FACULTAD DE INGENIERÍA Y COMPUTACIÓN Escuela Profesional de Ciencia de la
Computación
An Automatic Emotion Recognition System that uses the Human Body Posture
Trabajo de Investigación
Presentado por:
Juanpablo Andrew Heredia Parillo
Para Optar por el Grado Académico de:
Bachiller en Ciencia de la Computación
Asesor: Dra. Regina Paola Ticona Herrera
Arequipa, Enero 2021
who actually do”
— Steve Jobs
En primer lugar, quiero agradecer a mi familia, quienes me apoyan en todas las decisiones que tomo y me ayudaron en los momentos dif´ıciles que tuve que superar. Agradezco especialmente a mis padres por todo el apoyo brindado para forjarme como profesional.
Agradezco a la Universidad Cat´olica San Pablo, mialma matter, por haberme cobijado y brindado la formaci´on que ahora me permitir´a ayudar a construir una mejor sociedad.
Agradezco de forma muy especial a todos y cada uno de los profesores que me han ense-
˜
nado, porque son los ejemplos que deseo seguir en mi vida profesional. A mis amigos y compa˜neros, futuros colegas con los que espero trabajar en el futuro. Tambi´en al personal administrativo y de mantenimiento de la universidad, quienes me permitieron estudiar sin problemas ni limitaciones.
La comunicaci´on no verbal est´a muy presente en nuestras vidas, pero se puede interpretar de diferentes formas seg´un muchos factores. Con gestos no verbales, las personas pueden expresar mensajes expl´ıcitos e impl´ıcitos, lo que los hace inportante de comprender. Los m´etodos de visi´on por compu- tadora para reconocer los gestos corporales y los m´etodos para clasificaci´on de aprendizaje autom´atico ofrecen una oportunidad para comprender lo que las personas expresan con sus cuerpos. Este trabajo de investigaci´on se centra en las emociones expresadas por gestos corporales, en particular la postura. As´ı, se propone un sistema de reconocimiento autom´atico de emociones a partir de im´agenes, que utiliza una red neuronal de grafos convolucionales para reali- zar la clasificaci´on. Generalmente, el enfoque de aprendizaje profundo necesita muchos ejemplos de entrenamiento, pero estos son dif´ıciles de obtener para el reconocimiento de emociones posturales, por lo que el modelo propuesto se en- trena bajo un algoritmo de meta aprendizaje basado en el “modelo agn´ostico”, que permite entrenar con pocos ejemplos. Solo se prob´o el algoritmo de meta aprendizaje propuesto, que demostr´o la adaptabilidad y expande la aplicabili- dad del las redes neuronales de grafos convolucionales.
Palabras clave: Reconocimiento de Emociones · Clasificaci´on de posturas · Meta aprendizaje.
Non-verbal communication is very present in our lives, but it can be in- terpreted in different ways according to many factors. With nonverbal gestures people can express explicit and implicit messages, which makes them impor- tant to understand. Computer vision methods for recognising body gestures and machine learning classification methods offer an opportunity to unders- tand what people express with their bodies. This research work focuses on the emotions expressed by body gestures, particularly the posture. Thus, an automatic emotion recognition system from images is proposed, which uses a graph convolutional neural network to perform the classification. Generally, deep learning approach needs many training samples, but these are difficult to obtain for posture emotion recognition, thus, the proposed model trains under a meta-learning algorithm based on the “agnostic model”, which allows trai- ning with few examples. Only the meta-learning algorithm was tested, which demonstrated the adaptability and expands the applicability of the graph con- volutional neural networks.
Keywords:Emotion Recognition · Posture Classification · Meta-learning.
Abreviaturas
HCI Human-Computer Interaction FER Facial Emotions Recognition FACS Facial Action Coding System SVM Support Vector Machine CNN Convolutional Neural Network RNN Recurrent Neural Network LSTM Long Short Term Memory HPE Human Pose Estimation
RMPE-PAF Realtime Multi-person Pose Estimation using Part Affinity Fields HAR Human Action Recognition
GCNN Graph Convolutional Neural Network
BEAST The Bodily Expressive Action Stimulus Test MAML Model-Agnostic Meta-Learning
KAP Keypoints Acquisition Process
´ Indice general
1. Introduction 1
1.1. Motivation and Context . . . 1
1.2. Problem Statement . . . 2
1.3. Objective . . . 3
1.3.1. Specific Objectives . . . 3
1.4. Work Organisation . . . 3
1.5. Schedule . . . 4
2. Sentiment Analysis & Deep Learning: Preliminaries 5 2.1. Sentiment Analysis . . . 5
2.1.1. Verbal Sentiment Analysis . . . 5
2.1.2. Visual Sentiment Analysis . . . 7
2.2. Methods to Classify Emotions . . . 10
2.2.1. Evaluation Methods . . . 11
2.3. Deep Learning approaches for Human Posture Study . . . 12
2.3.1. Human Pose Estimation . . . 13
2.3.2. Human Action Recognition . . . 16
2.4. Meta-Learning . . . 18
2.4.1. Optimisation . . . 18
2.4.2. Model-based . . . 18
2.4.3. Metric-learning . . . 18
2.5. Final Considerations . . . 19
3. State of the Art: Review 20 3.1. Abstraction of the Human Body . . . 20
3.1.1. Human Pose Estimation (HPE) . . . 20
3.1.2. Human Action Recognition (HAR) . . . 23
3.2. Emotion Recogniser from Human Posture . . . 26
3.3. Meta-Learning Algorithms . . . 27
3.3.1. Meta-learning in GCNN . . . 28
3.4. Final Considerations . . . 29
4. Emotion Recognition System from Human Posture Images 30 4.1. Bases of the proposal . . . 30
4.2. Proposed Method . . . 31
4.2.1. Data Pre-processing: Task Universe Definition . . . 31
4.2.2. Meta-learning Model Implementation and Training . . . 32
4.3. Final Considerations . . . 33
5. Experiments 34 5.1. Data Collection . . . 34
5.2. Data Pre-processing: Task Universe definition . . . 35
5.3. Model Implementation and Training . . . 36
6. Conclusions and Future Works 39 6.1. Future Works . . . 39
Bibliography 45
´ Indice de tablas
1.1. Schedule of activities of this research work. . . 4 3.1. Comparative frame of the methods develop in ‘Abstraction of the Human
Body’ section. . . 25
´ Indice de figuras
2.1. Steps of the traditional FER process [34]. . . 8
2.2. Overview of the deep learning approach FER process [34]. . . 8
2.3. Examples of body gestures, taken from [44]. . . 8
2.4. General description of emotion recognition systems based on body gestu- res [44]. . . 9
2.5. Scalability of deep learning methods [5]. . . 14
2.6. Overall process of top-down approach [10]. . . 14
2.7. Overall process of bottom-up approach [10]. . . 14
3.1. Overall process of RMPE-PAF [5]. . . 21
3.2. Architecture of the two-branch multi-stage CNN [5]. . . 21
3.3. Architecture of HR-net [60]. . . 22
3.4. Architecture of CPN, taken from [8]. . . 23
3.5. The skeleton spatial-temporal representation [69]. . . 23
3.6. Overall pipeline of the ST-GCN method [69]. . . 24
3.7. Architecture of the Spatial-Temporal Module proposed in [67]. . . 24
3.8. Overview of the framework proposed in [74]. . . 25
3.9. Pipeline of the proposed method of [55]. . . 26
3.10. Points of cameras in [55]. . . 27
3.11. Simple diagram of MAML [17]. . . 28
4.1. General diagram of the parts that make up the proposal. . . 32
5.1. Image examples of BEAST dataset [11]. . . 34 5.2. Outputs example of the KAP, image is taken from BEAST [11] dataset. . . 36 5.3. Accuracy graph of the first ten training epochs. Additional adjustment was
applied in remarked bars (epochs 4,7 & 10). . . 37
Cap´ıtulo 1 Introduction
Nowadays, there is an increasing interest on improving Human-Computer Interaction (HCI) to develop more friendly applications [3, 21, 38]. Sentiment Analysis is one of the techniques used to achieve HCI in a more natural and empathetic way. Sentiment analysis can be applied to different input data types, which can be verbal (text and speech) or nonverbal, which in turn could be audio content (music, nature sounds, etc.) or images (human gestures, signals, symbols, etc.). In this context, artificial intelligent models have demonstrated their ability to predict sentiments to determine the perception of people about aspects of daily life. This kind of analysis is often defined as a classification task [57], therefore, many of the related methods are based on machine learning or deep learning.
