Información Importante
La Universidad Santo Tomás, informa que el(los) autor(es) ha(n) autorizado a usuarios internos y externos de la institución a consultar el contenido de este documento a través del Catálogo en línea de la Biblioteca y el Repositorio Institucional en la página Web de la Biblioteca, así como en las redes de información del país y del exterior con las cuales tenga convenio la Universidad.
Se permite la consulta a los usuarios interesados en el contenido de este documento, para todos los usos que tengan finalidad académica, nunca para usos comerciales, siempre y cuando mediante la correspondiente cita bibliográfica se le dé crédito al trabajo de grado y a su autor.
De conformidad con lo establecido en el Artículo 30 de la Ley 23 de 1982 y el artículo 11 de la Decisión Andina 351 de 1993, la Universidad Santo Tomás informa que “los derechos morales sobre documento son propiedad de los autores, los cuales son irrenunciables, imprescriptibles, inembargables e inalienables.”
CONTROL DE POSICIÓN DE UN UAV MEDIANTE UNA ESTRATEGIA DE CONTROL PREDICTIVO PARA LABORES DE MONITOREO
JUAN FERNANDO JOJOA GÓMEZ SERGIO FABIÁN MORENO CÁRDENAS
UNIVERSIDAD SANTO TOMÁS
DIVISIÓN DE INGENIERÍAS Y ARQUITECTURA FACULTAD DE INGENIERÍA MECATRÓNICA
CONTROL DE POSICIÓN DE UN UAV MEDIANTE UNA ESTRATEGIA DE CONTROL PREDICTIVO PARA LABORES DE MONITOREO
JUAN FERNANDO JOJOA GÓMEZ SERGIO FABIÁN MORENO CÁRDENAS
Proyecto de grado presentado como requisito parcial para optar el título de Ingeniero Mecatrónico.
Director:
Edwin González Querubín, M.Sc. Ingeniero Mecatrónico
UNIVERSIDAD SANTO TOMÁS
DIVISIÓN DE INGENIERÍAS Y ARQUITECTURA FACULTAD DE INGENIERÍA MECATRÓNICA
DEDICATORIA
Dedico este proyecto a mi padre y a mi madre, que gracias a su apoyo incondicional se logró la finalización de este. A mi familia por darme ánimos de seguir adelante y acompañarme en esta etapa de mi vida.
JUAN FERNANDO JOJOA GÓMEZ
Dedico esta tesis en primer lugar a mis padres y a mi familia, quienes son siempre la motivación para crecer académicamente y como persona.
A Adriana, mi apoyo incondicional todos estos años.
AGRADECIMIENTOS
Agradecemos primeramente a Dios, por la oportunidad de llevar a cabo nuestros estudios y por la sabiduría dada.
TABLA DE CONTENIDO
Pág.
INTRODUCCIÓN ... 1
1. FORMULACIÓN DEL PROBLEMA ... 2
1.2. JUSTIFICACIÓN ... 3
1.3. ALCANCE ... 4
1.4. OBJETIVOS ... 5
1.4.1 Objetivo general ... 5
1.4.2 objetivos específicos ... 5
2. MARCO DE REFERENCIA ... 6
2.1 Vehículo aéreo no tripulado ... 6
2.2 Dinámica de un cuadricóptero. ... 10
2.3 Control predictivo basado en modelo. ... 12
2.3.1 Metodología. ... 13
2.3.2. Modelo de predicción. ... 16
2.3.3. Predicción salida del proceso. ... 22
2.3.4. Trayectoria de referencia ... 23
2.3.5. Función de coste o Función objetivo ... 24
2.3.6 Ley de control ... 25
2.4 MPC en Espacio de Estados: ... 25
2.4.1. Modelo del proceso ... 25
2.4.2. Actualización de la respuesta libre (cálculo recursivo) ... 26
2.4.3 Respuesta forzada ... 26
2.4.4 Perturbaciones ... 27
2.4.5 Predicción de la salida ... 27
2.4.6. Trayectoria de referencia ... 28
2.4.7. Función de coste. ... 28
2.4.8 Ley de control ... 29
2.5. Manejo de restricciones ... 30
2.5.1. Programación cuadrática MPC ... 30
2.6.1. Respuesta libre ... 39
2.6.2. Respuesta forzada ... 40
2.6.3. Predicción de la salida ... 41
2.6.4. Función de coste ... 42
2.7. Observador de estados ... 43
2.7.1. Observabilidad ... 44
2.7.2. Controlabilidad ... 44
2.7.3 Filtro de Kalman ... 45
3. DISEÑO METODOLÓGICO ... 48
3.1. Revisión Bibliográfica. ... 48
3.2. Planteamiento del modelo. ... 48
3.2.1. Caracterización del sistema ... 48
3.3. Implementación del controlador. ... 49
3.3.1. Simulación sistema MIMO ... 49
3.3.2. Implementación sistema MIMO ... 49
4. MÉTODO ... 50
4.1. Modelos matemáticos ... 50
4.1.1. Modelo matemático control de altitud. ... 50
4.1.2. Modelo matemático control Orientación ... 53
4.1.3 Modelo matemático control posición en eje X ... 55
4.1.4 Modelo matemático control posición en eje Y ... 57
4.2. Simulación sistema MIMO ... 60
4.2.1 Simulación sistema MIMO (altura-orientación) ... 61
4.2.2 Simulación sistema MIMO (posición X – posición Y)... 66
4.2.3 Simulación sistema MIMO 4x4. ... 71
4.3. Implementación control multivarible en espacio de estados en drone (AR.Drone 2.0 parrot) ... 76
4.3.1. Variables del proceso ... 77
4.3.2. Interfaz gráfica de control ... 77
4.3.3. Implementación control predictivo sistema MIMO 4x4. ... 78
LISTA DE FIGURAS
Pág.
Figura 1. Cuadricoptero (Parrot AR. Drone 2.0)... 7
Figura 2. Helicóptero convencional ... 8
Figura 3. Pares generados por los rotores ... 9
Figura 4. Movimientos básicos cuadricóptero ... 10
Figura 5. Ejes de control principales ... 11
Figura 6. Fuerzas y momentos del cuadricóptero. (Estructura interna parrot) ... 12
Figura 7. Estrategia MPC ... 14
Figura 8. Estructura de estrategia de control ... 15
Figura 9. Modelo de predicción ... 16
Figura 10. Respuesta al impulso ... 17
Figura 11. Respuesta al escalón ... 18
Figura 12. Salida predicha ... 23
Figura 13. Trayectoria de referencia ... 24
Figura 14. Acciones de control futuras ... 34
Figura 15. Operación completa del filtro de Kalman ... 47
Figura 16. Pruebas Altitud ... 51
Figura 17. Prueba cambio altitud ... 51
Figura 18. Salida estimada altitud ... 52
Figura 19. Prueba Orientación ... 54
Figura 20. Salida estimada Orientación ... 54
Figura 21. Prueba posición eje X ... 56
Figura 22. Salida estimada posición eje X ... 56
Figura 23. Prueba posición eje Y ... 58
Figura 24. Salida estimada posición eje Y ... 58
Figura 25. Simulación 1. control MIMO (Altitud-Orientación) ... 62
Figura 26. Simulación 2. control MIMO (Altitud-Orientación) ... 63
Figura 27. Simulación 3. control MIMO (Altitud-Orientación) ... 65
Figura 28. Simulación 1. Control MIMO (posición eje X – posición eje Y) ... 67
Figura 29. Simulación 2. Control MIMO (posición eje X – posición eje Y) ... 68
Figura 30. Simulación 3. Control MIMO (posición eje X – posición eje Y) ... 70
Figura 31. Simulación 1. Control MIMO 4x4. ... 72
Figura 32. Simulación 2. Control MIMO 4x4. ... 74
Figura 33. Simulación 3. Control MIMO 4x4. ... 75
Figura 34. Diagrama de bloque del sistema ... 77
Figura 35. Interfaz de control drone ... 77
Figura 37. Prueba 1. Implementación control. ... 80
Figura 38. Prueba 2. Implementación control. ... 81
Figura 39. Prueba 3. Implementación control. ... 83
Figura 40. Prueba 4. Implementación control. ... 84
Figura 41. Prueba 5. Implementación control. ... 85
ANEXOS
Pág. Anexo 1. Algoritmo implementación en Matlab sistemas MIMO 2x2 ...¡Error! Marcador no definido.
Anexo 2. Algoritmo implementación Matlab sistema MIMO 4x4 ... ¡Error! Marcador no definido.
GLOSARIO
UAV: Unmanned aerial vehicle Ti: Torque de entrada
MPC: Control Predictivo basado en Modelos Ts: Tiempo de muestreo
P: Horizonte de Predicción DMC: Dynamic Matrix Control
GPC: Generalized Predictive Control
CARIMA: Controlled Auto-Regresive Integrated Moving Average SISO: Entrada única, Salida única.
MIMO: Múltiple entrada, Múltiple salida. LTI: Lineal Invariante con el Tiempo. LQR: Regulador lineal cuadrático.
RESUMEN
El presente trabajo consiste en la implementación de un método de control predictivo basado en modelo (MPC), para el control de la posición un UAV, en este proyecto se utiliza un parrot A.R Drone 2.0.
El algoritmo de control predictivo utilizado en este proyecto es el, MPC en espacio de estados, el cual depende del modelo en espacio de estados de cada una de las variables a controlar. Este algoritmo, se desarrolló para las diferentes variables a controlar, altitud, roll, pitch y yaw, también se realizan las respectivas simulaciones por medio del software Matlab, para su posterior implementación en el software Labview.
La principal meta del control predictivo es de resolver de una forma eficiente los problemas de control de procesos, los cuales pueden presentar comportamientos dinámicos complejos, como puede ser el acoplamiento entre variables, inestabilidad e incluso restricciones en alguna de sus variables. La estrategia de este tipo de control, consiste en utilizar un modelo matemático del proceso, y de esta manera obtener una serie de predicciones del futuro comportamiento del proceso, en base a estas predicciones y a una referencia deseada para la variable a controlar, se calculan las señales de control futuras haciendo que dicha variable converja en sus respectivos valores de referencia, respetando las diferentes restricciones en la variable del sistema en caso que existan.
ABSTRACT
This work involves the implementation of model predictive control (MPC) method to control a UAV position. In this project, a parrot A.R Drone 2.0 is used. The predictive control algorithm used in this project is the state space MPC, which depends on the state space model of each controlled variables. This algorithm was developed for different control variables: altitude, roll, pitch and yaw. The respective simulations were made by Matlab software for subsequent implementation in the Labview software.
