Ingeniero Gareth Barrera Sanabria, Directora de Proyecto, por la paciencia y dedicación con la que aportó en el desarrollo, por la confianza demostrada desde el inicio de la tesis y por la buena implementación de la tutoría y orientación brindada durante estos semestres de trabajo continuo. A todas aquellas personas y amigos que aportaron su granito de arena para el buen desarrollo del proyecto, en especial a Claudia Patricia Barrios, Germán Enrique Álvarez, Edgar Agudelo Acuña, Luis Ernesto Carrillo, Edgar Steven Tellez, Camilo Rodríguez, Vicente Bocanegra; Cada uno de ellos participó en conjunto para determinar el camino correcto para un mejor desarrollo personal y profesional.
Pruebas de Análisis de Resultados
Las organizaciones han generado una cantidad cada vez mayor de información a lo largo de los años; se ha hecho necesario utilizar técnicas informáticas más eficaces para comprender mejor esos datos. El principal objetivo de esta tesis es obtener conocimiento de los datos del entorno gestionado por el usuario y cómo este los adapta a sus necesidades intuitivas, obteniendo resultados y aplicando efectos mediante técnicas de minería de datos, también modelos que ayuden a comprender el comportamiento. de individuos y también agruparlos en segmentos para brindar mejores y más diferenciados servicios.
INTRODUCCION
- ANTECEDENTES
- MOTIVACIÓN
- BREVE DESCRIPCIÓN DE LA EMPRESA A SIMULAR
- PLANTEAMIENTO DEL PROBLEMA
- OBJETIVOS DE LA TESIS
- Objetivos Específicos. A continuación se enlistan
- ALCANCES Y LIMITACIONES
- Alcances. A continuación se enlistan
- Limitaciones. A continuación se enlistan
- ORGANIZACIÓN DE LA TESIS
Realizar un análisis exhaustivo del estado del arte de los sitios web responsivos y del uso de técnicas de minería de datos para tal fin. Análisis del paquete weka [60] utilizado para gestionar técnicas de minería de datos.
MARCO DE REFERENCIA
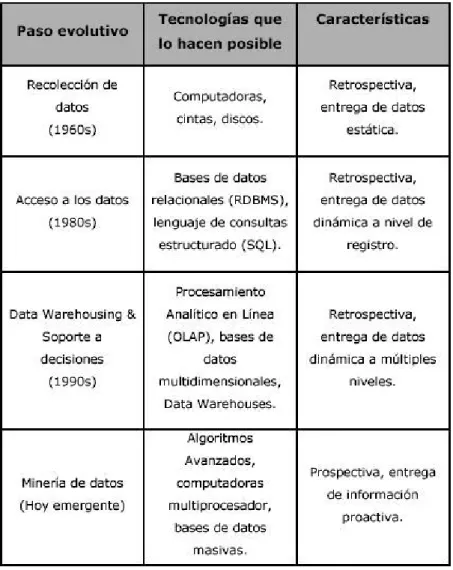
DESCUBRIMIENTO DE CONOCIMIENTO EN BASES DE DATOS (KDD) [63]
Las etapas del proceso KDD se muestran más claramente en la Figura 2.1. Vale la pena señalar que el proceso KDD es interactivo e iterativo e implica muchos pasos con muchas decisiones tomadas por el usuario.