1.1. Motivation and Context
Human communication is not exclusive in verbal mode. Non-verbal expressions are also important and can transmit as much information as verbal ones. However, it is im- portant to correctly interpret them, because each person has different knowledge, beliefs, culture, and experiences about non-verbal communication [33]. A non-verbal message might contain information about the emotional state, attitude, or intentions of somet- hing [33]. Thus, it is necessary to give more importance to people non-verbal interactions to improve communication and avoid misunderstandings.
There are various forms of non-verbal communication, such as facial expressions, eye contact, hand gestures, and body posture. Even the arm positions, body posture, and physical presence (e.g., the colour of clothing), are considered non-verbal communi- cation [52]. Generally, non-verbal communication studies focus on body communication because it produces direct communication between the sender and the receiver [52].
An interesting form of non-verbal communication is the one expressed from the body posture. Some researchers found that people can express emotions without moving their hands or making facial expressions, but with gestures or body postures [9]. Working with human posture has been challenging because it is difficult to validate as emotions are not clearly expressed in body posture as in facial gestures [44].
There are many situations where a person is interested in the emotional state of others, but these people do not want or cannot share that information in a traditional channel such as speech or writing. For example, in classrooms, teachers would like to have some idea about the emotional state of students to improve their teaching methods;
in tourist centers (such as museums), staff want to know how satisfied visitors are with the service. In these and other similar examples, a computer system can be very useful, applying areas such as computer vision, data science, semantic web, etc. In these and other similar examples, a computer system can be very useful, applying areas such as computer vision, data science, semantic web, etc.
Deep learning computer vision algorithms play an important role because they can predict or estimate an emotional state simply by using images. Almost all non-verbal emotional expressions can be in images, so computer vision algorithms are the natural and most common methods to use [73]. Today, there are not many works that identify emotions only with postures, because the challenges it implicates. Therefore, this is an area that requires new approaches and contributions that continue to drive its development.
1.2. Problem Statement
The problem of developing an automatic system for recognising emotions in body posture can be separated into three subproblems [44, 59]. First, the way to capture or recognise the posture of one or more people using images or videos as input; second, the way of representing the posture since the location of the joints is not enough to recognise an emotion; and third, the classification of emotions groups according to human posture.
The first problem, recognising the posture of an image, is itself a task with serious difficulties, such as partial occlusion of people, and ignorance of the number of people acting on the image [5]. Occlusion refers to the non-visibility of some parts of a person’s body, either because they are interacting with objects or with other people. Currently, there are methods that effectively deal with occlusion; however, many of them do not turn out to be efficient when used to obtain the posture of many people (this is more detailed in the next chapter). Processing time is also an issue, and while many methods have become accurate they still take a long time. The best models to solve this problem require a powerful computing environment, so this is an area that continues to be investigated;
but this is not the focus of the present research work.
For the people posture representation, the second problem, a graph representation could be used[44]. These kind of graphs could be called as skeleton graphs, where each node represents a joint of the body, and the edges represent continuous joints or body limbs. This representation is currently used to estimate human actions, a topic that can give a guideline to follow. In addition, the skeleton could have depth information for each node, in this case it would represent a 3D posture with better possibilities of being understood and processed. However, recognising positions in 3D from 2D images is more time consuming and currently difficult to achieve with a high accuracy [26].
For solve the third problem, the classification into emotions, a processing of the skeleton graph is necessary [19, 48]. This processing is mainly about creating new features or extracting information from the skeleton [44]. In some works, the authors tried to generate new information from the recognised posture and then apply a classification method. Since machine learning or deep learning approaches are used for this classification task, a good and large dataset is important. This has been a big problem due to the low popularity of analysis of feelings and emotions only from the human position. Therefore, many researchers created their own dataset which is not easily shared or published, making
it difficult to compare between them. To solve the need for a large dataset, some training algorithms and frameworks have emerged that allow machine learning-based methods to learn with little data or allow them to achieve generality for later better fit [23]. These algorithms are recognised as part of a recent area: meta-learning.
1.3. Objective
The general objective of this research is to propose a system or algorithm for the recognition of emotions expressed with the posture of the human body that is captured from images or videos.
1.3.1. Specific Objectives
Carry out an adequate review of the state of the art on related topics and especially on works related to the recognition of emotions from the human posture.
Select or adapt an adequate dataset that allows the training and validation of the proposed model. The dataset must have full body postures labelled with emotions.
Process training data using efficient methods, which will be chosen by empirical tests. The method must be able to work with images and videos.
Propose a meta-learning algorithm for a graph convolutional neural network, which allows obtaining competitive results in the recognition of emotions of human posture, with relatively little training data.
1.4. Work Organisation
This research work is organised in the following way:
In Chapter 2, preliminary knowledge on the main topics of this work, sentiment analysis, human pose estimation, human action recognition, machine learning classifiers and meta-learning, are presented.
Chapter 3, presents the related works in the state of the art for the different topics explained in the preliminaries chapter.
Chapter 4, presents the bases of the proposal and the description of the parts of it.
Furthermore, the proposed meta-learning algorithm is explained.
Chapter 5, presents the description of each applied experiment and the results ob- tained. In addition, the description of the datasets used and a pre-processing of them.
Chapter 6, presents the conclusions reached by the research carried out.
1.5. Schedule
This work is developed following the schedule presented in Table 1.1.
Tabla 1.1: Schedule of activities of this research work.
Date Tasks
* Selection of relevant research papers to support the work.
25 / 04 / 2020 * Statement of the problem and identification of limitations.
* Definition of the objectives and the relevant topics to be developed.
23 / 05 / 2020 * Identify research works related to the recognition of emo- tions from human postures.
* Evaluation of related works in the state-of-the-art.
20 / 06 / 2020 * Identify and review techniques and methods that will be the basis of the work.
* Identify the scientific contribution of this research work.
25 / 07 / 2020 * Preliminary design of the proposed solution.
* Review and evaluation of the proposed solution.
22 / 08 / 2020 * Compare and discuss the preliminary results.
* Complete design of the proposed solution.
* Complete the implementation of the solution.
26 / 09 / 2020 * Design and implementation of the experiments to be carried out.
24 / 10 / 2020 * Execution of the experiments.
* Discussion and justification on the results achieved.
28 / 11 / 2020 * Discover the conclusions and possible future works.
* Write the corresponding research article.
26 / 12 / 2020 * Correction and editing of the entire document.
Cap´ıtulo 2
Sentiment Analysis & Deep Learning: Preliminaries
In this chapter, the topics related to this research work are explained: Sentiment Analysis, Deep Learning, Meta-learning, and classification techniques.
It begins with a general review of the sentiment analysis and the two great branches it has: verbal and visual. Then, both branches are explored a bit, explaining the analysis of text and speech by the verbal branch, and facial and body gestures by the visual one. The sentiment analysis of body gestures, the subject of this work, requires an abstraction of gestures to later classify them into emotion groups. For this reason, the concepts necessary to understand the computer vision methods based on deep learning for the abstraction of body gestures and the classification techniques based on machine learning, are defined.
The most used datasets in the research community and the evaluation metrics that assess the performance of the proposals are also developed. Finally, to overcome the limited amount of data available to classify the emotions of a recognised posture, a machine learning sub-field, called Meta-learning, is also reviewed.
