas muy aprovechables a niveles específicos, y se han abierto nuevos campos para la innovación, suficientemente interesantes para motivar la investigación en esta área..
(33) Capítulo 2: Diseño e implementación de los sistemas BTSM 1,0 y STMS 1,0.. CAPITULO 2: DISEÑO E IMPLEMENTACION DE LOS SISTEMAS BTSM 1,0 y STMS 1,0. En el presente capítulo se abordan aspectos generales relacionados con la implementación y diseño de las aplicaciones BTMS 1,0 y STMS 1,0. Paralelamente se hará un análisis del estándar XTM 1,0 como gramática abstracta XML para el intercambio de mapas de tópicos diseñados para la Web, además de un amplio estudio del paquete Topic Maps for Java (TM4J) como instrumento fundamental que servirá de base del proceso de implementación de ambas aplicaciones mencionadas anteriormente.. 2.1.. El estándar XML Topic Maps 1.0.. La publicación del modelo Topic Maps como estándar por la International Organization for Standardization (ISO) en el año 2000 y su posterior adaptación al lenguaje XML mediante la especificación XTM, para una mejor incorporación de éste a la Web, ha ido despertando un interés creciente.. A pesar de que el modelo tiene, en un primer acercamiento, un componente principalmente técnico o tecnológico que puede dificultar su comprensión, los presupuestos teóricos que lo sustentan conceptualmente son muy cercanos a los que maneja la documentación. Al dirigirse sus primeras aplicaciones hacia el desarrollo de sistemas informáticos de Gestión de Conocimiento empresarial y el mantenimiento y gestión de sitios Web, los documentalistas del área comenzaron a prestarle atención, al tiempo que sus impulsores desde el área técnica descubrían la utilidad de los vocabularios controlados como punto de partida idóneo para la construcción de Topic Maps.(Pepper and Moore, 2001). 2.1.1. Características generales del estándar XTM 1,0. Los inicios del estándar Topic Maps se localizan en los trabajos que el llamado Grupo de Davenport, surgido de un consorcio de empresas, comenzó en 1991 con la intención de desarrollar un estándar para la documentación técnica de software (Pepper and Moore,.
(34) Capítulo 2: Diseño e implementación de los sistemas BTSM 1,0 y STMS 1,0. 2001). Dividido en dos subgrupos en 1993, uno de ellos se centró en definir una DTD para el contenido de los manuales, que dio como resultado la DTD DocBook que esta diseñada para documentación del área informática, aunque muchos autores de otros campos lo han ido adaptando porque su estructura refleja la idea abstracta que se tiene de un libro; el otro subgrupo, Conventions for the Application of HyTime (CApH), tenía como objetivo desarrollar un índice común a partir de distintas fuentes de documentación. Esta tarea, que en principio les pareció que no revestiría grandes dificultades, resultó más compleja de lo esperado.. En 1996 el grupo de trabajo de Standard Generalized Markup Language (SGML) de la ISO aceptó el borrador desarrollado, denominado entonces “Topic Navigation Maps”. Finalmente, en el verano de 1999 fue aceptado como norma en la International Organization for Standardization / International Electrotechnical Comission (ISO/IEC) y publicada como ISO/IEC 13250:2000.. A comienzos del 2000 se funda una organización independiente, TopicMaps.Org, con el objetivo de adaptar esta norma a un lenguaje más adecuado para la Web. Basándose en las recomendaciones XML y el estándar para enlaces XML Linking Language (XLink) del World Wide Web Consortium (W3C), publicó la primera versión de una DTD para expresar Topic Maps en marzo de 2001, conocida como XTM.. La especificación XTM 1,0 fue admitida por la ISO he incorporada al estándar mediante una Enmienda Técnica. En mayo del 2002 la ISO aprobó y publicó la segunda edición de la norma, recogida finalmente como ISO/IEC 13250:2003 (Eíto Brun, 2001).. El modelo intenta proporcionar un esquema de representación de estructuras de conocimiento, en forma de red semántica, asociarlas con recursos de información y que incorpore un valor añadido similar al que un índice analítico añade a un libro. Denominado “GPS del universo de información” por Charles F. Goldfarb, el desarrollador de los lenguajes de marcado y del lenguaje SGML, los Topic Maps permite tanto organizar.
