CIS1330IS13
Miner PC Adviser:
Software Asesor en la compra de computadores
Antonio Andrés Jiménez Navas Simón Santiago Soriano Pérez
PONTIFICIA UNIVERSIDAD JAVERIANA FACULTAD DE INGENIERIA CARRERA DE INGENIERIA DE SISTEMAS
CIS1330IS13
Miner PC Adviser:
Software Asesor en la compra de computadores
Autor(es):
Antonio Andrés Jiménez Navas Simón Santiago Soriano Pérez
MEMORIA DEL TRABAJO DE GRADO REALIZADO PARA CUMPLIR UNO DE LOS REQUISITOS PARA OPTAR AL TÍTULO DE INGENIERO DE SISTEMAS
Director
Ing. Alexandra Pomares Quimbaya Ph.D.
Jurados del Trabajo de Grado
-
-
Página web del Trabajo de Grado
http://pegasus.javeriana.edu.co/~CIS1330IS13/
PONTIFICIA UNIVERSIDAD JAVERIANA FACULTAD DE INGENIERIA CARRERA DE INGENIERIA DE SISTEMAS
Página ii PONTIFICIA UNIVERSIDAD JAVERIANA
FACULTAD DE INGENIERIA
CARRERA DE INGENIERIA DE SISTEMAS
Rector Magnífico
Joaquín Emilio Sánchez García S.J.
Decano Académico Facultad de Ingeniería
Ingeniero Jorge Luis Sánchez Téllez
Decano del Medio Universitario Facultad de Ingeniería
Padre Antonio José Sarmiento Nova S.J.
Director de la Carrera de Ingeniería de Sistemas
Ingeniero Germán Alberto Chavarro Flórez
Director Departamento de Ingeniería de Sistemas
Artículo 23 de la Resolución No. 1 de Junio de 1946
Página iv AGRADECIMIENTOS
Agradecemos a la Universidad por el conocimiento brindado durante 5 años de carrera, por los diferentes espacios de crecimiento personal y profesional que nos otorgó. Nos sentimos orgullosamente Javerianos y cargaremos con este nombre con honor y prestigio.
De igual forma agradecemos a nuestras familias que durante todo este proceso, y desde que nacimos, nos dieron todo su apoyo, confianza, educación, amor y cariño para lograr nuestras metas y sueños.
Agradecemos a nuestras novias Pilly y Jessica por apoyarnos durante todo el desarrollo de nuestro trabajo de grado regalándonos paciencia, amor y apoyo incondicional que nos sirvió para creer en nosotros y alcanzar esta gran meta.
Agradecemos al equipo de maratones de programación donde no solo pudimos aumentar nuestros conocimientos sino que además encontramos un grupo de amigos y personas con grandes capacidades y cualidades.
CONTENIDO
CONTENIDO ...
VILUSTRACIONES ...
VIITABLAS...
IXI
-
INTRODUCCIÓN ...1
II
-
DESCRIPCION
GENERAL
DEL
TRABAJO
DE
GRADO ...2
1.
O
PORTUNIDAD,
P
ROBLEMÁTICA,
A
NTECEDENTES...2
1.1. Descripción del contexto ... 2
1.2. Pregunta de Investigación ... 3
1.3. Justificación ... 3
1.4. Impacto Esperado ... 3
2.
D
ESCRIPCIÓN DELP
ROYECTO...4
2.1. Objetivo general ... 4
2.2. Fases Metodológicas o conjunto de objetivos específicos ... 4
III
-
MARCO
TEÓRICO ...6
1.
M
ARCOC
ONCEPTUAL...6
1.1. Conceptos Básicos ... 6
1.2. Trabajos Importantes en el Área ... 8
1.3. Comparación de las Herramientas tecnológicas existentes actualmente y que intentan resolver el problema. ... 10
2.
M
ARCOI
NSTITUCIONAL...14
IV
-
DESARROLLO
DEL
TRABAJO ...16
1.
M
INERPC
A
DVISER:
S
ISTEMA DE RECOMENDACIÓN BASADO ENS
ENTIMENTA
NALYSIS...16
1.1. ¿Qué es Miner PC Adviser? ... 16
1.2. Proceso llevado a cabo en MPCA ... 16
1.3. Estrategia de recomendación basada en Sentiment Analysis ... 17
1.4. Diseño del sistema ... 21
1.5. Validación... 50
2.
M
ETODOLOGÍA...54
2.1. Scrum ... 54
2.2. Pair Programming ... 56
2.3. Control de versiones mediante Git ... 56
Página vi
V
-
RESULTADOS
Y
REFLEXIÓN
SOBRE
LOS
MISMOS...58
1.
R
ESULTADOS...58
1.1. Cumplimiento de Objetivo General ... 58
1.2. Cumplimiento de Objetivos Específicos ... 58
1.3. conocimiento aprendido ... 59
2.
R
EFLEXIONES...60
2.1. Importancia del control de versiones ... 60
2.2. Ventajas y desventajas de la metodología SCRUM ... 60
VI
-
CONCLUSIONES,
RECOMENDACIONES
Y
TRABAJOS
FUTUROS 61
1.
C
ONCLUSIONES...61
1.1. Se respondió a la pregunta de investigación ... 61
1.2. Se cumplieron los objetivos ... 61
1.3. Es posible realizar una recomendación a partir de Sentiment Analysis ... 61
2.
R
ECOMENDACIONES...61
2.1. control de versiones ... 61
2.2. Realizar el trabajo de grado en pareja ... 62
3.
T
RABAJOSF
UTUROS...62
3.1. realizar la recomendación utilizando múltiples clasificadores ... 62
3.2. Establecer filtros subjetivos ... 62
3.3. establecer perfiles de usuario ... 62
3.4. preprocesamiento de la información para entrenamiento de clasificadores ... 62
ILUSTRACIONES
Ilustración IV-1: “Proceso llevado a cabo en MPCA” ... 17
Ilustración IV-2: “Proceso de extracción de datos, diagrama de entradas y salidas” ... 18
Ilustración IV-3: “Proceso de creación de clasificadores” ... 19
Ilustración IV-4: “Cálculo de índices por producto” ... 20
Ilustración IV-5: “Entradas y salidas del proceso de filtrado” ... 21
Ilustración IV-6: “Diagrama de Componentes” ... 22
Ilustración IV-7: “Esquema Base de Datos” ... 23
Ilustración IV-8: “Diagrama de Clases del Módulo de Persistencia” ... 25
Ilustración IV-9: “Diagrama de Clases del Módulo de Extracción de Datos” ... 27
Ilustración IV-10:”Nube de palabras positiva” ... 37
Ilustración IV-11:”Nube de palabras negativa” ... 37
Ilustración IV-12: “Diagrama de clases del módulo de presentación” ... 39
Ilustración IV-13:”Interfaz Gráfica Primera Ventana” ... 41
Ilustración IV-14: “Pantalla, lista de productos” ... 42
Ilustración IV-15: “Pantalla, detalle de producto” ... 43
Ilustración IV-16: “Pantalla, Nube de palabras” ... 44
Ilustración IV-17: “Demostración de uso de herramientas de desarrollo de Chrome” ... 45
Página viii
TABLAS
Tabla III-1: “Comparación de Métodos de Sentiment Analysis” ... 10
Tabla III-2: “Comparación de Blogs de Tecnología” ... 13
Tabla IV-1: “Ejemplo de clasificación de comentarios”... 19
Tabla IV-2: “Recomendaciones” ... 20
Tabla IV-3: “Interfaz MpcaIClassifier” ... 28
Tabla IV-4: “Interfaz MpcaITrainableClassifier” ... 29
Tabla IV-5: “Clase MpcaRecommender” ... 30
Tabla IV-6: “Clase MpcaRecommendation” ... 31
Tabla IV-7: “Tabla de recomendaciones con rangos de índices” ... 31
Tabla IV-8:”Descripción de la interfaz MpcaAPI” ... 32
Tabla IV-9:”Clase MpcaFilter, descripción de métodos” ... 35
Tabla IV-10:”Miembros de la clase MpcaProduct” ... 35
Tabla IV-11: “Ejemplo, descriptor de entrenamiento y pruebas de clasificadores” ... 47
Tabla IV-12: “Descriptor de recomendaciones” ... 49
Tabla IV-13: “Ejemplo de descriptor de filtro” ... 50
Tabla IV-14: “Descripción de pruebas de clasificadores” ... 51
Tabla IV-15: “Efectividad de clasificadores” ... 53
Página x
Tabla IV-17: “Ejemplo de historiasde usuario” ... 55
ABSTRACT
When you want to buy a specific computer and generally have little to no clue on what kind of performance to expect out of said computer, or you generally just want to look into what kind of feedback other customers have based on their experiences with it, you google it and are generally presented with hundreds upon hundreds of customer reviews on the subject. With such a vast amount of results, you probably will feel overwhelmed and try to figure out how best to take advantage of these piles of feedback, sometimes making snap decisions based on only some reviews that may be caught your eye. How can you make sure that you are making the most informed decision possible? This is where Miner PC Adviser steps in. MPCA uses Sentiment Analysis techniques and Web Scraping to analyze the amount of rele-vant data found, which in turn allows it to advise you whether or not to buy the computer.
