Análisis visual de la evolución de temas en Corpus de documentos usando árboles de Similitud
72
0
0
Texto completo
(2) Agradecimiento. Agradezco a CONCYTEC y FONDECYT por brindar la subvención para realizar este trabajo de investigación. A mi familia Andres Rodrı́guez, Lucy Urquiaga, Isabel, Claudia y Noelia por el apoyo en todo momento a lo largo del desarrollo de la tesis. A mi asesora, Mg. Ana Maria cuadros Valdivia, por su inversión de tiempo y conocimientos para lograr los objetivos planeados. A los profesores por brindarme sus conocimientos, los cuales han sido muy útiles para poder finalizar este trabajo. Al único y sabio Dios, el cual sustenta todas las cosas.. I.
(3) Resumen. En este trabajo se propone visualizar la evolución temática de corpus de documentos usando Neighbor joining tree (NJT). Para poder lograr esto es necesario extraer vectores caracterı́sticos que conserven una fecha probabilista aproximada, ademá s conservar su información temática. Para este fin se utilizó trabajos previos como CITATION-Latent Dirichlet Allocation (CITATION-LDA) que posee la ventaja de conservar la información antes mencionada, haciendo uso de las citas bibliográficas como vector caracterı́stico para la extracción del tema. Mediante probabilidad es posible obtener una fecha aproximada del tópico analizado, esto gracias a que cada elemento del vector caracterı́stico es un documento que posee una fecha de publicación. Esto se uso para construir el mapa visual a través del algoritmo Neighbor joining tree antes usado para la construcción de árboles filogenéticos y Radial layout un método para presentar los resultados de una forma visualmente organizada en el cual se pueda apreciar las relaciones de similitud. También se agregó a la visualización interactividad para facilitar el trabajo de análisis de usuario. Los resultados muestran la evolución de temas organizados por similitud de contenido y temporal ademá s de la interacción temática, comparación de similaridades entre tópicos e información entre de metadatos es superior a métodos anteriormente propuestos.. Palabras Clave: Visualización temporal de temas, visualización de la evolución temática, modelos de temas probabilisticos, CITATION-LDA, Neighbor joining tree.. III.
(4) Abstract. In this thesis, we propose to visualize the topic evolution of corpus of documents using NJT. In order to achieve this, it is necessary to extract characteristic vectors that keep an approximate probabilistic date, as well as preserve their thematic information. For this purpose, previous works such as CITATION-LDA were used, which has the advantage of conserving the aforementioned information, making use of bibliographic citations as a characteristic vector for extracting the topic. By means of probability, it is possible to obtain an approximate date of the analyzed topic, this thanks to the fact that each element of the characteristic vector is a document that has a date of publication. This was used to construct the visual map through the algorithm Neighbor joining tree used previously for the construction of phylogenetic trees and Radial layout a method to present the results in a visually organized way in which appreciate the similarity relationships. Interactivity was also added to the visualization to facilitate user analysis work. The results show the evolution of topics organized by content and temporal similarity in addition to the thematic interaction, comparison of similarities between topics and information between metadata is superior to previously proposed methods.. Keywords: Temporal visualization of topics, probabilistic topic models, visualization of topics evolution, CITATION-LDA, Neighbor joining tree.. V.
(5) Índice general. Agradecimiento Resumen . . . . Abstract . . . . . Sumario . . . . . Lista de Figuras Lista de Tablas .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. XIII. 1. Introducción 1.1. Contextualización . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.2. Motivación y Objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3. Organización . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 1 1 4 5. 2. Conceptos Previos 2.1. Consideraciones Iniciales . . . . . . . . . . . . . . . . 2.2. Analisis Visual (Visual analytics) . . . . . . . . . . . . 2.2.1. Visualización e Interacción . . . . . . . . . . . 2.3. Método neigbour joining tree(NJT) . . . . . . . . . . . 2.4. Dynamic Time Warping (DTW) . . . . . . . . . . . . . 2.5. Modelado Probabilistico de Tema . . . . . . . . . . . 2.5.1. Probabilistic Latent Semantic Analysis (PLSA) 2.5.2. Latent Dirichlet Allocation . . . . . . . . . . . 2.6. Consideraciones Finales . . . . . . . . . . . . . . . . 3. Visualización de Temas 3.1. Consideraciones Iniciales . . . . . . . . . . . . 3.2. Técnicas para la visualización de temas . . . 3.2.1. TopicNets . . . . . . . . . . . . . . . . . 3.2.2. MetaToMATo . . . . . . . . . . . . . . . 3.2.3. Topic Model Checking . . . . . . . . . . 3.2.4. Serendip . . . . . . . . . . . . . . . . . . 3.2.5. Visualization topic model using Graph 3.3. Consideraciones Finales . . . . . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . . .. I III V VI XI. . . . . . . . . .. 7 7 7 9 9 11 12 13 17 19. . . . . . . . .. 21 21 21 22 22 23 23 24 25. 4. Visualización de temas evolutivos 27 4.1. Consideraciones Iniciales . . . . . . . . . . . . . . . . . . . . . . . . . 27 4.2. Técnicas de Visualización de temas evolutivos . . . . . . . . . . . . . 27 4.2.1. Evolutinary transition discovery . . . . . . . . . . . . . . . . . 27 VII.
(6) VIII. ÍNDICE GENERAL. 4.2.2. Dynamic Topic Models(DTM) . . . . . . . . . . . . 4.2.3. Detecting Topic Evolution of Scientific Literature 4.2.4. Discovering the Topology of topics . . . . . . . . . 4.2.5. HierarchicalTopics . . . . . . . . . . . . . . . . . . 4.2.6. TopicFlow . . . . . . . . . . . . . . . . . . . . . . . 4.2.7. Probabilistic Generative Model for citations . . . 4.2.8. ThemeDelta . . . . . . . . . . . . . . . . . . . . . . 4.2.9. Hierarchical Topic Evolution Model . . . . . . . . 4.3. Consideraciones Finales . . . . . . . . . . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. 28 29 30 31 32 33 34 35 36. 5. Propuesta de trabajo 5.1. Consideraciones Iniciales . . . . . . . . . . . . . . . . . . . . . . . . 5.2. Etapas del proceso de la propuesta de trabajo . . . . . . . . . . . . 5.2.1. Extracción de caracterı́sticas (Feature Extraction) . . . . . 5.2.2. Matriz de Similitud (Similarity Matrix) . . . . . . . . . . . . 5.2.3. Método de Proyección (Projection Method) . . . . . . . . . . 5.2.4. Visualización e Interacción (Visualization and Interaction) . 5.3. Consideraciones finales . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . .. 37 37 38 38 40 43 44 49. 6. Caso de estudio 51 6.1. Consideraciones Iniciales . . . . . . . . . . . . . . . . . . . . . . . . . 51 6.2. Estudio de Caso: Conjunto de Datos PUBMED . . . . . . . . . . . . 51 6.2.1. Análisis de Evolución Temática en PUBMED . . . . . . . . . . 52 7. Conclusiones y Trabajos Futuros 61 7.1. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61 7.2. Contribución . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61 7.3. Trabajos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62 Referencias Bibliográficas. 66.
(7) Índice de figuras. 1.1. Detalle de de propuesta, visión general. . . . . . . . . . . . . . . . . 2.1. Visual Analytics integra la visualización cientı́fica y de información con las disciplinas centrales adyacentes: gestión y análisis de datos y percepción y cognición humana. (Keim et al. (2008)) . . . . . . . 2.2. Visualización de las señales EEG de diferentes pacientes cada uno con seis etapas de sueño . . . . . . . . . . . . . . . . . . . . . . . . . 2.3. Esquema de reconstrucción del algorı́tmo neigbour joining tree , (a) matriz de entrada al algoritmo, (b) resultado de la reconstrucción (Valdivia, 2007) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4. Esquema de reconstrucción del algoritmo neigbour joining tree 2.4 2.5. Ejemplo de warping path Müller (2007) . . . . . . . . . . . . . . . . . 2.6. Tareas de análisis de temas (Zhai and Massung (2016)) . . . . . . . 2.7. Tareas de análisis en múltiples temas (Zhai and Massung (2016)) . 2.8. Generación de palabras de una mixtura de múltiples temas (Zhai and Massung (2016)) . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.9. Función de verosimilitud de PLSA (Zhai and Massung (2016)) . . . 2.10.M-Step de el EM Algorithm para estimación PLSA (Zhai and Massung (2016)) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.11.M-Step de el EM Algorithm para estimación PLSA (Zhai and Massung (2016)) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.12.Ilustración de LDA: PLSA con Dirichlet prior. (Zhai and Massung (2016)) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.13.Distribución de palabras en el tema k y la distribución de temas en el documento d (fuente: datacamp) . . . . . . . . . . . . . . . . . . . 2.14.Algoritmo LDA (Blei et al. (2003)) . . . . . . . . . . . . . . . . . . . .. 5. 8 9. 10 10 11 12 14 15 16 16 17 18 18 19. 3.1. Captura de pantalla de la herramienta TopicNets donde se muestra los keywords relacionados por temas por diferentes colores. Gretarsson et al. (2012) . . . . . . . . . . . . . . . . . . . . . . . . . . 22 3.2. Herramienta MetaToMATo en la cual se muestra temas y metadatos Snyder et al. (2013) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 3.3. Captura de pantalla de Topic Model Checking donde se puede ver el análisis de un tema con diferentes nú mero de temas. Murdock and Allen (2015) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 IX.