Desarrollo y entendimiento del dominio de aplicación: El conocimiento previo relevante y las metas del usuario final
Limpieza y pre-procesamiento de datos: Operaciones básicas tales como la eliminación del ruido, recolectar la información necesaria para modelar y decidir
- Consolidación del conocimiento descubierto: Incorporar este conocimiento dentro del funcionamiento del sistema, o simplemente documentarlo y reportarlo
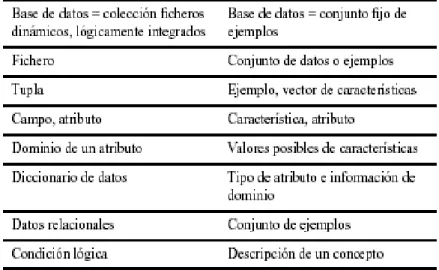
- Limitaciones del aprendizaje sobre las bases de Datos [63]. Se podría pensar que una simple traducción de términos es suficiente para poder aplicar sobre las bases
- Aplicaciones de minería de datos. Las siguientes son algunas aplicaciones de Minería de Datos las cuáles han sido desarrolladas exitosamente en los últimos años
- MÉTODOS Y TAREAS DE MINERÍA DE DATOS [19]
- APLICACIONES EN INTERNET
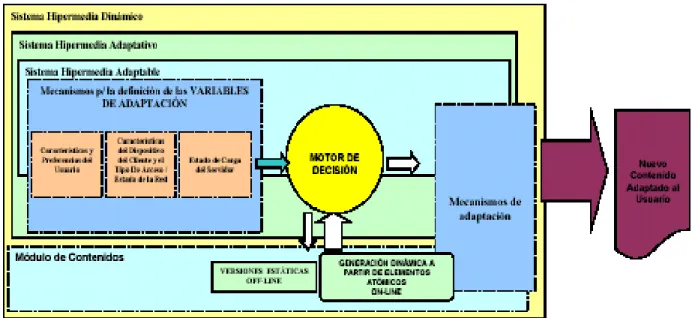
- SHAAD: SISTEMA HIPERMEDIA ADAPTABLE, ADAPTATIVO Y DINÁMICO [11]
Realizar entrenamiento en los conjuntos de bases de datos en lugar del conjunto de instancias. El proceso de minería de datos automatiza el proceso de descubrir patrones y tendencias útiles. La minería de datos tiene tres componentes principales [26]: Agrupación o clasificación, Reglas de asociación y Análisis. Componentes principales [26]: Agrupación o clasificación, Reglas de asociación y Análisis de secuencia.
En el proceso de minería de datos se obtienen varias reglas de este tipo con diferentes niveles de abstracción. A continuación se mencionan cuáles son estas diferencias y cuáles son las ventajas de utilizar la minería de datos. El modelo se construye analizando los registros de la base de datos descritos por atributos.
Esta opción aumenta la calidad de la información obtenida por nuestro proceso de minería de datos.
Las características y preferencias del usuario: Bajo este concepto se incluye todo lo referente a preferencias y conocimientos del usuario. Por preferencias
Aquí se definen las características a tener en cuenta al realizar la adaptación de contenidos, es decir, los valores de entrada del sistema hipermedia adaptativo. Características y preferencias del usuario: Este concepto incluye todo lo relacionado con las preferencias y conocimientos del usuario.
El dispositivo de acceso del Usuario: Como se expreso anteriormente, paralelamente con la creciente expansión de Internet se ha producido un amplio
Estado de carga del servidor: los usuarios son más que conscientes de experimentar situaciones fallidas o de acceso denegado.
Estado de carga del servidor: Por parte de los usuarios es más que conocida la experiencia de situaciones de accesos fallidos o rechazados por parte del
- Adaptabilidad / Adaptatividad. En este punto vamos a rescatar los conceptos existentes en torno a la Adaptabilidad o la Adaptatividad de los contenidos en los
- Estructura del SHAAD. Como es de saberse la Personalización y la Adaptatividad van unidas entre sí de forma paralela, lo cual nos indica que juntas son
- Promotion y Demotion. La promotion hace a un link o una página más fácil encontrar poniendo una referencia de ella más cercano a la página principal del sitio (en
Su finalidad es definir las características ya mencionadas: características y/o preferencias del usuario, tipo de dispositivo de acceso del usuario, tipo de acceso a la red, estado de la red y estado de carga del servidor. Cuestionarios de respuesta directa al usuario para conocer sus características y preferencias. Monitorear el comportamiento del usuario para inferir las características del usuario a partir de su interacción.
Mecanismos para definir las características del dispositivo de acceso del usuario y el tipo de acceso/estado de la red: En este módulo, como antes, se ilustran algunas técnicas que parecen servir al mismo propósito. Un sitio responsivo puede reconocer cuando las expectativas de los usuarios se desvían de la estructura del sitio.

PREPARACIÓN DE LOS DATOS Y DISEÑO
- METODOLOGÍA DE DESARROLLO
- SELECCIÓN DE LOS DATOS
- PRE-PROCESAMIENTO DE LOS DATOS
- SITIO WEB
- Casos de Uso. A continuación se describe uno de los diagramas que globaliza de modo general la aplicación en desarrollo, en el cual se encuentra cada uno de los
La preparación de datos para un estudio de Minería de Datos suele consumir la mayor parte del esfuerzo invertido en todo el proceso de Minería. La limpieza de datos se puede utilizar para eliminar el ruido y corregir inconsistencias en los datos. La integración de datos une datos de múltiples fuentes en un almacén de datos coherente, como un almacén de datos o un cubo de datos.
