Algoritmos heurísticos para la búsqueda por palabras clave en documentos XML basados en la metaheurística ACO
77
0
0
Texto completo
(2) Pensamiento. “El secreto del éxito es dedicarse por entero a un fin.” José Martí.
(3) Dedicatoria. A mis padres por estar siempre conmigo y confiar en mí todo el tiempo..
(4) Agradecimientos A mi familia por estar siempre a mi lado. A mi tutor por haberme ayudado, guiado y apoyado durante todo este tiempo. A Yailén Martínez Jiménez, por soportarme y darme su ayuda incondicional. A Linet por estar siempre que la necesito, en las buenas y las malas. A Javier por darme siempre apoyo y tenerme paciencia. A todos mis amigos por estar siempre conmigo en los momentos difíciles, en especial a Isel, Carlos A., Frank, Lisandra, Addel y Leticia. A todos mis compañeros de trabajo que día a día comparto con ellos, en especial los miembros del grupo de BD. A todas las personas que de una forma u otra tuvieron que ver con la realización de este Trabajo de Diploma. En especial a Dios, que sin él nada sería posible..
(5) Resumen La búsqueda por palabras clave está integrada en muchas aplicaciones. Recientemente, este tipo de búsqueda ha captado la atención de las comunidades de bases de datos y la atención de la web. El éxito de esta está en que evita que el usuario aprenda complejos lenguajes de consulta como XPath/XQuery; o que necesiten conocer el esquema de datos del XML. Existe una gran variedad de algoritmos que realizan esta búsqueda, hasta el momento, todos son exhaustivos. En esta tesis se estudian los mismos y se crea una heurística que es aplicada a los principales algoritmos de la metaheurística Optimización basada en Colonia de Hormigas para resolver dicho problema. Además se validan estos de acuerdo a determinadas pruebas estadísticas demostrando su superioridad en cuanto a costo computacional sobre el exhaustivo de mejor comportamiento según la literatura. Por último se crea una función multiobjetivo que combina el costo computacional y la calidad de la solución y se evalúan con ella los nuevos algoritmos propuestos. Palabras Clave: búsqueda por palabras clave, XML, Optimización basada en Colonia de Hormigas..
(6) Abstract Keyword search is integrated in many applications. Recently, this kind of search has captured the attention of web and database communities. The success of this search is in that avoids the user to learn complex queries languages like XPath/XQuery, or knowing the underlying schema of the queried XML data. There are a great variety of algorithms to carry out this search, but they are all exhaustive until this moment. In this thesis these algorithms are studied and a heuristic one is created that is applied to some algorithms of the Ant Colony Optimization metaheuristic to solve the keyword search problem. Besides, these algorithms are validated according to statistic tests demonstrating their superiority according to computational cost on the exhaustive algorithm of better behavior according to the literature. Finally, a multiobjetive function is created, which combines the computational cost and the solution quality. This function is used to evaluate the propose algorithms. Keywords: keyword search, XML, Ant Colony Optimization..
(7) Tabla de Contenido INTRODUCCIÓN. ....................................................................................................................... 1 CAPÍTULO 1. FUNDAMENTACIÓN TEÓRICA. ..................................................................... 8 1.1 XML y la descripción del problema ..................................................................................... 8 1.1.1 LCA, SLCA, ELCA y CLCA ................................................................................................ 9 1.1.2 Notación ..................................................................................................................... 10 1.2 Semántica SLCA ................................................................................................................. 11 1.2.1 Algoritmos basados en SLCA ...................................................................................... 12 1.3 Semántica ELCA ................................................................................................................. 16 1.3.1 Algoritmos basados en ELCA ...................................................................................... 17 1.4 Metaheurísticas Poblacionales.......................................................................................... 20 1.4.1 Inteligencia Colectiva ................................................................................................. 20 1.5 Conclusiones parciales ...................................................................................................... 21 CAPÍTULO 2. ALGORITMOS PARA LA BÚSQUEDA POR PALABRAS CLAVE BASADOS EN AS, ACS y MMAS. ........................................................................................... 24 2.1 Modelo Matemático ......................................................................................................... 24 2.2 Metaheurística ACO .......................................................................................................... 25 2.2.1 Modos de funcionamiento general ............................................................................ 26 2.2.2 Tareas de diseño ........................................................................................................ 28 2.2.3 Principales algoritmos de la metaheurística ACO ...................................................... 29 2.2.4 Análisis de la complejidad temporal .......................................................................... 33 2.3 Heurística para la búsqueda por palabras clave ............................................................... 34 2.3.1 Algoritmo Keyword Search Ant System ..................................................................... 35 2.3.2Algoritmo Keyword Search Ant Colony System .......................................................... 37 2.3.3 Algoritmo Keyword Search Max-Min Ant System ...................................................... 38 2.4 Interfaz para visualización de los algoritmos .................................................................... 40 2.5 Conclusiones Parciales ...................................................................................................... 41 CAPÍTULO3. PRUEBA EXPERIMENTAL Y ANÁLISIS DE LOS RESULTADOS ............. 44 3.1 Marco experimental estadístico........................................................................................ 44 3.1.1 Pruebas estadísticas utilizadas ................................................................................... 45 3.2 Resultados experimentales ............................................................................................... 46 Dimensión 2......................................................................................................................... 47 Dimensión 3......................................................................................................................... 50.
(8) Tabla de Contenido Dimensión 10 ...................................................................................................................... 52 3.3 Problema multiobjetivo .................................................................................................... 55 3.4 Evaluación en el modelo multiobjetivo ............................................................................. 55 Dimensión 2......................................................................................................................... 56 Dimensión 3......................................................................................................................... 57 Dimensión 10 ...................................................................................................................... 59 3.5 Conclusiones Parciales ...................................................................................................... 61 CONCLUSIONES ...................................................................................................................... 62 RECOMENDACIONES ............................................................................................................. 63 REFERENCIAS BIBLIOGRÁFICAS ........................................................................................ 64 ANEXOS..................................................................................................................................... 67.
(9) Tabla de Figuras Figura 1.1 Ejemplo de un documento XML [17]. ........................................................... 8 Figura 1.2 Diferentes situaciones de lca (v1, v2) y lca (u1, u2 ) [17]. ............................ 9 Figura 1.3 Pseudocódigo del algoritmo Stack. .............................................................. 13 Figura 1.4 Pseudocódigo del algoritmo Indexed Lookup Eager. .................................. 14 Figura 1.5 Pseudocódigo del algoritmo Scan Eager. ..................................................... 14 Figura 1.6 Un ejemplo de un árbol XML para ilustrar el funcionamiento del algoritmo MSLCA [6]. .................................................................................................................... 15 Figura 1.7 Pseudocódigo del algoritmo Incremental Multiway-SLCA (MSLCA). ...... 17 Figura 1.8 Pseudocódigo del algoritmo Dewey Inverted List. ...................................... 18 Figura 1.9 v y child_elcacan(v). .................................................................................... 19 Figura 1.10 Pseudocódigo del algoritmo Indexed Stack. .............................................. 19 Figura 2.1 Procedimiento general de ACO ................................................................... 27 Figura 2.2 Estructura genérica de ACO. ....................................................................... 28 Figura 2.3 Interfaz de la aplicación desktop .................................................................. 40 Figura 2.4 Resultados de una ejecución del algoritmo KSAS....................................... 41 Figura 3.1 Resultados del costo computacional para dos palabras clave de una muestra aleatoria de 25 XML (t). ................................................................................................. 49 Figura 3.2 Resultados del costo computacional para tres palabras clave de una muestra aleatoria de 25 XML (t). ................................................................................................. 52 Figura 3.3 Resultados del costo computacional para 10 palabras clave de una muestra aleatoria de 25 XML (t). ................................................................................................. 54.