2.1. Sentiment Analysis
Studying emotions is useful since the emotional state of people has an important role in human-human interactions. Often the success of these interactions depends on the emotional intelligence of those involved individuals [4]. Sentiment analysis seeks to auto- matically extract or classify feelings, emotions, or opinions from sources such as reviews, speeches, images. Most of the apps that use sentiment analysis are web apps, especially with social media, because there is a lot of information about people that could be used to recognise their emotions and opinions [24, 57].
In the research community, there are three main ways to study sentiments: using text, speech, or images, which are explained below.
2.1.1. Verbal Sentiment Analysis
Within verbal sources, we include the two forms of communication with words, by writing and speaking. These types of analyses are closely related to Natural Language Processing techniques and supervised artificial intelligence methods [57].
2.1.1.1 Sentiment Analysis in Text
Text sentiment analysis is also known as opinion mining. It is the study of people’s opinion about entities and their attributes using computing [41]. It is considered a multifa- ceted artificial intelligence problem, which includes human intelligence and a collection of electronic intelligence methods to extract features from text and classify users sentiment.
Its aim is to minimise the gap between humans and computers [30].
To achieve an understanding of this topic, some definitions proposed by [41] are used. First, an opinion can be represented according to the entities (Definition 2.1) and relationships among entities that the text refers. Thus, opinions are about any node or any node attribute.
Definition 2.1 (Entity). It could be a product, service, event, or topic. Entities are represented as (T, W), where T represents a sub-component hierarchy, andW represents the entity attributes. Each sub-component can have its attributes. Thus, entities could be represented as a tree graph and each node is an entity with its attributes, and the edges between nodes represent a part-of relationship.
Mainly, there are two kinds of opinion: normal opinions and comparative opinions. A comparative opinion expresses a comparison between two or more entities. An opinion can be defined as neutral, positive, or negative; this category is called opinion orientation.
To transform unstructured text into structured data, opinions could be represented as in Definition 2.2.
Definition 2.2(Opinion representation). An opinion can be represented according to [40], as a five-tuple (Ei, Aij, Oijkl, Hk, Tl).Ei represents the entity,Aij the aspects of the same entity,Oijkl is theAij opinion orientation,Hkis the opinion holder, andTl is a timestamp.
The orientation Oijkl can also contain data about levels of intensity.
Furthermore, emotions are people’s subjective feelings or thoughts. In [45], six pri- mary emotions of people are described: love, joy, surprise, anger, sadness, and fear. Each one can also have different intensities that could be expressed in a sentence, but recogni- sing them is still a difficult task.
According to Kaur et al. [30], the process for the sentiment analysis of text process begins with the creation of the sentiment lexicon, then, the detection of subjectivity of the text, and finally the detection of sentiments or emotions.
2.1.1.2 Speech Sentiment Analysis
Communication through voice is one of the main components of affective computing in human-computer interaction. Speech is a more natural and spontaneous source, making automatic sentiment processing difficult [43].
Unlike the sentiment detection using text, working with audio containing sponta- neous speech is a challenging topic that has received little attention [31]. Speech analysis has some difficulties such as noisy audio due to non-ideal recording conditions, foreign accents, spontaneous speech production, and a wide range of topics [43].
To facilitate the speech analysis, some studies transcribe speech into text and classify it, complementing it with the characteristics of the audio or its parameters such as pitch,
volume or intensity, timbre, frequency, and pause when speaking, whose changes express different information from the speaker to the listener. With this composite classification the results obtained are better than just using a text transcription [3, 43, 62].
2.1.2. Visual Sentiment Analysis
A picture is worth a thousand words. Images are very valuable, especially when they convey human emotions and feelings [66]. The main research task in the analysis of visual feelings revolves around modelling, detecting, and exploiting the feelings expressed in or from the image [57].
The recognition of emotions in images can be classified into two groups, those that allow to recognise the emotions of the actors and those that allow to recognise the emotions of the author or viewer [57]. By actors, it refers to the people who appear in the image.
In this type of images, the objective is to recognise the emotions that these people are expressing at that moment. It is common to analyse facial expressions and body gestures to recognise emotions and feelings. In the other group, the aim is to analyse the emotion that the image itself expresses to the observer, for example, the image of a beach can express relaxation and joy; to do this, it is possible to analyse the colours, the semantics of the present objects, etc.
This work is related to the emotion recognition of the actors in images; therefore, the two main types of study of this group, the sentiment analysis of facial expression and the sentiment analysis of body gestures, are reviewed below.
2.1.2.1 Facial Expression Sentiment Analysis
Facial expression sentiment analysis is also known in the scientific community as Facial Emotions Recognition (FER). For a better understanding of this topic, some defi- nitions presented by [34], are explained below.
Definition 2.3(Facial Action Coding System). The Facial Action Coding System (FACS) is based on facial muscle movements. This system is able to characterise human emo- tions [15]. This system encodes the facial muscles movement in Action Units.
Definition 2.4 (Facial Action Units). These units encode the actions of muscle groups, which are seen when the facial expressions of a emotion occurs [14]. Several individual action units are detected to recognise emotions, thus, a system classifies according to the combinations of these action units.
Definition 2.5 (Facial Landmarks). These landmarks are recognisable points in the face such as the end of the nose or the start of the eyebrows. The location of each of the two landmarks are used as a feature vector of FER [27].
Currently, there exist two types of approaches to perform FER: traditional and deep learning based, both are represented in Figure 2.1 and Figure 2.2, respectively.
In traditional FER approaches, this is made up of three steps, as shown in Figure 2.1:
(i) the detecting of the face region and its landmarks; (ii) the extraction of spatial and temporal features; and(iii)the application of a classifier such as Support Vector Machine (SVM) or Random Forest.
Figura 2.1: Steps of the traditional FER process [34].
Figura 2.2: Overview of the deep learning approach FER process [34].
On the other hand, deep learning-based FER methods reduce reliance on pre- processing techniques by allowing end-to-end learning [64]. Inside the deep learning mo- dels, Convolutional Neural Network (CNN) is the most used. With this, the input image is processed with the convolution layer filters to produce feature maps. Then a fully con- nected network combines the feature maps and the final classification is generated using a normalisation algorithm such as softmax. Figure 2.2 shows the procedure used by a CNN-based FER approach.
2.1.2.2 Body Gesture Sentiment Analysis
Body Gesture could be facial expressions, body posture, gestures, and eye move- ments; which indicates the inner state of a person [44]. Figure 2.3 shows some examples of body gestures that express emotions, which can be understood as a subset of body language.
Figura 2.3: Examples of body gestures, taken from [44].
Gestures are an important form of non-verbal communication that allows commu- nicating feelings or thoughts. In [46], gestures are classified as follows:
Intrinsic: Head nod as a sign of affirmation or consent is probably innate, even people who are born blind use it.
Extrinsic: Turning to the sides as a sign of rejection is a gesture we learn in early childhood. For example, babies turn their heads when they have had enough milk from their mother breasts, or older children when they refuse a spoonful of food during feeding.
A result of natural selection: For example, the expansion of the nostrils to oxygenate the body in preparation for battle or escape.
After the face, the hands are probably the richest source of body language informa- tion. For instance, hands position can determine whether a person is honest (hands turn to the interlocutor) or they will not be sincere (hands hidden behind the back). Similarly, the head position reveals many information about the emotional state. For instance, lifting the chin expresses superiority or arrogance, while exposing the neck means submission.
The torso is one of the least analysed parts of the body, however, it can also express interesting data such as interest in something from an angle of inclination.
Figura 2.4: General description of emotion recognition systems based on body gestu- res [44].
The general process to recognise emotional body gesture begins with the abstraction of the human body [44]. Deep learning algorithms are usually applied to comply this task [44, 59]. Once the model of the body is obtained, features that allow to classify the body abstraction into a group of emotions, are extracted. The way these features are obtained, and the modelling of emotions vary in many methods.
