I would also like to thank my fellow researchers for their support and advice, especially thanks to Héctor Buendía Escalona and Josué Enríquez. Thanks to my siblings, Cindy Sánchez and Luis Javier Sánchez, for always being by my side.
Acronyms and Abbreviations
Glossary
Introduction
On the other hand, genetic programming (GP) is an evolutionary algorithm that can find a function that is adapted to a classification problem. To the best of our knowledge, classifiers built with GP started to appear around 2000 (see Section 2.5).
Motivation
To the best of our knowledge, no one has tried to use feature properties to design selection techniques, and we believe that it can improve the performance of SGP. To the best of our knowledge, no one has attempted to use feature properties to design selection techniques, and we believe that it can improve the learning phase of SGP.
Objectives
Contribution
List of Publications
Journal Article
Proceedings
Thesis Outline
We then include in the comparison the state-of-the-art selection schemes, Angle-Driven Selection [15] and Novelty Search [72]. Finally, we compare EvoDAG with the proposed heuristics with eighteen classifiers, sixteen of which are from the scikit-learn python library [80]: Perceptron, MLPClassifier, BernoulliNB, GaussianNB, KNeighborsClassifier, NearestCentroid, LogisticRegression, LinearSVC, SVC, SGDClassifier, PassiveAg gressiveClassifier, DecisionTreeClassifier, ExtraTreesClassifier, RandomForestClassifier, AdaBoostClassifier and GradientBoostingClassifier; and others are two automatic machine learning libraries: autosklearn [23] and TPOT [76].
Genetic Programming
1 Genetic Programming
A Brief Introduction to Evolutionary Computing
Thus, with the passage of time, there is a change in the constitution of the population, i.e., the population is the "unit of evolution". Representation. It is the structure of a solution in such a way that it can be used for the algorithm.
General Concepts of Genetic Programming
Representation
Solution of a Problem
Semantic Genetic Programming for Supervised Learn- ing Problemsing Problems
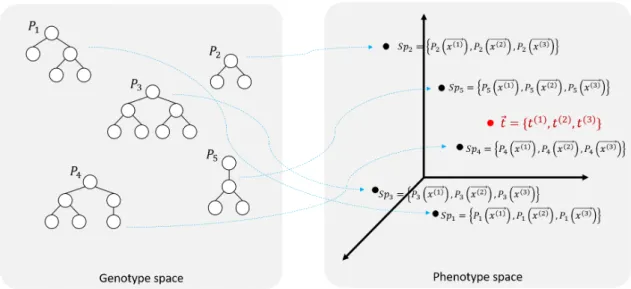
As we can see, the goal of Semantic Genetic Programming (SGP) in supervised learning problems is to find the tree structure of the individual whose semantics is as close as possible to the target in the semantic space. It may seem easy to find the individual whose semantics is closest to the target.
EvoDAG
Model
It is formally defined as Equation 1.7, where µ and σ represent the mean and standard deviation of the variable xi for the class samples only. It is formally defined as Equation 1.8, where Ny is the number of samples of classy and δ(·) returns 1 if its input is true and 0 otherwise.
Evolution process
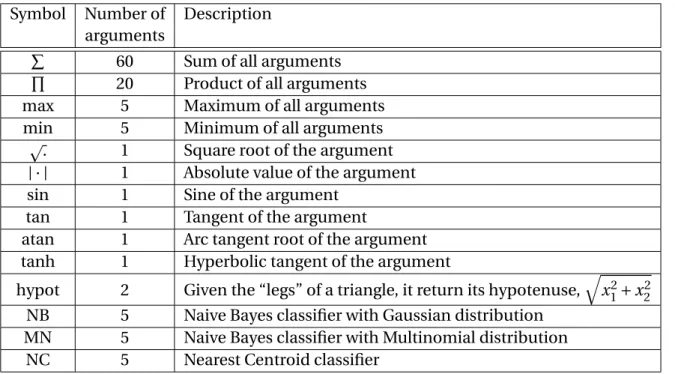
The input is at the bottom of the figure, and the output is at the top. That is, a function fk is randomly selected from F, representing the number of arguments, which is selected from the population P using tournament selection or any of the heuristics analyzed in this thesis (see Chapter 3).