(10) INTRODUCCIÓN. En el trabajo de desarrollo de software o más específicamente de Sistemas de Información que utilizan Bases de Datos, una de las tareas iniciales y de constante innovación lo es sin duda lo que se suele llamar Análisis de Requisitos. Muchas técnicas y metodologías se han descrito para esto, la gran mayoría tratando de visualizar gráficamente lo que el o los usuarios “comunican” de alguna manera a los desarrolladores. Es conocido que en la Ingeniería del Software, se han establecido como estándares cuestiones como el Lenguaje Unificado de Modelado (UML en inglés), y basado en este, la Arquitectura Dirigida por Modelos (MDA en inglés), que propugna una especie de capa descriptiva de lo que se desea del nuevo software o sistema en lo que se conoce como Modelo Independiente de la Computación (CIM). Sin embargo las herramientas y los algoritmos propuestos para obtener este nivel y su transformación al Modelo Independiente de la Plataforma (PIM en inglés) con el uso de los diagramas UML no encuentran aún una forma definitiva. Evidentemente, contar con métodos y algoritmos que permitieran buscar por palabras clave desde documentos previamente redactados por usuarios, permitiría a los desarrolladores encontrar con mayor rapidez el vocabulario esencial que constituye el dominio de la futura aplicación, sobre todo si esta es un Sistema de Información. Ayudaría esto entre otras cosas a crear una Ontología de Dominio. Aportaría además en el versionamiento de las Reglas de Negocio, ya que estas son modeladas como un árbol en un documento XML y cada vez que es insertada una regla se necesita hacer una búsqueda en el árbol para ver si es necesario hacer una inserción o si simplemente ya esta regla había sido creada y solo es necesario la activación de la misma. Por otra parte, otro tipo de Sistema de Información muy en boga en la actualidad son los de Apoyo a la Toma de Decisiones basada en Almacenes de Datos (AD). Mucho se ha pretendido hacer también en la confección de estos AD a partir de sistemas de información heredados u operativos como se les conoce. La gran mayoría de estos últimos, creados sobre bases de datos relacionales, que en una primera fase deben ser analizados (sus metadatos) para poder transformar a un modelo dimensional, más acorde para los AD. Contar con algoritmos y métodos que permitan buscaren un XML. 1.
(11) Introducción. generado automáticamente cuales serían las futuras dimensiones y hechos es de gran importancia. Los documentos XML se han convertido en el estándar para la representación de datos y el intercambio de información en Internet. Debido a la flexibilidad estructural y heterogeneidad de estos resulta muy difícil para el usuario hacer consultas estructuradas que expresen lo que el usuario necesita. Actualmente, la búsqueda por palabras clave ha surgido como un popular paradigma para la recuperación de información sobre estos documentos. Uno de los méritos más significativos de la búsqueda por palabras clave en documentos XML es la simplicidad con que esta se realiza, ya que los usuarios no necesitan aprender un complejo lenguaje de consulta (XPath) o conocer la estructura de los datos subyacentes. Sin embargo, este formato simple de consultas puede no ser preciso y puede devolver un largo número de resultados que pueden ser clasificados en diferentes tipos y de los cuales muy pocos serían de interés para el usuario [1-8]. Para los documentos XML, donde los datos son vistos como un árbol estructurado jerárquicamente, una semántica natural para la búsqueda por palabras clave sería devolver todos los nodos que contengan todas las palabras clave en sus subárboles. Sin embargo, esto traería consigo que se le devolvieran al usuario una gran cantidad de nodos, muchos de los cuales solo servirían de nodos de enlace a los que realmente contienen las palabras clave [6]. Un resultado efectivo de una consulta debería cumplir con dos condiciones: 1. Los subárboles devueltos contienen en sus nodos todas las palabras clave a partir del nodo raíz. 2. Si se elimina algún nodo del subárbol no cumple la condición 1. A cada nodo interno v del árbol que representa al XML se le llama nodo elemento, y a la etiqueta que le corresponde etiq (v). A cada nodo hoja le corresponde un dato, y se le llama nodo valor. Por esto la efectividad en cuanto a la relevancia del resultado es la parte más crucial de la búsqueda por palabras clave en documentos XML y puede resumirse en tres problemas esenciales. 1) Se debe poder identificar eficazmente el tipo de nodo o nodos objetivo que se intentan encontrar con esta consulta. 2) Se debe poder inferir eficazmente los tipos de nodos de la condición que se quieren encontrar con esta. 2.
(12) Introducción. consulta. 3) Se debe evaluar cada resultado de la consulta en consideración con los dos problemas anteriores. La mayoría de los algoritmos que se han implementado para desarrollar este tipo de búsqueda realizan una búsqueda exhaustiva en el XML y se basan en diferentes semánticas como Lowest Common Ancestor (LCA), Smallest LCA (SLCA), Efficient LCA (ELCA) y Compact LCA (CLCA) siendo la segunda semántica la que mejores resultados ha generado de acuerdo a la literatura. Todos los algoritmos mencionados anteriormente realizan de cierta manera una búsqueda exhaustiva en el documento, porque aunque ellos no buscan nodo por nodo los métodos que utilizan si lo hacen. Por esto cuando estamos en presencia de XML realmente grandes estos algoritmos requieren de una gran cantidad de tiempo para ejecutarse, a pesar de que se tenga un equipamiento con gran capacidad de procesamiento. Lo que el usuario realmente desea es obtener un subárbol mínimo que maximice la cantidad de palabras que está buscando, es decir, no es más que resolver un problema de optimización, tratar de encontrar la mejor solución posible que satisfaga las necesidades del usuario. Existen muchos algoritmos para resolver problemas de optimización, que van desde los métodos exactos como el Simplex, que resuelve problemas lineales y continuos con restricciones, encontrando el óptimo de una función objetivo determinada, hasta los métodos aproximados, siendo los metaheurísticos los de mejor desempeño hasta el momento. Otros métodos permiten resolver problemas no necesariamente lineales, incluso problemas discretos, en una forma exacta o aproximada con técnicas que determinan un óptimo barriendo un espacio de soluciones. Pese a esto existen también muchos problemas que por su naturaleza, no pueden ser resueltos por un método de búsqueda exhaustivo debido ya sea a la no existencia del método o a que su complejidad aumente de manera no polinomial, en el último caso se enmarca nuestro problema cuando el documento XML sobre el cual se va a realizar la búsqueda es muy extenso. Debido a esto ha habido un impulso en el desarrollo de procedimientos eficientes para resolver este tipo de problemas, donde tiene tanta importancia la rapidez del proceso como la calidad de las soluciones, estos procedimientos son conocidos como métodos heurísticos. 3.
(13) Introducción. Los estudios realizados demuestran que los métodos heurísticos dependen en gran medida del problema a resolver para el cual han sido diseñados. En la actualidad existen los métodos metaheurísticos, los cuales han sido proyectados con el propósito de obtener mejores resultados que los tradicionales métodos heurísticos. Debido a la amplia variedad de algoritmos metaheurísticos se han realizado algunas clasificaciones de ellos. Estas clasificaciones responden a las características que presentan estos procedimientos, dando lugar a los siguientes grupos: Metaheurísticas de trayectoria simple: se utiliza el término de trayectoria simple porque el proceso de búsqueda que desarrollan estos métodos se caracteriza por una trayectoria en el espacio de soluciones; es decir, que partiendo de una solución inicial, son capaces de generar un camino o trayectoria en el espacio de búsqueda a través de operaciones de movimiento. En este tipo de metaheurísticas se destacan: la Búsqueda Tabú (Taboo Search) [9], Recocido Simulado (Simulated Annealing) [10], Búsqueda de Vecindades Variables (Variable Neighborhood Secar) [11], Búsqueda Local Guiada (Guided Local Search) [12], Búsqueda Local Iterativa ( Iterated Local Search) [13], entre otras. Metaheurísticas poblacionales: Las metaheurísticas basadas en población, o metaheurísticas poblacionales, son aquellas que emplean un conjunto de soluciones (población) en cada iteración del algoritmo, en lugar de utilizar una única solución como las metaheurísticas del grupo anterior. Estas proporcionan de forma intrínseca un mecanismo de exploración paralelo del espacio de soluciones, y su eficacia depende en gran medida de cómo se manipule dicha población. Dentro de esta clasificación se destacan los Algoritmos Evolutivos (Evolutionary Algorithms; EA) [14] y los algoritmos basados en Inteligencia Colectiva (Swarm Intelligence; SI) [15, 16]. Dentro de los algoritmos basados en SI se encuentra la Optimización basada en Colonia de Hormigas (Ant Colony Optimization; ACO), y dentro de sus principales algoritmos se destacan Sistema de Hormigas, Sistema de Colonia de Hormigas y Sistema de Hormigas Max-Min. Aunque la búsqueda por palabras clave en documentos XML ha sido ampliamente tratada, hasta el momento siempre ha sido a través de algoritmos exhaustivos, por lo que no existe un método metaheurístico para resolver este tipo de problema, por lo que 4.