Figure 2.4 shows the aforementioned process, in this, the two steps from the top, Human Detection and Body Pose Estimation, encompasses the abstraction phase of the human body. This process is similar for all body gestures. For example, to classify
hand signals in the same image, it would be necessary to perform a deeper and more detailed abstraction of the person to recognise the joints of the hands as the knuckles of the fingers.
In the present research work, human posture is studied as a transmitter of emotions.
Therefore, in the following section, one of the most used approaches for the abstraction of human posture is reviewed, the deep learning approach.
2.2. Methods to Classify Emotions
Sentiment Classification techniques can be roughly divided into machine learning approach, lexicon based approach, and hybrid approach [42].
Lexicon-based approaches are based on a collection of known, pre-compiled senti- ment terms; they are divided into dictionary-based and corpus-based. Statistical or se- mantic methods can be used to find the polarity of sentiment. The sentiment lexicons are important in most methods.
Methods using machine learning approaches are divided into supervised and unsu- pervised learning methods. These groups differ in the training data, while supervised ones need a large number of labelled data, the unsupervised ones are able to train with a few or no labelled data. Machine learning classifiers can be separated into three types according to [42], Probabilistic Classifier, Linear Classifier, and Decision tree Classifier.
Probabilistic Classifiers. These methods use mixture models to perform the classifica- tion. In a mixture model, each class is taken as a mixture component. Each component of the mixture contains the probability of sampling a term for the respective component.
A popular classifier of this type is the Na¨ıve Bayes, explained in Definition 2.6 (taken from [42]).
Definition 2.6 (Na¨ıve Bayes Classifier). This method calculates the posterior probability of a class. For text, it is based on the word distribution in the document. Bayes’ theorem is used to predict the probability that a set of features belongs to a class, as shown in Equation 2.1.
P(class|f eatures) = P(class)∗P(f eatures|class)
P(f eatures) (2.1)
P(class) is the prior probability of a class (i.e., the probability that a set of random characteristics is of that class), P(f eatures|class) is the prior probability that a set of characteristics is classified asclass, andP(f eatures) is the prior probability that a certain feature set will occur.
Linear Classifiers. These methods receives three inputs, X, A and b.X represents the feature frequency of a normalised item,Arepresents a vector of linear coefficients with the same dimensionality as X,b is a scalar. The linear prediction is obtained byp=A.X+b.
The prediction p is a separation hyper-plane of different classes. One of the most used algorithms is SVM (Definition 2.7).
Definition 2.7 (Support Vector Machine (SVM) [22]). This method determines linear separators of the search space, which ones can separate the classes. The SVM builds a
nonlinear decision surface in the original feature space by mapping the instances non- linearly to an inner product space. In that inner product space, the classes are separated by hyper-planes.
Decision Tree Classifier. These methods give a hierarchical decomposition of the trai- ning data space. This decomposition is done by conditions of the attribute values; that condition can be the presence or absence of specific characteristics. The decomposition is recursive until the leaf nodes contain a certain number of records that are used for classification. Random Forest, explained in Definition 2.8, is used by many recent works.
Definition 2.8 (Random Forest [61]). Also called Random Decision Forests. It is an ensemble learning method for classification, regression, and other tasks. It is built with multiple decision trees at the time of training. The output could be the mode of the classes or the mean prediction of individual trees. This approach solves the tendency of decision trees of overfitting the training data.
2.2.1. Evaluation Methods
To evaluate the precision of the classifier, the F1 score metric is commonly used.
First, to understand this metric, we define some terms.
Definition 2.9 (True Positives (TP)). These are the positive values predicted correctly, i.e. the value of the actual class is yes and the value of the predicted class is alsoyes.
Definition 2.10 (True Negatives (TN)). These are the negative values predicted co- rrectly, i.e. the value of the actual class is no and the value of the predicted class is also no.
Definition 2.11 (False Positives (FP)). These are the positive values predicted inco- rrectly, i.e. the value of the actual class is no and the value of the predicted class is yes.
Definition 2.12 (False negatives (FN)). These are the negative values predicted inco- rrectly, i.e. the value of the actual class is yes and the value of the predicted class is no.
With these terms (Definitions 2.9 2.10 2.11 2.12) we can define the evaluations or quality values that intervene in F1: the accuracy, the precision, and the recall.
Definition 2.13 (Accuracy). This is the ratio of the results predicted correctly to the total results. It can be obtained as follows:Accuracy = (T P+T N)/(T P+F P+F N+T N).
Definition 2.14 (Precision). This is the ratio of positive results predicted correctly to the total positive results predicted. It can be obtained as follows:P recision=T P/(T P+F P).
Definition 2.15 (Recall - Sensitivity). This is the ratio of positive results predicted co- rrectly to all results in actual classyes. It can be obtained as follows:Recall =T P/(T P+ F N)
F1 Score
This is a harmonic mean of precision and recall. The highest F1 score is 1.0, and it happens when there are perfect values of precision and recall. The F1 score is calculated by Equation 2.2. The F1 score is more useful than accuracy in many situations, especially if an unbalance class distribution is used. Furthermore, accuracy works best if FP and FN are similar; if they are different, both precision and recall must be considered.
F1 = 2· precision∗recall
precision+recall (2.2)
2.3. Deep Learning approaches for Human Posture Study
Deep learning is a powerful and effective machine learning technique that can learn multiple representations or features of input data [73]. Deep learning applies multi-layered artificial neural networks with a lot of neurons. A neural network allows the modelling of complex nonlinear functions, as there are more layers, and therefore more neurons, the function will be more complex. Definition 2.16 explain the concept of neural network.
Definition 2.16 (Neural Network). A Neural Network consist of many information pro- cessing units called neurons, organised in layers. The neural network learns by adjusting the weight of the connections between neurons, similar to the brain’s learning process.
Based on their topology, neural networks can be classified intodirect-feeding net- works and recurring/recursive networks. Direct-feeding neural networks refer to the traditional neural network model, as defined in Definition 2.16, its main feature is that they have all the data available for training from the beginning.
On the other hand, Recurrent Neural Network (RNN) is a kind of network whose connections build a directed cycle. A RNN also has an internal memory that allows serial data processing. The RNN performs the same task for each element of a sequence, thus, each output depends on all the above calculations.
A special type of direct-feeding network, widely used in the present, is the CNN (Definition 2.17). On the RNN side, one of the most sophisticated and popular models is the Long Short Term Memory (LSTM) network (Definition 2.18).
Definition 2.17 (Convolutional Neural Network (CNN)). This is mainly used in compu- ter vision. CNN consists of multiple type of layers: (1) Convolutional layers, which create a feature map by applying a filter that scans the entire image, a few pixels at a time;
(2) Pooling layers (downsampling), which reduce the amount of information generated by convolutional layers, these layers also filter essential information; (3) Fully connected input layers, which flatten the outputs of previous layers into a single vector; (4) Fully connected layers, which use weights to process their input for better prediction; and (5) Fully connected output layers, which generate the final values to determine a class.
Definition 2.18(Long Short Term Memory network (LSTM)). This is a RNN that learns long-term dependencies. It can process entire data streams such as voice or video. A LSTM
unit has a cell, an input gate, an output gate, and a forget gate. The cell remembers values at arbitrary time intervals using the state of the cell. The three gates regulate the flow of data into and out of the cell.
2.3.1. Human Pose Estimation
Human Pose Estimation (HPE) is a hard task of computer vision, whose objectives are modelling and recognising human postures [5]. The pose is recognised from the pre- diction of the location of the main human joints, then that information is used to model, as a graph, the human skeleton that represents the posture.
HPE methods are classified into single-person pose estimation and multi-person pose estimation. The objective of single-person methods is to find or estimate the keypoints locations in an area determined by the person, the number of key points is already known.