RESUMEN
Cuando se quiere comprar un computador específico y generalmente se tiene poca o ninguna idea de qué tipo de rendimiento se espera del computador, o simplemente se desea informar sobre la retroalimentación que ofrecen otros usuarios basados en su experiencia, se busca en google y generalmente presenta cientos de reviews de usuarios hablando del tema. Con esa cantidad de resultados, probablemente se podría sentir abrumado e intentar de encontrar la mejor manera de tomar ventaja de esas pilas de comentarios, algunas veces haciendo rápidas decisiones basándose solamente en algunos reviews que podrían llamar la atención. ¿Cómo se puede asegurar que se está tomando la decisión más informada posible? En ese punto es cuando ingresa Miner PC Adviser. MPCA usa técnicas de Sentiment Analysis y Web Scraping
Página xii RESUMEN EJECUTIVO
La problemática atacada por medio de este proyecto consistía en que no existe un sistema de recomendación en compra de computadoras basado en el análisis de los comentarios de los usuarios en blogs de tecnología usando técnicas de sentiment analysis.
Una gran cantidad de información es desperdiciada en internet al no aprovechar la experien-cia de los usuarios en el momento de comprar un computador.
La solución propuesta consistía en el desarrollo de un sistema que por medio de Web Scra-ping extrajera los comentarios de los usuarios sobre computadores en blogs de tecnología y analizándolos con técnicas de sentiment analysis descubriera qué tan bien o qué tan mal se habla de un computador. El proceso anterior con la finalidad de poderle dar al usuario una recomendación acerca de comprar o no comprar un computador dependiendo de sus necesi-dades.
La herramienta seleccionada para realizar el proceso de Web Scrapping fue Jsoup, la cual es una librería de Java que permite navegar sobre los documentos HTML de manera sencilla. La herramienta seleccionada para realizar el proceso de Sentiment Analysis fue LingPipe, la cual, por medio de análisis de texto libre, puede clasificar la información dependiendo de su estruc-tura. Finalmente, para realizar la recomendación, se calculó el índice de polaridad de cada uno de los comentarios de un computador (utilizando LingPipe) para poder evidenciar qué tan bien y qué tan mal se habla de él, y, tomando como base esos resultados, darle una recomen-dación al usuario.
I - INTRODUCCIÓN
El presente documento tiene como propósito presentar los objetivos, la planeación y el desa-rrollo de un sistema con miras a solucionar la problemática de realizar recomendaciones utili-zando Sentiment Analysis[23] y datos de páginas web extraídos por medio de Web Scra-ping[36]. El nombre de este sistema es Miner PC Adviser y sus siglas durante el resto del documento serán MPCA.
A continuación serán presentados tanto la formulación del proyecto como el desarrollo y las conclusiones del mismo. La estructura básica del documento es la siguiente:
Marco Teórico: Explica de manera breve todos los aspectos teóricos que fueron tenidos en cuenta para el desarrollo del trabajo de grado.
Desarrollo del Trabajo de Grado y Metodología: Indica de qué manera se llevó a cabo el proceso desde la investigación hasta la conclusión del proyecto. Muestra la estrategia utiliza-da para diseñar el sistema MPCA: sistema de recomenutiliza-dación de compra de computadores basado en Sentiment Analysis, de qué manera fue desarrollado el prototipo y su validación.
Resultados y reflexión sobre los mismos: Ilustra los resultados obtenidos y las reflexiones que se realizaron a partir del trabajo desarrollado.
Página 2 II - DESCRIPCION GENERAL DEL TRABAJO DE GRADO
1. OPORTUNIDAD, PROBLEMÁTICA, ANTECEDENTES
Actualmente existen varios y diversos blogs sobre tecnología [3][4][5][6][7][8][9] en los que las personas pueden consultar información sobre computadores. Adicionalmente, algunos de estos blogs manejan la figura de review en la que se hace una valoración sobre el producto lo cual le permite al usuario formarse una opinión a partir de lo que allí encuentra. También existen tiendas online [13][14][15], algunas especializadas en productos tecnológicos, que permiten hacer búsqueda de productos parametrizada por medio de especificaciones técnicas como procesador o memoria RAM y algunas otras características como precio o tamaño.
Si bien, en la Web se encuentra la información suficiente para que una persona pueda encon-trar un computador que se ajuste a sus necesidades, para conseguir este objetivo, debe realizar varias consultas, tanto en tiendas on-line para acotar su búsqueda, como en blogs de tecnolo-gía para informarse sobre cada uno de los productos que hasta el momento tiene como posibi-lidad de compra.
Las desventajas de realizar las tareas anteriores son: el gran esfuerzo que debe hacer una per-sona para encontrar información relevante acerca del computador en varios blogs de internet y el tiempo que conlleva realizar esto, pues los blogs de tecnología contienen grandes canti-dades texto y es necesaria una lectura ardua para poder analizar la información importante. Además, la omisión de información útil durante la búsqueda puede ser un factor importante, ya que ésta no se encuentra centralizada ni resumida.
1.1. DESCRIPCIÓN DEL CONTEXTO
Adicionalmente, existen múltiples herramientas que permiten realizar Sentiment Analysis
para clasificar texto. Este proyecto de grado aprovecha dichas herramientas para realizar una recomendación al usuario teniendo en cuenta los comentarios realizados a los computadores en los blogs de tecnología, los cuales están compuestos de texto no estructurado.
1.2. PREGUNTA DE INVESTIGACIÓN
¿Cómo aconsejar a las personas en la elección de un computador que se ajuste a sus necesi-dades, aplicando técnicas de minería de textos y Sentiment Analysis sobre la información existente en blogs y tiendas de tecnología?
1.3. JUSTIFICACIÓN
Actualmente no existe una herramienta que aconseje a las personas en la compra de un computador basado en diversas fuentes de información, como páginas especializadas en tec-nología, tiendas online de tecnología y opiniones de muchos usuarios acerca de estos produc-tos en reviews online. Además, existe mucha información en la web que podría ser de utilidad al escoger un producto, información que va desde especificaciones técnicas hasta opiniones sobre la calidad de un producto en particular. Finalmente, gracias a los avances en minería de textos y sentiment analysis, actualmente es factible analizar textos semi-estructurados tenien-do la posibilidad de extraer aspectos, características de un producto, opiniones acerca de cada una de ellas, conocer quién y en qué momento realizó la opinión y determinar la polaridad de la misma (positiva, negativa o neutral)[1].
