ESPACIOS DE HILBERT Y APLICACIONES A
MÁQUINAS DE SOPORTE VECTORIAL
Laura Sánchez Gómez
Tesis presentada al Departamento de Matemáticas, Facultad de Ciencias, Pontificia Universidad Javeriana para optar por el grado de Matemáticas
Dirigida por: Gerardo R. Chacón Ph.D.
Agradecimientos 5 Introducción 7
1 preliminares 11
1.1 Espacios de Hilbert 11
1.2 Optimización con Restricciones en Rn 34
2 máquinas de soporte vectorial 39 2.1 Aprendizaje de Máquinas 39
2.2 Máquinas de Soporte Vectorial 44 2.3 Dualidad de Lagrange 49
3 aplicación 59 Bibliografía 63
Quiero agradecer principalmente a Gerardo Chacón Ph.D., por su eterna pa-ciencia y disposición para trabajar conmigo y ayudarme a cumplir mis sueños; a Renato Colucci Ph.D. por sus aportes a este trabajo, a la Pontificia Universi-dad Javeriana por brindarme los medios para alcanzar este logro, y a todos los profesores que hicieron parte del proceso.
El Aprendizaje de Máquinases un tema de gran interés que ha ido creciendo en los últimos años y del que tenemos referencia a partir de la ciencia ficción. En este momento, se habla de aprendizaje de máquinas como algo natural, a pesar de ser un objetivo que todavía parece ser lejano. Las llamadas Máquinas de So-porte Vectorial, surgen como una posible manera de desarrollar el aprendizaje en máquinas, siendo un método novedoso en la clasificación de datos.
La teoría del aprendizaje de máquinas comenzó a crecer a partir de1900, donde empezaron a surgir diferentes técnicas de aprendizaje que promovieron el desa-rrollo del concepto. Las máquinas de soporte vectorial pueden ser vistas como una aplicación del Análisis Funcional, que surgió como un nuevo grupo de algo-ritmos de aprendizaje, y tiene sus raíces en la Teoría del Aprendizaje Estadístico [5]. La Teoría del Aprendizaje Estadístico fue desarrollada por los matemáticos rusos Vladimir Vapnik y Alexey Chervonenkis en 1974. Más adelante, en 1992, Vapnik, Isabelle Guyon, Bernhardt E. Boser presentaron en la conferencia sobre Teoría del Aprendizaje Computacional (COLT) una investigación acerca de algo-ritmos muy similares a los que hoy se denominan Máquinas de Soporte Vectorial. A partir de entonces, a nivel mundial existe mucha gente trabajando en el tema, el cual ha ido adquiriendo importancia con diferentes aplicaciones en campos como las finanzas, la bioinformática y la genética entre otros [6], [17], [19], [20], [21].
Las máquinas de soporte vectorial constituyen una técnica de clasificación de datos, en la cual se cuenta con dos o más grupos de clasificación y se parte de un conjunto de datos de muestra previamente catalogados en esos grupos. Se proporciona un nuevo conjunto de datos, los cuales deben ser clasificados en los grupos establecidos anteriormente. Para esto, se cuenta con una serie de algorit-mos y funciones, entre otras herramientas, que permiten realizar la clasificación de forma correcta. Mediante estas herramientas, se compara el grado de simila-ridad entre los datos de muestra y los nuevos datos, de manera que habiendo establecido ciertos parámetros de similitud, es posible establecer a qué grupo pertenecen los datos problema [5].
La técnica antes mencionada se desarrolla por medio de los denominados Nú-cleos Reproductivos. En 1907, Stanislaw Zaremba introdujo por primera vez un núcleo correspondiente a determinada clase de funciones. Dos años después, Ja-mes Mercer descubrió que dichos núcleos poseían una propiedad particular, la propiedad reproductiva. A partir de ahí, Mercer comenzó a estudiar funciones reales que satisfacían la propiedad reproductiva en la Teoría de Ecuaciones Integrales de Hilbert, y las nombró núcleos definidos positivos, y fue Eliakim H. Moore en 1935, quien amplió la teoría a funciones complejas. En1950, Nachman Aronszajn publicó “Teoría de Núcleos Reproductivos” donde demostró que cada núcleo re-productivo definido positivo y simétrico, determina un único Espacio de Hilbert con Núcleo Reproductivo, teorema que ahora se conoce como el Teorema de Moore - Aronszajn [9].
En el Departamento de Matemáticas de nuestra Universidad, el tema de Má-quinas de Soporte Vectorial es poco conocido, a pesar de que constituye una interesante aplicación del análisis funcional a problemas actuales [10], [14], [15]; por lo tanto, en el presente trabajo, se realizará una recopilación bibliográfica y un estado del arte sobre la Teoría de los Núcleos Reproductivos en espacios de Hilbert Funcionales, enfocándose en sus propiedades e importancia en el desarro-llo del aprendizaje de máquinas por medio del algoritmo de máquinas de soporte vectorial, y se mostrarán aplicaciones que tiene toda esta teoría en el mundo real y más específicamente en Colombia.
El primer capítulo está compuesto por temas preliminares, necesarios para el estudio de la Teoría de Núcleos Reproductivos. La sección1.1, es una recopilación de definiciones y resultados básicos de la Teoría de Espacios de Hilbert, nos ba-saremos en [1], [2], [3], [11]. La sección1.2, incluye teoría sobre Optimización con Restricciones en Rn, haciendo uso de [12], [16]. El segundo capítulo trata sobre
1
P R E L I M I N A R E SEn este primer capítulo haremos una recopilación de conceptos previos nece-sarios para la Teoría de Máquinas de Soporte Vectorial. En la primera sección, encontraremos una introducción a la Teoría de Espacios de Hilbert y posterior-mente a la Teoría de Núcleos Reproductivos. La segunda sección, describe la Optimización con Restricciones enRn.
1.1 espacios de hilbert
Los Espacios de Hilbert son espacios vectoriales con propiedades adicionales, que los dotan de ciertas nociones geométricas similares a los espacios de dimen-sión finita. Comenzaremos con la definición de espacio vectorial y a partir de ahí, iremos desarrollando la teoría.
Definición 1.1.1. Sea (X,K,+,·) un espacio vectorial, con dos operaciones, definidas
como+ :X×X→Xy·:X×K →Xtales que para todox,y,z∈X, y todoα,β∈K
(i) x+y=y+x
(ii) (x+y) +z=x+ (y+z)
(iii) Existe un único0∈Xtal quex+0=x
(iv) Para todox ∈X, existe un único −x ∈Xtal quex+ (−x) =0
(v) 1·x =x
(vi) (αβ)·x=α(β·x)
(vii) α·(x+y) =αx+αy
(viii) (α+β)·x=α·x+β·x
Observación 1.1.2. Para el resto del documento, denotaremos por K al cuerpo R ó al
cuerpoC.
Definiremos a continuación el producto interno.
Definición1.1.3. Sea X un espacio vectorial. Un producto interno sobreX es una fun-ciónh·,·i:X×X→Ktal que para todox,y,z ∈X
(i) hx+y,zi=hx,zi+hy,zi
(ii) hαx,yi=αhx,yi
(iii) hx,yi=hy,xi
(iv) hx,xi>0;hx,xi=0si y sólo six=0
A continuación, daremos la definición de una norma sobre un espacio vectorial X, y posteriormente, de base de Schauder.
Definición1.1.4. SeaXun espacio vectorial. Una normak · k:X→R+ es una función
que satisface:
(i) kxk=0si y sólo six =0
(ii) kαxk=|α|kxk, para todo α∈K y todox∈X
(iii) kx+yk6kxk+kyk, para todox,y∈X
Definición1.1.5. Sea(X,k · k) un espacio normado. Si existen vectorese1,e2,e3,. . . ∈ X tales que para todo x ∈ X, existen α1,α2,α3,. . . ∈ K con kx − (α1e1+. . .+ αnen)k →0, cuandon→∞, decimos que{ei}es unaBase de SchauderparaX.
El producto interno cuenta con las siguientes propiedades: Teorema1.1.6(Identidad del Paralelogramo).
kx+yk2+kx−yk2=kxk2+kyk2 ∀x,y∈X
dondekxk2 =hx,xi.
Demostración.
kx+yk2+kx−yk2 = hx+y,x+yi+hx−y,x−yi
= hx,x+yi+hy,x+yi+hx,x−yi−hy,x−yi = hx,xi+hx,yi+hy,xi+hy,yi+hx,xi
−hx,yi−hy,xi+hy,yi = 2hx,xi+2hy,yi
= 2kxk2+kyk2
Teorema 1.1.7(Identidad de Polarización). Sik · k norma, satisface la Identidad del Paralelogramo, entonces, para todox,y∈X,
(i) SiK =R
hx,yi= 1
4
kx+yk2−kx−yk2
(ii) SiK =C
Rehx,yi= 1
4
kx+yk2−kx−yk2
Imhx,yi= 1
4
kx+iyk2−kx−iyk2
Demostración. (i) SeaK =R, y sean x,y∈X
1 4
kx+yk2−kx−yk2 = 1
4(hx+y,x+yi−hx−y,x−yi)
= 1
4(hx,xi−hx,xi+hy,yi−hy,yi+2hx,yi+hy,xi)
= 1
2(hx,yi+hy,xi) Como K=R,hx,yi=hx,yi, entonces
= 2
2hx,yi
= hx,yi
(ii) SeaK =C, y sean x,y∈X. Veamos primero la parte real,
1 4
kx+yk2−kx−yk2 = 1
4(hx+y,x+yi−hx−y,x−yi)
= 1
2(hx,yi+hy,xi)
= 1
2
hx,yi+hx,yi = Rehx,yi
Veamos ahora la parte imaginaria, 1
4
kx+iyk2−kx−iyk2 = 1
4(hx+iy,x+iyi−hx−iy,x−iyi)
= 1
2(hx,iyi+hiy,xi)
= 1
2i
Teorema1.1.8(Desigualdad de Cauchy-Schwarz). |hx,yi|6kxkkyk ∀x,y∈X Demostración. Sea α∈K, entonces
0 6 kx−αyk2 = hx−αy,x−αyi
= hx,x−αyi−αhy,x−αyi
= hx,xi−αhx,yi−αhy,xi+|α|2hy,yi = kxk2−αhy,xi−αhy,xi+|α|2kyk2 = kxk2−2Re(αhy,xi) +|α|2kyk2
Siy6=0, entonces tomamosα= hy,xi
kyk2, entonces
0 6 kxk2−2Re hy,xi
kyk2 hy,xi !
