INSTITUTO POLITÉCNICO NACIONAL.
ESCUELA SUPERIOR DE INGENIERÍA
MECÁNICA Y ELÉCTRICA UNIDAD ZACATENCO.
SECCIÓN DE ESTUDIOS DE POSGRADO E
INVESTIGACIÓN.
“ SOFTWARE PARA COMPRESIÓN
Y DESCOMPRESIÓN DE VIDEO
UTILIZANDO LA NORMA MPEG ”
T E S I S
QUE PARA OBTENER EL GRADO DE:
MAESTRO EN CIENCIAS EN
INGENIERÍA ELECTRÓNICA
PRESENTA:
ARTURO SÁNCHEZ ALMARAZ
DIRECTOR DE TESIS:
ÍNDICE.
Página.
Índice. i
Índice de figuras. iv
Índice de tablas. vi
Nomenclatura. vii
Acrónimos. ix
Resumen. xvi
Abstract. xviii
Introducción. 1
Objetivo. 3
Justificación. 3
Contenido del trabajo. 4
CAPITULO 1. PRINCIPIOS DE LA COMPRESIÓN DE SECUENCIAS DE
VIDEO. 5
1.1. Estándares de codificación de video. 5
1.1.1. La serie H de compresión de video. 6
(a) Estándar H.261. 6
(b) Estándar H.263. 8
1.1.2. MJPEG. 9
1.1.3. MPEG-1. 9
1.1.4. MPEG-2. 11
1.1.5. MPEG-4. 14
1.2. Elección del estándar MPEG-1. 16
1.3. Técnicas de compresión de datos utilizadas en el
estándar MPEG-1. 17
1.3.1. Transformada discreta coseno (DCT). 19 1.3.1.1 Transformada rápida coseno (FCT). 23
1.3.2. Cuantización. 25
1.3.3. RLE “Run Lenght Encoding”. 25
Página
1.3.5. Algoritmos de predicción. 29
1.3.5.1 DPCM. 30
1.3.5.2 Predicción adaptable. 31
1.3.6. Compensación de movimiento. 31
1.3.6.1 Estimación de movimiento. 33 1.3.6.2. Búsqueda logarítmica. 34
1.4. Manejo de gráficos en la PC. 36
1.4.1. Vesa bios extension (VBE). 37
a) Principales diferencias entre controladores. 39 b) Modos de video disponibles en el VBE. 40
c) Funciones del VBE. 43
d) Información del estado de una función VBE. 44
1.4.2. Manejo de la Memoria. 45
CAPITULO 2. DISEÑO Y DESARROLLO DEL SOFTWARE. 48
2.1. Memoria expandida o EMS. 49
2.2. Diseño del decodificador. 51
2.2.1. Buffer de Entrada 52
2.2.2. Demultiplexión de la cadena de datos. 54 2.2.3. Decodificación de códigos de longitud variable. 61
2.2.4. Descuantización 63
2.3. Diseño del codificador. 68
2.3.1. Elección del tipo de imagen a codificar. 69
2.3.2. Estimación de movimiento. 71
CAPITULO 3. RESULTADOS. 76
3.1. Rendimiento del codificador- decodificador de video. 78
3.1.1. Razón de compresión. 79
3.1.2. Rendimiento en tiempo del codificador. 83 3.1.3. Rendimiento en tiempo del decodificador. 84
Página
CAPITULO 4. CONCLUSIONES. 90
4.1. Sugerencias para el mejoramiento del sistema. 91
APÉNDICE A. ESTRUCTURA DEL CÓDIGO FUENTE. 93
APÉNDICE B. ESTRUCTURA GENERAL DEL CODIFICADOR Y
DECODIFICADOR. 95
INDICE DE FIGURAS.
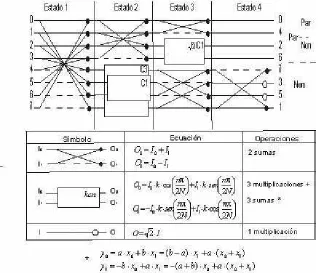
Página. 1.1. Esquema del cálculo de la transformada rápida coseno en un
dimensión. 24
1.2. Ordenamiento zig-zag utilizado para efectuar la codificación. 26 1.3. Los pixeles A,B,C,D, se utilizan para calcular el valor del pixel X. 30 1.4. Proceso de estimación de movimiento de un MB. 33 1.5. Ejemplo de búsqueda logarítmica con desplazamiento inicial de 4
pixeles. 35
2.1. Definición de la clase CEms. 49
2.2. Interfaz pública de la clase CEms. 50
2.3. Diagrama a bloques del decodificador diseñado. 51 2.4. (a) Buffer lleno, el inicio y final de datos coinciden con el inicio y final
físicos del buffer. (b) Se han leído la mayoría de los datos del buffer. (c) Cantidad de datos requeridos en la siguiente solicitud de lectura. (d) Se han insertado datos detrás del índice de lectura obligando a
realizar una lectura circular 53
2.5. Organización jerárquica de una secuencia de video en la norma
MPEG. 54
2.6. Decodificación de las diferentes capas de una cadena comprimida. 58
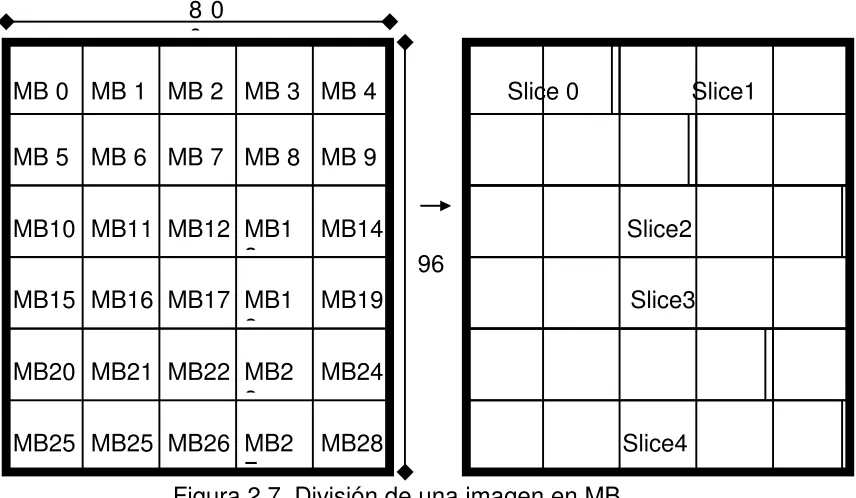
2.7. División de una imagen en MB. 59
2.8. Proceso de decodificación de un MB 60
2.9. Decodificación de un bloque. 61
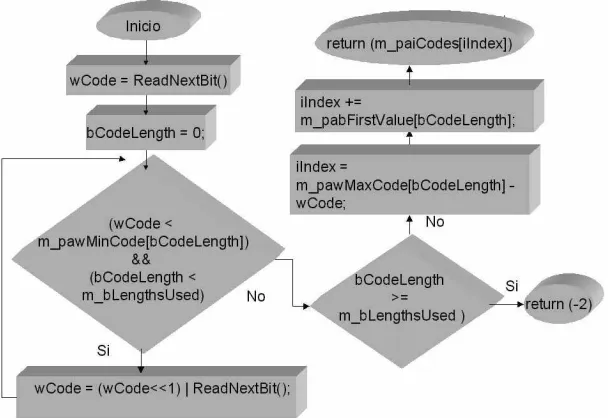
2.10. Variables miembro de la clase CMpegHuffTable. 62 2.11. Método int DecodeNext(...) que permite extraer un código de longitud
variable de la cadena de entrada. 62
2.12. Matrices definidas por el estándar MPEG. (a) Matriz de cuantización
intra. (b) Matriz de cuantización no intra. 63
Página.
