Facultad de Ciencias - Universidad de Cantabria
Herramientas para el despliegue de aplicaciones basadas en
componentes.
César Cuevas Cuesta
[email protected]
Director:
José María Drake Moyano.
Grupo de Computadores y Tiempo Real
Departamento de Electrónica y Computadores.
Santander, Septiembre de 2008
Curso 2007/2008
En primer lugar, agradecer a mi mentor José María Drake Moyano, por haberme guiado en la elaboración de esta tesis y sobre todo por haberme dado la oportunidad de pertenecer a CTR, para mi mucho más que un puesto laboral.
En segundo lugar a mis compañeros del despacho-12, Ángela, Iñaki, Laura, quien diseñó las reglas de generación mediante las cuales pude desarrollar las herramientas que se presentan en este trabajo, y Álvaro, quién lo único que no saben él y su intuición es que lo saben todo, y en general a todos mis compañeros de CTR.
Este trabajo ha sido financiado por el Ministerio de Educación y Ciencia del Gobierno de España dentro del proyecto THREAD (TIC2005-08665-C03-02), por el Programa IST de la Comisión Europea dentro del proyecto FRESCOR (FP6/2005/IST/5-034026), por la Red de Excelencia ARTIST2 y por el programa de Consorcios Estratégicos Nacionales en Investigación Técnica (CENIT) dentro del proyecto HESPERIA. Este trabajo refleja sólo el punto de vista del autor; la UE no se responsabiliza del uso que se pueda hacer de la información contenida.
CASE Computer Aided Software Engineering. GUI Graphic User Interface.
OMG Object Management Group. CCM CORBA Component Model. CCM Container Component Model.
CORBA Common Object Request Broker Architecture. LwCCM Light weight CCM.
RT-EP Real Time Ethernet Protocol. ICE Internet Communication Engine. PIM Platform Independent Model. PSM Platform Specific Model.
BIM Business Interface Management. SLICE Specification Language for ICE. IDL Interface Description Language. UML Unified Modelling Language. XML Extensible Markup Language.
IDE Integrated Development Environment. SWT Standard Widget Toolkit.
AWT Abstract Windowing Toolkit.
WSAD WebSphere Studio Application Developer. MVC Model Viewer Controller.
MDA Model Driven Architecture. EMF Eclipse Modelling Framework. MOF Meta-Object Facility.
CWM Common Warehouse Metamodeling. XMI XML Model Interchange.
Índice de figuras:... 7
1. PROGRAMACIÓN GENERATIVA. ... 1
1.1 Programación generativa y automatización del desarrollo de las aplicaciones informáticas. . 1
1.2 Programación generativa y tecnología de componentes. ... 4
1.3 Programación generativa y modelos no funcionales. ... 6
1.4 La tecnología de componentes CCM, marco contextual de esta tesis. ... 7
1.5 Objetivos de la tesis. ... 7
2. TECNOLOGÍA DE COMPONENTES CCM Y GENERACIÓN AUTOMÁTICA DE CÓDIGO. ... 9
2.1 Introducción. ... 9
2.2 Proceso de desarrollo de un componente CCM. ... 10
2.3 Desarrollo de una aplicación basada en componentes. ... 13
2.4 Especificación D&C sobre el proceso, la información y las herramientas de componentes. 14 2.5 Especificación de herramientas... 17
3. EL ENTORNO ECLIPSE. ... 20
3.1 Introducción a Eclipse: historia y breve descripción. ... 20
3.2 El workbench de Eclipse... 20
3.3 Arquitectura de la plataforma Eclipse... 21
3.4 Gestión de recursos y entorno de programación... 22
3.5 Las bibliotecas SWT y JFace. ... 23
3.6 Aplicación de la tecnología XML: W3C-Schema y herramientas de análisis... 27
3.7 Repositorio de componentes y plataformas (Repository). ... 28
3.8 Desarrollo de una herramienta de navegación en forma de plug-in. ... 29
4. DISEÑO DE HERRAMIENTAS DE GENERACIÓN DE CÓDIGO. ... 32
4.1 Generación de código en base a plantillas. ... 32
4.2 Especificación de las plantillas. ... 33
4.3 Especificación de la funcionalidad de los generadores de código. ... 34
4.4 Ejemplos de herramientas. ... 38
5. CONCLUSIONES Y LÍNEAS FUTURAS. ... 49
6. REFERENCIAS. ... 51
7. ANEXOS. ... 52
7.1 Anexo A. Especificación de la funcionalidad del generador de código del constructor (home) de un componente. ... 52
FIGURA 1.2-FASES EN LA AUTOMATIZACIÓN DE LA GENERACIÓN DEL CÓDIGO. ... 1
FIGURA 1.3-ELEMENTOS DE UN MODELO GENERATIVO DE DOMINIO. ... 3
FIGURA 1.4-UTILIZACIÓN DE LA PG EN LAS TECNOLOGÍAS DE COMPONENTES. ... 5
FIGURA 1.5-TECNOLOGÍA DE COMPONENTES PARA PROGRAMACIÓN GENERATIVA. ... 5
FIGURA 1.6-GENERADOR DE CÓDIGO Y GENERADOR DE MODELO NO FUNCIONAL... 6
FIGURA 2.1-NIVELES DE ABSTRACCIÓN DE UN COMPONENTE. ... 10
FIGURA 2.2-EJEMPLO DE LA INFORMACIÓN QUE SE MANEJA EN EL NIVEL PIM. ... 11
FIGURA 2.3-EJEMPLO DE LA INFORMACIÓN QUE SE MANEJA EN EL NIVEL BIM... 12
FIGURA 2.4-EJEMPLO DE LA INFORMACIÓN QUE SE MANEJA EN EL NIVEL PSM. ... 12
FIGURA 2.5-PROCESO DE DESARROLLO DE UNA APLICACIÓN BASADA EN COMPONENTES. ... 13
FIGURA 2.6-PLANTILLAS W3C- SCHEMA DE LA ESPECIFICACIÓN D&C. ... 15
FIGURA 3.1–EL WORKBENCH DE ECLIPSE. ... 21
FIGURA 3.2–JERARQUÍA DE RECURSOS DEL WORKSPACE... 22
FIGURA 3.3–JERARQUÍA DE VISORES... 24
FIGURA 3.4–VISOR DE TEXTO. ... 24
FIGURA 3.5–VISOR DE LISTA... 24
FIGURA 3.6–VISOR DE ÁRBOL. ... 24
FIGURA 3.7–VISOR DE TABLA. ... 24
FIGURA 3.8–JERARQUÍA DE PROVEEDORES DE ETIQUETAS... 25
FIGURA 3.9–JERARQUÍA DE PROVEEDORES DE CONTENIDO... 25
FIGURA 3.10–ESTRUCTURA DEL REPOSITORIO. ... 29
FIGURA 3.11–HERRAMIENTA DE NAVEGACIÓN. ... 31
FIGURA 4.1–ELEMENTOS DE ENTRADA Y SALIDA EN EL PROCESO DE GENERACIÓN DE CÓDIGO EN BASE A PLANTILLAS. ... 32
FIGURA 4.2–HERRAMIENTA DE GENERACIÓN DE CÓDIGO.ENTRADAS Y SALIDAS... 32
FIGURA 4.3–COMPOSICIÓN DE UNA HERRAMIENTA... 35
FIGURA 4.4–ARQUITECTURA DE HERRAMIENTAS DE GENERACIÓN. ... 36
FIGURA 4.5–CLASE PERFORMER... 36
FIGURA 4.6–CLASE TEMPLATOR... 37
FIGURA 4.7–CLASE NAVIGATOR... 38
FIGURA 4.8–MENÚ AÑADIDO A LA BARRA DE MENÚS DEL WORKBENCH DE ECLIPSE. ... 39
FIGURA 4.9–SUBMENÚ AÑADIDO AL MENÚ CONTEXTUAL... 40
FIGURAS 4.10 Y 4.11–GUI BÁSICA Y VARIANTE MÁS COMPLEJA... 40
FIGURA 4.12–CUADRO FILEDIALOG... 41
FIGURA 4.13-ELECCIÓN DE LA IMPLEMENTACIÓN DEL COMPONENTE. ... 41
FIGURA 4.15–ARQUITECTURA DE LA PARTE GRÁFICA DE USUARIO EN NUESTRAS HERRAMIENTAS. ... 45
1. PROGRAMACIÓN
GENERATIVA.
