Métodos de regresión borrosa posibilística Aplicaciones
82
0
0
Texto completo
(2) El que suscribe, Salvador Brito Seoane, hago constar que el trabajo titulado “Métodos de Regresión Borrosa Posibilística. Aplicaciones” fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del tutor. Firma del jefe del Laboratorio. Fecha. II.
(3) Dedicatoria A mí amada y adorada madre por quererme y apoyarme en cada momento de la vida. A mi padre que espero se sienta orgulloso y que sigua descansando en paz.. III.
(4) Agradecimientos A mi mamá por tanta ternura, amor, cariño y por darme tanta fuerza, aliento y esperanzas para salir adelante. A Dios por su luz. A mi padrastro, padrino, mis tíos, primos y suegros que siempre me apoyaron y creyeron que si podía. A Claudia mi novia que tantas veces tuvo que planificarme para poder realizar todas las tareas y por levantarme el ánimo cuando no tenía deseos de estudiar. A mis tutoras Lisset y Gladita por aceptarme como tesiante, por tanta ayuda profesional que me brindaron con sus consejos y estar siempre pendientes y preocupadas por mi tesis. A Yanet y Yoanni por dedicarme tiempo y paciencia para vencer muchas asignaturas. A los compañeros de aula que me ayudaron. Por último y no por eso menos importante, a mis amigos (Sady, Luis Javier, Viti, Luis Miguel, Dueñas, José M, Dainel, Luis Felipe, Juan Luis, Yuniel) por apoyarme, respetarme, compartir en todo momento, ayudarme en los proyectos, por ser pacientes y sobre todo por quererme. A todos sus padres que tanto se molestaron para facilitarnos el estudio. A todos MUCHAS GRACIAS Salvador Brito Seoane.. IV.
(5) RESUMEN En esta tesis se presentan de manera resumida los conceptos fundamentales de la teoría de conjuntos borrosos. Se definen los detalles y definiciones fundamentales de los números borrosos L-R de Dubois y Prade, los números borrosos triangulares y los números borrosos triangulares simétricos. Se exponen los elementos fundamentales de la regresión borrosa y se muestran diferentes modelos de regresión reportados en la literatura haciendo énfasis en las medidas de bondad de ajuste. Se presentan los aspectos principales en la modificación del análisis, diseño e implementación del software “efuzzy 1.0” obteniéndose de esta manera la nueva versión 2.0. Se explica la utilización de la biblioteca commons-math3-3.2 para dar solución a problemas de optimización lineal y eliminar la dependencia total con el software Mathematica. Se expone algunas características y ventajas del software Lingo, así como la estructura que debe tener un fichero con extensión .lg4 para resolver el modelo de Nadimi utilizando el Lingo. Se muestra una aplicación con datos reales para el diagnóstico de la hipertensión arterial en niños considerando si tienen alto o bajo riesgo de ser hipertensos. Se obtienen varios modelos de regresión borrosa a partir de los métodos estudiados y se compara con la regresión clásica.. V.
(6) ABSTRACT In this thesis, a summary of the basic concepts of the theory of fuzzy sets is presented. Details and definitions of the fuzzy numbers of LR Dubois and Prade, triangular fuzzy numbers and the symmetric triangular fuzzy numbers are defined. The fundamentals of fuzzy set and different regression models reported in the literature with emphasis on measures of goodness of fit are exposed. The main aspects are presented in the modification of the analysis, design and implementation of the software "efuzzy 1.0" obtaining as a result, the new version 2.0. The use of commons-math3-3.2 library is explained for solving linear optimization problems and to eliminate total dependence with the Mathematica software. Some features and advantages of the software Lingo are exposed, and also the structure that must have a file with .lg4 to solve the Nadimi model using the Lingo. An application is displayed, which has real data for the diagnosis of hypertension in children considering whether they have high or low risk of being hypertensive. Several fuzzy regression models are obtained from the methods studied and a comparison is made with classical regression.. VI.
(7) ÍNDICE INTRODUCCIÓN ....................................................................................................................... 1 1.. TEORÍA DE LOS CONJUNTOS BORROSOS .......................................................................... 5. 1.1. Subconjunto borroso .......................................................................................................................... 5. 1.1.1 1.2. Definiciones básicas de conjuntos borrosos .................................................................................... 6. Intervalos de confianza y números borrosos .................................................................................... 10. 1.2.1. Intervalos de confianza .................................................................................................................. 10. 1.2.2. Números Borrosos ......................................................................................................................... 11. 1.3. Algunos tipos especiales de números borrosos ................................................................................ 13. 1.3.1. Números borrosos L-R de Dubois y Prade ..................................................................................... 13. 1.3.2. Números borrosos triangulares ..................................................................................................... 14. 1.3.2.1 1.4. Número Borroso Triangular Simétrico. ................................................................................ 15. Regresión borrosa ............................................................................................................................ 15. 1.4.1. Justificación de la regresión borrosa ............................................................................................. 18. 1.4.2. Modelos de Regresión Borrosa Posibilística .................................................................................. 19. 1.4.2.1. Regresión Borrosa Posibilística presentada por Hideo Tanaka ............................................ 20. 1.4.2.2. Modelo de Regresión Borroso Simétrico introducido por Tanaka. ...................................... 21. 1.4.2.3. Modelo de Savic y Pedrycs ................................................................................................... 22. 1.4.2.4. Modelo de Regresión Borrosa introducido por Shakouri y Nadimi ..................................... 22. 1.4.2.5. Otros modelos basados en teoría de la posibilidad ............................................................. 23. 1.4.3. 1.4.3.1. Índice de Bondad del Ajuste SIM2 para números simétricos ............................................... 25. 1.4.3.2. Índice de Bondad del ajuste SIM3para números simétricos ................................................. 26. 1.4.3.3. Índice de Bondad del Ajuste SIM4 para números simétricos ............................................... 26. 1.4.3.4. Medida de ajuste de la tendencia central ............................................................................ 27. 1.4.4 1.5. Índices de Bondad de Ajuste.......................................................................................................... 24. Algunas aplicaciones ...................................................................................................................... 27. Consideraciones finales .................................................................................................................... 28. VII.
(8) 2.. ANÁLISIS, DISEÑO E IMPLEMENTACIÓN DEL SOFTWARE “EFUZZY 2.0” .......................... 29. 2.1. Patrones de diseño ........................................................................................................................... 29. 2.1.1 2.2. Patrón Visitor ................................................................................................................................. 30. Modificaciones en el análisis, diseño e implementación del software efuzzy 1.0 ............................. 31. 2.2.1. Diagramas de casos de uso ............................................................................................................ 31. 2.2.2. Diagramas de clases ....................................................................................................................... 33. 2.2.3. Diagramas de actividad .................................................................................................................. 37. 2.2.4. Artefactos del sistema ................................................................................................................... 38. 2.2.5. Implementación del software ........................................................................................................ 39. 2.3. Utilización del commons-math3-3.2.jar ............................................................................................ 40. 2.3.1 2.4. Clases utilizadas para resolver problemas de optimización lineal ................................................. 41. Lingo ................................................................................................................................................ 41 2.4.1.1. Ventajas ................................................................................................................................ 42. 2.5. Consideraciones finales .................................................................................................................... 43. 3.. MANUAL DE USUARIO Y APLICACIONES ......................................................................... 44. 3.1. Manual de usuario ........................................................................................................................... 44. 3.1.1. Requerimientos ............................................................................................................................. 44. 3.1.2. Ficheros de entrada ....................................................................................................................... 44. 3.1.3. Ventana inicial del software .......................................................................................................... 45. 3.1.4. Interfaz principal de la aplicación .................................................................................................. 45. 3.1.4.1. Menú Analizar ...................................................................................................................... 46. 3.1.4.2. Menú Ayuda ......................................................................................................................... 53. 3.2. Validación de los métodos implementados ...................................................................................... 54. 3.3. Aplicación de la regresión lineal borrosa posibilística a problemas de hipertensión arterial en niños 58. 3.3.1. Modelos para los escolares normotensos considerando datos borrosos triangulares simétricos. 59. 3.3.2. Modelos para los escolares hipertensos considerando datos borrosos triangulares simétricos .. 61. VIII.