1
INTRODUCCIÓN
El control predictivo basado en modelo (MPC) es una metodología que se encuentra en el campo de la ingeniería de control moderna. Esta estrategia de control utiliza un modelo para predecir las salidas del proceso y calcular las acciones de control futuras a través de la minimización de una función de coste u objetivo. El MPC representa grandes ventajas respecto al control tradicional y a otras técnicas de control moderno. Entre sus principales ventajas se encuentra el poder tratar con sistemas multivariables, la posibilidad de incorporación de restricciones, controlar una gran variedad de procesos, que van desde dinámicas simples hasta dinámicas complejas, como son los procesos con grandes tiempos muertos, fase no mínima etc., también introduce un control anticipativo, el cual permite compensar las perturbaciones medibles. Por otra parte, la desventaja más considerable es la complejidad del algoritmo lo cual requiere un coste computacional elevado, por esta razón inicialmente se ha aplicado en procesos con dinámica lenta, por otra parte, si dicha dinámica no cambia y no existen restricciones, la mayor parte de los cálculos se pueden realizar fuera de línea, lo cual haría que el controlador resultase simple [15].
2
1. FORMULACIÓN DEL PROBLEMA
El control de los cuadricópteros o cuadrirrotores es un tema que se ha abordado desde distintas perspectivas, tanto la identificación del modelo del sistema como la técnica de control usada, obteniendo distintos resultados. Los modelos dinámicos se han obtenido con aproximaciones matemáticas a partir de leyes físicas o en forma experimental, llegando a tener una gran fidelidad. Por su parte, el tipo de control usado va desde control monovariable, hasta control multivariable, robusto, no lineal, etc.
Existen distintos trabajos de postgrado en los que se aborda este tema y en los que se ha observado que algunas técnicas de control no son buenas, debido a las incertidumbres presentes en el modelamiento y las perturbaciones no medibles. Para este caso uno de los mejores temas a tratar es el control predictivo, el cual permite trabajar con sistemas no lineales, estables, inestables, con retardos de transporte, fase no mínima; así como considerar restricciones en las variables que intervienen en el sistema.
3 1.2. JUSTIFICACIÓN
4 1.3. ALCANCE
5 1.4. OBJETIVOS
1.4.1 Objetivo general
Controlar la posición de un UAV mediante una estrategia de control predictivo para labores de monitoreo.
1.4.2 objetivos específicos
Identificar el UAV utilizando herramientas computacionales para obtener las características dinámicas del sistema.
Diseñar un estimador para observar las variables internas del proceso aplicando teoría de espacio de estados.
6
2. MARCO DE REFERENCIA
Los vehículos no tripulados son uno de los temas de mayor interés para la comunidad científica en los últimos años, en especial los vehículos aéreos no tripulados. Los drones cada vez son más comprados por el público en general y esto ha hecho de ellos uno de los objetos de investigación más famosos, específicamente la forma de controlar su vuelo, de hacerlos más estables en el aire y de generar seguimiento de trayectorias o vuelos autónomos de cualquier tipo.
2.1 Vehículo aéreo no tripulado
El auge de los drones o vehículos aéreos no tripulados (UAV), ha hecho que sean objeto de investigación, debido a su gran número de aplicaciones, incluidas: misiones de rescate y búsqueda, vigilancia, inspección, fotografía, cartografía, operaciones marítimas etc. Para llevar a cabo este tipo de posibles aplicaciones, es necesario imponer nuevas exigencias en materia de control y navegación con el fin de hacerlos más estables ante posibles perturbaciones [1]. Una de las principales ventajas de estas aeronaves es su capacidad para volar sin necesidad de un piloto humano a bordo, puesto que pueden ser remotamente controlados o tener un vuelo autónomo, el cual ha sido previamente programado. Esta autonomía es coordinada por los diferentes algoritmos de control que poseen este tipo de vehículos y el cual ayuda a que responda de manera satisfactoria al presentarse con un evento inesperado, (como colisiones o perturbaciones no medibles) [3].
Sin embargo, este tipo de UAV plantea problemas de ingeniería, los cuales deben ser abordados con el fin de ser capaz de volar de forma autónoma y de manera eficiente.
7
limitadas, por lo tanto, pueden provocar inestabilidad al ser operado en condiciones no muy lejanas a las de equilibrio [5].
Dentro del segmento de aeronaves denominadas drones, encontramos los “Multirotores” (helicópteros de más de 2 rotores de sustentación), y entre ellos se ubica principalmente los de 4 hélices (denominamos “Cuadricópteros”) [4]. En este tipo helicóptero su control se da cambiando la velocidad de rotación de sus cuatro rotores, así pues, logra obtener un vuelo estable y preciso a través del balance de las fuerzas de propulsión ejercidas por las cuatro hélices accionadas por sus respectivos motores eléctricos [6]. Al comparar el cuadricóptero (figura 1) con un helicóptero convencional (figura 2), este tipo de aeronave posee un mayor dinamismo al ser maniobrado. No obstante, su control se hace mucho más complejo dado que posee una mayor inestabilidad dinámica.
Figura 1. Cuadricoptero (Parrot AR. Drone 2.0)
8
Figura 2. Helicóptero convencional
Fuente: http://www.modeltronic.es/v912-wltoys-max-helicoptero-40cm-24ghz-con-gyro-p-8753.html
Hay unas grandes ventajas que tiene este tipo de UAV con respecto del convencional, citando algunas de ellas:
Aumento de capacidad de carga gracias al empuje generado por los cuatro rotores.
Alta maniobrabilidad, lo cual permite el despegue y el aterrizaje, así como vuelos en entorno complicados.
Diseño mecánico sencillo, lo cual proporciona un control de movimiento a través de accionamiento directo de los rotores variando su velocidad [5]. Y como principales desventajas:
Presenta un aumento de peso dado que consta de una estructura mayor a la de uno convencional, la cual soporta los cuatro motores.
Aumento de consumo de energía puesto que posee cuatro rotores funcionando al tiempo.
9
dextrógira, mientras que el aumento de la velocidad de 2 y 4 resulta en una guiñada levógira [7].
Figura 3. Pares generados por los rotores
Fuente: Sevilla Fernández, Luis: Modelado y Control de un Cuadricóptero [7]
Este tipo de helicóptero está lejos de simplificar su tarea de su control, a causa de que los pares y fuerzas necesarios para controlar este tipo de sistemas no son sólo aplicados por los efectos aerodinámicos, sino también por el efecto de acoplamiento que aparece entre la dinámica del robot y la del cuerpo del dispositivo, como consecuencia del principio de acción-reacción originado en la aceleración y desaceleración del grupo motor-hélice [5] [6]. Por otra parte, también es un sistema subactuado como anteriormente se menciona, en el cual sólo hay cuatro rotores que generan cuatro empujes de entrada (Ti) para el control de los seis grados de libertad de la aeronave en vuelo [6].
10
En cambio, otros autores presentan el modelo dinámico para el helicóptero a través de la formulación Lagrange-Euler, considerando además las dinámicas de los rotores, y para el control hicieron comparación entre dos técnicas de control: PID y LQ, en el diseño del controlador PID se consideró el modelo linealizado en torno al origen y para el diseño del control LQ se usó una estructura bilineal [5].
2.2 Dinámica de un cuadricóptero.
El movimiento básico de este tipo de aeronave se genera a partir de los cambios de la velocidad de giro de cada uno de los rotores, los cuales modifican el empuje y el par inducido (figura 4). Para dirigir el vehículo es necesario hacer que cada uno de los pares de la hélice, correspondientes a un mismo rotor, giren en un mismo sentido [8].
Figura 4. Movimientos básicos cuadricóptero
a) Control de ascenso y descenso b) Control cabeceo (Pitch)
Descenso Ascenso Avanzar Retroceder
c)Control de alabeo (Roll) d) Control de guiñada (Yaw)
Movimiento derecho Movimiento izquierda Rotación izquierda Rotación Derecha Fuente: Autores del proyecto
11
Las traslaciones en las tres direcciones del espacio se producen generando un empuje diferencial entre dos rotores alternos. Al provocar una rotación alrededor de alguno de los ejes “X” o “Y”, se obtiene un movimiento traslacional; Esto es, si el el cuadricptero rota alrededor del eje “X” (roll), se va a obtener una traslación a lo largo del eje “Y”, y si el vehículo rota alrededor del eje “Y” (pitch), se va a obtener una traslación a lo largo del eje “X” (Figura 5).
De este modo, para realizar un desplazamiento en la dirección “X”, se deberá disminuir la velocidad la velocidad de los motores 1 y 2, y aumentar la del 3 y 4, permitiendo un movimiento positivo (avanzar), para un movimiento negativo (retroceder) se aumenta la velocidad de los motores 1 y 2 y se disminuye la velocidad de los motores 3 y 4 (figura 4.b), de igual manera para obtener un desplazamiento en la dirección “Y”, se deberá disminuir la velocidad de los motores 2 y 3, y aumentar la de 1 y 4, lo que producirá un movimiento hacia la izquierda, para producir el movimiento hacia la derecha, igualmente se aumenta la velocidad de los motores 2 y 3, y disminuir la de los motores 1 y 4 (figura 4.c).
Finalmente, el incremento de la velocidad de rotación de los motores 2 y 4, el cual permitirá realizar una guiñada “yaw” dextrógira, mientras que el aumento de la velocidad en los motores 1 y 3 resulta una guiñada levógira (figura 4.d) [7] [8].
Figura 5. Ejes de control principales
Fuente: Autores del proyecto
12
control corresponden al empuje vertical ejercido por los rotores y los momentos de alabeo, cabeceo y guiñada de la aeronave [8].
Figura 6. Fuerzas y momentos del cuadricóptero. (Estructura interna parrot)
Fuente: Autores del proyecto
2.3 Control predictivo basado en modelo.
El control predictivo basado en modelo (MPC) es un tipo de control que ha venido creciendo en gran medida durante las últimas décadas en el sector académico y en el sector industrial. Este tipo de control consiste en considerar y optimizar variables importantes para un proceso, no sólo en el instante actual, sino también en el futuro; esto se hace con métodos heurísticos y a través de la simulación de las variables del proceso en el futuro [11].
