1
UNIVERSIDAD TÉCNICA PARTICULAR DE LOJA
La Universidad Católica De LojaMODALIDAD PRESENCIAL
ESCUELA DE CIENCIAS DE LA COMPUTACIÓN
Plataforma POIS
–
Linked Data.
Aplicación a los recorridos de los buses de la UTPL
TRABAJO DE FIN DE CARRERA PREVIO A LA
OBTENCIÓN DEL TÍTULO DE INGENIERO EN
SISTEMAS INFORMÁTICOS Y
COMPUTACIÓN
Autor:
Cueva Tacuri, Cúmar Ramiro
Director:
Ing. López Vargas, Jorge Afranio
i
CERTIFICACIÓN
Ingeniero Jorge A. López V. DIRECTOR CERTIFICA:
Haber dirigido y supervisado el desarrollo del presente proyecto de Tesis previo a la obtención del título de INGENIERO EN SISTEMAS INFORMÁTICOS Y COMPUTACIÓN, presentado por el alumno Sr. CÚMAR RAMIRO CUEVA TACURI, y una vez que este cumple con todas las exigencias y requisitos legales establecidos por la Universidad Técnica Particular de Loja, autorizo su presentación para los fines legales pertinentes.
Loja, Octubre de 2011
F.---
ii
CERTIFICACIÓN
Ingeniera Diana Torres CO-DIRECTORA CERTIFICA:
Haber dirigido y supervisado el desarrollo del presente proyecto de Tesis previo a la obtención del título de INGENIERO EN SISTEMAS INFORMÁTICOS Y COMPUTACIÓN, presentado por el alumno Sr. CÚMAR RAMIRO CUEVA TACURI, y una vez que este cumple con todas las exigencias y requisitos legales establecidos por la Universidad Técnica Particular de Loja, autorizo su presentación para los fines legales pertinentes.
Loja, Octubre de 2011
iii
AUTORÍA
El presente proyecto de tesis con cada una de las observaciones, análisis, evaluaciones, conclusiones y recomendaciones emitidas, son de absoluta responsabilidad del autor.
De igual manera, es necesario indicar que la información de otros autores incluida en el presente trabajo se encuentra debidamente especificada en las fuentes de referencia y apartados bibliográficos.
iv
CESIÓN DE DERECHOS
Yo, CÚMAR RAMIRO CUEVA TACURI, declaro ser autor del presente trabajo y eximo expresamente a la Universidad Técnica Particular de Loja y a sus representantes legales de posibles reclamos o acciones legales.
Adicionalmente declaro conocer y aceptar la disposición del Art. 67 del Estatuto Orgánico de la
U i e sidad Té i a Pa ti ula de Loja ue su pa te pe ti e te te tual e te di e: Fo a pa te
del patrimonio de la Universidad la propiedad intelectual de investigaciones, trabajos científicos o técnicos y tesis de grado que se realicen a través, o con el apoyo financiero, académico o institucional (operativo) de la universidad .
v
AGRADECIMIENTO
A Dios por hacer que un sueño sea convertido en realidad.
Mi más profundo agradecimiento a mis Padres, cuya confianza ha sido depositada en mí durante todo este tiempo, de igual manera a mis hermanos por permitirme tomar prestado su tiempo para ser invertido en alcanzar esta meta y el apoyo brindado de una u otra forma.
A mi director de Tesis Ing. Jorge López, por su acertada labor de dirección, a la cual ha dedicado gran parte de su tiempo y sin el cual este trabajo no podría haber sido culminado.
A mi co-directora Ing. Diana Torres, por la predisposición demostrada desde el inicio hasta el final del proyecto y la colaboración brindada. De igual forma a todas las personas cercanas que de alguna manera y de forma desinteresada brindaron su apoyo en el transcurso de esta meta, cuando más se los necesitaba.
vi
DEDICATORIA
Dedicado a Aquel que permitió que esta meta sea cumplida, Aquel que me brindó su apoyo y compañía durante todo este tiempo y estoy seguro que lo seguirá haciendo en adelante, Dios. A mis padres por ser mi ejemplo a seguir, por ser este sueño compartido y por no perder su confianza en mí. A ustedes hermanos que siempre han estado presentes en cada instante de este trayecto y me han motivado a seguir hasta el final, en especial a ti Franklin.
A ti bonita, que has compartido junto a mi todo este caminar, siendo el mejor soporte para no desmayar.
Y en especial a todos los amigos y compañeros que nunca dudaron que llegaría el momento en que el esfuerzo sería recompensado.
ÍNDICE DE CONTENIDOS
CERTIFICACIÓN
I
CERTIFICACIÓN
II
AUTORÍA
III
CESIÓN DE DERECHOS
IV
AGRADECIMIENTO
V
DEDICATORIA
VI
ÍNDICE DE FIGURAS
1
ÍNDICE DE TABLAS
3
1.
ESTADO DEL ARTE
4
1.1. Introducción 4
1.2. Linked Data 5
1.3. RDFStore 7
1.3.1. Sparql Update 8
1.3.2. SPARUL y El Proceso Asistido de Actualización 9
1.4. Puntos de Interés 11
1.5. Trabajo Relacionado 13
1.6. Trabajo futuro 15
2.
VOCABULARIO RDF
17
2.1. Construcción 17
2.1.2. Definición de Elementos Finales y sus Atributos 18
2.1.3. Estructura de Vocabulario 19
2.1.3.1. Consideraciones de Nomenclatura 20
2.1.3.2. Descripción de Conceptos 20
2.1.3.3. Esquema Preliminar 22
2.1.3.4. Esquema Final 23
2.1.3.5. Relaciones Binarias 24
2.1.3.6. Diagrama RDF 25
2.1.4. Validación del Vocabulario 25
2.1.4.1. Instancias de Vocabulario 26
2.1.4.2. Consultas SPARQL 27
2.1.4.3. Resultados de Validación 32
2.2. URI’s 33
2.2.1. Definición 33
2.2.2. Uri’s para el Vo a ulario 34
2.3. Publicación de Vocabulario 35
2.3.1. Generación de la Descripción del Vocabulario 36
2.3.2. PURL 36
2.3.2.1. Configuraciones 37
2.3.3. Apache HTTP Server 38
2.3.3.1. Negociación de Contenido (Content Negotiation) 38
2.3.3.2. Configuraciones 38
2.3.4. Pruebas 39
2.3.4.1. VAPOUR 40
3.
BACKEND
43
3.1. OpenLink Virtuoso 43
3.1.1. Carga de Tripletas al Store 43
3.1.2. Sparql Endpoint 45
3.1.2.1. Formatos de Respuesta 46
3.1.2.2. SPARQL basado en REST 47
3.1.2.3. Pruebas 48
3.1.3. Autenticación sobre EndPoint 49
3.2. Vocabulary of Interlinked Datasets (VoID) 54
3.3. Servicio REST - CRUD 56
3.3.1. Framework 57
3.3.1.1. Funcionamiento del Servidor REST 58
3.3.2. URIs de Recursos 61
3.3.3. Métodos del API 63
3.3.3.1. Eliminar una Ruta 63
3.3.3.2. Agregar una nueva parada 64
3.3.3.3. Eliminar parada 64
3.3.3.4. Actualizar Propiedad 65
3.3.3.5. URL para Imágenes 66
3.3.4. Pruebas 67
4.
CLIENTE
68
4.1. Tecnologías 68
4.2. Integración 69
4.3. Funcionalidades 70
4.3.1. Verificación de Existencia de Estudiante 70
4.3.2. Visualización de Vivienda 70
4.3.3. Visualización de Parada Frecuente 70
4.3.4. Registro de Vivienda 70
4.3.5. Registro de Parada Frecuente 70
4.4. Pruebas 71
4.4.1. CASO 1 71
4.4.2. CASO 2 71
4.4.3. CASO 3 72
5.
DISCUSIÓN
73
7.
RECOMENDACIONES
75
8.
BIBLIOGRAFÍA
76
9.
