Clasificación de imágenes de microscopía celular en la prueba de Papanicolaou por medios computacionales
65
0
0
Texto completo
(2) Universidad Central “Marta Abreu” de Las Villas Facultad de Ingeniería Eléctrica Centro de Estudios de Electrónica y Tecnologías de la Información. TRABAJO DE DIPLOMA Título: Clasificación de imágenes de microscopía celular en la prueba de Papanicolaou por medios computacionales.. Autor: Wendelin Curbelo Jardines [email protected]. Tutor: Dr. C. Juan Valentín Lorenzo Ginori Profesor Titular Consultante, Investigador titular [email protected].. Santa Clara 2012 “Año 54 de la Revolución ".
(3) Hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ingeniería Biomédica, autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicados sin autorización de la Universidad.. Firma del Autor Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Autor. Firma del Jefe de Departamento donde se defiende el trabajo. Firma del Responsable de Información Científico-Técnica.
(4) i. PENSAMIENTO. ¿Quién se atreverá a poner límites al ingenio de los hombres? Galileo Galilei..
(5) ii. DEDICATORIA A mi mamá y a mi abuelita que tanto se han sacrificado por mí. El apoyo de ustedes es mi mayor recompensa..
(6) iii. AGRADECIMIENTOS A mi mamá, que ha sido más que madre una amiga sincera capaz de apoyarme sin juzgarme en todas las decisiones que he tomado en la vida. Ha sido un hombro firme en el cual me he apoyado para llorar y para reír, me ha mostrado el camino correcto y me enseñó a nunca darme por vencida. Es mi ejemplo a seguir como mujer luchadora, capaz, defensora de sus ideas y principios. A mi abuelita, que siempre ha estado a mi lado enfrentando cualquier desafío, a pesar de su edad avanzada, que me ha dado tanto amor y día a día se esfuerza por hacer realidad mis caprichos. A mi padrastro, que me ha brindado un apoyo incondicional toda mi vida. Es un padre y amigo que nunca me defrauda, capaz de correr cuando tengo algún problema y con el cual puedo hablar abiertamente. A mis hermanos que con sus muestras de cariño me han alegrado la vida, cuando más agobiada he estado. Se han privado de satisfacciones personales para que yo, por estar lejos de casa las tuviese. A mi papá y mi madrasta que me han apoyado incondicionalmente e hicieron más fácil para mí, la realización de este trabajo. A Orestes Zulueta, quien durante estos 5 años ha sido mi motor impulsor para enfrentar cualquier desafío, pero sobre todas las cosas ha sido mi familia en todo momento. A todos mis amigos, pero en especial a Yusniel Echemendía y Maite Morán, los cuales fueron protagonistas en mi historia universitaria y con los cuales he compartido experiencias inolvidables. A mi tutor Dr. C. Juan V. Lorenzo Ginori por su esfuerzo, dedicación y apoyo en la realización de esta investigación. A mis familiares, amistades, compañeros, conocidos, amigos de mis padres que de una forma u otra han contribuido a que estos 5 años hayan sido maravillosos..
(7) iv. TAREA TÉCNICA Con este trabajo se persigue contribuir a la creación de un programa computacional con las herramientas de Matlab, destinado a realizar el control de calidad de la prueba de Papanicolaou a partir de la clasificación de las células cervicales mediante rasgos del núcleo celular. El objetivo final es lograr una mejoría en la predictividad negativa de ésta a partir de un control de calidad eficiente de la misma.. Firma del Autor. Firma del Tutor.
(8) v. RESUMEN Este trabajo recoge información detallada acerca de la prueba de Papanicolaou como procedimiento para detectar la presencia de células anómalas en la cérvix y resume la importancia de la realización periódica de esta prueba. Se reconocen diferentes estrategias para el mejoramiento de la prueba, como el desarrollo de equipos automatizados para el control de calidad, con lo cuales se reduce notablemente los debidos errores de lectura e interpretación. El trabajo está enfocado en la clasificación de las células mediante el procesamiento digital de imágenes, utilizando la segmentación de los núcleos, la extracción de características de los mismos y el análisis de los datos resultantes. Para ello se trabajó con las imágenes de la base de datos Herlev (Hospital Universitario) como referencia para los métodos de clasificación, estas fueron previamente ordenadas en 7 clases. A partir de esto se definieron rasgos representativos a los núcleos de las células para poder clasificarlas como normales (sin anomalía) o anómalas (con algún tipo de desviación de la normalidad). Para implementar los algoritmos clasificadores (clasificador lineal, de Mahalanobis y la Maquina de Soporte Vectorial) se empleó la programación en Matlab, mediante diferentes herramientas como las funciones regionprops, crossvalind, classify, svmtrain, svmclassify, classperf y algunas utilidades de la clase de datos cell array. Posteriormente se analizaron los resultados de todos los experimentos realizados en cuanto a la tasa de error, la tasa de clasificación correcta, la sensibilidad, la especificidad, la predictividad positiva y la predictividad negativa. Se determinaron los valores medios y las desviaciones estándar de todos los parámetros antes mencionados y se realizó un análisis estadístico mediante la prueba de Kruskal-Wallis para determinar cuál de los 3 clasificadores resultó ser el más eficiente en la clasificación de las células con rasgos de los núcleos celulares.. ,.
(9) vi TABLA DE CONTENIDOS. PENSAMIENTO................................................................................................................. i DEDICATORIA ................................................................................................................ ii AGRADECIMIENTOS .....................................................................................................iii TAREA TÉCNICA ........................................................................................................... iv RESUMEN ........................................................................................................................ v INTRODUCCIÓN ............................................................................................................. 1 CAPÍTULO 1. GENERALIDADES SOBRE LA PRUEBA DE PAPANICOLAOU. ......... 4 1.1 Prueba de Papanicolaou. ........................................................................................... 4 1.2 Importancia de la prueba de Papanicolaou................................................................ 6 1.3 Estrategias que existen para la de mejora de la prueba de Papanicolaou. ................... 7 1.4. Equipos automatizados para el control de calidad de la prueba de Papanicolaou...... 8 1.5. Control de calidad mediante el procesamiento digital de imágenes. .......................... 9 CAPÍTULO 2. MATERIALES Y MÉTODOS. ............................................................... 11 2.1. Base de datos Herlev.............................................................................................. 11 2.1.2. Agrupamiento de las células. ........................................................................... 13 2.2. Rasgos utilizados para la clasificación. .............................................................. 14 2.2.1 Entropía. .......................................................................................................... 15 2.3 Formación de la estructura de datos. ....................................................................... 15 2.4 Parámetros para la evaluación de la calidad de los clasificadores. .......................... 17 2.5. Herramientas Matlab utilizadas en la clasificación y evaluación de las células. ...... 20 2.5.1. Función crossvalind de Matlab. ....................................................................... 20 2.5.2. Función classify de Matlab. ............................................................................. 20.
(10) vii 2.5.3. Función svmtrain de Matlab. ........................................................................... 21 2.5.4. Función svmclassify de Matlab. ....................................................................... 21 2.5.5. Función classperf de Matlab............................................................................ 22 2.6 Programas para la clasificación y evaluación. ......................................................... 22 CAPÍTULO 3. RESULTADOS Y DISCUSIÓN ............................................................... 24 3.1. Resultados del clasificador lineal. .......................................................................... 24 3.1.1. Experimento para una clasificación con un par de clases (clases 3 y 4) ............ 26 3.1.2. Experimento para una clasificación con un par de clases (clases 1 y 7). ........... 27 3.1.3. Valores medios de la evaluación de calidad del clasificador lineal. .................. 28 3.2. Resultados del clasificador mediante la distancia de Mahalanobis. ......................... 30 3.2.1. Valores medios de la evaluación de calidad del clasificador de Mahalanobis. .. 32 3.3. Clasificador de máquina de soporte vectorial (SVM). ............................................ 34 3.3.1. Valores medios de la evaluación de calidad del clasificador SVM. .................. 35 3.4. Análisis estadístico mediante pruebas no paramétricas. .......................................... 36 CONCLUSIONES Y RECOMENDACIONES ................................................................ 40 Conclusiones ................................................................................................................ 40 Recomendaciones ......................................................................................................... 41 REFERENCIAS BIBLIOGRÁFICAS .............................................................................. 42 ANEXOS ......................................................................................................................... 45.