2.15. Código del método BYTE ReadNextBit(void) 67
2.16. Código que busca el siguiente código de inicio en una cadena de
datos. 68
2.17. Diagrama a bloques del codificador de secuencias de video. 69 2.18. Código que permite codificar una secuencia de video a formato
MPEG. 69
2.19. Gráfica de decisión entre codificación intra y no-intra mediante
varianzas. 72
2.20. Código que realiza la estimación de movimiento. 73 2.21. Criterio de decisión para utilizar o no vectores de movimiento. 74 2.22. Extracto de código del método FindVector(...) que realiza la
búsqueda logarítmica. 75
3.1. Código que permite medir los tiempos de despliegue de pixeles
utilizando el controlador SVGA256.bgi y la clase CVesa. 77 3.2. Comparación de la razón de compresión para diferentes valores de
Q. 81
3.3. Imágenes de la secuencia mar. (a) Imagen original. (b) Imagen
descomprimida. 86
3.4. Imágenes de la secuencia edu. (a) Imagen original. (b) Imagen
descomprimida. 87
3.5. Imágenes de la secuencia naveluz. (a) Imagen original. (b) Imagen
descomprimida. 88
3.6. Imágenes de la secuencia alien. (a) Imagen original. (b) Imagen
descomprimida. 88
3.7. Imágenes de la secuencia nieve. (a). Original. (b) Descomprimida. 89 3.8. Imágenes de la secuencia playa. (a). Original. (b) Descomprimida. 89 A.1. Organización de los archivos fuente de la aplicación final. 94
B.1. Estructura del decodificador. 95
INDICE DE TABLAS.
Página 1.1. Algunos estándares o proyectos de la serie H y sus aplicaciones. 7 1.2. Resoluciones de los formatos de la familia CIF. 8 1.3. Desplazamiento posible para diferentes códigos de vectores. 36
1.4. Formato de los modos VBE. 42
1.5. Modos de video definidos por VESA. 42
1.6. Modos de texto definidos por VESA. 42
1.7. Funciones del VBE. 43
1.8. Información de estado al finalizar una función. 44 1.9. Principales funciones para manipular la memoria expandida. 47 2.1. Códigos de inicio de una secuencia de video en el estándar MPEG. 55 3.1. Tiempos de ejecución de llenado de cuadros utilizando un controlador
SVGA256.BGI y/o funciones basadas en el estándar VBE. 78 3.2. Características de las secuencias utilizadas en las pruebas de
rendimiento. 78
3.3. Razones de compresión C y tamaño del archivo de salida S (en Megabytes) para diferentes valores del factor de escala de cuantización (Q).
81
3.4. Comparación entre la codificación con compensación de movimiento y sin compensación de movimiento (Sn en Megabytes). 82 3.5. Comparación del tiempo requerido para comprimir una secuencia
utilizando compensación de movimiento y sin compensación. 84 3.6. Mediciones del tiempo requerido para realizar la decodificación de las
secuencias codificadas cuando Q = 5. 84
NOMENCLATURA.
Y, Cb y Cr Componentes de color luminancia (Y) y crominancias para el azul (Cb) y el rojo (Cr) respectivamente.
R, G y B Componentes de color rojo, verde y azul respectivamente.
MB Macrobloque.
GOP Grupo de Imágenes.
DC Coeficiente de corriente directa o coeficiente (0,0) de una matriz de 8x8.
AC Coeficiente de corriente alterna o 63 coeficientes que no son de DC de una matriz de 8x8.
I Imagen codificada intra.
P Imagen codificada por predicción hacia atrás en el tiempo. B Imagen codificada por predicción bidireccional.
D Imagen donde se codifican sólo los coeficientes DC. T[i] Transformada directa coseno en una dimensión. V[x] Arreglo en una dimensión de valores de una imagen.
c(k) Factores de peso de la Transformada Coseno Discreta (DCT) y de la Transformada Inversa Coseno Discreta (IDCT) en una dimensión.
V[n] Transformada inversa coseno en una dimensión. T[i,j] Transformada directa coseno en dos dimensiones. V[x,y] Arreglo en dos dimensiones de valores de una imagen.
c(i,j) Factores de peso de la DCT y de la IDCT en dos dimensiones. T DCT en dos dimensiones obtenida mediante matrices.
V IDCT en dos dimensiones obtenida mediante matrices. M Matriz de transformación para la DCT e IDCT.
hi Histograma de una imagen.
r Redundancia.
Cmax Nivel de compresión máximo.
−
l Rendimiento de compresión posible mediante códigos de longitud variable.
b Número de bits por pixel. MSE Error cuadrático medio. MAD Diferencia absoluta media.
SAD Suma absoluta de las diferencias entre dos Macrobloques (MB’s).
varc Varianza del MB a codificar.
vard Varianza de las diferencias entre dos MB’s.
C Razón de compresión.
n Número de muestras utilizadas por los datos sin comprimir. nc Número de muestras utilizadas por los datos comprimidos.
Q Factor de escala de cuantización.
i[u,v] Matriz de 8x8 coeficientes DCT cuantizados. c[u,v] Matriz de 8x8 coeficientes DCT.
m[u,v] Matriz o tabla de cuantización.
Cn Razón de compresión donde n es igual al factor Q utilizado. S Tamaño en megabytes del archivo de salida del compresor. Sn Tamaño en megabytes del archivo de salida del compresor
donde n es igual al factor Q utilizado. ERMS Raiz cuadrada del error cuadrático medio.
f1(x,y) Imagen original sin comprimir.
ACRÓNIMOS.
AC (Alternating Current). Los coeficientes DCT son llamado de AC debido a que estos modifican el nivel constante proporcionado por el coeficiente DC haciendo que la señal o función que estos representan tenga variaciones similares a las variaciones que presenta una señal de corriente alterna. Entre más coeficientes AC se tomen para recuperar una señal ésta será más parecida a la original.
ATM (Asynchronous Transfer Mode). Este tipo de tecnología se encarga de organizar y empaquetar información digital para su posterior transmisión.
AVI (Audio Video Interleaved). Formato de archivos creados por Microsoft para el almacenamiento entrelazado de diferentes tipos de información tales como video, audio, texto, etc.
CCITT (Comité Consultatif International Telégraphique et Teléphonique). Parte de la Unión Internacional de Telecomunicacines (ITU). Encargado de los estándares internacionales de comunicación.
CI (Circuitos integrados). Conjunto de circuitos electrónicos encapsulados en un chip, que en conjunto realizan una tarea específica.
CIF (Common Intermediate Format). Formato de secuencias de video que define algunas características específicas para los cuadros o imágenes de una secuencia (352 pixeles por 288 líneas y 30 cuadros por segundo).
DC (Direct Current). Coeficiente de la DCT, llamado de DC debido a que proporciona un nivel promedio constante de la función a la cual representa. Este coeficiente es el que más información proporciona por lo cual no puede ser desechado.
no utiliza números complejos.
DOS (Disk Operating System). Sistema operativo para las computadoras personales desde su aparición. Tiene como principal característica el ocupar pocos recursos computacionales. Es un sistema de consola (no gráfico) y monousuario.
DPCM (Differential Pulse Code Modulation). Algoritmo de codificación basado en diferencias. En secuencias de video este algoritmo permite aprovechar la correlación existente entre imágenes consecutivas. DSP (Digital Signal Processor). Procesador diseñado para ejecutar de
forma optimizada las operaciones relacionadas con el procesamiento de señales, generalmente imágenes, video y/o sonido.
DVD (Digital Versatile Disc). Es un tipo de tecnología de disco óptico en el cual se puede almacenar un mínimo de 4.7 GB GigaBytes (1024 MegaBytes), por lo que son utilizados para almacenar grandes cantidades de información tales como películas o material multimedia. DWT (Discrete Wavelet Transform). Tipo de transformación utilizado en
compresión de imágenes basado en la descomposición de una función en funciones más simples, lo cual hace más sencillos los cálculos.
EMM (Expanded Memory Manager). Se encarga de administrar la memoria expandida del sistema.
EMS (Expanded Memory Specification). Especificación que consiste básicamente en un “driver” instalable que pone a disposición de los usuarios funciones (mediante la interrupción 67h) para acceder a la memoria expandida del sistema.