La reducción de datos puede reducir el tamaño de los datos mediante la agrupación en clústeres, la eliminación de funciones redundantes, etc., por ejemplo. Esta tabla almacena los datos obtenidos sobre a qué grupo pertenece cada usuario, esto es producto de la minería utilizando el algoritmo weka (ver Tabla 3.8).

HERRAMIENTA,(S) Y ALGORITMO,(S) DE MINERIA UTILIZADO,(S)
HERRAMIENTA,(S) DE MINERÍA DE DATOS UTILIZADA,(S)
ALGORITMO,(S) ELEGIDO, (S) PARA EL ANÁLISIS
Durante el resto del desarrollo de este apartado se realizarán las pruebas pertinentes con cada uno de los algoritmos, utilizando diferentes subconjuntos de datos de toda la base de datos, con el objetivo de analizar la información desde diferentes perspectivas. La herramienta que se utilizará para ejecutar los algoritmos de minería es WEKA. Las siguientes secciones explican en detalle cada uno de los algoritmos utilizados. Las secciones anteriores describen las herramientas que se utilizarán para aplicar los algoritmos de minería de datos. Cada uno de ellos cuenta con una gran cantidad de algoritmos de distintos tipos que persiguen objetivos diferentes.
Durante el desarrollo restante de esta sección, se realizarán pruebas relevantes con cada uno de los algoritmos, utilizando diferentes subconjuntos de la base de datos. Este algoritmo funciona de la siguiente manera: primero, realiza una selección aleatoria de las instancias, cada una de las cuales inicialmente representa un promedio o centro del grupo.
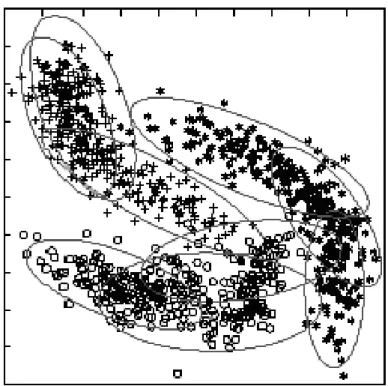
PRUEBAS Y ANALISIS DE RESULTADOS
- PRUEBAS A (ADAPTATIVIDAD)
- Selección de los mecanismos de definición del estado de la red. El estado de la red puede variar dependiendo de donde se necesite utilizar el servicio, no obstante se
- Selección de los mecanismos de definición del estado de carga del servidor
- DESARROLLO E IMPLEMENTACIÓN DEL SISTEMA ADAPTATIVO
- VENTAJAS Y DESVENTAJAS DE IMPLEMENTAR LOS MECANISMOS DE ADAPTACIÓN SOBRE EL SERVIDOR O SOBRE UN PROXY
- PRUEBAS B (MINERÍA DE DATOS)
- Conjuntos de datos de las pruebas. Los datos utilizados para estas pruebas, fueron sacados de los siguientes atributos
- Clasificación de Usuarios. En esta sección se habla sobre los resultados obtenidos después de realizar el proceso de weka
Su funcionamiento también puede ser Intranet o Extranet, dependiendo de la aplicación que le quieras dar. La promoción se aplica a medida que se manipulan los enlaces (Clic en cada uno) como se puede observar en la Figura 5.5, tanto fuera como dentro del lugar donde se encuentran. Esta condición se ejecuta mientras avanza la iteración en el mismo enlace porque hay un límite en las acciones que se pueden realizar y mostrar en la página web.
Cada vez que quieras ejecutarlo en diferentes servidores, es necesario configurar y asignar los paquetes respectivos para su correcto funcionamiento. Este archivo se almacena en esta dirección como un CD con las clases y los archivos generados (mining\WEB-INF\results\ar.arff) adjunto, ver Figura 5.7.

