Cap. VII Estadística no paramétrica 136
Capítulo
VII
Análisis de datos categóricos y análisis de
variables de distribución libre
... ...
Objetivo del
Capítulo
Desarrollar la metodología de
prueba de hipótesis para variables
de distribución libre. Analizar las
aplicaciones
para
variables
Cap. VII Estadística no paramétrica 137
7.1 Introducción
Consideramos a los métodos estadísticos no paramétricos como aquellos que no requieren conocimientos de ningún parámetro de la población, también denominados de distribución libre. Así también existen situaciones en algunos problemas cuando las variables que intervienen no necesariamente son variables intervalares; en algunos casos pueden ser variables nominales o variables ordinales. Y en el caso de que exista asociación lineal entre las variables dependientes e independientes, pero del tipo mencionado con anterioridad, no resulta conveniente aplicar el coeficiente de correlación de Pearson, si no cumplen las condiciones y requisitos de uso que requiere en este caso el citado coeficiente. Entonces se podrá usar el coeficiente de Spearman (rs),
el cual es un caso particular del coeficiente de Pearson (rxy).
La expresión datos categóricos se refiere al tipo de datos obtenidos al medir variables utilizando una escala de medida nominal o de escala ordinal con pocos niveles, estos tipos de variables abundan en las investigaciones sociales y/o psicológicas. En una investigación clínica se pueden encontrar variables como el tipo de trastorno psicológico (neurosis, esquizofrenia, ansiedad, depresión, etc), o se puede clasificar a los pacientes como tratados y no tratados, recuperados y no recuperados. En una investigación social se puede clasificar a los sujetos de acuerdo con las actitudes u opiniones que manifiestan hacia un objeto en particular (desde muy de acuerdo, hasta muy en desacuerdo)
Estudiaremos el análisis para:
1. Dos variables que pueden ser intervalares pero que no cumplen los supuestos básicos de pruebas paramétricas vistas en el capítulo anterior, o también es el caso que las dos variables sean ordinales (r de Spearman)
2. Una variable: proporciones y bondad de ajuste (prueba Binomial y Chi cuadrado respectivamente)
3. Dos variables: tablas de contingencia bidimensionales (Chi cuadrado de Pearson, medidas de asociación para datos ordinales y nominales).
4. Múltiples variables: MODELOS LOGLINEALES JERÁRQUICOS, Modelos LOGIT
7.2 Análisis de datos categóricos con dos variables relacionadas o también dos variables intervalares que no cumplen los requisitos que exigen las pruebas paramétricas
Coeficiente de correlación por rangos de Spearman
Este coeficiente de correlación se utiliza cuando una o ambas escalas de medidas son ordinales, ejemplo: una variable es el orden de llegada en una carrera y la otra la estatura de los corredores. Es especialmente útil en el caso donde el tamaño de muestra es pequeño (menor de 30), es decir el número de pares de puntajes “n” que se desea asociar. Cuando el número de dichos pares es muy grande, por el teorema del límite central, la condición de normalidad se minimiza, y el modelo que se emplea es uno paramétrico; también, cuando los puntajes se jerarquizan (o se ponen en correspondencia biunívoca con el conjunto de números ordinales) se prevean muchos “empates”, esto es que en el ordenamiento varios puntajes tendrán el mismo número ordinal. Si estás dos situaciones ocurrieran, lo más conveniente es utilizar el coeficiente de correlación de Pearson.
Pero si el número de puntajes que se desean correlacionar fuera n < 30, y los empates son pocos entonces se puede trabajar con el coeficiente de Spearman.
El coeficiente de correlación por rangos (rs) se calcula aplicando la siguiente fórmula:
r
s =) 1 ( 6
1 2
2
n n
Cap. VII Estadística no paramétrica 138
Para el cálculo de (rs) es necesario obtener la diferencia “d” entre los rangos, y si una de las escalas
no es ordinal, entonces se asigna rango a las puntuaciones.
Además de obtener el grado de asociación entre dos variables con rs, se puede saber acerca de la
dependencia o independencia de dos variables aleatorias, como sigue:
Prueba bilateral:
H0 : La variable x y la variable y son mutuamente independientes.
Ha : i) Cuándo existe la tendencia de que los valores altos de x sean pareados con los valores altos de y.
ii) Cuando existe la tendencia de que los valores bajos (o pequeños) de x sean pareados con los valores altos (o grandes) de y.
Ejemplode aplicación:
A un grupo de 10 estudiantes de la UPeU se les aplicó una prueba de matemáticas (x) y una prueba de lógica (y), se obtuvieron los siguientes puntajes (escala de 0 – 100):
Estudiante x y
A 84 52*
B 75 39
C 98* 48
D 70** 32**
E 75 40
F 80 36
G 83 38
H 75 37
I 84 50
J 90 46
Sumatoria
* Calificación más alta ** Calificación más baja
a) Se desea saber el grado de semejanza entre las calificaciones obtenidas por los estudiantes en las pruebas x e y
b) H0: Las calificaciones obtenidas en matemáticas son mutuamente independientes de las
calificaciones obtenidas en lógica por los 10 estudiantes, contra la alternativa bilateral, al 0.05 de nivel de significancia.
Ha: Existe una correlación positiva o negativa entre las calificaciones obtenidas en ambas pruebas (dependencia).
Solución
Cap. VII Estadística no paramétrica 139
Estudiante x y Rango de x Rango de
y
Rx-Ry=d d2
A 84 52* 3.5 1 2.5 6.25
B 75 39 8 6 2 4
C 98* 48 1 3 -2 4
D 70** 32** 10 10 0 0
E 75 40 8 5 3 9
F 80 36 6 9 -3 9
G 83 38 5 7 -2 4
H 75 37 8 8 0 0
I 84 50 3.5 2 1.5 2.25
J 90 46 2 4 -2 4
Sumatoria 42.5
* Calificación más alta
** Calificación más baja
a) Aplicando la formula de rs
b) A fin de comprobar la hipótesis propuesta anteriormente acerca de la dependencia o independencia entre las calificaciones obtenidas por los estudiantes, lo haremos al 5 % de nivel de significancia y una prueba de hipótesis de dos colas en el SPSS
Pasos a seguir en el SPSS (en el SPSS solamente introducir la data, tal cual es y el software se encarga de hacer los rangos y las respectivas diferencias)
Analizar<correlaciones bivariadas<pasar las dos variables<marcar la prueba de Spearman<aceptar
Salida en el SPSS
Correlaciones
Matemáticas Lógica
Rho de Spearman Matemáticas Coeficiente de
correlación 1.000 .739(*)
Sig. (bilateral) . .015
N 10 10
Lógica Coeficiente de
correlación .739(*) 1.000
Sig. (bilateral) .015 .
N 10 10
* La correlación es significativa al nivel 0,05 (bilateral).
7 4 2 . 0 2 5 7 6 . 0 1 ) 1 1 0 0 ( 1 0
) 5 . 4 2 ( 6 1 )
1 ( 6 1 =
r 2
2
s rs
n n
Cap. VII Estadística no paramétrica 140
b. Sig 0.015 < 0.05, por lo tanto concluimos que existe una correlación significativa entre los cursos
Coeficiente “TAU” ( ) de Kendall
Esta medida de correlación está basada en intervalos jerarquizados de las observaciones, más que en los números mismos, con la ventaja de que la distribución de dicho coeficiente no depende de la distribución de x e y; siempre y cuando las observaciones representadas por x e y sean independientes y continuas. Este coeficiente desarrollado por Kendall (1938), es preferido por algunos investigadores sobre el coeficiente de Spearman, no obstante que ( ) es más difícil de calcular que (rs), la ventaja principal de Kendall es que su distribución tiende a la distribución
normal más rápidamente que la de Spearman.
La formula está definida por:
2 ) 1 (n n Q P
Ejemplo de aplicación
Considerando una situación de indisciplina en un grupo de niños de 5 años de edad en una guardería, a nueve niños (que aparentemente eran los catalogados más agresivos tanto por sus padres como por la persona encargada de ellos en la guardería), se les aplicó una prueba para confirmar el grado de agresividad. Por una semana se hicieron registros observacionales, día a día y bajo ciertas condiciones, por lo que los registros obtenidos en promedio fueron los siguientes: (ROy), registros observacionales en la guardería; (ROx), registros observacionales en sus hogares, Ry, rangos o intervalos en la guardería Rx, rangos o intervalos en sus hogares.
