UNIVERSIDAD POLITÉCNICA DE MADRID
ESCUELA TÉCNICA SUPERIOR DE INGENIEROS DE TELECOMUNICACIÓN
Development of a Question Answering system for Legal Urban Information
Retrieval
Master of Science in Telecommunication Engineering
Ramón Martínez Jiménez
JUNE 2022
MASTER OF SCIENCE IN TELECOMMUNICA- TION ENGINEERING
MASTER THESIS
Title: Development of a Question Answering system for Legal Urban Information Retrieval Author: Ramón Martínez Jiménez
Tutor: Luis Alfonso Hernández Gómez Speaker:
Department: SSR
TRIBUNAL MEMBER
President: Vocal: Secretary: Substitute:
The members of the court appointed agree to award the qualification of:...
Madrid, ...th June 2022
UNIVERSIDAD POLITÉCNICA DE MADRID
ESCUELA TÉCNICA SUPERIOR DE INGENIEROS DE TELECOMUNICACIÓN
Development of a Question Answering system for Legal Urban Information
Retrieval
Master of Science in Telecommunication Engineering
Ramón Martínez Jiménez
JUNE 2022
Table of Contents
List of Figures iii
List of Tables v
Abbreviations vii
Abstract vii
1 Introduction and objectives 1
1.1 Introduction . . . 1
1.2 Objectives . . . 2
2 State of the art 5 2.1 Introduction to Natural Language Processing . . . 5
2.2 Information retrieval systems . . . 6
2.3 Deep Learning techniques within NLP . . . 8
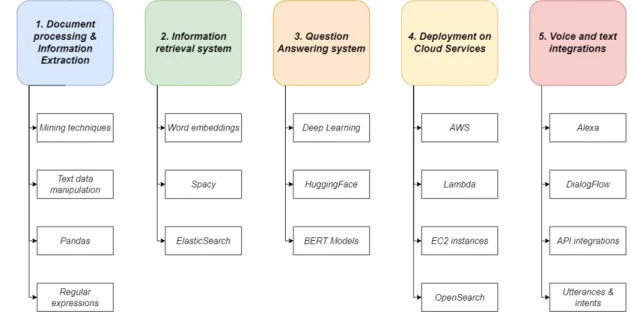
3 NLP pipeline development 11 3.1 Tools and Technology . . . 11
3.2 Legal documentation analysis . . . 12
3.2.1 Text extraction techniques . . . 13
3.2.2 Python libraries for text extraction . . . 16
3.2.3 Text mining . . . 17
3.3 Information retrieval systems | ElasticSearch . . . 19
3.3.1 Indexes and search engine . . . 21
i
3.3.2 Queries ElasticSearch . . . 24
3.4 Question Answering systems . . . 26
3.4.1 BERT models . . . 26
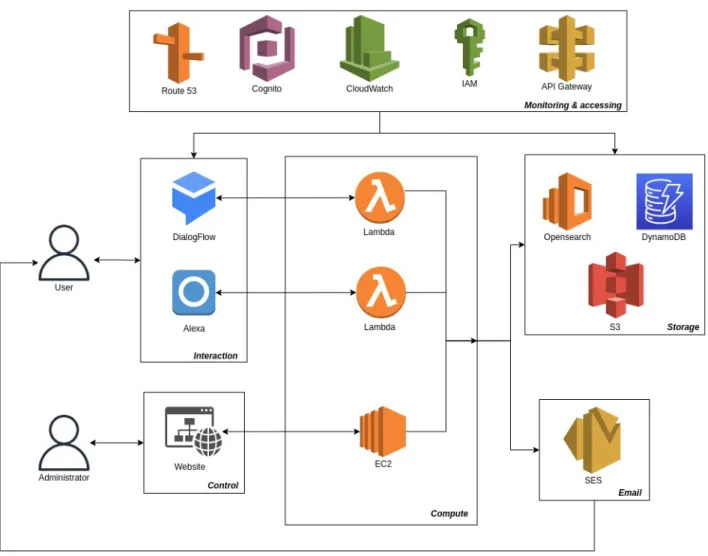
4 Cloud deployment 31 4.1 Architecture . . . 31
4.1.1 Computation module . . . 33
4.1.2 Interaction module . . . 33
4.1.3 Storage module . . . 34
4.1.4 Monitoring and access module . . . 34
4.1.5 Email module . . . 35
4.2 Voice interface through Alexa . . . 36
4.2.1 What is Amazon Alexa? . . . 37
4.2.2 System backend . . . 39
4.3 Text interface through DialogFlow . . . 40
4.3.1 What is Google Dialogflow? . . . 41
4.3.2 System backend . . . 42
4.4 Management platform through Streamlit . . . 42
4.4.1 Functionalities . . . 43
4.4.2 Web Deployment . . . 45
5 Conclusions and future trends 47 5.1 Conclusions . . . 47
5.2 Future Trends . . . 48
Additional content 50
Social, environmental and ethical impacts and considerations 50
Economic budget 50
Bibliography 58
List of Figures
1.1 Example of a complete conversational Flow . . . 2
1.2 Development steps carried out in this project . . . 3
1.3 Common conversation between one user and the final chatbot . . . 4
3.1 Example of one sheet present in the whole document . . . 14
3.2 Procedure for extracting information from raw documents . . . 17
3.3 Boxplot of length body of stored articles . . . 19
3.4 ElasticSearch WorkFlow . . . 21
3.5 Queries ES . . . 25
3.6 Score obtained from queries . . . 25
3.7 Model Behaviour . . . 28
4.1 Complete architecture for Cibeles Plus Project . . . 32
4.2 User interaction through voice channel . . . 36
4.3 Example of a conversation with Alexa skill and detection of basic elements 38 4.4 User interaction through text channel . . . 41
4.5 Example of user conversation with Cibeles+ through the twitter bot. . . . 43
4.6 Drop view in Streamlit App . . . 44
4.7 Update view in Streamlit App . . . 44
4.8 Query view in Streamlit App . . . 45
4.9 Admin interaction through Streamlit App . . . 46
iii
List of Tables
3.1 BERT models performance used for QA purpose . . . 28
v
vi
Abbreviations
• AI - Artificial Intelligence
• AWS - Amazon Web Services
• BKD tree - Binary K-Dimensional tree
• CV - Computer Vision
• DL - Deep Learning
• DNS - Domain Name System
• ES - ElasticSearch
• IAM - Identity and Administrator Management
• JSON - Javascript Object Notation
• ML - Machine Learning
• NLP - Natural Language Processing
• NLU - Natural Language Understanding
• SDK - Software Development Kit
• TF-IDF - Term Frequency - Document Inverse Frequency
• VrDU - Visually-rich Document Understanding
• QA - Question Answering
• BERT - Bidirectional Encoder Representations from Transformers
vii
Abstract
There is a growing trend for using artificial intelligence systems in all areas. From the automotive to the health sector, these new technologies are changing the current land- scape, placing many as the beginning of the next industrial revolution. Among all the research fields currently flourishing, one of the most promising is the so-called natural language processing (NLP). This discipline studies text analysis techniques to create in- telligent systems capable of understanding texts and even providing answers to complex questions. One of the products that have emerged as a result of this discipline are chat- bots, intelligent systems that respond to questions asked by users with relative freedom of response. This Master Thesis focuses on developing a chatbot capable of answering legal and administrative urban information questions. Specifically, it focuses on creating an information retrieval system that uses deep learning models to analyze and extract relevant information from a specific text to answer questions asked by users. In turn, the interaction between the system and the users will be carried out through Alexa and Dialogflow, intelligent conversation systems capable of being deployed on multiple devices.
