Estudio de la Relevancia de Compartir Palabras Clave de Búsqueda en Internet Edición Única
82
0
0
Texto completo
(2) Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey Escuela de Tecnologı́as de Información y Electrónica Programa de Graduados. Los miembros del comité de tesis recomendamos que la presente tesis de Alice Paillat Liaigre sea aceptada como requisito parcial para obtener el grado académico de Maestra en Ciencias con especialidad en: Sistemas Inteligentes. Comité de Tesis:. Dr. Leonardo Garrido Asesor Principal. Dr. Ramón Brena. Dr. José Luis Aguirre. Sinodal. Sinodal. Dr. David A. Garza Salazar Director del Programa de Graduados. Junio de 2006.
(3) Agradecimientos Quiero agradecer primero a mi asesor el Dr. Leonardo Garrido por todos sus consejos y su apoyo brindado durante el desarrollo de la presente tesis. Me gustarı́a agradecer a todos los doctores que fueron mis profesores durante este año y medio por todos los conocimientos aportados. Agradezco a todos mis amigos mexicanos por el apoyo en esta experiencia, y particularmente a mis compañeros de maestrı́a Adriana Canseco y José Luis Jaramillo. También agradezco a mis compañeros de equipo durante los diferentes proyectos que llevamos a cabo a lo largo de la maestrı́a, por sus enseñanzas y tiempo. Quiero también agradecer a mis compañeras del equipo de fútbol del semestre Enero-Mayo 2006, por todos los buenos momentos que compartimos. Agradezco mucho a mi novio Ulises Chávez por su paciencia y gran apoyo. Y finalmente me gustarı́a agradecer a todas las personas del ITESM Campus Monterrey y la EPF en Francia que hicieron posible el intercambio del cual fui parte..
(4) Índice general 1. Introducción 1.1. Motivación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.2. Definición del problema . . . . . . . . . . . . . . . . . . . . . . 1.2.1. Internet: una gigante base de datos desordenada . . . . 1.2.2. La falta de conocimiento y experiencia de los usuarios . 1.2.3. Las palabras-clave: no representativas y no informativas 1.3. Hipótesis y preguntas de investigación . . . . . . . . . . . . . . 1.4. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.5. Alcances . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.6. Organización . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.7. Conclusión . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. 1 1 2 2 2 4 4 5 5 5 5. 2. Marco Teórico 2.1. Tecnologı́a basada en agentes . . . . . . . . . . . . . . . . . 2.1.1. Agentes . . . . . . . . . . . . . . . . . . . . . . . . . 2.1.2. Sistemas Multiagentes . . . . . . . . . . . . . . . . . 2.1.3. Los Agentes de Información . . . . . . . . . . . . . . 2.2. Recuperación de Información . . . . . . . . . . . . . . . . . 2.2.1. Los Sistemas de Recuperación de Información . . . . 2.2.2. Modelos de Recuperación de Información . . . . . . 2.2.3. Técnicas de Mejora . . . . . . . . . . . . . . . . . . . 2.2.4. Filtraje de Información y Filtraje Colaborativo . . . 2.3. La Representación de la Información . . . . . . . . . . . . . 2.3.1. Procesamiento general de la Información . . . . . . . 2.3.2. El algoritmo TF-IDF . . . . . . . . . . . . . . . . . . 2.4. Modelación de los usuarios . . . . . . . . . . . . . . . . . . . 2.4.1. Conceptos de modelación . . . . . . . . . . . . . . . 2.4.2. Los algoritmos de clustering conceptual jerarquizado 2.5. Conclusión . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . .. 6 6 7 9 11 15 15 16 18 22 24 24 24 25 25 26 28. 3. Trabajo Relacionado: Los Sistemas de Búsqueda existentes 3.1. Los sistemas no-colaborativos . . . . . . . . . . . . . . . . . . . 3.1.1. Almathaea . . . . . . . . . . . . . . . . . . . . . . . . . 3.1.2. Calvin . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.1.3. Letizia . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.1.4. WebMate . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. 30 30 30 31 32 33. ii. . . . . . . . . . . . . . . . ..
(5) 3.2. Los sistemas con base a semejanza entre agentes . . . 3.2.1. The Fab System . . . . . . . . . . . . . . . . . 3.2.2. Herlocker . . . . . . . . . . . . . . . . . . . . . 3.2.3. Knowledge Recommendation System . . . . . . 3.3. Los sistemas con base a semejanza entre palabras-clave 3.3.1. Community Search Assistant - Xerox . . . . . . 3.3.2. I-Spy . . . . . . . . . . . . . . . . . . . . . . . . 3.4. Los sistemas que usan métodos de clustering . . . . . 3.4.1. Mooter . . . . . . . . . . . . . . . . . . . . . . 3.4.2. Snaket . . . . . . . . . . . . . . . . . . . . . . . 3.4.3. WebProfiler . . . . . . . . . . . . . . . . . . . . 3.5. Criterios analizados . . . . . . . . . . . . . . . . . . . . 3.6. Conclusión . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . de . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . búsqueda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 4. Diseño del sistema propuesto 4.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.2. El Procesamiento de la Información . . . . . . . . . . . . . . . . 4.2.1. La representación de los documentos . . . . . . . . . . . . 4.2.2. La modelación de los usuarios y la actualización del perfil 4.2.3. La determinación de la relevancia de una página . . . . . 4.3. El Sistema Multiagente . . . . . . . . . . . . . . . . . . . . . . . 4.3.1. La Arquitectura del Sistema . . . . . . . . . . . . . . . . . 4.3.2. Las Interacciones entre los Agentes . . . . . . . . . . . . . 4.3.3. Definición PEAS del agente de búsqueda . . . . . . . . . . 4.3.4. Propiedades del Ambiente del Agente . . . . . . . . . . . 4.4. Conclusión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . .. . . . . . . . . . . . . .. 33 33 35 36 37 37 37 38 38 38 38 38 41. . . . . . . . . . . .. 42 42 42 43 43 45 45 46 47 49 49 50. 5. Experimentos 5.1. El prototipo del sistema multiagente para los experimentos . . . . . . . . . . 5.2. La generación de los perfiles de usuarios del sistema . . . . . . . . . . . . . . 5.3. Escenarios experimentales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.3.1. Escenario Experimental 1 . . . . . . . . . . . . . . . . . . . . . . . . . 5.3.2. Escenario Experimental 2 . . . . . . . . . . . . . . . . . . . . . . . . . 5.3.3. Escenario Experimental 3 . . . . . . . . . . . . . . . . . . . . . . . . . 5.3.4. Escenario Experimental 4 . . . . . . . . . . . . . . . . . . . . . . . . . 5.3.5. Escenario Experimental 5 . . . . . . . . . . . . . . . . . . . . . . . . . 5.4. Evaluación del Funcionamiento de un Sistema de Recomendación de Información 5.4.1. Eficiencia y Eficacia . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.4.2. Los criterios de evaluación escogidos . . . . . . . . . . . . . . . . . . . 5.4.3. La determinación de la relevancia de una página . . . . . . . . . . . . 5.5. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.5.1. Escenario Experimental 1 . . . . . . . . . . . . . . . . . . . . . . . . . 5.5.2. Escenario Experimental 2 . . . . . . . . . . . . . . . . . . . . . . . . . 5.5.3. Escenario Experimental 3 . . . . . . . . . . . . . . . . . . . . . . . . . 5.5.4. Escenario Experimental 4 . . . . . . . . . . . . . . . . . . . . . . . . . 5.5.5. Escenario Experimental 5 . . . . . . . . . . . . . . . . . . . . . . . . . 5.6. Análisis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. iii. 51 51 54 56 56 56 57 57 57 58 58 59 59 60 60 60 62 62 63 63.
(6) 5.6.1. 5.6.2. 5.6.3. 5.6.4.. Dependencia a la experiencia de los usuarios . . . . . . . . . Dependencia a los temas . . . . . . . . . . . . . . . . . . . . . Un uso muy limitado de la semejanza entre usuarios . . . . . Compartir las palabras-clave de búsqueda permite encontrar relevantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.6.5. Entre más experimentados, mejores sugerencias . . . . . . . . 5.6.6. La repartición de la experiencia . . . . . . . . . . . . . . . . . 5.7. Conclusión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6. Conclusiones 6.1. Resultados . . . 6.2. Contribuciones 6.3. Trabajo Futuro 6.4. Conclusión . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . . . . . . . . . . . . . páginas . . . . . . . . . . . . . . . . . . . .. 65 66 66 66. . . . .. 67 67 68 68 69. . . . .. . . . .. . . . .. . . . .. 63 65 65. Appendices. 72. A. Evaluación de páginas. 73. iv.