ANEXOS
78
9.1. ANEXO A 79
INSTALACIÓN DE PLUGIN - OWLDoc 80
9.2. ANEXO B 81
CONFIGURACIONES - PURL 82
9.3. ANEXO C 84
INSTALACIÓN DE SERVIDOR PURL 85
9.4. ANEXO D 89
APACHE WEB SERVER: Instalación y Configuración 90
Instalación 90
Configuraciones 90
9.5. ANEXO E 93
VAPOUR: VALIDACIÓN DE VOCABULARIO 94
9.6. ANEXO F 98
INSTALACIÓN DE VIRTUOSO SERVER 99
9.7. ANEXO G 102
VIRTUOSO: CARGA DE DATOS AL STORE 103
9.8. ANEXO H 105
URIs – POIS REST SERVER 106
9.9. ANEXO I 108
PRUEBAS SERVICIO REST - POIS 109
9.10. ANEXO J 131
CASOS DE USO 132
9.10.2. Visualizar Vivienda 132
9.10.3. Visualizar Parada Frecuente 133
9.10.4. Registro de Vivienda 133
9.10.5. Registro de Parada Frecuente 134
9.11. ANEXO K 135
INTERFAZ DE CLIENTE 136
9.11.1. INGRESO 136
9.11.2. PRINCIPAL 136
9.11.3. VIVIENDA 137
9.11.4. PARADA FRECUENTE 137
9.11.5. PARADAS EXISTENTES 138
9.12. ANEXO L 139
5.8.1 CASO 1: Cédula Incorrecta 140
5.8.2 CASO 2: Cédula Correcta NO existente en el Store 140
5.8.3 CASO 3: Cambiar Parada Frecuente y Vivienda 144
Cúmar Ramiro Cueva Tacuri 1
ÍNDICE DE FIGURAS
Figura 1: Linked Open Data Cloud 6
Figura 2: Tabla de la BD Relacional 9
Figura 3: Extracto de Vocabulario - RDFs 21
Figura 4: Vocabulario - Esquema Preliminar 22
Figura 5: Vocabulario – Esquema Final 23
Figura 6: Relaciones Binarios 24
Figura 7: Diagrama RDF – Vocabulario: Generado con el plugin OntoGraf de Protégé 25
Figura 8: Instancias de Prueba 27
Figura 9: URIs for Vocabularies 33
Figura 10: Partes de una PURL 36
Figura 11: Funcionamiento de Server PURL 37
Figura 12: Content Negotiation - Archivo RDF 39
Figura 13: Content Negotiation - Archivo HTML 40
Figura 14: Interfaz del servicio VAPOUR 41
Figura 15: Resumen de Validación – VAPOUR 42
Figura 16: Diagrama ER – IRBU 44
Figura 17: Extracto del archivo OWL de salida 45
Figura 18: EndPoint generado por Virtuoso 46
Figura 19: Caracteres codificados 49
Figura 20: Usuarios Virtuoso Server 50
Figura 21: Roles Virtuoso Server 50
Figura 22: Error de Privilegios 51
Figura 23: Creación de Usuario 52
Figura 24: Servidor de Autentificación 53
Figura 25: Editor VoID - DERI 55
Figura 26: Servidor REST – POIS 59
Figura 27: Estructura función – Server REST 60
Figura 28: Correspondencia de Parámetros 61
Figura 29: Parámetro Opcional 61
Figura 30: Directorio Servidor Apache 62
Figura 31: Desplazamiento e inserción de Parada 64
Figura 32: Desplazamiento y eliminación de Parada 65
Figura 33: Doble codificación de una URL 66
Figura 34: Petición HTTP – ExtJs 69
Figura 35: Documentación Generada con OWLDoc 80
Figura 36: Registro Server PURL OCLC 82
Figura 37: Registro de Dominio - PURL 83
Figura 38: Registro de PURL Individual 83
Cúmar Ramiro Cueva Tacuri 2
Figura 40: Instalación PURL – Especificación de BackEnd 86
Figura 41: Instalación PURL – Permisos 86
Figura 42: PURL – Interfaz Principal 87
Figura 43: PURL – Creación de Dominio Público 87
Figura 44: PURL – Creación de Dirección 88
Figura 45: Estructura de Directorios 91
Figura 46: URI y parámetros – VAPOUR 94
Figura 47: Petición RDF/XML – VAPOUR 95
Figu a 48: “i Co te t Negotiatio - VAPOUR 95
Figura 49: Class - Petición RDF/XML – VAPOUR 96
Figura 50: Class - Sin 'Content Negotiation' - VAPOUR 96
Figura 51: Property - RDF/XML – VAPOUR 97
Figura 52: Property - Sin 'Content Negotiation' - VAPOUR 97
Figura 53: Interfaz Principal 100
Figura 54: Interfaz de Administración - CONDUCTOR 100
Figura 55: Carga de Archivo OWL 103
Figura 56: Grafo Creado 103
Figura 57: Verificación de Tripletas 104
Figura 58: Mensaje de Error al ingresar una cédula incorrecta, 140
Figura 59: Mensaje para ingresar un nuevo individuo. 140
Figura 60: Mensaje de bienvenida. 140
Figura 61: Aviso de Selección 141
Figura 62: Formulario sobre Vivienda 141
Figura 63: Información sobre Vivienda 142
Figura 64: Selección de Parada Frecuente 142
Figura 65: Información sobre Parada 143
Figura 66: Capas visibles 143
Cúmar Ramiro Cueva Tacuri 3
ÍNDICE DE TABLAS
Tabla 1: Stores y Métodos de Actualización 8
Tabla 2: Resultados Benchmarking 10
Tabla 3: At i utos de u POI de atego ía Clí i a e dos e to os dife e tes 13
Tabla 4: Preguntas Base para Generación de Vocabulario 18
Tabla 5: Elementos del Vocabulario 19
Ta la 6: U i s de Vo a ula io 35
Tabla 7: Prefijos de Individuos 44
Tabla 8: Formatos de Respuesta 47
Tabla 9: Lista de parámetros 47
Tabla 10: Métodos HTTP - CRUD 57
Cúmar Ramiro Cueva Tacuri 4
1.
ESTADO DEL ARTE
Linked Data y su aplicación en sistemas de puntos de interés
georeferenciados y mecanismos de actualización de información
almacenada en un RDFStore
1.1.
Introducción
El crecimiento de Internet en los últimos años, tomando como punto de referencia América del Sur, demuestra que el índice de penetración es considerablemente mayor al del resto de los continentes[1] lo que permite tener una perspectiva que apunta a que Internet es cada vez una red de tal magnitud que se expande a través del globo.
Con este avance considerable de la red, el paradigma de la información y comunicación se mantienen en igual forma sin alteraciones, donde podemos navegar a través de una vasta cantidad de información y movilizarlos de una página a otra por medio de interconexiones también llamadas Hyperlink1, los cuales a medida que avanzamos traen hacia nosotros gran cantidad de contenido. Esto demuestra que la web se basa en la visualización de información, puesto que su base es HTTP2, lo cual viene a ser un aspecto muy útil para que las personas podamos comprender lo que se muestra, pero por otro lado, solo se tiene enlaces externos o documentos aislados, cuya relación no constituye mayor información.
La estructura manejada por la información en internet nos lleva a tener un espacio, donde para llegar a la información que verdaderamente requerimos, sea necesario recorrer gran cantidad de información poco relevante hasta poder llegar a nuestro objetivo, esto debido a que los enlaces entre las páginas no son más que eso 'enlaces' entre documentos estáticos que no aportan más que visualización para su entendimiento, donde el usuario puede recorrer a través de un navegador web. En cambio, los buscadores indexan toda la masa de datos analizando su contenido para brindar al usuario una alternativa rápida a lo que intenta localizar.
El creador del internet, Tim Berners-Lee, sostiene la idea de que la información contenida en recursos estáticos (documentos HTML) no es suficiente para el objetivo de internet, lo que hace pensar en una forma en que los contenidos sean quienes se vinculen a otros para generar solo información valiosa que a su vez pueda llevar a otro tipo de información que de alguna manera está vinculada. Este concepto es conocido
1
w3schools.com. HTML Links. http://www.w3schools.com/html/html_links.asp
2
Cúmar Ramiro Cueva Tacuri 5
como Linked Data [2], el mismo que será tratado en el apartado 1.2.
A medida que los servicios dentro de internet se expanden, aparecen servicios que escapan del esquema tradicional, uno de ellos es el servicio desarrollado a partir del posicionamiento global (GPS) también conocidos como Location-BasedService (LBS). La popularización de dispositivos gps integrados y de la tecnología asistida (a-gps), ha permitido que la cantidad de usuarios crezca y se convierta en un mercado explotable. Muestras de esto se pueden apreciar en aplicaciones que intentan aprovechar las ventajas de estos dispositivos integrados en los teléfonos móviles principalmente, entre ellas están Pocket Life3, Stuck4 y Waze5.