(9) 3.3.3. Modelo para los escolares normotensos considerando datos borrosos triangulares ................... 62. 3.3.4. Modelo para los escolares hipertensos considerando datos borrosos triangulares ..................... 63. 3.4. Consideraciones finales .................................................................................................................... 64. CONCLUSIONES...................................................................................................................... 66 RECOMENDACIONES.............................................................................................................. 67 REFERENCIAS BIBLIOGRÁFICAS .............................................................................................. 68 ANEXOS ................................................................................................................................. 71. IX.
(10) Introducción. Introducción “El mundo es un lugar borroso” (Aranguren and Muzachiodi, 2003). La mayoría de los fenómenos que ocurren a diario son imprecisos en la descripción de su naturaleza. Esta imprecisión puede estar asociada con su forma, posición, momento, color o textura entre otros elementos. En muchos casos el mismo concepto puede tener diferentes grados de imprecisión en diferentes contextos o en el tiempo. Un día cálido en invierno no es lo mismo que un día cálido en primavera. La definición exacta de cuando la temperatura pasa de fría a caliente es imprecisa, pues resulta imposible identificar un punto de corte tal que al realizar una variación de sólo un grado, la temperatura del ambiente pase de ser considerada fría a caliente. Este tipo de imprecisión o borrosidad asociado continuamente a los fenómenos, es común en casi todos los campos de estudio: sociología, física, biología, finanzas, ingeniería, y psicología entre muchos otros (Aranguren and Muzachiodi, 2003). La Regresión Borrosa aparece en la historia de los análisis de regresión en 1982 (Tanaka et al., 1982), gracias a Hideo Tanaka y sus colaboradores. El análisis de regresión borrosa se fundamenta en el análisis de regresión tradicional de la estadística e intenta extender su aplicación a datos que pueden modelarse a través de subconjuntos borrosos. El análisis de regresión borrosa ha sido estudiado y aplicado en diferentes áreas tal como la modelación de datos económicos o financieros (Aguilera Cuevas and Rodríguez Betancourt, 1999), la ingeniería de software (Conte et al., 1986), el reconocimiento de un patrón de estimación humana (Romero Cortés and Aguilar Vázquez, 1999). La lógica borrosa estudia elementos de la lógica tradicional aplicados a valores borrosos. Los elementos de un conjunto borroso son pares ordenados que indican el valor del elemento y su grado de pertenencia a dicho conjunto. De esta manera, la lógica borrosa maneja la incertidumbre presente en la estructura de un conjunto de datos. Los conjuntos borrosos fueron introducidos por primera vez en 1965, por Zadeh (Zadeh, 1965), pero sus orígenes se remontan hasta 2,500 años. La lógica borrosa (Morales Martínes, 2010) puede ser vista como un “lenguaje” que permite trasladar sentencias del lenguaje natural a un lenguaje matemático formal. Mientras 1.
(11) Introducción la motivación original fue ayudar a manejar aspectos imprecisos del mundo real, la práctica temprana de la lógica borrosa permitió el desarrollo de aplicaciones prácticas. Aparecieron numerosas publicaciones que presentaban los fundamentos básicos con aplicaciones potenciales. Esta fase marcó la fuerte necesidad de distinguir la lógica borrosa de la poderosa teoría de las probabilidades. Los paquetes estadísticos profesionales como el SPSS (Predictive Analytics Software) (IBM®. 2014), SAS (SAS-Institute-Inc., 2004), Statistica (StatSoft-Inc., 2005), Statgraphics (Statgraphics.Net, 2005) entre otros no tienen incorporados procesamientos que trabajen con datos borrosos. Es por ello que se diseñó e implementó el sistema efuzzyV1.0 (Software de análisis estadístico borroso) (Denoda Pérez et al., 2011) que contiene entre sus funcionalidades realizar análisis de regresión borrosa mediante el método de Hideo Tanaka en un entorno gráfico, obtener estadígrafos descriptivos borrosos como media, mediana, moda y varianza, así como calcular los índices de bondad de ajuste Sim3 y R2 borroso. Como objetivo general se propone: “incorporar nuevas funcionalidades al sistema de análisis de regresión borrosa efuzzy, para aumentar su aplicabilidad implementando nuevos métodos de regresión y mejorando los existentes. Para lograr dicho objetivo general, se proponen los objetivos específicos: 1. Estudiar, seleccionar e implementar nuevos métodos de regresión borrosa posibilística e incorporarlo al software efuzzy. 2. Seleccionar un método para resolver los problemas de programación lineal y eliminar la conexión con el Mathematica. 3. Validar los métodos implementados. 4. Aplicar dichos métodos a la solución de problemas reales. Como preguntas de Investigación se proponen: 1. ¿Cuáles son los fundamentos matemáticos de los métodos de regresión borrosa posibilística más importantes?. 2.
(12) Introducción 2. ¿Cómo es el diseño del sistema efuzzy para incorporar la implementación de nuevos métodos de regresión borrosa? 3. ¿Cuáles son los métodos implementados en bibliotecas de software libre que resuelven problemas de programación lineal? Justificación de la investigción Como se había mencionado con anterioridad, los paquetes estadísticos profesionales no incluyen aún técnicas de estadística borrosa. El sistema efuzzy ya elaborado incluye técnicas de estadística descriptiva borrosa y tiene incorporado un método de regresión borrosa posibilístico. En esta investigación se desea incorporar nuevos métodos de regresión borrosa a este sistema para obtener una valiosa herramienta en manos de los investigadores. La versión 1.0 del efuzzy necesita la conexión con el kernel del Mathematica (este es un software propietario) para resolver un problema de programación lineal siendo entonces primordial la implementación de un método de Programación Lineal para eliminar tal conexión. La regresión borrosa permite el manejo de cantidades afectadas por imprecisión e incertidumbre que no son manejables usando la regresión probabilística. Cuando se dispone de pocas observaciones para hacer una regresión probabilística se añade a este problema la dificultad de poder comprobar la normalidad de los errores. En esta situación una alternativa de modelación ventajosa es un modelo borroso que pueda incorporar un nivel de confianza posibilístico. Por otra parte, en aquellos modelos donde los datos sean insuficientes o imperfectos, originados por la imprecisión o vaguedad, se ha demostrado que es útil el uso de un tratamiento difuso o borroso (Morales Martínes, 2010). Viabilidad de la investigación El estado actual de la lógica borrosa ofrece una amplia gama de ideas a desarrollar en este trabajo. Para el desarrollo de esta investigación se cuenta con los recursos necesarios para acometer las tareas propuestas. Se cuenta con la investigación desarrollada por una de las 3.
(13) Introducción tutoras: Lisset Denoda Pérez en su tesis de pregrado relativo al tema de regresión borrosa. Además contamos con la tesis de maestría de Jorge Luis Morales que puede ser de mucha ayuda en la elaboración de este proyecto. El primer paso para la realización de este trabajo fue la confección del marco teórico. Para ello se realizó una amplia revisión de la literatura consultando libros, artículos y páginas de internet, entre otras fuentes. Sus elementos esenciales se encuentran expuestos de manera resumida en el primer capítulo de la presente tesis. Como conclusión de la elaboración del marco teórico se enuncia la siguiente hipótesis de investigación: “La incorporación de otros métodos de regresión borrosa y de bibliotecas de software libre que resuelvan problemas de programación lineal al software efuzzy incrementa su independencia y sus posibilidades de aplicación” La tesis se estructura en tres capítulos. El primero de ellos contiene una presentación detallada de las formulaciones matemáticas más importantes relacionadas con la lógica borrosa. Se definen los números borrosos triangulares y triangulares simétricos. Se exponen los elementos fundamentales de la regresión borrosa, se introducen varios modelos de regresión borrosa posibilística así como los índices de bondad de ajuste. En el capítulo dos se precisan las modificaciones realizadas en el diseño e implementación del software “efuzzy 1.0”. También se expone la utilización de la biblioteca de software libre commonsmath3-3.2 para dar solución a problemas de optimización lineal. En el capítulo tres se muestra el manual de usuario del software y aplicaciones con datos reales. Se obtuvieron varios modelos de regresión borrosa aplicados a la hipertensión arterial en edad pediátrica. Todos los capítulos terminan con un epígrafe de consideraciones finales en el que se resumen los aspectos más importantes que se trataron. El trabajo concluye con el enunciado de las conclusiones y algunas recomendaciones valiosas para trabajos futuros, se relaciona la bibliografía y se muestran algunos anexos.. 4.
