INSTITUTO POLITÉCNICO NACIONAL
ESCUELA SUPERIOR DE INGENIERÍA MÉCANICA Y ELÉCTRICA
“
Clasificación de patrones con
Memorias Asociativas Bidireccionales
α
-
β”
T
E
S
I
S
Q U E P A R A O B T E N E R E L T Í T U L O D E :
INGENIERO EN COMUNICACIONES Y ELECTRÓNICA
P R E S E N T A N
Sandra Paola Torres Jurado
Jesús García Díaz
MÉXICO, D.F. 2009
ASESORES: Dra. María Elena Acevedo Mosqueda
RESUMEN
En este trabajo presentamos la implementación del modelo de Memoria Asociativa
Bidireccional BAM α-β como clasificador de patrones. El modelo de la BAM α-β es un algoritmo basado en las memorias asociativas α-β que cuenta con la característica de
recuperar todo lo que aprende y que además funciona por sí misma como un clasificador, pero con un rendimiento escaso. Es por ello que resulta natural considerarle como la base para el desarrollo de un clasificador de alto rendimiento, añadiendo lo que sea requerido. En este trabajo se analizó el comportamiento de las
diferentes etapas que constituyen a la BAM α-β, de manera que se pudieron determinar
los algoritmos necesarios a añadir al modelo para lograr que funcionara como un clasificador.
Parte fundamental del presente trabajo es el uso de la codificación Johnson-Möbius
modificado, pues sin éste el algoritmo propuesto resulta ineficiente.
El porcentaje de recuperación correcta del clasificador propuesto en este trabajo supera a los mejores clasificadores existentes en la actualidad, lo cual habla a favor del modelo BAM α-β, así como del modelo de Memorias Asociativas α-β.
PLANTEAMIENTO DEL PROBLEMA
En la actualidad existen diversas aplicaciones donde el uso de un clasificador resulta fundamental. La labor básica de los clasificadores consiste en dividir un conjunto de patrones que poseen ciertas características en pequeños subconjuntos llamados clases, es decir la clasificación de un patrón consiste en determinar la región (clase) a la que pertenece de ese conjunto. Lamentablemente la mayoría de los clasificadores existentes a la fecha no cuentan con un rendimiento lo suficientemente alto para ser aplicados a determinadas tareas.
Los clasificadores son ampliamente usados en gran cantidad de áreas de estudio. Por ejemplo en la medicina, donde se maneja muchísima información que resulta necesario clasificar, de manera que se le pueda brindar al especialista una mejor interpretación de la misma y de esta manera se puedan determinar las decisiones idóneas que el médico debe tomar. Otra área importante donde se utilizan clasificadores es la robótica aplicada a procesos industriales, donde se persigue la meta de automatizar y optimizar algún proceso de clasificación de productos, reduciendo tiempo y costo. Otra área donde encontramos clasificadores es en la teledetección, pues nos permiten determinar y clasificar un objeto, fenómeno o superficie a través del análisis de los datos y de esta manera poder atacar determinado problema que se presente. En estas y muchas más aplicaciones se puede implementar un clasificador, puesto que su propósito es facilitar y optimizar cierto proceso o tarea de una especifica área de estudio.
JUSTIFICACIÓN
Un clasificador puede ser muy útil aplicado a tareas cartográficas (un ejemplo es la creación de un prototipo actualizado de mapa topográfico digital). También resulta útil en el campo de la ingeniería biomédica, ya sea en el tratamiento de imágenes o en el análisis y agrupamiento de datos médicos, cuyo fin último es proporcionar al profesional una ayuda en la toma de decisiones. O bien puede ser útil en el campo de la informática al momento de organizar documentos como lo hace un navegador WEB, el cual mediante una palabra clave irá clasificando los archivos que se deseen utilizar. Éstas y muchas más aplicaciones, tanto para la investigación como para la vida diaria, pueden resultar una herramienta muy importante para la simplificación de una tarea específica. Durante años las ciencias de la computación han buscado simular, a través de la programación, los diversos procesos que el cerebro humano realiza de forma automática. El cerebro humano realiza cotidianamente asociaciones sobre objetos, personas, animales, etcétera; estas clasificaciones permiten al ser humano identificar los diferentes aspectos de su entorno, y de esta manera puede interactuar con el mismo. Las asociaciones que el cerebro humano realiza son de una complejidad tal que difícilmente podrían ser simuladas fielmente por medios electrónicos; sin embargo, en cierta forma esto se ha logrado (o al menos se han hecho grandes avances) mediante la implementación de algoritmos matemáticos, particularmente los relacionados al
concepto de “Memorias Asociativas”. La memoria asociativa que maneja el cerebro ha sido observada y estudiada largamente, de manera que los algoritmos de “Memorias
Asociativas” computacionales han tenido un crecimiento importante a lo largo del
tiempo, lográndose que el porcentaje de asociaciones correctas sea cada vez mayor. Los modelos basados en el concepto de memorias asociativas se han desarrollado y estudiado desde los años sesenta. Una de las aplicaciones principales que se les puede dar a estas memorias es la de implementarlas como clasificadores; esto es, organizar un conjunto de objetos mediante el análisis de sus características dentro de determinadas clases.
Las memorias asociativas han tenido una gran aceptación por la efectividad que han demostrado tener en la clasificación de diferentes bases de datos; en el presente proyecto utilizaremos el modelo de las memorias asociativas BAM α-β, el cual constituye unos de los modelos con mejor rendimiento en la actualidad.
Con el paso del tiempo se han venido utilizando diversos algoritmos basados en diferentes enfoques para la creación de un clasificador; entre los que se encuentran el
Todos estos algoritmos han utilizado la base de datos Iris Plant para realizar sus pruebas, las cuales nos permiten observar que el algoritmo CHAT ha obtenido el mayor porcentaje de clasificación con el 96.56% de clasificación correcta.
El proyecto consistirá en implementar esta memoria asociativa α-β como un clasificador, lo cual no se ha realizado a la fecha. Se realizarán comparaciones con otros clasificadores utilizando la base de datos Iris Plant, la cual contiene información sobre tres tipos de flor de iris (Setosa, Virginica y Versicolor), tomando en cuenta las características del sépalo (largo y ancho) y pétalo (largo y ancho). Esta base de datos ha sido utilizada para pruebas de varios algoritmos clasificadores a lo largo del tiempo en todo el mundo, es por ello que en base a ella se realizarán las comparaciones que
nos permitirán concluir cuales son las ventajas de utilizar la BAM α-β como clasificador,
OBJETIVOS
OBJETIVO GENERAL
Habilitar la Memoria Asociativa Bidireccional α-β (BAM α-β) como clasificador mediante la codificación Johnson-Möbius modificada.
OBJETIVOS PARTICULARES
Implementar las memorias asociativas α-β.
Aplicar el código Johnson-Möbius modificado, y la BAM α-β para la clasificación de la base de datos Iris Plant.
Base de datos
Iris Plant
Codificación
Johnson-Möbius
BAM α-β
Obtiene las matrices
máx y min
MODELO PROPUESTO
A continuación se muestra el diagrama a bloques de las dos etapas (etapa de aprendizaje y etapa de recuperación) en las que consiste el modelo propuesto en el presente trabajo.
FASE DE APRENDIZAJE
Dentro de esta etapa se ingresará la información de la base de datos Iris Plant para posteriormente hacer las pruebas pertinentes. Esta base de datos será codificada utilizando el código Johnson- Möbius modificadocon el fin de eliminar el ruido mezclado
que la BAM α-β (Memoria Asociativa Bidireccional α-β) no puede manejar para
recuperar los patrones.
Una vez codificada la base de datos Iris Plant, será introducida a la BAM α-β para
generar el conjunto fundamental (matriz de aprendizaje) y así obtener mediante el
operador α las matrices máx y min.
FASE DE RECUPERACIÓN
En la fase de recuperación se obtendrá la clasificación de un determinado patrón. Para ello será previamente codificado con el código Johnson- Möbius modificado.