Teniendo en cuenta la disponibilidad de la información y la existencia de las técnicas necesa-rias para recuperar y analizar la misma, se propone construir una herramienta que permita aconsejar a las personas en la elección de un computador que se ajuste a sus necesidades, aplicando técnicas de minería de textos y sentiment analysis sobre la información existente en blogs y tiendas online de tecnología.
1.4. IMPACTO ESPERADO
Página 4
te en diferentes páginas Web especializadas y aconseje al usuario en la compra de un compu-tador teniendo en cuenta la experiencia de otros usuarios, utilizando sentiment analysis.
2. DESCRIPCIÓN DEL PROYECTO
En esta sección se presenta el objetivo general del proyecto, sus objetivos específicos y las fases metodológicas que se seleccionaron para el desarrollo de la propuesta.
2.1. OBJETIVO GENERAL
Desarrollar un prototipo de una aplicación que aconseje a las personas en la elección de un computador que se ajuste a sus necesidades utilizando técnicas de minería de textos junto con
sentiment analysis en blogs y tiendas de tecnología.
2.2. FASES METODOLÓGICAS O CONJUNTO DE OBJETIVOS ESPECÍFICOS
2.2.1. Investigación teórica
Realizar un marco teórico que describa el estado del arte en los temas de minería de datos, minería de textos, sentiment analysis y recuperación y análisis de información de fuentes de datos en la web.
2.2.2. Definición del Product Backlog[16]
Teniendo en cuenta el objetivo general y la problemática, especificar las características y las historias de usuario que describan la funcionalidad del prototipo a realizar.
2.2.3. Fuentes De Datos
Buscar y seleccionar las fuentes de datos, determinar la estructura de los datos y establecer el modelo de recuperación de información para cada una de las fuentes.
2.2.4. Selección de Técnicas de Minería de Textos
A partir de la investigación realizada para la construcción del marco teórico, la especificación de requerimientos y la escogencia de las fuentes de datos, seleccionar las técnicas de minería de textos y las técnicas de recuperación y análisis de información en la web que mejor se adecuen para el desarrollo del proyecto teniendo en cuenta las restricciones de tiempo.
2.2.5. Desarrollo
Diseñar, implementar y probar un prototipo que dé una solución a la problemática planteada, aplicando las técnicas seleccionadas de minería de textos y “Sentiment Analysis” sobre las fuentes de datos.
2.2.6. Evaluación
Página 6 III - MARCO TEÓRICO
En esta sección se definen el marco conceptual y marco institucional. El primero muestra la investigación inicial realizada y los conceptos importantes que se deben tener en cuenta para el entendimiento total de este documento. El segundo enuncia el marco institucional sobre el que se realizó la propuesta, esto incluye la institución a la que pertenece esta propuesta y las demás organizaciones que estuvieron involucradas en el desarrollo.
1. MARCO CONCEPTUAL
A continuación se enuncian y se definen los conceptos básicos que son de vital importancia para entender el documento en su totalidad. Además, se presentan comparaciones realizadas en la investigación inicial para que el lector pueda apreciar las diferencias entre las herra-mientas existentes que fueron tomadas en cuenta para la realización de la propuesta.
1.1. CONCEPTOS BÁSICOS
Web Scraping
Es una técnica de Ingeniería computacional para la extracción de información de páginas web. Usualmente, este tipo de programas simulan la exploración humana de la World Wide Web[36]
Clasificador
El término clasificador se utiliza en referencia al algoritmo utilizado para asignar a un ele-mento entrante no etiquetado una categoría concreta conocida [2]. El clasificador toma como base las características de los elementos para clasificarlos.
Selector
Es una consulta para elementos HTML que permite ubicar uno o varios elementos del docu-mento por medio de sus atributos. [37]
Minería de datos es el proceso de extracción de conocimiento válido, previamente desconoci-do e información comprensible de grandes fuentes de datos [21].
Minería de textos
Minería de textos, también conocida como text data mining o descubrimiento de conocimien-to de bases de daconocimien-tos textuales se refiere generalmente al proceso de extraer conocimienconocimien-to o patrones interesantes y no triviales de documentos de texto no estructurados. Se puede ver como una extensión de la minería de datos [22].
Sentiment analysis
Sentiment analysis es una técnica que consiste en analizar opiniones escritas en un lenguaje natural y determinar si indican una posición negativa, positiva o neutral respecto a un sujeto [23].
Scrum
Scrum es una metodología de desarrollo ágil para realizar proyectos complejos. Scrum origi-nalmente fue formalizado para proyectos de desarrollo de software, pero sirve para cualquier clase de proyecto [24].
API
(Application Programming Interface) es un conjunto de funciones que ofrece un sistema de información con una capa de abstracción para ser utilizado por otro software.
Word cloud
Página 8
1.2. TRABAJOS IMPORTANTES EN EL ÁREA
Incluso hace 13 años, la información que se encontraba en internet ya era bastante grande y se esperaba que creciera exponencialmente [39]. El estudio de esta información es importante, pues hay demasiados datos sin analizar que podrían contribuir a realizar aplicaciones perso-nalizadas a las personas que navegan por la Web. Este problema es posible de resolver por medio de la minería de datos sobre textos no estructurados, semi-estructurados y estructura-dos. Aunque la Minería de Datos en la Web tiene muchos objetivos, parte de éstos son el descubrimiento de información en los textos, en las bases de datos y en los datos multimedia que se encuentran fluyendo en la Web [35].
La minería en la web posee 3 problemas básicos: Encontrar la información relevante, 1) crear conocimiento a partir de la información disponible, 2) personalizar a información y 3) apren-der de los usuarios. Para resolver estos problemas, se utilizan técnicas de minería de datos en la Web que permiten extraer gran cantidad de información que fluye en ella [33].
El problema de los datos en la Web es que la gran mayoría no son estructurados, es decir, es texto libre, audio, video, etc. (A lo cual se le llama datos multimedia) Pero esto no significa que sea el único tipo de datos que hay en la Web, además de los datos no estructurados, se pueden encontrar datos semi-estructurados y datos estructurados. Los primeros, son los más difíciles de manejar, debido a que necesitan un pre-procesamiento para convertir de algo que “no se entiende” a información que se puede leer y entender [11]. Los datos semi -estructurados son aquellos que poseen parcialmente una estructura, por ejemplo los documen-tos HTML tienen “tags” que pueden servir de base para la búsqueda y extracción de informa-ción. Los últimos, pueden ser datos que se encuentran en tablas o bases de datos, los cuáles deben estar estructurados para estar en estos formatos [12].
Para procesar esta gran variedad de tipos de datos, se utilizan técnicas especializadas de mi-nería de datos, más específicamente de la mimi-nería de textos. La Recuperación de Información o Information Retreival (IR), es una técnica que se encarga de encontrar documentos con información útil, al igual que desechar aquellos que no la tengan. De esta forma, se genera una colección de documentos útiles. La Extracción de Información o Information Extraction
y no estructurados), al igual que darles una estructura a estos documentos. En combinación con la IR, ésta técnica es muy útil para la recolección de conocimiento nuevo. Por último, las de Aprendizaje de máquina o Machine Learning, es una técnica utilizada para “aprender” acerca de los usuarios y sus comportamientos mientras navegan por la Web [9].
La combinación de las técnicas anteriores y otras (como los motores de búsqueda) pueden hacer que la información que se encuentra en internet sea aprovechada para generar nuevo conocimiento, además de la personalización de la información de quien la lee.
1.2.1. Sentiment Analysis
El Sentiment Analysis es una técnica relativamente nueva por lo que todavía no existe un procedimiento estándar. Sin embargo, existen diferentes acercamientos y se han desarrollado varias herramientas que facilitan la clasificación de texto con el fin de detectar su “polari-dad”. Dos de las técnicas utilizadas para realizar sentiment analysis son: clasificadores de texto utilizando la librería LingPipe y clasificadores de texto utilizando el Google Prediction API. Google Prediction API ofrece dos opciones:1) hosted model, que consiste en un clasifi-cador previamente entrenado por Google por lo que no hay necesidad de utilizar un conjunto de entrenamiento, y 2) trained model, que consiste en un clasificador que debe ser entrenado. En la sección IV -1.3.2 se detalla el proceso de creación y entrenamiento de los clasificadores
En la Tabla III-1: “Comparación de Métodos de Sentiment Analysis se comparan los métodos anteriormente mencionados.
