Implementación de la versión 3 0 de la herramienta UCShell
62
0
0
Texto completo
(2) El que suscribe: Humberto López León, hago constar que el trabajo titulado “Implementación de la versión 3.0 de la herramienta. UCShell”, fue. realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la universidad.. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del tutor. Firma del jefe del Laboratorio. Fecha.
(3) Dedicatoria.
(4) Agradecimientos.
(5) Resumen UCShell es un ambiente integrado para el desarrollo y puesta a punto de Sistemas Expertos. Se han implementado diferentes versiones del sistema que han incorporado nuevas funcionalidades y facilitan la interacción usuario-sistema. En este trabajo se presenta la versión 3.0 de UCShell que perfecciona las funcionalidades de la versión anterior (2.1) e incorpora otras que son útiles para la edición y puesta a punto de las bases de conocimiento. La nueva versión agrega facilidades para insertar las sentencias principales del lenguaje y permite visualizar, de forma amena, el recorrido que hace la máquina de inferencia por las reglas de sus bases de conocimiento. UCShell 3.0 se implementó según los aspectos fundamentales del patrón de arquitectura MVC, lo cual posibilita el estudio del sistema por dentro y facilita su mantenimiento..
(6) Abstract. UCShell is an integrated development and fine tuning environment for expert systems. We have implemented different versions of the system that have incorporated new functionality and ease the user-system interaction. In this thesis UCShell version 3.0 is presented. It improves the functionality of the previous version (2.1) and adds others that are useful for editing and fine tuning of knowledge bases. The new version adds facilities to insert the key sentences of the language and displays, in an entertaining manner, the travel making of the inference machine by rules of their knowledge bases. UCShell 3.0 was implemented according to the fundamental aspects of the MVC architectural pattern, which allows the study of the system on the inside and facilitates maintenance..
(7) Tabla de contenidos INTRODUCCIÓN...................................................................................................................... 1 CAPÍTULO I. AMBIENTES DE DESARROLLO PARA SISTEMAS EXPERTOS. PROCESOS DE INFERENCIA............................................................................................................................ 4 I.1.. Las Máquinas de Inferencia ................................................................................ 4. I.1.1.. Mecanismos de inferencia ............................................................................. 5. I.1.2.. Aplicaciones de las máquinas de inferencia .................................................. 7. I.2.. UCShell como máquina de inferencia ................................................................. 9. I.3.. Los Patrones arquitectónicos.............................................................................. 11. I.3.1.. Descripción de la arquitectura MVC ............................................................ 12. I.3.2.. Beneficios de usar el patrón MVC ................................................................ 15. I.3.3.. Variantes del patrón MVC ............................................................................ 15. I.3.4.. Implementación del patrón MVC con el API de Java ................................... 16. I.4.. Análisis de la arquitectura de UCShell 2.1 ........................................................ 17. I.5.. Conclusiones del capítulo ................................................................................... 18. CAPÍTULO II. REDISEÑO DEL SISTEMA UCSHELL.................................................................. 19 II.1.. El proceso de diseño en la Ingeniería de Software. ........................................... 19. II.1.1.. Descomposición del diseño de software. .................................................... 19. II.1.2.. Métricas para el control de la calidad de un software. ............................... 20. II.1.3.. Diseño procedimental en UCShell 2.1.......................................................... 20. II.1.4.. Diseño de la arquitectura de UCShell 2.1. ................................................... 21. II.1.5.. Inconvenientes en el diseño de la clase Window. ....................................... 24. II.2.. El patrón de arquitectura MVC y el sistema UCShell. ...................................... 25. II.3.. Análisis y solución de las deficiencias funcionales en UCShell 2.1. ................ 28. II.3.1.. Fallas en el manejo de excepciones. ............................................................ 28. II.3.2.. Comportamiento inadecuado en la compilación de archivos. .................... 30. II.3.3.. Comportamiento inadecuado en la gestión de los proyectos. .................... 33.
(8) Tabla de contenidos II.3.4. II.4.. Falla del sistema al detener y reiniciar la inferencia paso a paso. ............... 38. Conclusiones del capítulo. .................................................................................. 39. CAPÍTULO III. VERSIÓN 3.0 DE UCSHELL .............................................................................. 40 III.1. Bondades de la versión 3.0 de UCShell. ............................................................. 40 III.1.1.. Ventajas del nuevo diseño de UCShell. ........................................................ 40. III.1.2.. Subsanación de errores en UCShell 3.0. ...................................................... 41. III.1.3.. Nuevas funcionalidades ............................................................................... 42. III.1.3.1.. Menú generador de sentencias. .............................................................. 42. III.1.3.2.. Visualización de la inferencia en UCShell 3.0........................................... 47. III.2. Usos de UCShell 3.0 en el proceso de enseñanza-aprendizaje. ......................... 49 III.2.1.. UCShell en el estudio de la IA ...................................................................... 49. III.2.2.. UCShell en el estudio de los Compiladores.................................................. 50. III.3. Conclusiones del capítulo ................................................................................... 50 CONCLUSIONES GENERALES ................................................................................................ 51 RECOMENDACIONES ............................................................................................................ 52 REFERENCIAS........................................................................................................................ 53.
(9) Introducción INTRODUCCIÓN En los años 80 y 90 del siglo pasado, los Sistemas Expertos (SE) fueron motivo de interés dentro de la Inteligencia Artificial (IA). Se pueden citar como ejemplos de implementaciones exitosas a DENDRAL, dedicado al estudio de los compuestos químicos y su estructura global (Feigenbaum and Buchanan, 1993), MYCIN, cuya funcionalidad estaba orientada al diagnóstico de enfermedades infecciosas en la sangre (Shortliffe, 2012), PLANT/DS, utilizado para el diagnóstico de enfermedades y daños producidos por insectos en soya (Michalski et al., 1982), entre otros. A pesar de que en la actualidad los SE no son un tema novedoso, continúan teniendo un amplio perfil de aplicación en esferas tan disímiles como: la medicina, los procesos industriales, la educación y otras áreas del conocimiento en general. Estos sistemas son capaces de simular, de forma correcta, el razonamiento humano en un dominio restringido del conocimiento. En la realización de un SE actúan dos entes humanos: el o los expertos y el ingeniero de conocimiento. El ingeniero de conocimiento es el responsable de extraer del o los expertos el conocimiento para después plasmarlo en el SE en alguna Forma de Representación del Conocimiento (FRC). El saber de cualquier SE se almacena en una Base de Conocimiento (BC), en alguna de las FRC. Esa información de la BC se traduce, generalmente, por el sistema a alguna forma interna que debe interpretar una máquina de inferencia, la cual es un módulo de la aplicación que contiene los mecanismos necesarios para ejecutar el proceso de inferencia y arribar a conclusiones adecuadas respecto a un problema determinado. El laboratorio de Informática Educativa, perteneciente al Centro de Estudios Informáticos (CEI) de la UCLV, tiene una vasta experiencia en el desarrollo de herramientas para la implementación y puesta a punto de SE. Evidencia de esto es la máquina de inferencia UCShell, de la cual se desprenden un conjunto de versiones diferentes en busca de su mejor funcionamiento. La versión UCShell 1.0. 1.
(10) Introducción fue implementada en el lenguaje Borland Pascal sobre el Sistema Operativo MSDOS, mientras que para el Sistema Operativo Windows fue implementada en el lenguaje Object Pascal una segunda versión conocida como WUCShell. En busca de una aplicación multiplataforma y con mejoras en el proceso de inferencia, se desarrolló la versión UCShell 2.0 en el lenguaje Java. Esta versión provee a los usuarios de un Ambiente de Desarrollo Integrado (ADI o IDE) que facilita la edición de las BC, para lo cual se auxilia de la biblioteca UCShell Library 2.0 que contiene los mecanismos de inferencia y de compilación (Fernández, 2011). Posteriormente fue implementada la versión 2.1 de UCShell que hereda las funcionalidades de la versión anterior y presenta mejoras en la interfaz visual. Además incorpora al sistema mecanismos útiles para la puesta a punto de las BC y una ayuda para que los ingenieros del conocimiento puedan consultar de forma interactiva (Acosta, 2012). UCShell 2.1 es un software profesional que ha sido usado, con éxito, en las empresas y en el proceso de enseñanza-aprendizaje. Su uso en la práctica ha hecho aflorar algunas deficiencias que deben resolverse, algunas de ellas tienen que ver con el funcionamiento en sí y otras se relacionan con el diseño. Basado en la afirmación hecha en el párrafo anterior, la presente investigación se traza los objetivos que seguidamente se enuncian. Objetivo General Implementar una nueva versión de UCShell que solvente los problemas funcionales y de diseño que se han detectado en la versión actual. Objetivos Específicos 1. Evaluar los beneficios y perjuicios de diseñar e implementar UCShell según el patrón arquitectónico Modelo-Vista-Controlador (MVC). 2. Reestructurar y editar el código fuente de la versión 2.1 de UCShell de tal forma que facilite su mantenimiento. 3. Aplicar el MVC si se demuestra su factibilidad.. 2.
