DETECCIÓN Y PRESENTACIÓN DE MUEBLES DE ACCIDENTES DE TRÁFICO EN LA CIUDAD DE MÉXICO MEDIANTE TÉCNICAS GEOSTADÍSTICAS Y MACHINE LEARNING”. Por su parte, el gobierno de la Ciudad de México cuenta con datos recopilados por diversas instituciones, como el C5 y la PGJ, que si bien no tienen la calidad deseada, son el primer paso para lograr sistemas de información confiables.
Planteamiento del problema
- Objetivos
- Objetivo general
- Objetivo Específicos
- Supuesto
- Alcances y limitaciones del proyecto
- Estructura de tesis
Descubrir y proponer patrones de ocurrencia de accidentes de tránsito en la Ciudad de México basados en unidades territoriales aplicando técnicas geoestadísticas y de aprendizaje automático utilizando datos del gobierno local y Open Street Map. En el Capítulo 4 se establece nuestro objeto de estudio, el cual nos ayudará a definir los datos disponibles para el estudio de los accidentes de tránsito y su relación con la infraestructura urbana de la Ciudad de México.
Conceptos previos
Minería de datos y aprendizaje de máquina
- Árboles de decisión
- Árbol de clasificación CART
- Bosque Aleatorio
- AdaBoost
- Gradient Boosting Classifier
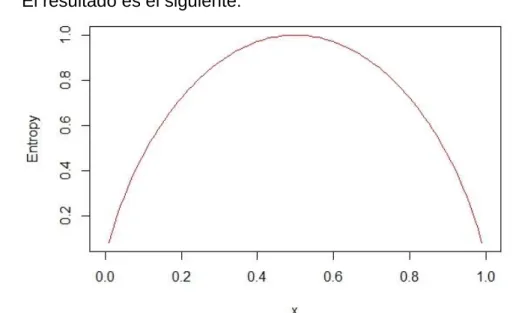
Para ello, el algoritmo utiliza la entropía para calcular el cambio de homogeneidad resultante de la separación de cada una de las variables. Una comprensión lógica de la función de pérdida dependerá de lo que se esté optimizando.
Evaluación del modelo
- Técnicas de remuestreo: validación cruzada
- Métricas de evaluación
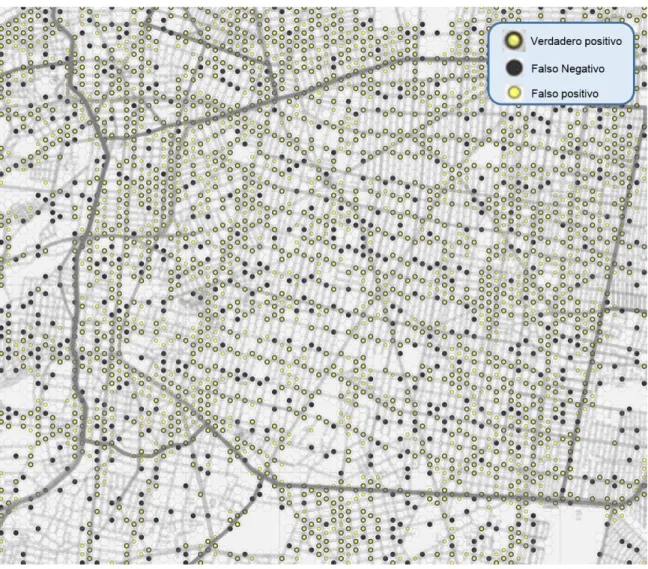
Un método común para describir el rendimiento de un modelo de clasificación binaria es la matriz de confusión, una tabulación cruzada de las clases observadas con las clases predichas, donde las celdas diagonales indican los casos en los que las clases se predijeron correctamente. Ilustre el número de errores para cada caso posible. La medida más simple es la tasa de precisión, que nos dice que las clases observadas y predichas también coinciden.