Keywords
NLP - Artificial Intelligence - Information retrieval - Question Answering - Deep Learn- ing - Elasticsearch - Summarization - Alexa - Dialogflow - AWS
ix
Resumen
Actualmente hay una creciente tendencia por el uso de sistema de inteligencia artificial en todos los ambitos. Desde la industria automovilista hasta el sector salud, estas nuevas tecnologias estan cambiando el panorama acutal, situando para muchos como el cominezo de la siguiente revolución industrial. Entre todos los campos de investigación que actual- mente estan en auge, uno de los que más trayectoria tiene es el llamado natural language processing (NLP). Esta disciplina estudia tecnicas de analisis de textos con el fin de crear sistemas inteligentes que sean capaces de comprender textos e, incluso, dar respuestas a preguntas complejas. Uno de los productos que han surgido a raiz de esta disciplina son los chatbots, sistemas inteligentes que responden a cuestiones realizadas por usuarios con relativa libertad de respuesta. Este Trabajo Fin de Máster se centra en el desarrollo de un chatbot capaz de responder a cuestiones legales y administrativas del ambito urban- istico. Concretamente, se centra en la creación de un sistema de information retrieval que use modelos de aprendizaje profundo para analizar y extraer información relevante de un texto concreto para responder a preguntas realizadas por los usuarios. A su vez, la interacción entre el sistema y los usuarios se llevará a cabo a través de Alexa y Dialogflow, sistemas inteligentes de conversación capaces de ser desplegados en multiples dispositivos.
Palabras Clave
NLP - Artificial Intelligence - Information retrieval - Question Answering - Deep Learn- ing - Elasticsearch - Summarization - Alexa - Dialogflow - AWS
xi
Chapter 1
Introduction and objectives
1.1 Introduction
This project arises from a public contract made by Saturno Labs for the Madrid City Council. This contract is a continuation of a previous contract made by both parties, which dealt with creating a chatbot that could provide citizens with legal and adminis- trative urban information through an intelligent agent. The result of this original con- tract was a conversational agent capable of answering fixed questions in the urban field through conversational services and was named the Cibeles project. This prototype uses both Alexa and Twitter direct messages to interact with the user using voice and text.
On the other hand, the logic of the system is supported by the lambda functions offered by Amazon, a serverless solution that allows us to focus on the development of the code rather than server specifications. Besides, it provides a statistics panel deployed on Google Cloud services where you can observe the use and frequency of the implemented queries.
The obtaining of urban information for the answer construction is done through an API enabled by city council people with all the urban information of the localities available within the territory of Madrid. All this information can be sent, at the user’s request, through an email service implemented in Amazon Web Services (AWS).
In this Master Thesis, we have extended the initial prototype to get a more robust and complete NLP system called the Cibeles+ project. The functionality proposed for this new project is to offer the user a procedure to consult urban information of a specific address. For this purpose, Alexa will be used as a voice communication channel with the user and Twitter as a text communication channel. Regardless of the medium used by the user, they will obtain the information required either from the already structured databases of the Madrid City Council or the newly added functionality. Furthermore, this new one will get the relevant response directly from the legal document by applying the NLP techniques, which will be seen in chapter2. Thus, the final interaction will present a conversational flow similar to the one shown in figure1.1.
1
Figure 1.1: Example of a complete conversational Flow
1.2 Objectives
Figure 1.1 illustrates the basic flow that any user could perform when interacting with the system for asking for legal or administrative urban information. To support all these functionalities, the main objectives of this Master Thesis will be to design and create each one of the modules necessary to obtain the required functionalities. Specifically, the following development steps are proposed:
• Creation of a legal text ingestion system capable of categorising and dividing the text appropriately to analyse the complete text in a much simpler and intuitive way.
• Creation of an advanced search system that compares queries made by users with parts of the text to obtain a list of parts more related to the question asked.
• Creation of a system that uses deep learning models to summarise the parts of the text most similar to the question asked by the user to obtain short and direct answers.
• Once this system is working, it is proposed to move this development to the cloud, following a similar approach to the one used in the original contract. To do this, We will study the services offered by AWS to see which ones best fit each case. In turn, we will explore DialogFlow as a possible solution for the textual part. Dialogflow is a natural language understanding platform from Google used to design and inte-
grate a conversational user interface in the mobile app, web application, device, bot, interactive voice response system, and so on.
• On the other hand, since the system integration to be developed in the original prototype would take a long time and could generate difficulties, as well as the original prototype was written in a language that would soon cease to be supported by AWS, it has been decided to replicate all the original functionalities in the same language as the rest of the functions.
These are the general objectives we will address along with the development of this thesis. However, for illustrative purposes, these objectives have been represented in figure 1.2 to show in a more straightforward way everything that will be studied and designed throughout this thesis.
Figure 1.2: Development steps carried out in this project
We should note that this project was devised as a proof of concept using the latest Arti- ficial Intelligence techniques applied in Natural Language Processing. For this reason, the problem was initially constrained to a single chapter of the complete legal documentation (chapter 8 of the urban planning terms). However, the intention from the outset to was to create a tool capable of scaling the solution not only to the entire legal document studied (i.e. all the chapters that make up the document) but to have many more documents to be analysed within the system. Thus, the project is focused on solving this problem on a large scale, but tests and trials are carried out within the specific chapter proposed at the beginning of the contract.
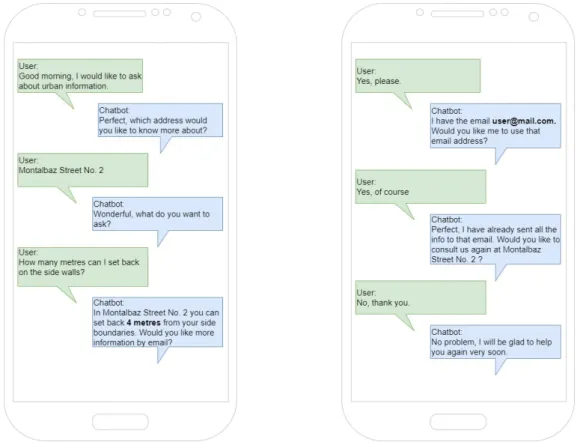
Therefore, the work will combine more traditional technologies with more disruptive and novel techniques to achieve a system that will help streamline public administra- tion and help citizens obtain urban planning information quickly and efficiently. As an illustrative example of what the system is expected to deliver to an average user, a typ- ical example of user experience with the final system version through a text channel is shown in Figure 1.3. Furthermore, in chapter 3 we will indicate which NLP techniques are applied in this project to achieve an information retrieval/question answering system that solves the use case. Besides, In chapter4, we will show the final design with all the
Figure 1.3: Common conversation between one user and the final chatbot
necessary modules and components deployed in the production environment to lead the project’s final architecture.
Chapter 2
State of the art
2.1 Introduction to Natural Language Processing
Within the field of AI, there are different sub-sections. Thus, all those techniques or systems that attempt to emulate human thought could be included as AI [1] [2]. Within this field is included the field known as machine learning [3]. This field contains all those techniques based on taking historical data about a specific area and applying algorithms and statistical models to obtain an inference or prediction close to reality. This field is used in multiple disciplines, from predicting housing prices, detecting possible fraud, and detecting possible physical anomalies in a medical scanner, among others. This field of AI has undergone enormous advances in recent years. Thanks to this, it has spread to different domains, from industry and automotive to banking and healthcare.