+|hy,xi|
2
kyk4 kyk 2
= kxk2−2|hy,xi| 2
kyk2 +
|hx,yi|2
kyk2
= kxk2−|hx,yi|
2
kyk2
Luego,
|hx,yi|26kxk2kyk2
Sacando raíz cuadrada a ambos lados de la desigualdad, obtenemos el resultado.
Observación1.1.9. La igualdad se obtiene siy=0ó sikx−αyk2=0i.e. six=αy.
Proposición1.1.10. Sikxk=hx,xi1/2, entonceskx+yk6kxk+kyk. Demostración.
kx+yk2 = hx+y,x+yi
= hx,xi+hx,yi+hy,xi+hy,yi
Ahora, daremos la definición de Espacio de Banach, y posteriormente de Espa-cio de Hilbert.
Definición 1.1.11. Un espacio es completo si toda sucesión de Cauchy es convergente dentro del espacio.
Definición1.1.12. Un espacio normado completo se dice unEspacio de Banach. Definición1.1.13. Un espacioHcompleto, con producto interno se dice unEspacio de Hilbert.
El producto interno, es una función continua.
Lema1.1.14. SeaX un espacio con producto interno; Sean (xn),(yn)sucesiones en H tales quexn →xyyn→yconx,y∈H. Entonces
hxn,yni → hx,yi Demostración.
|hxn,yni−hx,yi| = |hxn,yni−hxn,yi+hxn,yi−hx,yi|
6 |hxn,yn−yi|+|hxn−x,yi
6 kxnkkyn−yk+kxn−xkkyk
Como(xn) es convergente, existeM > 0tal que kxnk6My comokxn−xk →0 ykyn−yk →0, se obtiene el resultado.
Introduciremos ahora funciones denominadas operadores lineales, es decir, funciones definidas sobre espacios vectoriales, en particular, son funciones de-finidas sobre espacios normados.
Definición1.1.15. Un operador linealT es una función con dominioD(T)y rangoR(T)
ambos espacios vectoriales definidos sobre el mismo cuerpoKque satisface
(i) T(x+y) =T x+T y para todox,y∈D(T)
(ii) T(αx) =αT xpara todoα∈K y todox∈D(T)
Definiremos a continuación operadores lineales acotados.
Definición 1.1.16. Sea T : D(T) ⊂ X → Y un operador lineal. T es acotado si existe c > 0tal que
kT xkY 6ckxkX
Definición1.1.17. Six6=0, entonces kT xkY
kxkX
6cpara todox6=0,x∈D(T). Definimos
kTk:= sup
kT xk
kxk :x6=0,x ∈D(T)
Lema1.1.18. SeaT acotado. Entonces,
(i)
kTk = sup
kT xk
kxk :kxk=1
= sup{kT xk:kxk=1}
(ii) k · kes una norma en el espacio vectorial de los operadores lineales acotados.
Demostración. (i)
kTk = sup
1
kxkT x
:x 6=0,x∈D(T)
= sup T x
kxk
:x 6=0,x∈D(T)
= sup{kT yk:kyk=1}
(ii) Veamos ahora quek · k es una norma en el espacio de los operadores.
Vea-mos quekTk=0⇔T x=0
kTk=0 → sup{kT xk:kxk=1}=0
⇔ kT xk=0 ∀x∈D(T);kxk=1
⇔ T x =0 ∀x∈D(T);kxk=1 Ahora bien siy6=0, y∈D(T)entonces y
kyk tiene norma 1y por lo tanto,
0=T
y
kyk
= 1
kykkT yk → kT yk=0
Veamos ahora quekαTk=|α|kTkpara todoα∈K. kαTk = sup{kαT xk:kxk=1}
= sup{|α|kT xk:kxk=1}
= |α|sup{kT xk:kxk=1}
Veamos ahora quekT+Lk6kTk+kLk paraLoperador lineal acotado.
kT +Lk = sup{k(T +L)xk:kxk=1}
= sup{kT x+Lxk:kxk=1}
6 sup{kT xk+kLxk:kxk=1}
= sup{kT xk:kxk=1}+sup{kLxk:kxk=1}
= kTk+kLk
Observación1.1.19. SiT es un operador lineal acotado,
kT xk6kTkkxk
Teorema1.1.20. SeaX normado,dim(X)<∞. Entonces todo operador lineal es acota-do.
Demostración. Sea {e1,. . .,en} una base de X. Sea x ∈ X, x =α1e1,. . .,αnen. Sea T :X→Xun operador lineal, entonces
kT xk = kT(α1e1+. . .+αnen)k
= kα1T e1+. . .+αnT enk
6 |α1|kT e1k+. . .+|αn|kT enk
6 m´ax
16i6nkT eik(|α1|+. . .+|αn|)
6 c−1 m´ax
16i6nkT eikkxk
dondec−1 m´ax
16i6nkT eikes constante, luegoT es acotado. Teorema1.1.21. SeaT :D(T)⊂X→Y,X, Yespacios normados.
(i) T es continuo si y sólo siT es acotado.
(ii) SiT es continuo en un punto, entoncesT es continuo enD(T).
Demostración. (i) ⇐) Sea x ∈ D(T) arbitrario y ε > 0. Tomemos 0 < δ < ε
kTk,
T 6=0, entonces sikx−yk< δ
El casoT =0es trivial.
⇒)Seanx,y∈D(T). Dado ε > 0existeδ > 0tal que ky−zk < δ, entonces,
kT y−T zk< ε. Sea z=y− δx
2kxk. Entonces,
ky−zk=
δx 2kxk
= δ
2 < δ
Luego por continuidad se tiene que
kT y−T zk=kT(y−z)k=
T
δx 2kxk
< ε → δ
2kxkkT xk< ε
→ kT xk< 2ε δ kxk
LuegoT es acotado.
(ii) T es continua eny, por lo tantoT es acotada, así, por (i),T es continua.
Corolario1.1.22. SeaT :D(T)⊂X→Y acotado. Entonces,
(i) Sixn →x, xn,x ∈D(T), entoncesT xn →T xenY. (ii) N(T)es cerrado.
Demostración. (i) Se tiene directamente de la continuidad deT.
(ii) Sea (xn) ⊂ N(T) convergente. Supongamos xn → x. Como T es acotado, T xn → T x pero T xn = 0 entonces, T xn → 0. Luego T x = 0, entonces x ∈ N(T)y por lo tantoN(T) es cerrado.
Teorema1.1.23. SeaT :D(T)⊂X→Y lineal y acotado,Y espacio de Banach. Entonces existe una extensión Tˆ : D(T) → Y tal que Tˆ|D(T) = T, Tˆ es lineal y acotado, ykTˆk =
kTk.
Demostración. Sea x ∈ D(T)\D(T), existe (xn) ⊂ D(T) tal que xn → x. Entonces
(xn) es de Cauchy y como T es continua, (T xn) es de Cauchy enY. Así, como Y es completo, existe y ∈ Y tal que T xn → y. Definimos ˆT x := y. Veamos que ˆT x está bien definido. Supongamoswn →x, (wn)⊂D(T).
Luego ˆT está bien definido enD(T)\D(T).
Definimos ahora ˆT|D(T) = T. Sean x,w ∈ D(T)\D(T), α,β ∈ K. Existen D(T) ∋ xn →x, D(T)∋wn→w
ˆ
T(αx,βw) = l´ım
n→∞
T(αxn+βwn)
= l´ım
n→∞
T(αxn) +T(βwn)
= α l´ım n→∞
T xn+β l´ım n→∞
T wn
= αT xˆ +βT wˆ Seax ∈D(T)\D(T), entonces
kTˆk = nl´ım→
∞
T xn
= l´ım
n→∞k
T xnk
6 l´ım
n→∞k
Tkkxnk
= kTkkxk
entonces, ˆT es acotado ykTˆk6kTk.
Por otro lado,
kTˆk = supkT xˆ k:kxk=1,x∈D(T) kTk = sup{kT xk:kxk=1,x ∈D(T)}
entonceskTˆk>kTk, debido a que tomamos el supremo sobrekTˆk ⊃ kTk.
Supongamos que contamos con un espacio con producto interno, es posible completar dicho espacio, de manera que se obtenga un espacio de Hilbert, como se muestra a continuación.
Teorema 1.1.24. Sea X un espacio con producto interno. Entonces existe un espacio completo con producto internoHy un operador linealT tal queT :X→W ⊂Hsea un isomorfismo deXenW yW sea denso enH.
Demostración. Xes un espacio normado, por lo tanto, existeHespacio de Banach, W⊂Hdenso enHy T :X→W isomorfismo de espacios normados.
Nótese que siz,w∈W, podemos definir
dondeT x=zy T y=w.