Niños ROx ROy Rx Ry, A B C D E F G H I 84 80 78 76 70 64 62 50 47 60 64 71 61 58 57 54 55 52 1 2 3 4 5 6 7 8 9 4 2 1 3 5 6 8 7 9
Paso 1. Cada distribución de puntajes que representa a cada variable x o y, se jerarquiza de
la misma manera que cuando se calcula el coeficiente de Spearman para obtener Rx y Ry, Pero con la modificación de que un conjunto de rangos (x o y) debe estar ordenado en una secuencia natural y creciente. El objetivo de este paso es tener una referencia que se utilizará más adelante.
Paso 2. Se obtiene la columna (P) de rangos más altos y la columna (Q) de rangos más
bajos que tengan como referencia la columna Ry. Esto se obtiene de la siguiente manera: se considera el valor numérico del primer niño (en la columna Ry., “4”, en nuestro ejemplo) y se cuenta hacia abajo cuántos valores numéricos son menores que él (en este caso 2,1 y 3 son los tres valores menores que él); también se cuentan cuántos valores son mayores que él (5, 6, 8, 7, y 9 son los cinco valores mayores que él).
Donde: n = Número de casos o sujetos P = Suma de rangos más altos Q = Suma de rangos más bajos
Cap. VII Estadística no paramétrica 141
Rx Ry
1 4
2 2
3 1
4 3
5 5
6 6
7 8
8 7
9 9
Cantidad P de rangos más altos
Cantidad Q de rangos más bajos
5 3
Para obtener el segundo sujeto (2 en nuestro ejemplo), hay uno más bajo que él (el “1” es más bajo que el segundo sujeto) y seis más altos que el segundo sujeto (3, 5, 6, 8,7 y 9).
Rx Ry
1 4
2 2
3 1
4 3
5 5
6 6
7 8
8 7
9 9
Cantidad de rangos más altos (P)
Cantidad de rangos más bajos (Q)
5 3
6 1
En el caso de nuestro tercer sujeto (1) se excluyen los sujetos anteriores a él y se sigue contando hacía abajo cuántos hay menores que él y cuántos mayores en su valor numérico.
Para nuestro tercer sujeto (1) no hay un valor numérico menor que él (0) pero hay 6 más altos 3, 5, 6, 8,7 y 9).
Rx Ry
1 4
2 2
3 1
4 3
5 5
6 6
7 8
8 7
9 9
Primer sujeto Tres rangos más bajos que el primer sujeto Cinco rangos más altos que el primer sujeto
Segundo sujeto Un rango más bajo que el segundo sujeto Seis rangos más altos que el segundo sujeto
Tercer sujeto (Cero rangos más bajos que él)
Cap. VII Estadística no paramétrica 142
Cantidad de rangos más altos (P) Cantidad de rangos más bajos (Q)
5 3
6 1
6 0
Se seguirá sucesivamente este método hasta el último sujeto, que siempre va a ser cero rangos más altos y cero rangos más bajos.
Paso 3. Una vez que se tienen todas las columnas anteriores se obtiene la sumatoria de la columna
de rangos más altos, la cual la denotaremos como P.
A la sumatoria de la columna de rangos más bajos, la denotaremos con Q.
Sujetos ROx ROy Rx Ry,
Rangos más altos P Rangos más altos Q A B C D E F G H I 84 80 78 76 70 64 62 50 47 60 64 71 61 58 57 54 55 52 1 2 3 4 5 6 7 8 9 4 2 1 3 5 6 8 7 9 5 6 6 5 4 3 1 1 0 3 1 0 0 0 0 1 0 0
31 5
Paso 4 El resultado se sustituye en la formula ( ) “Tau” de Kendall
72 . 0 36 26 2 ) 1 9 ( 9 5 31 2 ) 1 (n n Q P
Interpretación: Existe una correlación significativa entre lo detectado por los padres y lo
detectado por la guardería con respecto al nivel de agresividad de los niños menores de 5 años.
Reporte en el SPSS
Correlaciones
Registro_guardería Registro_hogar
Tau_b de Kendall Registro_guardería Coeficiente de
correlación 1.000 .722(**)
Sig. (bilateral) . .007
N 9 9
Registro_hogar Coeficiente de
correlación .722(**) 1.000
Sig. (bilateral) .007 .
N 9 9
** La correlación es significativa al nivel 0,01 (bilateral).
Cap. VII Estadística no paramétrica 143
7.3 Análisis de datos categóricos con una variable
Se contrastan hipótesis para proporciones y sobre bondad de ajuste, si la variable es dicotómica o dicotomizada (es decir, si sólo tiene dos categorías), puede utilizarse la prueba Binomial (también llamada contraste para una proporción). Para contrastar la hipótesis nula de que la proporción de cualquiera de las dos categorías de la variable toma un determinado valor. Si la variable es politómica se utiliza la prueba de bondad de ajuste, es decir, si las proporciones observadas o empíricas se ajustan a una determinada distribución teórica (Chi cuadrado).
Prueba Binomial para una muestra
La prueba Binomial permite averiguar si una variable dicotómica sigue o no un determinado modelo de probabilidad, es decir permite contrastar la hipótesis de que la proporción observada de aciertos se ajusta a la proporción teórica de una distribución Binomial. En el SPSS si el tamaño de muestra es pequeño, es decir menor o igual a 25 datos use la prueba Binomial, si por el contrario trabaja con grandes muestras, es decir mayor de 25 utiliza la distribución normal.
Ejemplo: Usando la data que ofrece el SPSS “Datos de empleados.sav”. Asumiendo que el 70% de los empleados de los EEUU es de raza blanca, se quiere saber si en la muestra de esta entidad bancaria de donde provienen los datos de este ejemplo; este % se mantiene (se utilizará la variable minoría (clasificación étnica))
Pasos: Analizar<pruebas no paramétricas<Binomial<pasar la variable a estudiar<en contratar variable introducir el porcentaje .70) <aceptar
Resultados
El SPSS toma como categoría de referencia la correspondiente al primer caso del archivo de datos. En nuestro ejemplo el primer caso le corresponde el código 0, la categoría de referencia es la categoría minoría = “no” es decir raza blanca. Las hipótesis a contrastar son:
Ho: m i nor i a0 0.7
Ha: m i nor i a0 0.7
Prueba binomial
Categoría N
Proporción observada
Prop. de prueba
Sig. asintót. (unilateral) Clasificación
de minorías
Grupo 1
No (raza blanca) 370 .8 (0.78) .7 .000(a)
Grupo 2 Sí (raza de color) 104 .2
Total 474 1.0
a Basado en la aproximación Z.
Cap. VII Estadística no paramétrica 144
¿Más del 70% de los empleados en la entidad bancaria pertenece a la raza blanca?
Puesto que el nivel crítico (sig 0.000<0.05), rechazamos la Ho, por lo tanto concluimos que la verdadera proporción poblacional de sujetos blancos (minoría=no) es mayor del 70%.
Ejemplo: Con la misma data del ejemplo anterior “datos de empleados.sav” que lo tiene el SPSS
Se desea probar estadísticamente que la proporción de hombres son mayores al de mujeres de los empleados de un banco respecto a sus tres categorías laborales:
Primero “segmentamos archivo” en función de la categoría laboral: comparar grupos de casos
Ho: la proporción entre hombres y mujeres no difieren
Bi nom i al Test
M asculino 157 . 43 . 50 . 012a Fem enino 206 . 57
363 1. 00
M asculino 27 1. 00 . 50 . 000a 27 1. 00
M asculino 74 . 88 . 50 . 000a Fem enino 10 . 12
84 1. 00 G r oup 1
G r oup 2 Tot al G r oup 1 Tot al G r oup 1 G r oup 2 Tot al G éner o
G éner o
G éner o Cat egor í a labor al
Adm inist r at ivo
Segur idad
Dir ect ivo
C a t e g o r y N O b s e r v e d P r o p . T e s t P r o p . A s y m p . S ig . ( 2 -t a ile d )
Cap. VII Estadística no paramétrica 145
Conclusión:
Dado que el Sig para todos las categorías es menor del 5%, entonces decimos al nivel de significancia del 5% que la categoría laboral si difiere en todos los casos con respecto al género, siendo al nivel administrativo la proporción de mujeres es más alta (57%) con respecto a los hombres, sin embargo sucede lo contrario a nivel directivo la proporción de hombres es más alta (88%) con respecto a las mujeres y es más notable en el personal de seguridad donde el 100% son hombres.