Las posibilidad que giran en torno a la geolocalización son variadas, estas se basan desde la visualización en real-time de determinados elementos sobre un mapa georeferenciado hasta la interacción con otros usuarios. Dentro de estos servicios también se enmarca un concepto conocido como Puntos de Interés (PoI) [3] que será descrito en el apartado 1.4.
1.2.
Linked Data
La web está conformada por información en gran cantidad, la forma tradicional de publicar datos en la web de forma masiva se basa en formatos como csv, xml y el propio HTML, esto limita la estructura y semántica de los datos, puesto que estos formatos no fueron vistos como mecanismos de enlaces entre ellos, sino más bien como formas de intercambio de información. De tal forma que un enlace dentro de un documento (hyperlink) no representa suficiente descripción sobre el documento al cual se enlaza, lo que dificulta de sobre manera el saber si la información contenida en él, es lo suficientemente relevante como para ser visitado.
Esto ha llevado a tener una visión más amplia de la web, a visualizarla como un espacio global en donde documentos y datos sean vinculados de tal manera que el acceso a ellos genere un beneficio adicional, el conocimiento.
Linked Data, se basa en la ideología de conservar un conjunto de mejores prácticas para hacer que el contenido de la web sea público y mantenga conexión entre sí, para ello sus lineamientos radican en los siguientes 4 estamentos definidos por Tim Berners-Lee (2006) los mismos que consisten en:
Usar URIs6 para nombrar las cosas.
Cúmar Ramiro Cueva Tacuri 6
Ofrecer información sobre los recursos mediante estándares (RDF, SPARQL) Incluir enlaces a otras URIS, que permita descubrir más cosas.
Tomando estos principios se puede hacer una calificación de la calidad de nuestros datos en torno a la perspectiva de Linked Data [6]:
1. Los datos se encuentra en la red (en cualquier formato), pero con una licencia abierta.
2. Hacerlos disponibles como datos estructurados (ej. Excel en lugar de una imagen)
3. Usar formatos no-propietarios (ej. csv en lugar de Excel)
4. Usar URLs para identificar cosas, así las personas pueden enlazarte.
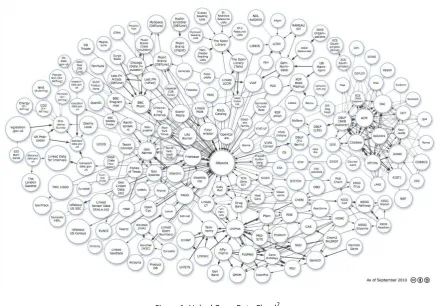
[image:18.595.101.539.413.719.2]5. Enlazar sus datos a los datos de otras personas para proporcionar un contexto. Este tipo de calificativo es conocido como un entorno 5 estrellas. La idea que se persigue es publicar datos de forma estandarizada, uniforme y mediante una forma genérica de consumo. Desde el lanzamiento de estos principios el trabajo en Linked Data ha llevado a que gran cantidad de datos sean colocados de manera pública y bajo un estándar en la nube conocida como Linked Open Data la misma que se muestra en la Figura 1, cuya última actualización es a Septiembre del 2010.
Figura 1: Linked Open Data Cloud7
La aplicabilidad de Linked Data en la web transforma el paradigma de una web de
7
Cúmar Ramiro Cueva Tacuri 7
documentos a una web de cosas, donde se pueden determinar y reconocer las relaciones entre estas. Para ello Linked Data utiliza el estándar de representación conocido bajo el nombre de RDF. El mismo que hace posible esta relación de los datos y la transición hacia un web de cosas [4].
Este modelo para el intercambio de datos en la web, se destaca por ser directo, etiquetado y toda su estructura está basada en grafos, cuyo elemento principal son las
U‘I s. Su base para realizar estas relaciones se basa en la estructura Triple que maneja RDF también conocida como Tripletas.
Las propiedades en las que se basa el esquema RDF es conocido como Vocabulario, pero para definirlo es necesario utilizar una extensión semántica conocida bajo el estándar de RDFSchema [5] el mismo que es propuesto por la W3C. Esta extensión de RDF es utilizada para describir clases (similares a las utilizadas en POO), propiedades y otros recursos que pueden ser descritos, con eso se obtienen recursos agrupados en categorías similares.
Debido a sus beneficios RDF se ha convertido en la web actual, en el formato en que están escritos los datos. [6]
1.3.
RDFStore
Esta i fo a ió t a sfo ada a t ipletas, las is as ue ea e la es e t e osas
manteniendo el principio de Linked Data, necesitan, al igual que los datos relaciones normales, un almacén de datos donde puedan ser guardadas y consultadas.
Lo que comúnmente se conoce en los ambientes relaciones como Base de Datos, dentro de Linked data, el almacenamiento de tripletas es conocido bajo el nombre de RDFStore. Estos son sistemas específicos para el almacenamiento de Grafos RDF, estos Stores proporcionan mecanismos de backend para la extracción y almacenaje de información. El estándar propuesto para este propósito por la W3C es SPARQL [7].
Cúmar Ramiro Cueva Tacuri 8
1.3.1.
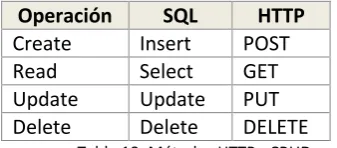
Sparql Update
Si bien SPARQL es el estándar de consulta para la extracción de datos del RDFStore, para el proceso de realizar las operaciones restantes CRUD (CreateReadUpdateDelete) sobre los grafos almacenados, se ha motivado la tendencia a utilizar el lenguaje de actualización conocido como SPARQL/UPDATE, el mismo que inició de la aportación de miembros de la compañía Hewlett-Packard8 y que la W3C ha acogido para crear un borrador [11] orientándolo a ser
definido como un estándar de la mano de SPARQL. Algunos de los almacenes de RDF que implementan esta solución pueden ser observados en la Tabla 1.
Las facilidades que Sparql 1.1 Update presenta, se basan en permitir: - Insertar nuevas tripletas en un grafo RDF.
- Eliminar tripletas de un grafo RDF.
- Llevar a cabo un conjunto de operaciones de actualización en una sola acción. - Crear un nuevo grafo RDF en un RDFStore
- Eliminar un grafo RDF en un RDFStore
Además de poseer una sintaxis similar a la utilizada por SPARQL, lo que permite tener una curva de aprendizaje menor, facilitando la interacción.
RDFStore Método de Actualización
4store9 SPARQLUpdate
BigData10 SPARQLUpdate
BigOwlim11 SPARQLUpdate(mediante Fuseki)
TDB12 SPARQLUpdate(mediante Jena13)
Virtuoso14 SPARQLUpdate AllegroGraph15 SPARQLUpdate
Sesame16 API Nativo
Tabla 1: Stores y Métodos de Actualización
Cúmar Ramiro Cueva Tacuri 9
de conjuntos de datos de entre 100 y 200 millones de tripletas, el análisis y los resultados se pueden encontrar publicados en la red17.
1.3.2.
SPARUL y El Proceso Asistido de Actualización
Otros mecanismos utilizados para la actualización de datos se basan en la construcción de sistemas intermedios utilizados como puentes para la transformación de la información, en la mayoría son sistemas de bases de datos relacionales.
Existe otro método implementado en la extracción de datos desde Wikipedia conocido como DBPedia Live [12] en donde se distinguen 3 tipos de actualización. La primera es la actualización basada en SPARUL sobre un mismo gráfoRDF, la segunda mencionada es sobre distintos grafos, al igual que la anterior basándose en SPARUL. Mientras que la tercera es una mezcla entre SPARUL y una Base de
Datos ‘ela io al. Este p o eso es o o ido o o RDBassistedupdateprocess . Si bien estos dos métodos implican cambios en el RDFStore, el utilizar SPARUL de forma aislada conlleva la utilización de acciones complejas para realizar una determinada actualización sobre el Store puesto que, como se mencionó anteriormente, las tripletas conforman un grafo relacionado.
En cambio, el proceso asistido para la actualización, utiliza una tabla relacional para representar las tripletas existentes, de tal forma que puedan ser recuperadas y analizadas para determinar los cambios que deben ser llevados a cabo sobre el RDFStore. Los datos de las tripletas son almacenados de forma serializada en un objeto JSON para su posterior comparación.