1.1 Programación generativa y automatización del desarrollo de las aplicaciones informáticas.
El lugar tan relevante que los sistemas informáticos ocupan hoy en día en nuestra sociedad, contrasta con el bajo nivel de evolución que actualmente tiene la ingeniería software que se utiliza para desarrollarlos. De la ingeniería software se espera que sea capaz de gestionar tanto la complejidad que año a año se duplica como la productividad que se necesita para cubrir la expansión de los objetivos a los que se aplica y la calidad que se requiere para ser aplicada a sistemas que son críticos desde el punto de vista social o económico. Desafortunadamente, la ingeniería software que actualmente se usa no es capaz de satisfacer estas expectativas. Vista con la perspectiva de un siglo de experiencia de revolución industrial en otras ingenierías, la ingeniería software se encuentra en las primeras fases de su evolución. En ella domina la producción a medida, que hace “a mano” cada producto, frente a la producción en cadena que utilizan otras ingenierías más maduras y con la que consiguen garantizar niveles superiores de productividad y calidad. Como se muestra en la figura 1.1, que describe los grandes hitos en la evolución de la revolución industrial, ésta no ha sido una tarea sencilla sino que ha requeridos casi dos siglos para alcanzar su madurez.
1826
1913
1980
- Diseño de piezas intercam-biables - John Hall - Fabricación de mosquetes - Líneas de producción - Henry Ford - Fabricación de coches - Líneas de ensamblado automático con robots. - General Motors - Fabricación de coches
Figura 1.1 - Principales hitos en la revolución industrial.
En contraposición a esta evolución propia de las ingenierías mecánicas, eléctrica, electrónica, etc., en la figura 1.2 se muestra la evolución de la ingeniería software.
Código Código Código Código Código
Modelo Modelo Modelo Modelo Modelo
Nivel 1 Nivel 2 Nivel 3 Nivel 4 Nivel 5 ¿?
1. Se utiliza únicamente el código, que, simultáneamente, es el medio de definir la funcionalidad del programa, de documentar su contenido y de transmitir los conceptos de diseño incluidos en él. Apoyado por el hecho de que requiere un único documento y sólo un editor de texto es aún hoy en día muy frecuentemente utilizado.
2. El diseñador diseña y escribe el programa utilizando el código como elemento principal. Únicamente utiliza el modelo como forma de comunicar a otros diseñadores humanos las ideas de diseño que se incluyen en él.
3. El diseñador utiliza de forma combinada el modelo y el código como medios de diseñar y codificar el programa. En las fases iniciales en que domina el diseño, utiliza el modelo y, haciendo uso de generadores de código, traduce el modelo a código. Posteriormente, en las fases de codificación y verificación trabaja directamente sobre el código, y con herramientas de ingeniería inversa mantiene el modelo sincronizado con el código que escribe. Es la metodología que corresponde a los actuales entornos CASE (Computer Aided Software Engineering) de programación.
4. El diseñador sólo piensa sobre el modelo, el cual, a través de un generador automático de código, es codificado para su posterior interpretación de forma convencional por un computador. El código se genera porque lo requiere la máquina, pero no se requiere de programador que lo sepa interpretar. Es la metodología que utilizan los entornos basados en componentes, como los entornos de diseño de GUIs (Graphic User Interface). Es el nivel al que se destina este trabajo. 5. Sólo existe el modelo, el cual representa el medio con el que el diseñador diseña el programa, y
así mismo, es lo que interpreta el computador para implementar la funcionalidad que se le requiere. Actualmente sólo es utilizado para dominios de aplicación muy específicos.
La programación generativa (PG, en adelante) [1] constituye una metodología básica para ser aplicada en el nivel 4 y representa un paso más en la evolución de la ingeniería software en busca de la automatización de los procesos de desarrollo y ensamblado de los sistemas informáticos. Se basa en dos principios:
i. Se traslada el objetivo del diseño al desarrollo de familias de productos o dominios de aplicación compuestos por componentes estandarizados. Estos a su vez se utilizan para diseñar aplicaciones concretas que se construyen ensamblando los componentes ya disponibles.
ii. Se diseñan herramientas que automatizan la generación del código de los componentes y su ensamblado en sistemas informáticos.
Así pues, la PG es un paradigma de la ingeniería software basado en el modelado de familias de sistemas software tales que, dada la especificación de requerimientos en el diseño de un sistema concreto, pueda generarse automáticamente un producto intermedio o final perfectamente especializado y optimizado por ensamblado de componentes reutilizables más elementales y configurados de acuerdo con su uso en él, por medio de lo que se conoce como “conocimiento de configuración”. Por consiguiente, la PG se centra en familias de sistemas software en vez de en sistemas únicos. En lugar de construir miembros individuales de una familia desde cero, todos ellos pueden ser generados a partir de lo que se conoce como un modelo generativo de dominio, esto es, un modelo de una familia de sistemas compuesto por tres elementos:
i. Dominio-problema: metodología y formalismo empleados para especificar de forma precisa la
funcionalidad de los miembros de la familia y las opciones de configuración que admiten.
ii. Dominio-solución: conjunto de implementaciones de los componentes disponibles a partir de
los cuales cada miembro de la familia puede ser ensamblado y la descripción de los parámetros y mecanismos con los que se configuran cada una de sus opciones.
iii. El ya referido conocimiento de configuración, que representa la correspondencia entre la especificación de un miembro y el miembro finalizado, esto es, el conocimiento de las relaciones precisas entre las características de configuración especificadas para cada componente y la forma en que esas características se hacen efectivas en el producto. Visto desde el prisma de los dos primeros elementos, el conocimiento de configuración representa la forma en que se relacionan las características y opciones de configuración del dominio-problema con la selección de implementaciones y valores de los parámetros en el dominio-solución, así como las restricciones entre características y las optimizaciones que pueden conseguirse en el diseño de un sistema concreto.
En la figura 1.3 podemos ver una ilustración de estos tres elementos.
Dominio-problema: Glosario de conceptos y términos así como propiedades y
características propias del dominio. Dominio-solución: - Parámetros de configuración. - Requerimientos de conexión. - Requerimientos de instanciación. Conocimiento de configuración: - Combinaciones ilegales de características. - Características por defecto. - Reglas de ensamblado. - Optimización.
Figura 1.3 - Elementos de un modelo generativo de dominio.
El problema con la actual ingeniería software es que usualmente llegamos a un sistema software concreto pero sin saber cómo hemos llegado. La mayor parte del conocimiento de diseño se pierde y esto hace que el mantenimiento y evolución del software sea muy difícil y costosa. En PG queremos capturar el conocimiento de configuración en forma de programa, es más, aspiramos a capturar tanto conocimiento de producción en forma de programa como sea posible, el cual no sólo incluye el conocimiento de configuración, sino también otros aspectos como estrategias de testeo, diagnosis de errores, soporte para depuración, etc.
La PG engloba dos ciclos de desarrollo completos: uno para diseñar e implementar un modelo generativo de dominio (desarrollo para en el futuro poder aplicar reutilización), cuyo ámbito es una familia de sistemas y otro para emplear el modelo generativo en la producción de sistemas concretos (desarrollo aplicando reutilización), el cual ha de ser cuidadosamente diseñado para aprovechar los activos reutilizables en forma sistemática. El aspecto crucial del primer ciclo de desarrollo es la selección y delimitación de la familia de sistemas. Su primer paso es establecer la amplitud de su ámbito, esto es, decidir qué características deben incluirse y cuales no. Para ello hemos de analizar los objetivos del proyecto, los mercados actuales y potenciales, las posibilidades tecnológicas, etc. Una amplitud de ámbito extensa incrementa la reutilización del dominio en futuras aplicaciones, pero en contrapartida conlleva el desarrollo de elementos complejos que son difíciles de evolucionar y mantener. Conseguir un equilibrio en la amplitud del ámbito entre las necesidades actual y futura es un
1.2 Programación generativa y tecnología de componentes.
La tecnología de componentes software [2,3] constituye uno de los paradigmas de la ingeniería software con mayor futuro para incrementar la calidad del software, acortar los tiempos de desarrollo de los productos y gestionar el continuo incremento de su complejidad.