Posteriormente el patrón introducido será operado con las matrices máx y min
Este par de algoritmos (que hemos denominado análisis S/A y análisis M) son descritos a detalle en la sección 3.3.2 y 3.3.3 respectivamente
En la opción A se realiza primero el análisis de los patrones aprendidos que contienen exclusivamente ruido aditivo y exclusivamente ruido sustractivo (análisis S/A), y posteriormente se lleva a cabo el análisis de los patrones con ruido mezclado (análisis M).
Si se opta por la opción B se realizará lo mismo que en la opción A, excepto porque ahora se realizará primero el análisis de los patrones con ruido mezclado (análisis M) y posteriormente el de los patrones con exclusivamente ruido aditivo y exclusivamente ruido sustractivo (análisis S/A).
En el capítulo 4, donde se encuentran las pruebas realizadas, se mencionarán las diferencias entre utilizar una u otra opción.
Registro
Codificación
Johnson-Möbius
Operar el registro con las matrices
máx y min
Obtener vectores r y
Realizar operación
AND r y
Opera vector one-hot con el Linear
Associator Sí
¿Se cumple el criterio de clasificación?
Sí
Se obtiene la clasificación
B
¿Contiene sólo ceros?
Se analizan los patrones con ruido
mezclado
Sí
No
No es posible clasificarlo
No
¿ r AND es vector one-hot?
Opera vector one-hot con el Linear
Associator
¿ r AND es
vector one-hot? sólo ceros? ¿Contiene
Se analizan los patrones con ruido
mezclado
Se obtiene la clasificación
Sí
Sí No
No
ÍNDICE
ÍNDICE DE FIGURAS ... XI ÍNDICE DE TABLAS ... XII
CAPÍTULO I ... 1
1.1 INTRODUCCIÓN ... 1
1.2 RECONOCIMIENTO DE PATRONES ... 3
1.2.1 ENFOQUES DEL RECONOCIMIENTO DE PATRONES ... 4
1.2.2 ETAPAS DEL RECONOCIMIENTO DE PATRONES ... 4
1.3 CLASIFICACIÓN ... 6
1.4 IMPORTANCIA DE LOS CLASIFICADORES Y APLICACIONES ... 7
1.5 MEMORIAS ASOCIATIVAS BIDIRECCIONALES (BAM) ... 9
1.6 MEMORIAS ASOCIATIVAS BIDIRECCIONALES α-β (BAM α-β) Y SUS APLICACIONES ... 12
1.7 ESTADO DEL ARTE ... 12
1.7.1 CLASIFICADOR BAYESIANO ... 13
1.7.2 K-NEAREST NEIGHBOR (K-NN) ... 17
1.7.3 CLASIFICADOR HÍBRIDO ASOCIATIVO CON TRASLACIÓN (CHAT) ... 18
CAPÍTULO 2 ... 21
2.1 MEMORIAS ASOCIATIVAS ... 21
2.1.1 LERNMATRIX DE STEINBUCH ... 24
2.1.2 CORRELOGRAPH DE WILLSHAW, BUNEMAN & LONGUET-HIGGINS ... 25
2.1.3 LINEAR ASSOCIATOR DE ANDERSON-KOHONEN ... 26
2.1.4 HOPFIELD ... 28
2.1.5 MEMORIAS ASOCIATIVAS α y β ... 30
2.1.5.1 MEMORIAS HETEROASOCIATIVAS α-β ... 30
2.1.5.1.1 MEMORIAS HETEROASOCIATIVAS α-β TIPO V ... 31
2.1.5.2 MEMORIAS AUTOASOCIATIVAS α-β ... 32
2.1.5.2.1 MEMORIAS AUTOASOCIATIVAS α-β TIPO V ... 32
2.1.5.2.2 MEMORIAS AUTOASOCIATIVAS α-βTIPO Λ ... 33
CAPÍTULO 3 ... 35
3.1 MEMORIAS ASOCIATIVAS BIDIRECCIONALES α-β ... 35
3.2 ETAPA DE RECUPERACIÓN COMO FUNDAMENTO DE LA CLASIFICACIÓN DE LA BAM α-β ... 40
3.2.1 EJEMPLO ... 41
3.3 LA CLASIFICACIÓN DE LA BAM α-β ... 45
3.3.1 ELEMENTOS DE LA BAM α-β QUE PERMITEN LA CLASIFICACIÓN ... 46
3.3.2 ALGORITMO DE CLASIFICACIÓN (ANÁLISIS S/A) ... 50
3.3.3 ALGORITMO DE CLASIFICACIÓN (ANÁLISIS M) ... 53
3.4 DIAGRAMA DE FLUJO DEL ALGORITMO DE CLASIFICACIÓN PROPUESTO 55 3.5 CODIFICACIÓN JOHNSON-MÖBIUS MODIFICADO ... 60
3.6 BASE DE DATOS IRIS PLANT ... 62
CAPÍTULO 4 ... 63
4.1 EJEMPLO DE CLASIFICACIÓN CON EL ANÁLISIS S/A ... 63
4.2 EJEMPLO DE CLASIFICACIÓN CON EL ANÁLISIS M ... 74
4.3 PRUEBAS ... 83
4.4 CONCLUSIONES ... 91
4.5 APORTACIONES Y TRABAJO FUTURO ... 91
APÉNDICE A………..93
GLOSARIO ... 98
ÍNDICE DE FIGURAS
Figura 1.1 Etapas del Reconocimiento de Patrones ... 5
Figura 1.2 Memoria Asociativa ... 9
Figura 1.3 Esquema de la BAM como una caja negra ... 10
Figura 2.1 Diagrama a bloques de una memoria asociativa ... 21
Figura 3.1 Diagrama a bloques de una Memoria Asociativa Bidireccional ... 35
Figura 3.2 Diagrama a bloques de la BAM α-β ... 35
Figura 3.3 Esquema del proceso en el sentido de x a y ... 37
Figura 3.4 Esquema del proceso en el sentido de y a x ... 38
Figura 3.5 Esquema del proceso en el sentido de x a y ... 40
Figura 3.6 Sistema de traducción utilizando la BAM α-β ingresando patrón aprendido ... 45
Figura 3.7 Sistema de traducción utilizando la BAM α-β ingresando patrón con ruido ... 46
Figura 4.1 Distribución de los 20 registros de los atributos A1 y A2 de las clases versicolor y virginica ... 64
Figura 4.2 Distribución de los patrones aprendidos y el patrón a clasificar ... 65
Figura 4.3 Distribución del patrón introducido sobre el plano cartesiano ... 67
Figura 4.4 Posición k=10 del patrón comparado con el patrón introducido ... 69
Figura 4.5 Posición k=2 del patrón comparado con el patrón introducido ... 70
Figura 4.6 Posición k=4 del patrón comparado con el patrón introducido ... 71
Figura 4.7 Área de los patrones aprendidos de la clase versicolor en sus cuadrantesI y III ... 72
Figura 4.8 Área de los patrones aprendidos de la clase virginica en sus cuadrantesI y III ... 73
Figura 4.9 Áreas de distribución entre la clase vesicolor y la clase virginica ... 74
Figura 4.10 Distribución de los patrones aprendidos y el patrón a clasificar ... 75
Figura 4.11 Identificación de los valores de K que cumplen rk=0 y s-k=0 ... 76
Figura 4.12 Distribución de los patrones 13,18 y 19 respecto al patrón introducido ... 79
Figura 4.13 Distribución de los patrones aprendidos de la clase versicolor respecto al patrón introducido ... 80
Figura 4.14 Distribución el patrón introducido dentro del plano cartesiano ... 81
Figura 4.15 Analogía para los conjuntos 1 y 2 ... 83
Figura 4.16 Porcentajes de recuperación del análisis S/A y M (1) ... 85
Figura 4.17 Porcentajes de recuperación del análisis S/A y M (2) ... 86
Figura 4.18 Porcentajes de recuperación del análisis S/A y M combinados (1) ... 86
Figura 4.19 Porcentajes de recuperación del análisis S/A y M combinados (2) ... 87
Figura 4.20 Porcentajes de recuperación del análisis S/A y M del 70% al 80% ... 88
ÍNDICE DE TABLAS
Tabla 1.1 Asociaciones (x,y) ... 10
Tabla 1.2 Ejemplos de patrones ruidosos ... 11
Tabla 1.3 Porcentaje de efectividad de los algoritmos con enfoque Bayesiano ... 17
Tabla 1.4 Porcentaje de efectividad de los algoritmos con enfoque basado en métrica ... 18
Tabla 1.5 Porcentaje de efectividad del algoritmo con enfoque Asociativo ... 19
Tabla 2.1 Fase de aprendizaje para Learnmatrix de Steinbuch ... 24
Tabla 2.2 Fase de aprendizaje para una red asociativa... 26
Tabla 2.3 Operación α ... 30
Tabla 2.4 Operación β ... 30
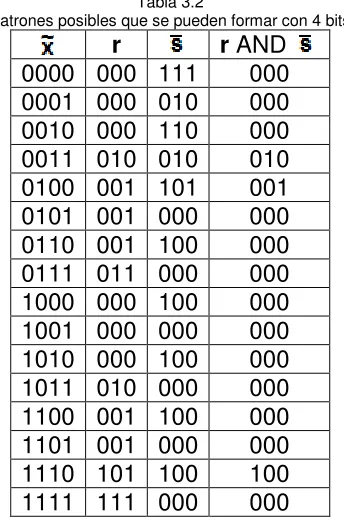
Tabla 3.1 Posibles combinaciones para la determinación del patrón introducido ... 47
