UNIVERSIDAD TÉCNICA PARTICULAR DE LOJA La Universidad Católica de Loja
TITULACIÓN DE INGENIERO EN INFORMÁTICA
TEMA:
"Publicación de datos universitarios enlazados observando los principios de Linked Data"
Trabajo de fin de titulación.
AUTORA: Calva Cumbicus, Rosa Alba
DIRECTOR: Piedra Pullaguari, Nelson Oswaldo, Ing.
Centro universitario Guayaquil
I
Certificación
Ingeniero.
Nelson Oswaldo Piedra Pullaguari
DIRECTOR DEL TRABAJO DE FIN DE TITULACIÓN
C E R T I F I C A:
Que el presente trabajo, denominado: “PUBLICACION DE DATOS
UNIVERSITARIOS ENLAZADOS OBSERVANDO LOS PRINCIPIOS DE LINKED DATA " realizado por el profesional en formación: Calva Cumbicus Rosa Alba; cumple con los requisitos establecidos en las normas generales para la Graduación en la Universidad Técnica Particular de Loja, tanto en el aspecto de forma como de contenido, por lo cual me permito autorizar su presentación para los fines pertinentes.
Loja, Septiembre de 2012
II
Cesión de derechos
“Yo Calva Cumbicus Rosa Alba declaro ser autor (a) del presente trabajo y eximo
expresamente a la Universidad Técnica Particular de Loja y a sus representantes legales de posibles reclamos o acciones legales.
Adicionalmente declaro conocer y aceptar la disposición del Art. 67 del Estatuto Orgánico de la Universidad Técnica Particular de Loja que su parte pertinente textualmente dice: “Forman parte del patrimonio de la Universidad la propiedad intelectual de investigaciones, trabajos científicos o técnicos y tesis de grado que se realicen a través, o con el apoyo financiero, académico o institucional (operativo) de la universidad”.
... Calva Cumbicus Rosa Alba 1103924021
III
DEDICATORIA
Dedico este trabajo de Tesis a Dios y a mi Virgencita Del Cisne por permitirme poder culminar este proyecto de tesis, a mi querido Esposo Omero Castillo, a mi adorado hijo Homerito Fernando, a mis Padres Samuel Calva y Bélgica Cumbicus, a cada uno de mis hermanos, hermanas por el apoyo incondicional que he recibido a lo largo de mi vida, a mis Cuñados (as) a toda mi familia, a mis amigas (os), compañeros de universidad y de tesis por el gran apoyo que de su parte he recibido,
a cada uno de mis profesores
IV
AGRADECIMIENTO
Doy infinitas gracias a Dios nuestro Padre Celestial y Nuestra Madre Santísima en vocación a la Virgencita del Cisne de la cual soy fiel devota por todas las bendiciones que a diario recibo, mil gracias también a toda mi familia en especias mis adorados padres Samuel y Bélgica, mis hermanos, hermanas por su amor y apoyo incondicional, nunca podría pagarles todo el apoyo que de su parte he recibido, a mis queridas amigas amigos por la motivación que siempre me han sabido dar para que logre mi meta, gracias también a todos mis profesores por
brindarme con paciencia sus
conocimientos para llegar a ser una profesional, a mis compañeros de tesis gracias por todos chicos, gracias al Ing. Nelson Piedra un gran ser humano le quedo inmensamente agradecida por su apoyo, paciencia, por su motivación. Y como no agradecer a mi amado Esposo Omero Castillo mil gracias mi amor por todo el apoyo que me brindaste por tu paciencia y comprensión para que pueda culminar mi objetivo a mi tesorito el regalo más hermoso que Diosito me ha dado mi Homerito Fernando mi bebe precioso.
A todos les quedo eternamente
V
ÍNDICE GENERAL
ÍNDICE GENERAL ... V ÍNDICE DE TABLAS ... VIII ÍNDICE DE GRÁFICOS ... IX RESUMEN ... X INTRODUCCIÓN ... XI
CAPÍTULO I ... 1
1. ESTADO DEL ARTE... 1
1.1. HISTORIA ... 1
1.2. EVOLUCIÓN DE LA WEB ... 2
1.2.1. FUNDAMENTOS DE LA WEB ... 2
1.2.2. WEB SOCIAL ... 2
1.2.3. WEB SEMÁNTICA ... 3
1.2.4. WEB DE DATOS LINKED DATA ... 4
1.3. LINKED DATA ... 4
1.3.1. PRINCIPIOS ... 6
1.3.2. PROCESO DE PUBLICACIÓN DE DATOS ... 7
1.3.3. TECNOLOGÍAS ... 8
1.4. RESOURCE DESCRIPTION FRAMEWORK RDF... 10
1.5. MOTORES DE REPRESENTACIÓN (RDF DATA STORE) ... 11
1.6. EXPLOTACIÓN DE DATOS SPARQL (PROTOCOL AND RDF QUERY LANGUAGE) ... 13
1.6.1. VISUALIZACIÓN Y CONSUMO DE DATOS ... 14
1.7. TRABAJOS RELACIONADOS ... 15
1.7.1. PROYECTO LODUM Linked Open Data University of Münster ... 15
1.7.2. THE OPEN UNIVERSITY data.open.ac.uk ... 16
1.7.3. BIO2RDF Project ... 16
VI
1.8. Análisis de LINKED DATA como estrategia de OPEN DATA en el ámbito
universitario e investigativo ... 17
CAPITULO II ... 19
2. PROBLEMA: ... 19
2.1. ACCESO A LA INFORMACIÓN UNIVERSITARIA... 20
2.1.1. DATOS NECESARIOS ... 20
2.1.2. DATOS EXISTENTES EN LA ACTUALIDAD ... 20
2.1.3. OBTENCIÓN DE DATOS ... 21
2.2. IDENTIFICACIÓN Y SELECCIÓN DE FUENTES ... 21
2.3. PROPUESTAS DE SOLUCIÓN ... 21
CAPÍTULO III ... 23
3. DESCRIPCIÓN DE PROCESOS APLICANDO LINKED DATA ... 23
3.1. APLICACIÓN DE LINKED DATA ... 23
3.2. IDENTIFICACIÓN DE DATOS. ... 23
3.3. SELECCIÓN DE DATOS ... 23
3.4. EXTRACCIÓN DE DATOS ... 23
3.5. PREGUNTAS QUE SE PRETENDE RESPONDER ... 24
3.6. REUTILIZACIÓN DE VOCABULARIOS ... 25
3.7. PLAN DE DESAMBIGUACIÓN ... 27
3.8. PLAN DE ISTANCIACIÓN ... 31
3.8.1. RECOLECCIÓN DE DATOS EN UNA TABLA DE EXCEL ... 31
3.8.2. CREACIÓN DE NUEVOS VOCABULARIOS... 32
3.8.3. DESCRIPCIÓN DE CLASES Y PROPIEDADES DE LOS VOCABULARIOS ... 33
3.8.4. ESTABLECER RELACIONES ENTRE LAS TABLAS MYSQL. ... 35
3.9. Generación de Código RDF. ... 37
3.10. CREACIÓN DE UNA MACRO EN EXCEL PARA EXTRAER LOS DATOS DE LAS TABLAS. ... 37
3.10.1. CÓDIGO DE LA MACRO ... 37
3.11. GENERACIÓN DEL CÓDIGO N3. ... 39
3.12. RESULTADO DEL MINDSWAP ... 39
VII
3.14. RESULTADO DEL VALIDADOR ... 41
3.15. GRAFICO RDF ... 43
CAPITULO IV ... 45
4. CONSULTAS Y RESULTADOS ... 45
4.1. INSTALACIÓN DEL 4STORE ... 45
4.2. CARGAR EL CÓDIGO RDF AL 4STORE ... 46
4.3. RESULTADOS DE LA APLICACIÓN ... 48
4.4. CONSULTAS EN SPARQL CON LOS RESULTADOS ... 49
4.5. CONSULTAS DESDE LA DBPEDIA ... 70
CAPÍTULO V ... 73
5. DISCUSIÓN Y ANALISIS ... 73
CAPITULO VI ... 81
6. CONCLUSIONES Y RECOMENDACIONES ... 81
6.1. CONCLUSIONES... 81
6.2. RECOMENDACIONES ... 82
ANEXOS ... 83
VIII
ÍNDICE DE TABLAS
TABLA 1: CONJUNTO DE DATOS ABIERTOS ... 5
TABLA 2: EJEMPLO DE TRIPLETA RDF CON DATOS DE LA UTPL ... 11
TABLA 3: MOTORES DE REPRESENTACIÓN RDF DATA STORE. ... 12
TABLA 4: LISTA DE PREGUNTAS QUE SE PRETENDE RESPONDER CON LA UTILIZACIÓN DE LINKED DATA. ... 25
TABLA 5: PLAN DE DESAMBIGUACIÓN DE VOCABULARIOS ... 27
TABLA 6: VOCABULARIOS AMBIGÜOS ... 30
TABLA 7: LISTA DE VOCABULARIOS SELECCIONADOS ... 31
TABLA 8: VOCABULARIOS CREADOS PARA LA ELABORACIÓN DEL PROYECTO. ... 33
TABLA 9: PROPIEDADES DE LA CLASE UNIVERSITY ... 33
TABLA 10: PROPIEDADES DE LA CLASE TYPE ... 34
TABLA 11:PROPIEDADES DE LA CLASE CATEEGORY ... 34
