UNIVERSIDAD AUTONOMA METROPOLITANA
UNIDAD ETAPALAPA
DIVISION
:
CIENCIAS BASCAS E INGENIERíA
CARRERA :
MATERIA :
TITULO :
FECHA
:
ALUMNO :
LICENCIADO
EN
COMPUTAC16N
PROYECTO DE INVESTIGAC16N
I y
II
ALGORITMOS GENÉTICOS
AGOSTO DE
1992
PORTILLA ENRIQUEZ JOSÉ JORGE
MATRíCULA :
86224042
-
INTRODUCCION, 1-
PRINCIPIOS BASICOS DE LOS ALGORITMOS GENETICOS, 1-
Método Basado en CAlculos, 2-
Indirectos, 2-
Directos, 2-
Método Enumerativo, 3-
Algoritmos de Búsqueda Aleatoria, 4-
Algoritmo Genético Simple, 6-
Reproducci&n, 6-
Crossver, 6-
Mutación, 7-
Esquemas Similares, 8-
Dispositivo patron, 8-Terminología, 8
-
FUNDAMENTOS MATEMATICOS DE LOS ALGORITMOS GENETICOS, 9-
& Quién vivira y quién morira ? El teorema fundamental, 10-
& Son procesos útiles los esquemas ?, 12-
IMPLEMENTACION DE ALGORITMO GENETIC0 EN COMPUTADORA,-
Reproducci6n, Crossover y Mutaci6n. 15-
Programa principal. 21-
4 Cómo trabajar bien ?, 22-
Parametros de AGS, 24-
Estadísticas de Generaci6n Inicial, 24-
Codificaciones, 24-
Discretizaci6n, 24-
Represiones, 2513
-
ORIGENES Y APLICACIONES DE LOS ALGORITMOS GENETICOS, 25-
Aplicaciones de algoritmo genético de interes hist6rico., Bagley y el programa-
Rosenberg y la simulaci6n de celda biol6gica, 26-
Cavicchio y Reconocimiento del modelo, 28-
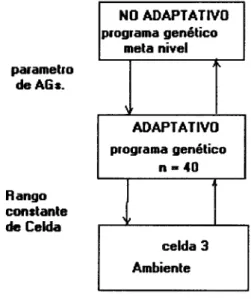
Weinberg, Simulaci6n de Celda y Metanivel de AG., 29-
Hollstien y la optimizaci6n de funcibn, 29-
Métodos de Selecci6n por Hollstien., 30-
Métodos de preferencia de casamiento, 30-
Frantz y el efecto posicional, 30-
Bosworth, Foo y Zeigler-
Genes Reales., 31-
Box y operaci6n Evolucionaria, 31-
Otras técnicas evolucionarias de optimizaci6n., 32-
Fogel, Owens y Walsh-Programaci6n Evolucionaria., 32-
De Jong y la funci6n de Optimizaci6n, 33-
Esquemas de Selecci6n Alterna, 36-
Mecanismos de Escalas, 37-
Procedimientos de Ordenamiento, 38-
Optimizaci6n de Sistemas de Tubería, 39-
Optimizaci6n Estructural vía algoritmo genetico., 40-
Registro de imagen medica con algoritmos geneticos, 40-
OPERADORES AVANZADOS Y TECNICAS EN BUSQUEDAS GENETICAS, 41-
Dominancia, 42-
Diploidismo y Dominancia en AGS, Una perspectiva histórica, 44-
Implemetación por computadora de Diploidismo Trialelico y Dominancia, 45-
Inversión y otros operadores de reordenamiento, 48-
Operadores de reordenamiento en AGS, perspectiva histórica, 49-
Teoría de operadores de reordenamiento, 51-
Otros micro operadores, 52-
Segregación, Translocación y Estructuras multiples, 52-
Duplicación y Borrado, 53Algoritmos Geneticos
"ALGORITMOS
GENÉTICOS"
INTRODUCCION
Recientemente se han hecho estudios basados en
los
algoritmos geneticos; asi mismo se han efectuado pruebas, experimentos y problemas aplicables. Los algoritmos geneticos fueron desarrollados por John Holland, colegas y estudiantes en la Universidad de Michigan y cuyas metas fueron:l. Abstraer y explicar rigurosamente procesos adaptativos de sistemas naturales.
2. Diseiiar sistemas artificiales que retienen mecanismos importantes de sistemas naturales.
Estas metas han guiado a importantes descubrimientos para la ciencia tanto de sistemas naturales como artificiales.
Los algoritmos geneticos han sido te6rica y empiricamente probados para exploraci6n en espacios complejos, lo cual se explica mejor en el libro "ADAPTACION
EN
SISTEMASNATURALES Y ARTIFICIALES" de
Holland
(1975).Actualmente son aplicados en los círculos científicos, de negocios y de ingeniería, debido al creciente número de aplicaciones, y porque son computacionalemente simples y poderosos para su mejoramiento.
En el transcurso de nuestro trabajo explicaremos con mas detalle los Algoritmos Geneticos y hablaremos tambien de
los
metodos de exploraci6n en dichos algoritmoslos
cuales son: metodo basado en C~ICUIOS, metodo enumerativo y metodo casual.PRINCIPIOS
BASICOS DE LOS ALGORITMOS GENETICOS.