Among all the fields where machine learning and deep learning are making significant advances, one of the most important is natural language processing [4]. The area of natural language processing (also known as NLP) is the one that encompasses all those techniques and algorithms in charge of processing, analyzing and obtaining information from raw text documents. This field was one of the first areas where artificial intelligence techniques were applied [5]. The first algorithms used in this field were based on extensive statistical models and semantic rules to extrapolate the information contained in a paragraph into a language that a mathematical algorithm could understand. Thus, the first steps in this field were based on the study of semantics and grammar and how these factors can be transformed into a mathematical environment to be analyzed.
Therefore, identifying tasks required to understand the relationship between all terms involved could be useful to analyze texts grammatically. These tasks can be grouped into low-level tasks, where fundamental elements of the text are handled. These tasks are, among others:
• Detection of sentence boundaries.
• Tokenization, i.e., detection of individual tokens within the sentence (words, punc- tuations).
• Part-of-speech tagging: Classifying words according to a specific category (verb, adverb).
5
Also, using these low-level tasks, high-level tasks can be completed, for instance:
• Identifying grammatical/spelling errors: This task is commonly observed in typical messaging applications (e.g. WhatsApp) or even in writing tools like the one used to write this thesis to correct grammatical errors obtained during typing.
• Named entity recognition: This task consists of identifying words or phrases and categorizing them according to various classes (e.g. locations, people, genres, medicines).
Through the correct application of these tasks, it is possible to address certain use cases widespread in multiple fields, such as health, legal or research. Among the use cases that can be addressed by solving the above tasks, we can find cases such as the classification of complete texts or extracting topics from the text. But among all these, two use cases are especially interesting for this project. These cases are the creation of information retrieval system [6] and question answering [7] [8]. These two cases, very similar to each other, consist in obtaining useful information from a text or document related to the delivery of a query. However, while the first case is well solved and solutions on the market offer great results concerning the proposed objective, the second use case is much more complicated to deal with. This use case is still under study and is far from having efficiency as good as the one observed in information retrieval systems. However, for this project, it is necessary to study and apply both approaches to obtain a good solution that meets the objectives proposed in 1.2. Thus, we will address and study the latest trends in both use cases to obtain a complete information retrieval and question answering system.
2.2 Information retrieval systems
To build an information retrieval and question answering system correctly, it is necessary, as said before, to transform the words into numerical representations capable of being used by the latest algorithms and techniques in the field of NLP. Word Embedding [9] is one of the main approaches that allow this transformation of words into a vector space that is understandable and manageable by algorithms. This approach is based on the representation of terms by number vectors capable of being quantified and processed by a given algorithm. Within this approach, we can find multiple open source solutions that could be the basis of the information retrieval tool to be created. We studied two com- monly known algorithms among the various solutions: Term frequency-inverse Document Frequency (TF-IDF) and Word2Vec.
The first one was called Term Frequency - Inverse Document Frequency (also known by its acronym TF-IDF) [10]. This algorithm is based on the statistical usage measurement of a particular term within a set of documents. The vectorisation process is very similar to that used in One Hot Encoding [11] but replaces the corresponding values for a word by its TF-IDF value. This value is obtained by multiplying the Term Frequency (TF) statistical value by the Inverse Document Frequency (IDF) value. TF value indicates the ratio of the occurrence of a given term in a document to the total number of words in that document.
TF ( t ) = ( N u m b e r of t i m e s t e r m t a p p e a r s in a d o c u m e n t ) / ( T o t a l n u m b e r of t e r m s in the d o c u m e n t )
On the other hand, the IDF value is a logarithmic ratio that indicates the total number of documents by the total number of documents where a specific term occurs. So, using those two terms, it is possible to construct a vector space from multiple documents where higher values would indicate the occurrence of less frequent words within the entire vector space.
IDF ( t ) = l o g _ e ( T o t a l n u m b e r of d o c u m e n t s / N u m b e r of d o c u m e n t s w i t h t e r m t in it )
Thus, it would be possible to identify specific terms of a query performed by the vectorising user query. This vector would be compared by using this algorithm with a complete set of documents, thus obtaining the one where the query terms are repeated more frequently. This document, therefore, will have more similarity with the query than any other type of document within the whole set of the vector space.
The other algorithm studied was called Word2Vec [12]. In this case, an entire corpus composed of multiple documents is analysed, and a vector space of all terms appearing in the corpus is created based on the semantic closeness of a word concerning another term. Thus, using this technique, it is possible to mathematically obtain the semantic relationship between two terms. Unlike the previous algorithm, the vector space can be much smaller given the semantic nature of the approach. Furthermore, by including the semantic meaning within the algorithm, it is possible to use far fewer vectors to represent a large set of terms as many of them can have very similar representations, whereas using TF-IDF, it is necessary to have a vector representation of the corpus size for each word.
The latter approach has been widely extended for multiple NLP applications, given its small corpus size and high performance in obtaining similarities between terms. However, this approach has a significant disadvantage for our particular use case. To create a sufficiently robust Word2Vec algorithm, it is necessary to use a large and diverse corpus to represent each term properly. For this particular use case, the research department at Stanford University created a dataset of all Wikipedia articles in the format necessary to create the vector representation needed for this algorithm. This dataset is called the Stanford Question Answering Dataset (SQUAD) [13] and is widely used in the NLP field for training new AI models and algorithms and testing models for question answering benchmark. The results obtained after applying this dataset to the Word2Vec algorithm are excellent. The problem lies in the language used. The whole dataset is trained in English, making most models useless for our use case since we want an information retrieval system in Spanish.
Obtaining an information retrieval system in Spanish based on Word2Vec is not only enough to translate the answer but also to transform and adapt the whole vector space created to the Spanish language. To do so correctly, the most efficient solution is the translation of the SQUAD dataset into Spanish. However, this solution is not as trivial as using another NLP tool to translate the SQUAD dataset from English to Spanish.
Furthermore, this approach could introduce translation errors that would affect the per- formance of the final algorithm. Therefore, an alternative approach would be to convert the SQUAD dataset itself into the Spanish language manually. Although there are few pieces of research about translating the SQUAD dataset to Spanish [14], the proposed solution does not obtain such an optimal result for this particular use case, as we will see below.
In the case of the TF-IDF algorithm, it is not necessary to use a vast corpus to create
the vector space with which to apply the algorithm. Moreover, thanks to the document reprocessing explained in the previous section, we can use the dataset composed of the document’s articles to build a good TF-IDF algorithm. However, for many documents, the vector space created with the TF-IDF technique is much larger than that produced by Word2Vec, which could cause difficulties when deploying it in a cloud service due to its size.
Those are the main two techniques used for information retrieval cases, but it is required to test and prove their effectiveness in choosing the best option for this project. To do so, studying frameworks and libraries that suit each of them is needed. We will start with the Word2Vec technique using the Spacy library. SpaCy [15] a library for advanced Natural Language Processing in Python and Cython. It’s built on the latest research and was designed from day one to be used in actual products. Spacy also contains many models and algorithms based on the Word2Vec technique mentioned above. In addition, Spacy has a compelling text similarity and pattern search engine, facilitating the process of text cleaning and tokenisation. Finally, spacy offers multiple tools for training your statistical models to perform various NLP tasks [16]. This training allows the creation of custom vector spaces for specific use cases such as question-answering systems for nutritional doubts.
