Propuesta de análisis de datos no estructurados para generar decisiones oportunas en la empresa GMD
149
0
0
Texto completo
(2) 2. JURADO DE LA SUSTENTACIÓN ORAL …………………………. Presidente Isabel Juana, Guadalupe Sifuentes. …………………………. Jurado 1 Samuel Alonso, Oporto Díaz. ………………………… Jurado 2 Percy, Diez Quiñones Panduro. Entregado el: 30/10/2017. …………………………………… Graduando Katia Elizabeth, Garvich San Martín. Aprobado por:. ……………………………………… Asesor de Tesis Marco Antonio, Bazalar Herrera.
(3) 3. UNIVERSIDAD SAN IGNACIO DE LOYOLA FACULTAD DE INGENIERÍA. DECLARACIÓN DE AUTENTICIDAD. Yo, Katia Elizabeth Garvich San Martín, identificada con DNI N° 45508147 Bachiller del Programa Académico de la Carrera de Ingeniería Informática y Sistemas de la Facultad de Ingeniería de la Universidad San Ignacio de Loyola, presento mi tesis titulada: Propuesta de análisis de datos no estructurados para generar decisiones oportunas en la empresa GMD. Declaro en honor a la verdad, que el trabajo de tesis es de mi autoría; que los datos, los resultados y su análisis e interpretación, constituyen mi aporte. Todas las referencias han sido debidamente consultadas y reconocidas en la investigación.. En tal sentido, asumo la responsabilidad que corresponda ante cualquier falsedad u ocultamiento de la información aportada. Por todas las afirmaciones, ratifico lo expresado, a través de mi firma correspondiente.. Lima, octubre de 2017. …………………………………………… Katia Elizabeth, Garvich San Martín DNI N° 45508147.
(4) 4. EPÍGRAFE La información es la gasolina del sigo XXI y el análisis de datos es el motor de combustión.. (Peter Sondergaard, 2014) Vicepresidente de Gartner.
(5) 5. ÍNDICE GENERAL DEDICATORIA. 10. AGRADECIMIENTOS. 11. RESUMEN. 12. ABSTRACT. 13. INTRODUCCIÓN. 14. IDENTIFICACIÓN DEL PROBLEMA. 15. FORMULACIÓN DEL PROBLEMA. 19. Problema General. 19. Problemas específicos. 19. MARCO REFERENCIAL. 21. Antecedentes Internacionales. 21. Antecedentes Nacionales. 25. Estado del Arte. 26. Marco Teórico. 30. Big Data.. 30. Características del Big Data.. 30. Tipos de Datos.. 34. Tipos de análisis. 35. Estructura de la solución de Análisis de Datos No estructurados.. 36. Cuando considerar una solución de Análisis de Datos No estructurados.. 38. Beneficios de la solución de Análisis de Datos No estructurados.. 39. Desafíos del Análisis de Datos No Estructurado.. 41. OBJETIVOS. 42. Objetivo general. 42. Objetivos específicos. 42. JUSTIFICACIÓN DE LA INVESTIGACIÓN. 43. Justificación Teórica. 43. Justificación Práctica. 43. ALCANCE DEL PROYECTO. 44. LIMITACIONES DEL PROYECTO. 44. HIPOTESIS. 45. MATRIZ DE CONSISTENCIA. 46. MARCO METODOLÓGICO. 48. Metodología y Enfoque. 48. Paradigma. 48.
(6) 6. Método. 49. VARIABLES. 49. Variable Independiente. 49. Variable Dependiente. 49. POBLACIÓN Y MUESTRA. 50. Población. 50. Muestra. 50. UNIDAD DE ANÁLISIS. 50. INSTRUMENTOS Y TÉCNICAS. 51. Instrumentos. 51. Técnicas. 54. PROCEDIMIENTOS Y MÉTODO DE ANÁLISIS. 56. Procedimiento. 56. Método de Análisis. 56. PROPUESTA DE ANÁLISIS DE DATOS NO ESTRUCTURADOS. 57. Metodología para el desarrollo de la Tesis. 57. Situación actual de la organización. 59. Capacidades técnicas y de negocio de GMD. 59. Capacidades Técnicas.. 60. Capacidades de Negocio.. 61. Planeamiento del proyecto de Tesis. 63. Plan de Gestión del Tiempo.. 63. Plan de Gestión de riesgos.. 64. Requerimientos del Proyecto. 64. Requerimientos Funcionales.. 65. Requerimientos No Funcionales.. 66. Análisis de las Principales plataformas de Big Data. 67. Presupuesto e Inversión. 70. Diseño de la infraestructura. 71. Plataforma de Análisis de grandes volúmenes de datos. 74. Sistema Hadoop.. 75. Stream computing.. 75. Integración de información y Gobierno.. 76. Aceleradores.. 76. Interfaces de usuario.. 76. Gestión de análisis y decisiones.. 76. Herramientas para el análisis de grandes volúmenes de datos. 77.
(7) 7. InfoSphere BigInsights.. 77. InfoSphere Streams.. 88. InfoSphere Information Server.. 92. IBM Cognos. Propuesta de Análisis de Datos No Estructurados Completa. 101 117. RESULTADOS. 118. DISCUSIÓN. 127. CONCLUSIONES. 129. RECOMENDACIONES. 131. REFERENCIAS. 132. ANEXOS. 134. Anexo 1: Formato de Encuesta. 134. Anexo 2: Respuestas de la encuesta. 137. Anexo 3: Validación de encuesta por Juicio de Expertos. 144. Anexo 4: Presupuesto. 146. Anexo 5: Cronograma. 147. Anexo 6: Aprobación del Gerente Línea de GMD. 148. Anexo 7: Uso de productos IBM Big Data sobre el Cloud de GMD. 149. ÍNDICE DE TABLAS TABLA N° 1: Evaluación pregunta 1. 15. TABLA N° 2: Evaluación pregunta 2. 16. TABLA N° 3: Evaluación pregunta 2. 17. TABLA N° 4: Capacidades funcionales y productos IBM para Big Data.. 29. TABLA N° 5: Hipótesis. 45. TABLA N° 6: Matriz de consistencia. 47. TABLA N° 7: Variables e Indicadores. 49. TABLA N° 8: Estadístico Alfa de Cronbach del instrumento. 54. TABLA N° 9: Estadísticas de Total de elemento. 55. TABLA N° 10: Hitos y entregables del proyecto de tesis. 63. TABLA N° 11: Tablero de Riesgos. 64. TABLA N° 12: Requerimientos Funcionales. 65. TABLA N° 13: Requerimientos No Funcionales. 66. TABLA N° 14: Ingresos Big Data por proveedor a nivel mundial. 67. TABLA N° 15: Componentes open source del InfoSphere BigInsights. 78. TABLA N° 16: HBase vs. HDFS. 86.
(8) 8. TABLA N° 17: HBase vs. RDBMS. 87. TABLA N° 18: Componentes de la suite InfoSphere Information server. 97. TABLA N° 19: Evaluación pregunta 1. 118. TABLA N° 20: Evaluación pregunta 2. 119. TABLA N° 21: Evaluación pregunta 3. 120. TABLA N° 22: Evaluación pregunta 4. 121. TABLA N° 23: Evaluación pregunta 5. 122. TABLA N° 24: Evaluación pregunta 6. 123. TABLA N° 25: Evaluación pregunta 7. 124. TABLA N° 26: Evaluación pregunta 8. 125. TABLA N° 27: Evaluación pregunta 9. 126. ÍNDICE DE FIGURAS FIGURA N° 1: Evaluación pregunta 1. 16. FIGURA N° 2: Evaluación pregunta 2. 17. FIGURA N° 3: Evaluación pregunta 2. 18. FIGURA N° 4: Árbol de Problemas. 20. FIGURA N° 5: Plataforma de Análisis de Big Data. 28. FIGURA N° 6: Volumen de data disponible vs. Volumen de data procesada. 31. FIGURA N° 7: Características del Big Data, modelo de las 3V. 33. FIGURA N° 8: Estructura de la solución de Análisis de datos No estructurados. 36. FIGURA N° 9: Desafíos del Análisis de datos No estructurados. 41. FIGURA N° 10: Ciclo de vida del desarrollo de la solución propuesta. 58. FIGURA N° 11: vCenter del Cloud Computing. 60. FIGURA N° 12: Inversión y facturación de la empresa GMD. 61. FIGURA N° 13: Alianzas estratégicas de la empresa GMD. 62. FIGURA N° 14: Magic Quadrant for Data Science Platforms. 68. FIGURA N° 15: Cotización del licenciamiento de la plataforma IBM Big Data. 70. FIGURA N° 16: Carga de trabajo Cloud Computing vs. Big Data. 72. FIGURA N° 17: Diseño de la infraestructura Cloud. 73. FIGURA N° 18: Diseño de un nodo del cluster Hadoop. 74. FIGURA N° 19: Plataforma de Análisis de Big Data - Productos y 5Vs de IBM. 75. FIGURA N° 20: Diseño de la arquitectura del servicio InfoSphere BigInsights. 79. FIGURA N° 21: InfoSphere BigInsights Web Console. 80. FIGURA N° 22: La interfaz de hoja de cálculo BigSheets. 82. FIGURA N° 23: Visualización de datos en BigSheets. 82.