Prueba de Rachas
Rachas para probar la aleatoriedad (secuencia de casos que se está repitiendo)
Ejemplo
Los artículos que salen de un proceso se clasifican como defectuosos o no defectuosos. Se tuvo la siguiente sucesión n de artículos observados en el tiempo.
DNNNNNNDDNNNNNNDDDNNNNNDNNNDDNNNDD
¿Sugieren estos datos una falta de aleatoriedad de defectuosos o no defectuosos? Ho: existe aleatoriedad
Ha: No existe aleatoriedad
Añadir nuevo nombre
Cap. VII Estadística no paramétrica 146
Prueba de rachas
2
11
23
34 11
- 1. 751 . 080 Valor de pr uebaa
Casos < Valor de pr ueba Casos >= Valor de pr ueba
Casos en t ot al Núm er o de r achas
Z
Sig. asint ót . ( bilat er al)
ARTI CULO S. RECO DI F
Mediana a.
Como el nivel de significancia es 0.08, no podemos rechazar Ho, concluimos que si existe aleatoriedad.
Prueba de Kolmogorov
Sirve para contrastar la hipótesis nula de que la distribución de una variable se ajusta a una determinada distribución teórica de probabilidad. A diferencia de las anteriores pruebas esta ha sido diseñada para evaluar el ajuste de variable categórica. La prueba de Kolmogorov también se adapta a situaciones en la que interesa evaluar a situaciones de ajuste cuantitativo.
Ejemplo: Con la misma data “datos de empleados.sav” usar la variable “Salario inicial”
Ho: Las puntaciones de salario inicial se ajustan a una distribución normal Ha: Las puntaciones de salario inicial no se ajustan a una distribución normal
Prueba de Kol mogorov- Smi rnov par a una muest ra
474 $17, 016. 09
$7, 870. 638
. 252 . 252 - . 170 5. 484 . 000 N
Media Desviación t í pica Par ámet r os nor m alesa, b
Absolut a Posit iva Negat iva Dif er encias más
ext r emas
Z de Kolmogor ov- Smir nov Sig. asint ót . ( bilat er al)
Salar io inicial
La dist r ibución de cont r ast e es la Nor mal. a.
Se han calculado a par t ir de los dat os. b.
Sig 0.000 < 0.05 por lo tanto rechazamos la Ho, es decir al nivel de significancia del 5% concluimos que los datos no siguen una distribución normal.
Ejemplo: (archivo autoaccidentes “accidents.sav”) base de datos sobre el nº de accidentes
Cap. VII Estadística no paramétrica 147
conductor o chofer y que además registra el nº de accidentes en los 5 años. Se desea probar que el nº de accidentes sigue una distribución de Poisson (Alpha = 1%)
Ho: la variable sigue una distribución de Poisson (Poisson son para ocurrencias raras)
O ne- Sampl e Kol mogorov- Smi r nov Test
500 1. 72 . 065 . 065
- . 041
1. 460 . 028 N
Mean Poisson Par am et er a, b
Absolut e Posit ive Negat ive Most Ext r em e
Dif f er ences
Kolmogor ov- Sm ir nov Z Asym p. Sig. ( 2- t ailed)
númer o de accident es más allá de
5 años
Test dist r ibut ion is Poisson. a.
Calculat ed f r om dat a. b.
Los datos no se ajustan a una distribución de Poisson
Es bueno reconsiderar pues sabemos que debe seguir una distribución de Poisson, sería bueno discernir por género.
Cap. VII Estadística no paramétrica 148 Prueba de Kolmogorov-Smirnov para una muestra
sexo del asegurado
número de accidentes más allá de 5
años
Masculino N 250
Parámetro de Poisson(a,b) Media 1.98
Diferencias más extremas Absoluta .047
Positiva .047
Negativa
-.033
Z de Kolmogorov-Smirnov .750
Sig. asintót. (bilateral) .627
Femenino N 250
Parámetro de Poisson(a,b) Media 1.47
Diferencias más extremas Absoluta .074
Positiva .074
Negativa
-.042
Z de Kolmogorov-Smirnov 1.164
Sig. asintót. (bilateral) .133
a La distribución de contraste es la de Poisson. b Se han calculado a partir de los datos.
Para los dos casos el nivel de significancia es mayor del 0.05 por lo tanto no podemos rechazar la Ho, por lo tanto demostramos que la variable sigue una distribución de Poisson
7.4 Prueba Chi cuadrada
La prueba Chi-Cuadrada es una de las pruebas más frecuentemente utilizadas para el contraste de variables cualitativas, aplicándose para comparar si dos características cualitativas están relacionadas entre sí, si varias muestras de carácter cualitativo proceden de igual población o si los datos observados siguen una determinada distribución teórica.
Para su cálculo se calculan las frecuencias esperadas para compararlas con las observadas en la
realidad. Se calcula el valor del estadístico 2, como:
e e
o 2
2 ( )
; donde
O Valor observado e Valor esperado =
g en era l to ta l
co lu mn a to ta l x fila to ta l
Supóngase que en una determinada muestra se observan una serie de posibles sucesos E1, E2, E3, . .
. , EK, que ocurren con frecuencias O1, O2, O3, . . ., OK, llamadas frecuencias observadas y que,
según las reglas de probabilidad, se espera que ocurran con frecuencias e1, e2, e3, . . . ,eK llamadas
frecuencias teóricas o esperadas. Se desea saber si las frecuencias observadas difieren significativamente de las frecuencias esperadas.
2
mide el grado de acuerdo entre frecuencias observadas y esperadas, suponiendo que Ho es verdadera.
Cap. VII Estadística no paramétrica 149
.
Las aplicaciones más importantes de la distribución Chi cuadrado, son:
Con una sola variable: Prueba de bondad de ajuste, ejemplo: prueba de normalidad
Con dos variables:
Prueba de independencia
Prueba de homogeneidad de poblaciones.
Cuando consideramos que los valores de una tabla han sido extraídos de una población, entonces nos interesaría probar las siguientes dos hipótesis:
La prueba de la Independencia, que se efectúa para probar si hay asociación entre las variables
categóricas A y B
La prueba de Homogeneidad, que es una generalización de la prueba de igualdad de dos
proporciones. En este caso se trata de probar si para cada nivel de la variable B, la proporción con respecto a cada nivel de la variable A es la misma.
7.4.1 La prueba de la independencia
Permite determinar si dos variables categóricas son independientes (no están asociadas o no están relacionadas) cuando ambas se han medido en la misma unidad de análisis.
Las n unidades de análisis se clasifican en categorías mutuamente excluyentes de modo que las frecuencias se presentan en una tabla de contingencia bivariada o de doble entrada o tabla de f
filas x c columnas.
Los totales marginales no están controlados por el investigador.
Si designamos las columnas por r y las filas o renglones por k, se tendrá una tabla de r x k.
Los grados de libertad serán iguales a n = (r-1)(k-1), así que en una tabla de "2 x 2", los grados de libertad son: (2-1)(2-1)= 1 G.L.; en la tabla "3 x 4" será (3-1)(4-1) = 6 G.L.
Si se tuviera los niveles de un solo criterio, también se utiliza la Chi- cuadrado, y los grados de libertad es igual al número de niveles menos uno (n-1); el valor esperado para cada frecuencia es el correspondiente al promedio.
Pasos para la prueba de hipótesis:
1. Hipótesis estadísticas:
Ho: Las dos variables categóricas son independientes
(Es decir, no hay asociación entre ellas)
Ha: Las dos variables categóricas están relacionadas
(Es decir, son dependientes)
2. Nivel de significancia: α = 0.5 ó 0.01 ó 0.10, etc.
Tomado de Design and Analysis of Experiments in
Cap. VII Estadística no paramétrica 150
3. Función Pivotal:
e e
o 2
2 ( )
4. Regiones:
5. Valor de la Chi cuadrada experimental:
6. Decisión: La regla de decisión consiste en rechazar la hipótesis nula a un nivel α de significación si el valor calculado de la estadística de prueba es mayor que el valor crítico de extremo superior de una distribución Chi- Cuadrada.