Ahora, siz,w∈W, existen(zn), (wn)⊂W tales quezn →z ywn →w. Definimoshz,wi:= l´ım
n→∞h
zn,wni.
Veamos ahora queh·,·iestá bien definido y que además es un producto interno.
Seanzn→z,wn→w, veamos que
|hzn,wni−hzn,wni|=0
l´ım n→∞
|hzn,wni−hzn,wni| = nl´ım→
∞(hzn,wni
−hzn,wni)
= |hz,wi−hz,wi|
Así, |hzn,wni−hzn,wni|→0.
Veamos ahora queh·,·ies un producto interno. Sean z,w,v∈H y seaα∈K
(i)
hz+w,vi = hz,vi+hw,vi hz+w,vi = l´ım
n→∞hzn
+wn,vni
= l´ım
n→∞(hzn,vni+hwn,vni) = l´ım
n→∞
hzn,vni+ l´ım n→∞
hwn,vni
= hz,vi+hw,vi
(ii)
hαz,wi = αhz,wi hαz,wi = l´ım
n→∞
hαzn,wni
= l´ım
n→∞
(αhzn,wni)
= α l´ım n→∞h
zn,wni
(iii)
hz,wi = hw,zi hz,wi = l´ım
n→∞h
zn,wni
= Dl´ım
n→∞zn, l´ımn→∞wn
E
= Dl´ım
n→∞wn, l´ımn→∞zn
E
= l´ım
n→∞h
wn,zni
= hw,zi
(iv)
hz,zi > 0
hz,zi = l´ım
n→∞
hzn,zni
> 0
hz,zi=0 ⇔ z=0
hz,zi=0 ⇔ l´ım
n→∞hzn,zni =0
⇔ l´ım
n→∞
zn =0
⇔ z=0
Definición1.1.25. Un funcional lineal es un operador lineal con rango en el espacio de los escalares
f:D(f)→K
Definición1.1.26. SeaXun espacio vectorial normado. Definimos elDual Algebráico y elDoble Dual Algebráico como
X∗ = {f:X→K :f es lineal}
X∗∗ = {g:X∗→K :g es lineal}
respectivamente.
Para cadax ∈X, definimosgx :X∗→K tal quegx(f) :=f(x). Nótese que gx es lineal, conf,h∈X∗
gx(αf+βh) = (αf+βh)(x)
Por lo tanto,gx ∈X∗∗.
Ahora, a cadax ∈ Xle corresponde un gx ∈ X∗∗. Definimos entonces la Inmer-sión CanónicaQcomo
Q : X→X∗∗ x7→gx Veamos que Qes lineal, seaf∈X∗
Q(αx+βy) = gαx+βy(f)
= f(αx+βy) = αf(x) +βf(y) = αgx(f) +βgy(f)
= αQ(x) +βQ(y)
Definición1.1.27. SeaT :X→Y operador lineal, dondedim(X)<∞ydim(Y)<∞. Sea {e1,. . .,en} una base para X y {b1,. . .,bm} una base para Y. Tomemos x ∈ X, entonces
x=α1e1+. . .+αnen y por lo tanto
T x=α1T e1+. . .+αnT en Asociamos al operadorT ↔(τjk)j=1,...,m
k=1,...,n
de modo que
T ek =
m X
j=1 τjkbj
Ahora, seaf :X →K un funcional lineal. f(x) =α1f(e1) +. . .+αnf(en)asociamos a
f↔(f(e1),. . .,f(en)). Definimos, parak=1,. . .,n fk(ej) :=δkj =
1 Si k =j 0 Si k 6=j Proposición1.1.28. {f1,. . .,fn}son una base paraX∗.
Demostración. (i) Veamos que los fk′s son linealmente independientes. Supon-gamos que
n X
k=1
βkfk =0
→
n X
k=1
βkfk(ej) =0 ∀j=1,. . .,n
(ii) Veamos ahora que {f1,. . .,fn}generaX∗. Seaf∈X∗ f(x) = α1f(e1) +. . .+αnf(en) fj(x) = αj
f(x) = f1(x)f(e1) +. . .+fn(x)f(en)
f =
n X
j=1
f(ej)fj
Luego{f1,. . .,fn}es una base paraX∗. Más aun, dim(X∗) =dim(X) =n.
Lema 1.1.29. Sea x ∈ X, dim(X) < ∞. Si x es tal que f(x) = 0 para todo f ∈ X∗, entoncesx=0.
Demostración.
x = α1e1+. . .+αnen
f(x) =
n X
j=1
αjf(ej) =0 ∀f∈X∗
entonces, para cualquier vector (β1,. . .,βn), n X
j=1
αjβj = 0. En particular, para
todoi, tomemos(0,. . .,0, 1,
i-ésima
0,. . .,0), entonces,αi=0para todoi, y por lo
tantox=0.
Teorema 1.1.30. Todo espacio finito dimensional es algebráicamente reflexivo, i.e. X es algebráicamente reflexivo siQes biyectiva. Sea
Q:X → X∗∗ x 7→ Q(x)
Demostración. Veamos que Q es inyectiva. Supongamos que Q(x) = 0, es decir
Q(x)(f) = 0 para todo f ∈ X∗∗, entonces f(x) = 0 para todo f ∈ X∗, luegox = 0.
AsíN(Q) = {0} y por lo tantoQ es inyectiva. Luego Q−1 : R(Q) → Xexiste y es un operador lineal. Más aun, como dim(X)<∞, entonces dim(X) =dim(R(Q)).
Pero sabemos que dim(X∗∗) = dim(X∗) = dim(X) = dim(R(Q)), entonces, X∗∗ =
R(Q).
Observación1.1.31. X′ ⊂X∗
Definición1.1.32. Un isomorfismoT entre dos espacios normadosXeYes un operador lineal biyectivoT :X→Y tal que
kT xk=kxk
para todox∈X.
A continuación, introduciremos los conceptos de suma directa y los comple-mentos ortogonales, veamos algunas propiedades de la ortogonalidad primero. Iniciaremos recordando la definición de distancia entre un punto y un conjunto. Definición1.1.33. Sean xun punto,Y un conjunto arbitrarios. Definimos la distancia entrexyY como
d(x,Y) := ´ınf{d(x,y) :y∈Y}
= ´ınf{kx−yk:y∈Y}
Definición1.1.34. Dos vectoresx,yenHson ortogonales sihx,yiH=0.
Definición 1.1.35. Sea X un espacio métrico y sea M ⊂ X. M es convexo si para todo x,y ∈ M, el segmento que los une está totalmente contenido en M. Es decir, sea St(x,y) :=xt+ (1−t)y, St(x,y)∈Mpara todot∈[0,1].
Teorema1.1.36. SeaXun espacio con producto interno. SeaM⊂Xno vacío, completo y convexo. Entonces six∈X, existe un únicoy∈Mtal quekx−yk=d(x,M).
Demostración. Six∈M, entoncesd(x,M) =0y kx−xk=d(x,M).
Ahora, si x /∈ M,d(x,M) = ´ınf{kx−yk:y∈M}. Por propiedades del ínfimo,
existe(yn)⊂Mtal quekx−ynk →d(x,M). Veamos que (yn)es de Cauchy. Sea x−yn=vn,
kvn+vmk = k−ym−yn+2xk
= kyn+ym−2xk
= 2
yn+ym 2 −x
> 2d(x,M)
nótese que yn+ym
Ahora bien
kyn−ymk2 = kyn−x+x−ymk2
= kvm−vnk2
= −kvm+vnk2+2
kvmk2+kvnk2
6 −4(d(x,M))2+2kx−ynk2+kx−ymk2
→0, sin,m →∞
Entonces,(yn)⊂Mes de Cauchy y por lo tanto yn →y∈M. Luego
d(x,M) = l´ım
n→∞k
x−ynk
=
x−nl´ım→
∞yn
= kx−yk
Estudiaremos ahora la unicidad. Supongamos que existey∈Mtal que
kx−yk=d(x,M)
ky−yk2 = k(y−x) − (y−x)k2
= −k(y−x) + (y−xk2+2ky−xk2+ky−xk2
= −4
y+y 2 −x
2
+4(d(x,M))2
6 −4(d(x,M))2+4(d(x,M))2
= 0
así,y=y.
Lema1.1.37. SeaXun espacio con producto interno,Y ⊂Xun subespacio completo. Si x∈X, sabemos que existey∈Y tal que
ky−xk=d(x,Y)
Entoncesz:= x−yes ortogonal al espacioY, i.e.,hz,wi=0, para todow∈Y.
Demostración. Supongamos que existe ¯y∈Y tal quehz, ¯yi 6=0. kz−αy¯k2 = hz−αy,¯ z−αy¯i
Queremos quehy,¯ zi−α¯ ky¯k2=0. Tomemos ¯α= hy,¯ zi
ky¯k2. Entonces,
kz−αy¯k2 = kzk2−|hz, ¯yi|
2
ky¯k2
6 kzk2− (d(x,Y))2
Pero z−αy¯ = x− (y+αy¯) con (y+αy¯) ∈ Y, lo que es una contradicción. Así, hz, ¯yi=0.
Definición1.1.38. SeaY⊂Xcompleto
(i) Definimos elcomplemento ortogonalcomoY⊥ :={x∈X:x⊥Y}. Nótese queY⊥ es no vacío, pues contiene siempre al0.
(ii) Un espacio Xes unasuma directa de dos subespaciosY,Zi.e. X=Y⊕Zsi todo vectorx∈Xse escribe de manera única como x=y+zdondey∈Y yz∈Z.
Teorema 1.1.39. Sea H un espacio de Hilbert y Y ⊂ H un subespacio cerrado de H. Entonces,
H =Y⊕Y⊥
Demostración. Por el lema anterior, para todo x ∈ H, existe z ∈ Y⊥. Pero x =
z+ (x−z) =z+ydondeyes tal quekx−yk=d(x,Y).