(9) 9. FIGURA N° 24: Texto de ejemplo (World Cup 2010). 83. FIGURA N° 25: Resultado de cómo trabaja el análisis de texto. 84. FIGURA N° 26: Proceso de ejecución de la herramienta de análisis de texto. 85. FIGURA N° 27: Ejemplo del esquema de tabla en la BD NoSQL HBase. 87. FIGURA N° 28: Diseño de la arquitectura de la Base datos NoSQL HBase. 88. FIGURA N° 29: Diseño de la arquitectura del servicio InfoSphere Streams. 90. FIGURA N° 30: Modelo simple de la arquitectura del servicio InfoSphere Streams. 91. FIGURA N° 31: Funciones de integración del InfoSphere Information Server. 93. FIGURA N° 32: Fases de la integración de Información. 95. FIGURA N° 33: Arquitectura del InfoSphere Information Server. 97. FIGURA N° 34: Interfaz de usuario del IBM Cognos Business Insight. 103. FIGURA N° 35: Página de Inicio: Abrir un Dashboard existente. 104. FIGURA N° 36: Abrir un Dashboard existente en el Business Insight. 105. FIGURA N° 37: Mover los contenedores de gráficos. 105. FIGURA N° 38: Eliminar los contenedores de gráficos. 106. FIGURA N° 39: Modificar los tipos de pantalla. 106. FIGURA N° 40: Modificar los tipos de pantalla. 107. FIGURA N° 41: Interfaz Avanzada de usuario del IBM Cognos Business Insight. 108. FIGURA N° 42: Reporte de Gráfico de Barras. 110. FIGURA N° 43: Reporte de Gráfico de Radar. 110. FIGURA N° 44: Calendario de mapas de calor. 111. FIGURA N° 45: Reporte Theme River. 111. FIGURA N° 46: Reporte para las redes sociales. 112. FIGURA N° 47: Reporte de visualización jerárquica. 113. FIGURA N° 48: Mapa de árbol. 114. FIGURA N° 49: Arquitectura de la integración de Cognos BI y BigInsights. 115. FIGURA N° 50: IBM Cognos Dynamic Query integrado con IBM Cognos BI. 116. FIGURA N° 51: Arquitectura de grandes volúmenes de datos Completa. 117. FIGURA N° 52: Evaluación pregunta 1. 118. FIGURA N° 53: Evaluación pregunta 2. 119. FIGURA N° 54: Evaluación pregunta 3. 120. FIGURA N° 55: Evaluación pregunta 4. 121. FIGURA N° 56: Evaluación pregunta 5. 122. FIGURA N° 57: Evaluación pregunta 6. 123. FIGURA N° 58: Evaluación pregunta 7. 124. FIGURA N° 59: Evaluación pregunta 8. 125. FIGURA N° 60: Evaluación pregunta 9. 126.
(10) 10. DEDICATORIA “Dedico este trabajo a mis padres por todo el amor que me han dado y porque me enseñaron a esforzarme al máximo y nunca rendirme. Todo los soy y todo lo que he logrado se los debo a ustedes.”.
(11) 11. AGRADECIMIENTOS Agradezco a cada uno de los que confiaron y me apoyaron en la elaboración y desarrollo de esta investigación, gracias a todos. por. ayudarme. a. superar. las. dificultades surgidas a lo largo del camino. Agradezco también a mis padres por todo el apoyo y confianza que siempre me han dado y especialmente a Gabriel Jiménez por asesorarme y aconsejarme a lo largo de esta investigación..
(12) 12. RESUMEN Hoy en día, las empresas depositan mucha confianza en la toma de decisiones que realizan sobre sus negocios, basándose en la información que poseen sobre sus operaciones internas y lo que ocurre en el mercado. Estas decisiones, que son tomadas en un contexto de alta y creciente competencia, se toman cada vez más utilizando y analizando la mayor cantidad de información que la empresa posea, dado que una decisión errónea o tomada fuera tiempo (Es decir, cuando ya es demasiado tarde) puede afectar significativamente a una organización.. La toma de decisiones implica incertidumbre y por lo tanto riesgo. Para minimizar estos riesgos es necesario generar decisiones oportunas en base a un análisis de información que sea eficiente y lo más cercado al tiempo real. Por tanto, la información en una empresa debe ser clara, precisa, oportuna, completa, de fácil acceso y sobre todo necesaria y no superflua.. Para la presente investigación, tomaremos como caso de estudio a la empresa GMD S.A. (afiliada a Advent International), en base a la cual se elaborará la propuesta de solución para análisis de datos No estructurados, con la finalidad que los jefes y gerentes de proyecto puedan generar decisiones oportunas y eficientes mediante el análisis en tiempo real o casi real de la data correspondiente a los proyectos..
(13) 13. ABSTRACT Nowadays, companies place a lot of confidence in the decision making they make about their businesses, based on the information they have about their internal operations and what happens in the market. These decisions, which are taken in a context of high and growing competition, are increasingly taken using and analyzing the largest amount of information that the company possesses, given that a wrong decision or taken outside time (That is, when it is too much late) can significantly affect an organization.. Decision making implies uncertainty and therefore risk. To minimize these risks it is necessary to generate timely decisions based on an analysis of information that is efficient and closer to the real time. Therefore, the information in a company must be clear, precise, timely, complete, easily accessible and above all necessary and not superfluous.. For the present investigation, we will take as a case study the company GMD S.A. (affiliated with Advent International), based on which the solution proposal for unstructured data analysis will be elaborated, with the purpose that project managers can generate timely and efficient decisions through real-time or near-real-time analysis of the information corresponding to the projects..
(14) 14. INTRODUCCIÓN En la actualidad, debido al gran avance que existe día a día en las tecnologías de información, las organizaciones han tenido que enfrentarse a nuevos desafíos que les permitan analizar, descubrir y entender, más allá de lo que sus herramientas tradicionales reportan, sobre grandes y variados volúmenes de datos que se generan rápidamente; asimismo, durante los últimos años el gran crecimiento de las aplicaciones disponibles en internet ha sido parte importante de la generación de decisiones de negocio en las empresas.. La primera pregunta que debemos hacernos es ¿Qué es el análisis de datos no estructurados y porqué se ha vuelto tan importante? pues, en términos generales según IBM, es una tendencia en el avance de la tecnología que ha abierto las puertas hacia un nuevo enfoque de entendimiento y toma de decisiones, la cual es utilizada para describir enormes cantidades de datos que tomaría demasiado tiempo y sería muy costoso, cargarlos en una base de datos relacional para su análisis. Por lo tanto, el concepto de Análisis de datos no estructurados aplica para todos aquellos datos que no puede ser procesados o analizados utilizando procesos o herramientas tradicionales.. El presente trabajo de tesis tiene como objetivo proponer una solución de Análisis de datos No estructurados con la finalidad de resolver la problemática sobre la generación de decisiones oportunas en la implementación de proyectos de TI para la empresa GMD. Durante el desarrollo de la investigación se expondrá el problema, alcance, limitaciones, objetivos y metodología para obtener los resultados, conclusiones y recomendaciones del estudio..
