Por tu comprensión, paciencia y el aliento que me brindaste, que siempre me ayudó a superar los momentos más difíciles y complicados. A la señora Oly, señora Mary, Tania, Mario, Celes y Carmen, maravillosos amigos que me apoyaron durante el proceso doctoral.
Estado del arte
El trabajo actual se centra en investigar nuevas estrategias de control para la cooperación entre un conjunto de robots. Se muestra un estudio relacionado con los controles aplicados a robots móviles.

ESTADO DEL ARTE 3 cuales constituyen un desaf´ıo para la teor´ıa e ingenier´ıa de control [8–10] y una inspiraci´ on
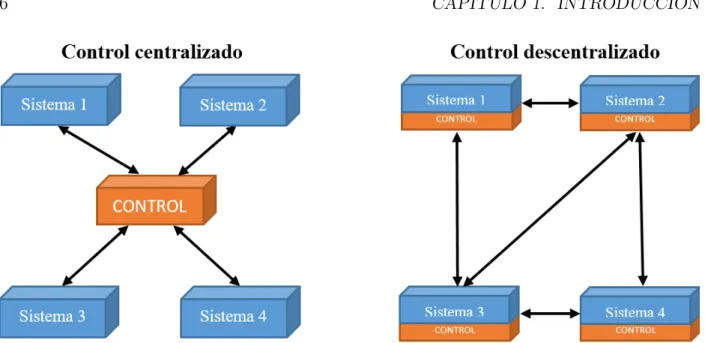
Las estrategias de control cooperativo distribuido o descentralizado para el consenso SMA han recibido especial atención porque ofrecen una solución atractiva para el control de sistemas a gran escala, tanto en términos de complejidad en la formulación del problema como en términos de la carga computacional requerida. 35]. Se han realizado investigaciones sobre varios enfoques algorítmicos para el control de la formación, como líder-seguidor, conductual, líder virtual y teoría de grafos, etc.
ESTADO DEL ARTE 5
El trabajo de consenso reciente para sistemas dinámicos de primer orden amplía aún más los resultados al considerar ajustes más generales. Por ejemplo, en 2013, Terelius et al.[44] estudiar el control de consenso para un sistema multiagente con un nodo defectuoso.
ESTADO DEL ARTE 7 Por otro lado, el problema de consenso tambi´ en se ha estudiado para sistemas de segun-
63], donde presentan el control cooperativo a través de la evaluación estatal para el control de entrenamiento basado en la visión de robots móviles. La principal diferencia entre ellos es el diseño del estado o función.
Planteamiento del problema
PLANTEAMIENTO DEL PROBLEMA 11 tipo líder-seguidor virtual cooperativo para la formación de dos robots móviles de dos ruedas.
PLANTEAMIENTO DEL PROBLEMA 11 cooperativo tipo l´ıder seguidor virtual para la formaci´ on de dos robots m´ oviles de dos ruedas
Aportaciones
Control distribuido asíncrono de múltiples robots tipo péndulo invertido mediante una estrategia basada en eventos”, Congreso Nacional de Control Automático, San Luis Potosí 2018. Linares-Flores, “Control de - implementación de múltiples robots móviles autoequilibrados mediante comunicación activada por eventos ”, Congreso Nacional de Control Automático, Puebla, 2019.
Justificaci´ on
Contreras-Ordaz, M., “Estimación y control de la actitud del vehículo autoequilibrado: LoboMixci”, Congreso Mexicano de Robótica, Mazatlán, Sinaloa 2017. Guerrero-Sanchez, “Control descentralizado basado en eventos para el consenso de múltiples robots tipo péndulo invertido en el esquema líder-seguidor; Consenso líder-seguidor descentralizado basado en eventos para un grupo de robots autoequilibrados de dos ruedas”, Revista Iberoamericana de Autom´atica e Infor´atica industrial, 2019.
Hip´ otesis
Objetivos
Diseñar un algoritmo de control para la estabilización (regulación) de la postura del robot suboperado. Diseñar un algoritmo de control descentralizado para la formación de un conjunto de robots autoequilibrados.
Organizaci´ on de la tesis
Implementar un control para la formación de un conjunto de N robots del tipo autoequilibrado de baja potencia, basado en la propiedad de planitud diferencial y donde la comunicación entre los robots se realiza mediante una estrategia activada por eventos. Luego se discuten los conceptos de control de sistemas multiagente y el problema de consenso para sistemas dinámicos en forma de integradores simples e integradores dobles y los criterios necesarios que deben cumplirse.
Teor´ıa de Grafos
El grado de un vértice es el número de aristas que tienen su vértice como cabeza. El grado externo de un vértice ∈G es el número de aristas que tienen su vértice como cola.