2 visita
2 visitas Ciudad 3: 1 visitas
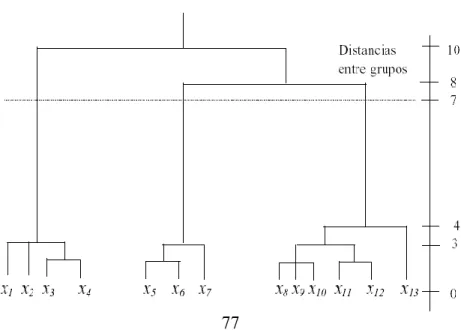
ANÁLISIS DE CLUSTERING
- Conclusiones para el análisis de clustering. Las conclusiones mas adecuadas para estas pruebas realizadas son las siguientes
El algoritmo seleccionado fue k-means fuel, se analizaron varias técnicas de minería pero este algoritmo fue el más adecuado a las necesidades propuestas, se fusionó este algoritmo y se trabajó en los conteos de ciudades, el archivo de prueba no tomó en cuenta la edad. porque no era un parámetro muy confiable, por su variación y porque estos son muy grandes. Como se mencionó anteriormente, el algoritmo k-means nos da un resultado de cómo clasifica a los usuarios en sus respectivos grupos, los datos de entrada no eran reales, la base de datos se recopiló con datos ficticios, porque no había base de datos más confiable, pero tenga en cuenta que el El algoritmo desarrolló los objetivos esperados, donde daría recomendaciones incluso a los usuarios que no estuvieran registrados, les aparecería una opción relacionada con su edad. Se sabe que antes se mencionó que no se tenía en cuenta la edad para el archivo de prueba, pero aun así nos sirve para la clasificación de un nuevo usuario.
Al analizar los resultados obtenidos con el algoritmo implementado, es necesario contar con una base de datos real, pero no ficticia, ya que al ejecutar diversas pruebas los datos no variaron mucho. Esto no quiere decir que el algoritmo utilizado para el problema propuesto sea malo, lo que pasa es que los datos contienen una secuencia de entrada y los conteos fueron muy similares. Lo interesante del algoritmo K-means es que puede especificar el número deseado de grupos y, al mismo tiempo, los datos devueltos son muy fáciles de interpretar.
CONCLUSIONES Y TRABAJOS FUTUROS
CONCLUSIONES
El preprocesamiento de datos consumió una buena parte del tiempo invertido en desarrollar y comprender los algoritmos. Se obtuvieron interesantes patrones de conocimiento sobre el comportamiento de los Usuarios en el Sitio Web, aunque se podrían obtener mejores conocimientos si los datos facilitados por los Usuarios fueran completamente reales. No se puede ignorar que la facilidad para encontrar herramientas de licencia gratuita facilitó la aplicación de algoritmos para extraer datos generados a partir de logs, un valor añadido interesante a la hora de desarrollar un proyecto de esta envergadura.
Los grupos creados nos permiten analizar mejor los usuarios que interactúan con el sistema y obtener características generales para mejorar determinados servicios. Es importante entender que con la segmentación que se obtiene mediante el análisis de clustering se deben aplicar estrategias más personalizadas según cada perfil, porque este es el núcleo de todo y hoy en día es muy importante saber diferenciar a los usuarios y ofrecerles los servicios adecuados. que todos necesitan, independientemente del sitio web de la empresa.
TRABAJOS A PROYECTAR
Ampliar el campo de las pruebas, es decir, utilizar herramientas que permitan obtener una representación gráfica de los resultados o generar una perspectiva diferente de los resultados y otras variables.
BIBLIOGRAFIA
BIBLIOGRAFÍA
Descomposición de algoritmos de minería de datos (FUV abril http://userpages.umbc.edu/~kjoshi1/data-mine/proj_rpt.htm. Lenguaje de programación JAVA (FUV noviembre/2003) → http://www.javahispano.org/ tutoriale. type.action?type=j2se - http://java.sun.com - http://www.sun.com Herramienta de modelado de datos Rational Rose Modeler → http://www.rational.com/products/rose/modeler / modelador.jsp.
And Advances in Knowledge Discovery and Data Mining, Fayyad, Piatetsy-Shapiro, Smyth y Uthurusamy Eds., AAAI Press, Menlo Park, California, 1996. Yudong Yang, Jinlin Chen, and Hongjiang Zhang, "Adaptive Delivery of HTML Contents", 9th International World Wide Web Conference - The Web: The Next Generation, Amsterdam, 2000.
GLOSARIO
Análisis prospectivo de datos: Análisis de datos que predice tendencias, comportamientos o eventos futuros basándose en datos históricos. Clasificación: Proceso de dividir un conjunto de datos en grupos mutuamente excluyentes de modo que cada miembro de un grupo sea "el más cercano". Dimensión: en una base de datos relacional o plana, cada campo de un registro representa una dimensión.
Modelo de predicción: estructura y procedimiento para predecir los valores de variables específicas en un conjunto de datos. Navegación de datos: el proceso de ver las distintas dimensiones, "caras" y niveles de una base de datos multidimensional.
DIAGRAMAS DE SECUENCIA Figura 1 – Guardar Registro Usuario