(15) 15. IDENTIFICACIÓN DEL PROBLEMA La información se ha convertido en el activo más valioso con el que cuentan las empresas en la actualidad y dicha información se incrementa día a día sobre todo para aquellas empresas que realizan mayor cantidad de transacciones. Sin embargo, el principal problema a resolver es cómo obtener el máximo provecho de esta información mediante herramientas que permitan extraer, procesar, analizar y visualizar grandes y variados volúmenes de datos, con la finalidad de brindar respuestas a las necesidades de negocio y tomar decisiones de manera oportuna. Para la presente tesis tomaremos como caso de estudio la empresa GMD S.A (afiliada a Advent International), la cual se dedica al outsourcing de Procesos de Negocio y Tecnologías de la Información (TI). El problema se centra en la falta de herramientas para la extracción, procesamiento, análisis y visualización de grandes volúmenes de datos no estructurados correspondientes a la fase de Implementación de los proyectos; causando que dicha información no sea analizada y utilizada de la manera más rápida y eficiente por los gerentes de proyectos, para generar decisiones oportunas. Es decir: “La toma de decisiones, no está sustentada en un análisis de información que incluya datos no estructurados, con la finalidad de minimizar los costos de los proyectos y generar decisiones oportunas durante la implementación de los proyectos de GMD”. Como consecuencia de este problema, se crean sobrecostos, pérdida de oportunidades de negocio e insatisfacción en los clientes.. En el 2016, se realizó una encuesta a 18 jefes de proyecto y 17 gerentes de proyectos de GMD, para recopilar información sobre los principales problemas en la toma de decisiones durante la fase de implementación de los proyectos. Los resultados fueron los siguientes:. Pregunta 1 - ¿Se cuenta con la información para generar decisiones oportunas? Categoría. Frecuencia. Porcentaje. No Si Total general. 18 17 35. 51% 49% 100%. TABLA N° 1: Evaluación pregunta 1 FUENTE: Elaboración propia.
(16) 16. FIGURA N° 1: Evaluación pregunta 2 FUENTE: Elaboración propia. Como se muestra en la tabla 1 y figura 1, el 51% de los encuestados afirman contar con la información suficiente para la toma de decisiones; sin embargo, el 49% considera que no cuentan con la información necesaria para generar decisiones de manera oportuna.. Pregunta 2 - ¿Se agilizaría la toma de decisiones si contara con información (no estructurada) como audios, videos, documentos, imágenes, entre otros? Categoría. Frecuencia. Porcentaje. No Si Total general. 6 29 35. 17% 83% 100%. TABLA N° 2: Evaluación pregunta 2 FUENTE: Elaboración propia.
(17) 17. FIGURA N° 2: Evaluación pregunta 2 FUENTE: Elaboración propia. Como se muestra en la tabla 2 y figura 2, el 83% de los encuestados considera que generarían decisiones de manera más oportuna si contarán con data no estructurada como videos, audios, documentos, imágenes, entre otros; mientras que sólo un 17% considera lo contrario.. Pregunta 3 - ¿Cuáles son los principales problemas en la toma de decisiones en los proyectos de GMD? Opciones de la encuesta. Frecuencia. En el análisis de datos, no se toma en cuenta la data no estructurada como videos, audios, imágenes, correos, documentos entre otros. Problemas de acceso hacia la información relevante GMD no cuenta con herramientas para el análisis y procesamiento de grandes volúmenes de datos.. 13 19 22. Demoras en el análisis de información. 23. La información no se encuentra centralizada. 28. Total general. 105. TABLA N° 3: Evaluación pregunta 2 FUENTE: Elaboración propia.
(18) 18. FIGURA N° 3: Evaluación pregunta 2 FUENTE: Elaboración propia. Como se muestra en la tabla 3 y figura 3, un total de 28 encuestados considera que la falta de centralización de la información es el principal problema en la toma de decisiones; en segundo lugar, con 23 votos, se tienen las demoras en el análisis de información; en tercer lugar, con 22 votos, se tiene la falta de herramientas para el análisis y procesamiento de grandes volúmenes de datos; en cuarto lugar, con 19 votos, se tienen los problemas de acceso hacia la información relevante y en quinto lugar, con 13 votos, se tiene que en análisis de datos no se toma en cuenta la data no estructurada.. Por tanto, en el presente proyecto de investigación, se realizará una propuesta para el análisis de datos no estructurados, con la finalidad que los jefes y gerentes de proyecto de GMD puedan generar decisiones oportunas y eficientes, mediante el análisis en tiempo real o casi real de la data correspondiente a los proyectos. Para esto, tomaremos como objeto de estudio lo siguiente: costos, documentación propia de los proyectos, quejas de los clientes y documentos de lecciones aprendidas..
(19) 19. FORMULACIÓN DEL PROBLEMA Problema General ¿Cuál es el impacto que ocasiona la falta de herramientas para la extracción, procesamiento, análisis y visualización de grandes volúmenes de datos no estructurados, en la generación de decisiones oportunas durante la implementación de los proyectos de GMD? Problemas específicos ¿Cuál es el impacto que ocasiona la falta de herramientas para la extracción y procesamiento de grandes volúmenes de datos no estructurados, en el tiempo de análisis de información para la generación de decisiones oportunas?. ¿Cuál es el impacto que ocasiona la falta de herramientas para el análisis y visualización de grandes volúmenes de datos no estructurados, en el tiempo de análisis de información para la generación de decisiones oportunas?. ¿Cuál es el impacto que ocasiona la falta de herramientas para la extracción y procesamiento de grandes volúmenes de datos no estructurados, en tiempo real o casi real, en la reducción de costos en los proyectos de TI de GMD?. ¿Cuál es el impacto que ocasiona la falta de herramientas para el análisis y visualización de grandes volúmenes de datos no estructurados, en tiempo real o casi real, en la reducción de costos en los proyectos de TI de GMD?.
(20) 20. Diagrama del árbol de Problemas. Efectos. Pérdida de oportunidades de negocio. Problema Central. Quejas de los clientes. Posible pérdida de clientes. Insatisfacción del cliente. Sobrecostos en los proyectos. Falta de herramientas para la extracción, procesamiento, análisis y visualización de grandes volúmenes de datos no estructurados en la generación de decisiones oportunas en la implementación de proyectos de GMD. Retraso en el análisis de información. El análisis de datos no es en tiempo real. Causas No hay herramientas para el procesamiento y análisis de grandes volúmenes de datos. FIGURA N° 4: Árbol de Problemas FUENTE: Elaboración propia. Problemas al acceder a la información.
(21) 21. MARCO REFERENCIAL Antecedentes Internacionales En la universidad University of Twente (Netherlands), Mike Padberg (2015), realizó una tesis de maestría sobre Big Data e Inteligencia de Negocios (BI), una estrategia orientada a datos para organizaciones de comercio electrónico en la industria hotelera. El objetivo de la tesis fue crear un enfoque práctico para convertir a una organización en una orientada a los datos, para esto utilizaron las tecnologías de análisis de grandes volúmenes de datos (no estructurados) y optimizaron el proceso de Business Intelligence, con la finalidad de obtener mayor valor de los datos disponibles y utilizarlos para la toma de decisiones. Como resultado, se indicó que el análisis de datos no estructurados es considerado como un nuevo tema y área de investigación donde pueden distinguirse dos corrientes: La primera de personas sin experiencia en informática o ingeniería de software, quienes argumentan que está relacionado con la inteligencia de negocios y la toma de decisiones. El segundo grupo con experiencia en informática o ingeniería de software, quienes argumentan que es un facilitador de inteligencia artificial y algoritmos más inteligentes. En conclusión, el uso de tecnologías para el análisis de datos no estructurados y el Business Intelligence, permiten obtener mayor valor de los datos disponibles y contribuyen en la toma decisiones oportunas para favorecer la comprensión sobre el comportamiento de los clientes, permitiendo un enorme aumento en el desempeño. Asimismo, es importante maximizar la visualización de los datos disponibles mediante un formato o interfaz comprensible y fácil de entender.. En la universidad Ryerson University (Canadá), Feroz Alam (2015), realizó una tesis sobre la migración datos entre las bases de datos relacionales y no relacionales (NoSQL). El objetivo de la tesis fue realizar un estudio comparativo entre las BD’s relacionales y No relacionales para el procesamiento y análisis de grandes volúmenes de datos no estructurados para la toma de decisiones de negocio. Como resultado, Se propuso una metodología para la migración exitosa de datos desde una BD relacional hacia una BD NoSQL. Asimismo, se validó el procesamiento y análisis de datos no estructurados para la toma de decisiones. En conclusión, La demanda de bases de datos NoSQL está aumentando debido a sus características diversificadas que ofrecen escalabilidad rápida y fácil, gran disponibilidad, arquitectura distribuida, buen desempeño y rápido análisis de la información para la toma de decisiones de negocio..