LingPipe Google Prediction API
(hosted model)
Google Prediction API (trained model)
Costo Gratis Gratis (puede ser
retira-do en cualquier momen-to ya que es un demo)
Cuota gratis. Una vez superada la cuota se cobra por cada 1000 prediccio-nes.
Persistencia del
modelo entrenado
Sí El modelo está persistido
en un host de Google con su propio
Página 10
miento host externo
Entrenamiento con diferentes tipos de datos
Solo texto plano
No es posible el entre-namiento
[image:24.612.101.522.89.166.2]Sí, puede ser entrenado con múltiples tipos de datos
Tabla III-1: “Comparación de Métodos de Sentiment Analysis”
LingPipe: La librería LingPipe provee una serie de clases y métodos que permiten crear clasificadores de texto por medio de una lista de categorías y un conjunto de entrenamien-to. Una vez creado y entrenado el clasificador, se puede proceder a realizar predicciones.
Google Prediction API: Google ofrece un servicio Web que puede ser utilizado para pre-decir y clasificar tomando como base múltiples tipos de datos tales como cadenas de carac-teres y numéricos. Entre sus diferentes usos se destaca la posibilidad de hacer Sentiment Analysis.
1.3. COMPARACIÓN DE LAS HERRAMIENTAS TECNOLÓGICAS EXISTENTES
ACTUALMENTE Y QUE INTENTAN RESOLVER EL PROBLEMA.
A continuación se muestra la Tabla III-2: “Comparación de Blogs de Tecnología de compara-ción entre diversos portales existentes que ofrecen funcionalidades similares al proyecto pro-puesto en este documento. Aunque existen herramientas que cuentan con varias característi-cas deseables, hasta el momento no se conocen herramientas que satisfagan todas las necesi-dades que se pretenden cubrir con el proyecto propuesto, es decir, recomendaciones basadas en sentiment analysis por medio del análisis de los comentarios de los usuarios de un compu-tador. Adicionalmente, ninguna de las herramientas descritas centran su funcionalidad en el análisis de los comentarios de los usuarios ni utilizan como fuente de información comenta-rios realizados en otros sitios web.
En la Tabla III-2 se hace una comparación de un conjunto de blogs de tecnología selecciona-dos y los servicios que éstos ofrecen.
notebookre-zon.com sor.co.uk view.co.uk rect.com om view.com
Permite realizar
búsqueda x x x x x x
Búsqueda parametri-zable por caracterís-ticas
técni-cas x x x x x
Portal
especiali-zado en
reviews de
compu-tadores x x x x
Da la po-sibilidad de realizar comenta-rios sobre cada
Página 12
Recomien-do otros
productos x x x x x
Da una
califica-ción al
producto x x x x x
Lista las
caracterís-ticas
técni-cas x x x x x x
Muestra informa-ción
deta-llada del
producto x x x x x
Tienda onli-ne/Portal
de
com-pras x x
una com-paración con otros productos
Ofrece formas alternas
para
vi-sualizar o comparar los comen-tarios de otros
usuarios x x
Realiza análisis sobre los
comenta-rios x
Muestra
pros y
contras del
[image:27.612.102.524.79.646.2]producto x x
Página 14
Se puede observar el caso particular de Amazon.com, que aunque según el cuadro cumple con la mayoría de características deseables, tiene aspectos con posibilidades de mejorar que se pretenden suplir con la propuesta plasmada en el presente documento. En primer lugar, Amazon.com no muestra información resumida, por el contrario, bombardea al usuario con grandes cantidades de información que pueden resultar agobiantes y poco atractivas a la hora de querer obtener información rápida y precisa, y finalmente, aunque Amazon.com realiza análisis sobre los comentarios de los compradores y permite comparar y ver de forma paralela las opiniones negativas y las positivas, no centraliza su funcionalidad en los mismos ni ofrece más de una fuente de comentarios, como blogs de tecnología, dejando a un lado una fuente de información primordial para conocer la satisfacción de los clientes sobre un producto.
Frente a esta oportunidad de mejora, este trabajo busca proponer una estrategia de recomen-dación en donde, además de usar la información técnica, se analicen los comentarios de los usuarios.
2. MARCO INSTITUCIONAL
Teniendo en cuenta la Misión de la Pontificia Universidad Javeriana:
“La Pontificia Universidad Javeriana es una institución católica de educación superior, fundad y regentada por la Compañía de Jesús, comprometida con los principios educativos y las orientaciones de la entidad fundadora.
Ejerce la docencia, la investigación y el servicio con excelencia, como universidad integrada a un país de regiones, con perspectiva global e interdisciplinar, y se propone:
1. La formación integral de personas que sobresalgan por su alta calidad humana, ética, académica, profesional, y por su alta responsabilidad social; y,
2. La creación y el desarrollo de conocimiento y de cultura en una perspectiva crítica e innovadora,
Acuerdo No. 576 del Consejo Directivo de la Pontificia Universidad Javeriana, 26 de Abril de 2013” [20]
Este trabajo busca crear una herramienta innovadora que utilice las tecnologías y los recursos existentes con el fin de suplir algunas necesidades de las personas que actualmente desean adquirir un computador.
Página 16 IV -DESARROLLO DEL TRABAJO
1. MINER PC ADVISER: SISTEMA DE RECOMENDACIÓN BASADO EN SENTIMENT ANALYSIS
En esta sección se explica qué es MPCA, cómo funciona, la estrategia detrás de este y el pro-ceso llevado a cabo para su construcción.
1.1. ¿QUÉ ES MINER PC ADVISER?
Miner PC Adviser es un sistema de recomendación de computadores basado en sentiment analysis. Su propósito es recomendar a un usuario específico sobre la compra de un compu-tador teniendo como base los comentarios y experiencias de usuarios plasmadas en reviews
de blogs de tecnología y tiendas online.
Ilustración IV-1: “Proceso llevado a cabo en MPCA”
Para llevar a cabo el diseño del sistema se tuvo en cuenta los diferentes componentes tales como: las posibles entradas, el procesamiento de estas y las salidas.
Como entradas se consideraron las diferentes páginas web utilizadas como fuentes de datos, como procesamiento se consideró el Sentiment Analysis y el filtrado de información teniendo en cuenta las necesidades del usuario (plasmadas como características físicas del computador deseado) y finalmente se estableció que la salida sería una recomendación para el usuario.
La Ilustración IV-1: “Proceso llevado a cabo en MPCA” describe el proceso desde la extrac-ción de datos utilizando Web Scraping hasta la realización de la recomendación basada en
Sentiment Analysis.
1.3. ESTRATEGIA DE RECOMENDACIÓN BASADA EN SENTIMENT ANALYSIS
Miner PC Adviser utiliza Web Scrapping y Sentiment Analysis para la extracción de datos y clasificación de comentarios. A continuación se describe la estrategia utilizada para realizar una recomendación.
