Visualización de resultados de algoritmos de agrupamiento
77
0
0
Texto completo
(2) DEDICATORIA. A mi madre, a Mayito, a toda mi familia y amigos.. II.
(3) AGRADECIMIENTOS. A Oves, Carlos y Romel por su guía y dedicación en este trabajo A mi madre, a Mayito y a toda mi familia por su apoyo incondicional A Alcides por su guía y consejos A Baranda, Albanis y el Chinón por su amistad eterna A mi novia por darme soporte y comprensión cuando más lo necesitaba A Donna, el chino y Dayana por su esfuerzo en la revisión de esta tesis A todos mis amigos, que sin su apoyo hubiese sido imposible la realización de este trabajo.. III.
(4) RESUMEN. RESUMEN. En la mayoría de las técnicas de visualización de resultados de algoritmos de agrupamiento, la calidad de la misma se ve afectada por el aumento de la cantidad de elementos del conjunto de datos a analizar, y de la dimensión de los mismos. El objetivo de la investigación consiste en desarrollar un sistema informático que permita visualizar los resultados de algoritmos de agrupamiento, mediante el diseño de un modelo de visualización que pretende superar las desventajas referidas anteriormente. Como resultado se desarrolló el software ClusVis que implementa el modelo de visualización que se propone en la investigación. Dicha herramienta le permite al usuario extraer información relevante sobre las soluciones de estos algoritmos, a través de consultas visuales e interacciones realizadas sobre el gráfico.. IV.
(5) ABSTRACT. ABSTRACT. In most visualization techniques results clustering algorithms, the quality of it is affected by the increase in the number of elements in the dataset analyzed, and the size of them. The aim of the research is to develop a computer system to visualize the results of clustering algorithms, by designing a display model that aims to overcome the disadvantages mentioned above. As a result, developed the software that implements ClusVis display the model proposed in the research. This tool allows the user to extract relevant information about the solutions of these algorithms through visual queries and interactions carried out on the graph.. V.
(6) TABLA DE CONTENIDOS. TABLA DE CONTENIDOS. INTRODUCCIÓN .............................................................................................................1 1. MINERÍA VISUAL DE DATOS................................................................................1 1.1.. AGRUPAMIENTO ..............................................................................................3. 1.2.. VISUALIZACIÓN ...............................................................................................7. 1.3.. ANÁLISIS DE LAS TÉCNICAS MÁS USADAS PARA LA VISUALIZACIÓN. DE RESULTADOS DE ALGORITMOS DE AGRUPAMIENTO ................................ 11 1.4.. CONCLUSIONES PARCIALES ....................................................................... 20. 2. VISUALIZACIÓN DE RESULTADOS DE ALGORITMOS DE AGRUPAMIENTOS ........................................................................................................ 22 2.1.. DISEÑO DEL MODELO DE VISUALIZACIÓN DE LOS RESULTADOS DE. ALGORITMOS DE AGRUPAMIENTO ...................................................................... 22 2.1.1.. RELACIÓN ENTRE LA REPRESENTACIÓN VISUAL Y. LAS. CARACTERÍSTICAS DE LOS DATOS .................................................................. 22 2.1.2.. ESTRUCTURA DEL MODELO VISUAL PROPUESTO ..........................24. 2.1.3.. POSIBLES INTERACCIONES A REALIZAR SOBRE EL MODELO. PRPUESTO.............................................................................................................. 27 2.2.. PLATAFORMA DE DESARROLLO ................................................................ 29. 2.3.. DISEÑO DEL SISTEMA................................................................................... 30. 2.4.. IMPLEMENTACIÓN DEL MODELO ..............................................................33 VI.
(7) TABLA DE CONTENIDOS. 3.. 2.5.. FLUJO DE TRABAJO DEL SISTEMA ............................................................. 38. 2.6.. CONCLUSIONES PARCIALES ....................................................................... 44. SOFTWARE ClusVis-M3D......................................................................................45 3.1.. REQUERIMIENTOS .........................................................................................45. 3.2.. INSTALACIÓN DE LA APLICACIÓN ............................................................45. 3.3.. MANUAL DE USUARIO .................................................................................. 47. 3.4.. CONCLUSIONES PARCIALES ....................................................................... 57. CONCLUSIONES GENERALES ....................................................................................58 RECOMENDACIONES ..................................................................................................59 BIBLIOGRAFÍA.............................................................................................................. 60. VII.
(8) INTRODUCCIÓN. INTRODUCCIÓN La cantidad de información está continuamente creciendo; sin embargo, la habilidad de los humanos para procesarla y asimilarla permanece constante (Dixon, 1997). Además, la información en sí misma tiene pocas ventajas, su sistematización, incorporación y utilización son los elementos que aportan su valor añadido: el conocimiento. Es necesario crear sistemas que generen conocimiento, para asegurar el uso productivo de la información y apoyar en la toma de decisiones, contribuyendo de esta forma a la Gestión del Conocimiento (Bueno, 2001, Dalkir, 2005). La magnitud gigantesca de los datos puede evidenciarse en los siguientes ejemplos (Bramer, 2007): ·. El satélite TIERRA genera 1TB de datos diariamente, compuesto en su totalidad por imágines del tipo ráster que son tomadas de diferentes localizaciones del planeta.. ·. El proyecto del Genoma Humano almacena cientos de bytes por cada una de los billones de bases genéticas.. ·. El censo de los Estados Unidos en el año 1990 generó una considerable suma que sobrepasó el millón de millones de bytes.. ·. Muchas compañías en el mundo mantienen Data Warehouses de transacciones de clientes. Un data warehouse pequeño puede contener cientos de millones de transacciones.. Gracias a los avances en la tecnología actual, que han posibilitado el almacenamiento de esta inmensa cantidad de datos, se hace cada vez más relevante y verídico el hecho de que los datos contienen conocimientos que son un eje central en el crecimiento o caída de una compañía. Este conocimiento puede conducir a importantes descubrimientos científicos, nos permite hacer una predicción del tiempo y de desastres naturales, nos puede conducir a la cura de enfermedades letales, además puede significar literalmente, la diferencia entre la vida o la muerte (Bramer, 2007). 1.
(9) INTRODUCCIÓN. En general se asume que, de todos los datos que son generados, se puede almacenar únicamente una cuarta parte y de la misma puede ser analizada otra cuarta parte, perdiéndose así la mayor cantidad de la información (Perez and Ortega, 2005). Debido a ello debemos citar lo expuesto por Bramer: el mundo se ha vuelto “rico en datos pero pobre en conocimiento” (Bramer, 2007). El conocimiento se gestiona de diversas formas y hacerlo requiere de la integración de expertos de diferentes ramas científicas enfocados en la búsqueda de soluciones concretas para problemas específicos. La minería de datos integra la recuperación y extracción de información, el análisis de datos, el resumen, la categorización, la clasificación, el agrupamiento, la visualización, la tecnología de bases de datos y el aprendizaje automático (Tan, 1999). La categorización, la clasificación y el agrupamiento son utilizados para refinar resultados de la recuperación y extracción de información, y de esta forma contribuir al descubrimiento de conocimiento. Especialmente el agrupamiento y los procesos post-agrupamiento permiten organizar la información, detectar información relevante y crear un nuevo conocimiento a partir de la información disponible en una colección especificada o resultante de un proceso de recuperación de información. La visualización de dichos resultados puede ayudar a asimilar rápidamente esta información y proveer resultados que apoyen y complementen descripciones textuales o resúmenes estadísticos. Permite conocer rápidamente cuán bien definidos están los grupos, cuán diferentes son uno del otro, cuál es su tamaño, y cómo son las pertenencias de las observaciones hacia el grupo siendo fuertes o marginales, entre otros. Visualizar la solución de un agrupamiento proporciona numerosas facilidades. El usuario analista durante el proceso (altamente interactivo) de construcción del modelo puede obtener, rápidamente, respuestas previas mediante la visualización; la cual puede sugerir la adecuación de la solución y la conducción a experimentos futuros. Por otra parte, el usuario no analista consigue examinar y consultar la solución final del agrupamiento mediante la visualización.. 2.
