ESCUELA SUPERIOR DE INGENIERÍA MECÁNICA Y ELÉCTRICA
“
EVALUACIÓN DE UN SWITCH DE BAJA LATENCIA PARA
APLICACIÓN EN CLÚSTER
”
T
É
S
I
S
Q U E P A R A O B T E N E R E L T Í T U L O D E :
INGENIERO EN COMUNICACIONES Y ELECTRÓNICA EN LA ESPECIALIDAD DE
COMPUTACIÓN.
P R E S E N T A :
ROSA ADRIANA RIVERA DÍAZ
ASESORES:
DR. KLAUS MICHAEL LINDIG BOS
M. en C. JERARDO RODRIGUEZ COROY
GRACIAS….
Miguel
Por tu apoyo, por creer en mí, por darme esa confianza, ya que sin ella no hubiera podido concluir este episodio de mi vida en el que encontré enojos, alegrías, desesperación, frustraciones, lágrimas, pero siempre te tuve a mi lado para darme esas palabras de aliento y seguir. Todo el tiempo que estuve contigo fue de aprendizaje y puedo decir que hasta el último día de tu existencia fue así, inclusive en el momento de escribir estas líneas llenas de dolor por tu partida y a la vez llenas de alegría por la culminación de este trabajo que es también tuyo.
Gracias por todo lo aprendido en el tiempo que estuvimos juntos. Gracias por ser mi Amigo, Compañero, Cómplice y Maestro.
Rodri
Por tu comprensión por esos fines de semana que no pude estar contigo por estar realizando mis tareas, preparando clases, preparando mi examen, solo te puedo decir que el sacrificio valió la pena, Gracias por estar a mi lado y ser el pilar de mi vida.
Papá y Mamá
Por fin cumplí con ese compromiso que tenía con ustedes, Gracias por todo el apoyo y las palabras de aliento que tuve para continuar con este sueño hecho realidad.
OBJETIVO GENERAL:
Efectuar la comparación de los protocolos de comunicación Ethernet e Infiniband en un clúster, utilizando tarjetas de comunicación y switches para ambos protocolos.
OBJETIVOS PARTICULARES:
Evaluar los tiempos de ejecución con estos protocolos de comunicación, basado en un conjunto de programas de prueba homologados.
Implementar un clúster, utilizando tarjetas de comunicación y switches para ambos protocolos.
Realizar el análisis de los resultados obtenidos, con base a lo observado en ambos protocolos.
JUSTIFICACIÓN:
Capítulo 1. ... 10
El cluster de computadoras... 10
1.1 Cómputo paralelo ... 10
1.2 El modelo formal de cómputo paralelo ... 13
1.3 Realización física de la PRAM ... 14
1.4 El cluster ... 15
1.5 Arquitectura básica de un cluster ... 16
1.5.1 Inicialización ... 17
1.5.2 Operación ... 18
1.6 Arquitectura Beowulf ... 18
1.7 OpenMOSIX. Sistema de Imagen Única ... 20
1.8 Principales diferencias entre supercomputadoras y clusters Beowulf ... 21
1.9 Clusters en México ... 22
Capítulo 2 ... 24
Algunas topologías de redes de interconexión ... 24
2 Redes de interconexión fija ... 25
2.1 La red de bus común ... 25
2.2 La topología de anillo ... 27
2.3 La topología estrella ... 28
2.4 La malla y toroide en dos dimensiones ... 30
2.5 El toroide en tres dimensiones ... 35
2.6 El hipercubo... 37
2.7 Algunas consideraciones de factibilidad ... 41
2.8 Redes conmutadas ... 43
2.8.1 La red crossbar ... 43
2.8.2 La red mariposa ... 44
2.8.3 La generalización de la red mariposa para switches mayores a 2 x 2 ... 48
2.8.4 La red de Benes ... 50
2.8.5 Algunas características de la red “árbol grueso” construida a partir de switches crossbar escalonados. ... 51
3.1 La estructura de capas del protocolo Ethernet ... 64
3.1.1 La subcapa de control lógico de enlace ... 65
3.1.2 La subcapa de control de acceso al medio ... 66
3.1.3 La subcapa de reconciliación y la interfaz independiente del medio ... 67
3.1.4 La capa física ... 68
3.1.5 Dispositivos 100BASE-X ... 69
3.1.6 Codificación ... 70
3.1.7 Canal físico de cobre ... 71
3.1.8 Canal físico de fibra óptica ... 72
3.1.9 Codificación ... 74
3.1.10 El esquema de direccionamiento ... 74
3.2 El protocolo Infiniband ... 81
3.2.1 Características ... 82
3.2.2 Arquitectura IBA ... 84
3.2.3 Topologías ... 85
3.2.4 La operación basada en colas ... 87
3.2.5 Componentes IBA ... 87
3.2.6 Enlaces y repetidores ... 88
3.2.7 Adaptadores de canal ... 88
3.2.8 Switches ... 89
3.2.9 Enrutadores ... 90
3.2.10 Componentes de administración... 90
3.2.11 Administrador de subred ... 91
3.2.12 Agentes de administración de subred ... 91
3.2.13 Agentes de servicios generales ... 91
3.3 Características de IBA ... 92
3.3.1 Pares de colas (QP) ... 92
3.3.2 Tipos de servicio ... 93
3.3.3 La arquitectura IBA por capas ... 94
3.3.4 La capa física ... 95
3.3.5 La capa de enlace ... 95
3.3.8 La capa de transporte ... 97
3.3.9 Capas superiores ... 99
3.3.10 Administración de subred ... 99
3.3.11 Servicios generales ... 100
3.3.12 Direccionamiento ... 101
3.3.13 Direccionamiento por identificadores locales ... 102
Capítulo 4 ... 104
Evaluación física de los protocolos Ethernet e Infiniband con programas de prueba ... 104
4.1 Lizard... 105
4.2 Flops... 107
4.3 Linpack ... 108
4.4 Evaluación, Ethernet ... 108
4.4.1 Análisis del ping-pong ... 109
4.4.2 Aplicación Cluster Ethernet ... 114
4.5 Evaluación, Infiniband ... 116
Figura 1. 1 Algoritmo de la FFT... 11
Figura 1. 2 El modelo de PRAM ... 14
Figura 1. 3 Arquitectura de una máquina paralela ... 15
Figura 1. 4 Un clúster típico ... 17
Figura 2. 1 Máquina de bus común ... 25
Figura 2. 2 Figura de configuración de anillo ... 27
Figura 2. 3 el ancho de bisección... 28
Figura 2. 4 La configuración estrella ... 29
Figura 2. 5 Esquema simplificado de un switch estrella ... 29
Figura 2. 6 La topología de malla. Cada cuadro un procesador ... 31
Figura 2. 7 Un toroide en dos dimensiones ... 31
Figura 2. 8 La trayectoria del procesador 1 al 11 ... 32
Figura 2. 9 Un toroide en 3 dimensiones con N=3 ... 36
Figura 2. 10 Hipercubos de orden 1, 2, 3 y 4 ... 38
Figura 2. 11 Un hipercubo de orden 5 ... 38
Figura 2. 12 Un switch de datos para el toroide 2D ... 42
Figura 2. 13 (a) La red gráfica bipartita (b) su realización física ... 43
Figura 2. 14 La gráfica de la red mariposa con 8 entradas y salidas ... 44
Figura 2. 15 El switch crossbar con dos entradas y salidas ... 45
Figura 2. 16 La realización física de la red mariposa... 46
Figura 2. 17 Un ejemplo de conflicto interno: las asignaciones 0 -- 2 y 2-- 3 no pueden transmitirse simultáneamente ... 48
Figura 2. 18 La red mariposo con switches de M por M ... 49
Figura 2. 19 La red de Benes con N=3 ... 50
Figura 2. 20 Las trayectorias para la asignación 1--3 ... 50
Figura 2. 21 Un árbol grueso de 16 entradas/salidas de 2 niveles ... 52
Figura 2. 22 Un árbol grueso de 8 entradas/salidas de 3 niveles ... 53
Figura 2. 23 El mismo árbol con switches de 2 por 2 entradas y salidas ... 53
Figura 2. 24 mismo árbol configurado como una red unidireccional ... 54
Figura 2. 25 Una trayectoria posible desde la entrada 2 a la salida 6 ... 55
Figura 2. 26 Otra trayectoria posible desde la entrada 2 a la salida 6... 56
Figura 2. 27 (a) El árbol grueso binario de 16 entradas/salidas (b) El mismo árbol con switches cross de 4 por 4 ... 57
Figura 3. 1 Interconexión full duplex ... 62
Figura 3. 2 Una red full dúplex ... 63
Figura 3. 3 Relación entre el estándar IEEE 802.3 y el modelo OSI ... 64
Figura 3. 4 La estructura de capas del estándar IEEE 802.3 ... 65
Figura 3. 5.Datagrama Ethernet ... Figura 3. 6 Datagrama, acceso al medio (MAC) ... 70