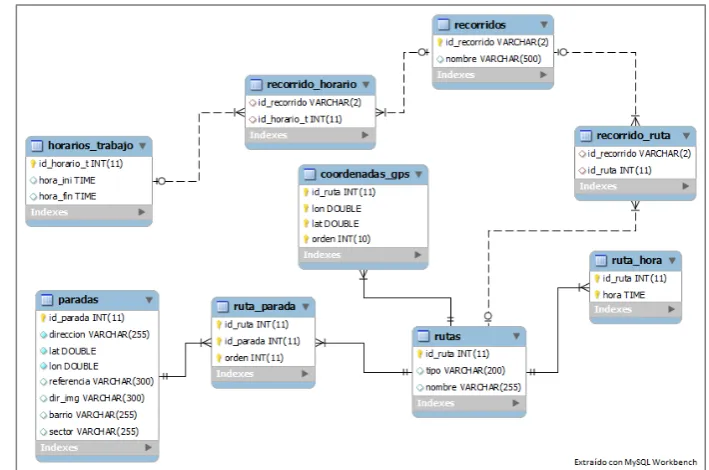
Un esquema de la forma en que los datos se almacenan en la Base Relacional puede ser apreciado en la Figura 2.
Figura 2: Tabla de la BD Relacional
17
Cúmar Ramiro Cueva Tacuri 10
La principal diferencia entre estas dos formas de actualización radica en la complejidad que adquiere SPARUL, con la utilización de un Base de Datos Relacional esto se reduce significativamente de tal forma que las sentencias y operaciones realizadas por SPARUL luego de este proceso es mínima.
El rendimiento de cada uno de estos métodos ha sido evaluado por el equipo de la Universidad Leipzing, los cuales han obtenido un conjunto de métricas que se pueden observar en la Tabla 2.
p Added Removed Retained Strategy Time
taken (sec)
0.5 124924 124937 123319 SQL 240
RDF 200
0.8 79605 79710 318149 SQL 200
RDF 250
0.9 44629 44554 402748 SQL 170
RDF 300
Tabla 2: Resultados Benchmarking18
Debido a que estos métodos son utilizado para la actualización de contenido en DBPedia, la medición fue realizada para simular cambios en 5000 recursos distintos, por cada uno de estos se considera los conjuntos N y O los mismos que hacen referencia al antes y después de la modificación de esa tripleta, la magnitud del cambio realizado se basa en el porcentaje p. Donde ha tenido una variación de p=0.9, p=0.8, p=0.5 correspondientes a un cambio del 10%, 20%, 50% de la tripleta respectivamente.
En base a estos dos conjuntos se puede determinar la cantidad de tripletas removidas (O – N), añadidas (N – O) y mantenidas (N O). Además, de estas consideraciones la comparativa fue ejecutada sobre el RDFStore de Virtuoso. La tabla muestra la eficiencia de la solución basada en un entorno de Base de Datos Relacional cuando existe un solapamiento suficiente entre los conjuntos O y N (p=0.9, p=0.8). A diferencia del caso en que existe menor solapamiento, en donde la solución RDF tiene mejor desempeño (p=0.5), esto debido al costo adicional de comparativas frente a la cantidad de tripletas que debe eliminar e insertar.
Esta comparativa basada en la estructura de DBPedia permite apreciar que para
18
Cúmar Ramiro Cueva Tacuri 11
ambientes donde los UPDATES al RDFStore son frecuentes y los mismos involucran un cambio mínimo en la estructura de las tripletas, una solución basada en la utilización de una Base Relacional presenta ventajas, frente a la utilización de la solución SPARUL por sí sola. Esto basado en que la solución con SPARUL necesita de la utilización de FILTROS que ralentizan la búsqueda y además de ignorar la duplicación de datos que se realiza en la Base Relacional.
1.4.
Puntos de Interés
La creación de Point of Interests (POI), han sido un elemento relevante en la evolución de las redes sociales basadas en geolocalización, estos consisten en la localización de un punto específico sobre un mapa, el mismo que puede resultar de importancia para otras personas19.
Su utilidad es variada, puesto ue se puede o side a a p á ti a e te ual uie osa
que pueda ser ubicada por una coordenada geográfica un punto de utilidad, como Supermercados, Escuelas e incluso paradas de buses o domicilios de personas, tema sobre el cual se desarrolla la plataforma Points of Interesting Semantic(POIS).
A medida que la información geográfica ha sido accesible y manejable, los POIs han constituido el pilar fundamental, puesto que desde tiempo atrás se ha venido explotando de forma no dirigida estas oportunidades, así existen utilidades capaces de brindar información sobre determinados sitios de interés a usuarios, muchos de ellos vía web y otros creados para dispositivos específicos20. La mayor parte de estos están orientados al sector hotelero y turístico, basándose en información manejada por el sector público para la categorización.
El transportar esta información a la web permite que sea manejada por los usuarios, logrando que ellos sean quienes realicen su clasificación, permitiendo tener así una
isió ás la a de lo ue esulta de i te és , esto edia te la utiliza ió de étodos de
categorización basados en rankings asignados por los mismos usuarios.
Fabricantes de dispositivos de navegación los han venido incluyendo como valor añadido a sus productos para brindar al usuario una experiencia basada en información, uno de ellos es el fabricante Garmin21 para cuyos dispositivos existe una gama muy amplia de
POIs, que pueden ser obtenidos de forma gratuita o mediante pago.
Con relación a servicios de POIs basados en internet, el principal exponente de su uso y
Cúmar Ramiro Cueva Tacuri 12
utilidad es Google con su iniciativa Maps22, la misma que permite la visualización de información en forma de POIs basados en una determina posición geográfica, principalmente orientado a mostrar información en tiempo real sobre el tráfico. El punto de partida para la creación de estos POIs es mediante la aplicación MapMaker23 en
donde se puede apreciar la categorización existente para los diferentes puntos.
La información que se maneja sobre cada punto de interés varía de un proveedor a otro, en este caso GPS-WAYPOINTS24 realiza la categorización de los POIs utilizando agrupaciones en subcategorías que permiten al usuario encontrar de forma rápida los elementos de interés y permitiendo agrupar atributos comunes. En cambio MapMaker de Google ofrece una gran cantidad de categorías de POIs específicas, sin utilizar sub-categorías directamente. Otros proveedores como GeoTourGuide25 y Geovative26, llevan el concepto de POI un nivel más arriba incluyendo en ellos elementos multimedia para brindar información audiovisual de sitios de interés localizados geográficamente.
Una comparativa entre los atributos que cada proveedor maneja se puede apreciar en la Tabla 3 do de se des i e los at i utos de u POI ajo la atego ía de lí i a e los
entornos GPS-WAYPOINTS y MapMaker. Como se puede apreciar, la alternativa de Google maneja gran cantidad de atributos relacionados a esta categoría específica de POI, lo que da una visión muy clara de la representación de los atributos que un POI de igual categoría puede tener en dos diferentes servicios.
GPS-WAYPOINTS MapMaker Latitud Longitud Altitud Nombre Descripción País Localización Límite de Velocidad Dirección Teléfono URL Latitud Longitud Nombre Idioma Tipo Nombre Atributos Categoría Precisión Popularidad Categorías Adicionales Horas Laborables Métodos de Pago URL de foto Dirección
Parcela# Calle
[image:24.595.216.441.459.700.2]Cúmar Ramiro Cueva Tacuri 13 Sitio Web Correo Electrónico Teléfono Fax Móvil Descripción
Información de Ubicación Sublocalidad Localidad Ciudad Distrito/Condado Estado/provincia Código postal
Tabla 3: At i utos de u POI de atego ía Clí i a e dos e to os dife e tes
Con la definición de Linked Data, la creación de POIs es un tema central, puesto que estos constituyen una puerta de entrada hacia información contenida en diferentes medios pero que se encuentra enlazada con el POI inicial, con ello, se obtiene información específica de gran utilidad partiendo de un mismo inicio, todo esto dependiendo de la definición que se haya dado en el vocabulario para la estructura RDF que será almacenada en el RDFStore.
1.5.