(10) INTRODUCCIÓN. Las condiciones y dificultades presentes en el análisis post-agrupamiento nos conduce a formular el siguiente problema de investigación: PROBLEMA DE INVESTIGACIÓN Existen técnicas de visualización para facilitar el entendimiento de los resultados de algoritmos de agrupamiento. En su mayoría, a medida que aumenta la cantidad de elementos y grupos en los datos a analizar, comienza a actuar el solapamiento y se dificulta significativamente la extracción de conocimientos específicos. Esto no implica que tales técnicas no realicen un buen trabajo en el agrupamiento de datos. Debemos considerar que los aspectos de usabilidad, como interfaces intuitivas y no sobresaturadas1, visualizan la mayor cantidad de características del conjunto de datos; el cual no está muy referenciado y refinado por la complejidad del problema. La mayoría de las técnicas de visualización de resultados de algoritmos de agrupamiento no son igualmente convenientes para todos los tipos de datos, debido a que en muchos casos presentan deficiencias cuando los datos son multiparamétricos de muchas dimensiones2. Además, los usuarios no están siempre dotados de conocimientos requeridos para interpretar y analizar el significado de estos resultados, de ahí la necesidad de representaciones visuales que hagan más intuitiva la interpretación de la información mostrada y la no dependencia de la dimensión del conjunto de datos. OBJETIVO GENERAL ·. Desarrollar un sistema informático que permita realizar el análisis visual de los resultados obtenidos por algoritmos de agrupamiento.. 1 2. Ocurre el solapamiento cuando existe una gran aglomeración visual en los datos. Se dice que existe grandes dimensiones en los datos cuando el número de atributos es mayor que tres.. 3.
(11) INTRODUCCIÓN. OBJETIVOS ESPECÍFICOS ·. Diseñar un modelo de representación gráfica capaz de visualizar los resultados de algoritmos de agrupamiento a través de mallas tridimensionales.. ·. Implementar un conjunto de interacciones básicas para el trabajo sobre la malla resultante.. ·. Definir e implementar un mecanismo para la gestión de consultas visuales sobre la malla.. JUSTIFICACIÓN DE LA INVESTIGACIÓN La visualización de los resultados de algoritmos de agrupamiento es considerado de gran utilidad para los especialistas mediante representaciones tridimensionales sobre mallas y brinda facilidades inimaginables para la interpretación de los resultados y para el apoyo en la toma de decisiones. Por otro lado, las medidas de calidad de los resultados de los algoritmos de agrupamiento, pueden medirse mediante la parametrización de metáforas visuales asociadas al modelo resultante. Una vez más el color, el volumen y la forma se identifican como medidas de calidad para medir la misma tanto entre grupos como entre los elementos de un mismo grupo. Mediante esta técnica de visualización, se reduce la visualización tradicional de resultados de algoritmos de agrupamientos a la visualización de la topología de los grupos solamente, disminuyendo considerablemente la complejidad del modelo y el número de objetos a visualizar y aumentando el entendimiento de los resultados sin obviar la fiabilidad del algoritmo. Se cuenta con un laboratorio equipado profesionalmente con el personal calificado y dotado para asistir de consultante. Se cuenta con los conocimientos necesarios sobre programación y sobre las técnicas de visualización. Debemos partir de que tanto las técnicas de visualización existentes como los algoritmos de agrupamiento han sido, en el transcurso de los años, objetos de estudios de los grupos de computación gráfica y de inteligencia artificial de la UCLV respectivamente, por lo que se puede confiar en que los objetivos propuestos serán alcanzados. 4.
(12) INTRODUCCIÓN. HIPÓTESIS DE INVESTIGACIÓN La visualización de los resultados de algoritmos de agrupamiento usando mallas tridimensionales disminuye considerablemente la complejidad del modelo y el número de objetos a visualizar. Aumenta la posibilidad para interpretar el modelo y mantiene la topología de los grupos. ESTRUCTURA GENERAL DE LA TESIS El presente informe de la investigación consta de tres capítulos. El primer capítulo aborda los aspectos teóricos relacionados con la minería visual de datos. Se brinda una definición del agrupamiento y se caracterizan los algoritmos de agrupamiento de acuerdo a una clasificación dada. Se exponen elementos importantes sobre la visualización científica y la visualización de la información, así como su importancia en la extracción del conocimiento. Por último se realiza un análisis de algunas de las principales técnicas de visualización de los resultados de estos algoritmos y se enfatiza en las desventajas comunes que presentan. En el capítulo 2 se brinda una solución al problema planteado y se fundamentan matemáticamente algunas de las definiciones auxiliares usadas en el software. Se expone el diseño y desarrollo de una herramienta que implementa el modelo de visualización propuesto, su flujo de trabajo, así como un conjunto de interacciones que le brindan potencialidad y usabilidad a la aplicación. En el capítulo 3 se presentan algunas cuestiones y requerimientos que deben cumplirse en el sistema para poder ejecutar el software. Se ofrece un manual de usuario de la aplicación y finalmente. se. brindan. las. conclusiones. 5. y. recomendaciones. del. trabajo..
(13) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. 1. MINERÍA VISUAL DE DATOS Por lo general, los usuarios especifican algunos parámetros para restringir el espacio de búsqueda. Posterior a ello, la minería de datos es ejecutada por algún algoritmo y finalmente, los patrones encontrados por el algoritmo son presentados al usuario a través de la pantalla. Esto se debe a que la cantidad de patrones generados por un algoritmo, excede habitualmente el número que puede ser interpretado y evaluado en forma textual, considerando que la información asociada a los patrones es visualizada. Se debe mencionar que la visualización sirve como un canal de comunicación de post-procesamiento entre la computadora y el usuario. Con el uso de visualizaciones apropiadas, el usuario puede estar estrechamente integrado al proceso de descubrimiento del conocimiento (KDD) produciendo una mejora significativa en el conocimiento obtenido a través de dicho proceso: La calidad de los patrones resultantes se puede incrementar abasteciendo adecuadas visualizaciones de datos y conocimiento, debido a que la capacidad humana para reconocer patrones puede ser usada, además para incrementar significativamente la efectividad de los patrones minados (Ankerst, 2000). El término “minería visual de datos” no cuenta con una única definición, debido a la diferencia de criterios existentes entre los autores que tratan el tema. La minería visual de datos está conformada por la integración de varias disciplinas tales como: bases de datos,. minería de datos y. visualización. Esta pretende ayudar tanto en el. descubrimiento del conocimiento, como en el apoyo en la toma de decisiones cuando se presentan grandes volúmenes de datos. Incluye mecanismos interactivos de respuesta rápida basados en técnicas de navegación, filtros, facilidades para la construcción de consultas dinámicas y algoritmos de agrupamiento guiados con técnicas de visualización interactivas; para así encontrar comportamientos y tendencias en los datos (Suárez, 2003). Otra definición, menos explicativa, pero igual de precisa es la abordada en la siguiente cita: 1.