(11) Introducción 4. Resolver los problemas encontrados en el sistema. 5. Incorporar nuevas funcionalidades al sistema que resuelvan las posibles falencias que se detecten durante el transcurso de la investigación. Preguntas de Investigación 1. ¿Qué elementos debe caracterizar a una aplicación, de este tipo, que se desarrolle según el patrón MVC? 2. ¿Qué transformaciones del diseño de la versión 2.1 de UCShell, se hacen necesarias para facilitar su mantenimiento y estudio? 3. ¿Cuáles son los problemas detectados en el sistema? 4. ¿Qué nuevas funcionalidades deberán incorporarse? Justificación UCShell es una herramienta profesional de usos docente, investigativo y de aplicación. Algunas de las asignaturas de la disciplina Inteligencia Artificial la incorporan como medio de enseñanza y como objeto de estudio en los cursos de pregrado y postgrado, no obstante también se puede utilizar para el desarrollo de Sistemas Basados en el Conocimiento, los cuales pueden ser fuente fiable de apoyo al trabajo de especialistas en disímiles áreas del saber.. 3.
(12) Capítulo I. CAPÍTULO I. AMBIENTES DE DESARROLLO PARA SISTEMAS EXPERTOS. PROCESOS DE INFERENCIA. La Inteligencia Artificial (IA) es una rama de la Ciencia de la Computación, que se basa en la observación de los mecanismos humanos para simular, de alguna forma, su comportamiento y resolver variados problemas que no son solubles por las vías convencionales o en los cuales la solución convencional se complejiza demasiado. Entre las diferentes técnicas de la IA, cabe señalar las siguientes: los Algoritmos Genéticos (AG), las Redes Neuronales Artificiales (RNA) y los Sistemas Expertos (SE). Los SE son programas que resuelven problemas de un dominio de aplicación concreto de manera similar a como lo haría un experto humano en esa materia. Un SE debe ser capaz de explicar sus conclusiones y el razonamiento subyacente (Bratko, 1990). Para el desempeño de sus funciones, los SE, hacen uso de una o varias Bases de Conocimiento (BC) que son interpretadas por una Máquina de Inferencia (MI), la cual contiene los mecanismos de inferencia e interactúa con el usuario, en forma similar a como lo hace un experto humano. Las BC contienen, en alguna de las Formas de Representación del Conocimiento (FRC) existentes, los hechos y reglas necesarias para caracterizar y dar solución al problema que se pretende resolver. Entre las distintas FRC se pueden citar las siguientes: scripts, redes semánticas, frames y las Reglas de Producción (RP). Esta última FRC es una las más populares y es la que ha usado UCShell desde su origen. Antes de poder formalizar el conocimiento plasmado en una BC, es necesario extraerlo de dos fuentes posibles: pública o privada. El conocimiento público lo aporta la literatura y por eso ya está formalizado, mientras el privado lo atesoran los expertos en la materia y es necesario extraerlo usando diversas técnicas, por ejemplo las entrevistas a los expertos.. I.1. Las Máquinas de Inferencia Una MI es un intérprete genérico que implementa los métodos necesarios para manipular la BC, en función de obtener un razonamiento adecuado respecto al problema 4.
(13) Capítulo I. en cuestión. A través del proceso de inferencia se obtiene información o se establecen conclusiones lógicas que no están expresadas de forma explícita en el conocimiento representado (Bello, 2002). Para ello se hace uso de una base de datos o memoria de trabajo donde se almacenan los conocimientos previos (hechos iniciales) y las conclusiones parciales basadas en las reglas que se han ido probando.. I.1.1. Mecanismos de inferencia Los mecanismos de inferencia no son más que métodos de búsqueda que realizan una exploración dentro de un espacio de búsqueda. Para el caso de los SE, el espacio de búsqueda está formado por la BC y la memoria de trabajo, posiblemente representado en alguna forma interna que genera el compilador del sistema y la MI durante el proceso de compilación. Los métodos de búsqueda pueden hacer la exploración del espacio de búsqueda en dos direcciones: con encadenamiento hacia atrás (backward chaining) también conocido como dirigido por objetivos y con encadenamiento hacia adelante (forward chaining) o dirigido por datos. Dirección de búsqueda dirigida por objetivos La dirección de búsqueda dirigida por objetivos, como su nombre lo indica, parte de un objetivo inicial que se busca en la conclusión de una regla, para después intentar probar sus condiciones, de ahí que también se denomine encadenamiento hacia atrás ya que parte de la conclusión final e intenta probar las premisas que deben cumplirse para que eso ocurra. Lezcano establece (Lezcano et al., 2000) el proceso general que debe seguir una MI para responder una solicitud P cuando se usa la dirección de búsqueda con encadenamiento hacia atrás. Ese proceso, modificado para el caso específico cuando se usa la FRC conocida como reglas de producción, es en general el siguiente: Paso1: Determinar si P es un hecho, una pregunta o la conclusión de una regla.. 5.
(14) Capítulo I. . Si es un hecho, concluye que P es verdadero (deberá estar en la memoria de trabajo: porque estaba como tal cuando se cargó la BC o porque se probó durante un proceso de inferencia previo a la prueba actual).. . Si es una pregunta, se interroga al usuario acerca de P y se concluye que el valor introducido es el valor de P (pasa a la memoria de trabajo como un hecho).. Paso 2: Si no se ha podido probar P en el paso 1, es porque forma parte de la conclusión de alguna (o algunas) regla, por tanto, se necesita obtener el conjunto de reglas R que tienen a P como conclusión y que aún no se han probado totalmente. Si R está vacío, no es posible probar P. Paso 3: Emplear una estrategia de control para seleccionar una regla Ri del conjunto R, lo cual introduce un orden de selección. Paso 4: Probar las condiciones de la regla Ri para lo cual se regresa al paso 1 tomando a cada una de las premisas como el objetivo Pa actual. Si todas las premisas se cumplen P queda probado, se aplica la acción consecuente de Ri y P pasa como un hecho a la memoria de trabajo. Dirección de búsqueda dirigida por datos La dirección de búsqueda dirigida por datos, como lo indica su nombre, toma como referente los hechos conocidos, para introducir en la memoria de trabajo las conclusiones de las reglas cuyos antecedentes se satisfagan con los hechos ya probados, de ahí que también se denomine encadenamiento hacia delante. Las MI que utilizan la dirección de búsqueda dirigida por datos, dan comienzo al proceso de inferencia con la actualización de la memoria de trabajo, al cargar los valores que el usuario fija a algunos atributos iniciales (hechos explícitos en la BC). Partiendo de este estado inicial, la búsqueda de la solución para una solicitud P según el encadenamiento hacia adelante, por lo general sigue los siguientes pasos: Paso 1: Determinar si P es un hecho o una pregunta.. 6.
(15) Capítulo I. . Si es un hecho, concluye que P es verdadero (deberá estar en la memoria de trabajo: porque estaba como tal cuando se cargó la BC o porque se probó durante un proceso de inferencia previo a la prueba actual).. . Si es una pregunta, se interroga al usuario acerca de P y se concluye que el valor introducido es el valor de P (pasa a la memoria de trabajo como un hecho).. Paso 2: Si no se ha podido probar P en el paso 1, es necesario modificar el estado actual de la memoria de trabajo (mientras sea posible) hasta satisfacer la solicitud P (se encuentre en la memoria de trabajo). Obtener el conjunto de reglas aplicables R (una regla es aplicable si sus condiciones son satisfechas con el estado actual de la memoria de trabajo). Paso 3: Si R está vacío, no es posible probar P, de lo contrario emplear una estrategia de control para seleccionar una regla Ri del conjunto R, lo cual introduce un orden de selección. Paso 4: Modificar la memoria de trabajo agregando las conclusiones de la regla Ri y aplicar la acción consecuente de esta regla. Si P está en la memoria de trabajo, concluye que P es verdadero, de lo contrario se regresa al paso 3.. I.1.2. Aplicaciones de las máquinas de inferencia La MI, es el componente más importante que tiene cualquier sistema dedicado al desarrollo de SE, ya que ella es la que realiza el proceso de inferencia que permite obtener las conclusiones que resuelven o pretenden resolver el problema planteado. Normalmente las MI se integran dentro de un sistema que incluye varias facilidades adicionales, las cuales juegan un papel importante en la puesta a punto del SE que se esté implementando y todo el sistema se enmarca dentro de un ambiente general que facilita la interacción entre los diferentes componentes. Cada máquina de inferencia usa una FRC particular, aunque algunas admiten más de una, y también pueden poseer diferentes mecanismos para controlar el proceso de inferencia. Todos estos aspectos se relacionan con la etapa de diseño e implementación de la MI en sí y del sistema en general. 7.