Tabla 3.2 Patrones posibles que se pueden formar con 4 bits ... 48
Tabla 3.3 Patrón introducido 0111 ... 48
Tabla 3.4 Relación entre el patrón x1 y el patrón introducido 0111 ... 48
Tabla 3.5 Relación entre el patrón x2 y el patrón introducido 0111 ... 49
Tabla 3.6 Patrón introducido 0001 ... 49
Tabla 3.7 Relación entre el patrón x1 y el patrón introducido 0001 ... 49
Tabla 3.8 Relación entre el patrón x2 y el patrón introducido 0001 ... 49
Tabla 3.9 Patrón introducido 0100 ... 50
Tabla 3.10 Relación entre el patrón x3 y el patrón introducido 0100 ... 50
Tabla 3.11 Ejemplos de ruido aditivo para el valor 1010 ... 60
Tabla 3.12 Ejemplos de ruido sustractivo para el valor 1010 ... 60
Tabla 3.13 Ejemplos de ruido combinado para el valor 1010 ... 61
Tabla 3.14 Ejemplos de codificación Johnson-Möbius ... 62
Tabla 4.1 Atributos A1 y A2 pertenecientes a las clases versicolor y virginica ... 63
Tabla 4.2 Patrón a clasificar ... 65
Tabla 4.3 Comparación de la codificación del atributo A1 del patrón introducido y un patrón en el cuadrante I ... 68
Tabla 4.4 Comparación de la codificación del atributo A2 del patrón introducido y un patrón en el cuadrante I ... 68
Tabla 4.5 Comparación de la codificación del atributo A1 del patrón introducido y un patrón en el cuadrante III ... 69
Tabla 4.6 Comparación de la codificación del atributo A2 del patrón introducido y un patrón en el cuadrante III ... 69
Tabla 4.7 Comparación de la codificación del atributo A2 del patrón introducido y un patrón en el cuadrante II ... 70
Tabla 4.8 Comparación de la codificación del atributo A2 del patrón introducido y un patrón en el cuadrante II ... 71
Tabla 4.9 Patrón a clasificar ... 74
Tabla 4.10 Codificaciones obtenidas de los patrones k=n del atributo A1 ... 77
Tabla 4.11 Codificación obtenida del patrón introducido del atributo A1 ... 78
Tabla 4.13 Codificación obtenida del patrón introducido del atributo A2 ... 78
Tabla 4.14 Patrón a clasificar ... 80
Tabla 4.15 Combinaciones generadas de ruido mezclado con 2 atributos ... 81
Tabla 4.16 Combinaciones generadas de ruido mezclado con 3 atributos ... 81
Tabla 4.17 Número de patrones aprendidos por clase en los cuadrantes II y IV ... 82
Tabla 4.18 Resultado de pruebas realizadas ... 84
Tabla 4.19 Resultado de pruebas del 70% al 80% de S/A y M ... 88
Tabla 4.20 Resultado de pruebas del 70% al 80% de S/A y M combinados ... 88
Tabla 4.21 Porcentajes de recuperación de los diferentes clasificadores ... 90
CAPÍTULO I
1.1 INTRODUCCIÓN
El tema del reconocimiento de patrones abarca un área de estudio bastante amplia, y es por ello que a lo largo de su evolución se han venido utilizando diversas técnicas para tratar el tema, que básicamente busca semejar el funcionamiento del cerebro humano, en cuanto a percepción y procesamiento de patrones se refiere.
Comprender en qué consiste el reconocimiento de patrones es fundamental para el entendimiento de la importancia de la presente tesis, ya que está íntimamente ligado con el proceso de clasificación y recuperación de patrones.
Antes de hablar del reconocimiento de patrones, es necesario definir qué es un patrón. Así pues, los patrones son entidades que tienen ciertas características, mismas que exhiben cierta regularidad en una colección de observaciones conectadas en el espacio, tiempo o en ambos, y que pueden servir como modelo.
Por ejemplo:
Tenemos una colección de imágenes de rostros humanos vistos de frente. Al observarlos encontraremos los siguientes patrones:
La nariz se encuentra en el centro de los rostros de la colección. Los labios se encuentran bajo la nariz.
Los ojos se encuentran sobre la nariz.
Las orejas se encuentran a los lados del rostro. Las cejas se encuentran sobre los ojos.
De este modo hemos determinado las características principales que debe tener un ente para poder decir que se trata de un rostro humano. Es decir, hemos propuesto el patrón del rostro humano.
Ahora bien, estos patrones al encontrar ciertas similitudes pueden ser clasificables, y se entiende por clasificación al ordenamiento por clases o categorías de un objeto, basándose en sus propiedades o características en cuestión.
Para que se pueda llegar a clasificar objetos, se necesitan herramientas computacionales potentes que puedan identificar las propiedades o características de cierto grupo de objetos.
clasificación con el uso de las memorias asociativas, las cuales tienen como propósito fundamental el de recuperar correctamente patrones completos a partir de los patrones de entrada, los cuales pueden estar alterados con ruido. En el diseño de una memoria asociativa tenemos dos etapas: la fase de aprendizaje y la fase de recuperación; La fase de aprendizaje es donde se genera la memoria asociativa a partir de las asociaciones (entrada, salida) del conjunto fundamental, y la fase de recuperación que es donde la memoria asociativa opera sobre un patrón de entrada para obtener un patrón de salida [1].
Dentro de este enfoque asociativo se trabajará más específicamente con las Memorias Asociativas Bidireccionales α-β (BAM α-β), modelo que está basado en las Memorias Asociativas α-β, las cuales fueron creadas en el CIC (Centro de Investigación en Computación) por el Dr. Cornelio Yáñez Márquez [9]. Estas memorias están consideradas como las de mayor rendimiento en la actualidad [2].
El modelo de la BAM α-β siempre recupera de forma correcta todos los patrones entrenados. En capítulos posteriores se explicará el fundamento matemático para sostener lo dicho anteriormente.
La BAM α-β consta de 4 etapas, dos de ellas se utilizan en el sentido hacia adelante y las dos restantes en sentido contrario, lo que permite la bidireccionalidad del modelo. Para la creación del clasificador sólo se trabajará con las dos primeras etapas; las cuales constan de dos memorias autoasociativas α-β máx y min, construidas a partir de los patrones de entrada. La primera etapa consiste en obtener un vector llamado one-hot a partir de un patrón de entrada, por lo tanto en la segunda etapa la tarea principal es recuperar de manera acertada el patrón correspondiente [1].
Este modelo trabaja con valores binarios, y tiene la característica de que puede recuperar los patrones aprendidos cuando existe solamente un tipo de ruido en los mismos: aditivo o sustractivo, pero no así cuando existe ruido mezclado. Es debido a esto que resulta necesario implementar una codificación sobre los patrones, para que así, no exista ruido mezclado y se puedan recuperar los mismos.