Figura 3. 7 corresponde a la secuencia 101001101 ... 72
Figura 3. 8 una red de área ... 83
Figura 3. 9 IBA aplicado a un sólo anfitrión ... 84
Figura 3. 10 La red IBA ... 85
Figura 3. 11 dos subredes IBA enlazadas por un ruteador ... 85
Figura 3. 12 componentes de una subred IBA ... 86
Figura 3. 13 El nodo de procesamiento ... 87
Figura 3. 14 El adaptador de canal ... 89
Figura 3. 15 El switch IBA ... 90
Figura 3. 19 segmentación de datos ... 98
Figura 3. 20 elementos de administración de subred ... 100
Figura 3. 21 servicios generales ... 101
Figura 3. 22 direcciones IBA ... 102
Figura 4. 1 esquema de dos servidores ... 104
Figura 4. 2 Cluster CIDETEC ... 114
Figura 4. 3Rendimiento Lizad 10 Ethernet GB/s ... 115
Figura 4. 4 Rendimiento Lizard 10 GB/s Infiniband ... 117
Índice de Tablas
Tabla 1.1 Principales diferencias entre supercomputadoras y clusters Beowulf ... 21
Tabla 1. 2 Clusters en México ... 23
Tabla 2. 1 incremento de velocidad, ζ, como función de p ... 26
Tabla 2. 2 La distancia entre vecinos para N = 4 ... 32
Tabla 2. 3 incremento de velocidad, ζ, como función de p ... 34
Tabla 2. 4 incremento de velocidad de ejecución, ζ, para diferentes valores de p ... 36
Tabla 2. 5 distancia entre el nodo 0 y los demás nodos del cubo ... 39
Tabla 2. 6 incremento de velocidad, ζ, como función de p ... 40
Tabla 2. 7 algunas características de las redes examinadas ... 40
Tabla 2. 8 Un ejemplo numérico para 64 procesadores ... 41
Tabla 2. 9 retardo promedio de la red mariposa para asignaciones aleatorias. ... 48
Tabla 2. 10 cantidades de interruptores y retardos de propagación... 51
Tabla 2. 11 Una red de 16 procesadores con switches de distinto orden ... 57
Tabla 2. 12 Cantidad de niveles (CN), de switches (CS) y de interruptores (CI) para diferentes cantidades de procesadores (N) y órdenes de switch (K) ... 59
Tabla 3. 1 Algunas características de fibras ópticas ... 74
Tabla 3. 2 Una gráfica y b) un árbol de expansión de la misma ... 76
Tabla 3. 3 Una gráfica con pesos, b) y c) dos árboles de expansión ... 77
Tabla 3. 4 una red de cinco nodos ... 78
Tabla 3. 5 Determinación del árbol de expansión para la gráfica de la figura 9 ... 80
Tabla 3. 6 a) la gráfica original y b) el árbol de expansión resultante... 81
Tabla 3. 7 Tipos de servicio ... 94
Tabla 4. 1 Análisis del ping-pong (1) ... 110
Tabla 4. 2 Tiempo de transmisión y Ancho de banda ... 112
Tabla 4. 3 Tiempo de transmisión y Ancho de banda en cluster ... 116
Tabla 4. 4 Análisis de pingpong Infiniband ... 118
10
Capítulo 1.
El cluster de computadoras
La demanda de mayor velocidad de procesamiento ha sido constante a lo largo de la historia de la computación y no se prevé que esto cambie en el futuro. Los problemas que requieren alta velocidad de procesamiento se encuentran en las áreas de cálculo numérico, modelado, simulación numérica de problemas científicos, de diseño de productos, en procesamiento de imágenes y otros campos, en una gran variedad de disciplinas científicas y de ingeniería.
Generalmente, el encontrar una solución a este tipo de problemas requiere una gran cantidad de cálculos numéricos similares sobre un determinado conjunto de datos. Utilizando técnicas de programación paralela, el tiempo requerido para efectuar estos cálculos se puede reducir en función a la cantidad de elementos de procesamiento disponibles. Históricamente, la solución técnica para permitir la interacción de un gran número de procesadores toma la forma de las llamadas supercomputadoras, constituidas por procesadores y elementos de comunicación especialmente diseñados para este fin. Por su propia naturaleza, las supercomputadoras no se benefician del factor de escala inherente a productos de amplio consumo, como por ejemplo las máquinas personales, que en consecuencia resultan extremadamente costosas. También, su período de obsolescencia es relativamente corto, lo que dificulta la amortización de su costo de adquisición. Finalmente, el ambiente de software utilizado en estas máquinas depende en general del fabricante de la máquina y no obedece a las características del software de uso común, lo que dificulta su uso.
1.1 Cómputo paralelo
El término “cómputo paralelo” se utiliza actualmente para una gran variedad de
11
datos). La máquina paralela corresponde, entonces, al modelo de múltiples instrucciones, múltiples datos (multiple instruction, multiple data – MIMD) de la
taxonomía de Flynn.
Como ejemplo, considérese el algoritmo utilizado para resolver numéricamente la transformada de Fourier sobre N=2n muestras de datos, donde n es un entero
positivo. Este algoritmo conocido como la transformada rápida de Fourier (fast Fourier transform – FFT) requiere la evaluación de (N/2)log2N operaciones
[image:12.612.201.410.264.582.2]llamadas mariposas, donde cada operación es de la forma x=a+bW, y=a-bW, y a, b, x, y, W son números complejas. El flujo de datos y resultados parciales se ilustra en la siguiente Figura 1. 1 para N=16:
Figura 1. 1 Algoritmo de la FFT
Ahora bien, en el tiempo 1 8 procesadores ejecutan la mariposa sobre los datos
de entrada (nótese que se aplican en orden invertido bit a bit) y exportan uno de sus resultados a otro procesador. Por ejemplo, el procesador ubicado en la fila superior exporta sus resultados a la misma fila (a sí mismo), y a la inmediata inferior. En el tiempo 2 los mismos procesadores repiten la operación sobre los
12
Para el ejemplo anterior resulta que las (N/2) log2N = 32 operaciones igual a otros
tantos tiempos de ejecución que requeriría un solo procesador se pueden ejecutar en 4 tiempos si se cuenta con 8 procesadores, un incremento de velocidad igual al número de procesadores, lo que es óptimo.
En la práctica, la cantidad de muestras a procesar es, desde luego, mucho mayor a las del ejemplo. Supóngase que se desean procesar 65,536 muestras (216). Un
solo procesador requeriría 524,288 tiempos de ejecución. Si tuviéramos 32,768 procesadores, tardaríamos 16 tiempos. En general, no se dispone de esta cantidad de procesadores, por lo que se recurre a la partición del problema en tareas independientes entre sí, en el sentido de que su ejecución no requiere de resultados generados por otras tareas, ni que el control de ejecución de una tarea depende de las demás (independencia de datos y control). Para el ejemplo anterior, y suponiendo que se dispone de 8 procesadores, la partición puede tomar la forma siguiente:
El procesador 1 ejecuta una FFT parcial sobre los datos 0 al 15, el procesador 2 sobre los datos 16 al 31, etc. Estas operaciones son claramente independientes entre sí, y requieren 32 unidades de tiempo cada una. Como los 8 procesadores procesan 8x16=128 datos, y requerimos procesar 65,536, este proceso se repite 65,536/128=512 veces y se requieren 512x32=16,384 unidades de tiempo. Al terminar, los 8 procesadores intercambian sus resultados parciales. Esta partición se repite 16/4=4 veces. El tiempo total requerido es, entonces, 4(16,384)= 65,536 y el incremento de velocidad corresponde a 524,288 /65,536 = 8, igual al número de procesadores.