(11) INTRODUCCIÓN. 1. INTRODUCCIÓN La prueba de Papanicolaou (llamada así en honor a su creador, Georgios Papanicolaou, médico griego que fue pionero en citología y detección temprana de cáncer), también llamada citología de cérvix o citología vaginal, se realiza para diagnosticar el cáncer cervicouterino, conocer el estado funcional de las hormonas e identificar las alteraciones inflamatorias a través del análisis de las células descamadas. Esta prueba es un examen citológico en el que se toman muestras de células epiteliales en la zona de transición del cuello uterino, en busca de anormalidades celulares que orienten (y no que diagnostiquen) la presencia de una posible neoplasia de cuello uterino. La prueba de Papanicolaou (prueba citológica) es un análisis de gran importancia para la detección y diagnóstico precoz del cáncer cervical. Debido a la gran masividad con que se realizan estas pruebas, el estudio de las imágenes de microscopía que en ellas se generan representa una gran carga de trabajo para los analistas humanos. Esta situación provoca que a través de los posibles efectos de la subjetividad y el cansancio, en situaciones donde los casos positivos no son frecuentes, se produzcan falsos negativos, lo que constituye un peligro potencial para la salud de las pacientes. Para controlar este efecto adverso, se desarrollan en la actualidad algoritmos y programas de computación que puedan ser empleados en el control de calidad de los resultados de la prueba. Este control se logra a partir de la detección de posibles falsos negativos, para que estos puedan ser reanalizados por el personal médico especializado y de esta forma se consiga mejorar la predictividad negativa de la prueba. Este trabajo tiene entre sus fundamentos lo recogido en los lineamientos No. 131 y 132 del VI Congreso del Partido Comunista de Cuba, en los que se establece: 131. Es fundamental sostener y desarrollar los resultados alcanzados en el campo de la biotecnología, la producción médico-farmacéutica, la industria del software y el proceso de informatización de la sociedad, las ciencias básicas, las ciencias naturales, los estudios y el empleo de las fuentes de energía renovables, las tecnologías sociales y educativas, la transferencia tecnológica industrial, la producción de equipos de tecnología avanzada, la nanotecnología y los servicios científicos y tecnológicos de alto valor agregado..
(12) INTRODUCCIÓN. 2. 132. Perfeccionar las condiciones organizativas, jurídicas e institucionales para establecer tipos de organización económica que garanticen la combinación de investigación científica e innovación tecnológica, desarrollo rápido y eficaz de nuevos productos y servicios, su producción eficiente con estándares de calidad apropiados y la gestión comercializadora interna y exportadora, que se revierta en un aporte a la sociedad y en estimular la reproducción del ciclo. Extender estos conceptos a la actividad científica de las universidades. Con este trabajo se persigue realizar una contribución al estudio, desarrollo y evaluación de algoritmos y programas mediante el procesamiento digital de imágenes orientados al control de calidad de la prueba de Papanicolaou. El desempeño de los mismos será evaluado a partir de su implementación en el análisis de imágenes cervicales contenidas en la base de datos Herlev (imágenes de microscopía reales). Para ello se propusieron los siguientes objetivos: Objetivo General Verificar la posibilidad de clasificar las células por métodos computacionales, en imágenes de la prueba de Papanicolaou, solamente con rasgos de los núcleos celulares. Objetivos Específicos Registrar, organizar y analizar críticamente información sobre la prueba de Papanicolaou y el análisis computacional de la misma. Determinar rasgos representativos en los núcleos de las células cervicales para mejorar la detección de patologías en imágenes de microscopía a través de un algoritmo clasificador. Evaluar el desempeño de los algoritmos clasificadores implementados, principalmente en la solución del problema de la clasificación binaria.. Tareas de investigación Realizar una revisión bibliográfica sobre el tema, sistematizando la información obtenida y haciendo un análisis crítico de la misma..
(13) INTRODUCCIÓN. 3. Seleccionar y programar el cálculo de un conjunto de rasgos representativos de los núcleos celulares en la prueba de Papanicolaou. Implementar y probar experimentalmente algoritmos de clasificación para la detección de anomalías en las imágenes de citología cervical. Evaluar el comportamiento de los algoritmos de clasificación aplicados, en términos de los índices de efectividad para la clasificación binaria. Realizar un análisis estadístico para la comparación de los algoritmos de clasificación implementados. Organización del informe El informe se ha estructurado en tres capítulos que abordan las siguientes temáticas: CAPÍTULO 1. “Generalidades sobre la prueba de Papanicolaou”. Este capítulo recoge información detallada acerca de la prueba de Papanicolaou y determina el procesamiento digital de imágenes como método para la evaluación de calidad de la misma. CAPÍTULO 2. “Materiales y métodos”. En este capítulo se definen rasgos representativos a los núcleos de las células para implementar los algoritmos clasificadores CAPÍTULO 3. “Resultados y discusión”. En este capítulo se evalúa la calidad de los algoritmos clasificadores a través de los experimentos realizados y se realiza un análisis estadístico según los resultados de éstos..
(14) CAPÍTULO 1. GENERALIDADES SOBRE LA PRUEBA DE PAPANICOLAOU.. 4. CAPÍTULO 1. GENERALIDADES SOBRE LA PRUEBA DE PAPANICOLAOU. Este capítulo recoge información detallada acerca de la prueba de Papanicolaou como procedimiento para detectar la presencia de células anómalas en la cérvix; y el descenso del número de nuevos casos de cáncer cervical por año, a partir de su implementación. Además, aborda aspectos de los tratados en las Guías Europeas para la calidad del cribado del cáncer cervical, como el personal, los métodos para su realización, los factores que afectan la calidad de la muestra, entre otros. Resume la importancia de la realización periódica de esta prueba, para el diagnóstico y prevención de cualquier tipo de anomalía existente en la zona del cuello uterino o vaginal; así como la optimización de la calidad con que se produzca dicho examen. Se proponen estrategias para el mejoramiento de la prueba, como el desarrollo de equipos automatizados para el control de calidad, con los cuales se reduce notablemente los debidos errores de lectura e interpretación. A pesar de que la incorporación de estos equipos automáticos disminuye la aparición de falsos negativos se pretende encaminar el trabajo hacia otro método que evalúa la calidad de la prueba mediante el procesamiento digital de imágenes, utilizando la segmentación de los núcleos, la extracción de características de los mismos y el análisis de los datos resultantes. 1.1 Prueba de Papanicolaou. El cáncer invasor del cuello del útero es la causa más frecuente de muerte por cáncer en las mujeres de los países en desarrollo y sus tasas de incidencia en la región de América Latina y el Caribe se encuentra entre las más altas del mundo. En Cuba, ha venido ocupando entre los lugares tercero y cuarto en incidencia, y del tercero al quinto en mortalidad. El cáncer de cuello uterino es una neoplasia potencialmente prevenible. Su causa dominante es el Virus del Papiloma Humano (VPH) [1]. La detección temprana de signos precursores de esta enfermedad mediante la prueba de Papanicolaou, permite una alta probabilidad de curación. Debido al carácter masivo de su aplicación en la población femenina, se genera una considerable carga de trabajo para los laboratorios que analizan en microscopios los frotis resultantes de esta.
(15) CAPÍTULO 1. GENERALIDADES SOBRE LA PRUEBA DE PAPANICOLAOU.. 5. técnica citológica. En un frotis típico se pueden encontrar hasta 300000 células, lo que limita la productividad a no más de unas 60-80 citologías por día de trabajo y observador [2]. La falta de programas de cribado o el inadecuado uso de sus métodos son los principales responsables de su alta incidencia. Por ello se expondrá un breve resumen de las Guías Europeas, para asegurar la calidad en el cribado del cáncer cervical mediante la prueba de Papanicolaou [3]: Personal y organización: el personal del laboratorio debe estar entrenado y dirigido por un profesional médico. El laboratorio debe procesar una cantidad suficiente de muestras para mantenerse con un adecuado nivel para experto. Además se incluye que las muestras serán procesadas, evaluadas, y reanalizadas ante citologías sospechosas o dudosas. El laboratorio debe tener control de calidad interno y externo. Se expondrá brevemente los factores que afectan la calidad de la muestra [4]: • Inflamación o infección vaginal • Embarazo • Manipulación física o irritación química como: tacto vaginal previo, desinfectantes en crema o líquidos, gel lubricante, medicación vaginal, duchas vaginales o geles espermicidas (menos de 24hs antes del estudio) • Radioterapia. • En el caso de embarazo o puerperio, la calidad del extendido disminuye debido a cambios reactivos inflamatorios; recomendándose esperar a 6-8 semanas postparto en mujeres que hayan realizado su examen dentro de los 3 años previos y concurran al seguimiento. En este trabajo se utilizan las imágenes de microscopía celular (Figura 1) tomadas en la prueba de Papanicolaou mediante el método convencional..
(16) CAPÍTULO 1. GENERALIDADES SOBRE LA PRUEBA DE PAPANICOLAOU.. 6. Figura 1. Imágenes de un campo, correspondiente a un frotis en la prueba de Papanicolaou convencional. 1.2 Importancia de la prueba de Papanicolaou. La prueba de Papanicolaou es un método que sirve para la prevención y detección de la aparición de cáncer de cuello del útero [5] [6]. Además de estos datos, aporta un panorama sobre el estado general del útero, el nivel hormonal y la existencia de otras infecciones. Si el resultado de la prueba de Papanicolaou es negativo, la cérvix es normal. Pero cuando el resultado es positivo, entonces significa la presencia de células anómalas, no necesariamente que exista un cáncer. Usualmente significa que es necesario realizar un intenso reconocimiento con otros exámenes, colposcopía o biopsia. La importancia de la detección de infecciones cérvico vaginales radica en que pueden evitarse complicaciones posteriores, como enfermedad pélvica inflamatoria, ruptura prematura de membranas, abortos, sepsis de un recién nacido, esterilidad. Por eso es importante la prevención mediante exámenes periódicos. Y aún más importante es que la calidad de esta prueba sea óptima La vaginosis bacteriana (Figura 2), las infecciones micóticas (Figura 3) y el Trichomonas vaginalis (Figura 4), son infecciones muy frecuente, localizadas por la prueba. Esto nos demuestra que no solo previene el cáncer de cérvix, sino que detecta cualquier tipo de anomalía existente en esta zona del organismo [7] [8]..