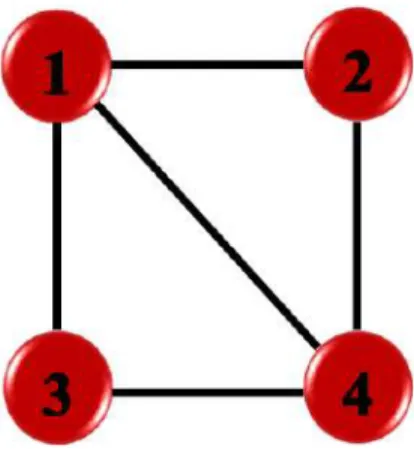
TEOR´ IA DE GRAFOS 19 como el que se ejemplifica en la Figura 2.2, mientras que si es balanceado por naturaleza,
TEORÍA DE GRÁFICOS 19 como se ilustra en la Figura 2.2, aunque equilibrado por naturaleza. Ejemplo: Considere un gráfico no dirigido representado por cuatro agentes e interconectados entre sí, como se muestra en la Figura 2.4.
CONSENSO DE SISTEMAS MULTIAGENTES 21
Consenso de Sistemas Multiagentes
Dado un gráfico G = (V, E), interpretamos (vi, vj) ∈ E de manera que el nodo vj pueda obtener información del nodo vi para retroalimentación de control. Definición 2 (Control Distribuido) Se dice que el control dado por ui = ki(xi1, xi2, .., ximi) para someki(·) simi distribuido < N, ∀i, es decir, la entrada de control de cada nodo depende de un buen subconjunto de todos los nodos.
CONSENSO DE SISTEMAS MULTIAGENTES 23 siguiente forma
Formación de sistemas dinámicos representados por la dinámica de un doble integrador. Para este tipo de sistemas se pueden desarrollar estrategias para controlar formaciones, es decir, conducir a los agentes de un sistema cooperativo a una configuración específica, donde cada agente es descrito por la dinámica de un doble integrador.
Planitud Diferencial
Sistemas SISO LTI
Supongamos por el momento que la salida plana F es simplemente una función del vector de estado x. Además, como el sistema es lineal, supongamos que F es una función lineal del vector de estado x¡.
Sistemas MIMO LTI
Ya que desde aquí sólo podemos obtener
PLANITUD DIFERENCIAL 27 Donde la matriz B es de rango completo m y constituido por los vectores columna B =
Tenga en cuenta que para un sistema controlable de una sola entrada, una salida plana F está dada por la combinación lineal, o cualquier múltiplo constante de los mismos, de los estados iniciales obtenidos utilizando la última fila de la inversa de la matriz de controlabilidad [96].
Control disparado por eventos
CONTROL DISPARADO POR EVENTOS 29
Comunicaci´ on entre agentes basada en eventos
La transferencia de información entre agentes basada en eventos cubre dos funciones principales [101]. La función de evento toma como entrada el valor actual del estado del agente i, xi, y una memoria mi de xi la última vez que ei fue positivo.
CONTROL DISPARADO POR EVENTOS 31 Como se observa, en un control distribuido con comunicaci´ on basada en eventos, cada agente
Este capítulo presenta el modelado del robot móvil de tipo péndulo invertido (RMPI) con la restricción de rotación alrededor de su propio eje (lo que da como resultado un sistema de cuarto orden). Además, se muestra el diseño de una estrategia de control distribuido con comunicación activada por eventos, que resuelve el problema de consenso líder-seguidor para un conjunto de robots móviles de tipo péndulo invertido (RMPI).
Modelado del Sistema RMPI
El control sobre su avance y autoequilibrio también se presenta a través del enfoque de Planitud Diferencial. Finalmente, se muestran los resultados experimentales del consenso RMPI múltiple basado en el esquema de control propuesto.