Implementation
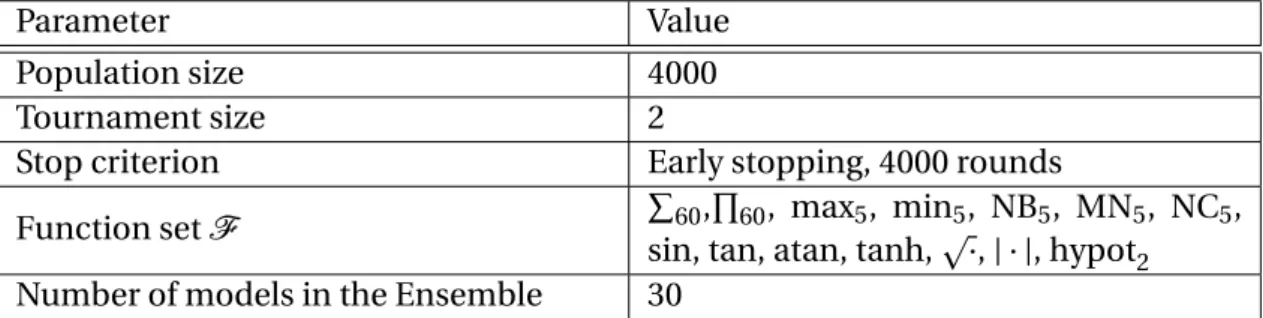
EvoDAG calculates the semantics of descendants based on the application of their root function and the semantics of their parents or arguments. With parental semantics, it is only necessary to apply the function that the offspring has in its root node.
Representation of Classification Problems
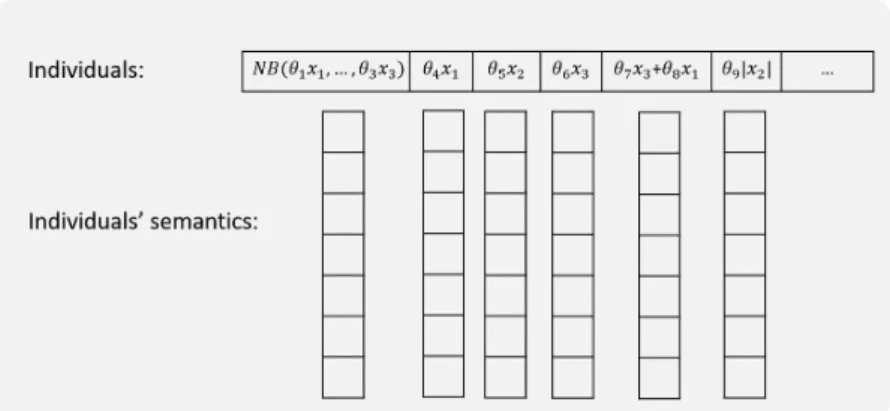
In this sense, the semantics of the individual corresponds to a vectorS~p∈Rn, where represents the number of input vectors. However, in EvoDAG, each individual contains a set of semantic vectors, one per class, where each vector contains the semantics for a specific class.
Ensemble
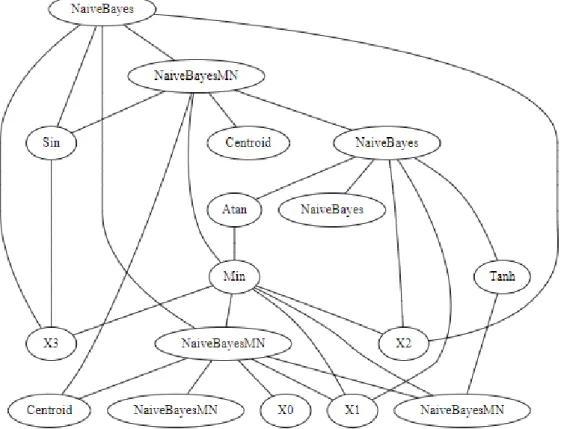
In the case of the Naive Bayes and Nearest Centroid classifiers, the output is the log-likelihood. As we explained in Section 1.3, the semantics of the individual is the vector whose inputs are all the responses of the individual's function to all input vectors.