(16) Capítulo I. La elaboración de un SE, en cualquier ambiente, exige que se conozcan las FRC y las estrategias de inferencia y control de la herramienta que se use como máquina de inferencia (Gutiérrez, 1991). Existe una variada gama de ambientes que integran máquinas de inferencia como un componente más, entre ellas se pueden citar las siguientes: ARIES es un ambiente de trabajo, diseñado por especialistas cubanos. El módulo que contiene la MI, se denomina de igual forma que el sistema, utiliza las RP como FRC y además admite la definición de proposiciones y variables que pueden presentarse al usuario como interrogantes junto con un valor de certidumbre (Valdés et al., 1994). El proceso de inferencia utiliza las dos direcciones de búsquedas clásicas: backward chaining y forward chaining. VP-EXPERT es un Shell para el desarrollo de SE diseñado para ejecutarse sobre el sistema operativo MS-DOS. Esta aplicación consta de tres componentes fundamentales: un editor para la creación de las bases de conocimiento, una interfaz de usuario (con limitaciones gráficas signadas por la época de su surgimiento) y un motor de inferencia para dar respuesta a las consultas de los usuarios. El sistema usa las RP como FRC e implementa una búsqueda a ciegas primero en profundidad, siguiendo el encadenamiento hacia atrás en el árbol de inferencia (Friederich and Gargano, 1989). JESS (Java Expert System Shell) es un motor de reglas y scripts para la plataforma Java. Puede usarse desde dos ópticas diferentes: como un Shell para la construcción de SE o como un lenguaje de programación de propósito general (Friedman, 2003). La MI de JESS incorpora, una versión mejorada de RETE, que es un algoritmo de reconocimiento de patrones eficiente para implementar los sistemas basados en reglas (Garcia-Montoro et al., 2006), y utiliza la dirección de búsqueda dirigida por datos en el proceso de inferencia. Prolog es un lenguaje de programación lógica ampliamente usado en la IA, como Shell para el desarrollo de SE que utilizan como FRC las RP. Dispone de su propia MI, la cual implementa una búsqueda a ciegas dirigida por objetivos. En el proceso 8.
(17) Capítulo I. de inferencia utiliza el método de búsqueda primero en profundidad como estrategia de resolución de conflictos y se auxilia del mecanismo “vuelta atrás” (backtracking) para la exploración del árbol de inferencia (Mellish and Clocksin, 2003). Se necesita de un procedimiento que controle el backtracking y que garantice que un objetivo no sea preguntado en más de una ocasión, pues el operador de corte (!) que posee el lenguaje no resuelve ese problema.. I.2. UCShell como máquina de inferencia UCShell es una máquina de inferencia para realizar aplicaciones expertas. Las BC que interpreta este sistema utilizan las RP como FRC, sin embargo la sintaxis definida para su edición admite especificar variables y acciones que permiten al Ingeniero del Conocimiento guiar el proceso de inferencia, de acuerdo a las características del problema a resolver. En la figura I.1 se muestra la gramática empleada para la definición sintáctica de las BC que utiliza UCShell.. Figura I.1 Sintaxis de la Base de Conocimiento de UCShell1. External: En este bloque se declaran, separadas por coma, aquellas variables que pertenecen a otra BC y se necesita conservar su valor. Asks: Contiene las variables “preguntables” o lo que es lo mismo, aquellas variables que toman valor de acuerdo a datos introducidos o seleccionados por el usuario. Es posible asociar a cada variable una lista de valores posibles que constituyen su dominio, cuando es discreto, y un texto que explica el por qué se hace la pregunta.. 1. Tomado de FERNÁNDEZ, L. F. 2011. UCShell 2.0: Un ambiente para el desarrollo de sitemas expertos. Universidad "Mata Abreu" de Las Villas.. 9.
(18) Capítulo I. Rules: Es en este bloque que se definen las reglas, las cuales tienen la forma IF<condición>THEN<conclusión>.. La condición admite el uso de todos los. operadores definidos para el sistema, sin embargo el resultado al evaluarla debe ser booleano. Actions: Este bloque es obligatorio dado que en él se definen las acciones del proceso de inferencia y es el punto de entrada o lugar por dónde el SE comienza la búsqueda. La primera implementación de UCShell se desarrolló en el lenguaje Borland Pascal sobre el sistema operativo MS-DOS, como un módulo del Sistema para la Enseñanza de Sistemas Expertos desarrollado en el CEI (Lezcano, 1998). El método de búsqueda empleado por esa versión es una búsqueda a ciegas primero en profundidad. Este sistema solo admite la dirección de búsqueda backward channing y, en correspondencia con el comportamiento tradicional de las MI, no explora todas las posibles soluciones del problema en cuestión sino que se detiene al encontrar la primera. Como parte de las investigaciones del grupo Informática Educativa del CEI, se obtuvo una segunda versión de UCShell que se implementó específicamente para el sistema operativo (SO) Windows y pasó a denominarse WUCShell, en alusión a ese SO. La nueva versión se programó sobre el lenguaje Object Pascal y mantuvo el mismo método y dirección de búsqueda pero difiere en que, por defecto, devuelve todas las soluciones que encuentra (explora todas las reglas que tienen el atributo a probar en su conclusión, aunque ya esté probado). Para excluir de la búsqueda alguna regla con un <atributoc> en su conclusión, que ya se ha probado, es necesario incluir la sentencia EXCLUDE <atributoc> como primera premisa de esa regla. Posteriormente se obtuvo UCShell 2.0 que tiene la ventaja de ser multiplataforma dado que está programada en el lenguaje Java. En su implementación incorpora la dirección de búsqueda dirigida por datos a la vez que mantiene los métodos de búsquedas de las versiones anteriores. Por defecto devuelve la primera alternativa de solución que encuentra, pero permite al Ingeniero del Conocimiento especificar que se desean obtener. 10.
(19) Capítulo I. todas las soluciones posibles en el proceso de inferencia, para lo cual se le adicionó la sentencia FINDALL (Fernández, 2011).. I.3. Los Patrones arquitectónicos A pesar de que la Programación Orientada a Objeto (POO) se enfoca en la reutilización de código, no se logrará una reutilización efectiva a menos que sea respaldada por un buen diseño (Buschmann et al., 1996). Una aplicación bien diseñada garantiza robustez y modularidad, lo cual aporta claridad en la implementación y facilidades para su mantenimiento. Un diseño de software adecuado debe basarse en soluciones ya probadas con éxito en otras ocasiones, pues de esta forma se garantiza la robustez en la aplicación y las facilidades de mantenimiento. Estas soluciones son las que se conocen como Patrones, dado que se pueden aplicar a determinados tipos de problemas que aparecen repetidamente en el desarrollo de sistemas de software (Alencar et al., 1996). Esta definición refiere a un esquema básico de diseño, que cada desarrollador adapta a las peculiaridades de su aplicación sin violar los principios generales del patrón. Los patrones, en el desarrollo de software, son recursos útiles para identificar la solución de un problema concreto, pues en ellos se encuentra documentada la experiencia acumulada de los diseñadores de software en solucionar ciertos tipos de problemas. La aplicación adecuada de estos patrones garantiza un diseño correcto del producto en menos tiempo, ya que solo es necesario adaptar la propuesta de solución al problema que se pretende resolver. Además, el uso de los patrones facilita la comunicación entre los miembros del equipo de desarrollo de software y permite que se obtengan aplicaciones con un alto por ciento de reusabilidad en sus componentes (Fowler, 2002). Existe una amplia gama de patrones en la Ingeniería de Software (IS), cada uno centrado en algún esbozo general de un tipo de problema, que puede ser de diseño, de análisis, de arquitectura, entre otros. Los problemas referentes a la arquitectura de software abordan la selección de los elementos estructurales del sistema, las interfaces entre ellos, su comportamiento, sus colaboraciones y su composición (Bass et al., 2003). Por tanto, un patrón de arquitectura especifica una serie de subsistemas y sus responsabilidades 11.
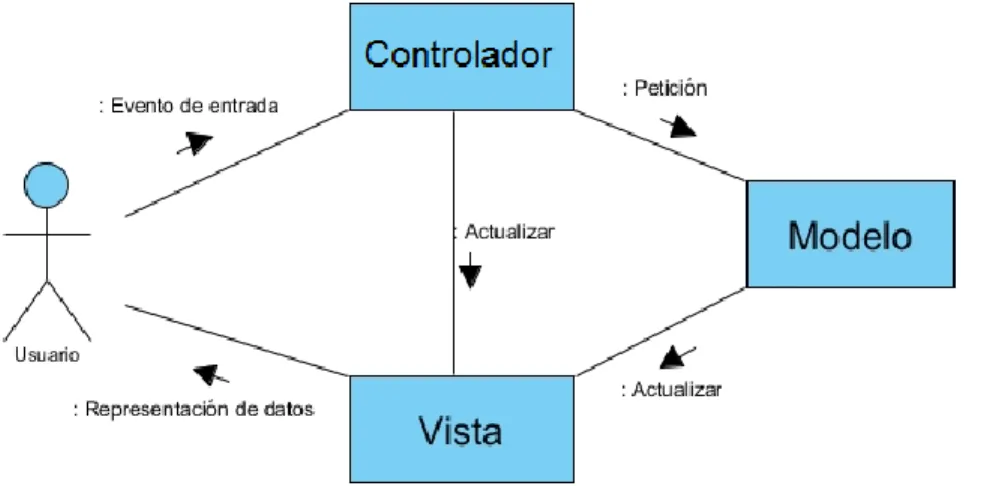
(20) Capítulo I. respectivas, e incluyen reglas para organizar las relaciones entre ellos. En esencia expresan un esquema organizativo estructural fundamental para sistemas de software (Mitchell, 2003). Dentro de los patrones arquitectónicos se destaca la arquitectura Modelo-VistaControlador (MVC), la cual separa la lógica de negocio de la interfaz gráfica de la aplicación y se auxilia de un módulo responsable de la gestión de los eventos sobre esa interfaz. Esto garantiza una correspondencia entre lo que se muestra al usuario y los datos internos de la aplicación. En busca de este objetivo se propone la confección de tres módulos principales: el Modelo, la Vista y el Controlador.. I.3.1. Descripción de la arquitectura MVC En la Figura I.2 se muestra la perspectiva clásica de las relaciones entre las componentes del patrón MVC, sin embargo, existen otras implementaciones de esta arquitectura que proponen dependencias y asociaciones diferentes, las cuales se abordarán más adelante.. Figura I.2 Diagrama de interacción entre las componentes del patrón MVC2. Seguidamente se describen el Modelo, la Vista y el Controlador con énfasis en sus responsabilidades dentro del flujo de una aplicación basada en la arquitectura MVC.. 2. Tomado de GONZÁLEZ, Y. D. & ROMERO, Y. F. 2012. Patrón Modelo-Vista-Controlador. Revista Telem@tica.. 12.