(8) X. ÍNDICE DE FIGURAS 3.4. Las tres vistas principales de Serendip: CorpusViewer, TextViewer y RankViewer. Alexander et al. (2014) . . . . . . . . . . . . . . . . . . 24 3.5. Los temas que comparten términos clave está n vinculados y residen más cerca, la fortaleza del enlace representa cómo distinguir un término clave es de un tema, el tamaño del nodo del tema representa la prevalencia en el corpus. Rönnqvist et al. (2014) 25 4.1. Esquema de procesamiento de Evolutionary transition Discovery . 4.2. Grafo propuesto en Dynamic Topic Models(DTM) que representa cada tema por un conjunto de palabras de manera anual y en la parte de inferior, la fuerza de cada tema en una serie de tiempo.(Blei and Lafferty, 2006) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.3. Detección de tópicos en artı́culos cientı́ficos de manera anual He et al. (2009) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.4. Topologı́a de temas donde las relaciones son definidas por las citaciones Jo et al. (2011) . . . . . . . . . . . . . . . . . . . . . . . . . 4.5. Arquitectura del sistema HierarchicalTopics Dou et al. (2013) . . . 4.6. Resumen del sistema TopicFlow Malik et al. (2013) . . . . . . . . . . 4.7. Cada nodo representa un tema y el tamaño es su importancia el color verde son los temas nuevos y los rojos los más antiguos Wang et al. (2013) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.8. Evolución de los temas a través del los años 1993-2007 Wang et al. (2013) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.9. Visualización de la campaña de Barack Obama en ThemeDelta Gad et al. (2015) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.10.Descubriendo la evolución de temas en el conjunto de datos Addresses Song et al. (2016) . . . . . . . . . . . . . . . . . . . . . . .. 28. 5.1. Proceso de obtención de la propuesta de visualización . . . . . . . . 5.2. (Izquierda) Enfoque de LDA para extraer temas (palabras clave), (Derecha) enfoque de CITATION-LDA para extraer temas (conjunto de citas). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.3. Resultado de CITATION-LDA. Distribución de probabilidad en citas 5.4. matriz de similitud por contenido en 2D . . . . . . . . . . . . . . . . 5.5. matriz de similitud por contenido en 3D . . . . . . . . . . . . . . . . 5.6. matriz de similitud resta de fechas en 2D . . . . . . . . . . . . . . . 5.7. matriz de similitud resta de fechas en 3D . . . . . . . . . . . . . . . 5.8. matriz de similitud algoritmo propuesto, vista 2D, k = 1000 . . . . 5.9. matriz de similitud algoritmo propuesto, vista en 3D, k = 1000 . . . 5.10.matriz de similitud resta de fechas en 2D . . . . . . . . . . . . . . . 5.11.matriz de similitud resta de fechas en 3D . . . . . . . . . . . . . . . 5.12.Esquema de reconstrucción del algorı́tmo neigbour joining tree . . 5.13.Vista principal de nuestra propuesta de visualización . . . . . . . . 5.14.Sección principal (A), NJT aplicado a temas . . . . . . . . . . . . . . 5.15.Sección (B), vector caracterı́stico de un tema seleccionado, ordenado cronológicamente . . . . . . . . . . . . . . . . . . . . . . . 5.16.Top Venues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.17.Top Words . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.18.WordCloud . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 38. 29 30 31 32 33. 34 34 35 36. 39 40 41 41 42 42 43 43 43 43 44 45 46 46 47 47 47.
(9) ÍNDICE DE FIGURAS 5.19.Sección (B), detalle del vector caracterı́stico, al pasar el mouse aparecen mayor información del documento . . . . . . . . . . . . . . 5.20.Selección de tres temas, y comparación en la parte inferior de los vectores caracterı́sticos. . . . . . . . . . . . . . . . . . . . . . . . . . . 5.21.Árbol de similitud por contenido de los artı́culos que conforman el tema 12 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.22.Árbol de similitud por contenido de los artı́culos que conforman el tema 8 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.23.Serie temporal de el conjunto de documentos seleccionado . . . . . 6.1. Grupo de temas usando NJT sin colorear. Cada nodo representa un tema y la proximidad entre nodos significa que tan similares son en contenido. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6.2. Visualizando la proporción de los venues en cada tema. . . . . . . . 6.3. Grupo de temas usando NJT coloreado por venues . . . . . . . . . . 6.4. Grupo de temas usando NJT coloreado por venues . . . . . . . . . . 6.5. Words cloud del grupo A . . . . . . . . . . . . . . . . . . . . . . . . . 6.7. Búsqueda de la palabra malaria en los 20 temas y visualizado en el tamaño del nodo . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6.8. Búsqueda de la palabra rna en los 20 temas y visualizado en el tamaño del nodo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6.6. Words cloud del grupo B . . . . . . . . . . . . . . . . . . . . . . . . . 6.9. NJT temá tico solo por contenido y distancia Dynamic Time Warping (DTW) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6.10.NJT temático solo por contenido y distancia y distancia coseno . . 6.11.Nuestro enfoque, unión de matrices por contenido y tiempo con distancia DTW . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6.12.Comparación de visualizaciones con diferentes enfoques. . . . . . . 6.13.Tres muestras: A (Temas 2 y 16), B (18 y 9), C (temas 3, 8 y 0) . . . 6.14.Evolución de los temas: muestra A Temas 2 (rojo) y 16 (azul) . . . . 6.15.Evolución de los temas: muestra B Temas 18 (rojo) y 9 (azul) . . . . 6.16.Evolución de los temas: muestra C Temas 3 (verde), 8 (morado) y 0 (rojo) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. XI. 47 47 48 48 49. 53 53 54 55 55 56 56 56 57 57 57 57 58 59 59 60.
(10) Índice de cuadros. 6.1. 6.2. 6.3. 6.4. 6.5. 6.6. 6.7. 6.8.. Entropı́a en distintos número de grupos en LDA-CITATION Muestra A (Temas 2) año: 2007.567 . . . . . . . . . . . . . Muestra A (Temas 16) año: 2006.636 . . . . . . . . . . . . . muestra B (temas 18), año: 2009.123 . . . . . . . . . . . . . muestra B (temas 9), año: 2009.625 . . . . . . . . . . . . . Muestra C (temas 3), año: 2009.744 . . . . . . . . . . . . . Muestra C (temas 8), año: 2010.120 . . . . . . . . . . . . . Muestra C (temas 0), año: 2010.419 . . . . . . . . . . . . .. XIII. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. 52 58 58 59 59 59 60 60.
(11) CAP ÍTULO 1. Introducció n. 1.1. n. Contextualizació. En la actualidad se están creando datos de manera acelerada. En el año 2010 se generó 1012 GB de datos habiendo sido obtenidos de diferentes medios (Villars et al., 2011). Esto gracias al aumento de tecnologı́as que hace posible registrar gran parte de nuestra actividad. Como consecuencia el procesamiento automático para la generación de conocimiento útil se ha convertido en un reto debido a la gran acumulación de datos imposibles de poder analizar de manera convencional. Gran parte de esta aumento en la cantidad de datos viene relacionado con las colecciones de artı́culos cientı́ficos. La publicación colectiva es alrededor 2,5 millones y su crecimiento ha sido del 3 % y un 3,5 % al año Ware and Mabe (2015). Como resultado su exploración ha despertado el interés de la comunidad cientı́fica dada la importancia al momento de iniciar una nueva investigación. Debido a esta gran cantidad de datos, explorar artı́culos cientı́ficos de manera individual se puede convertir en una tarea ardua y difı́cil, una mejor manera de extraer información ú til es aplicando métodos no supervisados para la extracción de temas y evaluar los resultados a través de análisis visual para una mayor comprensión de la información. Dentro de los principales métodos no supervisadas están las técnicas de modelado de temas probabilisticos. Entre las más conocidas y que demuestran mayor precisión están Probabilistic Latent Semantic Analysis (PLSA) Hofmann (1999) y Latent Dirichlet Allocation (LDA) Blei et al. (2003), una comparativa de estas técnicas se encuentra en Alghamdi and Alfalqi (2015). Estos métodos se encargan de extraer tópicos de colecciones de documentos analizando cual 1.