En una arquitectura basada en componentes, las aplicaciones se construyen ensamblando componentes reutilizables que se encuentran disponibles y que han sido diseñados con independencia de las aplicaciones en las que se utilizan. Un componente es un módulo software que ofrece de forma auto-contenida y opaca:
i. La especificación de su funcionalidad y servicios ofertados (contrato de uso).
ii. Los servicios externos a él que necesita para implementar su funcionalidad y los recursos que requiere para ser ejecutado (contrato de instanciación).
iii. La información introspectiva (metadata) que se necesita para su manejo y ensamblado, en particular, por parte de entornos de diseño y desarrollo basados en herramientas.
iv. Los elementos de código ejecutable que lo implementan, y uno o múltiples entornos de ejecución.
El diseño de las aplicaciones ensamblando componentes proporciona muchas ventajas:
i. La arquitectura que resulta es simple y está basada en interfaces y no en complejos protocolos de comunicación entre subsistemas.
ii. Permite escalar y reconfigurar el sistema que se diseña con sólo modificar el plan de despliegue y sin tener que modificar el código de bajo nivel.
iii. Simplifica la evolución y el versionado de los sistemas al requerir únicamente la sustitución de componentes y en su caso el desarrollo de nuevos componentes con funcionalidad y especificación bien definida.
Los componentes son siempre parte de un dominio de aplicación bien definido y pertenecen a una tecnología estandarizada que define la conectividad y los modelos de interacción entre ellos.
Existen diferentes tecnologías de componentes, cada una destinada a una determinada plataforma de ejecución. Por ejemplo COM, COM+, DCOM y .NET son tecnologías de componentes destinadas a la plataforma Windows de Microsoft, Java Beans y EJB para la plataforma Java, la tecnología CCM (Corba Component Model) de la organización OMG (Object Management Group) requiere como plataforma el middleware CORBA (Common Object Request Broker Architecture), etc.. La tecnología de componentes en que se encuadra esta tesis es la tecnología CCM (Container Component Model) que se desarrolla en el grupo CTR (Computadores y Tiempo Real) de la Universidad de Cantabria, tecnología que veremos en mayor detalle en la sección 1.4 y en el capítulo 2.
Una tecnología de componentes no tiene obligatoriamente que hacer uso de la PG. Cuando la plataforma de destino de una familia de componentes esta muy bien delimitada, los componentes pueden ser distribuidos con implementaciones de código binario directamente ejecutables y configurables durante su instanciación, asignando valores a los parámetros de configuración que tienen declarados. Sin embargo, cuando la plataforma es heterogénea y distribuida, se requiere que cada componente disponga de múltiples implementaciones y así, cuando se ensambla la aplicación, debe seleccionarse la instancia adecuada de acuerdo con la naturaleza del procesador en el que debe ejecutarse. Esta solución conlleva no sólo tener que incluir todas las posibles implementaciones, según el lenguaje de programación, sistema operativo o middleware de ejecución, sino que posiblemente, las implementaciones también tengan que ser actualizadas cuando la versión de alguno de los elementos de la plataforma se modifica.
La PG reduce el problema de la multiplicidad de las implementaciones. Como se muestra en la figura 1.4, el entorno de desarrollo puede almacenar cada componente como un paquete que contiene
diferentes modelos de especificación o comportamiento así como uno o un reducido número de elementos de código parametrizable, pero sin implementaciones ejecutables. En este caso, cuando en una aplicación se necesita una instancia del componente, una herramienta de generación de código analiza el plan de despliegue, y, en función de los requerimientos y de la naturaleza de la plataforma, genera el código ejecutable de la instancia del componente.
Figura 1.4 - Utilización de la PG en las tecnologías de componentes. AlarmMger Logger IOController Repositorio de componentes Solución Paquete componente Modelo uso Modelo configuración Modelo reactivo Modelo instanciación Implementació n Implementació n Implementación Herramientas diseño Instancia de componente Proceso diseño
La asociación de la PG con las tecnologías de componentes reduce la complejidad de éstas y simplifica los procesos de mantenimiento y actualización de versiones. Por ello, las tecnologías de componentes que han aparecido en el último lustro incorporan el paradigma de PG formalizando el concepto de contenedor, que facilita la incorporación de código generado con herramientas automáticas. Como se muestra en la figura 1.5, la implementación de la instancia de un componente que se ensambla en una aplicación se compone de dos partes: el código de negocio, que es código generado por el diseñador del componente para implementar la funcionalidad de negocio propia del dominio de aplicación, y el contenedor (wrapper), que representa la parte del código de la instancia que facilita la ejecución del componente en la plataforma de ejecución e implementa los mecanismos de conexión con otros componentes de acuerdo con los recursos del middleware disponible. El código del contenedor lo genera
una herramienta automática en función de los modelos asociados al componente y del plan de despliegue que describe la plataforma en que se ejecuta y los recursos
Descriptor componente Modelo uso Modelo comportamiento Modelo instanciación Plan de despliegue Código negocio Instancia componente Generador código (Copiado)
1.3 Programación generativ
ran los aspectos relativos a los mo
icación que se
de
ón de los modelos no funcionales en una tecnología de co
a y modelos no funcionales. Las tecnologías de componentes convencionales sólo conside
delos funcionales de los componentes, por lo que describen los componentes a través de los servicios que ofrecen o los servicios que requieren para operar. En ambos casos esos servicios se describen mediante interfaces y la conectividad de los componentes se formula a través de la compatibilidad de las interfaces ofertadas por los componentes servidores con las interfaces requeridas por los componentes clientes. Así mismo, la instanciación de los componentes se formula a través de la compatibilidad entre los recursos que los componentes requieren para poder ser instalados, lo cual se describe en su modelo de instanciación y los recursos de que dispone la plataforma en la que el plan de despliegue indica que deben instalarse, que se describen en el modelo de la plataforma.
Sin embargo, en muchos casos esto no es suficiente ya que entre los requisitos de la apl
diseña hay requisitos no funcionales (respuesta de tiempo real, uso de recursos, etc.) que también deben satisfacerse. Para estos casos se proponen [4, 5, 6] extensiones de la especificación de componentes que permitan describir los aspectos relacionados con su comportamiento no funcional y herramientas que analizan la adecuación de éstos a los requisitos de la aplicación en la que se integran.
Los modelos no funcionales de los componentes son básicamente estructuras de datos formuladas acuerdo con una determinada especificación, que describen las características que son consecuencia del código del componente y que se necesitan conocer para analizar la adecuación del mismo en los aspectos no funcionales que se están considerando. Habitualmente estos modelos son simples conjuntos de datos que no son analizables de por sí para un determinado componente, sino que necesitan ser integrados con los de otros componentes en el contexto de una aplicación para que se genere un modelo completo de la aplicación, el cual sí es analizable y sus resultados pueden ser contrastados con los requisitos especificados.
Como se muestra en la figura 1.6, la gesti
mponentes es similar a la PG, en la que en función de modelos parciales de los componentes se genera el modelo completo de la aplicación que proporciona la información no funcional requerida. No es propiamente PG, ya que su objetivo no es la generación del código, sino la generación de los modelos de comportamiento no funcional de las aplicaciones.
Figura 1.6 - Generador de código y generador de modelo no funcional. Comp_C Comp_B Comp_A Comp_C Main Aplicación Modelo no funcional Generador de código Generador de modelo no funcional Plan de despliegue Paquete componente (con extensión no funcional)
(código) Modelo funcional
1.4 La tecnología de componentes CCM, marco contextual de esta tesis.
Como hemos significado anteriormente, la tecnología de componentes en que se encuadra esta tesis es la tecnología CCM (Container Component Model). Su objeto es desarrollar aplicaciones complejas basadas en componentes con capacidad de admitir requisitos de tiempo real estrictos y laxos y que puedan ser ejecutadas en plataformas embebidas con recursos limitados. La tecnología toma como punto de partida la especificación LwCCM (Light weight CCM) [7], y en ella se hacen un conjunto limitado de modificaciones:
i. No se utiliza CORBA como soporte de comunicación entre componentes, sino que ésta se efectúa a través de conectores, que son un tipo especial de componente que engloba en su código los servicios de comunicación requeridos y que pueden basarse en diferentes mecanismos de comunicación. La conexión entre los componentes y el conector es siempre local.
ii. Se han introducido nuevos servicios y mecanismos en los contenedores que permiten controlar las estrategias de planificación de los threads que utilizan los componentes. El objetivo de estos servicios es garantizar la predecibilidad del comportamiento temporal de las aplicaciones.
iii. Para la descripción de las interfaces e implementaciones de los componentes, de las plataformas y de las aplicaciones se utilizan los formatos definidos en la especificación Deployment and
Configuration of Component-based distributed applications Formal/06-04-02 (D&C, en
adelante) [8] de OMG. Esta especificación también ha sido extendida [9] para que incorpore información introspectiva (metadata) del comportamiento temporal de los componentes y de las plataformas y que es utilizada para gestionar la planificabilidad de la aplicación.
