Descubrimiento de reglas de decisión basado en el procesamiento del lenguaje natural a partir de descripciones IF THEN
105
0
0
Texto completo
(2) Este documento es Propiedad Patrimonial de la Universidad Central “Marta Abreu” de Las Villas, y se encuentra depositado en los fondos de la Biblioteca Universitaria “Chiqui Gómez Lubian” subordinada a la Dirección de Información Científico Técnica de la mencionada casa de altos estudios. Se autoriza su utilización bajo la licencia siguiente: Atribución- No Comercial- Compartir Igual. Para cualquier información contacte con: Dirección de Información Científico Técnica. Universidad Central “Marta Abreu” de Las Villas. Carretera a Camajuaní. Km 5½. Santa Clara. Villa Clara. Cuba. CP. 54 830 Teléfonos.: +53 01 42281503-1419.
(3) Dedicatoria A mi abuelito Pepe por apoyarme siempre en todo lo emprendido en la vida..
(4) Agradecimientos La realización de esta tesis comprende un largo camino que siempre he realizado junto a mi familia, es por ello que quiero agradecerles a ellos en primer lugar su apoyo incondicional en este viaje que aquí concluye y abre nuevos horizontes. Quisiera agradecer a todos aquellos que me acompañaron no solo en esta etapa universitaria sino en el preuniversitario a mis profesores del IPVCE Ernesto Guevara, en especial a Fito que me enseñó la importancia de aprender la historia, a la profesora Norma Blae Chaviano por sus clases excepcionales de matemática y a Osmeli por mantener el empeño en la mejora de mis redacciones. Por último a todos mis profesores de la universidad que hicieron posible mi crecimiento como profesional, en especial a Ramiro y Blanca Esther por sus clases magistrales y sus enseñanzas para la vida como profesional. A Leticia por sus clases, por su dedicación en la tesis y las enseñanzas que me transmitió, por su apoyo constante en el desarrollo de la investigación. A mis compañeros de aula de la UCLV por la diversión de estos 5 años y su apoyo sobre todo en esta última etapa, espero que sigamos unidos. A todos los integrantes del grupo de jóvenes de la Capilla del Capiro, en especial a Eduarda, David, Chabeli y Yoel por los encuentros tan divertidos en estos años. Al P. Juan Manuel Fernández Triana que aunque no esté presente físicamente siempre me apoyó en el estudio y me enseñó a ser mejor persona cada día gracias a sus buenos consejos. Y por último a mi familia: mi hermano, mi mamá, mi papá, mis abuelos aunque uno no está presente siempre luchó para que estudiara y me graduara, a mis tías, a mi tío Javier, y mis primos. A todos ellos, a los que no he podido nombrar pero también estuvieron, a los que pasaron de forma fugaz y a los que vendrán para participar en mi vida, a todos: Muchas Gracias..
(5) Resumen En la actualidad las empresas han enfocado sus esfuerzos en la prestación de servicios, surgiendo los procesos de negocio con el objetivo de buscar la excelencia de la calidad a través de la satisfacción del cliente, la reducción de costos y la optimización de los recursos. Para la modelación de estos procesos han surgido estándares, uno de los más recientes es el Modelado y Notación de Decisiones (DMN), que ofrece una notación para modelar decisiones lógicas y dependencias entre éstas y elementos de datos; por ello, se ha convertido en uno de los más utilizados en el mundo empresarial actualmente. La modelación de decisiones es una tarea compleja y costosa; sin embargo, no existen aún propuestas que permitan automatizar este proceso a partir de descripciones textuales siguiendo el estándar DMN. Por eso, este trabajo se enfoca en la obtención de reglas de decisión a partir de descripciones textuales basándose en la aplicación de técnicas de procesamiento del lenguaje natural (NLP). Los principales resultados obtenidos son: un modelo conceptual que transita por tres etapas para la extracción de reglas de decisión mediante el empleo de técnicas de NLP, un procedimiento general que describe cómo extraer los elementos de las reglas, y el sistema DecisionRuleMiner que implementa el modelo propuesto. La validación realizada muestra que la mayoría de las reglas extraídas a partir de las oraciones seleccionadas de 15 fuentes diferentes, se correspondieron con las reglas obtenidas por un modelador experto en DMN, obteniéndose la mayor coincidencia para las oraciones tipo A..
(6) Abstract Currently, companies have focused their efforts on the provision of services, arising business processes with the aim of seeking excellence in the quality through customer satisfaction, cost reduction and resource optimization. For modeling these processes, standards have emerged, one of the most recent being Decision Modeling and Notation (DMN), which offers a notation for modeling logical decisions and dependencies between these decisions and data elements; therefore, it has become one of the most used in the business world today. Decision modeling is a complex and expensive task; however, there are still no proposals to automate this process based on textual descriptions following the DMN standard. Thus, this work is focused on obtaining decision rules from textual descriptions based on the application of Natural Language Processing techniques (NLP). The main obtained results are: a conceptual model that goes through three stages for the decision rule extraction through the use of NLP techniques, a general procedure that describes how to extract elements from rules, and the DecisionRuleMiner system that implements the proposed model. The validation shows that most of the extracted rules from the selected sentences from 15 different sources corresponces to the obtained rules by an expert modeler in DMN, obtaining the highest coincidence for type A sentences..
(7) Índice Introducción ................................................................................................. 1 Capítulo 1 Acerca de la modelación de decisiones y las técnicas de procesamiento del lenguaje natural ........................................................... 7 1.1 Procesamiento del lenguaje natural .................................................................. 7 1.1.1 Niveles de procesamiento del lenguaje natural .......................................... 7 1.1.2. Tareas de procesamiento del lenguaje natural ............................................ 8. 1.1.3. Principales herramientas para procesar textos .......................................... 10. 1.2 1.3 1.4. Principales enfoques en la extracción de patrones en textos .......................... 11 Modelación de decisiones ................................................................................ 18 Consideraciones finales del capítulo ............................................................... 23. Capítulo 2 Modelo para el descubrimiento de reglas de decisión a partir de descripciones IF-THEN ............................................................ 25 2.1 Conceptualización del modelo para el descubrimiento de reglas de decisión 25 2.2 Procedimiento general para obtener las reglas de decisión ........................... 27 2.2.1 Etapa 1. Análisis a nivel de texto .................................................................. 29 2.2.2 Etapa 2. Análisis a nivel de oraciones de decisión de la forma antecedenteconsecuente............................................................................................................. 30 2.2.3 Etapa 3. Extracción de los elementos de las reglas de decisión .................... 35 2.3 2.4. Diseño e implementación del modelo propuesto ............................................. 46 Conclusiones parciales .................................................................................... 49. Capítulo 3 DecisionRuleMiner y su evaluación...................................... 52 3.1 Descripción del software DecisionRuleMiner ................................................. 52 3.1.1 Objetivo del sistema DecisionRuleMiner ...................................................... 52 3.1.2 Generalidades del sistema DecisionRuleMiner ............................................. 53 3.1.3 Interfaz gráfica de DecisionRuleMiner ......................................................... 54 3.1.4 Operaciones con DecisionRuleMiner ............................................................ 57 3.2 3.3 3.4 3.5. Descripción de algunas fuentes de decisiones ................................................. 64 Descripción de los casos de estudio ................................................................ 69 Resultados de la evaluación ............................................................................ 70 Conclusiones parciales .................................................................................... 76. Conclusiones .............................................................................................. 78 Recomendaciones ...................................................................................... 79 Referencias bibliográficas ........................................................................ 80.
(8) Anexos. 87. Anexo 1. Listado de oraciones seleccionadas para la validación por cada tipo identificado ................................................................................................................. 87 Anexo 2. Listado de oraciones utilizadas para la validación por cada tipo identificado ................................................................................................................. 91 Anexo 3. Ejemplos de reglas obtenidas por DecisionRuleMiner y por el modelador experto ........................................................................................................................ 93.