7. Conclusión
Ejemplo 1
La tabla siguiente muestra los resultados de un estudio en el que se clasificaron en forma cruzada 100 jóvenes, en edad escolar, de acuerdo con el grado de delincuencia y el contacto con los padres durante los ratos libres. ¿Proporcionan estos datos evidencia suficiente como para indicar que las dos variables están relacionadas? sea α = 0.05
Tiempo libre compartido
con los padres Delincuente
No
delincuente Total
Alto 10 29 39
Bajo 41 20 61
Ho: El grado de delincuencia es independiente del tiempo libre que comparten los padres con
sus hijos
Ha: El grado de delincuencia depende del tiempo libre que comparten los padres con sus hijos
Cap. VII Estadística no paramétrica 151
Función Pivotal:
e e
o 2
2 ( )
O Valor observado
e Valor esperado =
to ta l
co lu mn a to ta l
x fila to ta l
Regiones:
Pasos para calcular el valor experimental 2 exp
9 . 1 9 1 0 0
5 1 * 3 9
11
e 1 9.1
1 0 0 4 9 * 3 9
12
e 3 1.1
1 0 0 5 1 * 6 1
21
e 2 9.9
1 0 0 4 9 * 6 1
22
e
4 5 2 . 1 6 9 . 2 9 ) 9 . 2 9 2 0 ( 1 . 3 1 ) 1 . 3 1 4 1 ( 1 . 1 9 ) 1 . 1 9 2 9 ( 9 . 1 9 ) 9 . 1 9 1 0
( 2 2 2 2
2
Valor experimental: 2 1 6.4 5 2
Decisión: El valor experimental es mayor (16.452 > 3.84) que el valor teórico, por lo tanto rechazamos la hipótesis nula.
Valor de p exacto da el SPSS (p=,000)
Conclusión: Al nivel de significancia del 1% podemos concluir que el grado de delincuencia depende del tiempo libre que comparten los padres con sus hijos (p=,000).
Reporte en SPSS
1° Base de datos
2° Ponderar casos: Datos< Ponderar casos <ponderar casos mediante<pasar la variable
Cap. VII Estadística no paramétrica 152
Cap. VII Estadística no paramétrica 153
4° Reporte
Tabla de contingencia Tiempo libre compartido *
DELINCUENCIA
Recuento
DELINCUENCIA
Total DELINCUENTE
NO DELINCUENTE Tiempo libre
compartido
ALTO 10 29 39
BAJO 41 20 61
Total 51 49 100
5° Prueba de hipótesis
Decisión: Como el valor Sig = 0.000 < 0.05, la prueba es significativa; esto es el grado de delincuencia depende del tiempo invertido por los padres en sus hijos. Nota: no se puede hacer una inferencia pues los datos pertenecen a una muestra no probabilística.
Ejemplo 2.
Cap. VII Estadística no paramétrica 154
Solución:
Abrir el archivo del SPSS “encuesta general USA 1991.sav” Analizar<estadísticos descriptivos<tablas de contingencia
Reporte del SPSS:
Tabl a de cont i ngenci a Sexo del encuest ado * Ni vel de f el i ci dad
206 374 53 633
32. 5% 59. 1% 8. 4% 100. 0%
261 498 112 871
30. 0% 57. 2% 12. 9% 100. 0%
467 872 165 1504
31. 1% 58. 0% 11. 0% 100. 0%
Recuent o % de Sexo del encuest ado Recuent o % de Sexo del encuest ado Recuent o % de Sexo del encuest ado Hom br e
Mujer Sexo del encuest ado
Tot al
Muy f eliz Bast ant e f eliz
No dem asiado
f eliz Nivel de f elicidad
Tot al
Cap. VII Estadística no paramétrica 155
Sexo del encuestado Mujer Hombre
R
ec
uen
to
100,0%
80,0%
60,0%
40,0%
20,0%
0,0%
0,13% 0,08%
0,57%
0,59%
0,30% 0,33%
No demasiado feliz Bastante feliz Muy feliz Nivel de felicidad
Pruebas de chi - cuadrado
7. 739a 2 . 021
7. 936 2 . 019
4. 812 1 . 028
1504 Chi- cuadr ado de Pear son
Razón de ver osim ilit udes Asociación lineal por lineal
N de casos válidos
Valor gl
Sig. asint ót ica ( bilat er al)
0 casillas ( . 0%) t ienen una f r ecuencia esper ada inf er ior a 5. La f r ecuencia m í nima esper ada es 69. 44.
a.
Decisión: Al nivel de significancia del 5% concluimos que existe alguna relación significativa (sig=0.021) entre las variables, a favor de los varones, esto quiere decir que en mayor porcentaje los varones presentan más altos niveles de felicidad.
Nota: Existen tres factores que pueden alterar el resultado de las pruebas de asociación e independencia como lo son el tamaño de la muestra, la fidelidad de los datos y el sesgo muestral; antes de sacar alguna conclusión es necesario revisar estos factores ya que cualquiera de ellos puede distorsionar severamente el resultado.
7.4.2 Prueba de la Homogeneidad
Supóngase que en una determinada muestra se observan una serie de posibles sucesos E1, E2, E3, . .
. , EK, que ocurren con frecuencias o1, o2, o3, . . ., oK, llamadas frecuencias observadas y que,
según las reglas de probabilidad, se espera que ocurran con frecuencias e1, e2, e3, . . . ,eK llamadas
frecuencias teóricas o esperadas. Se desea saber si las frecuencias observadas difieren significativamente de las frecuencias esperadas.
Ejemplo: Se presupone que la prevalencia de cáncer se incrementa en el intervalo de edad 51 a 65 años, mientras que entre los intervalos de edad de 36 a 50 y de 20 a 35 la proporción no es tan alta; se obtuvo una muestra observacional sobre un registro de pacientes que arrojan la siguiente tabla:
EDAD
20 - 35 36 - 50 51 - 65
Cap. VII Estadística no paramétrica 156
Deseamos contrastar si la prevalencia del n° de casos de cáncer es homogénea a los intervalos de edad o alternativamente que las proporciones de enfermos guardan una determinada relación a 1, 1, 4 respectivamente, es decir que la proporción de individuos en el último intervalo de edad es el doble que en el conjunto de los dos intervalos de edad.
Ho: las proporciones de individuos esperadas con cáncer se ajustan para cada intervalo de edad Ha: las proporciones de individuos esperadas con cáncer no se ajustan para cada intervalo de edad
Pasos en el SPSS:
1º. Dado que la data se encuentra en una tabla de frecuencia, la forma de introducir es la siguiente: las edades se codifican (1=20-35), (2=36-50), (3=51-65), entonces en el SPSS en vista de datos ingresamos la variable edad con sus códigos respectivos, para la variable Nº de casos la respectiva frecuencia para cada intervalo de edad, luego hacer como se indica a continuación: Datos<ponderar casos<ponderar casos mediante<pasar “N_casos”<aceptar
2º. Analizar<pruebas no paramétricas<Chi cuadrado<seguir los pasos observando la siguiente figura.
Cap. VII Estadística no paramétrica 157
(df = grados de libertad)
Se puede observar que la 1.5 0 2 5.9 9 e x p
2
t a b u l a r
e r i me n t a l , por lo tanto estamos aceptando que las proporciones de individuos con cáncer si se ajustan a la proporción de cada intervalo de edad. Nota: se llega a la misma conclusión si observamos el Sig de la prueba: Sig =0.472 > 0.05 por lo tanto no podemos rechazar la Ho.
Nota: En el caso que se rechaza la hipótesis nula cuando se realiza la prueba Chi cuadrado
Ho: No hay relación entre las variables en estudio.
Entonces el próximo paso es determinar el grado de asociación de las dos variables categóricas, para ello se usan las llamadas medidas de asociación como:
Análisis para medir la asociación de variables nominal por nominal
Análisis para medir la asociación de variables ordinal por ordinal
Salida en el SPSS (para pedir la prueba, siga los siguientes pasos)
Analizar>estadísticos descriptivos>tablas de contingencia>pasar las variables (una a filas y la otra a columnas)>clip en estadísticos>seleccionar el estadístico correspondiente>
continuar>aceptar
7.5 Análisis para variables de nivel nominal por nominal
Coeficiente de contingencia C
Cap. VII Estadística no paramétrica 158
2 2
n C
Donde:
C = Coeficiente de contingencia 2
= Valor calculado de Chi Cuadrada. n número total de casos (tamaño muestral) El valor de C varía entre 0 y 1
C 0, significa que no hay asociación entre las variables
C>.20, indica una buena asociación entre las variables; sin embargo hay que tomar también en consideración el tamaño de la tabla o de los datos.