Esta tecnología CCM que se está desarrollando en nuestro grupo CTR se enmarca en tres proyectos de investigación. En cada uno de ellos se abordan aspectos diferentes:
i. En el proyecto Thread [10, 11, 12] se aborda el tiempo real estricto, para lo cual la tecnología se adapta a una plataforma de ejecución de tiempo real, esto es, se utiliza lenguaje Ada y se emplean MaRTE OS como sistema operativo y RT-EP (Real Time Ethernet Protocol) como protocolo de comunicación.
ii. En el proyecto HESPERIA [13,14] se adapta la tecnología a sistemas distribuidos de tiempo real laxo y se utiliza como plataforma el middleware ICE (Internet Communication Engine) de la empresa ZeroC.
iii. En el proyecto FRESCOR [15] se adapta la tecnología para que opere en tiempo real estricto sobre plataformas abiertas haciendo uso de los contratos de servicio y los recursos virtuales que se desarrollan en el proyecto.
1.5 Objetivos de la tesis.
El objetivo de la tesis ha sido el desarrollo de un entorno integrado para la automatización de los procesos de generación de código y de generación de modelos no funcionales para la tecnología CCM. Dentro de este objetivo se ha buscado que el proceso de desarrollo de las herramientas sea sencillo y esté estandarizado.
ii. Diseño del repositorio de la tecnología CCM, definiendo una arquitectura de ficheros estandarizada en la que cada documento tiene fijada su localización en función de su contenido y del papel que juega en la tecnología. Con la estandarización del repositorio se hace muy ágil la declaración de los parámetros de entradas y salidas de las herramientas.
iii. Definición de diferentes estrategias para desarrollo de herramientas:
a. Herramientas implementadas mediante extensión de Eclipse, donde se hace uso de los puntos de extensión que ofrece Eclipse para la conexión con herramientas ya disponibles y otras desarrolladas a propósito.
b. Herramientas diseñadas a partir de una meta-herramienta que permite construir código en función de un diccionario de patrones (segmentos parametrizados de código).
c. Herramientas diseñadas de forma específica que se integran en el entorno a través de la estandarización de las interfaces de usuario y de la forma en que se invocan desde las cajas de herramientas que ofrece Eclipse.
iv. Validación del entorno y de las metodologías de desarrollo de herramientas, diseñando e implementando un conjunto de las herramientas que se requieren en los diferentes proyectos que actualmente están realizándose.
2. TECNOLOGÍA DE COMPONENTES CCM Y GENERACIÓN
AUTOMÁTICA DE CÓDIGO.
2.1 Introducción.
En este trabajo se aborda la aplicación de la PG al desarrollo de componentes y aplicaciones utilizando la tecnología CCM. En este capítulo se analiza esta tecnología desde el punto de vista del entorno de desarrollo, esto es:
De los procesos de especificación, análisis, diseño y gestión que se utilizan. De la información que se maneja.
De los actores que intervienen en el proceso.
De las herramientas que se necesitan para automatizar los procesos de generación de código. En general, el proceso de desarrollo de aplicaciones basadas en componentes se compone de dos fases independientes pero complementarias.
i. Desarrollo de los componentes: consiste en especificar, diseñar, empaquetar y distribuir los componentes como unidades independientes, reutilizables y concebidos en función de un dominio de aplicación, pero no destinados a una aplicación específica. Veremos esta fase del proceso en mayor detalle en la sección 2.2.
ii. Desarrollo de las aplicaciones: el desarrollo de una aplicación concreta se lleva a cabo para dar solución a un problema que se tiene especificado y planteado. En primer lugar se diseña la aplicación como un conjunto de instancias de los componentes registrados en el entorno, configurados e interconectados de forma adecuada para implementar la funcionalidad deseada en la aplicación. En segundo lugar, se identifica la plataforma en la que se va a ejecutar la aplicación, y, de acuerdo con la composición de ésta última, se decide su despliegue en la plataforma, se transfiere el código que proceda al nudo en que se va a ejecutar, y por último se lanza la ejecución coordinada de la misma. Analizaremos esta fase en mayor detalle en la sección 2.3.
Una tecnología de componentes se propone para que sea implementada por diferentes organizaciones y en el proceso de desarrollo deben operar herramientas creadas por diferentes entidades y posiblemente compartidas con otras tecnologías que tienen procesos comunes. A fin de tener un modelo de referencia común y garantizar la interoperatividad de las herramientas, la organización OMG ha definido la especificación D&C. Ésta es la especificación que se utiliza en el marco de la tecnología CCM. Estudiaremos este modelo de referencia en la sección 2.4.
Por último, en la sección 2.5 procederemos a una enumeración y breve descripción de las principales herramientas que se requieren en el proceso de desarrollo de los componentes y de las aplicaciones.
2.2 Proceso de desarrollo de un componente CCM.
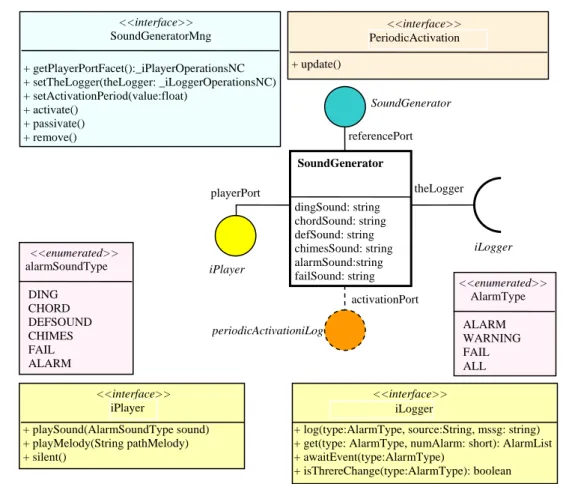
En la figura 2.1 se muestran los tres niveles de abstracción en los que se desglosa la descripción de cualquier componente. A fin de simplificar, pondremos como ejemplo el componente SoundGenerator. SoundGenerator.ccd <<D&C-OMG>> <<Slice>> iPlayer.ice> JSSSoundGenerator.pic <<D&C-OMG>> ICE_CCM JSSSoundGenerator.pic <<D&C-OMG>> SoundGeneratorMng.java <<java>> <<java>> iPlayerOperationsNC.java write write Implementator (domain expert) Slice2java BMI_Generator j ICE-CMM_Generator
PIM: Platform Idependent Model write write
Specifier (domain expert)
BIM: Business Implementation Model
JSSSoundGenerator.java <<java>>
PSM: Platform Specific Model
JSSSoundGeneratorExec.java <<java>> JSSSoundGeneratorHome.java <<java> JSSSoundGeneratorWrapper.java <<java> Planner
(platform expert) Executable component instance
Figura 2.1 - Niveles de abstracción de un componente.
i. Nivel PIM (Platform Independent Model): Describe el comportamiento del componente con independencia de su implementación o del middleware con el que se accede a él. Es el modelo que utiliza el desarrollador de las aplicaciones al integrarlo en sus diseños para decidir la idoneidad de su funcionalidad, sus posibilidades de configuración y cómo debe ser utilizado. Su descripción se realiza mediante el fichero que describe la interfaz del componente (p.e.
SoundGenerator.ccd.xml), siendo tanto su contenido como su formato conformes a la
especificación D&C. A partir de él se tiene acceso a los ficheros que definen la funcionalidad de las interfaces y que también son parte de este modelo (p.e. iPlayer.ice y iLogger.ice). Como en ICE-CCM utilizamos por defecto el middleware ICE, resulta más fácil como lenguaje de especificación el lenguaje SLICE (Specification Language for ICE), aunque en otras versiones CCM se utiliza IDL (Interface Description Language). La información típica que corresponde a este nivel se muestra en la figura 2.2. Toda ella es información externa del componente: declaración de puertos (facetas y receptáculos), incluyendo la descripción de las interfaces que implementan, declaración de las interfaces de gestión del ciclo de vida del componente, declaración de los thread externos que requiere y declaración de los atributos de configuración.