(22) 22. En la universidad de San Andrés (Argentina), José Manso (2015), realizó un estudio sobre el análisis de modelos de negocio basados en Big Data para operadores móviles. El objetivo de la tesis fue analizar los modelos de negocios para operadores móviles basados en Big Data y generar un marco referencial que integre las mejores prácticas para maximizar la generación de valor. Como resultado, se elaboró una propuesta de modelo de negocio basado en Big Data para operadores móviles que permite ganar rentabilidad a largo plazo frente a los competidores. En conclusión, el tráfico de datos móviles está creciendo exponencialmente alcanzando volúmenes de información sin precedentes. Asimismo, los datos que genera una organización pueden ser tanto estructurados como no estructurados y se pueden obtener de múltiples fuentes de información tanto internas como externas a la organización, por tanto, es importante para las empresas explotar y analizar estos datos en tiempo real o casi real para utilizar el valor de estos activos con el fin de tomar mejores decisiones.. En la universidad de Barcelona (España), Galimany suriol (2014), realizó un estudio sobre la creación de valor en las empresas a través del Big Data. El objetivo de la tesis fue determinar, analizar y justificar la aportación del análisis de grandes volúmenes de datos no estructurados sobre las empresas mediante la creación de valor y ventajas competitivas. Como resultado, se indicó que el análisis de datos no estructurados trae importantes ganancias en términos de eficiencia y nuevos productos a las empresas, asimismo el procesamiento de datos permite obtener información y mejorar la toma de decisiones. Por lo tanto, esta información junto con la experiencia favorece la obtención de nuevos conocimientos para mejorar procesos, reducir costos, implementar nuevos procesos, productos o variables relevantes en la producción. Por otro lado, también permite tener un conocimiento más profundo de cómo es y cómo se comporta la empresa internamente; es decir, como es el entorno en el que se mueve y cómo influye esto en la empresa y en los stakeholders, con la finalidad de entender y analizar cómo se comportan frente a los productos, cuáles son sus expectativas, cuáles son sus sugerencias y cómo podemos satisfacerlos. En conclusión, el análisis de grandes volúmenes de datos no estructurados es una fuente importante de valor para las empresas, pues, aunque es una nueva tendencia, numerosos casos reales sustentan la idea de que es un percusor de nuevas innovaciones y por tanto de ventajas competitivas que no solo transforman las empresas y sus productos, sino que son capaces de crear y transformar mercados..
(23) 23. En la universidad Helsinki Metropolia University of Applied Sciences (Finlandia), Kevin Blasiak (2014), realizó un estudio sobre Big Data, una revolución en la Gestión, el papel emergente del Big Data en las empresas. El objetivo de la tesis fue proporcionar una visión general sobre las capacidades que tiene el análisis de grandes volúmenes de datos no estructurados y las oportunidades que se derivan de su aplicación, creando una comprensión sobre su papel en las decisiones de la alta gerencia y determinando su posición dentro de un modelo de toma de decisiones. Como resultado, se indicó que el análisis de grandes volúmenes de datos no estructurados es una tecnología que puede originar la creación de ventajas competitivas fuertes. Asimismo, permite favorecer el giro de negocio de la empresa mediante estadísticas sencillas y algoritmos predictivos. En Conclusión, dentro de las organizaciones, el análisis de datos no estructurados debe justificar su propósito como herramienta de gestión y desafiar la cultura corporativa para redefinir la toma de decisiones.. En la universidad de Cantabria (España), García López (2013), realizó un estudio sobre el análisis de las posibilidades de uso de Big Data en las organizaciones. El objetivo de la tesis fue determinar en qué consiste el término Big Data, a qué hace referencia y que tipo de tecnología está relacionada, asimismo, indicar como lo utilizan las grandes empresas para obtener ventajas competitivas frente a sus competidores. Como resultado, se indicó que la tecnología Big Data (Análisis de datos estructurados y no estructurados), no solo sirve para obtener grandes cantidades de datos, sino también para analizarlos y conseguir información y conocimiento, asimismo también permite conocer las preferencias y demandas de los clientes, las debilidades internas de la empresa y la tecnología Big Data las debilidades de los competidores, con lo que se obtiene una gran ventaja competitiva. En conclusión, seguirá evolucionando, por tanto, las empresas deben aprovechar la gran avalancha de datos que se generan, captando únicamente aquellos que pueden ser transformados en información y conocimiento.. En la universidad de Amsterdam (Netherlands), Niels Mouthaan (2012), realizó un estudio con la finalidad de examinar los efectos del análisis de Big Data en la creación de Valor sobre las organizaciones. El objetivo de la investigación fue definir el análisis de grandes volúmenes de datos, en términos de creación de valor, basado en la diversidad de datos que existe en la actualidad. Sobre este punto índico que el 80% de la data propia de las organizaciones es No estructurada y el análisis de datos tradicional tiende a analizar sólo la data estructurada (el 20% restante), causando que una fuente de información potencial y valiosa sea ignorada. Como método de investigación se.
(24) 24. realizaron dos casos de estudio, el primero sobre los participantes de un show de música en el cual se analizaron los tweets recolectados del Twitter y el segundo sobre una página de internet sobre retail en el cual el análisis de grandes volúmenes de datos no estructurados requería un poder computacional. Como resultado de los casos de estudio, el análisis de datos no estructurados actuó como medio para la creación de Valor pues ofrecía ventajas significativas para el cliente. Asimismo, mejoró la eficiencia de las transacciones que se realizaban entre la página web y sus clientes a través de la mejora en la actividad de búsqueda. En conclusión, el análisis de datos no estructurados puede crear valor en dos formas: Mediante la mejora en la eficiencia de las transacciones y soportando la innovación al crear nuevos o mejores productos y servicios en una organización.. En la universidad Chalmers University (Suecia), Petter Näsholm (2012), realizó una tesis de maestría sobre la extracción de Data desde una Base de datos NoSQL como un paso hacia el análisis visual e interactivo de los datos NoSQL (No estructurados). El objetivo de la tesis fue resolver el problema de extracción e importación de datos que existe entre las Bases de datos NoSQL y las aplicaciones tradicionales, con la finalidad de ser capaz de analizar y visualizar datos y tendencias para la toma de decisiones de negocio, generando ventajas competitivas. Como resultado, se aplicó una solución con herramientas para la importación de datos (como Casandra y Neo4j) en la plataforma de las aplicaciones de negocio, logrando que éstas pudieran soportar las características de las bases de datos NoSQL. En conclusión, se logró adaptar una solución que permita la comunicación entre las bases de datos NoSQL y las aplicaciones de negocio, permitiendo a las organizaciones analizar y visualizar la data no estructurada para mejorar la toma de decisiones y generar ventajas competitivas. En el instituto IMT – Institutions Markets Technologies (Italia), Gian Marco De Francisci Morales (2010), realizó un estudio con la finalidad de proporcionar un marco coherente para la investigación en el campo de análisis de datos a gran escala sobre el Cloud Computing. Para alcanzar este objetivo, se centraron en la problemática del Big Data (“Un increíble "diluvio de datos" está ahogando al mundo.”) y adoptaron los principios de la investigación de base de datos, pues consideraron que los resultados en estos campos son relevantes. Asimismo, estudiaron los algoritmos de análisis de datos más comunes y definieron una carga de trabajo de análisis representativa. Como resultado, se proporcionó un terreno común en el que los sistemas de base de datos y el Cloud Computing fueran capaces de comunicarse y prosperar. En conclusión, el análisis.
(25) 25. de Data es el proceso de inspección de datos con el propósito de extraer información útil que permita la toma de decisiones y el Cloud Computing es una tecnología alternativa y emergente para el análisis de datos a gran escala. En Conclusión, existe una gran necesidad por generar mayor valor en las empresas, mediante el adecuado análisis de la información, cuyo volumen crece día a día.. Antecedentes Nacionales En la universidad UPC (Perú), Mérida Fonseca y Ríos Alvarado (2014), realizaron una investigación sobre una propuesta de plataforma de Big Data orientado al sector turístico. El objetivo de esta investigación fue aprovechar el análisis de grandes volúmenes de datos, en los procesos del sector turístico e identificar en tiempo real la necesidad de los clientes. Para esta investigación se utilizó como metodología un enfoque cualitativo para la descripción de los procesos. Asimismo, se consideraron, en el análisis, las plataformas Oracle y Microsoft. Como resultado, presentaron la propuesta de una plataforma de Big Data que ofrece procesos para la extracción de data (estructurada y No estructurada), procedimientos para el procesamiento de datos y procesos para la gestión de información.. En. conclusión, los procesos internos del Sector turístico pueden ser aprovechados como fuentes de información para permitir un análisis más profundo de las características de los consumidores y clientes potenciales..