(9) Introducción Hace algunos años las estrategias de negocio de las empresas se orientaban al cumplimiento de sus objetivos. Esta forma de actuar de las empresas sigue vigente, pero estas se han enfocado más en la prestación de servicios, surgiendo así los procesos de negocio con el objetivo de buscar la excelencia de la calidad a través de la satisfacción del cliente, mediante la reducción de costos y la optimización de los recursos. Un proceso de negocio se puede definir como (Davenport, 1993): “Un conjunto estructurado, medible de actividades diseñadas para producir un producto especificado, para un cliente o mercado específico. Implica un fuerte énfasis en cómo se ejecuta el trabajo dentro de la organización, en contraste con el énfasis en el qué, característico de la focalización en el producto”. Un proceso de negocio está definido por su objetivo o meta productiva (Francesch, 2007), puede ser desglosado en subprocesos y a su vez cada uno de ellos en funciones, cada función en tareas y éstas pueden ser organizadas por reglas de negocio. Las reglas de negocio se pueden definir como las acciones que median entre los datos y la gestión de éstos facilitando la toma de decisiones de los empresarios. La gestión de procesos de negocio (Business Process Management; BPM) es una disciplina que se encarga de: “apoyar los procesos de negocio utilizando métodos, técnicas y software para diseñar, promulgar, controlar y analizar procesos operativos que involucren a personas, organizaciones, aplicaciones, documentos y otras fuentes de información” (van der Aalst, Hofstede and Weske, 2003). Modelado y Notación de Procesos de Negocio (Business Process Model and Notation; BPMN) es un estándar legible y entendible soportado por el Grupo de Gestión de Objetos (Object Management Group; OMG) para la modelación de procesos de negocio (Friedrich, 2010), cada elemento de un diagrama de proceso BPMN tiene definida semánticas, estos elementos tienen cuatro categorías básicas como: Objetos de flujo (Eventos, Actividades, Rombos de control de flujo), Objetos de conexión (Flujo de secuencia, Flujo de Mensaje, Asociación), Carriles de piscina (Pool, Lane) y Artefactos (Objetos de Datos, Grupo, Anotación), además se basa en una técnica de modelado precedente muy conocida hoy en día que es el Lenguaje Unificado del Modelado. Sin embargo, BPMN no es muy adecuado para modelar decisiones. Para suplir esta 1.
(10) necesidad, surgió el Modelado y Notación de Decisiones (Decision Model and Notation; DMN) como un estándar reciente de OMG. DMN complementa BPMN, el cual no modela las decisiones lógicas en detalles, con una notación para modelar decisiones lógicas y dependencias entre decisiones y elementos de datos. DMN permite a los usuarios controlar sus procesos y decisiones organizacionales de una manera más eficiente y efectiva. Por ejemplo (Silver, 2016), constituye el estándar para suplir las necesidades de los gerentes al representar las acciones a tener en cuenta para modelar exámenes médicos, el manejo de solicitudes de empleo, la inscripción de los estudiantes en una escuela determinada, el proceso de renta de carros, el proceso de préstamo en un banco, la realización de una reservación, entre otros. DMN defiende y permite la descomposición de la lógica compleja en subdecisiones atómicas simples. Propone un lenguaje de expresión inequívoco dirigido a usuarios empresariales en lugar de a expertos técnicos. Además, puede expresar enlaces entre decisiones, modelos de conocimiento tales como modelos de minería de datos y estructuras de información. Es por eso que DMN se ha convertido en un tema relevante para las organizaciones y la investigación (Silver, 2016). DMN es un estándar compatible con muchos productos del software; donde el usuario es menos dependiente de los productos privativos1. Las decisiones en este estándar son modeladas y ejecutadas usando la misma notación, permitiendo usar los resultados de análisis de negocio como “código”, haciendo que los cambios en las reglas detrás de la decisión sean realmente fáciles. Una decisión es definida por la Real Academia de la Lengua Española2 como “determinación, resolución que se toma o se da en una cosa dudosa”. La especificación del DMN en la versión 1.1 de OMG3 definió una decisión como “el acto de determinar un valor de salida, a partir de varios valores de entrada, usando una lógica que define cómo la salida es determinada por las entradas”. DMN define dos niveles para las decisiones: el nivel de requisitos y el nivel lógico. El nivel de requisitos está definido por las subdecisiones o datos de entrada que se necesitan para tomar una decisión. El nivel lógico está expresado como una tabla de decisión o por expresiones del lenguaje.. 1. http://www.bpm-guide.de/2015/07/20/dmn-decision-model-and-notation-introduction-by-example/ http://www.rae.es/ 3 http://www.omg.org/spec/DMN/1.1/ 2. 2.
(11) DMN es importante porque valida la necesidad de un nuevo tipo de modelo específicamente para la lógica de decisión, separado y distinto de los modelos ya existentes, constituye una especificación de Tecnología de la Información (Information Technology; IT), y es una confirmación de que hay demanda de un nuevo tipo de producto de software dirigido a la modelación y gestión de decisiones. Un modelo de decisión no equivale a un documento de requisitos basados en textos. Un modelo de decisión se comunica a través de diagramas estructurados y tablas, no con texto plano no estructurado. Los diagramas y las tablas pueden ser revisados simultáneamente por todos los interesados a diferencia de los requisitos basados en textos. Además, desde el modelo se conforma la estructura y reglas correspondientes a las decisiones. Las tablas de decisión son otro tipo de regla de negocio (Ross, 2010) que se pueden gestionar y modificar. Ellas se utilizan normalmente cuando existe una cantidad uniforme de condiciones que se deben evaluar y un conjunto de acciones determinado que se deben emitir cuando se cumplen las condiciones. Una tabla de decisión es una tabla, representando el conjunto exhaustivo de expresiones condicionales mutuamente exclusiva, dentro de un área problemática predefinida (Vanthienen and Dries, 1992). Las tablas de decisión son especialmente idóneas para las reglas de negocio que tienen varias condiciones, añadir otra condición es tan fácil como añadir otra fila o columna. Las tablas de decisión son controladas por la interacción de condiciones y acciones al igual que el conjunto de reglas if/then. En una tabla de decisión la acción se decide a través de más de una condición, y se puede asociar más de una acción con cada conjunto de condiciones. Si se cumplen las condiciones, se realiza la acción o acciones correspondientes. Los componentes de una tabla de decisión son (Silver, 2016): el nombre de la variable, la etiqueta de salida, la expresión de entrada, los valores de entrada y salida, las reglas de decisión y el componente de la salida. El modelado de decisiones con DMN presenta a las compañías un estándar novedoso para la gestión de decisiones, permite tener un potencial de rentabilidad y una ventaja competitiva (FICO Decisions, 2015). Con la estandarización de los procesos de decisión, los requisitos de decisión y la lógica, las organizaciones reducirán los costos, agilizarán el tiempo de comercialización, simplificarán la capacitación y realizarán mejoras operacionales generalizadas. 3.
(12) Muchos especialistas han tenido en cuenta que la modelación es una tarea compleja y costosa, a partir del análisis de los factores que hacen este proceso tan complicado, entre ellos: la necesidad de capacitación de personal experto, el consumo de tiempo para modelar y el necesario pre-procesamiento de los datos para la obtención de los requisitos de negocio de cada empresa. Es por ello que se han realizado algunos trabajos que intentan automatizar la modelación de procesos de negocio a partir de las descripciones textuales (Ghose, Koliadis and Chueng, 2007; Gonçalves, Santoro and Baião, 2009; Friedrich, 2010; Friedrich, Mendling and Puhlmann, 2010; Sinha and Paradkar, 2010; Caporale, 2016). Se destaca la propuesta presentada por Friedrich (Friedrich, 2010) que permite la generación automática de modelos de procesos de negocio siguiendo la notación BPMN a partir de descripciones textuales en lenguaje natural. Sin embargo, al ser DMN un estándar relativamente nuevo, no aparece reportado aún en la literatura algún trabajo que permita la modelación automática siguiendo este estándar. Todo ello constituye una problemática a la cual aún la ciencia no ha dado respuestas definitivas, lo cual justifica el planteamiento del problema de investigación siguiente: La modelación de decisiones es una tarea compleja y costosa; sin embargo, no existen aún propuestas que permitan automatizar este proceso a partir de descripciones textuales siguiendo el estándar DMN. El objetivo general de la investigación consiste en obtener reglas de decisión a partir de descripciones textuales de tipo IF-THEN basándose en la aplicación de técnicas de procesamiento del lenguaje natural. Este se desglosa en los siguientes objetivos específicos: 1. Identificar las técnicas de procesamiento del lenguaje natural, así como las principales herramientas que las soportan que sean útiles para extraer reglas de decisión a partir de descripciones textuales. 2. Crear un modelo que garantice el descubrimiento efectivo de reglas de decisión a partir de oraciones de la forma IF-THEN. 3. Desarrollar un sistema que incorpore el modelo propuesto para el descubrimiento de reglas de decisión a partir de oraciones de la forma IF-THEN, mediante el uso de técnicas de procesamiento del lenguaje natural. 4.. Validar el sistema desarrollado a partir de descripciones de procesos de negocio. 4.