SoundGenerator activationPort theLogger playerPort iPlayer iLogger periodicActivationiLog ger SoundGenerator referencePort dingSound: string chordSound: string defSound: string chimesSound: string alarmSound:string failSound: string <<interface>> iPlayer + playSound(AlarmSoundType sound) + playMelody(String pathMelody) + silent() <<interface>> iLogger
+ log(type:AlarmType, source:String, mssg: string) + get(type: AlarmType, numAlarm: short): AlarmList + awaitEvent(type:AlarmType) + isThrereChange(type:AlarmType): boolean <<enumerated>> alarmSoundType DING CHORD DEFSOUND CHIMES FAIL ALARM <<enumerated>> AlarmType ALARM WARNING FAIL ALL <<interface>> SoundGeneratorMng + getPlayerPortFacet():_iPlayerOperationsNC + setTheLogger(theLogger: _iLoggerOperationsNC) + setActivationPeriod(value:float) + activate() + passivate() + remove() <<interface>> PeriodicActivation + update()
Figura 2.2 - Ejemplo de la información que se maneja en el nivel PIM.
ii. Nivel BIM (Business Implementación Model): Describe una implementación concreta del componente en la que se han definido los recursos en que basa su funcionalidad. Es el modelo que se introduce para que el diseñador que desarrolla el código de negocio que implementa el componente pueda trabajar de forma libre y sin necesidad de conocer la tecnología de distribución subyacente. Un mismo componente puede poseer múltiples implementaciones con diferentes requerimientos en cuanto a recursos de la plataforma, pero todas ellas pueden ser adaptadas a la tecnología de una plataforma específica utilizando herramientas automáticas. Su descripción se realiza mediante el fichero de implementación (p.e.
JSSSoundGenerator.pid.xml), cuyo formato y contenido son conformes a la especificación
D&C. A partir de él se accede a los ficheros que contienen la interfaz que define la funcionalidad de gestión requerida por la tecnología del componente de negocio (p.e.
SoundGeneratorMng.java) y a los ficheros que definen la funcionalidad que ofrecen las facetas
del componente y la que requiere encontrar por sus receptáculos (p.e.
<<interface>> <<interface>> <<interface>> CCMBusinessLifeControl CCMBusinessLifeControl JSSSoundGenerator playerPortFacet 1 owner 1 iPlayerOperationsNC PlayerPortFacet - setTheLogger: - _LoggerOperationsNC - dingSound: string - chimesSound: string …. + JSSSoundGenerator() + setTheLogger(theRecepo: _iLoggerOp..) + setDingSound(sound: string) + setChordSound(sound: string) ... + activate() + passivate() + remove() + playSound(sound: AlarmType) + playMelody(path string) + silent()
Figura 2.3 - Ejemplo de la información que se maneja en el nivel BIM.
iii. Nivel PSM (Platform Specific Model): Describe una implementación completa del componente, dispuesta para ser instanciada y ejecutada en la plataforma. Integra en ella el código de negocio que aporta la funcionalidad del componente y los ficheros de código, generados automáticamente por herramientas, que proporcionan los recursos para poder operar sobre una plataforma determinada, ICE-CCM en este caso. Se describe mediante el fichero de descripción de la implementación, cuyo formato y contenido es conforme a la especificación D&C (p.e.
ICE-CCMJSSSoundGenerator.pid.xml). Desde él se referencian los ficheros *.java que constituyen
el código ejecutable del componente (JSSSoundGeneratorWrapper.java,
JSSSoundGeneratorExecutor.java y JSSSoundGeneratorHome.java). En el diagrama de
clases de la figura 2.4 se muestra la información que se maneja en el nivel PSM. Es básicamente un programa Java compuesto por la clase JSSSoundGenerator importada del nivel BIM y que se maneja sin modificar más que el conjunto de clases Java que constituyen el contenedor y cuyo código se ha generado mediante una herramienta automática.
Figura 2.4 - Ejemplo de la información que se maneja en el nivel PSM. _SoundGeneratorOperations theExec theContext JSSSoundGeneratorWrapper JSSSoundGeneratorExec JSSSoundGeneratorContext JSSSoundGenerator theImpl SoundGeneratorMng _SoundGener t O ti ccm _SoundGener t O ti multimedia _SoundGener t O ti database JSSSoundGeneratorHomeWrapper
Introducido por el diseñador. Generado automáticamente.
2.3 Desarrollo de una aplicación basada en componentes.
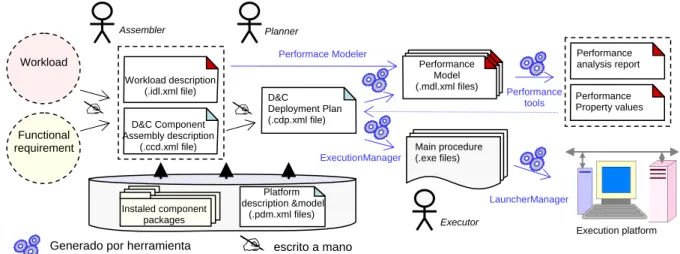
En la figura 2.5 se muestran las fases junto con los actores, las herramientas y los productos que intervienen en el proceso de ensamblado, despliegue y ejecución de una aplicación.
El ensamblador (assembler) construye la aplicación como un conjunto de instancias de componentes interconectadas entre sí de forma que se implemente la funcionalidad requerida en su especificación. Estas instancias han de corresponder a componentes instalados en el entorno de desarrollo y las interconexiones deben satisfacer los requisitos establecidos en el modelo de cada componente. El ensamblador toma las decisiones basándose únicamente en la especificación de los componentes, sin necesidad de elegir en esta fase la implementación concreta del componente que se utiliza. La descripción de la aplicación se formula como la de un componente más (es una aplicación porque es útil de por si), en este caso como un componente compuesto, a través de un fichero
.cad.xml (Component Assembly Description) acorde a la especificación D&C. Si la aplicación tiene
requerimientos no funcionales (por ejemplo, tiempo real) también tiene que modelar la carga de
trabajo (workload) que representa, esto es, declarar las transacciones que se ejecutan en ella, la
frecuencia con que lo hacen y los requisitos temporales que se requieren.
Functional requirement Workload Instaled component packages Platform description &model (.pdm.xml files) D&C Component Assembly description (.ccd.xml file) Workload description (.idl.xml file) D&C Deployment Plan (.cdp.xml file) Main procedure (.exe files) Performance Model (.mdl.xml files)
#
#
Performance Property values Performance analysis report Performance tools Assembler Planner Executor Performace Modeler ExecutionManager LauncherManager Execution platform#
escrito a mano Generado por herramientaFigura 2.5 - Proceso de desarrollo de una aplicación basada en componentes.
La siguiente fase es el despliegue. En ella, el planificador (planner) parte de la descripción de la aplicación y construye el plan de despliegue (deployment plan), en el cual se asigna cada instancia de componente al nudo procesador en que se va a ejecutar, se formulan los valores de las propiedades de configuración de cada una de esas instancias y se asigna el mecanismo de comunicación a utilizar en la interacción entre cada dos instancias. El plan de despliegue se formula mediante un fichero
*.cdl.xml definido en el estándar D&C y constituye de hecho la descripción de la aplicación. En el
plan de despliegue se determina implícitamente (o explícitamente cuando se necesite) la implementación específica del componente que se utiliza en cada instancia de la aplicación. Esta selección se realiza en función del procesador en que se ejecuta, de los otros componentes a los que se conecta y de los valores que se asignan a los parámetros de configuración.
2.4 Especificación D&C sobre el proceso, la información y las herramientas de componentes.
Los objetivos del estándar D&C son unificar las diferentes especificaciones propuestas por los diferentes promotores de tecnologías y plataformas a fin de hacer ínteroperables las herramientas que constituyen los entornos de desarrollo de las aplicaciones distribuidas basadas en componentes y formalizar los procesos y la información que se gestiona en el despliegue de dichas aplicaciones. El despliegue es entendido en esta especificación como el conjunto de tareas a desarrollar entre la adquisición del software elaborado y la ejecución del mismo sobre una plataforma. Esto requiere especificación para las tareas en lo referente a:
Requerimientos de despliegue del software.
Mecanismos de empaquetamiento del software y de su información introspectiva (metadata) para su distribución desde el diseñador hasta el instalador (planner).
