COLEGIO DE POSTGRADUADOS
INSTITUCIÓN DE ENSEÑANZA E INVESTIGACIÓN EN CIENCIAS AGRÍCOLAS
CAMPUS MONTECILLO
POSTGRADO DE SOCIOECONOMÍA, ESTADÍSTICA E INFORMÁTICA ESTADÍSTICA
PRUEBA DE BONDAD DE AJUSTE PARA LA
DISTRIBUCIÓN PARETO, BASADA EN LA
INFORMACIÓN DE KULLBACK-LEIBLER
ANA CELIA LUQUE GUERRERO
T E S I S
PRESENTADA COMO REQUISITO PARCIAL
PARA OBTENER EL GRADO
DOCTOR EN CIENCIAS
MONTECILLO, TEXCOCO, ESTADO DE MÉXICO
RESUMEN
PRUEBA DE BONDAD DE AJUSTE PARA LA DISTRIBUCIÓN PARETO,
BASADA EN LA INFORMACIÓN DE KULLBACK-LEIBLER
Ana Celia Luque Guerrero, Dr.
Colegio de Postgraduados, 2007
En este trabajo se presenta una prueba de bondad de ajuste para la distribución Pareto basada en la información de discriminación de Kullback-Leibler (1951) propuesta por Sheng Song (2002). Considerando que la distribución Pareto, no presenta el parámetro de escala, se aplicó la transformación logaritmo a esta distribución obteniendo como resultado la distribución Exponencial de dos parámetros, la cual es una distribución de localización y escala (Lehman y Casella, 1998). Se comprobó que la estadística de prueba de Kullback-Leibler es invariante. Se aplicó la metodología que propone Song, la cual se basa en los espacios m’ésimos entre estadísticas de orden validados por la log verosimilitud. El cálculo de m se obtuvo a través de Simulación Monte Carlo . También mediante un experimento de Simulación Monte Carlo se calculó el poder de la prueba de Kullback-Leibler propuesta, la cual se comparó con el poder de la prueba de bondad de ajuste de Kolmogorov-Smirnov considerando las distribuciones, Lognormal, Weibull y Gamma como alternativas a la distribución Pareto. Con respecto al tamaño de la prueba, los resultados obtenidos por medio de simulación son muy parecidos a los valores α que se consideraron, confirmando que la prueba trabaja adecuadamente. Como conclusión más importante, se observó que la prueba de Kullback-Leibler resultó ser más poderosa que la prueba de Kolmogorov-Smirnov. Todos los cálculos se hicieron en lenguaje R.
ABSTRACT
GOODNESS-OF-FIT TEST FOR PARETO DISTRIBUTION, BASED ON
KULLBACK-LEIBLER INFORMATION
Ana Celia Luque Guerrero, Dr.
Colegio de Postgraduados, 2007
This paper presents a goodness-of-fit test for Pareto distribution based on the Kullback-Leibler (1951) discrimination information, as proposed by Sheng Song (2002). By considering the fact that Pareto distribution does not present the scale parameter, the logarithm transformation was used. As a result, a exponential distribution with location parameter was obtained, which is a localization and scale distribution (Lehman and Casella, 1998). It was proven that Kulback-Leibler test statistic is invariant. The methodology proposed by Song was used, which is based on mth-order spaces among order statistics validated by loglikelihood. The calculus of m was obtained through Monte Carlo Simulation. Additionally, the power of the proposed Kullback-Leibler test was also estimated. This was then compared to the Kolmogorov-Smirnov goodness-of-fit test by considering the Lognormal, Weibull and Gamma distributions as alternatives to Pareto distribution. With regard to the size of the test, the results obtained are quite similar to the
α values considered. This confirmed the adequate function of the test. It was observed, as the most remarkable conclusion, that the Kullback-Leibler test was more powerful that the Kolmogorov-Smirnov one
.
DEDICATORIA
A MIS PADRES
BLAS LUQUE Y CELIA GUERRERO, quienes con su gran ejemplo y apoyo
me impulsaron constantemente con mucho amor, motivando mi superación.
Papi, sintiendo siempre tu presencia y tu protección desde cualquier lugar que te encuentres. Con mis mejores recuerdos para ti…- Siempre conmigo, siempre contigo-
A MI ESPOSO
LOMBARDO, mi compañero y amigo. Afortunadamente tuve y tengo la dicha de recorrer este camino y lo hago contigo, compartiendo momentos difíciles y muchos otros más, felices y gratificanes.
A MIS HIJAS
AGRADECIMIENTOS
Alcanzar el objetivo de obtener un Doctorado en Ciencias es el mejor momento para dar las Gracias a todas las personas que me apoyaron y me ayudaron a través de estos años satisfactorios, pero también difíciles.
En primer lugar, expreso mi agradecimiento y reconocimiento al Dr. Humberto Vaquera Huerta, por su claridad, interés y entusiasmo, que orientó y motivó en todo momento mi proceso formativo; desde mi ingreso al doctorado hasta la dirección de esta tesis; investigación que presento con gran satisfacción y que complementa de manera importante mi formación como Estadística.
Agradezco de manera sensible a uno de los profesores que más he admirado desde que conocí el mundo de la Estadística, al Dr. Ignacio Méndez Ramírez, quien junto con su esposa Lupita me han brindado el privilegio de su amistad, e innumerables atenciones que motivaron mi pasión por el conocimiento estadístico.
A mis asesores Dr. Gilberto Rendón Sánchez, Dr. Vicente González Romero y Dr. Enrique Villa Diharce, por compartir conmigo su experiencia, sabiduría y fraterna compañia.
A mis sinodales Dr. Sergio Pérez Elizalde y Dr. David del Valle Paniagua, de quienes siempre recibí respaldo y atenciones como estudiante, y en la última parte de mi tesis, por sus sugerencias, de gran valor.
A todos mis profesores del Instituto de Socioeconomía, Estadística e Informática Estadística del Colegio de Postgraduados, por su gran apoyo y enseñanza comprometida.
A todo el personal del Instituto de Socioeconomía, Estadística e Informática Estadística del Colegio de Postgraduados por su gran comprensión y sincera amistad.
A las autoridades del Instituto Politécnico Nacional en especial al Dr. Enrique Villa Rivera, Director General del I.P.N., visionario que en todo momento impulsa y alienta la superación académica de todo el personal del Instituto.
Al Dr. Luis Humberto Fabila Castillo, Secretario de Investigación y Postgrado del I.P.N, por su respaldo y motivación para seguir adelante, hasta culminar exitosamente esta etapa.
Al Dr. Adrián Luis García García, ex Director del CICATA, Unidad Querétaro, quien alentó y apoyo en todo momento mi proceso formativo.
A mis compañeros del CICATA Unidad Querétaro, por su amistad y apoyo solidario.
Al Comité Técnico de Prestaciones a Becarios del IPN (COTEPABE), a la Comisión de Operación y Fomento de Actividades Académicas del IPN (COFAA), y al CONACyT, por el importante apoyo complementario que recibí, a través de permisos, beca y reconocimiento de mis estudios.
A mis compañeros de estudios tanto de Maestría como de Doctorado de Estadística, con quienes compartí muchos momentos especiales y emotivos. Mi especial agradecimiento a Paulino Pérez Rodríguez y a Hortensia Reyes Cervantes.