(35) Capítulo 2: Diseño e implementación de los sistemas BTSM 1,0 y STMS 1,0. documentos digitales como navegar a través de la estructura semántica que los conecta entre sí (R. Newcomb and Biezunski, 2002).. 2.1.2. Componentes del modelo. El núcleo central del modelo definido por el estándar ISO/IEC 13250:2003 Topic Maps está constituido por tres elementos básicos: Topic, Association, y Occurrence (Pepper and Moore, 2001). Esta tríada de conceptos fue recogida como el TAO de los Topic Maps por Steve Pepper, uno de los editores de XTM. Un Topic Maps se funda sobre el concepto de topic, el cual constituye la representación material o concreta del subject, percepción humana abstracta de una realidad. La noción de subject es el punto de partida conceptual sobre el que descansa el modelo, siendo definido en la norma en los siguientes términos. “En el sentido más amplio, un subject es cualquier cosa, con independencia de si existe o tiene otras características específicas, sobre la cual puede decirse cualquier cosa con cualquier significado” según (Pepper and Moore, 2001). Para aclarar la definición se indica que “el corazón invisible de cada topic es el subject que su autor tenía en mente cuando fue creado ” según (Colmenero Ruiz, 2003). Así, el término topic indica el objeto u elemento del Topic Maps que representa al subject al que se está refiriendo, haciéndolo real para el sistema. Entre topic y subject se establece una relación biunívoca en la cual un subject es representado por un único topic y viceversa. Cada topic es una instancia de una o más clases de topics (denominados también topic types), que pueden o no indicarse de forma explícita. Los topic types o clase de topic son topics igualmente. Esta relación claseinstancia según la especificación XTM lo realiza mediante el elemento instanceOf. El proceso de materialización de los subjects como topics hace posible la asignación de características a éstos últimos. Cada topic puede tener las características siguientes: una denominación (topic name), un o unos ejemplos o descripciones (topic occurrence) y un rol.
(36) Capítulo 2: Diseño e implementación de los sistemas BTSM 1,0 y STMS 1,0. como miembro de una asociación. Dos topics con las mismas características se consideran idénticos, produciendo duplicidad, por lo que uno de ellos se eliminará cuando el Topic Maps sea procesado.(Pepper and Moore, 2001) El nombre, legible para los humanos, de un topic se inscribe a través del topic name. Dado que un mismo concepto puede ser designado con una gran variedad de nombres, e incluso ninguno válido, el modelo permite definir nombres normalizados a los topics que sean significativos desde el punto de vista semántico, al mismo tiempo que concede la posibilidad de asociar otros libremente con vistas a su procesamiento por distintas aplicaciones. Así un topic puede desde no tener nombre hasta disponer de varios, mediante la asignación de múltiples base name. Una occurrence es cualquier información que es especificada como relevante para un subject dado. En puridad, son recursos externos de información, enlazados mediante una referencia que sirve para su localización, que aclaran o ejemplifican el contenido del topic. La occurrence puede incluir también información como datos de caracteres, lo que es especialmente útil cuando su cantidad es pequeña (por ejemplo, fechas de nacimiento, publicación, coordenadas, definiciones cortas…). El tercer elemento del núcleo central del modelo topic maps es la association que es una relación entre uno o mas topics donde cada uno de ellos juega un rol como miembro de dicha asociación. Esta relación estaría expresada, en forma implícita, por la expresión verbal que uniría los dos topics, asumiendo que éstos representarían los sustantivos de la frase así formada. Por ejemplo, “el sol es una estrella” o “la miel es elaborada por las abejas”. El número de topics involucrados en una association no está limitado aunque lo más frecuente es que sean dos (asociaciones binarias) o, en menor grado, tres (asociaciones ternarias)..