(14) Introducción. estamos en presencia del siguiente problema de investigación: Encontrar nuevas alternativas de búsqueda en el ámbito de las metaheurísticas poblacionales que permitan obtener soluciones con mayor efectividad que las propuestas existentes en el área de estudio. Para la solución de este problema daremos respuesta a las siguientes preguntas de investigación: ¿Es posible aplicar los principales algoritmos de la metaheurística ACO a la búsqueda por palabras clave? ¿Qué función heurística definiría mejor el problema? Comparados con uno de los algoritmos exhaustivos que realizan esta búsqueda ¿Cuál es más eficiente? Entre los algoritmos metaheurísticos analizados, ¿cuál trabaja mejor para este problema específico? Para dar solución al problema científico se plantea como objetivo general de esta tesis: Optimizar el proceso de búsqueda por palabras clave en documentos XML usando la metaheurística ACO. Este objetivo se desglosa en los siguientes objetivos específicos: 1. Plantear un modelo matemático que resuelva la búsqueda por palabras clave en documentos XML de forma óptima. 2. Proponer una heurística para la búsqueda por palabras clave en documentos XML. 3. Aplicar los algoritmos Sistema de Hormigas, Sistema de Colonia de Hormigas y Sistema de Hormigas Max-Min al problema de la búsqueda por palabras clave en documentos XML utilizando la heurística creada. 4. Propiciar a través de una Interfaz Gráfica de Usuario simple, la aplicación de los algoritmos ajustados al problema propuesto. 5. Comparar con uno de los algoritmos exhaustivos ya existentes para demostrar la efectividad de los nuevos métodos de búsqueda. 6. Evaluar para este problema cuál de los algoritmos metaheurísticos es mejor aplicar. 5.
(15) Introducción. Esta. investigación. forma. parte. del. proyecto. de. investigación. institucional. (anteriormente territorial aprobado por el CITMA) Desarrollo de métodos y tecnologías avanzadas de Ingeniería de Software para el desarrollo de Sistemas de Información y se cuenta desde el inicio con los recursos materiales necesarios para desarrollarla, por lo que se consideró viable la misma. Como hipótesis de investigación podemos plantear que: contar con algoritmos óptimos de búsqueda de palabras clave en documentos XML, facilitará la labor de análisis de requisitos en el desarrollo de software y más específicamente de sistemas de información que usen estructuras de bases de datos y de almacenes de datos. La tesis está estructurada en 3 capítulos, en el capítulo uno se plantea el problema que se quiere resolver, también se explican algunos de los algoritmos exhaustivos que existen para resolver este tipo de problema. Por último, se definen las metaheurísticas poblacionales, específicamente los algoritmos basados en inteligencia colectiva haciendo énfasis en la metaheurística ACO. Seguidamente, en el capítulo 2 se explica cómo se realiza la recuperación de información en documentos XML, planteándose un modelo matemático para optimizar esta búsqueda. Se propone una heurística para guiar a las hormigas en la búsqueda de las palabras clave. Se muestra cómo funciona el proceso de búsqueda al aplicar los algoritmos adaptados de Sistema de Hormigas, Sistema de Colonia de Hormigas y Sistema de Hormigas Max-Min mediante el correspondiente pseudocódigo de cada uno. Posteriormente, en el capítulo 3 se describen en el marco experimental las pruebas estadísticas que se van a realizar, estas pruebas se aplican al algoritmo exhaustivo que mejor funcionamiento muestra según la bibliografía y a los tres propuestos. Además se crea un modelo que engloba los dos objetivos que se persiguen con la aplicación de algoritmos metaheurísticos, la minimización del tiempo y la maximización de la calidad de la solución. El documento culmina con las conclusiones y las recomendaciones del autor.. 6.
(16) Capítulo 1 “Fundamentación Teórica”.
(17) CAPÍTULO 1. FUNDAMENTACIÓN TEÓRICA. En este capítulo se describe el problema de la búsqueda por palabras clave en documentos XML y algunos de los algoritmos exhaustivos que existen para resolver dicho problema. Además se tratan de manera general las metaheurísticas poblacionales haciendo énfasis en los algoritmos basados en inteligencia colectiva y dentro de ellos la metaheurística ACO.. 1.1 XML y la descripción del problema Un XML es modelado como un árbol arraigado y etiquetado como el que se muestra en la figura 1.1. Cada nodo interno de v en un árbol corresponde a un elemento XML, llamado nodo elemento, y esta etiquetado con una etiq (v). Cada nodo hoja del árbol corresponde a un dato que es un valor, llamado nodo valor. Por ejemplo, en la figura 1.1 “Dean” y “Title” son nodos elementos, “John” y “Ben” son nodos valor. En este modelo los nodos atributos son modelados como hijos de un nodo elemento asociado, y no se distinguen de los nodos elementos [17]. A cada nodo (elemento o valor) en el árbol XML se le asigna un identificador único, Dewey ID. Un nodo v1precede a otro nodo v2en un recorrido en preorden por el árbol, si y solo si pred(v1). pred(v2). La relación. entre dos identificadores funciona como si. comparáramos dos secuencias. Además la información que preserva este identificador también puede ser usada para detectar hermanos y relaciones ancestro-descendiente entre los distintos nodos[17].. Figura 1.1 Ejemplo de un documento XML [17].. Un nodo u es un hermano del nodo v si y solo si pred(u) difiere del pred(v) solo en el último componente. Por ejemplo, 0.1.1.0 (Title) y 0.1.1.1 (Instructor) son nodos hermanos, pero 0.1.1 (Class) y 0.1.1.1 (Instructor) no son hermanos. 8.
(18) Capítulo 1 “Fundamentación Teórica”. Un nodo u es un ancestro de un nodo v si y solo si pred(u) es un prefijo del pred(v). Por ejemplo, 0.1 (Classes) es un ancestro de 0.1.2.0.0 (John). Para simplificar, se usa u v para denotar que pred(u) pred(v). u≤v denota que u v o u=v. También se usa u v para denotar que u es un ancestro de v, o lo que es lo mismo, que v es un descendiente de u. Nótese que si u v entonces u v, pero en sentido contrario no se cumple la implicación.. 1.1.1 LCA, SLCA, ELCA y CLCA A continuación mostramos las definiciones de algunas de las semánticas de árboles. Definición 1. Ancestro Común más Cercano (LCA). Para dos nodos cualesquiera v1 y v2 si y solo si: 1) u precede a (≺) v1 y u ≺v2, 2) para cualquier u´, si u´≺v1 y u´≺v2, entonces u´≺u. El LCA de los nodos v1 y v2 se denota lca (v1, v2), y es igual que si dijéramos lca (v2, v1).. Figura 1.2 Diferentes situaciones de lca (v1, v2) y lca (u1, u2 ) [17].. Definición 2. Menor LCA (SLCA). El SLCA de l conjuntos S1, S2,….Sl se define de la siguiente manera [1]: slca(S1, S2,…., Sl)={v∈lca(S1, S2,….Sl)∀v´∈lca(S1, S2,…., Sl), v⊀v´ } Un nodo v es llamado SLCA de S1, S2,…, Sl si v∈slca(S1, S2,….Sl). Definición 3.Exclusivo LCA (ELCA). El ELCA de l conjuntos S1, S2,…., Sl se define de la siguiente manera [1]: elca(S1, ··· ,Sl)={u |∃v1∈S1, ··· ,vl∈Sl ,(u = lca(v1, ··· ,vl)∧∀i∈ [1, l], ∃x(x ∈lca(S1, ··· ,Sl)∧child(u, vi)≺x))} donde child(u,vi) es el hijo de u en el camino de u hasta vi.. 9.
(19) Capítulo 1 “Fundamentación Teórica”. Definición 4. LCA Compacto (CLCA). Dado l nodos, v1∈S1, ···, vl∈Sl, u=lca (v1, ···,vl). Se dice que u domina a vi si u = slca (S1, ··· , Si−1, ··· ,Sl ). u es un CLCA con respecto a estos l nodos, si y solo si u domina cada vi. El siguiente teorema fue planteado por [18] y plantea: La relación entre los nodos LCA, los SLCA y los ELCA de l conjuntos S1,…,Sl es .. 1.1.2 Notación Dada una lista de l palabras clave Q= {w1, w2,….,wl} y un documento XML, T, el problema es encontrar un conjunto de subárboles significativos definidos por (t, M). Por cada subárbol (t, M), t es el nodo raíz del subárbol y M es el conjunto de los nodos que coinciden con las palabras clave, debe haber al menos un nodo que coincida por cada palabra clave. Un nodo coincide con una palabra clave, si contiene alguna, y t=lca (v1, ··· ,vm), asumiendo que M=[v1, ···, vm]. En la literatura ha habido diferentes propuestas para la búsqueda de subárboles significativos, basada en LCA, SLCA, ELCA, MLCA[18] e interconexión [19]. La mayoría de estos trabajos utilizan un índice invertido de los identificadores para cada palabra clave. Utilizando el índice invertido, para una consulta de l palabras clave, también es posible tener l listas S1, S2,…, Sl. Cada Si contiene un conjunto de nodos que contienen la palabra clave ki, y los nodos que contiene Si son nodos que coinciden con alguna palabra clave. El |Si| denota el número de nodos de Si. Para no perder la generalidad, asumimos que S1 tiene la menor cardinalidad entre los l conjuntos. La |S| es igual a la mayor cardinalidad entre todos los subconjuntos (|S|= max1≤i≤l |Si |). De aquí en adelante se usa d para denotar el peso del árbol XML, no sería d más que la mayor longitud de todos los Dewey IDs de los nodos del árbol XML. Dados dos nodos u y v con sus respectivos Dewey IDs, se puede encontrar el lca(u,v) en un tiempo O(d), basado en que el lca(u,v) tiene un Dewey ID que es igual al prefijo común más largo del pred(u) y el pred(v). Nótese que el lca(u,v) existe para dos nodos cualesquiera en un árbol, porque ambos son descendientes del nodo raíz. Con los Dewey IDs comprar dos nodos toma un tiempo O(d), y calcular un lca de dos nodos también toma el mismo tiempo. También existe otro código para un árbol XML 10.