However, one of the drawbacks of this library is that the tokenisation model used for the Spanish language did not fit well with the use case initially proposed. At the same time, trying to re-train the Spacy embedded model with the translated SQUAD dataset would take a long time to adapt the dataset entries to the format required for the Spacy pipelines. On the other hand, there was another framework whose approach suits better in this project. This framework also makes use of the TF-IDF technique. This framework is called ElasticSearch, a distributed search and analytics engine that enables near real- time search of all data types. So, given its perfect fit with the proposed use case, ease of use, and performance, the framework chosen to continue constructing an information retrieval system was ElasticSearch. In section 3.3 this framework will be addressed in detail, defining what it is and explaining how we used it to build an adaptive information retrieval system.
2.3 Deep Learning techniques within NLP
Nevertheless, the classical techniques described in the previous section can fall short of extracting the whole semantic meaning. In the end, more traditional methods based on written rules and statistical models can extract information about the frequency of terms in the text, occurrence of specific words or categorization of sentences using hand-created statistical models. Another drawback of this approach is that it may be prohibitive to extend these rules to a much broader scope of performance. Hence the need to look for techniques capable of analyzing the whole context of the text and obtaining deeper semantic relationships within each sentence. Furthermore, this approach would allow us to tackle much more complete tasks such as summarizing text, extracting sentiments within a text or even question-answering use cases, as we discussed previously. This last case is one of the primary use cases we will carry out in this project and will be addressed by Deep Learning based techniques.
Within the NLP field, we can find a compelling set of techniques that use algorithms based on neural networks [17], a robust architecture for executing specific tasks from a relatively large collection of data. This subset of algorithms within Machine Learning is known as Deep Learning and currently encompasses the most powerful algorithms capable of performing truly unique tasks. Therefore, part of the development we will carry out in this project will be based on this algorithm. Specifically, tasks as critical as question answering will be carried out by techniques of this style, but we will address that in chapter3.
One of the first examples of deep learning models used within the NLP field was the so-called recurrent neural networks [18] (also known as RNN). Although these networks have existed for decades (they were created in the late 80s), they have been a fundamen- tal pillar in the development of NLP applications, specifically in speech and written text recognition. These networks have the particularity of using part of the processed infor- mation that has been stored in a small memory as input within the neural network itself.
This fact allows these networks to handle the prediction of long sequences excellently.
Thus, this type of architecture is ideal for audio and text recognition applications and grammatical translation. One of the best known is the so-called Long-short term memory [19] (also known as LSTM). This architecture allowed to solve a recurrent problem in this type of architecture, called gradient vanishing problem [20]. Thanks to this simple design, this type of architecture could learn to perform tasks requiring memory of events that occurred hundreds or even millions of iterations earlier. That is why this type of network was ideal for predicting long and repetitive sequences, such as those discussed above.
However, with the advent of another type of architecture, the NLP field made expo- nential advances. These architectures are called transformers [21], which use attention mechanisms. These mechanisms serve as shortcuts between the context vector and the input received from the model, allowing to draw the available dependencies between the input received and the output obtained. Thanks to these new mechanisms, it is possible to dispense with the previous architectures based on recurrent or convolutional mechanisms.
In turn, these types of architectures are superior in terms of efficiency and versatility, positioning themselves as the new state of the art within NLP [22]. Among all the use cases we can address with transformers are those as complex as summarizing complex text in several lines, obtaining specific information about a given text or question answer- ing cases, among many others. The latter are the ones we will address throughout this thesis, so in section 3.4 we will study the different alternatives available on the market and compare the effectiveness of each of them.
As proven, the new architectures offer significant advances in the most complex fields within the NLP field. However, the more traditional technologies based on statistical models still work perfectly well for indexing or NER cases. Search engines such as Elas- ticSearch are a clear example. Thus, it is possible to use each approach’s benefits to create hybrid systems that solve much more complex use cases. Therefore, we can find conversational agents capable of maintaining a moderately challenging conversation with a user [23], or even systems capable of onboarding a new employee in the company and solving his most common questions [24]. Likewise, significant advances in this field can be observed through transformer architecture within the Spanish language. For example, one of the most ambitious projects in this language is called MarIA [25], which is supposed to be the largest deep learning model in the Spanish language.
These examples show a clear competitive advantage when developing AI-based systems within the NLP field, opening up a range of short/medium-term possibilities. This project has arisen as a result of further exploring the opportunities of these tools and combining all these techniques to obtain a system that solves a real and valuable use case for citizens.
Chapter 3
NLP pipeline development
This chapter will address the NLP techniques discussed in chapter 2 more practically, describing, in detail, how we have applied and adapted them to the specific use case in this Master Thesis. In the following sections in this chapter:
• First, we will present the tools and technology we have used in our development.
• Then, we will describe how we have addressed the analysis of the legal documents to find an appropriate approach for extracting and classifying information from the legal text.
• After that, we will present how we have applied and combined more traditional and novel techniques within the field of NLP. Therefore, we will describe in different sections the information retrieval and question answering systems we have used to solve the problem posed: to obtain a concise answer to a question asked by a user of the system.
Thus, throughout this chapter, we will discuss all the NLP techniques and conclude with those techniques that are best suited to the use case.
3.1 Tools and Technology
Before starting with the explanation of the NLP pipeline to be developed, it is interesting to discuss the tools and technologies used in this project. This project has been devel- oped in Python [26] because it offers two significant advantages over other languages and environments.
Python has been used for this project mainly because of its widespread adoption as a programming language for artificial intelligence environments. Most AI-related projects are built using Python, so it is much easier to employ this language for the whole back-end of the system and all AI models implemented. For the front-end parts of the system they have been used:
• For the voice interaction, we have used Alexa and Dialogflow management console
11
to create the conversational flow for each interaction. This flow will be connected to the back-end part hosted in the logic module to construct a response.
• For the interaction with the administrator, Streamlit [27], a python library focused on creating web interfaces for user interaction, has been used. This part will be hosted by an EC2 instance which, in turn, will support this module’s logic.
These parts will be dealt with in more detail in chapter4. In addition to the widespread use of this programming language in AI environments, some multiple Python-compatible libraries and frameworks offer great help for data analysis and natural language processing.
These are:
• Pandas: Pandas [28] is a data analysis library built on top of the Python program- ming language. It will be used for managing, splitting and converting data and saving it into the desired format.
• Matplotlib: Matplotlib [29] is a comprehensive library for creating static, animated, and interactive visualizations in Python. It will be used for plotting results and revealing possible relationships among variables.
• HuggingFace: Huggingface [30] is an open-source community where people share and contribute AI models for multiple fields, especially NLP tasks. Besides, they offer an SDK for Python programming language to use their models properly. These models will be the ones that are going to be studied in the latter sections.
Finally, a few minor libraries are used throughout the project, although their function is not as critical as those mentioned above. In addition, other types of libraries will be used in specific sections of the project so that they will be addressed in their respective sections.
During the following sections, we will deal with the development carried out for the creation of the AI pipeline of this project, detailing at each moment the actions carried out and the modules used, as well as the problems that have arisen and how these problems have been solved.