Ejemplo de aplicación (Pagano, 2009. Pág. 485)
Un investigador de la sexualidad humana quiere determinar si existe una relación entre el género y la hora del día preferida para tener relaciones sexuales. Se realiza una encuesta cuyos resultados aparecen en la siguiente tabla; los datos de las entradas son la cantidad de individuos que prefieren la mañana, la tarde o la noche:
Género Mañana Tarde Noche Total
Masculino 46 24 20 90
Femenino 28 21 42 91
Total 74 45 62 181
Paso 1 Aplicando la definición de la distribución 2 vista anteriormente, se obtiene 2= 12.380
Paso 2 Se calcula el coeficiente de contingencia C utilizando la formula:
2 5 3 . 0 3 8 . 1 2 1 8 1
3 8 . 1 2 2
2
n C
Salida en el SPSS (para pedir la prueba, siga los siguientes pasos)
Analizar>estadísticos descriptivos>tablas de contingencia>allí marque la prueba que corresponde a su problema)
Medidas simétricas
Valor
Sig. aproximada
Nominal por nominal
Coeficiente de contingencia
,253 ,002
N de casos válidos 181
Prueba de significancia
Cap. VII Estadística no paramétrica 159
Requisitos para el uso del coeficiente de contingencia:
1. Datos nominales.
2. Muestreo aleatorio. Con la finalidad de comprobar la significancia estadística del coeficiente de contingencia, la muestra se debe obtener en forma aleatoria.
Ejemplo de aplicación
Se desea investigar la posible relación entre la categoría laboral que ocupa el trabajador y si considera su vida excitante o aburrida. Emplear la data del SPSS “encuesta general USA 1991.sav”
Paso 1 Los datos obtenidos al realizar este estudio se concentran en una tabla de contingencia,
de la siguiente forma:
Tabla de contingencia Categoría ocupacional * ¿Su vida es excitante o aburrida?
¿Su vida es excitante o aburrida?
Total Excitante Rutinaria Aburrida
Categoría ocupacional
Directivo o profesional liberal
Recuento 129 78 3 210
% de Categoría
ocupacional 61.4% 37.1% 1.4% 100.0%
Empleado técnico, administrativo o comercial
Recuento 125 156 13 294
% de Categoría
ocupacional 42.5% 53.1% 4.4% 100.0%
Servicios Recuento 56 73 6 135
% de Categoría
ocupacional 41.5% 54.1% 4.4% 100.0%
Agricultura, forestal y pesca
Recuento 16 9 0 25
% de Categoría
ocupacional 64.0% 36.0% .0% 100.0%
Producción de precisión, manufactura o reparación
Recuento 38 65 6 109
% de Categoría
ocupacional 34.9% 59.6% 5.5% 100.0%
Operario, fabricación y mano de obra en general
Recuento 45 83 7 135
% de Categoría
ocupacional 33.3% 61.5% 5.2% 100.0%
Total Recuento 409 464 35 908
% de Categoría
ocupacional 45.0% 51.1% 3.9% 100.0%
Paso 2 Aplicando la definición de la distribución 2 vista anteriormente, se obtiene 2=
41.829
Paso 3 Se calcula el coeficiente de contingencia C utilizando la formula:
2 1 0 . 0 8 2 9 . 4 1 9 0 8
8 2 9 . 4 1 2
2
Cap. VII Estadística no paramétrica 160
Salida en el SPSS
Medi das si mét ri cas
. 210 . 000
908 Coef icient e de
cont ingencia Nom inal por
nom inal
N de casos válidos
Valor
Sig. apr oximada
Asumiendo la hipót esis alt er nat iva. a.
Em pleando el er r or t í pico asint ót ico basado en la hipót esis nula.
b.
Prueba de significancia
La significancia estadística del coeficiente de contingencia se puede obtener a partir de la magnitud de la 2 obtenida con la siguiente regla de decisión:
Si 2 c r i t2 ,en to n ces
C es significativo
Para nuestro ejemplo la 2tabular o crítica con 10 gl. y al nivel de significancia de 5% es 18.31,
entonces dado que el valor calculado es de 41.829, esto es: 41.829 18.31, podemos concluir que el coeficiente de contingencia calculado es estadísticamente significativo, por lo que se rechaza la hipótesis nula; por lo que podemos concluir que se considera si la vida es excitante o aburrida esta relacionada a la categoría laboral que ocupa el trabajador, es decir se puede observar que la vida es más excitante para los profesionales que ocupan cargos directivos o profesionales liberales de igual manera para aquellos que trabajan en agricultura forestal y pesca.
Llegamos a la misma conclusión observando el Sig=,000<0.05 que se obtiene al pedir el análisis del coeficiente de contingencia
Coeficiente de correlacion (phi) para un diseño 2 x 2
Cuando ambas variables son nominales y dicotómicas, es posible determinar el grado de asociación entre las variables de interés. Este coeficiente ( ) también es un caso particular del coeficiente de correlación de Pearson, y se utiliza con cierta frecuencia, aunque no necesariamente en este aspecto, en la elaboración y análisis de pruebas. En capítulos posteriores se considera la independencia o dependencia de dos variables en una nuestra determinada; cuando se haga este análisis, a partir de las hipótesis establecidas, si la conclusión estadística a la que se llega es la existencia de una dependencia, el análisis estadístico más lógico a seguir es conocer el grado de asociación que implica la dependencia entre las variables o las muestras. Para conocer esto, necesitamos un número, y este número nos lo indicara el coeficiente de correlación ( ),
pero recuérdese que está supeditado al diseño 2 x 2, al tamaño de muestra y a la proporción de las variables dicotomizadas. Cuando el número de casos en una variable es igual al de la otra variable, el coeficiente ( ) tendrá el máximo valor de 1; cuando los totales marginales son diferentes no se alcanzara el máximo valor de 1.
Coeficiente
) )( )( )(
(a b a c b d c d b c
a d
Ejemplo de aplicación
Cap. VII Estadística no paramétrica 161
200 del sexo masculino y 200 del sexo femenino, se les emplea para establecer dicha escala y se analizan las respuestas, obteniéndose lo siguiente: de las personas del sexo masculino 160 están de acuerdo y 40 en desacuerdo; de las del sexo femenino 40 están de acuerdo y y 160 no lo están. Calcule el coeficiente ( ) de correlación y concluya, considerando los resultados obtenidos.
Solución:
Paso 1 Se acomodan los datos obtenidos en una tabla de doble entrada, de dos reglones y dos columnas (tabla de contingencia 2x2)
Acuerdo Desacuerdo Total Masculino 160 (a) 40 (b) 200 Femenino 40 (c) 160 (d) 200 Total 200 200 400
Paso 2 se aplica la definición de ( )
0.6 0
) 2 0 0 )( 2 0 0 )( 2 0 0 )( 2 0 0 (
) 4 0 )( 4 0 ( ) 1 6 0 )( 1 6 0 ( ) )( )( )(
(a b a c b d c d b c
a d = 0.60
Salida en el SPSS
Medidas simétricas
Valor Sig. aproximada
Nominal por nominal
Phi ,600 ,000
V de Cramer ,600 ,000
N de casos
válidos 400
Prueba de significancia de
Para poder comprobar la significancia de dicho coeficiente se utilizará la siguiente definición:
2 2
n
Donde:
n = Número total de casos, n =400
= 0.60 2
= Valor Chi Cuadrado
Sustituyendo los valores anteriores se obtiene:
2 2
n
2 (4 0 0)(0.6 0)2 1 4 4 2 1 4 4Este resultado se contrasta al valor crítico de ji cuadrada, calculado mediante la siguiente regla de decisión R.D:
Si 2 c r i t2 ,en t o n ces significativa
Cap. VII Estadística no paramétrica 162
Para un diseño de 2x2, los grados de libertad será 1, entonces g.l. = 1
84 . 3
2 %) 5 ( 2
cri t , por lo tanto e xp 1 4 4
2
e r i me nt al , entonces podemos concluir que la
prueba es significativa, esto es =0.46 ¡es significativo!