El MPC se desarrolló a partir de la década de los años setenta, cuando surgieron algoritmos que usaban un modelo dinámico para predecir el efecto de las acciones de control futuras en la salida, dichas acciones se determinaban a partir de la optimización del error predicho sujeto a restricciones en el proceso. Este tipo de control se hizo popular en la industria, en especial en el sector petroquímico, en el cual, los procesos son de dinámicas lentas que permitían su implementación, además, la simplicidad del algoritmo de control atrajo mucho la atención de este
Roll
13
sector; se hicieron diversos tipos de aplicaciones dentro de las que se destacan procesos multivariables.
La estrategia del (MPC) es la de resolver en cada periodo de muestreo un problema de optimización de control óptimo en lazo abierto para un horizonte finito, donde posteriormente se aplican las acciones de control que resultan de esta optimización, manteniéndolas hasta el siguiente intervalo de muestreo. Aunque las predicciones se realizan en lazo abierto, la estrategia las corrige midiendo el estado de las variables del proceso previamente a la etapa de optimización en la que se busca minimizar una función de coste, dando así un efecto de control realimentado. Esta optimización se lleva a cabo minimizando la función de coste, en la cual se encuentra involucrado el error de predicción futuro (este, es la diferencia entre las trayectorias de referencias de las variables controladas y sus respectivas predicciones) y las restricciones (si existen) en las distintas variables del proceso. La variable independiente de esta función de coste son las “futuras”, de modo que los valores de éstas que minimizan dicha función son las acciones que se aplicarán a las entradas del proceso [15].
2.3.1 Metodología.
La metodología de los controladores pertenecientes a la familia MPC, se caracteriza por la siguiente estrategia
1. El modelo del proceso es utilizado para predecir las futuras salidas a lo largo de un horizonte determinado 𝑃 (horizonte de predicción), de longitud
𝑁 intervalos de muestreo. Los valores 𝑦(𝑘 + 𝑖|𝑘)1, para 1 = 1 … 𝑁,
corresponden a las predicciones de la salida en los instantes 𝑘 + 𝑖
(fututo), los cuales son calculadas en el instante 𝑘 (presente). Estas predicciones de salida, dependen de los valores conocidos hasta el instante 𝑘 (entradas y salidas conocidas), así como de las señales de control futuras 𝑢(𝑘 + 𝑖|𝑘)2, para 𝑖 = 1 … 𝑁, las cuales se han de calcular
14
para ser enviadas al sistema. Estas señales de control están proyectadas a lo largo de un horizonte, permaneciendo constantes a partir de 𝑘 + 𝑁𝑐
(figura 7).
2. Definida la trayectoria de referencias futuras 𝑅(𝑘 + 𝑖|𝑘)3, para 𝑖 = 1 … 𝑁,
(la cual va a describir el comportamiento deseado del proceso o a qué estado se desea llevar), la serie de señales de control futuras son calculadas de tal forma que se le logre mantener el proceso lo más cerca posible de dicha trayectoria, haciendo que el error sea mínimo. Dicha trayectoria puede ser representada mediante una función de cualquier orden o podría ser un valor fijo en el tiempo (figura 7).
3. Obtenidos los valores de la trayectoria de referencias futuras 𝑅(𝑘 + 1|𝑘)
y las predicciones de salida 𝑦(𝑘 + 𝑖|𝑘), se restan, consiguiendo como resultado una ecuación de error de predicción, la cual está en función de las acciones de control futuras 𝑢(𝑘 + 𝑖|𝑘) (figura 7) [15] [12].
Figura 7. Estrategia MPC
Fuente: Autores del proyecto.
15
Para resumir lo anteriormente mencionado, la metodología del control predictivo basado en modelo (MPC) puede resumirse en tres pasos:
En cada instante de muestreo (Ts) y haciendo uso del modelo del sistema, se predicen las futuras salidas para un determinado horizonte de predicción (P), estas predicciones de la salida, dependen de valores conocidos (entradas y salidas conocidas), hasta ese instante de muestreo y de las señales de control futuras que serán calculadas.
Las señales de control futuras se calculan optimizando un criterio en el que se desea mantener el proceso de acuerdo a una trayectoria de referencia; este criterio es representado matemáticamente por una función objetivo.
Por último, se envía la señal de control calculada al proceso mientras que se desechan las demás señales, ya que en cada instante de muestreo son obtenidas nuevamente con los nuevos valores, repitiendo el primer paso [13]. La siguiente imagen (figura 8) se muestra la estructura de la estrategia de control anteriormente mencionada.
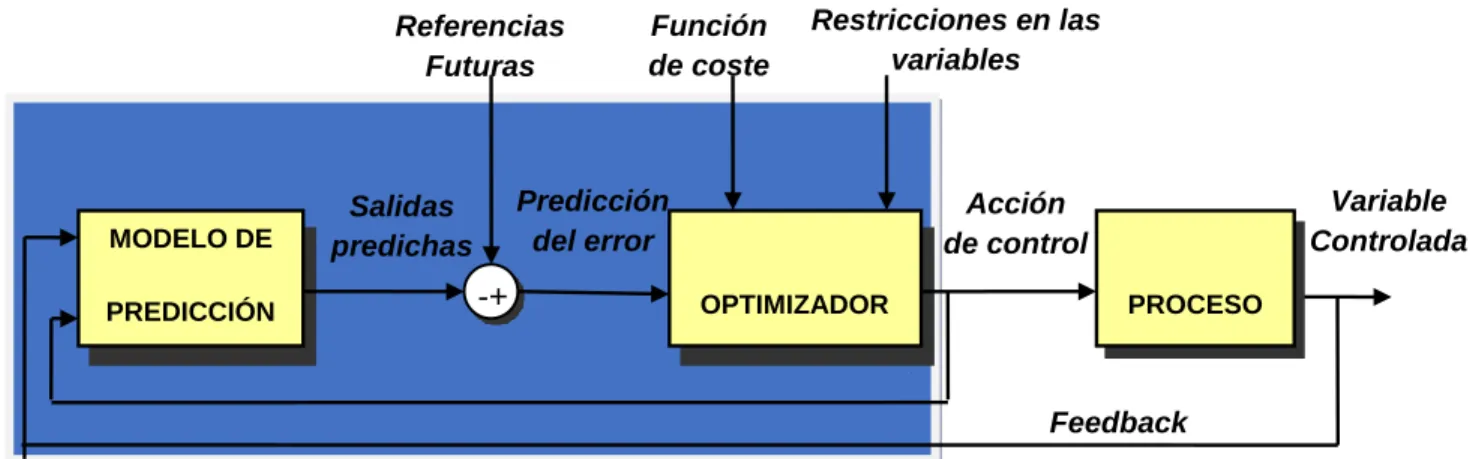
Figura 8. Estructura de estrategia de control
Fuente: González Querubín, Edwin Alonso: Algoritmos de control predictivo multivariable para procesos con dinámica rápida [15].
MODELO DE
PREDICCIÓN OPTIMIZADOR
Salidas predichas
Referencias Futuras
Predicción del error
Función de coste
PROCESO Acción
de control
Variable Controlada
Feedback
-+
16 2.3.2. Modelo de predicción.
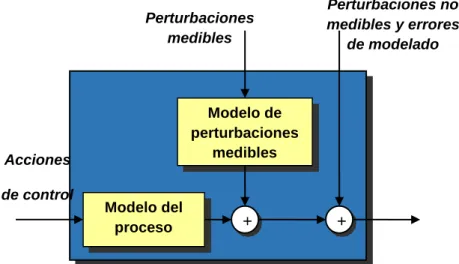
En la estrategia de control predictivo basado en modelo (MPC), este es el componente más crucial para realizar un control óptimo. Este es el resultado de la caracterización del sistema o proceso real, en el cual se reúne toda la información posible de su dinámica, con el fin de que esta información permita realizar predicciones lo más parecidas a la realidad. En este componente se pueden incluir los efectos de las perturbaciones medibles, no medibles y errores de modelado, y de esta forma efectuar las respectivas correcciones (de ser necesarias) de manera anticipada “feedforward”. En dado el caso que estos ambos modelos sean lineales, se aplicaría el principio de superposición, sumando las salidas de cada submodelo para llegar a una salida general (figura 9) [15].
Anteriormente se ha mostrado la forma genérica cómo se resuelve el problema MPC, el cual consiste básicamente en minimizar la función de coste, haciendo uso del modelo del sistema u proceso, para calcular las predicciones. La solución del problema depende principalmente del tipo de modelo que se use para calcular las predicciones [13].
Figura 9. Modelo de predicción
Fuente: González Querubín, Edwin Alonso: Algoritmos de control predictivo multivariable para procesos con dinámica rápida [15].
Modelo del proceso
Modelo de perturbaciones
medibles
+ +
Acciones
de control
Perturbaciones medibles
Perturbaciones no medibles y errores
17 2.3.2.1. Modelo del proceso
Las representaciones más comunes del modelo son: Respuesta al impulso, respuesta al escalón, función de trasferencia y de espacio de estados.
2.3.2.1.1. Modelo respuesta al impulso.
La relación entrada-salida de este modelo está dada por la (ecuación 2.1).
𝑦(𝑡) = ∑ ℎ𝑘𝑢(𝑡 − 𝑘)
∞
𝑘=1
(2.1) Los coeficientes ℎ𝑘son valores muestreados del proceso luego de aplicársele un
impulso unitario de ancho un intervalo de muestreo donde sólo se consideran N valores (figura 10).
𝑦(𝑡) = ∑ ℎ𝑘𝑢(𝑡 − 𝑘) = 𝐻(𝑧−1)𝑢(𝑡) ∞
𝑘=1
(2.2)
Figura 10. Respuesta al impulso
Fuente: González Querubín, Edwin Alonso: Algoritmos de control predictivo multivariable para procesos con dinámica rápida [15].
Donde 𝐻(𝑧−1) = ℎ1𝑧−1+ ℎ2𝑧−2+ ⋯ + ℎ𝑁𝑧−𝑁 y 𝑧−1 representa el retardo unitario. Finalmente, la predicción de la salida en el instante t, está dada por la ecuación:
𝑦(𝑡 + 𝑗) = ∑ ℎ𝑘𝑢(𝑡 + 𝑗 − 𝑘|𝑡) = 𝐻(𝑧−1)𝑢(𝑡 − 𝑘 𝑁
𝑘=1
18
(2.3) Las ventajas de este modelo son su sencillez para la descripción de la dinámica de procesos ya sean de fase no mínima o con retardos y, el hecho de que no se requiera información previa. En cuanto a desventajas, éste no puede representar procesos inestables y su gran número de coeficientes resultados del muestreo que aparecen en el modelo [15].