(13) Las preguntas de investigación planteadas son: . ¿Cuáles técnicas de procesamiento del lenguaje natural son las idóneas para extraer reglas de decisión a partir de descripciones textuales?. . ¿Cuál herramienta es idónea para la extracción de reglas de decisión?. . ¿Qué nuevos algoritmos pueden garantizar el descubrimiento efectivo de las reglas de decisión a partir de oraciones de la forma IF-THEN?. . ¿Qué técnicas de procesamiento del lenguaje natural incluir en un sistema que permita el descubrimiento de las reglas de decisión a partir de oraciones de la forma IF-THEN?. . ¿Cómo validar el sistema desarrollado a partir de descripciones de procesos de negocio?. Después de haber realizado el marco teórico se formuló la siguiente hipótesis de investigación como presunta respuesta a las preguntas de investigación: La aplicación de técnicas de procesamiento del lenguaje natural, a partir de oraciones de la forma IFTHEN obtenidas de descripciones textuales, permite la obtención automática de las reglas de decisión. Para lograr los objetivos trazados y demostrar la hipótesis establecida se acometieron las tareas de investigación siguientes: 1.. Análisis de las técnicas propuestas de procesamiento del lenguaje natural para la extracción de las reglas de decisión a partir de descripciones textuales.. 2.. Identificación y estudio de las principales herramientas para la extracción de reglas de decisión y selección de aquellas que contribuyen al pre-procesamiento textual.. 3.. Estudio de los principales algoritmos para la extracción de decisiones a partir de descripciones textuales.. 4.. Determinación de la forma que describirán los textos para la extracción de las reglas de decisión.. 5.. Diseño e implementación de un sistema que permita obtener las reglas de decisión a partir de oraciones de la forma IF-THEN de manera automatizada.. 6.. Estudio y selección de las fuentes que permiten validar el sistema propuesto.. 7.. Estudio de la efectividad en la extracción de las reglas de decisión en los principales clasificadores existentes sobre la representación creada.. 5.
(14) El valor teórico de la investigación radica en la concepción y definición de métodos para la extracción de patrones que permitan obtener las reglas de decisión de manera automatizada explotando las ventajas de las técnicas de procesamiento de lenguaje natural. El valor práctico se evidencia en el software que recibe como entrada descripciones de procesos y obtiene reglas de decisión a partir de oraciones de la forma IF-THEN. La concepción, definición e implementación de métodos que permiten extraer reglas de decisión a partir de oraciones de la forma IF-THEN tiene una aplicación potencial en la descripción automatizada de los procesos de negocio en las organizaciones, garantizando de esta forma destinar menos tiempo y esfuerzo a la modelación y por tanto disminuyendo los costos, evidenciándose así el valor económico de la propuesta. La tesis está estructurada en tres capítulos. En el Capítulo 1 se abordan los principales conceptos asociados al procesamiento del lenguaje natural. Se presenta, además, un análisis de los principales enfoques para la extracción de patrones en textos y también se hace un análisis de la modelación de decisiones. En el Capítulo 2 se presenta el modelo propuesto para el descubrimiento de reglas de decisión a partir de descripciones IFTHEN. Se describe en detalles la conceptualización del modelo, su procedimiento general y las etapas que lo componen. En el Capítulo 3 se describen las principales características de las descripciones de procesos de negocio y se identifican los tipos de oraciones IF-THEN. Finalmente, se presenta el diseño experimental y se comentan los resultados obtenidos al descubrir automáticamente, siguiendo el modelo propuesto, las reglas de decisión a partir de descripciones en lenguaje natural. Este documento culmina con las conclusiones, las recomendaciones, las referencias bibliográficas y los anexos.. 6.
(15) Capítulo 1. Acerca de la modelación de decisiones y las técnicas de procesamiento del lenguaje natural. En este capítulo se abordan los principales conceptos asociados al procesamiento del lenguaje natural. Se presenta, además, un análisis de los principales enfoques para la extracción de patrones en textos. Finalmente, se hace un análisis de la modelación de decisiones y la necesidad que existe de automatizar este proceso.. 1.1 Procesamiento del lenguaje natural El procesamiento del lenguaje natural es un campo de la informática, la inteligencia artificial y la lingüística computacional (Joshi, 2016). Los retos de este campo frecuentemente implican reconocimiento del habla, compresión del lenguaje natural, generación del lenguaje natural, conexión del lenguaje y máquina de percepción, sistemas de diálogo, o alguna combinación de éstos. A continuación, se describirán en detalles los niveles, las tareas y las herramientas para el procesamiento del lenguaje natural. 1.1.1 Niveles de procesamiento del lenguaje natural El procesamiento del lenguaje natural es una serie de técnicas computacionales para analizar y representar textos naturales en uno o más niveles de análisis lingüístico con el objetivo de lograr un procesamiento del lenguaje similar al humano para una serie de tareas o aplicaciones particulares (Liddy, 1998). Los niveles de análisis lingüístico son: fonológico, morfológico, léxico, sintáctico, semántico, discurso y pragmático. Estos niveles reflejan un tamaño cada vez mayor de la unidad de análisis, así como una mayor complejidad y dificultad a medida que avanzamos del fonológico al pragmático. En el nivel fonológico se realiza un análisis del sonido de las palabras. En el nivel morfológico se realiza un análisis de la estructura interna de las palabras y el proceso de formación de las mismas (Chowdhury, 2010). En el nivel léxico se realiza una interpretación de la palabra de forma individual, mediante un análisis de su significado léxico y la etiqueta POS (Part-of-speech; POS) asociada. En el nivel sintáctico se realiza un análisis de las palabras que conforman una oración para encontrar su estructura gramatical y las dependencias entre las palabras que la conforman. El nivel semántico es el encargado de determinar los posibles significados de una oración, 7.
