Algunos de ellos son la dificultad para estimar la duración de las actividades, la aparición de nuevas tareas que pueden retrasar las que están en curso o la incertidumbre provocada por el factor humano. A partir de la segunda etapa el rendimiento comienza a decaer y existe mayor probabilidad o riesgo de sufrir algún problema de salud [MEL06].
Propuesta
Estructura del documento
El tercer apéndice contiene el script de creación de la base de datos (ver apéndice E). A continuación se muestra la Figura 5.17, donde se puede ver un diagrama completo del diseño de la base de datos.
Objetivos 5
Objetivos específicos
- Objetivo 1: Extracción de conocimiento
- Objetivo 2: Desarrollo de una aplicación web
Antecedentes 9
Descripción general
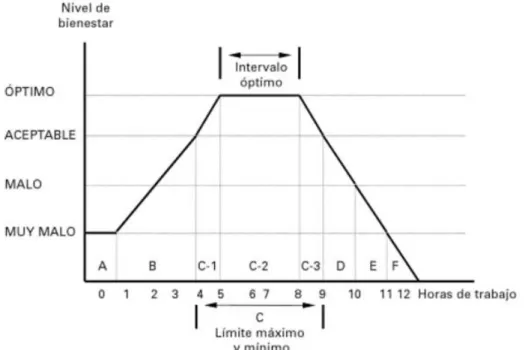
Según esta curva, existe una relación entre la jornada laboral y el nivel de bienestar del trabajador, donde tanto no trabajar como trabajar por un período de tiempo muy largo es malo. En este último caso, en el que se trabaja durante un periodo muy prolongado, el nivel de bienestar es bajo a pesar de tener una alta sensación de satisfacción, ya que el exceso de trabajo también puede provocar trastornos psicológicos.
Estrés y otros problemas
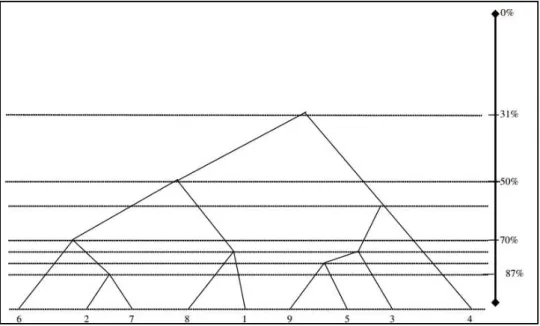
Estos robos de tiempo no siempre se pueden evitar, pero se pueden minimizar o realizar de la manera más productiva posible, para que tengan el menor impacto posible en el rendimiento. En la figura 3.2 se puede ver una representación de cómo varía el nivel de resistencia dependiendo de la fase de estrés en la que se encuentra el individuo.
Herramientas de gestión del tiempo personal
- Herramientas de time tracking
- Herramientas de asistente personal
Se puede acceder a Harvesta online o desde varias plataformas, y al igual que Toggl, se ha integrado en diversas herramientas que les aportan un gran valor añadido. También proporciona monitorización de la respiración y, una vez evaluado el nivel de estrés del usuario, ofrece una variedad de recomendaciones personalizadas y artículos para leer.
Extracción y explotación del conocimiento
- Big Data
- Big Data Analytics
- Ciencia de datos
- Ingeniería de datos
Cada conjunto de datos requiere un tratamiento de limpieza de datos y la aplicación de diferentes técnicas. De esta forma, los científicos pueden analizar grandes volúmenes de datos que serían inaccesibles con medios tradicionales.

Algoritmos de Aprendizaje automático
- Algoritmos de clustering
- Algoritmos jerárquicos
- Algoritmos planos
- Ventajas y desventajas
- Criterios de calidad
- Árboles de decisión
- Algoritmos de construcción de árboles de decisión
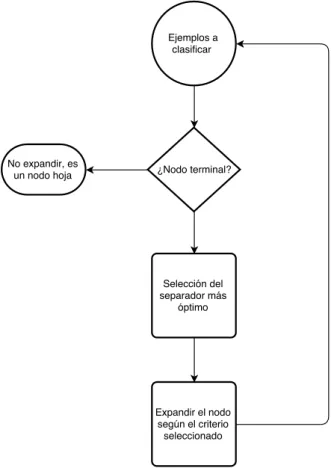
Los criterios de calidad son importantes para evaluar la calidad y confiabilidad de los grupos generados por algoritmos de agrupamiento. La Figura 3.8 muestra un diagrama que muestra el procedimiento para utilizar un árbol de decisión.