2.3.2.1.2. Modelo respuesta al escalón.
Tiene las mismas ventajas e inconvenientes que el modelo anterior. Su respuesta se observa en la (figura 11) y la salida se representa mediante la siguiente ecuación:
𝑦(𝑡) = 𝑦0+ ∑ 𝑆𝑘∆𝑢(𝑡 − 𝑘|𝑡) = 𝑦0+ 𝑆(𝑧−1)(1 − 𝑧−1)𝑢(𝑡) 𝑁
𝑘=1
(2.4)
Figura 11. Respuesta al escalón
Fuente: González Querubín, Edwin Alonso: Algoritmos de control predictivo multivariable para procesos con dinámica rápida [15].
Los coeficientes 𝑆𝑘 son los valores medidos de la respuesta al escalón en cada
19
∆𝑦(𝑡 + 𝑗|𝑡) = ∑ 𝑆𝑘∆𝑢(𝑡 + 𝑗 − 𝑘|𝑡)
𝑁
𝑘=1
(2.5) 2.3.2.1.3. Modelo función de transferencia.
Se utiliza un modelo discreto del sistema u proceso para obtener la salida dada por la ecuación:
𝐴(𝑧−1)𝑦(𝑡) = 𝐵(𝑧−1)𝑢(𝑡)
(2.6) Donde 𝑢(𝑡) e 𝑦(𝑡) son las variables de entrada y salida respectivamente. A y B son polinomios en el operador retardo 𝑧−1.
Los polinomios A, B están dados por:
𝐴(𝑧−1) = 1 + 𝑎
1𝑧−2+ 𝑎2𝑧−2+ ⋯ + 𝑎𝑛𝑎𝑧−𝑛𝑎
𝐵(𝑧−1) = 𝑏
1𝑧−2+ 𝑏2𝑧−2+ ⋯ + 𝑏𝑛𝑏𝑧−𝑛𝑏
(2.7) De acuerdo a lo anterior, mediante la (ecuación 2.8) se calcula la predicción de la salida:
𝑦(𝑡 + 𝑗|𝑡) =𝐵(𝑧
−1)
𝐴(𝑧−1)𝑢(𝑡 + 𝑗|𝑡)
(2.8) Este tipo de representación requiere que se tenga un buen conocimiento del sistema u proceso, en cuanto a su orden, para la obtención de los polinomios A y B, puesto que se debe disponer de un modelo la más preciso posible. Este modelo tiene como ventaja que es útil para representar procesos inestables y el número de parámetros que dispone es mínimo [15] [13].
2.3.2.1.4. Modelo en el espacio de estados.
20
𝑥(𝑡 + 1) = 𝐴𝑥(𝑡) + 𝐵𝑢(𝑡) 𝑦(𝑡) = 𝐶𝑥(𝑡)
(2.9)
En el caso monovariable 𝑦(𝑡) y 𝑢(𝑡) son escalares y 𝑥(𝑡) es el vector de estados. Para el proceso se tiene la misma descripción pero con el vector u de dimensión 𝑚
y el vector y de dimensión 𝑛.
Si se considera como variable de entrada los incrementos de la señal de control
∆𝑢(𝑡) en lugar de 𝑢(𝑡), Puede ser usado un modelo incremental. Este modelo se puede escribir en la forma genérica de espacio de estados, teniendo en cuenta que
∆𝑢(𝑡) = 𝑢(𝑡) − 𝑢(𝑡 − 1). Al combinar esta expresión con la (ecuación 2.9) se obtiene [13]:
[𝑥(𝑡 + 1) 𝑢(𝑡) ] = [
𝐴 𝐵 0 𝐼] [
𝑥(𝑡)
𝑢(𝑡 − 1)] + [ 𝐵
𝐼] ∆𝑢(𝑡)
𝑦(𝑡) = [𝐶 0] [ 𝑥(𝑡) 𝑢(𝑡 − 1)]
(2.10) Se define el nuevo vector de estado como 𝑥̅(𝑡) = [𝑥(𝑡) 𝑢(𝑡 − 1)]𝑇, el modelo incremental toma la siguiente forma general:
𝑥̅(𝑡 + 1) = 𝑀𝑥̅(𝑡) + 𝑁∆𝑢(𝑡) 𝑦(𝑡) = 𝑄𝑥̅(𝑡)
(2.11) Para minimizar la función objetivo, hay que calcular las predicciones a lo largo del horizonte. En el caso del modelo incremental, se obtiene utilizando la (ecuación 2.11) de manera recursiva.
𝑦̂(𝑡 + 𝑗) = 𝑄𝑀𝑗𝑥̂(𝑡) + ∑ 𝑄𝑀𝑗−𝑖−1𝑁∆𝑢(𝑡 + 𝑖)
𝑗−1
𝑖=0
(2.12)
Nótese que dichas predicciones necesitan una estimación insesgada del vector de estados 𝑥(𝑡). Si éste no es accesible será necesario incluir un observador de estados, el cual calcula la estimación por medio de la siguiente ecuación:
𝑥̂(𝑡|𝑡) = 𝑥̂(𝑡|𝑡 − 1) + 𝐾(𝑦𝑚(𝑡) − 𝑦(𝑡|𝑡 − 1))
21
Donde 𝑦𝑚(𝑡) es la salida medida. Si la planta se encuentra sujeta a perturbaciones en forma de ruido blanco el cual afecta a la salida y al proceso, con matices de covarianza conocidas, este observador se convierte en un filtro de Kalman. La ganancia 𝐾, se calcula resolviendo una ecuación de Riccati [13].
Las predicciones a lo largo del horizonte vienen dadas por:
y =
[
ŷ(t + 1|t) ŷ(t + 2|t)
. . . ŷ(t + N2|t)]
=
[
QMx̂(t) + QN∆u(t)
QM2x̂(t) + ∑ QM1−iN∆u(t + i) 1
i=0 .
. .
QMN2x̂(t) + ∑ QMN2−1−iN∆u(t + i) N2−1
i=0 ]
(2.14) La ecuación anterior puede ser expresada de forma vectorial como:
𝐲 = 𝐅𝐱̂(𝐭) + 𝐇𝐮
(2.15) Donde 𝑢 = [∆𝑢(𝑡) ∆𝑢(𝑡 + 1) .. . ∆𝑢(𝑡 + 𝑁𝑢− 1)]𝑇 es el vector de incrementos de
control futuros, H es una matriz triangular inferior por bloques cuyos elementos no nulos vienen definidos por 𝐻𝑖𝑗 = 𝑄𝑀𝑖−𝑗𝑁 y la matriz F está dada por:
F =
[ QM QM2
. . . QMN2]
22
calculadas. La secuencia de control 𝑢 se calcula minimizando la función objetivo, que para el caso de (𝛿(𝑗) = 1 𝑦 𝜆(𝑗) = 𝜆 )) puede ser escrito como:
𝐉 = (𝐇𝐮 + 𝐅𝐱̂(𝐭) − 𝐑)𝐓𝜹(𝐇𝐮 + 𝐅𝐱̂(𝐭) − 𝐑) + 𝛌𝐮𝐓𝐮
(2.17)
Esta representación posee la ventaja que puede extenderse al caso multivariable, así como la de analizar la representación interna.
2.3.3. Predicción salida del proceso.
La salida predicha está formada por la suma de dos señales: la respuesta libre (la cual depende de las entradas pasadas) y la respuesta forzada (la cual depende de las entradas futuras).
𝑃𝑟𝑒𝑑𝑖𝑐𝑐𝑖ó𝑛 𝑆𝐴𝐿𝐼𝐷𝐴 = 𝑃𝑟𝑒𝑑𝑖𝑐𝑐𝑖ó𝑛 𝑅𝑒𝑠𝑝. 𝐿𝐼𝐵𝑅𝐸 + 𝑃𝑟𝑒𝑑𝑖𝑐𝑐𝑖ó𝑛 𝑅𝑒𝑠𝑝. 𝐹𝑂𝑅𝑍𝐴𝐷𝐴
𝑦𝑝(𝑘 + 𝑗|𝑘) = 𝑓 + 𝐻∆𝑢(𝑘 + 𝑗 − 1|𝑘)
(2.18)
Respuesta libre
La respuesta libre como se dijo anteriormente, depende de las entradas o acciones de control pasadas y representa la evolución del proceso en el futuro, cuando la entrada aplicada en el intervalo anterior se mantiene constante [15].
Las entradas futuras son iguales a la entrada en el instante 𝑘 − 1:
𝑢𝑓(𝑘 − 𝑗) = 𝑢(𝑘 − 𝑗) 𝑝𝑎𝑟𝑎 𝑗 = 0,1,2, … 𝑢𝑓(𝑘 + 𝑗) = 𝑢(𝑘 − 1) 𝑝𝑎𝑟𝑎 𝑗 = 0,1,2, …
(2.19)
Respuesta Forzada
La respuesta forzada como se menciona anteriormente, depende de las entradas o acciones futuras (valores aún desconocidos) y mide cómo evoluciona el proceso debido a dichos cambios [15].
𝑢𝐻(𝑘 − 𝑗) = 0 𝑝𝑎𝑟𝑎 𝑗 = 0,1,2, …
𝑢𝐻(𝑘 + 𝑗) = 𝑢(𝑘 + 1) − 𝑢(𝑘 − 1) 𝑝𝑎𝑟𝑎 𝑗 = 0,1,2, …
23
Figura 12. Salida predicha
Fuente: González Querubín, Edwin Alonso: Algoritmos de control predictivo multivariable para procesos con dinámica rápida [15].