1.3.1. Extracción de datos
Página 18 Ilustración IV-2: “Proceso de extracción de datos, diagrama de entradas y salidas”
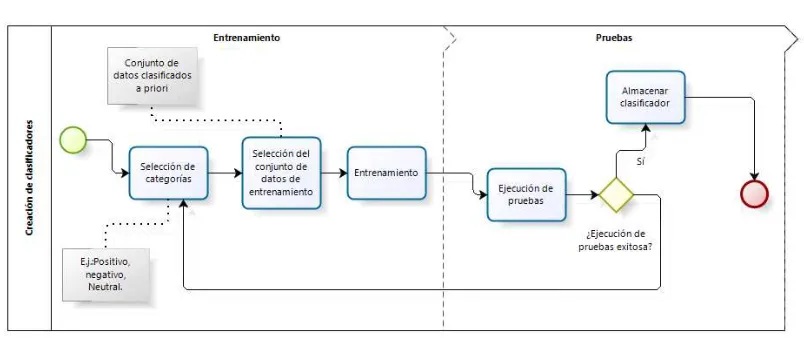
1.3.2. Creación de clasificadores
El proceso de creación de clasificadores se divide en 2 etapas principales: 1) entrenamiento y 2) pruebas. En la Ilustración IV-3 se muestra el proceso de creación de clasificadores. Duran-te la etapa de entrenamiento se seleccionan las caDuran-tegorías en las que deben ser clasificados los datos. Paso seguido se selecciona un conjunto de datos de entrenamiento, datos de los que se debe conocer a priori su clasificación y finalmente se ejecuta el entrenamiento que actúa co-mo una “caja negra”, ya que depende de la herramienta, API o librería que se esté utilizando para crear el clasificador. En la etapa de pruebas se clasifica un conjunto de datos empleando el modelo generado de los cuales se conoce su clasificación a priori, y a partir de los resulta-dos arrojaresulta-dos se mide la precisión calculando el porcentaje de datos correctamente clasifica-dos. Para determinar si una prueba fue exitosa, la precisión del clasificador debe superar un umbral previamente establecido por el desarrollador. Para el caso particular de MPCA se decidió, después de realizar múltiples pruebas, un umbral de 80% de precisión.
Entradas
•Blogs de tecnología •Tiendas online
Proceso
•Web Scraping
Salidas
•Características físicas de los productos •Comentarios de
Ilustración IV-3: “Proceso de creación de clasificadores”
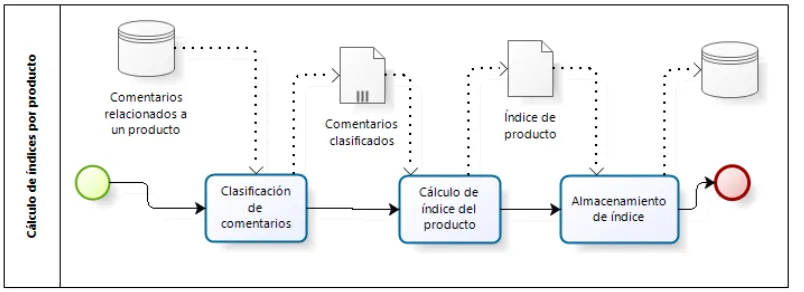
1.3.3. Cálculo de índices de polaridad a partir de clasificadores
Para realizar la recomendación se calcula un puntaje que denominaremos índice de polari-dad por cada categoría con el fin de saber a cuál tiene más probabilidades de pertenecer. MPCA calcula este índice como el porcentaje de comentarios pertenecientes a cada categoría, por ejemplo:
Teniendo en cuenta la Tabla IV-1: “Ejemplo de clasificación de comentarios el producto X tiene 5 comentarios en total, de los cuales 3 son positivos y 1 es negativo, por lo tanto los índices equivalen a ¾ = 75% y ¼ = 25% respectivamente.
Comentario Clasificación
Producto sin defectos Positivo (+) Muy buena calidad Positivo (+) Excelente producto Positivo (+)
Pésimo producto Negativo (-)
Tabla IV-1: “Ejemplo de clasificación de comentarios”
[image:33.612.113.515.86.255.2]Página 20
comentarios que pertenecen a cada categoría como se muestra en el ejemplo anteriormente mencionado. En la Ilustración IV-4: “Cálculo de índices por producto se muestra el proceso con las entradas y salidas para cada tarea.
Ilustración IV-4: “Cálculo de índices por producto”
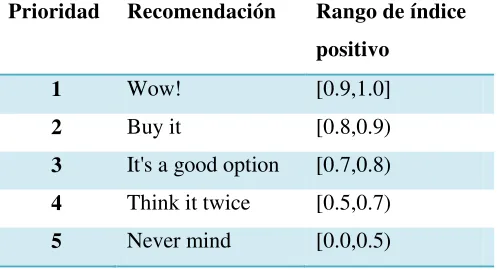
1.3.4. Generación de recomendaciones
Basado en los índices de polaridad de cada producto se genera la recomendación tomando en cuenta una lista de rangos que establecen una recomendación dependiendo de los índices de cada categoría. La Tabla IV-2: “Recomendaciones muestra las recomendaciones que pueden ser dadas al usuario ordenadas por prioridad siendo 1 la más recomendada y 5 la menos re-comendada.
Prioridad Recomendación
1 Wow!
2 Buy it
3 It's a good option
4 Think it twice
5 Never mind
Tabla IV-2: “Recomendaciones”
[image:34.612.109.511.168.314.2]1.3.5. Filtrado a partir de características técnicas
A partir de las necesidades del usuario, plasmadas en características físicas de los computado-res, se establecieron filtros con los que se puede interactuar para acotar el conjunto de pro-ductos disponibles.
Ilustración IV-5: “Entradas y salidas del proceso de filtrado”
En la Ilustración IV-5: “Entradas y salidas del proceso de filtrado se muestran las entradas y salidas del proceso de filtrado. Como se puede observar, la salida, compuesta por un conjunto de computadores, puede constituirse como una nueva entrada para repetir el proceso de filtra-do e ir reducienfiltra-do el conjunto de productos.
1.4. DISEÑO DEL SISTEMA
El diseño de un sistema es uno de los procesos más cuidadosos e importantes de todo el desa-rrollo. Un buen diseño permite mantenibilidad, escalabilidad y modificabilidad, de esta mane-ra los cambios que se deban realizar no tendrán un gmane-ran impacto sobre los componentes del sistema.
1.4.1. Arquitectura
En esta sección se explica el diseño del sistema, el cual se realizó con el fin de cumplir con las características anteriormente nombradas.
Con el fin de separar responsabilidades, se diseñó la arquitectura del sistema dividida en 5 grandes módulos: 1) Modelo y persistencia, 2) Extracción de datos, 3) Sentiment analysis, 4)
Entrada
•Conjunto de computadores •Filtro
Proceso
•Aplicación de filtro
Salida
Página 22
Recomendación, 5) API y 6) Presentación. Adicionalmente, para persistir los datos y soportar el módulo de persistencia se planteó la utilización de una base de datos de Oracle.
La Ilustración IV-6: “Diagrama de Componentes muestra un diagrama de componentes y la manera en la que los componentes se comunican entre ellos. En las subsecciones siguientes se explicará en detalle cada uno de los 6 módulos y el esquema de base de datos utilizado.
1.4.2. Esquema de Base de Datos
Para el desarrollo del proyecto se tuvo en cuenta que se debía guardar diferentes datos; desde la información técnica de cada uno de los productos y las páginas de donde sería extraída dicha información, hasta los datos calculados después de realizar el proceso de Sentiment analysis para soportar el proceso de recomendación. La Ilustración IV-7: “Esquema Base de Datos presenta el esquema de base de datos utilizado.
Página 24
1.4.3. Módulo de persistencia (MPCA_PersistenceModule)
Una vez definida la base de datos y los diferentes Objetos a ser persistidos, se procedió a representar cada una de las entidades como una clase de Java por medio de JPA 2.1 ya que esta tecnología brinda la facilidad de hacer “transparente” el manejo de la base de datos por medio de clases en Java. A continuación se describen las entidades más relevantes para en-tender el modelo planteado (Por facilidad, se omitirá el prefijo “Mpca”). Dicho modelo puede ser apreciado en la Ilustración IV-8: “Diagrama de Clases del Módulo de Persistencia.
Comment: Representa un comentario realizado por una persona al respecto de un computador.