(14) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. La minería visual de datos es una etapa en el proceso del KDD que utiliza la visualización como un canal de comunicación entre la computadora y el usuario para producir patrones novedosos e interpretables (Ankerst, 2000). Esta definición sitúa la minería visual de datos en las dos últimas etapas del proceso del KDD, llamadas minería de datos y evaluación, donde patrones novedosos son producidos por determinados algoritmos y luego visualizados para convertirlos en patrones interpretables. De acuerdo con esta última definición podemos clasificar la minería visual de datos en tres clases: ·. Visualización de los datos: Los datos son visualizados inmediatamente sin apoyo previo en los resultados de algún algoritmo sofisticado. Mediante la interacción y la operación sobre la visualización, el usuario tiene control total sobre la búsqueda en el espacio de búsqueda y los patrones son obtenidos mediante la exploración de los datos.. ·. Visualización de resultados intermedios: Un algoritmo ejecuta un análisis sobre los datos sin producir los patrones finales pero sí un resultado intermedio que puede ser visualizado apropiadamente. Luego el usuario recupera patrones interesantes en la visualización del resultado intermedio y reconfigura las entradas del algoritmo para volver a ponerlo en ejecución y de esta manera refinar la solución final. Una motivación básica para esta clase es hacer la parte algorítmica independiente de la aplicación. Un algoritmo de minería de datos puede ser muy útil en un dominio pero puede tener muchas desventajas en otro dominio. Puesto que no existe un algoritmo apropiado para todas las aplicaciones, la parte principal es ejecutada y sirve como base multipropósito para posteriores análisis dirigidos por el usuario.. ·. Visualización de los resultados de la minería de datos: Un algoritmo ejecuta la tarea de minería de datos y realiza la extracción de patrones ocultos en los datos. Estos patrones son visualizados para hacerlos interpretables. Basado en la visualización, el usuario puede querer retornar al algoritmo y volverlo a ejecutar con diferentes parámetros de entrada (Ankerst, 2000) . 2.
(15) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. 1.1. AGRUPAMIENTO El volumen de datos es cada día mayor y esto se debe al crecimiento exponencial de las colecciones de datos no estructurados. Por tanto, es fundamental el desarrollo de técnicas que permitan el análisis exploratorio de los datos. El análisis de grupos permite descubrir la estructura interna de estos e identificar distribuciones interesantes y patrones subyacentes en los mismos, considerando muy poca o ninguna información a priori (Levine and Domany, 2001). El análisis de grupos es descrito como una herramienta para el descubrimiento debido a la potencialidad de revelar relaciones (basadas en datos complejos) no detectadas previamente. Los algoritmos de agrupamiento son usados para encontrar una estructura de grupos que se ajuste al conjunto de datos, logrando homogeneidad dentro de los grupos y heterogeneidad entre ellos (Anderberg, 1973). El análisis de agrupamiento es un método primario para la minería de datos. Es usado como herramienta para obtener una aproximación de la distribución del conjunto de datos. Es empleado además para enfocar el posterior análisis y el procesamiento de los datos o como etapa de pre-procesamiento para otras operaciones algorítmicas sobre los grupos detectados. Los elementos dentro de los grupos deben ser internamente homogéneos (cohesión interna), mientras que de grupo a grupo deben ser heterogéneos (separación externa) (Anderberg, 1973). Cuando el agrupamiento se basa en la similitud de los objetos, se desea que los que pertenezcan (Ankerst, 2000) al mismo grupo sean tan similares como se pueda y los objetos que pertenecen a grupos diferentes sean tan diferentes como sea posible (Höppner et al., 1999, Kruse et al., 2007). El concepto de “similitud” tiene que ser especificado acorde a los datos. En la mayoría de los casos los datos son vectores de valores reales, por lo se requieren algunas medidas (distancias, similitudes, o disimilitudes) para cuantificar el grado de asociación entre ellos. Como ejemplos de dichas medidas tenemos la distancia euclidiana, la distancia Minkowski – que es equivalente a la distancia Manhatan o city-block, y a la Euclidiana cuando g es 1 y 2, respectivamente 3.
(16) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. (Batchelor, 1978) - , la distancia Euclidiana Heterogénea, la distancia Camberra, el coeficiente coseno, el coeficiente de Dice, el de Jaccard, entre muchas otras. Los métodos de agrupamiento se clasifican siguiendo varios criterios: tipo de datos de entrada del algoritmo, criterios para definir la similitud entre los objetos, conceptos en los cuales se basa el análisis y forma de representación de los datos, entre otros (Halkidi et al., 2001). Una clasificación general distingue dos tipos: aquellos basados en una función objetivo y los jerárquicos(Han and Kamber, 2001, Pedrycz, 2005). Esta primera categoría más general se refiere a la construcción de particiones (grupos) del conjunto de datos sobre la base del perfeccionamiento de algún índice, conocido también como función objetivo. En esencia, dividir n objetos en un número positivo de k grupos, generalmente especificado a priori. El objetivo de estos métodos es encontrar la mejor división de los datos en k grupos basada en una medida de similitud dada y conservar el espacio de particiones posibles en k subconjuntos solamente. La mayoría de los algoritmos que siguen esta técnica son esencialmente basados en prototipos, comienzan con una partición inicial, usualmente aleatoria, y proceden con su refinamiento(Kruse et al., 2007). Uno de los algoritmos que sigue esta primera categoría y que ha sido ampliamente utilizado es el k-medias (k-means). Este algoritmo funciona mejor con grupos que tienen forma convexa y requiere que el número de grupos a obtener se especifique a priori, por tanto requiere un cierto conocimiento del dominio, ya que es sensible a cómo se hizo inicialmente la partición. El algoritmo k-medias tiene una complejidad temporal O(Ikn), donde I se utiliza para indicar número de iteraciones, n el número de objetos y k el número de grupos (Kaufman and Rousseeuw, 1990). A partir de él se han derivado varios como el x-medias (x-means) que estima eficientemente el número de grupos, el llamado conjunto k-medias (batch k-means) (Berry, 2004), el PAM (Kaufman and Rousseeuw, 1990) y sus mejoras CLARA y CLARANS (Ng and Han, 1994). Los algoritmos jerárquicos, por su parte, hacen una descomposición jerárquica de los objetos. Dentro de ellos, los aglomerativos (bottom-up) consideran que cada objeto constituye un grupo; 4.
(17) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. donde inicialmente existen tantos grupos como objetos tiene la colección. Sucesivamente se unen hasta que todos los objetos formen un único grupo, considerando generalmente alguna de las medidas de distancia, dentro de ellas, el enlace simple (Gower and Ross, 1969) y el enlace completo (Backer and Hubert, 1976); estas son ampliamente utilizadas. Los divisivos (top-down) a su vez consideran inicialmente que existe un único grupo al cual pertenecen todos los objetos y sucesivamente dividen los grupos en otros más pequeños, hasta que cada grupo contenga un único objeto. La construcción de la jerarquía se puede detener por criterios automáticos o del usuario. Muchas veces combinar o dividir grupos es comprometido y no puede ser deshecho o refinado. Las técnicas jerárquicas han sido utilizadas en problemas de minería de datos, a pesar de tener alta complejidad temporal, generalmente cuadrática. El BIRCH (Zhang et al., 1996) es una variante con complejidad lineal pero no descubre grupos con calidad, requiere de parámetros de entrada que pueden forzar el tamaño de los grupos, es además sensible al orden de los datos de entrada y es cuestionable su uso en datos con alta dimensionalidad. También se encuentra el CURE que es capaz de captar grupos de varias formas y tamaños, tiene una alta complejidad O(n2log n) y es sensible a varios parámetros de entrada(Guha et al., 1998). Otros tipos de métodos han emergido para el análisis de grupos, principalmente motivados en problemas específicos de minería de datos. El agrupamiento basado en densidad (density-based clustering) agrupa objetos vecinos de un conjunto de datos basándose en condiciones de densidad. Estos difieren de los algoritmos que obtienen particiones mediante la relocalización iterativa de puntos a partir del número de grupos. Los algoritmos DBSCAN (Ester et al., 1996) y DENCLUE(Hinneburg and Keim, 1998) son ejemplos de algoritmos basados en densidad. Ambos tienen una complejidad O(nlogn), no funcionan de manera adecuada con datos de alta dimensionalidad y dependen altamente de los parámetros iniciales. También se encuentra el OPTICS (Ankerst et al., 1999) que es una variante mejorada del DBSCAN. El agrupamiento basado en celdas (grid-based clustering) es esencialmente propuesto para la minería de datos espaciales. Algunos algoritmos basados en celdas son STING (Wang et al., 5.