(14) Capítulo 1. 1. Teoría de los Conjuntos Borrosos. Regresión borrosa En este capítulo se expone la teoría de los conjuntos borrosos y se introducen los modelos de regresión borrosa así como índices de bondad de ajuste para los mismos.. 1.1. Subconjunto borroso. La matemática de conjuntos borrosos que podría denominarse como clásica, se basa en la lógica aristotélica fundamentada en el principio que muestra que una proposición únicamente puede ser verdadera o falsa (1,0 respectivamente), pero no ambas cosas a la vez, es decir no existiendo ningún grado de verdad intermedio. Como consecuencia de dicho principio, en la teoría de conjuntos, para un subconjunto A definido sobre un conjunto universo o referencial X, un elemento del universo pertenece o no pertenece a dicho conjunto A, es decir, no existe ningún tipo de ambigüedad sobre su pertenencia. Matemáticamente la pertenencia a un conjunto se expresa a través de una función característica A (x) que asigna valores a todos los elementos de A en el conjunto discreto (Casalino et al., 2004). Dicho valor es 0 cuando el elemento no pertenece al conjunto y 1 cuando el elemento pertenece totalmente. Es decir, matemáticamente la función característica viene dada por:. A : X {0,1} 1 x A x X A ( x) 0 x A. (1.1). Del principio del tercero excluido se deriva el principio de exclusión. Este indica que si un elemento x del universo X pertenece a un conjunto A, no pertenece a su complemento, A c y viceversa. Matemáticamente podemos expresar el principio de exclusión como:. x X , si A ( x) 1 Ac ( x) 0. (1.2). Un conjunto borroso es un conjunto para el cual la pertenencia de un elemento está definida de forma borrosa. Así, si se denomina X como al universo o conjunto referencial, un subconjunto borroso, que se denotará de la siguiente manera A , es aquel en el que la 5.
(15) Capítulo 1 pertenencia de un elemento x X tiene asignado un nivel de verdad que puede tomar valores en el conjunto continuo [0,1]. El nivel de pertenencia de un elemento x vendrá dado por su función de pertenencia o función característica A (x) . Así, se puede definir a un subconjunto borroso como A {( x, A ( x)) | x X } siendo la función de pertenencia:. A : X [0,1] x X A ( x) [0,1]. (1.3). Donde 0 indica la no pertenencia al conjunto A y 1 la pertenencia absoluta. Evidentemente, existe una degradación del nivel de pertenencia de forma que si A ( x) 0.9 , el nivel de pertenencia del elemento x es muy elevado, y si A ( x) 0.1 el nivel de pertenencia de x es muy bajo. Así puede interpretarse como el grado en que un elemento particular que se considera cumple con las especificaciones que definen a los elementos del conjunto en cuestión y no debe interpretarse como la probabilidad de pertenencia. Si la probabilidad de que un elemento x pertenece al conjunto A es de 0.9 y se afirma que x pertenece al conjunto A , tenemos un 90 % de probabilidad de acertar, pero el elemento intrínsecamente pertenece o no pertenece a A . Cuando se dice que la función de pertenencia de x es 0.9 se quiere decir que cumple en nuestro criterio con el 90% de las características que definen los elementos del conjunto A . En resumen, la probabilidad indica incertidumbre estadística mientras que la función de pertenencia indica vaguedad y subjetividad. Además, se puede observar que un conjunto ordinario o “crisp” es un caso particular de un conjunto borroso, para el cual únicamente se diferencian dos niveles de pertenencia: la pertenencia absoluta y la no pertenencia. 1.1.1 Definiciones básicas de conjuntos borrosos En esta sección se presentan las definiciones y resultados básicos relacionados con los conjuntos borrosos. Para un estudio más profundo se pueden consultar (Buckley and Eslami, 2002). Definición 1.1 (Conjunto Vacío) El Subconjunto borroso A es vacío si y solo si A ( x) 0 x X y se escribe A . 6.
(16) Capítulo 1. Definición 1.2 (Igualdad) Si A y B son dos subconjuntos borrosos de un conjunto X, se dice que A B sí y solo si A ( x) B ( x) x X .. Definición 1.3 (Cardinalidad escalar) La cardinalidad escalar de un conjunto borroso A en el conjunto finito X, se define como:. | A |. . xX. A. ( x). (1.4). Cuando X es finito, ( {x1 ,....., xn } ), el conjunto borroso A se puede expresar como: n. A A ( x1 ) / x1 ..... A ( xn ) / xn A ( xi ) / xi. (1.5). i 1. Donde el + y la. . deben entenderse en el sentido de la teoría de conjuntos. Por convenio,. los pares A ( x) / x con A ( x) 0 se omiten. En el caso de que X no sea finito, la notación es:. A A ( x) / x X. (1.6). Definición 1.4 (Inclusión) Si A y B son dos subconjuntos borrosos de un conjunto X, se dice que A es subconjunto de B sí y solo si A ( x) B ( x) x X , esta relación se expresa como A B . Si el conjunto universo es finito, se pueden relajar la condición anterior para medir el grado en el que un conjunto borroso está incluido en otro (Galindo Gómez, 2008) S ( A, B ) . 1 {| A | max{ 0, A ( x), B ( x)}} |A| xX. (1.7). 7.
(17) Capítulo 1. Definición 1.5 (Subconjunto propio) Si A y B son dos subconjuntos borrosos de un conjunto X, se dice que A es subconjunto propio. de. AB. si y solo si. B. sí. y. sólo. AB y. si. A ( x) B ( x) x X ,. y. se. escribe. como. AB. El concepto de cardinalidad de un conjunto borroso no tiene nada que ver con el similar en el caso de conjuntos comunes (número de elementos), sino que se refiere más bien a su tamaño. Definición 1.6 (Soporte) El soporte de un subconjunto borroso A , dentro de un conjunto universal X, es el conjunto convencional (crisp) que contiene todos los elementos de X que tienen un grado de pertenencia mayor que 0 en A . sop( A ) {x X | A ( x) 0}. (1.8). Un concepto muy útil es el conjunto de nivel (umbral) α, grado de presunción, o α-corte, como se conoce en la bibliografía sobre conjuntos borrosos. Este concepto permite un enfoque muy interesante de la teoría de conjuntos borrosos, ya que la familia formada por los α-cortes contiene toda la información sobre el conjunto borroso. Definición 1.7 (Conjunto de nivel α o α-corte) Dado un número [0,1] y un conjunto borroso A , se define el conjunto de nivel α o αcorte de A como el conjunto A cuya función característica se define: 1 si A ( x) . A ( x) . 0 en cualquier otro caso. (1.9). En conclusión, el α-corte se compone de aquellos elementos cuyo grado de pertenencia supera o iguala el umbral α. Hablamos de α-cortes estrictos si: 1 si A ( x) . A ( x) . 0 en cualquier otro caso. (1.10) 8.
(18) Capítulo 1. Cualquier conjunto borroso A se puede representar mediante la unión de sus α-cortes de la siguiente manera:. A ( x) max [ A ( x)] [ 0,1]. (1.11). Definición 1.8 (Altura) La altura de un conjunto borroso A es el supremo (o el máximo, cuando el conjunto universo X es finito) de la función de pertenencia A (x) :. alt ( A ) Sup A ( x) xX. (1.12). Definición 1.9 (Núcleo) Se define el núcleo de un subconjunto borroso como al α-corte que presenta un grado de verdad 1:. nucl ( A ) {x X | A ( x) 1} .. (1.13). Las propiedades fundamentales de conjuntos borrosos y relaciones, tales como altura, núcleo, soporte y α-corte, se ilustran en la figura 1.1.. Figura 1.1 Altura, núcleo, conjunto soporte y α-corte de un conjunto borroso A Definición 1.10 (Normalidad) El subconjunto borroso A es normal si:. 9.