1.2 RECONOCIMIENTO DE PATRONES
A lo largo del siglo pasado se llevaron a cabo muchas investigaciones en el área del reconocimiento de patrones, en todas sus diversas áreas.
Cuando se trabaja en este campo de estudio, se debe lidiar con la incapacidad de los modelos actuales de reconocimiento de patrones en comparación con la gran complejidad del cerebro humano.
No obstante, en los últimos años ha existido un gran progreso en el área y, aunque aún se está lejos de lograr que una máquina pueda hablar y entender al ser humano completamente, los avances indican que las recompensas justificarán el esfuerzo.
“El Reconocimiento de patrones es una técnica de la inteligencia artificial y es empleado
por tecnologías como el procesamiento de lenguaje natural y la visión computacional”
[5].
El Reconocimiento de Patrones incluye, entre sus principales tareas, la clasificación y la recuperación de patrones.
“El reconocimiento de patrones se apoya de otras técnicas de la Inteligencia Artificial como” [5]:
Lógica difusa Minería de datos Redes neuronales Agentes
1.2.1 ENFOQUES DEL RECONOCIMIENTO DE PATRONES
Los principales enfoques de Reconocimiento de Patrones son los siguientes [5] [7]: Enfoque estadístico-probabilístico. Este enfoque está basado en la teoría de la probabilidad, y específicamente en el teorema de Bayes. Es el primer enfoque que existió.
Clasificadores basados en métricas. Se basan en el concepto de métrica y espacios métricos para poder realizar la clasificación.
Enfoque sintáctico-estructural. Se basa en la teoría de autómatas y lenguajes formales. Se enfoca más en la estructura de los objetos que desea clasificar que en mediciones numéricas.
Enfoque lógico-combinatorio. La modelación del problema debe ser lo más cercana posible a la realidad del mismo, sin hacer suposiciones que no estén fundamentadas. Se utiliza para conjuntos difusos además de utilizar la lógica simbólica, circuitos combinacionales y secuenciales.
Enfoque Neuronal. Se basa en modelos matemáticos de las neuronas biológicas, esto es, emular la forma en cómo interactúan nuestras neuronas.
Enfoque Asociativo. Creado en el Centro de Investigación en Computación del IPN en 2002, utiliza los modelos de memorias asociativas para crear clasificadores robustos. Esta tesis girará en torno al enfoque asociativo, por lo que en el transcurso de ella se manejarán conceptos importantes como lo son las memorias asociativas [9].
1.2.2 ETAPAS DEL RECONOCIMIENTO DE PATRONES
“Dentro del sistema de reconocimiento de patrones, existen una serie de etapas que están bien definidas” [8]:
Pre procesado y adquisición de datos. Definición de características.
Figura 1.1 Etapas del Reconocimiento de Patrones
Pre procesado y adquisición de datos
Aquí los patrones son tratados de tal forma que se pueda trabajar de una forma más sencilla y eficaz. Para ello se trata de eliminar el ruido que se produce por el proceso de adquisición de los patrones.
Definición de características
En esta etapa se lleva a cabo la búsqueda de las características que representen a los patrones para así clasificarlos de la forma más adecuada. Su propósito es estudiar los descriptores de región como características elegidas y verificar su validez.
Selección y extracción de características
La selección de características consiste en remover las características que definitivamente no aportan información a la clasificación.
Con la extracción de características lo que se pretende es mejorar el escenario en el que tendrá que actuar el clasificador; se trata de trasladar el espacio de patrones a otro de igual o menor dimensión en el que se produzcan las mejoras deseadas.
1.3 CLASIFICACIÓN
La etapa más importante del reconocimiento de patrones es la que corresponde a la implementación de un clasificador.
Un clasificador, o regla de clasificación, es un proceso dentro del cual la tarea principal consiste en dividir el espacio de un conjunto de características en regiones de decisión asociadas a las clases, es decir que la clasificación de patrones consiste en determinar a qué subgrupo de un conjunto de patrones pertenece, tomando en cuenta sus características.
El proceso de clasificación se compone de tres fases: La elección del modelo
Aprendizaje (entrenamiento del clasificador) Verificación de resultados
Para poder construir el clasificador en primer lugar deben estudiarse cómo se distribuyen los patrones de cada clase y establecer una función discriminante adecuada utilizando los prototipos disponibles. Posteriormente es necesario elegir un modelo, para este caso se trabajará con las memorias asociativas bidireccionales α-β (BAM α-β) [1]. Ahora bien, para poder construir el clasificador, utilizando el modelo de memorias asociativas, es importante utilizar una herramienta para la construcción de éste, ya sea utilizando software o hardware. Es importante señalar que en la presente tesis se utilizará únicamente software.
El clasificador diseñado está programado en visual C#, esto debido a que el lenguaje de programación C# resulta ser muy estable, rápido y además es multiplataforma.
Una vez elegido el clasificador éste debe ajustarse a los datos del problema mediante un proceso de aprendizaje, que en Reconocimiento de Patrones se realiza mediante un conjunto de entrenamiento (conjunto fundamental) a cuyos elementos se llaman patrones.
En el caso de este proyecto, los patrones son obtenidos de la base de datos Iris Plant; esta base consta de 150 datos, los cuales se encuentran clasificados dentro de tres clases diferentes de flor del iris (Setosa, Versicolor y Virginica).
1.4 IMPORTANCIA DE LOS CLASIFICADORES Y APLICACIONES
“Clasificar ha sido, y es hoy en día, un problema básico para un amplio espectro de disciplinas, que se extiende de las ciencias básicas a la ingeniería” [3]. Dependiendo de la ciencia y del periodo histórico, el problema de clasificar se presenta de manera diferente. La clasificación no sólo facilita la manera de estudiar un fenómeno, sino que también ayuda a organizar y facilitar la información requerida.
Uno de los propósitos fundamentales común a todas las disciplinas, es el de dividir un conjunto de objetos en categorías (clasificar), para así poder simplificar el estudio de un determinado fenómeno. Estas categorías (clases) se construyen de manera tal que cada objeto sea similar, en cierta forma, a otro objeto del mismo grupo; y posteriormente objetos de distintos grupos tienden a ser diferentes [3].
A continuación se presentan algunas aplicaciones importantes de clasificadores en diversas áreas de la ciencia e ingeniería:
Imágenes geoespaciales:
Conforme transcurre el tiempo, a nivel mundial se vienen generando colecciones de datos en escalas enormes, almacenadas en ordenadores, servidores.
Dentro de estas grandes colecciones de datos están aquellas de tipo geoespacial (imágenes satelitales entre otros), requeridas por las diversas comunidades académicas y científicas. La información actual disponible en la Web, acerca de las imágenes de satélite, se limita a la información de metadatos, como son las coordenadas geográficas, la fecha de adquisición, el tipo de sensor y el modo de adquisición. Esta restricción limita seriamente la utilidad de los datos para los usuarios. En aras de superar esta limitación e incrementar la utilidad de los datos geoespaciales, se requiere la adopción de nuevas tecnologías que hagan posible el acceso a la información de percepción remota en base a contenidos y semánticas. Dentro de los procedimientos que hacen posible extraer mayor información de las imágenes, se encuentra la clasificación de las mismas.
La clasificación de estas imágenes genera un aumento en su aplicabilidad a tareas cartográficas, un ejemplo sería la creación de un prototipo actualizado de mapa topográfico digital. Los mapas topográficos son una representación del relieve de la superficie terrestre.
Indican todo aquello construido por el hombre como ciudades, poblaciones, presas, líneas de electricidad, teléfono, etc.
Se utilizan a menudo como mapas generales de consulta y sirven de base para elaborar otros mapas y gráficos, como los perfiles fluviales y los cortes topográficos. Asimismo, son utilizados para conseguir una buena orientación espacial [4].
Biomédica
En el ámbito de la medicina es de gran interés el conservar e incrementar el tamaño de bases de datos que contengan información relacionada a células de pacientes que padecen alguna enfermedad. Este interés se debe a que las células contienen ciertas características, las cuales son indicadores de determinadas enfermedades. Así, una correcta clasificación de la información celular de un paciente permite realizar un diagnóstico más preciso sobre el mismo.