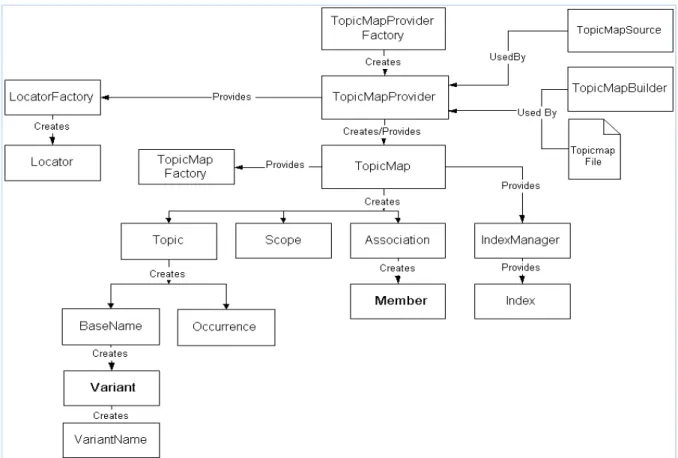
(37) Capítulo 2: Diseño e implementación de los sistemas BTSM 1,0 y STMS 1,0.. 2.1.3. Entornos de aplicación. Las aplicaciones del modelo Topic Maps derivan fundamentalmente de dos de sus características principales: formar una capa o nivel independiente de los recursos que organiza, sean éstos documentos con cualquier grado de estructuración o datos, y la facultad de navegar a través de la estructura semántica que conforman y los recursos que enlaza.. La primera característica posibilita su uso para la organización y representación del conocimiento sobre un dominio específico. A su vez la segunda característica es, en sí misma, una aplicación: un sistema de navegación hipertextual, semejante a una segunda generación de sistemas hipertextuales caracterizados por la separación entre enlaces, sistemas de navegación y los recursos. En fin la combinación de ambas características permite aplicaciones multifuncionales, considerando la navegación sólo a través de la estructura del conocimiento expresado y la navegación tanto por la estructura como por los recursos.. 2.2.. Análisis del paquete Topic Maps for Java (TM4J).. TM4J es un paquete de código abierto para el trabajo con Topic Maps que soporta el estándar XTM 1,0. El núcleo de TM4J es un conjunto de Application Programming Interface (API) desarrollada en lenguaje Java que permite importar, exportar y manipular Topic Maps(Groschupf and Kerk, 2003).. 2.2.1. Arquitectura básica. A continuación se muestra un modelo de la arquitectura del TM4J (Véase Fig. 2.1). Se realiza una explicación de las clases más importantes dentro del modelo:.
(38) Capítulo 2: Diseño e implementación de los sistemas BTSM 1,0 y STMS 1,0. TopicMapProviderFactory Clase abstracta que tiene implementaciones separadas para cada una de las formas de almacenamiento que soporta TM4J. Su único propósito es permitir la conexión con la forma de almacenamiento. Una vez creada una instancia de la clase TopicMapProviderFactory, esta puede ser usada para crear una instancia de la interfaz TopicMapProvider llamando al método newTopicMapProvider(Ahmed, 2004).. TopicMapProvider La interfaz TopicMapProvider representa la conexión al mecanismo de almacenamiento que se utiliza. TopicMapProvider gestiona objetos TopicMap y se utiliza para añadir nuevas instancias de TopicMap o eliminarlas proporcionando los medios para acceder a estos objetos(Ahmed, 2004).. Fig. 2.1 Arquitectura básica del TM4J.
(39) Capítulo 2: Diseño e implementación de los sistemas BTSM 1,0 y STMS 1,0. TopicMapSource La interfaz TopicMapSource es una abstracción de una combinación de datos y procesamiento que genera un TopicMap. La fuente más común de un topic maps son archivos escritos con la sintaxis XTM o Linear Topic Maps (LTM) que generan Topic Maps al ser procesados por TopicMapBuilder(Ahmed, 2004).. TopicMap La interfaz TopicMap representa un único Topic Maps y proporciona los métodos necesarios para crear, modificar y eliminar elementos de una instancia(Ahmed, 2004).. LocatorFactory La interfaz LocatorFactory proporciona métodos para crear objetos que representan las direcciones a los recursos(Ahmed, 2004).. Locator Provee un constructor independiente para representar las direcciones de recursos(Ahmed, 2004).. TopicMapFactory Proporciona métodos para copiar un TopicMap hacia otro. El método que permite copiar tiene dos formas de realizar la copia, una copia completa del objeto, sus hijos y las referencias mientras la otra, llamada copia somera solo realiza la copia del objeto y sus hijos pero no de las referencias(Ahmed, 2004).. IndexManager Proporciona acceso a los índices de los objetos de un Topic Maps. Cada instancia de TopicMap tiene una instancia de IndexManager que puede ser recuperado llamando al método getIndexManager de la interfaz TopicMap(Ahmed, 2004)..