TABLA 12: PROPIEDADES DE LA CLASE AUTHORITY ... 34
TABLA 13: PROPIEDADES DE LA CLASE FACULTY ... 34
TABLA 14: PROPIEDADES DE LA CLASE CARRER ... 35
IX
ÍNDICE DE GRÁFICOS
GRAFICO 1: MUESTRA EL CONJUNTO DE DATOS ABIERTOS QUE HAN SIDO PUBLICADOS DESDE EL 01/05/2007 HASTA EL MÁS RECIENTE PUBLICADO
EL 19/09/2011. ... 6
GRAFICO 2: ESQUEMA DE PUBLICACIÓN DE DATOS ... 8
GRAFICO 3: GRAFO SENTENCIA RDF ... 10
GRAFICO 4: MAPA CONCEPTUAL DE UNIVERSIDADES. ... 11
GRAFICO 5: CONSULTA SPARQL EN DBPEDIA ... 14
GRAFICO 6: RELACIÓN DE LAS TABLAS UTILIZANDO MYSQL ... 36
GRAFICO 7. CÓDIGO N3 INGRESADO EN LA HERRAMIENTA DE MINDSWAP. ... 39
GRAFICO 8. CÓDIGO RDF ... 40
GRAFICO 9. MUESTRA EL VALIDATOR SERVICE CON EL CÓDIGO RDF PARA VERIFICAR SI EL CÓDIGO RDF ES CORRECTO. ... 41
GRAFICO 10. RESULTADOS QUE ARROJA EL VALIDATION SERVICE PRESENTANDO EL SUJETO PREDICADO Y OBJETO EN FORMA DE TABLA EXCEL. ... 42
GRAFICO 11. MODELO RDF EN FORMA GRÁFICA. ... 44
GRAFICO 12. PANTALLA DEL TERMINAL DE LINUX UBUNTU ... 48
GRÁFICO 13. CONSULTAS DESDE LA DBPEDIA CON PREDICADO Y OBJETO PARA UNIVERSIDADES DEL ECUADOR ... 71
GRÁFICO 14. CONSULTAS DESDE LA DBPEDIA CON SUJETO Y PREDICADO DE UTPL ... 72
X
RESUMEN
El gran problema de la web de hoy es la aglomeración de información que se encuentra disponible en la red, donde la búsqueda de datos se vuelve cada vez más tediosa tomando en cuenta el sector educativo de las Universidades del Ecuador donde la información la mantienen de forma individual es decir en páginas web de cada Universidad, el objetivo de este trabajo es lograr que la información tanto de aspecto general y académico se encuentre relacionada y enlazada tomando en cuenta los principios de Linked Data con el objetivo de mejorar la calidad de información que el usuario requiere.
El desarrollo de componentes de este proyecto de Tesis les permitirá publicar datos en formato RDF, entendible por máquinas sobre: Aspectos académicos y de organización de Universidades Ecuatorianas.
Se recolectó toda la información académica y de aspecto general de 69 Universidades del Ecuador almacenándolas en tablas divididas cada una por su clase y propiedades de las mismas, así mismo se creó una Macro para evitar la sobre escritura de la información y poder obtener el código N3 para posterior a ello convertirlo en código RDF.
XI
INTRODUCCIÓN
Tim Berners-Lee -creador de la WWW- presentó un conjunto de buenas prácticas para la publicación y vinculación/conexión de datos estructurados en la Web, los
principios de Linked Data1. Esto supone una evolución de la Web hacia un espacio
global de información en el que la navegación se realiza a través de datos estructurados enlazados en lugar de documentos Web, como sucede ahora.
Para las iniciativas OER (Open Educational Resource), Linked Data permite pasar de una Web en la que los recursos son documentos HTML en la que el usuario humano es el destinatario de la información publicada, a una Web de Datos Enlazados que están expresados en RDF (W3C, 2009a), un lenguaje para
representar significados sobre recursos, en la que agentes software pueden
explotar estos datos de forma automática (recopilándolos, agregándolos, interpretándolos, publicándolos, mezclándolos, etc.), potenciados por vocabularios y ontologías que usan especificaciones explícitas y formales de una conceptualización compartida (Gruber, 1993:1999).
El objetivo de este trabajo de tesis es recolectar datos académica de las Universidades del Ecuador y presentarlas en forma estructurada utilizando la tecnología RDF, con el fin de facilitar la búsqueda de información, de tal manera que se logra tener una mejor accesibilidad a la información.
1 Linked Data
1
CAPÍTULO I
1.
ESTADO DEL ARTEEn este capítulo se realiza una breve descripción sobre el estado del arte de los principales componentes que permiten el desarrollo de este proyecto de tesis “Publicación de datos universitarios enlazados observando los principios de Linked Data”. Entre los elementos necesarios y de gran importancia para el desarrollo de este proyecto se tiene la Web Semántica, Linked Data y uno de los principales componentes que es RDF Y SPARQL.
1.1. HISTORIA
La historia del “World Wide Web”, se dice que fue creada aproximadamente
a finales de los años 80, y a lo largo de los años 90 como un proyecto para un laboratorio propuesto por Tim Berners Lee, para difundir investigaciones e ideas a lo largo de la organización y a través de la red (Berners-Lee, 2007).
Para fines de 1990 la primera versión del WORL WIDE WEB se presentó sobre una máquina tipo NEXT, la cual tuvo capacidad de inspeccionar y transmitir documentos en HIPERTEXTO. La www ha experimentado una evolución sorprendentemente rápida, revolucionando la vida del mundo entero, proporcionando nuevas oportunidades en el ámbito tecnológico, económico y social, ya que se ha convertido en el repositorio más grande de información. Al igual que el crecimiento impresionante de la web, las tecnologías que permiten el funcionamiento de la misma han evolucionado
rápidamente, desde las más básicas HTML2, y HTTP3, hasta las actuales
como JAVA4, PHP5, XML6, etc.
2
Hyper Text Mark Language http://www.w3.org/MarkUp/
3
http://www.w3.org/Protocols/
4
www.oracle.com/technetwork/java/index.html
5
http://php.apache.org/
6
2 1.2. EVOLUCIÓN DE LA WEB
WEB 1.0: La Web 1.0 se trata de una Web estática de sólo lectura, donde las páginas son programadas en el lenguaje HTML es decir que los usuarios no podían interactuar en el contenido de las páginas, sino
más bien limitarse a la información que los webmaster publicaran en ella.
WEB 2.0: También conocida como la Web Social se puede decir que es una evolución de la Web 1.0.En la actualidad es la web que se utiliza, esta web ya no es estática ni solo lectura sino que ya los usuarios pueden tener más acceso a la información, debido a que en ésta ya se puede interactuar entre usuarios, formando así una red de personas donde se puede interactuar a través de los espacios que se han generado en el internet. Tales como blogs, Google Groups, Twitter, Facebook, y un sinnúmero de aplicaciones que permiten la interrelación de información.
1.2.1. FUNDAMENTOS DE LA WEB
La web se fundamenta en dos factores principales como son el protocolo HTTP y el lenguaje HTML.
El protocolo HTTP es el principal protocolo de la Wold Wide Web. Es un protocolo que está orientado a conexión porque emplea para su funcionamiento un protocolo de comunicaciones TCP (Transport Control Protocol) de modo conectado, que establece un canal de comunicaciones entre el cliente y el servidor.