On the other hand, the objective of multi-person methods is to estimate the postures of everyone in the image, it is difficult because the number of people is unknown and they may be in a strange position or in occlusion. For a better understanding of HPE, it is necessary to explain two terms, keypoints (Definition 2.19) and heatmaps (Definition 2.20).
Definition 2.19 (Keypoint). In this work, and in most works on HPE, the keypoints refer to the joints of the body. Keypoints are usually labelled with numbers (e.g., the neck typically is the keypoint one or two), this label and the number of key points may vary depending on the datasets.
Definition 2.20 (Heatmaps). Heatmaps, in the HPE context, are the common way of representing keypoints location. If we want to recognise 15 keypoints, we will have to estimate 15 heatmaps.
Single-person approaches are classified into directregression-basedandheatmap- based. The former uses the output feature maps to backtrack keypoints directly. Heatmap- based approaches first generate heatmaps and then predict the keypoints based on them.
Furthermore, multi-person methods are classified intotop-downapproaches andbottom- up approaches. Top-down methods estimate postures in two stages: first, detection and location of people, each with a bounding box; second, the location of the keypoints of the people detected. On the other hand, in bottom-up methods the construction of postures also has two stages: in the first stage the location of all the parts of the body present in the scene are predicted; once all the keypoints that these parts represent are recognised and located, on the second stage, the keypoints that belong to the same person are grouped.
Most works under the last paradigm efficiently estimate the position of people, even when there are many people on the scene.
Figure 2.5 shows the performance comparison between both paradigms, Cascaded Pyramid Network [8] was used for the top-down paradigm, and Realtime Multi-person Pose Estimation using Part Affinity Fields (RMPE-PAF) [5] was used for the bottom- up paradigm. It is clear that the performance of RMPE-PAF is scalable in terms of the number of people to estimate their posture.
Figure 2.6 and Figure 2.7 show in a general way what the process of top-down and bottom-up approaches is like, respectively.
Figura 2.5: Scalability of deep learning methods [5].
Figura 2.6: Overall process of top-down approach [10].
Figura 2.7: Overall process of bottom-up approach [10].
2.3.1.1 Datasets
Deep learning models require a lot of data for training. For HPE, there are several datasets available to everyone that, according to [7], are widely used in the research community.
Max Planck Institute for Informatics (MPII) Human Pose Dataset [2]
It is one of the benchmarks for evaluating the estimate of the articulated human pose1. This dataset contains 24,920 frames manually selected. These Frames are extracted from 3,913 videos downloaded from Youtube covering 491 different human activities. Annota- tions include 16 body joints, a 3D view of the head and torso, and the position of the eyes and nose; these annotations were developed by workers at Amazon Mechanical Turk (MTurk)2. Images or frames have multiple annotated postures that are suitable for tasks
1MPII Human Pose Datasethttp://human-pose.mpi-inf.mpg.de
2Amazon Mechanical Turk overview https://www.mturk.com/
such as 2D single or multiple pose estimation and action recognition.
Leeds Sports Pose (LSP) [28]
This dataset has 2000 annotated images with body poses. Images were obtained from Flickr by searching and downloading 8 sports tags (athletics, badminton, baseball, gy- mnastics, parkour, soccer, tennis, and volleyball)3. Annotations include 14 joint loca- tions. There is an extended version, the Leeds Sports Pose Extended (LSP-extended) dataset [29] that extends only the LSP training set. LSP-extended contains 10,000 Flickr images that were collected by searching and downloading 3 tags (parkour, gymnastics and athletics). Each annotation was developed with Amazon Mechanical Turk.
Microsoft Common Objects in Context (COCO) Dataset [39]
This dataset was originally developed for object detection and semantic segmentation in images; currently, it has been expanded for image captioning and keypoint detection or HPE4. Images come from Google, Bing, and Flickr; annotations were developed with MTurk. COCO has over 200,000 images and 250,000 people tagged annotated. Anno- tations include 17 body joints and human body segmentation instances. Additionally, COCO has around 120,000 unlabelled images that can be used for unsupervised or semi- supervised learning.
PoseTrack [1]
This dataset is the integrated expansion of MultiPerson PoseTrack [26] and MPII Video Pose dataset [25]. Currently, PoseTrack is the largest dataset for performing multi-person pose estimates and person tracking5. Annotations include a unique track ID for each per- son in a video, a head bounding box, and 15 body joint locations. All pose annotations were made with VATIC [63]. PoseTrack contains 550 videos with 41 to 151 frames. The videos are about many human activities and are divided into 292, 50 and 208 videos for training, validation and testing, respectively.
2.3.1.2 Evaluation Metrics
According to [7], most of the research works that seek to estimate human posture, evaluate the performance and quality of their results with the following metrics.
Percentage of Correct Parts (PCP) [16]
This metric measures the accuracy of the location of the body’s limbs. A limb is considered well localised if its end-points fall into a specific threshold with respect to the annotated end-points of the same limb. The threshold can be set as a percentage of the corresponding limb length. In addition to the mean PCP, the PCP of the important extremities (torso, upper legs, lower legs, upper arms, forearms, head) is usually also reported.
Percentage of Correct Keypoints (PCK) [70]
This metric measures the accuracy of the location of the body’s joints. If a body joint falls within the threshold pixels of the ground truth joint, this joint is correct. The threshold can be a fraction of the size of the person’s bounding box, a radius normalised by the torso height of each sample [53], for example, a threshold of 50 % of the segment length of the head, is defined as [email protected] in [2].
3LSP Datasethttps://sam.johnson.io/research/lsp.html
4COCO’s latest keypoint detection taskhttp://cocodataset.org/#keypoints-2019
5PoseTrack Dataset and Benchmarkhttps://posetrack.net/
Average Precision (AP)
This evaluation method allows to work similar to object detection task, this metric was also called Average Precision of Keypoints (APK) [70]. If a key point prediction is within a threshold of the actual location, this prediction is considered TP. In multi-person tasks, the postures are linked to the corresponding actual postures; this link can be made with the order of the PCKh score. On the other hand, any unbound prediction is considered FP [49]. Moreover, the mean Average Precision (mAP) is obtained from the AP of every body joint.
2.3.2. Human Action Recognition
One of the ultimate goals of research related to artificial intelligence is that machines can understand humans, their actions and intentions to do something that could make the computer more useful for daily life [35]. To do this, the Human Action Recognition (HAR) was created, a topic that covers studies in computer vision such as human detection in videos, HPE, human tracking and the analysis and understanding of series data. [72, 47].
According to [71], HAR algorithms are based on two paradigms: Bag-of-Visual- Words framework and deep learning. The former is a staged method whose pipeline contains a feature extraction, a feature encoding, and a classification. Deep learning is an end-to-end framework that takes videos as input and employs a multi-layered neural network to process them and generate a prediction.
In recent years, there are some interesting works that have started to use Graph Convolutional Networks, explained in Definition 2.21, according to [69].
Definition 2.21(Graph Convolutional Neural Network). This type of network works only with graphs as inputs. The principle of building a Graph Convolutional Neural Network (GCNN) follows two streams: (i) spectral perspective, where the convolution locality of the graph is considered in the form of spectral analysis; (ii) spatial perspective, where the convolutions are applied directly on nodes and their neighbours.
2.3.2.1 Datasets
In this section, some datasets available and recurrently used for works of HAR, according to [6], are presented.
HOLLYWOOD & HOLLYWOOD-2: human actions datasets [37]
This dataset is a benchmark for performing HAR in realistic and challenging circumstan- ces6. HOLLYWOOD-2 has 12 classes of actions and 10 classes of scenes distributed in 3669 videos taken from 69 movies. Specifically, the 12 actions are AnswerPhone, Driving- Car, Eat, Fight, GetOutCar, HandShake, HugPerson, Kiss, Run, SitDown, SitUp, and StandUp.