A todos los amigos con quienes tuve oportunidad de estudiar y convivir durante este tiempo. Gracias
CONTENIDO
1. INTRODUCCIÓN ... 1
2. OBJETIVOS ... 4
3. MARCO TEÓRICO ... 5
3.1 DISTRIBUCIÓN PARETO ... 5
3.1.1 REGLA 80/20 ... 5
3.1.2 DEFINICIÓN DE LA DISTRIBUCIÓN PARETO ... 6
3.1.3 ESTIMADORES DE MÁXIMA VEROSIMILITUD DE LA DISTRIBUCIÓN PARETO ... 8
3.1.4 OTRAS APLICACIONES DE LA DISTRIBUCIÓN PARETO ... 9
3.2 CONCEPTOS DE LA TEORÍA DE LA INFORMACIÓN ... 9
3.2.1ENTROPÍA ... 10
3.2.2MEDIDAS DE ENTROPÍA ... 10
3.2.3UNIDADES DE ENTROPÍA ... 11
3.2.4ENTROPÍA DE SHANNON PARA UNA VARIABLE CONTINUA ... 12
3.2.5ESTIMADOR NO PARAMÉTRICO DE ENTROPÍA ... 12
3.3DISCREPANCIA INTRÍNSECA ... 13
3.3.1MEDIDA DE DIVERGENCIA. DIVERGENCIA DE KULLBACK-LEIBLER ... 13
3.3.2LA ENTROPÍA Y LA DIVERGENCIA DE KULLBACK-LEIBLER ... 14
3.4 PODER O POTENCIA DE UNA PRUEBA... 14
3.5 PRUEBA DE HIPÓTESIS Y TAMAÑO DE LA PRUEBA... 15
4. PRUEBA DE BONDAD DE AJUSTE PARA LA DISTRIBUCIÓN PARETO, BASADA EN LA INFORMACIÓN DE KULLBACK-LEIBLER ... 17
4.1PLANTEAMIENTO DEL PROBLEMA ... 17
4.2TRANSFORMACIÓN DE LA DISTRIBUCIÓN PARETO ... 17
4.3CONSTRUCCIÓN DE LA PRUEBA ... 18
4.4.IMPLEMENTACIÓN DE LA PRUEBA ... 19
5.ESTIMACIÓNDELPODERDELAPRUEBA ... 21
5.1DISTRIBUCIÓN EMPÍRICA DEL ESTADÍSTICO DE PRUEBA DE KULLBACK-LEIBLER ... 21
5.2ESTIMACIÓN DEL PODER DE LA PRUEBA. ... 22
5.3PRUEBA DE KULLBACK-LEIBLER CON LAS DISTRIBUCIONES ALTERNATIVAS ... 22
5.3.1VALORES CRÍTICOS ... 23
5.4PRUEBA DE KOLMOGOROV-SMIRNOV ... 25
6.EJEMPLOSDEAPLICACIÓNDELAPRUEBADEKULLBACK-LEIBLER ... 27
7.DISCUSIÓN DE LOS RESULTADOS ... 28
8.CONCLUSIONES ... 30
9. LITERATURA CITADA ... 31
ANEXOS ... 34
ANEXO A PROGRAMA EN R PARA REALIZAR LA PRUEBA DE BONDAD DE AJUSTE ... 34
ANEXO B TABLAS VALORES CRÍTICOS CMNα DE LA ESTADÍSTICA KLMN ... 44
ANEXO C TABLAS DE LA ESTIMACIÓN DE LA POTENCIA... 48
LISTA DE FIGURAS
FIGURA 1. FORMA DE LA DISTRIBUCIÓN DE LA ESTADÍSTICA KLmn ... 21
LISTA DE TABLAS
TABLA1.VALORES CRÍTICOS Cmnα DE LA ESTADÍSTICA KLmn.TABLA RESUMIDA ... 24TABLA2.VALORES CRÍTICOS D DE LA ESTADÍSTICA DE KOLMOGOROV_SMIRNOV ... 26
TABLA3.TIEMPOS DE FALLA ... 27
TABLA4.VALORES CRÍTICOS Cmnα DE LA ESTADÍSTICAKLmn ,α=0.01 ... 43
TABLA5.VALORES CRÍTICOS Cmnα DE LA ESTADÍSTICAKLmn ,α=0.025 ... 44
TABLA6.VALORES CRÍTICOS Cmnα DE LA ESTADÍSTICA KLmn,α=0.05 ... 45
TABLA7.VALORES CRÍTICOS Cmnα DE LA ESTADÍSTICA KLmn,α=0.10 ... 46
TABLA8. POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=10,α =0.10 ... 47
TABLA9. POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=10, α =0.05 ... 47
TABLA10. POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=10, α =0.01 ... 48
TABLA11. POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=30, α =0.10 ... 48
TABLA12. POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=30, α =0.05 ... 49
TABLA13. POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=30, α =0.01 ... 49
TABLA14. POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=50, α =0.10 ... 50
TABLA15. POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=50, α =0.05 ... 50
TABLA16. POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=50, α =0.01 ... 51
TABLA17.POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=100,α =0.10 ... 51
TABLA18.POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=100,α =0.05 ... 52
TABLA19.POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=100,α =0.01 ... 52
TABLA20.POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=200,α =0.10 ... 53
TABLA21.POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=200,α =0.05 ... 53
TABLA22.POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=200,α =0.01 ... 54
TABLA23.POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=225,α =0.10 ... 54
TABLA24.POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=225,α =0.05 ... 55
TABLA25.POTENCIA DE KOLMOGOROV-SMIRNOV Y KULLBACK-LEIBLER PARA N=225,α =0.01 ... 55
TABLA26.ESTIMACIÓN DEL TAMAÑO DE LA PRUEBA DE BONDAD DE AJUSTE DE KULLBACK-LEIBLER ... 56
1. INTRODUCCIÓN
Desde el punto de vista estadístico, probar si las especificaciones de un modelo
son las adecuadas es extremadamente importante. La validez de los
procedimientos inferenciales dependen en gran parte de la suposición de que una
distribución de datos en particular, sea la correcta.
Se han desarrollado muchos procedimientos para determinar si una variable
aleatoria pertenece a una distribución específica. Todos estos procedimientos se
conocen como “pruebas de bondad de ajuste”.
En este trabajo se presenta el caso de una prueba de bondad de ajuste para la
distribución Pareto, basada en la información de discriminación de
Kullback-Leibler (1951), propuesta por Song (2002).
Para la distribución Pareto se han publicado varios estudios de bondad de ajuste,
entre ellos se tienen los de Porter III y cols. (1992), quienes utilizaron pruebas
modificadas de Kolmogorov-Smirnov, Anderson Darling y Cramer-von Mises.
También Beirlant, de Wet y Goegebeur (2005, 2006), aplicaron pruebas de
bondad de ajuste para la distribución Pareto, modificando la estadística de
Jackson originalmente propuesta para probar exponencialidad.
Estudios relacionados con el uso de la información de Kullback-Leibler en
pruebas de bondad de ajuste, los realizaron Arizono y Ohta (1989), aplicándola s
en una prueba de normalidad, Ebrahimi et al (1992,) y Ebrahimi (1998)
publicaron resultados sobre pruebas de exponencialidad de vida residual, también
basándose en esta información de discriminación de Kullback-Leibler, Senoglu y
Sürücü (2004), hicieron pruebas de bondad de ajuste para probar normalidad,
exponencialidad y uniformidad. Utilizando la misma prueba, Pérez, Vaquera y
Villaseñor (2005), la aplican con la distribución Gumbel y Park (2005), aplicó la
prueba de Kullback-Leibler para exponencialidad considerando datos censurados
Las áreas de aplicación de la distribución Pareto, incluyen la Economía, en donde
se utiliza para calcular riesgos y obtener información de valores extremos mínimos
en finanzas y seguros, en esta especialidad se le conoce con el nombre de
Distribución Bradford, se aplica también en investigación de operaciones (Porter
III and et al, 1992)
Lawless (1982), Meeker & Escobar (1998), Wu & Chang (2003) y Balakrishnan y
cols. (2004) la han considerado en estudios de tiempos de vida en experimentos
con censura Tipo II. Este tipo de censura, se refiere al caso en el que de un total
de n unidades que se ponen a prueba, ésta finaliza al tiempo en el que la m-ésima
unidad falle (1≤m≤n). De esta forma, la muestra censurada Tipo II, tiene solo las m
observaciones más pequeñas en una muestra aleatoria de n unidades.