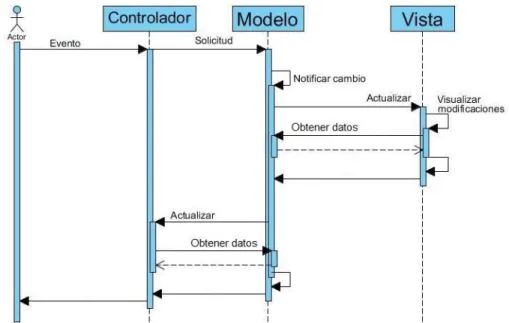
(21) Capítulo I. El Modelo está compuesto por el conjunto de clases que gestionan la lógica de negocio de la aplicación, por esta razón encapsula los datos y funcionalidades principales del sistema, sin tener en cuenta la representación específica de la salida o el comportamiento de la entrada de la aplicación (Li and Cui, 2005). Esta componente no dispone de referencias al Controlador o a la Vista, sino que el propio sistema es el encargado de proveer las interfaces necesarias para la comunicación entre el Modelo y sus Vistas, cuando ocurra un cambio en los datos por el accionar del Controlador. La Vista refiere a la interfaz de usuario, dado que es la componente encargada de visualizar los datos, de forma adecuada, en respuesta a las solicitudes del usuario. Su interacción con el Modelo ocurre a través de una referencia al propio Modelo, pero se limita a la realización de consultas sobre la información contenida, puesto que esta relación no implica modificaciones en dicha información (Gamma et al., 1993). En la práctica, es común la existencia de diferentes instancias de la Vista para un mismo conjunto de datos del Modelo. Al Controlador lo integran las clases responsables de procesar los eventos generados por el usuario desde la Vista, para luego ser traducidos en solicitudes al Modelo. Estas solicitudes pueden implicar cambios en los datos internos de la aplicación o solo comprender la respuesta a una consulta, como también pueden significar cambios en la propia Vista desde donde fueron generadas (Freeman, 2004). Según Frank Buschmann (Buschmann et al., 1996) el flujo de control e interacción entre estas componentes puede ser descrita como se muestra en la Figura I.3. Por simplicidad, este diagrama de secuencia solo muestra una única Vista asociada a un Controlador, pero en la práctica un Modelo puede representarse por más de una Vista y cada una de ellas puede tener un Controlador independiente para el tratamiento de los eventos. Este escenario muestra, como paso inicial, la interacción del usuario con el sistema, que puede traducirse como una solicitud de cambio en los datos del Modelo o una mera consulta de la información. Partiendo de este estado, la secuencia de pasos puede verse como se describe seguidamente:. 13.
(22) Capítulo I. 1. El Controlador capta el evento generado desde la interfaz del sistema, lo interpreta y efectúa la solicitud adecuada al Modelo. 2. El Modelo realiza el servicio solicitado por el Controlador y notifica a la Vista para que actualice la información visualizada. 3. La Vista solicita los datos modificados en el Modelo y ejecuta los procedimientos de actualización. 4. El Controlador también es advertido de los cambios ocurridos en los datos internos del sistema y utiliza esta información para activar o desactivar ciertas funcionalidades de la aplicación, por ejemplo, opciones de la barra de menú o de la barra de herramientas. Al terminar esta secuencia, está garantizada la correspondencia entre los datos internos de la aplicación y lo que se muestra al usuario. El Controlador queda a la espera del próximo evento provocado por el usuario desde la interfaz para, de esta forma, dar inicio nuevamente al proceso descrito anteriormente.. Figura I.3: Diagrama se secuencia de la arquitectura MVC3. 3. Tomado de BUSCHMANN, F., MEUNIER, R., ROHNERT, H., SOMMERLAD, P. & STAL, M. 1996. PatternOriented Sofware Architecture a System of Patterns.. 14.
(23) Capítulo I. I.3.2. Beneficios de usar el patrón MVC El estilo de arquitectura MVC fue diseñado con el objetivo de facilitar la implementación de sistemas múltiples y sincronizados, por lo que es muy popular en el desarrollo de sistemas de representación gráfica de datos (Kosayba, 2006). Dentro de los beneficios que conlleva incorporar el patrón MVC al diseño de una aplicación, resaltan los siguientes: Modularidad: cada componente de la aplicación puede implementarse por separado e incluso por diferentes desarrolladores al mismo tiempo, lo que favorece el trabajo en equipo y el futuro mantenimiento de la aplicación. Sincronización: El Modelo y sus Vistas están conectados dinámicamente, ya que la interacción entre estas componentes ocurre en tiempo de ejecución, no en tiempo de compilación (González and Romero, 2012). De esta forma se garantiza la visualización actualizada, de los datos, en todo momento. Reusabilidad: El patrón MVC propone un diseño que desacopla la Vista de la representación interna de los datos (el Modelo), lo que hace de cada componente una parte independiente, donde las modificaciones individuales no afectan, en la mayoría de los casos, a la implementación de las demás componentes.. I.3.3. Variantes del patrón MVC El desarrollo de las técnicas computacionales ha influido en algunos aspectos de la arquitectura MVC, dando origen a ciertas variaciones del concepto original, ya que las relaciones clásicas entre las componentes de este patrón no satisfacen las necesidades de los clientes actuales (Fowler, 2006). Dentro de estas variantes puede citarse a ModelView-Adapter y Document-View, aunque es válido aclarar que existen otras propuestas de variación pero sus implementaciones son similares a las mencionadas anteriormente. Model-View-Adapter (Modelo-Vista-Adaptador): Esta variante de MVC está enfocada en el desacoplamiento total entre los datos del sistema y su representación visual. En ella se propone que la comunicación entre el Modelo y la Vista sea propiciada solamente a través del Adaptador, que es la componente que sustituye al Controlador de MVC.. 15.
(24) Capítulo I. Este esquema de relaciones entre las componentes de la arquitectura permite el acceso indirecto de múltiples Vistas al conjunto de datos, generalmente solo a través de un Adaptador. En el caso en que se necesite manipular los datos de forma diferente, con la misma interfaz visual, solo bastaría con añadir un nuevo Adaptador sin que esto implique modificaciones en la Vista o el Modelo (Zhang and Luo, 2010). Document-View (Documento-Vista): En algunas plataformas, como Java, las interfaces gráficas y el manejo de los eventos están estrechamente entrelazados, por lo que esta variante de la arquitectura MVC combina, en una sola componente, las responsabilidades de la Vista y el Controlador. La componente Documento corresponde con el Modelo en MVC y además contiene los mecanismos de comunicación con la Vista (Buschmann et al., 1996). En semejanza con la arquitectura original permite la creación de múltiples Vistas, sincronizadas pero diferentes, de un mismo Documento.. I.3.4. Implementación del patrón MVC con el API de Java El lenguaje de programación Java proporciona soporte para la implementación de la arquitectura MVC en aplicaciones desarrolladas en ese lenguaje. De hecho, dispone de la biblioteca Swing que es considerada un framework MVC para el diseño y construcción de interfaces gráficas (Gosling, 2000). La mayoría de las componentes de esta biblioteca, como JTree, JPanel y JButton, contienen un modelo de datos por defecto que puede ser modificado por el programador (Liang, 2013), lo que puede influir positivamente en la eficiencia de las componentes y la aplicación en general. Para el desarrollo de los sistemas basados en el patrón MVC, usando las tecnologías Java, es posible utilizar dos clases, Observador (la Vista) y Observable (el Modelo). Ambas clases son útiles en cualquier sistema, en el que algunos objetos se vean afectados por las modificaciones ocurridas en otro tipo de objeto y por lo tanto, necesiten ser advertidos cuando esto ocurra. Los objetos de tipo Observador son aquellos que están pendientes de las modificaciones ocurridas en los de tipo Observable (Cooper, 1998). Tomando en cuenta esta particularidad, el API de Java dispone de la clase Observable y de la interfaz Observer, las cuales pueden ser de utilidad en la creación de los objetos Observables y Observadores respectivamente.. 16.