(18) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. 1997), WaveCluster (Sheikholeslami et al., 2000) y CLIQUE (Agrawal et al., 1998). Estos algoritmos son escalables, tienen complejidad O(n), pero no son buenos para datos con alta dimensionalidad, ya que se focalizan en la modelación de la estructura geométrica de objetos en el espacio y no dependen de una medida de distancia. Existe una clasificación que divide el agrupamiento en conceptual y estadístico. Por otra parte, aquellos algoritmos que utilizan métodos geométricos y técnicas de proyección se clasifican en agrupamiento incompleto o heurístico (Höppner et al., 1999). Otras propuestas agrupan utilizando redes neuronales artificiales, por ejemplo, mapas auto-organizativos (Self Organizing Maps: SOM) (Halkidi et al., 2001). Algunos agrupamientos se basan en modelos (model-based clustering) encontrando buenas aproximaciones de los parámetros del modelo que mejor ajusten a los datos. Otra clasificación, no mutuamente excluyente a las ya presentadas, considera la forma de manipular la incertidumbre en términos del solapamiento de los grupos: agrupamiento duro y borroso. Las técnicas duras pueden ser deterministas o con solapamiento. Las deterministas crean una partición donde los grupos son mutuamente excluyentes y exhaustivos del universo de objetos. Los algoritmos con solapamiento crean un cubrimiento, donde un objeto puede pertenecer a más de un grupo. Las técnicas borrosas se subdividen en probabilísticas y posibilísticas. El algoritmo EM (Bradley et al., 1998), base del agrupamiento basado en modelos probabilísticos y su mejora FREM (Ordonez and Omiecinski, 2002), son variantes del algoritmo k-medias y asignan a los objetos una distribución de probabilidad de pertenencia a cada grupo. Estos manipulan datos de alta dimensionalidad, pero realizan un refinamiento muy costoso. Otra clasificación divide los algoritmos en estáticos e incrementales. Estos últimos tienen la habilidad de procesar nuevos datos que son adicionados a la colección, por ejemplo: el flujo de noticias. El algoritmo k-medias incremental (incremental k-means) es una muestra de este tipo de algoritmos (Berry, 2004). El análisis mixto de grupos (joint cluster analysis) es otra técnica de agrupamiento que integra aquellos métodos que trabajan tanto con las propiedades endógenas de los objetos, como con las 6.
(19) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. relaciones que existen entre ellos. El agrupamiento basado en restricciones (constraint-based clustering) reúne a aquellos algoritmos que consideran aspectos más significativos acorde a los requerimientos de la aplicación. La información obtenida de los resultados de un algoritmo de agrupamiento es extensa. Un modelo mixto o un modelo K-Means produce k*s (k: grupos, s: observaciones – objetos o puntos) probabilidades condicionales o distancias, lo que significa mucha información a procesar para un conjunto de datos de medianas o grandes dimensiones. Además, no siempre los usuarios finales que van a utilizar dicha información cuentan con el conocimiento técnico necesario para interpretar la salida de estos algoritmos de agrupamiento. La visualización de estos resultados puede ayudar a asimilar rápidamente esta información y proveer resultados que apoyen y complementen descripciones textuales o resúmenes estadísticos. Permite conocer rápidamente cuán bien definidos están los grupos, cuán diferentes son uno del otro, cuál es su tamaño, y cómo son las pertenencias de las observaciones hacia el grupo, si fuertes o marginales, entre otros. Visualizar la solución de un agrupamiento provee numerosas facilidades. El usuario analista durante el proceso (altamente interactivo) de construcción del modelo puede obtener de manera muy rápida respuestas previas mediante la visualización que pueden sugerir la adecuación de la solución y la conducción a experimentos futuros. Por otra parte, el usuario no analista puede examinar y consultar la solución final del agrupamiento mediante la visualización.. 1.2. VISUALIZACIÓN El campo de la visualización se enfoca en la creación de imágenes que conllevan a información notable sobre los datos subyacentes y los procesos. En las pasadas tres décadas ha tenido un crecimiento sin precedentes en el ámbito computacional y una adquisición de tecnologías que ha resultado en una creciente habilidad, tanto para percibir el mundo real con una muy detallada precisión como para modelar y simular complejos fenómenos. Dada estas capacidades, la visualización juega un papel crucial en la comprensión de extensos y complejos conjuntos de 7.
(20) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. datos que: en dos, tres o más dimensiones proveen información valiosa sobre diversas aplicaciones como procesos médicos, ciencia terrestre y espacial, flujos complejos y procesos complejos, entre muchas otras áreas. La visualización es un método computacional el cual transforma lo simbólico en geométrico, permitiendo a los investigadores observar sus simulaciones y procesos computacionales. La visualización ofrece una vía para observar lo inadvertido. En muchos campos está revolucionando la forma en que los científicos hacen ciencia. El objetivo de la visualización es apoyar los existentes métodos científicos proporcionando nuevos enfoques a través de los métodos visuales (Hansen and Johnson, 2005). La visualización, desde una perspectiva computacional, es la transformación de datos a una representación que puede ser percibida por los sentidos; sus resultados son visuales, auditivos, táctiles o una combinación de estos (J. Foley, 1994). La visualización puede dividirse en tres campos fundamentales: Visualización de Software, Visualización de Información y Visualización Científica (Suárez, 2003). La Visualización de Software comprende la visualización de algoritmos y de programas computacionales. La primera consiste en visualizar abstracciones de alto nivel que describen el software, mientras que la segunda se refiere al código real del programa y a sus estructuras de datos. Ambas pueden darse en forma estática o dinámica. La estática está representada generalmente por medio de organigramas, mientras que la dinámica se denomina animación de algoritmos. La visualización estática de código puede incluir algún tipo de mejoramiento de la impresión, mientras que la representación dinámica del programa puede destacar las líneas de código cuando están siendo ejecutadas. Por ejemplo, en el área de la visualización de la programación lógica, el principal objetivo es la representación gráfica adecuada tanto de las reglas de inferencia como del flujo entre ellas(Suárez, 2003). La Visualización de Información consiste en el uso interactivo de representaciones visuales, auditivas y sensoriales en general y de datos abstractos; con el objetivo de aumentar el 8.
(21) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. conocimiento. Es además, el proceso de interiorización del conocimiento mediante la percepción de información, el cual interviene en el paso de los datos a información y la posibilidad de la construcción del conocimiento al revelar patrones que subyacen de los datos (S. K. Card, 1999). La Visualización Científica permite generar y manipular una representación gráfica de un conjunto de datos. Las técnicas de visualización científica son aceptadas como una vía para la extracción de información relevante de un conjunto de datos de gran tamaño. Esto se debe a que el cerebro humano es capaz de analizar, con mayor facilidad, una simple imagen que resume una gran cantidad de información (Andrews, 2005). Los algoritmos de Visualización Científica transforman un conjunto de datos en otro y también sus dimensiones. Dichas transformaciones pueden categorizarse de acuerdo a su estructura, considerando los efectos que tienen las mismas en la topología y geometría del conjunto de los datos, y de acuerdo al tipo de datos con que opera el algoritmo, los cuales son: escalares, vectoriales, tensoriales y modelados. Estos últimos capturan todos los algoritmos que no se ajustan a ninguna de las categorías anteriores ni combinaciones entre estas(C. R. Johnson, 2005). La visualización científica es empleada de 3 formas: ·. Análisis exploratorio: se utiliza sobre datos donde no se conoce hipótesis de estos y se realiza una búsqueda interactiva de la información, usualmente al azar, que permite conformar una hipótesis sobre el conjunto de datos.. ·. Análisis confirmativo: se conoce una hipótesis sobre los datos y se realiza el chequeo específico de dicha hipótesis que provee la confirmación o la negación de la misma.. ·. Presentación: se conocen hechos sobre los datos, se realiza un proceso de reconocimiento de estos hechos y se obtiene una visualización que enfatice los mismos.. Son muchas las técnicas de visualización científica existentes. Diversos enfoques se han empleado para agruparlas y clasificarlas. Un enfoque establecido para clasificar las técnicas, es a través de los tipos de datos sobre los que operan. Según este criterio podemos encontrar las siguientes categorías (Hansen and Johnson, 2005, Theisel, 2000): 9.