FCT (Fast Cosine Transform). Algoritmo que aprovecha las propiedades de la DCT para calcularla con un número considerablemente menor de operaciones de las que se requieren para calcular dicha transformada.
convencionales. Existen varios estándares de HDTV que compiten entre si pero en general este formato permite tener pantallas más amplias con aproximadamente el doble de resolución que la que se tiene en sistemas como NTSC o PAL.
IBM (International Business Machines Corporation). Una de las compañías más importantes en la fabricación de productos relacionados con la computación. En 1981 produjo su primer computadora personal llamada IBM PC, la cual es la primera de lo que hoy conocemos como PC.
IDCT (Inverse Discrete Cosine Transform). Proceso inverso a la transformada coseno discreta utilizado para recuperar los valores de intensidad de color transformados en coeficientes DCT.
ISDN (Integrated Services Digital Network). Estándar internacional en comunicaciones para transmitir voz, video y datos sobre líneas telefónicas. Soporta tasas de transmisión de 64 Kbps (64,000 bits por segundo).
ISO (International Organization for Standardization). Organización internacional de estandarización fundada en 1946 la cual está compuesta por grupos nacionales de estándares de más de 75 países. El nombre de esta organización se deriva de la palabra griega iso que significa igual.
ITU (International Telecommunication Union). Organización intergubernamental a través de la cual las organizaciones publicas y privadas desarrollan telecomunicaciones. Fue fundada en 1865 y se convirtió en una agencia de las Naciones Unidas en 1947. Es responsable de adoptar tratados internacionales, regulaciones y estándares que gobiernen las telecomunicaciones. Las funciones de estandarización eran realizadas formalmente por el grupo CCITT, pero a partir de 1992 éste último no existe como una entidad separada.
elaboración de pequeñas aplicaciones exportables a la red (applets) y capaces de operar sobre cualquier plataforma a través, normalmente, de navegadores WWW. Permite dar dinamismo a las páginas web. JPEG (Joint Photographic Experts Group). Grupo de expertos en fotografía
que diseño la técnica de compresión de imágenes llamada JPEG con la cual es posible reducir la cantidad de datos de una imagen con una pérdida de información mínima.
MC (Motion Compensation). Técnica de compresión de video que permite aprovechar la alta correlación entre imágenes consecutivas para reducir la cantidad de datos necesarios para almacenar una secuencia de video.
LINUX Versión de libre distribución del sistema operativo UNIX; fue desarrollada por Linus Torvald.
MJPEG (Motion Joint Photographic Experts Group). Grupo de expertos derivado del grupo JPEG que utilizan las técnicas de compresión derivadas de este último para mejorarlas y adaptarlas para video. MMR (Modified Modified Read). Técnica de compresión utilizada en el
estándar MPEG-4 para comprimir patrones de formas.
MPEG (Moving Picture Experts Group). Grupo de expertos en imágenes en movimiento responsables de haber creado el grupo de estándares de compresión de video formado por MPEG-1, MPEG-2, MPEG-4, entre otros.
MSDOS (Microsoft Disk Operating System). Sistema operativo DOS propiedad de Microsoft.
NTSC (National Television System Committee). Grupo responsable de crear estándares de video y televisión en Estados Unidos. El sistema de televisión NTSC define una señal de video compuesta con una tasa de refresco de 30 cuadros por segundo (o 60 campos por segundo en el caso de video entrelazado) y una resolución de 525 líneas. Este sistema es utilizado en el continente Americano y en Japón.
al fabricante de un dispositivo que forma parte de una computadora por medio del cual es posible conocer las características del dispositivo en relación al fabricante del mismo.
PAL (Phase Alternation Line). El estándar de televisión dominante en Europa cuyas características son 625 líneas de resolución a 25 cuadros por segundo (o 50 campos por segundo en video entrelazado).
QCIF (Quarter-CIF). Formato de secuencias de video creado para consumir menos recursos. Como su nombre lo indica un cuadro en este formato equivale un cuarto del tamaño de uno en formato CIF es decir, maneja una resolución de 176 x 144.
RAM (Random Access Memory). Tipo de memoria utilizada en las computadoras la cual puede ser accesada de forma aleatoria es decir, cada unidad básica de memoria (generalmente 1 byte) puede ser alcanzada de forma independiente sin necesidad de pasar por las unidades previas. Cuando se desconecta la energía de alimentación de este tipo de memorias la información que contenían desaparece. RLE (Run Length Encoding). Tipo de codificación que permite reemplazar
un grupo de valores repetidos de forma consecutiva por un par de valores correspondientes al número de veces que se repite el valor más el valor mismo.
RMS (Root-Mean-Square). Algoritmo utilizado para determinar el valor promedio de un conjunto de valores.
ROM (Read Only Memory). Tipo de memoria en la cual los datos son pregrabados. Una vez que los datos son escritos en una memoria de este tipo, no pueden removidos y sólo pueden ser leídos. A diferencia de la memoria RAM éstas no necesitan estar energizadas para mantener su información.
del objeto fuente de los datos puede haber espacios en la matriz que no tienen datos y que no pertenecen al objeto. En estos casos la DCT requiere que dichos espacios sean rellenados con ceros y se incluyen como tales en los cálculos. En cambio la SA-DCT se adapta a la forma del objeto y no incluye los puntos indefinidos en sus cálculos lo cual agiliza los mismos.
SECAM (Systeme Electronique Couleur Avec Memoire). Formato de televisión de origen Francés adoptado en este país a partir de 1967. Utiliza 625 líneas de resolución y 25 cuadros por segundo. Actualmente es utilizado en una gran cantidad de países tanto de Europa como de África.
SVGA (Super Video Graphics Adapter). Estas siglas sirven para identificar sistemas de despliegue gráfico con capacidades por arriba de aquellas que otorgan los sistemas VGA.
TSR (Terminate and Stay Resident). Es una clase de utilería del DOS, la que una vez cargada en la PC, permanece en memoria y puede ser reactivada presionando una cierta combinación de teclas.
TV Televisión. Sistema de reproducción simultánea de sonido e imágenes en movimiento, transmitidas a distancia ya sea a través de ondas electromagnéticas o por medio de cable.
UNIX Sistema operativo multiusuario desarrollado en los años setenta y que se caracteriza por ser portátil y versátil.
VBE (Video Bios Extensión). Su objetivo principal es brindar soporte de software para las características no-VGA o SVGA de los controladores o tarjetas gráficas de los diferentes fabricantes.
VCL (Variable Length Coding). Es la etapa final en la compresión de video. Es un algoritmo que se basa en la frecuencia de ocurrencia de un símbolo. Al símbolo con mayor frecuencia de ocurrencia se le representa con la menor cantidad de bits.
relativamente simple aplicaciones genéricas que pudieran hacer uso de las características SVGA de la mayor cantidad de controladores posibles
VGA (Video Graphics Adaper). Sistema de despliegue gráfico desarrollado por IBM que se convirtió en un estándar para los sistemas de despliegue gráfico en las PC’s. En el modo de texto este sistema provee de una resolución de 720 x 400 pixeles, mientras que en gráfico permite resoluciones de 640 por 480 con 16 colores o 320 x 200 con 256 colores. En la actualidad la mayoría de las tarjetas de video brindan soporte VGA pero agregan capacidades superiores que generalmente son denominadas SVGA.
VO (Video Object). De acuerdo a sus características una imagen puede ser divida en varias partes llamadas objetos de video los cuales pueden ser manipulados de forma individual. Esta filosofía es utilizada en sistemas de compresión tales como el MPEG-4 y permite optimizar las técnicas de compresión y agregar capacidades de edición a los sistemas de compresión.
RESUMEN.
En este trabajo de tesis se desarrolló e implementó un programa computacional que
permite codificar y decodificar video en formato MPEG bajo el sistema operativo
MSDOS. Para almacenar las secuencias sin codificar se utiliza el formato de archivos
.avi. Todas las rutinas fueron desarrolladas en el lenguaje de programación C/C++.
Para desplegar el video en la pantalla se desarrollaron funciones que permiten
manejar la tarjeta de video mediante el estándar VESA (Video Electronics Standards
Association ), con lo cual se obtiene una mejora en la velocidad de despliegue de
aproximadamente diez a uno con respecto de los tiempos que se registran al utilizar
los controladores .BGI disponibles en las bibliotecas de compiladores C/C++.