(12) es la probabilidad de que una palabra pertenezca a un tema y a la vez cual es la probabilidad de que pertenezca a un artı́culo, de esta forma tras varios recorridos por los datos, el algoritmo es capaz de agrupar los temas existentes según un número de temas que ha sido preestablecido en el inicio del proceso. Las técnicas de visualización temas, por su parte proporcionan un medio conveniente para representar corpus de documentos en formas visuales que permiten a los usuarios comprender por completo las principales ideas de los datos. A su vez, este proceso facilita la comparación de datos y el reconocimiento de patrones Cao and Cui (2016). Los principales trabajos relacionados con visualización de temas como los que mostraremos a continuación hicieron uso del método probabilista LDA. En Gretarsson et al. (2012) y Snyder et al. (2013) proponen herramientas web de análisis visual interactivo, Gretarsson et al. (2012) usa grafos para la visualización usando el método collapsed variational inference algorithm (CVB0) y en Snyder et al. (2013) visualiza los temas de manera convencional con la ventaja que usa los metadatos para ayudar al momento de hacer la exploración temática. Otro trabajo relacionado que usa los metadatos en el análisis visual es Alexander et al. (2014) un añadido importante es que permite visualizar las palabras clave de cada tema en cada documento. Murdock and Allen (2015) hace uso del análisis visual para el problema de elección de parámetros en el modelado de tema. Y finalmente en Rönnqvist et al. (2014) extrae los temas para visualizar las relaciones mediante grafos a través de sus palabras claves. Todas estas formas de extracción y visualización de temas presentan las desventajas heredades de LDA que es que cada tema esta representado por un conjunto de palabras claves y no por documentos. Otra desventaja es que cuando se tiene gran cantidad de documentos, el componente temporal se convierte en una caracterı́stica importante el cual no está considerado en los trabajos anteriores. Para esto surgieron conceptos tales como visualización de temas evolutivos que es un área que involucra tanto la extracción de temas y la visualización para el descubrimiento de patrones temporales en datos del tipo textual. Se entiende por temas evolutivos la similitud de dos temas siendo uno más reciente que el otro. Estos procesan el componente temporal ya sea dividiendo un corpus en lotes pequeños por el atributo año o haciendo uso de las referencias bibliográ ficas para determinar el orden de publicación de los artı́culos. Para este fin los metadatos como el autor, referencias bibliográficas y las fechas de publicació n son caracterı́sticas importantes para poder medir la relevancia de artı́culos, importancia de temas, autores destacados (Sun et al., 2013) etc. Para la visualización de temas evolutivos, los primeros enfoques usaron el algoritmo PLSA para la extracción de temas en un conjunto de datos que previamente habı́an sido segmentados en intervalos de tiempo, para que 2.
(13) finalmente el calculado de la evolución temática sea viendo la relación de dos temas en diferentes tiempos y verificando su similitud a través de un umbral Mei and Zhai (2005). Trabajos posteriores siguieron enfoques similares en Blei and Lafferty (2006), He et al. (2009) y Malik et al. (2013) usan LDA para la extracción de temas con la diferencia que en He et al. (2009) hace uso de la red de citaciones. En Dou et al. (2013) propone hierarchical topic model (hLDA) una extensión de LDA para extraer una jerarquı́a de temas. En este trabajo con el fin de visualizar los temas segmenta el corpus de texto para terminar aplicando TimeRiver. La visualización en cuanto a los trabajos antes mencionados está sujeto a la pre-segmentación del conjunto de datos que generalmente es anual, esto como se detallará más adelante constituye una desventaja pues está sujeto a la definición del tamaño fijo de ventana de tiempo. Otros trabajos intentaron solucionar el problema de la ventaja fija para la segmentación de documentos entre ellos Song et al. (2016) propone un modelo jerárquico de evolución de temas (HTEM) que organiza los temas en una jerarquı́a temporal que muestra su evolución. Es de granularidad temporal variable, que hasta cierto grado es una ventaja, aun ası́ se debe especificar ya sea dı́as meses o años. Gad et al. (2015) es un sistema de análisis visual para la extracción de tendencias temporales en datos textuales, usa el algoritmo LDA con su propuesta de segmentación del corpus en longitud variable de ventana. Para la visualización usa una modificación de TimeRiver con palabras claves y conexiones entre temas. Aunque presenta una ventaja en cuanto a la selección de la ventana variable aun se debe definir la granularidad que es decidida por expertos. Para solucionar la segmentación de los datos en Jo et al. (2011) se propuso caracterizar un tema como una unidad cuantificada de cambio evolutivo en otras palabras no hace una segmentación previa del conjunto de datos en intervalos de tiempo. Los temas descubiertos son luego conectados para formar un grafo evolutivo de tópicos, hace uso del conteo de citaciones para la relaciones en el grafo evolutivo. En Wang et al. (2013) usa las citas bibliográficas en vez de las palabras de cada documento para entrenar el algoritmo LDA, propone también la mejora de eliminar la segmentación previa de los documentos por algú n intervalo de fechas. A pesar de presentar esta ventaja, la visualización solo muestra en parte los resultados haciendo falta una exploración más detallada. En resumen los trabajos previos, si bien es cierto que logran extraer correctamente temas de corpus de texto, en la mayorı́a de investigaciones cada tema esta representado como un conjunto de palabras que da como resultado la perdida de correspondencia entre tema y artı́culo, otro inconveniente es que no presentan una adecuada presentación de los datos al no poseer interacción en sus resultados para un análisis visual pertinente además la evolución temática 3.
(14) es difı́cil de interpretar cuando el conjunto de datos es grande. Por consiguiente, se pueden presentar mejorı́as en los aspectos relacionados a los problemas existentes en cuanto a la visualización de temas y la evolución temática, estas mejorı́as estarán concentradas en: (i) La visualización temas no muestran adecuadamente la evolución temporal. (ii) La forma de abordar el procesamiento temporal es por medio de lotes de documentos, lo que hace que los resultados dependan mucho del tamaño de las ventanas o mejor dicho del tamaño de cada lote. (iii) La exploración de temas solo es en el ámbito de palabras y no de documentos, es necesario enlazar temas-documentos. Para esto se investigará los temas relacionados con la proyección NJT y modelos evolutivos temáticos. El método NJT (Saitou and Nei, 1987) usado en proyección de documentos en (Valdivia, 2007), ha demostrado conservar una mejor relación local entre los documentos proyectados como también la visión global de la visualización. Esto se aplicará a temas haciendo un adecuado preprocesamiento de los datos para lograr los objetivos.. 1.2.. Motivació n y Objetivo. Como antes se habı́a mencionado, identificar información útil de corpus de documentos constituye una ardua tarea. Las colecciones de artı́culos cientı́ficos forman parte de esta creciente producción de datos. Este tipo de datos tienen caracterı́sticas propias como son las referencias bibliográficas de trabajos relacionados, la temporalidad (fecha de publicación del artı́culo cientı́fico). La extracción de temas es una manera de obtener conocimiento de estos tipos de corpus, para poder visualizar de manera correcta la relación entre temas y su evolución se usará la técnica NJT, este algoritmo conserva de forma notable las relaciones de similitud entre objetos de forma local como también muestra una correcta relación global, necesarias para una adecuada visualización. Como limitación está el hecho de que el Neighbor joining no ha sido aplicado a temas. Por consiguiente en este trabajo se tomaran las ventajas de los modelos de evolución temática como las del método NJT para visualización de temas que tenga la facultad de mostrar no solo las relaciones de similitud temática sino también su evolución tomando en cuenta el atributo temporal, siendo el proceso como se muestra en la 1.1 donde se puede ver la adquisición de documentos, seguido por el pre-procesamiento, luego estos datos son procesados con CITATION-LDA que tendrá como resultado temas como una distribución de citas (esto se detallará más adelante). Estos datos será n introducidos al algoritmo NJT para obtener las relaciones de similitud y evolución temática. 4.
(15) Figura 1.1: Detalle de de propuesta, visión general.. De esta forma el objetivo principal de este proyecto es diseñar una visualización que muestren la evolución temática a través de árboles de similitud (Neighbor joining) de modo que sea apropiado para tareas de análisis y exploración en temas. Para lograr este objetivo principal es necesario también realizar objetivos secundarios tales como: Evaluar la mejor medida de distancia que refleje la evolución de temas en una matriz de similitud, Analizar los métodos de extracción de temas probabilistas que tomen en consideración el componente temporal, lograr obtener una matriz de similitud que contenga información temporal, y elaborar un prototipo de herramienta que permita la interacción con el usuario de los resultados obtenidos.. 1.3.. Organización. Este trabajo está organizado en 6 capı́tulos, incluyendo esta introducción y la siguiente estructura: en el capitulo 2 se presentan los conceptos relacionados con modelado probabilistico de temas. En el capı́tulo 3 y capı́tulo 4 se describen los métodos más recientes en cuanto a visualización de temas y visualización de temas evolutivos respectivamente. En el capı́tulo 5 la propuesta de trabajo y finalmente en el capı́tulo 6 caso de estudio y conclusiones.. 5.