(25) Capítulo I. I.4. Análisis de la arquitectura de UCShell 2.1 La herramienta UCShell 2.1 es un producto informático integrado por cuatro componentes que pueden utilizarse individualmente, atendiendo a las necesidades de cada usuario. El carácter modular del sistema facilita el trabajo a los programadores en la etapa de mantenimiento y permite que otras aplicaciones puedan aprovechar las funcionalidades de algunos módulos, como por ejemplo, el que gestiona todo el proceso de inferencia, que es útil para que aplicaciones no expertas puedan inferir sobre BC previamente creadas (Fernández, 2011). Los módulos que componen a la versión 2.1 de UCShell son los siguientes: UCShell IDE 2.1: Es un IDE (ambiente de desarrollo integrado), generalmente usado por Ingenieros del Conocimiento, para editar y poner a punto las BC de un SE, cuenta con un editor que dispone de las funcionalidades básicas. Este módulo es el responsable de gestionar la creación de los proyectos, que pueden contener a una o varias BC, en dependencia de la complejidad del problema a resolver. Para ejecutar el proceso de compilación, esta aplicación utiliza la biblioteca UCShell Library 2.0, que también dispone de mecanismos de inferencia, los cuales se auxilian de componentes gráficas para la interacción con los usuarios. UCShell Library 2.0: Es una biblioteca que contiene las clases y métodos necesarios para el proceso de compilación, real o simbólico, de las BC que se editan en UCShell IDE 2.1. Además tiene incluida una máquina de inferencia que puede utilizarse en la ejecución de los SE desarrollados en el IDE anteriormente mencionado, de hecho, su propósito funcional es ofrecer los mecanismos que tiene incorporados, a otras aplicaciones que poseen una interfaz visual propia, pues este producto carece de esta componente. UCShell Compiler 2.0: Este software tiene la funcionalidad de ejecutar la compilación real (sin información simbólica) de una BC editada según la sintaxis que propone la versión 2.0 de UCShell. Dispone de una interfaz visual básica que le permite al usuario cargar una BC y generar la forma interna de la misma en caso de. 17.
(26) Capítulo I. no existir errores. Utiliza la biblioteca UCShell Library 2.0 para obtener los archivos compilados, sobre los cuales se puede realizar la inferencia. UCShell Symbolic Compiler 2.0: Es una versión del compilador que genera archivos compilados con información simbólica, los cuales pueden ser utilizados por otras aplicaciones, como es el caso de TeachShell (Morales, 2011), que se dedican al estudio de los SE. A pesar de que es menos profundo el chequeo de errores que se realiza en este tipo de compilación, no se admiten los comentarios como parte de la sintaxis de las BC. En semejanza al sistema homólogo UCShell Compiler 2.0, utiliza la biblioteca UCShell Library 2.0 para generar la forma interna de las BC compiladas, pero en este caso, incluyendo la información simbólica.. I.5. Conclusiones del capítulo En el presente capítulo se han expuesto los conceptos fundamentales sobre los procesos de inferencia dentro de la Inteligencia Artificial, destacando las funcionalidades y aplicaciones de las Máquinas de Inferencia como lo es el caso de UCShell. Además se han abordados algunos conceptos útiles para el desarrollo de esta investigación, como por ejemplo los patrones de Arquitectura, específicamente el estilo Modelo-VistaControlador y algunas de sus variantes e implementaciones. También se presentó, un análisis de la arquitectura de la versión 2.1 de UCShell, todo lo cual sirve de base para justificar y formalizar las modificaciones que se detallan en el siguiente capítulo.. 18.
(27) Capítulo II. CAPÍTULO II. REDISEÑO DEL SISTEMA UCSHELL En el presente capítulo se analizan los aspectos fundamentales del diseño de la versión 2.1 de UCShell, tomando como referente el patrón arquitectónico MVC, con el objetivo de obtener un nuevo diseño que mejore la calidad al sistema. Además se incluyen modificaciones no relacionadas directamente con el diseño, pero que son necesarias para garantizar el comportamiento adecuado de la aplicación.. II.1. El proceso de diseño en la Ingeniería de Software. Según Taylor (Taylor, 1959) el diseño no es más que el proceso de aplicar distintas técnicas y principios con el propósito de definir un dispositivo, proceso, o sistema, con los suficientes detalles como para permitir su realización física. El diseñador tiene la responsabilidad de obtener un modelo que se construirá en una etapa posterior. Dentro del ciclo de vida de la IS, el diseño de software es la actividad en la que los requerimientos de un producto informático son analizados para obtener una descripción de su estructura interna, que se usará como base para su posterior construcción (Kendall and Kendall, 2005). Este proceso es de vital importancia para la obtención de productos informáticos que satisfagan las necesidades de los clientes.. II.1.1. Descomposición del diseño de software. Desde el punto de vista técnico, Cataldi (Cataldi, 2000) descompone este proceso en cuatro subprocesos: a. El diseño de datos, modela el dominio de la información e incluye las estructuras de datos necesarias para la implementación del software. b.. El diseño arquitectónico, especifica las relaciones entre las componentes estructurales de la aplicación.. c.. El diseño procedimental, transforma los elementos estructurales de la arquitectura en una descripción algorítmica.. d.. El diseño de las interfaces, establece los mecanismos de comunicación del sistema con otras aplicaciones y con los usuarios. 19.
(28) Capítulo II. La realización de la versión 2.1 de UCShell tuvo en cuenta los aspectos técnicos de diseño que especifica la IS y en ese sentido se seleccionaron correctamente las estructuras de datos y los componentes visuales que facilitan la interacción con el usuario, sin embargo, se han detectado algunas deficiencias en el diseño algorítmico y de su arquitectura que serán abordados en epígrafes posteriores.. II.1.2. Métricas para el control de la calidad de un software. El modelo de requerimientos define las funcionalidades que solicita el usuario para satisfacer sus necesidades y según las especificaciones de la IS, la calidad del diseño se relaciona con el grado en que se cumplen las funcionalidades y características especificadas en ese modelo. Algunos autores proponen parámetros bien definidos para medir la calidad del software, los cuales incluyen aspectos del diseño. A continuación se comentan brevemente algunos de las métricas de control de la calidad de un software según McCall (McCall, 1994). Interoperabilidad: es el esfuerzo necesario para acoplar un sistema a otro. Reusabilidad: es el grado en el que un sistema o partes de uno puede volverse a utilizar en otras aplicaciones. Facilidad de mantenimiento: es el esfuerzo que se requiere para detectar y corregir errores en una aplicación. Confiabilidad: es el grado en que se espera que un programa cumpla su función con la precisión requerida. Tolerancia a errores: se determina por el daño que se produce cuando el programa encuentra un error.. II.1.3. Diseño procedimental en UCShell 2.1. El diseño procedimental se realiza después de haber establecido el diseño de los datos y especifica los detalles algorítmicos de un programa, los cuales serán codificados posteriormente en algún lenguaje de programación (Kendall and Kendall, 2005). De esta actividad en el desarrollo de software depende, en gran medida, que el sistema cumpla adecuadamente con los requerimientos del usuario. 20.
(29) Capítulo II. La versión 2.1 de UCShell ostenta mejoras algorítmicas respecto a las versiones anteriores, tal es el caso de los procesos de inferencia y de compilación, sin embargo, presenta irregularidades en la definición del comportamiento de algunos de sus objetos. Estas irregularidades, bajo determinadas circunstancias que no se tuvieron en cuenta en el análisis de tolerancia a fallos, provocan errores en la aplicación. Como consecuencia de lo anterior, son notables las excepciones que se producen durante la ejecución, que no tienen tratamiento alguno, y provocan fallas de funcionamiento, lo cual afecta la calidad del sistema y atenta contra su confiabilidad.. II.1.4. Diseño de la arquitectura de UCShell 2.1. La arquitectura de software define un sistema en términos de elementos computacionales, detallando además, las interacciones entre ellos. Los elementos computacionales son entidades tales como bases de datos, filtros o capas de un sistema jerárquico (que son los módulos definidos de acuerdo a las funcionalidades de la aplicación). Las interacciones que ocurren entre estas componentes pueden ser complejas, por ejemplo los protocolos del modelo cliente/servidor, o tan sencillas como los modificadores de acceso de un objeto y las llamadas a sus métodos. Diseñar la arquitectura de un software, según los autores Garlan y Shaw (Garlan and Shaw, 1993), implica definir sus aspectos estructurales como un conjunto de componentes, las jerarquías de control, los protocolos de comunicación, la sincronización y acceso de los datos, la asignación de la funcionalidad a los elementos del diseño, la composición de estos elementos, su distribución física, su escalabilidad y su desempeño. Este proceso está estrechamente vinculado a algunas de las técnicas del diseño de software, las cuales se abordan a continuación. Modularidad Las jerarquías de control representan la organización, generalmente jerárquica, de los módulos de una aplicación. Los módulos, según (Bass et al., 2003), son las componentes en las que se puede dividir un software, cada uno tiene una función específica y mediante su integración se deben satisfacer los requisitos del proveedor. La utilización de varios módulos organizados jerárquicamente, facilita la implementación 21.