(16) permite realizar la desambiguación de las palabras según el contexto (Chowdhury, 2010). En el nivel de discurso se realiza la interpretación, teniendo en cuenta las conexiones entre las oraciones, de la estructura y el significado transmitidos por textos compuestos por múltiples oraciones. Existen dos tipos de análisis de discurso: resolución anáforas y reconocimiento de la estructura del texto (Liddy, 1998). 1.1.2 Tareas de procesamiento del lenguaje natural Las tareas de procesamiento del lenguaje natural tienen gran aplicación en la solución de problemas reales. Éstas se dividen en sub-tareas que tributan a la solución de las tareas más complejas. Aunque las tareas de procesamiento del lenguaje natural están obviamente entrelazadas son frecuentemente subdivididas en categorías (Collobert et al., 2010; Jurafsky and James H. Martin, 2010). A continuación, se presentan las categorías en que están divididas: sintaxis, semántica, discurso y habla, que a su vez estas categorías se subdividen en subcategorías. La categoría sintaxis se puede subdividir en la lematización, la segmentación morfológica, la etiquetación de las partes de la oración, el análisis gramatical, la delimitación en oraciones, el stemming, la segmentación de palabras y la extracción de terminología. La lematización consiste en hallar el lema correspondiente a la palabra que se analiza, el lema es la forma que por convenio se acepta como representante de todas las formas en que se puede expresar una misma palabra. La segmentación morfológica consiste en la separación de las palabras en morfemas individuales e identifica la clase de los morfemas, esta tarea tiene la dificultad que depende en gran medida de la complejidad de la morfología del lenguaje con que se esté trabajando. El idioma inglés tiene morfología medianamente simple, especialmente morfología aglutinativa, por eso a menudo se ignora esta tarea. La etiquetación de las partes de la oración consiste en determinar las etiquetas asociadas a cada palabra, i.e., si es sustantivo, adjetivo, adverbio, o verbo, entre otras. Muchas palabras son especialmente comunes y pueden servir de múltiples partes de la oración. Por ejemplo, una misma palabra puede ser un sustantivo o verbo, esto trae como consecuencia que se inserte ambigüedad en los lenguajes, aunque los que tienen morfología aglutinativa pequeña son más propensos a tener ambigüedad. El análisis sintáctico permite obtener el árbol sintáctico de una oración dada, como la gramática de los lenguajes es ambigua, una misma oración puede tener múltiples análisis posibles. Hay dos tipos primarios de análisis sintáctico: análisis de dependencias y análisis constituyente. El análisis de 8.
(17) dependencias se enfoca en las relaciones entre palabras de una oración, mientras que el análisis constituyente se enfoca en construir el árbol sintáctico usando una gramática libre de contexto probabilística (Probabilistic Context-Free Grammar; PCFG). La delimitación de oraciones consiste en dado un texto, encontrar los delimitadores de las oraciones. Los delimitadores de las oraciones son marcados por signos de puntuación, pero éstos a menudo pueden utilizarse con otros propósitos (e.g., para representar abreviaturas); de ahí que la delimitación en oraciones es una tarea no determinística. El stemming consiste en la reducción de una palabra a su raíz. La segmentación de palabras separa una parte del texto continuo en palabras separadas. Para algunos lenguajes, esto es medianamente trivial, porque las palabras están separadas por espacios. Sin embargo, en otros lenguajes no se marca de esta forma la separación entre palabras, requiriéndose el conocimiento del vocabulario y la morfología de las palabras para dicho lenguaje. La extracción de la terminología permite obtener los términos relevantes de un corpus dado. La categoría semántica se puede subdividir en la semántica léxica, la traducción automática, el reconocimiento de entidades nombradas (Named Entity Recognition; NER), la generación del lenguaje natural, la comprensión del lenguaje natural, el desarrollo de sistemas del tipo pregunta-respuesta, el reconocimiento de la vinculación textual, la extracción de relaciones, el análisis de sentimiento, la segmentación y detección de tópicos y la desambiguación del sentido de la palabra. Dentro de estas tareas resultan de interés para esta investigación el NER que consiste en dado un texto, determinar qué elementos se asignan a nombres propios, tales como personas, ubicaciones u organizaciones. Esto a menudo es inexacto o insuficiente pues la primera palabra de una frase a veces es reconocida como un nombre propio y además las entidades nombradas a menudo son formadas por varias palabras, y solo son reconocidas algunas. También resulta de interés la comprensión del lenguaje natural, que convierte partes de un texto en representaciones más formales, como estructuras lógicas de primer orden que son más fáciles de manipular para los programas de computadora (Chowdhury, 2010). La extracción de relaciones también resulta de gran interés ya que, dada una parte de un texto, identifica las relaciones entre las entidades nombradas. Muchas palabras tienen más de un significado dependiendo del contexto, es por ello que resulta de gran utilidad realizar la desambiguación del sentido de las. 9.
(18) palabras, que consiste en dada una palabra seleccionar el significado que tiene el mayor sentido en el contexto. La categoría discurso se puede subdividir en el resumen automático, resolución de correferencias, y análisis del discurso. La resolución de correferencias es de gran utilidad para esta investigación, ya que es necesario determinar qué palabras se refieren a un mismo objeto. La resolución de anáfora es un ejemplo específico de esta tarea, y se ocupa específicamente por aparejar pronombres con los sustantivos correspondientes. Aunque en este trabajo solo se estudiarán las oraciones por separado, es importante para trabajos posteriores poder realizar previamente un análisis del discurso, con el objetivo de identificar la estructura del discurso del texto, es decir, la naturaleza de las relaciones del discurso entre oraciones (por ejemplo, elaboración, explicación, contraste) (Liddy, 2001). La categoría habla se puede subdividir en el reconocimiento de voz y la segmentación del habla. Esta categoría no es utilizada en esta investigación, ya que solo se trabajará con textos. 1.1.3 Principales herramientas para procesar textos Afortunadamente existen varias herramientas y recursos que realizan etapas del procesamiento del lenguaje natural, lo que facilita el desarrollo de aplicaciones que requieran un procesamiento previo de los textos a estudiar, ya que de otra manera sería un trabajo complejo y tedioso (Chowdhury, 2010). Los analizadores sintácticos MINIPAR4, UC Berkeley parser5 y el Stanford parser6 permiten determinar automáticamente las partes de la oración, reconocer su estructura sintáctica y las relaciones gramaticales entre las palabras que la conforman. Otros analizadores sintácticos o etiquetadores, por ejemplo, Brill tagger7, las herramientas NLP libremente disponibles de NLTK8, OpenNLP9 y GATE10, además de etiquetar incluyen otras funcionalidades para transformar los textos. Etiquetadores que han tenido gran éxito son TreeTagger11 y el Stanford POS tagger12.. 4. https://gate.ac.uk/releases/gate-7.0-build4195-ALL/doc/tao/splitch17.html https://github.com/slavpetrov/berkeleyparser 6 https://nlp.stanford.edu/software/lex-parser.shtml 7 https://github.com/wooorm/brill 8 http://www.nltk.org/ 9 http://opennlp.apache.org/ 10 https://gate.ac.uk 11 https://github.com/reckart/tt4j 5. 10.
(19) Los analizadores mencionados anteriormente solo extraen relaciones y dependencias entre los términos de cada oración; sin embargo, algunas aplicaciones necesitan realizar un análisis del significado basado en la representación del discurso. El analizador CCG13 (Combinatory Categorial Grammar) incluyendo el marco de trabajo Boxer (Curran, Clark and Bos, 2010) puede ser útil para extraer dependencias lógicas entre fragmentos textuales del documento. A veces se necesita realizar un análisis semántico del texto. Además del rol sintáctico, cada palabra en una oración también tiene un significado específico: la semántica. Los sistemas que intentan capturar relaciones semánticas son, por ejemplo, FrameNet14 (Baker, Fillmore and Lowe, 2010), desarrollados en la Universidad de Berkley. Existen varios recursos léxicos que contribuyen al análisis semántico, por ejemplo, la base de datos léxica WordNet15 (Miller, 2010) y VerbNet16, una jerarquía de términos independiente del dominio y de amplia cobertura con asignaciones a otros recursos léxicos como WordNet.. 1.2 Principales enfoques en la extracción de patrones en textos La extracción de patrones, relaciones y reglas a partir de textos es un área que se ha venido trabajando de forma intensa desde 1990. Las investigaciones sobre este tema se originaron por las necesidades de los sistemas de Extracción de Información (Information Extraction; IE). Un elemento clave de estos sistemas es un conjunto de reglas que permitan la extracción de textos que identifiquen información relevante a ser extraída desde textos estructurados, semi-estructurados y no estructurados. Estos sistemas permitieron los primeros acercamientos a la extracción automática de información desde textos. Entre las primeras propuestas que permitieron la extracción de relaciones entre elementos textuales están AutoSlog (Riloff, 2010), PALKA (Parallel Automatic Linguistic Knowledge Acquisition) (Moldovan, 2010), LIEP (Learning Information Extraction Patterns) (Huffman, 2010), CRYSTAL (S. G. Soderland, 2010), WHISK (Stephen Soderland, 2010), RAPIER (Robust Automated Production of IE Rules) (Califf and Mooney, 2010) y (LP) 2 (Ciravegna, 2010). 12. https://nlp.stanford.edu/software/tagger.shtml http://www.kr.tuwien.ac.at/staff/ps/aspccgtk/#downloadpieces 14 https://framenet.icsi.berkeley.edu/fndrupal/ 15 http://wordnet.princeton.edu/ 16 http://verbs.colorado.edu/verbnet/index.html http://verbs.colorado.edu/verb-index/VerbNet_Guidelines.pdf 13. 11.