En ocasiones se requiere caracterizar núcleos celulares de imágenes médicas de citologías para su posterior clasificación en dos categorías: sano o patológico. En esta área se pueden trabajar con distintos tipos de citología: citologías de tejido de mama, citologías peritoneales, citologías de pleura, de donde la característica principal bajo estudio que se extrae de los núcleos que se desea clasificar es la distribución de cromatina en los mismos.
El interés en el campo de la ingeniería biomédica es claro, puesto que se trata de un conjunto de herramientas aplicables tanto al tratamiento de imágenes como al análisis y agrupamiento de datos médicos, cuyo fin último es proporcionar al profesional una ayuda a la toma de decisiones [4].
Informática
En esta rama se tienen diversas aplicaciones como lo es la clasificación de documentos, esto se utiliza comúnmente al realizar búsquedas en internet a través de navegadores; mediante una palabra clave, el clasificador va discernir entre todos los documentos de texto, multimedia (video, sonido y animaciones) y software, que se encuentren en la red para así poder presentarle al usuario la categoría que desea.
En el reconocimiento del habla, se utiliza para identificar a las personas; esto es, si una persona es mujer u hombre, anciano o niño, dependiendo de las características de su voz [6].
Biometría
En el área de la biometría, la identificación de características del iris del ojo puede arrojar información valiosa acerca del posible padecimiento de ciertas enfermedades. La implementación de un clasificador en esta área resultaría de gran utilidad, pues basándose en ciertas características se puede clasificar el iris de un ojo como tendente a representar alguna(s) enfermedad(es) u otra(s) [6].
Reconocimiento de Caracteres
Una labor cotidiana en el servicio postal es la de clasificar los sobres en base a ciertas características, las cuales pueden ser el código postal o el país. Para agilizar esta labor es posible implementar una herramienta que, utilizando una técnica de reconocimiento de caracteres basada en un clasificador, pueda distinguir palabras sin importar el tipo de letra que haya sido utilizado para escribirlas. Posteriormente, y una vez identificadas las palabras escritas en cada sobre, un segundo clasificador sería capaz de ordenar los sobres en diferentes categorías, ya sea por código postal o país. De modo que con el uso de herramientas de clasificación se agiliza enormemente el proceso [6].
1.5 MEMORIAS ASOCIATIVAS BIDIRECCIONALES (BAM)
En la presente tesis trabajaremos con las Memorias Asociativas Bidireccionales α-β
denominadas BAM α-β, las cuales se basan en el modelo de las Memorias α-β [1]. Para hablar de la BAM α-β debemos antes presentar la definición general de Memorias
Asociativas y de las Memorias Asociativas Bidireccionales (BAM). Cabe mencionar que el término BAM proviene de Bidirectional Associative Memory.
[image:23.612.175.432.640.699.2]
Una Memoria Asociativa se puede definir como un sistema de entrada y salida como se muestra a continuación.
Figura 1.2 Memoria Asociativa
X Y
Donde x y y son los patrones de entrada y salida respectivamente. Cada patrón de entrada forma una asociación con el correspondiente patrón de salida (x,y).
Un ejemplo sería la correspondencia que tiene un nombre con su respectivo apellido en
este caso tenemos el nombre “Verónica Saucedo”, en donde se quiere a través del
nombre obtener el apellido. Por lo tanto al ingresar el nombre que corresponde al patrón de entrada x la memoria será capaz de asociar ese nombre con el apellido correspondiente (patrón de salida y), siempre y cuando lo haya aprendido con anterioridad. Este aprendizaje se encuentra constituido por un conjunto finito de asociaciones denominado conjunto fundamental.
Ahora una vez definido qué es una Memoria Asociativa se puede definir en qué consiste una Memoria Asociativa Bidireccional.
[image:24.612.180.441.335.391.2]La manera más sencilla de representar una memoria bidireccional, en general, es como una caja negra, tal como se muestra en la siguiente figura:
Figura 1.3 Esquema de la BAM como una caja negra
En esta figura las flechas indican el sentido del procesamiento de los datos que, como se puede observar, son representados por las letras x y y, además de sus respectivas versiones ruidosas y .
Entre los datos x y ydebe existir cierta correspondencia, la cual se ha de establecer de antemano. Para ejemplificar se muestran en la siguiente tabla las posibles correspondencias entre los datos x y y para un determinado problema:
Tabla 1.1 Asociaciones (x,y)
x y
Verónica Saucedo
Carlos Díaz
Humberto Sánchez
Rosa Fernández
La tabla anterior nos indica que existe una relación entre el nombre “Verónica” y el apellido “Saucedo”, y así sucesivamente para el resto de datos. De modo que el
“Saucedo”. De igual manera, este mismo objetivo debe cumplirse en sentido contrario,
es decir, a una entrada (por el lado derecho) “Saucedo” la BAM debe ser capaz de obtener a la salida (del lado izquierdo) un dato “Verónica”, dejando en claro el porqué
del apelativo Bidireccional.
Ahora bien, observando la figura notamos que hace falta definir el significado de las letras y . Este par de letras representan los mismos datos y , pero con cierta cantidad de ruido presente en ellos, es decir con ligeras variaciones que los modifican, pero sin volverlos irreconocibles al sistema. Por ejemplo, versiones ruidosas de las xde la tabla anterior podrían ser:
Tabla 1.2
Ejemplos de patrones ruidosos
Ver0nika Karloz Humverto
Roza
El funcionamiento de la BAM, vista como una caja negra, es análogo al del cerebro humano. Si introducimos a éste último un dato de entrada, como lo puede ser el nombre
“Verónica”, éste realiza un procesamiento que le da como resultado el apellido
correspondiente, siempre y cuando previamente haya aprendido a generar esta asociación (es decir, siempre y cuando haya conocido previamente a una persona de nombre “Verónica” y apellido “Saucedo”). De la misma manera, una memoria bidireccional recuperará la asociación (el apellido, para nuestro ejemplo) siempre y cuando haya pasado por una etapa de aprendizaje, en la cual generó la asociación de las x con las y.
Ahora bien, la memoria asociativa bidireccional es capaz de recuperar las asociaciones generadas en la etapa de aprendizaje, aún cuando la entrada sea x. Análogamente, nuestro cerebro fácilmente puede identificar que existen ligeros errores en la escritura de un nombre, y dará por hecho que se trata de versiones ruidosas de la escritura original del nombre, de modo que a pesar de estos errores de escritura podrá recuperar el apellido asociado. Si la cantidad de ruido fuera demasiada, nuestro cerebro no podría recuperar la asociación. Lo mismo sucede con las memorias bidireccionales, cuando el ruido tiene ciertas características no podrá recuperar el dato asociado.
Como ya se mencionó, la BAM es bidireccional, y será capaz de realizar las tareas ya descritas en sentido contrario.
1.6 MEMORIAS ASOCIATIVAS BIDIRECCIONALES α-β (BAM α-β) Y SUS APLICACIONES
Las Memorias Asociativas Bidireccionales α-β son un modelo desarrollado por Dra. María Elena Acevedo Mosqueda [1], en base al modelo de Memorias Asociativas α-β
desarrollado por el Dr. Cornelio Yáñez Márquez [9]. Este modelo, visto como una caja negra, funciona del mismo modo que todos los demás modelos de Memorias Asociativas Bidireccionales (cuyo funcionamiento básico se describió en la sección anterior), con la diferencia de que presenta un mayor rendimiento para recuperar asociaciones aprendidas.
La BAM α-β, desde su fundamento teórico, demuestra ser una memoria de muy alto rendimiento [1]. Bajo las condiciones necesarias ha demostrado recuperar el 100% de los datos aprendidos. Más adelante se mencionarán los puntos necesarios a satisfacer para lograr esta perfección en la recuperación de datos.
La eficacia de la BAM α-β ha sido ampliamente comprobada al ser utilizada con gran éxito en diversas aplicaciones prácticas. Algunas de ellas son las siguientes.
Identificador de huellas digitales
En esta aplicación se asociaron las huellas digitales obtenidas del “Fingerprint Verification Competition” a ciertos números enteros. La BAM α-β fue capaz de recuperar dichas asociaciones al 100%. Funcionando íntegramente en ambas direcciones, como era de esperarse. Es decir, al elegir una huella digital se recuperó correctamente su número asociado, y al elegir un número se recuperó correctamente la huella digital asociada [1].