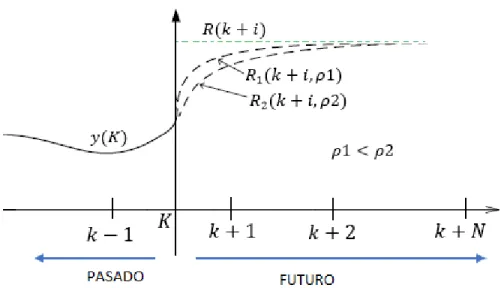
2.3.4. Trayectoria de referencia
La trayectoria de referencia 𝑅(𝑘 + 𝑖) define la forma a la que se desea llevar la variable controlada del proceso, desde una posición 𝑦(𝑘) hasta una posición deseada 𝑅(𝑘 + 𝑖), esta trayectoria de referencia puede tener una aproximación de primer orden, o puede ser constante en el tiempo tomando el valor de 𝑅(𝑘 + 𝑖)
(figura 10) [15][13]:
𝑅(𝑘) = 𝑦(𝑘)
𝑅(𝑘 + 𝑖) = 𝜌𝑅(𝑘 + 𝑖 − 1) + (1 − 𝜌)𝑅(𝑘 + 𝑖) 𝑝𝑎𝑟𝑎 𝑖 = 1,2, …
24
Figura 13. Trayectoria de referencia
Fuente: Autores del proyecto
2.3.5. Función de coste o Función objetivo
La finalidad de dicha función, es obtener la ley de control a partir de su minimización. La mayoría de los MPC, emplean diferentes tipos de función de coste, siendo la expresión para esta [15] [13]:
𝐽(𝑁0, 𝑁𝑝, 𝑁𝐶) = ∑ 𝛼(𝑗)[𝑅(𝑘 + 𝑗) − 𝑦(𝑘 + 𝑗|𝑘)]2+ ∑𝑁𝑗=1𝑐 𝜆(𝑗)[Δ𝑢(𝑘 + 𝑗 − 1)]2 𝑁𝑝
𝑗=𝑁0
(2.22) El índice 𝐽 es una expresión cuadrática compuesta por la suma de dos términos: 2 EL primer término está relacionado con el error de predicción, resultado de
la resta entre la salida predicha y la referencia ([𝑅(𝑘 + 𝑗) − 𝑦(𝑘 + 𝑗|𝑘)]), donde 𝑁𝑝 es el horizonte de predicción (instantes de muestreo) y 𝑁𝑜
determina a partir de qué instante se desea que la salida sea igual a la referencia.
3 El segundo término está relacionado con los incrementos futuros en las acciones de control Δ𝑢(𝑘 + 𝑗 − 1), estos incrementos se realizan a lo largo de un horizonte de control 𝑁𝑐 (instantes de muestreo), en donde una vez superado el instante (𝑘 + 𝑁𝑐) la acción de control permanece constante.
25 2.3.6 Ley de control
La secuencia de los movimientos futuros es calculada mediante un proceso de optimización, en el cual se minimiza la función de coste (ecuación 2.22) y puede incorporar una serie de restricciones, estas se originan debido a las limitaciones físicas del proceso a ser controlado (temperatura máxima de un horno, velocidad de llenado de un tanque), por cuestiones de seguridad, económicas etc. Las restricciones más comunes son las de límites mínimos y máximos para las variables del proceso y de velocidades de cambio en las variables controladas [15].
En caso de que no existan restricciones, la solución se obtiene analíticamente, y dado el caso que existan la optimización se efectúa empleando técnicas iterativas [15].
2.4 MPC en Espacio de Estados:
La mayoría de algoritmos de control predictivo se pueden diferenciar por el tipo de modelo usado para realizar las predicciones (DMC “Dinamic Matrix Control” o GPC “Generalized Predictive Control”). En este caso el MPC en espacio de estados, dispone de un modelo en espacio de estados del proceso, para posteriormente ser extendido directamente al caso MIMO el cual se desarrollará más adelante. En esta sección se muestra el funcionamiento del MPC para un sistema SISO [15] [13]. 2.4.1. Modelo del proceso
26
2.4.2. Actualización de la respuesta libre (cálculo recursivo)
Al ser ejecutado el algoritmo MPC por primera vez, la respuesta libre 𝑓4, se inicializa
con los valores obtenidos de las matrices 𝑄 y 𝑀 (ecuación 3.3 y 3.4), las cuales son obtenidas del modelo incremental (ecuación 2.10 y 2.11). Como se vio en la sección 2.1.3, ésta depende únicamente de las entradas pasadas. Nótese que la respuesta libre depende del vector de estados 𝑥̂(𝑡)5 (ecuación 3.3 y 2.15) [15][13].
𝑓 = 𝐹𝑥̂(𝑡)
(2.25)
F = ⌈ QM QM2
⋮ QMN𝑝
⌉
(2.26) Los valores de las matrices 𝑄 y 𝑀 son valores constantes (ecuación 2.27), los cuales dependen de: la matriz de estado 𝐴, matriz de entrada 𝐵 y de la matriz de salida 𝐶 (ecuación 2.9 y 2.10), por lo que la respuesta libre se actualiza con los nuevos estado y la entrada pasada 𝑢(𝑘 − 1) (ecuación 2.28), obtenidos mediante el filtro de Kalman.
𝑀 = ⌈𝐴 𝐵
0 𝐼⌉ 𝑄 = ⌈𝐶 0⌉
(2.27)
𝑥̂(𝑘) = ⌈ 𝑥(𝑘|𝑘) 𝑢(𝑘 − 1)⌉
(2.28)
2.4.3 Respuesta forzada
La respuesta forzada 𝑅𝑓 = 𝐻∆𝑢(𝑘 + 𝑁𝑐− 1), es la contribución dada por los
movimientos futuros en la entrada. Dichos movimientos están proyectados a lo largo del horizonte de control 𝑁𝑐, en donde para los instantes posteriores a éste las variaciones son nulas [15][13]:
4 La respuesta libre 𝑓, es un vector de dimensiones 𝑁
𝑝𝑥𝑁𝑥, donde 𝑁𝑥, representa el número de
estados del proceso.
27
[
𝑅𝑓(𝑘 + 1|𝑘) 𝑅𝑓(𝑘 + 2|𝑘) 𝑅𝑓(𝑘 + 3|𝑘)
⋮
𝑅𝑓(𝑘 + 𝑁𝑝|𝑘)] = 𝐻. ⌈
∆𝑢(𝑘|𝑘) ∆𝑢(𝑘 + 1|𝑘)
⋮
∆𝑢(𝑘 + 𝑁𝑐 − 1|𝑘)
⌉
(2.29) La variable 𝐻 representa una matriz triangular inferior en la cual sus elementos no nulos están definidos por 𝐻𝑖𝑗 = 𝑄𝑀𝑖−𝑗𝑁 (ecuación 2.14). La multiplicación de cada
columna de 𝐻 por su variación ∆𝑢, indica la contribución de dicha variación a la evolución del proceso:
𝐻 =
[
∑ QM1−iN 1
i=0
⋮
∑ QM𝑁𝑝−1−iN 𝑁𝑝−1
i=0 ]
(2.30)
2.4.4 Perturbaciones
Perturbaciones medibles: En el algoritmo MPC se considera que estas perturbaciones están constantes en el futuro:
∆𝑑(𝑘 + 1|𝑘) = ∆𝑑(𝑘 + 2|𝑘) = ⋯ = ∆d(𝑘 + 𝑁𝑝|𝑘) = 0
(2.31) En donde para el instante 𝑘 la variación en esta se puede calcular como:
∆𝑑(𝑘|𝑘) = 𝑑(𝑘) − 𝑑(𝑘 − 1)
(2.32) 2.4.5 Predicción de la salida
28
𝑆𝑎𝑙𝑖𝑑𝑎 𝑝𝑟𝑒𝑑𝑖𝑐ℎ𝑎=
𝑅𝑒𝑠𝑝𝑢𝑒𝑠𝑡𝑎 𝑙𝑖𝑏𝑟𝑒 +
𝑅𝑒𝑠𝑝𝑢𝑒𝑠𝑡𝑎 𝑓𝑜𝑟𝑧𝑎𝑑𝑎
[
𝑦𝑝(𝑘 + 1|𝑘) 𝑦𝑝(𝑘 + 2|𝑘) 𝑦𝑝(𝑘 + 3|𝑘)
⋮
𝑦𝑝(𝑘 + 𝑁𝑝|𝑘)]
= ⌈ QM QM2
⋮ QMN𝑝
⌉ ⌈ 𝑥(𝑘|𝑘) 𝑢(𝑘 − 1)⌉ +
[
∑ QM1−iN 1
i=0
⋮
∑ QM𝑁𝑝−1−iN 𝑁𝑝−1
i=0 ]
. ⌈
∆𝑢(𝑘|𝑘) ∆𝑢(𝑘 + 1|𝑘)
⋮
∆𝑢(𝑘 + 𝑁𝑐 − 1|𝑘) ⌉
(2.33) 2.4.6. Trayectoria de referencia
La trayectoria de referencia poder tomar un valor constante o puede tomar la forma de la (ecuación 2.21), su vector final será de 𝑁𝑝 coeficientes:
𝑅 =
𝑅(𝑘 + 1) 𝑅(𝑘 + 2) 𝑅(𝑘 + 3)
⋮ 𝑅(𝑘 + 𝑁𝑝)
(2.34) 2.4.7. Función de coste.