Requisitos de uso de
A fin de utilizar adecuadamente el coeficiente como medida de asociación entre las variables x e y, dicotomizadas, se deben tomar en cuenta las siguientes condiciones:
1. Datos nominales. Las variables x e y, deben ser nominales y dicotomizables, ya que únicamente se requerirían las frecuencias observadas (el número de veces que ocurren en cierta nominación).
2. Tabla de contingencia 2x2. Los datos deben poder colocarse en un diseño 2x2 (dos renglones - dos columnas). Es inadecuado aplicar el coeficiente donde se comparan varias grupos o categorías.
3. Muestreo aleatorio. Para poder comprobar la significancia y validez de , la muestra en estudio debe haber sido extraída en forma aleatoria (todos los elementos de la población deben tener la misma posibilidad de ser escogidos).
4. Cuando la muestra en estudio es pequeña (un criterio es que la frecuencia observada, en dos o más casillas, sea menor que 10). Se utilizará la definición de 2, pero con la corrección de Yates, también llamada de Pirie-Handem, que consiste en lo siguiente:
) )( )( )( (
5 . 0 2
2
b c d b c a b a
b c a d n
Donde ad bc = valor absoluto de la diferencia entre ad y bc.
Lambda. Medida de asociación que refleja la reducción proporcional en el error cuando se utilizan los valores de la variable independiente para pronosticar los valores de la variable dependiente. Un valor igual a 1 significa que la variable independiente pronostica perfectamente la variable dependiente. Un valor igual a 0 significa que la variable independiente no ayuda en absoluto a pronosticar la variable dependiente.
Coeficiente de incertidumbre. Medida de asociación que indica la reducción proporcional
Cap. VII Estadística no paramétrica 163
7.6 Análisis para variables de nivel tipo ordinal por ordinal
Coeficiente Gamma
Medida de asociación simétrica entre dos variables ordinales cuyo valor siempre está comprendido entre menos -1 y 1. Los valores próximos a 1, en valor absoluto, indican una fuerte relación entre las dos variables. Los valores próximos a cero indican que hay poca o ninguna relación entre las dos variables.
d de Somers
La “d de Somers” es importante pues se puede pronosticar las categorías de columna a partir de las categorías de fila; se usa para variables ordinales (filas y columnas). La d de Somers es una
extensión asimétrica de gamma.
Ejemplo:
Se quiere establecer la relación entre las variables ingesta de agua según el número de vasos por día y si la persona tiene un horario establecido para beber este líquido tan importante para la salud. La data se recogió haciendo uso de la metodología de la encuesta y se muestra en la siguiente tabla.
Tabla de contingencia AGUA * HORARIO
HORARIO
Total Siempre Casi siempre A veces
AGUA Ninguno 0 1 2 3
1 - 2 vasos 3 6 2 11
3 - 5 vasos 2 16 5 23
6 a más
vasos 3 5 2 10
Cap. VII Estadística no paramétrica 164
Medidas direccionales
Valor
Error típ. asint.(a)
T aproximada(b)
Sig. Aproximada Ordinal
por ordinal
d de Somer Simétrica
-.100 .148 -.669 .503
AGUA dependiente -.108 .161 -.669 .503
HORARIO dependiente -.092 .137 -.669 .503
a Asumiendo la hipótesis alternativa.
b Empleando el error típico asintótico basado en la hipótesis nula.
Interpretación: Cuánto más cercano el valor se encuentre a +1 o -1 mejor correlación presentará y su prueba de hipótesis Sig < 0.05
Para nuestro ejemplo la d de Somers presenta un valor de (d = -0.100) con una significancia de Sig = 0.503. Por lo tanto podemos concluir que no existe ningún tipo de asociación entre las variables.
Tau-b de Kendall
Medida no paramétrica de la correlación para variables ordinales o de rangos que tiene en consideración los empates. El signo del coeficiente indica la dirección de la relación y su valor absoluto indica la magnitud de la misma, de tal modo que los mayores valores absolutos indican relaciones más fuertes. Los valores posibles van de -1 a 1, pero un valor de -1 o +1 sólo se puede obtener a partir de tablas cuadradas.
Tau-c de Kendall
Medida no paramétrica de asociación para variables ordinales que ignora los empates. El signo del coeficiente indica la dirección de la relación y su valor absoluto indica la magnitud de la misma, de tal modo que los mayores valores absolutos indican relaciones más fuertes. Los valores posibles van de -1 a 1, pero un valor de -1 o +1 sólo se puede obtener a partir de tablas cuadradas.
7.7 Análisis para variables nominal por intervalo:
Coeficiente Eta
Cuando una variable es categórica y la otra es cuantitativa, seleccione Eta. La variable categórica debe codificarse numéricamente. Es una medida de asociación cuyo valor siempre está comprendido entre 0 y 1. El valor 0 indica que no hay asociación entre las variables de fila y de columna. Los valores cercanos a 1 indican que hay gran relación entre las variables. Eta resulta apropiado para una variable dependiente medida en una escala de intervalo (por ejemplo, ingresos) y una variable independiente con un número limitado de categorías (por ejemplo, sexo). Valores de eta próximos a uno indicarán mucha dependencia. El cuadrado de este coeficiente (eta²) puede interpretarse como la proporción de variabilidad de la variable dependiente, Y, explicada por los valores de la independiente, X, por lo que puede utilizarse como medida del grado de asociación existente entre las variables en cuestión. (Ferran A. M, 1996).
Ejemplo:
Cap. VII Estadística no paramétrica 165
Para realizar este análisis usamos el coeficiente Eta, pues se trata de relacionar una variable dependiente numérica asociada a una independiente categórica nominal.
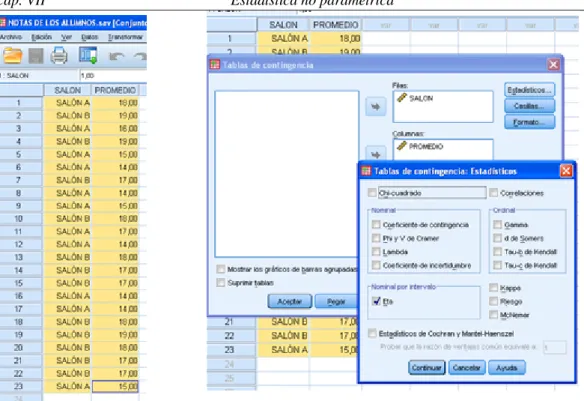
Pasos en el SPSS: analizar<estadísticos descriptivos<tablas de contingencia<pasar las variables como se observa en la figura anterior<pedir el coeficiente Eta<continuar<aceptar
Salida del SPSS
Tabla de contingencia SALON * PROMEDIO
Recuento
PROMEDIO
Total 14,00 15,00 16,00 17,00 18,00 19,00
SALÓN A 5 3 1 1 1 0 11
SALÓN B 0 0 0 5 4 3 12
Total 5 3 1 6 5 3 23
Medidas direccionales
Valor Nominal por intervalo Eta SALON dependiente ,846
PROMEDIO dependiente ,787
El coeficiente Eta, que se obtiene en el cuadro de salida presenta dos sentidos: Un primer caso considerando al salón como variable dependiente, para este caso se obtiene un Eta igual a 0.846. Un segundo caso, considerando al promedio, como la variable dependiente, para lo cual se obtiene un Eta igual a 0.787. En nuestro caso la variable promedio se considera como dependiente, por lo tanto Eta= 0.78, lo que indica que el promedio depende del salón donde provienen los alumnos, en otras palabras alguno de los profesores (A o B) utilizan una mejor didáctica lo cual hace obtener un mejor promedio en sus estudiantes (salón B).
Cap. VII Estadística no paramétrica 166
Eta2 = (,787)2 = 0.619 explica la variación del promedio de los estudiantes en función al salón al que pertenecen, la varianza de los datos que dependen del salón y que hacen predecir el promedio.
El gráfico bivariado que ofrece el SPSS es:
7.8 Otras pruebas
Kappa.
La opción kappa de Cohen mide el acuerdo entre las evaluaciones de dos jueces cuando ambos están valorando el mismo objeto. Un valor igual a 1 indica un acuerdo perfecto. Un valor igual a 0 indica que el acuerdo no es mejor que el que se obtendría por azar. Kappa sólo está disponible para las tablas cuadradas (tablas en las que ambas variables tienen el mismo número de categorías). (Cohen, 1960).