(22) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. ü Técnicas de visualización para datos volumétricos. ü Técnicas de visualización para fluidos. ü Técnicas de visualización para datos multiparamétricos. ü Técnicas de visualización de la información. Dentro de los enfoques establecidos para la especificación de los datos se definen características específicas como la dimensionalidad, el nivel de medición y la estructura. En este trabajo se utilizará el enfoque que se brinda en (Hansen and Johnson, 2005, Perez et al., 2006) para definir los mismos, el cual será descrito a continuación. Los datos volumétricos representan una malla de tres dimensiones donde cada punto tiene asociado un valor. En general los datos se definen como un conjunto S de m muestras, donde cada elemento de S es un vector de la forma (x, y, z, v) que contiene las coordenadas espaciales y un valor v, que es escalar (Gallagher, 1994). Los campos vectoriales representan una malla de dimensión menor o igual que tres donde cada punto está relacionado con un vector. Una de las áreas de mayor uso de los campos vectoriales es para representar datos de fluidos. Los datos multiparamétricos son aquellos en que el número de variables relacionadas con cada observación es mayor o igual que dos. Estas variables pueden ser cuantitativas o cualitativas y a su vez ordinales o nominales (Perez and Ortega, 2005, Theisel, 2000). En algunas aplicaciones, los datos presentan una estructura que no concuerda con ninguna de las anteriores o que sencillamente no puede ser definida con exactitud. A estos datos se le suele llamar información y entre las principales se identifican estructuras como árboles, grafos e hipertexto (Hansen and Johnson, 2005, Theisel, 2000).. 10.
(23) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. 1.3. ANÁLISIS DE LAS TÉCNICAS MÁS USADAS PARA LA VISUALIZACIÓN DE RESULTADOS DE ALGORITMOS DE AGRUPAMIENTO “El agrupamiento es un proceso subjetivo; el mismo conjunto de datos usualmente necesita ser agrupado de formas diferentes dependiendo de las aplicaciones” (Jain et al., 1999). Esta subjetividad hace el agrupamiento difícil, y aún más su validación. La visualización de los resultados de un algoritmo de agrupamiento puede ayudar a asimilar rápidamente esta información y proveer conocimientos que apoyen y complementen descripciones textuales o resúmenes estadísticos. Una forma de evaluación del agrupamiento muy sencilla es, por ejemplo, mediante la visualización del conjunto de datos cuando este es pequeño y los datos son bidimensionales. Sin embargo, esta forma de evaluación puede ser difícil al intentar realizar una visualización efectiva de un conjunto de datos de alta dimensionalidad (Hansen and Johnson, 2005). Para poder seleccionar una visualización adecuada para los datos agrupados que nos permita extraer información relevante, primeramente debemos definir cuales aspectos tomaremos como importantes para el análisis de los datos agrupados y las características de estos sobre los cuáles estará orientada nuestra visualización. Luego abordaremos algunas de las principales técnicas utilizadas para la representación visual de los algoritmos de agrupamiento atendiendo a estos aspectos. Se valorará la calidad de las visualizaciones atendiendo a conjuntos de datos muy extensos, los cuales poseen una dimensionalidad elevada. Se observarán además aspectos del análisis de grupos como el tamaño del agrupamiento, similitud interna, similitud externa y desviación estándar; para así obtener un aproximado de la calidad del agrupamiento. Estas propiedades son consideradas en (Klabbers, 2004) como suficientes para obtener una aproximación de la distribución del agrupamiento. Conjuntamente a los aspectos anteriores se hará referencia a los problemas existentes con la interacción en el análisis de grupos. 11.
(24) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. Matrices de dispersión (Scatterplot Matrix) Un diagrama de dispersión (scatterplot) ofrece información sobre un conjunto de datos bidimensional mediante la representación de todos los elementos sobre dos ejes perpendiculares y cada uno de estos representa una dimensión. Los elementos son dibujados como puntos. Una matriz de dispersión combina múltiples diagramas de dispersión con el fin de visualizar conjuntos de datos con una dimensión mayor que dos. Un conjunto de datos n-dimensional requiere una matriz de dispersión con n x n diagramas de dispersión. El diagrama de dispersión en la posición (i, j), 0 ≤ i, j < n de la matriz es una imagen mostrando la relación entre las dimensiones i y j de cada elemento. En otras palabras, un diagrama de dispersión en la posición (i, j) muestra como se relacionan las dimensiones i y j para este conjunto de datos. La Figura 1.3.1 muestra una matriz de dispersión.. Figura 1.3.1 Matriz de dispersión Un diagrama de dispersión en la posición (i, j) es la versión espejo de la posición (j, i). Un diagrama de dispersión en la posición (i, i) muestra la relación entre la dimensión i y ella misma. Esto significa que solo la parte inferior de la matriz (o la superior), contienen los elementos (i, j), 0 ≤ i < n Ʌ 0 ≤ j < n, que son de interés.. 12.
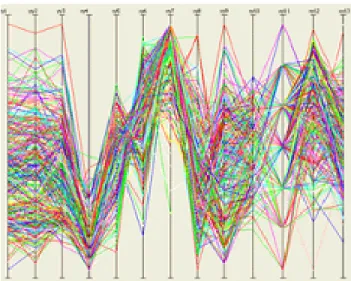
(25) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. Los diagramas de dispersión sufren de una cierta cantidad de aglomeración visual. La aglomeración se puede observar en los elementos que son dibujados unos encima de otros y la interacción es complicada sobre elementos que no son visibles o difícilmente visibles. Estas aglomeraciones dificultan la obtención de información sobre la distribución de los elementos. Una técnica para resolver el problema de la aglomeración, que no envuelva 3D, no ha sido encontrada todavía. Sin embargo, existen técnicas que se anticipan a esta debilidad. Un ejemplo de estas es el diagrama de dispersión de frecuencia. Dicho diagrama no dibuja los elementos directamente, en cambio, usa una malla para clasificar los elementos en grupos. Luego, se visualiza el número de elementos de cada grupo. Una matriz de dispersión utiliza numerosas vistas para representar las relaciones entre cada par de dimensiones. Para obtener una aproximación sobre la calidad de los grupos es necesario observar la mitad de los n2 diagramas de dispersión, quizás hasta sea necesario hacerlo varias veces. Este es un proceso lento: O(n2). La interacción es fácil, pero la aglomeración es un problema para la misma. Las matrices de dispersión ofrecen diversas vistas que deben ser combinadas en la mente de los observadores. Esto pone una carga extra en el observador. Además se puede notar que, acompañado del solapamiento de elementos, la aglomeración puede ser un problema durante la interacción. Coordenadas Paralelas Una representación en coordenadas paralelas mapea las dimensiones de un conjunto ndimensional en n equidistantes ejes paralelos. Esto resulta en un punto sobre cada eje para cada elemento. Para lograr que estos sean visibles, todos los puntos de un elemento son conectados por una línea. La siguiente figura muestra una representación de coordenadas paralelas:. 13.
(26) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. Figura 1.3.2 Coordenadas paralelas En una representación por coordenadas paralelas resulta fácil encontrar relaciones entre las múltiples dimensiones. Una razón para esto es que las líneas son dibujadas en la dirección natural de lectura. Se puede leer fácilmente un elemento siguiendo la línea a través de los ejes. Otra razón es que los grupos son fáciles de identificar, enfocándose en la cercanía de las líneas y siguiendo el comportamiento de arriba hacia abajo de las mismas. En la Figura 1.3.3 a) se resalta un grupo de elementos cercanos con un comportamiento similar. Una representación de coordenadas paralelas sufre del mismo tipo de aglomeración que un diagrama de dispersión. Esto no solo hace que las coordenadas paralelas sean menos legibles si existe solapamiento, sino que la interacción se torna más difícil también. En la Figura 1.3.3 b) se muestra este efecto.. 14.