Almacenamiento del software en el entorno de desarrollo de las aplicaciones antes de que se tomen las decisiones de despliegue sobre una plataforma determinada.
Describir la topología, los recursos y las capacidades de las plataformas en las que se despliegan las aplicaciones.
Planificar el despliegue de las aplicaciones, esto es, tomar las decisiones de cómo se distribuyen las instancias de los componentes en los nudos y cómo se hace uso de la infraestructura de ejecución.
Preparar los nudos y sus recursos para que puedan alojar el software que deben ejecutar. Lanzar la ejecución de la aplicación, monitorizarla y, en su caso, terminarla.
Hay dos razones por las que se ha seleccionado la especificación D&C:
i. Es neutra respecto a la tecnología de componentes y por ello es más fácil aplicarla a una nueva tecnología que se desarrolla.
ii. Está formulada mediante un metamodelo UML (Unified Modeling Language) que facilita su extensión para incorporar nuevos aspectos de diseño, como la gestión de recursos o el comportamiento temporal.
La adaptación del estándar D&C a una tecnología determinada se realiza a través de un conjunto de plantillas W3C-schema (schemas, en adelante) que definen el contenido y el formato de los documentos XML (Extensible Markup Language) que describen las interfaces, las implementaciones, los paquetes de los componentes, las plataformas distribuidas y la formulación del plan de despliegue que definen las aplicaciones basadas en componentes. En la figura 2.6, se muestran las cinco plantillas que cubren el estándar y las dependencias entre ellas.
DnCBasicTypes.xsd <<W3C Schema>> DnCCommonTypes.xsd <<W3C Schema>> DnCComponentDataModel.xsd <<W3C Schema>> DnCExecutionDataModel.xsd <<W3C Schema>> DnCTargetDataModel.xsd <<W3C Schema>>
Figura 2.6 - Plantillas W3C- schema de la especificación D&C.
Las clases que se definen en la especificación D&C para describir un componente se recogen en el
schema DnCComponentDataModel.xsd y son:
La clase PackageConfiguration describe un paquete de componente como elemento distribuible. Cada paquete contiene una única descripción de la interfaz de un componente y una o múltiples implementaciones del mismo.
La clase ComponentInterfaceDescription describe la citada interfaz del componente, la cual
a su vez describe su funcionalidad desde un punto de vista externo. Dos componentes que ofrezcan una misma interfaz, son mutuamente sustituibles entre sí en cualquier aplicación. La interfaz describe las operaciones, atributos, puertos y parámetros de configuración, que, en conjunto, proporcionan al diseñador la información necesaria para determinar su funcionalidad y la forma de uso.
La implementación de un componente puede ser monolítica, esto es, constituida por un conjunto de módulos de código (artifact) y por tanto independiente de otros componentes o puede estar recursivamente implementada como una agrupación plana de instancias de subcomponentes interconectados con una determinada topología, en cuyo caso la descripción del componente se formula con referencia a la descripción de sus subcomponentes. Las implementaciones monolíticas se describen mediante una clase MonolithicImplementationDescription y las implementaciones compuestas se describen mediante una clase
ComponentAssemblyDescription.
El modelo de datos de una plataforma contiene la información para desplegar sobre ella cualquier aplicación y está compuesto por un conjunto de nudos interconectados por redes de comunicación, pudiendo haber puentes entre las redes. Las clases que se definen en la especificación D&C para describir una plataforma se recogen en el schema DnCPlatformDataModel.xsd y son:
Interconnect: Describe los canales de comunicación entre nudos.
Bridge: Representa los switches o routers que interconectan los canales de comunicación y
permiten complejas capacidades de comunicación entre nudos.
Resource: Los recursos pueden estar asociados a los nudos, a los canales de comunicación o a
los puentes y representan elementos que están agregados a ellos y que proporcionan las capacidades que pueden ser requeridas por los componentes para poder instalarse en ellos.
SharedResource: Representa recursos que por su naturaleza son compartidos por diferentes
nudos de la plataforma. Al no estar directamente agregados a ningún elemento se consideran agregados al dominio.
Una aplicación basada en componentes se describe estableciendo las instancias de los componentes que la constituyen, asignando a cada una de ellas el nudo de la plataforma en que debe instanciarse y valores a sus propiedades de configuración, así como definiendo y calificando las conexiones entre los componentes. Toda esta información se reúne en un documento que denominamos plan de
despliegue. Las clases que se definen en la especificación D&C para describir un plan de despliegue
se recogen en el schema DnCExecutionDataModel.xsd y son:
Deployment Plan: representa el despliegue de una aplicación sobre una determinada
plataforma. Contiene la información relativa a los ficheros de código que son parte del despliegue (ArtifactDeploymentDescription), la forma de crear las instancias de los
componentes (MonolithicDeploymentDescription), y donde se han de instanciar
(InstanteDeploymentDescription). Contiene también información relativa a la conexión
entre los subcomponentes (AssemblyConnectionDescription) y a la correspondencia entre los
puertos externos y los de los subcomponentes. Por último, contiene la descripción de la interfaz que es implementada por la aplicación que se despliega (ComponentInterfaceDescriptor),
esto es, la descripción de su comportamiento visto desde fuera.
ImplementationDependency: formula una dependencia de la implementación de un
componente respecto del entorno de la plataforma e indica qué otras instancias de componentes o servicios deben estar instaladas en la plataforma antes de que la implementación sea desplegada.
PlanPropertyMapping: identifica la correspondencia entre una propiedad o puerto de la
aplicación que se despliega y la propiedad o puerto del subcomponente en el que delega.
ArtifactDeploymentDescription: Describe un fichero relativo a la información de un
componente que debe ser desplegado como parte del plan de despliegue de la aplicación. Contiene el localizador (URL) del fichero y los parámetros y requisitos de despliegue de cada componente, lo que hace autocontenido el plan de despliegue
(ImplementationArtifactDescription).
MonolithicDeploymentDescription: Describe el despliegue de un componente como parte de
un plan. Referencia la descripción de los elementos que son parte del despliegue
(ComponentImplementacionDescription)
PlanConnectionDescription: Describe una conexión que se establece entre puertos de los
componentes que constituyen la aplicación.
InstanceDeploymentDescription: Contiene la información que es necesaria para desplegar
una instancia de componente simple. Hace referencia a una descripción de un componente monolítico (MonolithicDeploymentDescription) e incluye el nombre de los nodos en los que
es instanciado el componente. Además, contiene propiedades que son usadas para configurar la instancia del componente.
2.5 Especificación de herramientas.
El diseño y ejecución de una aplicación basada en componentes son procesos que se realizan en el entorno de desarrollo y son asistidos por herramientas que garantizan la validez “por construcción” de los artefactos que se generan. Como veremos en el tercer capítulo, el entorno de desarrollo de la tecnología CCM se ha basado en Eclipse [13], el cual proporciona un conjunto de frameworks y servicios que simplifican la gestión de los recursos y el desarrollo de las herramientas.
Existen dos elementos básicos que constituyen el entorno de desarrollo: el repositorio y las
herramientas. El repositorio es una base de datos que está construida sobre el workspace de Eclipse y
en ella se almacenan los productos que se introducen y los productos intermedios y finales que generan las herramientas. En la sección 3.7 entraremos a describir en detalle la estructura y características del repositorio que se ha diseñado. En cuanto a las herramientas que requiere el entorno son múltiples y de muy diferente naturaleza. En la siguiente lista se enumeran, ordenadas de acuerdo con la fase del proceso de desarrollo en que se utilizan, aquellas que se han concebido, algunas ya desarrolladas (aparecen subrayadas y se presentarán en mayor profundidad en la sección 4.5.1) y otras pendientes de serlo. Veámoslas:
Herramientas de gestión del repositorio: tienen el objetivo de construir, mantener la coherencia y tanto introducir como extraer información de las diferentes secciones del repositorio.
Inicializador del repositorio: Reestructura el workspace de Eclipse en el que se invoca como un nuevo repositorio con la estructura y la información común apropiadas a la tecnología de componentes correspondiente.
Importador de interfaces: Introduce en el repositorio la información asociada a la interfaz que se importa, la cual viene definida por un fichero formulado en un lenguaje de especificación de interfaces, como IDL o SLICE. Comprueba que existe la información referenciada, necesaria para que pueda ser utilizada en el diseño de un componente.