(19) Capítulo 1 sup A ( x) 1 o sea sí alt ( A ) 1 .. xX. (1.14). En este caso, muchos autores consideran que A (x) es una “medida” de posibilidad y A es una distribución de posibilidad. El concepto de convexidad también juega un papel importante en la teoría de conjuntos borrosos. Las condiciones de convexidad se definen en referencia a la función de pertenencia. Definición 1.11 (Convexidad) El subconjunto borroso A es convexo si: x1 , x2 X , [0,1], A [x1 (1 ) x2 ] Min( A ( x1 ), A ( x2 )) x X. (1.15). Alternativamente, también se puede decir que el subconjunto borroso A es convexo si sus α-cortes, A son conjuntos convexos: , [0,1], A A. 1.2. Intervalos de confianza y números borrosos. En esta sección se dará la definición de números borrosos los cuales son un caso particular y de gran interés de los subconjuntos borrosos. Para ello se muestra en primer lugar el concepto de intervalo, que es fundamental dentro de los números borrosos. 1.2.1 Intervalos de confianza Un número ordinario a , puede interpretarse utilizando el concepto de función de pertenencia como:. 1 si x a 0 si x a. a ( x) . (1.16). De manera similar podemos definir un intervalo de confianza para un número ordinario. Tal intervalo será un conjunto binario clásico A, que representa cierto tipo de incertidumbre acerca del valor auténtico de dicho número. Por ejemplo, si el intervalo se denota por. A [a1 , a3 ], a1 , a3 , a1 a3 , este se puede considerar como una clase de conjuntos. En la figura 1.2 se expresa el intervalo como función de pertenencia: 10.
(20) Capítulo 1 0 si x a1 A ( x) 1 si a1 x a3 0 si x a 3 . (1.17). Si a1 a3 este intervalo indica un punto que es [a1 , a1 ] a1. Figura 1.2 Número ordinario A [a1 , a3 ] dado por un intervalo de confianza 1.2.2 Números Borrosos Un número borroso es expresado como un conjunto borroso definiendo un intervalo borroso en los números reales . Como la frontera de este intervalo es ambigua, el intervalo es además un conjunto borroso. Generalmente un intervalo borroso se representa por dos puntos extremos a1 y a 3 y un punto central a 2 que es el punto en donde se alcanza el valor máximo como [a1 , a2 , a3 ] . (Figura 1.3). Figura 1.3. Número borroso A [a1 , a2 , a3 ] Un número borroso es un subconjunto borroso N definido sobre la recta real y que cumple además las siguientes propiedades.. 11.
(21) Capítulo 1. 1. Es normal, es decir, que el núcleo de N es no vacío o lo que es lo mismo, existe al menos un elemento x de tal que N ( x) 1 2. Es convexo, geométricamente quiere decir que los α-cortes de N son intervalos cerrados y acotados. 3. El soporte de N está acotado. 4. La función de pertenencia es seccionalmente continua. Los números borrosos constituyen una herramienta valiosa para representar cantidades estimadas u observadas en el contexto de la lógica borrosa. Varios autores diferencian dentro del concepto de número borroso de acuerdo a si su núcleo es un valor real o si el núcleo es un intervalo de confianza. En nuestro caso no distinguimos a los números borrosos por la forma que se utilice para representar su núcleo. Son muchos los ejemplos prácticos en los que el grado de pertenencia de un determinado elemento del universo X se puede expresar como una función de una característica medible del mismo. El valor que toma un elemento x en la función de pertenencia de. N , N (x) , es interpretado por muchos autores como una “medida” de la posibilidad de ocurrencia de x, así el número borroso N es interpretado como una distribución de posibilidad. De forma general la función de pertenencia de un número borroso N puede escribirse como: f ( x) a1 x a 2 1 a 2 x a3 N ( x) g ( x) a 3 x a 4 en otro caso 0. (1.18). El intervalo de confianza [a1 , a4 ] es el soporte del número borroso y [a 2 , a3 ] es el núcleo del número borroso. Asimismo f(x) es creciente en el intervalo [a1 , a2 ] y g(x) es decreciente en el intervalo [a3 , a 4 ] (ver figura 1.4) 12.
(22) Capítulo 1. Figura 1.4 Forma general de un número borroso Sin embargo, en muchas ocasiones será más práctico operar con su representación a través de sus conjuntos de nivel o α-cortes. Estos son intervalos de confianza que se pueden representar como:. N {x | N ( x) } [ f 1 ( ), g 1 ( )] [n1 ( ), n2 ( )]. (1.19). Donde n1 ( ) (n2 ( )) serán funciones crecientes (decrecientes de ) con n1 ( ) n2 ( ). 1.3. Algunos tipos especiales de números borrosos. A continuación se introducen los números borrosos: L-R de Dubois y Prade, los números borrosos triangulares y como caso particular los simétricos. 1.3.1 Números borrosos L-R de Dubois y Prade La definición que se utiliza en este epígrafe está basada en el concepto definido por Dubois y Prade (Dubois and Prade, 1987): Definición 1.. es un número borroso de tipo LR si. ,. ,. y se definen. mediante la función: ax L( c ) for x a L A ( x) x R( a ) for x a cR. (1.20). 13.
(23) Capítulo 1 Donde L y R son funciones de pertenencias decrecientes para R+ en [0,1], y , para. ,y. para. .. 1.3.2 Números borrosos triangulares Los números borrosos triangulares son los más usados en la práctica por su relativa comodidad de manipulación. Sin embargo muchos autores han cuestionado su utilización indiscriminada. Como es evidente estos son la versión más sencilla del concepto general de número borroso L-R expuesto anteriormente. Un número borroso triangular (NBT) tiene, como su nombre lo indica, la forma triangular mostrada en la figura 1.5.. Figura 1.5 Número borroso triangular A [a1 , a2 , a3 ] . La función de pertenencia para este número borroso triangular viene dada por: x a1 a a si a1 x a 2 1 2 a x A ( x) 3 si a 2 x a3 (1.21) a3 a 2 0 en otro caso . donde el soporte viene dado por [a1 , a3 ] , su extensión izquierda es extensión derecha es. y su. . Por tanto sus - cortes vienen dados por:. A [a1 (a2 a1 ) , a3 (a3 a2 ) ] [a1 ( ), a2 ( )]. (1.22). 14.
(24) Capítulo 1 donde en este caso se sabe que A es un intervalo cerrado y acotado para 0 1donde: 1. a1 ( ) será una función monótona creciente de en el intervalo [0,1] 2. a2 ( ) será una función monótona decreciente de para 0 1 3. a1 (1) a2 (1) La monotonía creciente (decreciente) se demuestra, como es usual, probando que se cumple la relación. da1 ( ) da ( ) 0( 2 0) d d (Buckley, 2006b). Como se puede observar la función de pertenencia de un número borroso triangular es lineal. La extensión izquierda es la recta que pasa por (a1 ,0) y (a 2 ,1) y la extensión derecha es la recta que toma valores en (a 2 ,1) y (a3 ,0) . 1.3.2.1 Número Borroso Triangular Simétrico. Como se mostró anteriormente un número borroso triangular se denota por una terna de confianza donde los valores que la componen son el valor más pequeño posible, el valor de mayor pertenencia o el valor central y el valor más elevado posible, es decir, de la forma A [a1 , a2 , a3 ] , otra forma de denotar un número borroso triangular simétrico es mediante. las extensiones. y. explicadas en el sub-epígrafe anterior, obteniendo así. donde a es llamado valor medio o el centro, y. y. ,. son las extensiones izquierda y derecha. respectivamente. Si. =. = c entonces. es llamado un número borroso triangular simétrico, denotado. por: (1.23). 1.4. Regresión borrosa. La regresión borrosa es una relación de entrada-salida en la que los datos de entrada o de salida, o ambos, son números borrosos (Shakouri and Nadimi, 2009). A diferencia de la regresión lineal clásica en la que se supone que los parámetros son variables aleatorias con 15.