(27) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. Figura 1.3.3 Coordenadas Paralelas a) Resaltado de un grupo b) Aglomeración visual Disímiles técnicas han sido desarrolladas para tratar con los problemas de solapado. Una forma para mejorar la interacción en caso de aglomeración es usar un pincel angular. Mediante el uso de un pincel angular los elementos pueden ser seleccionados dependiendo de su ángulo con respecto a los ejes. Al usar esta técnica, incluso aquellos elementos que están sepultados bajo otros muchos elementos y por ende son inalcanzables, pueden ser seleccionables (Klabbers, 2004). Existen numerosas interacciones sobre los ejes que pueden ayudar con el análisis de los datos. Cuando usamos coordenadas paralelas, es generalmente difícil analizar un par de dimensiones si sus ejes están muy separados. El intercambio de ejes permite que estos puedan ser colocados uno al lado del otro. El solapamiento puede hacer la selección un poco problemática. El espacio entre los elementos puede ser incrementado mediante el cambio de la escala, logrando que la selección sea fácil. Ejes que representan el mismo tipo de datos pueden usar diferentes escalas y. 15.
(28) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. rangos. Esto resulta en una imagen distorsionada. De ahí que sea de mucha ayuda tener la capacidad de cambiar la escala y el rango (Klabbers, 2004). Coordenadas paralelas de orden ≥ 2 Una representación de coordenadas paralelas usa líneas rectas para conectar los ejes. Una línea recta puede ser interpretada como una curva de orden uno. Theisel (Theisel, 2000) introdujo la idea de utilizar curvas de orden superior. Curvas de orden superior no aglomeran tanto como las curvas de primer orden. Esto provoca que sea más fácil distinguir entre los elementos. En la práctica las curvas de orden superior son raramente usadas porque ellas dificultan el análisis. La principal razón para esto es que estas curvas sugieren más información de la que puede ser derivada de los datos. Esto se puede decir también acerca de las líneas rectas, pero las personas tienden a ver las líneas rectas como una conexión entre puntos. Mientras que el número de dimensiones no sea demasiado alto, es fácil apreciar la media, el tamaño de los grupos, la desviación estándar y una aproximación de la distribución de la imagen del agrupamiento. Esto se puede realizar mediante el chequeo de las líneas a través de todos ejes: O(n). La interacción es fácil, pero tiende a tornarse difícil una vez que los elementos comiencen a solaparse masivamente. La representación por coordenadas paralelas hace posible que el observador procese información para más de dos dimensiones al mismo tiempo. Esta técnica comparte una debilidad con la matriz de dispersión, sufren del mismo tipo de aglomeración. Ploteo de mosaico de colores (colormosaic plot) Para un n-dimensional conjunto de datos de tamaño m, un ploteo de mosaico de colores es una visualización de colores para una matriz de n x m valores. Cada columna i, 0 ≤ i < m, consiste en n rectángulos coloreados, representando los n valores del elemento i. La figura siguiente muestra un ploteo de mosaico de colores.. 16.
(29) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. Figura 1.3.4 Mosaico de colores Las herramientas de visualización de arreglos de genes (Seo and Shneiderman, 2002) a menudo usan este tipo de ploteo. Existen muchas razones por las que prefieren usar este en lugar de las coordenadas paralelas. Primero que todo los datos no son 100% precisos. Mediante el uso de puntos coloreados que ofrecen una precisión estricta, estos datos son reflejados en la visualización. Estos biólogos están muy interesados en valores tanto positivos como negativos. En el ploteo de mosaico de colores, los verdes y rojos son empleados para representar valores negativos y positivos respectivamente. El ojo humano puede detectar grandes áreas con rectángulos fundamentalmente rojos o verdes casi instantáneamente. Mientras el número de elementos de un grupo no sea muy alto, un estimado de la calidad puede ser derivado de la imagen bastante rápido. Áreas con un gradiente de color similar pueden ser detectadas en un orden de tiempo constante. Así la velocidad depende del número de áreas con gradiente de colores similares. El ser humano puede diferenciar hasta aproximadamente 10 gradientes de colores, de ahí que el número percibido de áreas con gradientes de colores 17.
(30) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. similares es limitada. Por esto, la velocidad está ligada al número de elementos pero generalmente es mucho más pequeña (Klabbers, 2004). La interacción puede ser un problema cuando se usa este ploteo. Aunque este no sufre de la misma aglomeración de los diagramas de dispersión y las coordenadas paralelas, cierta cantidad de elementos pueden estar solapados. Si existen más elementos que los que se pueden ajustar en la pantalla, el solapado puede existir. Allí la aglomeración puede evitarse separando el conjunto de datos en pedazos que sí se puedan ajustar a la pantalla (Klabbers, 2004). La rapidez de las observaciones depende mayormente de cómo está estructurada la imagen resultante. La estructura depende de cómo los elementos estén ordenados. Si no existe un ordenamiento natural de los elementos, estos pueden ser reordenados para una mejor estructura. Ello también se aplica a las dimensiones (Klabbers, 2004). Visualización mediante grafos La Visualización de Grafos soluciona el problema de visualizar información estructural o relacional construyendo representaciones de grafos o redes que son los modelos subyacentes en una gran cantidad de datos abstractos (Suárez, 2003). Usualmente se representa un grafo para visualizarlo como un conjunto de vértices y las aristas que los unen. Los vértices pueden ser símbolos tales como cajas o puntos, y las aristas curvas abiertas de Jordan. Sin embargo, esos estándares varían según la aplicación, pues un grafo tiene infinidad de formas de ser dibujado. La utilidad de una representación dada depende de su legibilidad (Martig and Señas, 2000) Por lo general, los vértices representan los elementos del conjunto de datos y las aristas las distancias (similitudes) entre los elementos. Una de las técnicas más importantes en la visualización de grafos el «layout» o esquema, que especifica la forma en que va a ser representado el grafo, pues de este depende en gran medida cuán útil o entendible pueda resultar dicha representación. Existen una gran variedad de 18.
(31) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. algoritmos de «layout» como el node-link, tree, tree+link, spring, space division, space nested, matrix y el cone tree 3D (Cui, 2009). Sus principales objetivos son: mejorar la distribución de los nodos y aristas, minimizar o evitar el cruce de aristas, representar las estructuras isomórficas en la misma forma, e incluso lograr mejoras en cuanto a la estética de la representación. Muchos de estos algoritmos son computacionalmente costosos, mientras que en layouts más prácticos, sus resultados comprometen en gran medida la estética del mismo. En la visualización de grafos existen, además del «layout», otras técnicas que se emplean para la reducción de la aglomeración visual - lo cual constituye uno de los principales problemas causado por la representación de grafos extensos – y estas son el edge displacement, el agrupamiento de nodos y el sampling (Cui, 2009). Obtener una aproximación de la calidad del agrupamiento es relativamente sencillo y se puede realizar en un orden de tiempo constante, esto se logra con solo ver la distribución de los nodos y la separación entre estos. El tamaño del grafo a representar es un problema clave en la visualización de estos. Extensos grafos generan numerosos problemas de gran dificultad. Si el número de elementos es muy grande, puede comprometer la representación y puede alcanzar los límites de la plataforma de visualización; aún si esto es posible mediante la selección del «layout» y se pueden representar todos los elementos, surge el problema de la visibilidad o la usabilidad porque puede resultar imposible discernir entre nodos y aristas. De hecho, la usabilidad se convierte en un problema incluso antes de llegar a la cuestión de discernir. Es bien conocido que la comprensión y el análisis detallado de los grafos es más fácil cuando el tamaño del mismo es pequeño. En general, representar completamente un grafo extenso puede ofrecer indicaciones sobre toda la estructura o sobre locaciones internas, haciendo un poco difícil la comprensión. Una técnica muy popular es representar grafos en 3D en lugar de en 2D. La ventaja es que esta extra dimensión brinda, literalmente, más “espacio” y esto facilita el problema de representar grandes estructuras. Además el usuario puede navegar para encontrar una vista sin 19.