3.2 Legal documentation analysis
The first step in developing this system has been the study of the legal documents them- selves. These documents are our system’s primary data source; however, it is very labori- ous to try to ingest all the entire texts without a previous cleaning and classification step.
In addition, these documents are not always in a format readable by the systems used, so it is necessary to convert them into a format manageable by these systems. So the first process carried out in this project was searching for a method capable of facilitating and speeding up the ingestion of this information for subsequent procedures.
To this end, we proceeded to analyse the different text cleaning and extraction tech- niques available on the market. After the appropriate analysis and applicability study for this use case, we will proceed to the selection of the method that offers the best results.
3.2.1 Text extraction techniques
As mentioned above, a crucial step in the analysis, cleaning and classification of text is to obtain the text from the raw sources, be they documents, images or websites. Therefore, having a tool that scrapes the texts from these raw sources is essential to start any text analysis. Thus, in this first section, we will study the different commercial or open-source solutions available on the market.
Before starting, it is necessary to explain the nature of the document to be analysed.
It is a legal document in the urban planning field, consisting of about 800 pages, with a clearly defined structure. On the other hand, it is a document that presents certain aesthetic and informative elements in its headers and footers that do not provide excessive information for the analysis we wish to carry out. As we will see later on, they are an obstacle to extracting the relevant text. Finally, this document is presented in two main formats, provided by the people of the Madrid City Council. These formats are .pdf and .docx. Both offer their advantages and disadvantages, so throughout this section, we will discuss which one best fits our use case. An example of a sheet in the document is the one in figure3.1.
Therefore, for the analysis and processing of this type of document, it is necessary to use a tool capable of handling this type of format and filtering or differentiating the aes- thetic/informative elements correctly, whether they are headings, enumerations or other kinds of stuff.
Among all the available tools and technologies, we will start by analysing the com- mercial solutions studied during the project’s development. These commercial solutions are offered by the leading technology companies in this market, i.e. Google, Amazon and Microsoft. Let’s start with the one provided by Amazon, called Amazon textract [31]. This service is a tool for extracting handwritten texts in any format, whether PDF, images, OCR... In addition, it is possible to differentiate elements within the text and obtain entire tables and forms within the document. Among all the commercial options, this tool is the one that offers the best performance for the specific case. Another great advantage it provides is a free layer of up to 1000 pages of analysis per month, which would fall within the limits of this pilot project. However, after several tests, several problems arise with the use of the tool:
• The information obtained is stored on AWS servers, and to extract it, you have to use the ASK offered by Amazon.
• Although it filters out almost all elements, some information remains after the pro- cess, such as informative text in the header.
• In case of scaling the project to more areas, Amazon’s service would also increase in price, so the proposed solution could be economically unfeasible.
For all these reasons, it was decided to explore other options. Between the other two commercial options, we have the Google Vision API [32], an API that offers the opportunity to extract text from images, converting even PDF files into images for further extraction, as well as applying other NLP techniques such as sentiment analysis or entity extraction. However, this solution offers worse performance than the AWS solution and
Figure 3.1: Example of one sheet present in the whole document
has similar drawbacks to those raised in AWS, so this option was discarded. Finally, the solution proposed by Azure (Microsoft cloud), called Text Analytics [33], offers only text analysis, sentiment analysis, entity extraction and sentence retrieval. None of this is helpful without properly extracting the text, so this option was discarded.
Among all the commercial solutions, the one that offers the best features is AWS.
However, open-source tools also provide similar characteristics to those presented in com- mercial ones. The main disadvantage of most of these solutions is that they require prior development to adapt the use case to the desired result, but they also offer greater versatility in including new functionalities.
Most of the libraries in Python are oriented to extracting information in PDF format, although some also deal with extracting text in multiple formats. In addition, there are some options based on deep learning models and focused on computer vision solutions that can extract information through images, but as the documents have only two formats (.pdf and .docx), it is not necessary to address this type of approach.
Firstly, we have PyPDF2 and PDFMiner [34][35] libraries, which are based on the handling of PDF files, not only the extraction of text from the PDF file itself but also the creation of PDF documents from raw text, the joining or splitting of PDFs as well as other functionalities that we can apply to PDF documents. Section3.2.2will look at these functionalities in more detail. On the other hand, we have the Python-Docx [36] library, which specialises in handling Word documents. The handling of this type of document offers certain advantages over the handling of PDF documents, such as greater control of aesthetic elements and formatting within the document. We will discuss these features in more detail in the next section. Another interesting option is textract [37] library, which is an aggregator of multiple text scraping libraries from multiple formats and fonts. This library not only allows the extraction of texts using PDF or Word documents but also to extract texts from Powerpoint files, web pages, images, audio, animations... It is the library that offers the most features among all those studied. However, as mentioned above, it is only an aggregator of other libraries that extracted text from each type of format separately. Specifically, for PDF and Word documents, it has used the same libraries mentioned above, and given that the formats of the documents to be used are not expected to change, the use of this library would be redundant. Therefore, it has been decided to discard the latter library. Finally, we have Tesseract OCR [38], a tool developed by the Google team for extracting text from images. Similar to the commercial solution proposed by Google but free to use, it can detect the texts in all types of documents (legal documents, traffic signs, and ID cards). This tool generates a dataset with data on the location of the words detected in the document and a confidence value that indicates how likely it is that the word is correct. Each row of the dataset represents a word in the document. The problem here is trying to reliably reconstruct the original document from each row of this generated dataset. Since other tools can obtain whole paragraphs following the same structure as the original document, this tool is less interesting than the ones mentioned above.
Besides all options shown previously, we did not study other options on the market due to time constraints or because they were discovered at a later stage of the project, but which are equally valid to apply. Specifically, we have HuggingFace [30], a repository of models based on deep learning that focus on solving NLP-related tasks. This repository offers a wide variety of models that address most of the functions studied in the NLP field, including summarization, question answering, and sentiment analysis. The model we are interested in studying, in this case, is the so-called LayoutLMv2 [39], a pre-trained model for understanding visually rich documents. This sub-branch of NLP, called visually-rich document understanding (VrDU), deals with information retrieval from digital/scanned documents. This approach is similar to that previously seen in the tools presented by Google or Amazon, where NLP and CV models are combined to achieve a common goal.
As seen in [39], the results obtained are good, so a viable option for future work would be the applicability of this model to the current system. However, it was decided to proceed with studying the libraries that handle word and pdf documents since these are the formats we will use.
3.2.2 Python libraries for text extraction
Once the multiple options on the market for extracting information from word and pdf documents have been studied, the options that have been chosen are the python libraries that handle this type of document. Therefore, in this section, we will compare these libraries, looking for each option’s strengths and weaknesses and applying the one that offers the best results to the case study.
First, we will start by describing the differences between a Word document and a PDF document. A word document is mainly composed of text streams grouped in block elements [40]. The main block element is the paragraph, where the text that makes up the document is displayed. Within this block element, there is another element called an inline text element. This element is a portion of the content that occurs inside a block- level item. An example would be a word that appears in bold or a sentence in all-caps.
The most common inline object is a run. Typically, a block-level element contains one or more inline elements, each containing some part of the paragraph’s text. In addition to these elements, there are other relevant elements within word structure like tables, but for our analysis, these elements will be ignored. In turn, the attributes of block elements specify their position within the page, while the characteristics of inline elements specify the formatting of the text they contain. Thus, for extracting text or other elements present in a word document, it is necessary to work at the paragraph level, first obtaining those paragraphs and extracting from them the text they contain.