Veamos quexse escribe de manera única. Supongamosx=y1+z1dondey1 ∈Y y z1 ∈Y⊥. Luego,
y+z = y1+z1 Y ∋(y−y1) = (z1−z)∈Y⊥
Entonces,
(y−y1)∈Y∩Y⊥ → hy−y1,y−y1i=0
→ y=y1
(z−z1)∈Y∩Y⊥ → hz−z1,z−z1i=0
→ z=z1
Teorema 1.1.40(Teorema de Representación de Riesz I). Todo funcional lineal aco-tadofen un espacio de HilbertHpuede ser representado como
f(x) =hx,zi
de forma única, dondezdepende def, más aun kfk=kzk.
Demostración. (i) Demostremos la representación. Sif≡0, basta tomarz=0y f(x) =hx,zipara todo x∈H.
Supongamos ahora f 6= 0. Como H es un espacio de Hilbert y N(f) es
cerrado, entonces
H=N(f)⊕N(f)⊥
Como f6=0,N(f)6=Hy por lo tantoN(f)⊥ 6=0. Fijemosx∈H.
Sea ˆz∈N(f)⊥ y consideremos el siguiente vector
v:=f(x)zˆ−f(zˆ)x Nótese que f(v) =0por lo tantox∈N(f). Así,
0 = hv, ˆzi
= hf(x)zˆ−f(zˆ)x, ˆzi = f(x)kzˆk2−f(zˆ)hx, ˆzi
luego,
f(x) = f(zˆ)hx, ˆzi kzk2
=
*
x, ˆzf(zˆ)
kzˆk2
+
Por lo tanto, tomando z= zfˆ (zˆ)
kzˆk2 obtenemos el resultado.
(ii) Veamos ahora que zes único. Supongamos que existez′∈H tal que f(x) =hx,zi=hx,z′i para todox ∈H
entonces hx,z−z′i=0para todox ∈H. En particular,
z−z′,z−z′
=0 → z−z′ 2
=0
(iii) Veamos ahora que kfk = kzk. Sabemos que f(x) = hx,zi para todo x ∈ H.
En particular
f(z) = hz,zi = kzk2
6 kfkkzk → kzk 6 kfk
Ahora,
|f(x)| = |hx,zi|
6 kxkkzk → kfk 6 kzk
Así, kfk=kzk.
Observación1.1.41. Sihx,yi=0para todox ∈H, entoncesy=0.
Definición 1.1.42. Sean X y Y dos espacios vectoriales sobre el mismo cuerpo K. Una
forma sesquilineal es una aplicaciónh :X×Y →K tal que para todox,x1,x2∈X, todo
y,y1,y2 ∈Y y todoα,β∈K
(i) h(αx1+βx2,y) =αh(x1,y) +βh(x2,y)
(ii) h(x,αy1+βy2) =αh¯ (x,y1) +βh¯ (x,y2)
Definición1.1.43. Una forma sesquilineal es acotada si existec > 0tal que
|h(x,y)|6ckxkkykpara todox∈Xy todoy∈Y.
Más aun,
khk := ´ınf{c > 0 :|h(x,y)|6ckxkkyk}
= sup
(x,y)∈X×Y
|h(x,y)|
kxkkyk
= sup
kxk=1
kyk=1
|h(x,y)|
Teorema1.1.44(Teorema de Representación de Riesz II). SeanH1 yH2espacios de Hilbert y h : H1×H2 → K una forma sesquilineal acotada. Entonces, existe un único operador lineal acotadoS:H1→H2 tal que
h(x,y) =hSx,yiH
2para todox∈H1 y para todo elementoy∈H2. Más aun,khk=kSk.
Demostración. Sea x fijo. Tomemos fx : H2 → K definido como fx(y) = h(x,y). Nótese quefxes lineal. Además,
|fx(y)| =
h(x,y)
= |h(x,y)|
6 khkkxkkyk
entoncesfxes acotado ykfxk=khkkxk.
Por elTeorema de Representación de Riesz I existe z∈ H1 tal quefx(y) = hy,ziH2.
Es decir, h(x,y) = hy,ziH
2 para todo y ∈ H2. Entonces h(x,y) = hy,ziH2 para todoy∈H2.
DefinamosS:H1 →H2como Sx=z
hS(αx1+βx2),yiH2 = h(αx1+βx2)
= αh(x1,y) +βh(x2,y)
= αhSx1,yi+βhSx2,yi
= hαSx1+βSx2,yiH2
para todo y ∈ H2. Entonces, hS(αx1+βx2) −αSx1+βSx2,yiH2 = 0 para todo y∈H2.
Veamos ahora quekhk=kSk.
khk = sup
x6=0 y6=0
|h(x,y)|
kxkkyk
= sup
x6=0 y6=0
|hSx,yi|
kxkkyk
> sup
x6=0
|hSx,Sxi|
kxkkSxk
= sup
x6=0
kSxk kxk = kSk
Así, Ses acotado ykSk6khk.
Ahora,
khk = sup
x6=0 y6=0
|h(x,y)|
kxkkyk
= sup
x6=0 y6=0
|hSx,yi|
kxkkyk
6 sup
x6=0 y6=0
kSxk kyk kxkkyk
= kSk
Así, khk6kSk, y por lo tantokhk=kSk.
Veamos ahora que S es único. Supongamos queSyT satisfacen h(x,y)H2 =hSx,yi=hT x,yi
para todo x∈H1 y todoy∈H2. Entonces,
hSx−T x,yi=0 ∀x ∈H1, y∀y∈H2
→ Sx−T x =0 ∀x∈H1
Introduciremos ahora Espacios de Hilbert con Núcleo Reproductivo. Este con-cepto es fundamental para las Máquinas de Soporte Vectorial, debido a que estos espacios permitirán la clasificación de los datos, cuando éstos no son linealmente separables.
Definición 1.1.45. Sea X ⊂ H no vacío y H un espacio de Hilbert de funciones f :
X → K, entonces H se denomina un Espacio de Hilbert con Núcleo Reproductivo
(RKHS)(Por sus siglas en inglés: Reproducing Kernel Hilbert Space.) , si existe una funciónK:X×X→K denominada núcleo reproductivo (En inglés reproducing kernel.)
deHque cumple con la siguiente propiedad:
Propiedad ReproductivaPara todox∈Xy toda funciónf∈H,
f(x) =hf,K(x,·)i
Observación 1.1.46. Si todos los funcionales de evaluación son acotados, la propiedad reproductiva se sigue directamente del Teorema de Representación de Riesz I1.1.40.
Veamos algunas propiedades.
Proposición1.1.47. Un Espacio de Hilbert con Núcleo Reproductivo determina un úni-co núcleo reproductivo.
Demostración. SeanKyK′generadores de Hun RKHS. KyK′ son simétricos pues
K(x,x′) =
K(x,·),K(x′,·)
=
K(x′,·),K(x,·)
=K(x′,x)
de manera análoga paraK′, luego, K′(x′,x) =
K′(x′,·),K(x,·)
=
K(x,·),K′(x′,·)
=K(x,x′)
peroK′es simétrico luego,
K(x,x′) =K′(x,x′)
Definición1.1.48. Dado K : X×X → K y entradasx1,. . .,xm ∈ X, la matrizK con
elementosKij := K xi,xj
i,j =1,. . . m, se denominaMatriz Gram deK (o matriz de kernels) respecto ax1,. . .,xm.
Definición1.1.49. Una matrizKm×m compleja, que satisface X
i,j
cic¯jKij >0 (1)
Definición1.1.50. SeaXno vacío. Una función KenX×Xtal que para todoi∈ N y
para todoxi ∈X, da lugar a una matriz definida positiva, se denominaKernel Definido Positivo, o simplemente kernel.
Proposición1.1.51. SiKes un kernel definido positivo yxi,xj ∈X, entonces (i) K(xi,xi)>0, para todoxi∈X
(ii) K(xi,xj) =K(xj,xi)
(iii) |K(xi,xj)|26K(xi,xi)K(xj,xj)
Demostración. (i) K(xi,xi) =hK(·,xi),K(·,xi)i=kK(·,xi)k>0 (ii) K(xi,xj) =
K(·,xi),K(·,xj)
=
K(·,xj),K(·,xi)
=K(xj,xi)
(iii) Tomemos xi,xj como nuestros únicos puntos. Construimos la matriz de kernels correspondiente
K(xi,xi) K(xi,xj)
K(xj,xi) K(xj,xj) !
Los determinantes de toda submatriz principal de una matriz definida po-sitiva son positivos, luego
K(xi,xi)K(xj,xj) −K(xi,xj)K(xj,xi) > 0 K(xi,xi)K(xj,xj) −K(xi,xj)K(xi,xj) > 0 K(xi,xi)K(xj,xj) −|K(xi,xj)|2 > 0
Así, |K(xi,xj)|2 6K(xi,xi)K(xj,xj).
Teorema 1.1.52 (Teorema de Moore-Aronszajn). Sea K un kernel reproductivo de-finido positivo y simétrico sobre un conjunto X. Entonces, existe un único espacio de Hilbert de funciones en X para el cual K es un kernel reproductivo i.e. un kernel repro-ductivo definido positivo y simétrico determina un único espacio de Hilbert con núcleo reproductivo.