(25) Capítulo 1. funciones de distribución de probabilidad, en la regresión borrosa, los coeficientes están sujetos a la teoría de la posibilidad (Zadeh, 1997). Por lo tanto, los datos de entrada (variable independiente X), los datos de salida (variable dependiente Y) y consecuentemente, la relación entre ellos es relajada. El análisis de regresión borrosa es una poderosa herramienta para la investigación y la predicción de conjuntos de datos imprecisos que contienen un grado de ambigüedad y de incertidumbre (M. Aqil, 2007, Buckley, 2006a, Z.W. Jin, 2005, H. Shakouri G., 2008). El objetivo principal de los modelos de regresión borrosa es encontrar el mejor modelo con el menor error posible. Dependiendo de cómo se define el error, este método se puede clasificar en dos clases: 1. Enfoque posibilístico (Tanaka H., 1995): Trata de minimizar toda la borrosidad del modelo, reduciendo al mínimo el total de extensiones de sus coeficientes borrosos, sujeto a la inclusión de los puntos de datos de cada muestra dentro de un intervalo de datos factible especificado (P.-T. Chang, 1994, M.S. Yang, 2002, Peters, 1994). 2. Modelo de mínimos cuadrados: El cual minimiza la suma de errores al cuadrado en el valor estimado, basado en sus especificaciones (Diamond, 1988, H.W. Ge, 2007). El análisis de regresión difusa fue introducido por primera vez por Tanaka et al. (P.-T. Chang, 1994), que estableció su idea sobre la base de la teoría de la posibilidad. Se modela el procedimiento de estimación de parámetros como un problema de programación lineal, donde las entradas son precisas y la salida es un número borroso. Más tarde se extendió de coeficientes borrosos triangulares a números difusos gaussianos (R. Coppia, 2006). El enfoque que se emplea en la tesis es un enfoque posibilista. En la regresión borrosa se asume que la relación entre la variable explicada y las explicativas. es. lineal,. pero. {(. en ,. este. caso. si. se. dispone. de. una. muestra:. las posibles divergencias que pudieran surgir entre la i-. ésima observación de la variable dependiente. y su estimación. , se expresa mediante. una relación borrosa del tipo: 16.
(26) Capítulo 1. Y A0 A1 x1 A2 x2 ...An xn. (1.24). En (1.24), los coeficientes. , son números borrosos, por lo que el j-ésimo. queda caracterizado por: A j {x, ( x)} { A j [ A1 j ( ), A2 j ( )] | 0 1} Aj. (1.25). Es decir, las divergencias que se producen respecto a la teórica relación lineal no tiene naturaleza aleatoria, sino borrosa. Así mismo se puede comprobar que el término de error no queda introducido como sumando en el hiperplano, sino que es incorporado en los coeficientes. , al asumirse que son números borrosos.. De forma análoga a la técnica de mínimos cuadrados, una vez que se disponga de la muestra, nuestro objetivo debe ser ajustar los coeficientes. .. Esta forma de modelación ofrece ciertas ventajas sobre la tradicional técnica de regresión: . Las estimaciones que se obtienen después de ajustar los coeficientes borrosos, no serán variables aleatorias de difícil tratamiento numérico, sino que son números borrosos cuyo tratamiento es más sencillo.. . Si el fenómeno de estudio es de carácter económico o social, las observaciones que del mismo se obtienen son consecuencia de la interacción entre las creencias, expectativas, etc., entre los agentes que participan en dicho fenómeno y por tanto no es del todo adecuado modelar dicho fenómeno utilizando la teoría probabilística.. En muchas circunstancias las observaciones de la variable dependiente, de la variable independiente o de ambas no vienen dadas por un número cierto, sino por un intervalo. Por ejemplo, el precio que se negocia en los mercados financieros durante una sesión para la venta de barriles de petróleo o de un determinado activo difícilmente es único, sino que este suele negociarse dentro de una banda delimitada por un precio máximo y por un precio mínimo. Para utilizar las técnicas de mínimos cuadrados o la más sofisticada de máximo verosimilitud deben cuantificarse las observaciones de la variable explicada (y explicativa) a través de un único número, utilizándose por ejemplo el precio medio negociado, el más asequible o el último precio en el modelo que se vaya a implementar. Es evidente que este proceder implica una importante pérdida de información. Para efectuar los métodos de 17.
(27) Capítulo 1. regresión borrosa no hace falta reducir el valor de las variables observadas a un número real, cuando son observados como intervalos, así podremos ajustar la relación funcional que busquemos trabajando con todos los valores observados siendo posible entonces utilizar toda la información disponible. 1.4.1 Justificación de la regresión borrosa En este epígrafe se justifica la necesidad de disponer de la técnica de regresión borrosa. La regresión borrosa permite el manejo de cantidades afectadas por imprecisión e incertidumbre que no son manejables usando la regresión probabilística. Existen muchas magnitudes cuantitativas que pueden representarse adecuadamente mediante números borrosos: mediciones con márgenes de error, valor de las monedas frente a otras monedas referenciales en los mercados financieros, precio de las materias primas (oro, plata, cobre, etc.) y de los combustibles fósiles (petróleo, gas, carbón, etc.). Este tipo de datos fundamentalmente cuantificables, pero con una imprecisión e incertidumbres provenientes de diversos orígenes, justifica la creación de un campo analítico propio para la regresión borrosa. Los “números intervalares”, como se ha visto son una versión simplificada de los números borrosos, también han sido considerados como números de interés para poder explicar su comportamiento (Sugihara et al., 2004, Sugihara K., 2004, Sánchez, 2003). Los números intervalares se manejan como un caso particular de la regresión borrosa. La presencia de la incertidumbre en la regresión probabilística queda plasmada en los intervalos de confianza, generalmente con un nivel del 95%, lo que es atribuido a factores aleatorios. Esta es la única forma de incertidumbre que maneja la teoría de probabilidades. La aleatoriedad y la imprecisión se consideran componentes de la vaguedad. Todas estas son formas de incertidumbre. Otras formas de incertidumbre son la ambigüedad y la incongruencia. Todas las formas de incertidumbre se pueden incorporar dentro de los modelos de regresión borrosa de manera natural. La información que se dispone a priori de los problemas, generalmente se traduce en restricciones a los modelos, éstas ayudan a obtener estimaciones más ajustadas a la 18.
(28) Capítulo 1. realidad. Estas restricciones también se pueden incorporar en algunos modelos de regresión probabilística, pero con consecuencias para los supuestos de la fundamentación teórica de tales modelos. Esto no ocurre en la regresión borrosa, donde la presencia de restricciones es consustancial a su formulación por no estar limitada su formulación a tantos supuestos como los de la regresión probabilística. En el análisis de regresión borrosa, las desviaciones entre los valores de pertenencia observados y los valores de pertenencia estimados se asume que dependen de la incertidumbre de la estructura del modelo. En cambio en el análisis de regresión lineal clásica, las desviaciones se suponen causadas por errores, de origen aleatorio, en las observaciones. La medida de posibilidad representa un sentido amplio de todas las alternativas posibles, como medida antagónica a la medida de necesidad que representa lo común a todas las alternativas posibles. Para datos dados por intervalos , diversos autores han desarrollado también un enfoque de regresión basado en la medida de necesidad (Tanaka and Lee, 1998). Cuando se dispone de pocas observaciones para hacer una regresión probabilística se añade a este problema la dificultad de poder comprobar la normalidad de los errores. En esta situación una alternativa de modelación ventajosa es un modelo borroso que pueda incorporar un nivel de confianza posibilístico (Kim et al., 1996). Los datos precisos (que son un caso particular de dato borroso) pueden ser modelados mediante la regresión borrosa. En estos casos puede considerarse las extensiones de los datos estimados como la alternativa a los intervalos de confianza de la regresión probabilística. 1.4.2 Modelos de Regresión Borrosa Posibilística Se puede considerar que la Regresión Borrosa aparece en la historia de los análisis de regresión en 1982, gracias a Hideo Tanaka y sus colaboradores (aunque existe una exposición previa de 1980, pasando a constituir una nueva alternativa de regresión frente a las muchas metodologías de regresión que existían para trabajar con números precisos.. 19.