On the other hand, we have PDF documents [41], which are constructed at the char- acter level, unlike different types of text documents such as word documents. That is, it does not consider larger elements such as paragraphs, sentences or even words but records character by character and the placement of this element within the overall document.
This type of structure makes it difficult to differentiate between relevant text belonging to a paragraph and text belonging to a page footer or description of a page.
At first sight, it seems more appropriate to use a tool that handles word documents, as its structure allows a better differentiation of the elements present in the document.
However, the libraries for handling PDF files that have been studied can apply an al- gorithm to group characters into larger groups such as words, sentences or paragraphs.
Thus, this type of library allows the reading of the document line by line, while in the word document, it is impossible to do so. After numerous tests to obtain text from the example sheet presented in figure3.1, it has been concluded that a word document limits the text acquisition capabilities to the structure provided by these files. On the other hand, PDF documents can be read directly by line, and the text present in these lines can be handled at will. At the same time, the PDF format is more widespread within the formal documentation of the municipality, so it is possible to scale this project to larger scopes more easily. These two points have made the difference in choosing PDF handling libraries as the tool for extracting text from legal documents. Therefore, in future steps, the approach applied, through these libraries, for the extraction and differentiation of the
elements present in the legal document will be explained.
3.2.3 Text mining
Once we have chosen the approach, it is necessary to map out an efficient development path for obtaining the relevant information within the legal document. In this case, the legal document to be analysed has a clearly defined and hierarchical structure, consisting of 4 possible hierarchical levels. Thus, we have titles, chapters, sections, and articles from the highest to the lowest level. The latter, the articles, are the smallest element within the document, where the actual information is found. Figure 3.1 shows an example of this hierarchy. Therefore, a good approach would be to atomise this document into smaller parts to make it easier to classify and search for information. Thus, a diagram of the process of obtaining a dataset with well-structured information would be the one presented in figure 3.2. As can be seen, this architecture intends to use the table of contents to obtain indexes into which the final document will be divided so that the system will classify the text obtained according to these indexes. To get the exact pages where the index is located, it is necessary to manually enter the pages where the table of contents starts and ends. Once these indexes have been obtained, we will search for lines that match each index within the document, corresponding to those sections where the relevant information is found. Once found, the program will read the subsequent lines until the following index is found. This process is repeated until the entire document has been read. Therefore, the CSV file will save as rows the smallest part of the documents, i.e. the articles, chapters, titles...
Figure 3.2: Procedure for extracting information from raw documents
We will use the two PDF management libraries presented above to achieve this goal.
PDFminer will be the library in charge of the extraction and conversion of the text ele- ments within the PDF to string format in such a way that it is easily manageable by the developed system. PyPDF2, on the other hand, offers more intuitive and straightforward handling of PDF documents, so we will use it to obtain certain pages that the previous library will subsequently process. Finally, for managing CSV files, Pandas library [28]
will be used.
It should be noted that techniques based on regular expressions have been used to
extract and classify the information at the different hierarchical levels within the dataset.
Regular expressions [42] are patterns used to match combinations of characters in strings.
These patterns help enormously in creating, cleaning, processing and obtaining relevant text information in word processing tasks. In our case, we will use these techniques through the re [43] library. A helpful tool for creating efficient patterns that regular expression techniques can use is [44].
These regular expression techniques have been used to apply different processing to the text obtained from the PDF. These processing go from text cleaning, recommended for any NLP-based task, to the classification of the text in its multiple hierarchical levels.
The tasks carried out to obtain the dataset have been as follows:
• Removal of unwanted characters generated from the extraction, such as vertical pipes, multiple blank spaces or consecutive dots.
• Removal of possible blank spaces at the beginning and end of each line read.
• Removal of patterns in outside elements such as headers, footers or additional infor- mative text.
• Obtaining the text belonging to each article by searching for patterns. The table of contents has been used to compare each document line read with the specific index being analysed within the table of contents. If the document line read matched the name of the index being processed at that moment, the program started to save all the following lines. This happened until the system detected a match between the line read and the next index in the table of contents. At that point, the program finished reading and saved all the lines read within the processed article.
Once this processing was done, each item’s metadata was obtained using regular ex- pression matches. These parameters were obtained to maximise the amount of informa- tion about each item. Thus, in the CSV generated after this processing, the following parameters are stored in separate columns:
• Title: Name of the item processed in that row.
• Page number: Page of the document where this article can be found.
• Condition: Shown the four possible hierarchical levels that this item belongs to.
• Ttile number: Number of the title to which the item belongs.
• Chapter number: Number of the chapter to which the item belongs. If the item has a higher hierarchical level, this value will be 0.
• Section number: Number of the section to which the item belongs. If the item has a higher hierarchical level, this value will be 0.
• Article number: Number of the processed article. If the item has a higher hierar- chical level, this value will be 0.
• Body: Legal text shown in the article. If the item has a higher hierarchical level, this value will be 0.
After applying this process using regular expression techniques to obtain a CSV file from a legal document, an error occurred. When checking certain items within the dataset, we could see that the body parameter was more extensive than average in some of them.
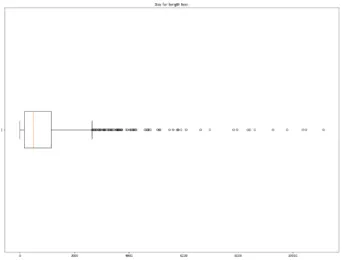
To observe this phenomenon, a simple boxplot was applied to the "length" parameter obtained from the body parameter, which indicates the number of characters in each article. The result can be seen in figure3.3.
Figure 3.3: Boxplot of length body of stored articles
As can be seen, there are a large number of outliers. Considering that the maximum number of characters an article has in a legal document is approximately 2000 characters, there is something wrong with obtaining articles. After checking the articles where this happened, we could observe that the text started from the beginning of the article being analysed until the end of the legal document. This fact indicates that the article fetching process could not recognise where the article ended, and the next item began. This problem was caused by finding within the lines of the PDF certain characters or spaces that made literal matching impossible. To solve this problem, the text processing explained above was applied again, but only to the already processed text of affected articles.
After this second processing, we observed that the number of outliers decreased. Fur- thermore, when checking the affected articles after this second processing, it could be observed that their size corresponded to the articles obtained. Therefore, applying sec- ond processing was sufficient to get good results.
Once all processing has been applied, it becomes possible to use search algorithms more intuitively. This will be the next point to be analysed in the following section: different search and information retrieval methods available on the market and their applicability and efficiency for the use case presented.
3.3 Information retrieval systems | ElasticSearch
In the previous section, we obtained a dataset containing all the information present in a legal document ideally classified in such a way that each row corresponded to each of the articles present in the document, while the columns of the dataset represented relevant information characterising each article (article title, section, chapter, text...). Thus, with a
differentiated dataset, we can move on to the next step in creating a complete information retrieval system. This step, which will be dealt with in this section, will be based on the search and study of an information retrieval system capable of identifying which dataset rows are most similar to a given sentence. Specifically, our objective will be the creation of an advanced search system capable of matching a given question asked by the user with one of these rows with sufficient similarity to assume that the information presented in this article is the one that answers the question asked by our user.
As we analysed it in section 2.2, one of the best solutions that fit the best in this project was the one called ElasticSearch. This is so because several reasons:
• Used as the leading search engine, among other algorithms, the so-called TF-IDF, which was one of the main algorithms we wanted to study and apply in this project.