(40) Capítulo 2: Diseño e implementación de los sistemas BTSM 1,0 y STMS 1,0.. 2.2.2. Cómo crear la estructura semántica en memoria. Para crear un Topic Maps en memoria lo primero es obtener una instancia de la interfaz TopicMapProviderFactory usando la implementación para almacenamiento en memoria que provee TM4J.. providerFactory = new org.tm4j.topicmap.memory.TopicProviderFactoryImpl();. Después de tener la instancia llama al método newTopicMapProvider que proporciona la interfaz TopicMapProviderFactory para obtener una instancia de TopicMapProvider.. provider = providerFactory.newTopicMapProvider();. Ahora se necesita una instancia de la interfaz Locator para representar la dirección del recurso. y. se. obtiene. con. el. método. getLocatorFactory. de. la. instancia. de. TopicMapProvider.. loc = provider.getLocatorFactory().createLocator(¨URI¨,¨http://www.tm4j.org/ex.xtm¨);. Y finalmente se llega al TopicMap al llamar al método createTopicMap de la instancia de TopicMapProvider.. tm = provider.createTopicMap(loc);. Para crear un Topic se usa el método createTopic de la instancia de TopicMap con un parámetro que representa un identificador dentro del Topic Maps.. topic = tm.createTopi(id);. Con el Topic creado, se le agrega el nombre con el método createName que proporciona la instancia de Topic..
(41) Capítulo 2: Diseño e implementación de los sistemas BTSM 1,0 y STMS 1,0.. topic = createName(null).setData(nombre);. Las occurrence se crean usando el Topic creado previamente, se le agrega el nombre y el tipo de Topic que representa.. occurrence = topic.createOccurrence(null); occurrence.setData(nombre); occurrence.setType(type_topic);. Otro elemento importante de la estructura de un Topic Maps son las association que permiten relacionar Topic. Se crea usando el método createAssociation de la instancia de TopicMap y tiene un tipo de asociación que es un Topic que proporciona una idea sobre la relación.. association = tm.createAssociation(null); association.setType(type_topic);. Para agregarle un miembro a la association se tiene que crear antes un member, asignarle el tipo de rol que jugara y el Topic que se quiere relacionar.. member = association.createMember(null); member.setRoleSpec(type_rol); member.addPlayer(topic);. 2.2.3. Cómo construir el fichero “.xtm” a partir de una estructura semántica. El proceso de exportar a un archivo “.xtm” requiere de múltiples pasos. En primer lugar se crea un objeto para serializar. La Fig.2.2 muestra el uso de la clase XMLSerializer, pero cualquier clase que implemente la interfaz ContentHandler puede utilizarse. En este caso se especifica el formato de salida y el archivo en el cual será escrito..
(42) Capítulo 2: Diseño e implementación de los sistemas BTSM 1,0 y STMS 1,0.. XMLSerializer serializer = new XMLSerializer(out_xtm_file, of);. Seguidamente se crear un objeto XTMWriter. El XTMWriter se conecta con el serializer mediante el método setContentHandler.. XTMWriter writer = new XTMWriter(); writer.setContentHandler(serializer);. Fig. 2.2 Exportando un archivo “.xtm” en TM4J. Posteriormente se crear un objeto TopicMapWalker que se conecta con el XTMWriter por medio del método setTopicMapHandler. Y finalmente se llama el método walk que tiene como parámetro la estructura que se quiere exportar hacia un archivo “.xtm”.. topicMapWalker walker = new TopicMapWalker(); walker.setHandler(writer); walker.walk(tm);.
(43) Capítulo 2: Diseño e implementación de los sistemas BTSM 1,0 y STMS 1,0.. 2.2.4. Cómo importar un fichero “.xtm” a memoria. El SerializedTopicMapSource proporciona una forma estándar para serializar los archivos Topic Maps. Al leer un archivo con una instancia de SerializedTopicMapSource, TM4J usa una instancia de la interfaz TopicMapBuilder para parsear el archivo. Actualmente TM4J proporciona dos implementaciones de esta interfaz, XTMBuilder que analiza el flujo de entrada como XML conforme a la XTM 1,0 y LTMBuilder que analiza el flujo de entrada de texto conforme a la notación de Ontopia Linear Topic Map (LTM). El siguiente ejemplo realiza la lectura de un archivo “.xtm” hacia la memoria conociendo la ubicación del archivo.. File tmFile = new File(topicMapFileName); FileInputStream inputStream = new FileInputStream(tmFile); String cadena = tmFile.toURI().toString(); Locator baseLoc = m_provider.getLocatorFactory().createLocator("URI", cadena); TopicMapSource src = new SerializedTopicMapSource(inputStream,baseLoc); TopicMapProvider provider = tmpf.newTopicMapProvider(); TopicMap topic_map = provider.addTopicMap(src);. 2.2.5. Cómo consultar una estructura semántica. El motor de búsqueda Tolog que forma parte de la distribución de TM4J permite evaluar consultas a un Topic Maps. Al realizar una consulta se tiene un conjunto de resultados que al iterar por ellos se extraen los resultados recuperados.. Crear un QueryEvaluator La interfaz principal para el motor de consulta Tolog es QueryEvaluator. Se debe usar la clase QueryEvaluatorFactory que proporciona un único método newQueryEvaluator que tiene como parámetro un TopicMap.. QueryEvaluator qe = QueryEvaluatorFactory.newQueryEvaluator(tm);.