(30) Capítulo II. del sistema, así como su comprensión y mantenimiento. Los patrones de diseño y de arquitectura de software pueden ser de utilidad para logar este objetivo. Ocultamiento de la información Los protocolos de comunicación y la sincronización y acceso de los datos, son aspectos relacionados con el principio de ocultamiento de la información o como también se conoce, la encapsulación de los datos. Este principio sugiere que los módulos deben especificarse de tal forma que los procedimientos y datos contenidos dentro de un módulo, sean inaccesibles a otros módulos que no necesiten esa información. En la POO existen tres niveles de acceso en el encapsulamiento: privado (el acceso a los datos está restringido a los métodos de la clase donde se definen), protegido (el acceso a los datos se extiende también a las clases que heredan de la clase donde se definen) o público (no existe restricciones en el acceso a los datos, estos pueden ser accedidos por cualquier otra clase). Es recomendable que los atributos de las clases sean privados y dispongan de métodos públicos para el acceso a ellos (Durán et al., 2007). De acuerdo con Joshua Bloch (Bloch, 2008), mediante la encapsulación se logra el desacoplamiento de los módulos del sistema en construcción, permitiendo que estos puedan ser desarrollados, probados, optimizados, utilizados y modificados de manera independiente. De esta forma, se alivia el costo del mantenimiento porque un módulo puede ser depurado sin afectar el desempeño de otros módulos. Asimismo, se incrementa la reutilización del software, ya que las componentes que no están fuertemente acoplados suelen resultar útiles en otros contextos además de aquellos para los cuales fueron desarrolladas. Acoplamiento y cohesión La asignación de la funcionalidad a los elementos del diseño, la composición de estos elementos, su distribución física, su escalabilidad y su desempeño deben definirse teniendo en cuenta los principios de acoplamiento y cohesión. Ambos principios están dedicados a la eficiencia de las colaboraciones entre las clases determinadas en el proceso de diseño. 22.
(31) Capítulo II. El acoplamiento no es más que el grado de interconexión entre los módulos de un sistema informático. En el diseño de software es deseable que su valor sea lo más bajo posible, puesto que de esta manera se evita la propagación de errores a lo largo del sistema o lo que también se conoce como evitar el “efecto onda” (López et al., 2004). La cohesión describe en qué forma están relacionados los elementos que conforman un módulo del sistema. Se dice que un módulo es cohesivo si ejecuta tareas sencillas y requiere de poca interacción con procedimientos definidos en otras partes de la aplicación. La cantidad de tareas de un módulo debe ser mínima, en busca de niveles altos de cohesión, lo cual implica facilidades en el proceso de prueba y mantenimiento de la aplicación en general (de Areba, 2001). El sistema UCShell está concebido en cuatro módulos esenciales: una biblioteca con los mecanismos de inferencia y compilación integrados, dos versiones del compilador (una de ellas permite la compilación de archivos con información simbólica), y el IDE, que es útil para la edición y puesta a punto de las BC. En esta última componente, el ambiente de trabajo, se integran las funcionalidades comprendidas en los demás módulos, lo que permite presentar al usuario las facilidades necesarias para el desarrollo un SE. Teniendo en cuenta las métricas del control de la calidad abordadas anteriormente, la arquitectura de UCShell 2.1 es favorable en cuanto a la reusabilidad, pues la biblioteca UCShell Library 2.0 está diseñada para que aplicaciones no expertas aprovechen los mecanismos de inferencia que contiene. También dispone de facilidades para la interoperabilidad, puesto que colabora con otros sistemas como es el caso de TeachShell, ya que la versión del compilador UCShell Symbolic Compiler 2.0 permite exportar BC para este tipo de software. Su carácter modular aumenta las facilidades de estudio y mantenimiento, lo que es una consecuencia directa de aplicar la técnica de Modularidad en el diseño de la arquitectura, no obstante, se encontraron algunas deficiencias en cuanto a las técnicas de ocultamiento de la información, acoplamiento y cohesión en el módulo que gestiona la interfaz visual del software.. 23.
(32) Capítulo II. La componente visual, encargada de la interacción con los usuarios, está compuesta por dos tipos de elementos: los relacionados con las funcionalidades del sistema (Ejemplo: el editor y el árbol de proyecto) y los responsables de interactuar con el usuario durante la ejecución de un SE (ejemplo: los diálogos para mostrar o explicar las conclusiones alcanzadas). La clase Window, perteneciente al módulo visual de UCShell 2.1, contiene los elementos encargados de las funcionalidades que brinda esta herramienta. A pesar de que el funcionamiento de esta clase es correcto, su diseño no es adecuado.. II.1.5. Inconvenientes en el diseño de la clase Window. Mediante un análisis detallado de la estructuración de la clase Window, se detectaron dos problemas fundamentales relacionados con las técnicas de diseño. Uno es la pobre encapsulación de la información de la clase, determinada por el abuso del nivel de acceso público en los datos. Esto atenta contra la protección de los atributos del objeto y eleva los niveles de acoplamiento, por lo que es recomendable forzar el acceso a la información mediante un conjunto de métodos pertenecientes a la interfaz pública de la clase, por ejemplo, los tradicionales métodos get y set. Otro problema de la clase Window es su bajo nivel de cohesión, que está determinado por la gran cantidad de responsabilidades que le fueron asignadas. De acuerdo con Larman (Larman, 1999), en la POO es crucial la eficiencia en la asignación de responsabilidades de una clase, pues de esta actividad dependen la solidez, capacidad de mantenimiento y de reutilización de las componentes del software. Se dice que una clase tiene baja cohesión si posee una cantidad excesiva de responsabilidades o se le asignaron algunas que no le corresponden y deberían haberse delegado a otras clases. Este tipo de clases son difíciles de comprender y de conservar y se ven afectadas, constantemente, por los cambios que puedan ocurrir en la implementación del sistema. La clase Window tiene la responsabilidad de mostrar la ventana principal de la aplicación UCShell, contiene las componentes visuales necesarias para la edición de las BC, la gestión de los proyectos y la salida del sistema, además de las barras de menú y de herramientas, que facilitan el funcionamiento del software. Conjuntamente con la 24.
(33) Capítulo II. responsabilidad de gestionar la visualización de los componentes gráficos, se encarga de procesar la información que esos componentes manipulan y esa gama de responsabilidades hace muy difícil comprenderla como entidad y dificulta el mantenimiento. En busca de solucionar las dificultades encontradas, es conveniente obtener un nuevo diseño de UCShell basado en el patrón de arquitectura MVC.. II.2. El patrón de arquitectura MVC y el sistema UCShell. El patrón arquitectónico MVC, como ya se ha apuntado anteriormente, separa la lógica de negocio de la interfaz visual de la aplicación, lo cual puede ayudar a obtener un nuevo diseño de UCShell con niveles más altos de cohesión en sus módulos. Este estilo de arquitectura es muy utilizado en el diseño de interfaces gráficas, debido a los bajos niveles de acoplamiento que generalmente permite alcanzar, lo cual también es conveniente para obtener una versión de UCShell con ventajas sustanciales en cuanto al diseño. La aplicación de la arquitectura MVC en la nueva versión de UCShell, implica un conjunto de transformaciones en el módulo UCShell IDE, que es el encargado de la gestión del ambiente de trabajo y además, donde está contenida la clase Window abordada en el epígrafe anterior. Después de la aplicación de técnicas del diseño de la IS, se obtuvo un conjunto de cinco nuevas clases que permitieron delegar responsabilidades que no le corresponden a la interfaz gráfica del sistema. Este nuevo diseño de la clase Window se obtuvo aplicando los principios de encapsulamiento, cohesión y acoplamiento, los cuales están presentes dentro de los fundamentos de la arquitectura MVC. En la figura II.1 se muestra la relación entre la clase Window y cinco nuevas clases, sobre las que se redistribuyó el conjunto de responsabilidades que anteriormente poseía la interfaz visual de UCShell IDE 2.1.. 25.
(34) Capítulo II.. Figura II.1 Diagrama de clases basado en el nuevo diseño de la clase Window. La asignación de tareas por clases es la siguiente: ProjectsManager: es la clase responsable de la gestión de los proyectos realizados en UCShell IDE, contiene los métodos que permiten crear, abrir o cerrar un proyecto. Con esta clase colaboran las clases EditorManager y Window. EditorManager: es la clase encargada de gestionar los archivos abiertos en el editor de UCShell IDE. Contiene los métodos pertinentes para cargar las BC en el editor, en diferentes pestañas, además notifica y guarda los cambios ocurridos durante la edición. Un objeto de la clase Window colabora con la ejecución de sus funciones. Output: es la clase que permite mostrar los resultados de algunas de las funcionalidades de UCShell IDE, como por ejemplo la compilación de las BC. Con esta clase colabora una instancia de la clase Window.. 26.