La figura 1.1 corresponde a la gráfica de datos del problema. En el análisis anterior no se consideró el tiempo de comunicación de los datos entre los procesadores. Si este tiempo es significativo en comparación al tiempo de ejecución, el incremento de velocidad disminuye en términos del máximo alcanzable. Considérese el ejemplo de la Figura 1. 1, suponiendo que el tiempo de
ejecución es la unidad, y que el tiempo de comunicación corresponde a la mitad del tiempo de ejecución. Cada n corresponde entonces a 1.5, y el tiempo total
requerido 1.5x4=6. El incremento de velocidad resultante es 32/6=5.333, claramente inferior al máximo alcanzable de 8. De lo anterior se desprende que una buena máquina paralela debe satisfacer los siguientes requisitos:
a) El esquema de interconexión entre procesadores debe corresponder en la mejor medida de lo posible a las gráficas de problema de los algoritmos a ejecutar. Como la misma máquina debe ser capaz de ejecutar muchos
algoritmos distintos, su esquema de interconexión debe “contener” las
13
b) El tiempo requerido para transferir un dato entre procesadores debe ser lo menor posible. Esto implica que el proceso de comunicación debe ser controlado por hardware. El manejo de situaciones especiales, tales como el acceso a una dirección de destino desde más de un procesador (colisión de destino), si es resuelto por software debe ser función del sistema operativo y no debe involucrar otras capas de software ubicadas entre la aplicación y el sistema operativo. En todo caso, el manejo de estas situaciones y la posible sincronización de procesos requerida, debe ser transparente para la aplicación.
Conviene confrontar estos requisitos con el modelo formal de máquina paralela, la PRAM.
1.2 El modelo formal de cómputo paralelo
En ciencias de la computación, una computadora paralela se define en términos de un modelo formal que permite establecer el rendimiento de la misma para la solución de problemas clasificados por su complejidad. El modelo tal vez más utilizado es el de la PRAM (parallel random-access machine, o máquina paralela
14 Figura 1. 2 El modelo de PRAM
Cuando más de un procesador accede a la memoria compartida en un mismo ciclo de máquina y a la misma dirección, se generan conflictos cuya solución define 7 clases de máquinas PRAM. El modelo más débil prohíbe esta situación tanto para lectura, como para escritura, esto es, la máquina detiene la ejecución [1]. Modelos más fuertes permiten la lectura concurrente, pero no la escritura. El modelo más fuerte permite la escritura concurrente, especificando que el dato escrito es el mayor (o, equivalentemente, el menor) de los datos proporcionados por los procesadores.
1.3 Realización física de la PRAM
Evidentemente, la PRAM es un modelo físicamente no realizable. El requerimiento de una memoria compartida accesible por un gran número de procesadores en forma concurrente no puede ser satisfecho en la práctica. Por otra parte, y haciendo referencia al modelo más fuerte, la determinación de cuál de P datos es el mayor (o menor) donde P es el número de procesadores, utilizando un algoritmo paralelo requiere log2P unidades de tiempo, lo que contradice el requerimiento de
la ejecución en un ciclo de máquina. Sin embargo, lenguajes de programación paralela como el FORTRAN (formula translation), asumen que el programa
compilado es ejecutado por una PRAM. Los fabricantes de máquinas paralelas proporcionan programas propietarios que emulan una PRAM como una extensión (de hecho, una biblioteca de rutinas) del sistema operativo. Esto es, la aplicación
“ve” una PRAM independientemente de la arquitectura física de la máquina en que
15
En prácticamente todas las máquinas paralelas, la memoria está físicamente distribuida en los procesadores que la conforman. La memoria de cada procesador es lógicamente dividida en dos áreas de direccionamiento, una que constituye la memoria propia, y otra que constituye parte de la memoria compartida del sistema. La memoria compartida es, entonces, la suma de las áreas de direccionamiento destinadas a ese fin de todos los procesadores.
El acceso a la memoria compartida se resuelve por medio de una red de interconexión que, idealmente, permite el acceso concurrente desde cualquier procesador a cualquier módulo de memoria. El problema de accesos concurrentes a un mismo módulo es resuelto por arbitraje. La consistencia de memoria, esto es, el garantizar que el contenido de las memorias caché de los procesadores y de las correspondientes direcciones en los módulos de memoria sea el mismo en todo momento, es resuelto por protocolos específicos ejecutados ya sea en hardware o software. La Figura 1. 3 reproduce una arquitectura típica de una máquina paralela:
Figura 1. 3 Arquitectura de una máquina paralela
1.4 El cluster
Actualmente, con los avances tecnológicos en microprocesadores de bajo costo, como los usados en las computadoras personales actuales (PC´s), estas máquinas ofrecen una gran capacidad de cómputo. Sin embargo, esta capacidad es aún insuficiente para resolver problemas de alto grado de complejidad o que requieren de recursos de almacenamiento que exceden lo disponible en una PC. A partir de la década de los años 90, muchos proyectos de investigación se llevan a cabo para utilizar un conjunto de máquinas de bajo costo comercialmente disponibles interconectadas a través de una Red de Área Local (LAN), como una
16
estos problemas complejos. A estos conjuntos de máquinas interconectadas se les conoce como clusters. Algunos ejemplos de proyectos relacionados con clusters
son el proyecto Beowulf [2] [3][4], NOW[5][6], SHRIMP[7], y muchos más.
Entonces, un cluster de computadoras es simplemente un conjunto de máquinas
interconectadas entre sí. En este sentido, el cluster no se diferencia de una red de
computadoras. Lo que distingue al cluster de una red es que todos los elementos
de procesamiento que lo conforman se dedican a la solución de un problema computacional complejo utilizando programación paralela.
En la actualidad, se cuenta con la tecnología necesaria para construir un cluster
de máquinas capaz de competir con algunas supercomputadoras, en cuanto a su capacidad de cómputo y almacenamiento, a un costo sustancialmente menor usando como elementos de procesamiento a PC’s o estaciones de trabajo de bajo costo. Un buen ejemplo se encuentra en la Universidad de Kentucky, donde el cluster KASY0 con un costo aproximado de 39,500 dólares y un rendimiento de 471 GFlops medido con HPL Linpack precisión simple (32bits) [8], rompió la barrera de los 100 dólares por GFlop a finales del año 2003.
De acuerdo a su finalidad, se pueden definir tres diferentes tipos de cluster:
- Sistemas Tolerantes a Fallas - Sistemas de Alta Disponibilidad
- Sistemas de Cómputo de Alto Rendimiento
Estos últimos sistemas son utilizados en la resolución de los problemas donde se requiere cómputo intensivo o gran cantidad de recursos computacionales. Este trabajo trata específicamente los sistemas Cómputo de Alto Rendimiento (High Perfomance Computing, HPC) basados en la arquitectura Beowulf y los Sistemas
de Imagen Única (Single System Image, SSI). 1.5 Arquitectura básica de un cluster
En un cluster, típicamente una de las máquinas que lo conforman posee teclado,
monitor y equipos de entrada/salida y constituye la máquina de control, mientras que las demás carecen de estos periféricos y operan como servidores. Los servidores y la máquina de control se interconectan típicamente por uno, o varios switches. La máquina de control puede adicionalmente poseer un enlace ya sea a una red propietaria de una organización, o a servicios como Internet. En este sentido, el cluster pude ser visto como una red local (Local Area Network, LAN),
17
Desdeel punto de vista de software, un cluster requiere una interfaz entre el
sistema operativo de las máquinas y el programa de aplicación, tanto para la inicialización del sistema como durante la operación del mismo. Este software de interfaz, también llamado middleware, interactúa con el protocolo de comunicación
utilizado por la red. De manera resumida, el middleware debe satisfacer los requerimientos de inicialización, y los correspondientes a la operación (ejecución de un programa de aplicación), como sigue:
Figura 1. 4 Un clúster típico
1.5.1 Inicialización
Al evocar el usuario un programa de control y manejo de cluster, como por
ejemplo el HPC de Microsoft, un parámetro solicitado es la cantidad de núcleos de procesamiento disponibles. Una vez proporcionado, el programa verifica la existencia de los mismos y determina las rutas de acceso disponibles entre estos núcleos. En general, pueden ser efectuadas por un programa de la máquina de control, o por un procesador ubicado en la tarjeta de comunicación de esta máquina. También, procesadores o lógica dedicada ubicada en los switches de interconexión pueden estar involucrados en el proceso.
18
Por otra parte, el protocolo también debe poseer la capacidad de detectar la inclusión, la remoción o la falla de un nodo de procesamiento. Si bien el tiempo de ejecución durante la fase de inicialización no es crítico, sí lo es para la verificación de la configuración. Dado que durante este proceso los procesadores no pueden ejecutar programas de aplicación, la interrupción generada por esta ejecución debe ser lo más breve posible.
1.5.2 Operación
La ejecución de un programa de aplicación puede requerir el intercambio de información entre dos o más procesadores en cualquier momento de la ejecución. Dada una configuración física de la red, el protocolo de comunicación puede sobreponer a esta configuración una configuración lógica para aprovechar de mejor manera los recursos de comunicación disponibles.