(7) Índice de figuras 2.1. 2.2. 2.3. 2.4. 2.5. 2.6. 2.7. 2.8.. Dimensiones de un Agente. . . . . . . . . . . . . . . . . . . Modelo de intermediación 1. . . . . . . . . . . . . . . . . . . Modelo de intermediación 2. . . . . . . . . . . . . . . . . . . Estructura de una aplicación interactiva basada en agentes. Sistema de Recuperación de Información. . . . . . . . . . . Proceso de Recuperación de Información. . . . . . . . . . . Elementos de un Sistema de Recuperación de Información. . Algoritmo WebDCC: Web Document Conceptual Clustering. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. 8 11 11 13 15 16 17 29. 3.1. 3.2. 3.3. 3.4.. Caracterı́sticas generales de los sistemas (1) Caracterı́sticas generales de los sistemas (2) Retroalimentación y manejo de consultas . Modelación de los usuarios . . . . . . . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. 39 39 40 40. 4.1. 4.2. 4.3. 4.4. 4.5. 4.6. 4.7. 4.8.. Ejemplo de perfil de usuario. . . . . . . . . . . . . . . . . . . Modelo de conocimiento para el tema de “fútbol”. . . . . . . Arquitectura del sistema. . . . . . . . . . . . . . . . . . . . . Programa desarrollado para la compartición de palabras-clave Definición del Agente de Búsqueda. . . . . . . . . . . . . . . . Definición del Protócolo IniciarAgente. . . . . . . . . . . . . . Definición del Protócolo PedirAyuda. . . . . . . . . . . . . . . Definición del Protócolo Ayudar. . . . . . . . . . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. 44 45 46 47 48 48 48 49. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. 52 52 52 53 53 53 58 61 61 62 63 64. . . . .. 5.1. Arquitectura del sistema. . . . . . . . . . . . 5.2. Definición del Agente Principal. . . . . . . . . 5.3. Definición del Agente de Búsqueda. . . . . . . 5.4. Definición del Protócolo IniciarAgente. . . . . 5.5. Definición del Protócolo PedirAyuda. . . . . . 5.6. Definición del Protócolo Ayudar. . . . . . . . 5.7. Evaluación de un Sistema de Recuperación de 5.8. Escenario Experimental 1. . . . . . . . . . . . 5.9. Escenario Experimental 2. . . . . . . . . . . . 5.10. Escenario experimental 3. . . . . . . . . . . . 5.11. Escenario experimental 4. . . . . . . . . . . . 5.12. Escenario experimental 5. . . . . . . . . . . .. v. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Información. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . ..
(8) Capı́tulo 1. Introducción 1.1.. Motivación. En respuesta a los retos emergidos de la enorme cantidad de información en Internet, se han desarrollados métodos de recuperación de información ([48], [13], [30] y [29]). Con estos métodos, se busca filtrar la información, regresando al usuario la información más relevante. Para apoyar estos métodos de recuperación, también se ha desarrollado una tecnologı́a basada en agentes de información ([39], [20], [27] y [38]). La idea principal de esa tecnologı́a es el uso de diferentes fuentes de información distribuida, con la meta de adquirir, manejar y mantener información relevante, en nombre de usuarios. En particular, existen agentes personales de información, que ayudan el usuario en su proceso de búsqueda de información en Internet. Los agentes son asistentes computacionales que pueden ejecutar varias tareas como las de buscar, filtrar o acceder información. Permiten ayudar al usuario y ahorrar tiempo. Los agentes personales de información actúan como asistentes, colaborando con el usuario y aprendiendo sus preferencias y costumbres. Para lograr esa función, tienen cierto conocimiento sobre el usuario, que está contenido en lo que se llaman perfiles de usuarios, o modelos de las preferencias e intereses del usuario por los cuales el agente puede asistir de manera más eficiente al usuario. Esos agentes pueden trabajar también de manera colaborativa, basándose en las evaluaciones de páginas de otros agentes, es el filtraje colaborativo. Este método consiste en usar la experiencia y la opinión de los otros agentes para influir en los resultados regresados por nuestro agente. En la mayorı́a de los agentes colaborativos, la información que se comparte es la evaluación de las páginas o documentos, es decir, es una forma de recomendación de páginas. Este trabajo de tesis es un enfoque innovador a los métodos de recuperación de información. La idea es recomendar no tanto las páginas directamente, sino las palabras de búsqueda. En efecto, las palabras-clave de búsqueda se consideran buenas cuando llegan a buenas páginas. Es reconocido que el posible desempeño mediocre de las búsquedas en Internet, a parte de ser debido a la falta de organización de Internet, también se debe a la falta de conocimiento y experiencia de los usuarios. Las palabras-clave usadas por los usuarios son representativas de ese conocimiento y esa experiencia. En la próxima sección se explica más a detalle el problema enfrentado.. 1.
(9) 1.2.. Definición del problema. El World Wide Web proporciona millones de páginas acerca de casi cualquiera tema, y se ha convertido desde hace algunos años en una fuente de datos inmensa. Cada persona, sin importar sus ocupaciones, sus conocimientos, o sus gustos, puede encontrar algo de su interés. La red Internet se ha vuelto el medio más usado para buscar información, y también la herramienta de trabajo más común. La información que se puede encontrar en Internet es muy variada: conocimiento general, información técnica muy precisa o páginas de uso comercial y mucho más. Internet es el acceso al saber fácil y rápido, por lo que permite conocer, aprender, comunicar y negociar ahorrando tiempo. Pero en la mayorı́a de los casos, buscar información en Internet no es tan fácil ni rápido. Eso se explica por varias razones, entre otras la falta de estructura de Internet, ası́ como el uso inadecuado de las palabras-clave, que está directamente relacionado con la falta de experiencia y de conocimiento del usuario. Se quiere entonces buscar una forma de compartir el conocimiento común a las personas usuarios de las búsquedas en Internet. De esa forma, si el usuario busca algo acerca de un tema cuyo nivel de conocimiento es bajo, puede conseguir el conocimiento de usuarios de nivel más avanzado. Esto a fı́n de mejorar la calidad de las búsquedas. Este tipo de enfoque se puede volver muy interesante para el nuevo usuario en un grupo. Por ejemplo, puede alcanzar más rápido la misma experiencia que los otros usuarios, y ası́ no pierde tiempo en páginas irrelevantes. Pero ante todo se puede preguntar uno ¿por qué encontrar información relevante en Internet es una tarea tan difı́cil? Después de la revolución en que consistió la llegada de las computadoras personales, Internet puede ser considerada como la segunda revolución en el mundo laboral y público. Ha cambiado totalmente las costumbres de trabajo, y de búsqueda de conocimiento en general. En efecto, permite el acceso virtual a fuentes de información inagotables. Por lo tanto permite ahorrar mucho tiempo en este proceso de búsqueda. Y más que ahorrar tiempo, permite el acceso a la información que, sin él, nunca se hubiera podido disponer, por simples lı́mites fı́sicos.. 1.2.1.. Internet: una gigante base de datos desordenada. Internet es una herramienta muy poderosa, por todas las razones dadas anteriormente. Sin embargo, el tiempo consumido en la búsqueda de las páginas adecuadas a nuestras necesidades puede ser muy largo, y sobre todo la calidad de los resultados de las búsquedas puede resultar muy baja a veces. El acceso al saber no es tan fácil y rápido como se pretende. El Web es distribuido, dinámico y crece muy rápidamente, lo que representa dificultades para las tecnologı́as de extracción de información tradicionales y los motores ni siquiera buscan en toda Internet [35]. Las búsquedas en Internet son difı́ciles simplemente por la gran cantidad de información que se genera. Internet es una base de datos tan enorme, con información tan heterogénea y difusa, que los motores de búsqueda no tienen mucho para referirse.. 1.2.2.. La falta de conocimiento y experiencia de los usuarios. Los modelos mentales son construcciones cognitivas de conocimiento y experiencia, usadas para interpretar el mundo [19]. Es precisamente lo que necesita un usuario de Internet para buscar de manera eficiente: conocimiento y experiencia. En el mundo fı́sico como 2.