Si la distribución Pareto se utiliza en términos de función de sobrevivencia (1-F),
se aplica de esta forma en disciplinas como confiabilidad, telecomunicaciones,
finanzas, seguros, estudios ambientales, geológicos y climatológicos.
Se tienen algunas referencias relacionadas con la distribución Pareto en estudios
en confiabilidad, como el de Ouyang y Wu (1994) quienes publicaron resultados
sobre intervalos predicción para observaciones ordenadas en estudios de pruebas
de vida; también el trabajo de Wu y Chang, (2003) trata sobre inferencia de la
distribución Pareto, basada en censura progresiva tipo II con retiros aleatorios. D.
Hanagal (1996a, 1996b) publicó diferentes estudios de estimación en sistemas de
confiabilidad bajo la distribución Pareto bivariada y otros resultados con la
distribución Pareto multivariada.
En el tema de estimación, se tiene la publicación de K. Vannman (1976), en
donde presenta estimadores basados en las estadísticas de orden de una
distribución Pareto. B. Arnold (1983,1989) también ha estudiado desde el punto
de vista bayesiano esta distribución, realizando estudios de estimación y
En la sección 4 se presenta el procedimiento de prueba de bondad de ajuste de
Kullback-Leibler, sin embargo, considerando que la distribución Pareto, no
presenta el parámetro de escala, se requirió aplicar la transformación logaritmo a
la distribución Pareto, obteniendo como resultado la distribución exponencial
recorrida, la cual es una distribución de localización y escala.
Con esta transformación, se aplicó la metodología metodología propuesta por
Song (2002), en la que desarrolla una prueba de bondad de ajuste con la
información de discriminación de Kullback-Leibler. Se calcularon los valores
críticos de Cmnα de la estadísticaKLmn y considerando que su distribución no
depende de los parámetros de localidad y escala, se aplicó la simulación Monte
Carlo. Se consideraron los niveles de significancia α =0.1, 0.025, 0.05 y 0.01,
tamaños de muestra de n=20 a 200 con separación de diez unidades entre un
calculo y otro y se generaron B=5,000 muestras aleatorias de tamaño n,
posteriormente, se calculó la estadística de pruebaKLmnpara cada m<n/ 2. El valor de Cmn( )α para cada m y n se determinó con el cuantil ( −1 α)x100 de la distribución empírica deKLmn.
En la sección 5 mediante simulación Monte Carlo se comparó el poder de las
pruebas de Kullback-Leibler propuesta y de Kolmogorov-Smirnov, se utilizaron las
distribuciones Gamma, Weibull y lognormal, como alternativas, y las tres pruebas
de bondad de ajuste se realizaron con los niveles de significancia de α =0.1, 0.05
y 0.01, tamaños de muestra de n=10, 30, 50, 100, 200 y 225 y se generaron =
B 5,000 muestras aleatorias para cada combinación deα y n, posteriormente,
se calculó el valor de la estadística correspondiente para cada una de las
pruebas.
El tamaño de prueba, resultó conveniente para diferentes tamaños de muestra, a
2. OBJETIVOS
2.1 Objetivo General
• Obtener una prueba de bondad de ajuste para la distribución Pareto, utilizando la distancia de Kullback-Leibler.
2.2 Objetivos Particulares
• Obtener los valores críticos de bondad de ajuste para la distribución Pareto considerando diferentes niveles de significancia y diferentes tamaños de
muestra obteniendo la tabla de valores críticos.
• Conocer el comportamiento de la prueba estudiada con respecto a su tamaño.
• Hacer la comparación de potencia y tamaño de la prueba de bondad de ajuste utilizando la distancia de Kullback-Leibler con la de Kolmogorov
Smirnov, aplicándolas con las distribuciones alternativas, Weibull, Gamma,
VILFREDO PARETO
July 15, 1848-August 19, 1923
3. MARCO TEÓRICO
3.1 Distribución PARETO
El nombre de ésta distribución es dado en honor al economista y sociólogo
italiano, Vilfredo Pareto (1848-1923), quien fue uno de los líderes de la llamada
Escuela de Lausanne, fundada por León Walras en el siglo XIX. Antes de que
Pareto cambiase su dirección política (hacia ideas del tipo de las de Sorel y
Mussolini), en su "Cours d'Économie Politique" publicado en 1896 y 1897,
presentó una exposición de la llamada Ley de Pareto de la distribución del
ingreso, ( Bouchaud, 2000)
Pareto, argumentó que en todos los países y épocas, la distribución de la riqueza
sigue un patrón regular logarítmico capturado en imágenes como una "cola" - en
cuyo extremo derecho, una pequeña fracción de la población es dueña de la
mayoría de la riqueza. Por ejemplo, en los Estados Unidos, 300 mil personas
(menos del 1,5%) posee el 10% de la riqueza. Bouchaud, (2000) indica que, la ley
de Pareto, sólo describe la cola de la distribución correspondiente a grandes
ingresos/riquezas como las que se encuentran empíricamente. Sin embargo este
concepto no se puede aplicar sobre la totalidad de la distribución.
3.1.1 Regla 80/20
La regla mide el porcentaje de desequilibrio entre la entrada y la salida. El
para muchos aspectos de la vida. Uno de los ejemplos en negocios más usado
comúnmente es cuando el 80 por 100 de beneficio de una compañía es generado
por el 20% de sus clientes.
Johnson & Kotz (1970), indican que la Ley de Pareto, se formuló para estudiar la
distribución del ingreso en una población utilizando la siguiente expresión
(conservando la notación original): α
−
= Ax
N
(3.1)
donde N es el número de personas que tienen un ingreso ≥x y A, ! son
parámetros (! es el parámetro de forma y también es conocida como la constante de Pareto).
3.1.2 Definición de la distribución Pareto
Johnson & Kotz (1970), indican que la forma de la distribución Pareto es la
siguiente:
[
]
−η = ≥ = x k x X xP( ) Pr k>0, η >0, x>k (3.2)
DondeP(x) es la probabilidad de que el ingreso sea igual o mayor a x y k
representa el ingreso mínimo. Como una consecuencia de (3.1), la función de
distribución acumulada de X, representando al “ingreso” puede escribirse como
η − − = x k x
Fx( ) 1 k>0, η >0, x>k
(3.3)
Esta distribución es una forma especial Pearson Tipo VI
La relación dada por (3.2) es ahora mejor conocida como “Distribución Pareto de
primera clase”.
Pareto propuso otras dos formas de la distribución. Una se refiere a la
“Distribución Pareto de segunda clase” (en ocasiones llamada distribución Lomax)
y está dada por
η ) ( 1 ) ( 1 C x K x Fx + −
= (3.4)
La otra distribución propuesta por Pareto es la “Distribución Pareto de tercera
clase” la cual tiene la siguiente función de distribución acumulada
θ ) ( 1 ) ( 2 C x e k x F bx x + −
= − (3.5)
Considerando la función de distribución en (4.2), se tiene la correspondiente
función de densidad Pareto
; )
( = k+1 k
x
x k x
p η k>0, x≥η ≥0, (3.6)
donde x es cualquier número más grande que η, el cual es (necesariamente
positivo), y k es un parámetro positivo.
La distribución Pareto también se le conoce como distribución Zeta o Ley de Zipf,
como la contraparte discreta de la distribución Pareto.
El valor esperado de una variable aleatoria que sigue una distribución Pareto es
1 ) ( − = k k X
E η k >1 (3.7)
(como k es un parámetro positivo, si se tuviera k ≤1, el valor esperado sería infinito).