(16) CAP ÍTULO 2. Conceptos Previos. 2.1.. Consideraciones Iniciales. En los conceptos previos se analizarán los temas relacionados con Analisis Visual, el cual es un fundamento principal en el trabajo relacionado ı́ntimamente con la propuesta. La teoria de Método neigbour joining tree(NJT), pues este es el algoritmo que nos permitirá tener la estructura de relaciones entre contenido y tiempo. La medida de similitud Dynamic Time Warping (DTW) que será un concepto importante en el momento de analizar las relaciones de similitud entre vectores de temas. Y por ultimo Modelado Probabilistico de Temas el cual nos permitirá extraer los temas de un corpus de documentos.. 2.2.. Analisis Visual (Visual analytics). Analisis visual surge como consecuencia del incremento de la cantidad de datos, y a la necesidad de poder interactuar con la información obtenida de algún procesamiento previo, donde la capacidad analı́tica humana puede ser crucial para la detección de patrones imposibles de distinguir de manera automática, como se muestra en la imagen 2.2 en la cual los patrones de sueño pueden ser evaluados por un experto gracias no solo al procesamiento previo sino a la visualización de datos en dos dimensiones. El primer autor en acuñar el termino lo definió como: El análisis visual es una consecuencia del campo de la visualización cientı́fica y de la información. Se refiere a ”la ciencia del razonamiento analı́tico facilitada por las interfaces visuales interactivas”Cook and Thomas (2005). Otra definición importante se encuentra en Seebacher et al. (2017) donde se define como el medio a través 7.
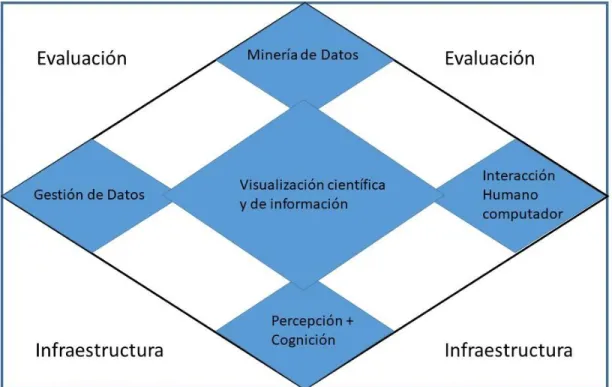
(17) del cual los humanos y las computadoras cooperan utilizando sus distintas capacidades para obtener los resultados más efectivos. Visualización de datos involucra varias áreas relacionadas las cuales trabajan juntas para lograr los objetivos, esto se muestra en la figura 2.1. Para que una investigación este dentro del marco de Análisis visual debe tener las siguientes caracterı́sticas claves tales como se define en Seebacher et al. (2017) y son: Énfasis en el análisis de datos, resolución de problemas y/o toma de decisiones. Aprovechando el procesamiento computacional mediante la aplicación de técnicas automatizadas para el procesamiento de datos, algoritmos de descubrimiento de conocimiento, etc. Participación activa de un ser humano en el proceso analı́tico a través de interfaces visuales interactivas.. Figura 2.1: Visual Analytics integra la visualización cientı́fica y de información con las disciplinas centrales adyacentes: gestión y análisis de datos y percepción y cognición humana. (Keim et al. (2008)). 8.
(18) Figura 2.2: Visualización de las señales EEG de diferentes pacientes cada uno con seis etapas de sueño. 2.2.1. Visualizació n e Interacció n Mostrar los resultados de algún tipo de análisis de datos de manera estática resulta muchas veces ser inadecuado cuando se quieren obtener información relevante para un analista. la incorporación del usuarios al capturar sus comentarios y permitirles modificar la consulta y/o la medida de similitud ya mejora el rendimiento Seebacher et al. (2016). Sin embargo, visualizar un espacio de similitud abstracto y explicar por qué se encontraron o no los resultados es altamente dependiente de la aplicación y del usuario esto puede llevar a situaciones en las que los usuarios desconocen de dónde provienen sus conocimientos y cómo las interacciones con el sistema generaron los resultados Seebacher et al. (2017).. 2.3.. Mé todo neigbour joining tree(NJT). El método Neighbor joining (Saitou and Nei, 1987) fue creado con para la reconstrucción filogenética de secuencias de ADN. También ha sido usado en proyección de documentos en (Valdivia, 2007), organización de imágenes Eler et al. (2009) Paiva et al. (2011), visualización de colecciones musicales Soriano et al. (2014) y ha demostrado su utilidad para dar sentido gráfico a diseños visuales Li et al. (2015). Neighbor joining ha demostrado conservar una mejor relación local entre los documentos proyectados como también la visión global del mapeamiento. La 9.
(19) idea principal de este algoritmo es ir agrupando los objetos más próximos hasta reconstruir completamente la estructura de relaciones de todos los elementos, teniendo como entrada una matriz y como estructura de salida la reconstrucción filogenética 5.12.. Figura 2.3: Esquema de reconstrucción del algorı́tmo neigbour joining tree , (a) matriz de entrada al algoritmo, (b) resultado de la reconstrucción (Valdivia, 2007). Para construir el árbol NJ necesitamos los n objetos y las medidas de similitud Dij . Para cada paso el algoritmo selecciona un par de nodos (i, j) con la mı́nima suma de longitud de rama Sij . es necesario también ir evaluando los factores Lix y Ljx . 2.4 (Cuadros et al., 2007). Figura 2.4: Esquema de reconstrucción del algoritmo neigbour joining tree 2.4. 10.
(20) 2.4. Dynamic Time Warping (DTW) Cuando se hace desea hacer una medida de similitud generalmente se asume que las dos series de tiempo que se quiere evaluar están alineadas en el eje-X, para solucionar este problema esta el algoritmos Dynamic Time Warping que consiste algoritmicamente como se explica en Müller (2007): Tenemos dos series de tiempo Q Y C de longitud n y m respectivamente donde: Q = q1 , q2 , ..., qi , ...qn. (2.1). Q = c1 , c2 , ..., cj , ...cm. (2.2). para alinear estas dos secuencias usando DTW se construye un matriz n por m donde el elemento (ith , j th ) de la matriz contiene las distancias d(qi , cj ) entre los dos puntos qi y ci (comú nmente se usa la distancia euclidiana ası́ que d(qi , cj ) = (qi , cj )2 ). cada elemento de la matriz (i, j) corresponde a la alineación entre los puntos qi y cj . Esto se ilustra en la (figura 2.5). Un Warping path W es un conjunto de elementos de la matriz que define un mapeo entre Q Y C. El elemento k th de W es definido como wk = (i, j)k ası́ que tenemos: W = w1 , w2 , ..., wk , ..., wk max(m, n) ≤ k < m + n + 1. (2.3). El path warping esta sujeto a varias restricciones como son, condiciones de limites, continuidad, nonotonicidad, que están hechas para optimizar el rendimiento de su calculo.. Figura 2.5: Ejemplo de warping path Müller (2007). 11.
(21) 2.5. Modelado Probabilistico de Temas Los modelos de temas probabilisticos son métodos sin supervisar usados para descubrir temas presentes en conjuntos de texto. Un tema se puede definir como la idea principal ya sea de una oración párrafo, segmento de texto u otra granularidad. La utilidad de estos métodos de extracción automática de temas radica en el hecho que en la actualidad numerosas aplicaciones hacen uso de análisis de temas, redes sociales, medios de comunicación como noticias escritas, y toda fuente donde exista información textual. Todos estos datos debido a su gran tamaño difı́cilmente serán procesados de forma manual. Análisis de temas usando métodos probabilisticos ofrecen una solución para la extracción de temas que será de utilidad para los fines donde se desee aplicar. En la figura 2.6 se puede ver la idea global que hay detrás del análisis de temas, donde se tiene un número determinado de temas y un conjunto de textos. La función principal como lo muestra la imagen es extraer cual es el grado de pertenencia de cada documento en cada tema.. Figura 2.6: Tareas de análisis de temas (Zhai and Massung (2016)). El algoritmo general sin hacer detalles en los aspectos matemáticos es el siguiente Zhai and Massung (2016): Entrada • Una colección de N documentos de texto C = {d1 , ...dN } • Número de temas: k 12.
(22) Salida • k temas: {θ1 , ..., θk } • Cobertura de cada tema en cada di : {πi1 , ..., πik }. Pk. j=1 πij. =1. • πij = probabilidad de cobertura del tema θj en el documento di Este algoritmo presenta como entrada una colección de datos y además por ser un método sin supervisar se debe especificar el número de temas. Como salida se tiene los k temas, la cobertura de cada tema en cada documento di en probabilidades. La manera intuitiva de definir un tema podrı́a ser a través de un té rmino, Estos términos que representarı́an cada tema se conseguirı́an mediante alguna técnica como por ejemplo analizar cuales son las palabras más recurrentes en un conjunto de textos luego para calcular la cobertura de un tema en cada documento, solo se contarı́a el nú mero de ocurrencia de ese termino-tema en el documento. Este enfoque de representar cada tema por una palabra trae consigo inconvenientes tales como la dificultad de representar temas complejos con una sola palabra y la ambigüedad de algunos términos. Para solucionar estos inconvenientes se determina la representación de un tema no solo como un término sino como una distribución de palabras, de esta forma se soluciona los problemas de la representación de temas con una sola palabra. Ahora para hallar la salida del algoritmo principal no es tan fácil como en el caso donde solo era una palabra por tema, en este caso es necesario usar un Modelo generativo. Un Modelo generativo es una manera de hacer uso de estadı́stica para análisis de textos, dicho de otra forma se genera un modelo de como las palabras han sido generadas, este es el que finalmente aprenderá del conjunto de datos de entrada.. 2.5.1. Probabilistic Latent Semantic Analysis (PLSA) PLSA es un modelo de temas que hace uso de Modelos Mixtos. Un Modelo Mixto es aquel que infiere que en la generación de un documento intervino más de un modelo generador, esto puede entenderse como que un documento ha sido generado por varios temas. PLSA está diseñado para extraer los temas de un conjunto de documentos además de calcular cual es la cobertura de cada tema en cada documento, para hacer esto se debe asumir dos cosas principales: Cada tema puede ser representado como una distribución de palabras. Un documento de texto es una muestra de la extracción de palabras de un modelo probabilı́stico. Como se muestra en la imagen 2.7 se tiene la entrada, la salida, un conjunto de datos de textos, los temas son representados por distribuciones y cada 13.