(32) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. solapamientos. Debido a esto muchos algoritmos clásicos de «layout» en 2D han sido generalizados a 3D. A pesar de su aparente simplicidad, la representación de grafos en 3D también puede introducir nuevos problemas. Objetos en 3D pueden ocultar a otros y puede resultar algo difícil encontrar la mejor “vista”. Como consecuencia, virtualmente todas las representaciones de grafos en 3D incluyen indicaciones adicionales como la transparencia y la cola en profundidad, entre otros (Herman, 2000). También permiten al usuario cambiar la vista moviéndose por el espacio, pero la habilidad de cambiar la perspectiva adiciona otra dificultad. Prácticas comunes como la minimización del cruce de las aristas puede verse afectado cuando el usuario cambia la perspectiva y puede ver los cruces desde otro ángulo. Las técnicas de visualización de grafos en 3D presentan significativas dificultades a pesar de todo el desarrollo técnico en el área y sus innegables atractivas características. La principal razón reside en las inherentes dificultades cognoscitivas de la navegación en 3D en nuestros sistemas actuales. Los conflictos perceptuales y de navegación son causados por la discrepancia del uso de pantallas 2D y dispositivos 2D para interactuar con un mundo en 3D. La limitación de las interacciones en 3D, como la habilidad para rotar un elemento sin lograr acercarse a este, puede proveer interacciones 3D que no causen desorientación. Por supuesto si se usara tecnología de punta como los sistemas VR-like, ejemplo Workbench y CAVE, y pantallas de alta definición estos problemas pueden ser resueltos, pero dichas tecnologías no se pueden adquirir fácilmente puesto que son muy caras y por tanto no pueden servir como base para el desarrollo de aplicaciones de visualización de la información (Herman, 2000).. 1.4. CONCLUSIONES PARCIALES La visualización de los resultados de algoritmos de agrupamiento provee disímiles ventajas para el análisis y la comprensión de los mismos. Luego de analizar las técnicas más usadas para la visualización de resultados de algoritmos de agrupamiento, podemos destacar que la alta dimensionalidad de los datos y el elevado número de 20.
(33) CAPÍTULO 1: MINERÍA VISUAL DE DATOS. elementos del conjunto de datos, son aspectos que tienen una fuerte influencia negativa en la calidad de la visualización, además de que se produce gran aglomeración visual con el incremento de dichas características. El modelo que se propondrá en el capítulo siguiente, presenta gran importancia. Se centra en el objetivo de erradicar estas deficiencias, evitando la oclusión y el solapado presente en la mayoría de las visualizaciones cuando trabajan sobre conjuntos altamente dimensionales y de numerosos elementos. Por tanto, es muy apropiado el desarrollo de una herramienta que implemente dicho modelo y le permita obtener al usuario una aproximación de la distribución de la solución de un algoritmo de agrupamiento.. 21.
(34) CAPÍTULO 2: VISUALIZACIÓN DE RESULTADOS DE ALGORITMOS DE AGRUPAMIENTOS. 2. VISUALIZACIÓN DE RESULTADOS DE ALGORITMOS DE AGRUPAMIENTOS En este capítulo se expone el diseño de un modelo de visualización basado en mallas tridimensionales, que es capaz de minimizar las principales desventajas de las visualizaciones analizadas hasta el momento. Se definen un número de interacciones sobre el gráfico que aumentan su potencialidad y le ofrecen al usuario facilidades para la realización de consultas visuales. Además se realiza todo un diseño de la arquitectura de un sistema que implementa este modelo y sus interacciones.. 2.1. DISEÑO DEL MODELO DE VISUALIZACIÓN DE LOS RESULTADOS DE ALGORITMOS DE AGRUPAMIENTO Para comenzar es válido aclarar que el análisis que se realizó en el epígrafe 1.3 fue atendiendo a la calidad de la visualización de la ya establecida solución del agrupamiento y no en vista de si puede proveer soportes para la toma de decisiones que puedan ayudar a formar dichas soluciones. Nos centraremos en la propuesta y diseño de un modelo de visualización cuya calidad no dependa en gran medida de la dimensionalidad de los datos y del número de elementos del conjunto de datos. También se propondrán interacciones que faciliten el análisis de la solución del agrupamiento. 2.1.1. RELACIÓN. ENTRE. LA. REPRESENTACIÓN. VISUAL. Y. LAS. CARACTERÍSTICAS DE LOS DATOS Las operaciones de búsqueda visual requieren de un escaneo de este tipo para localizar e identificar uno o más objetivos de acuerdo a un criterio determinado. En las tareas de identificación el usuario, a través de la búsqueda visual, puede obtener información semántica sobre los símbolos de interés. Entre las medidas para valorar la efectividad de una representación 22.
(35) CAPÍTULO 2: VISUALIZACIÓN DE RESULTADOS DE ALGORITMOS DE AGRUPAMIENTOS. con respecto a la búsqueda visual y a las tareas de identificación se incluyen el tiempo, la exactitud y la capacidad cognoscitiva para expresar la información (Nowell, 1997). Experimentos de analistas especializados han demostrado que el color es el mecanismo gráfico más efectivo para reducir el tiempo de búsqueda visual, seguido por el tamaño, la forma y por último los caracteres alfanuméricos (Nowell, 1997). Aunque existen varias teorías y experimentos realizados sobre el área que difieren un poco en cuanto al orden de estas propiedades, pero varias coinciden en que la codificación del color es mucho más efectiva que el tamaño y la forma. Por tanto a la hora de diseñar un modelo de visualización sería recomendable codificar las características más representativas de los datos a los cuales está orientado dicho modelo, con las propiedades más efectivas de la representación visual. Así se logra obtener una visualización potente donde el usuario puede extraer información sobre las características principales con mayor facilidad que sobre las secundarias, optimizando el tiempo que se requiere para interpretar el gráfico. Se considera que propiedades del análisis de agrupamientos - en función de las cuales se estimó la calidad de las técnicas anteriormente abordadas - como son: la similitud externa, la disimilitud interna media, la desviación estándar y la cantidad de elementos; van a ser suficientes para obtener información relevante que pueda caracterizar la solución y le brinde al usuario una aproximación de la distribución del agrupamiento (Klabbers, 2004). Dentro de estas propiedades, la media de la disimilitud interna y su desviación estándar, son de especial importancia porque brindan información sobre cuán diferentes son los elementos dentro del grupo y si se encuentran muy dispersos o no. Por tanto en el modelo de visualización que se propone una de estas características deberá ser codificada mediante el mapeo de colores.. 23.
(36) CAPÍTULO 2: VISUALIZACIÓN DE RESULTADOS DE ALGORITMOS DE AGRUPAMIENTOS. 2.1.2. ESTRUCTURA DEL MODELO VISUAL PROPUESTO Nuestro objetivo radica en lograr una visualización cuya calidad no se vea afectada por el aumento de la dimensionalidad de los datos y del número de elementos del conjunto de datos. Uno de los principales problemas que apreciamos en las técnicas abordadas en el capítulo anterior fue la aglomeración visual, causada por los aspectos mencionados en el párrafo anterior, que propicia a su vez la aparición de la oclusión y el solapamiento de elementos. Dicho problema ocurre fundamentalmente porque cada objeto del conjunto de datos tiene una representación en la visualización, es decir, se dibujan todos los elementos. Evidentemente mientras mayor sea el tamaño de la muestra mayor será la aglomeración visual. Al inicio de este capítulo habíamos aclarado que el propósito de la visualización era brindar información sobre la solución del agrupamiento y no brindar facilidades para la construcción de dicha solución. Luego, con el objetivo de independizar la visualización del tamaño del conjunto de datos, podemos sacrificar la información que nos brinda la representación de cada elemento y visualizar en función de las propiedades del agrupamiento mencionadas anteriormente. Esto simplifica mucho nuestro problema, pues solo tendríamos que codificar estas cuatro variables independientes. La visualización que proponemos intenta representar toda esta información en un único gráfico. La similitud externa es una medida entre grupos que muestra cuán cercanos (parecidos) o lejanos (diferentes) se encuentran los grupos entre ellos. La información que brinda esta medida es, en cierto sentido, espacial; por lo que se representará en el plano 2D, donde los grupos se codifican mediante regiones en el plano (x,y). La posición de cada región respecto a los demás, o mejor dicho, la distancia entre ellos, es proporcional a dicha medida. El propósito de esta representación es ilustrar las relaciones entre los grupos usando la distancia visual. De esta manera grupos que sean similares estarán unidos, mientras que grupos disímiles se representaran distantes.. 24.