El lenguaje HTML es otro factor principal de la World Wide Web. HTML ("Hypertext Mark-up Language", o "Lenguaje de Marcado de Hipertexto"), es un lenguaje de marcas (se insertan marcas o etiquetas en el texto) que permite representar de la mejor forma el contenido y referenciar otros recursos por ejemplo, imágenes, o enlaces a otros documentos que es, precisamente, la característica más destacada de la web, mostrar formularios para su posterior procesamiento, etc.
1.2.2. WEB SOCIAL
3
utilizar los enlaces de hipertexto que permiten a las personas pasar de un documento a otro, intercambiar información entre grupos sociales, etc. hace que esto se vuelva de mayor interés y dependencia para los usuarios.
1.2.3. WEB SEMÁNTICA
Uno de los problemas más importantes de la web de hoy es sobre la búsqueda de información realmente relevante, es decir los datos están ahí, pero ¿dónde?, para poder llegar a lo que se está buscando hay que leer mucho. La web Semántica busca que las máquinas entiendan y que al momento de realizar una búsqueda ésta presente las respuestas concretas y necesarias.
La web semántica [Berners-Lee 2001] propone superar las limitaciones de la web actual mediante la introducción de descripciones explícitas del significado, la estructura interna y la estructura global de los contenidos y servicios disponibles en la Web. Frente a la semántica implícita, el crecimiento caótico de recursos, y la ausencia de una organización clara de la web actual, la web semántica aboga por clasificar, dotar de estructura y anotar los recursos con semántica explícita procesable por máquinas.
La Web Semántica tiene como fin lograr que las máquinas respondan como si tuvieran inteligencia es decir que puedan entender y utilizar lo que la web contiene. Se dice que la Web Semántica es el futuro de la web actual, que facilitará la localización de recursos, la comunicación entre sistemas y programas. Es considerada la ampliación de la web actual que agrega una estructura y clasificación para captar el significado de los contenidos de las páginas para que las aplicaciones puedan procesar y relacionar contenidos provenientes de distintas fuentes; para que del trabajo entre humanos y ordenadores sea más completa. La Web Semántica está orientada más a nivel comercial para el intercambio de información o datos en la Web.
4 1.2.4. WEB DE DATOS LINKED DATA
La web de datos Linked Data se refiere a la web de los datos enlazados.
Linked Data permite pasar de una Web en la que los recursos son documentos HTML, a una Web de Datos Enlazados que están expresados en RDF (W3C, 2009a), un lenguaje para representar
significados sobre recursos, en la que agentes software pueden explotar
estos datos de forma automática (recopilándolos, agregándolos, interpretándolos, publicándolos, mezclándolos, etc.), potenciados por vocabularios y ontologías que usan especificaciones explícitas y formales de una conceptualización compartida (Gruber, 1993:199) .
Una de las mayores diferencias de la Web de Datos con respecto la Web que conocemos hasta hoy radica en que, en lugar de realizarse la navegación a través de documentos, se realiza a través de datos enlazados.
1.3. LINKED DATA
Linked Data que en español significa Datos Enlazados, permite construir la web de los datos es decir la forma que tiene la Web Semántica de vincular los datos que se encuentran distribuidos en diferentes fuentes de la Web, estos datos se vinculan y se explotan de una forma similar a la que se utiliza para vincular los documentos HTML.
La idea de Linked Data es que los enlaces HyperData permitirán a las
personas o las máquinas encontrar datos relacionados en la Web que no estaba vinculada con anterioridad, presentando al usuario la información más específica.
El objetivo del proyecto Linking Open Data desarrollado por el grupo de la W3C encargado de divulgar y explicar la Web semántica (Semantic Web Education and Outreach) es ampliar la web con una base de datos común mediante la publicación en la Web de bases de datos en RDF y mediante el establecimiento de enlaces RDF entre datos de diferentes fuentes.i
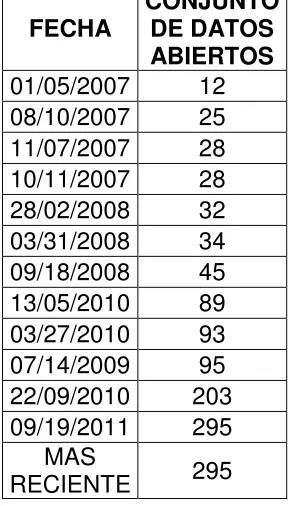
Existen algunas versiones que muestran los conjuntos de datos que han sido publicados en Linked Data, por los contribuyentes Linking Open Data de proyectos de la comunidad, otras personas y organizaciones. (Cyganiack 2007)
5
observar claramente como en el año 2007 del 05 de Enero cuando recién únicamente existían 12 conjuntos de datos publicados hasta la actualidad en la publicación más reciente que fue el 19 de septiembre del 2011 en
[image:17.612.255.399.217.470.2]el que ya existen 295 conjuntos de datos publicadosii
TABLA 1: CONJUNTO DE DATOS ABIERTOS
FECHA CONJUNTO DE DATOS ABIERTOS
01/05/2007 12
08/10/2007 25
11/07/2007 28
10/11/2007 28
28/02/2008 32
03/31/2008 34
09/18/2008 45
13/05/2010 89
03/27/2010 93
07/14/2009 95
22/09/2010 203
09/19/2011 295
MAS
6
GRAFICO 1: MUESTRA EL CONJUNTO DE DATOS ABIERTOS QUE HAN SIDO PUBLICADOS DESDE EL 01/05/2007 HASTA EL MÁS RECIENTE
PUBLICADO EL 19/09/2011.
Para que los datos puedan estar interconectados como si la web fuese una gran base de datos se deben seguir y respetar cuatro pasos denominados principios de Linked Data.
1.3.1. PRINCIPIOS
Hay cuatro principios o reglas básicas que Tim Berners- Lee propone en su
artículo publicado en Julio del 2006, los mismos que se expresan a continuación:
1. Utilice URIs como nombres para las cosas.- Al nombrar las cosas mediante URIs, estamos ofreciendo una abstracción del lenguaje natural para así evitar ambigüedades y asi brindar una forma estándar y unívoca para
referirnos a cualquier cosa.iii
2. Usar HTTP URIs para que la gente pueda buscar los nombre.- Se debe usar URIs sobre HTTP para asegurar que cualquier recurso pueda ser buscado y accedido en la Web.
3. Cuando alguien busca un URI, proveer información útil, utilizando las normas (RDF, SPARQL).- Cuando se busca y accede a un recurso identificado
0 50 100 150 200 250 300 350
CONJUNTO DE DATOS ABIERTOS
7
mediante una URI HTTP, se debe obtener información útil sobre dicho recurso representada a través de estándares en RDF.
4. Incluye enlaces a otros URI. para que puedan descubrir más cosas.- Esta regla es necesaria para enlazar datos que se encuentran en la Web, de tal manera que no se queden aislados y así poder compartir la información con otras fuentes externas y que otros sitios puedan enlazar sus propios datos de la misma forma que se hace con los enlaces en HTML.
1.3.2. PROCESO DE PUBLICACIÓN DE DATOS
Para la publicación de datos es necesario considerar los principios que deben cumplir estos datos para ser considerados Linked Data:
Nuestros recursos deben ser unívocamente identificables a través de
su URI. Las URIs deben estar basadas en el esquema HTTP para hacer su gestión descentralizada y para hacer su acceso universal a través de la web.
Los recursos deben ser descritos mediante RDF que es el modelo de
datos de la web semántica. De entre las diferentes representaciones RDF, al menos la serialización oficial en XML, RDF/XML, debe estar disponible para cada recurso.
Para crear una auténtica web de datos es necesario que los datos
estén enlazados. Nuestros recursos deben incluir referencias en forma de enlaces RDF a otras fuentes de datos y, en la medida de lo posible, deberían ser referenciados desde recursos externos.
8
GRAFICO 2: ESQUEMA DE PUBLICACIÓN DE DATOS
1.3.3. TECNOLOGÍAS
Las tecnologías a utilizar en la web semántica contienen lenguajes para la representación de ontologías, parsers, lenguajes de consulta, entornos de desarrollo, módulos de gestión (almacenamiento, acceso, actualización) de ontologías, módulos de visualización, conversión de ontologías, y otras herramientas y librerías. Los lenguajes más utilizados son:
1. OWL: Lenguaje de marcado construido sobre RDF y codificado en XML para publicar y compartir datos usando ontologías en la Web.
2. XML: Es una tecnología sencilla que tiene a su alrededor otras que la complementan y la hacen mucho más grande. En la actualidad desempeña un rol muy importante ya que permite la compatibilidad entre sistemas para compartir la información de una manera segura, fiable y fácil.