Traductor inglés-español/español-inglés
En esta aplicación se asociaron 120 palabras en inglés a 120 palabras en español. Una
vez más la BAM α-β demostró ser sumamente eficiente, al recuperar al 100% los patrones asociados en ambas direcciones. Incluso recuperó las asociaciones de
patrones de entrada ruidosos, aunque con ciertas limitaciones (la BAM α-β no es
inmune al ruido mezclado, tema sobre el cual se hablará a detalle en el capítulo dos) [1].
1.7 ESTADO DEL ARTE
diseñado con este propósito, los cuales se pueden encontrar publicados en diversas revistas.
Los algoritmos de clasificación publicados son puestos a prueba bajo determinados métodos que permiten comparar la eficiencia de unos con otros. Para realizar estas pruebas, y para garantizar que las comparaciones con los resultados de otros algoritmos sean válidas, se deben utilizar bases de datos idénticas en las pruebas. De esta manera, los resultados obtenidos para diversos algoritmos, son susceptibles de ser comparados entre ellos.
Existen varios métodos que permiten probar los algoritmos de clasificación, tales como el método K-fold cross validation, Leave One Out y Hold One Out.
Observando la literatura existente de reconocimiento de patrones, notamos que una de las bases de datos más ampliamente utilizadas es la base de datos Iris Plant del
Machine Learning Repository [11]. Por ello, y en busca de ser capaces de comparar la eficiencia del algoritmo BAM α-β con la mayor parte de los algoritmos de clasificación existentes, utilizaremos esta base de datos para realizar las pruebas pertinentes en nuestro clasificador.
Ahora bien, existen diversos tipos de clasificadores, donde cada uno de ellos se basa en determinado enfoque. Los clasificadores que actualmente se han desarrollado y que presentan una eficiencia muy alta se basan en los siguientes enfoques:
Bayesiano. Métrica
Redes neuronales Asociativo
A continuación se hablará de los rasgos o características generales de los clasificadores basados en los enfoque arriba listados.
1.7.1 CLASIFICADOR BAYESIANO
El clasificador Bayesiano se basa en la utilización del Teorema de Bayes, el cual básicamente consiste en permitir estimar las probabilidades de las hipótesis (sucesos mutuamente excluyentes A1, A2,…, An que determinan que ocurra el suceso B) después de conocer el resultado de la experimentación, debido a la cual sucedió el suceso B
[10].
El Teorema de Bayes, para calcular la probabilidad condicional de cualquier hipótesis
Ai(i=1,2,…,n), se muestra a continuación:
P Ai|B P AiP BP B|Ai ∑ P AP Ai P B|Ai
k P B|Ak n
k 1
La importancia del Teorema de Bayes radica en el hecho de que permite cambiar el sentido de la probabilidad condicional. Esto lo hace sumamente útil cuando es más fácil calcular la probabilidad de B, dado que ha ocurrido A, que de A dado que ha ocurrido B.
Podemos interpretar los elementos de la fórmula de la siguiente manera:
aposteriori apriori X verosimilitudevidencia
El conocimiento a posteriori es la probabilidad de que ocurra el evento dado que ha ocurrido el evento B. Y será igual al producto del conocimiento a priori con la verosimilitud, dividido por la evidencia.
El conocimiento a priori es la probabilidad de que ocurra Ai, sin importar el comportamiento del evento B, es decir P(Ai) la probabilidad de B dado Ai define la
verosimilitud, es decir, qué tan probable es que suceda B dentro del espacio definido por el evento Ai, es decir (P(B|Ai). Finalmente, la evidencia P(B)=∑n P
k 1 (Ak)P(B|Ak)
indica la probabilidad de que ocurra B si se tiene todo el conocimiento a priori y la
verosimilitud.
Usualmente, los eventos en el teorema de Bayes están expresados en términos de variables aleatorias y distribuciones de probabilidad, por lo que normalmente en la práctica el teorema toma la siguiente forma:
P Ai|B P AiP Bp B|Ai ∑nP AP Ai p B|Ak p B|Ai k k 1
Evidentemente, para determinar la probabilidad P(Ai|B) resulta necesario conocer todas las distribuciones de probabilidad asociadas al problema a resolver y todas las probabilidades P(B|Ai), que representan la información a priori.
Lo anterior puede ser útil para reconocer patrones si las clases y los patrones se modelan como eventos o variables aleatorias. La idea general es la siguiente: un patrón (evento representado por una variable aleatoria vectorial X) pertenece a la clase i
(evento representado por la variable aleatoria vectorial Ci) si su probabilidad de (1.1)
(1.2)
pertenecer a esa clase es más grande que la probabilidad de pertenecer a las demás clases.
El clasificador Bayesiano determina la clase de determinado patrón al hacer comparaciones entre los resultados obtenidos para cada una de las clases, siguiendo la siguiente regla:
X Ci siP Ci|X Cj|X i j
La cual establece que si se conoce que el evento (patrón en el caso específico del clasificador) X ocurrió (es decir que fue presentado al sistema), se calcula la probabilidad de que ocurra Ck k=1,2,…,n se clasifica en la clase Ci si dicha probabilidad es la mayor de todas, es decir, si la probabilidad de pertenencia de X a Ci es mayor a cualquier otra Cj.
Al usar el teorema de Bayes en la ecuación anterior, y tomando en cuenta que las probabilidades siempre son positivas, queda lo siguiente:
P Ci|X Cj|X
P Ci p X|Ci
P X
P(Cj)p X|Cj
P X
P Ci p X|Ci (Cj)p X|Cj
Ahora bien, dado que ln (la función logaritmo natural) es una función monótona creciente, es decir del tipo: F(x) < f(y) ↔ x < y, se puede hacer la siguiente sustitución en la expresión anterior:
P Ci p X|Ci p(Cj)p(X|Cj)
(P Ci ) (p X|Ci ) P(Cj) p(X|Cj)
di dj condk (P Ck ) p X|Ck
Donde dk define una función discriminante para el clasificador.
(1.4)
(1.5)
(1.6)
(1.7)
(1.8)
(1.9)
Así pues, que un patrón desconocido sea clasificado en una clase Ci en particular, implica tener todo el conocimiento a priori de cada clase Ci y su distribución de probabilidad correspondiente, lo que raramente sucede en la práctica, debido a la complejidad y arduo trabajo que implicaría.
Tomando a consideración lo mencionado hasta ahora, el algoritmo para diseñar un clasificador Bayesiano quedaría como se enlista a continuación:
1. Obtener una muestra representativa S de los objetos a clasificar. 2. Determinar cada una de las clases Ck que formarán parte del sistema.
3. Determinar, con base en la muestra y en la cardinalidad de cada clase, las probabilidades P(Ck).
4. Determinar los rasgos útiles que se van a utilizar para clasificar, y elaborar cada distribución de probabilidad P(X|Ck) la cual va a ser dependiente del número y naturaleza de cada rasgo de la variable aleatoria vectorial X.
5. Aplicar la siguiente regla para clasificar un patrón desconocido de entrada X:
X Ci sidi dj i j condk (P Ck ) p X|Ck
El clasificador Bayesiano resulta ser muy robusto, sin embargo presenta la desventaja de necesitar de una estadística muy amplia y completa sobre todas las variables aleatorias que forman parte del sistema. Mientras más mediciones estadísticas se posean, más confiables serán los resultados, sin embargo esto implica en cierta forma haber realizado el proceso de clasificación a mano durante mucho tiempo para poder obtener una buena respuesta, lo cual resulta una tarea complicada que pocas veces encontramos en la práctica. Debido a esto, el uso del clasificador Bayesiano presenta limitaciones, forzando a los investigadores en este campo a establecer condiciones artificiales a las probabilidades condicionales de modo que sea funcional su uso.