Optimization of Parameters
Summary
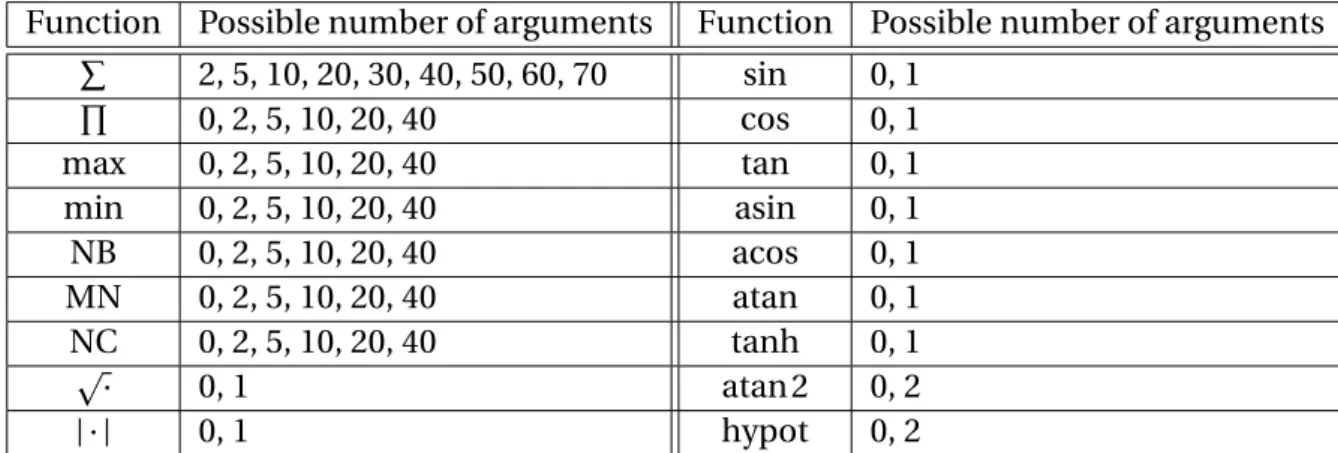
In this chapter, we introduced the key concepts of evolutionary computing (EC), genetic programming (GP), semantic genetic programming (SGP), and EvoDAG, the GP system we used to implement and test our proposed selection heuristic. If the number of arguments is zero, it means that the function is not included in the function set.
Related Work
2 Related Work
Indirect Semantic Genetic Programming
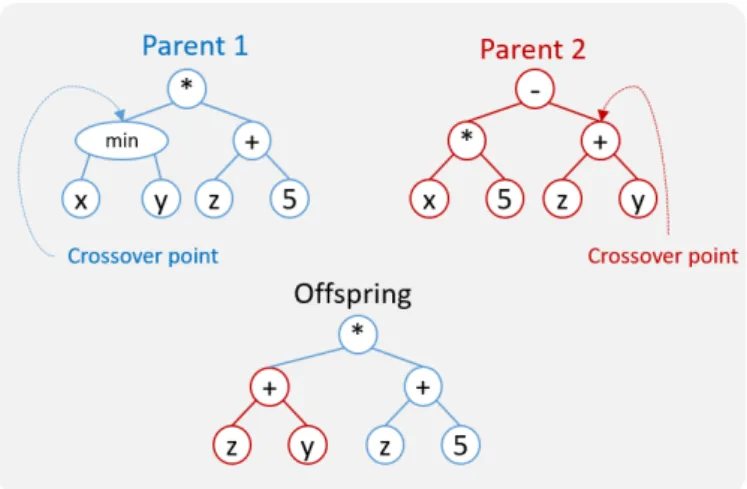
Based on the back-propagation algorithm, the partial derivative of the fitness function is calculated in the crossover point with the aim of knowing whether the values in the node should be higher or lower than the current ones. Then a subtree is searched in the second parent in such a way that when used as a transition point, the value of the function is incremented or decremented.
Direct Semantic Genetic Programming
The inverse function is used to compute the desired semantics in the child. Creates a plane in the semantic space using the parent semantics and the origin of the space. In other words, a descendant is a projection of the target in the line formed by the parent.

