Predicting the structure of water under such conditions is a difficult task by nature. The case retrieval algorithms used favor the recall of more recent cases.
CASE RETRIEVAL
This metric uses the difference between I40 and each of the thirteen other values of the input profile of the problem case with respect to points at 3 km intervals (starting at I1). This metric provides a more general indication of the similarity between the current case and the retrieved cases than Metric 1. For the problem case, the difference DI is between the mean value of the first five input profile values and the mean value of the last five input profile values. values are calculated.
The value of the Sobel filter (Gonzalez and Wintz, 1987) is calculated for the present case and all input profiles of the retrieved cases. The average temperature metric compares the average temperature, over the distance represented by each retrieved case, with that of the problem case. After obtaining the value of each of the above metrics for all cases in the Case Base, the best-fitting cases are determined as follows.
CASE REUSE AND ADAPTATION
The value of each metric is expressed on an absolute scale between 0 and 1; cases similar to the problem case will have a metric value close to 0; the more different the metric value of an instance is from that of the problem instance, the closer the value of the metric will be to 1. The best matches of each metric are then used to train a radial basis function neural network (as explained in the next section) in the adaptation phase of the recycling phase of the CBR. The metrics presented above are only applied to those cases (i) that have a date field equal to or within 2 weeks of the date field of one of the cases to obtain the latest forecast, or (ii) where the geographic location differs by less than 10 km from any of the cases used to train the network in the latest forecast.
The network acts as a function that retrieves representative solutions from a number of examples that are most similar to the current problem solving situation. The network does not require any human intervention and a small number of rules can be used to control its training.
Use of a Radial Basis Function Network
The network is retrained before any forecast is made using the retrieved cases and the network's internal knowledge (weights and centers). For each metric, the k best matches are used in the adaptation phase of the CBR cycle to train the network. If the value of the metric value associated with any of these two hundred cases is greater than three times the corresponding metric value of the best match, that case will not be used for training.
If the value of k is too high, it becomes increasingly difficult to train the network in the available time, while too small a value limits the generalization ability of the neural network. The input vector values are the differences between the last temperature value (of the input profile) and each of the input profile temperature values at 4 km intervals. The output of the network is the difference between the temperature at the current point and the temperature 5 km ahead.
Centre and Weight Adaptation
Initially, twenty vectors are randomly selected from the first set of training data and used as centers in the middle layer of the RBF network. All centers are associated with a Gaussian function whose width, for all functions, is set to the average value of the Euclidean distance between the two centers that are most separated from each other. The training of the network is accomplished by presenting the corresponding values of the input vector and the desired output values.
The closest center to each specific input vector is moved to the input vector by a percentage α of the existing distance between them. Centers are deleted when they do not contribute significantly to the output of the neural network: that is, it is a simple and efficient way to reduce the size of the network without dramatically reducing its memory.
Termination of Training
A new center is entered into the network when the average error in the training data set does not drop more than 10% after 10 iterations (using the entire training set.
CASE REVISION AND RETENTION
If the error margins are too wide, the prediction will be meaningless; therefore, a trade-off is made between a wide margin of error (which will ensure that the true solution is always within its bands) and an exact solution. The expected accuracy of the forecast depends largely on two factors: the water body for which the forecast is requested and the adequacy of the examples stored in the example database for that particular forecast. Therefore, forecasts produced around the equator may be assigned a smaller error interval than those obtained near the Falkland Islands.
Each time a cruise crosses a body of water, a new error limit ELz (0 < .z < 6) is calculated by averaging the error in all predictions made. The error limits are used in conjunction with the average error associated with each of the cases and is used to train the network to obtain a prediction. The values used in this formula were obtained empirically using data from all water masses of the Atlantic Ocean.
Case Retention - Learning
In such a situation, the operational strategy is then to use examples that refer to this marked region, centered at a position that is a distance x from the current position. The most important aspect of learning is that due to changing and storing the internal structure of the neural network and its parameter values. For this purpose, the weights and centers of the network and the width of the Gaussian functions associated with the centers are changed and saved during the fitting process.
Learning is a continuous process in which a neural network acts as a mechanism that generalizes profiles of input data and learns to recognize new patterns. A case base can be considered to function as a long-term memory, as it can maintain a huge number of cases that characterize previous situations. In contrast, stored network knowledge can be considered to behave as a short-term memory for recognizing recently learned patterns and allowing the system to adapt to localized situations.
RESULTS
This graph does not take into account the improvement achieved by using error bounds during the review phase of the CBR cycle. The experiment was performed with 25% of the data represented in Figure 1, this limitation being due to the availability of the satellite images and also because the available computing resources were insufficient to allow these tests to be run over the entire data set. Experiments were conducted to compare the performance, in terms of the average error obtained, of the hybrid system with other forecasting approaches: a Finite Impulse Response neural network (Corchado et al., 1998) a standard Radial Basis Function network (Corchado et al., 1997b), a linear regression model, an Auto-Regressive Integrated Moving Averages (ARIMA) model (Box and Jenkins, 1976) and a CBR system alone (Rees et al., 1996).
The prediction error with the CBR-ANN hybrid was found to be smaller than with any of the other prediction methods. In particular, the average prediction error outside the error bounds (0.001 °C) is significantly smaller than the value obtained by any of the other prediction methods. The standard deviation of the error also increased by more than 50% when using any of the other methods.
CONCLUSIONS
These percentages were found to increase by a factor of three when other prediction methods were used. on the quality of the cases and when these cases were collected, it was shown that it was possible to obtain a quality forecast even with data collected one year before the forecast was made. The RBF neural network plays an important role in the system; it adapts its structure in an unsupervised way to the characteristics of the environment and draws on information stored in relevant instances of previous prediction experience to generate a new prediction representative of all. The results obtained can be extrapolated to get a prediction for further distance ahead of the current location.
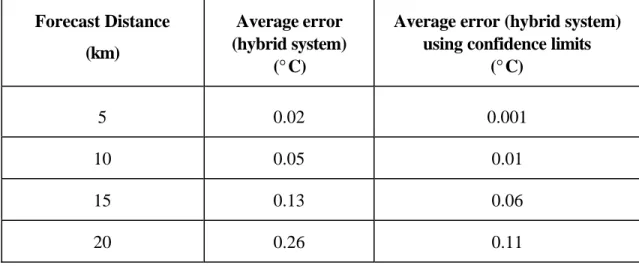
The further ahead the point for which the forecast is made, the more unreliable the forecast will be, as shown in Table 4. The limitations of this forecasting method are as follows. I). However, the structure of the system can be changed to make it possible to predict in such situations. ii) The system in its current form can only work effectively if there are no major discontinuities in the data. It is believed that this approach could potentially be applicable to other forecasting situations in other domains.
ACKNOWLEDGEMENTS
The geographic coordinates of the location of the location where the I40 value (of the input profile) is recorded. The approximate direction of the data trace orientation, represented by an integer x, (1 ≤ x ≤12) Return time The time when the instance was last received. Retrieval Location The geographic coordinates of the location at which the case was last retrieved.
1 Cases within an area bounded by a circle of radius P km centered on the current position of the vessel. X is the distance between the current position of the vessel and the geographical position of the case with a retrieval field equal to 4 and in which the average error is smaller than 0.05 and which has been retrieved within the last 20 km or 24 hours. 3 Cases from data recorded during the same month as the cases stored in the case base in which the prediction error is less than 0.05 and which were used during the last 24 hours or 50 km.

Captions for Figures
Case Base