Trabajo Relacionado
Actualmente la integración de estos POIs al concepto de web semántica, basándose en Linked Data, se puede ver reflejado en varios trabajos, como el realizado por el equipo de DBPedia para crear DBPediaMobile27 y el trabajo realizado en la universidad de Koblenz-Landau, donde se ha creado la propuesta de un entorno de puntos de interés capaz de permitir la interacción entre usuarios en un entorno colaborativo basado en POIs [13]. DBPediaMobile, tiene como principio ser una solución móvil para la exploración de los datos extraídos por DBPedia basándose en una aplicación LBS. Presentando información geolocalizada y relevante en forma de POIs al usuario, permitiendo hacer una exploración del espacio geográfico de forma interactiva. Siguiendo este mismo principio, la iniciativa de la Universidad de Koblenz-Landau, se basa en la creación de un sistema capaz de permitir a los usuarios de forma colaborativa crear, compartir y modificar puntos de interés mediante la utilización de un programa cliente. Además de proporcionar un mecanismo de revisión capaz de identificar diferentes Puntos de Interés que han sido puestos por los usuarios pero que hacen referencia a un mismo sitio, para ser agrupados en uno solo, formando así una herramienta de colaboración asistida. La iniciativa de vincular información geográfica con datos de forma enlazada, o más
27
Cúmar Ramiro Cueva Tacuri 14
explícitamente añadir una dimensión espacial a la web de datos, empezó con la iniciativa planteada por la Universidad de Leipzig denominada LInkedGeoData28, la cual se
encuentra enmarcada dentro de la nube de Linked Open Data. Esta iniciativa se enmarca en utilizar los datos recolectados por el proyecto libre OpenStreetMap29 y ser expresados
en formato RDF, de tal forma que la información geográfica sea enlazada a fuentes externas y tenga acceso público.
Otra Universidad vinculada a la iniciativa de POIs a través de LinkedData es la Universidad de Southampton en el Reino Unido, la misma que contiene un conjunto de Datasets sobre información variada y entre ellos uno bajo el nombre de Open Data Map30 que ubica diversos Puntos de Interés sobre un mapa georeferenciado.
Como se menciona, la aplicabilidad de los puntos de interés al sector turístico es el principal punto de partida, tomando como punto de referencia el caso de estudio sobre CRUZAR31. Se puede observar como las preferencias de los usuarios pueden ser tomadas en cuenta para determinar puntos de interés basados en perfiles de usuario. Con esto se logra que la información contenida en los puntos de interés no sea visualizada de forma estática sino de acuerdo a preferencias, lo que convierte a los puntos de interés en elemento principal de la construcción de rutas dinámicas interactivas bajo preferencias de usuario. A diferencia de los folletos genéricos que pueden ser encontrados en la mayoría de recorridos turísticos.
Otra aplicabilidad de los puntos de interés es el análisis, puesto que los puntos de interés se encuentran enmarcados bajo una localización geográfica, es de fácil análisis el determinar la concentración de puntos bajo un criterio en un determinado lugar, lo que incrementa de forma sustancial la toma de decisiones en diversos campos. E incluso pueden ser agrupados en base a criterios para ser evaluados o examinados.
La tarea de representar los POIs en Linked Data se realiza en base a la definición de un
vocabulario, pero debido a la variedad y diferentes usos que tienen, no existe un estándar para su representación, puesto que diferentes POIs manejan diferentes atributos como se menciona en [14].
El intento por crear Vocabularios que describan Puntos de Interés así como otros aspectos ha llevado a realizar avances como:
Basic RDF Geo Vocabulary32, el mismo que consiste de los elementos básicos para representar un POI como es Latitud, Longitud y Altitud.
GeoOnionVocabulary33, Se basa en el esquema del vocabulario anterior, pero
28 http://linkedgeodata.org/About 29 http://www.openstreetmap.org/ 30 http://opendatamap.ecs.soton.ac.uk/ 31 http://www.w3.org/2001/sw/sweo/public/UseCases/Zaragoza-2/ 32 http://www.w3.org/2003/01/geo/#vocabulary
Cúmar Ramiro Cueva Tacuri 15
orientado a la descripción de elementos en relación de distancia con otros. LGDVocabulary34, que es la base del proyecto Linked Geo Data para describir
puntos geográficos, manteniendo información sobre localización, datos referentes a una posición, características del sitio como religión, aparcamiento, altitud y una categoría.
GoodRelations35, orientado al E-Commerce permite describir productos y sus propiedades asociadas como valor, información sobre el sitio de venta, detalles de garantía, datos de la institución y otros.
csxPOISystem[13], utiliza un vocabulario capaz de clasificar a los puntos de
i te és e atego ías o o o u e to las is as que pueden pertenecer o tener subcategorías, lo que permite realizar interrelaciones entre ellas, donde cada categoría posee un conjunto de características.
Aunque la existencia de un Vocabulario común para la representación de POIs es aún un tema de discusión como se mencionó, la información contenida en aplicaciones que utilizan Puntos de Interés no semánticos y los vocabularios específicos que actualmente existen en Linked Data permiten tener una perspectiva global de los aspectos que se deben considerar para el planteamiento del vocabulario para el proyecto POIS.
En la actualidad existe un grupo que forma parte de la W3C bajo el nombre de "Points of InterestWorkingGroup"36 que fue lanzado el 30 Septiembre del 2010 y uno de sus fines es desarrollar especificaciones técnicas para la representación de "Puntos de Interés" como información para la web creando una recomendación de Vocabulario para POIs, la fecha preliminar de su lanzamiento está prevista para Abril del 2011.
El crecimiento y aplicabilidad de POIs junto a Linked data está en aumento, puesto que cada vez más las redes sociales incorporan características de geolocalización para sus usuarios y los dispositivos de localización son cada vez más accesibles.
1.6.
Trabajo futuro
La construcción de la plataforma Points of Interesting Semantic(POIS) como proyecto basado en Linked Data, tiene como objetivos la implementación de un Vocabulario genérico para la representación de Puntos de Interés, buscando ser lo más genérico posible capaz de englobar un sin número de categorías que pueden ser agregadas en un futuro.
Cúmar Ramiro Cueva Tacuri 16
determinado tipo de POIs, en este caso, las paradas realizadas por los Buses de la Universidad Técnica Particular de Loja y la ubicación de la vivienda y la parada más frecuente, de los estudiantes pertenecientes a la misma.
Esto contribuirá a la iniciativa de mantener información relacionada a la Universidad en formato accesible a través de LinkedData en este caso RDF.
La prueba de concepto sobre la representación de estos datos en RDF y su consumo, será basada en una aplicación Web que implemente un servicio de consulta capaz de permitir al usuario obtener los horarios de los recorridos de los buses según su parada habitual, definida previamente, para ello la aplicación permitirá que el usuario registre la posición de su domicilio.
Cúmar Ramiro Cueva Tacuri 17
2.
VOCABULARIO RDF
2.1.
Construcción
La creación del Vocabulario bajo la sintaxis RDF, permitirá definir el lineamiento principal de la plataforma POIS. Para este fin se hará uso de la herramienta Protégé 4.x37, puesto que presta de gran aceptación en los ambientes de trabajo semántico por su flexibilidad y gran cantidad de funcionalidades.
2.1.1.
Selección de Elementos Preliminares y Formulación de
Interrogantes
La construcción del vocabulario para la plataforma POIS, deberá cumplir como objetivo principal, el ser capaz de expresar y representar las paradas de buses de la UTPL como un punto de interés (POI). Además, de permitir la representación de Puntos de Interés de diferente índole, tales como Parques, lugares turísticos o edificios emblemáticos.
La Tabla 4 agrupa un conjunto de elementos y preguntas, a través de los cuales se generará el vocabulario para la plataforma POIS.
COD INTERROGANTE IMPORTANCIA
RECORRIDOS
IT1 A una hora Y que Rutas existen. ALTA
IT2 Cuáles son las paradas de la Calle X. ALTA IT3 Cuáles son las paradas de una Ruta X. ALTA IT4 Cuantas paradas realiza una Ruta X. ALTA
IT5 Que rutas [bajan | suben | suben o bajan] de la
Universidad ALTA
IT6 Que rutas pasan por la Parada X [a una Hora Y]. ALTA
IT11 [Cuales | Cuantos] barrios no poseen paradas de los
buses de la UTPL. MEDIA
Cúmar Ramiro Cueva Tacuri 18
IT12
A una hora X que Ruta debo elegir para [ subir a| bajar de ] la UTPL -- Considerando la Parada Frecuente de un Estudiante
MEDIA
IT15 Cuál es la parada de la Ruta X que se localiza más
cerca de mi casa ALTA
ESTUDIANTE
IT7 Que estudiante posee la cedula X ALTA
IT8 Cuál es la parada más frecuente de un estudiante X ALTA
IT13 Cuál es el [ barrio | sector ] con mayor número de
estudiantes MEDIA
IT14 Cuantos estudiantes toman el bus de la UTPL en el [
sector | barrio ] X MEDIA
GENÉRICOS
IT9 Cuáles son los POIs que se encuentran más cercanos
del Punto Y. ALTA
IT10 [Cuantos | Cuales] POIs X contienen un nombre con X
características ALTA
IT16 Cuál es el [ barrio | sector ] donde se ubican mayor
[image:30.595.118.527.90.482.2]cantidad de POIs MEDIA
Tabla 4: Preguntas Base para Generación de Vocabulario
2.1.2.