Fitness and Selection in Genetic Programming
For this reason, they used a fitness function that has no relation to the distance to the target in the semantic space. The second tournament selection is called Statistics-TS2; it is similar to Statistics-TS1 but aims to reduce code growth in the GP population. The second parent is chosen based on the positional relationship, with the goal that the line connecting the two parents is closest to the target point in the semantic space.
Classification in Genetic Programming
Second, the convex hull of the distant parents becomes larger, which increases the probability of covering the target semantics, and has a more accurate fit to the target semantics. To our knowledge, they are the first to use novelty research and semantics for evolving GP classifiers. Their results show that all their NS variants achieve competitive results against the traditional objective-based variants.
Summary
It uses backpropagation to propagate the expected semantics at intersections and searches the procedure library for those whose semantics are close to the desired ones. In parent trees, it searches for subtrees whose semantics are parsimonious with the parent's semantics. They proposed a selection scheme for choosing the parents such that the line connecting them is closed to the destination in the semantic space.
Selection Heuristics
3 Selection Heuristics
Motivation
Nevertheless, as we reviewed in Chapter 2, there have been approaches that investigate the behavior of EAs when replacing the fitness function or combining with other techniques in the task of parent selection. Thus, we include in this thesis the comparison of random selection for parental selection and negative selection. Our primary motivation is that the selection scheme used for one function may not be useful in another.
Parent Selection
- Parent Selection based on Fitness (fit)
- Random Selection of Parents (rnd)
- Parent Selection based on Cosine Similarity (sim) and Pearson’s Correlation Coefficient (prs)Correlation Coefficient (prs)
- Parent Selection based on the Accuracy (acc)
Specifically, in EvoDAG, each of the characters (or parents) is independently selected from the population P using a fitness-based tournament selection. Argument selection based on Pearson's correlation coefficient is illustrated using a simple example shown in Figure 3.8. Argument selection based on precision is illustrated with a simple example shown in Figure 3.9.

Negative Selection
- Negative Selection based on Fitness (fit)
- Random Negative Selection (rnd)
The goal of negative selection based on fitness is to remove non-fitness individuals from the population P with the idea of improving the quality of individuals generation by generation. Output: The individual that will be removed from the population P A←an individual randomly selected from the population P; f i t nessA←fitness ofA;. Output: The individual that will be removed from the population P A←an individual randomly selected from the population P; ReturnA;.
Summary
Parent selection based on cosine similarity (sim), which consists of selecting individuals whose semantic vectors ideally have right-angled corners. Parent selection based on Pearson's correlation coefficient (prs), which aims to select parents whose semantic vectors are not mutually correlated. This heuristic is designed based on the properties of the functionP and the Naive Bayes (NB and MN) and Nearest Centroid (NC) classifiers.
4 Experiments and Results
- Datasets
- Computer Equipment
- Performance Metrics
- Comparison of the Proposed Selection Heuristics and Classic Selection TechniquesClassic Selection Techniques
It is clear that the datasets are heterogeneous in terms of the number of samples, variables and classes. In addition to negative selection, we analyze the use of the classic scheme, negative tournament selection based on fitness (fit) and random selection (rnd). This is because the proposed heuristics are designed based on the properties of the functionsP.

Angle-Driven Selection
First, a parent is selected using a tournament based on fitness, like ADS' original proposal, and then the next arguments, or parents, are selected using a tournament based on the relative angle between a candidate and the first older. First, two individuals are randomly selected from the populationP, and the relative angle (Equation 4.1) between their semantics and the semantics of the first argument is calculated. The individual with the maximum angle between its semantics and the first parent semantic is selected as an argument.
Novelty Search
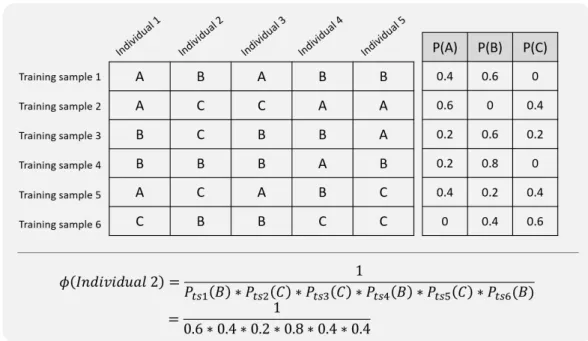
In the case of training sample 1, the probability of class A, P(A), is equal to 0.4 because there are only 2 A in 5 individuals. Specifically, in EvoDAG, each of the characters (or parents) is independently selected from the population P using a tournament selection based on novelty search. For each of the arguments, two individuals are randomly selected from the population and the youngest is chosen as the parent.