(23) documento por las probabilidades de cobertura de cada tema, PLSA se encarga de resolver esta tarea.. Figura 2.7: Tareas de análisis en múltiples temas (Zhai and Massung (2016)). En la figura 2.8 se aprecia el proceso de generación de una palabra que como se explica en Zhai and Massung (2016) consta de dos pasos: el primero elegir un componente del modelo para usar esta decisión está controlada por ambos un parámetro λB (denota la probabilidad de elegir el modelo Background) y el conjunto de πd,i (denota la probabilidad de elegir un tema θi si se decide no usar el modelo Background). Si no se usa el modelo Background, se debe elegir P uno de los k temas, que tiene la restricción ki=1 πd,i = 1 ası́, la probabilidad de elegir el modelo Background es λB mientras la probabilidad e elegir un tema θi es (1 − θi )θd,i . Una vez decidido que componente de la distribución de palabras usar, el segundo paso en el proceso de generación es extraer una palabra de la distribución seleccionada. Una vez diseñado el modelo generativo, la función de verosimilitud de esta probabilidad es una suma sobre todas las diferentes maneras de generar la palabra. 14.
(24) Figura 2.8: Generación de palabras de una mixtura de múltiples temas (Zhai and Massung (2016)). La función de verosimilitud se observa en la figura 2.9 en el cual la probabilidad de observar una palabra es la suma tanto del modelo Backgraund con los otros modelos de temas. Asumiendo que las palabras en un documento son generados independientemente, se asume que la función de verosimilitud para un documento d es la segunda ecuación de la figura 2.9 y que la función de verosimilitud para la colección entera C está dado por la tercera ecuación.. Después de obtener la función verosimilitud, el siguiente paso es realizar la estimación de los parámetros a través de EM algorithm para calcular la máxima verosimilitud para PLSA. El EM algorithm consta de dos pasos el E-step 2.10 y M-step 2.11. En el paso E-step, introducimos más variables ocultas por el motivo de tener más temas. La variable oculta z, que es un indicador de tema para cada palabra, este primer paso hace uso de la regla de Bayes para inferir la probabilidad de cada valor para z, 15.
(25) Figura 2.9: Función de verosimilitud de PLSA (Zhai and Massung (2016)). Figura 2.10: M-Step de el EM Algorithm para estimación PLSA (Zhai and Massung (2016)). 16.
(26) Figura 2.11: M-Step de el EM Algorithm para estimación PLSA (Zhai and Massung (2016)). 2.5.2. Latent Dirichlet Allocation LDA es una versión bayesiana del modelo PLSA con conocimiento a priori. Las ventajas que tiene LDA sobre PLSA es que posee un modelo generativo para documentos, a diferencia de PLSA que solo era para palabras, además de poder dar la probabilidad de un documento del cual no ha sido entrenado, en otras palabras un documento nuevo. En LDA, supone que la distribución de cobertura de tema (una distribución multinomial) para cada documento se extrae de una distribución anterior de Dirichlet, que define una distribución en todo el espacio de los parámetros de una distribución multinomial, es decir, un vector de probabilidades de temas. Del mismo modo, también se supone que todas las distribuciones de palabras que representan los temas latentes en una colección de texto provienen de otra distribución de Dirichlet. En PLSA, se supone que tanto la distribución de cobertura del tema como las distribuciones de palabras son parámetros (desconocidos) en el modelo. En LDA, ya no son parámetros del modelo, ya que se supone que provienen de las correspondientes distribuciones de Dirichlet (previas). Por lo tanto, LDA solo tiene parámetros para caracterizar estos dos tipos de distribuciones de Dirichlet. Una vez que estos parámetros sean fijos, el comportamiento de estas dos distribuciones de Dirichlet serı́a fijo, y ası́ el comportamiento de todo el modelo generativo también serı́a fijo. Una vez que 17.
(27) hemos muestreado todas las distribuciones de palabras para toda la colección (que comparte estos temas) y la distribución de cobertura de tema para un documento, el resto del proceso de generación de palabras en el documento es exactamente el mismo que en PLSA. En la imagen 2.12 se puede observar el algoritmo PLSA con la prioridad dirichlet que viene a ser al algoritmo LDA.. Figura 2.12: Ilustración de LDA: PLSA con Dirichlet prior. (Zhai and Massung (2016)). Figura 2.13: Distribución de palabras en el tema k y la distribución de temas en el documento d (fuente: datacamp). 18.
(28) En el algoritmo 2.14 solo se requiere nd,k el número de palabras asignadas al tema k en el documento d y nd,k , el número de veces que la palabra w está asignado al tema. El resultado practico de aplicar LDA será una distribución de temas en cada documento y una distribución de palabras para cada tema como muestra la imagen 2.13. Figura 2.14: Algoritmo LDA (Blei et al. (2003)). 2.6. Consideraciones Finales. En este capitulo se presentaron las principales técnicas para la extracción de temas de colecciones de documentos. LDA presenta algunas ventajas con respecto a su predecesor PLSA como en hecho de poder hacer evaluaciones de documentos nuevos entre otras. Una desventaja de estos métodos es que de cada tema no se puede obtener una fecha probabilista aproximada por el hecho de que un tema esta representado por un conjunto de palabras que no conservan información temporal. Para esto se necesita explorar las mejoras a estos modelos como también hacer uso de los metadatos de los datos usados.. 19.
(29) CAP ÍTULO 3. Visualizació n de Temas. 3.1. Consideraciones Iniciales Visualización de temas es una área interesante de investigación, pues a comparación de las visualizaciones a nivel solamente de palabras, tienen la capacidad de capturar la semántica de los datos. Como resultado producen visualizaciones que son más fáciles de interpretar Cao and Cui (2016). Las actuales investigaciones han desarrollado numerosas técnicas para el procesamiento automático de texto enfocados a la extracción de temas, una de ellas es el enfoque estadı́stico. Un tema se podrı́a definir como la idea principal en un texto, su correcta extracción podrı́a servir en muchas áreas como en el análisis de flujos de twitter relacionados con un producto, revisiones bibliográficas temáticas entre otros. (Topic Analysis) son técnicas sin supervisar de text mining basadas en probabilidades, siendo ú tiles para descubrir temas latentes en datos textuales (Zhai and Massung, 2016). Una vez extraı́dos los temas, es necesario presentarlos de manera que un usuario pueda llevar el proceso de análisis de manera rápida, para esto se han propuesto varios métodos, los cuales se detallan a continuación.. 3.2. Técnicas para la visualizació n de temas En las siguientes técnicas propuestas para la visualización de temas, se explorará en cada investigación la manera que obtuvo los tópicos, además de analizar como se visualizaron los resultados obtenidos. Las técnicas a continuación son los trabajos más recientes en esta área de estudio. 21.
(30) 3.2.1. TopicNets TopicNets Gretarsson et al. (2012) es una herramienta web de análisis visual e interactivo que hace uso de modelos de temas para grandes conjuntos de datos. Los datos son ingresados a esta herramienta luego se les aplica modelado de temas LDA. Los resultados son procesado aplicando un algoritmo de composición de grafos para finalmente visualizarlos y dar interacción. La forma de visualizar los resultados en TopicNets, es la exploración interactiva de temas que permite visualizar relaciones, subconjuntos de documentos y documentos individuales. La herramienta web puede verse en la figura 3.1 El algoritmo usado para generar el grafo de visualización es collapsed variational inference algorithm (CVB0) que mantiene un enlace entre cada tema segú n un umbral dado. TopicNets tiene otras funcionalidades de interacción que pueden ser examinadas en Gretarsson et al. (2012).. Figura 3.1: Captura de pantalla de la herramienta TopicNets donde se muestra los keywords relacionados por temas por diferentes colores. Gretarsson et al. (2012). 3.2.2. MetaToMATo MetaToMATo (Metadata y Topic Model Analysis Toolkit) Snyder et al. (2013) es una herramienta visual web (figura 3.3) que integra los temas obtenidos por LDA y los metadatos que están relacionados con el conjunto de datos de entrada. MetaToMATo hace uso de los metadatos para filtrar de una forma más rápida los temas que se están investigando de manera que se facilite la interacción del sistema con el usuario. 22.