(20) Capítulo 1 “Fundamentación Teórica”. que almacena tres números para cada nodo <inicio, final, nivel>, donde inicio es el número asignado por el recorrido en preorden, fin es el valor más largo que tome inicio entre los nodos del subárbol del cual ese nodo sea raíz, y nivel es simplemente el nivel del nodo en el árbol. Usando este código se pueden comparar dos nodos en un tiempo O(1), ya que solo se necesita eso para determinar la relación entre u<v, u v o u es el padre de v para dos nodos u y v, pero pese a esta ventaja la mayoría de la literatura utiliza solo el Dewey ID, el cual compara dos nodos en un tiempo O(d).. 1.2 Semántica SLCA La idea de realizar la búsqueda de palabras clave basada en la semántica SLCA consiste en que, cada nodo en T puede ser visto como una entidad en el mundo. Si u es un ancestro de v, podemos entender que la entidad representada por v pertenece a la entidad que representa u. Para una consulta por palabras clave, es más deseable devolver la entidad más específica que posea todas las palabras clave, entre todas las entidades retornadas, no debe existir ninguna relación ancestro-descendiente entre los nodos raíces t, que representan las entidades. A continuación enunciaremos algunas propiedades que son necesarias conocer para entender el comportamiento de los algoritmos que se verán en la próxima sección. Solo se enuncian, no se demuestran para no extender tanto este trabajo. Propiedad 1. Dado un conjunto S y dos nodos vi y vj con vi vj, entonces closest(vi,S)≤closest(vj,S). Propiedad 2. Sean V y U listas de nodos, donde V={v1, …, vl} y U={u1, …, ul}, tales que V≤U y vi≤ui para 1≤i≤l. Sean también el lca(V) y el lca(U) los LCA de los nodos en V y en U respectivamente. Entonces: 1.. Si lca(V)≥lca(U), entonces lca(U) lca(V). 2.. Si lca(V)<lca(U), entonces o el lca(V) lca(U) o lca(V) lca(U), entonces para cualquier W con U≤W, lca(V) lca(W). 11.
(21) Capítulo 1 “Fundamentación Teórica”. 1.2.1 Algoritmos basados en SLCA Existen diferentes algoritmos que utilizan la semántica SLCA para realizar la búsqueda por palabras clave en documentos XML, pero en este trabajo se debatirán los tres que mejores resultados muestran. El algoritmo Stack [8] no es más que una variante del algoritmo de mezcla ordenada que utiliza una pila para procesar todos los SLCAs. La idea general del mismo es el uso de una pila para simular el recorrido postorden de un árbol XML virtual formado por la unión de los caminos de la raíz a cada nodo S1, …, Sl. mientras que los nodos son leídos en preorden. Cuando una entrada está en el tope de la pila, lo cual significa que todos sus descendientes en S1,…, Sl han sido visitados, se sabe si la palabra clave aparece o no en el subárbol. Este algoritmo hace una lista de todas las palabras clave y procesa el prefijo común más largo del nodo que mejor ID tenga. El pseudocódigo de este algoritmo se muestra en la figura 1.3. Comienza creando una pila vacía y se tiene una lista de ID de los nodos que no han sido visitados, se lee el próximo nodo con el ID más pequeño y se realizan las operaciones necesarias. En esencia, el orden con que son leídos estos nodos es equivalente a un preorden de un árbol XML ignorando los nodos irrelevantes. Este algoritmo da como resultado una lista de SLCA por ejemplo, para slca (S1, …,Sl) en un tiempo O (. ), o también puede ser visto esto como O (. ) [3].. Podemos ver aquí que no se tiene en cuenta para determinar la complejidad del proceso de mezcla que se desarrolla en el algoritmo, si se tuviera esto en cuenta tendríamos entonces una complejidad de O (. ).. El algoritmo Stack trata todos los conjuntos de entrada S1,…, Sl como si fueran iguales pero algunas veces la cantidad de elementos de estas listas varía drásticamente. Por esto se crea el algoritmo Indexed Lookup Eager [3] que trata el caso en que |S1| es muy diferente del |S|.. 12.
(22) Capítulo 1 “Fundamentación Teórica”. Figura 1.3 Pseudocódigo del algoritmo Stack.. Propiedad 3. El. y el para l 2.. La complejidad temporal de este algoritmo es O (|. | |) ó O (. ∗. | |).. En la línea 3 del pseudocódigo que se muestra en la figura 1.4 del algoritmo puede verse que p representa el tamaño del búfer, que puede ser cualquier valor desde 1 hasta |S1|; mientras más pequeña es p, más rápido el algoritmo produce el primer SLCA. Cuando la frecuencia con que aparecen las palabras clave en el conjunto de listas de entrada del algoritmo no tiene diferencias significativas, el costo total de encontrar coincidencias usando búsqueda binaria puede exceder el costo total de encontrar las coincidencias mediante un escaneo de las listas de palabras clave. El algoritmo Scan Eager cuyo pseudocódigo se muestra en la figura 1.5 modifica la línea 15 del algoritmo Indexed Lookup Eager utilizando un escaneo lineal para encontrar lm() y rm(). Es decir, se aprovecha de que los accesos a cualquier lista de palabras clave son estrictamente en orden creciente en al algoritmo Indexed Lookup Eager.. 13.
(23) Capítulo 1 “Fundamentación Teórica”. Figura 1.4 Pseudocódigo del algoritmo Indexed Lookup Eager.. Scan Eager mantiene un cursor para cada lista de palabras clave y el cursor avanza de S2 hasta encontrar el nodo que está más cerca de v ya sea por la derecha o por la izquierda.. Figura 1.5 Pseudocódigo del algoritmo Scan Eager.. Para asegurar el buen funcionamiento de este algoritmo nótese que p tiene que ser no más pequeño que |S1|. La complejidad temporal de Scan Eager es un O ( 14.
(24) Capítulo 1 “Fundamentación Teórica”. ), o O (. ) [1]. Como puede verse, la complejidad temporal de Scan Eager. es la misma que la del algoritmo Indexed Lookup Eager, pero tiene dos ventajas. 1. Scan Eager comienza desde la lista de palabras clave más pequeña y no tiene que escanear hasta el final cada lista de palabras clave, por lo que termina mucho más rápido. 2. El número de operaciones de lca de Scan Eager es un O (l|S1|), que es usualmente mucho menos que el del algoritmo Stack, donde el número de operaciones lca representan un O (. ).. Para concluir con algoritmos que realizan la búsqueda basados en la semántica SLCA se describe el algoritmo Multiway-SLCA[6] que mejora la actuación del algoritmo Indexed Lookup Eager pero mantiene la misma complejidad temporal para el peor caso [3]. El funcionamiento de este algoritmo lo ilustramos con el siguiente ejemplo.. Figura 1.6 Un ejemplo de un árbol XML para ilustrar el funcionamiento del algoritmo MSLCA [6].. Ejemplo. Consideremos el conjunto de palabras clave de entrada algoritmo al XML de la figura 1.6. De acuerdo a esto Sa= , slca (Sa, Sb)=. y se le aplica el y Sb=. . Como |Sa| |Sb|, el algoritmo Indexed Lookup Eager. enumeraría cada uno de los nodos de Sa en orden creciente para producir un SLCA potencial. Esto trae consigo realizar 1000 operaciones slca para llegar a un resultado de tamaño 10. De esta forma fueron hechas grandes cantidades de computaciones redundantes, un ejemplo de esto es que el SLCA de ai y Sb dan el mismo resultado (x1) para 1≤i≤100. Conceptualmente, cada SLCA potencial que se ha computado por Indexed Lookup Eager puede ser pensado como siendo conducido por algunos nodos desde Sa (o S1 más general). El algoritmo Multiway-SLCA (MSLCA) selecciona un nodo “ancla” entre las l listas de palabras clave para a partir de ese nodo conducir las computaciones de SLCAs. 15.