Demostración. Definimos para cada x ∈ X, Kx = K(x,·). Sea H0 el espacio lineal generado por{Kx :x∈X}. Definimos un producto interno sobre H0como
* n X
j=1
βjKyj, m X
i=1 αiKxi
+
=
m X
i=1 n X
j=1 ¯
La simetría de este producto interno se tiene directamente de la simetría de K. SeaHla completación deH0respecto al producto interno. Entonces las funciones deH son de la forma
f(x) = ∞
X
i=1
αiKxi(x)
donde
∞
X
i=1
α2iK(xi,xi)<∞por la desigualdad de Cauchy-Schwarz. Veamos ahora que se cumple laPropiedad Reproductiva.
hf,Kxi = * ∞
X
i=1
αiKxi,Kx +
= ∞
X
i=1
αiK(xi,x)
= f(x)
Ahora veamos que H es único. Supongamos existe ˆH otro espacio de Hilbert de funciones para el que K es núcleo reproductivo. Para todo x,y ∈ X, por la
propiedad reproductiva tenemos que
hKx,KyiH = K(x,y)
= hKx,KyiHˆ
Pues por linealidad,h·,·iH = h·,·iHˆ en el espacio generado por {Kx : x ∈ X}. Así, H=Hˆ por la unicidad de la completitud.
Ejemplos1.1.53(Núcleos Reproductivos). SeaX⊂Rn
(i) Kernel PolinomialK(x,x′) =hx,x′id
(ii) Kernel GaussianoK(x,x′) =exp
−kx−x′k2 2σ2
Demostración. (i) Para demostrar que es un núcleo reproductivo, basta ver que la matriz de kernels es definida positiva.
X
ij
cic¯j
xi,xjd
= X
ij D
c1/di xi,c1/dj xjEd
> k *
X
i
c1/di xi,X j
c1/dj xj +d = k X i
Así, el Kernel polinomial es un núcleo reproductivo. (ii) Para demostras que
K(x,x′) =exp
−kx−x′k2
2σ2
es definido positivo, basta con demostrar que X
ij
cic¯j(−kxi−xjk2)>0
Supongamos n X
i=1
ci =0, entonces
n X
i,j=1
cic¯jkxi−xjk2 = n X
i,j=1 cic¯j
kxik2+kxjk2−hxi,xji−hxj,xii
=
n X
i=1
cikxik2
n X
j=1 ¯ cj+
n X
j=1
cjkxjk2
n X
i=1 ci
−
* n X
i=1 cixi,
n X
j=1 cjxj
+
−
* n X
j=1 ¯ cjxj,
n X
i=1 ¯ cixi
+ = − n X
i=1 cixi
2 − n X
i=1 ¯ cixi
2 6 0 Así, n X
i,j=1
cic¯j(−kxi−xjk2)es definido positivo, y por lo tantoexp
−kx−x′k2 2σ2
también lo es.
1.2 optimización con restricciones en Rn
En esta sección discutiremos problemas de optimización con restricciones en
Rn, tanto con restricciones de igualdad y desigualdad.
Consideremos el siguiente problema de optimización
minimizar f(x),
sujeto a: x∈X
ConX⊂Rn.
Definición1.2.1. Seaf : Rn → R y consideremos un problema de optimización como
en(2), donde X⊂Rn es no vacío
(i) Los puntos deXse denominansoluciones posiblespara(2).
(ii) Seaxˆ ∈X. Sif(x)> f(xˆ)para todox∈ X, entoncesxˆ se denomina unasolución óptima para el problema.
(iii) La colección de soluciones óptimas se denomina conjunto desoluciones óptimas alternativas.
(iv) Sea xˆ ∈ X. Si existe un entorno Nε(xˆ) de xˆ tal que f(x) > f(xˆ) para todo x ∈ X∩Nε(xˆ), entoncesxˆ se denomina unasolución óptima local.
(v) Seaxˆ ∈X. Sif(x)> f(xˆ)para todox∈X∩Nε(xˆ),x 6=xˆ, paraε > 0, entoncesxˆ se denomina unasolución óptima local estricta.
Teorema1.2.2. Consideremos el problema de optimización (2), dondeXes un conjunto convexo no vacío deRn, yf:X →Res convexa en X. Sixˆ ∈ Xes una solución óptima
local del problema, entoncesxˆ es una solución óptima global. Más aun, sixˆ es un mínimo local estricto, o si f es estrictamente convexa, entonces xˆ es la única solución óptima global.
Demostración. Como ˆx es una solución óptima local, entonces existe un entorno Nε(xˆ)de ˆx tal que
f(x)>f(xˆ) para todo x∈X∩Nε(xˆ) (3) Supongamos por contradicción que ˆxno es una solución óptima global, entonces exite ¯x tal quef(x¯)< f(xˆ)para algún ¯x∈X. Comofes convexa tenemos
f(λ¯x+ (1−λ)xˆ) 6 λf(x¯) + (1−λ)f(xˆ)
< λf(xˆ) + (1−λ)f(xˆ) = f(xˆ)
para λ ∈ (0,1). Si tomamos λ > 0 suficientemente pequeño, λx¯ + (1−λ)xˆ =
ˆ
x+λ(x¯−xˆ) ∈ X∩Nε(xˆ) lo que contradice (3), y por lo tanto ˆx es una solución óptima global.
Ahora, sea ˆxun mínimo local estricto. Luego por lo anterior, ˆxes un mínimo glo-bal. Veamos que es la única solución óptima gloglo-bal. Sea ¯x∈Xtal quef(x¯) =f(xˆ).
λ → 0+, obtenemos que xλ ∈ X∩Nε(xˆ) para todo ε > 0, lo que contradice el hecho de que ˆx es un mínimo local estricto y por lo tanto, ˆx es la única solución óptima global.
Supongamos ahora que fes estrictamente convexa y que ˆx es una solución ópti-ma local. Como la convexidad estricta implica la convexidad, entonces ˆx es una solución óptima global. Sea ¯x ∈ X, ¯x 6= x, tal queˆ f(x¯) = f(xˆ). Como f es estric-tamente convexa, f
1 2x¯+
1 2xˆ
< 1
2f(x¯) + 1
2f(xˆ) = f(xˆ). Dado que S es convexa, 1
2x¯ + 1
2xˆ ∈ S, lo que contradice el hecho de que ˆx es una solución óptima global, luego ˆxes la única solución óptima global.
Para la resolución de problemas de optimización con restricciones de igualdad, introduciremos el Método de Multiplicadores de Lagrange. Consideremos entonces un problema de la siguiente forma
minimizar f(x),
sujeto a:
gi(x) =0 i =1,. . .,m x ∈X
(4)
Este método nos dice que los valores extremos (o puntos críticos) de la función f(x), cuyas variables están sujetas a una restriccióng(x) =0, se encuentran en la
superficie deg =0entre los puntos donde
∇f=
n X
i=1 λi∇gi
paraλi ∈Rpara todo i =1,. . .,n, denominadosMultiplicadores de Lagrange.
Teorema 1.2.3. Sea f(x) diferenciable en una región cuyo interior contiene una curva suave
C:r(t) = (h1(t),. . .,hn(t)).
SiP0es un punto en Cdondeftiene un máximo (mínimo) local respecto a sus valores en la curvaC, entonces∇fes ortogonal aCenP0.
Demostración. Veamos que ∇f es ortogonal al vector de la velocidad de la cur-va C en el punto P0. Los valores de f en C están dados por la composición f(h1(t),. . .,hn(t)), derivando con respecto at obtenemos
df dt =
∂f ∂x1
dh1
dt +. . .+ ∂f ∂xn
dhn
En cualquier punto P0 donde f tiene un máximo (mínimo) local respecto a sus valores en la curva C, df
dt =0, entonces
∇f·v=0.
Consideremos ahora problemas de optimización con restricciones de desigual-dad. Sea
S={x ∈X:gi(x)60,i=1,. . .,m},
dondegi : Rn →R para i =1,. . .,m y X⊂ Rn no vacío. De esta forma, obtene-mos el siguiente problema de optimización
minimizar f(x),
sujeto a:
gi(x)60 parai=1,. . .,m, x ∈X
(5)
Observación1.2.4. Para el resto del documento, denotaremos
(i)
g1(x) 6 0 ... gm(x) 6 0 como g(x)60.
(ii)
λ1 = 0 ... λm = 0
como λ=0.
(iii)
h1(x) = 0 ... hm(x) = 0
Introduciremos ahora las Condiciones Karusch-Kuhn-Tucker para problemas de optimización convexos. La demostración de dicho Teorema puede encontrarse en [13], a continuación encontramos el enunciado.
Teorema 1.2.5 (Condiciones Karusch-Kuhn-Tucker). Supongamos (5) es un proble-ma de optimización convexo. Entonces,xˆ ∈ Xes una solución óptima si y sólo si, existe un vectorλ= (λ1,. . .,λm)∈Rm tal que
(i) ∇f(xˆ) +
m X
i=1
λi∇gi(xˆ) =0
2
M Á Q U I N A S D E S O P O R T E V E C T O R I A L2.1 aprendizaje de máquinas
El aprendizaje de Máquinas se puede entender como la habilidad de una má-quina para perfeccionarse a si misma simulando la forma en que los humanos aprendemos por medio de diferentes algoritmos. El aprendizaje de máquinas se divide en varios algoritmos, pero los dos más comunes pues han adquirido ma-yor importancia son [8]:
Aprendizaje Supervisado, donde contamos con{(xi,yi) :i =1,. . .,m}⊆X×Y un conjunto muestra previamente clasificados, donde los xi denominados entradas (los datos a clasificar) son vectores de características, y los yi de-nominados etiquetas (la clasificación) pertenecen ya sea a un conjunto dis-creto o a un conjunto continuo. Si Y = R hablamos de una regresión, y si
Y ={1, ...,n}hablamos de un problema de clasificación.