3. RDF: Tecnología esencial en la web semántica cuyo propósito es representar la información en la web bajo un modelo conceptual.
4. RDF Schema: Extensión semántica de RDF, basado en un lenguaje
primitivo de ontologías que proporciona los elementos básicos para la descripción de vocabularios.
9
6. Hipertext Markup Language – HTML: Un recurso representado en este formato mostrará información legible por un navegador Web y en consecuencia legible para un humano, sin embargo este tipo de representación no entregará información semántica útil en RDF.
7. HTML + RDFa: Es una especificación que permite expresar datos estructurados como atributos en algún lenguaje de marcado. Un recurso representado en este formato mostrará información legible tanto para un navegador Web como para aplicaciones que analicen código RDF, ya que toda la información semántica está incrustada como metadatos de la página Web. 8. RDF/XML: Un recurso representado en este formato entregará datos estructurados en RDF a través de marcas, analizables por algún tipo de procesador XML.
9. Notation 3: Un recurso representado en Notation 3, entregará tripletas RDF en un formato legible para humanos y a la vez procesables por analizadores RDF.
10. Notation Triples: Un recurso representado en este formato entregará datos de manera muy similar al formato Notation 3, con la diferencia que bajo este formato no se realizarán factorizaciones sintácticas del código RDF.
Las tecnologías de Linked Data que para el desarrollo de este proyecto y para poder llegar al objetivo esperado es la utilización de VOCABULARIOS ya
definidos como Foaf7, DC8, RDF, RDFS entre otros, el uso de herramientas de
la W3C como son MINDSWAP/CONVERTER9, esta herramienta se la utiliza
para convertir el código N3 obtenido a través de una Macro creada para obtener
el código N3 para luego convertirlo a código RDF/XML, RDF/VALIDATOR10
utilizado para validar los datos RDF. RDF/XML11 según la W3C es la sintaxis
normativa para la escritura de RDF, y SPARQL, esta es una de las principales tecnologías ya que se trata de un lenguaje estandarizado para realizar las consultas de los datos RDF. 4STORE es un RDF/SPARQL 4store, fue diseñado para el desarrollo de aplicaciones web semánticas, de esta manera permite hacer gran cantidad de consultas sobre la información almacenada por los usuarios. Según (Garlik, 2009) se citan las siguientes características.
Soporte para datos RDF. Disponible bajo GPL40.
Trabaja sobre sistemas operativos basados en UNIX. Soporte para SPARQL41.
Posee buen desempeño, escalabilidad y estabilidad sobre los datos
7http://xmlns.com/foaf/0.1/
8http://dublincore.org/documents/dcmes-xml/ 9www.mindswap.org/2002/rdfconvert
10
http://www.w3.org/RDF/validator
11
10
1.4. RESOURCE DESCRIPTION FRAMEWORK RDF
Por sus siglas en inglés RDF es un Marco de Descripción de Recursos, RDF es un lenguaje diseñado para apoyar a la web Semántica sirve como marco de apoyo a la descripción de recursos, o metadatos (datos sobre datos), para la Web, convirtiendo las declaraciones de los recursos en expresiones para ello se basa en la tripleta de sujeto, Predicado y Objeto.
Sujeto: Es el recurso al cual nos estamos refiriendo.
Predicado: Es el recurso que indica lo que estamos definiendo.
Objeto: Puede ser un recurso que puede considerarse el valor definido.
Por lo tanto una tripleta se representa mediante nodos conectados por líneas con etiquetas. Los nodos representan recursos y las líneas con etiquetas las propiedades de esos recursos. En la siguiente figura se muestra los 3 elementos de una tripleta que se representan mediante URIs.
GRAFICO 3: GRAFO SENTENCIA RDF
En el siguiente gráfico se presenta el Mapa Conceptual de Universidades
desarrollado con la herramienta de cmap Tools12. Utilizando los elementos de
RDF: Sujeto Predicado y Objeto
12
http://cmapdownload.ihmc.us/coe/Web_Installersv411.b117/install.htm Literal Propiedad
11
GRAFICO 4: MAPA CONCEPTUAL DE UNIVERSIDADES.
RDF pretende ser un soporte para la expresión de relaciones entre recursos de cualquier tipo con carácter universal y distribuido de modo que facilite la identificación de la información sin dar lugar a ambigüedades principalmente encaminado a ser procesado por aplicaciones en lugar de clientes humanos.
En la siguiente tabla se muestra algunos ejemplos de forma estructurada de acuerdo al mapa conceptual con datos de la UTPL. En lenguaje natural.
SUJETO PREDICADO OBJETO
UTPL Es Universidad
La autoridad de la UTPL Es Dr. José Barbosa Carbacho
La dirección web de la
UTPL Es www.utpl.edu.ec
La UTPL Es Privada
La categoría de la UTPL Es “A”
TABLA 2: EJEMPLO DE TRIPLETA RDF CON DATOS DE LA UTPL
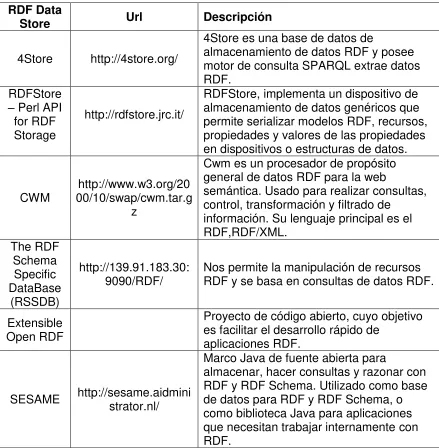
1.5. MOTORES DE REPRESENTACIÓN (RDF DATA STORE)
12
[image:24.612.121.560.180.628.2]En la siguiente tabla se puede apreciar algunos motores de representación.
TABLA 3: MOTORES DE REPRESENTACIÓN RDF DATA STORE.
RDF Data
Store Url Descripción
4Store http://4store.org/
4Store es una base de datos de
almacenamiento de datos RDF y posee motor de consulta SPARQL extrae datos RDF.
RDFStore
– Perl API
for RDF Storage
http://rdfstore.jrc.it/
RDFStore, implementa un dispositivo de almacenamiento de datos genéricos que permite serializar modelos RDF, recursos, propiedades y valores de las propiedades en dispositivos o estructuras de datos.
CWM 00/10/swap/cwm.tar.ghttp://www.w3.org/20 z
Cwm es un procesador de propósito general de datos RDF para la web
semántica. Usado para realizar consultas, control, transformación y filtrado de
información. Su lenguaje principal es el RDF,RDF/XML.
The RDF Schema Specific DataBase
(RSSDB)
http://139.91.183.30:
9090/RDF/ Nos permite la manipulación de recursos RDF y se basa en consultas de datos RDF.
Extensible Open RDF
Proyecto de código abierto, cuyo objetivo es facilitar el desarrollo rápido de
aplicaciones RDF.
SESAME http://sesame.aidministrator.nl/
Marco Java de fuente abierta para
13 JENA http://www.joseki.org/ http://jena.sourceforg
e.net/
Marco desarrollado por HP Labs Semantic Web Programme. Utilizado para manipular metadatos desde una aplicación Java. Código abierto que nos permite consultar y modificar datos RDF. Contiene el motor de consulta SPARQL
OPEN LINK VIRTUOS
O
http://virtuoso.openlin ksw.com
Virtuoso es un Data Store híbrido que combina las funcionalidades de los RDBMS27,
ORDBMS, bases de datos virtuales, RDF, XML y aplicaciones web (W3C, 2011 b).
1.6. EXPLOTACIÓN DE DATOS SPARQL (PROTOCOL AND RDF QUERY LANGUAGE)
Es el lenguaje estandarizado para la consulta de grafos RDF, normalizado por el RDF Data Access Working Group (DAWG) del Word Wide Web Consortium (W3C). Es una tecnología clave en el desarrollo de la Web Semántica que se constituyó como Recomendación oficial del W3C el 15 de
Enero de 2008.iv
Sparql hace posible consultar información desde bases de datos y otros orígenes de datos en sus estados primitivos a través de la web. Este lenguaje tiene bastante similitud a SQL, la diferencia principal es que SQL supone que los datos están implementados en tablas y SPARQL supone que los datos están implementados en grafos.
En la siguiente figura se puede observar la sintaxis de SPARQL13 utilizando
como ejemplo una consulta desde DBPEDIA14 la consulta muestra el
nombre del artista y el álbum del artista Timberland.