Exportador de interfaces: Retorna el fichero con la información que se necesita para transferir la interfaz a otro entorno. Una interfaz se exporta como un fichero *.zip que empaqueta su
descripción formal (IDL o SLICE) así como la descripción de las interfaces que referencia, necesarias para su uso en el diseño de un componente.
Importador de plataforma: Introduce en el repositorio la información asociada a la descripción de una determinada plataforma de ejecución, información en la que se incluyen los ficheros D&C que describen la estructura y los recursos de la plataforma y, opcionalmente, los ficheros que describen su comportamiento de tiempo real. La estructura y la interfaz de una plataforma se describen mediante un fichero *.tdm soportado por el schema
DnCTargetDataModel.xsd y el fichero que describe su modelo de tiempo real es de extensión
*.rtp y respaldado por el schema rtmContainers.xsd. Para la herramienta, la descripción de
la plataforma viene dada en archivos con extensión *.zip.
Exportador de plataforma: Retorna el archivo *.zip con la descripción completa de la
plataforma requerida para ser incorporada a otro entorno de desarrollo.
Traductores entre IDL y XML y entre SLICE y XML: Transforman el formato de ficheros de descripción de interfaces entre los formatos estandarizados *.idl o *.ice y los formatos
Herramientas de diseño de los componentes:
Importador de componente: Introduce en el repositorio partes de la información relativa a un componente, las cuales vienen definidas por diferentes ficheros que describen su especificación, sus interfaces, sus implementaciones, su código y los correspondientes modelos no funcionales, todo ello empaquetado en un archivo *.zip. Además, comprueba que la información
referenciada está disponible en el repositorio.
Exportador de componente: Retorna el archivo con la descripción completa existente en el repositorio del componente que se referencia.
Generador de la interfaz de gestión de un componente: Procesa la información referente a la especificación de un componente y, de acuerdo con ella, genera el código de las interfaces que deben ser implementadas por el código de negocio del componente.
Generadores del contenedor de un componente: Conjunto de herramientas parciales que generan el código del contenedor que adapta el código de negocio de un componente a la plataforma, de acuerdo con la descripción del componente y la implementación que se elija. o Generador de la clase con la que se implementa el caso de receptáculo múltiple (receptáculo
con múltiples conexiones).
o Generador de la clase ejecutor (executor) de un componente. o Generador de la clase contexto (context) de un componente.
o Generador del contenedor propiamente dicho (wrapper) del componente. o Generador del código del constructor (home) del componente.
Empaquetador de un componente: Genera el paquete de información (metadata, código, modelos, etc.) que constituye al componente como elemento distribuible. En él se incluye toda la información necesaria para que el componente pueda ser incorporado al entorno de desarrollo de aplicaciones.
Herramientas de desarrollo de las aplicaciones:
Instalador de un componente: Instala en el entorno de desarrollo de aplicaciones el paquete con el que se distribuye un componente, verifica que están instalados en el entorno los elementos referenciados en él y genera los elementos derivados de él que se requieren para su utilización dentro de dicho entorno.
Importador de aplicaciones: Introduce en el repositorio la información asociada a la aplicación que se importa, en forma de conjunto de ficheros que describen las diferentes partes de la aplicación (implementaciones, códigos y modelos no funcionales), todo ello empaquetado en un archivo *.zip.
Exportador de aplicaciones: Crea y retorna un archivo *.zip que contiene la información de la
aplicación disponible en el entorno para que pueda ser transferida a otro entorno.
Generador de aplicaciones: Genera la información que se necesita para ejecutar una aplicación. Tiene como entrada el plan de despliegue de la aplicación y todos los elementos del repositorio referenciados en él. Genera como salida el conjunto de particiones de código dispuestas para ser ejecutadas en los nudos de la plataforma de ejecución.
Herramientas de gestión de los modelos no funcionales:
Generador de modelos: Genera el modelo de comportamiento no funcional de una aplicación por composición de los modelos de comportamiento de los componentes que la conforman. Utiliza como entrada el plan de despliegue que describe la aplicación y todos los elementos del repositorio referenciados en él y genera como salida el modelo no funcional, formulado en un formato compatible con el entorno de análisis no funcional que se utilice.
Configurador del plan de despliegue: Incorpora al plan de despliegue los parámetros de configuración generados en el análisis no funcional de la aplicación.
Herramientas de despliegue y lanzamiento:
Lanzador de aplicaciones: Transfiere a los nudos de la plataforma de ejecución las particiones de código que constituyen la aplicación y ordena su ejecución.
El entorno Eclipse está muy bien dotado de editores especializados y por ello no se han desarrollado herramientas específicas para que el operador introduzca el código fuente o los ficheros XML de la especificación D&C. En el futuro desarrollaremos interfaces de usuario que asistan en la elaboración de los ficheros de descripción y modelado. Actualmente al disponer de las plantillas W3C-Schema que definen el formato y el contenido de estos documentos resulta fácil la introducción de esta información utilizando editores inteligentes que se guían por ellos.
3. EL
ENTORNO
ECLIPSE.
3.1 Introducción a Eclipse: historia y breve descripción.
La primera versión de Eclipse apareció en Noviembre de 2001, anunciada por IBM como una donación de 40.000.000$ a la comunidad de Código Abierto. Desde entonces, Eclipse se ha apoderado del mundo Java (y no sólo del mundo Java) a pesar del hecho de que Sun Microsystems todavía no se ha involucrado. En la actualidad Eclipse está completamente gestionado por eclipse.org, una organización independiente sin ánimo de lucro en la que, a pesar de todo, IBM juega un papel fundamental. Junto a ella, participan más de 150 compañías, como Ericsson, HP, Intel, etc. Pero no Microsoft.
Al tratar de describir Eclipse podríamos contestar que una GUI para aplicaciones Java o un IDE (Integrated Development Environment) de ese lenguaje, pero, según eclipse.org, Eclipse es una plataforma “para todo y para nada en particular”. Que se pueda utilizar Eclipse para desarrollar programas Java (desde luego que es uno de los más completos IDEs para Java) es únicamente una aplicación más de esta plataforma. Realmente, gracias a su arquitectura modular, Eclipse es altamente adaptable a muchos paradigmas de trabajo. De hecho, el IDE de Java no es más que un ejemplo de complemento (plug-in, en adelante) para Eclipse y un gran número de ellos han sido desarrollados por numerosas compañías y desarrolladores, como por ejemplo plug-ins para UML, para C++, etc.
Eclipse es más que un entorno de desarrollo. Con sus bibliotecas gráficas SWT (Standard Widget Toolkit) y JFace proporciona una alternativa a las bibliotecas AWT (Abstract Window Toolkit) y Swing de Sun, permitiendo la creación de aplicaciones Java que se aproximan más a las aplicaciones nativas tanto en los formatos de apariencia (look&feel) como en el grado de respuesta.
Finalmente, Eclipse proporciona un amplio marco de referencia para implementar aplicaciones Java. Además de las bibliotecas SWT y JFace encontramos componentes de nivel superior, como editores, vistas, gestores de recursos, de tareas y de problemas, un sistema de ayuda y varios asistentes. Eclipse utiliza todos ellos para implementar elementos como el IDE de Java o el área de trabajo (workbench, en adelante), pero también pueden ser usados en nuestras propias aplicaciones pues el modelo de licencia de Eclipse permite a los usuarios embeber estos componentes en sus propias aplicaciones, modificarlos y distribuirlos como parte de ellas.
Básicamente, Eclipse no es más que la base de la infraestructura de la Comunidad del WSAD (WebSphere Studio Application Developer) que ha sido promovida por IBM para promocionar la generación de productos de software libre. El núcleo es el mismo, siendo la principal diferencia que Eclipse, en su edición 3.0, consta de unos 90 plug-ins mientras que WSAD de unos 600.