Su desviación estándar es
2 1 − − = k k k η
σ k >2 (3.8)
(siguiendo la misma condición del comentario anterior si k ≤2, la desviación estándar sería infinita).
Los momentos originales se pueden calcular mediante la siguiente expresión
n k k n n − = ′ η
pero los momentos están definidos solo para k>n. Esto significa que la función
generadora de momentos, la cual es una serie de Taylor, en x con
! n
µ′ como
coeficientes, no está definida.
La función característica está dada por
) , ( ) ( ) , /
(t kη k iηt k k iηt
ϕ = − Γ − −
donde Γ(a,x)es la función gama incompleta.
Otras características matemáticas de la distribución Pareto son:
Esta distribución Pareto está relacionada con la distribución exponencial de la
forma siguiente
= f x k
k x
p( / ,η) ln( /η)
Además también la función delta Dirac es un caso límite de la distribución Pareto
) ( ) , / (
lim η =δ −η
∞
→ p x k x
k
3.1.3 Estimadores de Máxima Verosimilitud de la distribución Pareto
Petersen (2000), indica que la función de verosimilitud, L, para la distribución
Pareto con parámetros η y κ, dada una muestra x=(x1,x2,...,xn)es
∏
= + = n i k i k x k x k L 1 1; ) / ,(θ η 0<θ ≤min
{ }
xi , k>0Obteniendo la función logarítmica de verosimilitud
∑
= + − + = n i i x k nk k n k 1 ln ) 1 ( ln ln ) , ( θ η !se puede ver que !(k,η)aumenta monótonamente, con η, esto es, el valor más
grande del valor de η , es el valor más grande de la función de verosimilitud, así
x≥η, por lo que
i i x min ˆ=
η
Para encontrar el estimador para k, hacemos la correspondiente derivada parcial
y se determina en donde es igual a cero
0 ˆ ln 1 = − + = ∂ ∂
∑
= n i i x n k n k η !i
i x min ˆ=
η , ˆ
(ln i ln ) i
n k
x η
=
−
∑
3.1.4 Otras aplicaciones de la distribución Pareto
Se tienen algunas referencias relacionadas con la distribución Pareto en estudios
en confiabilidad, como el de Ouyang y Wu (1994) quienes publicaron resultados
sobre intervalos de predicción para observaciones ordenadas en estudios de
pruebas de vida; también el trabajo de Wu y Chang en 2003, trata sobre inferencia
de la distribución Pareto, basada en censura progresiva tipo II con retiros
aleatorios. D. Hanagal (1996a,1996b) publicó diferentes estudios de estimación en
sistemas de confiabilidad bajo la distribución Pareto bivariada y otros resultados
con la distribución Pareto multivariada.
En el tema de estimación, se tiene la publicación de K. Vannman (1976), en
donde presenta estimadores basados en las estadísticas de orden de una
distribución Pareto. B. Arnold (1983, 1989) también ha estudiado desde el punto
de vista bayesiano esta distribución, realizando estudios de estimación y
predicción bayesiana, así como inferencia para poblaciones con datos Pareto.
El uso de la distribución Pareto en estudios de confiabilidad es muy útil para
modelar unidades de una población que tengan distribución exponencial. Estas
unidades presentan una tasa de falla que varía de unidad en unidad de acuerdo a
una distribución gama (",κ), resultando que el tiempo de falla incondicional de una
unidad seleccionada al azar de la población, tiene una distribución Pareto de la
forma en (3.3) y con función de densidad dada en (3.6) Meeker & Escobar (1998).
3.2 Conceptos de la Teoría de la Información
Estos conceptos seutilizan en investigaciones de modelos neuronales y son muy
útiles en el ámbito de la ingeniería, especialmente en el entorno de la teoría de
comunicaciones, donde una de sus aplicaciones más comunes es la compresión
de los datos. Los conceptos a los que se refiere esta teoría son, entre otros,
3.2.1 Entropía
El concepto básico es la entropía, definida como una medida de incertidumbre
acerca del valor de una variable aleatoria #x$. Especificada por Shannon (1948) como H(#X)$, tiene la siguiente expresión formal:
[
( )]
log ) ( ) ( 1 x p x p X H n x∑
= − == E
) ( 1 log x p
donde, E(.) es el operador esperanza y p(#x) $%la distribución de probabilidad de la variable aleatoria. Si consideramos más de una variable, la entropía tendrá un
carácter conjunto y si se condiciona su comportamiento, la entropía será de
naturaleza condicional, ambos conceptos se sitúan en el ámbito bidimensional.
Así, sean “x” e “y”, dos variables aleatorias de tipo discreto, donde p(#x, y) $%es la
probabilidad conjunta y p(yx) es $%la probabilidad condicionada, y H(x,y)$% se define como la entropía conjunta:
[
( , )]
log ) , ( ) , ( 1 1 y x p y x p Y X H n x m y∑∑
= = − ==E
) , ( 1 log y x p
la cual es una medida de incertidumbre conjunta entre las dos variables aleatorias.
Y la entropía condicional H(yx)se define como
[
( )]
log ) , ( ) ( 1 1 x y p y x p X Y H n x m y∑∑
= = − =la cual es una medida del grado de incertidumbre de “y”, una vez que se conocen
los valores concretos de “x”.
3.2.2 Medidas de Entropía
En el caso de variables aleatorias continuas se definen las diferentes entropías en
La entropía fue introducida como medida cuantitativa de la información o, como
medida de la incertidumbre sobre una experiencia cualquiera con un número finito
de resultados posibles.
Si se considera un experimento aleatorio cuyos posibles resultados tienen sus
probabilidades respectivas de ocurrir, se sabe que existe una “cierta”
incertidumbre acerca del resultado particular que se presentará en caso de
realizar el experimento.
Es necesario cuantificar la incertidumbre asociada a un experimento aleatorio.
Para este fin, existen muchas medidas de incertidumbre, entre las más conocidas
se tiene la entropía de Shannon. Es importante ver que la entropía de Shannon
depende del número de resultados y de la probabilidad de ocurrencia de los
mismos.
Otras medidas como la de Hartley, únicamente depende del número de resultados
y no de la probabilidad de ocurrencia de los mismos, y se define como el logaritmo
del número de resultados posibles del experimento.
El objetivo de las medidas de entropía es cuantificar la incertidumbre asociada a
una variable aleatoria. (Pardo, 1997)
3.2.3 Unidades de Entropía
Al requerir medir la entropía, es necesario considerar en qué unidades se tiene
que medir. Se considera que las unidades de entropía se dá en logaritmos, los
cuales se pueden tomar con respecto a cualquier base que sea mayor que la
unidad. Si se toma en base dos, la unidad correspondiente se denomina BIT
(Binary digit) y puede definirse como la entropía correspondiente a una variable
aleatoria con dos resultados equiprobables.
Si se toma en base 10, la unidad correspondiente se denomina DIT (Decimal digit
o unidad de Hartley) y se define como la entropía de una variable aleatoria con
diez resultados equiprobables.
Si se toman en base e, la unidad correspondiente se denomina NAT y se aplica
en el concepto de entropía para variables aleatorias continuas. Cuando se toman
los logaritmos en base natural se tiene la ventaja de que se simplifican los
como la entropía correspondiente a una variable aleatoria con distribución
uniforme en el intervalo (0,e) (Pardo, 1997)
3.2.4 Entropía de Shannon para una variable aleatoria continua
Definición. Sea X ≡(X1,...,Xn)una variable aleatoria n-dimensional continua con función de densidad f(x), se denomina entropía de X a la expresión
∫
−
= n
R
dx x f x f X
h( ) ( )log ( )
Supuesto que la integral existe.
La entropía de Shannon en el caso continuo verifica que la entropía h(X)puede ser negativa.