(17) CAPÍTULO 1. GENERALIDADES SOBRE LA PRUEBA DE PAPANICOLAOU.. 7. Figura 2. Se observan células epiteliales pavimentosas cubiertas por tapizado uniforme cocobacilos.. Figura 3. Levaduras y pseudomicelios ramificados entre las células epiteliales pavimentadas.. Figura 4. Trichomonas vaginales, algunas en forma de pera, mostrando un núcleo elíptico en uno de sus extremos. 1.3 Estrategias que existen para la de mejora de la prueba de Papanicolaou. Si bien el cáncer de cuello uterino puede aparecer en cualquier edad, la mayor parte de los casos se presentan en la quinta y sexta década de la vida y las lesiones precursoras aparecen preferentemente antes, alrededor de los 35 años, lo que evidencia un prolongado período de.
(18) CAPÍTULO 1. GENERALIDADES SOBRE LA PRUEBA DE PAPANICOLAOU.. 8. latencia en la mayoría de los casos. Las relaciones sexuales precoces, la promiscuidad, las inmunodeficiencias y el tabaquismo son factores que aumentan el riesgo [9]. De aquí la expectativa de encontrar casos positivos es proporcionalmente pequeña, lo que fuerza una tendencia a lo rutinario del trabajo de lectura y diagnóstico citológicos cuyo mayor peligro es la aparición de los denominados falsos negativos, es decir, que algunos casos realmente positivos pasen, por una u otra razón, inadvertidos. Por ello se reconoce la importancia de establecer estrategias para el mejoramiento de la prueba de Papanicolaou [10]: 1. Mejora de los programas de reclutamiento y seguimiento. 2. Mejora de la calidad de la toma de la muestra citológica. 3. Técnicas alternativas de preparación de la muestra citológica. 4. Control de calidad de la observación. 5. Desarrollo de métodos automatizados. 1.4. Equipos automatizados para el control de calidad de la prueba de Papanicolaou. A partir de la experiencia de la aplicación de esta prueba durante muchos años, se ha podido determinar que existen diferentes factores que afectan la calidad de los resultados. Estos son, principalmente, los errores en la toma de las muestras, en su procesamiento y en su lectura e interpretación. Sobre este último caso, la necesidad de analizar una gran cantidad de muestras con muy baja tasa de casos positivos tiende a sesgar el resultado de la evaluación, y además provoca errores debidos a la rutina y a la fatiga de los analistas. Como consecuencia de los diferentes errores mencionados, aparece una cierta tasa de falsos negativos en el resultado final. Estos implican que un estado pre-maligno de las células pueda degenerar en un estado maligno antes de una próxima prueba, sin que la paciente sea sometida a tratamiento alguno. La aparición de falsos negativos motiva la necesidad de asegurar la calidad en la toma y procesamiento de las muestras, y además de disponer de métodos efectivos de revisión de las pruebas. Tanto en lo referido a la necesidad de incrementar la productividad de los laboratorios, como a la de reducir la tasa de falsos negativos, los métodos que utilizan el procesamiento digital de imágenes y la visión computacional, han comenzado a desempeñar en los últimos años un importante papel..
(19) CAPÍTULO 1. GENERALIDADES SOBRE LA PRUEBA DE PAPANICOLAOU.. 9. Giménez et al [11] presenta una valoración del estado de estas técnicas, desde su surgimiento en la última década del siglo XX hasta el año 2003, en la que se advierte una superioridad del sistema Autopap. Este sistema realiza el análisis de las muestras en dos modalidades: el cribado primario y el secundario. En el cribado primario se persigue diagnosticar con alta confiabilidad un cierto porcentaje de casos como negativos, con la consiguiente reducción de la carga de trabajo de los analistas humanos. Sin embargo, una evaluación de esta técnica [11] revela que aunque su valor predictivo negativo es muy alto, aún aparece una pequeña tasa de falsos negativos. Coon [12] analiza la relación costo-beneficio ya que en este caso constituye un problema no sólo económico, sino también ético. En el cribado secundario, Autopap se emplea para el control de calidad del trabajo realizado por los analistas humanos, mediante un nuevo análisis de los casos negativos. Los casos que resultan sospechosos, son sometidos a un nuevo análisis. La prueba de Papanicolaou ha evolucionado, durante los primeros años del siglo XXI, hacia la adopción de la citología de base líquida como el método estándar para preparar las muestras [12][13]. En materia de las tecnologías actuales, Cibas [13] analiza los nuevos sistemas hacia los cuales evolucionó el Autopap, por ejemplo el BD FocalPointTM Slide Profiler, que posee una mayor productividad y efectividad en el cribado primario. El empleo de este sistema y un análisis de su efectividad para el análisis de células glandulares atípicas, han sido presentados por Austin[14]. Otro sistema cuyo uso se encuentra difundido actualmente es el ThinPrep Imaging System, que acrecenta la productividad del analista humano hasta más de 300 láminas por día, con un incremento significativo de la sensibilidad, pero al mismo tiempo con cierta reducción de la especificidad. Finalmente, se cita el FocalPoint GS Imaging System, similar en su concepción al ThinPrep, en este caso con una productividad de 170 láminas por jornada de 8 horas. Todos estos sistemas se encuentran instalados en varios laboratorios de EE. UU. 1.5. Control de calidad mediante el procesamiento digital de imágenes. La experiencia de los analistas al examinar diferentes rasgos morfológicos de las muestras, constituye un factor determinante en el control de calidad de la prueba de Papanicolaou. A pesar de que la incorporación de estos equipos automáticos reduce notablemente los debidos errores de lectura e interpretación y consigo la aparición de falsos negativos, las investigaciones orientadas a perfeccionar el análisis de frotis convencionales (Figura 1) no han desaparecido [15].
(20) CAPÍTULO 1. GENERALIDADES SOBRE LA PRUEBA DE PAPANICOLAOU.. 10. [16]. Existe otro método para el control de calidad de la prueba de Papanicolaou, mediante el Procesamiento Digital de Imágenes, utilizando la segmentación de los núcleos, la extracción de características de los mismos y el análisis de datos obtenidos. Ver Diagrama 1.. Diagrama 1 La adquisición de la imagen se realiza a través de la prueba de Papanicolaou (tanto la convencional como la que emplea citología de base líquida), ésta representa un reto desde el punto de vista del consumo de tiempo, pues presupone realizar un enfoque adecuado del microscopio y obtener las imágenes correspondientes a todos los campos útiles en la lámina [17] [18]. Los sistemas más modernos disponen para esto, mecanismos robotizados y dispositivos de control del microscopio. No obstante, estas funciones, dado el carácter rutinario de las operaciones involucradas, presumiblemente podrían ser realizadas por personal de una menor calificación, siempre que posea un entrenamiento adecuado. La imagen adquirida se acondiciona, con el objetivo de mejorar su calidad mediante la eliminación de ruido y la realización de correcciones en la iluminación, el contraste y posibles inconsistencias en la tinción [19]. Luego se segmentan los núcleos de las células, para extraerle determinadas características que permitan detectar algún tipo de anomalía (detección de aquella pequeña fracción de los datos que difieren de las tendencias o patrones generales, identificación de las muestras poco usuales, sin información a priori). Las regiones que son objeto de búsqueda en la detección de anomalías de estas imágenes se caracterizan por ser peculiares, irregulares, anormales y en general difíciles de clasificar, por lo que es necesario utilizar para estos propósitos una gran diversidad de rasgos que puedan diferenciar unas regiones de otras. En cuanto al análisis de los datos obtenidos, se han descrito clasificaciones de las células en dos categorías (normales y anómalas o sospechosas), o más detalladas, tal como ocurre en estudios para siete clases que utilizan la base de datos Herlev [20]. Otros ejemplos describen algoritmos de clasificación basados en redes neuronales[21] y máquinas de soporte vectorial[22], este último para imágenes obtenidas a partir de citología de base líquida..