Aplicación web
- Arquitectura de tres capas
- Diferencias con la arquitectura de dos capas
- Ventajas y desventajas de las aplicaciones web
En esta iteración se realizó el diseño de la base de datos de la aplicación y se crearon módulos para acceder, importar y configurar el sistema.

Método de trabajo 33
KDD
Selección de Datos: El propósito de este proceso es obtener el mapa de datos y consta de dos partes. Esta fase implica operaciones como eliminar ruido y determinar estrategias para lidiar con datos faltantes e inconsistentes. La reducción de datos se realiza fusionando los registros y generando nuevos atributos basados en los existentes.
SEMMA
Interpretación y evaluación: En esta última fase se realiza una visualización de los patrones y una evaluación de los resultados obtenidos. También se decide si es necesario perfeccionar alguno de los procesos anteriores si los resultados generados no se consideran aceptables. Exploración: Análisis de datos de muestra mediante técnicas de visualización o herramientas estadísticas, buscando relaciones entre variables.
CRISP-DM
Evaluación: Los resultados obtenidos y el modelo se evalúan mediante herramientas estadísticas y comparaciones con otras muestras del conjunto de datos. Comprensión de los datos: Proceso que va desde la recopilación de datos hasta la verificación de su calidad. Preparación de datos: se selecciona un conjunto de datos y se realiza un preprocesamiento.
Elección de la metodología de extracción de conocimiento
Se eligió KDD para proporcionar una guía general de trabajo sin profundizar demasiado en cada proceso, dejando así mayor libertad al desarrollador. Además, no se establece un proceso de despliegue del sistema, por lo que se puede hacer una separación entre la extracción de conocimientos y patrones adquiridos, y el desarrollo del sistema que hace uso de ellos. Finalmente, fue la primera metodología aceptada en la comunidad científica, mientras que el resto puede verse como una implementación de sus procesos, lo que hace interesante su estudio y aplicación en un proyecto real.
Metodología de desarrollo del software
- Elección de la metodología de trabajo
La primera razón es que el grupo de trabajo es mínimo y no es necesario un número elevado de roles. Sin embargo, la realización de la extracción de conocimiento se aborda con un desarrollo en espiral, ya que es común refinar los procesos una vez finalizados, si no se logra el resultado deseado. En concreto se ha utilizado una variación, en este caso se trata del modelo espiral WIN WIN, donde se enfatiza la participación del cliente, y por tanto sigue una filosofía muy cercana a la metodología ágil.
Conceptos básicos de Scrum
- Definición de Scrum
- Equipo Scrum
- Elementos de Scrum
- Historias de usuario
Este rol es clave para el éxito del proyecto, ya que intenta evitar distracciones y barreras que puedan surgir en el equipo. Sprint Planning: Se define como una reunión de planificación al inicio de cada Sprint, donde el equipo de desarrollo y el Product Owner generan acuerdos y compromisos, especificando así el alcance de la iteración. Negociable: la redefinición de los criterios de aceptación y la creación o eliminación de historias de usuarios se negocian entre el cliente y el equipo.
Kanban
Estimable: A pesar de la incertidumbre, cada historia de usuario debe ser estimada, siempre y cuando esté bien definida y no falte conocimiento técnico y funcional. Verificable: antes de desarrollar la historia del usuario, los equipos solicitan criterios de aceptación del cliente para verificar la funcionalidad. Este flujo se divide en tres bloques, en función del estado de las historias de usuario: 'Pendiente', 'En proceso' y 'En proceso'.
Utilización de la metodología en el proyecto
- Uso de Scrum en el proyecto
A continuación se describe el modelo de historia de usuario seguido durante el desarrollo de este proyecto. Por ejemplo, la siguiente historia de usuario "HU1603" corresponde a la tarea número 3 de la semana 16. Pruebas de aceptación: Conjunto de pruebas necesarias para verificar que la historia de usuario se ha completado satisfactoriamente.

Marco tecnológico
- Medios hardware
- Medios software
Otro punto favorable es la multitud de complementos que ofrece para interactuar con otras herramientas8. También permite obtener gráficas de tiempo, algo muy útil para generar presupuestos e informes9. Spring Framework: este marco proporciona un modelo integral de programación y configuración para crear aplicaciones basadas en Java.
Planificación
- Iteración 0: Preparación del proyecto y esqueleto de la aplicación web 49
- Iteración 2: Modelo de la base de datos y módulos de acceso, impor-
- Iteración 3: Módulo de monitorización
- Iteración 4: Módulo de predicción
- Iteración 5: Refinamiento del proceso de extracción del conocimien-
Tiempo Efectivo: El tiempo invertido en completar una tarea sin agregar interrupciones. Finalmente se realizó una prueba no funcional del desempeño de la aplicación que se comunica con la base de datos.