El objetivo de un controlador MPC es llevar el proceso lo más cerca de la referencia en el sentido de mínimos cuadrados (ecuación 2.22), para obtener la función de coste, primeramente se calcula el error de predicción 𝐸𝑝, se cual se obtiene de la
resta, de las predicciones de la salida (ecuación 2.33) y la trayectoria de referencia (ecuación 2.34) [15] [13]:
𝐸𝑝(𝑘 + 1|𝑘) 𝐸𝑝(𝑘 + 2|𝑘)
𝐸𝑝(𝑘 + 3|𝑘) ⋮
𝐸𝑝(𝑘 + 𝑁𝑝|𝑘) =
𝑅(𝑘 + 1) 𝑅(𝑘 + 2) 𝑅(𝑘 + 3)
⋮ 𝑅(𝑘 + 𝑁𝑝)
−
𝑦𝑝(𝑘 + 1|𝑘) 𝑦𝑝(𝑘 + 2|𝑘)
𝑦𝑝(𝑘 + 3|𝑘) ⋮
𝑦𝑝(𝑘 + 𝑁𝑝|𝑘)
29
𝐸𝑝(𝑘 + 1|𝑘) 𝐸𝑝(𝑘 + 2|𝑘) 𝐸𝑝(𝑘 + 3|𝑘)
⋮ 𝐸𝑝(𝑘 + 𝑁𝑝|𝑘)
=
𝑅(𝑘 + 1) 𝑅(𝑘 + 2) 𝑅(𝑘 + 3)
⋮ 𝑅(𝑘 + 𝑁𝑝)
− ⌈ QM QM2
⋮ QMN𝑝
⌉ ⌈ 𝑥(𝑘|𝑘) 𝑢(𝑘 − 1)⌉ −
[
∑ QM1−iN 1
i=0 ⋮
∑ QM𝑁𝑝−1−iN 𝑁𝑝−1
i=0 ]
. ⌈
∆𝑢(𝑘|𝑘) ∆𝑢(𝑘 + 1|𝑘)
⋮
∆𝑢(𝑘 + 𝑁𝑐− 1|𝑘) ⌉
(2.35) Se expresa la función de coste (ecuación 2.22) en forma matricial, tomando los valores conocidos "𝐷" de la (ecuación 2.35) :
𝐷 = 𝑅 − 𝑓
𝑚𝑖𝑛∆𝑢 𝐽 = 𝑚𝑖𝑛∆𝑢 [𝐸𝑝𝑇 ∝ 𝐸𝑝+ ∆𝑢𝑇𝜆∆𝑢]
𝑚𝑖𝑛∆𝑢 𝐽 = 𝑚𝑖𝑛∆𝑢 [(𝐷 − 𝐻∆𝑢)𝑇 ∝ (𝐷 − 𝐻∆𝑢) + ∆𝑢𝑇𝜆∆𝑢]
(2.36) Las matrices ∝ y 𝜆 , contienen los coeficientes que ponderan los errores de predicción y el esfuerzo de control. Teniendo la siguiente estructura:
∝=
∝1 0 0 0 0 ∝2 0 0
0 0 ⋱ 0
0 0 0 ∝𝑁𝑝
𝜆 = ⌈
𝜆1 0 0 0
0 𝜆2 0 0
0 0 ⋱ 0
0 0 0 𝜆𝑁𝑐 ⌉
(2.37) 2.4.8 Ley de control
Si no existen restricciones de ningún tipo para las variables del proceso, para los movimientos de control la solución analítica que proporciona el óptimo es:
𝑢 = (𝐻𝑇𝐻 + 𝜆𝐼)−1𝐻𝑇(𝑤 − 𝐹𝑥̂(𝑡))
30 2.5. Manejo de restricciones
Como se menciona en la sección 2.1.6, éstas suelen estar motivadas debido a limitaciones físicas del proceso. Entre las más comunes se tienen tres tipos [15]:
Limitaciones en la velocidad de variación de la acción de control:
∆𝑢𝑚𝑖𝑛≤ ∆𝑢 ≤ ∆𝑢𝑚𝑎𝑥
Limitaciones en las magnitudes máximas y mínimas de la acción de control:
𝑢𝑚𝑖𝑛 ≤ 𝑢 ≤ 𝑢𝑚𝑎𝑥
Limitaciones en las magnitudes máximas y mínimas permitidas para las salidas:
𝑌𝑚𝑖𝑛 ≤ 𝑌𝑝 ≤ 𝑌𝑚𝑎𝑥
Para ser incluidas en el modelo de predicción exige un replanteamiento del problema de optimización.
2.5.1. Programación cuadrática MPC
Es uno de los métodos más usados por la mayoría de MPC, para dar solución a la ecuación de coste (ecuación 3.15) la cual se encuentra sujeta a restricciones, para esto se usa Programación Cuadrática. Su uso hace necesario reconfigurar dicha ecuación para llevarla a la expresión (ecuación 2.39) requerida por dicha programación [15].
𝐽𝑄𝑃 = 1 2𝑥
𝑇𝐻𝑥 + 𝐶𝑇𝑥
(2.39) La anterior ecuación está sujeta a las restricciones 𝐴𝑥 ≤ 𝐵, por lo tanto:
𝐽𝑄𝑃 = 1 2∆𝑢
𝑇𝐻∆𝑢 + 𝐶𝑇∆𝑢, sujeto a 𝐴∆𝑢 ≤ 𝐵
31 De acuerdo a la (ecuación 2.36) tenemos:
𝐽 = (𝐷 − 𝐻∆𝑢)𝑇 ∝ (𝐷 − 𝐻∆𝑢) + ∆𝑢𝑇𝜆∆𝑢 𝐽 = (𝐷𝑇− ∆𝑢𝑇𝐻𝑇) ∝ (𝐷 − 𝐻∆𝑢) + ∆𝑢𝑇𝜆∆𝑢
𝐽 = 𝐷𝑇 ∝ 𝐷 − 𝐷𝑇 ∝ 𝐻∆𝑢 − ∆𝑢𝑇𝐻𝑇 ∝ 𝐷 + ∆𝑢𝑇𝐻𝑇 ∝ 𝐻∆𝑢 + ∆𝑢𝑇𝜆∆𝑢
𝐽 = ∆𝑢𝑇(𝐻𝑇 ∝ 𝐻 + 𝜆)∆u − 2𝐷𝑇𝛼𝐻∆𝑢 + 𝐷𝑇𝛼𝐷
𝐽𝑄𝑃 = 1 2𝐽
𝐽𝑄𝑃 =
1 2∆𝑢
𝑇(𝐻𝑇 ∝ 𝐻 + 𝜆)∆u − 𝐷𝑇𝛼𝐻∆𝑢 +1
2𝐷
𝑇𝛼𝐷
𝐽𝑄𝑃 = 1 2∆𝑢
𝑇(𝐻𝑇 ∝ 𝐻 + 𝜆)∆u − 𝐷𝑇𝛼𝐻∆𝑢
(2.41) Se descarta el término 12𝐷𝑇𝛼𝐷 ya que este no influye en el óptimo, debido a que
no depende de ∆𝑢, obteniendo finalmente
𝐽𝑄𝑃 =
1 2∆𝑢
𝑇(𝐻𝑇 ∝ 𝐻 + 𝜆)∆u + (−𝐷𝑇𝛼𝐻)∆𝑢
(2.42)
Se observa en la (ecuación 2.42) que 𝐻 = (𝐻𝑇 ∝ 𝐻 + 𝜆) y 𝐶𝑇 = (−𝐷𝑇𝛼𝐻). Obteniendo la configuración deseada (ecuación 2.40). La matriz 𝐻 es constante y la matriz 𝐶𝑇 varía en cada iteración. Las ecuaciones 𝐽 y 𝐽
𝑄𝑃 tienen el mismo mínimo
y Hessiano, esto quiere decir que el problema sigue siendo un problema de optimización convexa, lo cual garantiza un mínimo global único; por lo tanto el algoritmo va a converger, si existe una solución ∆𝑢 que satisfaga las restricciones [15]. La desigual matricial (ecuación 2.40) se forma a partir de seis submatrices:
𝐴∆𝑢 ≤ 𝐵 = [ 𝐴1 𝐴2 𝐴3
] . ∆𝑢 ≤ [ 𝐵1 𝐵2 𝐵3 ]
(2.43) 2.5.1.1. Restricciones duras
32
Restricciones para los incrementos en la acción de control
Para que haya restricciones en la velocidad del cambio de la acción de control para todo horizonte de control 𝑁𝑐, se debe cumplir [15]:
∆𝑢𝑚𝑖𝑛≤ ∆𝑢 ≤ ∆𝑢𝑚𝑎𝑥
La anterior desigualdad también se puede escribir de la forma:
∆𝑢 ≤ ∆𝑢𝑚𝑎𝑥 −∆𝑢 ≤ −∆𝑢𝑚𝑖𝑛
(2.44)
Donde:
∆𝑢 = ⌈
∆𝑢(𝑘|𝑘) ∆𝑢(𝑘 + 1|𝑘)
⋮
∆𝑢(𝑘 + 𝑁𝑐− 1|𝑘) ⌉
(2.45) Teniendo en cuenta la (ecuación 2.44) y la (ecuación 2.45), las desigualdades se pueden expresar en forma matricial. Llegando a una expresión en términos de las matrices 𝐴1 y 𝐵1 (ecuación 2.43):
𝐴1. ∆𝑢 ≤ 𝐵1
(2.46)
⌈ 𝐼 −𝐼⌉ . ⌈
∆𝑢(𝑘|𝑘) ∆𝑢(𝑘 + 1|𝑘)
⋮
∆𝑢(𝑘 + 𝑁𝑐 − 1|𝑘)
⌉ ≤
[
∆𝑢𝑚𝑎𝑥1 ∆𝑢𝑚𝑎𝑥2
⋮ ∆𝑢𝑚𝑎𝑥𝑁𝑐 −∆𝑢𝑚𝑖𝑛1
−∆𝑢𝑚𝑖𝑛2 ⋮ −∆𝑢𝑚𝑖𝑛𝑁𝑐]
(2.47) Donde 𝐼 e suna matriz identidad de dimensiones 𝑁𝑐𝑥𝑁𝑐, y corresponde al término
𝐴1 y el vector de incrementos corresponde al término 𝐵1.
Restricciones de magnitud de la acción de control.
33
𝑢𝑚𝑖𝑛 ≤ 𝑢 ≤ 𝑢𝑚𝑎𝑥
La anterior desigualdad también se puede escribir de la forma:
𝑢 ≤ 𝑢𝑚𝑎𝑥 −𝑢 ≤ −𝑢𝑚𝑖𝑛
(2.48) Las acciones de control futuras 𝑢, para un horizonte de control 𝑁𝑐, dependen de los incrementos futuros ∆𝑢 y de la entrada aplicada en el instante anterior
𝑢(𝑘 − 1) (figura 10), estas están representadas como:
𝑢 = ⌈
𝑢(𝑘) 𝑢(𝑘 + 1)
⋮
𝑢(𝑘 + 𝑁𝑐− 1)
⌉ = ⌈
∆𝑢(𝑘|𝑘)
∆𝑢(𝑘 + 1|𝑘) + ∆𝑢(𝑘|𝑘) ⋮
∆𝑢(𝑘 + 𝑁𝑐 − 1|𝑘) + ⋯ + ∆𝑢(𝑘|𝑘) ⌉ + ⌈
𝑢(𝑘 − 1) 𝑢(𝑘 − 1)
⋮ 𝑢(𝑘 − 1)
⌉
(2.49) Llevando la (ecuación 3.27) a la forma de las inecuaciones (ecuación 3.26):
⌈
∆𝑢(𝑘|𝑘)
∆𝑢(𝑘 + 1|𝑘) + ∆𝑢(𝑘|𝑘) ⋮
∆𝑢(𝑘 + 𝑁𝑐− 1|𝑘) + ⋯ + ∆𝑢(𝑘|𝑘) ⌉ + ⌈
𝑢(𝑘 − 1) 𝑢(𝑘 − 1)
⋮ 𝑢(𝑘 − 1)
⌉ ≤ [ 𝑢𝑚𝑎𝑥1
𝑢𝑚𝑎𝑥2
⋮ 𝑢𝑚𝑎𝑥𝑁𝑐
]
− ⌈
∆𝑢(𝑘|𝑘)
∆𝑢(𝑘 + 1|𝑘) + ∆𝑢(𝑘|𝑘) ⋮
∆𝑢(𝑘 + 𝑁𝑐 − 1|𝑘) + ⋯ + ∆𝑢(𝑘|𝑘) ⌉ − ⌈
𝑢(𝑘 − 1) 𝑢(𝑘 − 1)
⋮ 𝑢(𝑘 − 1)
⌉ ≤ [ 𝑢𝑚𝑖𝑛1 𝑢𝑚𝑖𝑛2
⋮ 𝑢𝑚𝑖𝑛𝑁𝑐
]
(2.50) Las desigualdades (ecuación 2.50) se pueden expresar en forma matricial. Llegando a una expresión en términos de las matrices 𝐴2 y 𝐵2 :
⌈ 𝐼𝐿 −𝐼𝐿⌉ . ⌈
∆𝑢(𝑘|𝑘) ∆𝑢(𝑘 + 1|𝑘)
⋮
∆𝑢(𝑘 + 𝑁𝑐 − 1|𝑘) ⌉ ≤
[
𝑢𝑚𝑎𝑥1 𝑢𝑚𝑎𝑥2
⋮ 𝑢𝑚𝑎𝑥𝑁𝑐
−𝑢𝑚𝑖𝑛1
−𝑢𝑚𝑖𝑛2
⋮ −𝑢𝑚𝑖𝑛𝑁𝑐]
− 𝑢(𝑘 − 1).