El diseño del codificador consiste de un buffer de entrada, un bloque de conversión
de color de componentes RGB a componentes YCbCr, un bloque de predicción de
movimiento, un bloque de operaciones de compresión y por último un buffer de
salida. En el bloque de operaciones se aplica la transformada discreta coseno (DCT),
la cuantización de los coeficientes DCT resultantes y la codificación mediante
códigos de longitud variable o códigos Huffman de los coeficientes cuantizados. El
decodificador tiene una estructura muy similar a la del codificador y las operaciones
de descompresión consisten en aplicar el proceso inverso de las operaciones de
codificación, iniciando por la decodificación de códigos Huffman hasta aplicar la
transformada inversa discreta coseno (IDCT) y la conversión de componentes YCbCr
a RGB.
El resultado final de este desarrollo es un software que permite comprimir archivos
de formato AVI a formato MPEG, descomprimir archivos de formato MPEG a formato
AVI, visualizar archivos AVI, comparar dos archivos AVI y obtener el error RMS entre
ellos, visualizar el encabezado y los códigos de inicio más importantes de un archivo
MPEG y finalmente, verificar las capacidades de la tarjeta de video utilizada. Tanto el
codificador como el decodificador tienen como principales características el ser
compatibles con programas comerciales. El programa desarrollado trabaja bajo
muy bajos y su traslado a otra plataforma sería relativamente fácil; además, dado
que se desarrolló el 100% del código, se cuenta con la libertad de poder ampliar,
modificar y reutilizar dicho código sin incurrir en violaciones de derechos de autor,
por lo que se crean las bases para la investigación y desarrollo de programas de este
ABSTRACT.
This thesis work has developed and implemented a computational program that
allows codifying and decoding video in MPEG format under operating system
MSDOS. In order to store the sequences without codifying, it uses the avi file format.
All the routines were developed in the programming language C/C++.
In order to display video on the screen, functions that allow handling a video card by
means of standard VESA (Video Electronics Standards Association) have been
developed. This has created an improvement in the speed of display from
approximately ten to one with respect to the times that register when using the
controllers BGI available in the libraries of compilers C/C++.
The design of the encoder consists of an input buffer, a block of conversion of color of
components RGB to YCbCr components, a block of prediction of movement, a block
of operations of compression and finally an output buffer. The block of operations
applies the discrete cosine transform (DCT), the quantization of resulting DCT
coefficients and the coding by means of codes of variable length or Huffman codes of
the quantized coefficients. The decoder has a structure very similar to the one of the
encoder. The operations of decompression consist of applying the inverse process of
the operations of coding, initiated by decoding the Huffman codes until applying the
inverse discrete cosine transform (IDCT) and finally the conversion of YCbCr
components to RGB.
The final result of this development is a software that allows compressing files in AVI
format to the MPEG format, to decompress files from the MPEG format to the AVI
format, to visualize AVI files, to compare two AVI files and to obtain RMS error among
them, to visualize the header and the more important starting codes of MPEG files,
and finally to verify the capacities of the used video card. The encoder as well as the
decoder have like main characteristics that are compatible with commercial programs.
The developed program works under the MSDOS operating system. For this reason
the hardware requirements for their use are very low and its transfer to another
developed, it counts with the freedom of being able to extend, to modify and to reuse
INTRODUCCION
El siglo XX trajo consigo una evolución sin precedentes en las comunicaciones
basada en la generación y transmisión de señales eléctricas continuas conocidas
como señales analógicas. Gracias a este tipo de señales hoy podemos disfrutar de
servicios tales como las transmisiones de radio y televisión, telefonía, internet
mediante cables de teléfono, por nombrar sólo algunos. Sin embargo, la llegada de
las computadoras personales (PC) trajo consigo una evolución exponencial en las
capacidades de procesamiento y de integración de los circuitos integrados (CI) lo
cual entre otras muchas cosas propició la generación de cantidades de información
cada vez mayores y la necesidad de intercambiar dicha información puso en
entredicho las capacidades de las señales analógicas, lo cual dio impulso a las
señales digitales que han venido desplazando rápidamente a las señales analógicas
en prácticamente todo tipo de aplicaciones incluyendo los servicios antes
mencionados.
Las señales analógicas son formas de onda continuas variables en el tiempo y que
por su naturaleza son muy propensas a contaminarse por ruido durante su
transmisión y en muchas ocasiones no se puede diferenciar al ruido de la
información. En contraste en una señal digital el ruido introducido es más fácil de
detectar y por consecuencia eliminarlo. Además, la tecnología basada en señales
digitales introduce una gama muy amplia de oportunidades en servicios que
anteriormente eran impensables tales como servicios de radio y televisión
interactivos. No obstante las ventajas de las señales digitales, éstas son sólo un
eslabón más que se agrega al conjunto de herramientas que permiten obtener,
entender, estudiar, manipular y procesar información proveniente de un mundo cuyas
fuentes de información son de tipo analógico.
Los grandes avances tecnológicos generalmente vienen acompañados de nuevos
retos por resolver. Uno de los grandes retos que la tecnología digital ha traído
consigo es la necesidad de reducir los datos redundantes en las señales digitales
grandes volúmenes de datos que en ocasiones se generan y con ello permitir la
manipulación, procesamiento y almacenamiento de las señales deseadas. Además,
dicha necesidad crece a medida que la tecnología avanza y permite obtener
información de fuentes de datos cada vez más diversas y complejas, las cuales a su
vez generan cantidades mayores de datos. Un ejemplo claro de esto son las
secuencias de video digitales las cuales hoy es posible manipular, transmitir y
almacenar gracias a la capacidad de procesamiento de los dispositivos digitales;
pero también gracias al desarrollo de las técnicas de reducción de datos las cuales
se conocen con el nombre de técnicas de compresión de datos y en el caso
especifico del video técnicas de compresión de video.
El desarrollo de los algoritmos de compresión hoy en día es tal, que es posible
almacenar películas en un disco compacto, transmitir video a través de la red en
tiempos razonables, realizar transmisiones de televisión en formato digital en tiempo
real y con diferentes servicios tales como múltiples idiomas y sin tener que aumentar
el ancho de banda de transmisión. Uno de los estándares que ha hecho posible esto
es el MPEG ya que por su flexibilidad puede abarcar un gran número de
aplicaciones.
La compresión de video mediante el estándar MPEG está basada en las técnicas de
compresión de imágenes fijas añadiendo compensación de movimiento. Los
diferentes estándares conocidos como MPEG describen varias herramientas que
pueden ser utilizadas para realizar la compresión, la sintaxis de una cadena de bits
resultante de la compresión y la forma en que dicha cadena debe ser interpretada
por el decodificador. No se define al codificador.
Debido al gran número de operaciones necesarias para llevar a cabo la compresión
en formato MPEG, un sistema que realizara este tipo de compresión tenía que ser
implementado necesariamente mediante hardware ya que en la década pasada las
velocidades de procesamiento de las PC’s no eran suficientes para realizar esta
tarea adecuadamente mediante software; sin embargo debido al avance de la
video en tiempos razonables. Es por ello que se crearon sistemas para comprimir y
descomprimir video mediante software, lo cual implica una reducción considerable en
costo con respecto a un sistema por hardware.
Aunque en la actualidad existen sistemas que pueden realizar las tareas
mencionadas, estos no permiten ser modificados o mejorados excepto por sus
fabricantes; por tal motivo para poder realizar un avance en esta materia en nuestro
país, en el Laboratorio de Investigación en Procesamiento de Señales (LIPSE) se
decidió crear un sistema de compresión y descompresión de video con el estándar
MPEG que pueda servir de base para futuras investigaciones y que además sea
funcional y compatible con los sistemas existentes. La estructura del software
desarrollado se muestra de forma general en el apéndice B.
Objetivo.
Diseñar y crear un programa computacional que permita comprimir y descomprimir
video digital en el estándar MPEG.
Justificación.