(21) CAPÍTULO 2. MATERIALES Y METODOS. 11. CAPÍTULO 2. MATERIALES Y MÉTODOS. El trabajo se realiza con las imágenes de la base de datos Herlev (Hospital Universitario) como referencia para los métodos de clasificación, éstas han sido previamente ordenadas en 7 clases. A partir de esto se definen rasgos representativos a los núcleos de las células para poder clasificarlas como normales (sin anomalía) o anómalas (con algún tipo de desviación de la normalidad). Para implementar el algoritmo clasificador se toma como base el clasificador lineal [23], donde además de un conjunto de rasgos calculados para los núcleos celulares, se utilizaron rasgos del citoplasma y relaciones entre estos, hasta llegar a un total de 20 rasgos. En la implementación de los algoritmos clasificadores (clasificador lineal, de Mahalanobis y la Maquina de Soporte Vectorial) se emplea la programación en Matlab, utilizando herramientas como las funciones regionprops, crossvalind, classify, svmtrain, svmclassify, classperf y algunas utilidades de la clase de datos cell array. 2.1. Base de datos Herlev A partir de la base de datos de Herlev (hospital danés que ha realizado un estudio exhaustivo para la clasificación de diferentes muestras de células cervicales hasta la creación de una base de datos que sirve de punto de partida para diversos estudios[23]), se definen rasgos a los núcleos de las células para extraer diferentes características y así contribuir a la implementación de algoritmos clasificadores. La base de datos consta de 917 células (Figura 5) las cuales fueron clasificadas en 7 categorías por un panel conformado por técnicos experimentados y doctores en medicina. Cada célula se examinó por dos técnicos, y las muestras difíciles también por un doctor. En caso de discordancia la muestra quedó descartada. Las imágenes seleccionadas fueron acondicionadas y segmentadas por el personal del hospital. En este trabajo, para la clasificación, las células fueron agrupadas en 2 categorías: normales (sin anomalía) y anómalas (con algún tipo de desviación de la normalidad).. Figura 5. Célula de la base de datos Herlev. Se tiene al menos dos veces tantas células anómalas como células normales; la composición precisa de las clases se muestra en la Tabla 1..
(22) CAPÍTULO 2. MATERIALES Y METODOS. 12. Tabla 1. La distribución es de 917 células. Cantidad de. Clases. Categorías. Tipo de célula. 1. Normal. Superficial escamosa epitelial. 74. 2. Normal. Intermedia escamosa epitelial. 70. 3. Normal. Columnar escamosa epitelial. 98. 4. Anormal. Ligera escamosa displasia. 182. 5. Anormal. Moderada escamosa displasia. 146. 6. Anormal. Severa escamosa displasia. 197. 7. Anormal. Carcinoma in situ. 150. células. Subtotal. 242. 675. Como se aprecia en la Tabla 1, de las clases 1-3 las células son normales y de las clases 4-7 son anómalas. Para simplificar el trabajo se le ha asignado a cada clase un código para su identificación como se muestra en la Tabla 2: Tabla 2. Codificación de las 7 clases. Normal Superficial. supsqep. Normal Intermedia. intsqep. Normal Columnar. colep. Normal Ligera. mild_sqnkd. Anormal Moderada. mod_sqnkd. Anormal Severa. sev_sqnkd. Anormal Carcinoma. sqcelcarci.
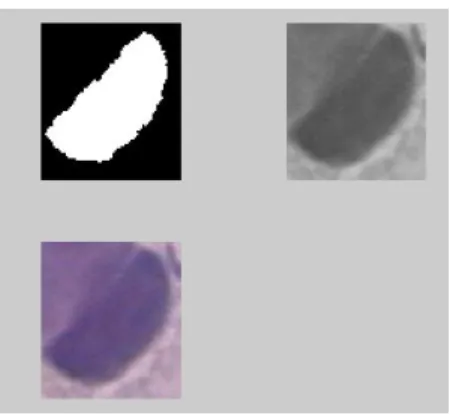
(23) CAPÍTULO 2. MATERIALES Y METODOS. 13 La Figura 6 muestra un ejemplo de las células que se tomaron en la base de datos Herlev para el trabajo. Una misma célula posee una imagen en RGB (inferior izquierdo) y además, una imagen que contiene su núcleo (está determinado por el color azul claro) segmentado (inferior derecho). Células para el trabajo. (a). (b). Figura 6. Células anormales tipo carcinoma. (a) Imagen RGB, (b) imagen segmentada 2.1.2. Agrupamiento de las células. Para organizar las imágenes en una misma estructura de datos a pesar de tener éstas diferentes dimensiones, se utiliza para el trabajo la clase ‘cell’ de Matlab [24], ésta permite agrupar la cantidad de imágenes que se desee en estructuras ‘cell array’ sin importar que las imágenes posean dimensiones diferentes. Con este propósito se realiza un programa que además, acondiciona el núcleo de las células para posteriormente definir rasgos y así extraer las características necesarias para la implementación de los algoritmos clasificadores (ver Anexo I). A continuación se explica brevemente este programa: Se define la cantidad de imágenes a concatenar en el ´´array´´ Se crean los ´´arrays´´ con el espacio necesario. Se leen las imágenes segmentadas y las imágenes en escala de grises. Se utiliza un contador para que el ciclo se repita hasta que se lea la última imagen a concatenar. Como resultado del programa se generan tres imágenes en cada celda: 1. Una máscara binaria para el núcleo, 2. La célula en escala de grises.
(24) CAPÍTULO 2. MATERIALES Y METODOS. 14. 3. La célula a color (RGB). Estas tres imágenes se agrupan en un ´´cell array´´ (Figura 7) que contiene todas las imágenes de una clase dada para el total de células que se desea analizar. Por ejemplo, la clase Anormal Carcinoma está determinada por un ‘cell array’ denominado sqcelcarci (según Tabla 2), donde cada una de sus células posee la máscara binaria para el núcleo, la célula en escala de grises y en el espacio RGB como se muestra en la Figura 7 (superior izquierdo, superior derecho e inferior izquierdo respectivamente).. Figura 7. Imagen contenida en una celda del cell array para una célula del tipo Anormal Carcinoma. 2.2. Rasgos utilizados para la clasificación. Para la clasificación de las células se definen rasgos propios de los núcleos celulares. Esta es la diferencia principal de este trabajo con lo descrito por Jantzen et al [23], donde se utilizan también para la clasificación rasgos del citoplasma. Para implementar lo anterior, se utiliza en lo fundamental la herramienta regionprops de Matlab [24]. Esta herramienta computa un conjunto de medidas de rasgos de los objetos presentes en una imagen etiquetada. En este trabajo, se utilizan los siguientes rasgos de los núcleos celulares: Intensidad Máxima. Intensidad Media. Intensidad Mínima. Solidez. Entropía. Excentricidad. Área..
(25) CAPÍTULO 2. MATERIALES Y METODOS. 15. Perímetro. El área y el perímetro también se utilizaron a partir de la siguiente relación: . (1). Los 9 rasgos anteriormente expuestos se aplican sobre las células en escala de grises y sobre la máscara binaria para los núcleos celulares. 2.2.1 Entropía. La Entropía es un rasgo que no se genera con la herramienta regionprops, sino que se crea una función (ver Anexo II) donde los argumentos de entrada son: La imagen que contiene el objeto segmentado (núcleos en escala de grises). La máscara binaria de segmentación que define la región donde se desea calcular la entropía (mask). Se define un vector de índices correspondientes a los elementos de „mask‟ que tienen valor 1. Se definen los valores de la imagen en las posiciones determinadas por el vector de índices (es decir, donde la máscara vale 1). Se eliminan los valores iguales a cero y se calcula la entropía de Shannon:. (2) 2.3 Formación de la estructura de datos. Para la extracción de rasgos se realiza un programa (ver Anexo III) que se describe a continuación: Se leen las imágenes almacenadas en los „arrays‟ ya creados (array para cada una de las clases), que contienen a su vez las células de las imágenes cervicales en escala de grises, en el espacio RGB, y la máscara binaria correspondiente al núcleo de las mismas. Se definen los rasgos a extraer (epígrafe 2.1.3). Se define un ciclo de iteraciones donde se aplica regionprops a las células en escala de grises y la máscara binaria de los núcleos. Luego se crea la matriz de rasgos..