Como se mencionó con anterioridad, el cluster se integra con componentes y subsistemas comercialmente disponibles, no optimizados para una configuración de red relativamente sencilla, sino desarrollados para ser usados en redes complejas de comunicación de datos. En consecuencia, es importante analizar las funciones soportadas por los protocolos asociados a estos componentes y subsistemas, con el objetivo de determinar cuáles de los servicios aportados por estos protocolos son requeridos por el esquema de cluster mostrado en la Figura 1. 4.
1.6 Arquitectura Beowulf
En 1994, la Agencia Espacial NASA comenzó el Proyecto Beowulf [3] en el Centro para la Excelencia en Datos Espaciales y Ciencias de la Información (CESDIS), cuyo resultado fue la construcción de un Cluster de 16 máquinas destinado al
Proyecto de Ciencias Espaciales y Terrestres (ESS) ubicado en el Centro de Vuelo Espacial de Goddard (GSFC). El concepto Beowulf se difundió rápidamente en la NASA y en las comunidades académicas y científicas a escala mundial. Un cluster Beowulf constituye una arquitectura escalable de muchas
computadoras, con elementos de hardware de uso común y bajo costo y no
contiene elementos de hardware especializados. Los nodos están constituidos por cualquier computadora capaz de ejecutar el Sistema Operativo LINUX o Windows Server, y software para el desarrollo de aplicaciones paralelas. Un cluster Beowulf
19
En su forma general, un cluster Beowulf posee un nodo Servidor y uno o varios nodos de cómputo llamados nodos Cliente, interconectados a través de una LAN. El nodo Servidor controla los nodos Cliente y también es la Consola y la interfaz hombre-máquina del Cluster.
Los nodos Cliente del sistema se usan sólo para propósitos de cómputo. Una característica importante de los Cluster del tipo Beowulf es su escalabilidad. Los
cambios en los microprocesadores y en su velocidad, o la tecnología de las redes de interconexión de los nodos, no afecta el modelo de programación. Por lo tanto, se garantiza la compatibilidad a los usuarios del sistema. Por otra parte, la madurez alcanzada por el Sistema Operativo LINUX y su robustez, la estandarización de librerías GNU para el "paso de mensajes" como PVM y MPI, garantizan a los programadores que las aplicaciones que desarrollen, se ejecutarán en futuras versiones de estos elementos de software y, por lo tanto, en Clusters del tipo Beowulf actualizados, independientemente de la plataforma de hardware.
Computacionalmente hablando, un cluster Beowulf constituye una sola máquina.
En la mayoría de los casos, los nodos Cliente no poseen teclados, ratones (mouse) o monitor, y son accedidos desde el nodo Servidor. Así, los nodos Cliente
representan un componente que posee una o varias Unidades de Procesamiento y memoria local que se suma a la memoria total del sistema. No existe necesidad de que los nodos Clientes sean accedidos directamente por sistemas externos, ni que éstos accedan al exterior. Por esta razón, los nodos Cliente forman una red privada (intranet) conectada al nodo Servidor. Para cumplir con ésta característica,
el nodo Servidor posee una interfaz de red NIC adicional que permite el acceso y uso del Cluster desde cualquier estación de trabajo externa. Los usuarios del
sistema acceden al nodo Servidor, bien sea desde la consola o por vía de otra red, Internet, etc. donde pueden editar y compilar sus aplicaciones y ejecutar su código en los nodos Cliente y Servidor del Cluster.
Tal vez el software de manejo de clusters más conocido sea el MPI (Message Passing Interface) escrito originalmente para uso con el sistema operativo LINUX
y, más recientemente, el HPC (High Performance Computing) de Microsoft. Uno
20 1.7 OpenMOSIX. Sistema de Imagen Única
Un cluster Beowulf constituye un sistema de imagen única (Single System Image,
SSI) donde los usuarios o procesos perciben al conjunto de máquinas como una unidad. Este es el modelo de referencia para muchos de los Sistemas Operativos que actualmente están en desarrollo para arquitecturas del tipo cluster. Si bien en
la actualidad no existe ningún sistema100% SSI para el sistema operativo LINUX, OpenMosix [8] representa una solución bastante cercana. Entre sus principales características SSI implementadas, está la capacidad de balancear de carga computacionalentre los nodos de forma dinámica y deproporcionar, al usuario, un espacio para el acceso a archivos similar a NFS pero distribuido entre los nodos del sistema llamado Mosix FileSystem (MFS).
OpenMosix es una extensión del Kernel del sistema operativo LINUX que aporta la
funcionalidad básica de cluster Middleware. Estas extensiones del Kernel son las
responsables de convertir un conjunto de computadoras interconectadas a través de una LAN, en una Supercomputadora, permitiendo que los nodos trabajen en estrecha cooperación. Los algoritmos encargados de compartir los recursos (Resource Sharing Algorithms) del sistema OpenMosix están diseñados para
responder en línea a las variaciones en el uso de recursos entre los nodos que componen el cluster. Esto se logra a través de la migración de procesos de un
nodo a otro de manera transparente para el usuario, con el objeto de balancear la carga entre los nodos del cluster. Así, el objetivo es mejorar el desempeño del
sistema completo y crear un ambiente multiusuario de tiempo compartido para la ejecución de aplicaciones secuenciales y paralelas.
La tecnología OpenMosix consiste en dos partes: Un mecanismo para la Migración Adelantada de Procesos (Preemptive Process Migration, PPM) y un conjunto de
algoritmos que permiten compartir los recursos entre los nodos de manera adaptativa. El mecanismo PPM es capaz de migrar cualquier proceso, en cualquier momento, acualquier nodo disponible del cluster.
Usualmente, las migraciones se basan en información provista por uno de los algoritmos para compartir recursos. Sin embargo, los usuarios pueden migrar sus procesos manualmente invalidando las decisiones tomadas por el sistema automáticamente. Estos algoritmos están detallados en [9].
OpenMosix no posee un sistema de Control Central. Cada nodo opera como un sistema completamente autónomo y toma sus propias decisiones de control de manera independiente. Este diseño particular permite la configuración dinámica del Cluster, donde los nodos pueden entrar o salir del conjunto de máquinas que
conforman el Cluster en cualquier momento, con un efecto mínimo de
21
para configuraciones de pequeña escala, como para configuraciones con gran cantidad de estaciones.
1.8 Principales diferencias entre supercomputadoras y clusters Beowulf
De manera resumida, la Tabla 1.1 indica las principales diferencias entre supercomputadoras y clusters Beowulf:
supercomputadora cluster
CPU tipo RISC:
tiempos de ejecución predecibles CPU tipo PC o servidor multinúcleo, varias unidades ejecutoras por núcleo predicción de saltos
tiempos de ejecución no predecibles red de interconexión dedicada,
controlada por hardware red de interconexión comercial, controlada por protocolo de comunicación de propósito general topología de la red de interconexión
fija, establecida por diseño topología de la red de interconexión arbitraria, definida por la LAN interfaz CPU-red de interconexión
contenida en los elementos de procesamiento
interfaz CPU-red de interconexión dada por tarjeta de comunicaciones ubicada en el bus de expansión emulación de la PRAM por biblioteca
contenida en el sistema operativo emulación de la PRAM por
middleware
ubicado entre el sistema operativo y la aplicación
sincronización de procesos
relativamente más sencilla sincronización de procesos relativamente más compleja diseño específico, alto costo por
[image:22.612.88.527.196.508.2]unidad de procesamiento componentes comerciales, bajo costo por unidad de procesamiento gracias al factor de escala de producción
Tabla 1.1 Principales diferencias entre supercomputadoras y clusters Beowulf
En términos generales, las diferencias arriba señaladas se traducen para la supercomputadora en menores tiempos de espera entre la solicitud de una transferencia y la respuesta a la misma (latencia), cantidad arbitraria de bytes por mensaje, sin necesidad de formatos y encabezados de los mensajes (costo adicional o overhead de la información útil), menores tiempos requeridos por la
22
Por lo señalado en el ejemplo de la FFT, para la supercomputadora el incremento en velocidad alcanzable es más cercano al límite p, donde p es el número de procesadores, aún para un pequeño número de instrucciones ejecutadas antes del proceso de comunicación (granularidad fina). Para el clúster, la cantidad de instrucciones ejecutadas antes del proceso de comunicación debe ser mucho más alta, para que el costo en tiempo de la comunicación no degrade significativamente el incremento de velocidad alcanzable (granularidad gruesa). Esto marca la diferencia entre los campos de aplicación: el cluster es más eficiente
para el procesamiento concurrente de grandes tareas, que para el procesamiento de programas paralelos como fueron definidos aquí. Por lo tanto, los protocolos de comunicación de menor latencia y menor costo de información adicional a la de datos útiles, y el uso de redes de alta conectividad constituyen los medios para ampliar el espectro de aplicaciones del clúster y, consecuentemente, mejorar su
competitividad con relación a las supercomputadoras.