3.2.5 Estimador no paramétrico de entropía
Para conocer la entropía de una función de densidad de probabilidades su
distribución tiene que ser completamente especificada, pero muchos
investigadores han desarrollado métodos no paramétricos para estimarla, como
los resultados que presenta Park (1995) considerando la propuesta de Vasicek
(1976), en la que presenta el estimador de la entropía, que la expresa H f( )
como:
1
1
0
( ) log d ( )
H f F p dp
dp −
=
⌠
⌡ (3.10)
usando el hecho de que la pendiente d 1( )
dpF p
− se puede expresar en la forma:
1
1 1 ( )
( ( )) d
F p
dp f F p
−
−
= (3.11)
De este modo para tener una idea del valor de la pendiente hay que estimar F
con la función de distribución empírica Fn y reemplazar el operador de
diferenciación por una diferencia entre dos cantidades. Esto conduce a un
estimador muy simple de la pendiente que se obtiene como el producto de 2n m y la
diferencia entre dos cuantiles muestrales, con lo cual el estimador de la entropía
(
( ) ( ))
1 1 log 2 nmn i m i m
i
n
H X X
n = m + −
= −
∑
(3.12)Donde m es un entero positivo más pequeño que n/2, X( )j =X(1)
si j<1, X( )j =X( )n si j>n y X(1) ≤...≤ X(n)son las correspondientes estadísticas de orden, basadas en una muestra aleatoria de tamaño n.
3.3 Discrepancia intrínseca
Es importante considerar la definición original de Kullback (1959), relacionada con
el concepto de discrepancia intrínseca la cual se presenta textualmente :
“Sea S=
{ }
p(x) el conjunto de todas las funciones de densidad regulares yabsolutamente continuas entre sí en un espacio muestral χ con respecto a una
medida dominante P.
dx ) x ( q ) x ( p log ) x ( p ) p q (
K =
∫
está definida, es no negativa y, para todo p,q∈S. 0
) p q (
K = , si y sólo si p=q, c.p.p.
En general, la divergencia de Kullback-Leibler no es simétrica, esto es
) q p ( K ) p q (
K ≠ .
Además si los soportes de p y q , χp y χq, respectivamente, son tales que
p
q ⊆χ
χ , entonces K(q p) diverge”.
3.3.1 Medida de Divergencia. Divergencia de Kullback-Leibler
Una vez considerada la definición de 3.3, se puede definir que una medida de
divergencia cuantifica la cantidad de información proporcionada por los datos, y
mide el grado de discrepancia entre dos poblaciones caracterizadas por sus
correspondientes distribuciones de probabilidad.
La divergencia de Kullback-Leibler o entropía relativa es una cantidad que mide la
diferencia entre dos funciones de densidad de probabilidad.
( ) ( ; ) ( ) log
( ) g x
K g f g x dx
f x ∞
−∞
=
∫
(3.13)Como K g f( ; )tiene la propiedad de que K g f( ; )≥0 y la igualdad se mantiene si
f
g = , el estimador de la información de Kullback-Leibler también ha sido
considerada como una estadística de prueba de bondad de ajuste por Arizono
(1989) y Ebrahimi (1992) entre otros.
3.3.2 La entropía y la divergencia de Kullback-Leibler en las pruebas de
bondad de ajuste
Las pruebas de bondad de ajuste basadas en la entropía muestral o bien en
divergencia de Kullback-Leibler son consistentes y presentan un buen
desempeño. Vasicek (1976) propuso una prueba de normalidad, basada en el
hecho de que la entropía de esta distribución excede a la de cualquier otra
distribución que tenga la misma varianza. Arizono y Otha (1976) desarrollaron
otra prueba para normalidad, pero basada en la divergencia de Kullback-Leibler,
que puede ser aplicada para hipótesis simples y compuestas.
Ebrahimi et al. (1992) desarrollaron una prueba de exponencialidad basada en la
divergencia de Kullback-Leibler. Song (2002) presentó una metodología general
para desarrollar pruebas de bondad de ajuste con distribución libre asintótica
basada en la divergencia de Kullback-Leibler. El procedimiento puede ser aplicado
a una gama amplia de distribuciones, entre las que destacan las distribuciones
siguientes: Normal, log-normal, logística, Gumbel, exponencial,
3.4 Poder o Potencia de la prueba
La potencia de una prueba es la probabilidad de rechazar la hipótesis nulaH0,
cuando esta es verdadera. La definición de potencia se usa principalmente para
una hipótesis alternativa simple. Si la hipótesis alternativa es compuesta se
emplea el término de Función Potencia, la cual se define como la función a la que
un valor θ del parámetro se le asocia la probabilidad de rechazar la H0si este
valor es el verdadero y su expresión es
[
Re H0]
)
(θ Pθ chazar
Si la hipótesis H0es simple del tipo θ =θ0 entonces el valor de la función potencia para θ0es elErrorTipoI :
α θ
β( θ)=
3.5 Prueba de hipótesis y Tamaño de la prueba
Cuando se usa una prueba ϕ, estamos sujetos a cometer cualquiera de los dos
tipos de errores posibles
0 1 )
(x = Si x>
ϕ 0 0 )
(x = Si x≤
ϕ
El criterio para encontrar la prueba óptima, es escoger la prueba ϕ* tal que las probabilidades de ambos errores sean mínimas.
En general, cuando se minimiza la probabilidad del ErrorTipoI se aumenta la
probabilidad del ErrorTipoII y viceversa.
Por esta razón fijamos un nivel de probabilidad αpara la probabilidad del
I Tipo
Error y se trata de obtener la prueba que hace mínima la probabilidad
delErrorTipoII . Es decir, entre todas las pruebas ϕ que satisfacen:
) usando
(ErrorTipoI ϕ
P ϕ ≤α <α1
0<α <1=α ∈ (0,1)
Note que si ϕ es de tamaño α y α <α1 entonces ϕ también es de tamaño α1.
Definición: Una prueba ϕ que satisface * es llamada una prueba de tamañoα.
El interés es que las pruebas, sean del tamaño lo más pequeño posible.
a) Probabilidad de rechazar H0cuando es verdadera
) / (Re ) usando
(ErrorTipoI P chazar H0usando w
P ϕ = ϕ θ∈
) 1 ) (
( x w
P = ∈
=
− θ
ϕ De donde ϕ es de tamaño α si
α θ θ∈ ((−)=1 )≤ maxP x
w **
b) Probabilidad de No rechazar H0cuando es falsa. * * * ) 0 ) ( ( ) usando
(ErrorTipoII P x w
P = = ∈Ω−
− θ
=1−P( (x)=1 ∈Ω−w)
− θ
ϕ
Entonces se desea encontrar la ϕ que satisface
α θ ϕ
θ∈ ( (−)=1 )≤ maxP x
w ** y minimiza
) 0
) (
( x w
P = ∈Ω−
− θ
ϕ o
=1−P( (x)=1 ∈Ω−w)
− θ
4.
PRUEBA DE BONDAD DE AJUSTE PARA LA DISTRIBUCIÓN
PARETO, BASADA EN LA INFORMACIÓN DE
KULLBACK-LEIBLER
4.1 Planteamiento del problema
Una variable aleatoria X, tiene función de distribución Pareto, X~P k( , )η si su función de densidad es de la forma
0 , 0 ) , , ( ) ;
( ⋅ = 0 η = η+1 k> x≥η≥ x k k x f x f k k (4.1)
donde η es el parámetro de localización y k es el parámetro de forma. Y kˆ y ηˆ
son respectivamente los estimadores de máxima verosimilitud:
∑
= − = n i i n y n k 1 ) ˆ ln (ln ˆ η{ }
1 ˆ mín ii n y
η
≤ ≤
=
Sean
{
X1,...,Xn}
observaciones independientes de una distribución F, con funciónde densidad de probabilidad f
( )
x;⋅, x∈ℜ.Se desea probar el siguiente juego de hipótesis
( )
; 0( ; , ):
0 f x f x kη
H ⋅ = (4.2)
contra la hipótesis alternativa:
( )
; 0( ; , ):
1 f x f x kη
H ⋅ ≠ (4.3)
El objetivo de esta hipótesis es conocer si una muestra aleatoria proviene de la
distribución Pareto.