(10) en el virtual, estos modelos se aprenden y se entrenan para mejorar, para resolver problemas más difı́ciles en un dominio particular. Mientras las capacidades necesarias para navegar en Internet son muy básicas, considerablemente más experiencia está requerida para buscar en Internet con palabras-clave [42]. Consideremos un novato en búsqueda de un tema en particular en Internet: este usuario tiene que pasar por muchas etapas para mejorar su modelo mental de esta tarea. Primero tiene que saber precisamente lo que está buscando, lo que consiste en el conocimiento mı́nimo para buscar. Segundo tiene que encontrar las buenas palabras para esta búsqueda. También tiene que entender cómo funciona básicamente el sistema de búsqueda, particularmente en este tema, averiguar cómo están organizadas y clasificadas las páginas sobre este tema en Internet. De esa manera puede interpretar los resultados de un motor de búsqueda, y adaptar sus palabras-clave en consecuencia. Todo eso es un proceso que puede ser largo. Por eso creemos que es bueno, especialmente para los buscadores novatos en algún tema, realizar búsquedas colaborativas en Internet, de tal manera que se reduzca el tiempo de aprendizaje del usuario, aprovechando el conocimiento y de la experiencia de los otros usuarios. Hölscher y Strube [29] definieron la experiencia en Internet como el conocimiento y las aptitudes necesarias para usar el World Wide Web y otros recursos de Internet de manera exitosa con la meta de resolver problemas. Se tiene que distinguir con el conocimiento a priori del usuario acerca del tema de búsqueda, lo que también resulta muy importante en el éxito de las búsquedas. Queremos diseñar un sistema que permite aprovechar de la experiencia de los expertos, o al menos de los que ya no son novatos. Los sistemas de recomendación, o de manera más general, los sistemas que permiten cierta personalización, son útiles en cualquier proceso de búsqueda de información. Ya sea en Internet, en telecomunicaciones con los sistemas de ubicación geográfica, o en búsqueda de información dentro de una empresa, siempre es bueno tener una máquina sugiriendo al usuario como puede hacer de mejor forma lo que está haciendo. Cuando uno empieza un proceso de búsqueda de información, es en la mayorı́a de los casos porque esperan resolver un problema, o lograr cierta meta, por los cuales su actual estado de conocimiento no es suficiente [17]. Desafortunadamente, los sistemas de información requieren que el usuario especifique qué es lo que quieren que el sistema extraiga. Además la gente no entiende los procesos internos del sistema, la arquitectura y el vocabulario usado para describir la información y resulta difı́cil adaptar su búsqueda al sistema. Por todo eso es relevante tener un sistema de recomendación, que permita usar los recursos del sistema de manera más eficiente. Se vuelve muy importante en la calidad de los resultados de búsquedas el nivel de conocimiento que tiene cada uno acerca de su tema de búsqueda: entre más se sabe del área más precisas son las palabras de búsquedas que usa el usuario. Ası́ funcionan las búsquedas en Internet: por ejemplo, si el usuario no sabe nada acerca de Teorı́a de Juegos, su búsqueda va a ser “Game Theory” nada más. Y los resultados de su búsqueda pueden salir no tan eficientes o relevantes como el querı́a. Aunque el usuario que ya sabe un poco más de Teorı́a del Juego, quizá va a buscar algo como “equilibria strategy game theory”, y el experto va a buscar algo en una base de datos dónde sabe que hay muchos papers acerca del tema. El proceso de búsqueda de cada uno se presenta ası́, y a uno le cuesta tiempo para conseguir este conocimiento. A parte de la falta de experiencia y conocimiento de los usuarios, el problema viene además del significado múltiple de las palabras: ¿cómo un motor de búsqueda puede hacer la diferencia entre el verbo “ser” y el “ser humano”? 3.
(11) Otra fuente de problema es la de la gran heterogeneidad de los usuarios [18]. Los motores de búsqueda clásicos, cómo Yahoo o aún Google, no se adaptan al usuario todavı́a, o al menos no de manera automática. Por ejemplo, se necesita saber a qué se dedica el usuario para buscar páginas relevantes acerca de la palabra “Morfologı́a”, ¿es el usuario médico, geólogo o lingüista? Es relevante conocer los gustos e intereses del usuario en general, pero también acerca de sus búsquedas precisamente [21]. Depende mucho del dominio de búsqueda: por ejemplo, en investigación cientı́fica se busca más por palabras-clave, mientras que si usamos Internet para compras, se tiende más a navegar gracias a las ligas hipertextos. Un gran esfuerzo se ha hecho últimamente para desarrollar sistemas que modelan los usuarios y adaptan las búsquedas a los usuarios dentro de comunidades. Lo veremos con más detalle en el marco teórico presentado en el capı́tulo 3.. 1.2.3.. Las palabras-clave: no representativas y no informativas. La falta de conocimiento y experiencia de los usuarios, descrita en la sección anterior, influye directamente sobre la calidad de las palabras-clave de búsqueda empleadas por el usuario. El problema al cual se enfrente cada usuario es el de qué palabras-clave usar, cuáles palabras-clave van a representar mejor su búsqueda. Eso es un problema muy difı́cil y es uno de los grandes problemas en búsqueda en Internet: ¿cómo puede un usuario especificar lo que no sabe? Muchas palabras pueden ser usadas para especificar un mismo problema, y una palabra puede ser usada por problemas completamente diferentes. Un análisis de las búsquedas en bibliotecas digitales encontró que casi la mitad de las búsquedas sin éxito están causadas por errores de semántica. Es decir, porque el usuario no supo usar la terminologı́a apropiada o porque no supo usar las palabras al nivel apropiado de especificidad. El usuario no sabe exactamente lo que está buscando, ya que precisamente está buscando algo, entonces sus palabras clave de búsqueda son lógicamente aproximadas o inadecuadas.. 1.3.. Hipótesis y preguntas de investigación. Se ha visto en la sección anterior que la fuente principal de los problemas de búsqueda en Internet es la mediocridad de las palabras-clave, y que a buenas palabras buenos resultados. Por lo tanto la hipótesis de este trabajo es la siguiente: recomendar las palabras-clave de los usuarios de un sistema de búsqueda en Internet, entre lo más experimentados y los novatos, permite diversificar los resultados de búsqueda. Por diversificar se entiende la posibilidad de encontrar páginas relevantes que, sin la búsqueda con nuevas palabras-clave, no se hubiera encontrado en el conjunto de resultados original. Una página relevante se definió como aquella que pertenece al directorio de páginas de Google [7]. Las preguntas de investigación a las cuales se intentará contestar a lo largo de la tesis son las siguientes: ¿Recomendar las palabras-clave es un buen método de mejora de las búsquedas? ¿Existen algunas caracterı́sticas de búsqueda bajo las cuales es más facil recomendar palabras-clave con éxito? Y por otro lado, ¿existen contextos bajo los cuales no ayuda mucho recomendar las palabras-clave de búsqueda? 4.
(12) 1.4.. Objetivos. El objetivo general de este trabajo de investigación es comprobar la relevancia del compartir de las palabras-clave como ayuda en las búsquedas en Internet. En otras palabras, se quiere comprobar que, a partir de una búsqueda original, usar nuevas otras palabrasclave permite llegar a nuevas páginas relevantes, una página relevante siendo una página que pertenece a un directorio de páginas. Para poder alcanzar esa meta, se tienen varios objetivos particulares: Desarrollar el sistema multiagente para la compartición de las palabras de búsqueda, de tal manera que se simulen usuarios del sistema. Desarrollar el algoritmo de creación y actualización de perfiles de usuario Proceder a experimentos sobre el sistema, tomando varios ejemplos de uso del sistema en algunos contextos, como escenarios experimentales. Analizar los resultados para poder averiguar los criterios de buen o malo funcionamiento del sistema, y averiguar si se comproba nuestra hipótesis.. 1.5.. Alcances. Este trabajo se enfoca al análisis totalmente objetivo y racional de un sistema de recomendación para palabras-clave de búsquedas en Internet. Se busca comprobar la relevancia de compartir las palabras-clave y más que todo se busca saber si efectivamente el uso de las palabras-clave como soporte es bueno. Serı́a muy interesante implementar un mismo sistema a más grande escala. Hacer encuestas sobre cierto tiempo de uso acerca de la eficiencia, subjetiva esa, del sistema podrı́a ser fuente de trabajo futuro.. 1.6.. Organización. El capı́tulo siguiente presenta el estado del arte en cuanto a los sistemas multiagentes y los métodos de recuperación de información en Internet. En el capı́tulo 3 se exponen algunos sistemas personales de información existentes. En el capı́tulo 4 se expone el sistema propuesto. Los experimentos se describen en el capı́tulo 5, y luego se dará lugar a una conclusión sobre este trabajo.. 1.7.. Conclusión. En esa primera parte planteamos el problema: la mediocridad de las palabras-clave de búsquedas usadas por los usuarios, que proviene de la falta de experiencia y conocimiento de ellos. En efecto, la calidad de las palabras-clave influye mucho sobre la calidad de los resultados de búsquedas. Presentamos los objetivos del trabajo, ası́ como las preguntas de investigación. El próximo capı́tulo se dedicará al estado del arte respeto a la tecnologı́a multiagente y la recuperación de información en Internet.. 5.