Ejemplo:
La tabla siguiente ofrece una medida del grado de acuerdo existente entre dos observadores o jueces al evaluar a 200 pacientes neuróticos según el tipo de neurosis padecida.
Resultado obtenido por dos jueces al diagnosticar una muestra de 200 pacientes
Segundo diagnóstico Primer
diagnóstico Fóbica Histérica Obsesiva Depresiva
Fóbica 20 8 6 1
Histérica 7 36 14 4
Obsesiva 1 8 43 7
Depresiva 2 6 4 33
Total 30 58 67 45
En el SPSS: Primero ponderar casos.
Cap. VII Estadística no paramétrica 167
Aceptar
Pedir el coeficiente Kappa: analizar<estadísticos descriptivos<tablas de contingencia<pasar las variables <pedir el coeficiente Kappa<continuar<aceptar
Medidas simétricas
Valor Error típ. asint.a T aproximadab
Sig. aproximada
Medida de acuerdo Kappa ,538 ,046 12,921 ,000
N de casos válidos 200
a. Asumiendo la hipótesis alternativa.
b. Empleando el error típico asintótico basado en la hipótesis nula.
El valor del estadístico Kappa (,538) y su nivel crítico (Sig aproximada 0.000) por lo tanto se rechaza la hipótesis nula y concluimos que existe un grado de acuerdo mayor que el esperado por el azar.
McNemar
Prueba no paramétrica para dos variables dicotómicas relacionadas. Contrasta los cambios en las respuestas utilizando la distribución de Chi-cuadrado. Es útil para detectar cambios en las respuestas debidas a la intervención experimental en los diseños del tipo "antes-después". Para las tablas cuadradas de mayor orden se informa de la prueba de simetría de McNemar-Bowker.
Ejemplo
Cap. VII Estadística no paramétrica 168
Estilo genérico de interacción social que presentan los ACES del Asentamiento Humano Virgen del Carmen la
Era, antes y después de la aplicación del programa. Pre test Pos test
N % n %
Déficit asertivo 8 30.8 3 11.5
Estilo pasivo dependiente 11 42.3 9 34.6
Estilo agresivo 2 7.7 2 7.7
Estilo asertivo 5 19.2 12 46.2
Respecto al estilo genérico que tenían los agentes comunitarios antes de aplicar el programa de intervención el 30.8% presentaron un déficit asertivo, mientras que al finalizar el programa sólo un 11.5% presentó este déficit. Así también se observa que al inicio del programa el 42.31% presentaban un estilo pasivo dependiente y después de la aplicación del programa este porcentaje disminuyó a un 34.6%. Además el 19.2% de los ACES que alcanzaron un estilo asertivo inicial, después de la intervención este se incrementó al 46.2%, observando el estilo de interacción social agresivo antes y después de la intervención el 7.7% se mantuvo aparentemente sin variación, sin embargo las dos personas que corresponden a este porcentaje inicial no son las mismas, las dos personas que presentan esta conducta después de la intervención, inicialmente presentaron una conducta pasiva dependiente.
Comprobación de hipótesis
La tabla muestra la prueba de McNemar-Bowker (Pardo 2002) prueba no paramétrica de orden mayor que dos, contrasta los cambios en las respuestas, utilizando la distribución de Chi cuadrado. Es útil para detectar cambios de respuesta debidas a la intervención experimental en los diseños del tipo antes – después), para la relación del estilo genérico de interacción social que presentaron los ACES antes y después de la aplicación del programa de intervención “Re hacer la vida”, lo que muestra que la potencia de la prueba (p_value ,014) es inferior al nivel de significación considerado (α = ,05), por lo tanto se rechaza la hipótesis nula de igualdad de proporciones y se concluye que las proporciones de sujetos que participaron en el programa mejoraron su estilo genérico de interacción social, demostrándose la efectividad del programa.
Prueba de McNemar-Bowker para el estilo genérico de interacción social que presentan los ACES del Asentamiento Humano Virgen del Carmen la Era, antes y después de la aplicación del programa.
Prueba de McNemar-Bowker
Valor Gl p-value
Prueba de McNemar-Bowker
12.571 4 ,014
N de casos válidos 26
Cap. VII Estadística no paramétrica 169
7.9 PRUEBAS PARA DOS MUESTRAS INDEPENDIENTES (NO PARAMÉTRICAS)
Compara dos grupos de casos en una variable. Se puede trabajar con la prueba U de Mann-Whitney, la prueba de Kolmogorov Smirnov para dos muestras, la prueba de Moses de reacciones extremas y la prueba de rachas de Wald-Wolfowitz.
Ejemplo: Se han desarrollado nuevos correctores dentales diseñados para que sean más comodos y estéticos, así como para facilitar un progreso más rápido en la realineación de la dentadura. Para averiguar si el nuevo corrector debe llevarse tanto tiempo como el modelo antiguo, se eligen 10 niños al azar para que lleven este último y otros 10 para que usen el nuevo. Mediante la prueba de U de Mann-Whitney podría descubrir que de media, los niños que llevan el nuevo corrector tenían que llevarlo puesto menos tiempo que los que llevaban el antiguo.
Datos: utilice variables numéricas que puedan ordenarse.
Supuestos: utilice muestras independientes aleatorias. La prueba U de Mann-Whitney requiere que las dos muestras probadas sean similares en la forma.
Se utiliza como alternativa a la prueba paramétrica de comparación de medias de dos muestras independientes; por lo tanto la escala de medida de la variable dependiente es cuando menos ordinal. (para pruebas paramétricas no se debe usar las escalas de Likert).
En el SPSS:
U de Mann-Whitney: mezclados los datos de ambas muestras, se procede a ordenarlos de menor a mayor; el estadístico de contraste es la suma de los rangos de cada grupo.
Reacciones extremas de Moses: se prueba si el rango de una variable ordinal es el mismo del grupo control y en de comparación, por lo que los valores son ordenados de forma ascendente. Z de Kolmogorov-Smirnov: se prueba si la distribución de una variable, la dependiente, es la misma en dos grupos.
Rachas de Wald-Wolfowitz: Se ordenan los casos de ambos grupos conjuntamente de menor a mayor para a continuación, realizar una prueba de rachas usando como criterio el conjunto de valores que pertenecen al mismo grupo.
7.10 Prueba de U Man Witney: ejemplo Empleados.sav
Es una excelente alternativa a la prueba T cuando no se cumplen los supuestos de normalidad y homocedasticidad o cuando los datos son de tipo ordinal o nominal.
Cap. VII Estadística no paramétrica 170
Ho: los grupos definidos por la variable minoría proceden de poblaciones similares, por lo tanto con igual promedio de salario inicial
Ha: los grupos definidos por la variable minoría proceden de poblaciones distintas, por lo tanto con diferente promedio de salario inicial
Ranks
370 249. 14 92180. 50
104 196. 10 20394. 50
474 Clasif icación de minor í as
No Sí Tot al Salar io inicial
N Mean Rank Sum of Ranks
Test St at i st i csa
14934. 500 20394. 500 - 3. 495 . 000 Mann- Whit ney U
Wilcoxon W Z
Asym p. Sig. ( 2- t ailed)
Salar io inicial
G r ouping Var iable: Clasif icación de minor í as a.
Los grupos definidos por la variable minaría proceden de poblaciones con distintos promedios
Pruebas de reacciones extremas de Moses Test
Sirve para estudiar si existen diferencias en el grado de dispersión o de variabilidad
Frequenci es
370 104 474 Clasif icación de minor í as
No ( Cont r ol) Sí ( Exper im ent al) Tot al Salar io inicial
Cap. VII Estadística no paramétrica 171
Moses Test
Test St at i st i csa, b
467 . 000 434 . 990
18 Sig. ( 1- t ailed)
O bser ved Cont r ol G r oup Span
Sig. ( 1- t ailed) Tr im med Cont r ol
G r oup Span
O ut lier s Tr immed f r om each End
Salar io inicial
Moses Test a.
G r ouping Var iable: Clasif icación de minor í as b.