Dada la gran cantidad de espacio que ocupa un archivo de video digital y debido a la
creciente demanda de transmisión de archivos de video y al gran ancho de banda
que se necesita para ello, es necesario reducir el tamaño de estos archivos sin que
se pierda la calidad del video y se obtenga un buen grado de reducción de los datos,
Contenido del trabajo.
En el capitulo 1 se presenta un análisis general de los estándares de compresión de
video que son o han sido los más utilizados por lo que son considerados pilares en el
desarrollo de técnicas de compresión de video. Una vez presentados los estándares
más importantes se describen los criterios de selección tomados en cuenta para
elegir el estándar que se utiliza en este trabajo de tesis. Posteriormente se hace un
bosquejo de las técnicas de compresión de imágenes utilizadas en el estándar
MPEG que se desarrolló. Finalmente se describe como se realizó el manejo de
gráficos en la PC y de la memoria expandida de la misma.
En el capitulo 2 se explica de forma detallada, con la ayuda de extractos de código,
el desarrollo y funcionamiento de los módulos para el manejo de la memoria
expandida, el decodificador y el codificador de video.
En el capitulo 3 se presentan mediciones de rendimiento en tiempo de ejecución del
despliegue de gráficos en el monitor de la PC, mediciones de la razón de compresión
y criterios de fidelidad alcanzados por el codificador de video desarrollado; así como
tiempos de ejecución utilizados por el decodificador.
En el capítulo 4 se presentan las conclusiones del trabajo de tesis realizado, así
como algunas sugerencias para su futuro mejoramiento.
En el apéndice A se da un bosquejo de como está organizado el software
desarrollado.
Finalmente se presentan las referencias bibliográficas utilizadas para la elaboración
del trabajo de tesis aquí presentado.
El desarrollo de esta tesis se llevó a cabo en el Laboratorio de Investigación en
Procesamiento de Señales (LIPSE) de la Escuela Superior de Ingeniería Mecánica y
CAPITULO 1. PRINCIPIOS DE LA COMPRESIÓN DE SECUENCIAS DE VIDEO.
Una secuencia de video es un conjunto de imágenes fijas consecutivas correspondientes a diferentes instantes de tiempo. Para una secuencia de video en formato CIF (“Common Intermediate Format”) el cual se utiliza generalmente para videoconferencia, las imágenes o cuadros tienen una resolución 360x288 (ancho x alto) y la frecuencia de despliegue es de 30 fps (cuadros por segundo). Si consideramos que se trata de una secuencia en color cuyos elementos básicos de despliegue o pixeles utilizan 24 bits para representar los tres componentes básicos de color (rojo, verde y azul o formato RGB) y utilizando la ecuación (1.1) [1] se tiene que cada cuadro de la secuencia tiene un tamaño de 311,040 bytes por lo que cada segundo de la secuencia tendrá un tamaño de 9,331,200 bytes aproximadamente 9.11 Mbytes. Con esto se puede ver la gran cantidad de datos generados por una secuencia de video lo cual provoca que la cantidad de recursos necesarios para manipular, transmitir y/o almacenar sea muy elevada. Es por ello que la compresión del volumen de información generado por una secuencia de video es tan importante e incluso, para algunas aplicaciones, indispensable.
(
)
(
)
8
7 *
* +
= Ancho Altura Bits por pixel
la imagen
Tamaño de (1.1)
donde:
Tamaño de la imagen es el tamaño de la imagen en bytes. Este valor es un número entero, es decir se elimina la parte fraccionaria.
El valor 8 en el denominador corresponde al número bits que forman un byte. El valor 7 se agrega para asegurar que, cuando la variable Bits por pixel sea igual a uno, los datos de la imagen den como resultado bytes completos, es decir, redondea hacia arriba el resultado final.
1.1. ESTÁNDARES DE CODIFICACIÓN DE VIDEO.
intentan resolver el mismo problema pero que son totalmente incompatibles entre sí, por ello surge la necesidad de la estandarización de tecnologías para lo cual se han creado a través de los años diferentes organizaciones que, dependiendo del tipo de industria, se encargan de la investigación y estandarización de tecnologías para facilitar su uso e impulsar la investigación alrededor de ellas. Tal es el caso de los estándares actuales de compresión de video, los cuales han contribuido de manera sustancial a desarrollar las técnicas de compresión y que además son utilizados de manera casi universal en las diferentes áreas donde se utilizan o proveen servicios audiovisuales.
Los estándares de codificación de video más importantes y que mayor aportación han tenido al desarrollo de la tecnología relacionada con la compresión de video y que además son los más utilizados son: H.261, H.263, MJPEG, MPEG-1, MPEG-2, y MPEG-4 [1], de los cuales a continuación se da una descripción de sus características generales haciendo énfasis en la parte correspondiente a las secuencias de video ya que es éste es el tema de este trabajo de tesis.
1.1.1. La Serie H de Compresión de Video.
En diciembre de 1984, el grupo de estudio CCITT (“Comité Consultatif International Telégraphique et Teléphonique”) organizó un grupo de especialistas en codificación
para telefonía visual para desarrollar un estándar en video transmisión para servicios ISDN (“Integrated Services Digital Network”). Originalmente el codificador fue
diseñado para operar en canales múltiplos de 384 kbits/s sin embargo, hoy en día la serie tiene especificaciones más agresivas y tiene tasas de transmisión de p x 64 kbits/s, donde p está en el intervalo de 1 a 30. La tabla 1.1 muestra una lista de
algunos de los estándares de la serie H así como la aplicación para la cual fueron diseñados, de los cuales el H.261 y H.263 son los más importantes [2].
(a) Estándar H.261.
p x 64 kbits/s donde p va de 1 a 30.
La codificación H.261 opera bajo una estructura jerárquica de capas de datos utilizando cuatro capas: la capa de imagen, la de grupo de bloques (GOB), la de macrobloque (MB) y la de bloque (8x8). Las capas son multiplexadas en serie para su transmisión y cada una se compone de un encabezado de información y de los datos que la alimentan. La capa de bloque es la capa fundamental y es en la que se realizan las operaciones de codificación-decodificación.
El proceso de codificación del estándar es un proceso basado en la Transformada Discreta Coseno (DCT). Primero se obtiene una predicción "interframe". Después el error de predicción es transformado al dominio de la frecuencia, donde se realiza una cuantización. Posteriormente, de manera opcional, se puede agregar compensación de movimiento. Finalmente se aplica la codificación VCL (código de longitud variable). En este estándar las dimensiones de la imagen están restringidas a dos tamaños, el formato común intermedio o CIF (“Common Intermediate Format”) y un cuarto de CIF o QCIF (“Quarter-CIF”). La familia de formatos CIF (tabla 1.2) fueron creados para permitir una interoperatividad entre los diferentes estándares de televisión existentes tales como el NTSC, PAL y el SECAM entre otros [1].
Tabla 1.1. Algunos estándares o proyectos de la serie H y sus aplicaciones.
Serie. Aplicación.
H.261. Estándar de la ITU (International Telecom Union) para codificación de videoconferencia.1990).
H.263. Codificación de video para comunicaciones con bajas tasas de transferencia.
H.310. Sistemas y terminales de comunicación audiovisual de banda ancha. H.320. Sistemas y equipo de terminales de telefonía visual de escaso ancho de
banda.
H.321. Adaptación de H.320 a terminales de telefonía visual y ambientes de B-ISDN (Broad-band-B-ISDN).
H.322. Sistemas y equipos de terminales de telefonía visual para redes de área local que provee una calidad de servicio garantizada.
H.323. Sistemas y equipos de terminales de telefonía visual para redes de área local que provee una calidad de servicio no garantizada.
(b) Estándar H.263.
La recomendación H.263 especifica un método de codificación que puede ser utilizado para comprimir componentes de imágenes en movimiento de servicios audiovisuales a tasas de transmisión muy bajas. La configuración básica del codificador de video está basada en el estándar H.261. El corazón de este estándar emplea una predicción entre imágenes híbrida para utilizar la redundancia temporal y la codificación por transformación de la señal residual y con ello reducir la redundancia espacial. Para la predicción de movimiento se utiliza precisión tanto de un pixel, como de medio pixel a diferencia del estándar H.261 que sólo permite utilizar precisiones de un pixel. Además de lo anterior, las principales diferencias entre el estándar H.263 y el H.261 se encuentran en la forma de codificar los coeficientes transformados y los vectores de movimiento.