4.2 Transformación de la distribución Pareto
Sin embargo, antes de probar la hipótesis de interés, se requiere aplicar una
transformación logaritmo a la distribución Pareto para obtener una distribución
Exponencial de dos parámetros (Lehman y Casella, (1998) pág. 486).
Y~Exp(ξ,b)con función de densidad
{
y}
b by
f(Y)( )= 1exp −( −ξ I(ξ,∞)(y) (4.4)
donde ξ =lnη y b=1/k
4.3 Construcción de la prueba
Ahora se va a considerar la información de discriminación de Kullback-Leibler
entre dos funciones de distribución para probar la hipótesis de interés.
[
]
∫
−∞∞= f y f y f y dy
F F
KL( , 0;!) ( )ln ( )/ 0( ,!) (4.5)
donde!es un vector de parámetros que en este caso, contiene a η;k.
La evaluación de KL(F,F0;!) requiere conocer a F y 0
F , por lo que ahora se debe
obtener un estimador muestral de KL(F,F0;!), considerando la hipótesis que se
quiere probar. Para este fin se aplicará la propuesta hecha por Song (2002).
Considerando la información de Kullback-Leibler dada en (4.8) y por propiedades
de los logaritmos se tiene:
∫
∫
−∞∞∞
∞
− −
= f y f y dy f y f y dy
F F
KL( , 0;!) ( )ln ( ) ( )ln 0( ,!) (4.6)
donde:
∫
∞ f(y)ln f(y)dy H(F) ∞− =− es la entropía de F.
Para obtener la estimación de la entropía,H
( )
F , se puede considerar el estimadorpropuesto por Vasicek (1976), dado por:
(
( ) ( ))
1 1
ln 2 n
mn i m i m
i
n
H Y Y
n = m + −
= −
∑
(4.7)donde m es un entero positivo menor que n/ 2,
{
Y(1),...,Y( )n}
, son las estadísticasde orden de la muestra
{
Y1,...,Yn}
, Yj =Y( )1, si j<1 y Yj =Y(n) si j>n.Para estimar de (4.5) la función
∫
∞∞
− f(y)ln f0(y,!)dy se utilizará la expresión
(
ˆ,ηˆ)
ln , 10 1
k Y f
n i
n
i
∑
=
− (4.8)
sustituyendo (4.7) y (4.8) en (4.5) se tiene la ecuación completa para el estimador
mn
KL :
(
)
1
( ) ( ) 0 ,
1 1
1 ˆ ˆ
ln ln ,
2
n n
mn i m i m i
i i
n
KL Y Y n f Y k
n m η
−
+ −
= =
= − −
∑
∑
teniendo como resultado la estadística de prueba para la distribución Exponencial
de dos parámetros.
A partir de este resultado se generaliza a una familia de localidad y escala, la cual
se consideró en este estudio para aplicarla en la prueba de bondad de ajuste de
Kullback-Leibler.
4.4 Implementación de la prueba
Una vez que se aplica la prueba si se obtienen valores grandes del estimador
mn
KL se rechaza H0a favor de la hipótesis alternativa, es decir; se rechaza la
hipótesis nula si KLmn ≥Cmn(α), así el valor de la constante crítica Cmn(α) se determina por el cuantil
(
1−α)
100de la distribución de KLmnbajo la hipótesis nula.Considerando que se tiene definido el tamaño de muestra n, ahora se tiene que
especificar el parámetro m. Song (2002) sugiere que de acuerdo a su teoría, m
debería escogerse de acuerdo al tamaño de muestra finito. Sin embargo en la
práctica escoger el valor de m óptimo es problemático; ya que no sólo depende
del tamaño de muestra, sino también de la alternativa en particular que se
considere. Por lo que Song (2002), probó hipótesis compuestas de normalidad
con parámetros no especificados, contra siete opciones de hipótesis alternativas
obteniendo el poder de la prueba por medio de simulación MonteCarlo.
Estas simulaciones mostraron que aún para n fija, no existe una m que sea óptima
O sea, si se tiene una distribución alternativa de especial interés, entonces la
mejor forma de escoger m, podría ser la m que proporcione el poder más alto en
la dirección de esta alternativa para el tamaño de muestra n dado y el nivel α
requerido.
Para este fin, se tiene el hecho de que la información de Kullback-Leibler
(
( , 0;)
0KL F F ! ≥ para todo !∈Θ en donde la igualdad se mantiene para algún
∈Θ
! si y solo si
0 ( ) ( , )
f x = f x ! . En otras palabras, bajo
(
)
0
( , ; 0
KL F F ! = , los
valores grandes de KL
(
( ,F F0;!)
favorecen la hipótesis alternativa sobre H0.Sobre esta propiedad se basa el método para seleccionar m. Dadas las
observaciones
{ }
Xi ni=1, se estima KL F F(
( , 0;!)
, con su estimador muestral, KLmn.La idea básica es escoger m que minimice KLmn.
La siguiente expresión nos presenta la forma de obtener
m: 0
(
( ))
1
1 ˆ ˆ
ˆ *: * arg : ln , ,
n
mn mn i
i m
m mín m m máx H H f X k
n = η
= = ≤ −
∑
(4.10)
es decir, mˆdebe de ser el valor mas pequeño de mˆ *, que maximice la entropía
5.
ESTIMACIÓN DEL PODER DE LA PRUEBA
5.1 Distribución empírica del estadístico de pruebaKLmn
Aplicando simulación Monte Carlo se probó que para este caso particular la
distribución empírica del estadístico de pruebaKLmnpara la distribución Pareto,
bajo H0, es prácticamente idéntica aún para tamaños de muestra pequeños y no
depende de los parámetros ky η .Para obtener la distribución empírica de KLmn
se mantuvieron fijos n,m ,kˆy ηˆ y se generaron B muestras aleatorias de tamaño
n para la distribución Pareto con parámetros ky η . Para calcular el valor de KLmn
se hicieron B realizaciones de la estadística de prueba y se generó la forma
aproximada de la distribución, obteniendo el histograma de las diferentes gráficas
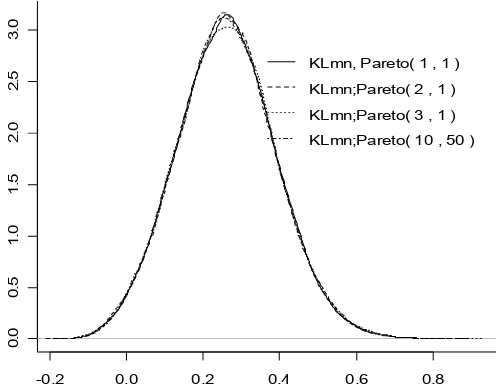
En la figura 1 se presenta la forma de la distribución de la estadística de prueba
mn
KL con n=10, m=4 y B=10,000 para cada combinación de los diferentes valores de parámetros especificados en la gráfica. Los cálculos se hicieron con el
programa en lenguaje R.
-0.2 0.0 0.2 0.4 0.6 0.8
0
.0
0
.5
1
.0
1
.5
2
.0
2
.5
3
.0
[image:29.612.186.434.427.620.2]KLmn, Pareto( 1 , 1 ) KLmn;Pareto( 2 , 1 ) KLmn;Pareto( 3 , 1 ) KLmn;Pareto( 10 , 50 )
5.2 Estimación del poder de la prueba
En esta sección se presenta la obtención del poder de la prueba de manera
comparativa para las pruebas de Kullback-Leibler y Kolmogorov Smirnov,
considerando las distribuciones, Lognormal, Weibull y Gamma como alternativas a
la distribución Pareto.