(26) 26. Estado del Arte En la actualidad los datos se han vuelto el activo más valioso para las empresas, pues cada vez más organizaciones se encuentran almacenando, procesando y extrayendo valor de grandes volúmenes de datos de diferentes tipos y tamaños; es decir, las empresas están buscando la forma de explotar todo el potencial de los datos para poder mejorar la toma de decisiones y obtener mayores ventajas competitivas. Al respecto, Gartner predijo que los datos empresariales crecerían un 800% desde el 2011 hasta el 2015, con 80% de los datos en formato no estructurado (por ejemplo, correos electrónicos, documentos, vídeos, imágenes y contenido de medios de comunicación social) y el 20% en formato estructurado (por ejemplo, transacciones de tarjetas de crédito e información de contacto).. El análisis de datos está evolucionando desde el procesamiento de datos tradicional; es decir sobre data histórica, hacia el procesamiento de grandes volúmenes de datos no estructurados en tiempo real. Esto se debe a que el análisis de datos en tiempo real permite monitorear los datos a medida que se generan y se transmiten a la organización, algo que no te permite el análisis tradicional. Por otro lado, cada vez son más los casos de uso empresarial que se basan en un análisis de información avanzado que permita agilizar y mejorar la toma de decisiones para crear ventajas competitivas.. En el 2012 Intel realizó una encuesta a 200 administradores de TI pertenecientes a grandes empresas y encontró que, aunque hoy en día la cantidad de datos procesados tradicionalmente, frente a la cantidad de datos procesados en tiempo real, se divide uniformemente; la tendencia indica que habrá un aumento en el procesamiento de grandes volúmenes de datos no estructurados en tiempo real. Por otro lado, la tecnología para el procesamiento de información en tiempo real o en tiempo casi real, está en continua evolución.. El análisis en tiempo real favorece el análisis predictivo, pues permite a las organizaciones adquirir una visión orientada hacia el futuro y ofrecer algunas de las oportunidades más interesantes para la conducción de valor a partir del análisis de grandes volúmenes de datos no estructurados. Por otro lado, el análisis de datos en tiempo real, ofrece la expectativa de un análisis predictivo rápido, preciso y flexible que se adapte rápidamente a las condiciones cambiantes del negocio, pues cuanto más rápido se analicen los datos, más oportunos serán los resultados y mayor será su valor predictivo..
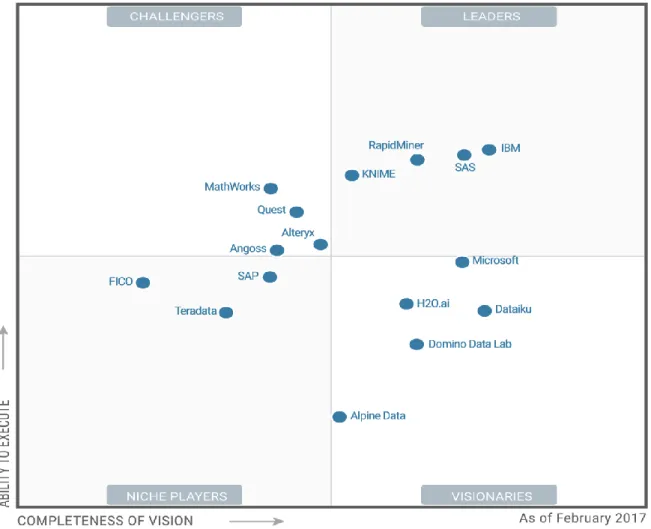
(27) 27. El alcance sobre el análisis de Big Data continuará expandiéndose, debido a que se centra principalmente en los negocios y en las fuentes de datos sociales como el correo electrónico, videos, tweets, Mensajes de Facebook, opiniones y comportamientos Web. Por lo tanto, el valor real del Big Data está en el conocimiento que produce cuando es analizado; es decir, cuando ayuda a descubrir patrones, indicadores para la toma de decisiones y la habilidad de responder al mundo con mayor inteligencia. Por último, el análisis de Big Data es un conjunto de tecnologías avanzadas, diseñadas para trabajar con grandes volúmenes de datos heterogéneos (Estructurados, semiestructurados y No estructurados).. Existen herramientas que permiten el procesamiento, análisis y visualización de grandes volúmenes de datos no estructurados en tiempo real. La plataforma de análisis de Big Data de IBM permitirá a GMD analizar un amplio conjunto de información mixta (de diferentes tipos y fuentes), analizar flujos de información en movimiento (en tiempo real) y descubrir y experimentar con nueva información. Asimismo, proporcionará la capacidad de empezar con una sola funcionalidad y fácilmente añadir otras conforme se requiera, ya que la pre-integración de sus componentes reduce el tiempo de implementación y el costo.. La Figura 5 muestra los componentes que conforman la plataforma de análisis de Big Data de IBM, entre los cuales destacan el Sistema Hadoop, Stream Computing y el Gestor de análisis y decisiones (Analytic Applications)..
(28) 28. FIGURA N° 5: Plataforma de Análisis de Big Data FUENTE: Libro Building Big Data and Analytics Solutions in the Cloud.. En la tabla 4, se muestra la relación entre las capacidades funcionales y los productos que ofrece IBM como herramientas para el procesamiento de Big Data. Para la presente investigación utilizaremos el InfoSphere Streams, InfoSphere BigInsight, InfoSphere Information Server y el Cognos BI como herramientas para la elaboración de la propuesta de Análisis de grandes volúmenes de Datos No estructurados.. Funcionalidad. Descripción de la funcionalidad. Producto IBM. Componentes de la plataforma. Optimiza el proceso de carga de Ingestión de datos. datos en el storage para dar soporte. InfoSphere. a las metas analíticas sensibles al. Streams. Stream Computing. tiempo. Convierte los valores de los datos Transformación de. desde el sistema y formato de origen. InfoSphere. datos. hacia el sistema y formato de. BigInsights. Sistema Hadoop. destino. Análisis. Descubre. y. comunicar. significativos en los datos.. patrones. Cognos. Gestión de análisis y decisiones.
(29) 29. Hacer. repetible. la. toma. de. Decisiones. decisiones en tiempo real sobre las. recurribles. políticas organizacionales y reglas. Cognos. Gestión de análisis y decisiones. de negocio Descubrir, Descubrimiento y exploración. grandes. navegar cantidades. y. visualizar data. InfoSphere. Interfaz de usuario. estructurada y no estructurada a. de. Information. (Visualización y. través de diferentes sistemas de. Server. descubrimiento). empresa y repositorios de datos. Reportes,. Proporcionar informes, análisis y. informes,. dashboards para ayudar a mantener. Visualizaciones y. la forma en que las personas. dashboards Integración de datos. Cognos. Gestión de análisis y decisiones. piensan y trabajan. Integración de diferentes tipos de. InfoSphere. Integración de. datos. Information. información y. Server. gobierno. TABLA N° 4: Capacidades funcionales y productos IBM para Big Data. FUENTE: Libro Building Big Data and Analytics Solutions in the Cloud..
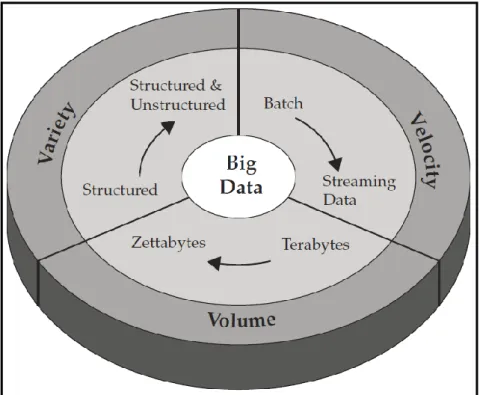
(30) 30. Marco Teórico Big Data. Existe mucha confusión sobre la definición de Big Data, al respecto podemos decir que el término Big Data aplica a toda aquella información que no puede ser procesada o analizada usando las herramientas o procesos tradicionales (Zikopoulos, Eaton y Deroos, 2012). En consecuencia, las organizaciones de hoy deben enfrentarse continuamente a los retos que implica el análisis de Big Data, pues si bien tienen acceso a un gran volumen de información, no saben cómo obtener valor de ella. Esto se debe a que la información se presenta en forma cruda o en formatos semiestructurados o no estructurados; por lo tanto, como resultado, no saben si vale la pena mantenerla.. La era del Big Data está en plena vigencia, debido a que el mundo está cambiando; es decir, hoy en día somos capaces de percibir más cosas y en consecuencia tendemos a tratar de almacenarla. Asimismo, mediante los avances en comunicaciones, las personas y cosas se están volviendo cada vez más interconectadas y no sólo por un tiempo sino casi todo el tiempo. Esta interconectividad es la responsable de las altas tasas de crecimiento de datos. Finalmente, debido a que los pequeños circuitos integrados son ahora tan baratos, podemos agregar inteligencia a casi todo. Características del Big Data. Según Mitchell, Locke y Wilson (2012), existen 3 características que definen el Big Data y son llamadas el modelo de las 3V (Volumen, Velocidad y Variedad), juntas estas características definen lo que es el Big Data, dado que han creado la necesidad de nuevas y mejores capacidades para aumentar las cosas que podemos hacer hoy, con la finalidad de proveer un mejor control y habilidad sobre el conocimiento existente.. Volumen. Se refiere al hecho de que Big Data implica analizar grandes cantidades de datos que se generan cada segundo en el mundo digital y que son creados por la interacción de personas, máquinas, redes, entre otros.. Esto se debe a que almacenamos todo (sin mencionar el análisis de la data almacenada) como: datos del entorno, datos financieros, datos médicos y la.