Aprendizaje No Supervisado, donde los datos no se encuentran entiquetados. Los algoritmos buscan patrones en los datos para crear una representación de ellos, que puede ser utilizada para toma de decisiones, para predecir futuras entradas, o para comunicar de forma eficiente las entradas xi a otras máquinas.
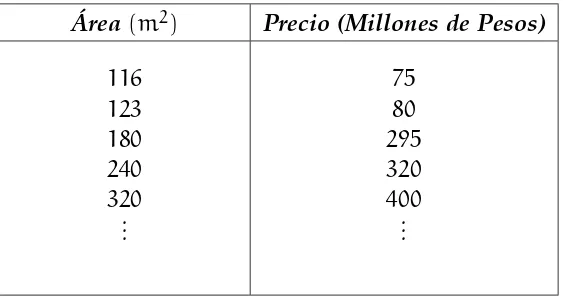
Ejemplos2.1.1. 1. Supongamos que queremos vender una casa. Sean xi ∈ X, i = 1,. . .,m las características de otras casas y sean yi ∈ Y = R, i = 1,. . .,m los precios de esas casas. Por medio de estos datos queremos determinar a qué precio podemos vender nuestra casa.
Supongamos nuestroxi es una sola característica.
Área(m2) Precio (Millones de Pesos)
116 123 180 240 320 ...
75 80 295 320 400 ...
Graficamos estos datos y realizamos una regresión (en este caso lineal) y obtenemos un precio estimado para nuestra casa de acuerdo con su área.
Figura1: Gráfica de área de las casas contra el precio, se realiza regresión lineal, con el fin de predecir a partir de ella el precio de una casa dada su área.
2. Sea Y = {0,1} Contamos con datos de tumores cancerígenos y no cancerígenos.
[image:40.595.102.384.85.234.2]Figura 2: Clasificación de tumores benignos y tumores malignos.
El algoritmo que estemos usando dividirá el plano de modo que los tumores cancerí-genos quedarán separados de los no cancerícancerí-genos. Así, cuando introduzcamos las caracterísiticas de un tumor nuevo, dependiendo de la sección del plano donde se encuentre, el algoritmo dirá si es o no cancerígeno.
Consideremos el problema de clasificación de puntos en dos conjuntos A =
{p1,. . .,pn} y B = {q1,. . .,qm}. Dicho problema es obviamente demasiado gene-ral a menos que coloquemos ciertas condiciones y cierto espacio ambiente.
Supongamos por un momento que los puntos son representables en el plano (digamos pi = (xi,yi)) y que buscamos hallar una recta que los divide. Este pro-blema resulta más sencillo pues basta con considerar las posibles ecuaciones de las rectas centradas en el origen y observar si existe una recta y una translación de dicha recta que nos permita resolver el problema.
Analicemos un poco más este procedimiento: Tomamos una función de la for-ma fm(x,y) = y−mx (un funcional lineal) y calculamos el subespacio Ker(fm). Luego procedemos a ver si existe un vector a tal que a+Ker(fm) constituye la recta buscada.
Miremos este procedimiento desde un punto de vista más abstracto: Podemos pensar en el espacio R2 como en un espacio de funciones definidas sobre el
conjunto{1,2}a valores reales. Es decir
[image:41.595.197.418.91.260.2]por medio de la identificación g ↔ (g(1),g(2)). Observemos que para cada i ∈
{1,2}se tiene que
|g(i)|6
q
(g(1))2+ (g(2))2
por lo tanto, los funcionales de evaluación γi : R2 →R definidos como γi(g) :=
g(i)son acotados.
En otras palabras, tenemos queγ1,γ2∈R2y por el Teorema de representación de Riesz, existen elementosK1 yK2 enR2tales que
γi(g) =hg,Kii.
Se puede ver fácilmente que en este caso K1 ↔ (1,0) y K2 ↔ (0,1). Esto nos dice que dichas funciones son además generadoras del espacio R2.
Si ahora observamos al funcionalfm por medio de su representación como vec-tor de R2: fm ↔ (−m,1), tenemos entonces que f = −mK1+K2 y por lo tanto
resolver el problema de hallar la recta adecuada puede ser visto como el pro-blema de hallar el hiperplano −mK1x+K2y= a dondea es cierta constante de manera que al sustituir los valores dados por los puntos iniciales del problema, nos resulte que los puntos de un conjunto estén a un lado diferente de la recta que los puntos del otro conjunto.
Es claro que este procedimiento puede no funcionar pues es posible que los puntos no puedan ser divididos por una recta. Pero entonces podríamos tratar de aumentar en cierta manera la dimensión del espacio y observar si tenemos mayores posibilidades de resolverlo.
Una forma de hacer esto es suponiendo que por ejemplo tenemos más funcio-nes del tipo de K1 y K2 con las que podemos trabajar. Digamos entonces que tenemos una familia de funciones K1,. . . Kn que forman una base de un cierto espacio vectorial V. Entonces el problema se reduce a encontrar un hiperplano de la forma
n X
i=1
αiKi(·) = C de manera que los puntos iniciales se encuentren divididos adecuadamente a cada lado del hiperplano.
Dichos funcionales son los llamados núcleos reproductivos. Explicaremos a con-tinuación cómo se desarrolla el algoritmo de máquinas de soporte vectorial antes de implementar núcleos reproductivos y posteriormente cómo se desarrolla una vez implementados.
Tomamos un conjunto de datos en X ⊂ Rn cuya clasificación es conocida (el
conjunto muestra). Supongamos que la clasificación es una clasificación binaria, y denotemos porAyBlos dos conjuntos de clasificación. SiXno es un conjunto linealmente separable, construimos una función, denominada función caracterís-tica (en inglés Feature Map) ϕ : X → H con dim(X) < dim(H), la cual envía
los vectores de nuestro conjunto muestra a un espacio de dimensión mayor, el espacio característico H (en inglés feature space). Debido a que queremos me-dir la similaridad entre los datos de muestra y los datos a clasificar, buscamos un espacio que tenga ciertas características geométricas, por lo tanto, se espera que dicha función característica envíe los datos a un espacio de Hilbert, donde por medio del producto interno caractericemos la similitud. Una vez calculadaϕ de forma explícita, separamos los datos deA y B por medio de un hiperplano, y procedemos a clasificar los datos nuevos. Los datos se clasifican midiendo la similaridad entre ellos y cada uno de los datos previamente clasificados, de la siguiente manera. Sea xi ∈ A y zi un dato a clasificar. Calculamos el producto interno
hϕ(xi),ϕ(zi)i
Después de determinar si zi pertenece a A o a B, calculamos nuevamente el hiperplano óptimo para separar aAde By posteriormente volvemos al espacio Xdonde estábamos trabajando inicialmente.
La funciónϕtiene dos problemas, primero, puede ser complicado determinar-la, y segundo, es posible quedim(H)sea muy alta, o incluso infinito.
Ejemplo2.1.2. SeaX=R2. Sea
ϕ:R2 → H=R4
(x1,x2) 7→ (x21,x22,x1x2,x2x1)
Cuando contamos con funciones de este tipo, donde miramos todos los productos ordena-dos de cierto grado, la dimensión del espacio de Hilbert estará dado por
d+n−1 d
= (d+n−1)!
d!(n−1)!
Como solución a esto, surgen los núcleos reproductivos. Utilizamos el Kernel Trick, el cual consisten en definir K(xi,zi) := hϕ(xi),ϕ(zi)i, donde K(·,·) es un núcleo reproductivo. De esta forma, no es necesario calcular ϕ y los datos son enviados por medio de K a un Espacio de Hilbert con Núcleo Reproductivo, dondeKcalculará la similitud entre los datos sin necesidad del producto interno.
2.2 máquinas de soporte vectorial
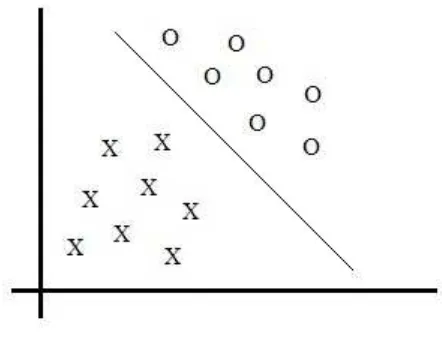
Sea Xun espacio de Hilbert, debido a que el producto interno es considerado una medida de similaridad. Sea{(xi,yi) :i =1,. . .,m}⊆X×{−1,1}un conjunto de datos linealmente separables (es decir que los datos se pueden separar por medio de un segmento de recta). Esto se denomina clasificación de datos, pues existen dos tipos de datos.
Supongamos que al graficar los datos obtenemos lo siguiente:
Figura3: Clasificación de datos linealmente separables.
Definición2.2.1. SeaH un espacio de Hilbert y seanx1,. . .,xm ∈H. Unhiperplano L en H se define como L = {x ∈ H : hw,xi+b = 0}, donde w ∈ H, b ∈ R.
Geomé-tricamente,w, el vector ponderación, es un vector perpendicular al hiperplano, ybes el
desplazamiento del hiperplano desde el origen.
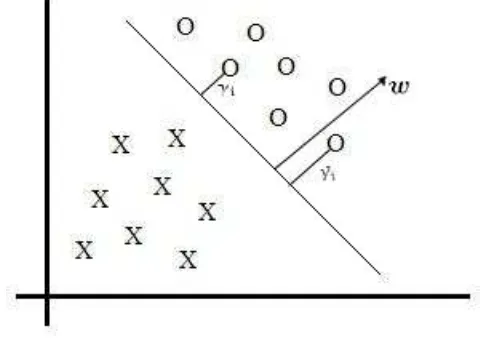
Definición2.2.2. Sea{(xi,yi) :i =1,. . .,m}un conjunto muestra de datos. Definimos elmargen funcionalde(w,b)con respecto al conjunto muestra como
ˆ
[image:44.595.159.399.342.513.2]Siγˆi> 0, esto implica que(xi,yi)se clasificó correctamente.