(25) Capítulo 1 “Fundamentación Teórica”. En este ejemplo, MSLCA primeramente tendrá en consideración el primer nodo de cada lista de palabras clave y de esos selecciona el último que aparezca en el árbol haciendo un recorrido en preorden. Es decir, entre a1 Sa y b1 Sb, se escogería b1como el nodo “ancla”. Después, usando b1 como nodo “ancla”, seleccionaremos el nodo más cercano (función closest) a b1 de cada uno de las l listas excepto de la lista a la cual pertenece el nodo “ancla” y se computará el lca de todos los nodos elegidos, por ejemplo el lca(a100, b1)=x1. El próximo nodo “ancla” se selecciona de la misma forma pero eliminando todos los nodos que aparezcan antes que el pred (b1) de cada lista de palabras clave. Entonces se selecciona b2, y el slca (b2, Sa)=x2. Es evidente que el algoritmo MSLCA permite saltar muchas computaciones innecesarias. De este algoritmo existen dos variantes, Basic Multiway-SLCA (BMS) e Incremental Multiway-SLCA (IMS) propuestas por [6], el pseudocódigo del segundo se muestra en la figura 1.7. El algoritmo BMS implementa la idea general que se ha visto hasta ahora. IMS introduce además una optimización con el objetivo de reducir el número de computaciones de lca que realiza el algoritmo BMS, el cual necesita recuperar los nodos en orden desde un conjunto no ordenado y esto trae consigo un gasto de tiempo extra. Por lo que de estas dos variantes analizaremos la variante optimizada, IMS. Este algoritmo computa SLCA iterativamente, en cada iteración se selecciona un nodo “ancla”. vm. y se almacena al igual que su índice m. IMS se optimiza básicamente en las. líneas 7-8. Nótese que cada llamada a la función closest requiere dos computaciones LCA. IMS reduce el número de computaciones LCA a un máximo de l, es decir como máximo una por cada lista de palabras clave. BMS e IMS dan como salida todos los nodos SLCA en un tiempo O (. ) [6].. 1.3 Semántica ELCA Los ELCAs son un superconjunto de SLCAs, los ELCAs pueden encontrar alguna información relevante que los SLCAs no pueden encontrar, en la figura 1.1 el nodo 0 (school) es un ELCA para la consulta Q= {John, Ben}, entonces la respuesta basada en ELCA sería “Ben” participa en un club de deportes en la escuela donde “John” es el decano.. 16.
(26) Capítulo 1 “Fundamentación Teórica”. 1.3.1 Algoritmos basados en ELCA La búsqueda por palabras clave basada en la semántica ELCA fue propuesta por primera vez por [8]. El algoritmo Dewey Inverted List [8] está basado en una pila y trabaja sobre un árbol en recorrido en postorden formado por los caminos desde la raíz a todos los nodos que coinciden con las palabras clave, su pseudocódigo es el de la figura 1.8. La idea general de este algoritmo es la misma que la del algoritmo Stack, en verdad actualmente el algoritmo Stack es una adaptación del algoritmo Dewey Inverted List para computar todos los SLCAs.. Figura 1.7 Pseudocódigo del algoritmo Incremental Multiway-SLCA (MSLCA).. Se leen todos los nodos que coinciden con las palabras clave de entrada en preorden, usando una pila para simular un recorrido en postorden. Cuando un nodo esta en el tope de la pila, todos sus descendientes han sido visitados y la información que contiene las palabras clave esta almacenada en la componente keyword de la pila. Cuando el componente keyword del tope de la pila es true para todas las entradas, entonces la palabra en el tope de la pila es un ELCA, y esto significa que el subárbol cuya raíz es el elemento en el tope de la pila contiene todas las palabras clave.. 17.
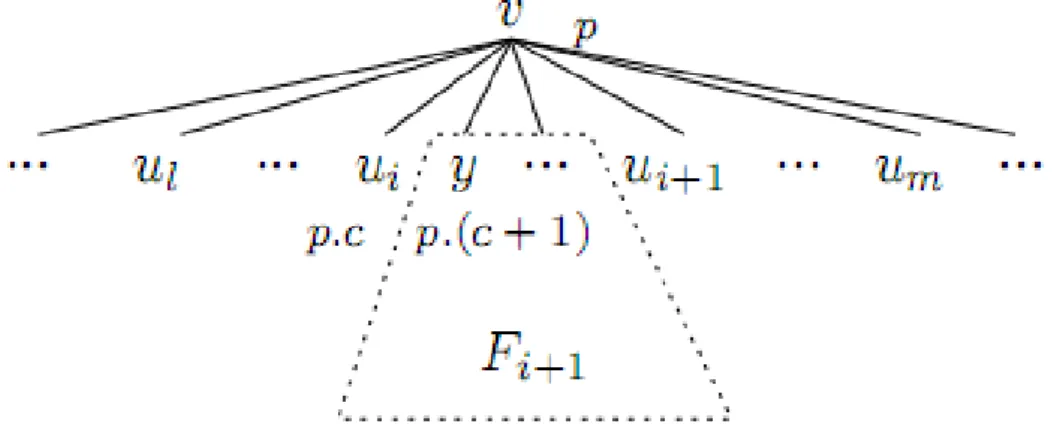
(27) Capítulo 1 “Fundamentación Teórica”. El algoritmo Dewey Inverted List devuelve una lista de ELCA en un tiempo O(. ) o O(. ), sin incluir el tiempo de mezcla de la lista l ordenada [8].. El algoritmo Indexed Stack 18] está basado en la siguiente propiedad, donde la efectividad está garantizada por la definición de LCA compacto y su equivalencia con ELCA.. Figura 1.8 Pseudocódigo del algoritmo Dewey Inverted List.. Propiedad 4. En este algoritmo el método más importante es isELCA [20]. Para probar si un nodo es un ELCA o no se debe probar que existe un nodo xi Si para todo i, tal que xi está 1) o por debajo de v en el árbol a la izquierda del camino de v a u1, es decir entre el predecesor de v y el predecesor de u1; 2) o en algún árbol Fi+1 que esté por debajo de v y entre los caminos de v a ui y de v a ui+1, para 1≤i≤m, es decir entre el hermano más próximo de ui y el predecesor de ui+1; 3) o por debajo de v a la derecha del camino de v a um. Cada caso de estos puede ser chequeado con una búsqueda binaria sobre Si. La complejidad del método isELCA es un O(|child_elca(v)|ldlog|S|).. 18.
(28) Capítulo 1 “Fundamentación Teórica”. Figura 1.9 v y child_elcacan(v).. Figura 1.10 Pseudocódigo del algoritmo Indexed Stack.. El algoritmo Indexed Stack devuelve todos los nodos ELCA en un tiempo O(. ) o lo que es lo mismo un O(. ) [4], su pseudocódigo se. encuentra en la figura 1.10.. 19.
(29) Capítulo 1 “Fundamentación Teórica”. 1.4 Metaheurísticas Poblacionales En el desarrollo de los procedimientos metaheurísticos es importante tomar en consideración la definición de los operadores que se ocupen de dirigir la búsqueda a zonas promisorias del espacio de solución. Para ello, se tienen que tener en cuenta dos factores importantes [21]: La exploración, también llamada diversificación en la literatura, es el proceso de guiar la búsqueda hacia regiones no exploradas. Un algoritmo que realice una insuficiente exploración podría obviar regiones enteras, por lo que si el óptimo se encontrase en una de esas regiones no tendría ninguna posibilidad de ser encontrado. La explotación, también llamada intensificación en la literatura, es el proceso de realizar una búsqueda minuciosa e intensa de mejores soluciones en un entorno cercano a buenas soluciones ya encontradas (considerando que son zonas más prometedoras). Este proceso es fundamental para obtener una mayor precisión en las soluciones encontradas; aunque, cuando caen en un óptimo local, suelen quedarse estancados en este.. 1.4.1 Inteligencia Colectiva Las metaheurísticas basadas en Inteligencia Colectiva son técnicas inspiradas en el estudio de comportamientos colectivos presentes en sistemas de la naturaleza, generalmente. de. carácter. descentralizado. y. auto. organizativo. [22].. Dicho. comportamiento social define los movimientos de las variables de decisión en el espacio de búsqueda y las orienta hacia soluciones óptimas. La expresión “Inteligencia Colectiva” fue introducida por Gerardo Beni, Suzanne Hackwood y Jing Wang en 1989, en el contexto de sistemas robóticos celulares. Caracterización de la Inteligencia Colectiva La principal característica de los algoritmos basados en la SI viene determinada por la estrecha colaboración social que presentan a través del sistema de comunicación que surge entre los individuos del colectivo [23]. Esta comunicación, a su vez, puede aparecer de forma directa o indirecta. La comunicación indirecta ocurre cuando un individuo altera el medio en que se desarrollan y los otros son capaces de captar estos cambios. La comunicación directa es aquella que ocurre a través de la obtención de la 20.