1.9 Clusters en México
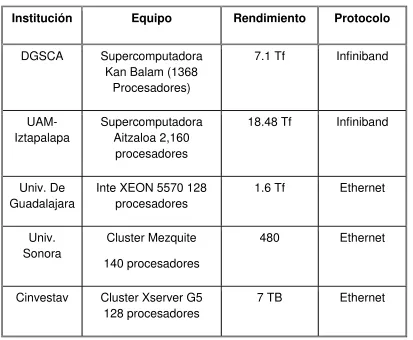
En México existe la supercomputadora (cluster) llamada Kan Balam de la
Dirección General de Servicios de Cómputo Académico de la UNAM, que tiene una capacidad de 7,113 billones de operaciones aritméticas por segundo, ó 7.1 TFlops, se trata de un cluster de 1,368 procesadores.
La UAM Iztapalapa cuenta con el cluster Aitzaloa, un arreglo de servidores ubicado en el Laboratorio de Supercómputo y Visualización en Paralelo (LSVP) que cuenta con 540 procesadores Quad Core, o 2,160 núcleos de procesamiento con una capacidad de 18.48 Teraflops. Cada nodo posee 16 GB en RAM, lo que suma 4.320 TB de RAM distribuida.
El CICESE, el IMP, la Universidad de Sonora y el CINVESTAV, entre otras instituciones mexicanas, cuentan con áreas o departamentos dedicados al uso, enseñanza o investigación en supercómputo. En el ámbito gubernamental, PEMEX, el Instituto Nacional de Metrología y la SHCP disponen de equipos de supercómputo.
23
Institución Equipo Rendimiento Protocolo
DGSCA Supercomputadora Kan Balam (1368
Procesadores)
7.1 Tf Infiniband
UAM-Iztapalapa
Supercomputadora Aitzaloa 2,160
procesadores
18.48 Tf Infiniband
Univ. De Guadalajara
Inte XEON 5570 128 procesadores
1.6 Tf Ethernet Univ.
Sonora
Cluster Mezquite 140 procesadores
480 Ethernet
Cinvestav Cluster Xserver G5 128 procesadores
[image:24.612.97.510.65.405.2]7 TB Ethernet
24
Capítulo 2
Algunas topologías de redes de interconexión
Los procesadores de una máquina paralela pueden ser interconectados de muchas formas. Este problema ha sido objeto de grandes esfuerzos de investigación a partir de la década de los ochenta y sigue siendo estudiado hoy en día. Para un tratado detallado de este tema, consúltese la referencia [10]. Los principales atributos de una buena red de interconexión pueden resumirse como sigue:
a) Poseer la menor latencia posible.
b) Ofrecer la mayor cantidad de enlaces entre procesadores posible. Idealmente, para que P procesadores puedan intercambiar información de manera concurrente, se requieren enlaces bidireccionales entre cada uno de los procesadores que conecta a todos los demás (la gráfica completa que se presenta más adelante).
c) Ofrecer una velocidad de comunicación alta, esto es, un ancho de banda alto.
d) La red debe ser escalable, en el sentido de que sea posible agregar más procesadores de acuerdo a los requerimientos de procesamiento.
e) La red debe ser redundante, en el sentido de que la falla de algún enlace no impida la operación de la red. Esto es, no debe poseer puntos de falla catastróficos.
f) Los objetivos anteriores deben lograrse al menor costo posible. Esto es, la red debe representar una fracción del costo total del sistema.
Como problema de ingeniería, las características anteriores no son todas alcanzables, en especial en lo referente a su costo, por lo que un esquema determinado representa un compromiso entre los factores citados arriba que debe cumplir los objetivos particulares planteados para el sistema. No puede ser objeto del presente trabajo presentar un análisis exhaustivo de las topologías existentes, por lo que aquí se presentan solamente algunas que han sido utilizadas, o se usan actualmente, en particular en sistemas tipo cluster.
25
la red crossbar, la mariposa y sus variantes, y una de gran importancia que será
descrita en el siguiente capítulo, la red de árbol grueso (fat tree). 2 Redes de interconexión fija
2.1 La red de bus común
Esta máquina cuenta con un solo medio de comunicación compartido por todos los procesadores, característica de la cual se deriva su nombre (véase Figura 2. 1). Se
trata claramente de la solución más sencilla y más económica posible. Por su propia naturaleza, permite solamente un enlace en un tiempo dado, por lo que en una situación de múltiples solicitudes de comunicación solamente una puede ser satisfecha a la vez y las restantes deben esperar a que se concluya la transacción previa. Lo anterior se puede lograr por dos mecanismos:
a) El protocolo de comunicación soporta colisiones y establece un mecanismo para resolver este conflicto. Un protocolo que posee esta característica es el protocolo Ethernet.
b) El sistema incluye un mecanismo de arbitraje, que ante la presencia de más de una solicitud asigna una prioridad mayor a una de ellas, misma que entonces es atendida mientras las demás esperan su turno. La asignación de prioridades puede ser fija, aleatoria, o circular tal que el procesador de mayor prioridad, después de ser atendido, se convierte en el procesador de menor prioridad y así sucesivamente.
Figura 2. 1 Máquina de bus común
26
datos al final de este lapso y deben esperar la conclusión de estas transacciones antes de reiniciar el procesamiento, se tiene la siguiente situación:
El trabajo útil, esto es, la cantidad de instrucciones ejecutadas, está dado por p(e).
El tiempo total requerido es e + p(c).
Si definimos el incremento de la velocidad de ejecución, ζ, como el cociente
, con p > 1, es fácil ver que ζ disminuye conforme p crece. Nótese que el incremento es igual a la unidad para p=1, puesto que entonces no hay comunicación entre procesadores. Para valores de p grandes, ζ → e/c. Esto es, el máximo valor de ζ que se puede obtener con esta red es independiente del número de procesadores y tiende en el límite a la relación tiempo de ejecución/tiempo de comunicación. Esta relación se conoce, también, como la granularidad del problema.
[image:27.612.266.347.395.503.2]Como ejemplo numérico, supóngase que e=10 y c=1. La Tabla 2. 1muestra a ζ para diferentes valores de p:
p ζ 1 1.000 2 1.667 5 3.333 10 5.000 --- --- 1000 9.901
Tabla 2. 1 incremento de velocidad, ζ, como función de p
27 2.2 La topología de anillo
Si se unen los dos extremos del bus común, se obtiene la configuración de anillo, como lo muestra la Figura 2. 2. En lo referente al incremento de la velocidad de procesamiento, esta configuración posee las mismas características que el bus común. Pero si el anillo se interrumpe en algún punto, el resultado es el bus común discutido arriba, esto es, el sistema puede seguir operando.
Figura 2. 2 Figura de configuración de anillo
Una característica importante de cualquier red es el ancho de bisección (bisection width), definido como la cantidad de enlaces que deben ser removidos para dividir
28 Figura 2. 3 el ancho de bisección
Así, antes del corte el procesador P1 se puede comunicar con el procesador P2 vía el enlace superior, pero también vía el enlace inferior al que están conectados los procesadores P4 y P3. El ancho de bisección es 2, porque dos enlaces deben ser removidos para obtener dos subredes de 2 procesadores cada una. En general, para redes más complejas que ésta, mientras mayor sea el ancho de bisección, mayor es el incremento de velocidad alcanzable para una cantidad de procesadores dada.