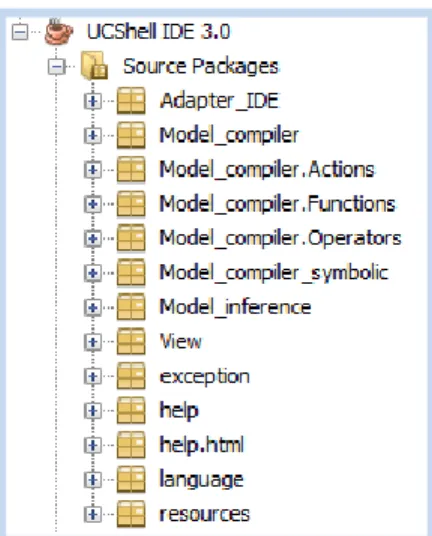
(35) Capítulo II. Help: es la clase responsable de crear la ayuda de UCShell IDE, que fue desarrollada con tecnologías Java. MyUtil: es una clase de propósito general que contiene métodos que son de utilidad para un amplio conjunto de clases que integran la herramienta UCShell IDE. El carácter estático de los métodos de esta clase permite el acceso a ellos sin necesidad de instanciarla. Con este reparto de responsabilidades, la nueva clase Window solo se encarga de mostrar al usuario el contenido de los datos de la aplicación, y para hacerlo pide colaboración a las clases mencionadas anteriormente. El nuevo diseño, aporta claridad y facilidades para el mantenimiento del código fuente, además de elevar el nivel de cohesión del módulo UCShell IDE en general.. Figura II.2 Estructura de los módulos en UCShell 3.0. La figura II.2 muestra la nueva organización de las clases según la arquitectura MVC. El paquete Adaprter_IDE representa al Controlador, pues contiene las clases que se encargan de la manipulación de los datos que maneja la aplicación, por ejemplo las clases ProjectsManager y Output, responsables de la gestión de los proyectos y la salida del sistema respectivamente. El Modelo está integrado por los dos compiladores del sistema (los paquetes Model_compiler_symbolic y Model_compiler, junto a sus paquetes internos) y la máquina de inferencia (el paquete Model_inference). Las funciones de la Vista, fueron delegadas en el paquete View, donde se agrupan el conjunto de clases que representan las interfaces visuales de UCShell IDE, esto incluye 27.
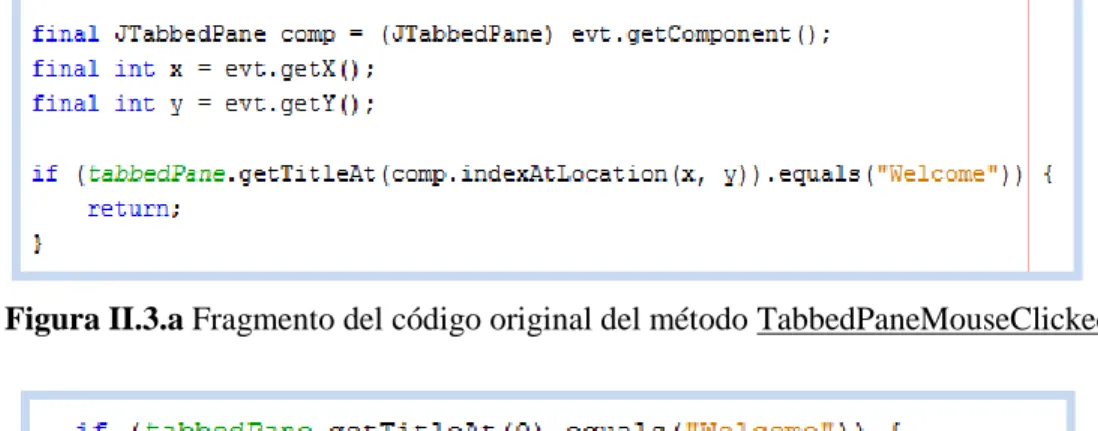
(36) Capítulo II. los diálogos de interacción con el usuario durante la ejecución de un SE y todo el ambiente de trabajo como tal. En la estructura de UCShell IDE 2.1 también se incluyen otros paquetes que agrupan recursos estáticos de la aplicación, como por ejemplo los archivos que conforman la ayuda del sistema.. II.3.. Análisis y solución de las deficiencias funcionales en UCShell 2.1.. La herramienta UCShell 2.1 se ha desempeñado con buenos resultados en sus dos campos de aplicación: en las empresas que desarrollan SE y en el proceso de enseñanza-aprendizaje de asignaturas de la disciplina IA.. La interacción de los. usuarios con el sistema ha permitido determinar algunas deficiencias, relacionadas con el funcionamiento de la aplicación. A continuación se detallan las situaciones más relevantes en las que se detectó un comportamiento inadecuado y además se le dio solución en la versión 3.0 de UCShell.. II.3.1. Fallas en el manejo de excepciones. En UCShell 2.1 existen algunas situaciones relacionadas con la interacción sistemausuario, que no se han tenido en cuenta, lo que implica que ciertos eventos, generados desde la interfaz, provoquen el lanzamiento de excepciones no tratadas. Esto hace que la ejecución del sistema pueda ser inestable e incluso interrumpida en ocasiones. Seguidamente se describen tres de estos casos. . Al dar clic sobre la zona superior del editor, sin señalar una pestaña en. específico, el método de la clase Window TabbedPaneMouseClicked, que es el encargado de tratar el evento de clic sobre las pestañas del editor, lanza la excepción ArrayIndexOutOfBoundsException. Esta excepción se eleva desde el método getTitleAt de la clase JTabbedPane, al intentar obtener el índice de la pestaña ubicada en las coordenadas del punto donde se dio el clic. Solución: El editor de UCShell 2.1 se implementó de forma tal que siempre tiene una pestaña abierta (si no se ha abierto ninguna, muestra la de bienvenida con título Welcome, que cierra cuando se abre otra cualquiera). Basado en esto, se modificó el. 28.
(37) Capítulo II. método TabbedPaneMouseClicked, para lo cual se sustituyeron las líneas de código que se muestran en la figura II.3.a, donde se utilizan las coordenadas del evento de clic para localizar la pestaña seleccionada, por el código que se muestra en la figura II.3.b. En esta segunda imagen se muestra una parte de la redefinición del método TabbedPaneMouseClicked, donde se intenta identificar si la primera pestaña del editor es la de bienvenida, y en tal caso salir del método. Esto hace la misma función de la definición original, con la ventaja que no eleva excepciones.. Figura II.3.a Fragmento del código original del método TabbedPaneMouseClicked. Figura II.3.b Fragmento del código modificado del método TabbedPaneMouseClicked. Al dar clic sobre el árbol de proyecto, sin estar ningún elemento del árbol seleccionado, el método encargado de tratar el evento de dar clic sobre el objeto JTree. (TreeMouseClicked. de. la. clase. Window),. eleva. la. excepción. NullPointerException, que es lanzada por el método getAnchorSelectionPath de la clase JTree. Solución: El tratamiento de este caso es sencillo, pero de vital importancia para evadir la excepción anteriormente mencionada. Solo basta comprobar si existe algún elemento del árbol seleccionado antes de dar tratamiento al evento de clic y de lo contrario no ejecutar ninguna acción. . Cuando se tiene un proyecto abierto y se intenta crear una nueva BC, esta se. abre después de creada. Para el caso en que se cancela la acción de crear la BC, el. 29.
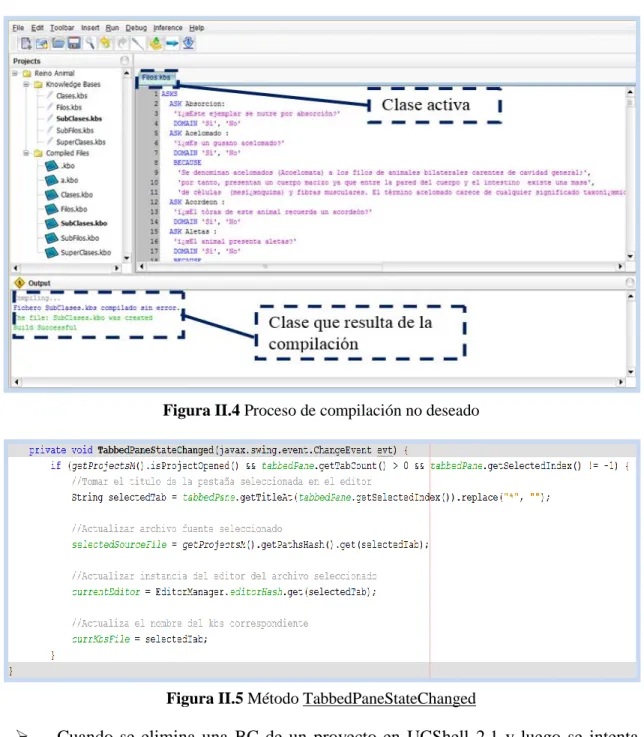
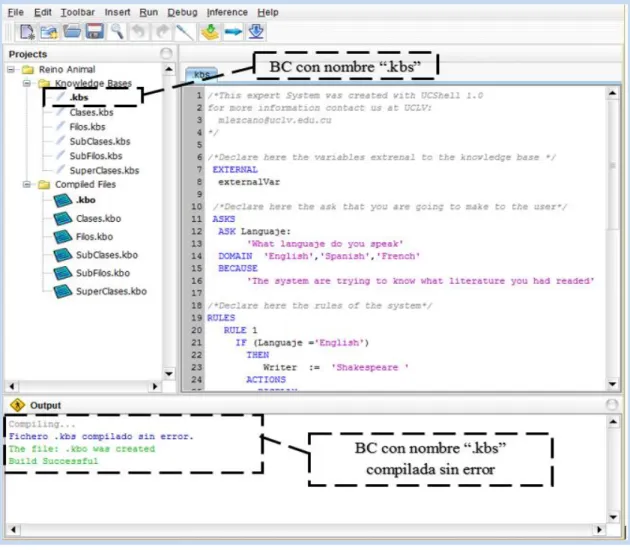
(38) Capítulo II. método. openSourceFile. de. la. clase. ProjectsManager. eleva. la. excepción. NullPointerException, pues se intenta abrir un archivo que no ha sido creado. Solución: El método openSourceFile utiliza el atributo booleano file_created de la clase CreateFile. Esta clase representa el diálogo que toma los datos para la creación de una nueva BC y su atributo file_created indica si se desea crear o no. La excepción se eleva dado que el valor booleano no se modifica a falso cuando se cancela la acción de crear una BC, ya sea por el botón Cancelar o porque se ha cerrado el cuadro de diálogo por la opción de la barra de título. Por tanto, para evitar que se intente abrir un archivo que no ha sido creado, es necesario asignar el valor de falso al atributo booleano file_created en los dos casos anteriormente mencionados.. II.3.2. Comportamiento inadecuado en la compilación de archivos. La compilación de BC en UCShell 2.1 funciona adecuadamente, sin embargo, existen situaciones en la que el sistema se comporta de forma incorrecta ante la petición de compilar los archivos de un proyecto. A continuación se explican estas situaciones y la solución dada en la versión 3.0 del sistema. . Cuando un proyecto tiene más de un archivo sólo se puede compilar el último. que se cargue debido a que cualquier compilación ulterior se realiza sobre el mismo archivo, aun cuando se cierren todos los demás. En la figura II.4 se ha realizado el siguiente proceso: primero se abrió el archivo Filos.kbs, después se abrió el archivo SubClases.kbs, se trabajó con él y se cerró, finalmente se intentó compilar el archivo que permaneció abierto (Filos.kbs) sin embargo el sistema compiló el archivo SubClases.kbs que es el que consideró activo (puede observarse este error resaltado dentro de cuadriláteros). Solución: En la versión 2.1 de UCShell un archivo se considera activo solo cuando se abre en el editor, pero deja de serlo en el momento en que se abre otra BC, por este motivo sucede la situación que anteriormente se expuso. Para solucionarlo se necesita un mecanismo que actualice adecuadamente el nombre del archivo activo. En la versión 3.0 de UCShell una BC se considera activa cuando está seleccionada en el editor y para. 30.