13
http://www.w3.org/TR/rdf-sparql-query/
14
14
GRAFICO 5: CONSULTA SPARQL EN DBPEDIA
1.6.1. VISUALIZACIÓN Y CONSUMO DE DATOS
15 1.7. TRABAJOS RELACIONADOS
Estados Unidos y Países de Europa como el Reino Unido, España, Francia, etc son países que lideran el uso de Linked Data. En España por ejemplo más de 18 universidades han construido la Red Temática Española de Linked Data. Tienen como objetivo transferir a la ciudadanía fuentes de datos, sobre materias como la información geoespacial de España, informes financieros de las empresas que cotizan la bolsa, referencias bibliográficas sobre alimentación y agricultura, trafico de autobuses y estado de las carreteras. Esta red se enmarca en el intento de los gobiernos de facilitar el acceso a los ciudadanos de la información pública.
Actualmente se han implantado proyectos LINKED DATA en todo el mundo enfocado en diversas áreas de aplicación tales como: técnicas, sociales, productivas, económicas, gubernamentales, de geo-ubicación; que han sido desarrollados con éxito, a continuación varios proyectos implantados en el ámbito universitario y de investigación:
1.7.1. PROYECTO LODUM Linked Open Data University of Münster
LODUM15 es un proyecto creado con el objetivo de disponer datos de
investigación de la Universidad de Münster como datos vinculados abiertos
para mejorar la transparencia y la visibilidad de la Universidad permitiendo la accesibilidad a los datos públicos. El enfoque integral del proyecto LODUM incluye una estrategia de acceso abierto para las publicaciones, así como la publicación de cualquier información de datos en línea para fomentar la colaboración tanto entre las facultades de la Universidad y sus asociados. El proyecto se plantea una arquitectura de alto nivel, donde su sistema se basa en un almacén de triples, que será accesible a través de un Data Store: data.uni.muenster.de (Se encuentra en desarrollo).
Actualmente se encuentra en desarrollo y servirá de base para cualquier aplicación construida en la parte superior de LODUM. Mientras que el foco actual está en los datos científicos y publicaciones, otros datos, tales como horarios de clases y los datos administrativos, también se puede integrar una vez que la infraestructura LODUM está en su lugar.. Estos datos adicionales que complementan la estrategia LODUM y permitir un mayor grupo de usuarios se beneficien de la infraestructura.
15
16
1.7.2. THE OPEN UNIVERSITY data.open.ac.uk
El proyecto data.open.ac.uk16 es una plataforma que se desarrollo como
parte del proyecto CSAC Lucero para extraer, conectar y exponer los datos disponibles en diferentes repositorios institucionales de la Universidad y ponerla a disposición abierta para que estos sean reutilizados.
Los conjuntos de datos se refieren a las publicaciones, cursos y material de audio/video producidos en la Open University, así como las personas involucradas en la toma de ellos. Todos estos datos están disponibles a través de formatos estándar (RDF y SPARQL) y la mayoría de los datos están disponibles bajo una licencia libre (Creative Commons Attribution
3.0 Unported License17).
El procesamiento de datos es una tarea permanente, incluyendo otros repositorios institucionales, proyectos de investigación específicos y enlaces a bases de datos externos de la información vinculada. Tratándose particularmente de:
Cursos y títulos de estudio en la unidad organizativa.
La OU Catálogo de la Biblioteca, haciendo importancia en el material
del curso.
Contenidos educativos abiertos disponible en el sistema Open
Learn18.
Información pública sobre el personal, la ubicación del campus de la
OU, etc.
1.7.3. BIO2RDF Project
El proyecto Bio2RDF19 tiene como objetivo centralizar datos sobre
bioinformática y dejarlos disponibles en RDF sobre la Web. La idea principal detrás de esto, es promover la visión de los datos enlazados dentro de la comunidad de la bioinformática mostrando su potencial al poder ser integrados y utilizados transparentemente por diferentes investigadores en el mundo. Para esto, cuentan con una amplia infraestructura de soporte a los datos ya publicados, además de documentación en donde explican cómo montar e incorporar nuevos nodos a la red de servidores del proyecto.
16
http://data.open.ac.uk/
17 http://creativecommons.org/licenses/by/3.0
18
http://www.open.edu/openlearn/
19
17
1.7.4. TRABAJOS EN LAS BIBLIOTECAS
En el ámbito bibliotecario por ejemplo existe el Linked Data Incubator
Group (LLD-XG) 20 que tiene como misión ayudar a aumentar la interoperabilidad global de datos de la biblioteca en la Web, al reunir a las personas involucradas en actividades de enfoque de la Web Semántica en la Red de datos en la comunidad bibliotecaria y más allá, aprovechando las iniciativas existentes, y la identificación de las pistas de colaboración para el futuro.
El grupo estudiará la forma existente bloques de construcción de la bibliotecología, como los modelos de metadatos, esquemas de
metadatos, estándares y protocolos para la construcción de sistemas de
interoperabilidad y de la biblioteca y entornos de red, animar a las bibliotecas para que su contenido y, en general reorientar sus enfoques para la interoperabilidad de datos hacia la Web, alcanzando también a otras comunidades. También se prevén estas comunidades como un proveedor potencial importante de bases de datos de autoridad (personas, temas ...) para la web de datos enlazados. A medida que estas evoluciones plantean la necesidad de un esfuerzo de estandarización compartida dentro de la comunidad bibliotecaria en torno a estándares Web (semántica), el grupo perfeccionar el conocimiento de esta necesidad, expresar los requerimientos de normas y directrices, y proponer un camino a seguir para la comunidad bibliotecaria para
contribuir a las acciones de una mayor estandarización Web.
1.8. Análisis de LINKED DATA como estrategia de OPEN DATA en el ámbito universitario e investigativo
Al hablar de Open Data21 traducido al español Datos Abiertos nos estamos
refiriendo a la información que puede ser vista por todo el mundo sin ningún tipo de restricciones, las Universidades en general cuentan con información que puede ser vista por todos pero en la actualidad la información universitaria se encuentra en forma individual, Linked Data sería una gran estrategia para Open Data ya que al unir toda esta cadena de información se estaría brindado al usuario mayor facilidad de descubrir la existencia de los datos, poder acceder a los mismos, encontrar información detallada, etc. Así los usuarios podrían tener una mejor visibilidad de los datos y por ende una mejor tomar de decisión.
18
La Fundación Open Data22 por ejemplo ofrece un lugar donde los miembros
de las distintas comunidades pueden unirse y trabajar en la alineación de los estándares de tecnología y herramientas de software que faciliten la visibilidad y la reutilización de los datos en todos los niveles de la cadena de información estadística. Promoviendo el acceso automatizado a los datos y metadatos estadísticos de esta manera, una mejor toma de decisiones se hace posible en muchos campos de investigación y formulación de políticas.
19
CAPITULO II
2. PROBLEMA:
Hoy en día buscar la información rápida y eficientemente se ha convertido en un problema elemental dentro de la red, esto se debe a muchos factores uno de ellos es el gran y extenso exceso de información disponible en la Web, o por que los buscadores actuales se limitan a conectar la información por palabras relacionadas al tema de consulta, en algunos casos presentan información irrelevante para el usuario, ello implica perder tiempo, costo de conectividad, entre otras.
Este gran volumen de información es abrumador, pues entre tanta información casi todas las veces desistimos en seguir intentando, u optamos por buscar otras alternativas de comunicación como vía telefónica, visitas institucionales etc.
En el caso de las universidades se ha detectado que al momento de consultar información de aspecto general y académico, por ejemplo, el usuario que no sabe la página web tiene que utilizar los buscadores conocidos, visualizando ante él aglomeración de datos, que provocan confusión, en algunos casos ya ingresando directamente a la página web de la universidad, la información está; pero se encuentra en forma individual es decir en cada página universitaria o si utilizo un buscador me presenta una gran cantidad de páginas, y al estar ingresando y buscando página por página se convierte en una actividad tediosa e insatisfactoria para el usuario. Y en último de los casos lo más molestoso para el usuario es que la información requerida no se encuentra publicada.
Debido a este tipo de problemas es que se ha decidido crear un repositorio que nos permita el almacenamiento de la información no solo de una sino de las universidades del Ecuador para que exista una mejor interoperabilidad.