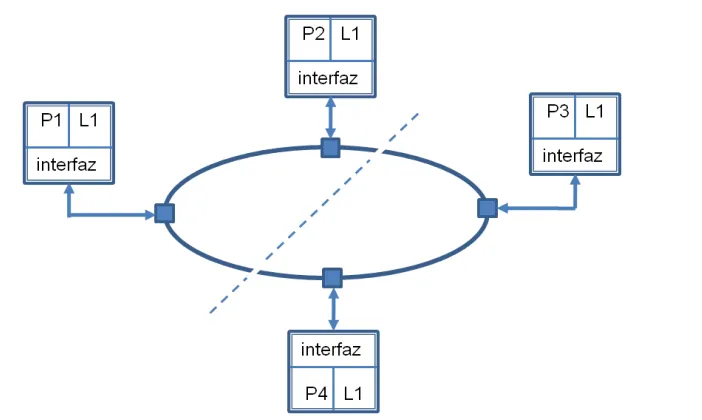
2.3 La topología estrella
Una forma de evitar el problema de las colisiones en caso de solicitudes concurrentes de acceso es mediante la configuración estrella que se muestra en la Figura 2. 4. Aquí, el punto de unión de los enlaces de los procesadores constituye básicamente un esquema de conmutación asociado a una memoria configurada como cola (memoria FIFO: first in-first out) capaz de almacenar un cierto número
29 Figura 2. 4 La configuración estrella
La operación del switch central puede resumirse como sigue (véase la Figura 2. 5 La lógica dedicada detecta, en cada una de p entradas, la presencia de una solicitud de transferencia de datos para cada unidad de tiempo. Si existe una solicitud, es atendida en cualquiera de las siguientes condiciones:
No existe otra solicitud en esta unidad de tiempo, y la cola no está llena.
Existe otra u otras solicitudes en las demás entradas, pero la entrada considerada es la de mayor prioridad y la cola no está llena.
En caso de que ninguna de las condiciones anteriores se satisface, el o los paquetes de datos adicionales son almacenados en la cola. Si ésta ya no tiene capacidad de almacenamiento, los paquetes adicionales se pierden y el o los procesadores afectados deben repetir la solicitud de acceso. Nótese que el esquema requiere de arbitraje, como ya se discutió para la configuración de bus común.
30
En caso de que la solicitud pueda ser atendida, la lógica dedicada configura a uno de los switches de salida para enviar el paquete a su destino. Es importante observar que el envío puede comenzar tan pronto como se disponga de la dirección destino, misma que está contenida en el encabezado del paquete. Esto es, no se requiere que el paquete esté contenido en su totalidad en la cola antes de comenzar el envío al destino final. Con ello se reduce considerablemente la latencia de acceso, lo que constituye la ventaja principal de la configuración. Pero la cola realiza una función adicional, esto es, la sincronización de los procesos de entrada y salida. La escritura de un paquete en la cola se efectúa con la frecuencia de operación de la tarjeta de interfaz del procesador, mientras que la lectura de la cola se efectúa con la frecuencia de operación del switch. Aunque nominalmente estas frecuencias son iguales, no coinciden en su fase ni son exactamente iguales entre sí, por lo que se requiere esta capacidad de sincronización.
Nótese que el esquema como se discutió arriba requiere 2p switches de un polo, un tiro. Este dato será comparado con el de otras configuraciones más adelante. Por otra parte, el switch es un punto de falla potencialmente catastrófico. Finalmente, aunque el switch constituye, de hecho, un esquema conmutado, no se considera a esta red como una red conmutada porque permite un solo enlace entre pares de procesadores en un tiempo dado. Redes conmutadas propiamente dichas permiten, en general, más de un enlace simultáneo entre pares de procesadores. Estos esquemas se discuten más adelante.
2.4 La malla y toroide en dos dimensiones
La malla es una topología en dos dimensiones que se muestra en la Figura 2. 6.
31 Figura 2. 6 La topología de malla. Cada cuadro un procesador
Tal vez la primera computadora paralela sea la máquina ILLIAC IV construida en la universidad de Illinois en Chicago. Esta máquina utiliza la configuración de toroide en dos dimensiones mostrada en la Figura 2. 7, en la que se observa que
cada procesador posee 4 enlaces, indistintamente de su ubicación en la red.
Figura 2. 7 Un toroide en dos dimensiones
32
optimización complejo. Por lo tanto, en la práctica se utiliza un algoritmo sencillo tal que cada nodo pueda resolver por sí mismo. Supóngase que se acepta la convención que toda comunicación ocurre primero en el sentido horizontal, hacia la derecha del procesador solicitante, y luego en el sentido vertical, hacia abajo del procesador solicitante. La Figura 2. 7 ilustra lo anterior para N=4 y suponiendo que
el procesador 1 desea una transferencia al procesador 11:
Figura 2. 8 La trayectoria del procesador 1 al 11
Se desprende de la Figura 2. 8 la trayectoria que posee una longitud igual a 4. Se puede determinar la distancia media entre procesadores como sigue.
Partiendo del nodo 1, se observa que existen dos vecinos a una distancia de 1 (los nodos 2 y 5). También, existen tres vecinos a una distancia de 2 (los nodos 3, 6 y 9). Procediendo de la misma manera, podemos construir la siguiente
Tabla 2. 2:
distancia cant. de vecinos 0 1 1 2 2 3 3 4 4 3 5 2 6 1
33
La distancia media entre vecinos es, entonces: [0(1)+1(2)+2(3)+3(4)+4(3)+5(2)+6(1)]/16 = 48/16=3
Nótese que el resultado anterior se obtiene a partir de cualquier nodo de la red. Como el toroide es una red que se cierra sobre sí misma, cualquier nodo puede ser ubicado en la esquina superior izquierda con simples rotaciones de la red. Sean dos nodos a una distancia de 1 vecinos cercanos. Asumiendo que el tiempo de comunicación es el mismo para cualquier par de vecinos cercanos, y suponiendo que no existen colisiones internas a la red, esto es, ningún arco entre dos vecinos cercanos es utilizado por más de una transferencia en un tiempo dado, entonces la distancia media representa una medida de la latencia de la red. En general, y para cualquier N, se puede probar que la distancia media, dm, está
dada por dm = N-1, y la distancia máxima, dM está dada por dM= 2(N-1).
Supóngase que la distancia media sea proporcional a la latencia de la red. Como se mencionó arriba, esto es correcto solamente si no existe contención interna a la misma. Como lo anterior depende del algoritmo específico que se ejecute, en ciencias de la computación se emplean modelos probabilísticos para estimar la latencia. Sin embargo, existen muchos algoritmos de importancia práctica que no generan contención interna, como por ejemplo la solución numérica de sistemas de ecuaciones parciales, algoritmos de procesamiento de imágenes ortogonales, y otros. Para esta clase de algoritmos, podemos comparar esta red con la de bus común como sigue:
a) Como para la red de bus común, el trabajo útil, esto es, la cantidad de instrucciones ejecutadas, está dado por p(e).
b) Como p=N2, el tiempo total requerido es ahora
e + (N-1)(c) = e + ( -1)(c).
El incremento de velocidad de ejecución en función al número de procesadores es, entonces:
Para p(e) >> (e), el incremento de velocidad ζ tiende a:
34
Esto es, a diferencia del bus común, el rendimiento del toroide en dos dimensiones no tiende a un límite para valores de p grandes.
Para el mismo ejemplo numérico, esto es, e=10 y c=1, la tabla 2.3 muestra el
incremento de velocidad de ejecución, ζ, para diferentes valores de p:
p ζ
4 3.636 9 7.500 16 12.308 25 17.875 --- --- 1024 249.756
Tabla 2. 3 incremento de velocidad, ζ, como función de p
Resumiendo, las principales características del toroide en dos dimensiones son las siguientes:
1.- La latencia crece linealmente con el orden de la red, esto es, proporcional a la raíz cuadrada del número de procesadores.
2.- La cantidad de enlaces entre procesadores es constante e igual a 4 para cualquier número de procesadores.
3.- La velocidad de comunicación entre vecinos cercanos depende de la tecnología empleada para construir los enlaces.
4.- La red es escalable, en principio sin límite, porque la cantidad de enlaces por procesador es constante e independiente del orden de la red.
5.- La red no posee puntos de falla catastróficos. Para cualquier enlace que falle, existen rutas alternas que interconectan los procesadores.
35 2.5 El toroide en tres dimensiones
Una manera de reducir la distancia media entre procesadores consiste en aumentar el orden de la red. Para el toroide en tres dimensiones de orden N, la cantidad de procesadores, p, es ahora p=N3. La Figura 2. 4muestra lo anterior para
N=3. Como para el caso del toroide en dos dimensiones, lo subsecuente se limita al caso de que la cantidad de procesadores por dimensión sea la misma, esto es, la red constituye un cubo. Para el caso general, consúltese [10].
Un algoritmo de enrutamiento sencillo similar al descrito para el toroide en dos dimensiones puede ser el siguiente. Supóngase que se acepta la convención que toda comunicación ocurre a partir del nodo solicitante primero en orden creciente de x, luego en orden decreciente de y finalmente en orden creciente de z.