(30) Capítulo 1 “Fundamentación Teórica”. ubicación de otros individuos mediante sonido, visibilidad u otra forma directa de interacción. Entre los algoritmos más significativos y estudiados de SI están: Optimización basada en Enjambre de Partículas [24]. Se caracteriza por ser un método inspirado en el movimiento natural desarrollado por las comunidades de animales, tales como las emigraciones de las bandadas de pájaros. En estos, la población representa un enjambre y está compuesta por una serie de partículas (pájaros) que representan soluciones a un problema determinado, donde cada una de ellas realiza un desplazamiento (cambia de posición) en el espacio de búsqueda. Cada partícula se desplaza influenciada por dos direcciones: una hacia la mejor partícula encontrada hasta el momento, y por la mejor posición por la que ha pasado. Este comportamiento es un ejemplo de comunicación directa. Optimización basada en colonia de hormigas (Ant Colony Optimization; ACO) [25]. Son métodos poblacionales inspirados en el comportamiento de las hormigas naturales. Los mismos realizan un proceso constructivo y estocástico guiado por unos rastros de feromona1 que van depositando cada hormiga, dando una medida de cuán deseado ha sido un determinado camino, y a través de una función de visibilidad que evalúa la calidad del desplazamiento. Es un ejemplo clásico de comunicación indirecta (conocido como Stigmergy [26]).. 1.5 Conclusiones parciales A partir de la revisión bibliográfica desarrollada para presentar este capítulo se pueden extraer las conclusiones siguientes: Los algoritmos exactos que existen para resolver el problema planteado pueden ser muy eficientes pero a la hora de realizar una búsqueda exhaustiva en documentos XML grandes pueden llevarse una gran cantidad de tiempo computacional. Los problemas de optimización combinatoria caen regularmente en la categoría de problemas para los que cuales existen algoritmos capaces de resolverlos de forma exacta, pero cuando su dimensión crece, estos se vuelven inaplicables computacionalmente; de modo que la aplicación de los métodos heurísticos representa una buena alternativa.. 1. Sustancia química olorosa que depositan las hormigas en su recorrido. La intensidad de esta sustancia disminuye a. 21.
(31) Capítulo 1 “Fundamentación Teórica”. Los algoritmos basados en Inteligencia Colectiva, en particular la metaheurística ACO es un modelo muy poderoso para dar solución a esta clase de problemas ya que propone formas muy precisas de emplear la cooperación entre agentes para la solución de problemas de optimización combinatoria. Por todo esto resulta de gran importancia probar que los algoritmos de la metaheurística ACO realizan esta búsqueda es un menor tiempo computacional sin dañar la calidad de la solución.. 22.
(32) Capítulo 2 “Algoritmos para la búsqueda por palabras clave basados en AS, ACS y MMAS”.
(33) CAPÍTULO 2. ALGORITMOS PARA LA BÚSQUEDA POR PALABRAS CLAVE BASADOS EN AS, ACS y MMAS. En este capítulo se presenta como se realiza la recuperación de información (RI) en documentos XML. Se modela el problema de optimización matemática que resuelve la problemática y a partir del mismo se propone una función heurística para los algoritmos de la metaheurística ACO, explicando la misma de manera más específica. Se hace un análisis de la complejidad computacional de los algoritmos de la metaheurística y se adaptan tres diferentes tipos de algoritmos de la metaheurística ACO a la búsqueda por palabras clave en documentos XML. Por último se implementa una interfaz gráfica para una mejor interacción con los algoritmos.. 2.1 Modelo Matemático La literatura recomienda utilizar como criterio de recuperación de información estructurada, como es la que nos brindan los XML, el siguiente principio: “Un sistema de recuperación de información deberá siempre recuperar la parte más específica del documento que dé respuesta a la consulta.”[17] Este principio es muy difícil de implementar algorítmicamente debido a la ambigüedad que puede apreciarse si dos nodos tienen iguales etiquetas y representan cosas totalmente diferentes. Por ejemplo, un creador y el producto que este creó pueden tener el mismo nombre, por lo tanto serían respuestas aceptadas por el usuario. Para resolver este problema bastaría con darle prioridades a los nodos, pero ¿por qué darle prioridades a todos los nodos si ese problema solo existiría cuando los nodos que se repitan sean palabras clave? Para dar solución a este problema en documentos XML existe una fórmula para calcular que tan buena es la solución que se le está brindando al usuario. Esta fórmula se conoce como función de context resemblance (CR) [17] y se muestra a continuación: (2.1). 24.
(34) Capítulo 2 “Algoritmos para la búsqueda por palabras clave basados en AS, ACS y MMAS”. Donde Cq es el conjunto formado por las palabras clave que el usuario está buscando y Cd es el conjunto de nodos del subárbol devuelto. El CR es igual a 1 cuando la cantidad de palabras clave que el usuario está buscando coincide con la cantidad de nodos del documento, esto se considera la respuesta perfecta. De acuerdo a este principio y a la función expuesta nuestro problema se plantearía de la siguiente manera: Dado un documento XML V (recordar que los XML son vistos como árboles) con elementos (nodos), donde Vi son los distintos fragmentos (subárboles) del documento que contienen todas las palabras clave, Cq es el conjunto de palabras clave de entrada y Cdi el conjunto de elementos (nodos) del fragmento (subárbol) i. |Cq| y |Cdi| son los respectivos cardinales de estos conjuntos. Este problema visto matemáticamente quedaría: (2.2) Después de garantizar que se cumpla esta condición, el problema a resolver no sería más que optimizar la siguiente función:. (2.3) Con esto se puede garantizar que la solución de este problema va a ser el menor subárbol que contenga todas las palabras clave. Este es el planteamiento del modelo matemático que resuelve la búsqueda por palabras clave en documentos XML.. 2.2 Metaheurística ACO Los algoritmos de ACO [25, 27-29] se inspiran directamente en el comportamiento de las colonias reales de hormigas para solucionar problemas de optimización combinatoria. Se basan en una colonia de hormigas artificiales; esto es, unos agentes computacionales simples que trabajan de manera cooperativa y se comunican mediante rastros artificiales de feromona. Los algoritmos de ACO son esencialmente métodos constructivos: en cada iteración del algoritmo, cada hormiga construye una solución al. 25.
(35) Capítulo 2 “Algoritmos para la búsqueda por palabras clave basados en AS, ACS y MMAS”. problema recorriendo un grafo de construcción G2. Cada arista del grafo, que representa los posibles pasos que la hormiga puede dar, tiene asociados dos tipos de información que guían el movimiento de la hormiga: Información heurística, mide la preferencia heurística de moverse desde el nodo r hasta el nodo s; es decir, la propensión a recorrer la arista ars. Se denota por ηrs. Las hormigas no modifican esta información durante la ejecución del algoritmo. Información de los rastros artificiales de feromona, mide la “deseabilidad aprendida”3 del movimiento de r a s. Imita de forma numérica a la feromona real que depositan las hormigas naturales. Esta información se modifica durante la ejecución del algoritmo dependiendo de las soluciones encontradas por las hormigas. Se denota por τrs.. 2.2.1 Modos de funcionamiento general El modo de operación básico de un algoritmo de ACO [25, 29, 30] es como sigue: las m hormigas (artificiales) de la colonia se mueven, concurrentemente y de manera asíncrona, a través de los estados adyacentes del problema (que puede representarse en forma de grafo con ponderaciones o sin ellas). Este movimiento se realiza siguiendo una regla de transición que está basada en la información local disponible en las componentes (nodos). Esta información local incluye la información heurística y memorística (rastros de feromona) para guiar la búsqueda. Las hormigas construyen incrementalmente soluciones al moverse por el grafo de construcción. Opcionalmente, las hormigas pueden depositar feromona cada vez que crucen un arco (conexión) mientras que construyen la solución (actualización en línea paso a paso de los rastros de feromona). Una vez que cada hormiga ha generado una solución, ésta se evalúa y el agente puede depositar una cantidad de feromona en dependencia de la calidad de su solución (actualización en línea de los rastros de feromona). Esta información guiará la búsqueda de las otras hormigas de la colonia en el futuro. Además, el modo de operación genérico de un algoritmo de ACO incluye dos procedimientos adicionales, la evaporación de los rastros de feromona y las acciones del demonio. La evaporación de feromona la lleva a cabo el entorno y se usa como un mecanismo que evita el 2. Como se dice en 28. Dorigo, M., G.D. Caro, and L.M. Gambardella, Ant algorithms for discrete optimization. Artificial Life, 1999. 5(2): p. 137-172., el conjunto de aristas puede conectar completamente los componentes. En este caso, la implementación de las restricciones está completamente integrada en la política de construcción de las hormigas. 3. Nótese que las hormigas solo se comunican de manera indirecta, a través de modificaciones del espacio físico que perciben. Esta forma de comunicación se denomina Estimergia Artificial.. 26.