La interoperabilidad es definida por la IEEE (2009) como “la habilidad de dos o
más sistemas o componentes para intercambiar información y para usar la
información que ha sido intercambiada”. En los sistemas de eLearning, la
interoperabilidad permite el intercambio y reutilización de recursos educativos (cursos, documentos, videos, tutoriales, etc.) que han sido desarrollados en plataformas educativas heterogéneas, lo cual permite:
Incrementar la calidad y variedad de recursos educativos disponibles en
20
Preservar el capital invertido en tecnología y desarrollo de recursos
educativos, ya que un recurso educativo podrá ser intercambiado o usado sin la necesidad de realizar costosas modificaciones.
Garantizar que los usuarios con diferentes plataformas hardware y
software puedan acceder a recursos educativos de fuentes heterogéneas, con perdidas mínimas tanto de contenido como de funcionalidad.
2.1. ACCESO A LA INFORMACIÓN UNIVERSITARIA
Para acceder a la información universitaria las universidades cuentan con páginas web, en la que cada Universidad presenta su información en diferentes aspectos tanto general como académico y de más servicios que cada universidad brinda, también se puede obtener información a través de folletos, publicaciones, utilizando medios de comunicación como teléfono radio, televisión, etc. El problema radica en la poca información que algunas universidades presentan en sus portales web para lo que hubo que utilizar otros medios como llamadas telefónicas
incluso utilizando en los buscadores como Google23.
2.1.1. DATOS NECESARIOS
Nuestro país cuenta con 69 Universidades por lo que se ha creído conveniente seleccionar los datos de mayor importancia; en este caso los datos necesarios para la elaboración del presente trabajo de tesis son los de aspecto general es decir los datos principales y básicos de las universidades y de aspecto académico
2.1.2. DATOS EXISTENTES EN LA ACTUALIDAD
Estos datos se encuentran en la página web de cada universidad algunos en archivos planos otros en Excel, también se encuentran en documentos físicos, algunos de los datos se ha obtenido por medio de información externa como medios de comunicación online como es el caso de la categoría de universidades, nombre de autoridad principal (Rector), entre otros
23
21 2.1.3. OBTENCIÓN DE DATOS
Para obtener los datos actualmente hay que ingresar a la página de cada Universidad algunos datos como; datos generales se encuentran en la página principal de cada universidad, en otros casos como para saber que categoría tiene la universidad o qué tipo de universidad es, he acudido al buscador Google. Los datos del aspecto académico en algunas universidades si se puede encontrar todos, sin embargo hay algunas universidades que tienen este inconveniente, en algunos casos las páginas se encuentran no disponibles ya que están en proceso de reconstrucción. Sin embargo se ha buscado otros medios para la obtención de los datos como buscadores, medios de comunicación
online, Senescyt24, etc.
2.2. IDENTIFICACIÓN Y SELECCIÓN DE FUENTES
Como es normal en la actualidad las universidades de nuestro país cuentan con una página web en la cual nos presentan información, publicidad, noticias en fin con respecto a la universidad, para el desarrollo del presente proyecto se ha escogido solo la información de aspecto general y académico que es el de interés y ayuda para la elaboración de este proyecto de tesis.
En el presente capítulo se realiza una descripción de la situación actual de las universidades de acuerdo a la información presentada en sus páginas web.
2.3. PROPUESTAS DE SOLUCIÓN
En la actualidad los datos se encuentran en cada página web universitaria, o en documentos externos, pero siempre de forma individual, lo que se pretende a través de la recolección de datos es, seleccionar los de mayor importancia y que satisfagan las necesidades del usuario para luego a través de la utilización de las herramientas de Linked Data poder enlazarlos y posterior a ello publicarlos.
A continuación se detalla el proceso general a seguir para resolver el problema usando Linked Data.
Para seleccionar los datos de mayor importancia se ha planteado una serie de preguntas que se pretende responder, en este caso las
24
22
preguntas son de aspecto general y académico, de las universidades del país.
Una vez planteadas las preguntas se procedió con la elaboración de los vocabularios, desambiguación y población de los mismos utilizando una tabla de Excel, luego estos datos pasan a ser transformados en código
N3 utilizando una Macro y a través de la herramienta Mindswap25 se
obtiene el código RDF, que así mismo pasa a ser validado utilizando la
herramienta VALIDATION SERVER26. Una vez obtenido el código RDF
este pasa a ser almacenado en una base de datos creada en 4STORE para su posterior consulta en SPARQL.
25www.mindswap.org/2002/rdfconvert
2626
23
CAPÍTULO III
3. DESCRIPCIÓN DE PROCESOS APLICANDO LINKED DATA
En el capítulo anterior ya se explico de manera general la propuesta de solución en el presente capítulo se describe cada paso a seguir para la elaboración de este proyecto.
3.1. APLICACIÓN DE LINKED DATA
En el presente capítulo se detalla paso a paso el proceso de construcción de la solución Linked Data propuesta.
3.2. IDENTIFICACIÓN DE DATOS.
Los datos necesarios que se requieren para el desarrollo del proyecto planteado se los puede resumir de la siguiente manera:
Universidades existentes en el país y que estén legalmente establecidas
que son en un número de 69.
Datos informativos de las universidades es decir localización, forma de
contactarse, etc.
Organización académica de las universidades tales como, facultades,
escuelas, etc.
3.3. SELECCIÓN DE DATOS
Todos los datos detallados en el ítem anterior se encuentran localizados en general en las páginas web oficiales de las universidades, ya sea como parte de repositorios, archivos planos (Documentos pdf, documentos de Word), en documentos de Excel.
3.4. EXTRACCIÓN DE DATOS
24
1. Como primer paso se procedió a recolectar los datos generales (datos
informativos) de cada universidad, por medio de sus páginas web, en algunos casos la información se encontraba muy limitada por lo que se utilizo otros medios para obtener la información completa.
2. Así mismo se copio toda la información de la organización académica
enfocándose más al área de facultades o Escuelas carreras títulos que se obtiene, modalidades de estudio mallas curriculares con respecto a las mallas curriculares hubo que obviarlas por motivo de que no se pudo obtener de todas las universidades por que estaban en proceso de modificaciones. En el capítulo 3 se presenta la estructura de las tablas en la que muestra las clases con sus respectivas propiedades.
3.5. PREGUNTAS QUE SE PRETENDE RESPONDER
25
TABLA 4: LISTA DE PREGUNTAS QUE SE PRETENDE RESPONDER CON LA UTILIZACIÓN DE LINKED DATA.
PREGUNTA QUE PODRÍAMOS EXPLOTAR CON LOS PROGRAMA DE ESTUDIO DE LA UTPL
1. Universidades que se encuentran en la región………….?
2. Listar las universidades cuyo nombre diga ejm. cuenca……….
3. Mostrar el nombre de la facultad y la universidad a la que pertenece?
4. Carreras que pertenezcan a la modalidad…………..?
PREGUNTAS DE ASPECTO GENERAL DE LAS UNIVERSIDADES
5. Nombre y dirección de las universidades existentes en el ecuador?
6. Mostrar los datos informativos de la universidad ………?
7. ¿mostrar la dirección de la universidad número.………?
8. Qué categoría tiene la Universidad ………de la provincia de………..?
PREGUNTAS DE ASPECTO ACADÉMICO CARRERAS
9. ¿Qué carreras hay en la universidad…………?
10. Universidades Públicas del Ecuador que tanga la carrera de……….?
11. ¿Qué modalidades hay en la universidad………..? y que sea de la región………?
12. ¿Qué carreras hay en la facultad de……… de la universidad de………
13. Universidades Privadas del Ecuador que tengan la carrera de……….
3.6. REUTILIZACIÓN DE VOCABULARIOS
26
diversos proyectos y trabajos similares a las necesidades del proyecto para lo cual retómanos y los rehusamos los ya propuestos satisfactoriamente, entre ellos los describo:
ACADEMIC INSTITUTION INTENAL STRUCTURE ONTOLOGY (AIISO)27
Un vocabulario para describir la estructura organizativa interna de una institución académica.
AIISO ROLES
AIISO Roles28 es un vocabulario para las funciones comunes que se
encuentran en instituciones académicas.
DUBLIN CORE
Es un modelo de metadatos elaborado y auspiciado por la DCMI (Dublin
Core Metadata Initiative)29, una organización dedicada a fomentar la
adopción extensa de los estándares interoperables de los metadatos y a promover el desarrollo de los vocabularios especializados de metadatos para:
FOAF (Friend Of A Friend)
FOAF30 del proyecto es la creación de una Red de lectura mecánica
páginas que describen las personas, los vínculos entre ellos y las cosas que crean y hacen, sino que es una contribución al sistema de información vinculado conocida como la Web . FOAF define una tecnología abierta y descentralizada para la conexión de los sitios web sociales y la gente que ellos describen.