Outlieres Valores atípicos
Podemos considerar que no se a considerado valores extremos y tomaríamos sig=0.990 Por lo tanto rechazamos la Ho
Prueba de Kolmogorov-Smirnov para dos muestras
Esta prueba sirve para contrastar la hipótesis si la variables proceden de la misma población
Frecuenci as
370 104 474 Clasif icación de minor í as
No Sí Tot al Salar io inicial
N
Est adí st i cos de cont rast ea
. 237 . 000 - . 237 2. 134 . 000 Absolut a
Posit iva Negat iva Dif er encias más
ext r emas
Z de Kolmogor ov- Smir nov Sig. asint ót . ( bilat er al)
Salar io inicial
Var iable de agr upación: Clasif icación de minor í as a.
Ho: Son de la misma población
Sig<0.05 rechazamos que los dos grupos comparados difieren significativamente del salario inicial
Wald-Wolfowitz Test
Similar a la prueba de rachas para una muestra, permiten contrastar si los valores provienen de la misma población,requiere al menos una escala de medida ordinal, es sensible no solamente a la diferencia de valores poblacionales.
Frequenci es
370 104
474 Clasif icación de minor í as
No Sí
Tot al Salar io inicial
N
Est adí st i cos de cont rast eb, c
40a - 16. 576 . 000 200a 4. 923 1. 000 Mí nimo posible
Máximo posible Salar io inicial
Núm er o de r achas Z
Sig. asint ót . ( unilat er al)
Hay 25 empat es int er - gr upos que implican 348 casos. a.
Pr ueba de Wald- Wolf owit z b.
Cap. VII Estadística no paramétrica 172
PRUEBAS PARA VARIAS MUESTRAS INDEPENDIENTES
7.11 Prueba de H de Kruskal_Wallis
Este procedimiento contiene varias pruebas, todas ellas diseñadas para analizar datos provenientes con una variable independiente categórica (con mas de dos niveles que definen mas de dos grupos o muestras) y una variable dependiente cuantitativa al menos ordinal, en la cual interesa comparar las muestras
Ejemplo: Archivo Empleados
Directivos y administrativos
Ranks
363 192. 29 27 252. 59 84 428. 04 474
Cat egor í a labor al Adm inist r at ivo Segur idad Dir ect ivo Tot al Salar io inicial
N Mean Rank
Test St at i st i csa, b
203. 112 2 . 000 Chi- Squar e
df Asymp. Sig.
Salar io inicial
Kr uskal Wallis Test a.
G r ouping Var iable: Cat egor í a labor al b.
Rechazamos la hipótesis de igualdad de promedios, las poblaciones comparadas difieren del promedio de salario inicial o sea que hay diferencia entre estas dos categorías laborales.
PRUEBA PARA DOS MUESTRAS RELACIONADAS
Permiten analizar datos con medidas repetidas
7.12 Prueba de Wilcoxon y Signo, Mc Nemar
Cap. VII Estadística no paramétrica 173
Ranks
474a 237. 50 112575. 00
0b . 00 . 00
0c 474 Negat ive Ranks
Posit ive Ranks Ties Tot al Salar io inicial
-Salar io act ual
N Mean Rank Sum of Ranks
Salar io inicial < Salar io act ual a.
Salar io inicial > Salar io act ual b.
Salar io inicial = Salar io act ual c.
Los rangos deberían ser iguales (112575)
Test St at i st i csb
- 18. 865a
. 000 Z
Asymp. Sig. ( 2- t ailed)
Salar io inicial - Salar io
act ual Based on posit ive r anks. a.
Wilcoxon Signed Ranks Test b.
Rechazamos la hipo de igualdad de promedios son iguales, las variables comparadas difieren significativamente Sign Test Frequenci es 474 0 0 474 Negat ive Dif f er ences a
Posit ive Dif f er ences b
Ties c
Tot al Salar io inicial
-Salar io act ual
N
Salar io inicial < Salar io act ual a.
Salar io inicial > Salar io act ual b.
Salar io inicial = Salar io act ual c.
Test St at i st i csa
- 21. 726 . 000 Z
Asymp. Sig. ( 2- t ailed)
Salar io inicial - Salar io
act ual Sign Test
a.
Concluimos igual
Mac Nemar para variable de tipo (Arch. Fumar y no)
Una muestra aleatoria de 150 estudiantes se sometió a un cuestionario de opinión acerca de si fumar produce cáncer al pulmonar. Obtenida la información se les dio una conferencia y se les presento una exposición llevada a cabo por un equipo de sanidad explicando los peligros de fumar y se les explico la relación sobre el efecto de fumar sobre el cáncer pulmonar
(se les hizo una encuesta y luego recibieron una charla y se quiere ver que tan fructífera fue esa charla)
Después de la conferencia
Antes de la
conferencia NO SI Total
NO 43 67 110
SI 10 30 40
150
Cap. VII Estadística no paramétrica 174
ant es de l a conf erenci a & despues de l a conf erenci a
43 67 10 30 ant es de la conf er encia
1 2
1 2 despues de la
conf er encia
1=no 2=si
Test St at i st i csb
150 40. 727 . 000 N
Chi- Squar e a Asym p. Sig.
ant es de la conf er encia & despues de la conf er encia
Cont inuit y Cor r ect ed a.
M cNem ar Test b.
Ho: la probabilidad de que la conferencia no tenga efecto sobre la opinión de los estudiantes es igual a que la probabilidad de que la conferencia si tenga efecto sobre la opinión de los estudiantes
Ha: la probabilidad de que la conferencia es mayor sobre la opinión de los estudiantes
El sig<0.05, rechazamos la Ho por lo tanto concluimos que si existe un efecto estadísticamente significativo de que la conferencia cambie la opinión de los estudiantes a favor de que el fumar si produce cáncer
NPar Tests
Detecta diferencia en la distribución de casos a través de dos variables categóricas relacionadas, los valores distintos se enumeran (es si o es no)
Mar gi nal Homogenei t y Test
2 77 57. 000 . 000 8. 775 6. 496 . 000 Dist inct Values
O f f - Diagonal Cases O bser ved M H St at ist ic Mean MH St at ist ic St d. Deviat ion of M H St at ist ic
St d. MH St at ist ic Asym p. Sig. ( 2- t ailed)
ant es de la conf er encia & despues de la conf er encia
Indican que se diferencian las distribuciones para las dos variables o también que la distribución de casos a través de las categorías de la variables antes es diferente que la distribución de casos a través de las categorías después
Por que se les llama marginal por que la suma de las columnas filas y columnas son diferentes
La prueba de MH es una extensión de la prueba de Mc Nemar de la respuesta binaria a la respuesta multinomial
La media o valor esperados de la estadística de la homogeneidad es 0.000
Cap. VII Estadística no paramétrica 175
PRUEBA PARA K MUESTRAS RELACIONADAS
7.13 En dos direcciones por rangos de friedman (
2
r)
Si se desean comparar varias muestras o grupos de puntajes pareados (a cada puntaje de un grupo le corresponde otro puntaje del otro grupo o grupos; también se suelen llamar grupos o muestras dependientes o correlacionas), y en las cuales los requisitos básicos para los métodos paramétricos no se cumplen (los puntajes de dichos grupos no se distribuyen normalmente y no hay homogeneidad de las varianzas), el pareamiento puede ser obtenido relacionando conjuntos de sujetos en una o más variables previas y aleatoriamente asignando a cada elemento del conjunto pareado varias condiciones diferentes, o, si los mismos sujetos son elementos de cada grupo a comprobar, entonces los conjuntos pareados resultan adecuados.
Esta prueba es una variación de la prueba t (Student), que se utiliza para comprobar una misma muestra medida dos veces. Por ejemplo, en el diseño antes-después, se utiliza la siguiente fórmula:
) 1 ( 3 ) ( ) 1 (
1 2 2
2
k n R k
n k i
r
Donde:
2
)
( Ri = Suma de rangos de cada uno de los grupos, elevada al cuadrado
K = Número de grupos
n = Número de conjuntos de mediciones
12 y 3 = Constantes
Ejemplo:
Suponga que se desea comprobar la hipótesis nula de que un grupo de 10 sujetos reaccionan de la misma manera ante tres situaciones diferentes; Se obtienen los siguientes resultados, que se ubican en cada uno de los tres grupos I, II, III
Puntajes
Sujeto Grupo 1 Grupo 2 Grupo 3 A B C D E F G H I J 25 30 21 28 19 22 31 17 25 33 28 33 19 31 22 21 33 14 21 35 29 32 16 32 23 25 34 21 24 37