Por inspección, se observa que la distancia máxima entre nodos es 3(N-1). También, se puede probar que la distancia media es dm=(3/2)(N-1) y el ancho de
bisección es 2N2. Bajo el supuesto de que la latencia es proporcional a la distancia media, el incremento de velocidad alcanzable toma la forma:
y, como N=p3,
36 Figura 2. 9 Un toroide en 3 dimensiones con N=3
Para valores de p grandes, el incremento de velocidad tiende a:
Para el mismo ejemplo numérico, esto es, e=10 y c=1, la Tabla 2.4 muestra el incremento de velocidad de ejecución, ζ, para diferentes valores de p:
p N ζ
27 3 20.8 64 4 44.1 125 5 78.2 216 6 123.4 343 7 180.5
512 8 249.8
Tabla 2. 4 incremento de velocidad de ejecución, ζ, para diferentes valores de p
Donde G es la granularidad. Nótese que esta red se aproxima más al ideal en el sentido de que el incremento de velocidad deseable es proporcional al número de procesadores.
37
1.- La latencia crece linealmente con el orden de la red, pero proporcional a la raíz cúbica del número de procesadores.
2.- La cantidad de enlaces entre procesadores es constante, pero igual a 6 para cualquier número de procesadores.
3.- La red es más costosa que el toroide en dos dimensiones por la mayor cantidad de enlaces, y porque cada nodo debe incorporar un esquema de conmutación que permita el acceso desde cualquiera de 6 enlaces al procesador, así como la comunicación entre cualquier par de enlaces.
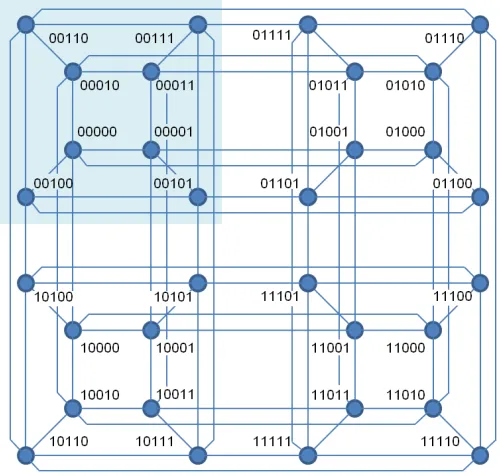
2.6 El hipercubo
Esta red es de gran importancia, tanto práctica como teórica. En el sentido práctico, porque es una red con altos rendimientos para muchos algoritmos de cálculo numérico. En el sentido teórico, porque su tratamiento matemático es relativamente sencillo y elegante. Por otra parte, se puede probar [10] que esta red
“contiene” a las redes aquí discutidas y otras más, en el sentido de que si un
algoritmo corre eficientemente en alguna de estas redes, también lo hace en el hipercubo.
Dado un conjunto de nodos enumerados como la secuencia ordenada < 0, 1, 2,
…, p >, donde p es de la forma p=2N con N un entero, entonces cada nodo posee
38 Figura 2. 10 Hipercubos de orden 1, 2, 3 y 4
La Figura 2. 11 muestra un hipercubo de orden 5 dibujado a partir de 4 cubos de
orden 3 proyectados en el plano:
[image:39.612.182.432.390.628.2]39
Las siguientes propiedades pueden verificarse fácilmente:
1.- La cantidad total de enlaces es N2N-1. Lo anterior se desprende de la observación de que cada nodo posee N enlaces por nodo y la red posee 2N nodos. Como cada enlace une a dos nodos, el resultado sigue.
2.- El ancho de bisección es 2N-1. En efecto, una bisección reduce el orden de los hipercubos resultantes a la mitad. Por inspección (véase la figura 15), la bisección del hipercubo de orden 1 genera dos hipercubos de orden 0 (un nodo en cada cubo). De manera similar, la bisección del hipercubo de orden 2 genera dos hipercubos de orden 1, etc. Por inducción, el resultado sigue. 3.- La distancia máxima entre nodos es N. La distancia media entre nodos es N/2.
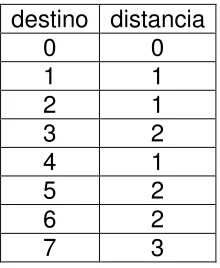
Por ejemplo, para el cubo de orden 3 y partiendo del nodo 0, los nodos 1, 2,
…, se encuentran a las distancias indicadas en la tabla ¡Error! No se encuentra el origen de la referencia.5 siguiente:
[image:40.612.252.362.283.417.2]destino distancia 0 0 1 1 2 1 3 2 4 1 5 2 6 2 7 3
Tabla 2. 5 distancia entre el nodo 0 y los demás nodos del cubo
De la tabla 2.8 se desprende que para el hipercubo con N=3 la distancia máxima es N. La suma de las distancias es 12, y la distancia media es 12/8 = 1.5 = N/2. Como el número de procesadores es 2N, entonces en términos de la cantidad de
procesadores, p, la distancia media es (½)log2p. Bajo los mismos supuestos de los
casos anteriores, esto es, que no existen colisiones en la red y de que la latencia es proporcional a la distancia media, el incremento de velocidad alcanzable toma la forma:
Para valores de p grandes, el incremento de velocidad tiende a:
40 Tabla 2. 6 incremento de velocidad, ζ, como función de p
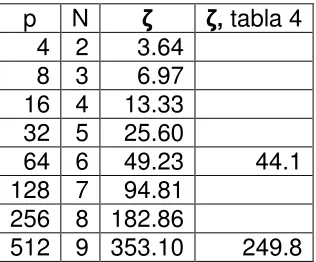
muestra el incremento de velocidad de ejecución, ζ, para diferentes valores de p. La columna 4 muestra el valor de ζ obtenido para el toroide en 3 dimensiones:
p N ζ ζ, tabla 4 4 2 3.64
8 3 6.97 16 4 13.33 32 5 25.60
64 6 49.23 44.1 128 7 94.81
256 8 182.86
512 9 353.10 249.8
Tabla 2. 6 incremento de velocidad, ζ, como función de p
Aunque el hipercubo es claramente la mejor de las redes de interconexión fija, no es fácilmente escalable en virtud de que el número de enlaces crece linealmente con el orden del cubo. Por esta razón, en la práctica se construyen hipercubos solamente para un número bajo de procesadores (p≤1024). Sin embargo, el
hipercubo constituye una referencia para la evaluación de redes conmutadas, que se examinan en el siguiente punto.
La tabla 2.7 resume las principales características de las redes de interconexión fija antes examinadas. En la tabla, p es el número de procesadores y N el orden de la red:
Topología Ancho de
bisección por nodo enlaces enlaces total de distancia media entre nodos Anillo 2 2 p (p-1)/2
Toroide 2-D 2N (p=N2) 4 2N2 N-1 Toroide 3-D 2N2 (p=N3) 6 3N3 (3/2)(N-1)
Hipercubo 2N-1 (p=2N) N N2N-1 N/2
41
Supóngase que p=64. Substituyendo este valor, de la tabla 2.8 resultan los siguientes valores:
Topología Ancho de
bisección por nodo enlaces enlaces total de distancia media entre nodos Anillo 2 2 64 32.5
Toroide 2-D 16 4 128 7 Toroide 3-D 32 6 192 4.5 Hipercubo 32 6 192 3
Tabla 2. 8 Un ejemplo numérico para 64 procesadores
Nótese que para p=64, el ancho de bisección y el total de enlaces es el mismo para el toroide 3D y para el hipercubo. Sea p=512. Entonces, el ancho de bisección es, respectivamente, 128 y 256, el total de enlaces 1536 y 2304, y la distancia media 10.5 y 4.5 para el toroide 3D y para el hipercubo. En conclusión, mientras mayor sea el ancho de bisección y la cantidad total de enlaces, menor es la distancia media y, en consecuencia, la latencia de la red. Claro está, también el costo crece en función a estos factores.
2.7 Algunas consideraciones de factibilidad
En aplicaciones tipo cluster los elementos de procesamiento son computadoras o
servidores comercialmente disponibles en las que el bus de expansión cuenta con un número limitado de espacios para tarjetas de comunicaciones. Considérese el bus PCIX operando a una frecuencia de 66 MHz con un formato de de 64 bits, lo que equivale a un ancho de banda de 528 MB/s (megabytes/segundo). Supóngase que se desea construir un toroide 2D con estas máquinas. Entonces, se requieren 4 tarjetas de comunicación por máquina, que en un tiempo determinado puede recibir la misma cantidad de solicitudes de transferencia de datos.
Tarjetas de comunicación de alta velocidad ofrecen actualmente anchos de banda de 10 Gb/s (gigabits/segundo) o más, equivalentes a 1 GB/s (gigabytes/segundo) bajo el esquema de codificación 8 a 10.