Una de las principales características del estándar H.263 es su objetivo de trabajar conjuntamente con el comité MPEG-4 en la investigación de nuevas técnicas de codificación y tecnologías que puedan ser candidatas a una recomendación o estándar. Esto permite que hoy en día el estándar H.263 permita comprimir video a tasas de transmisión por debajo de los 64 kbits/s lo que la hace una importante herramienta para determinadas aplicaciones.
Otra diferencia importante con el estándar H.261 es que el H.263 permite como entrada del codificador cinco formatos de imagen diferentes todos ellos de la familia CFI: sub-QCIF, QCIF, CIF, 4CIF y 16CIF cuyas resoluciones se muestran en la tabla 1.2.
Tabla 1.2. Resoluciones de los formatos de la familia CIF.
Formato del cuadro. Pixeles por línea. Lineas por cuadro.
Sub-QCIF 128 96
QCIF 176 144
CIF 352 288
4CIF 704 576
1.1.2. MJPEG.
MJPEG es un estándar de codificación de video proporcionado por JPEG (“Joint Photographic Experts Group”) el cual utiliza el estándar JPEG de compresión de imágenes fijas para codificar los cuadros individuales de una secuencia de video [3]. La ausencia de compensación de movimiento en este estándar permite que sea utilizado en la captura de video de alta calidad en tiempo real o en aplicaciones de edición sin embargo, la ausencia de compensación de movimiento también provoca que el nivel de compresión no sea elevado por lo que una vez que se ha capturado o editado el video en este formato generalmente se codifica en otros formatos tales como MPEG-1, MPEG-2 o MPEG-4 para su transmisión o almacenamiento.
1.1.3. MPEG-1.
A principios de la década de 1990 el grupo de expertos en imágenes en movimiento
conocido como MPEG comenzó la investigación en técnicas de codificación para almacenar video. El objetivo fue desarrollar un estándar de codificación que
permitiera comprimir secuencias de video y su respectivo audio (por ejemplo películas) para su almacenamiento digital en multimedios (DSM) y su transmisión a una tasa aproximada de 1.5 Mbps. El grupo MPEG tomó como punto de partida el estándar H.261 y el resultado quedó plasmado en la recomendación ISO/IEC 11172 mejor conocida como MPEG-1 [2].
En lo que respecta a las secuencias de video (la capa 2 del estándar), para su procesamiento el estándar las divide en seis capas: secuencia de video, grupo de imágenes (GOP), imagen, “slice”, macrobloque (MB) y bloque. Cada una de las capas están diseñadas con el objetivo de proveer un determinado grado de compresión, recuperación de errores, facilidad de reproducción con diferentes niveles de velocidad, acceso aleatorio, etc.
I) Imágenes codificadas Intra (Imágenes I o “intraframe”): son aquellas que para su codificación no requieren más información que la existente en ellas mismas.
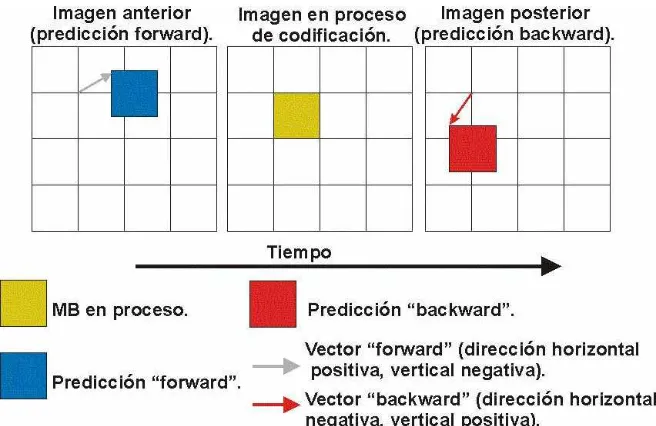
II) Imágenes codificadas por predicción (Imágenes P o “predicted”): son aquellas que se codifican mediante la predicción con una imagen anterior en el tiempo.
III) Imágenes codificadas bidireccionalmente (Imágenes B o “bidirectional-predicted”):
son aquellas que se codifican mediante la predicción con imágenes anteriores y/o posteriores en el tiempo.
IV) Imágenes de DC (Imágenes D): este tipo de imágenes son un caso especial de las imágenes I ya que se codifican con información solo de ellas mismas pero utilizan los coeficientes de DC de la DCT, por lo que su calidad es sumamente baja y son poco utilizadas.
Al igual que el estándar H.261 y el JPEG, la parte central de la codificación MPEG es la DCT y utiliza la cuantización y la codificación VLC para codificar los coeficientes resultantes. Las principales diferencias con el estándar H.261 son: su sintaxis utiliza seis capas por cuatro del estándar H.261, la compensación de movimiento no es opcional y permite resoluciones de medio pixel, permite la predicción con imágenes posteriores en el tiempo además de la predicción con imágenes anteriores y por último, utiliza matrices de cuantización en lugar de un solo valor.
Es importante resaltar que este estándar fue pensado para trabajar con estaciones de trabajo y/o PC por lo que se basa en secuencias de video con imágenes progresivas características de este tipo de dispositivos y no en secuencias con imágenes entrelazadas las cuales son utilizadas generalmente en transmisiones de televisión (TV). Las imágenes progresivas son aquellas que están formadas por líneas pertenecientes a un mismo instante de tiempo mientras que las imágenes entrelazadas están formadas por dos campos, el primero está formado por las líneas nones de la imagen tomadas en un instante de tiempo y el segundo contiene a las líneas pares tomadas en un instante diferente de tiempo.
1.1.4. MPEG-2.
lo cual se abandonó el desarrollo de MPEG-3 de tal manera que hoy en día las principales aplicaciones del estándar MPEG-2 se encuentran en la HDTV y los sistemas de almacenamiento digital para el hogar DVD (“Digital Versatile Disc”) [2].
El estándar MPEG-1 fue diseñado para codificar y almacenar audio y video en medios con tasas de error muy bajas por lo que el manejo de errores no es muy robusto. Además, el estándar antes mencionado fue creado para el procesamiento orientado al software, en donde los paquetes largos y variables pueden reducir el tiempo de cómputo.
Por otro lado, el estándar MPEG-2 es más general e incluye una gran cantidad de aplicaciones por lo que debe incluir una mayor flexibilidad a la existencia de errores. Además, debe permitir la entrega simultanea de múltiples programas o contenidos sin la necesidad de requerir una base de tiempo común.
A pesar de que existen diferencias en la forma de codificar las secuencias de video entre los dos estándares (se mencionan más adelante), las mayores diferencias se
encuentran en la forma de empaquetar las cadenas de datos lo cual se especifica en la capa de sistema del estándar y está relacionado con la forma de mezclar los diferentes servicios tales como secuencias de video, audio, texto, idiomas, entre otros. Ya que este trabajo se encarga exclusivamente de la compresión de las secuencias de video, dichas diferencias quedan fuera de su ámbito.
Otra diferencia importante entre los dos estándares en cuestión son los modos de escalabilidad existentes en el MPEG-2, los cuales permiten al receptor decodificar una parte de la cadena de datos y así desplegar una secuencia de imágenes con diferentes calidades. Esta función aunque no es tan completa como la existente en el estándar MPEG-4, permite la conexión entre varios usuarios con diferentes capacidades principalmente de ancho de banda.
Además de las diferencias antes mencionadas, existen otras diferencias menores resultado de la posibilidad de la codificación entrelazada. La primera es que en el estándar MPEG-2 existe la posibilidad de modificar el orden en el cual son codificados los coeficientes DCT para optimizar la codificación cuando se codifican imágenes entrelazadas. Otra diferencia es la posibilidad de utilizar cuantización lineal y no lineal.