[ 1 1 ⋮ 1 −1 −1 ⋮ −1]
34
Donde la matriz 𝐼𝐿 es una matriz triangular inferior de unos y ceros, con dimensiones
𝑁𝑐𝑥𝑁𝑐.
𝐼𝐿 = [
1 0 … 0 1 1 … 0 ⋮ ⋮ ⋮ ⋮ 1 1 … 1 ]
Figura 14. Acciones de control futuras
Fuente: Autores del proyecto
Restricciones de magnitud para las predicciones de la salida
Teniendo en cuenta la salida predicha (ecuaciones 2.33 y 2.15), las predicciones a lo largo de dicho horizonte no pueden infringir las restricciones del límite máximo y mínimo permitido [15]:
𝑌𝑚𝑖𝑛 ≤ 𝑌𝑝 ≤ 𝑌𝑚𝑎𝑥
La anterior desigualdad también se puede escribir de la forma:
35
𝐻∆𝑢 ≤ 𝑌𝑚𝑎𝑥 − 𝐿 −𝐻∆𝑢 ≤ −𝑌𝑚𝑖𝑛+ 𝐿
(2.52) Las desigualdades (ecuación 2.52) se pueden expresar en forma matricial. Llegando a una expresión en términos de las matrices 𝐴3 y 𝐵3 :
⌈ 𝐻 −𝐻⌉ . ⌈
∆𝑢(𝑘|𝑘) ∆𝑢(𝑘 + 1|𝑘)
⋮
∆𝑢(𝑘 + 𝑁𝑐 − 1|𝑘)
⌉ ≤
[
𝑦𝑚𝑎𝑥1
𝑦𝑚𝑎𝑥2
⋮ 𝑦𝑚𝑎𝑥𝑁𝑝 −𝑦𝑚𝑖𝑛1
−𝑦𝑚𝑖𝑛2 ⋮ −𝑦𝑚𝑖𝑛𝑁𝑝]
+
[
−𝐿(𝑘 + 1|𝑘) −𝐿(𝑘 + 2|𝑘)
⋮
−𝐿(𝑘 + 𝑁𝑝|𝑘) 𝐿(𝑘 + 1|𝑘) 𝐿(𝑘 + 2|𝑘)
⋮
𝐿(𝑘 + 𝑁𝑝|𝑘) ]
(2.53) Con las matrices generadas anteriormente 𝐴1, 𝐴2,𝐴3,𝐵1,𝐵2, 𝐵3, se construye la expresión general para las matrices del algoritmo QP (ecuación 2.43), dando lugar a la (ecuación 2.54):
[ 𝐴1 𝐴2 𝐴3
36
[ 𝐼 −𝐼
𝐼𝐿 −𝐼𝐿
𝐻 −𝐻]
⌈
∆𝑢(𝑘|𝑘) ∆𝑢(𝑘 + 1|𝑘)
⋮
∆𝑢(𝑘 + 𝑁𝑐− 1|𝑘)
⌉ ≤
[
∆𝑢𝑚𝑎𝑥1
∆𝑢𝑚𝑎𝑥2
⋮
∆𝑢𝑚𝑎𝑥𝑁𝑐
−∆𝑢𝑚𝑖𝑛1
−∆𝑢𝑚𝑖𝑛2
⋮
−∆𝑢𝑚𝑖𝑛𝑁𝑐
𝑢𝑚𝑎𝑥1− 𝑢(𝑘 − 1)
𝑢𝑚𝑎𝑥2− 𝑢(𝑘 − 1)
⋮ 𝑢𝑚𝑎𝑥𝑁𝑐−𝑢(𝑘−1)
−𝑢𝑚𝑖𝑛1+ 𝑢(𝑘 − 1)
−𝑢𝑚𝑖𝑛2+ 𝑢(𝑘 − 1)
⋮
−𝑢𝑚𝑖𝑛𝑁𝑐+ 𝑢(𝑘 − 1)
𝑦𝑚𝑎𝑥1− 𝐿(𝑘 + 1|𝑘)
𝑦𝑚𝑎𝑥2− 𝐿(𝑘 + 1|𝑘)
⋮
𝑦𝑚𝑎𝑥𝑁𝑝− 𝐿(𝑘 + 1|𝑘)
−𝑦𝑚𝑖𝑛1+ 𝐿(𝑘 + 1|𝑘)
−𝑦𝑚𝑖𝑛2+ 𝐿(𝑘 + 1|𝑘)
⋮
−𝑦𝑚𝑖𝑛𝑁𝑝+ 𝐿(𝑘 + 1|𝑘)]
(2.54) En donde: ∆𝑢 es de dimensiones 𝑁𝑐𝑥1, 𝐴 es de dimensiones (4𝑁𝐶+ 4𝑁𝑝)𝑥𝑁𝐶
permaneciendo constante en cada iteración, 𝐵 es de dimensiones (4𝑁𝐶+ 4𝑁𝑝)𝑥1, donde 𝐵1 es constante y 𝐵2𝑦 𝐵3 cambian en cada iteración.
2.5.1.2. Restricciones blandas
Este tipo de restricciones no siempre se debe cumplir, se usan cuando no existe la necesidad de definir restricciones duras para las variables controladas. Lo que quiere decir que permite infringir ligeramente los límites de las variables controladas. Para se utiliza la definición de variables e holgura o de sobrepaso. Este tipo de restricciones, puede evitar los problemas de factibilidad, que es cuando no existe una solución que satisfaga las restricciones duras [15].
Los límites de la variable controlada se definen como:
𝑌𝑚𝑖𝑛− 𝜀 ≤ 𝑌𝑝 ≤ 𝑌𝑚𝑎𝑥 + 𝜀
37
Donde 𝜀, es una variable de holgura, la cual debe incluirse en la ecuación de coste (ecuación 3.15):
𝐽 = 𝑚𝑖𝑛𝜀∆𝑢 [(𝐷 − 𝐻∆𝑢)𝑇 ∝ (𝐷 − 𝐻∆𝑢) + ∆𝑢𝑇𝜆∆𝑢 + 𝜀𝑇𝜌𝜀]
(2.55) La variable 𝜌, es una constante de ponderación, la cual busca penalizar los valores grandes de 𝜀. Por lo tanto, se mantiene en cero mientras no se infrinjan las restricciones, y es fuertemente penalizado si las infringe, obligan do a 𝜀 a tomar un valor pequeño o suficiente para evitar el problema de no factibilidad. A partir de esto, se obtiene una nueva expresión de la (ecuación 2.42) teniendo en cuenta la (ecuación 2.55) obteniendo:
𝐽𝑄𝑃 = 1 2∆𝑢
𝑇(𝐻𝑇∝ 𝐻 + 𝜆)∆u + (−𝐷𝑇𝛼𝐻)∆𝑢 +1
2𝜀
𝑇𝜌𝜀
(2.56) Llevando la (ecuación 2.56) a la forma matricial par a expresar la función de coste final se tiene:
𝐽𝑄𝑃 = 1 2𝑥
𝑇𝐻𝑥 + 𝐶𝑇𝑥
𝐽𝑄𝑃 = 1 2[
∆𝑢 𝜀 ]
𝑇
[(𝐻𝑇 ∝ 𝐻 + 𝜆) 𝐼1𝑇
𝐼1 𝜌 ] [ ∆𝑢
𝜀 ] + [(−𝐷
𝑇𝛼𝐻)
0 ]
𝑇
[∆𝑢 𝜀 ]
(2.57) Donde 𝐼1 es un vector de eros de dimensiones 1𝑥𝑁𝑐. Las nuevas matrices 𝐴3 y 𝐵3
son obtenidas de la siguiente manera:
𝑌𝑚𝑖𝑛− 𝜀 ≤ 𝑌𝑝 ≤ 𝑌𝑚𝑎𝑥 + 𝜀 𝑌𝑚𝑖𝑛−𝜀 ≤ 𝐹𝑥̂(𝑡) + 𝐻∆𝑢 ≤ 𝑌𝑚𝑎𝑥 + 𝜀
𝐿 = 𝐹𝑥̂(𝑡) 𝐻∆𝑢 − 𝜀 ≤ 𝑌𝑚𝑎𝑥− 𝐿 −𝐻∆𝑢 − 𝜀 ≤ −𝑌𝑚𝑖𝑛+ 𝐿
0 ≤ −𝜀
(2.58)
38
[ 𝐻 −𝐼𝑏 −𝐻 −𝐼𝑏] [
∆𝑢 𝜀 ] ≤ [
𝑌𝑚𝑎𝑥 − 𝐿 −𝑌𝑚𝑖𝑛+ 𝐿]
Donde 𝐼𝑏, es un vector de unos, de dimensiones 𝑁𝑝𝑥1. Teniendo estas nuevas matrices de las desiguales para las restricciones blandas, se obtiene una nueva expresión para la (ecuación 2.54) [15]:
[ 𝐼 −𝐼
𝐼𝐿 −𝐼𝐿
𝐻 −𝐻
𝐼𝑎𝑇
𝐼𝑎
𝐼𝑎 𝐼𝑎
𝐼𝑎 −𝐼𝑏 −𝐼𝑏 −1 ]
∆𝑢(𝑘|𝑘) ∆𝑢(𝑘 + 1|𝑘)
⋮
∆𝑢(𝑘 + 𝑁𝑐− 1|𝑘)
𝜀
≤
[
∆𝑢𝑚𝑎𝑥1
∆𝑢𝑚𝑎𝑥2 ⋮ ∆𝑢𝑚𝑎𝑥𝑁𝑐
−∆𝑢𝑚𝑖𝑛1 −∆𝑢𝑚𝑖𝑛2
⋮ −∆𝑢𝑚𝑖𝑛𝑁𝑐
𝑢𝑚𝑎𝑥1− 𝑢(𝑘 − 1)
𝑢𝑚𝑎𝑥2− 𝑢(𝑘 − 1) ⋮
𝑢𝑚𝑎𝑥𝑁𝑐−𝑢(𝑘−1) −𝑢𝑚𝑖𝑛1+ 𝑢(𝑘 − 1) −𝑢𝑚𝑖𝑛2+ 𝑢(𝑘 − 1)
⋮
−𝑢𝑚𝑖𝑛𝑁𝑐+ 𝑢(𝑘 − 1) 𝑦𝑚𝑎𝑥1− 𝐿(𝑘 + 1|𝑘)
𝑦𝑚𝑎𝑥2− 𝐿(𝑘 + 1|𝑘)
⋮
𝑦𝑚𝑎𝑥𝑁𝑝− 𝐿(𝑘 + 1|𝑘) −𝑦𝑚𝑖𝑛1+ 𝐿(𝑘 + 1|𝑘) −𝑦𝑚𝑖𝑛2+ 𝐿(𝑘 + 1|𝑘)
⋮
−𝑦𝑚𝑖𝑛𝑁𝑝 + 𝐿(𝑘 + 1|𝑘)
0 ]
39 2.6. Caso Multivarible
En el caso multivariable, donde se tiene 𝑚 variables manipuladas y 𝑛 variables controladas, se genera un costo mucho mayor en términos computacionales. Para obtener el modelo del proceso se realiza el mismo proceso que para un sistema SISO, solo que hay que tener en cuenta todas las variables manipuladas y controladas, este caso se tiene en cuenta estados desacoplados. Para el modelo del caso multivaribles se obtiene de la misma forma que el caso SISO presentado anteriormente. Al igual que en el caso SISO el vector de estados 𝑥̂(𝑡), se tiene a partir del observador de estados, pero para el caso MIMO, se tendrán 𝑚, vectores de estados por cada una de las 𝑛 salidas.