(31) Figura 3.2: Herramienta MetaToMATo en la cual se muestra temas y metadatos Snyder et al. (2013). 3.2.3. Topic Model Checking Topic Model Checking Murdock and Allen (2015) da una solución visual para la elección de parámetros correctos para el modelado de temas en este caso LDA. Esto toma en cuenta la perspectiva de usuarios encargados de establecer el modelo donde el número de temas no es decisión fácil de tomar pues es un método sin supervisar. TopicExplorer también ayuda en el momento de tomar decisiones referentes a qué palabras ignorar (”Stop List”) y cual es el número adecuado de veces para ejecutar el algoritmo de modelado de temas, debido a su aproximación a modelos bayesianos donde cada resultado puede ser diferente al anterior. La figura 3.3 muestra el sistema Topic Model Checking para el adecuado elección de número de temas.. Figura 3.3: Captura de pantalla de Topic Model Checking donde se puede ver el análisis de un tema con diferentes número de temas. Murdock and Allen (2015). 3.2.4. Serendip En Alexander et al. (2014) hace uso de modelos de tópicos LDA que incorpora los datos y metadatos, además de introducir una técnica para visualizar clasificaciones de palabras individuales. También usa técnicas de interacción 23.
(32) y métodos estadı́sticos. El sistema Serendip permite a los usuarios hacer exploraciones sobre colecciones de textos, pasajes dentro de textos y conjuntos de palabras que definen temas, entremezclando estos tipos y escalas en su consulta. Sus tres vistas 3.4 principales son: CorpusViewer, es una matriz reordenable que conecta documentos a temas, TextViewer permite un examen detallado de cómo se reflejan los temas dentro de un documento especı́fico. RankViewer permite a los usuarios examinar palabras especı́ficas y ver qué temas las usan.. Figura 3.4: Las tres vistas principales de Serendip: CorpusViewer, TextViewer y RankViewer. Alexander et al. (2014). 3.2.5. Visualization topic model using Graph. En Rönnqvist et al. (2014) hace uso de grafos para expresar de manera visual la estructura y significado de cada tema que han sido extraidos mediante modelos temas probabilistico (figura 3.5). Las conexiones entre nodos temá ticos los realiza mediante términos clave descriptivos. El layout es usado con el framework D3 para realizar grafo mediante force-directed. 24.
(33) Figura 3.5: Los temas que comparten términos clave están vinculados y residen más cerca, la fortaleza del enlace representa cómo distinguir un término clave es de un tema, el tamaño del nodo del tema representa la prevalencia en el corpus. Rönnqvist et al. (2014). 3.3. Consideraciones Finales. En este capitulo se presentaron las técnicas más relevantes de visualización de temas usando métodos probabilisticos en este caso LDA. Los trabajos mencionados en este capitulo presentaron herramientas web para análisis de temas, metadatos junto a los temas extraı́dos para ayudar a la comprensión de los mismos, selección de parámetros de manera visual y visualización usando grafos. La principal limitación que comparten los trabajos antes mencionados son que los temas son representados como un conjunto de palabras clave que hace perder la relación entre tema y articulo además de no incluir en el análisis el componente temporal.. 25.
(34) CAP ÍTULO 4. Visualizació n de temas evolutivos. 4.1. Consideraciones Iniciales. En el capitulo anterior se exploró la visualización de temas. En este se analizará los trabajos más relevantes relacionado con la forma de visualizar los temas cuando se tiene un componente temporal y por ende cambian en el tiempo dando cierta evolución temá tica. Los datos generalmente usados para los propósitos de este capitulo contienen en su mayorı́a marcas de tiempo o en otras palabras un componente temporal dentro de sus caracterı́sticas. En este contexto modelos de temas evolutivos (topic evolution models) se encarga del análisis de la importancia del tema y sus relaciones con otros temas.. 4.2. Técnicas de Visualizació n de temas evolutivos. Las técnicas que están a continuación tienen como principal caracterı́stica la extracción de temas por modelos probabilisticos de temas y el uso del componente temporal en colecciones de documentos de texto:. 4.2.1. Evolutinary transition discovery Fue propuesto en (Mei and Zhai, 2005) y hace un procesamiento de colección de documentos indexados por el tiempo, C = {d1 , d, ...dT }, donde di se refiere a un documento con una marca de tiempo i. Cada documento es una secuencia de palabras de un conjunto de vocabulario V = {w1 , w, ...w|v| }: EL objetivo es extraer un grafo evolutivo temático de un conjunto de flujo de texto C = {d1 , d, ...dT } automáticamente. Esto se puede definir a través de tres pasos: 27.
(35) 1. Particionar el documento en n posibles subcolecciones superpuestas con un intervalo variable o fijo tal que C = C1 ∪ ... ∪ Cn y Ci = {dti , ..., dti +li −1 } es una subcolección de li documentos en el time span [ti , ti + li − 1]. En general, ti < ti+1 , pero podrı́a ser que ti + li − 1gt; ti+1 , desde que Ci se puede superponer. 2. Extraer el tema más destacado de Θi = {θi,1 , ..., θi,ki } de cada subcolección Ci usando un modelo mixto probabilistico. 3. Por algún tema en diferentes subcolecciones, θ1 ∈ Θi y θ2 ∈ Θj donde i < j, decide si hay un transición evolucionarı́a basado en la similitud de θ1 y θ2 . La figura 4.1 muestra el corpus de documentos divididos en intervalos de tiempo y de cada intervalo un número de temas que se relacionan con los otros temas por un umbral de similitud.. Figura 4.1: Esquema de procesamiento de Evolutionary transition Discovery. (Mei and Zhai, 2005). 4.2.2. Dynamic Topic Models(DTM) Estos modelos son extensiones de LDA, un método probabilistico para la extracción de temas, teniendo como ventaja la inclusión del componente temporal. Este modelo fue propuesto en (Blei and Lafferty, 2006). El DTM capta la evolución de los temas en una secuencia organizada corpus de documentos. En el DTM, dividimos los datos por intervalo de tiempo, por ejemplo, por año. En el modelo los documentos de cada porción(por ejemplo los documentos de un año) con un componente modelo de tema K, donde los temas asociados con la porción t evoluciona a partir de los temas relacionados con la porción t − 1 (Srivastava and Sahami, 2009). 28.
(36) Utiliza Gaussian prior para los parámetros tema capturando la evolución temática durante intervalos de tiempo mediante el uso de este modelo Alghamdi and Alfalqi (2015). El grafo evolutivo obtenido se puede apreciar en la figura 4.2.. Figura 4.2: Grafo propuesto en Dynamic Topic Models(DTM) que representa cada tema por un conjunto de palabras de manera anual y en la parte de inferior, la fuerza de cada tema en una serie de tiempo.(Blei and Lafferty, 2006). 4.2.3. Detecting Topic Evolution of Scientific Literature Este modelo propuesto en He et al. (2009) aborda la evolución temática haciendo uso de las citas bibliográficas en artı́culos cientı́ficos. El modelo principal es LDA adaptado para hacer uso de la red de citación. Para la detección del tema se toma en cuenta el corpus contenido en D(t) como también los documentos que son citados en los mismos. Se utiliza el modelo Bayesiano para la identificación del nuevo tema. En este método descrito en (Alghamdi and Alfalqi, 2015), un documento consta de una distribución de vocabulario, una citación y una marca de tiempo. El corpus de documentos se dividen en un conjunto de subconjuntos basándonos en la marca de tiempo, por una unidad de tiempo t, los documentos correspondientes se representan con D(t). Se generan para cada unidad de 29.
(37) tiempo un tema independiente, la evolución temática se entiende como la relación entre los temas D(t) y D(t − 1). En Detecting Topic Evolution of Scientific Literature finalmente proponen dos métodos para la evolución de temas basados en citaciones, uno es independent topic evolution learning y accumulative topic evolution learning method, en el primero el análisis temático es independiente en cada intervalo de tiempo, mientras que en el segundo el último tema siempre depende de uno anterior. El resultado de su análisis puede apreciarse en 4.3.. Figura 4.3: Detección de tópicos en artı́culos cientı́ficos de manera anual He et al. (2009). 4.2.4. Discovering the Topology of topics Este enfoque propuesto en Jo et al. (2011) tiene la caracterı́stica principal de capturar la topologı́a de la evolución en un corpus de texto, a diferencia de otros enfoques este no caracteriza un tema en un determinado punto fijo de tiempo sino que se define un tema como una unidad cuantificada de cambio evolutivo. Los temas descubiertos son luego conectados para formar un grafo evolutivo de tópicos usando una medida derivada de la red de documentos subyacente. Este enfoque permite una distribución no homogénea de temas con el tiempo. Este método desarrolla un framework de aprendizaje evolutivo de temas por integración de LDA en la red de citaciones. Funciona de la siguiente manera: primero, se trata de identificar un nuevo tema mediante la identificación de los cambios de contenido significativas en un corpus de documentos. Si el nuevo contenido es diferente del contenido original, y el nuevo contenido es compartida por los documentos posteriores, el nuevo contenido se identifica como un nuevo tema. El siguiente paso es explorar la relación entre los nuevos temas y los temas originales. La relación entre los temas originales y los temas descubiertos son identificados usando el conteo de citaciones de ese articulo. El resultado del grafo evolutivo se puede ver en la figura 4.4. 30.