Se utilizaron para las tres pruebas de bondad de ajuste los niveles de significancia
de α =0.1, 0.05 y 0.01, tamaños de muestra de n=10, 30, 50, 100, 200 y 225 y
se generaron B =5,000 muestras aleatorias para cada combinación de α y n,
posteriormente, se calculó el valor de la estadística correspondiente para cada
una de las pruebas.
5.3 Prueba de Kullback-Leibler con las distribuciones alternativas
Para obtener la estadística de prueba KLmn de Kullback-Leibler, se calculó el
estimador de entropía (Hmn). Este estimador considera las estadísticas de orden,
el valor de n y el valor de m.
Se calculó el poder de la prueba para las 16 distribuciones alternativas con
diferentes combinaciones de los niveles de significancia y tamaños de muestra
antes mencionados. En cada caso las pruebas se realizaron con los parámetros
que se presentan a continuación.
Distribución Weibull: (1,1), (1,3), (2,3), (2,1), (3,1) y, (3.439,1)
Distribución Gamma: (1,1), (1,3), (2,3), (2,1), (3,1) y, (3.439,1)
Distribución Log-normal: (1,1), (1,0.4), (5,3), (10,0.2)
Para la distribución Weibull, se realizaron las pruebas con diferentes valores de
parámetros, estableciendo las siguientes correspondencias con otras
distribuciones de acuerdo a Makino(1984),
Weibull(1,3) = Exp(3)
Weibull(2,3) = Raleigh(;)
La distribución Weibull que se consideró, tiene parámetro de forma α y parámetro
de escala β con función de densidad
) ) / ( exp( ) 1 ( ) / )( / ( )
(x x x a
f = α β β α− − β para x>0
La distribución Gamma que se utilizó tiene parámetro de forma θ y parámetro de
escala β con función de densidad
{
( )}
( 1)exp ( / ) 1)
( θ θ β
θ
β x x
x
f − −
Γ
= para x >0, θ >0 y β >0
Para la distribución Gamma; solamente por comparación, se aplicaron los mismos
valores de los parámetros que para la distribución Weibull.
Se trabajó con la distribución Lognormal, con parámetro de localización µ y parámetro de forma σ2 con función de densidad:
π σ 2 1 ) ( x x
f = exp
− − 2 2 2 ) (ln σ µ
x ∀ x>0
Tamborero del Pino y Cejalvo (1996) indican las siguientes características para la
distribución Lognormal de acuerdo a los valores del parámetro de escala:
Lognormal (5,3) = Asimétrica, para valores medios y altos de &
Lognormal (1,0.4)= Conforme & decrece, la distribución es más simétrica Lognormal (1,1) = Exponencial negativa. Si & se acerca a la unidad Lognormal (10,0.2)= Normal. Para valores de &<0.2
Para esta distribución se trabajó con los parámetros antes indicados.
Las potencias de las pruebas de Kullback-Leibler se realizaron con la estadística
de pruebaKLmn, obtenidas por medio de simulación Monte Carlo utilizando el
programa en lenguaje R :
5.3.1 Valores críticos
Para determinar los valores críticos de Cmn( )α y KLmn, y considerando que su
simulación Monte Carlo. Se consideraron los niveles de significancia α =0.1,
0.025, 0.05 y 0.01, tamaños de muestra de n=20 a 200 con separación de
diez unidades entre un calculo y otro y se generaron B=5,000 muestras
aleatorias de tamaño n, posteriormente, se calculó la estadística de
pruebaKLmnpara cada m<n/ 2. El valor de Cmn( )α para cada m y n se determinó con el cuantil ( −1 α)x100 de la distribución empírica deKLmn.
En la tabla 1 se muestran de manera resumida los valores críticos Cmnα de la
estadísticaKLmn para la distribución Pareto, y en las tablas 2, 3, 4 y 5 (anexas) se
presentan los valores críticos para la estadística KLmn para los niveles de
significancia, de 0.01, 0.025, 0.05 y 0.1 respectivamente.
Nivel de significancia ( α)
n 0.01 0.025 0.05 0.1
Cmn m Cmn m Cmn m Cmn m
20 0.3889 4 0.3440 4 0.3058 4 0.2690 4
30 0.2910 5 0.2573 5 0.2329 5 0.2079 5
40 0.2366 6 0.2127 6 0.1931 6 0.1707 6
50 0.2050 6 0.1851 6 0.1669 6 0.1492 6
60 0.1792 8 0.1603 7 0.1470 6 0.1324 7
70 0.1598 7 0.1443 7 0.1320 7 0.1190 7
80 0.1456 7 0.1322 8 0.1206 8 0.1091 8
90 0.1363 8 0.1226 9 0.1131 10 0.1016 10
100 0.1248 9 0.1142 9 0.1050 9 0.0950 8
110 0.1187 10 0.1067 10 0.0981 10 0.0887 10
120 0.1111 8 0.1010 11 0.0927 11 0.0834 11
130 0.1059 11 0.0952 9 0.0881 10 0.0796 11
140 0.1005 13 0.0921 9 0.0843 11 0.0760 12
150 0.0939 11 0.0864 11 0.0795 12 0.0719 12
160 0.0913 11 0.0834 13 0.0768 11 0.0696 13
170 0.0880 11 0.0800 12 0.0735 12 0.0666 12
180 0.0845 12 0.0772 12 0.0713 12 0.0641 14
190 0.0817 13 0.0748 15 0.0687 15 0.0618 15
200 0.0787 12 0.0714 12 0.0660 14 0.0594 14
[image:32.612.143.469.323.620.2]5.4 Prueba de Kolmogorov-Smirnov
La prueba de Kolmogorov-Smirnov indica si un conjunto de observaciones
provienen de alguna distribución continua, completamente especificada. Sin
embargo una de las limitaciones para aplicar esta prueba, es cuando uno o más
parámetros de la distribución deben estimarse a partir de la muestra, por lo que
en estos casos no es muy conveniente aplicar la prueba, ya que no se pueden
utilizar los puntos críticos tabulados comúnmente, (Lilliefors, 1969).
Considerando que la distribución Pareto, no presenta el parámetro de escala, por
lo que no cumple con esta condición para aplicar la prueba de
Kolmogorov-Smirnov. Sin embargo, este problema se resolvió aplicando la transformación
logaritmo a la distribución Pareto, obteniendo como resultado la distribución
exponencial recorrida, la cual es una distribución de localización y escala (Lehman
y Casella, 1998) (explicada en el capítulo 2).
Lilliefors (1969), presenta tablas de la estadística de Kolmogorov-Smirnov, para
probar si un conjunto de observaciones provienen de una población exponencial
cuando la media no es especificada, y se estima a partir de la muestra.
En su trabajo, Lilliefors (1969), menciona que David y Johnson (1948), indican que
si los parámetros estimados son parámetros de escala o localización y los
estimadores satisfacen ciertas condiciones generales, entonces se aplica la
transformación integral de probabilidad, y entonces, la distribución conjunta de las
variables transformadas no dependerán del valor verdadero del parámetro. La
distribución dependerá de la forma funcional de la distribución de las variables
originales. Así se pueden construir las tablas con la estadística de
Kolmogorov-Smirnov para esa distribución en particular.
El procedimiento que presenta Lilliefors (1969) es:
dada una muestra de n observaciones se determina
) ( ) (
* X S X
F Máximo
D= − n
muestral. Si el valor deD excede el valor crítico en la tabla, entonces se rechaza
la hipótesis de que las observaciones vienen de una población exponencial.