(31) 31. lista sigue creciendo. Por ejemplo: Al hablar a través de un Smartphone se genera un evento, cuando las puertas de un tren se abren para que los pasajeros aborden se genera otro evento, cuando hacemos “Check in” para viajar en un avión, cuando descargamos música en Spotify, cuando cambiamos de canal en la televisión, etc. Todas estas acciones cotidianas generan nueva información a cada segundo.. Por lo tanto; las organizaciones se enfrentan día a día a volúmenes masivos de datos que no saben cómo administrar y en consecuencia terminan abrumados por toda la nueva información generada. Sin embargo; dentro del problema existe la oportunidad, pues mediante el uso de la plataforma y las herramientas correctas se puede obtener un análisis de la información crítica y útil, permitiendo un mejor entendimiento del negocio, los clientes y el mercado.. Por otro lado, mientras que la cantidad de data disponible para las empresas va en aumento, el porcentaje de data que puede ser procesada, comprendida y analizada disminuye, creando de este modo una zona ciega “The blind zone”. Esta zona ciega es algo desconocido y puede significar un problema o una oportunidad dependiendo del punto de vista. Finalmente, el tema sobre los volúmenes de data está evolucionando de “Terabytes” hacia “Petabytes” e inevitablemente seguirá hacia “Zettabytes” y toda esta información ya no podrá ser almacenada ni procesada en los sistemas tradicionales pues no cuentan con las capacidades necesarias (Zikopoulos, Eaton y Deroos, 2012).. FIGURA N° 6: Volumen de data disponible vs. Volumen de data procesada FUENTE: Libro Understanding Big Data.
(32) 32. Velocidad. Se refiere a la velocidad con la cual la data es generada y actualizada. Asimismo, en el mundo del Big Data la rapidez en el análisis de datos es uno de los factores claves, debido a que tradicionalmente el análisis se realizaba sobre data histórica. Big Data ha ampliado este concepto incluyendo el análisis en tiempo real.. En el mundo de los negocios, conseguir una ventaja sobre tus competidores significa identificar una tendencia, problema u oportunidad en solo segundos o incluso microsegundos antes que la competencia. Asimismo, más y más de los datos que se generan hoy en día tienen una vida útil muy corta, por tanto; las organizaciones deben ser capaces de analizar esta información lo más cercano al tiempo real si desean poder obtener algún conocimiento de esta data.. Lidiar efectivamente con Big Data requiere de la realización de un análisis contra el volumen y variedad de data mientras ésta está en movimiento no después de que está en reposo (Zikopoulos, Eaton y Deroos, 2012).. Variedad. Se refiere al hecho de que Big Data puede ser generada a través de diferentes orígenes o fuentes y en varios formatos y estructuras. Con la explosión de sensores, dispositivos inteligentes, redes sociales, entre otros; la data en las empresas se ha vuelto más compleja, pues incluye no solo data relacional y tradicional sino también data semi estructurada y no estructurada proveniente de páginas web, registros web, búsquedas indexadas, fórums de las redes sociales, e-mail, documentos, data de sensores de sistemas activos y pasivos, etc.. Asimismo, las empresas luchan por almacenar y realizar el análisis de datos requerido con la finalidad de ganar entendimiento sobre el contenido de estos registros, pues gran parte de la información que se genera no puede ser procesada ni administrada en las bases de datos tradicionales.. Por otro lado, la data estructurada o relacional representa sólo el 20% del total de data generada y disponible siendo el 80% restante data semi estructurada o no estructurada. Es en este punto donde las empresas han empezado a entender el valor y la oportunidad del Big Data y para poder capitalizar esta.
(33) 33. oportunidad, las empresas deben poder analizar todo tipo de datos, tanto relacional como no relacional (Zikopoulos, Eaton y Deroos, 2012).. FIGURA N° 7: Características del Big Data, modelo de las 3V FUENTE: Libro Understanding Big Data. Valor: La cuarta vital “V” del Big Data. Aunque el modelo de las 3V es una manera útil de definir el Big Data, según Mitchell, Locke y Wilson (2012), existe una cuarta “V” que también debe ser tomada en cuenta: “Valor”. Esto se debe a que para las organizaciones no tendría sentido implementar Big Data a menos que pudieran obtener mayor valor en sus negocios. Esto significa que la data no sólo puede ser usada dentro de una misma organización, sino que el valor puede provenir de venderla o proporcionando acceso a terceros.. Este deseo de maximizar el valor del Big Data es un imperativo de negocio clave. Asimismo, existen otras formas en las que Big Data ofrece nuevas maneras para generar valor. Por ejemplo, mientras que en los sistemas de análisis tradicionales de negocio se tenía que operar sobre data histórica que podía estar desfasada por semanas e incluso meses; en una solución de Big Data se puede analizar información en tiempo real..
(34) 34. Esto genera beneficios masivos para las organizaciones pues pueden responder de manera más rápida a las nuevas tendencias, retos y cambios del mercado. Por otro lado, las soluciones de Big Data pueden generar valor mediante el análisis del sentimiento contenido en los datos en lugar de sólo mirar la información en bruto. Por ejemplo, se puede llegar a entender cómo se sienten los clientes con respecto a un producto o servicio en particular. Esto es conocido como “Análisis del sentimiento”.. Big Data les da a las organizaciones la oportunidad de explotar una combinación de data existente y fuentes de datos disponibles, con la finalidad de extraer valor adicional mediante la mejora del conocimiento de negocios para la toma de decisiones y el tratamiento de los datos como activo que puede ser comercializado y vendido.. Tipos de Datos. Según Mitchell, Locke y Wilson (2012), existen 3 tipos básicos de datos:. Data estructurada. Se refiere a los tipos de datos que son usados por los sistemas de base de datos tradicionales; es decir, donde los registros se distribuyen dentro de campos y filas bien definidas, lo cual permite buscar, categorizar y ordenar fácilmente de acuerdo a ciertos criterios. Por ejemplo, cuando ingresamos los datos de algún cliente o empleado a través de formularios que piden datos como nombre, apellido, dirección, etc.. Data no estructurada. La data no estructurada es aquella que no tiene un formato predefinido y por tanto no puede ser almacenada en una base de datos tradicional. Por ejemplo, imágenes, videos, audios, textos, etc.. Data semiestructurada. Es aquella que combina los dos tipos de datos descritos anteriormente. Los datos semiestructurados no residen en bases de datos relacionales, pero presentan una organización interna que facilita su tratamiento. Por ejemplo, documentos XML o datos de ubicación anexados a las actualizaciones de las redes sociales..