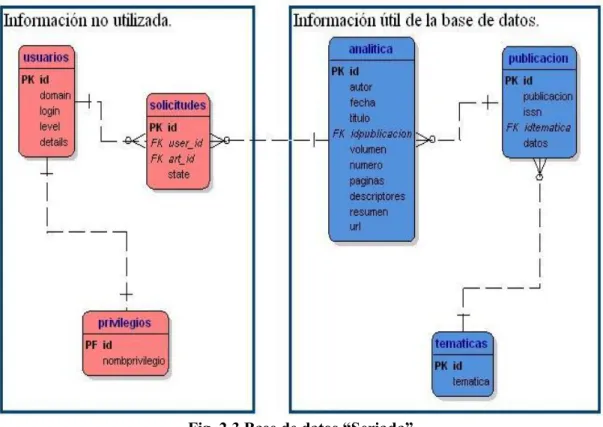
(44) Capítulo 2: Diseño e implementación de los sistemas BTSM 1,0 y STMS 1,0. Compilar la consulta Para compilar una consulta se utiliza el método prepareQuery(String queryString), donde el parámetro es una cadena que refleja la consulta a realizar. El resultado de este método es una instancia de PreparedQuery.. PreparedQuery pq = qe.prepareQuery(“select $TOPIC from” + “topicname ($TOPIC, $NAME)?”);. Evaluar la consulta Después de compilada la consulta se usa el método execute. Si la consulta es satisfactoria la ejecución de execute regresara un objeto TologResultsSet.. TologResultsSet rs = pq.execute();. 2.3.. Recuperación de la información de la base de datos “Seriada”.. Dublin Core es un modelo de metadatos elaborado y auspiciado por la Dublin Core Metadata Initiative (DCMI), una organización dedicada a fomentar la adopción extensa de los estándares interoperables de los metadatos y a promover el desarrollo de los vocabularios especializados de metadatos para describir recursos.. Este modelo se aplicó en el CDICT para obtener la información básica descriptiva sobre publicaciones que se emplean en la comunidad científica universitaria obteniendo como resultado la base de datos “Seriada”.. 2.3.1. Transformación hacia XTM 1,0. La información que se analiza para la transformación de la base de datos seriada en Topic Maps se refleja en azul en la Fig. 2.3. Después de un análisis de la información se tomaron las siguientes reglas para llevar la información a Topic Maps: Ø Cada título de la tabla analítica es un Topic..
Figure

+7





Documento similar
95 Los derechos de la personalidad siempre han estado en la mesa de debate, por la naturaleza de éstos. A este respecto se dice que “el hecho de ser catalogados como bienes de
A partir de los resultados de este análisis en los que la entrevistadora es la protagonista frente a los entrevistados, la información política veraz, que se supone que
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
(1886-1887) encajarían bien en una antología de textos históricos. Sólo que para él la literatura es la que debe influir en la historia y no a la inversa, pues la verdad litera- ria
1º) una motivación social minusvaloradora, despectiva o, incluso, estigmatizadora: las personas contra las que se discrimina, caracterizadas por lo general mediante su pertenencia a
No había pasado un día desde mi solemne entrada cuando, para que el recuerdo me sirviera de advertencia, alguien se encargó de decirme que sobre aquellas losas habían rodado
Sanz (Universidad Carlos III-IUNE): "El papel de las fuentes de datos en los ranking nacionales de universidades".. Reuniones científicas 75 Los días 12 y 13 de noviembre
(Banco de España) Mancebo, Pascual (U. de Alicante) Marco, Mariluz (U. de València) Marhuenda, Francisco (U. de Alicante) Marhuenda, Joaquín (U. de Alicante) Marquerie,