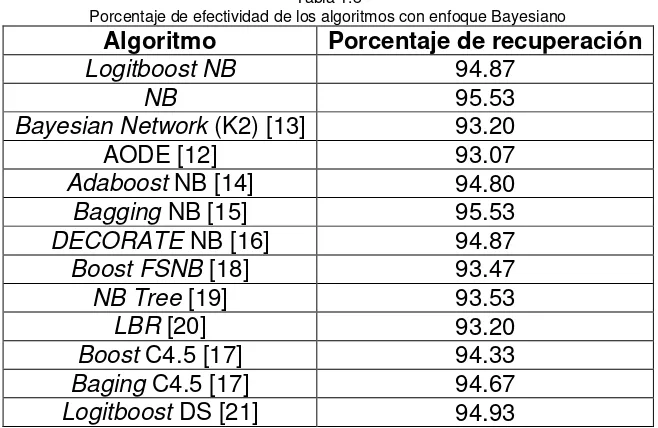
En la actualidad existen muchos algoritmos de clasificación basados en el enfoque Bayesiano. A continuación se enlistan los porcentajes de recuperación de diversos algoritmos, utilizando la base de datos Iris Plant:
Tabla 1.3
Porcentaje de efectividad de los algoritmos con enfoque Bayesiano
Algoritmo Porcentaje de recuperación
Logitboost NB 94.87
NB 95.53
Bayesian Network (K2) [13] 93.20
AODE [12] 93.07
Adaboost NB [14] 94.80
Bagging NB [15] 95.53
DECORATE NB [16] 94.87
Boost FSNB [18] 93.47
NB Tree [19] 93.53
LBR [20] 93.20
Boost C4.5 [17] 94.33
Baging C4.5 [17] 94.67
Logitboost DS [21] 94.93
Estos resultados se publicaron en el artículo Logitboost of Simple Bayesian Classifier [22], donde se comparan los porcentajes de clasificación correcta del algoritmo propuesto con doce algoritmos más basados también en el enfoque bayesiano.
1.7.2 K-NEAREST NEIGHBOR (K-NN)
El K-Nearest Neighbor es uno de los algoritmos de clasificación más eficaces y simples que existen hasta nuestros días; este algoritmo se basa de en el enfoque de métricas y consiste en la suposición de que los patrones cercanos entre si pertenecen a la misma clase.
Su fase aprendizaje es muy simple, pues se limita a almacenar los patrones del conjunto fundamental.
Su fase de clasificación también es simple, aunque más costosa en eficiencia.
Ante un nuevo patrón a clasificar se calcula su distancia (Euclideana) con respecto a los
n patrones existentes en el conjunto fundamental, y se consideran los k más cercanos. El clasificador busca los k-patrones más cercanos al dato que se quiera clasificar y le asigna la clase más frecuente entre ellos [24].
El algoritmo a seguir para k=1es el siguiente: 1. Seleccionar la métrica a utilizar.
2. Calcular la distancia de un patrón x por clasificar, a cada uno de los patrones del conjunto fundamental.
3. Obtener la distancia mínima.
Para k>1 el algoritmo es:
1. Seleccionar la métrica a utilizar.
2. Calcular la distancia de un patrón x por clasificar, a cada uno de los patrones del conjunto fundamental.
3. Ordenar los datos en orden ascendente. 4. Obtener los k menores valores de distancia.
5. Usar la regla de majority para asignar la clase al patrón x.
No obstante que el k-NN es altamente eficaz, su gran desventaja es la baja eficiencia mostrada cuando se trabaja con un conjunto grande de patrones [7].
A continuación se muestran los porcentajes de recuperación del algoritmo k-NN para
k=1 y k=3 que utiliza el enfoque basado en métricas [23]. Tabla 1.4
Porcentaje de efectividad de los algoritmos con enfoque basado en métrica Algoritmo Porcentaje de recuperación
1-NN 93.3
3-NN 90.79
1.7.3 CLASIFICADOR HÍBRIDO ASOCIATIVO CON TRASLACIÓN (CHAT)
Este clasificador se basa en la combinación de los modelos Lernmatrix de Steinbuch y
Linear Associator de Anderson-Kohonen para la clasificación de patrones, de modo que aprovecha las ventajas de estos y elimina las desventajas. El enfoque dentro del cual se encuentra es el asociativo.
Como se mencionó, los modelos en que se basa el CHAT presentan algunas desventajas. La Lernmatrix sólo puede aceptar patrones binarios como entradas, y se satura rápidamente, lo cual impide que la clasificación sea correcta. En cuanto al Linear Associator, éste elimina la restricción de patrones binarios a la entrada (ya que admite patrones con valores reales en sus componentes), sin embargo posee una fuerte restricción, que es la necesidad de que los patrones de entrada sean ortonormales para que la clasificación sea correcta.
El CHAT utiliza las representaciones vectoriales de los patrones para clasificar. Esto lo hace mediante la medición del menor ángulo entre un vector prototipo, de alguna de las clases contenidas en la memoria del clasificador y un vector desconocido del cual se desea obtener su clase asociada. Para una medición del ángulo antes mencionado, y obtener una asociación más precisa con su clase, es necesaria la traslación de ejes a un punto, en el espacio de características, donde los ángulos entre vectores, representantes de las diferentes clases involucradas, sean significativos para clases distintas y muy reducidas para la misma clase.
El algoritmo del CHAT se muestra a continuación [23]:
1.- Sea un conjunto fundamental de patrones de entrada de dimensión n con valores reales en sus componentes (a la manera del Linear Associator), que se aglutinan en m
clases diferentes.
2.-A cada uno de los patrones de entrada que pertenece a la clase k se le asigna el vector formado por ceros, excepto en la coordenada k-ésima, donde el valor es uno (a la manera de la Lernmatrix).
3.- Se calcula el vector medio del conjunto fundamental de patrones.
4.- Se toman las coordenadas del vector medio a manera de centro de un nuevo conjunto de ejes coordenados.
5.- Se realiza la traslación de todos los patrones del conjunto fundamental. 6.- La fase de aprendizaje es similar a la del Linear Associator.
7.- La fase de recuperación es similar a la que usa la Lernmatrix. 8.- Se traslada todo el patrón a clasificar a los nuevos ejes. 9.- Se procede a clasificar los patrones desconocidos.
El autor del CHAT describe en su trabajo de tesis una gran cantidad de experimentos donde se exhibe la superioridad del enfoque asociativo de clasificación de patrones, respecto de algunos clasificadores de la actualidad.
A continuación se muestran el porcentaje de recuperación de la tesis donde se utiliza el algoritmo del CHAT [23].
Tabla 1.5
Porcentaje de efectividad del algoritmo con enfoque Asociativo Algoritmo Porcentaje de recuperación
Hasta este punto se ha brindado una visión global del tema a tratar en el presente trabajo. Dentro de los temas que forman parte de esta visión global se incluyeron el de
Memorias Asociativas Bidireccionales (BAM) y el de BAM α-β. En los capítulos
siguientes se tratarán estos mismos temas, pero de forma más profunda.
En el capítulo 2 se ahonda sobre el tema de Memorias Asociativas y en particular sobre
las Memorias Asociativas α-β, pues éstas son la base del funcionamiento de la BAM α-β
y su conocimiento sirve de antecedente para comprender el capítulo 3.
En el capítulo 3 se trata de forma más profunda el tema de la BAM α-β, haciendo
hincapié en la importancia de la etapa de recuperación. Posteriormente se describen los
algoritmos que permitirán la implementación de la BAM α-β como clasificador.
CAPÍTULO 2
Existen muchas herramientas computacionales que se utilizan en el reconocimiento de patrones, una de las más importantes es la de las Memorias Asociativas. En nuestro proyecto trabajaremos con un modelo de memoria asociativa (la BAM α-β) [1], es por ello que en este apartado nos enfocaremos en el concepto de memorias asociativas.
2.1 MEMORIAS ASOCIATIVAS
Una metodología en el reconocimiento de patrones, conocida desde hace varias décadas, es la denominada como memorias asociativas; ésta tiene como “propósito fundamental el de recuperar completamente patrones aprendidos a partir de patrones de entrada, los cuales pueden estar alterados con ruido aditivo, sustractivo o mezclado”
[1].