Estado del arte
- Un enfoque de aprendizaje profundo para predecir riesgo de accidente de
- Prediciendo accidentes de tránsito a través de datos urbanos heterogéneos: un
- Predicción de frecuencia de accidentes en avenidas: modelos de regresión para
- Predicción de choque vehicular de alta resolución en la ciudad de Montreal . 30
- Modelos de predicción de accidentes para caminos urbanos
- Técnicas de minería de datos para modelar y predecir accidentes de tránsito en
25 historias de corto plazo y periódicas de accidentes de tránsito en Beijing durante el año 2016. Detectar y representar patrones de accidentes de tránsito con técnicas geoestadísticas y algoritmos de aprendizaje automático en la Ciudad de México.

Objeto de estudio
Datos recolectados y fuentes de información
Geolocalización de estaciones del Sistema de Transporte Colectivo Metro de México. A = "Afirmativo": se envió una unidad de respuesta a emergencias, llegó al lugar y confirmó la emergencia reportada (ADIP, 2019). N = “Negativo”: se envió una unidad de respuesta a emergencias, llegó al lugar, pero nadie confirmó la emergencia en el lugar ni se solicitó apoyo de la unidad (ADIP, 2019).
F = “Falso”: el evento reportado originalmente fue considerado falso en el sitio (ADIP, 2019). Los puntos de las intersecciones inseguras: Para el conjunto de datos de intersecciones peligrosas, el intervalo de calificación para la calidad de las transiciones se puede observar en la Tabla 11.

Metodología
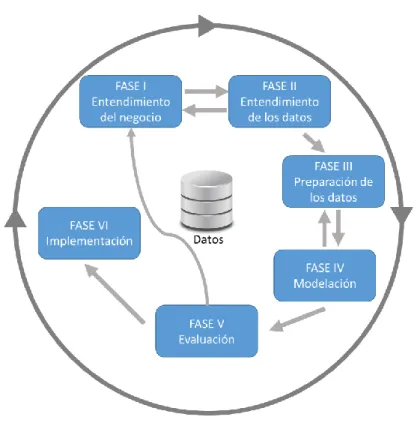
Metodología CRISP-DM
Según esta metodología, un proyecto de minería de datos se compone de 6 fases, las cuales se muestran en la Figura 4. En esta fase se describen los datos disponibles, lo que implica determinar la cantidad, el significado de los campos y la descripción formal de los formatos, en nuestro caso obtendremos datos sobre accidentes de tránsito en la Ciudad de México y las capas espaciales de los puntos de interés, datos relacionados con accidentes de tránsito y datos espaciales necesarios para utilizar las características espaciales que se utilizarán para el modelado. 46 Esto implica a partir de pruebas estadísticas básicas que revelan información de los datos, creación de tablas de frecuencia, gráficas de distribución, se verifica su consistencia, se identifican valores cero y valores que pueden constituir ruido para el proceso de modelación.
Pasos necesarios para crear el conjunto de datos final que se utilizará en la herramienta de modelado. En esta fase se preparan los datos para adaptarse a las técnicas de aprendizaje automático que se utilizarán más adelante, esto incluye selección de datos, limpieza, creación de variables adicionales, incorporación de diferentes fuentes de datos y cambios de formato.
Adaptación metodológica
- Pre procesamiento de datos
- Análisis exploratorio de datos
- Generación de las características indirectas
- Generación de áreas de influencia
- Generación de características directas
- Generación del conjunto de datos final para la modelación
- Generación de patrones
A continuación, para cada shapefile de la malla, se realiza una intersección con el shapefile de la red vial de la Ciudad de México, tomando solo los hexágonos donde se cruza la red vial donde ocurren los accidentes de tránsito. Ejemplo ilustrativo del proceso de suma de puntos por celda de la malla, para generar propiedades indirectas. Una vez procesados los accidentes de tránsito, como parte del proceso de modelación, se utilizarán los registros de 2014 a 2018 como conjunto de validación y entrenamiento y 2019 como conjunto de prueba, para luego agregarlos a cada una de las mallas hexagonales del mismo. manera procedió para las características indirectas.
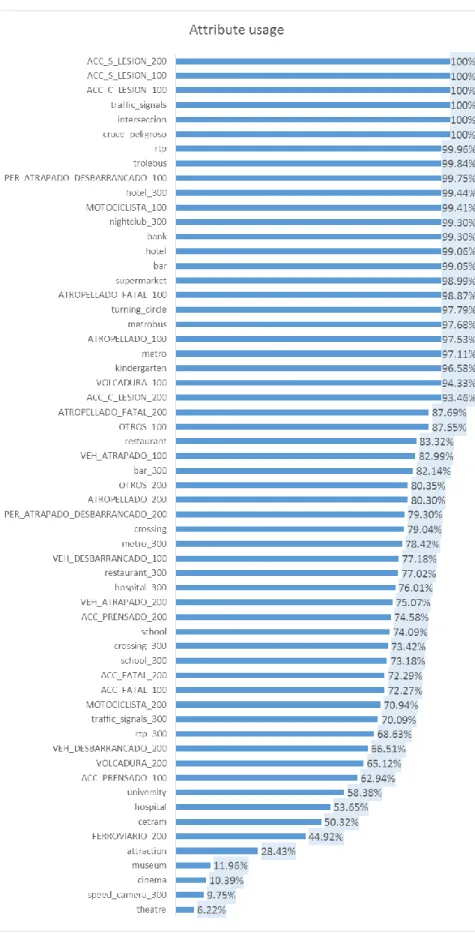
En total nos quedan 68 variables, de las cuales 41 son características indirectas, 26 características directas y la variable objetivo, el diccionario del conjunto de datos final se muestra en el apéndice IV. 6 Utilice todo el conjunto de datos para encontrar patrones generando reglas de clasificación.