42
destino es él mismo, o algún otro nodo de la red. Si el destino no es el nodo que recibe la solicitud, el procesador debe determinar cuál tarjeta de comunicaciones se enlaza con el destino o siguiente nodo en la trayectoria, y transferir el bloque de datos a esta tarjeta. En consecuencia, hasta 8 transferencias entre tarjetas de comunicación y memoria pueden ser requeridas en un tiempo determinado. Suponiendo que estas transferencias se efectúan con el esquema DMA (direct memory access) a la velocidad del bus de expansión, el ancho de banda efectivo
por solicitud se reduce a 66 MB/s. Este ancho de banda es la décimo sexta parte del ancho de banda de la tarjeta de comunicación, lo que constituye una seria limitante del esquema.
Una forma de resolver este problema consiste en asociar a cada nodo un switch de datos, que se encarga de enrutar los paquetes recibidos a sus respectivos destinos sin la intervención del procesador asociado a ese nodo. La Figura 2. 12muestra un esquema simplificado de este switch.
El switch incluye memorias configuradas como colas para propósitos de sincronización (véase también el punto I.3) y para evitar pérdidas de paquetes en caso de saturación de solicitudes de acceso. Nótese que el switch puede iniciar la re-transmisión de datos tan pronto reciba la dirección destino, contenida en el encabezado del paquete, lo que reduce considerablemente la latencia del proceso.
43 2.8 Redes conmutadas
2.8.1 La red crossbar
Esta red, inventada a fines del siglo XIX para ser aplicada en telefonía, permite la comunicación desde cualquier nodo de entrada a cualquier nodo de salida. Esto es, para el mismo número de entradas y salidas y si no existen solicitudes desde distintas entradas a una misma salida (colisiones de destino), permite la
transferencia de cualquier permutación de la secuencia ordenada < 1,2, …, N ) a
las salidas. La Figura 2. 13 muestra la gráfica correspondiente, conocida como
gráfica bipartita completa, y su realización física basada en interruptores de 1 polo, 1 tiro:
Figura 2. 13 (a) La red gráfica bipartita (b) su realización física
Para N entradas y salidas, la red requiere N2 interruptores, por lo que no se considera escalable sin límite. Sin embargo, para un número limitado de procesadores, es la mejor red posible porque introduce solamente un retardo de conmutación para cualquier transferencia sin colisiones de destino. El incremento de velocidad alcanzable es, entonces:
44 2.8.2 La red mariposa
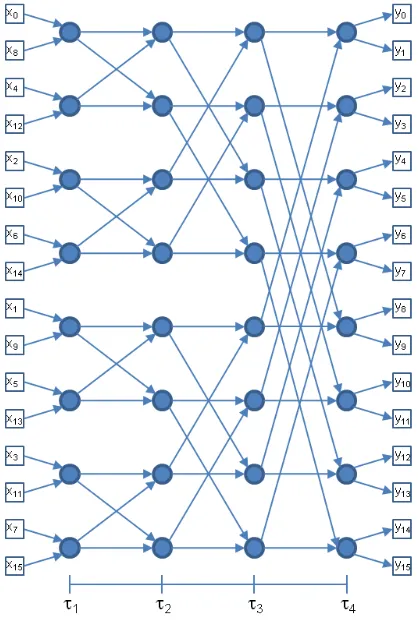
Para reducir el número de interruptores requerido por la red crossbar, se han
[image:45.612.218.365.243.412.2]propuesto muchas alternativas de redes escalonadas, de las cuales la más importante es, sin duda, la mariposa. En general, mientras la gráfica bipartita posee solamente una columna de nodos de entrada y otra de salida, redes escalonadas se fundamentan en gráficas que poseen columnas intermedias como se muestra en la Figura 2. 14:
Figura 2. 14 La gráfica de la red mariposa con 8 entradas y salidas
La red se construye a partir del siguiente algoritmo. Sea N el orden de la red. Entonces, la red posee p=2N filas y N+1 columnas, donde p es el número de entradas y salidas. Sea j el número de fila, con j=0,1,…,2N-1 y k el número de columna, con k=0,1,…,N. Entonces, cada nodo j,k posee un arco al nodo j,k+1 (arcos horizontales). Un segundo arco une al nodo j,k con el nodo j’,k+1 donde j’
es, ya sea, mayor a j, o menor a j (arcos diagonales).
Para obtener el valor de j’, definimos la cantidad de grupos de nodos, G, ubicados
en filas adyacentes en la columna k como G=2k. Entonces, la columna 0 posee 1 grupo, la columna 1 posee 2 grupos, etc. Cada grupo posee, entonces, p/G nodos. Substituyendo los valores para p y G en términos de N y k, se obtiene p/G=2N-k. Así, para N=3, la columna 0 posee un grupo con 2N-k=23-0=8 nodos, la columna 1 posee 2 grupos con 23-1=4 nodos cada uno, etc. Nótese que entre grupos no existe ningún arco diagonal a la siguiente columna (de la columna k a la columna k+1).
45
Entonces, j’ está dada por:
j’= g(p/G) + (i + p/2G)mod p/G, con i=0, 1, …,(p/G) -1.
Ejemplo. Sea N=3
Para k=0, tenemos g=0, p/G=8, p/2G=4 e i=0,1, …,7. Substituyendo estos valores en la expresión anterior, resulta:
Para j=0,1,…,7, j’= 0(8) + (i + 4)mod 8, de donde j’= 4, 5, 6, 7, 0, 1, 2, 3
Para k=1, resulta g=0,1; p/G=4, p/2G=2 e i=0,1, 2, 3. Substituyendo como arriba, se tiene:
Para j=0,1,2,3, j’= 0(4) + (i + 2)mod 4, de donde j’= 2, 3, 0, 1, y Para j=4,5,6,7, j’= 1(4) + (i + 2)mod 4, de donde j’= 6, 7, 4, 5.
Para k=2, resulta g=0,1,2,3; p/G=2, p/2G=1 e i=0,1. Substituyendo como arriba, se tiene:
Para j=0,1, j’= 0(2) + (i + 1)mod 2, de donde j’= 1, 0, y Para j=2,3, j’= 1(2) + (i + 1)mod 2, de donde j’= 3, 2, y Para j=4,5, j’= 2(2) + (i + 1)mod 2, de donde j’= 5, 4, y Para j=6,7, j’= 3(2) + (i + 1)mod 2, de donde j’= 7, 6
Substituyendo en la expresión j’= g(p/G) + (i + p/2G)mod p/G, con i=0, 1, …,(p/G) -1,
los valores de p y G se obtiene:
j’=g2N-k + (i + 2N-k-1)
mod 2N-k , con g = 0,1,…, 2k-1e i = 0,1,…, 2N-k-1.
La red mariposa se construye a partir de switches tipo crossbar de dos entradas y
salidas. De la figura 18 se desprende que ningún nodo ubicado en la columna k+1 puede recibir simultáneamente un dato desde el enlace horizontal y desde el enlace diagonal a la columna k. Si esto ocurriera, se tendría una colisión interna en la red. En consecuencia, los switches permiten únicamente las transferencias indicadas en la Figura 2. 15:
46
En la figura anterior, (a) es el símbolo del switch, (b) y (c) muestran las transferencias permitidas y (d) es la realización física basada en 4 interruptores de 1 polo y 1 tiro.
Considérese la figura 18, en las que se señalan algunas cuartetas de nodos, unidos por pares por dos enlaces horizontales y diagonales. Cada cuarteta se incorpora, entonces, a un switch, y la realización física de la red toma la forma mostrada en la Figura 2. 16:
Figura 2. 16 La realización física de la red mariposa
Nótese que en la realización física mostrada en la figura anterior, el orden de las entradas y salidas está alterado con relación a la gráfica de la red.
La red mariposa posee p/2 switches por columna, con N=log2p columnas, donde p
es el número de entradas, p=2N, y N el orden de la red. La cantidad total de switches es, entonces, (p/2)log2p. Como cada switch requiere 4 interruptores
1polo, 1 tiro, la cantidad total de interruptores es (2p)log2p. Comparado con la red
crossbar, que requiere p2 interruptores, se observa que la red mariposa requiere
menos interruptores que la red crossbar para toda p>4. Por ejemplo, sea p=64,
esto es, sea el orden N de la red igual a 6. Entonces, la red mariposa requiere 2(64)(6)=768 interruptores, mientras que la red crossbar requiere (64)2=4096. La red mariposa posee las siguientes propiedades, cuya demostración se encuentra en [10].