(20) En este epígrafe se describirán las principales propuestas que permiten la extracción de patrones, relaciones y reglas a partir de textos, las técnicas que utilizan y las herramientas más utilizadas a tales efectos. Así, será posible identificar qué es posible reutilizar para ser aplicado en la extracción de reglas de decisión a partir de descripciones textuales. PALKA facilita la construcción de una gran base de conocimiento de patrones lingüísticos de un corpus entrenado. Este sistema usa un conjunto de entradas y salidas de muestra en un dominio específico para construir patrones lingüísticos. La suposición subyacente de la aproximación de PALKA al método de representación y adquisición de patrones es que, en un dominio limitado, se usa frecuentemente un número relativamente pequeño de expresiones para describir cierta información. La mayoría de los patrones para un determinado dominio de aplicación puede cubrirse a partir de un conjunto textual de entrenamiento relativamente pequeño de un dominio dado (Moldovan, 2010). Algunas limitaciones de este enfoque son: solo adquiere patrones para cláusulas orientadas a verbos, existe la posibilidad de muchos conflictos cuando se involucran diversas estructuras en la aplicación y las relaciones entre patrones diferentes no se investigan. CRYSTAL es uno de los pioneros en la extracción de relaciones entre elementos de una oración. CRYSTAL induce automáticamente un conjunto de reglas de análisis de textos basadas en un corpus anotado. Las reglas aprendidas permiten extraer conceptos de interés para un dominio particular basado en el contexto lingüístico local. Estas reglas usan una combinación de la evidencia sintáctica, semántica y léxica para identificar referencias al concepto objetivo (S. G. Soderland, 2010). Desafortunadamente, esta propuesta requiere un corpus anotado manualmente y depende del dominio. Sin embargo, se utilizó con éxito junto con el sistema Webfoot para transformar el texto de las páginas web en una representación formal (S Soderland, 2010). WHISK es un algoritmo de aprendizaje supervisado, que requiere para su entrenamiento un conjunto de instancias manualmente etiquetadas. Dicho algoritmo aprende reglas en forma de expresiones regulares. WHISK aprende a identificar la relación entre hechos aislados; incluso, cuando la información relacionada se encuentra ampliamente dispersa en el documento. En tales casos, los fragmentos de texto se extraerán mediante reglas que operan localmente en el texto, y un procesamiento posterior es necesario para 12.
(21) vincular la información relacionada a los fragmentos extraidos (Stephen Soderland, 2010). RAPIER utiliza pares de documentos de muestra y plantillas para inducir reglas de coincidencia de patrones. RAPIER emplea un algoritmo de aprendizaje ascendente (bottom-up) que incorpora técnicas de varios sistemas de programación lógica inductiva y adquiere patrones ilimitados que incluyen restricciones sobre las palabras, las etiquetas POS y las clases semánticas presentes en las plantillas y en los textos (Califf and Mooney, 2010). RAPIER aprende patrones ilimitados que usan información sintáctica limitada, como el resultado de un etiquetador POS, y la información de la clase semántica, como la proporcionada por WordNet (Miller et al., 2010). El algoritmo (LP)2 hace un uso somero de las técnicas de NLP para superar la dispersión de los datos al procesar textos en lenguaje natural. Induce reglas simbólicas aprendiendo de ejemplos encontrados en un corpus etiquetado definido por el usuario (Ciravegna, 2010). El entrenamiento se realiza en dos pasos: inicialmente se aprende un conjunto de reglas de etiquetado; luego se inducen reglas adicionales para corregir los errores y la imprecisión en el etiquetado. La inducción se lleva a cabo mediante la generalización ascendente (bottom-up) de ejemplos en el corpus de entrenamiento. Las técnicas de NLP se usan en el proceso de generalización. AutoSlog, LIEP y CRYSTAL requieren pre-procesamiento sintáctico del texto y etiquetado semántico, mientras que WHISK no requiere un análisis sintáctico previo; sin embargo, WHISK funciona mejor con la entrada que ha sido anotada por un analizador sintáctico y un etiquetador semántico. CRYSTAL y WHISK tienen una representación más expresiva que los otros sistemas y están completamente automatizados. Los otros sistemas requieren reglas manualmente definidas y listas de palabras. clave. también. manualmente. seleccionadas,. ejemplos. manualmente. seleccionados para comenzar la inducción de las reglas, o una revisión humana de las reglas propuestas. WHISK funciona con una granularidad más fina que los sistemas como CRYSTAL y AutoSlog. Esos sistemas identifican el campo sintáctico, como el sujeto o el objeto directo, que contiene la frase objetivo, pero no identifican la frase objetivo en sí. WHISK y RAPIER aprenden los delimitadores exactos de la frase objetivo y no requieren un procesamiento posterior para recortar palabras extrañas.. 13.
(22) CRYSTAL utiliza una forma de agrupamiento para crear un diccionario de patrones de extracción mediante la generalización de patrones identificados en el texto por un experto. AutoSlog crea un diccionario de patrones de extracción al especializar un conjunto de patrones sintácticos generales, y asume que un experto luego filtrará los patrones que produce. PALKA aprende patrones de extracción que dependen de una jerarquía de conceptos para orientar la generalización y la especialización. Todos estos sistemas se basan en un análisis previo y detallad de las oraciones para identificar los elementos sintácticos y sus relaciones, y su salida requiere un procesamiento posterior para producir y llenar las plantillas finales. LIEP también aprende patrones, pero requiere un analizador de oraciones para identificar grupos de nombres, verbos, sujetos, etc. y asume que toda la información relevante se encuentra entre dos entidades que identifica como "interesantes". REXTOR (Relations EXtracTOR) (Katz and Lin, 2000) proporciona dos gramáticas separadas para extraer patrones arbitrarios de textos y construir expresiones ternarias (por ejemplo, sujeto-relación-objeto) a partir de ellos. REXTOR combina en conjunto, un modelo de lenguaje de estado finito y una representación de expresión ternaria. A pesar de sus limitaciones, una gramática de estado finito es un buen modelo de lenguaje natural para la extracción de patrones. Las reglas de extracción se utilizan para extraer patrones arbitrarios de textos según una especificación de gramática. REXTOR intenta eliminar la necesidad de la participación humana durante el análisis del contenido textual. Desafortunadamente, extrae un número limitado de tipos de relaciones entre los términos de los textos. La mayoría de estos sistemas realizan análisis sintáctico. Sin embargo, una estructura representacional sintácticamente informada se enfrenta al problema de las variaciones lingüísticas, el fenómeno en el cual el contenido semántico similar puede expresarse de diferentes formas. Por esa razón, otros análisis son necesarios para algunas aplicaciones. Desafortunadamente, la mayoría de ellos son específicos del dominio, necesitan colecciones textuales previamente anotadas y requieren interacción humana. Los algoritmos más exitosos hacen un uso escaso de las técnicas de NLP, tendiendo a evitar cualquier generalización sobre la secuencia de palabras inicial. Por lo tanto, no identifican las relaciones entre las palabras o frases, porque las relaciones entre patrones diferentes hasta ese momento no habían sido investigadas. Establecer tales relaciones es deseable tanto para la eficiencia de la representación como para la flexibilidad de la 14.