WebPage: Representa una página web de la que fue extraída información o comen-tarios sobre computadores.
CommentAddition: Representa información adicional de un comentario, como por
ejemplo, calificación del computador, polaridad del comentario, fecha del comenta-rio, etc.
Product: Representa un producto. En el caso específico de este proyecto, representa un computador.
ProductAddition: Representa información adicional de un computador, como por ejemplo, memoria RAM, disco duro, procesador, etc.
CommentIndex: Representa el índice de polaridad que le asigna un clasificador a un comentario.
ProductIndex: Representa el índice de polaridad que le es asignado a un producto.
Página 26
1.4.4. Módulo de Extracción de Datos (MPCA_DataExtractorModule)
Ya que las páginas web serían las principales fuentes de información, se diseñó y desarrolló un módulo dedicado a extraer los datos e información necesaria para poblar la base de datos con productos y comentarios.
A continuación se describen las clases más relevantes para entender el modelo planteado (por facilidad, se omitirá el prefijo “Mpca”). El diagrama de clases de dicho modelo se muestra en la Ilustración IV-9: “Diagrama de Clases del Módulo de Extracción de Datos”.
DataExtractor: Es la clase encargada de extraer toda la información proveniente de los páginas web. Extrae los productos y los comentarios sobre estos y los persiste en la base de datos.
ICommentsExtractor: Es la interfaz que deben seguir todos los extractores de co-mentarios por página.
AmazonCommentsExtractor: Esta clase implementa ICommentsExtractor y se
en-carga de extraer los comentarios de una URL de Amazon.
NeweggCommentsExtractor: Esta clase tiene el mismo objetivo que la anterior cla-se, solo que extrae los comentarios de una URL de Newegg.
TigerDirectCommentsExtractor: Esta clase tiene el mismo objetivo que la anterior clase, solo que extrae los comentarios de una URL de Tiger Direct.
Ilustración IV-9: “Diagrama de Clases del Módulo de Extracción de Datos”
1.4.5. Módulo de Sentiment Analysis (MPCA_SentimentAnalysisModule)
Una vez extraída la información y poblada la base de datos, se debía realizar el proceso de
sentiment analysis con el fin de calcular el índice de polaridad de cada uno de los comenta-rios y basado en ello, asignar puntajes a los comentacomenta-rios y productos para poder realizar una recomendación al usuario final.
Página 28
de parámetros, 2) entrenarlo a partir de un conjunto de datos de los que previamente se cono-ce su categoría, 3) probar la efectividad del mismo utilizando un conjunto de datos de los que previamente se conoce su categoría, 4) clasificar texto utilizando el modelo generado y 5) guardar el modelo para su futura utilización.
Para reflejar estas funcionalidades en el módulo de Sentiment Analysis se implementaron 2 interfaces, cada una con el propósito de reflejar el comportamiento de los diferentes tipos de clasificadores que se pueden utilizar: MpcaITrainableClassifier y MpcaIClassifier. Las im-plementaciones se muestran y explican a continuación:
MpcaIClassifier es la interfaz base que implementan todos los clasificadores en el proyecto. Provee el método classify para clasificar un texto y el método getCatego-ries para conocer las categorías o clases que es capaz de identificar. El método classi-fy retorna un objeto MpcaClassification que encapsula un Map de java cuyas llaves son Strings que representan una categoría y cuyo contenido son Doubles que repre-sentan el índice de polaridad calculado para dicha categoría.
MpcaIClassifier
MpcaClassification classify(String text); String[] getCategories();
Tabla IV-3: “Interfaz MpcaIClassifier”
respectiva categoría. Adicionalmente, esta interfaz extiende de MpcaIClassifier para contar con las funcionalidades básicas y ofrece dos métodos adicionales para saber si el clasificador ya fue entrenado y para conocer el tamaño del conjunto de entrena-miento que fue utilizado.
MpcaITrainableClassifier extends MpcaIClassifier
void train(String category,List<String> reviews); void train(Map<String,List<String>> reviews); boolean isTrained();
int trainingSize();
Tabla IV-4: “Interfaz MpcaITrainableClassifier”
1.4.5.1. LingPipe como clasificador principal
La razón más importante para elegir a Lingpipe sobre Google Prediction API fue el encon-trar varias desventajas al momento de usarlo en este proyecto. Una de ellas es el tiempo de latencia en el envío de los datos; al ser un clasificador que se utiliza de forma remota, se deben enviar los datos por internet lo cual consume una gran cantidad de tiempo. La se-gunda desventaja es que es pago y cuenta con un límite de consultas por mes, lo cual difi-culta la realización de pruebas dado el tamaño que éstas requieren. Google Prediction API
ofrece (pagando una cuota) 10 mil consultas al mes; para poder hacer la predicción com-pleta de los productos en la base de datos, son necesarias aproximadamente 5 mil consul-tas. En ese orden de ideas, solamente dos pruebas por mes podrían ser llevadas a cabo, lo cual no es viable tomando como base la cantidad de pruebas que fueron realizadas con
LingPipe.
[image:43.612.136.494.172.330.2]ser-Página 30
vicios sobre internet, se le debe sumar a lo anterior el tiempo de latencia en el envío de da-tos.
Dadas las ventajas y desventajas anteriormente mencionadas, se tomó la decisión de pres-cindir del clasificador de Google Prediction API. Aun así se diseñó el sistema de tal forma que, por medio de archivos descriptores, pueda hacer uso de éste y diferentes tipos de clasi-ficadores.
Para mayor detalle sobre estos descriptores puede referirse a la sección 1.4.9.
1.4.6. Módulo de Recomendación (MPCA_RecommenderModule)
En esta sección se explicará cómo fue el proceso para generar la recomendación basada en
Sentiment Analysis.
Para calcular las recomendaciones se crearon dos clases:
MpcaRecommender
MpcaRecommendation
La primera clase (Tabla IV-5: “Clase MpcaRecommender) ofrece métodos para generar la recomendación tomando como base un producto y el índice de polaridad.
MpcaRecommender
MpcaRecommendation doRecommendation(MpcaProduct product, long indexId);
MpcaRecommendation doRecommendation(MpcaProduct product, MpcaIndexType index)
Tabla IV-5: “Clase MpcaRecommender”
po-see características tales como el nombre, las categorías con un rango relacionado al índice de polaridad y su prioridad siendo 1 la más alta o la más recomendada.
Para mayor detalle sobre el archivo descriptor de recomendaciones puede referirse a la sec-ción 1.4.9.
class MpcaRecommendation implements Comparable<MpcaRecommendation>
String decision;
Map<MpcaPolarity, Range> ranges;
Integer priority;
Tabla IV-6: “Clase MpcaRecommendation”
Una vez creados los objetos MpcaRecommendation se procesa cada uno de los productos a los cuales, teniendo en cuenta los índices de polaridad, se les asigna la recomendación ade-cuada. En la Tabla IV-7: “Tabla de recomendaciones con rangos de índices se muestran las recomendaciones con los rangos utilizados para la creación del prototipo. Cabe anotar que estos rangos fueron establecidos para la realización del prototipo, sin embargo, pueden ser modificados por medio del descriptor de recomendadores.
Prioridad Recomendación Rango de índice
positivo
1 Wow! [0.9,1.0]
2 Buy it [0.8,0.9)
3 It's a good option [0.7,0.8)
4 Think it twice [0.5,0.7)
5 Never mind [0.0,0.5)
[image:45.612.105.512.186.344.2] [image:45.612.104.354.503.638.2]Página 32
En la siguiente sección se utilizarán los resultados de este módulo para que el usuario pueda interactuar con ellos.
1.4.7. Módulo API
Una vez finalizados los módulos anteriores, se procedió a realizar un API para que pudiera ser utilizado por diferentes aplicaciones, incluyendo el módulo de presentación (sección 1.4.8).