(29) Capítulo 1. Los primeros intentos de Regresión Borrosa están enfocados en base al principio posibilístico que acabamos de comentar, donde, recordemos, cada uno de los datos estimados. contiene, en términos difusos, al dato original. .. 1.4.2.1 Regresión Borrosa Posibilística presentada por Hideo Tanaka A continuación se presentará la regresión borrosa posibilística que dio origen de la regresión borrosa. Hideo Tanaka (Tanaka, 1987, Tanaka and Ishibuchi, 1992); plantea que en la relación yi f ( xi , A) para i 1,..., m se define el problema de regresión general. A partir de dicha formulación se puede introducir un modelo de regresión borrosa sustituyendo el número yi por el número borroso: (1.26) Se supone que se tiene un conjunto inicial de m observaciones, donde los valores de entrada son precisos X ij con i 1,. , m y j 1,. y están representados en la matriz de valores reales , n y la variable de salida Yi es imprecisa siendo sus valores. sujetos a funciones de pertenencia triangulares con parámetros. .. El objetivo principal de la regresión borrosa es encontrar el o los coeficientes representados por A que tengan la menor incertidumbre posible. Para obtener una solución, se considera que Yi tiene una función de pertenencia de tipo LR, y que los coeficientes. también tienen una función de pertenencia L j R j .. En este estudio la función objetivo f será una función lineal definida por: m. f ( x, A ) A0 A j x j .. (1.27). j 1. Yi tendrá una función de pertenencia triangular no simétrica. . Las restricciones. posibilísticas en el caso general son: para i = 1,…,m. (1.28). 20.
(30) Capítulo 1 para i = 1,…,m. (1.29). para j = 0,…,n. (1.30). Si se consideran funciones de pertenencia triangulares (no necesariamente simétricas), por ejemplo, funciones LR, las restricciones posibilísticas (1.28)-(1.29) se reducen a:. El valor de. para i = 1,…,m. (1.31). para i = 1,…,m. (1.32). indica un nivel de confianza. Si este valor está próximo a cero se tendrá un. punto de vista pesimista mientras que si el valor de h es cercano a uno el resultado será más optimista.. Si. los. coeficientes. es igual a. tienen. funciones. de. pertenencia. triangulares. .. Esta última forma es la más habitual de plantear las restricciones posibilísticas de la regresión borrosa. 1.4.2.2 Modelo de Regresión Borroso Simétrico introducido por Tanaka. Ahora bien, si se tiene números borrosos triangulares simétricos el modelo de programación lineal queda representado como: (1.33) Sujeto a:. Donde. para. de los coeficientes estimados,. , i = 1,2,…,m. (1.34). , i = 1,2,…,m. (1.35). , ϵ R son el centro y las extensiones es la matriz de observación de. ; i = 1,…,m es salida de observación borrosa.. entrada, y. Si los coeficientes son números borrosos triangulares, entonces ,. es igual a. .. 21.
(31) Capítulo 1. 1.4.2.3 Modelo de Savic y Pedrycs El planteamiento de la regresión borrosa de Tanaka está orientado a minimizar la incertidumbre, no se preocupa por el comportamiento de la estimación de los valores centrales. Sin embargo en la literatura se puede encontrar un modelo que incorpora una estimación específica de la tendencia central desarrollado por Savic y Pedrycs (Savic and Pedrycz, 1992). Este modelo consta de dos fases: . En la primera fase se realiza un ajuste de mínimos cuadrados entre los valores los valores. los cuales son los valores centrales de. y. con los que se logran los. valores modales a*j que son utilizados en la segunda fase. . En la segunda fase se utiliza el mismo criterio de vaguedad de la regresión borrosa (1.36). Sujeto a las condiciones posibilísticas: (1.37) (1.38) El modelo anterior tiene la virtud de disponer de una estimación que tiene una solución estándar para la tendencia central, pero conceptualmente no tiene la simplicidad de la solución de Tanaka. 1.4.2.4 Modelo de Regresión Borrosa introducido por Shakouri y Nadimi En este nuevo enfoque posibilístico se propone una nueva función objetivo que minimiza la suma de las distancias absolutas entre los centros observados y los valores estimados, en un óptimo nivel de h. En este enfoque, h está incluido en la función objetivo y se estima de manera óptima con alta exactitud. De esta manera, se estiman los coeficientes y h al mismo tiempo. Para reducir el error global del modelo de salida, se propone la siguiente función objetivo, basado en una medida de igualdad, al intentar optimizar toda la incertidumbre del modelo mediante la búsqueda de un valor óptimo para h:. 22.
(32) Capítulo 1. (1.39) sujeto a: , i = 1,2,…,m. (1.40). , i = 1,2,…,m. (1.41). ; ; a, c. R; c 0. En comparación con el enfoque de Tanaka, la formulación del problema es mucho más compleja (Shakouri and Nadimi, 2009), en el modelo de Tanaka el valor de h es introducido por el investigador mientras que en este modelo se estiman simultáneamente los coeficientes y el valor de h. Como la formulación es mucho más compleja puede requerir un mayor tiempo de solución pero si se utilizan adecuados software de optimización (LINGO, GAMS) la solución sólo requiere algunos segundos en una computadora moderna. 1.4.2.5 Otros modelos basados en teoría de la posibilidad Sakawa y Yano (Sakawa and Yano, 1992) propusieron cuatro modelos de regresión posibilística. Por otra parte en diversos trabajos se han tomado en consideración los índices de posibilidad y necesidad de Dubois y Prade al comparar dos números borrosos (Dubois D, 1983). 1. Sakawa y Yano (Sakawa M. Yano, 1992) propusieron cuatro modelos de regresión posibilística.Considerando la minimización de la siguiente función objetivo , se definen las siguientes restricciones con el índice de posibilidad (1.42). 23.
(33) Capítulo 1. 2. Considerando la minimización de la misma función objetivo se definen las restricciones con el índice de necesidad (1.43) 3. Considerando la maximización de la función objetivo. , se. definen las restricciones: (1.44) 4. Considerando la minimización de la misma función objetivo bajo los conjuntos de restricciones: (1.45) (1.46) Los autores plantean un modelo multi-objetivo para abordar estos cuatro problemas, puesto que junto a la función objetivo indicada, plantean maximizar el valor de h. Sin embargo este modelo ha sido muy criticado(Redden and Woodall, 1996) por ser muy sensible a los puntos extremos y por producir en ciertas condiciones todos los estimadores como números precisos (Modarres et al., 2004). 1.4.3 Índices de Bondad de Ajuste Para dimensionar la calidad del ajuste de cualquier regresión (Denoda Perez, 2011), se deben definir medidas que muestren la similitud o divergencia entre los números observados y estimados esto constituye un aspecto fundamental dentro del campo de la regresión borrosa. En esta sección se analizan diferentes índices de bondad que se pueden utilizar para determinar la calidad de la estimación obtenida a través del proceso de regresión. En el contexto de la regresión posibilística, se han desarrollado muy pocas medidas de bondad de ajuste siendo la más conocidas la medida de divergencia de Kim y Bishu, que tiene el grave inconveniente, de que no está normalizada, puesto que el numerador es independiente del denominador. La otra medida propuesta en la literatura, el R2 híbrido. 24.