Definición de Elementos Finales y sus Atributos
Elemento Atributos Anotaciones Interrogantes
Ruta
Nombre
IT1 | IT5 | IT15 Tipo
Horario
Fecha Dato de creación
Activa
Cúmar Ramiro Cueva Tacuri 19
Calle Secundaria | IT12
Imagen Dirección de la Img Lat
Lon
Pertenece_A_Ruta Referencia
Activa
Estudiante
[image:31.595.165.499.108.593.2]Cedula
IT7 | IT8 | IT13 Parada_Frecuente
Vivienda Dato geográfico
Genérico
Nombre
IT9 | IT10 | IT11 | IT14 | IT16 Lat
Lon
Calle Principal Calle Secundaria Sector
Barrio
Fecha Dato de creación
Tabla 5: Elementos del Vocabulario
2.1.3.
Estructura de Vocabulario
Cúmar Ramiro Cueva Tacuri 20
En el vocabulario para la plataforma POIS, debido a la información a representar que involucran los Puntos de Interés solamente es posible la reutilización del vocabulario Basic Geo38, el mismo que establece una representación de puntos
geográficos basándose en los atributos lon (longitud) y lat (latitud) de una coordenada geográfica, ignorando del mismo el atributo altitud.
Vocabularios ampliamente utilizados en diferentes ambientes como Doublin Core39 o FOAF40, no formarán parte de la Plataforma por no tener relación con la
información manejada.
2.1.3.1. Consideraciones de Nomenclatura
Los diagramas de vocabulario, como su posterior implementación sobre RDF mantendrán el siguiente estándar de nomenclatura, lo que facilitará el establecer relaciones entre los mismos:
Los conceptos serán nombrados en letras mayúsculas.
Las Propiedades Objeto serán nombradas en singular utilizando notación CamelCase41.
Las Propiedades de Datos serán nombradas en singular y en letras minúsculas, si contiene dos palabras serán separadas por un guión.
2.1.3.2. Descripción de Conceptos
2.1.3.2.1. RUTA
Concepto para la representación de información relativa a una ruta concreta. En la actualidad, en el sistema de transportación estudiantil de la UTPL, cada ruta es nombrada en base a las calles por las que la unidad de transporte realiza las paradas, y en ocasiones el barrio. De esta forma las Rutas poseen nombres de sintaxis similar a:
A . Ma uel Agustí Agui e Me adillo .
2.1.3.2.2. PARADA
Constituyen cada uno de los puntos geográficos que identifican los sitios donde los buses de la UTPL, se detienen dentro de una RUTA.
38 http://www.w3.org/2003/01/geo/wgs84_pos# 39 http://purl.org/dc/elements/1.1
40 http://xmlns.com/foaf/0.1/
Cúmar Ramiro Cueva Tacuri 21
2.1.3.2.3. ESTUDIANTE
Considerado un usuario del sistema de transportación estudiantil de la UTPL, el mismo que posee preferencias en cuanto a su PARADA y vivienda.
2.1.3.2.4. POIG
Un punto de Interés genérico capaz de representar otros elementos de forma directa.
2.1.3.2.5. ORDEN PARADA
Debido a que el actual sistema de transportación estudiantil involucra RUTAS y PARADAS, a su vez estas siguen una secuencia determinada, el conocimiento de esta secuencia, permitirá tanto el tratamiento de las PARADAS en orden, como la determinación de la PARADA INICIAL y FINAL del recorrido.
2.1.3.2.6. PARADA FRECUENTE
El enlace entre el estudiante y su parada seleccionada como preferida, que permite mantener un historial de selecciones, puesto que contiene una propiedad de fecha.
Cúmar Ramiro Cueva Tacuri 22
[image:34.595.117.531.127.508.2]2.1.3.3. Esquema Preliminar
Cúmar Ramiro Cueva Tacuri 23
2.1.3.4. Esquema Final
Cúmar Ramiro Cueva Tacuri 24
2.1.3.5. Relaciones Binarias
Cúmar Ramiro Cueva Tacuri 25
2.1.3.6. Diagrama RDF
Basado en el archivo RDF que contiene la estructura del vocabulario, se puede apreciar en la
Figura 7 el diagrama de relación entre los elementos del mismo.
Figura 7: Diagrama RDF – Vocabulario: Generado con el plugin OntoGraf42 de Protégé
De igual forma se puede generar un diagrama de modelo de datos mediante el servicio de validación de RDF de la W3C43. Este diagrama puede ser encontrado en la dirección:
[http://www.box.com/s/g26t41incyzd200ribze ]
2.1.4.
Validación del Vocabulario
En base a la construcción del vocabulario, tomando en consideración las relaciones establecidas entre conceptos, a continuación se demostrará la solución de las preguntas planteadas en el primer enunciado. Se debe considerar que no necesariamente todas las preguntas pueden o deben ser resueltas, ya que las preguntas iníciales son una abstracción general de lo que se intenta abarcar con el vocabulario.
Cúmar Ramiro Cueva Tacuri 26
La comprobación ha sido realizada basada en el lenguaje SPARQL, haciendo uso de la herramienta de navegación Gruff44 para AllegroGraph, un almacén de
tripletas, basándose en un archivo RDF para realizar la carga. Cabe recalcar que Gruff no soporta Sparql 1.1 el cual permite utilizar funciones de agregación, razón por la cual varias preguntas son omitidas o resueltas parcialmente.
2.1.4.1. Instancias de Vocabulario
Para la comprobación del vocabulario se trabajará con el siguiente esquema de instancias del vocabulario, el mismo que está estructurado en base a las preguntas iniciales.
El vocabulario puede ser descargado en formato RDFs desde la siguiente dirección:
[ http://www.box.net/shared/88cz8c06ojanjlhs11r6 ]
En apartados siguientes se mencionará la publicación del mismo, tanto en formato html como rdfs.
Cúmar Ramiro Cueva Tacuri 27 Figura 8: Instancias de Prueba
2.1.4.2. Consultas SPARQL
IT1:: A una hora Y que Rutas Existen
PREFIX pois: <http://localhost/POIS.owl#> SELECT *
WHERE {
?Ruta a pois:RUTA.
?Ruta pois:nombre ?NameRuta. ?Ruta pois:horario ?horaRuta.
FILTER( regex(str(?horaRuta), "10:00") ) }
IT2:: Cuales son las paradas de la calle X
PREFIX pois: <http://localhost/POIS.owl#>
SELECT ?Parada ?CallePrincipal ?CalleSecundaria WHERE
{
?Parada a pois:PARADA.
Cúmar Ramiro Cueva Tacuri 28 ?Poig pois:calle1 ?CallePrincipal.
?Poig pois:calle2 ?CalleSecundaria.
FILTER( regex(str(?CallePrincipal), "Eduardo Kigman") ||
regex(str(?CalleSecundaria), "Eduardo Kigman") )
}
IT3:: Cuales son las paradas de una Ruta X IT4:: Cuántas paradas realiza una ruta X
PREFIX pois: <http://localhost/POIS.owl#> SELECT ?NombreRuta ?RutaXPard ?ordenParada WHERE
{
?RutaX a pois:RUTA;
pois:nombre ?NombreRuta;
pois:ParadaConOrden ?RutaXPardConst. ?RutaXPardConst pois:num_secuencia ?ordenParada; pois:ParadaRelacionada ?RutaXPard.
FILTER( regex(str(?NombreRuta), "Rosales, Pradera Catacocha,"))
}
ORDER BY ?ordenParada
IT5:: Que rutas [bajan | suben | suben o bajan] de la Universidad
PREFIX pois: <http://localhost/POIS.owl#> SELECT ?nombreRuta
WHERE {
?RutaX a pois:RUTA; pois:nombre ?nombreRuta.
?RutaX pois:tipo ?SentidoRuta. FILTER ( ?SentidoRuta = "BAJA") }
order by ?nombreRuta
IT6:: Qué rutas pasan por la Parada X [a una hora Y]
PREFIX pois: <http://localhost/POIS.owl#> SELECT ?Num_Parada ?RutaXNombre ?refParada WHERE
{
?ParadaX a pois:PARADA.