(35) 35. Tipos de análisis A continuación de definen los conceptos de análisis de datos y análisis de información; asimismo, se indica que tipo de análisis es realizado a través de las herramientas de la plataforma Big Data y qué tipo de análisis es realizado por el gestor de proyecto para la toma de decisiones.. Análisis de datos. Según Judd, McClelland y Ryan (2011), el análisis de datos es un proceso que consiste en inspeccionar, limpiar y transformar datos con el objetivo de obtener información útil que permita al gestor de proyecto realizar un análisis de dicha información, a fin de obtener conclusiones que apoyen la toma de decisiones. Es decir, el análisis de datos puede ser usado en diferentes industrias para permitir que las compañías y las organizaciones tomen mejores decisiones empresariales. Asimismo, también puede ser usado en las ciencias para verificar o reprobar modelos o teorías existentes.. El análisis de datos se usa para describirlo todo. Por ejemplo, los bancos y las compañías de tarjetas de crédito, analizan los retiros y los patrones de gasto para prevenir el fraude o robo de identidad. Asimismo, las compañías de comercio electrónico (Ecommerce) examinan el tráfico en el sitio web o los patrones de navegación para determinar qué clientes son más o menos propensos a comprar un cierto producto o servicio, basándose en compras previas o patrones de visualización. Sin embargo, el análisis de datos moderno usa tableros de información que se basan en flujos de datos en tiempo real. El llamado análisis en tiempo real implica análisis e informes dinámicos basados en los datos introducidos en un sistema un minuto antes del tiempo actual de uso. Para el caso de la presente tesis, el análisis de datos en tiempo real es ejecutado de forma automática mediante la herramienta de la plataforma Big Data Infosphere Streams. Análisis de información. Según Izamorar (2018), el análisis de información es el proceso por el cual una persona (en nuestro caso un gestor de proyecto), realiza el análisis de un conjunto de datos procesados y organizados en reportes y/o dashboards, con el propósito de reducir la incertidumbre e incrementar el conocimiento. Asimismo, el análisis de Información favorece la resolución de problemas puesto que permite una adecuada toma de decisiones..
(36) 36. Estructura de la solución de Análisis de Datos No estructurados. Teniendo en cuenta que las empresas no tienen gran conocimiento acerca del análisis de grandes volúmenes de datos no estructurados, lo primero que se cuestionan es como puede estar conformada o estructurada la solución.. Al respecto, Mitchell, Locke y Wilson (2012), explican el siguiente diagrama que muestra cómo puede estar diseñada una solución de análisis de datos no estructurados, donde los cuadros rojos representan la propia solución. A la izquierda, se encuentran las diferentes fuentes de datos que pueden alimentar un sistema, por ejemplo: Datos abiertos (públicos o proporcionados por el gobierno, datos comerciales), redes sociales (Facebook, Skype, Twitter), datos internos (transacciones en línea o sistemas de análisis), entre otros.. FIGURA N° 8: Estructura de la solución de Análisis de datos No estructurados FUENTE: Libro the white book of Big Data.
(37) 37. La primera función de la solución es la integración de datos, la cual se realiza conectando el sistema a estas diferentes fuentes de datos (usando interfaces de aplicación estándar y protocolos).. Estos datos pueden ser transformados (es decir, cambiados a un formato diferente para un fácil almacenamiento y control) mediante la función “Transformación de datos” o monitoreados por desencadenadores claves (triggers) en la función “Procesamiento de eventos complejos”.. Esta función busca cada pieza de data, la compara con un conjunto de reglas y luego manda una alerta cuando una asociación es encontrada. Algunos motores de procesamiento de eventos complejos también permiten reglas basadas en tiempo.. Luego la data puede ser procesada y analizada casi en tiempo real, mediante la función “Análisis masivo en paralelo” y/o almacenada dentro de la función “Almacenamiento de datos” para un análisis posterior. Toda la data almacenada está disponible tanto para el análisis semántico como para el análisis histórico tradicional. Se debe tener en cuenta que el análisis histórico tradicional significa que la data no es analizada en tiempo real, más no que las técnicas de análisis utilizadas estén pasadas de moda.. La búsqueda de datos es también una parte importante dentro de la solución ya que permite a los usuarios acceder a los datos a través de diferentes formas. Por ejemplo, a través de páginas como Google, Bing, Baidu, Yahoo, entre otros; a través de una simple caja de texto se pueden ingresar los criterios de búsqueda para acceder a datos específicos.. Los datos (ya sean flujos de datos, datos capturados o nueva data generada durante el análisis) también pueden estar disponibles para las partes internas o externas que deseen utilizarlo. Esto puede ser en forma libre o mediante el pago de cuotas dependiendo de quién sea el propietario de los datos. Los desarrolladores de aplicaciones, socios de negocios u otros sistemas que consumen esta información, lo hacen a través de una “Interfaz de acceso a datos”, la cual está representada en el lado derecho del diagrama..
(38) 38. Finalmente, una de las funciones clave de la solución es la “Visualización de datos”, la cual presenta información de negocios en una forma significativa, relevante y fácil de entender.. Esta presentación puede ser textual (Listas o extractos) o gráfica (que van desde simples tablas y diagramas hasta animaciones complejas). Asimismo, esta visualización de datos debería darse en cualquier tipo de dispositivo, desde una PC hasta un Smartphone.. Esta flexibilidad es especialmente importante debido a la variedad de usuarios que existen, cuyas necesidades y preferencias varían. Algunos ejemplos de estos usuarios son: Personal que toma decisiones (administrativos, jefes, gerentes, etc.), consumidores de data (cualquier entidad recibiendo y usando datos), científicos de datos (para crear modelos de predicción), entre otros. Éstos están representados en la parte superior del diagrama.. Cuando considerar una solución de Análisis de Datos No estructurados. A continuación, se detallarán algunos principios que se deben tener en cuenta cuando se desea usar una solución de análisis de datos no estructurados:. Principio 1: Estas soluciones son ideales para analizar no sólo data estructurada sino también data semi o no estructurada proveniente de una infinidad de fuentes u orígenes.. Principio 2: Estas soluciones son ideales para el análisis iterativo y exploratorio de datos.. Principio 3: Estas soluciones son ideales cuando toda o casi toda la data necesita ser analizada versus una muestra de data o cuando una muestra de datos no es tan efectiva como usar un amplio conjunto de datos desde el cual realizar el análisis..
(39) 39. Asimismo, se debe considerar lo siguiente:. ¿Puede este tipo de plataforma complementar el análisis tradicional y alcanzar una sinergia con las soluciones existentes para conseguir mejores resultados en los negocios? Típicamente, la data usada en el análisis de warehouse tiene que estar documentada y ser de confianza antes de que pueda estar dentro de un esquema estricto de warehouse y si no puede encajar dentro de un formato tradicional de filas y columnas ni siquiera puede llegar al warehouse en la mayoría de los casos. En contraste, este tipo de solución no sólo va a aprovechar los datos en cantidades masivas de volumen, que no son típicamente adecuados para un ambiente tradicional de warehouse, sino que también va a renunciar a algunas de las formalidades y severidades de la data. El beneficio está en que se podrá preservar la fidelidad de los datos y ganar acceso a montañas de información para la exploración y descubrimiento de conocimiento en negocios.. Es importante indicar que las bases de datos convencionales son una importante y relevante parte de toda una solución de análisis. Asimismo, se vuelven más vitales cuando se usan en conjunto con una plataforma de análisis de datos no estructurados (Zikopoulos, Eaton y Deroos, 2012).. Beneficios de la solución de Análisis de Datos No estructurados. Existen diferentes beneficios de la solución, a continuación, se detallarán las más importantes, según Reda Chouffani (2013):. Mejor administración de los datos: Muchas de las plataformas de procesamiento de datos permiten actualmente analizar, recolectar y filtrar diferentes tipos de datos. Asimismo, las herramientas de análisis de datos no estructurados permiten a los usuarios trabajar con datos sin tener que realizar demasiados pasos técnicos complicados. Esta capa adicional de abstracción ha permitido numerosos casos de uso donde los datos, en una amplia variedad de formatos, han sido extraídos con éxito para fines específicos..