In turn, as we have seen in the previous section, this algorithm allows the use of the created dataset more efficiently than other types of options.
• It is a dynamic database focused on the indexed search of its rows from a query per- formed. This makes it especially attractive for our use case since it adapts perfectly to our needs.
• It is a system widely adopted by the multiple cloud services that are available today.
In addition, the provider chosen for this project, AWS, natively offers a service that integrates this search engine. This greatly facilitates its deployment and execution within the entire system.
Therefore, as mentioned before, ElasticSearch is the option that best suits our use case and the one that will be applied to create the information retrieval module on which the final solution is based.
ElasticSearch [45] is a distributed search and analytics engine that enables near real- time search of all types of data. This data can be structured, unstructured, numerical or even geospatial. Due to its wide range of performance, it is used in multiple use cases, including search boxes for websites or applications, data analysis in real-time or data storage produced by workflows in automated systems, among many other cases.
Many consider ElasticSearch (ES) as a dynamic database that applies text similarity algorithms to retrieve entries quickly. However, ES stores information as complex seri- alised data structures in JSON format. So, when you store a document within ES, this document is indexed to the data structure set up from the beginning, allowing you to access the information much more efficiently than in a standard database. The structure of each index is established at the outset when setting the ES parameters.
Each index can therefore be thought of as an optimised collection of documents and each document as a collection of fields in key-value format. This type of serialised struc- ture is very beneficial for the use case of this project, as the initial legal document was disaggregated into a dataset that can be perfectly serialised in a key-value format. Fur- thermore, this structure allows for differentiation between algorithms applied for each field type. Thus, textual fields are stored following an inverted index structure, while numeric and geo fields are stored in BKD trees.
Another great benefit of this system is that it has an SDK developed for python to
interact with the system. This SDK will be used to perform queries to the database, as well as to update the ES indexes with new documents.
Queries made to ElasticSearch are made through the REST API enabled within the search engine itself, which allows complex, structured queries or a combination of several fields in one to be handled. This point will be addressed later, and we will study the best combination of queries for the specific use case.
We will now explain in detail how the ES search engine works, what kind of data structure it allows to define in each index, and the specific parameters it allows to include.
3.3.1 Indexes and search engine
As mentioned above, ElasticSearch is composed of indexes, which offer a serialised and user-customisable data structure where documents will be stored in the different fields.
This structure will be used by the search engine established during the service creation to compare the queries made with the stored index fields. So, ES workflow is standing for figure3.4.
Figure 3.4: ElasticSearch WorkFlow
So, to start using the ES service, it is necessary first to define the index used for the documents. It should be noted that in this case, each document in the index will be each of the items previously differentiated by the processing of the legal document. In turn, each of the fields contained in the dataset where the articles are found will be the fields previously defined in the data structure of the index.
The number of settings this service allows to set up goes far beyond this project’s scope. However, we can find a list of all available settings for an index in [46]. At this stage, a list of the parameters to be set for this use case can be displayed:
• Analysis: Settings to define analyzers, tokenizers, token filters and character fil- ters. ES uses this setting to process unstructured text into structured text, applying text cleaning techniques such as stemming and stopwords removal, among other pa- rameters. This processing will be applied when indexing new text or searching text fields.
• Mapping: Enable or disable dynamic mapping for an index. This setting is used to define how a document, and its constituent fields, are indexed and stored in a given index.
• Similarities: Configure custom similarity settings to customize how search results are scored. This setting represents the search engine used by ES to compare the queries made with the fields of the indexed document.
Therefore, to obtain an index that worked correctly, the different settings of the ES service were modified to get the most optimal combination for this project. We should
note that these settings work correctly for this particular use case, i.e. analysis of legal documents. The language used in this case is very different from that used in other use cases (e.g. analysis of customer comments in e-commerce or analysis of tweets on a trending topic), so these settings should be studied for this specific use case.
Analyzers
Therefore, to analyse which parameters are best suited for this use case, we will explore the settings presented above. We will start with the parsing settings, text cleaning, and preprocessing techniques.
ES performs what is called a full-text search. This fact means that it shows the most relevant results, those that are most similar to the query, rather than those that exactly match the words and structure of the query. So, for a query like: Where can I find information about tall facades in urban environments? Of course, we can expect to return a document containing the terms "urban environments", but it would also be interesting to obtain the same action documents containing words such as "urban information" or
"urban facades". To obtain documents that present similar information in a more precise way, ES applies a parser. This parser is used both for the query performed and for the fields of the indexed documents. This parser is mainly composed of three blocks:
• Character filters: A character filter receives the original text as a stream of char- acters and can transform the stream by adding, removing, or changing characters.
In this case, this character filter is performed outside ES, so we will not use any character filter inside the ES service. Outside this service, character filtering will be performed using the regular expression library, explained in the previous sec- tion, eliminating special characters, double spacing and punctuation, and replacing accented vowels with normal vowels.
• Tokenizers: A tokeniser receives a stream of characters, breaks it up into individual tokens (usually individual words), and outputs a stream of tokens. The tokeniser we will use for this case is the default one that separates character streams by whitespace.
Thus, a sentence like "Información urbanistica en Madrid" will be separated into ["información," urbanisitica", "Madrid"].
• Token filters: A token filter receives the token stream and may add, remove, or change tokens. This is the most used field in this project. We applied a total of 5 filters. These filters are lowercase (converts uppercase to lowercase), stopwords (removes very repetitive words from the text), stemmer (gets the roots of each word), ASCII folding filter (converts alphanumeric characters and symbols that are not in Basic Latin Unicode to the ASCII equivalent) and finally synonyms (converts specific terms to other standard terms).
After applying these terms, we obtain a list of specific tokens that will be stored in their respective fields. It should be noted that this treatment will only be applied to text fields.
Mappers
As mentioned above, the mapping process within the ElasticSearch ecosystem is the pro- cess of defining how a document and its respective fields are stored and indexed within the dynamic database.
This parameter, within all ES settings, is therefore in charge of defining the type of data stored in each field that constitutes each document. This mapping can be of two forms: explicit, where the fields are determined from the creation of the dynamic database and have a fixed data type, and dynamic, where new fields can be added automatically by indexing them in the document. The latter kind of mapping is used when you want to experiment and explore the data that can be stored within ES. However, the best use case is explicit mapping for more control over what type of data is stored and in what form. Therefore, the explicit mapping will be used for this use case.
Then, once the type of mapping is defined, the fields to be stored in this document will be the same as those mentioned in section3.2.3. The data stored in these fields will be of three different types: text, integer and keyword. The first two are the basic types assigned for textual and numeric data. The third, the so-called keyword, is the most particular data type. This data type has been given to the field "section" and "condition" and is used to name structured contents that can identify the element stored in the database. These are identifying fields with few elements among their options, so they are clear candidates for this data type.
After adjusting the mapping for this index, we move on to the most critical point within the index parameters, the similarity engine.
Similarities
This last parameter within the ES index configuration is the one that defines which search engine will be used when comparing the queries made with the fields of the stored documents.
As discussed in section 2.2, the default search engine used by ES is based on the TF-IDF word embedding technique. Specifically, the default search engine is BM25 [47].