(26) CAPÍTULO 2. MATERIALES Y METODOS. 16. La matriz de rasgos está formada de la siguiente forma: canorfeats(i,:) = [relac ent statsxi.MeanIntensity statsxi.MaxIntensity statsxi.MinIntensity statsxi.Solidity statsxi.Eccentricity statsxi.Area statsxi.Perimeter];. El parámetro „relac‟ corresponde a la relación √Área/Perímetro y el parámetro „ent‟ hace alusión a la Entropía. La matriz de rasgos contiene los datos de las 917 células de la base Herlev. Esta matriz se denomina „canorfeatsto_R9’. La composición precisa de la matriz se muestra en la Tabla 3. Tabla 3. Matriz de rasgos (en la matriz hay tantos valores como células en las diferentes clases) RASGOS Intensidad Clases. Relac. Ent. Solidez. Área. Perímetro. Excentricidad. 1 (74 células). 9.0290. 0.0824. 0.9593. 1178. 130.468. 0.4134. 2 (70 células). 0.3490. 0.0980. 0.9674. 1575. 153.882. 0.5874. 0.5463. 0.7098. 0.4196. 0.970. 3340. 235.279. 0.7782. 4.8094. 0.2839. 0.3607. 0.1647. 0.976. 9422. 373.948. 0.3864. 18.7777. 6.0505. 0.3488. 0.6666. 0.145. 0.971. 5660. 301.421. 0.7354. 6 (197 células). 13.3669. 5.9119. 0.4104. 0.6431. 0.2784. 0.947. 3351. 250.693. 0.6794. 7 (150 células). 7.7204. 4.627. 0.276. 0.368. 0.219. 0.874. 1641. 212.551. 0.654. Media. Máxima. Mínima. 4.6893. 0.1465. 0.2431. 10.2350. 5.4129. 0.2348. 3 (98 células). 14.195. 5.6500. 4 (182 células). 15.986. 5 (146 células). Los datos presentados corresponden solamente a la primera célula de cada clase a modo de ilustración. También se crea un arreglo tipo ‘cell array’ (ver Anexo IV), de Nx1 donde N es la cantidad de células de la base Herlev, aquí se denotan los nombres de las diferentes clases (empezando por la clase 1 hasta la clase 7), y con ello se forma un arreglo general denominado herlevfeats. El arreglo se muestra a continuación: . supsqep. De la célula 1-74 (herlev1.mat). . intsqep. De la célula 75- 144 (herlev2.mat). . colep. De la célula 145-242 (herlev3.mat).
(27) CAPÍTULO 2. MATERIALES Y METODOS. . mild_sqnkd. De la célula 243-424 (herlev4.mat). . mod_sqnkd. De la célula 425-570 (herlev5.mat). . sev_sqnkd. De la célula 571-767 (herlev6.mat). . sqcelcarci. De la célula 768-917 (herlev7.mat). 17. Para que cada célula correspondiera con sus rasgos, se organizan las matrices de acuerdo con la clase a la que pertenecen (ver Anexo V), para formar una matriz de rasgos única denominada canorfeatsto_R9, por ejemplo, canorfeats1_R9.mat contiene los rasgos de la clase 1 (supsqep (herlev1.mat)) y así sucesivamente; quedando de la siguiente forma: 'canorfeats1_R9.mat'. supsqep (herlev1.mat). 'canorfeats2_R9.mat'. intsqep (herlev2.mat). 'canorfeats3_R9.mat'. colep (herlev3.mat). 'canorfeats4_R9.mat'. mild_sqnkd (herlev4.mat). 'canorfeats5_R9.mat'. mod_sqnkd (herlev5.mat). 'canorfeats6_R9.mat'. sev_sqnkd (herlev6.mat). 'canorfeats7_R9.mat'. sqcelcarci (herlev7.mat). Luego se unen estos dos arrays (herlevfeats y canorfeatsto_R9), para crear un fichero denominado clasific_R9, el cual es el punto de partida de los algoritmos de clasificación que se implementan en este trabajo (ver Anexo VI). 2.4 Parámetros para la evaluación de la calidad de los clasificadores. La Figura 8 refleja los posibles resultados de un proceso de clasificación binaria, ésta se analiza para comprender la importancia de la evaluación de la calidad en los clasificadores [25]..
(28) CAPÍTULO 2. MATERIALES Y METODOS. 18. Figura 8. Proceso de clasificación binaria En la figura mostrada se tienen las siguientes definiciones: a = cantidad de ocurrencias de yi = 1 | xi = 1 (células anómalas detectadas como anómalas), conocidas como verdaderos positivos. b = cantidad de ocurrencias de yi = 1 | xi = 0 (células normales detectadas como anómalas), conocidas como falsos positivos. c = cantidad de ocurrencias de yi = 0 | xi = 1 (células anómalas detectadas como normales), conocidas como falsos negativos. d = cantidad de ocurrencias de yi = 0 | xi = 0 (células normales detectadas como normales), conocidas como verdaderos negativos. A partir de estas definiciones se pueden calcular diferentes indicadores de desempeño como la sensibilidad, la especificidad, la predictividad positiva, la predictividad negativa y la tasa de clasificación correcta..
(29) CAPÍTULO 2. MATERIALES Y METODOS. 19 La sensibilidad (SE) o tasa de detección correcta es la probabilidad de que las anomalías sean detectadas correctamente. Se define como:. (3) La especificidad (SP) es la probabilidad de detectar correctamente las regiones normales, se calcula como:. (4) La predictividad positiva (PP) es la probabilidad de que los positivos hayan sido correctamente detectados. Se calcula como:. (5) La predictividad negativa (PN) o tasa bayesiana negativa es la probabilidad de que los negativos hayan sido correctamente detectados. Se calcula como:. (6) La tasa de clasificación correcta (RC) es la proporción del número total de casos que fueron clasificados correctamente.. (7) En resumen: Si disminuye „c‟ (falsos negativos), la sensibilidad y la predictividad negativa van a aumentar, por otro lado, si disminuye „b‟ (falsos positivos), la especificidad y la predictividad positiva también aumentarían. Y, por consiguiente la clasificación general sería mejor..
(30) CAPÍTULO 2. MATERIALES Y METODOS. 20. 2.5. Herramientas Matlab utilizadas en la clasificación y evaluación de las células. Para la clasificación de las células se utilizan 3 clasificadores; el clasificador lineal y el de la distancia de Mahalanobis implementados mediante la función classify de Matlab y el clasificador que emplea una máquina de soporte vectorial (SVM), a través de las funciones svmtrain y svmclassify. Para la evaluación de la calidad de estos clasificadores se trabaja con las funciones crossvalind y classperf. 2.5.1. Función crossvalind de Matlab. La función crossvalind tiene como argumento los siguientes parámetros [24]: Índices = crossvalind('Kfold', N, K) Crossvalind divide la muestra a clasificar en K grupos ordenados aleatoriamente. De esta partición se utilizan K-1 muestras para entrenamiento y el grupo restante para la evaluación, este proceso siempre toma un subconjunto diferente para la evaluación, hasta que clasifica todos los K introducidos.. 2.5.2. Función classify de Matlab. La función classify tiene como argumento los siguientes parámetros [24]: class = classify(sample,training,group) Esta herramienta clasifica los datos de cada fila de los grupos a entrenar (estos datos provienen de la. matriz de datos „canorfeatsto_R9‟, en este caso en normales y anómalas). Otra forma de utilizar classify es especificando el tipo de clasificador que se desea, de no hacerse este paso, Matlab toma por defecto el clasificador lineal. class = classify(sample,training,group,'type') ‘type’ : permite especificar el tipo de clasificador. Estas pueden ser:. lineal: con una densidad. normal. multivariada para cada grupo, con una estimación. mancomunada de covarianza. diagonal: similar al Lineal, pero con un estimado diagonal de la matriz de covarianza. cuadrático: las densidades de normalidad multivariadas con estimados de covarianza estratificados por grupos.. diagcuadrático: similar al cuadrático, pero con una estimación diagonal de la matriz de covarianza. Mahalanobis: usa la distancia de Mahalanobis con estimaciones estratificadas de covarianza. En este trabajo se utilizan el clasificador lineal y el de la distancia de Mahalanobis..
(31) CAPÍTULO 2. MATERIALES Y METODOS. 21. 2.5.3. Función svmtrain de Matlab.. Esta función tiene como argumento los siguientes parámetros [24]: svmstruct = svmtrain(training,group) training: matriz de datos de entrenamiento group: cell array con los nombres de los datos correspondientes a las filas en la matriz de entrenamiento. Su objetivo es entrenar el clasificador SVM tomando datos de dos grupos que se introducen mediante la variable group, por consiguiente, svmstruct contiene información acerca del clasificador entrenado, incluyendo los vectores de soporte; esto es usado por svmclassify para la clasificación. La variable group es un cell array de cadenas de caracteres de la misma longitud que el conjunto de entrenamiento que está definido para los dos grupos. En general group puede ser un vector columna, un arreglo de caracteres o un cell array de cadenas. En este trabajo se emplea un grupo de tipo numérico y el otro grupo de tipo cell array. Esta función también se define de la siguiente forma: Svmtrain(…,’Kernel_Function’,Kfun) Aquí se permite especificar la función Kermel. Kfun usa el mapa de los datos de entrenamiento dentro del espacio Kermel. El defecto de la función Kermel es el puntero de la clasificación. Kfun puede ser una de las siguientes cadenas: „lineal‟. Kermel Lineal o puntero. „quadratic‟. Kermel Cuadrático. „polynomial‟. Kermel Polinomial (por defecto orden 3). „rbf‟. Kermel de función de base radial. „mlp‟. Kermel de capa múltiple Perceptron (por defecto escala 1). 2.5.4. Función svmclassify de Matlab.. Esta función tiene como argumento los siguientes parámetros [24]: Group=svmclassify(svmstruct,sample) svmstruct: creada usando svmtrain.