(37) CAPÍTULO 2: VISUALIZACIÓN DE RESULTADOS DE ALGORITMOS DE AGRUPAMIENTOS. Para lograr esta idea proponemos usar técnicas de escalado multidimensional (Multidimensional Scaling MDS) que tratan sobre el siguiente problema: para un conjunto de similitudes (o distancias) observadas entre pares de objetos de un conjunto de N elementos relativos a p variables, se trata de encontrar una representación gráfica de estos en k-dimensiones (k < p), de modo que sus posiciones casi ajusten las similitudes (o distancias) originales. Aplicando un MDS a los elementos más representativos de los grupos, es decir, los centroides o los puntos medios de cada grupo; para un k = 2 se logra una representación aproximada en un plano cartesiano de la similitud relativa entre los grupos. Con el MDS se erradica también el problema de los datos multidimensionales, pues este se utiliza como función de mapeo entre las altas dimensiones originales y las dos dimensiones en que van a ser representados los datos. Para codificar el parámetro de la disimilitud interna media correspondiente a cada grupo, que es una medida de la relación de los elementos dentro del grupo - cuan semejantes son entre sí utilizaremos la tercera dimensión, el eje z. La estructura que utilizaremos para representar este modelo serán mallas tridimensionales, en vez de una estructura de puntos o cualquier otra parecida en 3D, porque lo que se está representando son los grupos como un todo y así se evita la confusión de que se puedan estar visualizando todos los elementos del agrupamiento. Hasta este momento nuestra visualización se vería como un paisaje tridimensional montañoso, donde cada pico representa un grupo y la altura de los mismos es proporcional a la similitud interna correspondiente a cada grupo, es decir, solo se visualizará la topología de los grupos. La cantidad de elementos por grupos será codificada a través del diámetro de la base de cada pico, este será proporcional al número de objetos dentro del grupo. A grupos numerosos corresponden picos de base ancha.. 25.
(38) CAPÍTULO 2: VISUALIZACIÓN DE RESULTADOS DE ALGORITMOS DE AGRUPAMIENTOS. Por último y sin restarle importancia, nos quedaría por codificar la desviación estándar de cada grupo, que es una medida estadística de varianza que se aplica sobre las similitudes de los objetos de cada grupo y nos sirve, entre otras cosas, para tener una noción de la presencia o no de ruido dentro de los mismos. El ruido son aquellos elementos que están muy separados del resto de los elementos del grupo. Anteriormente habíamos llegado a la conclusión de que la desviación estándar y la media de las disimilitudes internas, eran medidas de gran importancia dentro del agrupamiento y que la codificación mediante el color era el mecanismo más eficiente de la representación. Por tanto se representa la desviación estándar mediante un mapeo de colores. De acuerdo con varios especialistas del área de la visualización de la información, los colores no deberían ser usados para codificar diferencias cuantitativas, la diferencia de colores se expresa mejor como diferencias en una escala nominal, cambiar de rojo a verde no significa “algo más que otro” como es el caso de cambiar de un punto pequeño a uno grande. Realmente la mejor representación del espacio psicológico de similitud para los colores no es una línea sino un círculo. Por esto es difícil utilizar diferencias progresivas en los colores para entender el incremento o decremento progresivo de alguna cantidad. El color no está psicológicamente ordenado (Nowell, 1997). A pesar de esto, algunos investigadores han determinado que colores como el azul y el verde son asociados a información no crítica sobre los datos, el amarillo ligeramente crítica y el rojo y el naranja con estados críticos de los datos. Utilizaremos colores como el azul y el verde para expresar grupos de datos con menor desviación estándar, lo que significa que los datos están más cohesionados; y el rojo y el naranja para describir desviaciones mayores, es decir, grupos donde los elementos están más dispersos. Podremos encontrar grupos con menor desviación estándar buscando picos con colores azules o verdes, mientras que picos con colores sobre el rojo y el naranja representarán grupos con mayores desviaciones estándar y por lo tanto propensas a contener ruido.. 26.
(39) CAPÍTULO 2: VISUALIZACIÓN DE RESULTADOS DE ALGORITMOS DE AGRUPAMIENTOS. Podemos resumir que nuestra visualización a través de mallas tridimensionales consiste en un plano horizontal en 3D donde se elevan picos coloreados en numerosas locaciones y donde cada pico representa un grupo dentro del agrupamiento. La información asociada a cada grupo está dada por la locación del correspondiente pico en el plano, su altura, volumen y color. El resultado en general de nuestra representación es que logra enfatizar características sobre conjuntos de datos numerosos y cuyos elementos son altamente dimensionales. El usuario puede ser capaz de identificar grupos con una alta similitud buscando elevados picos, o grupos muy parecidos a través de picos muy cercanos. También puede identificar grupos con una baja desviación estándar mediante la búsqueda de cimas con colores dentro de la gama del azul y el verde. Grupos con alta desviación estándar, como ya mencionamos, suelen ser ruidosos y por tanto tienen un color rojo. Otra ventaja es que logra una visualización completa del conjunto de datos sin rebasar los límites del dispositivo visual. 2.1.3. POSIBLES INTERACCIONES A REALIZAR SOBRE EL MODELO PRPUESTO La navegación y la interacción pueden aumentar la potencialidad de los gráficos cuando se está tratando con extensos conjuntos de datos, por esto son esenciales en la visualización de la información. En esta temática se proponen y describen una serie de interacciones para mejorar el nivel de comprensión y la usabilidad sobre la malla tridimensional. Se comenzará con una de las interacciones tradicionales, el zoom. Mediante el mismo se puede ajustar el nivel de abstracción de la representación, el usuario puede escoger entre obtener información abstracta o detallada; por ejemplo: con observar desde un nivel alto toda la gráfica obtiene una aproximación visual de la distribución del agrupamiento o al acercarse a un nivel más bajo puede detallar información sobre la relación entre dos o más grupos específicos. Otra útil interacción tradicional es el pan (pannig). Se emplea mucho en la exploración del gráfico y consiste en mover suavemente la cámara a través de la escena. El zoom y el pan se 27.
Figure



+7






Documento similar
En un estudio clínico en niños y adolescentes de 10-24 años de edad con diabetes mellitus tipo 2, 39 pacientes fueron aleatorizados a dapagliflozina 10 mg y 33 a placebo,
• Descripción de los riesgos importantes de enfermedad pulmonar intersticial/neumonitis asociados al uso de trastuzumab deruxtecán. • Descripción de los principales signos
Debido al riesgo de producir malformaciones congénitas graves, en la Unión Europea se han establecido una serie de requisitos para su prescripción y dispensación con un Plan
Como medida de precaución, puesto que talidomida se encuentra en el semen, todos los pacientes varones deben usar preservativos durante el tratamiento, durante la interrupción
"No porque las dos, que vinieron de Valencia, no merecieran ese favor, pues eran entrambas de tan grande espíritu […] La razón porque no vió Coronas para ellas, sería
Abstract: This paper reviews the dialogue and controversies between the paratexts of a corpus of collections of short novels –and romances– publi- shed from 1624 to 1637:
E Clamades andaua sienpre sobre el caua- 11o de madera, y en poco tienpo fue tan lexos, que el no sabia en donde estaña; pero el tomo muy gran esfuergo en si, y pensó yendo assi
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