Dada la gran variedad de aplicaciones que puede manejar el estándar MPEG-2, se le hicieron a éste divisiones y subdivisiones. Esto permite que cada aplicación pueda tener diferentes grados de complejidad de acuerdo a sus necesidades, además de que el decodificador no necesita soportar todas las posibles combinaciones, especialmente para aplicaciones sencillas.
Las divisiones son denominadas perfiles (“profile”) y determinan los elementos
sintácticos que se pueden utilizar. La cadena de bits de MPEG-1 es acomodada en uno de los perfiles para mantener la compatibilidad hacía atrás. Incluso existe un perfil más simple que MPEG-1, el cual no permite imágenes B para disminuir el retardo y los requerimientos de memoria en los procesos de codificación-decodificación.
La mayoría de las aplicaciones MPEG-2 trabajan en el perfil principal (“main profile”). La principal diferencia entre los elementos de sintaxis de MPEG-1 y el perfil principal de MPEG-2 es la provisión de herramientas para video entrelazado y la habilidad de escalamiento tanto en la imagen como en la frecuencia de datos.
definen los intervalos permitidos de cada parámetro de la cadena de bits tales como resoluciones de imagen y frecuencias de despliegue. Se han definido 4 niveles: bajo, principal, alto-1440 (para el sistema europeo de alta definición) y alto. Sin embargo no todos los perfiles tienen definición para todos los niveles. Un ejemplo de sintaxis de una combinación perfil-nivel para el perfil principal y nivel principal seria: MP@ML ("main profile-main level").
1.1.5. MPEG-4.
El estándar MPEG-4 es otro estándar desarrollado por el grupo MPEG el cual tiene como objetivo proveer herramientas y algoritmos para el almacenamiento eficiente y transmisión y manipulación de datos de video en ambientes multimedia.
A diferencia de los estándares convencionales, el estándar MPEG-4 introduce una nueva forma de representar una escena basándose ahora en su contenido. La idea
principal es que una escena es vista como un conjunto de objetos de video (VO) con propiedades intrínsicas tales como forma, movimiento y textura. Esta representación
basada en contenido permite el acceso arbitrario a objetos específicos de la escena así como su manipulación.
En la codificación basada en objetos los cuadros o imágenes están definidas en términos de capas de planos de objetos de video o VOP (“video object planes”). Así cada VOP puede ser visto como una imagen particular y por tanto puede ser procesada por separado. Cada VOP es conocido a la hora de construir las secuencias de video (video sintético) o bien se define mediante segmentación semiautomática. En el primer caso, la información de la forma es representada por 8 bits y se conoce con el nombre de plano alfa de escala de grises. Este plano es utilizado para mezclar varios VOP’s y así formar la imagen de interés. De tal manera que, con 8 bits se pueden identificar hasta 256 objetos en una sola imagen. Para el segundo caso, la forma de un objeto es una máscara binaria, para identificar bordes de objetos individuales así como su posición en la imagen.
compensación de movimiento y codificación de la información de textura del objeto.
La forma del VOP o planos alfa está representada por un rectángulo que incluye totalmente la forma del objeto. Para su procesamiento dicho rectángulo se divide en MB de 16x16 rellenando con ceros los espacios que estén dentro de dicho rectángulo pero fuera de la forma del objeto. A su vez los planos alfa pueden ser de dos tipos: plano alfa binario y plano alfa de escala de grises. El plano alfa de escala de grises se codifica mediante compensación de movimiento utilizando la DCT, mientras que los planos alfa binarios se codifican utilizando diferentes técnicas de codificación tales como: codificación en cadena, árbol cuadrático (“quad-tree”), “modified modified Read” o MMR y codificación aritmética basada en contenido. A través del desarrollo del estándar se ha comprobado que la codificación aritmética basada en contenido es la más efectiva.
Los VOP’s intra y los que utilizan compensación de movimiento son codificados mediante la DCT de bloques de 8x8 de tal manera que la DCT se ejecuta de forma separada para cada uno de los planos de luminancias y crominancias. Por el contrario, para la codificación de la textura del objeto se utiliza una derivación de la DCT llamada DCT adaptada a la forma o SA-DCT (“shape adaptive DCT”). La idea principal de este método es codificar sólo los pixeles opacos que están dentro del objeto.
El estándar MPEG-4 también permite codificar imágenes fijas de una forma muy eficiente utilizando un método compatible con el estándar JPEG-2000, el cual básicamente está basado en la utilización de la transformada discreta wavelet (DWT) la cual es una subclase de la codificación de sub-banda o división de bandas. La
sub-banda más baja es codificada, después de su cuantización, mediante codificación DPCM (“Differential Pulse Code Modulation”); las bandas más altas se
codifican mediante una técnica de codificación conocida como “zero-tree”. Finalmente los datos resultantes de las técnicas anteriores son codificados mediante códigos de longitud variable por un codificador aritmético.
los 64 kbits/s lo cual lo hace apropiado para su uso en videoconferencia o internet. La idea principal de dividir una imagen en objetos permite que sea una herramienta muy importante en la edición y producción de video mediante computador sin embargo, para video real esta característica provoca la necesidad de tener hardware muy especializado que pueda realizar la segmentación a tal grado que para algunas aplicaciones es necesario la intervención humana para elegir los objetos ya que por ejemplo, en escenas con múltiples objetos en movimiento la segmentación automática de objetos no es posible por lo que dichos objetos tienen que ser seleccionados por un humano [2].
1.2. ELECCIÓN DEL ESTÁNDAR MPEG-1.
Los estándares pertenecientes al grupo MPEG son los más utilizados debido a su buen desempeño y a la gran cantidad de aplicaciones que abarcan sin embargo, tanto la serie H de estándares como el trabajo del grupo JPEG han jugado un papel muy importante en el desarrollo de los primeros. Una característica importante de resaltar de los estándares MPEG es que no son excluyentes uno de los otros dado que están pensados y desarrollados para diferentes aplicaciones por lo que uno no desplaza a los otros y en aplicaciones muy generales incluso tienen que convivir juntos.
El objetivo principal de este trabajo de tesis es sentar las bases en nuestro país en la investigación de las diferentes técnicas de compresión de secuencias de video. De tal forma que el estudio y comprensión detallada de las técnicas más utilizadas pueda generar, en un futuro cercano, la generación de nuevas técnicas y métodos de compresión de secuencias de video.
decodificador MPEG-2 deberá ser capaz de decodificar una secuencia en formato MPEG-1 lo que refuerza la decisión de elegir este último estándar.
En el estándar MPEG-4 el número de técnicas de compresión utilizadas por el mismo es mucho mayor lo que incrementa la complejidad de la implementación del mismo. Por otro lado, procesos como la segmentación o la codificación aritmética de código de longitud variable tienen que ser implementadas por hardware especializado que resulta ser costoso. La decisión de implementar el estándar MPEG-1 sobre el 4 se puede ver como la solución de un problema complejo. Primero, se divide el problema en problemas de menor complejidad y se resuelven por separado para posteriormente juntar las soluciones y resolver el problema complejo que se tenia al principio. Trasladando esto a los estándares en discusión, el desarrollo de la codificación-decodificación de secuencias MPEG-1 permite estudiar, comprender e implementar un grupo de técnicas de codificación necesarias para el desarrollo del MPEG-4, el siguiente paso podría ser desarrollar las técnicas de codificación restantes desarrollando por ejemplo el estándar JPEG-2000 y finalmente unir todas las técnicas en un desarrollo que permita comprimir y descomprimir secuencias en el formato MPEG-4.
Habiendo decidido realizar el desarrollo de un codificador-decodificador de secuencias de video en formato MPEG-1 a continuación se presenta un estudio más profundo de las técnicas de compresión que utiliza éste para posteriormente, en el siguiente capítulo, presentar la estructura detallada del mismo.
1.3. TÉCNICAS DE COMPRESIÓN DE DATOS UTILIZADAS EN EL ESTÁNDAR MPEG-1.
Existen diferentes métodos y técnicas de compresión cuyos resultados dependen directamente del tipo de datos que se desea procesar. De manera general los métodos de compresión de datos se dividen en compresión con pérdidas y sin pérdidas.