Este enfoque tiene sus bases en el concepto de memoria para almacenar y recuperar información, y está sustentado por teorías matemáticas establecidas como el álgebra lineal, la morfológica matemática o las álgebras min-máx.
En las ciencias de la computación nos interesa crear modelos matemáticos que se comporten como memorias asociativas y, con base en esos modelos, nos interesa crear, diseñar y operar sistemas (software o hardware) que sean capaces de aprender y recordar objetos, seres vivos, conceptos e ideas abstractas.
Todas las memorias asociativas constan de dos fases: la fase de aprendizaje y la fase de recuperación. Existen diversos modelos de memorias asociativas y cada una implementa estas fases de manera diferente.
En ambas fases, una memoria asociativa M puede formularse como un sistema de entrada y salida, idea que se esquematiza a continuación:
Figura 2.1 Diagrama a bloques de una memoria asociativa
Donde X es un conjunto de patrones de entrada y Y un conjunto de patrones de salida, representándose cada uno de estos patrones como un vector columna. Cada uno de los
X Y
patrones de entrada está asociado con su correspondiente patrón de salida, lo cual se puede representar de la siguiente manera (X,Y) .
Dado un número entero positivo k específico, la asociación será (xk,yk), donde xk y yk son los patrones que forman parte de los conjuntos X y Y, respectivamente.
“La memoria asociativa M se representa mediante una matriz, la cual se genera a partir de un conjunto finito de asociaciones. A este conjunto se le llama conjunto fundamental de aprendizaje. Este conjunto se representa de la siguiente manera” [1].
x y | 12 p
“A los patrones que conforman las asociaciones del conjunto fundamental de aprendizaje, se les llama patrones fundamentales. La naturaleza del conjunto fundamental proporciona un importante criterio para clasificar las memorias asociativas”
[1].
Tenemos dos tipos de memorias asociativas
Memoria autoasociativa es aquella que cumple x = y 12 p Memoria heteroasociativa la cual cumple que x ≠ y 12 p
Es posible que los patrones fundamentales sean alterados con diferentes tipos de ruido. Para diferenciar un patrón alterado del correspondiente patrón fundamental, usaremos la tilde en la parte superior; así, el patrón k es una versión alterada del patrón xk, y las entradas de la matriz M serán elementos del conjunto B. Sean m, n números enteros positivos; se denota por n la dimensión de los patrones de entrada, y por m la dimensión de los patrones de salida.
Cada vector columna que representa a un patrón de entrada tiene n componentes cuyos valores pertenecen al conjunto A, y cada vector columna que representa a un patrón de salida posee m componentes cuyos valores pertenecen al conjunto A. Es decir:
x An y y Am 123 p
La j-ésima componente de un vector columna se indica con la misma letra del vector, colocando a j como subíndice (j {1,2,3,…,n} o j {1,2,3,…,m}) según corresponda). La
j-ésima componente de un vector columna xµ se representa por x .
j
Al usar el superíndice t para indicar el transpuesto de un vector, se obtienen las siguientes expresiones para los vectores columna que representan a los patrones fundamentales de entrada y de salida, respectivamente:
(2.1)
x x1 x2 x3 t
( x1 x2 x3
xn )
An
y y1 y y3 t
( y1 y2 y3
yn )
Am
Problema general de las memorias asociativas:
Fase de aprendizaje.
Encontrar los operadores adecuados y una manera de generar una matriz M que almacene las p asociaciones del conjunto fundamental:
{(x1 y1 ) (x2 y2) (x3 y3) xp yp }
Donde xµ An y yµ Am µ {1,2,3,…,p}. Si tal que xµ ≠ yµ, la memoria será heteroasociativa; si m=n y xµ = yµ {1,2,3,...,p}, la memoria será autoasociativa.
Fase de recuperación
“Hallar los operadores adecuados y las condiciones suficientes para obtener el patrón fundamental de salida yµ, cuando se opera la memoria M con el patrón fundamental de entrada xµ; lo anterior para todos los elementos del conjunto fundamental y para ambos modos: autoasociativo y heteroasociativo” [1]. Exhibir y caracterizar, además, el ruido que puede soportar la memoria en el patrón de entrada ω, para entregar como salida yω.
Una vez dada la explicación sobre lo que es una memoria asociativa, se dará una breve explicación de los diferentes modelos de memorias asociativas que han existido a lo largo de los años. Estos modelos que se presentan son de los más representativos y por lo tanto han servido para el diseño e implementación de memorias asociativas más complejas.
(2.3)
(2.4)
2.1.1 LERNMATRIX DE STEINBUCH
El primer modelo matemático de memoria asociativa de que se tiene noticia es la Lernmatrix de Steinbuch [25], desarrollada en 1961 por el científico alemán Karl Steinbuch, quien publicó su artículo en una revista llamada Kybernetik, y a pesar de la importancia de su modelo y las potenciales aplicaciones, el trabajo pasó casi inadvertido.
La Lernmatrix es una memoria heteroasociativa que puede funcionar como un clasificador de patrones binario, si se escogen adecuadamente los patrones de salida; es un sistema de entrada y salida que al operar acepta como entrada un patrón binario xµ An, {0,1} y produce como salida la clase yµ Ap
que le corresponde (de entre p clases diferentes), codificada ésta con un método simple a saber el cual tiene el nombre de one-hot:
Para representar la clase k {1,2,…,p}, se asignan a las componentes del vector de salida yµ los siguientes valores: yk=1,
j
y =0 para =1, 2, …, -1, +1, …, .j k k p
Algoritmo de la Lernmatrix de Steinbuch
Fase de aprendizaje
En la tabla se esquematiza la fase de aprendizaje parta la Lernmatrix de Steinbuch, con la pareja de patrones fundamentales ( ,x y ) |A xAn m
Tabla 2.1
Fase de aprendizaje para Learnmatrix de Steinbuch 1
x x2 … j
x … … xn
1
y m11 m12 m1j m1n
2
y m21 m22 m2j m2n
i
y mi1 mi2 mij min
m
y mm1 mm2 mmj mmn
Cada uno de los componentes mij de M, la Lernmatrix de Steinbuch, tiene valor cero al inicio y se actualiza de acuerdo con la regla mij= mij+∆ mij, donde:
si 1 x
si 1 y x 0
0 en otro caso
m m
i j
m m
ij i j
Siendo ε una constante positiva escogida previamente.
Fase de recuperación
Consiste en encontrar la clase a la que pertenece un vector de entrada xω An, que le corresponde al patrón xω; en virtud del método de construcción de los vectores yµ la clase debería de obtenerse sin ambigüedad.
La i-ésima coordenada yi del vector de clase yω Am se obtiene como lo indica la siguiente expresión, donde es el operado máximo:
1
1 1
1 si
0 en otro caso
n m n
ij j h hj j
j j
j
m x m x
y
2.1.2 CORRELOGRAPH DE WILLSHAW, BUNEMAN & LONGUET-HIGGINS
El Correlograph [26], dispositivo óptico elemental capaz de funcionar como una memoria asociativa que fue desarrollado en Inglaterra por los científicos Willshaw, Buneman & Longuet-Higgins en 1969.
Este modelo consta de las dos etapas ya mencionadas, (fase de aprendizaje y fase de recuperación).
Fase de aprendizaje
El Correlograph consta de tres pantallas opacas y una fuente de luz; el aparato genera correlogramas de puntos luminosos en una de las pantallas (la cual se perfora precisamente en esos puntos), a partir de pares de patrones de huecos realizados en las otras dos pantallas.
Con el fin de ilustrar la fase de aprendizaje del Correlograph, consideremos la pareja de patrones de huecos formados en las pantallas A y B (los llamaremos patrón A y patrón
B).
Fase de Recuperación
Cada correlograma así generado se usa entonces para obtener cada uno de los patrones de entrada partiendo de su patrón asociado.
A pesar de las evidentes diferencias entre el Correlograph y la Lernmatrix, los autores Willshaw, Buneman & Longuet-Higgins tomaron como punto de partida este dispositivo óptico para crear un ente al que llamaron red asociativa, la cual no es otra cosa que un modelo de memoria asociativa tipo crossbar parecida a la Lernmatrix, pero con una regla de aprendizaje diferente a la regla de Steinbuch.