?ParadaX pois:referencia ?refParada.
Cúmar Ramiro Cueva Tacuri 29 pois:ParadaConOrden ?RutaXPardConst;
pois:nombre ?RutaXNombre.
?RutaXPardConst pois:ParadaRelacionada ?RutaXParada;
pois:num_secuencia ?Num_Parada.
FILTER(regex(str(?refParada), "Laguna") && ?RutaXParada = ?ParadaX )
}
IT7:: Qué estudiante posee la cédula X
PREFIX pois: <http://localhost/POIS.owl#> SELECT ?EstudianteX
WHERE {
?EstudianteX a pois:ESTUDIANTE.
?EstudianteX pois:cedula ?cedEstudiante.
FILTER(regex(str(?cedEstudiante), "1104665621")) }
IT8:: Cuál es la parada más frecuente de una estudiante X.
PREFIX pois: <http://localhost/POIS.owl#> SELECT ?callePrincipal ?calleSecundaria WHERE
{
?EstudianteX a pois:ESTUDIANTE.
?EstudianteX pois:cedula ?cedEstudiante. ?EstudianteX pois:Prefiere ?preferEnlace. ?preferEnlace pois:VinculadaA ?PrdPreferida. ?PrdPreferida pois:LocalizadaEn ?poigLoc. ?poigLoc pois:calle1 ?callePrincipal; pois:calle2 ?calleSecundaria.
FILTER(regex(str(?cedEstudiante), "1104665621")) }
IT9:: Cuáles son los POIs que se encuentran más cercanos al punto Y. La definición de 'cercano' es aún imprecisa así como la forma de determinar distancia entre dos puntos geográficos, por ahora se simulará asumiendo que esto se basa en estimación de la diferencia de los valores.
PREFIX pois: <http://localhost/POIS.owl#>
PREFIX geo:
Cúmar Ramiro Cueva Tacuri 30 WHERE
{
?PuntoInt a pois:POIG.
?PuntoInt pois:CoordenadaGeo ?CoordXY. ?CoordXY geo:lat ?LatPoig;
geo:long ?LonPoig.
FILTER ((?LatPoig>-3.98)&&(?LonPoig<-78.99)) }
IT10:: [Cuantos | Cuales] POIs X contienen un nombre con X características.
Aplicado solo a elementos que no constituyen una parada, puesto que las paradas no poseen nombres, solo los puntos genéricos.
PREFIX pois: <http://localhost/POIS.owl#> SELECT *
WHERE {
?PuntoInt a pois:POIG.
?PuntoInt pois:nombre ?NamePoig.
FILTER(regex(str(?NamePoig), "abc")) }
IT11:: [Cuántos | Cuáles] barrios no poseen paradas de los buses de la UTPL.
Se utilizará una búsqueda basada en el nombre del barrio.
PREFIX pois: <http://localhost/POIS.owl#>
PREFIX geo:
<http://www.w3.org/2003/01/geo/wgs84_pos#> SELECT *
WHERE {
?ParadaX a pois:PARADA; pois:LocalizadaEn ?Poig.
?Poig pois:barrio ?PoigBarrio.
FILTER(regex(str(?PoigBarrio), "La Pradera")) }
order by ?ParadaX
IT12:: A una hora X que Ruta debo elegir para [subir a | bajar de] la UTPL (parada frecuente)
Cúmar Ramiro Cueva Tacuri 31 PREFIX pois: <http://localhost/POIS.owl#>
SELECT ?NombreRuta WHERE
{
?RutaX a pois:RUTA.
?RutaX pois:tipo ?TipoRuta. ?RutaX pois:horario ?HoraRuta. ?RutaX pois:nombre ?NombreRuta. FILTER( (?TipoRuta = "BAJA") &&
(regex(str(?HoraRuta), "10:00")) ) }
IT13:: Cuál es el [barrio|sector] con mayor número de estudiantes
Al igual que para dar respuesta a otras interrogantes que hacen referencia a cantidad, es necesario utilizar funciones de agregación disponibles en SPARQL 1.1
PREFIX pois: <http://localhost/POIS.owl#> SELECT ?cedEstd
WHERE {
?EstdX a pois:ESTUDIANTE. ?EstdX pois:ViveEn ?PoigEstd. ?PoigEstd pois:barrio ?BarrioEstd. ?EstdX pois:cedula ?cedEstd.
FILTER (?BarrioEstd = "Gran Colombia") }
IT14:: Cuántos estudiantes toman el bus de la UTPL en el [sector | barrio] X.
PREFIX pois: <http://localhost/POIS.owl#> SELECT ?CedEstdX
WHERE {
?EstdX a pois:ESTUDIANTE; pois:Prefiere ?ParadaF; pois:cedula ?CedEstdX. ?ParadaF pois:VinculadaA ?ParadaX. ?ParadaX pois:LocalizadaEn ?PoigPrd. ?PoigPrd pois:barrio ?Barrio.
FILTER(?Barrio = "San Sebastian") }
Cúmar Ramiro Cueva Tacuri 32
implementación de un algoritmo que determine la proximidad de los resultados. Por ahora no se lo considera.
PREFIX pois: <http://localhost/POIS.owl#>
PREFIX geo:
<http://www.w3.org/2003/01/geo/wgs84_pos#> SELECT DISTINCT ?ParadaY
WHERE {
?RutaX a pois:RUTA;
pois:nombre ?NombreRuta; pois:ParadaConOrden ?PardCons.
?PardCons pois:ParadaRelacionada ?ParadaY.
?ParadaY pois:LocalizadaEn ?PoigPardY.
?PoigPardY pois:CoordenadaGeo ?CoordPoigPardY. ?CoordPoigPardY geo:lat ?LatParadaY.
?EstdZ a pois:ESTUDIANTE. ?EstdZ pois:cedula ?cedEstd.
?Estdz pois:ViveEn ?PoigCasaEstdz.
?PoigCasaEstdz pois:CoordenadaGeo
?CoordPoigCasaEstdz.
?CoordPoigCasaEstdz geo:lat ?LatEstdZ.
}
ORDER BY ?ParadaY
IT16:: Cuál es el [barrio|sector] donde se ubican mayor cantidad de POIs
PREFIX pois: <http://localhost/POIS.owl#> SELECT ?POIS
WHERE {
?POIS a pois:POIG.
?POIS pois:sector ?sectorPOIS.
FILTER( ?sectorPOIS = "Pio Jaramillo Alvarado") }
2.1.4.3. Resultados de Validación
Cúmar Ramiro Cueva Tacuri 33
para el cálculo de cantidades.
Además, la determinación de conceptos como "cercano a" que se basa en Coordenadas geográficas, deberá definirse, de tal forma que se implemente un método (algoritmo) que permita extraer tal medida en base a una distancia pre-establecida o a su vez el uso de las funciones geográficas de sparql.
2.2.
URI’s
2.2.1.
Definición
La localización de recursos dentro del internet está basada en la asignación de URI a los recursos, siendo este también una premisa importante en el ámbito de Linked Data. Siguiendo esta línea W3C establece algunas recomendaciones [25] generales. Así también el gobierno del Reino Unido ha creado un documento de orientación, el mismo que puede ser encontrado en [26], orientado a la representación de conocimiento en el área pública del gobierno.
Figura 9: URIs for Vocabularies Fuente: http://data.gov.uk/resources/uris
Siguiendo este principio se han establecido las siguientes URIs para el vocabulario pois, las is as ue se est u tu a ajo el es ue a de hash a espa e45
donde el vocabulario se construye con la colocación del nombre de la clase o
p opiedad de fo a di e ta e la U‘I a te edida de u o odí # .
Cúmar Ramiro Cueva Tacuri 34
Ot a fo a de posi le ep ese ta ió es o o ida o o slash a espa e 46
do de la dife e ia adi a e la utiliza ió del / e luga del # . La ep ese ta ió hash a espa e ha sido elegida po p esta a o si pli idad al
usuario al intentar acceder a determinada información del vocabulario.
Vocabulario: /{prefijo}/{vocabulary} Clases: /{prefijo}/{vocabulary}#{class} Propiedades: /{prefijo}/{vocabulary}#{property}
2.2.2.