Dado un conjunto muestra S = {(xi,yi) : i = 1,. . .,m}, definimos el margen funcio-nal de(w,b)respecto aScomo
ˆ
γ= m´ın
i=1,...,mγˆi
Definición2.2.3. Definimos el margen geométrico γi como la menor distancia entre xi y el hiperplanoL, la cual está dada por
γi =yi
w
kwk,xi
+ b
kwk
Definimos el margen geométrico de(w,b)respecto aScomo
γ= m´ın i=1,...,mγi
Veamos el origen de esta fórmula. Sean xi un dato en el plano y xi′ un punto en el hiperplano, el cual está dado por
xi′=xi−γi
w
kwk
Ahora, comoxi′ es un punto del hiperplano,
w,x′
i
+b=0
Reemplazamos y obtenemos
w,xi−γi w
kwk
+b=0
Despejamosγi
hw,xii− γi kwkh
w,wi+b = 0 kwk(hw,xii+b)
kwk
= γikwk
2
kwk
kwk
hw,xii+b kwk
= γikwk
w
kwk,
xi
+ b
kwk
= γi
γi=yi
w
kwk,xi
+ b
kwk
. (6)
Intuitivamente, lo que queremos es que todos losxinos queden lo más lejos po-sible del hiperplano, pues de esta forma la máquina tendrá más confianza sobre su clasificación. Aquellos datos que se encuentran muy cercanos al hiperplano los llamaremos vectores de soporte. Para que los vectores de soporte estén lo más alejados posible del hiperplano, planteamos el siguiente problema de optimiza-ción:
Proposición2.2.4(Clasificador de Margen Óptimo). SeaS={(xi,yi) :i =1,. . .,m} un conjunto muestra. El hiperplano que soluciona el problema de optimización
m´ax γ,w,b
γ,
sujeto a: yi(hw,xii
X+b)>γ i=1,. . .,m
kwk=1
provee el máximo margen geométrico, y por lo tanto es un hiperplano óptimo.
Demostración. Nótese quekwk=1es una restricción no convexa, además, por (6)
γ= γˆ
kwk. Reemplazando en nuestro problema de optimización, obtenemos
m´ax ˆ
γ,w,b ˆ γ
kwk,
Sujeto a: yi(hw,xii
X+b)>γˆ i=1,. . .,m
Ahora, contamos con una restricción convexa, pero nuestro objetivo γˆ
kwk es no
convexo. Fijemos ˆγ = 1. Más aun, maximizar 1
kwk, es lo mismo que minimizar kwk2, por lo que nuestro problema de optimización se transforma en
m´ın γ,w,b
1 2kwk
2, Sujeto a: yi(hw,xii
X+b)>1 i=1,. . .,m
Con el fin de mantener la continuidad del presente trabajo, la Teoría de Dualidad de Lagrange se desarrollará en la sección2.3. Escribiremos la restricción como
gi(w) = −yi(hw,xii
X+b) +160 El Lagrangiano está dado por
L(w,b,α) = 1
2kwk 2−
m X
i=1
αi[yi(hw,xii
X+b) −1]
donde los αi > 0 son los multiplicadores de Lagrange. Hallemos la derivada parcial deLrespecto a wy a b, e igualemos a cero
∂ ∂wL(
w,b,α) =w−
m X
i=1
αiyixi =0
de la ecuación anterior obtenemos que
w=
m X
i=1
αiyixi (7)
∂
∂bL(w,b,α) = m X
i=1
αiyi =0 (8) Reemplazamos ahora (7) y (8) en el Lagrangiano
L(w,b,α) = 1
2hw,wiX− m X
i=1
[αiyihw,xii
X+bαiyi−αi]
= 1
2 * m
X
i=1
αiyixi, m X
j=1
αjyjxj +
X
−
m X
i=1 αiyi
* m X
j=1
αjyjxj,xi +
X
−b m X
i=1
αiyi+ m X
i=1 αi
= 1
2 m X
i,j=1
αiαjyiyj xi,xj
X− m X
i,j=1
αiαjyiyj xi,xj
X+ m X
i=1 αi
=
m X
i=1
αi−1
2 m X
i,j=1
αiαjyiyj xi,xj
X
m´ax
α W(α) = m X
i=1
αi−1
2 m X
i,j=1
αiαjyiyj xi,xj
X, Sujeto a:
αi>0 i =1,. . .,m m
X
i=1
αiyi =0
Supongamos ahora que α∗ denota los parámetros que resuelven el problema de optimización dual, y quew∗=
m X
i=1
α∗iyixi denota su vector ponderación debi-do a (7).
Nótese que el valor deb∗no se obtiene de resolver el problema dual, sino que se obtiene directamente del problema original y está dado por
b∗= −
m´ax i:yi=−1
hw∗,xii+ m´ın
i:yi=1
hw∗,xii
2
Ahora bien, las condiciones KKT, establecen que las soluciones óptimasα∗,(w∗,b∗)
deben satisfacer
α∗i[yi(hw∗,xii+b∗) −1] =0, i=1,. . .,m
Esto implica que sólo para entradasxi, para las cuales el margen funcional es igual a 1, los α∗i son distintos de cero. Así, sólo estas entradas son tenidas en cuenta para calcular el vector ponderación w∗, y son los puntos que
denomina-mosvectores de soporte.
Finalmente, el hiperplano óptimo en la representación dual está dado en tér-minos de esos vectores de soporte
f(x,α∗,b∗) =
m X
i=1
yiα∗ihxi,xi+b∗= X
i∈sv
yiα∗ihxi,xi+b∗
dondesvdenota el conjunto de los índices de los vectores de soporte.
Teorema 2.2.5 (Teorema de Mercer). Sea K : X×X → R continuo. K es un núcleo
reproductivo definido positivo enXsi y sólo si Z
X Z
X
K(x,x′)f(x)f(x′)dxdx′>0
para toda funciónf∈L2(X,µ). Dondeµes la medida de Lebesgue [22].
Demostración. ⇒)Parafcontinua, la suma de Riemann satisface X
ij
K(xi,xj)f(xi)f(xj)µ(Ei)µ(Ej)>0
Nótese que la integral del enunciado es el límite de dichas sumas y por lo tanto es no negativa. Para f ∈ L2(X,µ), aproximamos f con una función continua y obtenemos el resultado.
⇐)Supongamos que
n X
i,j=1
cicjK(zi,zj) = −δ > 0
ComoKes continua, existe un entorno abierto Ui dexi tal que n
X
i,j=1
cicjK(zi,zj)6
−δ 2
para todo zi ∈Ui. Es posible aproximar con una función continuafa X
i ci µ(Ui)
IUi.
2.3 dualidad de lagrange
Consideremos el siguiente problema de optimización
minimizar f(x),
sujeto a:
gi(x)60 parai =1,. . .,m, hi(x) =0 parai =1,. . .,l x∈X
(9)
Éste será denominado el problema original. El problema dual de Lagrange, se define de la siguiente manera
maximizar θ(u,v),
sujeto a: u>0
(10)
donde
θ(u,v) =´ınf
f(x) +
m X
i=1
uigi(x) + l X
i=1
vihi(x) :x∈X
(11)
es laFunción Dual de Lagrange, donde los vectores u y v, tienen como compo-nentesuiparai =1 . . .,myvi parai=1 . . .,la los multiplicadores de Lagrange. Nótese que los multiplicadores de Lagrange ui correspondientes a las restriccio-nes de desigualdad gi(x) 6 0 deben ser no negativos; mientras que los multi-plicadores de Lagrange vi de las restricciones de igualdad hi(x) = 0, no tienen restricción en el signo.
Dado un problema original, existen varios problemas duales de Lagrange, de-pendiendo de cuáles restricciones son dadas por gi(x) 6 0 y hi(x) = 0 y cuales son dadas por el conjuntoX. Debido a esto,Xdebe tomarse de manera apropiada, teniendo en cuenta qué es lo que quiere obtenerse de la solución del problema dual.
Es posible escribir los problemas original y dual de manera vectorial. Consi-deremos f : Rn → R, y consideremos también g : Rn → Rm y h : Rn → Rl.
minimizar f(x),
sujeto a: g(x)60 h(x) =0 x ∈X
(12)
y el problema dual como
maximizar θ(u,v),
sujeto a: u>0
(13)
donde
θ(u,v) =´ınff(x) +u⊤g(x) +v⊤h(x) :x ∈X
A continuación estudiaremos la relación entre los problemas original y dual de Lagrange. Para estudiar la interpretación geométrica de la dualidad de La-grange, consideremos un problema original más sencillo, que contenga una sola restricción de desigualdad y ninguna de igualdad
minimizar f(x),
sujeto a: g(x)60 x ∈X
(14)
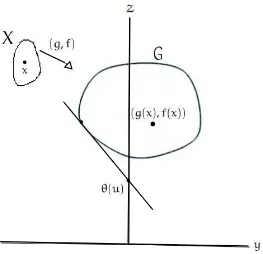
dondef:Rn →R, g:Rn→R y definimos el siguiente conjunto G⊂R2 como
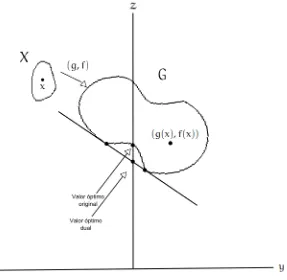
G={(y,z) :y=g(x),z=f(x)para algúnx ∈X} (15) esto es,Ges la imagen deX, bajo el mapa(g,f). El problema original, consiste en
Figura4: Interpretación geométrica de la Dualidad de Lagrange, cuando no existe brecha dual.