(38) Figura 4.4: Topologı́a de temas donde las relaciones son definidas por las citaciones Jo et al. (2011). 4.2.5. HierarchicalTopics. HierarchicalTopics Dou et al. (2013) es un sistema de análisis visual que integra el algoritmo Topic Rose Tree y visualizaciones interactivas (figura 4.5). El algoritmo Topic Rose Tree, basado en modelos de temas hierarchical topic model (hLDA), genera una jerarquı́a de tópicos. La interfaz visual interactiva propuesta está diseñada para presentar el contenido del tema y la evolución temporal de los tópicos de forma jerárquica a través de Hierarchical ThemeRiver basado en havre2002themeriver una metáfora para representar y analizar visualmente temas y su evolución temporal. 31.
(39) Figura 4.5: Arquitectura del sistema HierarchicalTopics Dou et al. (2013). HierarchicalTopics ayuda al análisis visual y evolutivo de los temas, las limitaciones que presenta es que cada tema es presentado como un conjunto de palabras claves. Otra limitación es en cuanto al análisis evolutivo, que tiene como primer paso una segmentación de corpus de textos previo a la aplicación de la metáfora ThemeRiver.. 4.2.6. TopicFlow TopicFlow Malik et al. (2013) es una herramienta que usa modelado de temas en datos de Twitter para la agrupación de tweets relacionados en temas generados automáticamente y que muestra los resultados en una visualización interactiva en la cual se puede apreciar la evolución de estos temas. Para la aplicación de modelos de temas en este caso LDA, los tweets se dividen en un número determinado de contenedores que se define como parámetro de entrada, cada contenedor representa un intervalo de tiempo de la misma longitud sin restricción en el número de tweets. LDA se aplica de forma independiente para los tweets de cada contenedor. La visualización que muestra la evolución temática de TopicFlow emplea un diagrama de Sankey O’Brien (2012). Los nodos en el gráfico representan los temas y las rutas entre los nodos en las divisiones de tiempo vecinas representan similitud de tema. Las rutas se ponderan por la relación de los temas según lo calculado por la métrica de similitud del coseno. El color se usa en el gráfico para distinguir los temas por su estado de evolución: emergentes, finales, continuos o independientes. 32.
(40) Figura 4.6: Resumen del sistema TopicFlow Malik et al. (2013). 4.2.7. Probabilistic Generative Model for citations Este enfoque fue propuesto en Wang et al. (2013), difiere de la forma más comú n de generar un grafo evolutivo temático donde la temporalidad es extraı́da a través de la segmentación de secuencias de texto en ventanas fijas de tiempo, como en el caso de Evolutinary transition discovery. Este forma de procesar trae como consecuencia inconvenientes pues el resultado se ve afectado por la elección de la ventana de tiempo o mejor dicho que tamaño será el subconjunto de documentos a procesar como consecuencia puede traer un análisis incorrecto de la evolución Wang et al. (2013). Probabilistic. Generative Model for citations. aprovecha las relaciones de. citación que existen en el documento, de modo que trabaja con el texto y el conjunto de citas, dejando de lado la agrupación de subcolecciones de documentos por ventanas de tiempo. En este trabajo se propone representar el grafo como un conjunto de çitación de documentos”donde cada uno de los documentos es representado como una bolsa de citas bag of citations para posteriormente modelar estos documentos con un modelo generativo probabilista. El grafo evolutivo generado se puede ver en (4.7, 4.8): 33.
(41) Figura 4.7: Cada nodo representa un tema y el tamaño es su importancia el color verde son los temas nuevos y los rojos los más antiguos Wang et al. (2013). Figura 4.8: Evolución de los temas a través del los años 1993-2007 Wang et al. (2013). 4.2.8. ThemeDelta. ThemeDelta es un sistema de análisis visual para la extracción de tendencias temporales en datos textuales Gad et al. (2015). El algoritmo que propone para el procesamiento interno es Topic Modeling Based Segmentation como se muestra en la figura 4.9. Este algoritmo analiza a través de segmentación dinámica grupos de datos según sus marcas de tiempo, en otras palabras es de longitud de ventana variable, para luego aplicar a cada grupo el algoritmo LDA. Posteriormente los resultados son visualizados utilizando lı́neas sinuosas de ancho variable para mostrar esta evolución en una lı́nea de tiempo, utilizando color para categorı́as y ancho de lı́nea para la fuerza de palabras clave. 34.
(42) Figura 4.9: Visualización de la campaña de Barack Obama en ThemeDelta Gad et al. (2015). A pesar de tener una segmentación de ventana variable, aún se tiene que considerar como parámetros de entrada la granularidad de segmentación (por ejemplo, dı́as, semanas o meses discretos). Esta granularidad varı́a de una aplicación a otra y es decidida por expertos en el dominio Gad et al. (2015).. 4.2.9. Hierarchical Topic Evolution Model En Song et al. (2016) se propone un modelo jerárquico de evolución de temas (HTEM) que organiza los temas en una jerarquı́a temporal que muestra su evolución como se puede observar en la figura 4.10. Para esto se hizo uso de nested Distance-Dependent Chinese Restaurant Process(nddCRP) para modelar simultá neamente las dependencias entre los datos y la relación entre los cluster. La manera que nddCRP funciona es asumiendo que probablemente los documentos con marcas de tiempo próximas hablen de lo mismo, mientras que aquellos con marcas de tiempo distantes pueden enfocarse en cosas diferentes. El nddCRP puede descubrir la evolución del tema a varias escalas. En los diferentes niveles del árbol pueden establecerse con distintas granularidades de tiempo. Sean años, meses o dı́as. Esto es un una ventaja con respecto a métodos jerárquicos de temas anteriores, sin embargo aún se debe especificar directamente la granularidad del tiempo que es un inconveniente. 35.
(43) Figura 4.10: Descubriendo la evolución de temas en el conjunto de datos Addresses Song et al. (2016). 4.3. Consideraciones Finales. Las bases para la visualización de temas evolutivos en la mayorı́a de trabajos presentados es segmentar previamente el corpus a analizar para posteriormente aplicar técnicas de visualización. Esta perspectiva presenta limitaciones en cuanto al criterio para aplicar el tamaño de cada segmento en el preprocesamiento lo que se convierte en una desventaja. Un trabajo que no presento esta limitación es CITATION-LDA Wang et al. (2013) en el cual los datos no son segmentados de manera previa, sino que las fechas aproximadas son calculadas después de extraı́dos los temas. Esta trabajo previo se usará como parte de la propuesta en los siguientes capı́tulos.. 36.
(44) CAP ÍTULO 5. Propuesta de trabajo. 5.1. Consideraciones Iniciales Para realizar los objetivos mencionados en el capitulo 1, ser hará uso de LDA(latent dirichlet allocation), un algoritmo probabilista que extrae temas de un conjunto de datos, el cual se detalló en los capı́tulos anteriores. Una mejora llamada CITATION-LDA (Wang et al., 2013) tiene la ventaja de obtener más información útil haciendo uso de las citas bibliográficas de un documento de texto, esto tiene como resultado un número determinado de temas extraı́dos que son representados por distribuciones de citas como también el total de documentos procesados que están representados por una distribución de temas, además esta mejora tiene ventaja de conservar una fecha estadı́stica aproximada de cada tema, haciendo idóneo para procesar estos resultados con otros algoritmos de clustering. En la propuesta del trabajo como se muestra en la figura 5.1 se tienen cuatro partes significativamente destacadas: Feature Extraction, encargado de recibir la base de datos y pre-procesarlo para luego aplicar el algoritmo CITATION-LDA. El resultado de esto serán los vectores caracterı́sticos de un conjunto de temas y además de fechas probabilistas de cada tema. Similarity Matrix, Una vez extraı́do los resultados de feature Extraction se calculará las matrices de similitud, tanto de los vectores caracterı́sticos de temas y de las fechas probabilistas. Estas dos matrices se unirán en una sola matriz(se detallará más adelante). Projection Method, se usará el algoritmo NJT conservando su funcionamiento natural en ADN, de tal forma que muestre la evolución en colecciones de documentos. Radial Layout, este algoritmo trabaja en la manera de presentación de los resultados para una correcta visualización. Además de esto se añadió 37.
(45) interactividad que se explicará detalladamente en las siguientes secciones.. Figura 5.1: Proceso de obtención de la propuesta de visualización. 5.2. Etapas del proceso de la propuesta de trabajo 5.2.1. Extracció n de caracterı́sticas (Feature Extraction) Extracció n de temas usando CITATION-LDA La extracción de temas a través de CITATION-LDA (Wang et al., 2013) hace uso del algoritmo base LDA, anteriormente explicado. La ventaja de CITATION-LDA es a diferencia de LDA donde la forma de representar los temas en el resultado es por un conjunto de palabras bag of words, CITATION-LDA lo hace a través de un conjunto de citas bag of citation 5.3. Otra ventaja sobre el clásico LDA en la asignación de una fecha probabilista aproximada a cada tema, de tal forma que se puede obtener la distribución de temas de cada documente a la misma vez que cada tema en el documento conservará una fecha aproximada. 38.