(32) CAPÍTULO 2. MATERIALES Y METODOS. 22. sample: matriz de datos de prueba (a ser clasificado) Su objetivo es clasificar utilizando la máquina de soporte vectorial. Clasifica cada fila de los datos de la prueba con la información de un clasificador de máquina de soporte vectorial mediante la estructura svmstruct creada usando svmtrain. La matriz de datos de prueba debe tener el mismo número de columnas como los datos que se usaron en el entrenamiento del clasificador en svmtrain. Group indica el grupo para el cual la fila de la prueba es asignada. 2.5.5. Función classperf de Matlab. La función classperf provee una interfaz para seguir el desempeño durante la validación de los clasificadores (lineal, Mahalanobis, SVM) y acumula los resultados de éstos. A continuación se ejemplifican los parámetros de su argumento [24]: cp = classperf(herlevfeats); classperf(cp,class,test) cp es el objeto de evaluación del clasificador. La evaluación del desempeño se mide a través de los siguientes parámetros: Tasa de error Tasa de cuantificación correcta Sensibilidad Especificidad Predictividad positiva Predictividad negativa. 2.6 Programas para la clasificación y evaluación. El programa (ver Anexo VII) para un algoritmo clasificador lineal y de Mahalanobis, se describe a continuación: . Lee el fichero „clasific_R9’ el cual contiene la matriz de rasgos de las clases „canorfeatsto_R9’ y el cell array „herlevfeats’ con los nombres abreviados de las 7 clases.. . Se seleccionan de forma aleatoria los conjuntos de prueba y de entrenamiento, mediante crossvalind.. . El comando cp = classperf(herlevfeats), se inicializa..
(33) CAPÍTULO 2. MATERIALES Y METODOS. Se entrena el clasificador usando la alternativa lineal o Mahalanobis según el algoritmo de. 23. clasificación que se desee implementar mediante classify. . Se utiliza un ciclo for, para garantizar que el proceso de evaluación se repita K veces donde mediante crossvalind las muestras numeradas obtendrán siempre distribuciones diferentes.. Se evalúa la calidad del clasificador mediante los valores de la tasa de error, la tasa de cuantificación correcta, la sensibilidad, la especificidad, la predictividad positiva y la predictividad negativa que el programa devuelve.. El clasificador SVM (ver Anexo VIII) se describe a continuación: Lee el contenido del fichero a emplear. Se seleccionan de forma aleatoria los conjuntos de prueba y de entrenamiento. Mediante svmtrain y svmclassify con Kermel de función de base radial se implementa el clasificador SVM. . Se evalúa la calidad del clasificador mediante los valores de la tasa de error, la tasa de cuantificación correcta, la sensibilidad, la especificidad, la predictividad positiva y la predictividad negativa que el programa devuelve..
(34) CAPÍTULO 3. RESULTADOS Y DISCUSIÓN. 24. CAPÍTULO 3. RESULTADOS Y DISCUSIÓN En este capítulo se analizan los resultados de todos los experimentos realizados en cuanto a los índices de efectividad: tasa de error, la tasa de cuantificación correcta, la sensibilidad, la especificidad, la predictividad positiva y la predictividad negativa (se usó k=10 en cada corrida). Se determinan los valores medios y las desviaciones estándar de todos los parámetros antes mencionados y se realiza un análisis estadístico (se repitieron las corridas dos veces) mediante la prueba de Kruskal-Wallis para determinar cuál de los 3 clasificadores es el más eficiente en la clasificación de las células con rasgos de los núcleos celulares. 3.1. Resultados del clasificador lineal. La Tabla 4 muestra los resultados correspondientes al clasificador lineal para el experimento donde todas las clases tienen sus nombres reales, pero en el programa se especifica cuáles de ellas son negativas o positivas. Esto se realiza de la siguiente manera (ver Anexo VII): posval={'mild_sqnkd' 'mod_sqnkd' 'sev_sqnkd' 'sqcelcarci'} Células con algún tipo de anomalía. negval={'supsqep' 'intsqep' 'colep'} Células sin anomalía Posteriormente estos comandos se introducen como especificación en la función classperf de la siguiente forma: classperf(cp,class,test,'Positive',posval,'Negative',negval). Para evaluar la clasificación se analizan detalladamente los resultados correspondientes a la sensibilidad y la predictividad negativa. Tabla 4. Clasificación para 7 clases (cada clase con su nombre correspondiente), mediante el clasificador lineal (917 muestras y k=10) Parámetros. 10 Iteraciones. ER. 0.6333. 0.5912. 0.5588. 0.5549. 0.5514. 0.5564. 0.5599. 0.5559. 0.5545. 0.5551. CR. 0.3667. 0.4088. 0.4451. 0.4412. 0.4486. 0.4436. 0.4401. 0.4441. 0.4455. 0.4449. SE. 0.9091. 0.9091. 0.9100. 0.8839. 0.8839. 0.8812. 0.8877. 0.8868. 0.8863. 0.8844. SP. 0.8750. 0.8776. 0.8472. 0.8660. 0.8926. 0.8904. 0.8947. 0.8974. 0.8950. 0.8926. PP. 0.9524. 0.9524. 0.9430. 0.9478. 0.9581. 0.9570. 0.9588. 0.9598. 0.9590. 0.9583. PN. 0.7778. 0.7818. 0.7722. 0.7304. 0.7347. 0.7303. 0.7427. 0.7415. 0.7396. 0.7347.
(35) CAPÍTULO 3. RESULTADOS Y DISCUSIÓN. 25. Se puede constatar que la clasificación no tiene resultados favorables puesto que la sensibilidad y la predictividad negativa, dan valores relativamente bajos. Como los resultados de la clasificación no corresponden con lo esperado, se decide trabajar con el arreglo de los nombres, es decir,. se implementará una clasificación binaria, donde existen dos grandes grupos: células. normales (clase 1, 2, 3) y células anómalas (clase 4, 5, 6, 7). Con estas nuevas condiciones en el programa (ver Anexo VII) no se especifican los parámetros de posval y negval, por tanto se suprimen, quedando la función classperf de la siguiente manera: classperf(cp,class,test) Ahora el ‘array’ para los nombres será herlevbi.mat, la matriz de rasgos sigue siendo la misma canorfeatsto_R9 y el fichero con los dos arreglos antes mencionados estará determinado por clasific_R9_nom2. Con este nuevo fichero trabaja el programa para la clasificación lineal. Los resultados para este experimento se muestran en la Tabla 5. Tabla 5. Clasificación binaria (normal o anómala), empleando el clasificador lineal (917 muestras y k=10).. Parámetros. 10 Iteraciones. ER. 0.1522. 0.1304. 0.1055. 0.1066. 0.1089. 0.1198. 0.1199. 0.1185. 0.1188. 0.1200. CR. 0.8478. 0.8696. 0.8945. 0.8934. 0.8911. 0.8802. 0.8801. 0.8815. 0.8812. 0.8800. SE. 0.7917. 0.8542. 0.8889. 0.8958. 0.9008. 0.9034. 0.8817. 0.8808. 0.8756. 0.8719. SP. 0.8676. 0.8750. 0.8966. 0.8926. 0.8876. 0.8719. 0.8795. 0.8817. 0.8832. 0.8830. PP. 0.6786. 0.7069. 0.7529. 0.7478. 0.7415. 0.7158. 0.7233. 0.7265. 0.7280. 0.7276. PN. 0.9219. 0.9444. 0.9579. 0.9602. 0.9615. 0.9620. 0.9541. 0.9540. 0.9521. 0.9506. Como se aprecia en la tabla anterior (Tabla 5) los resultados fueron superiores a los expuestos en la Tabla 4, por lo que se puede concluir que la clasificación binaria permite que el clasificador tenga un mejor entrenamiento y por consiguiente haga una mejor identificación de las células. Aunque los resultados expuestos en la Tabla 5 son satisfactorios, lo ideal sería obtener todos los valores de sensibilidad y predictividad negativa más cercanos a 1, puesto que así se garantizaría la eliminación de los falsos negativos (ver epígrafe 2.4)..
(36) CAPÍTULO 3. RESULTADOS Y DISCUSIÓN. 26. 3.1.1. Experimento para una clasificación con un par de clases (clases 3 y 4) Como se persigue investigar la capacidad de evaluación del clasificador, se analizan las posiciones de las 7 clases (Figura 9), y se decide realizar algún experimento que clasifique solamente a un par de ellas que estén suficientemente separadas entre sí y además que pertenezcan a grupos diferentes (normal o anómala). La clasificación que se lleva a cabo es la binaria puesto que mejorar los índices en este tipo de clasificación es la meta principal de este experimento.. Área del núcleo (pixeles) Figura 9. Distribución de los núcleos. Con este fin, se realiza un experimento con las clases 3 y 4 (Normal Columnar y Anormal Ligera, respectivamente). La prueba se realiza de la siguiente manera: El programa tiene como fichero „classbi_R9_C2’, que contiene la matriz de rasgos de las células, matrixprueb_R9, y el „cell array’ con los nombres de las 2 clases, „nombresbi_R9_C2’. Ver Anexo VII. Los resultados se muestran en la Tabla 6..