(36) Capítulo 2 “Algoritmos para la búsqueda por palabras clave basados en AS, ACS y MMAS”. estancamiento en la búsqueda y permite que las hormigas busquen y exploren nuevas regiones del espacio. Las acciones del demonio son acciones opcionales (que no tienen un contrapunto natural) para implementar tareas desde una perspectiva global que no pueden llevar a cabo las hormigas por la perspectiva local que ofrecen. Ejemplos son: observar la calidad de todas las soluciones generadas y depositar una nueva cantidad de feromona adicional sólo en las transiciones/componentes asociadas a algunas soluciones, o aplicar un procedimiento de búsqueda local a las soluciones generadas por las hormigas antes de actualizar los rastros de feromona. En ambos casos el demonio reemplaza la actualización en línea a posteriori de feromona y el proceso pasa a llamarse actualización fuera de línea de rastros de feromona. En ACO el significado de los rastros de feromona y la función heurística o de visibilidad dependen totalmente del problema a resolver. En el caso específico de los rastros de feromona, cuando se está en presencia de un problema de secuenciación (Viajante de Comercio [31], Asignación Cuadrática [32], entre otros), donde el orden en que aparecen las componentes en una solución influye en la calidad de ésta, los rastros de feromona son asociados a los arcos del grafo, con el objetivo de premiar las buenas secuencias de componentes4. Por otra parte, en problemas de asignación (Selección de Rasgos [33], Partición de Conjuntos [34], entre otros) donde los cambios de posición entre componentes de una solución no influye en la calidad de la misma, los rastros de feromona son asociados a los nodos del grafo5. La estructura general de ACO es como sigue [25]: Procedimiento metaheurística ACO; Actividades Programadas Construir Soluciones de las Hormigas Actualizar Feromonas Evaporación de la Feromona Acciones del Demonio (opcional) Fin de las Actividades Programadas Fin del Procedimiento Figura 2.1 Procedimiento general de ACO. 4 5. Mide la deseabilidad de la colonia por una determinada secuencia de nodos. Mide la deseabilidad de la colonia por un estado en específico, no interesa de donde fue alcanzado.. 27.
(37) Capítulo 2 “Algoritmos para la búsqueda por palabras clave basados en AS, ACS y MMAS”. Este procedimiento se anida en el siguiente procedimiento iterativo: Paso1: Inicializar los valores de feromona iteraciónActual=1 Paso2: Repetir Procedimiento metaheurística ACO iteraciónActual = iteraciónActual +1 Hasta que: criterio de parada Figura 2.2 Estructura genérica de ACO.. Para los métodos de ACO existen distintos criterios de parada [29], entre los que se encuentran: Se alcanza un número máximo de iteraciones o ciclos. Se obtiene una solución con una calidad deseada. Se alcanza un tiempo límite o predeterminado de procesamiento. Se obtiene un número máximo de evaluaciones de la función objetivo.. 2.2.2 Tareas de diseño Observando las aplicaciones actuales de ACO, se pueden identificar algunas directivas sobre cómo atacar problemas utilizando esta metaheurística. Estas directivas se pueden resumir en las seis tareas de diseño que se enumeran a continuación [30]: 1.. Representar el problema como un conjunto de componentes (nodos) y transiciones (aristas) a través de un grafo que será recorrido por las hormigas para construir soluciones.. 2.. Definir de manera apropiada en base a las características del problema, el significado de los rastros de feromona. 3.. .. Definir de manera apropiada la preferencia heurística o función de visibilidad asociada a cada componente o transición.. 4.. Si es posible, implementar una búsqueda local eficiente para mejorar las soluciones obtenidas por ACO.. 5.. Escoger un algoritmo de ACO específico y aplicarlo al problema que hay que solucionar teniendo en cuenta las características propias de cada uno de estos algoritmos. 28.
(38) Capítulo 2 “Algoritmos para la búsqueda por palabras clave basados en AS, ACS y MMAS”. 6.. Refinar los parámetros del algoritmo de ACO seleccionado.. Dentro de los algoritmos de ACO las diferencias fundamentales radican en la regla de transición de estados que utilizan para la construcción de las soluciones y en el tratamiento que le dan a los rastros de feromona. Debido a esto, aparecen en la literatura distintos algoritmos ACO.. 2.2.3 Principales algoritmos de la metaheurística ACO Entre los algoritmos de ACO disponibles para problemas de optimización combinatoria [35] se encuentran: el Sistema de Hormigas (Ant System; AS) [36], el Sistema de Colonia de Hormigas (Ant Colony System; ACS) [37], el Sistema de Hormigas MáximoMínimo (Max-Min Ant System; MMAS) [38], el Sistema de Hormigas con Ordenación Jerárquica (Rank-Based Ant System) [39], el Sistema de Hormigas Mejor-Peor (BestWorst Ant System) [40], entre otros. Esta técnica comienza a tener la madurez tecnológica adecuada para su utilización en problemas reales, como puede verse en la publicación del libro [35]. A continuación se presenta una pequeña descripción de los algoritmos Sistema de Hormigas, Sistema de Colonia de Hormigas y Sistema de Hormigas Max-Min, debido a que fueron seleccionados para llevar a cabo este trabajo. El Sistema de Hormigas (AS, por sus siglas en inglés) [36, 41], desarrollado por Dorigo en su tesis doctoral en 1992 [42], fue el primer algoritmo de ACO. Su versión actual (Ant Cycle) apareció conjuntamente con otras variantes de éste, como el Sistema de Hormigas Densidad (Ant Density) y Sistema de Hormigas Calidad (Ant Quality). El AS se caracteriza por el hecho de que, la actualización de feromona se realiza una vez que todas las hormigas han completado sus soluciones, y se lleva a cabo como sigue: primero, todos los rastros de feromona se reducen en un factor constante, implementándose de esta manera la evaporación de feromona según la ecuación (2.4), (2.4) donde ρ se conoce como constante de evaporación y es la encargada de reducir los rastros de feromona para evitar el estancamiento de las soluciones y τij la cantidad de feromona asociada al arco aij. A continuación, cada hormiga de la colonia deposita una cantidad de feromona en función de la calidad de su solución, según la ecuación (2.5), 29.
(39) Capítulo 2 “Algoritmos para la búsqueda por palabras clave basados en AS, ACS y MMAS”. (2.5) donde. tk. f (C ( S k )) , representa la cantidad de feromona a depositar por la hormiga k. en cada arco a ij de su solución encontrada ( S k ). Este valor depende de la calidad de dicha solución ( C ( S k ) ). Las soluciones en el AS se construyen como sigue. En cada paso de construcción, una hormiga k escoge ir al siguiente nodo con una probabilidad que se calcula como:. (2.6). donde N ik es el vecindario alcanzable por la hormiga k cuando se encuentra en el nodo i. Los parámetros alfa (. ) y beta (. ) controlan el proceso de búsqueda. Para. tiene una búsqueda heurística estocástica clásica, mientras que para de la feromona tiene efecto. Un valor de. =0 se. 0 sólo el valor. 1 lleva a una rápida situación de. convergencia (stagnation) [28]. El vector Pijk. contiene las probabilidades de. movimiento calculadas para los nodos de la vecindad ( N ik ) de la hormiga k. El valor representa el elemento (i, j) en la matriz de feromona y. ij. ij. se denomina función de. visibilidad o función heurística y mide la calidad de un estado j a partir del estado i. El Sistema de Colonia de Hormigas (ACS, por sus siglas en inglés) [37, 43] es uno de los primeros sucesores del AS que introduce tres modificaciones importantes con respecto a dicho algoritmo de ACO: 1. El ACS usa una regla de transición distinta y más agresiva, denominada regla proporcional pseudo-aleatoria. Sea k una hormiga situada en el nodo r, q 0. 0,1 un. parámetro y q un valor aleatorio en [0,1], el siguiente nodo i se elige aleatoriamente mediante la siguiente distribución de probabilidad:. 30.