2.6.1. Respuesta libre
La respuesta libre 𝑓 se calcula de la misma forma que en el caso SISO, sólo que se inicializa con valores diferentes de las matrices 𝑄 𝑦 𝑀, teniendo tantas respuestas libres como 𝑛 salidas, los estados 𝑥̂(𝑡) también cambian dependiendo de cada salida:
𝑓 = 𝐹𝑥̂(𝑡)
⌈ 𝐹1
⋮ 𝐹𝑛
⌉ =
𝑄1𝑀1
𝑄1𝑀12 ⋮ 𝑄1𝑀11N𝑝
⋮ 𝑄𝑛𝑀𝑛 𝑄𝑛𝑀𝑛2
⋮ 𝑄𝑛𝑀𝑛nN𝑝
Donde:
𝑥̂(𝑡) =
[
𝑥1(𝑘|𝑘) 𝑢1(𝑘 − 1)
𝑥2(𝑘|𝑘) 𝑢2(𝑘 − 1)
𝑥𝑛(𝑘|𝑘)
40
[ 𝑓1
⋮ 𝑓𝑛
] = [
𝐹1 0 … 0 0 𝐹2 … 0 ⋮ ⋮ ⋱ ⋮ 0 0 … 𝐹𝑛
] . [ 𝑥̂1(𝑡)
⋮ 𝑥̂𝑛(𝑡)
]
(2.60) 2.6.2. Respuesta forzada
La respuesta forzada es calculada Igual que en el sistema SISO:
𝑅𝑓 = 𝐻∆𝑢(𝑘 + 𝑁𝑐 − 1)
∆𝑢 =
[
∆𝑢1(𝑘|𝑘) ∆𝑢1(𝑘 + 1|𝑘)
⋮
∆𝑢1(𝑘 + 1𝑁𝑐− 1|𝑘) ∆𝑢2(𝑘|𝑘) ∆𝑢2(𝑘 + 1|𝑘)
⋮
∆𝑢2(𝑘 + 2𝑁𝑐 − 1|𝑘) ⋮
∆𝑢𝑚(𝑘|𝑘)
∆𝑢𝑚(𝑘 + 1|𝑘)
⋮
∆𝑢𝑚(𝑘 + 𝑚𝑁𝑐− 1|𝑘)]
; ∆𝑢 = [ ∆𝑢1 ∆𝑢2 ⋮ ∆𝑢𝑚
41
𝐻 =
[
∑ 𝑄1𝑀11−i𝑁1
1
i=0
⋮
∑ 𝑄1𝑀11𝑁𝑝−1−i𝑁 1 1𝑁𝑝−1
i=0
∑ 𝑄2𝑀21−i𝑁2 1
i=0
⋮
∑ 𝑄2𝑀22𝑁𝑝−1−i𝑁 2 2𝑁𝑝−1
i=0
∑ 𝑄𝑛𝑀𝑛1−i𝑁𝑛
1
i=0
⋮
∑ 𝑄𝑛𝑀𝑛𝑛𝑁𝑝−1−i𝑁𝑛 𝑛𝑁𝑝−1
i=0 ]
[ 𝑅𝑓1
⋮ 𝑅𝑓𝑛
] = [
𝐻1 0 … 0 0 𝐻2 … 0
⋮ ⋮ ⋱ ⋮
0 0 … 𝐻𝑛𝑥𝑚 ] [
∆𝑢1 ∆𝑢2
⋮ ∆𝑢𝑚
]
(2.61) En la (ecuación 2.61) se observa el vector de respuesta libre para todas las 𝑛
salidas.
2.6.3. Predicción de la salida
La evolución de la predicción de salida (ecuación 2.14), para el caso MIMO, se realiza teniendo en cuenta las (ecuaciones 2.60 y 2.61):
𝑆𝑎𝑙𝑖𝑑𝑎 𝑝𝑟𝑒𝑑𝑖𝑐ℎ𝑎=
𝑅𝑒𝑠𝑝𝑢𝑒𝑠𝑡𝑎 𝑙𝑖𝑏𝑟𝑒 +
42 [ 𝑦𝑝1 𝑦𝑝2 𝑦𝑝3 ⋮ 𝑦𝑝𝑛] = [ 𝑓1 ⋮ 𝑓𝑛 ] + [ 𝑅𝑓1 ⋮ 𝑅𝑓𝑛 ] (2.62) 2.6.4. Función de coste
Al igual que en el caso SISO, los vectores anteriormente calculados son reemplazados en la ecuación de coste (2.35):
𝐸𝑝1 𝐸𝑝2 𝐸𝑝3 ⋮ 𝐸𝑝𝑛 = 𝑅1 𝑅2 𝑅3 ⋮ 𝑅𝑛 − [ 𝑦𝑝1 𝑦𝑝2 𝑦𝑝3 ⋮ 𝑦𝑝𝑛] (2.63) 𝐸𝑝1 𝐸𝑝2 𝐸𝑝3 ⋮ 𝐸𝑝𝑛 = 𝑅1 𝑅2 𝑅3 ⋮ 𝑅𝑛 −[
𝐹1 0 … 0
0 𝐹2 … 0 ⋮ ⋮ ⋱ ⋮ 0 0 … 𝐹𝑛
] . [ 𝑥̂1(𝑡)
⋮ 𝑥̂𝑛(𝑡)
] − [
𝐻1 0 … 0
0 𝐻2 … 0
⋮ ⋮ ⋱ ⋮
0 0 … 𝐻𝑛𝑥𝑚 ] [ ∆𝑢1 ∆𝑢2 ⋮ ∆𝑢𝑚 ] (2.64) Se expresa la función de coste (ecuación 2.22) en forma matricial, tomando los valores conocidos "𝐷" de la (ecuación 2.64):
𝐷 = 𝑅 − 𝑓
𝑚𝑖𝑛∆𝑢 𝐽 = 𝑚𝑖𝑛∆𝑢 [(𝐷 − 𝐻∆𝑢)𝑇 ∝ (𝐷 − 𝐻∆𝑢) + ∆𝑢𝑇𝜆∆𝑢]
Las matrices ∝ y 𝜆 , se forman con submatrices ∝𝑖 y 𝜆𝑖, correspondiente a cada
variable manipulada del proceso.
∝= ⌈
∝1 0 0 0 0 ∝2 0 0
0 0 ⋱ 0
0 0 0 ∝𝑛
⌉ 𝜆 = ⌈
𝜆1 0 0 0 0 𝜆2 0 0 0 0 ⋱ 0 0 0 0 𝜆𝑚
⌉
43
Finalmente es obtenido el vector de incrementos futuros para todas las variables manipuladas [15]:
∆𝑢 = 𝑀. 𝐷
𝑀 = (𝐻𝑇𝛼𝐻)−1𝐷𝑇𝜆𝐻
∆𝑢 =
[
∆𝑢1(𝑘|𝑘) ∆𝑢1(𝑘 + 1|𝑘)
⋮
∆𝑢1(𝑘 + 1𝑁𝑐 − 1|𝑘)
∆𝑢2(𝑘|𝑘)
∆𝑢2(𝑘 + 1|𝑘) ⋮
∆𝑢2(𝑘 + 2𝑁𝑐 − 1|𝑘)
⋮ ∆𝑢𝑚(𝑘|𝑘) ∆𝑢𝑚(𝑘 + 1|𝑘)
⋮
∆𝑢𝑚(𝑘 + 𝑚𝑁𝑐 − 1|𝑘)]
(2.66)
2.7. Observador de estados
En la práctica, sólo son medibles algunas variables de estado de un sistema o proceso, mientras que las otras no están disponibles para ser medidas de forma directa. Para este caso, es necesario estimar las variables que no puedan medirse directamente; a esa estimación suele llamarse observación. Para un sistema práctico es necesario observar o estimar las variables no medibles a partir de las variables de salida y las de control [13].