(13) Capı́tulo 2. Marco Teórico En este capı́tulo, primero se presenta el estado del arte en cuanto a la tecnologı́a basada en agentes, y particularmente los agentes personales en Internet. La segunda parte de este capı́tulo se enfoca a los métodos de recuperación de información en Internet, más especificamente a cómo se puede representar la información y procesarla con la meta de un filtraje colaborativo. La tercera parte se enfoca a la representación de la información. La última parte trata de la modelación de los usuarios. Se dedica otro capı́tulo entero al estudio de los sistemas de búsquedas colaborativas.. 2.1.. Tecnologı́a basada en agentes. Los conceptos de Agente Racional y de Sistemas MultiAgentes (SMA) se han afianzado como una nueva aproximación para el desarrollo de sistemas que trasciende el ámbito de la Inteligencia Artificial (IA), y encuentra aplicación en muchas áreas de la informática [41]. La tendencia actual de la IA se enfoca en el concepto de agente racional. Un agente racional es una entidad que hace lo correcto para cumplir con sus metas. Los agentes están situados en su ambiente. Los Sistemas Multiagentes buscan lograr la cooperación de un conjunto de agentes autónomos para la realización de una tarea, que está más allá de las capacidades individuales o del conocimiento de cada miembro del conjunto de agentes. La cooperación depende de las interacciones entre los agentes e incorpora tres elementos: la colaboración, la coordinación y la resolución de conflictos. La noción de agente surgió en el área de Inteligencia Artificial Distribuida. Estudia la resolución de un problema de forma colaborativa por un grupo distribuido de entidades o agentes inteligentes. La colaboración viene de los dos hechos siguientes: a veces un agente no es capaz de resolver el problema por si mismo, o es más rentable o eficiente la solución conjunta. Existen dos grandes partes dentro de la IAD (Inteligencia Artificial Distribuida): La Resolución de Problemas Distribuidos Un problema particular puede resolverse por un número de nodos que cooperan en dividir y compartir conocimiento sobre el problema y su solución. Las tareas que cada agente realiza están prefijadas de antemano, cada agente tiene una conducta fija, y hay un plan centralizado de resolución del problema. Suele haber un miembro que ejerce un control global.. 6.
(14) Los Sistemas Multiagentes Agentes autónomos trabajan juntos para resolver problemas. No hay un sistema global de control, los datos están descentralizados. La computación es ası́ncrona. Los agentes pueden decidir dinámicamente qué tareas deben realizar y quien realiza cada tarea. En las secciones que siguen se describe más a detalle cada uno de los conceptos esenciales a los sistemas multiagentes.. 2.1.1.. Agentes. No hay una definición universalmente aceptada del término agente (similar a la falta de consenso con respecto a la definición de la Inteligencia Artificial), y cada definición depende del dominio de aplicación (agente de información, agente móvil...). De forma muy general, un agente es “cualquier cosa que pueda verse como percibiendo su entorno a través de sensores y actuando sobre el entorno a través de efectores” [47]. Otra definición más precisa para nosotros, del mismo autor, serı́a la siguiente: “Un agente es un sistema informático que es capaz de realizar acciones autónomas de forma flexible en algún entorno para cumplir sus objetivos de diseño”. Woolridge [51] dio una definición débil y una fuerte de qué es un agente. La noción débil dice que un agente es un sistema computacional que tiene las caracterı́sticas siguientes: Autonomia - Un agente opera sin una intervención directa de humanos o otros, y tiene control sobre sus acciones y su estado interno. Capacidad social - Los agentes interactúan con los otros vı́a un lenguaje de comunicación expresivo, intercambiando mensajes. Reactividad - El agente percibe su entorno, y responde de manera temporal a los cambios que ocurren en ello. Pro-actividad - Los agentes no actúan solo como respuesta a su entorno, sino que son capaces de mostrar un comportamiento orientado directamente hacia un objetivo, tomando iniciativas. Una noción más fuerte de un agente agrega caracterı́sticas humanas a su definición como conocimiento, creencias, intenciones y obligaciones: Movilidad - Habilidad para trasladarse en un red electrónica. Veracidad - Es la suposición de que un agente no comunica información falsa intencionadamente. Benevolencia - Es la suposición de que un agente no tiene objetivos contradictorios y siempre intenta realizar la tarea que se le solicita, que no hace cosas que no le pidieron. Racionalidad - Un agente es racional si tiene unos objetivos especı́ficos y siempre intenta llevarlos a cabo. Aprendizaje y Adaptación - Mejoran su comportamiento a partir de la experiencia.. 7.
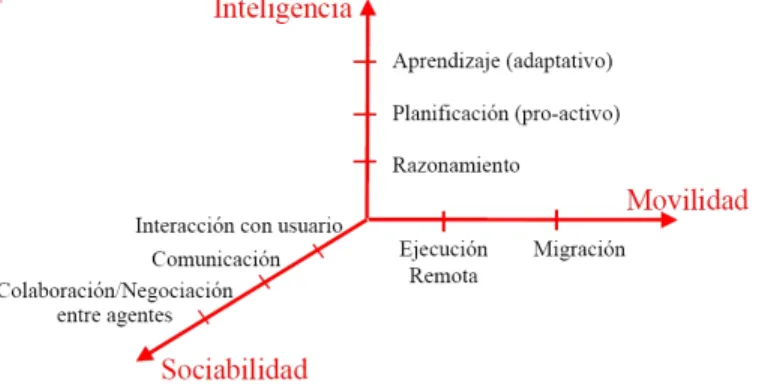
(15) Se puede representar las dimensiones de un agente como en la figura 2.1 [41]:. Figura 2.1: Dimensiones de un Agente. Un agente autónomo es un programa que opera en paralelo con el usuario. Autonomı́a significa que el agente siempre está corriendo, al menos de manera conceptual. El agente puede descubrir una condición que puede interesar el usuario e independientemente decidir notificarle al usuario. El agente debe de seguir activo esperando a cualquier entrada de información de parte del usuario (sus acciones). Los agentes se pueden clasificar en varias categorı́as [32]: Agentes colaborativos Estos agentes enfatizan su autonomı́a y cooperación (con otros agentes) para realizar sus tareas. Pueden aprender, pero este aspecto no tiene tanta importancia para su operación. Para tener un conjunto coordinado de agentes colaborativos, éstos tienen que negociar para alcanzar compromisos mutuamente aceptados en alguna forma. Pueden usarse para: • Resolver problemas que son demasiado grandes para sistemas centralizados (debido a limitaciones de recursos o en los que se necesita tolerancia a fallas). • Permitir la interconexión y operación de sistemas existentes. • Dar solución a problemas inherentemente distribuidos. • Dar solución a problemas en los que existen varias fuentes de información. • Dar solución a problemas en donde la experiencia se encuentra distribuida. Agentes de interfaz Los agentes de interfaz ponen énfasis en su autonomı́a y aprendizaje para realizar sus tareas. El caso más claro de este tipo de agentes corresponde al de un asistente personal que colabora con su usuario en el mismo ambiente de trabajo. La colaboración con el usuario no necesariamente requiere de un lenguaje explı́cito de comunicación de agentes. Esencialmente, los agentes de interfaz asisten y dan soporte al usuario para aprender el uso de una aplicación. El agente del usuario observa y monitorea sus acciones a través de la interfaz con el usuario, y le da sugerencias para mejorar su tarea. Ası́, el agente del usuario actúa como un asistente personal que coopera con el usuario para realizar una tarea con la aplicación. Los agentes de interfaz aprenden para mejorar su ayuda al usuario en cuatro formas: 8.
(16) • Al observar e imitar al usuario. • Al recibir retroalimentación del usuario. • Al recibir instrucciones explicitas del usuario. • Al pedir consejo a otros agentes. La colaboración con otros agentes (si es que existe), se limita a preguntar consejo, y no a conseguir compromisos como el caso de agentes colaborativos. Agentes móviles Los agentes móviles son programas de software capaces de viajar por redes de computadora, como por Internet, de interactuar con hosts, pedir información a nombre de su usuario y regresar a su lugar de origen una vez que ha realizado las tareas especificadas por su usuario. Agentes de información / Internet Los agentes de información realizan la tarea de administrar, manipular o recolectar información proveniente de varias fuentes distribuidas. Los agentes de información pueden ser estáticos o móviles, pueden ser no cooperativos o sociales, y pueden o no aprender. Por ejemplo, un agente de información estático, interactuarı́a con varios motores de búsquedas de Internet y organizarı́a fuentes de información (ejemplo las URL de interés, y que cumplen con algún criterio de búsqueda), las cuales se entregarı́an como respuesta al usuario. Agentes hı́bridos Los agentes hı́bridos son aquellos que en su funcionamiento poseen la combinación de dos o más de las capacidades de los tipos anteriormente explicados.. 2.1.2.. Sistemas Multiagentes. Un sistema multiagente es un sistema en el cual varios agentes llevan a cabo metas comunes, o individuales, tomando en cuenta toda la comunidad de agentes. De manera muy general un sistema multiagente consta de la arquitectura siguiente: Interfaz con el usuario Se encarga de recibir requerimientos del usuario, enviarlos al módulo de razonamiento, y de presentar los resultados al usuario. Debe contar con los medios que permitan al usuario actualizar o modificar las metas y los conocimientos del agente. Módulo de razonamiento Se encarga, basándose en el conocimiento y las metas del agente, de evaluar diferentes alternativas de solución además de negociar y seleccionar la mejor opción. Es capaz de tornar en cuenta los mensajes provenientes de otros agentes, o bien, de negociar con otros agentes. Puede, en base a los mensajes que reciba de otros agentes, o de la percepción que tenga de variables del ambiente, actualizar su base de conocimientos. Metas Corresponden a los estados meta en la búsqueda de soluciones del agente. 9.