(34) Capítulo 1. sigue sin estar normalizado, puesto que no es posible determinar su valor máximo. Tampoco el R2 tradicional probabilístico está normalizado en el ámbito difuso. En (Donoso Salgado, 2006) se pueden encontrar seis medidas de bondad y ajuste normalizadas (varían entre 0 y 1) que controlan diversos aspectos de la similitud entre dos números borrosos y que evalúan la calidad de una estimación de regresión borrosa. Además se realiza una calificación para saber hasta qué punto cumplen con su objetivo: . SIM1 pondera las diferencias entre las distribuciones de posibilidad de Yi e Yˆi incluyendo la totalidad de las funciones de pertenencia.. . SIM2 mide las diferencias en el soporte, tanto del punto central como sus dos extensiones, entre los valores de salida y sus respectivas estimaciones.. . SIM3 mide las diferencias tanto de las extensiones como de la tendencia central.. . SIM4 mide la diferencia máxima de las extensiones de los datos de entrada con sus respectivas estimaciones.. . SIM5 mide la proximidad de las funciones de pertenencia con un solo punto, el supremo de la intersección.. . R 2 borrosomide las diferencias cuadráticas del valor central observado con el valor. central estimado. A continuación se explicarán los índices: SIM2, SIM3, SIM4y el R 2 borroso. 1.4.3.1 Índice de Bondad del Ajuste SIM2 para números simétricos Este índice mide las diferencias del punto central y de su extensión, entre los valores de salida y sus respectivas estimaciones. Si se tienen los valores de salida en la forma y las estimaciones como y su respectiva extensión por. , donde el punto central está representado por .. Se calcula el indicador Ti:. (1.47). Donde 25.
(35) Capítulo 1. (1.48) (1.49) Para el conjunto de los datos de una regresión se define el indicador de bondad de ajuste SIM2 (m indica la cantidad de datos) m. SIM 2 . (1 T ) i. i 1. (1.50). m. 1.4.3.2 Índice de Bondad del ajuste SIM3para números simétricos Este índice mide las diferencias la extensión como de la tendencia central. Por lo tanto de esta manera se define: (1.51) Con esta definición de. , se construye el índice de bondad y ajuste Sim3 que varía entre 0 y. 1: m. SIM 3 . (1 R ) i. i 1. (1.52). m. 1.4.3.3 Índice de Bondad del Ajuste SIM4 para números simétricos Otra medida de similitud basada en la métrica de Hausdorff está dada por la relación:. (1.53). Considerando. para el conjunto de m observaciones, se crea otro índice de bondad de. ajuste, que fluctúa entre 0, cuando los m números observados se encuentran muy distantes de los m números estimados, y 1, cuando las funciones de pertenencia de las m parejas de números difusos son iguales. Su formulación es la siguiente: m. SIM 4 . (1 U ) i. i 1. m. (1.54). 26.
(36) Capítulo 1. 1.4.3.4 Medida de ajuste de la tendencia central Para medir la calidad del ajuste de la tendencia central, se conoce de la regresión probabilística el coeficiente de determinación, llamado también R-cuadrado, que varía entre 0 y 1. En el caso borroso se propone un indicador R2 de tendencia central, cuya principal característica es que, a medida que las diferencias cuadráticas entre el valor observado y el valor central estimado tiende a cero, el indicador tenderá a uno: n. R 2borroso max (0,1 . (y y ) i. i 1. 2. i. ). n. (y y i 1. i. media. ). (1.55). 2. Donde ymedia es el promedio de las observaciones yi . Este indicador toma valores entre 0 y 1. Como el denominador que aparece en la expresión es el mismo que el denominador del coeficiente de determinación probabilístico, se puede mantener la interpretación de éste, en el sentido de que R 2 borroso es una medida de proporción de la parte de la variación cuadrática de los yi que es explicada por la regresión. Por ejemplo, si R 2 borroso resulta 0.8, lo interpretamos como que la regresión explica el 80% de la variación de los datos centrales. yi .. 1.4.4 Algunas aplicaciones El análisis de regresión borrosa ha sido aplicado en diferentes áreas tales como la modelación de datos económicos o financieros (Aguilera Cuevas and Rodríguez Betancourt, 1999), la ingeniería de software (Conte et al., 1986) y el reconocimiento de un patrón de estimación humana (Romero Cortés and Aguilar Vázquez, 1999). En (Donoso Salgado, 2006) se presenta un caso de aplicación a estudios sociológicos y demográficos, en el contexto de la llamada regresión ecológica. En (Morales Martínes, 2010) se aplicó al estudio de las fluctuaciones de la tasa de cambio del euro de acuerdo a las variaciones de los precios de diferentes productos exportables e importables como metales básicos, metales preciosos, alimentos, azúcar, energía, entre otros; obteniendo resultados satisfactorios. En la actividad aseguradora aplicaron los instrumentos de regresión borrosa 27.
(37) Capítulo 1. para la determinación de las Provisiones para Siniestros pendientes de declaración (IBNR) (Sánchez). En la rama turística se empleó esta técnica para la planificación presupuestaria en el Hotel Meliá Santiago de Cuba (Aguilera Cuevas and Rodríguez Betancourt, 1999). En (Reig Mullor and González Carbonell, 2002) la usaron al planificar la gestión de los materiales. Finalmente, es importante señalar que Tanaka ha aplicado el análisis de regresión posibilístico a casos prácticos concretos, como es el estudio de tensión en un puente en Japón (Kaneyoshi M.), donde las variables de entrada son los diversos factores de error que pueden existir en las especificaciones del puente. Otras aplicaciones se encuentran en (Tanaka H., 1987, Tanaka H., 1982).. 1.5 Consideraciones finales En este capítulo se han mostrado los conceptos fundamentales de la teoría de los conjuntos borrosos; así como los detalles y definiciones fundamentales de los números borrosos L-R de Dubois y Prade, los números borrosos triangulares y los números borrosos simétricos. Se presentan los elementos fundamentales de la regresión borrosa posibilística, varios modelos de regresión borrosa fueron descritos con su formulación y los índices de bondad de ajuste más usados. Se justifica la utilización de la regresión borrosa y se muestran algunas aplicaciones.. 28.
(38) Capítulo 2. 2. ANÁLISIS, DISEÑO E IMPLEMENTACIÓN DEL SOFTWARE “EFUZZY 2.0” En el presente capítulo se explican las modificaciones realizadas en el diseño e implementación del software “efuzzy 1.0”. Se muestra la plataforma de desarrollo y los diagramas creados para las fases de análisis y diseño de la herramienta “efuzzy 2.0”. También se expone la utilización de la biblioteca commons-math3-3.2 para dar solución a problemas de optimización lineal. Se expone la estructura que debe tener un fichero con extensión .lg4 para resolver el modelo de Nadimi utilizando el programa Lingo.. 2.1. Patrones de diseño. Los patrones de diseños ofrecen las soluciones "más prácticas" donde los expertos en el diseño orientado a objetos se sirven para crear sistemas (Larman, 1999). En la terminología de objetos el patrón es una descripción de un problema y su solución, que recibe un nombre y que puede emplearse en otros contextos; en teoría, indica la manera de utilizarlo en circunstancias diversas. Los patrones de diseño son una recopilación de los esfuerzos hechos en el análisis y diseño orientado a objetos (ADOO), que proporcionan al desarrollador un bagaje importante para enfrentarse a muchas problemáticas que aparecen con frecuencia en la construcción de software. Estos por lo tanto constituyen la base para la búsqueda de soluciones a problemas comunes en el desarrollo de software y otros ámbitos referentes al diseño de interacción o interfaces (Denoda Perez, 2011) Muchos patrones ofrecen orientación sobre cómo asignar las responsabilidades a los objetos ante determinadas categorías de problemas. Los patrones no se proponen descubrir ni expresar nuevos principios de la ingeniería del software; intentan codificar el conocimiento, las expresiones y los principios ya existentes (Larman, 1999). El catálogo más famoso de patrones se encuentra en “Design Patterns: Elements of Reusable Object-Oriented Software”, (Gamma et al., 1995), también conocido como el libro GOF (Gang Of Four).. 29.