Software utilizado en esta investigación
1 Crear malla hexagonal en la red vial de la Ciudad de México 2 Agregar características indirectas a cada celda. Ha desarrollado una gran comunidad activa de informática científica y análisis de datos, y en los últimos 10 años se ha convertido en uno de los lenguajes de programación más importantes para la ciencia de datos, el aprendizaje automático y el desarrollo de software en general tanto en el ámbito académico como en la industria. Además, R se utiliza para la creación del modelo de árbol de decisión (R Development Core Team, 2008; Rodrigo, 2020).
R es un lenguaje y un conjunto de módulos estadísticos que a través de cualquiera de las interfaces que tiene permite el análisis y presentación de datos, además cuenta con ciertos módulos que implementan el algoritmo C5.0 para dichos árboles. Finalmente utilizamos Quantum GIS (QGIS Development Team, 2019), que es un software de procesamiento de información geográfica que nos permite crear, recopilar, almacenar, procesar, analizar, gestionar y presentar todo tipo de datos espaciales y geográficos.
Resultados y discusión
Análisis exploratorio de los reportes de accidentes de tránsito C5
Los resultados del análisis exploratorio se muestran según nuestra metodología, es decir, gráficos estadísticos que describen la relación entre la frecuencia de los accidentes y los atributos temporales más importantes, principalmente de la base de datos de informes de accidentes de tráfico C5. En cuanto al número de accidentes por municipio, la gráfica 3 muestra que históricamente Iztapalapa tiene el mayor número de reportes de accidentes de tránsito, seguido de Cuauhtémoc. Esta puede ser una de las medidas que redujo el número de accidentes de tráfico por día y los mantuvo constantes.
Los mapas de calor del gráfico 6 muestran la frecuencia de notificaciones de accidentes de tráfico en relación con los días de la semana y el momento de su ocurrencia por año. El gráfico 7 muestra el número de accidentes por mes por año, con una variación entre los meses con mayor accidentalidad por año; Por ejemplo, para 2015, el mes de marzo fue el mes de mayor incidencia, al igual que octubre de 2019.

Análisis de la influencia del radio de hexágono sobre los resultados de
En cuanto a la parte espacial, estos mapas de densidad de puntos en la figura 10 identifican las zonas con mayor grupo de accidentes y es casi igual todos los años, principalmente en los límites de la alcaldía de Cuauhtémoc (colonias de Cuauhtémoc, San Rafael) , la densidad también se nota en el cruce del Circuito Bicentenario y Calzada Vallejo, principalmente en el cruce entre Calzada de Ignacio Zaragoza y Viaducto Río de la Piedad. Fuente: Elaboración propia con información derivada de la generación de mallas hexagonales generadas en (QGIS Development Team, 2019). Como se mencionó anteriormente, la determinación del radio del hexágono para la agregación de puntos de interés y accidentes de tránsito es un elemento clave para la modelización.
Nota: * es la división del número de observaciones de la clase minoritaria (accidente) por la clase mayoritaria (no accidente). Como resultado de generar variables directas e indirectas, nuestro conjunto de datos final para generar muestras queda como se muestra en el Apéndice IV, donde todas las variables son numéricas, de acuerdo con el conteo cuando se suman los puntos.