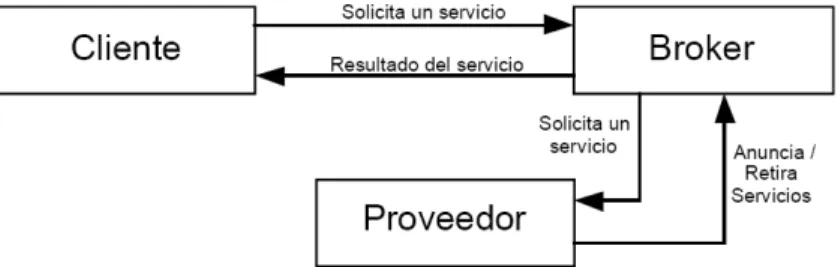
(17) Base de Conocimientos Se refiere a la información que tenga disponible el agente sobre la realidad que le rodea. Módulo de codificación y de decodificación de mensajes Este módulo se encarga de codificar los mensajes del agente en el formato de algún lenguaje de comunicación de agentes. También es capaz de recibir mensajes de otros agentes, decodificarlos (interpretarlos) y de enviar dichos mensajes al módulo de razonamiento. Como ejemplo de lenguaje de comunicación de agentes, puede citarse al ACL1 (usado en Jade [2]). Módulo de percepción Se refiere a los medios con los que cuente el agente, para monitorear variables del medio ambiente que le rodea. Módulo de comunicación Se encarga de enviar y recibir mensajes de otros agentes mediante protocolos de transporte (por ejemplo en Internet, vı́a TCP/IP y HTTP). Un sistema multiagente tiene las siguientes ventajas frente a un único agente o un acercamiento centralizado [32]: Un SMA distribuye los recursos informáticos y las capacidades de ejecución de tareas a lo largo de una red de agentes interconectados. Por lo tanto si un problema occurre, no todo el sistema se muere, ya que no existe un único punto de error. Permite la interconexión e interoperación de múltiples sistemas existentes. Modela los problemas en término de autónomos componentes que interactúan entre sı́, que es una forma natural de representar distribución de tareas, planificación de equipo etc. Recupera eficientemente, filtra y coordina globalmente información proveniente de fuentes espacialmente distribuidas. Proporciona soluciones en situaciones en donde el conocimiento está distribuido. Existe una clasificación de los agentes en un sistema de agentes cooperativos. Se describe a continuación [13]: Agentes proveedores - provider Constituyen la base de la cadena de consumo de información y servicios. Son agentes productores, que proporcionan capacidades, como por ejemplo servicios de búsqueda de información, a sus usuarios y a otros agentes. Agentes solicitantes - requester Consumen información y servicios ofrecidos por agentes proveedores en el sistema. Serı́an equivalentes a los consumidores en el mundo real. 1. Agent Communication Language. 10.
(18) Figura 2.2: Modelo de intermediación 1.. Figura 2.3: Modelo de intermediación 2. Agentes intermediarios - middle Su misión es mediar para que pueda tener lugar una correcta comunicación entre solicitantes y proveedores. Para que pueda llevarse a cabo una correcta mediación, los proveedores tienen que registrar sus capacidades ante uno, o varios agentes mediadores. Los solicitantes o consumidores pueden: • Solicitar a un agente intermediario quién de los posibles proveedores puede llevar a cabo un determinado servicio, o • La intermediación del mediador para la realización del servicio Existen diferentes modelos de intermediación, que se muestran en las figuras 2.2 y 2.3 [41]. En el primero no hay comunicación directa entre el proveedor y el solicitante. El Broker toma contacto con el proveedor, negocia, controla la transacción y devuelve los resultados al solicitante: En el segundo el resultado es una lista de proveedores que pueden proporcionar el servicio. Es el propio solicitante el encargado de contactar, negociar con el proveedor del servicio.. 2.1.3.. Los Agentes de Información. Los agentes de información son agentes software que tienen acceso a múltiples fuentes de información heterogéneas geográficamente distribuidas. Intentan resolver los problemas asociados al manejo de información en Internet. Los agentes pueden asistir al usuario en la búsqueda y filtrado de información relevante, informar cuando nuevos datos de interés están disponibles, negociar la compra o venta de productos, participar en subastas electrónicas etc. Los agentes de información ayudan al usuario en la ejecución de tareas. Para llevar a cabo este objetivo tienen que ser capaces de capturar y almacenar las preferencias del usuario. Además, 11.
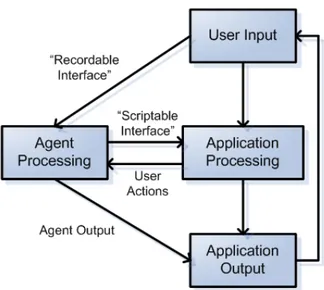
(19) deben de ser capaces de actuar adecuadamente ante nuevas situaciones no previstas, es decir, deben de tener capacidad de aprendizaje (esta es una de las caracterı́sticas más difı́ciles de conseguir). Los agentes pueden llevar a cabo sus tareas de manera independiente o trabajar de manera coordinada con otros agentes. En función de la habilidad para cooperar con otros en la ejecución de tareas los agentes se pueden clasificar en agentes no cooperativos (agentes individuales) y agentes cooperativos (sistemas multiagente). Una primera clasificación, en cuanto a las habilidades de los agentes, es la siguiente: Agentes racionales - Se utilizan en comercio electrónico y median por su usuario en compras o subastas, por ejemplo agentes que buscan el mejor precio de un producto. Agentes de adaptación - Son capaces de adaptarse por su mismo a cambios en su entorno. En Internet los agentes tienen que construirse para tratar con información incierta e incompleta, de una manera fiable y segura. Tienen enfoque a personalización, adaptación al usuario y aprenden de su comportamiento. Agentes de información móviles - Son capaces de viajar autónomamente a través de Internet de un sitio a otro para la ejecución de sus tareas en diferentes servidores (por ejemplo para obtener información). También se puede hacer una clasificación en función de las tareas [41]: Búsqueda - Ayudan al usuario en la tarea de recuperación de información en Internet. (ej. Citeseer [5]) Monitorización - Vigilan los cambios en una página indicada por el usuario, la aparición de páginas en buscadores etc. Se comunica con el usuario a través de e-mail. (ej. Tracerlock [11]) Filtrado - Seleccionan información en función de las preferencias del usuario.(ej. BotBox [4]) Navegación - Son agentes de interfaz que ayudan al usuario a navegar por Internet. (ej. Letizia [36]) Comercio Electrónico - Recomendar productos, comparar precios. (ej. MySimon [9]) Para resolver problemas complejos los agentes deben cooperar con otros agentes. Las ventajas son la simplicidad, la flexibilidad, la robustez, la escalabilidad, la integración. Los dos aspectos clave son el mecanismo de intermediación entre los agentes y la forma de resolver las heterogeneidades de información (ontologı́as). Un agente de búsqueda, autónomo, e integrado al proceso de navegación de un usuario, presenta las caracterı́sticas básicas expuestas en la figura 2.4.. Básicamente, el usuario introduce datos para que los procese la aplicación, en general las palabras-clave necesarias a la búsqueda. Esa información también es enviada al agente de búsqueda. El agente envı́a los resultados del procesamiento de la información a la aplicación. Y finalmente la aplicación despliega la información necesaria al usuario. Nótese que la aplicación 12.
(20) Figura 2.4: Estructura de una aplicación interactiva basada en agentes. también puede regresar información útil hacia el agente, por ejemplo las acciones del usuario e la aplicación, que puede ser muy relevante para determinar y actualizar el perfil del usuario. En [36] Henry Liebermann expone ciertos principios de diseño para los agentes autónomas de interfaz: Sugerencias preferibles que acciones Los agentes de búsqueda trabajan mejor cuando las decisiones no son crı́ticas. En las situaciones no crı́ticas, el agente no tiene que tomar la mejor decisión, sino que ofertar una sugerencia que es mejor que nada o lo suficientemente buena. Por ejemplo serı́a muy peligroso, o la gente no va a querer dejar un agente decidir comprar una casa en una página de bienes raı́ces, mientras que los usuarios tienen menos miedo a dejar un agente sugerir que página es mejor ver que otra. No es un decisión tan crı́tica ver tal o tal página. Una recomendación de páginas solo puede aumentar la probabilidad de que el usuario encuentre la buena página. Por lo tanto sugerencias hacen de la relación usuarioagente una actividad de cooperación. En ese tipo de interacción, algo muy importante es que la actividad y sobre todo la retroalimentación de parte del agente no moleste al usuario en su ambiente de trabajo. Tampoco el agente debe actuar en contra del usuario, y no debe insistir en la aceptación o el rechazo de parte del usuario. Algo importante en la interacción con el usuario es que las posibilidades de presentación y de acciones del usuario se hacen bajo muchos limitantes. Siempre hay muchas posibilidades de qué información desplegar al usuario, y qué es lo que va a hacer el usuario después, y eso debe de estar definido en la fase de diseño de la aplicación. Los investigadores del equipo de Koenemann en la universidad de Rutgers [34] llegaron a la conclusión que la recomendación explicita de palabras es mejor que la reformulación directa. Los usuarios sienten que tienen más control en los resultados, y la reformulación directa necesita una explicación de los procesos a los usuarios para que funcione bien. Entonces se tiene que construir sistemas de recomendaciones de palabras cuyas el usuario pueda escoger, pero el usuario tiene que poder ver y entender la relación entre las palabras que le proponen y las que puso originalmente. En otras palabras, el usuario 13.