Results of the Comparison of our Proposed Selection Heuristics against ADS and NVS
Comparison of EvoDAG and State-of-the-Art Classi- fiersfiers
After analyzing the performance of the different selection schemes, it is time to compare EvoDAG with the state-of-the-art classifiers. We selected EvoDAG only with the combination of the selection schemes: acc-rnd, rnd-rnd, fit-fit, ads-rnd, nvs-rnd. It can be seen that the results of TPOT are statistically different from those obtained with EvoDAG fit-fit, the classical selection schemes, EvoDAG ads-rnd, and EvoDAG nvs-rnd, those of the state-of-the-art.
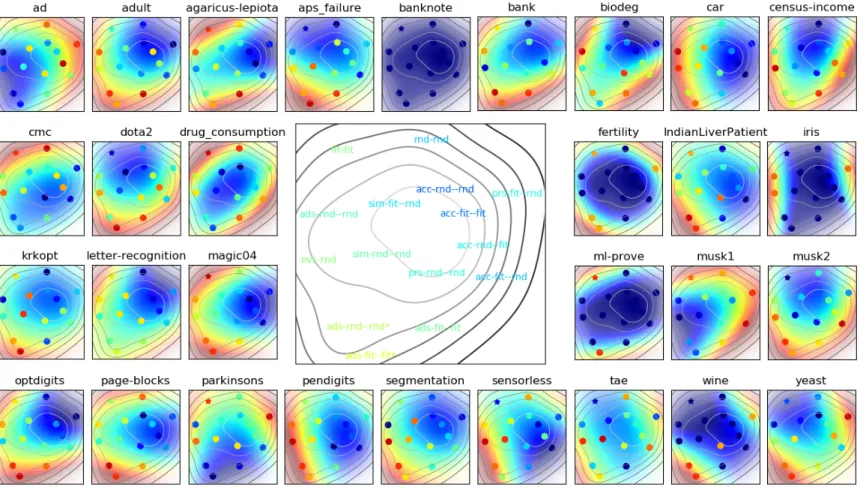
Visualization Map for Classifiers and Datasets
Based on the suits of the middle card, the best combination of selection schemes is acc-rnd-rnd, followed by acc-fit-fit. Based on the ranking of selection techniques' combinations, the performance of acc-rnd–rnd is similar to acc-fit–fit, sim-fit–rnd and prs-fit–rnd. On the button on the left we can see all the versions of ads, especially the worst combinations are ads-rnd-rnd* and ads-fit-fit.
Summary
Conclusions
Finally, accuracy-based tournament selection (acc) tries to select parents whose predictions are different, and this is measured by the accuracy score. For negative selection, we tested the use of negative tournament selection based on ability and random selection. In this experiment, we confirmed that using EvoDAG acc-rnd, which uses precision for parent selection and random negative selection, statistically outperformed EvoDAG fit-fit using classical fitness-based selection techniques.
Discussion
Based on the experiments (see Chapter 4), the combination of selection techniques acc-rnd has significantly better results than selection based on fitness (pass-fit), and the selection of parents based on Novelty Search or Angle-driven selection. Based on the experiments (see Chapter 4), the combination of random selection for parent and negative selection (rnd-rnd) was better than using novelty search for parent selection and negative random selection (nvs-rnd). When random selection was used for parental and negative selection, it outperformed the classical selection schemes based on fitness.
Future Work
Using the selection heuristic based on accuracy for parent selection, and random negative selection, made EvoDAG competitive with state-of-the-art classifiers and auto machine learning techniques.
Bibliography
Geometric semantic crossover with an angle-aware pairing scheme in genetic programming for symbolic regression. Semantic backpropagation for the design of search operators in genetic programming.IEEE Transactions on Evolutionary Computation. Semantic-based crossover in genetic programming: Application to real-valued symbolic regression. Genetic programming and evolvable machines.