MODELADO DEL SISTEMA RMPI 35 tros dados en la Tabla La ubicaci´ on de las coordenadas cartesianas est´ an representadas
2Jpθ˙2−mbg(R+Lcosθ) Considerando las ecuaciones de movimiento de Euler-Lagrange del sistema de la forma. Debido a que se utilizarán motores de CC para impulsar las ruedas del robot móvil, la dinámica de los motores se incluirá en la dinámica del robot.
Dise˜ no del control para el RMPI
DISEÑO DE CONTROL PARA EL RMPI 39 Considerando que el vehículo operará cerca de la posición angular de equilibrio x3 =θ ≈0.
Para lograr la convergencia de F a la referencia deseada F ∗ , se propone un control basado en planicidad de la siguiente manera. F = z4 y considerando u = CA13B(¯u−A4x), el sistema se parametriza desde la salida plana mediante la siguiente cadena de integradores.
DISE ˜ NO DEL CONTROL PARA EL RMPI 41
Resultados de simulaci´ on
La segunda prueba consistió en utilizar una trayectoria de referencia similar a la prueba anterior. La Figura 3.5 muestra las respuestas de los estados del RMPI. Se observa que los estados siguen las referencias deseadas tanto en posición como en velocidad.

DISE ˜ NO DEL CONTROL PARA EL RMPI 43
En esta prueba, también se aplicó una perturbación al péndulo con una amplitud máxima de 0,2 rad, como se ve en la Figura 3.6. Finalmente, en la Figura 3.6 se observa la respuesta del control a la trayectoria y la perturbación aplicada.

DISE ˜ NO DEL CONTROL PARA EL RMPI 45
Resultados Experimentales
DISE ˜ NO DEL CONTROL PARA EL RMPI 47
Control de consenso de m´ ultiples RMPI
Control basado en planitud y comunicaci´ on basada en even- tostos
Entonces la función de gi > 0 y el gráfico extendido que contiene el líder se denotan por G. Lo anterior indica que la función de evento (3.22) depende de los estados actuales zi y que las memorias generadas existieron mi desde la última comunicación.
CONTROL DE CONSENSO DE M ´ ULTIPLES RMPI 51 Observaci´ on 2: En este trabajo se asume que el grafo G ¯ est´ a fuertemente conectado, es
Implementaci´ on de la estrategia de control
CONTROL DE CONSENSO DE M ´ ULTIPLES RMPI 53
Resultados
Resultados a nivel simulaci´ on
Consenso con un l´ıder con posici´ on constante
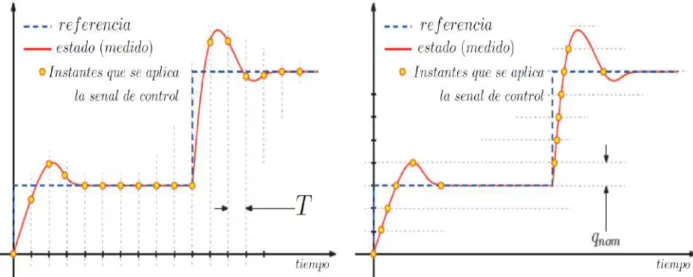
La Figura 3.14(a) muestra la señal de control calculada por el algoritmo propuesto para cada uno de los robots. La Figura 3.14(b) muestra la evolución del número de eventos para cada uno de los móviles, es decir, los casos en los que la función de evento determinó que debía existir comunicación entre los agentes.