(23) interpretación. Además, no era habitual utilizar otras fuentes de conocimiento, como diccionarios u otros recursos léxicos. Estos sistemas a menudo dependen de enfoques basados en NLP básico (por ejemplo, usando análisis sintáctico) y requieren el desarrollo manual de recursos (por ejemplo, gramáticas y autómatas de estado finito), otros son interesantes en la aplicación de técnicas de aprendizaje automático (por ejemplo, aprendizaje inductivo y relacional). A pesar de las desventajas identificadas, las experiencias iniciales se han utilizado con éxito en otros sistemas más recientes que intentan descubrir patrones y sus relaciones a partir de documentos textuales; porque, aunque la extracción de patrones de textos surgió de la necesidad de enriquecer los sistemas de recuperación de información, existen muchas aplicaciones reales en las que la extracción de patrones y sus relaciones a partir de textos es de gran importancia. Por ejemplo, se propuso un sistema para extraer interacciones proteína-proteína del texto científico en (Ono et al., 2010). Este sistema sigue un enfoque simple que recopila las palabras clave que se relacionaron con la interacción de proteínas de las literaturas biológicas y busca patrones particulares que incluyen la palabra clave. Descubrimiento de reglas de inferencia a partir del texto (Discovery of Inference Rules from Text; DIRT) (Lin & Pantel, 2001) es un método no supervisado para descubrir reglas de inferencia a partir del texto, como "X es autor de Y X escribió Y", "X resolvió Y X encontró una solución a Y ", y" X causó que Y Y sea disparado por X”. Este método se basa en árboles de dependencia. En esencia, considera, si dos caminos tienden a vincular los mismos conjuntos de palabras, sus significados son similares. Como un camino representa una relación binaria, genera una regla de inferencia para cada par de caminos similares. DIRT considera pocas relaciones de dependencia y las usa para descubrir significados similares. Otro tipo de reglas, las relaciones causa-efecto, se extrae de los textos en lenguaje natural en (Sorgente, Vettigli and Mele, 2010). Este enfoque une las reglas y los métodos de aprendizaje automático para combinar la ventaja de cada uno. En particular, Sorgente, Vettigli y Mele primero identifican un conjunto de pares de causa y efecto plausibles a través de un conjunto de reglas lógicas basadas en relaciones de dependencias entre palabras, luego utilizan la inferencia bayesiana para reducir el número de pares producidos por patrones ambiguos. La extracción automática de 15.
(24) relaciones causales es también una tarea muy difícil. De hecho, hay pocos patrones explícitamente lexico-sintácticos que están en correspondencia exacta con una relación causal, mientras que hay una gran cantidad de casos que pueden evocar una relación causal no de una manera única. En particular, los autores identifican palabras que están en una relación causal dentro de una sola oración donde la relación está marcada por una unidad lingüística específica y la causalidad está explícitamente representada (ambos argumentos de las relaciones están presentes en la oración). Sorgente, Vettigli y Mele detectan palabras nominales que denotan una ocurrencia (un evento, un estado o una actividad), o sustantivos que denotan una entidad, ya sea como una de sus lecturas o metonimias. Para cada patrón lexico-sintáctico se define una expresión regular para reconocer las oraciones que contienen dicho patrón, y se define un conjunto de reglas para detectar causas y efectos. Las reglas para la detección de causas y efectos se basan en las relaciones establecidas en el árbol de dependencias de la oración (Marneffe and Manning, 2010). Se han desarrollado varios trabajos para extraer patrones y relaciones de documentos legales y regulaciones (Dragoni et al., 2010; Papanikolaou, 2010; Wyner and Peters, 2010). En (Wyner and Peters, 2010), los autores propusieron un enfoque para identificar y extraer reglas condicionales y deónticas, especificando los antecedentes, las consecuencias, los agentes, los temas, las acciones y las excepciones. Ellos identifican y extraen los componentes de alto nivel de las reglas de las regulaciones en inglés, aplicando y ampliando las herramientas de NLP actuales ampliamente disponibles (GATE y Stanford Analyzer). Las reglas hacen uso del análisis sintáctico e información léxica y semántica. Para identificar y extraer elementos, definen nomenclaturas y reglas de JAPE. Un diccionario geográfico es una lista de cadenas asociadas con un concepto central, que se representa como una anotación en la cadena; las reglas de JAPE se usan para crear traducciones complejas, usando anotaciones y expresiones regulares como entrada para producir anotaciones como salida. Para asociar roles gramaticales (sujeto y objeto) con roles temáticos (agente y tema), los autores utilizan información gramatical del Stanford Parser (información de anotación pasiva e información de dependencia) junto con información sobre los roles temáticos derivados de VerbNet. Este enfoque identifica y extrae elementos relevantes; sin embargo, todavía tiene limitaciones para extraer relaciones entre los elementos identificados.. 16.
(25) En (Papanikolaou, 2010), el autor propone una herramienta de NLP para analizar y extraer información de textos legales y reglamentos de forma automática. Este trabajo se centra en textos que describen específicamente las políticas: reglas, prohibiciones, medidas necesarias que deben implementarse para brindar seguridad en la computación en la nube. Desafortunadamente, esta herramienta necesita que los expertos usen el editor para resaltar y marcar porciones de textos que se deben traducir a reglas legibles por máquina. Además, se creó manualmente una base de datos de conceptos y relaciones que aparecen en un proveedor de servicio de términos en la nube. Por lo tanto, esta información está siendo considerada por la herramienta para representar la información dada por la terna (verbo, sujeto, objeto), extrayendo los términos y condiciones contenidos en un documento. Otro enfoque que combina diferentes técnicas de NLP para la extracción de reglas de documentos legales fue propuesto en (Dragoni et al., 2010). Este trabajo combina la información lingüística proporcionada por WordNet junto con la extracción de reglas basada en la sintaxis de textos legales mediante la explotación del Stanford Analyzer, y la extracción basada en lógica de dependencias entre fragmentos de dichos textos mediante el uso de la herramienta de análisis CCG. Esta propuesta tiene la desventaja que no realiza la resolución de correferencias, y los términos utilizados en el texto legal y aquellos que se usan en las reglas no están alineados. En (Liu et al., 2010), los autores propusieron un nuevo enfoque para extraer entidades y aspectos de textos de opinión. Este trabajo utiliza las relaciones de dependencia entre las palabras de opinión y los aspectos, así como entre las palabras de opinión y los aspectos en sí para extraer aspectos. Las reglas se obtienen en base a las relaciones de dependencia sintáctica. Las principales desventajas de estos trabajos previos son: la mayoría de los enfoques no explotan los principales beneficios del NLP, ya que utilizan un número limitado de tipos de relaciones entre los términos; la mayoría de ellos dependen del dominio y necesitan información adicional, como ontologías, diagramas o modelos; y algunos de ellos requieren interacción humana. Las principales experiencias que podemos obtener de estos trabajos relacionados son: la mayoría de los enfoques se basan en los árboles sintácticos y en las relaciones de dependencias (Marneffe and Manning, 2010).. 17.