UCF datasets
These data sets were developed by the Department of Electrical and Computer Enginee- ring at the University of Central Florida (UCF, USA). The most relevant for this research work are:
6HOLLYWOOD2 Human Actions and Scenes Dataset https://www.di.ens.fr/~laptev/actions/
hollywood2/
UCF50 [51] is an action recognition dataset with 50 action categories, consisting of realistic videos taken from YouTube in 20107. This dataset is an extension of the UCF YouTube Action dataset.
UCF101 [58] is an action recognition dataset of realistic action videos, collected from YouTube8, having 101 action categories. This dataset is an extension of UCF50 dataset.
NTU RGB+D Dataset [54]
This is a large-scale data set for RGB + D HAR just over 56000 video samples and 4 million frames9. This dataset contains textbf 60 action classes, including daily and health- related actions. To obtain the data, the Microsoft Kinect v2 camera was used, this camera has sensors that allow obtaining accurate data. The joint data consists of 3D locations of 25 body joints, in addition, the corresponding pixels in the RGB maps and the depth maps are also provided for each joint. For data collection, 40 subjects between 10 and 35 years of age were invited. Three cameras were used at the same time to capture three horizontal views (at −45◦, 0◦, and +45◦) of the same action.
Kinetics [32]
The Kinetics human action video dataset was developed byDeepMind, an artificial intelli- gence research laboratory10. This dataset has 400 action classes, with at least 400 videos for each one, in its first version. Each clip lasts 10s and is taken from different YouTube videos. The annotations were made with MTurk. The action classes can be: actions of one person, e.g. jumping, talking; person-person actions, e.g. kissing, dancing tango; and person-object actions, e.g. throwing a ball, cleaning a car.
2.3.2.2 Evaluation Metrics
HAR can be evaluated with common classification metrics, such as F1 score and the Accuracy. Moreover, other metrics can also be used to predict the trajectory of the movement [35], such as the Average Displacement Error, the Final Displacement Error (FDE), and the Average Non-linear Displacement Error (ANDE).
There are two recent evaluations techniques related to skeleton-based work, cross- subject (XS) evaluation and cross-view (XV) evaluation. Both are used in the NTU RGB+D dataset [54]. Both evaluations establish the distribution of data for training and testing. For the cross-subject evaluation, it is divided in train group and test group, each consists of samples from 20 subjects. For cross-view evaluation, the split is more complex. The training set consists of the examples of front and side views of the actions, while the test set includes examples of 45-degree views of one of the sides.
7UCF50 - Action Recognition Datasethttps://www.crcv.ucf.edu/data/UCF50.php
8UCF101 - Action Recognition Dataset https://www.crcv.ucf.edu/data/UCF101.php
9Action Recognition Datasets: NTU RGB+D Dataset and NTU RGB+D 120 Datasethttp://rose1.
ntu.edu.sg/datasets/actionrecognition.asp
10DeepMind: Kineticshttps://deepmind.com/research/open-source/kinetics
2.4. Meta-Learning
According to [23], approaches based on deep learning have some limitations con- cerning the availability of datasets and the computing capacity. For this research work, the amount of data is an important problem, therefore, it is necessary to use a method that allows to obtain competitive results with limited data. Meta-learning is a learning paradigm in which the model gains experience in multiple learning episodes and uses this experience to improve its future learning [23]. In other words, with meta-learning, a machine learning model could learn to learn.
During base learning, an inner (or lower, base) learning algorithm solves a task such as image classification, defined by a dataset and an objective. During meta-learning, an outer (or upper, meta) algorithm updates the inner learning algorithm, such that the model learned by the inner algorithm improves an outer objective. For instance, this objective could be to generalise performance or to speed up the learning of the inner algorithm. Learning episodes of the base task, can be seen as providing the instances needed by the outer algorithm in order to learn the base learning algorithm.
Commonly, the meta-learning algorithms are separated into three groups:
2.4.1. Optimisation
Optimisation-based methods include those where the inner-level task is literally solved as an optimisation problem and focuses on extracting meta knowledge required to improve optimisation performance. The most famous of these methods is perhaps Model- Agnostic Meta-Learning (MAML) [17], where the meta-knowledge is the initialisation of the model parameters in the inner optimisation, namely θ0. The goal is to learn θ0 such that a few inner steps on a few training instances produces a classifier that performs well on validation data. This is also performed by gradient descent, differentiating through the updates to the base model. It is often applied to few-shot learning where few inner-loop steps may be sufficient.
2.4.2. Model-based
In model-based (or black-box) methods the inner learning step is wrapped up in the feed-forward pass of a single model. The model embeds the current dataset into activation state, with predictions for test data being made based on this state. Typical architectures include RNN, CNN, or hypernetworks that embed training instances and labels of a given task to define a predictor that inputs testing example and predicts its label. In this case, the whole inner-level learning is contained in the activation states of the model and is entirely feed-forward. Outer-level learning is performed with the meta-knowledge. It is not clear that black-box models can successfully embed a large training set into a rich base model.
2.4.3. Metric-learning
Metric-learning or non-parametric algorithms are thus far largely restricted to the popular but specific few-shot application of meta-learning. The idea is to perform non- parametric ‘learning’ at the inner (task) level by simply comparing validation points with training points and predicting the label of matching training points. Here the outer-level
learning corresponds to metric learning (finding a feature extractor that encodes the data to a representation suitable for comparison). As before, the meta-knowledge is learned on source tasks and used for target tasks.
2.5. Final Considerations
In this chapter, the most relevant concepts related to sentiment analysis and the fundamentals of deep learning approaches, were explored. Different methods to carry out sentiment analysis and emotion recognition were described, making clear the problems they present and the approaches to their solutions. Deep learning algorithms are esta- blished as the most suitable to be used in this research, since with them we can obtain competitive results and they are appropriate algorithms for many implementation envi- ronments. There is not much data to train deep learning algorithms for our objective, therefore, meta-learning is studied as it offers a way to solve these shortcomings.
All of this knowledge conform the basis of this research, in order to better analyse and study the state-of-the-art in this domain. These related works are explained in the next chapter.
Cap´ıtulo 3
State of the Art: Review
In this chapter, the related works are exposed to lay the foundations of this research work. This is divided into three parts: (i) a review of the work that solves the capture and abstraction of human posture; (ii) a review of the state-of-the-art works that recognise the emotions of human postures; and (iii) GCNN related and applicable meta-learning algorithms.
3.1. Abstraction of the Human Body
The human body abstraction process is one of the most relevant aspect of this research work, because it is the basis for processing human postures. There are different forms of body abstraction, from which the machine can know the real human pose and abstract it.
There are mainly three basic ways to capture posture: using a method based on deep learning of computer vision, using special sensors such as the Microsoft Kinect that allow obtaining a 3D representation of human posture, and directly using a motion capture system with special costume for target people and several sensors. This research work focuses on methods based on deep learning because they only need RGB-images as input.
HPE is the subject of computer vision responsible for capturing posture, therefore the relevant methods of this are reviewed below.
We are also interested in the way of treating the recognised posture, for this we also review HAR works. A special group of HAR methods, skeleton-based methods, are explai- ned in the final part of this section because they work from a human posture represented as a skeleton, as a graph.
3.1.1. Human Pose Estimation (HPE)
Due to the increasing development of deep learning, the HPE has progressed even in its use for real-world applications [10, 7]
One of the most important jobs in recent years is RMPE-PAF, presented by Cao et al. in [5], a bottom-up method of deep learning. This job is applied in real time to multiple people and is the basis for many subsequent research. RMPE-PAF is an approach based on the non-parametric representation or ‘part affinity fields’, which allows learning to associate parts of the body with the corresponding person, in the image. The general
Figura 3.1: Overall process of RMPE-PAF [5].
pipeline or process of the method is illustrated in Figure 3.1. The inputs to the system are colour images (Figure 3.1(a)), outputs consist of 2D keypoint locations for each person in the image (Figure 3.1(e)). To obtain this result, a CNN is used that simultaneously predicts a set of 2D confidence maps with locations of the body parts (Figure 3.1(b)) and a set of 2D vectors of the fields of affinity of the parties; these vectors encode the degree of association between parts (Figure 3.1(c)). Confidence maps and affinity fields are analysed using a greedy algorithm that relates them and generates the porstures (Figure 3.1(d)).