Resultados 55
Requisitos deseables de la aplicación web
REQ_NF_02 Una de las propiedades que debe tener una aplicación es la concurrencia, ya que puede haber más de un usuario en el sistema al mismo tiempo solicitando una base de datos. REQ_NF_03 La aplicación debe integrar el módulo de seguridad para que el usuario no pueda. REQ_NF_04 Agregar un sistema que permita al usuario cerrar sesión después de un cierto período de inactividad. REQ_NF_05 En términos de accesibilidad, la navegación entre diferentes páginas debe ser lo más intuitiva posible para el usuario.
Arquitectura del sistema
REQ_F_01 Disponibilidad de una interfaz de registro de usuarios y acceso al sistema REQ_F_02 Desarrollo de un proceso de importación de registros. De esta manera no es necesario volver a compilar el sistema si desea realizar cambios (configurabilidad).
Iteración 0: Preparación del proyecto y esqueleto de la aplicación web
Para el desarrollo de la aplicación se eligió el lenguaje Java, por lo que se utilizó Spring Framework. Los controladores son aquellas clases que actúan como intermediarios entre el cliente y el servidor, mientras los procesos ejecutan la lógica de la aplicación. También contiene una carpeta de recursos, que se diferencia de las demás carpetas de recursos analizadas en el párrafo anterior principalmente en que almacena recursos que se ejecutan en el lado del cliente, como CSV y javascript.
Iteración 1: Extracción de conocimiento
- Datos disponibles y selección
- Preproceso
- Transformación
- Agregación por días
- Agregación por semanas
- Minería de datos
- Proceso de clustering
- Generación de dendrogramas
- Árboles de decisión
- Definición de patrones
- Conclusiones
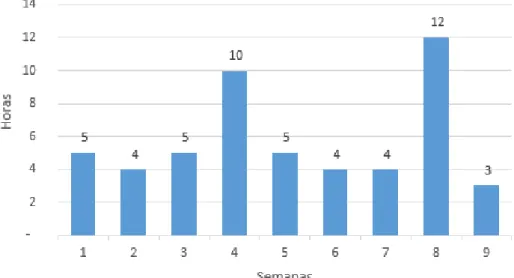
Proyecto de tarea: esta es una etiqueta que incluye todos los grupos de tareas similares. A los días en los que no se trabajó se les asignó un valor de -1, independientemente del impacto que pudiera tener. El promedio de días trabajados se sitúa entre seis y siete días y el tiempo efectivo es el mayor de los tres grupos.
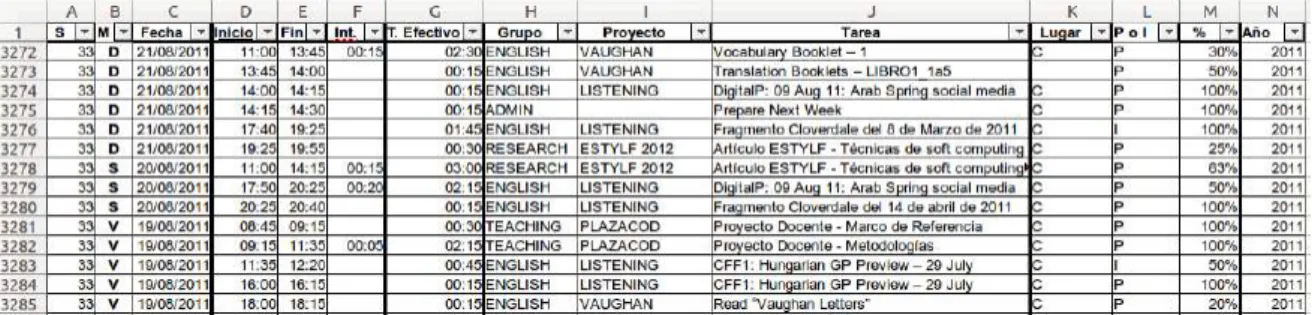
Iteración 2: Modelo de la base de datos y módulos de acceso, importación y
Se diferencia de la tabla anterior en que el proceso que utiliza estos datos tiene en cuenta la configuración de los días "peso". Así, el usuario puede cambiar las reglas sin tener que cambiar el código fuente de la aplicación. El último módulo creado en esta iteración es uno de configuración, cuyo propósito es permitir al usuario definir por defecto el peso de los días, es decir, el número total de horas dedicadas a realizar tareas en cada día de la semana, al mismo tiempo que pudiendo distinguir entre días vísperas y festivos.