(21) tiene que tener confianza en el sistema. Aprovechar de la información dada por el usuario Las acciones ejecutadas por el usuario constituyen información que el sistema puede usar para inferir las metas y los intereses del usuario, sin interacción explı́cita de parte del usuario. Cada acción requerida de parte del usuario es una perdida de tiempo y una molestia, y se tiene que evitar eso. Los motores de búsqueda tienen una interacción mı́nima: entrar una consulta, un conjunto de palabras, y darle “Enter”. Pero aún ası́ es un poco pesado regresar a la página de búsqueda cada vez que se tiene que buscar algo. Hay que estudiar entonces qué forma de interacción podemos usar, y con eso qué forma de retroalimentación de parte del usuario podemos usar (ver sección Evaluación de una página). Aprovechar del tiempo de reflexión del usuario Una desventaja de interfaz sencilla de conversación con el usuario, por ejemplo Google, es que el sistema se queda inactivo mientras el usuario piensa qué página ver. Por eso tener un agente autónomo que siempre está procesando la información es una economı́a de tiempo. Es particularmente importante en tareas de búsqueda o exploración. También se puede usar ese tiempo en profundizar las búsquedas anteriores, o actualizar los perfiles etc. La atención del usuario puede ser distribuida Una consecuencia de hacer correr un agente de manera continúa es que no se puede asegurar que el usuario le está poniendo atención al agente. El usuario puede estar mandando información al agente sin saber bien dónde está dirigida la información, y de la misma manera el agente puede desplegar algo al usuario en un momento inoportuno. Por lo tanto hay que estudiar el contexto en cada situación. Agentes de interfaz autónomos pueden tener una ganancia diferente entre deliberación y acción. La diferencia del mundo del agente entre el tiempo de deliberación y el tiempo de acción es un problema muy famoso en Inteligencia Artificial. Ya que pensar en el problema consume tiempo, las caracterı́sticas del problema pueden haber cambiado al momento de ejecutar la acción. Una interfaz autónoma puede no concordar con los estilos cognitivos de todos los usuarios Es importante realizar que los usuarios tienen modelos cognitivos diferentes, y a cada uno le puede aparecer la interfase o muy práctica o muy ineficiente. A algunos usuarios le pueden molestar las cosas no lineales por ejemplo. Lo que a veces puede molestar es que el usuario siente que tienen la obligación de poner atención a cada cambio de pantalla, aunque él esté absorbido en otra actividad. Un usuario con más experiencia puede estar más a gusto con solo “echar un ojo” de vez en cuando al sistema, mientras que usuarios ya acostumbrados a por ejemplo los video juegos van a estar más a gusto con una aplicación más completa visualmente.. 14.
(22) Figura 2.5: Sistema de Recuperación de Información.. 2.2.. Recuperación de Información. La Recuperación de Información (RI) (en inglés Information Retrieval ) es el problema de la selección de información documental desde dispositivos de almacenamiento, en respuesta a consultas realizadas por un usuario. Se desea que la información recuperada sea relevante para el usuario y que se obtenga en un intervalo de tiempo adecuado.. 2.2.1.. Los Sistemas de Recuperación de Información. La Recuperación de Información se lleva a cabo mediante los Sistemas de Recuperación de Información (SRI), que se encargan del almacenamiento y organización de un conjunto de documentos para su posterior recuperación por los usuarios. Los SRI manejan bases de datos documentales, como visto en la figura 2.5. Las tareas fundamentales en un SRI son las siguientes [48]: Cómo representar los documentos en la base documental Cómo representar las necesidades de información de los usuarios en forma de consultas Cómo evaluar la satisfacción de una necesidad de información por un documento Cómo presentar los resultados de la consulta al usuario Cómo reafinar los resultados de una consulta previa Según el mismo autor, el proceso de recuperación de la información es el presentado en la figura 2.6. Los elementos de un sistema de recuperación de información son: Base de Datos Documental. Almacena los documentos y una representación de sus contenidos. La representación suele estar compuesta por términos ı́ndice. El módulo de indexación genera automáticamente estas representaciones. 15.
(23) Figura 2.6: Proceso de Recuperación de Información. Sistema de consulta. El usuario formula las consultas mediante un lenguaje de consulta (interfaz de consulta). Lleva a cabo la interfaz con el usuario mostrando los documentos recuperados (interfaz de respuesta). Mecanismo de evaluación. Evalúa el grado en que los documentos satisfacen la consulta y recupera los que considera relevantes mediante una técnica de RI. En la figura 2.7 se presentan los elementos fundamentales de un sistema de recuperación de información.. 2.2.2.. Modelos de Recuperación de Información. Existen distintos modelos de Recuperación de Información (RI) dependiendo del tipo de consulta considerado (lenguaje de consulta) y del mecanismo de evaluación de consultas. Belkin y Croft proponen una clasificación en función de a filosofı́a seguida por el mecanismo de evaluación de consultas al emparejar consultas y documentos: Modelos de RI basados en coincidencia exacta. Seleccionan aquellos documentos que se adecuan totalmente a la consulta. El representante de este grupo es el modelo boleano de RI, que no permite ordenar los resultados por relevancia (muy empleado en las empresas). Modelos de RI basados en coincidencia parcial. Los modelos de coincidencia parcial no exigen una adecuación total y ordenan los resultados por relevancia. Podemos distinguir dos grupos, según emparejen documentos individuales o grupos de éstos con la consulta: Individuales • Modelo vectorial: basado en funciones de similitud. • Modelo probabilı́stico: basado en la regla de Bayes. • Modelos difusos: operadores de lógica difusa.. 16.
(24) Figura 2.7: Elementos de un Sistema de Recuperación de Información. En red: comparan con grupos de documentos conectados: • Basadas en clusters • Basadas en técnicas de navegación, usando redes de conexión entre los documentos. A continuación se explica más a detalle el modelo vectorial, dejando el modelo boleano ya que no se va a usar este método en este trabajo. En efecto, el modelo vectorial se adapta muy bien a la representación de la información contenida en las páginas, ya que se usan vectores de palabras, pudiendo usar las funciones de similitud para determinar las semejanzas entre las páginas. Mientras que el modelo boleano no permite trabajar en las similitudes, y por lo tanto es pobre en esa información. Modelo vectorial Todavı́a basándonos en el libro de Salton [48], los documentos son vectores de números reales en [0,1] (vectores en un espacio n-dimensional) dij = {wd1j , wd2j , . . . wdnj } donde wdij es el peso del término i en el documento j. Las consultas tienen la misma representación que los documentos, para determinar los términos relevantes de la consulta. La evaluación empareja cada documento con la consulta determinando el grado en que dicho documento la satisface mediante una medida de similitud. Como ejemplo de similitud tenemos las siguientes formulas, donde d es el documento y q la consulta, y ti el término considerado (una palabra en el documento): 17.
(25) El producto escalar: SIM (d, q) =. n X. ti q i. i=1. Coseno:. n P. ti q i. SIM (d, q) = s i=1 n P. i=1. Distancia:. sX. SIM (d, q) = −. (t2i qi2 ). |ti − qi |2. i. Al existir grados de relevancia, los resultados obtenidos se pueden ordenar en función de éstos. El tamaño de salida se puede controlar, poniendo un valor lı́mite al número de documentos recuperados, o devolviendo únicamente aquellos documentos que superan un umbral de relevancia fijado.. 2.2.3.. Técnicas de Mejora. Los Sistemas de Recuperación de Información (SRI) pueden ser mejorados de varias formas: usando la retroalimentación de relevancia y usando la información que nos proporciona Internet. Retroalimentación de relevancia La retroalimentación de relevancia (relevance feedback en inglés) es el refinamiento de la consulta por parte del usuario en función de la salida proporcionada por el SRI. En los años sesenta, John Rocchio [45] propuso un método que llamó Retroalimentación de relevancia. Por las razones dadas en la definición del problema, el usuario no puede empezar su búsqueda con las palabras-clave ideales (las que mejor especifiquen lo que se quiere buscar). Tampoco el usuario va a poder reformular sus palabras, y no va a buscar a entender las complejidades del sistema. Sin embargo, podemos suponer que el usuario sı́ va a poder reconocer e indicar cuando el objeto encontrado es relevante o no. Rocchio sugirió que el sistema podrı́a usar las caracterı́sticas (frecuencia de las palabras y distribución) de estos objetos relevantes o no, para modificar o reformular la consulta, hasta que la consulta finalmente sea ideal. El papel del usuario en esa interacción es indicar la relevancia o no relevancia del objeto extraı́do. La reformulación de la consulta es interna al sistema, y el único conocimiento del usuario acerca de esa reformulación es por la lista de resultados dada por el sistema. Este tipo de interacción esta descrita por system-controlled. Sin embargo el usuario tiene cierta influencia sobre la reformulación. Otro método posible para la reformulación es de desplegar al usuario nuevas palabras que le pueden ser útiles en su búsqueda. Estas nuevas palabras tienen algo en común, sea co-occurence en el documento, o contextos similares, con las que puso originalmente el usuario. Este tipo de enfoque es user-controlled, al menos el usuario controla cómo son reformuladas las consultas.. 18.