Los procesos de compresión sin pérdidas son aquellos en los cuales la operación inversa o proceso de descompresión permite recuperar los datos exactos que se tenían antes de realizar la compresión. La idea básica de este tipo de compresión es quitar la información que puede ser recreada a partir de los datos restantes es decir, la información redundante. Este tipo de compresión tiene como principal ventaja que puede ser aplicada a cualquier tipo de datos además de que para algunos tipos de datos es el único método de compresión permisible. Por otro lado, para este tipo de métodos el nivel de compresión es sumamente dependiente de la naturaleza de los datos y en la mayoría de los casos dicho nivel es sumamente bajo lo cual resulta insuficiente para algunas aplicaciones.
El análisis estadístico de las señales de video muestra que existe una fuerte correlación entre imágenes consecutivas en una secuencia lo cual se conoce como correlación temporal. Del mismo modo dichos análisis muestran que también existe una no menos fuerte correlación entre los elementos o pixeles contiguos que componen una imagen lo que se conoce como correlación espacial. De tal manera que la compresión de secuencias de video está basada en tres principios básicos:
- Reducción de la redundancia espacial con la que se busca reducir la redundancia entre pixeles de la misma imagen la cual es producto de los cambios graduales en niveles de intensidad de color entre pixeles contiguos, lo que es una característica peculiar de las imágenes reales por lo cual, para llevar a cabo este proceso se utilizan técnicas de compresión de imágenes fijas.
- Reducción de la redundancia temporal para remover las similitudes entre imágenes sucesivas producto de cambios pequeños entre imágenes consecutivas. Para llevar a cabo este proceso se utiliza la codificación por diferencias y compensación de movimiento.
- Reducción de la redundancia entre los datos comprimidos generados de los procesos anteriores para lo cual se utilizan técnicas de compresión sin pérdidas.
La compresión de secuencias de video es realmente la adaptación y utilización de un conjunto de herramientas y técnicas de compresión, las cuales en conjunto permiten llevar a cabo una reducción de datos considerable. En el caso específico del estándar MPEG-1 estas técnicas de compresión son: transformada discreta coseno (DCT), cuantización, algoritmos de código de longitud variable, codificación RLE (“Run Lenght Encoding”), algoritmos de predicción y compensación de movimiento.
1.3.1. Transformada Discreta Coseno (DCT).
La DCT es una derivación del análisis de Fourier en el cual se establece que cualquier función periódica puede ser representada por la suma de funciones sinusoidales de una frecuencia y múltiplos enteros de dicha frecuencia, siempre y cuando las funciones sinusoidales tengan la amplitud y la fase apropiadas. La gran ventaja de la DCT con respecto a otras transformadas derivadas del análisis de Fourier es que ésta convierte una función periódica en una suma de funciones cosenoidales, por lo que sólo se trabaja con números reales y el tiempo de cálculo es menor.
La efectividad de determinada técnica de compresión depende directamente del tipo de información que se va a comprimir. La DCT no produce por si sola una reducción de la cantidad de información; sin embargo sí provoca que una parte significativa de la energía de la imagen se concentre en los componentes de baja frecuencia por lo que una gran cantidad de coeficientes resultantes tendrá un nivel de energía bajo. Por esta razón la DCT es una herramienta que permite ordenar los datos de tal manera que otras herramientas de compresión puedan ser utilizadas para reducir la cantidad datos de una forma eficiente.
En la compresión de imágenes se utilizan bloques de datos de 8x8 y se transforman mediante la DCT en un conjunto también de 8x8 de coeficientes de funciones cosenoidales ordenados según el incremento de sus frecuencias. El proceso inverso de la DCT consiste en encontrar, mediante los coeficientes de funciones cosenoidales, el conjunto de datos con los cuales se obtuvieron dichos coeficientes. Este proceso es denominado Transformada Inversa Discreta Coseno (IDCT) [4]. La transformación de un arreglo V (de una dimensión) de N números, en un arreglo T de N coeficientes DCT está definida por:
∑
− = + = 1 0 2 ) 1 2 ( cos ] [ ) ( ] [ N n N i x x V i c iT π (1.2)
donde:
(0)= 1 , ( )= 2 ,k ≠0
N k
La IDCT que es utilizada para revertir el proceso está definida por [4]:
∑
− = + = 1 0 2 ) 1 2 ( cos ] [ ] [ ] [ N i N i n i T i c nV π (1.3)
Aunque el simple uso de la DCT no produce compresión, si produce una acumulación de energía en los coeficientes de frecuencias bajas además de una disminución en el orden de magnitud de algunos de los coeficientes con respecto a los valores de entrada. Si se utiliza N=1 en la ecuación (1.3), se obtiene un promedio de los valores reales que se utilizaron para obtener los coeficientes de DCT. El
primer coeficiente de DCT es conocido como coeficiente DC (corriente directa), es decir, representa un voltaje constante; los demás coeficientes son conocidos como
AC (corriente alterna) ya que su representación está dada por una curva sinusoidal. Dado que los coeficiente de DC y AC conllevan diferentes niveles de información, normalmente son codificados en forma diferente.
Uno de los puntos más importantes de la DCT es que los coeficientes de mayor orden tienden a contribuir con menos información a la imagen. Se pueden desechar los coeficientes de mayor orden y aún así tener una buena aproximación de la imagen. El número de coeficientes que se pueden desechar depende del grado de compresión y de pérdida que se desee.
Debido a la correlación entre pixeles horizontales y verticales se puede obtener una mejor compresión utilizando la DCT en dos dimensiones, que está dada por:
∑ ∑
− = − = + + = 1 0 1 0 2 ) 1 2 ( cos 2 ) 1 2 ( cos ] , [ ) , ( ] , [ N x N y N j y N i x y x V j i c j iT π π (1.4)
donde: 0 , 2 ) ,
( = i y j≠
N j i c 0 , 1 ) ,
( = i y j=
La IDCT en dos dimensiones está definida por:
∑ ∑
− = − = + + = 1 0 1 0 2 ) 1 2 ( cos 2 ) 1 2 ( cos ] , [ ) , ( ] , [ N i N j N j y N i x j i T j i c y xV π π (1.5)
El método más conveniente de expresar la DCT de dos dimensiones es con un producto de matrices [4] en donde la DCT está definida por:
T
MVM
T = (1.6)
Y la IDCT es:
TM M
V = T (1.7)
Donde V es una matriz de 8X8 y M es la siguiente matriz:
) 8 . 1 ( 16 105 cos 2 1 16 91 cos 2 1 16 77 cos 2 1 16 63 cos 2 1 16 49 cos 2 1 16 35 cos 2 1 16 21 cos 2 1 16 7 cos 2 1 16 90 cos 2 1 16 78 cos 2 1 16 66 cos 2 1 16 54 cos 2 1 16 42 cos 2 1 16 30 cos 2 1 16 18 cos 2 1 16 6 cos 2 1 16 75 cos 2 1 16 65 cos 2 1 16 55 cos 2 1 16 45 cos 2 1 16 35 cos 2 1 16 25 cos 2 1 16 15 cos 2 1 16 5 cos 2 1 16 60 cos 2 1 16 52 cos 2 1 16 44 cos 2 1 16 36 cos 2 1 16 28 cos 2 1 16 20 cos 2 1 16 12 cos 2 1 16 4 cos 2 1 16 45 cos 2 1 16 39 cos 2 1 16 33 cos 2 1 16 27 cos 2 1 16 21 cos 2 1 16 15 cos 2 1 16 9 cos 2 1 16 3 cos 2 1 16 30 cos 2 1 16 26 cos 2 1 16 22 cos 2 1 16 18 cos 2 1 16 14 cos 2 1 16 10 cos 2 1 16 6 cos 2 1 16 2 cos 2 1 16 15 cos 2 1 16 13 cos 2 1 16 11 cos 2 1 16 9 cos 2 1 16 7 cos 2 1 16 5 cos 2 1 16 3 cos 2 1 16 1 cos 2 1 8 1 8 1 8 1 8 1 8 1 8 1 8 1 8 1 → = π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π π M