La tabla 2 muestra los valores críticos de D
Nivel de significancia para D=MáximoF*(X)−SN(X)
n 0.20 0.15 0.1 0.05 0.01
3 0.451 0.479 0.511 0.551 0.600
4 0.396 0.422 0.449 0.487 0.548
5 0.359 0.382 0.406 0.442 0.504
6 0.331 0.351 0.375 0.408 0.470
7 0.309 0.327 0.350 0.382 0.442
8 0.291 0.308 0.329 0.36 0.419
9 0.277 0.291 0.311 0.341 0.399
10 0.263 0.277 0.295 0.325 0.380
11 0.251 0.264 0.283 0.311 0.365
12 0.241 0.254 0.271 0.298 0.351
13 0.232 0.245 0.261 0.287 0.338
14 0.224 0.237 0.252 0.277 0.326
15 0.217 0.229 0.244 0.269 0.315
16 0.211 0.222 0.236 0.261 0.306
17 0.204 0.215 0.229 0.253 0.297
18 0.199 0.210 0.223 0.246 0.289
19 0.193 0.204 0.218 0.239 0.283
20 0.188 0.199 0.212 0.234 0.278
25 0.170 0.180 0.191 0.210 0.247
30 0.155 0.164 0.174 0.192 0.226
Más de
30 .86/'N .91/'N .96/'N 1.06/'N 1.25/'N
6. APLICACIÓN DE LA PRUEBA DE KULLBACK-LEIBLER EN UN
EJEMPLO DE OBSERVACIONES DE TIEMPOS DE VIDA
Considerando los resultados de 20 tiempos de falla en un estudio de
sobrevivencia, reportados por Ouyang y Wu (1994) en su trabajo sobre intervalos
de predicción para observaciones ordenadas con distribución Pareto, se aplicaron
los resultados obtenidos en este trabajo. El programa en lenguaje R para este
ejemplo se anexa al final.
30.101 30.150 30.374 30.581 30.871 31.086 31.398 31.752 31.792 31.960 32.260 32.517 32.636 33.002 33.552 33.721 34.002 34.023 34.150 35.274 Tabla 3. Tiempos de falla
Se aplicó la prueba de Kullback-Leibler, para probar si los datos de tiempo de falla
tienen distribución Pareto, contra la alternativa de que no se distribuyen Pareto.
En la prueba se consideró un tamaño de muestra n=20, un valor de m=4 y un nivel de significancia de 0.05
Los resultados obtenidos con el programa de cómputo R se anexan al final del
trabajo.
Se considera la siguiente regla de decisión:
Se rechaza la hipótesis nula si, KL4,20 ≥C4,20,(.05) El valor de KL4,20 = 0.3514342
Valor crítico C4,20(0.05)= 0.3572
Como KL4,20<C4,20(.05)entonces No se rechaza la hipótesis nula
El resultado de la prueba indica que los datos de tiempo de falla que se
consideraron en el ejemplo tienen distribución Pareto con un nivel de significancia
7. DISCUSIÓN DE LOS RESULTADOS
- Se aplicó la prueba de bondad de ajuste de Kullback-Leibler propuesta por
Song (2000), para la distribución Pareto. Debido a que la distribución
Pareto no es invariante, se le aplicó la transformación logaritmo obteniendo
como resultado la distribución Exponencial de dos parámetros, la cual es
una distribución de localización y escala (Lehman y Casella, 1998).
-
- Se obtuvo la tabla de valores críticos Cmnα, de la estadística KLmn para la
distribución Pareto, estos valores se obtuvieron por simulación Montecarlo
a niveles de significancia, 0.01, 0.025, 0.05 y 0.1, tamaños de muestra n de
5 a 200 y para valores de m de 4 a 15. (Tabla 1)
- La prueba de bondad de ajuste de Kullback-Leibler, para la distribución
Pareto, considerando como distribuciones alternativas la Weibull, Gamma,
y Lognormal, observando en general que para las tres distribuciones, la
potencia de la prueba, aumenta, conforme se incrementa el tamaño de la
muestra.
- Para el caso de la distribución alternativa Weibull, se consideraron 5
combinaciones de parámetros. Para el caso de tamaño de muestra
n = 10 a los diferentes niveles de significancia considerados (0.10, 0.05 y
0.1), el poder de la prueba de Kullback-Leibler, presentó valores más altos
en la mayoría de los casos, que para la prueba de Kolmogorov-Smirnov.
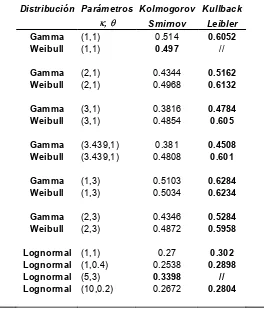
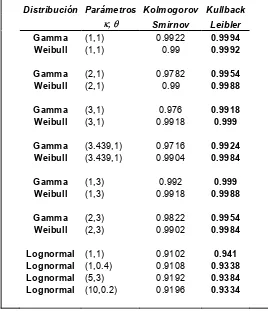
(Tablas 4, 5 y 6).
- Para esta misma distribución, la potencia de Kullback-Leibler, para n=30
fue mayor en todos los casos y para el tamaño de muestra n=50, n=100,
n=200 y n=225, con α diferentes, la potencia fue igual a uno, viendo que
para estos tres últimos tamaños de muestra, resultó idéntica a la potencia
- Para la distribución Gamma, con tamaño de muestra igual a 10, el
resultado del poder de la prueba con los diferentes niveles de significancia
considerados (0.01, 0.05 y 0.1), se presentó de manera muy semejante a la
distribución Weibull, siendo mayor en practicamente todos los casos que
para la prueba de Kolmogorov- Smirnov. (Ver Tablas 4 , 5 y 6)
- Para esta misma distribución, la potencia de Kullback-Leibler, para n=30
fue mayor en los 16 casos. Para los tamaños de muestra; n=50, n=100,
n=200 y n=225, la potencia fue igual a uno, viendo que para los tres últimos
tamaños de muestra, resultó idéntica a la potencia de la prueba de
Kolmogorov- Smirnov. (Tablas de la 7 a la 21)
- Tamborero del Pino y Cejalvo (1996) indican que para la distribución
Lognormal, de acuerdo a los valores del parámetro de escala & , si este tiene valores medios y altos entonces la distribución es asimétrica, en este
trabajo se probó la hipótesis alterna de Lognormal (5,3) y en las tablas 8, 9
y 10 se observa que para esta combinación de parámetros al tamaño de
muestra más bajo ( n=10) y para los tres niveles de significancia (0.10, 0.05
y 0.01), la prueba de Kullback-Leibler no reportó valor para la potencia, por
lo que la prueba no converge para estos casos.
- Con tamaños de muestra mayores de 10, la distribución Lognormal,
presentó resultados del potencia de la prueba muy parecidos a los que se
obtuvieron con las distribuciones Weibull y Gamma. (Tablas de la 4 a la 21)
- Con respecto al tamaño de la prueba, los resultados obtenidos por medio
de simulación son muy parecidos a los valores α de que se consideraron.
Se obtuvo el tamaño de la prueba con diferentes parámetros a diferentes
combinaciones de niveles de significancia y tamaños de muestra;
8. CONCLUSIONES
- Se derivó una prueba de bondad de ajuste de Kullback-Leibler, para la
distribución Pareto observando que la potencia de la prueba de Kullback-
Leibler, aumenta conforme se incrementa el tamaño de la muestra, lo
que demuestra que es una PRUEBA CONSISTENTE
- Con respecto al tamaño de la prueba, los resultados obtenidos por
medio de simulación son muy parecidos a los valores de que
se consideraron.
- Como conclusión más importante, se observó que la prueba de
Kullback-Leibler resultó ser más poderosa que la prueba de bondad de ajuste de
Kolmogorov-Smirnov.