(26) En el sistema de Fitzpatrick y Dent [23] se agregan palabras extraı́das tanto de los documentos encontrados por esta misma consulta como de los documentos seleccionados por consultas anteriores similares. Crean un “contexto” de consultas, dadas las consultas anteriores, pero también se ha hecho eso con los perfiles de los usuarios [38]. Por ejemplo: Redefinición de los pesos de los términos de la consulta original, aumentando los de aquellos términos presentes en los documentos relevantes recuperados y reduciendo los de los irrelevantes, sin añadir o eliminar ningún término. Expansión de la consulta, basada en el cambio de pesos y la adición/eliminación de términos presentes en los documentos relevantes e irrelevantes recuperados, respectivamente. La técnica de expansión de consultas que mejores resultados ha obtenido en los SRI vectoriales es la Ide dec-hi : d0 = d +. nr X. R i − Si. i=1. donde d es el vector de la consulta original, Ri es el vector del i-ésimo documento relevante recuperado, Si el vector del i-ésimo documento no-relevante recuperado, y nr el número de documentos relevantes recuperados. La técnica Ide dec-hi se basa en mezclar el vector de la consulta original con los de los documentos recuperados. Se redefinen automáticamente los pesos de los términos de la consulta sumando los pesos de los términos en los documentos relevantes y restando los de los irrelevantes. La adición de términos se efectúa incluyendo en la consulta original todos los términos procedentes de los documentos relevantes recuperados que no existieran anteriormente. Entonces aquı́ se sitúa la pro-actividad de un agente de información: en base a la confirmación de los documentos relevantes recuperados se refina el proceso de búsqueda. A parte del uso de la retroalimentación de relevancia (relevance feedback ), existe información que el sistema puede dar al usuario para orientarlo de cara a facilitar el análisis de la respuesta: Cantidad de documentos recuperado: permite refinar la consulta con términos más especı́ficos o más genéricos. Uso del tesauro de palabras relacionadas, sinónimas, genéricas o especı́ficas Información sobre cómo formular una consulta. En la Recuperación de Información en Internet Facilitar la recuperación de información en Internet es una tarea fundamental dada la trascendencia que ha tomado: Los buscadores utilizan algoritmos cada vez más potentes. Los buscadores se especializan cada vez más. Las aplicaciones usan técnicas avanzadas.. 19.
(27) Internet está formado por un conjunto dinámico de documentos, por lo que las formulas del espacio vectorial deben ser aproximadas. El modelo del espacio vectorial supone que los documentos son independientes entre sı́, pero Internet está formado por documentos (páginas) entrelazados, donde esta información (enlaces) puede ser utilizada, además de la frecuencia de términos. Los modelos de RI que ofrecen mejores resultados para Internet son los de red: comparan con grupos de documentos conectados. Los sistemas de búsqueda para Internet son los siguientes: Buscadores genéricos: directorios y motores de búsqueda (actualmente los buscadores combinan ambas estrategias). Buscadores especializados (turismo, salud, artı́culos...) Buscadores inteligentes Multi-buscadores (regresan los resultados de varios motores de búsqueda) Meta-buscadores (procesar los resultados de motores con sus propios algoritmos) Agentes inteligentes Los directorios son taxonomı́as jerárquicas que intentan clasificar los distintos temas o áreas de conocimiento (arte y cultura, ciencia y tecnologı́a, ciencias sociales, etc.). El ejemplo más significativo es Yahoo![12]. Algunos contienen más de 100 mil categorı́as jerarquizadas y millones de sitios Web clasificados. La ventaja es que si encontramos algo seguramente será útil. Los inconvenientes es que muchas veces la clasificación no es suficientemente especializada y no todo lo que existe en Internet está clasificado. Es necesario desarrollar sistemas que clasifiquen automáticamente. En cuanto a los motores de búsqueda, sus componentes son los siguientes: Robot - Realiza peticiones a sitios remotos para localizar nuevas páginas y/o cambios en las páginas. Le pasa las páginas al modulo de indexación o Indexador. Indexador - Analiza la página y actualiza el ı́ndice. Utilizan técnicas de Recuperación de Información (procesan el texto, eliminan palabras vacı́as, extraen raı́ces...). Motor de Búsqueda - Es el encargado de analizar la consulta del usuario y utilizando el ı́ndice buscar y ordenar por relevancia las páginas que satisfacen mejor la consulta. Interfaz de Usuario - Captura la consulta y muestra los resultados. Las estrategias de los robots de búsqueda para decidir qué páginas visitar son los siguientes: Partir de páginas con muchos enlaces y/o de los sitios más populares y/o admitir solicitudes para visitar el sitio (cola de peticiones). Utilizar los enlaces para hacer un recorrido en anchura, en profundidad, o combinadas con medidas de popularidad (visitar las de mayor calidad, por ejemplo páginas que apuntan a ella, técnica empleada por Google). Visitar periódicamente páginas. Los buscadores pueden contener enlaces inválidos. Algunos buscadores aprenden la frecuencia con la que cambian las páginas. 20.
(28) Mediante directivas los administradores de sitio pueden controlar el comportamiento de los robots, por ejemplo impedir indexar algo. Sin embargo, los frames, las mapas de imágenes, y las páginas dinámicas son fuentes de problemas. En cuanto a las estrategias para decidir qué indexar, cada robot utiliza un algoritmo particular. Se tiene en cuenta: Tı́tulo de la página o primeros párrafos Contenido completo de la página Meta-etiquetas Imágenes, o textos alternativos de las imágenes. El rol del indexador es obtener una representación interna (ı́ndice) de las páginas que les proporciona el robot. Para eso se analiza el contenido de las páginas: por ejemplo lista de parada (Altavista y Google entre otros) o extracción de raı́ces (Lycos). Los ı́ndices se organizan en archivos invertidos: es una lista de palabras (vocabulario) y páginas en las que aparecen dichas palabras. Además se puede almacenar (mayor requisitos de espacio): la posición de la palabra en la página, información acerca del uso de mayúsculas o tipo de letra utilizado, la fecha de creación o el texto asociado a los enlaces. Los motores de búsqueda tienen como objetivo encontrar en el ı́ndice las páginas relacionadas con la consulta u ordenarlas por relevancia. Se usan criterios de: Localización - Mayor relevancia cuando las palabras aparecen en el tı́tulo, o al comienzo. Frecuencia - Número de veces que aparecen las palabras de la consulta. Popularidad - Una página es mejor cuando más enlaces apuntan a ella. Las interfaces de consulta tienen que proveer una caja de texto para introducir consulta (secuencia de palabras), un módulo de tratamiento de mayúsculas/minúsculas, extracción de raı́ces...Debe proporcionar al usuario cierta información acerca del funcionamiento del buscador. Las interfases de respuesta tiene que mostrar los resultados: X páginas más relevantes (tı́tulo, URL, tamaño, resumen), total de páginas etc. También se puede incorporar funciones avanzadas (idioma, tipo de archivo, fecha de actualización etc.). Algunos buscadores son especializados en un dominio en particular, y tienen estrategias y heurı́sticas especializadas. Algunos son más inteligentes que otros: proponen consultas en lenguaje natural ([3] y [10]). Los meta-buscadores se encargan de recoger e integrar los resultados obtenidos por diferentes motores de búsqueda, presentándolos al usuario de forma uniforme. Como cada buscador particular sólo indexa una parte de Internet, y utiliza algoritmos propios de indexación, la hipótesis es que se ofrecerá mejores resultados si se conoce la respuesta de varios buscadores. Es muy fácil para un usuario cambiar de motor de búsqueda, cómo lo dice el director de la tecnologı́a de Google [46], el éxito para un motor de búsqueda no es garantizado, uno nunca sabe cual va a ser mejor próximamente, sobre todo con la impresionante velocidad con la cual se desarrollan los diferentes métodos de búsqueda. El lado lucrativo de los motores 21.