(37) CAPÍTULO 3. RESULTADOS Y DISCUSIÓN. 27. Tabla 6. Experimento para dos clases separadas y de diferentes grupos (3 y 4), empleando el clasificador lineal. Parámetros. 10 Iteraciones. ER. 0.1429 0.0893 0.0595 0.0714 0.0929 0.0952 0.1077 0.0987 0.0876 0.0893. CR. 0.8571 0.9107 0.9405 0.9286 0.9071 0.9048 0.8923 0.9013 0.9124 0.9107. SE. 0.9474 0.9459 0.9636 0.9315 0.9121 0.9083 0.9055 0.9172 0.9264 0.9341. SP. 0.6667 0.8421 0.8966 0.9231 0.8980 0.8983 0.8676 0.8718 0.8864 0.8673. PP. 0.8571 0.9211 0.9464 0.9577 0.9432 0.9429 0.9274 0.9301 0.9379 0.9290. PN. 0.8571 0.8889 0.9286 0.8780 0.8462 0.8413 0.8310 0.8500 0.8667 0.8763. Con estos resultados se puede constatar que el clasificador (en este caso lineal) da resultados favorables ya que se observa por inspección que los valores de sensibilidad y predictividad negativa mejoran en cada iteración que realiza el programa. Pero el hecho que estas clases aunque pertenezcan a diferentes grupos no sean muy diferentes, puesto que la clase Anormal Ligera presenta una leve anomalía, influye un poco en los resultados. 3.1.2. Experimento para una clasificación con un par de clases (clases 1 y 7). Se decide realizar una prueba con las clases 1 y 7, que además de ser las más separadas entre sí y pertenecer a grupos diferentes, (clase 1-normal, clase 7-anómala) el tipo de células que las caracterizan poseen grandes diferencias, ya que la clase 1, Normal Superficial, no presenta ningún tipo de anomalía y la clase 7, Anormal Carcinoma, muestra la más severa anomalía. Con estos nuevos requisitos el programa trabaja de la siguiente manera: El programa tiene como fichero „class_R9_C17’, que contiene la matriz de rasgos, „matrixnum_R9_C17’ y el „cell array’ con los nombres de las 2 clases correspondientes al experimento, „nombres_R9_C17’. Ver Anexo VII. Los resultados se muestran en la Tabla 7..
(38) CAPÍTULO 3. RESULTADOS Y DISCUSIÓN. 28. Tabla 7. Experimento para dos clases (1 y 7) mediante el clasificador lineal.. Parámetros. ER. 10 Iteraciones 0. 0.0227 0.0149 0.0225 0.0179 0.0296 0.0318 0.0279 0.0299 0.0313. CR. 1.0000 0.9773 0.9851 0.9775 0.9821 0.9704 0.9682 0.9721 0.9701 0.9688. SE. 1.0000 0.9667 0.9778 0.9667 0.9733 0.9556 0.9524 0.9583 0.9556 0.9533. SP. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. PP. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. PN. 1.0000 0.9333 0.9565 0.9355 0.9487 0.9184 0.9123 0.9219 0.9167 0.9136. Como se evidencia, los resultados mostrados en la Tabla 7, son superiores a todos los expuestos anteriormente. Por lo que se puede decir que mientras más separadas estén las clases y más diferentes sean sus características distintivas, mejor será el comportamiento del clasificador. También se observa que los valores de especificidad y predictividad negativa son óptimos, y aunque estos índices de efectividad no son los principales en el análisis que se pretende realizar en este trabajo, los resultados obtenidos representan una disminución de los falsos negativos. 3.1.3. Valores medios de la evaluación de calidad del clasificador lineal. Para determinar los valores medios y las desviaciones estándar de los datos que evalúan la calidad del clasificador (tasa de error, tasa de cuantificación correcta, sensibilidad, especificidad, predictividad positiva y predictividad positiva), se realizan 3 corridas de los programas correspondientes a cada experimento antes expuesto. Los datos obtenidos fueron organizados en una matriz, para posteriormente procesarlos mediante la función de Matlab normfit. Esta función estima el valor medio, la desviación estándar y la distribución normal de los datos obtenidos (ver Anexo IX). Los resultados se muestran en las Tablas 8, 9, 10 y 11. La Tabla 8 muestra los datos medios correspondientes al clasificador lineal para el experimento donde todas las clases tienen sus nombres reales, pero en el programa se especifica cuáles de ellas son normales o anómalas..
(39) CAPÍTULO 3. RESULTADOS Y DISCUSIÓN. 29. Tabla 8. Valores medios de los índices de efectividad correspondientes al clasificador lineal para el experimento de todas las clases, con sus respectivos nombres. Parámetros Media(Mu) ER CR SE SP PP PN. 0.5282 0.4718 0.8713 0.9154 0.9665 0.72. Sigma. Muci. 0.0257 0.0257 0.024 0.0152 0.0056 0.036. ± 0.0192 ± 0.0192 ± 0.0179 ± 0.0114 ± 0.0042 ± 0.0269. La Tabla 9 muestra los datos medios de la clasificación usando el clasificador lineal para el arreglo binario de las células, donde las clases 1, 2 y 3 toman el nombre de „Normal‟ (por pertenecer a esta clasificación), mientras que las clases 4, 5, 6 y 7 están definidas como „Anormal‟ (por las mismas razones anteriores). Tabla 9. Valores medios de los índices de efectividad correspondientes al clasificador lineal para una clasificación binaria. Parámetros Media(Mu) ER CR SE SP PP PN. 0.0197 0.0197 0.0231 0.0219 0.0365 0.0091. Sigma. Muci. 0.0197 0.0197 0.0231 0.0219 0.0365 0.0091. ± 0.0147 ± 0.0147 ± 0.0173 ± 0.0164 ± 0.0273 ± 0.0068.
(40) CAPÍTULO 3. RESULTADOS Y DISCUSIÓN. 30. Tabla 10. Valores medios de los índices de efectividad correspondientes al clasificador lineal para las clases 3 y 4.. Parámetros Media(Mu) ER CR SE SP PP PN. 0.1076 0.8924 0.9177 0.8448 0.9173 0.8488. Sigma. Muci. 0.0214 0.0214 0.0264 0.0473 0.0205 0.0373. ± 0.016 ± 0.016 ± 0.0197 ± 0.0353 ± 0.0154 ± 0.0279. Tabla 11. Valores medios de los índices de efectividad correspondientes al clasificador lineal para las clases 1 y 7. Parámetros Media(Mu) ER CR SE SP PP PN. 0.0321 0.9679 0.9520 1.0000 1.0000 0.9130. Sigma. Muci. 0.0140 0.0140 0.0211 0 0 0.0358. ± 0.0105 ± 0.0105 ± 0.0158 0 0 ± 0.0268. 3.2. Resultados del clasificador mediante la distancia de Mahalanobis. Para establecer una comparación en cuanto a la calidad de clasificación se tabularon los mismos datos para el clasificador mediante la distancia de Mahalanobis, como los anteriores para el clasificador lineal. Los ficheros utilizados en estos experimentos son los mismos citados en el epígrafe 3.1, para cada una de las pruebas. Los resultados se muestran en las Tablas 12, 13, 14 y 15..
(41) CAPÍTULO 3. RESULTADOS Y DISCUSIÓN. 31. Tabla 12. Clasificación para 7 clases (cada clase con su nombre correspondiente), empleando la distancia de Mahalanobis.. ER 0,5385 0,5525 0,5699 0,5479 0,5502 0,5493 0,5453 0,5525 0,5607 0,5518. CR 0,4615 0,4475 0,4301 0,4521 0,4498 0,4507 0,4547 0,4475 0,4393 0,4482. Parámetros de evaluación SE SP 0,8971 0,9130 0,9037 0,8913 0,8806 0,8873 0,8736 0,8854 0,8817 0,8750 0,8837 0,8750 0,8919 0,8810 0,8889 0,8808 0,8847 0,8756 0,8874 0,8760. PP 0,9683 0,9606 0,9568 0,9553 0,9521 0,9520 0,9546 0,9543 0,9521 0,9523. PN 0,7500 0,7593 0,7241 0,7143 0,7241 0,7283 0,7437 0,7391 0,7308 0,7361. La Tabla 13 muestra los resultados del experimento realizado para todas las clases divididas en dos grupos (normales y anómalos). Ver Anexo VIII. Tabla 13. Experimento para una clasificación binaria con un clasificador mediante la distancia de Mahalanobis.. ER 0,1333 0,0889 0,0889 0,0884 0,0973 0,0956 0,1006 0,0962 0,1098 0,1031. CR 0,8667 0,9111 0,9111 0,9116 0,9027 0,9044 0,8994 0,9038 0,8902 0,8969. Parámetros de evaluación SE SP 1,0000 0,8182 1,0000 0,8788 1,0000 0,8788 0,9583 0,8947 0,9333 0,8916 0,9306 0,8950 0,9167 0,8932 0,9167 0,8993 0,8889 0,8907 0,8917 0,8988. PP 0,6667 0,7500 0,7500 0,7667 0,7568 0,7614 0,7549 0,7652 0,7442 0,7589. PN 1,0000 1,0000 1,0000 0,9835 0,9737 0,9728 0,9676 0,9679 0,9573 0,9587.