Uri
’s
para el Vocabulario
Vocabulario URI
POIS /POIS/vcblr
Clases
ESTUDIANTE /POIS/vcblr#ESTUDIANTE
ORDEN_PARADA /POIS/vcblr#ORDEN_PARADA
PARADA /POIS/vcblr#PARADA
PARADA_FRECUENTE /POIS/vcblr#PARADA_FRECUENTE
POIG /POIS/vcblr#POIG
RUTA /POIS/vcblr#RUTA
Propiedades
Activa /POIS/vcblr#activa
Barrio /POIS/vcblr#barrio
Calle1 /POIS/vcblr#calle1
Calle2 /POIS/vcblr#calle2
Cedula /POIS/vcblr#cedula
Fecha /POIS/vcblr#fecha
Horario /POIS/vcblr#horario
Imagen /POIS/vcblr#imagen
Nombre /POIS/vcblr#nombre
Num_secuencia /POIS/vcblr#num_secuencia
ContieneEstudiante /POIS/vcblr#ContieneEstudiante
Cúmar Ramiro Cueva Tacuri 35
CoordenadaGeo /POIS/vcblr#CoordenadaGeo
ElegidaPor /POIS/vcblr#ElegidaPor
LocalizadaEn /POIS/vcblr#LocalizadaEn
MarcadaEn /POIS/vcblr#MarcadaEn
OrdenEnRuta /POIS/vcblr#OrdenEnRuta
OrdenParada /POIS/vcblr#OrdenParada
ParadaConOrden /POIS/vcblr#ParadaConOrden
ParadaRelacionada /POIS/vcblr#ParadaRelacionada
PerteneceAParada /POIS/vcblr#PerteneceAParada
Prefiere /POIS/vcblr#Prefiere
Referencia /POIS/vcblr#referencia
Sector /POIS/vcblr#sector
Tipo /POIS/vcblr#tipo
VinculadaA /POIS/vcblr#VinculadaA
[image:47.595.138.487.107.328.2]ViveEn /POIS/vcblr#ViveEn
Tabla 6: U i s de Vo a ula io
2.3.
Publicación de Vocabulario
La publicación del vocabulario implica permitir el acceso al mismo desde cualquier lugar de la web, basándose comúnmente en la visualización del mismo en dos formas diferentes, la primera una vista entendible para las personas regularme basado en un documento HTML. Y la segunda un formato entendible para las máquinas en este caso RDF.
El acceso a estas definiciones se gestiona a través de la misma URI, es decir, la URI devolverá uno de los dos formatos según lo solicitemos. Este proceso es conocido como Dereference URI47 mediante un proceso conocido como negociación de contenido.
Basado en esto, son necesarios dos servicios específicos, que pueden o no ejecutarse en equipos físicamente separados, aunque esto es recomendable. El primer servicio se encargará de receptar las peticiones y resolverlas (similar a un DNS), mientras que el segundo almacenará y devolverá la información relativa al vocabulario.
En la actualidad existen servidores dedicados en la Internet que permiten realizar la función de re-direccionar hacia el almacenaje del vocabulario, como lo es PURL48 gestionado por OCLC49.
47 Dereferencing HTTP URIs.
http://www.w3.org/2001/tag/doc/httpRange-14/2007-08-31/HttpRange-14.html (draft)
Cúmar Ramiro Cueva Tacuri 36
En el presente trabajo se utilizará el servicio público de PURL para la publicación y para el almacenaje del vocabulario se utilizará un servidor Web Apache, el mismo que será instalado sobre una plataforma Linux, en este caso Ubuntu 11.04.
2.3.1.
Generación de la Descripción del Vocabulario
La creación del archivo de descripción para el vocabulario (necesario para la publicación) es generado mediante la utilización de OWLDoc[27], un plugin para Protégé, que permite exportar un vocabulario (ontología) a una versión HTML similar a la presentada por los JavaDoc. El plugin ha sido utilizado mediante la versión 4.x de Protégé.
Su instalación y uso puede ser encontrada en el ANEXO A
2.3.2.
PURL
El servicio de Persistent Uniform Resource Locator, conocido comúnmente como PURL, brinda identificadores permanentes para recursos en la web. Lo que permite mantener redirecciones a recursos que pueden cambiar a través del tiempo. Una lista de los servidores en internet que prestan este servicio puede ser encontrada en [28].
Figura 10:Partes de una PURL50
Su funcionamiento se basa en el uso de redirecciones51 bajo el protocolo HTTP,
para el uso en Web Semántica se ha estandarizado el uso de la redirección 303 See Other para el uso con PURL. Este tipo de redirección especifica que la respuesta a una solicitud puede ser encontrada en una URI diferente y que debe ser recuperada mediante el uso del método GET. Hay que notar que la redirección 303 y todas las del tipo 3xx son llevadas a cabo por los agentes de usuario sobre HTTP(user agents).
49 http://www.oclc.org
Cúmar Ramiro Cueva Tacuri 37
En donde:
a. El usuario realiza una petición GET a un servidor PURL, especificando un cierto tipo de contenido indicado por el campo Accept request-header. b. El servidor PURL emplea la redirección 303 para re-direccionar la petición
del usuario.
c. El servidor de destino (a donde apunta la redirección 303) realiza la operación de 'content negotiation' para finalmente devolver un recurso a la petición del usuario.
Figura 11:Funcionamiento de Server PURL
2.3.2.1. Configuraciones
Basado en las especificaciones de inicio de este apartado, se utilizará un servidor público PURL al cual se vinculará una dirección web en donde se alojarán los datos del vocabulario. En este caso serán:
Server PURL: http://purl.oclc.org
Servidor Web (apache): http://200.0.29.117:8080/pois/conten Para que se pueda utilizar la uri del servidor PURL
http://purl.oclc.org/POIS/vcblr
Como una uri desreferenciada que enlaza al vocabulario publicado en la dirección:
http://200.0.29.117:8080/pois/conten
Cúmar Ramiro Cueva Tacuri 38
Recordando que este proceso es ejecutado sobre un servicio en internet. En caso de requerir una instancia propia de PURL se puede contemplar la instalación de este, como se detalla en el ANEXO C.
2.3.3.
Apache HTTP Server
Apache HTTP Server52 es un proyecto mantenido por la comunidad de
desarrolladores de Apache Software Fundation53, el cual en la actualidad se ha
convertido en uno de los Servidores HTTP más robustos y confiables.
2.3.3.1. Negociación de Contenido (Content Negotiation)
El proceso de devolver un recurso diferente al usuario basado en una misma URI es conocido como Negociación de Contenido54, con lo cual el
usuario o aplicación puede solicitar determinado tipo de contenido que desea aceptar como respuesta, esto en base al campo Accept request-header que el protocolo HTTP especifica.
Una vez configurado nuestra PURL, la misma que referencia a nuestro servidor HTTP, será necesario colocar dentro de este último, nuestro contenido y configurar la recuperación del mismo mediante la negociación de contenido.
2.3.3.2. Configuraciones
La negociación de contenido es llevada a cabo mediante la sobre escritura de peticiones a una URL, para ello Apache HTTP Server posee un módulo que permite hacer uso de esta funcionalidad, conocido bajo el nombre de mod_rewrite55. Este módulo hace uso de expresiones regulares para realizar el re-direccionamiento a un determinado recurso o URL.
El proceso de configuración puede ser encontrado en el ANEXO D.
52
http://httpd.apache.org/
53 http://apache.org/
Cúmar Ramiro Cueva Tacuri 39
Mediante este proceso nuestro servidor web será capaz de responder a una petición en función del contenido solicitado, en este caso pudiendo responder mediante un archivo HTML o RDF.
2.3.4.
Pruebas
La comprobación de la funcionalidad completa de la publicación del vocabulario será evaluada en base al funcionamiento descrito en la Figura 11. Para ello se utilizará la utilidad cURL56, la misma que es una librería que automatiza el
intercambio de archivos.
El primer test de prueba será realizado para recuperar la versión en RDF del vocabulario. Para ello utilizamos los siguientes parámetros en cURL:
curl -i -H "Accept: rdf/xml" -L http://purl.oclc.org/POIS/vcblr
Figura 12:Content Negotiation - Archivo RDF
En donde especificamos el tipo de documento solicitado mediante la sentencia:
Accept: rdf/xml. Obteniendo con ello el archivo Vocabulario.rdf que fue colocado en el servidor Apache.
El segundo test se basa en la recuperación del archivo HTML del Vocabulario, para ello utilizamos:
curl -i -H "Accept: text/html" -L http://purl.oclc.org/POIS/vcblr
56