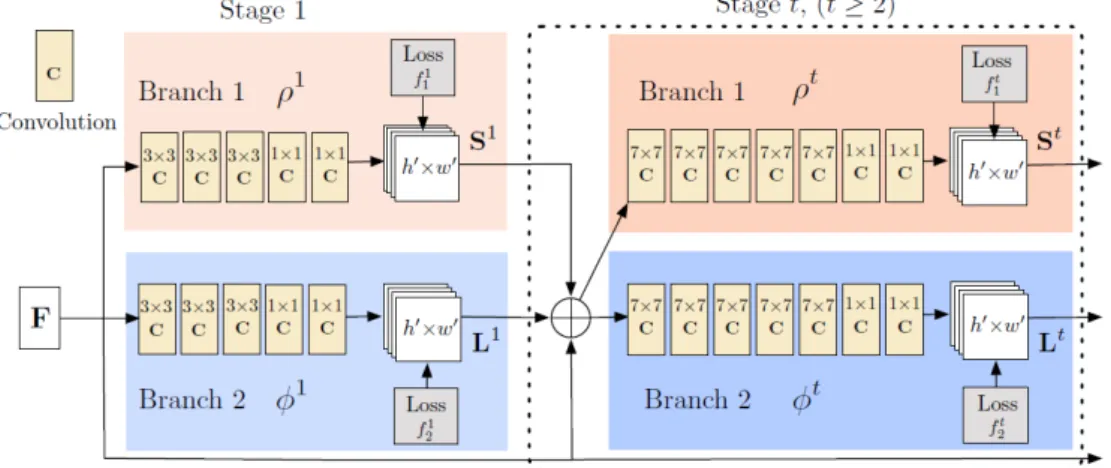
Figure 3.2 shows a part of the RMPE-PAF architecture, specifically its CNN. The network has two branches, in the Figure 3.2, each branch is differentiated with a colour, branch 1 is in beige and branch 2 in blue. In branch 1 the confidence maps are obtained, while the affinity fields are obtained in the other branch. Both branches are iterative architectures and improve their predictions in the following stages t. After each stage, intermediate supervision takes place.
This method is evaluated in the MPII data set and in the COCO 2016 key point
Figura 3.2: Architecture of the two-branch multi-stage CNN [5].
challenge data set. In the comparison in the MPII data set, the mAP was measured according to the PCKh threshold, achieving the best results in precision and execution time for bottom-up methods. In COCO, the similarity of the key point of the object was used to calculate the mAP, again achieving the best results for the bottom-up methods.
One of most valuable contributions of Cao et al. [5], is their short execution time, achieving the speed of 8.8 fps for a video with 19 people, but it only achieves 61.8 of accuracy. The most accurate methods are usually those based on top down approach;
according to [7] the more accurate methods are the Deep High-Resolution network [60], followed by simple baseline for HPE [68] and Cascaded Pyramid Network [8].
Deep High-Resolution Representation Learning for HPE called as HR-net, is propo- sed by Sun et al. [60]. HR-net solves HPE by learning reliable high-resolution renderings.
The HR-net architecture (Figure 3.3) starts with a high resolution sub-network; gradually, high to low resolution sub-networks are added one by one and more stages are formed.
The multi-resolution sub-networks are connected in parallel. Multiple multi-scale fusions are performed so that each high to low resolution representation receives information from the others.
Figura 3.3: Architecture of HR-net [60].
Predicted heat maps are potentially more accurate. The Hr-net results are given in the COCO keypoint detection challenge (75.5 AP in the test-dev set) and in MPII dataset (92.3 of [email protected] in the test set). In addition, this model show its superiority in pose tracking task over the PoseTrack dataset.
The simple baseline model, as the name implies, is a simple way to solve HPE [68].
The idea behind this model is assesses how good could a simple method for HPE and person tracking be? and the answer results in a simple but very effective method and architecture, which seeks to become the basis or starting point for future research work on HPE and people tracking. The proposed HPE model is based on a few aggregate deconvolutionary layers in a backbone, which could be the ResNet [20]. The backbone net can change to improve the results. The ResNet was chosen because it is on of the most common backbone network to perform the image feature extraction. The added layers are located at the last convolution stage, usually called C5. Three deconvolutional layers with batch normalisation and ReLU is used. Each layer has 256 filters with 4 ×4 kernel. A 1×1 convolutional layer is added over the last stage in the ResNet to get the heatmaps for each keypoint. For training, the backbone is initialised by pre-training in ImageNet [12].
Figura 3.4: Architecture of CPN, taken from [8].
Using a ResNet-152 as the backbone, the model achieves the highest AP (73.7) in COCO test-dev set.
The network structure named Cascading Pyramid Network (CPN) [8] includes two stages: GlobalNet and RefineNet (see Figure 3.4). The GlobalNet is a pyramid network that can successfully locate simple keypoints, such as eyes and hands, but may not accurately recognise occluded or invisible keypoints. The RefineNet tries to handle the hard keypoints integrating the levels of Global-Net feature representations. The CPN is a top-down approach. This method achieves competitive results at COCO challenge, with a 73.0 AP on the test-dev set
Currently, the bottom-up methods are the fastest, they can be executed in real time.
However top-down approaches continue to be more accurate in the most commonly used datasets.
3.1.2. Human Action Recognition (HAR)
In this section, studies related to HAR, which are based on GCNN are explored.
Specifically those that use skeleton graphs as input, since they represent a link with the results obtained by some HPE method.
One of the relevant works for HAR with skeleton data is the Spatial Temporal Graphing Networks for Skeleton Based Action Recognition (ST-GCN) [69]. The authors propose a way to represent the skeletal sequences for HAR, for this, they extend the GCNN to space-time convolutions. As illustrated in Figure 3.5, this model uses formulated skeleton sequences. Within this graph there are two types of edges: spatial edges, which
Figura 3.5: The skeleton spatial-temporal representation [69].
Figura 3.6: Overall pipeline of the ST-GCN method [69].
form the natural skeleton, andtemporal edges, which connect the same joint over time;
This representation is one of the most relevant contributions of the work. The method implements several convolutional layers that gradually generate a top-level feature map on the graph, this is presented in the central part of Figure 3.6. The results are obtained by the standard SoftMax classifier. This model is evaluated in the NTU-RGB+D dataset, reaching 81.5 and 88.3 precision in XS and XV respectively.
In [67], authors propose a novel deep architecture for skeletal human action recog- nition by better modelling the spatial and temporal features of human actions. The basic structure is a spatial-temporal module (STM) which contains motif-based GCNNs with variable temporal dense block (VTDB). Figure 3.7 shows that STM contains a motif-based graph convolution sub-module for modelling spatial information, where a weighted adja- cency matrix is used for modelling action-specific spatial structure. The VTDB is used to encode temporal features from different ranges (T1, T2, and T3). TransLayer repre- sents the transition layer in VTDB. A residual connection is applied on each STM. The non-local block is used only in the last stage of the network to reduce computation. Motif- GCNs effectively fuse information from different semantic roles of physically connected and disconnected joints to learn high-order features. This model achieves improvements over the state-of-the-art methods on two challenging large-scale datasets, Kinetics and NTU-RGB+D.
Figura 3.7: Architecture of the Spatial-Temporal Module proposed in [67].