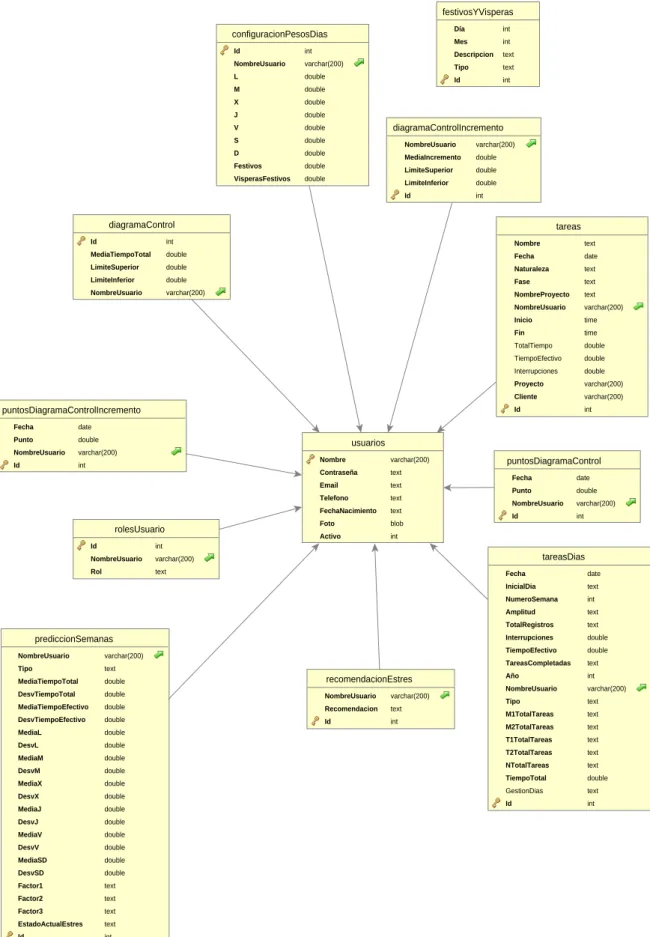
Iteración 3: Módulo de monitorización
Por un lado, generar gráficas de control y gráficas de curvas de tensión. Una vez calculadas la media y la desviación estándar de los datos obtenidos, se generan gráficos de control y trazados de curvas de voltaje. Una vez hecho esto, queremos calcular el estado de estrés actual del usuario.
Iteración 4: Módulo de predicción
Como se vio anteriormente, observar la curva de estrés muestra cómo la productividad varía según el nivel de estrés de la persona. Por ejemplo, si comparamos la curva de estrés de una semana intensa con la de una semana menos productiva, vemos que en un nivel de estrés óptimo, el rendimiento en la semana intensa es mucho mayor que en la semana menos productiva. Si observamos cómo se comporta la curva cuando el nivel de estrés supera el nivel óptimo, podemos ver que el rendimiento disminuye más en una semana intensiva que en una semana menos productiva.

Iteración 5: Refinamiento del proceso de extracción de conocimiento y prue-
- Refinamiento del proceso de extracción de conocimiento
- Proceso de clustering
Este apéndice muestra algunas partes del código y configuraciones creadas para la aplicación web. Listado D.1: Configuración de ruta de propiedad y controlador La siguiente lista muestra el nombre de las vistas. La siguiente lista muestra un ejemplo de la configuración de la máquina de estados y sus transiciones.
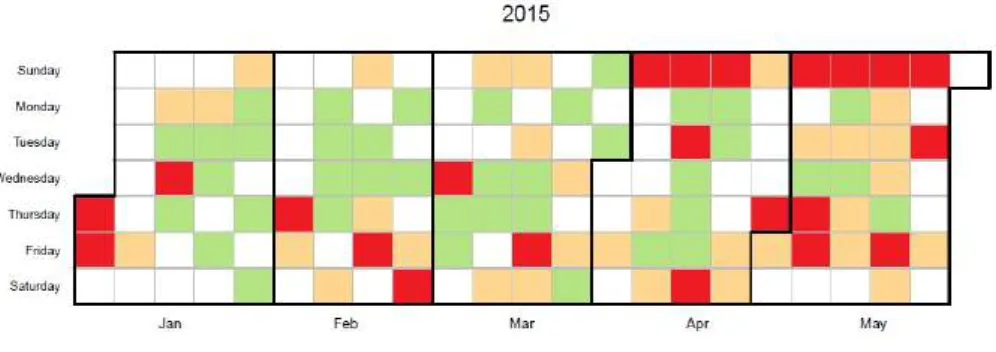
La página de productividad diaria muestra un mapa de calor de la productividad diaria del usuario así como información de cada uno de los colores. Esta página muestra la previsión de carga de trabajo para la próxima semana.