RESULTADOS 57
Consenso con un l´ıder con posici´ on lineal variante en el tiempotiempo
De la misma forma que la prueba anterior, la Figura 3.17(a) muestra la señal de control calculada por el algoritmo propuesto para cada uno de los robots. En la parte inferior, en la Figura 3.17(b), está el número de eventos desencadenados en cada uno de los teléfonos móviles.
Consenso en tiempo continuo vs Consenso basado en even- tostos
La figura refleja que los estados alcanzan la referencia en la posición lineal determinada por el líder, mientras que la posición angular está controlada. Se puede observar que en esta prueba se genera una mayor cantidad de eventos que en la prueba anterior, y esto se debe a que la posición de referencia proporcionada por el agente líder cambia constantemente y los agentes necesitan proporcionar una mayor cantidad de información, la cual es razonable.
Lo anterior muestra que la técnica de control propuesta en este trabajo logra reducir el tráfico de datos y el consumo computacional y energético, todo ello sin sacrificar el rendimiento del sistema.
RESULTADOS 61
Resultados Experimentales
La respuesta de los controladores se muestra en la Figura 3.21, donde se observa un ligero sobrepaso cuando se inicia la prueba. Cabe mencionar que la dinámica de comportamiento del RMPI es en tiempo continuo y solo la red de comunicación es asíncrona, lo que implica que la red de comunicación definida por G es variante en el tiempo, y permanece conectada según las solicitudes de información del momento.

RESULTADOS 63
RESULTADOS 65
La Figura 3.25 muestra esta comparación, donde se observa que efectivamente los datos transmitidos son muy similares a los datos obtenidos por el sistema de captura de movimiento Optitrack. Además, el sistema de captura de movimiento tendría un mayor impacto si el sistema RMPI pudiera moverse en el plano incluso con una superficie no uniforme.