(40) Capítulo 2 “Algoritmos para la búsqueda por palabras clave basados en AS, ACS y MMAS”. si q. q0. (2.7). sino ( q. q 0 ):. (2.8). Como puede observarse, la regla tiene una doble intención: cuando q ≤ q0, explota el conocimiento disponible, eligiendo la mejor opción con respecto a la información heurística y los rastros de feromona. Sin embargo, si q > q0 se aplica una exploración controlada, tal como se hacía en el SH. En resumen, la regla establece un compromiso entre la exploración de nuevas conexiones y la explotación de la información disponible en ese momento. 2. Las hormigas aplican una actualización en línea paso a paso de los rastros de feromona que favorece la generación de soluciones distintas a las encontradas. Cada vez que una hormiga viaja por una arista a ij , aplica la regla:. ij. donde. (1. )*. ij. 0. (2.9). (0,1] es un segundo parámetro de decremento de feromona. Como puede. verse, la regla de actualización en línea paso a paso incluye tanto la evaporación de feromona como la deposición de la misma. Ya que la cantidad de feromona depositada es muy pequeña (de hecho, t0 es el valor del rastro de feromona inicial y se escogiese de tal manera que, en la práctica, se corresponda con el límite menor de rastro de feromona, esto es, con la elección de las reglas de actualización de feromona del ACS ningún rastro de feromona puede caer por debajo de t0), la aplicación de esta regla hace que los rastros de feromona entre las conexiones recorridas por las hormigas disminuyan. Así, esto lleva a una técnica de exploración adicional del ACS ya que las conexiones atravesadas por un gran número de hormigas son cada vez menos atractivas para el resto que se encuentra trabajando en. 31.
(41) Capítulo 2 “Algoritmos para la búsqueda por palabras clave basados en AS, ACS y MMAS”. la iteración actual, lo que ayuda claramente a que no todas las hormigas sigan el mismo camino. 3. Sólo el demonio (y no las hormigas individualmente) actualiza la feromona, es decir, se realiza una actualización de feromona fuera de línea de los rastros. Para llevarla a cabo, el ACS sólo considera una hormiga concreta, la que generó la mejor solución global, Smejor-global (aunque en algunos trabajos iniciales se consideraba también una actualización basada en la mejor hormiga de la iteración, en ACO casi siempre se aplica la actualización por medio de la mejor global). La actualización de la feromona se hace evaporando primero los rastros de la misma en todas las conexiones utilizadas por la mejor hormiga global (es importante recalcar que, en el ACS, la evaporación de feromona sólo se aplica a las conexiones de la solución, que es también la usada para depositar feromona) tal como sigue: (1. ij. p) *. ij. aij. S mejor. global. (2.10). A continuación el demonio deposita feromona a los arcos previamente evaporados: ij. Donde. t. f (C ( S mejor. ij. global. t. aij. S mejor. global. (2.11). )) , es decir, la cantidad de feromona está en. dependencia de la calidad de la mejor solución encontrada hasta el momento C ( S mejor. global. ).. El Sistema de Hormigas Max-Min (MMAS, por sus siglas en inglés) [38, 44] ha sido específicamente desarrollado para obtener una fuerte exploración de las soluciones y para mejorar los estancamientos prematuros de las soluciones presentados por los anteriores algoritmos de ACO en la solución de algunos problemas discretos. Para obtener esta mejora el MMAS presenta los siguientes aspectos: 1. Para explotar las mejores soluciones encontradas durante la ejecución del algoritmo, después de cada iteración sólo una hormiga adiciona feromona a su camino encontrado. Esta hormiga puede ser la que obtuvo la mejor solución en la iteración actual (mejor solución en la iteración) o la hormiga que ha obtenido la mejor solución desde el inicio de la ejecución hasta el momento (mejor solución global).. 32.
(42) Capítulo 2 “Algoritmos para la búsqueda por palabras clave basados en AS, ACS y MMAS”. Estudios desarrollados en [38] muestran que para obtener un mejor rendimiento del MMAS es preciso realizar una actualización en la que se utilicen ambos elementos. 2. Utilizar rangos para los rastros de feromona, de forma tal que ningún rastro sea menor que una cota mínima ni mayor que otra máxima [τmin, τmax]. Estos valores son calculados dinámicamente por el algoritmo [38]; de esta forma se logra no tener mucha diferencia entre valores en la matriz de feromona. Para esto, si algún rastro de feromona es menor que el permitido τij<τmin será inicializado con el valor mínimo permitido τij= τmin. Lo mismo sucede para todos los valores de feromona que superan al valor máximo permitido τij>τmax, τij=τmax. 3. Adicionalmente, algunos trabajos [38, 45, 46] proponen que los valores iniciales de feromona al inicio del algoritmo sean τmax. De esta forma se obtiene una alta exploración del espacio de búsqueda al inicio del algoritmo. En el MMAS las hormigas se mueven del estado i al j de igual manera que se realiza en el AS (ecuación 2.6).. 2.2.4 Análisis de la complejidad temporal La complejidad temporal de los algoritmos ACO está determinada fundamentalmente por la estrategia de exploración que utilizan, donde un conjunto de m hormigas construyen soluciones de magnitud nn, hasta que se cumpla un número máximo de iteraciones (determinado por la condición de parada cs). Un elemento que influye en la complejidad de esta estrategia es la forma de actualizar los rastros de feromona, pero por ser particular de cada algoritmo ACO, no se tendrá en cuenta para el análisis siguiente. De manera general la función que describe dicho comportamiento es: (2.12) donde (nn-1) es resultado de la naturaleza constructiva de los métodos ACO, ya que una hormiga para moverse del nodo i al j, necesita en el peor de los casos, evaluar todos los nodos adyacentes a i (ecuación ()). Por tanto la complejidad de la estrategia de exploración de la metaheurística ACO es: (2.13). 33.
Figure
![Figura 1.1 Ejemplo de un documento XML [17].](https://thumb-us.123doks.com/thumbv2/123dok_es/7304303.448042/17.892.138.762.810.1018/figura-ejemplo-de-un-documento-xml.webp)
![Figura 1.2 Diferentes situaciones de lca (v1, v2) y lca (u1, u2 ) [17].](https://thumb-us.123doks.com/thumbv2/123dok_es/7304303.448042/18.892.147.762.542.796/figura-diferentes-situaciones-lca-v-v-lca-u.webp)

![Figura 1.6 Un ejemplo de un árbol XML para ilustrar el funcionamiento del algoritmo MSLCA [6].](https://thumb-us.123doks.com/thumbv2/123dok_es/7304303.448042/24.892.205.661.558.694/figura-ejemplo-árbol-xml-ilustrar-funcionamiento-algoritmo-mslca.webp)
+7





Documento similar
que hasta que llegue el tiempo en que su regia planta ; | pise el hispano suelo... que hasta que el
Para ello, trabajaremos con una colección de cartas redactadas desde allí, impresa en Évora en 1598 y otros documentos jesuitas: el Sumario de las cosas de Japón (1583),
Sanz (Universidad Carlos III-IUNE): "El papel de las fuentes de datos en los ranking nacionales de universidades".. Reuniones científicas 75 Los días 12 y 13 de noviembre
(Banco de España) Mancebo, Pascual (U. de Alicante) Marco, Mariluz (U. de València) Marhuenda, Francisco (U. de Alicante) Marhuenda, Joaquín (U. de Alicante) Marquerie,
d) que haya «identidad de órgano» (con identidad de Sala y Sección); e) que haya alteridad, es decir, que las sentencias aportadas sean de persona distinta a la recurrente, e) que
Ciaurriz quien, durante su primer arlo de estancia en Loyola 40 , catalogó sus fondos siguiendo la división previa a la que nos hemos referido; y si esta labor fue de
En la parte central de la línea, entre los planes de gobierno o dirección política, en el extremo izquierdo, y los planes reguladores del uso del suelo (urbanísticos y
Sólo que aquí, de una manera bien drástica, aunque a la vez coherente con lo más tuétano de sí mismo, la conversión de la poesía en objeto -reconocida ya sin telarañas