Consideremos ahora el problema dual
maximizar θ(u),
sujeto a: u>0
(16)
Para solucionar el problema dual de Lagrange, debemos considerar primero el problema subyacente
θ(u) =´ınf{f(x) +ug(x) :x ∈X} (17) Si tomamos u > 0, (17), es equivalente a minimizar z+uy sobre los puntos
(y,z) deG. Sea z+uy = α, la ecuación de una recta, con pendiente −uy cuya intersección con el eje z es α. Geométricamente, minimizar z+uy = α signifi-ca bajar la recta tanto como sea posible (de forma paralela), de modo que siga interceptando a G. Nótese que después de minimizar dicha recta, el punto de intersección con el ejez, es precisamenteθ(u), dado u>0. Así, para cada u>0,
obtenemos un θ(u); resolver el problema de optimización dual, es
precisamen-te tomar el más grande de todos los θ(u) obtenidos del problema subyacente.
[image:52.595.156.419.85.339.2]como del problema dual, son iguales. Cuando esto ocurre, decimos que no existe brecha dual (en inglés Dual Gap).
En general, queremos que tanto el problema original, como el problema dual tengan la misma solución. Introduciremos algunas hipótesis, de modo que no vaya a haber brecha dual. Para esto, presentamos dos teoremas, el Teorema de la Dualidad Débily posteriormente elTeorema de la Dualidad Fuerte.
Figura5: Interpretación geométrica de la Dualidad de Lagrange, cuando se presenta bre-cha dual.
Teorema2.3.1(Teorema de la Dualidad Débil). Consideremos el problema de optimi-zación original(12), y su problema dual(13). Sea x una solución del problema original, esto esx ∈ X, g(x) 6 0y h(x) = 0. Sea(u,v) solución del problema dual, con u > 0. Entonces
f(x)>θ(u,v)
Demostración. Recordemos, por (11) que la función dual de Lagrange está dada por
θ(u,v) =´ınf
f(x) +
m X
i=1
uigi(x) + l X
i=1
[image:53.595.175.462.205.485.2]además, tenemos quex ∈X, u>0,g(x)60yh(x) =0, luego
θ(u,v) = ´ınff(xˆ) +u⊤g(xˆ) +v⊤h(xˆ) :xˆ ∈X
6 f(x) +ug(x) +vh(x)
6 f(x)
Corolario2.3.2. Con la notación del Teorema2.3.1, se cumple la siguiente desigualdad
´ınf{f(x) :x∈X,g(x)60,h(x) =0}>sup{θ(u,v) :u>0} (18)
Por el Corolario anterior, podemos ver que el valor óptimo del problema origi-nal, es mayor o igual que el valor óptimo del problema dual. Cuando la desigual-dad es estricta, decimos que existe una brecha dual, entre ambos problemas. En la siguiente figura, vemos un ejemplo de un problema de optimización, donde existe una brecha dual entre el problema original y el problema dual. Nótese que la brecha dual depende de que G sea o no convexo, por lo tanto, bajo ciertas condiciones de convexidad, que veremos en el Teorema de la Dualidad Fuerte, la solución tanto del problema de optimización original como del problema de op-timización dual es la misma. A continuación veremos un lema, necesario para el Teorema de la Dualidad Fuerte.
Lema 2.3.3. Sea X subconjunto no vacío, convexo de Rn. Sean ψ : Rn → R y
g : Rn → Rm funciones convexas, y sea h : Rn → Rl una función afín, i.e. una
función de la formah(x) = Ax+b. Sean tambiénu0 ∈R, u∈Rm yv ∈Rl. Conside-remos los siguientes sistemas:
Sistema1:
ψ(x) < 0 g(x) 6 0 h(x) = 0
para algúnx∈X.
Sistema2:
Si el Sistema1no tiene solución x, entonces el Sistema2tiene solución(u0,u,v). De
manera inversa, si el Sistema2tiene solución(u0,u,v), conu0> 0, entonces el Sistema
1no tiene solución.
Demostración. Supongamos primero que el Sistema 1 no tiene solución. Defini-mos el siguiente conjunto:
S={(p,q,r) :ψ(x)6p,g(x)6q,h(x) =r, para algúnx∈X} Ses convexo. En efecto, sean(p1,q1,r1), (p2,q2,r2)∈S. Veamos que
(p1,q1,r1)t+ (1−t)(p2,q2,r2)∈S parat∈[0,1]
Queremos ver que
p1t+ (1−t)p2 > ψ(x), q1t+ (1−t)q2 > g(x),
r1t+ (1−t)r2 = h(x). Sit =0
p2 > ψ(x),
q2 > g(x), r2 = h(x). Sit =1
p1 > ψ(x),
q1 > g(x),
r1 = h(x).
Ahora bien, como el Sistema1 no tiene solución,(0,0,0)∈/ S
y dado queSes convexo, existe un vector no cero(u0,u,v)tal que,
(u0,u,v)⊤[(p,q,r) − (0,0,0)] =u0p+u⊤q+v⊤r>0, (19) para cada (p,q,r) ∈ cl(S). Sea x ∈ X fijo. Por la definición de S, p,q pueden tomarse arbitrariamente grandes, luego u0 > 0 y u > 0, de forma que (19) se
satisfaga. Veamos que(ψ(x),g(x),h(X))∈cl(S). Sea
una bola abierta en R3. Sea (a,b,c) ∈ Bε(ψ(x),g(x),h(x)), con a = ψ(x) +ε/2,
b = g(x) y c = h(x), como ε > 0, (a,b,c) ∈ S, luego (ψ(x),g(x),h(X)) ∈ cl(S).
Así,
u0ψ(x) +u⊤g(x) +v⊤h(x)>0.
Como esto se tiene para cualquier x∈X, el Sistema2, tiene solución.
Supongamos ahora que el Sistema2tiene una solución(u0,u,v), tal queu0>0,
u>0yu0ψ(x) +u⊤g(x) +v⊤h(x)>0para todox ∈X. Seax ∈Xtal queg(x)60 y h(x) =0. Luego
u0ψ(x) +u⊤g(x) > 0 u0ψ(x)>−u⊤g(x) > 0
pues u > 0 y g(x) 6 0. Pero u0 > 0, luego necesariamente ψ(x) > 0, y por lo
tanto el Sistema1no tiene solución.
Finalmente, el siguiente teorema nos dice que bajo ciertos supuestos de con-vexidad, no existe brecha dual entre el problema de optimización original y el problema de optimización dual.
Teorema2.3.4(Teorema de la Dualidad Fuerte). SeaXsubconjunto no vacío, convexo de Rn. Sean f : Rn → R y g : Rn → Rm funciones convexas, y h : Rn → Rl una
función afín. Supongamos que se cumple la siguiente restricción. Existe x¯ ∈ X tal que g(x¯)< 0yh(x¯) =0, con0∈int(h(X)), dondeh(X) ={h(x) :x ∈X}. Entonces,
´ınf{f(x) :x∈X,g(x)60,h(x) =0}=sup{θ(u,v) :u>0} (20) donde θ(u,v) = ´ınf{f(x) +u⊤g(x) +v⊤h(x) : x ∈ X}. Más aun, si el ínfimo es finito, entoncessup{θ(u,v) :u>0}, es alcanzado en(u, ˆˆ v)conuˆ >0. Si el ínfimo es alcanzado enxˆ, entoncesuˆ⊤g(xˆ) =0.
Demostración. Seaα=´ınf{f(x) :x ∈X,g(x)60,h(x) =0}. Por hiótesis, existe una solución del problema original ¯xy por lo tanto,α < ∞. Siα= −∞, entonces por
el Corolario2.3.2, sup{θ(u,v) : u> 0}= −∞ y por lo tanto, (20) se satisface. Así,
podemos suponer que αes finito. Consideremos el siguiente sistema f(x) −α(x) < 0,
g(x) 6 0,
h(x) = 0
para algún x ∈ X. Este sistema no posee solución debido a la definición de α. Luego por el Lema2.3.3, existe un vector (u0,u,v)distinto del cero, con(u0,u)>
(0,0) tal que
Veamos ahora que u0 > 0. Supongamos u0 = 0. Por hipótesis, existe ¯x ∈ X, tal
que g(x¯)< 0 yh(x¯) =0. Sustituyendo en (2.3), obtenemos que u⊤g(x¯) >0, pero
como g(x¯) < 0 y u > 0, entonces u = 0. Ahora, u0 = 0 y u = 0, por lo tanto v⊤h(x) > 0para todo x ∈ X. Como 0 ∈ int(h(x)), podemos escoger unx ∈X tal queh(x) = −λv, conλ > 0. Sustituimos para obtener06v⊤h(x) = −λkvk2, como
λ > 0 y kvk2 > 0, entonces esto implica que v = 0. En consecuencia, si u 0 = 0, entonces(u0,u,v) = (0,0,0)lo que es una contradicción. Así,u0> 0.
Ahora bien, sean ˆu=u/u0 y ˆv=v/v0. Dividiendo (2.3) entreu0, obtenemos f(x) +uˆ⊤g(x) +vˆ⊤h(x)>α para todo x∈X. (21) Así,
θ(u, ˆˆ v) =´ınf{f(x) +uˆ⊤g(x) +vˆ⊤h(x) :x∈X}>α.
Por el Teorema de la Dualidad Débil,θ(u, ˆˆ v) = α, y por el Corolario 2.3.2 (u, ˆˆ v)
es solución del problema dual.