3.2 El workbench de Eclipse.
Los distintos componentes del workbench de Eclipse son los editores, las vistas y las perspectivas. Una perspectiva es una combinación y disposición de ventanas y herramientas orientadas a tareas concretas, de forma que una aplicación puede definir la disposición (layout) inicial de una página especificando una perspectiva. La plataforma Eclipse proporciona algunas predefinidas como la de Java, la de desarrollo de plug-ins o la de depuración y, naturalmente, las aplicaciones son libres de definir sus propias perspectivas. Así pues, un plug-in puede, sin ser obligatorio, añadir una o varias perspectivas al workbench. Además de los editores, cuya descripción creemos innecesaria, las vistas son el otro elemento fundamental de la ventana de trabajo de Eclipse. Cada perspectiva muestra inicialmente unas vistas determinadas dispuestas de forma concreta. Ejemplos de vistas son el
Explorador de Paquetes y el Navegador de Recursos, a las que nos referiremos en la sección
3.4.4, así como las vistas de Problemas, de Tareas, etc. Una de las vistas más útiles para el desarrollo de programas es la vista Outline. Esta vista soporta navegación por dentro de un fichero de código
fuente. Para Java, la vista muestra entradas para campos y métodos así como sentencias import y clases internas. Diversas vistas Editor de Java Vista Package Explorer Vista Outline Perspectiva Java en uso
Figura 3.1 – El workbench de Eclipse. 3.3 Arquitectura de la plataforma Eclipse.
3.3.1. Plug-ins y puntos de extensión.
La arquitectura basada en plug-ins es uno de los puntos fuertes de la plataforma Eclipse. Ésta tiene un pequeño núcleo cuyo propósito es la ejecución de los plug-ins que se instalan sobre él. Cualquier otra funcionalidad de Eclipse es proporcionada por ellos. De hecho, el propio núcleo también es formalmente un plug-in, constituyendo, junto con los plug-ins de compatiblidad y de lanzamiento, el mínimo conjunto de plug-ins requeridos por cualquier aplicación basada en Eclipse. Adicionalmente, el núcleo contiene algunas interfaces y clases de interés general, como la clase Platform, que gestiona todos los complementos instalados, la clase Plugin y la clase Preferences, que implementa una forma persistente de almacenar preferencias.
Esta arquitectura tiene la consecuencia de que Eclipse puede extenderse prácticamente de manera ilimitada desarrollando plug-ins y haciendo uso de la funcionalidad de los plug-ins ya existentes a través de los puntos de extensión que ofertan. Éstos juegan un papel crucial en la arquitectura basada en plug-ins. La idea central de construcción de un entorno en Eclipse es que un plug-in puede constituir una nueva extensión apoyándose en los puntos de extensión ofrecidos por otros plug-ins
componentes, es más, es aquí donde un plug-in describe a qué puntos de extensión se conecta y qué puntos de extensión añade a la plataforma.
3.3.2. Algunos Plug-ins.
Existen varios plug-ins disponibles para la implementación de GUIs. Estos incluyen SWT y JFace, pero también componentes de nivel superior como vistas, editores de texto y formularios, recogidos en los paquetes de la familia org.eclipse.ui. El workbench de Eclipse está implementado con la ayuda de estos plug-ins y podemos utilizarlos en nuestras propias aplicaciones sin dificultades en temas de licencias, pues todos ellos están cubiertos por la Common Public License 1.0.
También cabe mencionar la familia de plug-ins org.eclipse.help, que implementan un completo sistema de ayuda para el usuario final o la familia org.eclipse.team, que soportan el desarrollo de software en equipo.
3.3.3. Desarrollo de complementos.
Al crear plug-ins las cosas son bastante diferentes que en la creación de aplicaciones Java independientes, pues hemos de definir cómo se integra el plug-in en el workbench de Eclipse. Para soportar este proceso de desarrollo, Eclipse proporciona una perspectiva especial, la de desarrollo de plug-ins, que tiene como función especial el asistente para la creación de nuevos proyectos de desarrollo de plug-ins. Para crear uno nuevo hay varias plantillas disponibles y todas ellas resultan en plug-ins que pueden ser inmediatamente ejecutados y testeados. Una vez finalicemos de utilizar el asistente, éste crea los ficheros y la estructura de carpetas inicial del plug-in.
3.4 Gestión de recursos y entorno de programación. 3.4.1. Jerarquía de recursos del workspace de Eclipse.
Eclipse distingue tres tipos básicos de recursos en un workspace: los proyectos, las carpetas y los ficheros.
a. Proyecto: es un nudo raíz de un árbol de recursos. Los proyectos son estructuras que contienen todos los recursos de un producto software y pueden controlar cómo éste es ensamblado a partir de sus componentes. Los proyectos no se pueden anidar, aunque pueden referirse a otros proyectos prerrequeridos y contener ficheros y carpetas, actuando como directorio raíz para ellos. Los proyectos pueden estar equipados con una o varias naturalezas. Cada naturaleza describe un aspecto conductual específico del proyecto.
b. Carpeta: puede contener ficheros y subcarpetas anidadas.
c. Fichero: nudo hoja en un árbol de recursos. Así pues, un fichero no puede contener otros recursos.
Figura 3.2 – Jerarquía de recursos del workspace 3.4.2. Almacenamiento de los recursos.
En Eclipse todos los recursos se almacenan directamente en el sistema de ficheros del procesador en que se ejecuta (host) y, por tanto, la estructura de recursos en el workspace de Eclipse se correlaciona directamente con la estructura del sistema de ficheros del host, mapeándose los recursos directamente sobre los correspondientes elementos: proyectos y carpetas sobre directorios y ficheros sobre ficheros. Así pues, como cada recurso en el workspace se corresponde con un recurso en el sistema de ficheros anfitrión, cada uno tiene dos direcciones: la dirección dentro del workspace y la localización en el sistema de ficheros del host. La ventaja es que se puede acceder a los recursos aun cuando Eclipse no esté instalado o no esté funcional.
Por defecto, los recursos en Eclipse son almacenados en el directorio del workspace (representada su ruta por ../ ), el cual, también por defecto, es eclipse/workspace (naturalmente, es posible crear
un directorio para el workspace en una localización diferente) y cada proyecto está contenido en un subdirectorio tal que ../nombreSubdirectorio.
3.4.3. Sincronización de recursos.
Por cada recurso, Eclipse almacena una información reflectiva (metadata) en el directorio
../.metadata. A veces ocurre que el estado de un recurso no coincide con el estado de los metadatos
correspondientes (en particular esto sucede cuando un fichero del workspace es modificado fuera de Eclipse). En estos casos, para sincronizar de nuevo los recursos hay que aplicar la función de sincronización Refresh, función que puede ser aplicada también a carpetas y proyectos, con lo que podemos fácilmente resincronizar un árbol completo.
3.4.4. Navegación.
En el workbench de Eclipse, las dos vistas adecuadas a la navegación por los recursos son la vista
Navegador de Recursos y el Explorador de Paquetes. La primera muestra los diferentes
proyectos con su estructura de carpetas y ficheros dispuestos jerárquicamente en forma de árbol, de forma análoga al sistema de ficheros del host y nos permite navegar en la forma usual a través de ella. La segunda está contenida por defecto en la perspectiva Java y muestra los diferentes proyectos con su estructura de paquetes y las unidades de compilación. Los paquetes no son recursos reales sino virtuales y la estructura de paquetes de un proyecto se deriva de la declaración de paquete al comienzo de cada fichero Java. Las unidades de compilación pueden constar de varios recursos: el fichero fuente y uno o varios ficheros binarios (varios en el caso de haber clases internas o anidadas).
3.5 Las bibliotecas SWT y JFace. 3.5.1. Introducción.
Eclipse no sólo posee un excelente entorno de desarrollo de Java, sino que también ofrece las librerías SWT y JFace que proporcionan recursos para implementar GUIs muy avanzadas, pudiendo sustituir con ventaja a las librerías AWT y Swing. La librería SWT implementa una interfaz independiente de la plataforma adaptada en cada caso al procesador en el que se encuentra instalado Eclipse, y sus clases simplemente delegan en las funciones de este sistema de ventanas nativo (host WS, en adelante). La principal ventaja de SWT es la integración de una aplicación basada en SWT con el host, con lo que tanto el look&feel como el grado de respuesta de aplicaciones SWT no son diferentes de los de aplicaciones nativas. Así pues, las aplicaciones basadas en SWT adoptan la apariencia del OS en el que se ejecutan y son indistinguibles de las interfaces de usuario de aplicaciones nativas. En cuanto a desventajas, SWT requiere gestión explícita de recursos porque utiliza recursos del host WS para las imágenes, los colores y las fuentes, recursos que deben ser liberados cuando ya no son necesarios. Finalmente, apuntar que, como la plataforma Eclipse está completamente implementada sobre la base de SWT, SWT debería ser nuestra primera elección cuando implementemos plug-ins para Eclipse.