Este módulo se compone de 3 funcionalidades expuestas por medio de Web Services: 1) Ob-tener filtros, 2) Listar productos aplicando filtros y 3) ObOb-tener nube de palabras de un produc-to. La Tabla IV-8:”Descripción de la interfaz MpcaAPI” describe la interfaz por la cual se puede acceder a las funcionalidades ofrecidas por éste módulo.
MpcaAPI
Funcionalidad Método del API
Obtener filtros List<MpcaFilter> getFilters();
Listar productos aplicando filtros List<MpcaProduct> getProducts(List<MpcaFilter> filters);
Obtener nube de palabras de un producto
Image getWordCloud(MpcaProduct product);
Tabla IV-8:”Descripción de la interfaz MpcaAPI”
En las subsecciones siguientes describe en detalle las 3 funcionalidades del API.
1.4.7.1. Obtener filtros
Parte del objetivo principal de MPCA es darle la posibilidad al usuario de ubicar un pro-ducto que se adapte a sus necesidades. Para ello se planteó la funcionalidad de filtrado que, por medio de características físicas permite acotar el conjunto de productos.
Estos filtros se aplican a partir de las características físicas de cada producto, que para el caso del prototipo son: capacidad de memoria RAM, capacidad del Disco Duro y fabrican-te.
El servicio Web permite obtener la lista de filtros disponibles por medio del método getFil-ters que retorna una lista de MpcaFilter. Por medio de los métodos de esta clase se puede configurar un filtro que acote el conjunto de productos a uno que cumpla con las caracterís-ticas deseadas por el usuario.
La Tabla IV-9:”Clase MpcaFilter, descripción de métodos”
class MpcaFilter<T extends Comparable>
Método Descripción
MpcaFilter(String name); Constructor de la clase. Recibe un String que describe el nombre del filtro.
ej. "RAM", "Disco duro", "Fabricante",etc. String getName(); Método que permite obtener el nombre del filtro void setName(String name); Método que permite establecer el nombre del filtro
Map<T,Boolean> getValues();
Método que retorna un Map en donde cada llave representa la característica de un producto y el valor relacionado representa si dicha característica debe ser filtrada o no.
ej. En un filtro de nombre “Fabricante” el mapa puede conte-ner las parejas:
1. Apple -> True
2. Samsung -> False
3. Toshiba -> True
Página 34
void setValue(T key, Boolean value);
Método que permite establecer el valor de una llave del mapa de características. Este valor determina si dicha característica debe ser filtrada o no como se explica en el ejemplo del mé-todo getValues.
muestra y describe cada uno de los métodos públicos de esta clase.
class MpcaFilter<T extends Comparable>
Método Descripción
MpcaFilter(String name); Constructor de la clase. Recibe un String que describe el nombre del filtro.
ej. "RAM", "Disco duro", "Fabricante",etc. String getName(); Método que permite obtener el nombre del filtro void setName(String name); Método que permite establecer el nombre del filtro
Map<T,Boolean> getValues();
Método que retorna un Map en donde cada llave representa la característica de un producto y el valor relacionado representa si dicha característica debe ser filtrada o no.
ej. En un filtro de nombre “Fabricante” el mapa puede conte-ner las parejas:
4. Apple -> True
5. Samsung -> False
6. Toshiba -> True
Un mapa con estos datos implica que se desea mostrar los productos que cumplan con que el fabricante sea “Apple” o “Toshiba” y se desea omitir aquellos cuyo fabricante sea “Samsung”.
void setValue(T key, Boolean value);
Tabla IV-9:”Clase MpcaFilter, descripción de métodos”
1.4.7.2. Listar productos aplicando filtros
El servicio Web permite obtener la lista de productos que cumplen con los criterios especi-ficados por una lista de filtros. Teniendo en cuenta la lista de filtros, se buscan los produc-tos que cumplan con los criterios especificados. Los producproduc-tos son enviados en un List de
MpcaProduct. En la Tabla IV-10:”Miembros de la clase MpcaProduct” se muestran los miembros de la clase MpcaProduct.
Miembro Descripción
int id; Identificador único del producto
String model; Modelo del producto String brand; Fabricante del producto
int ram; Capacidad de memoria RAM en GB
int hardDisk; Capacidad de disco duro en GB String
recommen-dation;
Recomendación calculada por MPCA
Integer priority; Prioridad de la recomendación (entre menor sea el número es más probable que la recomendación sea positiva).
Image image; Imagen del producto Map
<String, Double> polaritiesIndex;
Mapa en donde la llave representa una categoría como "positivo" o "negativo" y el valor representa el índice de polaridad
Página 36 1.4.7.3. Obtener nube de palabras de un producto
Obtener nube de palabras de un producto se consideró como una funcionalidad que podría enriquecer el sistema por lo que se implementó este Servicio Web.
Este Servicio Web permite obtener una nube de palabras dependiendo del índice de polari-dad del producto. Como ejemplo se crearon 2 nubes de palabras utilizando la herramienta
online Wordle1
. Las ilustraciones Ilustración IV-10:”Nube de palabras positiva” e Ilustra-ción IV-11:”Nube de palabras negativa” muestran una nube de palabras formadas con co-mentarios positivos y negativos respectivamente.
1
Ilustración IV-10:”Nube de palabras positi-va”
Ilustración IV-11:”Nube de palabras negati-va”
1.4.8. Módulo de Presentación (MPCA_AndroidApp)
Después del desarrollo de los módulos encargados de extraer información, procesarla y gene-rar una recomendación, se inició el desarrollo del módulo de presentación por medio del cual los usuarios podrán interactuar con la aplicación. En esta sección se especifica cómo fue el desarrollo de este módulo y cómo funciona.
1.4.8.1. Herramientas Utilizadas
Página 38
por medio de dispositivos Android para dar un valor agregado al sistema creado, ya que no estaba contemplado en el alcance inicial.
Para desarrollar este módulo se utilizaron las herramientas ofrecidas por Google para el desarrollo en dispositivos Android:
ADT Android
SDK Android
El primero contiene todas las herramientas necesarias para desarrollar aplicaciones en An-droid (incluyendo el SDK de AnAn-droid, pero para mejor explicación de esta sección se deci-dió tratarlos por separado). Dentro de estas se encuentra el IDE Eclipse (versión Helios), el cual contiene los plugins necesarios para el despliegue de la aplicación en los dispositivos.
El segundo posee el Kit de Desarrollo de Software (SDK por sus siglas en inglés) con to-das sus versiones (desde el nivel 1 al 19) de Android. Además, incluye todos los drivers para el manejo de dispositivos emulados y físicos.
1.4.8.2. Funcionalidades
Para el desarrollo de este módulo se plantearon 4 funcionalidades plasmadas en actividades de Android del lado del front-end y Web Services del lado del back-end: 1) Filtrado de productos, 2) Listado de productos, 3) Detalle de producto y 4) Nube de palabras. Cada una de estas actividades de Android está compuesta de una ventana en la Interfaz Gráfica de Usuario y está representada por una clase que se comunica con el API de MPCA en el
Ilustración IV-12: “Diagrama de clases del módulo de presentación”
Página 40 1.4.8.3. Filtrado de productos
Para obtener los filtros disponibles se hace uso del Servicio Web Obtener Filtros el cual re-torna una lista de MpcaFilter. A partir de esta lista se crea la interfaz gráfica de usuario de-pendiendo del tipo de filtro: si el filtro es de Strings(ej. Marca, Modelo) se muestran che-ckboxes y si el filtro es de Integers(ej. RAM, Disco Duro) se muestra una barra que le per-mite al usuario establecer un rango.