However, ES offers a variety of options to choose from as search engines. They are based to a greater or lesser extent on information retrieval techniques. In turn, they all offer algorithm customisation parameters (e.g. normalisation parameters). Therefore, to choose the search engine best suited to this specific case, it was decided to perform a performance test, creating an ES database for each available search engine and filling it with the articles obtained in3.2.3. After that, a battery of simple queries was performed in each database to see how efficient the result of each one was. At the end of the test, the most efficient search engine was based on the divergence from the randomness algorithm [48]. Thus, the best search engine for this use case was established after some readjustment of algorithm customisation parameters.
3.3.2 Queries ElasticSearch
Once you have established the best configuration for the index that will store the docu- ment, you can address which type of query will be used for this particular case. Like the indexes, the queries used to obtain the indexes can also be customised [49]. Specifically, two of all the parameters available in the query have been used.
The first one is the filter itself applied to the query. This parameter filters the number of documents to be queried by setting specific document fields. As mentioned above, the use case in question is limited to title 8 of the legal document. However, this legal document is structured so that it is possible to categorise by chapters each residence to which this rule applies. Thus, a single zoning rule applies to a home located on a particular street, classified by titles and chapters. In turn, using one of the technological systems offered by the Madrid City Council, called Callejero, it is possible to obtain to which title and chapter each address corresponds. Therefore, by making an API call to this system with the address of the place of residence you want to obtain information, it is possible to get which title and chapter correspond to that address. With this information, it is possible to filter the articles to which the query corresponds, obtaining a higher performance of the ES system.
The second one is related to the number of fields used to obtain the comparisons and the relations between these fields. ES offers a wide variety of options regarding which document fields to use for the comparison. Therefore, given that the queries would be textual, it was decided that the fields to be studied and which would provide the most information would be the title of the article and the body of the article.
In addition, of all the options offered by ES for queries, those based on text comparisons have been used. Within these types of queries, ES offers a wide variety [50], but three categories have been studied:
• Match query: Returns documents that match a provided text value. The provided text is compared with a specific field.
• Multi-match query: Returns documents that match a provided text value. The provided text is compared with multiple fields. At the same time, this option offers multiple configuration options:
– Best fields: Finds documents which match any field but use the score value from the best field to determine which document is returned.
– Cross fields: Treats fields with the same analyser as though they were one big field. In other words, provided text must be present in at least one field for a document to match.
– Most fields: Finds documents which match any field and combines the score value from each field to determine which document is returned.
• Simple query string: Returns documents based on a provided query string, using a parser with a limited but fault-tolerant syntax.
It should be noted that the same parser established during the creation of the index is applied to each query, obtaining the exact processed text stored in each field of each of the two elements.
As in the previous section, all the options presented were tested using a battery of questions. Likewise, the same index configuration during the last section has been used.
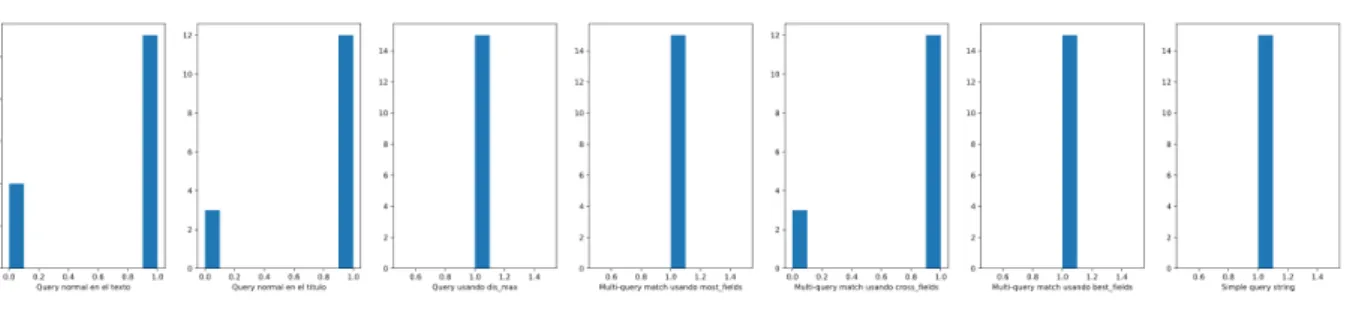
Thus, and applying this benchmark, the results are shown in figure 3.5.
Figure 3.5: Queries ES
As can be seen, each graph consists of a two-bar histogram where the first bar indicates the number of errors and the second bar shows the number of correct answers. A hit is indicated as those questions asked whose returned items correspond to the requested information. Otherwise, it is stated as wrong. Thus, it can be seen that among the 15 questions asked, three configurations obtained a 100% success rate. These are the multi-matching configuration with best fields, most fields, and single query string. Given that these three configurations show similar results, the one we have decided to use for the system is the best fields configuration since it is the default configuration for using multiple fields and, therefore, the best optimised for the ES search engine.
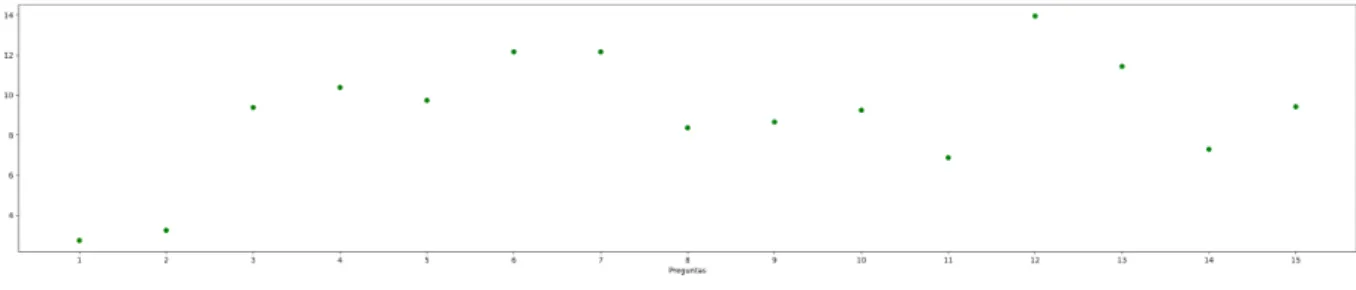
Finally, it should be noted that each result obtained from the comparison has a score value that indicates the level of similarity between the returned document and the query performed. If we get these scores from the set of queries performed and plot them, we obtain the results shown in figure3.6. As we can see, there are questions where the score is below 4 points despite giving a correct result. In later sections, we will look at how to deal with such low scores and what strategies to follow to avoid erroneous results. For the time being, by setting a numerical threshold, we could automatically classify the answers obtained as wrong or correct.
Figure 3.6: Score obtained from queries
As can be seen, ES is an excellent tool for the indexing of large amounts of docu- ments and the creation of complex information retrieval and question answering systems.
Throughout this section, we have tested multiple configurations for indexing documents and creating efficient queries optimally suited for our use case. Finally, we have obtained a system capable of obtaining from a large document a minimum portion of information where the answer to the question asked by the user can be found, with very high efficiency.
Now the problem lies in how to obtain a concrete answer from that portion of information.
This problem will be addressed in the following section.
3.4 Question Answering systems
As seen in section2.3, current NLP-based solutions are based not only on statistical mod- els and hand-written rules but also on the latest neural network architectures. Among these architectures, the transformers stood out among all the others, based on an at- tention mechanism that replaced the recurrence and convolution mechanisms that had been used years ago. These new architectures solve more complex use cases, including sum