(29) de búsqueda, con los comerciales que vienen en las páginas, han motivado las compañı́as en invertir en la investigación. Dentro de la perpetua competición entre las compañı́as de búsquedas en Internet, lo que podemos hacer nosotros es aprovechar esta tecnologı́a, usando los resultados de estos motores y agregándoles nuestros propios algoritmos. Eso es la meta-búsqueda, o Meta Search en inglés. Entonces la falta de calidad que podemos encontrar en los motores de búsqueda en Internet se puede resolver con el uso de un sistema de meta-búsqueda. La calidad del sistema depende de las páginas usadas por supuesto, pero de todos los métodos usados: la modelación del usuario, el proceso de las palabras-clave puestas por el usuario y los diferentes algoritmos de filtraje. Un sistema de meta-búsqueda es ideal para probar los diferentes métodos que se tiene, porque ofrece una cantidad de información enorme, y está bastante bien estructurado (todas las páginas de resultados de Google por ejemplo siguen la misma estructura).. 2.2.4.. Filtraje de Información y Filtraje Colaborativo. Hay dos grandes formas de enfoque para desarrollar agentes inteligentes que ayudan los usuarios a encontrar información relevante en Internet: los basados en el contenido (contentbased en inglés) y los que tienen un enfoque colaborativo [14]. En los agentes basados en el contenido, el sistema busca objetos que concuerdan con el análisis del contenido, usando las preferencias del usuario. En el enfoque colaborativo el sistema trata de encontrar usuarios con intereses similares para que le den recomendaciones. El sistema lo hace analizando los perfiles y sesiones de los usuarios. Asume que si a un usuario similar le gustó tal objeto, a este también. A veces se clasifican estos dos enfoques como Web Content Mining para el primero y Web Usage Mining para el segundo [14]. La clasificación también se puede hacer de la manera siguiente: de un lado el filtraje de información (Information Filtering o IF) que está basado en el contenido, y del otro lado el filtraje colaborativo (Collaborative Filtering o CF). Se ha probado que, juntando los dos tipos de enfoque, se puede eliminar las debilidades de cada uno cuando se usa solo, guardando las ventajas. Particularmente se ha probado [27] que una combinación personalizada de agentes y de opiniones de una comunidad da mejores recomendaciones que agentes o opiniones solos, es decir que un sistema muy interactivo es más eficiente. El filtraje colaborativo automático es un método muy popular para reducir la cantidad enorme de información disponible en Internet. Se usa a veces en complemente de lo que es filtraje de información basado en el contenido. Los servicios de recomendación colaborativa son una alternativa interesante a las técnicas tradicionales de Recuperación de Información. Tı́picamente identifican los vecinos o usuarios más cercanos a un usuario en el espacio de las precedentes calificaciones, y recomiendan los elementos que han sido bien calificados en el pasado. El filtraje colaborativo permite agregar información cuando los sistemas tienen dificultades en analizar algunas cosas como sentimientos, ideas etc. Permite medir satisfacción más lejos que con el puro contenido de las páginas. Permite también regresar páginas que sı́ pueden ser de interés al usuario, aunque no contiene la información que él querı́a, páginas que nunca hubiera encontrado él solo. El problema del filtraje colaborativo en Internet es el de predecir que tanto le va a gustar la página al usuario, en base a un conjunto de opiniones dentro de una comunidad de usuario. Opiniones pueden ser medidas por varias cosas. Si queremos un sistema completamente automático, es mejor tomar en cuenta los parámetros de navegación del usuario, que dar 22.
(30) calificación. También cuando un usuario califica una página, puede ser una calificación muy diferente de otro usuario, y sin embargo tener la misma opinión sobre la página, y también tener la misma calificación y opinar diferente. Apenas empiezan a tener cierta memoria los motores de búsqueda, por ejemplo el Personalized Google y su Search History [6] y generalmente no toman en cuenta la historia: cada una de las búsquedas iniciadas están consideradas como totalmente nuevas. Y sobre todo, los motores actuales ignoran las regularidades que existen en los métodos y preferencias de búsquedas de los usuarios en general y de los grupos de usuarios. Usuarios similares tienden a buscar páginas similares con palabras similares, y es más, tienden a seleccionar los mismos resultados. Sin embargo, en un ambiente como Internet, hay una probabilidad muy alta que alguién haya formulado una buena consulta para cierta información en un pasado reciente. Algunos estudios sobre el motor de búsqueda Excite revelaron que casi un tercio de las consultas están sometidas más de una vez. Eso nos apoya en nuestra creencia: el conocimiento colectivo, via las consultas de los usuarios, puede ser usado para ayudar a los usuarios individuales en formular sus necesidades en una terminologı́a apropiada. Por eso creemos que para cada búsqueda serı́a muy relevante que el motor este informado y use las palabras-clave similares que han sido usadas en la misma comunidad de usuarios. El cálculo de la semejanza El cálculo de la semejanza entre las consultas se puede hacer de varias formas. Wen [28, 50] hizo un trabajo de comparación entre todas, y podemos usar la que es más conocida cómo el algoritmo de Porter: La función de semejanza está definida como a continuación:. similaritykeyword (p; q) =. KN (p; q) M ax(kn(p), kn(q)). dónde kn(p) es el número de palabras-clave en la consulta, KN (p; q) el número de palabras en común en las consultas. Si las palabras de la consulta tienen peso, se usa la formula siguiente [48]: k P. cwi (p) × cwi (q). similaritykeyword (p; q) = s i=1 m P i=1. s. wi2 (p)×. n P. i=1. wi2 (q). dónde cwi (p) y cwi (q) son los pesos del la ia palabra en común de las consultas p y q respectivamente, y wi2 (p) y wi2 (q) los pesos del la ia palabra de cada una de las consultas p y q respectivamente. Sin embargo, existen muchos métodos, y se pueden ir mejorando según los resultados que se obtienen.. 23.
(31) 2.3.. La Representación de la Información. La representación de la información es una parte muy importante en un sistema de recomendación, ya que todos los algoritmos dependen de él, ası́ como la calidad de los resultados.. 2.3.1.. Procesamiento general de la Información. Los documentos de texto se representan por una componente estructurada en campos (Tı́tulo, autor, fuente, resúmenes, palabras-clave etc.) y una componente no estructurada (el texto tal cual llega). Esta representación se obtiene mediante procedimientos de indexación que asignan un conjunto de ı́ndices a cada documento en función del análisis de su contenido. Cada ı́ndice representa uno o más términos. La indexación puede efectuarse manual o automáticamente. La indexación automática se está imponiendo cada vez más por la gran longitud de los textos procesados. Está basada en el cálculo de la frecuencia de aparición de los términos en los documentos. Los términos con mayor poder de resolución (medida de la validez de un término como ı́ndice) son los de las frecuencias intermedias. Los de frecuencias muy altas o muy bajas no son significativos para representar el contenido de un documento. Usar frases de términos como ı́ndices mejora la recuperación, al tener mayor poder de resolución que los términos individuales. Para determinar los términos a usar como ı́ndices en la indexación automática, se efectúan varios pasos: Extracción de los términos existentes en la base documental mediante un autómata finito. Eliminación de los términos muy comunes en el idioma considerado usando una lista de palabras vacı́as (stoplist), donde estarán artı́culos, preposiciones y adverbios. Reducción a la raı́z (lematización o stemming) de los términos, eliminando los sufijos (ver Algoritmo de Porter [43]). Cada documento es un vector de ı́ndices ponderados. Hay varias formas de calcular el peso de un término ı́ndice. La más sencilla es la indización binaria (1 si el término aparece en el documento, y 0 en otro caso), pero esta indexación provoca una pérdida de información. El uso de pesos mejora sensiblemente la recuperación. Una de las más empleadas es la frecuencia documental inversa (IDF) de Salton [48].. 2.3.2.. El algoritmo TF-IDF. Este algoritmo es uno de los más famosos y los más usados en filtraje colaborativo. La idea básica del algoritmo es de representar cada documento como un vector en un espacio vectorial para que los documentos similares tengan vectores similares. Cada dimensión del vector representa una palabra y su peso. Los valores de los elementos del vector por un documento están calculados como una combinación de la frecuencia T F (w, d) (el número de veces que la palabra w se encuentra en el documento d) y la frecuencia del documento DF (w) (el número de documentos dónde se encuentra al menos una vez la palabra w). Con la frecuencia de documento se puede calcular la frecuencia inversa: IDF (w) = log 24. |D| DF (w).
Figure

+7






Outline
Documento similar
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
El nuevo Decreto reforzaba el poder militar al asumir el Comandante General del Reino Tserclaes de Tilly todos los poderes –militar, político, económico y gubernativo–; ampliaba
que hasta que llegue el tiempo en que su regia planta ; | pise el hispano suelo... que hasta que el
Abstract: This paper reviews the dialogue and controversies between the paratexts of a corpus of collections of short novels –and romances– publi- shed from 1624 to 1637:
Missing estimates for total domestic participant spend were estimated using a similar approach of that used to calculate missing international estimates, with average shares applied
We have created this abstract to give non-members access to the country and city rankings — by number of meetings in 2014 and by estimated total number of participants in 2014 —
Por lo tanto, en base a su perfil de eficacia y seguridad, ofatumumab debe considerarse una alternativa de tratamiento para pacientes con EMRR o EMSP con enfermedad activa
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