(46) Figura 5.2: (Izquierda) Enfoque de LDA para extraer temas (palabras clave), (Derecha) enfoque de CITATION-LDA para extraer temas (conjunto de citas).. De esta forma como resultado también se obtiene como parte del procesamiento una distribución de citas para cada tema 5.3. Una cita hace referencia a un documento que también estará incluido en el corpus y que conserva consigo toda la información como por ejemplo la fecha de publicación, de esta forma se puede calcular una fecha aproximada según el lugar donde este la mayor fuerza del tema y que citas estén dentro de esa alta probabilidad a través de esta formula matemática 5.1:. |K| X. D · P (Ci ). .. i=0. 39. (5.1).
(47) Figura 5.3: Resultado de CITATION-LDA. Distribución de probabilidad en citas. 5.2.2. Matriz de Similitud (Similarity Matrix) Matriz de similitud usando DTW DTW es un método originalmente usado en series de tiempo, aunque se puede aplicar a otros datos. Es útil cuando las los dos vectores caracterı́sticos no tienen la misma longitud o no están alineadas con el eje X. Uno de los inconvenientes de DTW es su costo computacional, sin embargo, presenta buenos resultados cuando hay pocos datos Mitsa (2010). El algoritmo encuentra la distancia entre series temporales de diferentes longitudes sin ningú n problema. Teniendo la serie de tiempo X = x1 , x2 , ..., xm con longitud m y otra serie de tiempo Y = y1 , y2 , ..., yk con longitud k. El camino warping W = w1 , w2 , ..., wN donde max(k, m) ≤ N < k + m − 1 se encuentra utilizando la programación dinámica para calcular la distancia acumulada Cd (i, j):. Cd (i, j). =. dist(i, j) + mı́n{Cd (i − 1, j − 1), Cd (i − 1, j), Cd (i, j − 1)} (5.2). Donde k×m matriz de distancia esta definida tal que el (i, j) elemento contiene la distancia de Xi y Yj Mitsa (2010). La deformación de trayectoria está sujeta a varias restricciones, como condiciones de contorno, continuidad, monotonı́a, que se realizan para optimizar el rendimiento de su cálculo. Matriz de similitud por tiempo Normalmente cuando se obtiene una matriz de similitud tiene que aplicarse también una medida de distancia que depende de que datos se están analizando. Los más comunes son: distancia euclidiana, similitud coseno entre otros. 40.
(48) Figura 5.4: matriz de similitud por contenido en 2D. Figura 5.5: matriz de similitud por contenido en 3D. Generalmente cuando la similitud se basa solo en el contenido y no toma en cuenta el componente tiempo, la matriz se visualiza como se muestra en las figuras (5.4, 5.5), donde los valores menores se ven de colores azules mientras los valores mayores más claros con tonalidades rojizas. Tanto la figura (5.4, 5.5) muestra que normalmente no existe un patrón al momento de obtener una matriz de distancia, sino que por el contrario los valores solo dependen de el tipo de datos que se está analizando y la medida de similitud empleada. Para que el algoritmo NJT pueda mostrar el componente temporal en datos que no sean del tipo filogenia, es necesario adaptar la matriz de distancia de tal forma que los valores que presenten fechas menores en el tiempo, tengan prioridad en el orden del algoritmo, para esto es necesario que cuenten con valores menores, para que sean los primeros en ser conectados por el algoritmo. Un detalle es que si solo se trabaja con las fechas como una noción para obtener la matriz de similitud, en este caso restar las fechas de publicación de cada articulo, seria incorrecta porque el comportamiento es como se muestra en las imágenes (5.6, 5.7). El error en esta primera noción es que la resta produce los valores menores(que serán los primeros en unir el algoritmo) cerca de la diagonal, en otras palabras la jerarquı́a temporal no podrá ser mostrada en el resultado final. La manera correcta de obtener una matriz de similitud que luego de introducirse como entrada al algoritmo NJT muestra una jerarquı́a de tiempo es basándonos en una lógica simple de conservación de la fecha mayor como se explica en al algoritmo propuesto en este trabajo (alg 1) Tanto en la (ec. 5.3) y (ec. 5.4) provienen de una misma ecuación (ec. 5.5) modificada. Analizada en (Cooper et al., 2005). La ecuación 5.5 propuesta originalmente para resaltar el componente 41.
(49) Figura 5.6: matriz de similitud resta de fechas en 2D. Figura 5.7: matriz de similitud resta de fechas en 3D. Algorithm 1 Calcular la matriz de similitud para fechas 1: procedure M ATRIZ S IMILITUD T EMPORAL(f echas, k) f echaM in = min(f echas) 2: lenF echas = len(f echas) 3: matrizSim = zeros(lenF echas, lenF echas) 4: for each integer i in lenF echas do 5: for each integer j in lenF echas do 6: if (i = j) then 7: if f echas(i) − f echaM in) > (f echas(j) − f echaM in) then 8: 9:. 10: 11:. 12: 13: 14: 15: 16: 17: 18: 19:. matrizSim(i, j) = 1 − exp. − (f echas(i)−f echaMin).days k. (5.3). − (f echas(j)−f echaMin).days k. (5.4). else matrizSim(i, j) = 1 − exp end if else matrizSim(i, j) = 0; end if end for end for Return matrizSim end procedure. 42.
(50) Figura 5.8: matriz de similitud algoritmo propuesto, vista 2D, k = 1000. Figura 5.9: matriz de similitud algoritmo propuesto, vista en 3D, k = 1000. Figura 5.10: matriz de similitud resta de fechas en 2D. Figura 5.11: matriz de similitud resta de fechas en 3D. temporal en conjunto de imágenes. El resultado del algoritmo anterior se pueden ver en las figuras 5.8, 5.9, 5.10, 5.11 con diferentes valores k, Sk (i, j) = exp. −tj | − |ti K. (5.5). 5.2.3. Método de Proyecció n (Projection Method) Método neigbour joining tree(NJ) Neighbor joining ha demostrado conservar una mejor relación local entre los documentos proyectados como también la visión global del mapeamiento. La idea principal de este algoritmo es ir agrupando los objetos más próximos hasta reconstruir completamente la estructura de relaciones de todos los elementos 5.12. 43.
(51) Figura 5.12: Esquema de reconstrucción del algorı́tmo neigbour joining tree. Para nuestro proyecto, la matriz de distancia de entrada al NJT será el promedio de dos matrices una obtenida con nuestra propuesta donde se usará las fechas probabilistas de cada tema y la otra con la distancia DTW que usa el vector caracteristico de los temas. Obtenido esta matriz se pocederá a aplicar el método de proyección NJT.. 5.2.4. Visualizació n e Interacció n (Visualization and Interaction) Radial Layout El diseño radial se ha utilizado en la visualización del algoritmo NJ. En Paiva et al. (2015) se usó para soportar tareas de clasificación a través del análisis visual de los datos y en Li et al. (2015) es usado para agrupar diseños de visualización que generan una categorización. También se usó con otros tipos de árboles, como minimum spanning tree (MST) Soramaki et al. (2016) para visualizar datos de los mercados financieros. La idea principal del diseño radial es asignar cada subárbol una cuña de ancho angular proporcional a un número de hojas en ese subárbol. La cuña de un vértice interno se divide entre sus hijos, y los bordes de los árboles se dibujan a lo largo de bisectrices de ángulo de cuña, de modo que pueden tener cualquier longitud sin violar la disyunción Bachmaier et al. (2005).. Interacció n y Descripció n de Funcionalidades En la imagen 5.13 se puede apreciar la vista principal de la propuesta. Ha sido diseñada con el propósito de analizar temas. Una vez seleccionado un tema, se puede apreciar en la parte inferior el vector caracterı́stico de citas que lo representa y en la Parte derecha los metadatos procesados de dicho tema. 44.
Figure



+7






Documento similar
De la Salud de la Universidad de Málaga y comienza el primer curso de Grado en Podología, el cual ofrece una formación generalista y profesionalizadora que contempla
Para recibir todos los números de referencia en un solo correo electrónico, es necesario que las solicitudes estén cumplimentadas y sean todos los datos válidos, incluido el
1) La Dedicatoria a la dama culta, doña Escolástica Polyanthea de Calepino, señora de Trilingüe y Babilonia. 2) El Prólogo al lector de lenguaje culto: apenado por el avan- ce de
que hasta que llegue el tiempo en que su regia planta ; | pise el hispano suelo... que hasta que el
Ciaurriz quien, durante su primer arlo de estancia en Loyola 40 , catalogó sus fondos siguiendo la división previa a la que nos hemos referido; y si esta labor fue de
Las manifestaciones musicales y su organización institucional a lo largo de los siglos XVI al XVIII son aspectos poco conocidos de la cultura alicantina. Analizar el alcance y
Fuente de emisión secundaria que afecta a la estación: Combustión en sector residencial y comercial Distancia a la primera vía de tráfico: 3 metros (15 m de ancho)..
La campaña ha consistido en la revisión del etiquetado e instrucciones de uso de todos los ter- mómetros digitales comunicados, así como de la documentación técnica adicional de