RESULTADOS 67
En el capítulo anterior se mostró el análisis y desempeño de un sistema de Robot Móvil Tipo Péndulo Invertido (RMPI) con la restricción de avanzar en un solo eje. Además, este capítulo se basa en el estudio del sistema RMPI que puede moverse de forma autónoma en el avión, lo que representa un gran desafío ya que es un sistema de sexto orden altamente no lineal.
Modelado del Sistema RMPI con desplazamiento en un plano
Modelado Cinem´ atico del Sistema RMPI
MODELADO DEL SISTEMA RMPI 71 se obtiene que las siguientes coordenada cartesianas
Modelado Din´ amico del Sistema RMPI
MODELADO DEL SISTEMA RMPI 73
Por tanto, la energía cinética rotacional queda definida por la siguiente expresión T2 =Jw w2.
MODELADO DEL SISTEMA RMPI 75 agrupando t´ erminos, el Lagrangiano se reescribe de la siguiente forma
Para evaluar la relación entre il y el voltaje ul,r, se utilizará la ecuación del motor de CC.
MODELADO DEL SISTEMA RMPI 77 con
Reescribiendo el sistema anterior en forma matricial, se obtiene el modelo no lineal del sistema RMPI como. mbRLφ+mbL2sinθ) ˙ψ2cosθ+mbgLsinθ. Dado que la matriz Λ es definida positiva, el sistema anterior se escribe en la forma φ¨.
DISE ˜ NO DEL CONTROL PARA EL RMPI 79
Dise˜ no del control para el RMPI
De esta manera, se seleccionan las variables de estado de posición angular de la rueda x1, velocidad angular de la rueda x2, posición angular del péndulo x3, velocidad angular del péndulo x4, posición angular de rotación del vehículo x5 y velocidad angular. de rotación RMPI x6, y a partir de ahí el vector de estado se define como x= (x1 x2 x3 x4 x5 x6)T con un vector de control de entrada u = (ul ur)T y considerando que el RMPI operará cerca de la posición angular de equilibrio x3 = θ ≈ 0, y con velocidad angular cercana a cero, es decir Por tanto, el sistema se escribe en su forma lineal típica de un sistema LTI multivariable (Linear Time-Invariant, en inglés) de la siguiente manera.
DISE ˜ NO DEL CONTROL PARA EL RMPI 81
Modelo Linealizado del sistema RMPI representado me- diante la salida plana.diante la salida plana
Mientras que las entradas de control del RMPI se expresan de la siguiente forma: ur = ¯ur−c17x2−c18x3−c19x4. Para lograr la convergencia de F a una referencia deseada F∗, se propone un control virtual o auxiliar basado en planaridad de la siguiente manera.
Resultados de Simulaci´ on
DISE ˜ NO DEL CONTROL PARA EL RMPI 85
Control de m´ ultiples RMPI
Consenso de M´ ultiples RMPI basado en planitud diferen- cial en el plano y comunicaci´ on basada en eventoscial en el plano y comunicaci´on basada en eventos
La función de evento incorpora todos los errores de cada uno de los estados del sistema, un umbral de activación y las memorias de estado, como se describe. Entonces la función de control distribuido (4.37) queda representada de la siguiente manera por las memorias m1,i, m2,i de los estados zi, ξi.
CONTROL DE M ´ ULTIPLES RMPI 89
Prueba de Estabilidad: Comunicaci´ on disparada por even- tostos
Lo anterior indica que la función de evento (4.38) depende de los estados actuales zi, ξi y las memorias m1,i, m2,i generadas desde la última vez que existió comunicación. Cuando se cumple la función de evento (4.38), el estado del agente i (zi, ξi) se transmite a los agentes con los que tiene comunicación y se almacena como memorias m1,i, m2,i y los controles (ul,i, ur ,i) se define en (4.39), que se calcula con los datos actualizados.
CONTROL DE M ´ ULTIPLES RMPI 91 considerando
Observación 2: En este trabajo se supone que el grafo G¯ es fuertemente conexo, es decir, existe un camino entre cada par de vértices. Primero, suponemos que ¯eZ = 0 y demostramos que el sistema ε˙Z = ˜AzεZ es asintóticamente estable.
CONTROL DE M ´ ULTIPLES RMPI 93
Implementaci´ on de la estrategia de control
Este bloque recibe la señal de control interno ¯ui = [¯ur,i u¯l,i]T determinada por el algoritmo de consenso y envía la correspondiente señal de control ui al robot para regular la postura, desplazamientos y ángulos de rotación del RMPI. Este último bloque contiene el control de consenso del robot i descrito en (4.39), que involucra a los agentes j con los que hay comunicación.
CONTROL DE M ´ ULTIPLES RMPI 95
Resultados a nivel Simulaci´ on
CONTROL DE M ´ ULTIPLES RMPI 97
Finalmente, se muestra el comportamiento en el plan de los 5 RMPI y el entrenamiento que realizan en las 3 referencias deseadas dadas al líder (ver Figura 4.14). Se observa que cada uno de los RMPI parte de diferentes posiciones y con diferentes actitudes (t= 0).

CONTROL DE M ´ ULTIPLES RMPI 99
RMPI
2 RMPI
4 RMPI
CONTROL DE M ´ ULTIPLES RMPI 101
Conclusiones
Por otro lado, desde el enfoque de control por consenso y la formación de sistemas multiagente, no se ha reportado ningún trabajo donde se introduzca el esquema de control diferencial de planitud. Este prototipo se utilizará para futuras pruebas tanto de control de roles como de control de consenso y entrenamiento.
Trabajo Futuro
La placa de desarrollo utilizada es de bajo costo, la cual contiene soporte en el software MATLAB/Simulik, el cual permite implementar la ley de control propuesta para el balanceo, desplazamiento de consenso y conformación. TRABAJO FUTURO 105observadores de orden extendido para estimar la dinámica desconocida del.
TRABAJO FUTURO 105 observadores de orden extendido para la estimaci´ on de la din´ amica no conocida del
Lin, "Adaptive neural network control of a self-balancing two-wheeled scooter," IEEE Transactions on Industrial Electronics, vol. Han, "Distributed formation control of networked multiagent systems using a dynamic event-triggered communication mechanism," IEEE Transactions on Industrial Electronics, vol.