(26) 1.3 Modelación de decisiones La gestión de decisiones empresariales (Bussiness Decision Management; BDM) es tanto una disciplina de gestión (un enfoque particular para definir, mantener y mejorar la lógica empresarial) como un conjunto de tecnologías que respalda esta disciplina. BDM, primeramente, define las decisiones, y luego determina las reglas de decisión que se requieren. Existen muchos tipos de reglas de negocio, uno de esos tipos constituye las reglas de decisión (Silver, 2016). La lógica de decisión de BDM no debe estar descrita por textos no estructurados sino por modelos compuestos de diagramas y tablas con una estructura definida. Las decisiones de negocio varían en la complejidad y el grado de impacto que tienen en el negocio. Existen en este ámbito dos tipos de decisiones: las operacionales y las estratégicas. Las decisiones operacionales son las que afectan una simple transacción o cliente. Las decisiones estratégicas son las que ocurren con poca frecuencia y afectan la gerencia y el control del negocio. DMN es creado con la intención de resolver decisiones operacionales, ofrece una notación para modelar decisiones lógicas y dependencias entre decisiones y elementos de datos. Sus usuarios pueden controlar sus procesos y decisiones organizacionales de una manera más eficiente y efectiva (Silver, 2016). DMN defiende y permite la descomposición de la lógica compleja en subdecisiones atómicas simples. Propone un lenguaje de expresión inequívoco dirigido a usuarios empresariales en lugar de a expertos técnicos. Además, puede expresar enlaces entre decisiones, modelos de conocimiento tales como modelos de minería de datos y estructuras de información. Es por eso que este estándar se ha convertido en un tema relevante para las organizaciones y la investigación (Silver, 2016). En este epígrafe se mencionarán los cinco elementos principales del estándar DMN: el diagrama de requisitos de decisión (Decision Requierements Diagram; DRD), la tabla de decisión, el lenguaje de expresión suficientemente amigable (Friendly Enough Expression Language; FEEL), la expresión de caja (boxed expression), el meta modelo y el esquema. Se describirán en detalles los elementos del DRD y las tablas de decisión. El método DMN comienza con la decisión comercial como un todo y los elementos disponibles de datos de entrada. El nodo de decisión superior en DRD representa la decisión comercial de extremo a extremo. El método luego guía al modelador en la descomposición descendente de ese nodo de decisión en una jerarquía de decisiones de 18.
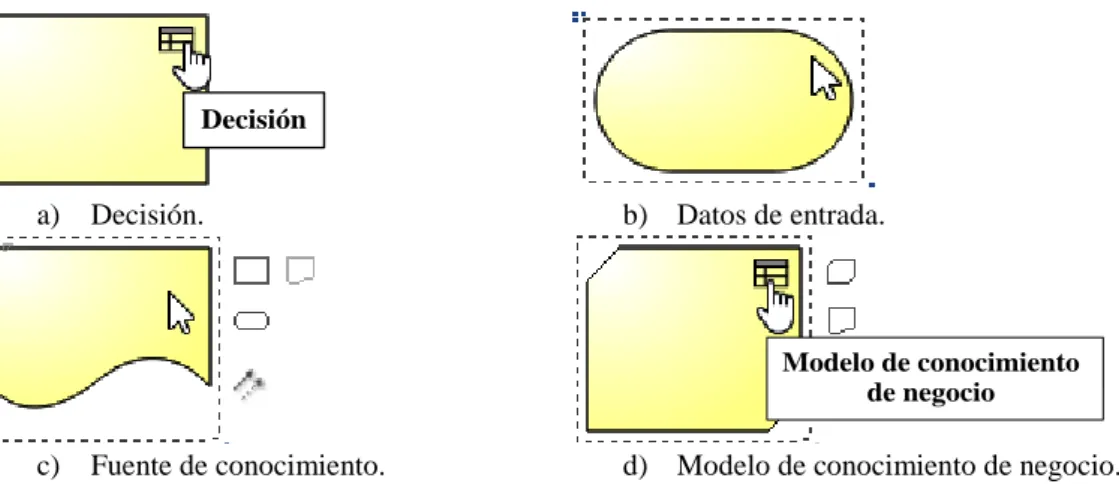
(27) soporte y, finalmente, hasta los datos de entrada. Para ayudar en esa descomposición, el método proporciona un conjunto de patrones comunes de lógica de decisión útiles para modelar escenarios específicos. DRD se utiliza para la representación de las dependencias de información de una decisión, o requisitos en forma de decisiones de soporte y datos de entrada. DRD constituye una vista posiblemente truncada o filtrada de un grafo de requisitos de decisión (Decision Requirements Graph; DRG). Los DRD tienen el propósito de ser creados por personas de negocio y analistas de negocio, no por arquitectos técnicos o desarrolladores. Este elemento es capaz de captar en un solo diagrama, una vista de alto nivel de toda la lógica de decisión de extremo a extremo, incluso cuando esa lógica se ejecuta en múltiples pasos separados en el tiempo. Él puede incluir decisiones humanas y decisiones externas, en las cuales la lógica de decisión no está definida en el modelo. Este diagrama tiene diferentes componentes para representar decisiones, requisitos de información, decisiones de soporte, datos de entrada, modelos de conocimiento de negocio (Business Knowledge Models; BKM), requisitos de conocimiento y fuentes de conocimiento. En la Figura 1 se expone la representación las cuatro componentes principales del DRD.. Decisión. a). Decisión.. b) Datos de entrada.. Modelo de conocimiento de negocio. c). Fuente de conocimiento.. d) Modelo de conocimiento de negocio.. Figura 1: Representación de los principales componentes de un DRD.. Según DMN, en un DRD existen tres tipos de conectores, como se describe en la Tabla 1. Todos estos conectores establecen una relación de requisito, como se describe en el manual oficial de DMN17.. 17. https://docs.signavio.com/userguide/editor/en/modeling_and_notations/dmn/what_is_dmn.html. 19.
(28) Tabla 1: Tipos de conectores en DMN. Requisito (conector) Requisito de información. Descripción Un conector de requisito de información comienza en una entrada de datos o elemento de decisión y apunta al elemento de decisión que requiere la información.. Requisito de conocimiento Un conector de requisito de conocimiento comienza en un modelo de conocimiento de negocio y apunta para una decisión o un modelo de conocimiento de negocio. Requisito de autoridad. Un requisito de autoridad va desde un elemento de entrada hacia una fuente de conocimiento dependiente, o desde una fuente de conocimiento hacia cualquier elemento del grafo de requisito de decisión dependiente.. En DMN dentro de cada decisión o nodo BKM en un DRD, la determinación del valor de salida del conjunto de valores de entrada se denomina lógica de decisión. El formato lógico más común lo constituyen las tablas de decisión. En este, se admite una variedad de diseños de dichas tablas, uno de ellos considera las reglas como filas (rules as rows), siendo éste el diseño predeterminado. Una tabla de decisión es una representación tabular de un conjunto de expresiones de entrada y salida relacionadas, organizadas en reglas que indican qué valores de salida se aplican a un conjunto específico de valores de entrada. La tabla de decisión contiene todas (y solo) las entradas requeridas para determinar la salida. Además, una tabla completa contiene todas las combinaciones posibles de valores de entrada (todas las reglas). La lógica de decisión en una tabla de decisión es equivalente a una lista de expresiones de la forma if-then. Cada una de las expresiones de la forma if-then constituye una regla de decisión. Es bastante común que una decisión dependa de tales decisiones de soporte, que a su vez pueden depender de sus propias decisiones de soporte. Esta cadena de decisiones de soporte puede ser bastante larga. El resultado de una decisión de soporte se convierte en una entrada a la decisión dependiente. En una tabla de decisión, la combinación de un encabezado de columna de entrada (expresión de entrada) y una celda de la tabla en esa columna (valor de entrada) define una condición booleana utilizada en una regla de decisión. Una tabla de decisión consiste de varios elementos, como se muestra en la Figura 2. A continuación, se describirán los principales:. 20.
(29) . Un nombre del elemento de información: Éste será generalmente el nombre de la decisión o del BKM para el cual la tabla de decisión proporciona la lógica de decisión.. . Una etiqueta de salida: Puede ser cualquier texto para describir el resultado de la tabla de decisión. El resultado de una tabla de decisión debe referenciarse usando el nombre del elemento de información, no la etiqueta de salida, en otra expresión.. . Un conjunto de entradas (cero o más): Cada entrada está conformada por una expresión de entrada y una cantidad de valores de entrada. La especificación de la expresión de entrada y todos sus valores se conoce como la cláusula de entrada.. . Un conjunto de salidas (una o más): Una única salida no tiene nombre, solo un valor. Dos o más salidas se llaman componentes de salida. Cada componente de salida debe ser nombrado. Cada salida (componente) deberá especificar un valor de salida para cada regla. La especificación del nombre del componente de salida (si hay varias salidas) y todos los valores de salida se conoce como una cláusula de salida.. . Una lista de reglas (una o más) en filas o columnas de la tabla (dependiendo de la orientación): Cada regla se compone de los valores de entrada específicos y los valores de salida de la fila (o columna) de la tabla. Si las reglas se expresan como filas, las columnas son cláusulas, y viceversa.. Nombre del elemento de información. Expresión de entrada. Entradas y salidas en columnas. Indicador de política de golpeo. Etiqueta de salida Nombres de los componentes de salida Elemento opcional de salida por defecto Valores permitidos opcionales. Reglas en filas. Número de reglas. Elemento de entrada. Irrelevante. Elemento de salida. Figura 2. Componentes de una tabla de decisión.. La tabla de decisión muestra las reglas en una notación abreviada al organizar las entradas en las celdas de la tabla. Esta notación abreviada ofrece todas las entradas en el 21.