(42) CAPÍTULO 3. RESULTADOS Y DISCUSIÓN. 32. Tabla 14. Experimento para dos clases separadas y de diferentes grupos (3 y 4), empleando la distancia de Mahalanobis.. ER 0,1071 0,0893 0,0714 0,0541 0,0647 0,0659 0,0769 0,0676 0,0637 0,0714. CR 0,8929 0,9107 0,9286 0,9459 0,9353 0,9341 0,9231 0,9324 0,9363 0,9286. Parámetros de evaluación SE SP 1,0000 0,8333 0,9500 0,8889 0,9667 0,9074 0,9744 0,9306 0,9592 0,9222 0,9661 0,9167 0,9275 0,9206 0,9359 0,9306 0,9432 0,9325 0,9286 0,9286. PP 0,7692 0,8261 0,8529 0,8837 0,8704 0,8636 0,8649 0,8795 0,8830 0,8750. PN 1,0000 0,9697 0,9800 0,9853 0,9765 0,9802 0,9587 0,9640 0,9682 0,9602. Tabla 15. Experimento para las clases 1 y 7, empleando la distancia de Mahalanobis. ER 0,0000 0,0000 0,0000 0,0000 0,0090 0,0150 0,0321 0,0337 0,0398 0,0446. CR 1,0000 1,0000 1,0000 1,0000 0,9910 0,9850 0,9679 0,9663 0,9602 0,9554. Parámetros de evaluación SE SP 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,9722 1,0000 0,9535 1,0000 0,9020 1,0000 0,8966 1,0000 0,8788 1,0000 0,8649. PP 1,0000 1,0000 1,0000 1,0000 0,9868 0,9783 0,9545 0,9524 0,9441 0,9375. PN 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000. Los resultados antes expuestos, evidencian que el clasificador mediante la distancia de Mahalanobis es superior al clasificador lineal, porque los índices de sensibilidad y predictividad negativa de éste, evidencian que una mayor disminución de los falsos negativos. 3.2.1. Valores medios de la evaluación de calidad del clasificador de Mahalanobis. Para determinar los valores medios y las desviaciones estándar de los índices de efectividad (tasa de error, tasa de cuantificación correcta, sensibilidad, especificidad, predictividad positiva y.
(43) CAPÍTULO 3. RESULTADOS Y DISCUSIÓN. 33. predictividad positiva), se realiza la misma operación utilizada en el clasificador lineal. Los resultados obtenidos se muestran en las Tablas 16, 17, 18 y 19. Tabla 16. Valores medios de los índices de efectividad correspondientes al clasificador de Mahalanobis para el experimento de todas las clases, con sus respectivos nombres. Parámetros Media(Mu) ER CR SE SP PP PN. 0.5413 0.4587 0.8878 0.8916 0.9582 0.7434. Sigma. Muci. 0.0199 0.0199 0.0319 0.0272 0.0099 0.0480. ± 0.0149 ± 0.0149 ± 0.0238 ± 0.0203 ± 0.0074 ± 0.0358. Tabla 17. Valores medios de los índices de efectividad correspondientes al clasificador de Mahalanobis para una clasificación binaria. Parámetros Media(Mu) ER CR SE SP PP PN. 0.0873 0.9127 0.9299 0.8811 0.9359 0.8709. Sigma 0.0245 0.0245 0.0095 0.0568 0.0275 0.0241. Muci ± 0.0183 ± 0.0183 ± 0.0071 ± 0.0424 ± 0.0205 ± 0.018. Tabla 18. Valores medios de los índices de efectividad correspondientes al clasificador de Mahalanobis para una clasificación con las clases 3 y 4. Parámetros Media(Mu) ER CR SE SP PP PN. 0.0464 0.9536 0.9434 0.9729 0.9848 0.9020. Sigma. Muci. 0.0185 0.0185 0.0171 0.0253 0.0142 0.0282. ± 0.0265 ± 0.0265 ± 0.0245 ± 0.0362 ± 0.0204 ± 0.0404.
(44) CAPÍTULO 3. RESULTADOS Y DISCUSIÓN. 34. Tabla 19. Valores medios de los índices de efectividad correspondientes al clasificador de Mahalanobis para una clasificación con las clases 1 y 7. Parámetros Media(Mu) ER CR SE SP PP PN. 0.0456 0.9269 1.0000 0.8604 0.9374 1.0000. Sigma. Muci. 0.0225 0.0426 0 0.0711 0.0269 0. ± 0.0168 ± 0.0317 0 ± 0.0531 ± 0.0202 0. 3.3. Clasificador de máquina de soporte vectorial (SVM). El programa en Matlab correspondiente para el clasificador SVM tiene como limitación no admitir conjuntos de datos muy grandes y por esto los experimentos se limitan al caso de dos clases específicas (ver Anexo VIII). En la Tabla 20 se muestran los resultados de este programa para la clasificación de las clases 3 y 4. Tabla 20. Experimento para dos clases (3 y 4) mediante el clasificador SVM.. ER 0,1429 0,1053 0,0714 0,0893 0,0786 0,0774 0,0765 0,0673 0,0757 0,0821. CR 0,8571 0,8947 0,9286 0,9107 0,9214 0,9226 0,9235 0,9327 0,9243 0,9179. Parámetros SE SP 0,7000 0,9444 0,7500 0,9730 0,8276 0,9818 0,7949 0,9726 0,8163 0,9780 0,8136 0,9817 0,8261 0,9764 0,8462 0,9793 0,8182 0,9816 0,8163 0,9725. PP 0,8750 0,9375 0,9600 0,9394 0,9524 0,9600 0,9500 0,9565 0,9600 0,9412. PN 0,8500 0,8780 0,9153 0,8987 0,9082 0,9068 0,9118 0,9221 0,9091 0,9077. Para las clases 1 y 7 también se implementa la clasificación mediante el clasificador SVM. Los resultados obtenidos se muestran en la Tabla 21..
(45) CAPÍTULO 3. RESULTADOS Y DISCUSIÓN. 35. Tabla 21. Experimento para dos clases (1 y 7) mediante el clasificador SVM.. ER 0,0435 0,0444 0,0588 0,0549 0,0531 0,0519 0,0570 0,0500 0,0446 0,0402. Parámetros SE SP 0,8750 1,0000 0,8667 1,0000 0,8261 1,0000 0,8387 1,0000 0,8684 0,9867 0,8889 0,9778 0,8868 0,9714 0,9000 0,9750 0,9104 0,9778 0,9189 0,9800. CR 0,9565 0,9556 0,9412 0,9451 0,9469 0,9481 0,9430 0,9500 0,9554 0,9598. PP 1,0000 1,0000 1,0000 1,0000 0,9706 0,9524 0,9400 0,9474 0,9531 0,9577. PN 0,9375 0,9375 0,9184 0,9231 0,9367 0,9462 0,9444 0,9512 0,9565 0,9608. En ambos experimentos, se observa por inspección que los parámetros de especificidad y predictividad negativa dan valores significativamente altos, por lo que se puede decir que los falsos positivos han disminuido. Aunque estos parámetros no son los principales en el análisis que se pretende realizar en este trabajo, los resultados obtenidos representan una buena clasificación. 3.3.1. Valores medios de la evaluación de calidad del clasificador SVM. Para determinar los valores medios de los índices de efectividad correspondientes al clasificador SVM con la clases 3 y 4 se tabularon en SPSS 20 datos obtenidos a través de su programa correspondiente (ver anexo X), para k=20. Luego se le aplica a estos datos un análisis estadístico descriptivo para obtener la media y la desviación típica. Los resultados de muestran en la Tabla 22. Tabla 22. Valores medios de los índices de efectividad correspondientes al clasificador SVM (clases 3 y 4).. N ER CR SE SP PP PN N válido (según lista). 20 20 20 20 20 20 20. Mínimo ,0364 ,9235 ,8000 ,9703 ,9388 ,9000. Máximo ,0765 ,9636 ,8947 1,0000 1,0000 ,9474. Media Desv. típ. ,066030 ,0097091 ,933970 ,0097091 ,839143 ,0207937 ,985000 ,0107246 ,968337 ,0224952 ,919345 ,0104713.
Figure



+7





Documento similar
La campaña ha consistido en la revisión del etiquetado e instrucciones de uso de todos los ter- mómetros digitales comunicados, así como de la documentación técnica adicional de
You may wish to take a note of your Organisation ID, which, in addition to the organisation name, can be used to search for an organisation you will need to affiliate with when you
Where possible, the EU IG and more specifically the data fields and associated business rules present in Chapter 2 –Data elements for the electronic submission of information
The 'On-boarding of users to Substance, Product, Organisation and Referentials (SPOR) data services' document must be considered the reference guidance, as this document includes the
In medicinal products containing more than one manufactured item (e.g., contraceptive having different strengths and fixed dose combination as part of the same medicinal
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
This section provides guidance with examples on encoding medicinal product packaging information, together with the relationship between Pack Size, Package Item (container)