(40) 40. Beneficios. de. Velocidad,. capacidad. y escalabilidad. por. usar. el. almacenamiento en el Cloud: Las organizaciones que deseen utilizar conjuntos de datos substancialmente grandes, deberían considerar a los proveedores de servicios Cloud, pues pueden proveer tanto el almacenamiento como el poder computacional necesarios para soportar la solución. El almacenamiento en la nube (Cloud) permite a las organizaciones analizar conjuntos de datos masivos sin tener que realizar una inversión significativa de capital en Hardware para poder almacenar la data internamente. Los usuarios finales pueden visualizar los datos: La solución requiere de herramientas de visualización de datos que presenten la data en tablas, gráficos y diapositivas fáciles de leer. Debido a la gran cantidad de datos que son examinados, estas aplicaciones deben ser capaces de ofrecer motores de procesamiento que permitan a los usuarios consultar y manipular la información rápidamente, incluso en tiempo real. Algunos proveedores de herramientas de visualización son: IBM, Microsoft, Oracle, entre otros. Las organizaciones pueden encontrar nuevas oportunidades de negocio: Conforme las herramientas de análisis van madurando, se hace más evidente la ventaja competitiva que significa ser una empresa basada en datos. Por ejemplo: Para las elecciones presidenciales de EE.UU en el 2012, los líderes de campaña en ambos partidos, tanto democráticos como republicanos, vieron una necesidad crítica por obtener información sobre los votantes y sus intereses o problemas específicos; ya que al tomar esta información y hacerle frente a sus problemas a través de un correo personalizado o mediante volantes, significaba la posibilidad de ganar o influir en una votación. Por lo tanto, la información sobre nuestras preferencias, gustos y disgustos es crítica para las empresas. Las redes sociales han identificado oportunidades para generar ganancias en base a la data que recolectan, vendiendo publicidad basada en los intereses particulares de los usuarios. Esto permite a las empresas dirigirse a grupos específicos de clientes que encajan en determinado perfil. Los métodos y capacidades para el análisis de datos evolucionan: Los datos ya no son simples números dentro de una base de datos. Los archivos de texto, audio y video también pueden proveer conocimiento de valor; determinadas herramientas pueden reconocer patrones específicos basados en un criterio determinado. Mucho de esto sucede al utilizar herramientas de procesamiento del.
(41) 41. lenguaje natural, el cual puede resultar vital para minería de textos y análisis de sentimientos. Desafíos del Análisis de Datos No Estructurado. El siguiente gráfico muestra los retos que enfrentan las organizaciones con "grandes volúmenes de datos no estructurados". Según Shields, A. (2014), la complejidad en la integración de datos es el mayor desafío.. 35%. Integración de datos 29.00%. Iniciar con el proyecto adecuado. 27%. Alm acenar grandes volúm enes de datos. 25%. Falta de personal con conocim ientos en Big Data 22%. Propiedad de los datos y otros asuntos políticos Falta de patrocinio em presarial. 20%. Privacidad y seguridad de datos. 20% 17%. Lidear con data en tiem po real. Big Data Challenges. 16%. m odelo de negocios no convincente. 14%. Datos de m ala calidad. 13%. Inm adurez de fuentes y tipos de datos. 12%. Arquitecturas de data Warehouse existentes Infraestructura inadecuada. 8%. Falta de un esquem a para Big Data. 8% 6%. Altos costos. 4%. Otros 0%. 5%. 10%. 15%. 20%. FIGURA N° 9: Desafíos del Análisis de datos No estructurados FUENTE: Must-know: An overview of "big data". 25%. 30%. 35%. 40%.
(42) 42. OBJETIVOS Objetivo general Determinar el impacto de implementar una propuesta de análisis de datos no estructurados, con las herramientas IBM InfoSphere BigInsights, Streams, Information Server y Cognos BI, para generar decisiones oportunas durante la implementación de los proyectos de GMD. Objetivos específicos Determinar el impacto de implementar una propuesta de análisis de datos no estructurados, en la reducción del tiempo de extracción y procesamiento de datos para favorecer la generación de decisiones oportunas.. Determinar el impacto de implementar una propuesta de análisis de datos no estructurados, en la reducción del tiempo de análisis y visualización de datos para favorecer la generación de decisiones oportunas.. Determinar el impacto de implementar una propuesta de análisis de datos no estructurados, en la reducción de costos en los proyectos de TI de GMD, mediante la reducción en el tiempo de extracción y procesamiento de datos.. Determinar el impacto de implementar una propuesta de análisis de datos no estructurados, en la reducción de costos en los proyectos de TI de GMD, mediante el análisis y visualización de datos en tiempo real o casi real..
(43) 43. JUSTIFICACIÓN DE LA INVESTIGACIÓN Justificación Teórica Big Data es el gran conjunto de datos estructurados y no estructurados que cada año aumenta su tamaño y que puede originarse a través de diferentes fuentes como: redes sociales, consultas en motores de búsqueda, correos, Información propia de las empresas, entre otros. En la actualidad, las empresas acumulan cada vez más y más de estos datos; sin embargo, no cuentan con las herramientas, experiencia y conocimientos necesarios para aprovecharla y generar ganancias. Lira Segura, J. en el diario Gestión (2014), indicó que las empresas cuentan con grandes cantidades de datos; sin embargo, no saben qué hacer con ellos; por lo tanto, es momento de que vean el análisis de datos no estructurados como una fuente de riqueza y comiencen a obtener ganancias en lugar de verlo como una carga. Por otro lado, de acuerdo con un estudio de Edgell Knowledge, sólo el 80% de los minoristas ha escuchado sobre el término “Grandes volúmenes de datos no estructurados” y de ellos, sólo el 47% entiende cómo aplicarlo a su negocio. Asimismo, según el IDC, el 90% de los datos a nivel mundial han sido creados tan sólo en los últimos dos años, estimando que el volumen de registros digitales crezca a 1.2 millones de zetabytes este año y 44 veces más durante la siguiente década.. Justificación Práctica GMD es una empresa dedicada a la provisión de soluciones de tecnología de la información (servicios de outsourcing de TI) a empresas a nivel nacional de diferentes sectores como comercio, banca y finanzas, gobierno, entre otros. La fase de implementación de las soluciones de TI es la etapa más corta y critica del proyecto, pues es la etapa donde se desarrolla el servicio de acuerdo con el alcance ofrecido y vendido al cliente; por tanto, es indispensable poder contar con una solución de análisis de datos que permita agilizar la toma de decisiones y reducir los costos de los proyectos. Para lograr este objetivo, es necesario incluir la mayor cantidad de información disponible, tanto estructurada (Aprox. 20% de la información total) como no estructurada (Aprox. 80% de la información total), con la finalidad de obtener el máximo provecho posible.. Con respecto al punto anterior, Intel indicó lo siguiente: El análisis de grandes volúmenes de datos no estructurados, ofrece la promesa de proveer información valiosa.
(44) 44. que puede crear ventajas competitivas, desatar nuevas innovaciones e impulsar mayores ingresos. (IT Center, 2014, p.3).. ALCANCE DEL PROYECTO La siguiente investigación abarcará únicamente la presentación de una propuesta para el análisis de datos no estructurados, con la finalidad de generar decisiones oportunas en la fase de implementación de proyectos de TI (Área de Implementación, Innovación y Gestión de proyectos de la Línea de Negocio ISO), de la empresa GMD. Dicha generación de decisiones es responsabilidad de los jefes y gerentes de proyectos de TI.. Asimismo, se analizará la situación actual (Antes) mediante una encuesta realizada por los jefes y gerentes de proyecto, con la finalidad de medir el tiempo en la recolección, búsqueda, procesamiento y análisis de datos actual. Asimismo, se medirá el tiempo ideal esperado por los jefes y gerentes para la obtención de resultados en un análisis de datos.. Por último, para el análisis de la situación posterior (después) se utilizará la técnica de juicio de expertos, mediante la cual se realizará una encuesta a expertos en la materia, con la finalidad de sustentar los hallazgos e hipótesis de la presente tesis.. LIMITACIONES DEL PROYECTO Por temas de costo y tiempo, la presente investigación no abarcará el proceso de implementación y construcción de la solución, ni los temas relacionados a la infraestructura de Hardware.. Asimismo, se tendrá como limitante la disponibilidad de tiempo de los jefes y gerentes de proyectos y expertos en la materia para realizar las encuestas que sustentarán los hallazgos..
Figure



+7





Documento similar
En suma, la búsqueda de la máxima expansión de la libertad de enseñanza y la eliminación del monopolio estatal para convertir a la educación en una función de la
6 Para la pervivencia de la tradición clásica y la mitología en la poesía machadiana, véase: Lasso de la Vega, José, “El mito clásico en la literatura española
[r]
Figura 1. Trayectoria textual de los materiales impresos a lo largo de una unidad didáctica Fuente: elaboración propia... Por cuestiones de espacio, limito el análisis a las
d) que haya «identidad de órgano» (con identidad de Sala y Sección); e) que haya alteridad, es decir, que las sentencias aportadas sean de persona distinta a la recurrente, e) que
En este trabajo estudiamos la obra poética en español del escritor y profesor argelino Salah Négaoui, a través de la recuperación textual y análisis de Poemas la voz, texto pu-
A ello cabría afladir las intensas precipitaciones, generalizadas en todo el antiguo reino valenciano, del año 1756 que provocaron notables inundaciones y, como guinda final,
En la parte central de la línea, entre los planes de gobierno o dirección política, en el extremo izquierdo, y los planes reguladores del uso del suelo (urbanísticos y