A little more recent study presented by Zhao et al. [74], they propose an end-to-end framework that combines neural networks with probabilistic models. This method is a Ba- yesian neural network (BNN) model. The model is a combination of graph convolutions and a short-term memory network (LSTM). The graphical convolutions allow capturing the spatial dependence of the body’s joints, while the LSTM captures the temporal depen- dence of the postures. This model is probabilistic because it considers the parameters of the model as random variables, which allow a better handling of the movement data due
Figura 3.8: Overview of the framework proposed in [74].
to its randomness. Inspired by adversary learning, a discriminator is added to regularise the model parameters and be able to deal with new data. The classification is defined as a Bayesian inference problem, which helps reduce over-fitting. The general framework of this model is presented in Figure 3.8, where the blue arrows represent the data flow at test time and the red arrows the flow at training time. This model achieved competitive results in the evaluated datasets, showing its effectiveness.
Shi et al. [56] present a two-stream approach that merges spatial and motion data.
For this model, joints and bones are defined as spatial data. The joints are the vertices of the skeletal graph and the bones are the edges. This model uses skeleton graphs as directed graphs, which provide information about the direction and dynamics of the limbs of the body. Directed graphs are processed by their Directed Graph Neural Network (DGNN) to extract features and perform HAR. The movement information is represented in the same graph structure used. The model can be extended from processing images to videos
Tabla 3.1: Comparative frame of the methods develop in ‘Abstraction of the Human Body’
section.
Method Cites Topology Classifier Dataset Metrics Results Human Pose Estimation
RMPE-PAF, 2017 [5]
2134 Two-branch multi-stage CNN
– MPII &
COCO
AP coco test-dev
61.8
CPN, 2018 [8] 271 GlobalNet + RefineNet
– COCO AP coco
test-dev
73.0 Simple Baseline,
2018 [68]
275 ResNet – COCO AP coco
test-dev
73.7 HR-net,
2019 [60]
260 HR-net – COCO
& MPII
AP coco test-dev
75.5 Human Action Recognition
ST-GCN, 2018 [69]
465 ST-GCN SoftMax NTU
RGB+D XS XV
81.5 89.3 Bayesian GCN-
LSTM, 2019 [74]
5 BNN & GCN- LSTM
Bayesian NTU RGB+D
XS XV
81.8 89.0 Directed GNN,
2019 [56]
36 DGNN SoftMax NTU-
RGB+D XS XV
89.9 96.1 GCN Motif &
VTDB, 2019 [67]
7 Motif-based GCN & VTDB
– NTU-
RGB+D XS XV
84.2 90.2
by changing the 2D convolutions into 3D convolutions and altering the obtaining of direct graphs. The final model outperforms current state-of-the-art performance on two large- scale data sets, Kinetic and NTU-RGB+D.
Table 3.1 reviews the important criteria for comparing the previously studied met- hods for the HPE and HAR topics. One of the most relevant criteria is the Results of the evaluation metrics of a common dataset among the works. The most accurate jobs are Directed Graph Neural Network [56] for HAR (the metrics XS and XV are explain in Section 2.2.2.2, this metrics are the official way to present results with the NTU RGB+D dataset), and HR-net [60] for HPE. Another interesting criterion is ‘Cites’, with this we can know the relevance of the works.
3.2. Emotion Recogniser from Human Posture
As stated before, there are a small number of research papers on emotion recognition of the human pose and not all use deep learning methods to capture human posture. One of them is present by Shen et al. in [55].
In [55], An approach is proposed that uses postural and movement data, using a two-branch model. One branch processes the motion data, which is in optical flow representation; this branch contains the Time Segment Network (TSN) [65]. The other branch deals with the positions with the Spatial-Temporal Graph Convolutional Networks (ST-GCN) [69]. The outputs of both branches are concatenated and processed into a residual fully-connected network. Since ST-GCN generates a vector shorter than TSN, a residual feature encoder is used to increase the number of features to equal the output of TSN. Figure 3.9 presents this process.
Figura 3.9: Pipeline of the proposed method of [55].
Based on their experimentation, Shen et al. state that bodily gestures that contain emotional information are related to the speed and acceleration of joint movement. For their testing, they create their dataset, which is similar to NTU RGB+D dataset. The authors chose six basic types of emotions (fear, anger, sadness, surprise, happiness, and disguise) to collect data from 80 volunteers (40 women and 40 men) between 17 and 31 years old. Data was collected using Hikvision network cameras, recording videos from 15 different views simultaneously (as shown in Figure 3.10). The experimental results show that the method improves precision in individual categories and in cross-subject
Figura 3.10: Points of cameras in [55].
and cross-view evaluations, which are established in a similar way to NTU RGB+D.
There are other works, such as the ones proposed in [19, 48], that classify postures without using computer vision methods to capture the postures, but some kind of sensor such as the Kinect camera. Griffin et al. in [19] specifically recognise the type of laugh (hilarious, social, awkward, false) given a posture. Once the pose is captured, a feature extraction is applied to it. The extracted features may represent shoulder movements as the correlation of left and right shoulder-hip distances, for example. After probing various classifier methods, such as SVM and Random Forest, the authors concluded that Random Forest achieves better results.
In [48], Piana et al. propose an automatic recognition method of the emotions ex- pressed by body gestures, which uses the SVM as a classifier. The proposed framework is made up of four layers: (i) Physical Signals Layer, which includes the process of capturing the posture and saving it as 2D and 3D coordinates; (ii) Feature Layer, in which 2D and 3D data are processed to extract relevant features; (iii) Med-level Representations Layer, in which a statistical representation of the features is constructed; and (iv) High-level Concepts Layer, where the SVM is used to classify the results of layer three into emotion groups.
On the other hand, there are works like the ones described in [38, 55], that classify emotions using deep learning methods. These methods use the Softmax at the end of its CNN to obtain a probability vector of the classes to which the entry belongs to. The work of Lee et al. [38] use the person’s face and the rest of the image in isolation. This method is not necessarily based on posture, but on supporting the study on the face with the rest of the image, what they call context.
3.3. Meta-Learning Algorithms
Meta-learning methods allow the deep learning model to learn optimally and with relatively little training data.
One of the most important Meta-Learning algorithm is the agnostic model, a.k.a.
MAM

![Figura 2.1: Steps of the traditional FER process [34].](https://thumb-us.123doks.com/thumbv2/123dok_es/12559319.0/19.892.115.754.101.520/figura-2-1-steps-traditional-fer-process-34.webp)
![Figura 2.3: Examples of body gestures, taken from [44].](https://thumb-us.123doks.com/thumbv2/123dok_es/12559319.0/19.892.141.749.341.496/figura-examples-of-body-gestures-taken-from-44.webp)
![Figura 2.2: Overview of the deep learning approach FER process [34].](https://thumb-us.123doks.com/thumbv2/123dok_es/12559319.0/19.892.134.728.127.270/figura-overview-deep-learning-approach-fer-process-34.webp)
![Figura 2.4: General description of emotion recognition systems based on body gestu- gestu-res [44].](https://thumb-us.123doks.com/thumbv2/123dok_es/12559319.0/20.892.166.731.604.897/figura-general-description-emotion-recognition-systems-based-gestu.webp)
![Figura 2.5: Scalability of deep learning methods [5].](https://thumb-us.123doks.com/thumbv2/123dok_es/12559319.0/25.892.127.775.110.844/figura-2-5-scalability-of-deep-learning-methods.webp)
![Figura 2.6: Overall process of top-down approach [10].](https://thumb-us.123doks.com/thumbv2/123dok_es/12559319.0/25.892.336.559.135.306/figura-overall-process-of-top-down-approach-10.webp)
![Figura 2.7: Overall process of bottom-up approach [10].](https://thumb-us.123doks.com/thumbv2/123dok_es/12559319.0/25.892.141.751.380.584/figura-overall-process-of-bottom-up-approach-10.webp)
![Figura 3.1: Overall process of RMPE-PAF [5].](https://thumb-us.123doks.com/thumbv2/123dok_es/12559319.0/32.892.265.630.122.449/figura-3-1-overall-process-of-rmpe-paf.webp)