RDF SCHEMA (RDFs)
El RDFs31 Describe propiedades y clases de recursos RDF
27http://vocab.org/aiiso/
28http://vocab.org/aiiso-roles/
29 http://dublincore.org/
30
http://www.foaf-project.org/
27 3.7. PLAN DE DESAMBIGUACIÓN
El acto de descubrimiento, corrección o eliminación de datos erróneos de una base de datos es conocido como limpieza de datos, es decir debemos conseguir que nuestros datos sean de calidad.
La Limpieza de datos se diferencia de la validación de datos, en que la validación de datos cumple la función de rechazar los registros erróneos durante la entrada al sistema. El proceso de limpieza de datos incluye la validación y además la corrección de datos, para alcanzar como se dijo anteriormente datos de calidad, es así que se procedió a realizar la desambiguación de los términos cuya definición tiene diferentes acepciones y que en definitiva su concepción es la misma es decir se definió los homónimos y sinónimos existentes en el vocabulario planteado.
[image:39.612.111.562.417.722.2]En la siguiente tabla se presenta nuevamente los vocabularios esta vez con los sinónimos que presentan algunos de los vocabularios para evitar una posible ambigüedad en los mismos.
TABLA 5: PLAN DE DESAMBIGUACIÓN DE VOCABULARIOS
URI Type Decription Sinonimo
UNIVERSITY Class Organización Educativa
NAME OF
UNIVERSITY
IN ENGLISH Property Nombre de la universidad en ingles
NAME Property Nombre de la universidad -
TYPE Property Tipo de universidad (Privada/Pública) CLASE
CATEGORY Property Categoría de la universidad según la calificación de CONEA -
SEDE Property Sede de la universidad EXTENSION
LOCATION Class Ubicación física de la universidad UBICACIÓN, DIRECCIÓN,
AREA
ADDRESS Property Dirección domiciliaria de la universidad -
COUNTRY Property País de ubicación de la universidad -
REGION Property Región de la universidad (Costa, Sierra, Amazonía) -
PROVINCE Property Provincia donde se encuentra la universidad ESTADO, DEPARTAME
28
CITY Property Ciudad universidad donde se encuentra la LUGAR
CONTACT Class Datos para contactar a la universidad -
WEB Property Sitio web de la universidad DIRECCIÓN
PHONE/FAX Property Teléfono o fax de la universidad -
EMAIL Property Dirección de correo electrónico CORREO ELECTRÓNIC
O
ZIP CODE Property Código postal de la universidad -
AUTHORITY Class Datos de la autoridad de la Universidad -
NAME
AUTHORITY Property Nombre de la autoridad RECTOR, CANCILLER
AUTHORITY Property Correo electrónico de la autoridad CORREO
PHONE
AUTHORITY Property Teléfono de la autoridad MÓVIL
ACADEMIC
OFFERINGS Class
Proceso en el cual se seleccionan los programas a dictarse en determinado período académico, indicando sus
respectivas asignaturas y la
configuración de docentes y horarios por cada una de ellas.
-
ACADEMIC
YEAR Property Período del Año académico -
FACULTY Class Datos de la facultad ESCUELA
NAMEFS Property Nombre de la facultad y escuela FACULTAD, ESCUELA
EXTRA CURRICULA R
ACTIVITIES
Class Actividades complementarias SEMINARIOS, CURSOS
Name ECA Property Nombre complementario del seminario o curso
Type Property Tipo del Curso sea: presencial u online
Duration Property Tiempo de duración del seminario o curso
Responsible Property Tutor responsable del seminario o curso
ENCARGADO
, GUIA,
RESPONSAB LE
PROGRAMM
29 profesional. Name
Programme Property Nombre del programa académico PENSUM DE ESTUDIO
Title Property Título que oferta la carrera -
Academic
Area Property Área Académica del programa -
Modality Property Modalidad de estudios de un programa académico. -
Academic
Level Property Nivel Académico del programa GRADO
Director Property Persona responsable de dirigir la organización y actividades de un programa académico
AUTORIDAD, RESPONSAB LE
Duration Property Tiempo de duración de la Carrera o programa Académico TIEMPO
Professional
profile Property
Conjunto de capacidades y
competencias que identifican la
formación de un profesional -
Occupational
field Property Área profesional. donde se desarrollara el
CAMPO OCUPACION AL,ÁREA REQUIREME
NTS Class Requisitos de graduación
Approval Requirement
s Property
Requerimientos necesarios para aprobar el programa académico
SUBJECTS Class Asignaturas que componen un programa académico MATERIAS, ASIGNAATUR
AS Name
Subject Property Nombre de la asignatura
Credits Property Número de créditos que acumulará el estudiante para aprobar una asignatura
Subject Type Property Tipo de materia correspondiente a los grupos (Genérica, Troncal, complementaria y Gestión Productiva)
Level Property Nivel en que se dicta la asignatura
Competences Property Habilidades, actitudes y conocimientos que surgen como resultado del aprendizaje de la asignatura.
TYPE
30 CES
Specific
Competences Property Competencias especificas del programa académico
Generic
Competences Property Competencias genéricas del programa académico
DESCRIPTIO N
COMPETEN CES
Class
Knowledge Property Conocimientos científicos conceptuales y teóricos.
Skills Property
Destrezas para ejecutar tareas con éxito, utilizar herramientas y realizar trabajos. Se desarrollan con la práctica y la experiencia.
Attitudes Property Predisposiciones y comportamientos que adoptará el profesional frente a situaciones concretas
La mayoría de los términos a utilizar en esta lista de vocabularios no presentan ambigüedad. En la siguiente tabla se detalla los vocabularios que presentan ambigüedad.
TABLA 6: VOCABULARIOS AMBIGÜOS
TÉRMINO DESAMBIGUACIÓN
AUTORIDAD
PROGRAMAS
Tipo Autoridad
Autoridad de Gobierno Autoridad genérica Autoridad de la iglesia Autoridad Publica
Autoridad de documento Suplica a la autoridad Control a la autoridad Autoridad de Policía Programa de estudio Programa de tv Programa de radio Programa de fiesta
ÁREA Área de estudio
31
Área de superficie Área bio-geográfica Área lingüística
3.8. PLAN DE ISTANCIACIÓN
Se procedió en primer lugar a la creación de un formulario de instanciación de datos en Excel, definiendo la estructura correcta para luego proceder a ingresar los mismos, una vez que los datos se extrajeron de las Fuentes respectivas, y luego procedimos a clasificarlos de acuerdo a la estructura planteada observando claramente el Segundo principio de Linked Data. A continuación se detalla el proceso.
3.8.1. RECOLECCIÓN DE DATOS EN UNA TABLA DE EXCEL
Una vez analizado todos los vocabularios planteados en la tabla 6, se ha decidido trabajar con algunos de los vocabularios no fue posible utilizar todos debido al tipo de datos recolectados y en algunos casos la complejidad ya sea porque no existían datos o por encontrarse algunas páginas en reconstrucción, es por este motivo que se obvió algunos vocabularios en la presente tabla se detallan los vocabularios con los que se va a trabajar en este proyecto de tesis.
Luego de tener ya bien definida el esquema se procedió a la recolección de los datos de las diferentes universidades del Ecuador, por diferentes medios como páginas web de las universidades, llamadas telefónicas información externa, etc.
[image:43.612.119.565.553.714.2]La estructura de la tabla es la siguiente:
TABLA 7: LISTA DE VOCABULARIOS SELECCIONADOS
TERMINO Type Decription
NAME Property nombre de la universidad
NAME OF
UNIVERSITY IN
ENGLISH
Property Nombre de la Universidad en ingles
TYPE Property tipo de universidad (Privada/publica)
CATEGORY Property categoria de la universidad según la calificación de CONEA
32
ADDRESS Property Dirección domiciliaria de la universidad
COUNTRY Property Pais de ubicación de la universidad
REGION Property Región de la universidad (Costa, Sierra, Amazonía)
PROVINCE Property Provincia donde se encuentra la universidad
CITY Property ciudad donde se encuentra la universidad
CONTACT Class Datos para contactar a la universidad
WEB Property Sitio web de la universidad
PHONE/FAX Property Telefono o fax de la universidad
EMAIL Property dirección de correo electrónico
FACULTY Class Datos de la facultad
NAMEFS Property nombre de la facultad y escuela
AUTHORITY Class datos de la autoridad de la escuela y facultad
NAME
AUTHORITY Property nombre de la autoridad
AUTHORITY Property correo electronico de la autoridad
PHONE
AUTHORITY Property telefono de la autoridad
SCHOOL Class datos de la escuela
ACADEMIC YEAR Property Periodo del Año académico
Responsible Property Tutor responsable del seminario o curso
Name Programme Property Nombre del programa académico
Title Property título que oferta la carrera
Academic Area Property Area Academica del programa
Modality Property Modalidad de estudios de un programa académico.