Ilustración IV-13:”Interfaz Gráfica Primera Ventana”
1.4.8.4. Listado de productos
La segunda ventana (Ilustración IV-14: “Pantalla, lista de productos”) ofrece una vista general de cada producto, que consta de la marca, el modelo y la recomendación ofrecida por MPCA. Los productos listados en esta ventana se obtienen por medio del Servicio Web
Página 42 Ilustración IV-14: “Pantalla, lista de productos”
1.4.8.5. Detalle de producto
Ilustración IV-15: “Pantalla, detalle de producto”
1.4.8.6. Nube de palabras
Página 44 Ilustración IV-16: “Pantalla, Nube de palabras”
1.4.9. Descriptores
Dichos descriptores son archivos que contienen información sobre la estructura de un objeto o la descripción de un proceso. En el caso particular de este proyecto se hizo uso de 4 archi-vos descriptores:
1.4.9.1. Descriptor de página web para extracción de información
Aprovechando la estructura HTML de las páginas Web, los selectors del lenguaje CSS y el hecho de que los blogs de tecnología y tiendas de tecnología online usan una plantilla simi-lar para su contenido, se estableció la utilización de un archivo por cada página web que se usó como fuente de datos. Cada uno de estos archivos contiene un conjunto de tuplas cuyo primer elemento es el nombre de la propiedad del producto (capacidad de memoria RAM, capacidad de Disco duro, tamaño de pantalla, etc.) y cuyo segundo elemento es el selector de CSS que ubica el elemento en la página web.
Ilustración IV-17: “Demostración de uso de herramientas de desarrollo de Chrome”
En la Ilustración IV-17: “Demostración de uso de herramientas de desarrollo de Chrome las herramientas de desarrollo de Chrome permiten ver la etiqueta exacta en la que se en-cuentra ubicada la información que hace referencia a la capacidad de memoria RAM de un computador, lo cual se vería plasmado en los archivos descriptores de la siguiente forma:
Página 46 En donde “ram” hace referencia a la propiedad y lo que resta de la línea (“div.section.techD div.attrG tbody tr 4 td.value”), por medio de CSS, describe la ubica-ción de la etiqueta que contiene la informaubica-ción requerida.
1.4.9.2. Entrenamiento y prueba de clasificadores
Para describir el proceso de entrenamiento y prueba de distintos clasificadores se estableció el uso de un archivo XML con etiquetas para describir conjuntos de datos, clasificadores, categorías y pruebas. En la Tabla IV-11: “Ejemplo, descriptor de entrenamiento y pruebas de clasificadores se muestra un ejemplo de descriptor de entrenamiento y prueba de clasifi-cadores y en la Ilustración IV-18: “Diagrama de relación entre etiquetas se muestra, por medio de UML, las relaciones entre cada uno de los objetos representados con etiquetas y las propiedades que poseen con el fin de dar la posibilidad de obtener diferentes configura-ciones.
<traningAndTest> <datasets>
<dataset id = "newEggPositive" details = "Polaridad Positiva de newegg"> <query>
SELECT ca.mpcaComment FROM MpcaCommentAddition </query>
</dataset> </datasets> <classifiers>
<classifier id="c1" class = "sentimentAnalysis.MpcaLingPipeClassifier" > <category name = "POSITIVE">
<dataset ref="newEggPositive"/> </category>
</classifier> </classifiers> <tests> <test>
<classifier ref = "lingPipeClassifier2"/> <expectedCategory name = "POSITIVE"> <dataset ref="newEggPositive"/> </expectedCategory>
</test> </tests>
[image:61.612.119.525.53.576.2]</traningAndTest>
Tabla IV-11: “Ejemplo, descriptor de entrenamiento y pruebas de clasificadores”
Página 48 <Query>, etiquetas que contienen una sentencia JPQL por medio de la que se obtiene un subconjunto de comentarios de la base de datos. La propiedad maxResults se utiliza para limitar la consulta. La etiqueta <Classifier> describe un clasificador. La propiedad class es utilizada para identificar la Clase que va a ser instanciada para realizar la clasificación. A su vez, el clasificador puede tener varias categorías que son descritas con la etiqueta <Ca-tegory> que está compuesta por varios <Dataset>. Finalmente, la etiqueta <Test> descri-be el proceso de pruebas que se realiza para verificar la precisión de los clasificadores creados. Cada prueba hace referencia a un clasificador y tiene un conjunto de <Expected-Category> que están compuestas de la misma manera que <Category> pero son utilizadas para probar los resultados del clasificador al momento de clasificar el conjunto de datos versus la categoría esperada descrita por la propiedad name de <ExpectedCategory>.
1.4.9.3. Descripción de recomendadores
En el descriptor de recomendadores (archivo en XML) se establecen unos rangos de valo-res por polaridad (clasificación), valo-resultado de la aplicación del módulo de Sentiment Analysis, con una de las siguientes recomendaciones, teniendo en cuenta que la primera es la más recomendada y la última la menos recomendada:
WOW! BUY IT!
IT’S A GOOD OPTION THINK IT TWICE NEVER MIND!
En la Tabla IV-12: “Descriptor de recomendaciones se puede contemplar un ejemplo del archivo XML con las recomendaciones.
recommender_descriptor.xml
<recommender>
<recommendation decision = "BUY IT!" priority = "2"> <polarity polarity = "POSITIVE" min = "0.8"/> </recommendation>
<recommendation decision = "NEVER MIND!" priority = "4"> <polarity polarity = "POSITIVE" min = "0" max = "0.499999"/> <polarity polarity = "NEGATIVE" max= "2"/>
</recommendation>
[image:63.612.104.513.357.599.2]<recommendation decision = "NOT CLASSIFIED" priority = "10000000"/> </recommender>
Página 50 1.4.9.4. Parametrización de filtros
Para tener la posibilidad de crear múltiples filtros se creó un archivo XML que permite describir las diferentes características de un filtro. Este archivo está compuesto por la eti-queta raíz <filters> y la etiqueta <filter> que tiene 2 propiedades: id para identificar la ca-racterística del producto a ser filtrada y que tiene que coincidir con una adición del produc-to en la base de daproduc-tos y name que tiene como valor la cadena de texto que le será mostrada al usuario. En la Tabla IV-13 se muestra un ejemplo del descriptor de filtros.
Ejemplo de descriptor de filtro
<filters>
<filter id = "brand" name = "Brand"/> <filter id = "ram" name = "Memory Size"/> <filter id = "HD" name = "Hard Disk"/> </filters>
Tabla IV-13: “Ejemplo de descriptor de filtro”
1.5. VALIDACIÓN
1.5.1. Efectividad de clasificadores
resulta-dos para ser utilizado en Miner PC Adviser. En las tablas que se muestran a continuación se pueden ver los resultados obtenidos con los clasificadores con los que se realizaron pruebas.
1 Prueba de
concepto
Se ejecutó una prueba para aprender a utilizar LingPipe .
2 Test == Train Se ejecutó una prueba en la que el clasificador fue probado con el mismo conjunto de datos de entrenamiento con el fin de probar el correcto funcionamiento del clasificador.
3 Estrellas Para esta prueba se utilizaron los datos de la siguiente manera:
Positivos: Comentarios con 4 y 5 estrellas de todos los blogs seleccionados.
Negativos: Comentarios con 1 o 2 estrellas de todos los blogs seleccionados.
4 Híbrido Para esta prueba se utilizaron los datos de la siguiente manera:
Positivos: Comentarios con 5 estrellas de todos los blogs se-leccionados y clasificados como positivos en la página Ne-wEgg.
Negativos: Comentarios con 1 o 2 estrellas de todos los blogs seleccionados y clasificados como negativos en la página Ne-wEgg.
[image:65.612.105.510.119.501.2]
Tabla IV-14: “Descripción de pruebas de clasificadores”
En la Tabla IV-15: “Efectividad de clasificadores, en la última columna, se puede evidenciar la efectividad de cada uno de los clasificadores que se probó. Esta efectividad fue calculada utilizando un conjunto de datos de prueba del cual se conocía a priori su clasificación real. Teniendo en cuenta la clasificación real y la clasificación dada por el clasificador se calculó el número de aciertos como un porcentaje del total de datos.