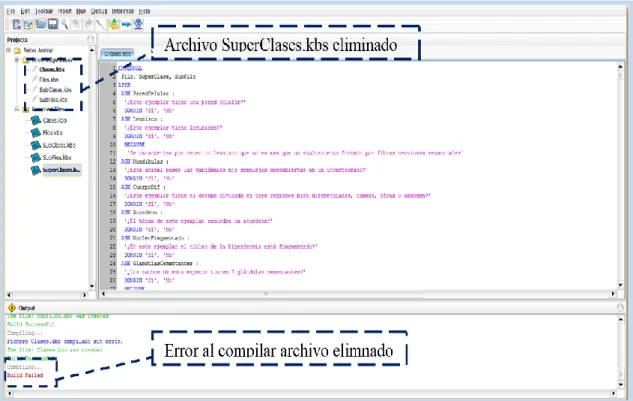
(39) Capítulo II. lograr esto se implementó el método TabbedPaneStateChanged que es responsable de atender el evento de cambio en las pestañas de este componente (figura II.5).. Figura II.4 Proceso de compilación no deseado. Figura II.5 Método TabbedPaneStateChanged. . Cuando se elimina una BC de un proyecto en UCShell 2.1 y luego se intenta. compilar todo el proyecto, en la salida del sistema se muestra un error de fallo en la compilación debido a que se intentó compilar un archivo que ya no existe. Esto no es correcto dado que cuando se elimina una BC no tiene sentido intentar compilarla. En la figura II.6 se ha realizado el siguiente proceso: Se compilaron todas las BC del 31.
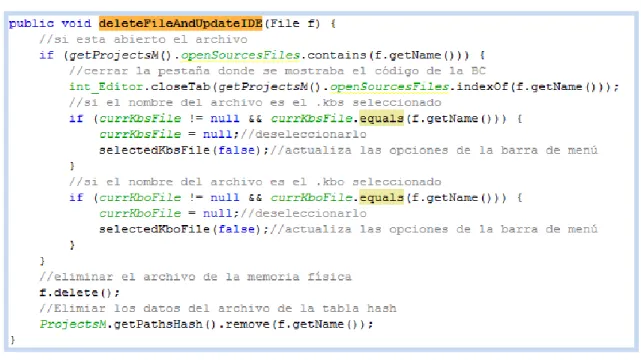
(40) Capítulo II. proyecto “Reino Animal” 4 y la compilación fue exitosa para todos los casos, se eliminó el archivo SuperClases.kbs y al intentar compilar nuevamente el proyecto completo muestra un error en la compilación de una de las BC (la eliminada).. Figura II.6 Error inválido en la compilación. Solución:. En. UCShell. 2.1,. la. clase. Window. utiliza. el. método. deleteFileAndUpdateIDE para mantener actualizada la interfaz en cuanto a los archivos contenidos en un proyecto. Este método se encarga de cerrar la BC eliminada, si estaba en edición, y eliminar el archivo de la memoria física. Sin embargo, con esta rutina no se han eliminado totas las referencias a la BC del sistema, pues aun su nombre y dirección absoluta están almacenados en una tabla hash (atributo pathsHash de la clase Window), que contiene la información de los archivos contenidos en el proyecto que se encuentra abierto.. 4. Es un sistema experto para clasificación taxonómica de animales. SOSA, D. R. 2013. Estudio práctico del sistema UCShell. Mejoras necesarias. Universidad Central "Marta Abreu" de LAs Villas.. 32.
(41) Capítulo II. La información almacenada en el atributo pathsHash se utiliza en el proceso de compilación y por tanto, al ordenar la compilación de todos los archivos de un proyecto, se intentará acceder a la dirección del archivo eliminado, el cual no fue retirado de la tabla hash. Basado en esto, en la versión 3.0 de UCShell se redefinió el método deleteFileAndUpdateIDE teniendo en cuenta lo explicado anteriormente. En esta nueva versión el atributo pathsHash pertenece la clase ProjectsManager y es accedido a través de una instancia de la misma dentro de la clase Window. En la figura II.7 se muestra el método redefinido.. Figura II.7 Método deleteFileAndUpdateIDE redefinido. II.3.3. Comportamiento inadecuado en la gestión de los proyectos. En UCShell 2.1 la gestión de los proyectos comprende la definición del comportamiento de la herramienta ante las peticiones de abrir, cerrar, crear o modificar un proyecto. Algunas de estas funcionalidades no tienen en cuenta ciertos casos, en los que el sistema tiene un comportamiento erróneo. Seguidamente se explican estos casos y cómo fueron tratados en la versión 3.0 de UCShell. . La versión 2.1 de UCShell permite la creación de proyectos con igual nombre. dentro del mismo espacio de trabajo, en tal caso, sobrescribe el proyecto existente. De. 33.
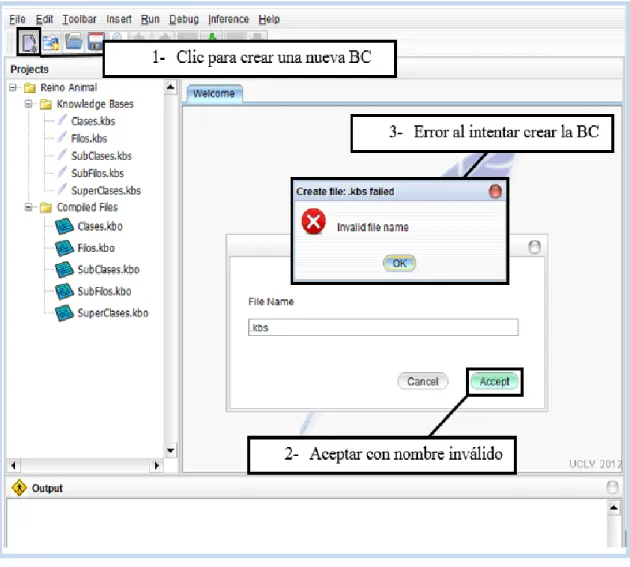
(42) Capítulo II. igual forma sucede al intentar crear una BC con un nombre que ya existe dentro del proyecto. Solución: El método createProjectFileSystem, definido en la clase Window de la versión 2.1 de UCShell, es el responsable de crear el conjunto de archivos para cada nuevo proyecto. La figura II.8 muestra el código original que verifica si existe el directorio que se intenta crear. Para esta verificación se instancia un objeto de la clase File, propia de la plataforma Java, cuyo parámetro en el constructor, en este caso, es el nombre del proyecto definido por el usuario, para luego preguntar si ya existe. El error en esta codificación radica en que el objeto File no se debe instanciar con el nombre del proyecto, sino con la dirección del espacio de trabajo donde será creado (esto incluye el nombre del proyecto definido por el usuario, pero al final de la cadena). La figura II.8.b muestra la solución a este inconveniente. En la versión 3.0 de UCShell el método createProjectFileSystem modificado, se encuentra como parte de la interfaz pública de la clase ProjectsManager.. Figura II.8.a Verificación original del método createProjectFileSystem. Figura II.8.b Verificación del método createProjectFileSystem en la versión 3.0. El método NewFileMenuItemActionPerformed definido en la clase Window (responsable de crear las nuevas BC) tiene un comportamiento similar al método anteriormente explicado, pues contiene la misma forma de verificar si existe algún archivo con igual nombre del que se intenta crear. La solución para este comportamiento erróneo es implementar la misma lógica que expresa el código de la figura II.8.b.. 34.
Figure

+7
Documento similar