Duration Property Tiempo de duración de la Carrera o programa Académico
3.8.2. CREACIÓN DE NUEVOS VOCABULARIOS
33
TABLA 8: VOCABULARIOS CREADOS PARA LA ELABORACIÓN DEL PROYECTO.
VOCABULARIO CLASE
UNV Universidad
UNVA Autoridad
UNVC Carrera
UNVCR Titulo de la carrera
UNVCT Categoría
UNVF Facultad
UNVT Tipo de universidad
3.8.3. DESCRIPCIÓN DE CLASES Y PROPIEDADES DE LOS VOCABULARIOS
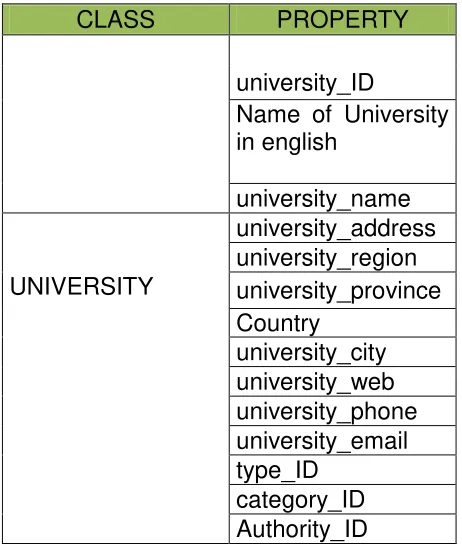
Las siguientes tablas nos muestran cada clase con sus respectivas propiedades, con estos datos se estará poblando la base de datos.
TABLA 9: PROPIEDADES DE LA CLASE UNIVERSITY
CLASS PROPERTY
university_ID
Name of University in english
university_name university_address university_region
UNIVERSITY university_province
Country university_city university_web university_phone university_email type_ID
[image:45.612.208.439.406.680.2]34
TABLA 10: PROPIEDADES DE LA CLASE TYPE
CLASS PROPERTY
TYPE type_ID
type_description
TABLA 11: PROPIEDADES DE LA CLASE CATEEGORY
CLASS PROPERTY
CATEGORY category_ID
[image:46.612.206.439.437.516.2]category_description
TABLA 12: PROPIEDADES DE LA CLASE AUTHORITY
CLASS PROPERTY
authority_ID authority_name
AUTHORITY authority_email
authority_phone
TABLA 13: PROPIEDADES DE LA CLASE FACULTY
CLASS PROPERTY
university_ID
FACULTY faculty_ID
35
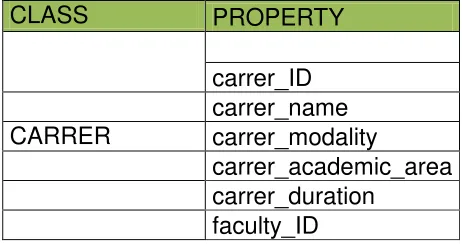
TABLA 14: PROPIEDADES DE LA CLASE CARRER
CLASS PROPERTY
carrer_ID carrer_name
CARRER carrer_modality
carrer_academic_area carrer_duration
faculty_ID
TABLA 15: PROPIEDADES DE LA CLASE CARRER_TITLE
CLASS PROPERTY
CARRER_TITLE carrer_title_ID
carrer_title_name
3.8.4. ESTABLECER RELACIONES ENTRE LAS TABLAS MYSQL.
Para comprobar y establecer las relaciones se utilizo la herramienta de
MySql32, en la siguiente gráfico se puede observar las relaciones de
las tablas ya con los datos recolectados.
3232
36
GRAFICO 6: RELACIÓN DE LAS TABLAS UTILIZANDO MYSQL
Posteriormente importamos los datos recolectados en las plantillas de EXCEL hacia la Base de Datos LUD de tal manera que procedimos luego a realizar consultas en SQL para poder verificar si las relaciones entabladas permitan generar las consultas planteadas:
***** LISTAR LAS UNIVERSIDADES QUE TIENEN LA CARRERA INGENIERO EN SISTEMAS ********
select UNIVERSITY.university_name, FACULTY.faculty_name, CARRER.carrer_name, CARRER_TITLE.carrer_title_name from UNIVERSITY join FACULTY inner join CARRER inner join CARRER_TITLE on (UNIVERSITY.university_ID=FACULTY.university_ID and
FACULTY.faculty_ID=CARRER.faculty_ID and
CARRER.carrer_ID=CARRER_TITLE.carrer_ID) where CARRER_TITLE.carrer_title_name='INGENIERO EN SISTEMAS INFORMATICOS Y COMPUTACION
37 resultado:
university_name faculty_name carrer_title_name
UNIVERSIDAD
TECNICA PARTICULAR DE LOJA
ESCUELA DE
CIENCIAS DE LA
COMPUTACION
INGENIERO EN
SISTEMAS
INFORMÁTICOS Y
COMPUTACIÓN
3.9. Generación de Código RDF.
Posteriormente de realizadas las consultas de prueba procedimos a generar el código RDF para lo cual se elaboró una macro dentro de EXCEL partiendo de la estructura realizada en la base de datos LUD de MYSQL a pesar de existir varias macros que realizaban la misma tarea de transformación se procedió a realizar una macro propia que se adapte a nuestros requerimientos.
3.10. CREACIÓN DE UNA MACRO EN EXCEL PARA EXTRAER LOS DATOS DE LAS TABLAS.
Dado que los datos existentes en las tablas se los podía reutilizar para generar un archivo plano que posea el código N3 y debido a que generar este archivo de forma manual sería un proceso sumamente extenso además de que existiría la probabilidad de cometer errores en la sintaxis del mismo, se diseño una macro que contribuya a automatizar la generación del código N3.
Es así que esta macro quedó de la siguiente manera:
3.10.1. CÓDIGO DE LA MACRO
Private Sub INSERTAR_Click()
Dim seguir As Boolean, fila As Integer, inserta As Integer
inserta = 15 seguir = True fila = 2
Do While seguir = True
38 If seguir Then
'Inserta Filas
For n = 1 To inserta
Worksheets("UNIVERSITY").Rows(fila).Insert Next n
'salta a la fila
fila = fila + (inserta + 1) End If
Loop End Sub
Este código inserta un número determinado de filas en blanco, luego deja una fila con datos y continua insertando filas, el proceso se repite hasta cuando no encuentra registros.
Posterior a la ejecución de la macro se vinculó las celdas a una hoja de cálculo en una estructura que posee la sintaxis en formato N3, de aquí se obtuvo el código que sería insertado en un archivo de texto para su posterior transformación a formato RDF.
Aplicación de la MACRO para la generación de las filas de datos de la tabla: CATEGORY a formato RDF en notación N3:
unv: univct 1 rdf:type unvct: TYPE unv:univct1 rdf:type unvct:TYPE
unvct: category_ID 01 ; unvct:category_ID 01 ;
unvct: category_description " A ". unvct:category_description "A".
unv: univct 2 rdf:type unvct: TYPE unv:univct2 rdf:type unvct:TYPE
unvct: category_ID 02 ; unvct:category_ID 02 ;
unvct: category_description " B ". unvct:category_description "B".
unv: univct 3 rdf:type unvct: TYPE unv:univct3 rdf:type unvct:TYPE
unvct: category_ID 03 ; unvct:category_ID 03 ;
unvct: category_description " C ". unvct:category_description "C".
unv: univct 4 rdf:type unvct: TYPE unv:univct4 rdf:type unvct:TYPE
unvct: category_ID 04 ; unvct:category_ID 04 ;
unvct: category_description " D ". unvct:category_description "D".
unv: univct 5 rdf:type unvct: TYPE unv:univct5 rdf:type unvct:TYPE
unvct: category_ID 05 ; unvct:category_ID 05 ;