(30) mismo orden en cada regla y, por lo tanto, tiene una serie de ventajas de legibilidad y verificación. Como se muestra en la Figura 2, las componentes de una tabla de decisión son las siguientes: . Nombre de la variable: Cuando la tabla es la expresión de valor directo de una decisión, el nombre de la variable es idéntico al nombre de la decisión. Cuando la tabla es la expresión de valor de un BKM, el nombre de la variable que se muestra en la pestaña en la parte superior es el nombre del BKM.. . Etiqueta de salida: Cuando la tabla es la expresión de valor directo de una decisión, la etiqueta de salida debe coincidir con el nombre de la variable, pero cuando la tabla es la expresión de valor del BKM, esta celda puede dejarse vacía o usar el nombre del BKM. En una decisión con salida compuesta (más de una columna de salida), la salida de la tabla es una estructura de datos en la que cada columna representa un componente de salida. Debajo de la etiqueta de salida opcional que abarca las columnas de salida, el nombre del componente de salida se debe mostrar en la parte superior de cada columna de salida.. . Expresión de entrada: Normalmente es un nombre calificado que hace referencia a una variable de entrada. Técnicamente, se permite que sea una expresión simple, es decir, una expresión aritmética.. . Valores de entrada y salida: Son una fila de encabezado de tabla de decisión, también puede mostrar listas opcionales de valores de entrada y valores de salida que definen el dominio de valores posibles para la expresión de entrada o la salida.. . Valor de entrada: Las celdas de las columnas de entrada se llaman valores de entrada. Un valor de entrada puede ser un valor literal o una lista de valores, o un nombre de variable o una lista de nombres, o un rango de valores numéricos o de fecha/hora o una lista de rangos. Técnicamente, un valor de entrada es solo un fragmento de una expresión. En combinación con la expresión de entrada, el valor de entrada define una expresión booleana completa, con un valor verdadero o falso.. . Valor de salida: Las celdas de la columna de entrada se denominan valores de salida, ya sea un valor literal o una expresión que se ajusta al tipo de datos de salida y (si está presente) la lista de valores permitidos.. 22.
(31) . Reglas de decisión: Cada fila de la tabla debajo de la fila del encabezado representa una regla de decisión, la lógica determina el valor de salida de la combinación de valores de entrada. Para cualquier regla, si las expresiones de condición para todas las columnas de entrada se evalúan como verdaderas, se dice que la regla coincide. Las columnas de la tabla de decisión siempre están unidas por conjunciones AND.. . Salida compuesta: Se dice que una tabla de decisión con más de una columna de salida tiene una salida compuesta. Cualquier regla que coincida, selecciona su valor de salida para cada una de las columnas de salida.. Precisamente estos elementos de las tablas de decisión son los que en este trabajo serán obtenidos automáticamente utilizando técnicas del NLP a partir de las descripciones de procesos de negocio.. 1.4 Consideraciones finales del capítulo El NLP ha tenido éxito en la extracción de patrones en textos, no obstante, en la mayoría de los trabajos reportados en la literatura no se han explotado todos sus beneficios en tal sentido. Dentro de los niveles del NLP, los más utilizados en la extracción de patrones han sido el léxico, el sintáctico y el semántico. El léxico ha sido de los más utilizados porque permite realizar un análisis del significado léxico y la etiqueta POS asociada a cada palabra. El sintáctico se ha destacado por encontrar las estructuras gramaticales y las dependencias entre las palabras. El análisis semántico, aunque en menor medida, ha sido abordado en algunos trabajos, debido a sus potencialidades para extraer la información que caracteriza los textos. El semántico ha permitido poder desambiguar las palabras según su contexto. La etiquetación de las partes de la oración, el análisis sintáctico, el reconocimiento de entidades nombradas, desambiguación del sentido de las palabras y la resolución de correferencias son las tareas del NLP más empleadas para extraer patrones desde textos. La etiquetación de las partes de la oración resulta de gran utilidad para evitar la ambigüedad en el lenguaje. El árbol sintáctico y las relaciones de dependencias entre las palabras, dentro del análisis sintáctico, son los resultados más utilizados para extraer patrones en textos. Además, el reconocimiento de entidades nombradas también ha sido ampliamente explotado para identificar nombres propios, ubicaciones u organizaciones, valores monetarios y otros datos como fecha y hora. A las palabras tener más de un significado dependiendo del. 23.
(32) contexto, resulta de gran utilidad la desambiguación del sentido de las palabras. Dada la existencia de pronombres que pueden referirse a un mismo objeto se tiene en cuenta la importante tarea de resolución de correferencias. La mayoría de los enfoques exitosos para la extracción de patrones en textos utilizan los árboles sintácticos y las relaciones de dependencias sin explotar bien las técnicas del NLP al ser dependiente del dominio, necesitan información adicional, como ontologías, diagramas o modelos; requiriendo algunos de la interración humana. Aunque existen diversas herramientas que soportan las técnicas del NLP, el Stanford Analyzer es una de las más utilizadas por su efectividad y eficiencia en el procesamiento textual. Teniendo en cuenta, por un lado, los principales componentes de un DRD y de las tablas de decisión; y por otro, las características de las descripciones de los procesos de negocio, se desea obtener de manera automática dichos componentes explotando las ventajas de las técnicas de NLP. Aunque no existen experiencias previas para la notación DMN, en esta tesis se utilizarán elementos de las experiencias relacionadas que abordan la extracción de patrones desde textos en el contexto de las reglas de decisión.. 24.
(33) Capítulo 2. Modelo para el descubrimiento de reglas de decisión a partir de descripciones IF-THEN. En este capítulo se presenta el modelo propuesto para el descubrimiento de reglas de decisión a partir de descripciones de la forma IF-THEN. Se describe en detalles la conceptualización del modelo. Además, se describe su procedimiento general y cada una de las etapas que lo componen. Finalmente, se presenta la estructura del modelo que permite pre-procesar las descripciones textuales y obtener automáticamente las reglas de decisión siguiendo la notación DMN.. 2.1 Conceptualización del modelo para el descubrimiento de reglas de decisión La extracción automática de reglas de decisión siguiendo la notación DMN, a partir de descripciones de procesos de negocio, es un área que no ha sido lo suficientemente exploradora en la actualidad. Por eso, en esta tesis se propone un modelo conceptual que fundamente este proceso. El valor metodológico del modelo propuesto consiste en integrar conceptos interrelacionados, que sirven de base para el establecimiento de procedimientos para la obtención de reglas de decisión de manera automatizada a partir de descripciones textuales de la forma IF-THEN. Como es característico de un modelo, se definen objetivos, principios, premisas, entradas, salidas, procedimientos y control. El objetivo general del modelo es dotar a los investigadores y desarrolladores en el campo de la modelación de procesos de negocio de una herramienta que posibilite la obtención automática de reglas de decisión a partir de descripciones textuales de la forma IF-THEN. Los principios en que se sustenta el modelo son: Consistencia lógica. En función de la ejecución de sus pasos en la secuencia planteada y la correspondencia con la lógica de la ejecución de este tipo de estudio. Flexibilidad. Por la potencialidad de aplicarse a la extracción de otros tipos de reglas, no necesarimente reglas de decisión. Además, por la capacidad de actualización y reajuste en los diferentes procesos y procedimientos específicos.. 25.
Figure



+7






Documento similar