Algoritmo C5.0
- Algoritmo C5.0 árbol de decisión
- Algoritmo C5.0 árbol de decisión basado en reglas
Cuando exista al menos una estación RTP y exista más de 1 accidente dentro del área del accidente donde hubo atrapamiento o vuelco en un radio de 100 metros. Cuando exista al menos una estación RTP y existan más de 30 accidentes dentro del área de influencia de los accidentes, donde no haya víctimas en un radio de 100 metros. Cuando no exista parada RTP, uno o menos accidentes dentro del área de influencia para accidentes con y sin daños en un radio de 100 metros.
Donde hay 2 o menos intersecciones, no hay paradas RTP, hay 1 o menos accidentes en el área de impacto de accidentes con lesiones dentro de un radio de 100 metros, hay 4 o menos accidentes en el área de impacto de accidentes sin heridos en un radio de 100 metros. Donde existan 2 o menos intersecciones, no existan hospitales en el área de influencia de hospitales en un radio de 300 metros donde existan 4 o menos accidentes en el área de influencia de accidentes.
Resultados de la comparación con otros algoritmos basado en árboles
Podemos mencionar algunos estudios similares, como (Fuentes & . Hernández, 2009), donde investigan la influencia de la estructura espacial en la ocurrencia de accidentes de tránsito, donde utilizan un modelo de regresión binomial negativo, el cual da un resultado estadísticamente significativo. actitud positiva. En (Lankarini, et al., 2013) encontraron que el alumbrado público, las condiciones climáticas, las pendientes pronunciadas de las calles, la geometría de las calles y el estado de la superficie de la red vial son factores importantes en la ocurrencia de accidentes. Las paradas de RTP, metrobús y trolebús también juegan un papel importante en los accidentes de tráfico.
Atractivos como bares y una zona influyente de 300 metros de discotecas tienen una relación positiva con la ocurrencia de accidentes de tránsito. Dinámica de los accidentes de tránsito en la Ciudad de México: un enfoque de sistemas complejos.
Diccionario de datos de las bases de accidentes de tránsito de C5
El departamento de emergencias fue enviado, llegó al lugar y confirmó la emergencia reportada. O cuando acuden urgencias al lugar y se dan cuenta de que el incidente no coincide con el reportado inicialmente. La unidad de respuesta a emergencias fue enviada y llegó al lugar, pero nadie solicitó apoyo de la unidad en el lugar del hecho.
Incidente que requiere la movilización de recursos de emergencia, excluyendo delitos o emergencias médicas. Incidente que no requiere recursos de emergencia al considerarse una falsa alarma.

Muestra del conjunto de datos usados
Fuente: Elaboración propia con datos (Geofabrik GmbH Karlsruhe, 2018). b) Intersecciones, Alcaldía Cuauhtémoc, Ciudad de México. Fuente: Elaboración propia con datos (Geofabrik GmbH Karlsruhe, 2018). b) Reportes del accidente del C5 de 2019, Alcaldía de Cuauhtémoc, Ciudad de México.

Generación de malla hexagonal en QGIS
Diccionario del conjunto de datos final para la clasificación con
Incidente en autopista con uno o más heridos que requieran unidad de atención prehospitalaria con un área de influencia de 100 metros de radio. Incidente en autopista con uno o más heridos que requieran unidad de atención prehospitalaria con área de influencia de 200 metros de radio. Incidente en autopista con uno o más cadáveres que requieran de una unidad de atención prehospitalaria con un radio de 100 metros de área de influencia.
Incluye incidentes viales y otros no relacionados con un vehículo con un radio de 100 metros de área de influencia. Incluye incidentes viales y otros no relacionados con un vehículo con un radio de 200 metros de área de influencia.

Árbol de decisión generado con el algoritmo C5.0 en R