(39) Capítulo 2. Siguiendo el libro de GOF los patrones se clasifican según el propósito para el que han sido definidos: . Creacionales: solucionan problemas de creación de instancias, ayudan a encapsular y abstraer dicha creación.. . Estructurales: solucionan problemas de composición (agregación) de clases y objetos.. . De comportamiento: soluciones respecto a la interacción y responsabilidades entre clases y objetos, así como los algoritmos que encapsulan.. Su utilización permite obtener diseños flexibles, modulares y reutilizables. 2.1.1 Patrón Visitor En programación orientada a objetos, el patrón visitor es una forma de separar el algoritmo de la estructura de un objeto. La idea básica es que se tiene un conjunto de clases que conforman la estructura de un objeto. Cada una de estas clases elemento tiene un método aceptar (accept()) que recibe al objeto visitante (visitor) como argumento; las clases concretas de un visitante pueden ser escritas para hacer una operación en particular. El patrón visitor especifica cómo sucede la interacción en la estructura del objeto. Además simula el envío doble (Double-Dispatch) en un lenguaje convencional orientado a objetos de envío único (Single-Dispatch), como son Java o C++. En su versión más sencilla, donde cada algoritmo necesita iterar de la misma forma, el método accept de un elemento contenedor, además de una llamada al método visit del objeto visitor, también pasa el objeto visitor como argumento al llamar al método accept de todos sus elementos hijos. Este patrón es ampliamente utilizado en intérpretes, compiladores y procesadores de lenguajes, en general. Visitor es un patrón de comportamiento, que permite definir una operación sobre objetos de una jerarquía de clases sin modificar las clases sobre las que opera. Representa una operación que se realiza sobre los elementos que conforman la estructura de un objeto.. 30.
(40) Capítulo 2 2.2. Modificaciones en el análisis, diseño e implementación del software efuzzy 1.0. El lenguaje UML El UML (Lenguaje Unificado de Modelado) es una herramienta que cumple con el enlace entre quien tiene la idea del desarrollo de una aplicación y el desarrollador de esta, lo que lleva al éxito en los proyectos o sistemas de desarrollo de aplicaciones; es decir, ayuda a capturarla idea de un sistema para comunicarla posteriormente a quien está involucrado en su proceso de desarrollo; esto se lleva a cabo mediante un conjunto de símbolos y diagramas (Schmuller, 2000). Este lenguaje además tiene como objetivos principales la especificación, visualización, construcción y documentación de los productos de un sistema de software, teniendo en cuenta esto se utilizó para el diseño de la versión 2.0 del efuzzy. Este lenguaje es usado por el RUP (Rational Unified Process) (Jacobson et al., 2000) como lenguaje de modelado para lo cual se basa en todos sus tipos de diagramas, que constituyen diferentes vistas del modelo del producto. Los diagramas que componen la estructura de un producto escrito por el lenguaje UML son: diagrama de casos de uso, diagrama de clases, diagrama de componentes, diagrama de transición de estados, diagrama de despliegue, diagrama de actividad, diagrama de interacción. De estos diagramas mencionados, los empleados fueron: diagrama de casos de uso, diagrama de clases, diagrama de actividad, y diagrama de despliegue. La herramienta empleada para el modelado de todos los diagramas correspondientes a las fases de análisis y diseño fue Visual Paradigm para UML versión 9.0. 2.2.1 Diagramas de casos de uso Un diagrama de casos de uso (Ambler, 2005) muestra las relaciones entre actores y casos de uso dentro de un sistema, estos son una descripción de las acciones desde el punto de vista del usuario. Para los desarrolladores del sistema, esta es una herramienta valiosa, ya que es una técnica de aciertos y errores para obtener los requerimientos del sistema desde el punto de vista del usuario. Esto es importante si la finalidades crear un sistema que pueda ser utilizado por las personas en general (no sólo por expertos en computación).. 31.
(41) Capítulo 2. Los modelos de casos de uso proporcionan un medio sistemático e intuitivo de capturar requisitos funcionales del sistema basándose en los requerimientos de los usuarios. Ellos dirigen todo el proceso de desarrollo de un software ya que constituyen el punto de partida para llevar a cabo la mayoría de las actividades: el análisis, diseño y prueba del software (Jacobson et al., 2000). Este modelo se realiza identificando cada actor del sistema como los posibles usuarios para los cuales está realizado el mismo. La herramienta efuzzy v.2.0 está destinada a cualquier tipo de usuario, pudiendo ser un estudiante, especialista o investigador en computación, matemática o ramas similares. En el diagrama de la figura 2.1 se le ha nombrado a ese actor como Usuario.. Figura 2.1 Diagrama de casos de uso El usuario mediante el segundo caso de uso puede obtener diferentes modelos de regresión borrosa: Modelo de Hideo Tanaka tanto para números borrosos triangulares como para los triangulares simétricos y el Modelo de Savic y Pedrycs. Mediante el tercer caso de uso se puede obtener la formulación matemática del Modelo de regresión borrosa propuesto por 32.
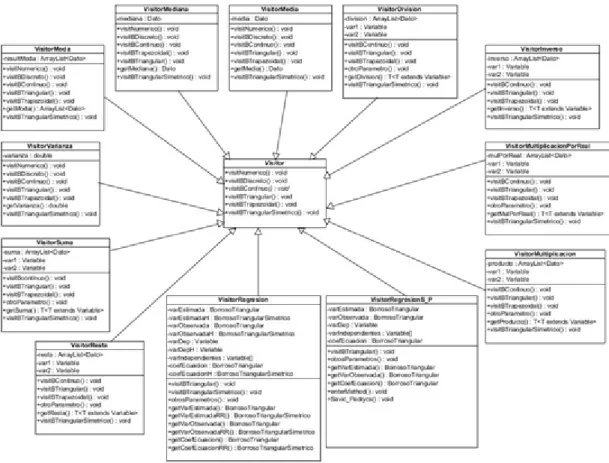
(42) Capítulo 2. Nadimi y Shakouri en un fichero con extensión .lg4 (fichero de entrada al software de optimización LINGO) para obtener la solución utilizando dicho software. 2.2.2 Diagramas de clases Los diagramas de clase UML (Ambler, 2005) muestran las clases de un sistema, sus interrelaciones, y las operaciones y los atributos de las clases. Son capaces de: . Explorar conceptos de dominio en forma de un modelo de dominio.. . Analizar los requisitos de un modelo conceptual de análisis.. . Esbozar el diseño detallado de un software orientado a objetos.. Un modelo de clase comprende uno o más diagramas de clase y las especificaciones de respaldo que describe los elementos del modelo, incluyendo clases, las relaciones entre las clases, y las interfaces. El software se compone de la interfaz de usuario con nombre efuzzyV2.0.jar y la biblioteca fuzzy.jar que provee los métodos que realizan las funcionalidades propias del sistema. Además se hace uso de la biblioteca jfreechart-1.0.10.jar para generar gráficos y la biblioteca commons-math3-3.2.jar para resolver los problemas de optimización lineal obtenidos a partir de los métodos de regresión lineal borrosa posibilística. Con la utilización de esta biblioteca se pudo eliminar la conexión que desarrollaba el efuzzy en su versión anterior con el software Mathematica mediante el JLink.jar. JFreeChart es distribuido con el código fuente completo sujeto a las condiciones de la licencia GNU Lesser General Public Licence lo que le permite ser usado en aplicaciones de softwares libres. CommonsMath es un paquete de optimización que provee algoritmos para optimizar la función objetivo o de costo (minimizar o maximizar), además posee componentes matemáticos y estadísticos escritos en Java. No posee ninguna dependencia externa más allá de los componentes de Commons y la plataforma de Java y todos los algoritmos se encuentran documentados. A continuación se expone el diseño de clases de la biblioteca fuzzy.jar.. 33.
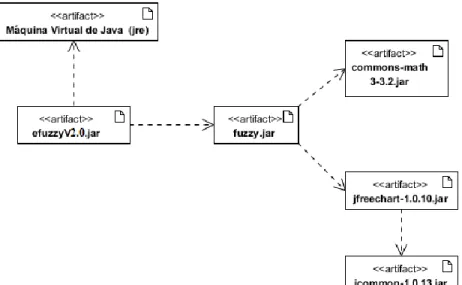
Figure

![Figura 1.3. Número borroso A [ a 1 , a 2 , a 3 ]](https://thumb-us.123doks.com/thumbv2/123dok_es/7360619.461207/20.918.199.508.691.896/figura-número-borroso-a-a-a-a.webp)
![Figura 1.5 Número borroso triangular A [ , a a a 1 2 , 3 ] .](https://thumb-us.123doks.com/thumbv2/123dok_es/7360619.461207/23.918.145.559.417.642/figura-número-borroso-triangular-a-a-a-a.webp)

+7




Documento similar