A continuacih podremos observar las caracteristicas principales de los algoritmos genkticos como
los
son:-
Definici6n-
Origen-
Clasificaci6n-
Diferencias-
Ejemplos donde se utilizan.Los algoritmos geneticos realizan exploraci6n, y se basan en la mecanica de seleccibn natural y que combinan la supervivencia entre estructuras con informaci6n casual, formando asi el algoritmo de exploraci6n cuya caracteristica principal es tener una actitud de exploraci6n humana.
Algoritmos Geneticos
nuevos puntos de exploraci6n de forma mejorada.
Los algoritmos geneticos explotan de manera eficiente la informacibn hist6rica para especular
Un punto central de investigaci6n en los Algoritmos Geneticos son el balance entre eficiencia y eficacia para sobrevivir en diferentes ambientes. Para ello se requiere fortalecer dicho algoritmo
o sistema artificial lo cual podría resultar m i s costoso o redisefiar dicho sistema eliminando as¡ algunas de sus partes haciendolo reducido y eficiente para alcanzar mayores niveles.
Los disefiadores de Sistemas Artificiales "HARDWARE-SOFTWARE" como sistemas de Ingeniería, Computaci6n, Negocios se podran maravillar de la eficiencia y flexibilidad de sistemas biol6gicos cuya caracteristicas son los Rasgos de Autoreparacicin y Autoguía, pero que existen escasamente en sistemas Artificiales sofisticados.
Los algoritmos geneticos son teorica y empiricamente probados para exploraci6n robusta en espacios complejos, el cual se explica mejor en "ADAPTAC16N EN SISTEMAS NATURALES Y
ARTIFICIALES" (1975) de Holland.
La tecnica de optimizaci6n de funci6n y aplicaci6n de control, han establecido un acercamiento a problemas, que requieren de la exploraci6n eficiente y efectiva.
Actualmente son aplicados en los círculos científicos, de negocios y de ingeniería debido a el creciente número de aplicaci6nes , y porque son computacionilmente simples y poderosos por su exploraci6n para su mejormiento.
Los algoritmos geneticos no son limitados por suposiciones restrictivas sobre el espacio, ejemplos de estos los tenemos en matemiticas como son : Encontrar la derivada de cierta funcibn, Continuidad de funciones etc.).
Existen tres metodos de Exploraci6n en los algoritmos geneticos y son:
-
Metodo Basado en CAlculos.-
Metodo Enumerativo.-
Mdtodo Casual.M6todo Basado en Cdlculos
Se subdividen en dos clases principales Indirectos y Directos
Indirectos : Buscan un valor miximo y/o mínimo, resolviendo la ecuaci6n no lineal resultante de poner el gradiente de la funci6n obejtiva igual a cero se tiene una funci6n de plano no obligada a encontrar un posible pico que restrinja la exploraci6n a esos puntos con inclinacidnes de cero en todas direcciones.
Directos : Buscan un valor bptimo local, esperando sobre la funcibn y moviendo en una direcci6n relativa al gradiente local. (Noci6n de Hill-Climbing : Encontrar la mejor forma de subir la funci6n en la direcci6n permitida de la pendiente.)
Gendticos
Aunque tanto el mdtodo directo como el indirecto han sido perfeccionados y mejorados carecen de fortaleza debido a que ambos rndtodos son de alcance local y la 6ptima buscada darh los mejores vecinos de puntos comunes.
X
Función para metodos basados en los calculos.
M6todo Enumerativo
Estos han sido considerados de muchas formas y tamailos, 6ste se basa en un espacio de exploraci6n finito o discretamente infinito, la exploracibn de algoritmos comenz6 buscando los valores de la funci6n objetiva en cada punto del espacio.
Aunque es simple este tipo de algoritmo y la enumeraci6n es una clase muy humana de exploraci6n, estos deberdn ser descartados ya que carecen de eficiencia, debido a que muchos espacios ademhs de poderlos explorar en cierto tiempo tienen la oportunidad de usar la informaci6n para fines prhcticos.
El esquema enumerativo se puede observar muchas veces en la programaci6n dinhmica pero rompe en problemas de tamailo y orden de complejidad, con lo que los esquemas menos enumerativos son similares y mhs abundantemente usados para problemas reales.
Algoritmos Geneticos
160
120
80
10
O
I
"
I0.20 0.40 0.60 0.80
funcicm para búsqueda por d b d o tradicicmal
Algoritmos de Búsqueda Aleatoria
Los algoritmos Aleatorios fueron alcanzado popularidad por su corto camino basado en ~ l c u l o s
y esquemas enumerativos, no se espera que a traves del tiempo sean mejores que los esquemas enumerativos y ademas no necesariamente implican búsqueda de direcci6nes.
Los algoritmos geneticos son un ejemplo de procedimientos de búsqueda cuya herramienta es escoger aleatoriamente para guiar hacia un nivel de investigacicin mas alto por medio del parhmetro espacio.
La optimizaci6n busca el mejorar la ejecuci6n hacia algun punto o puntos 6ptimos.
Los algoritmos geneticos difieren de los procedimientos de búsqueda y optimizaci6n en cuatro
formas:
1) Los Algoritmos Geneticos trabajan codificaci6n de el conjunto de parhmetros, y no los
parametros de ellos mismos.
2) Los Algoritmos Geneticos buscan en una poblaci6n de puntos, no en un punto simple.
3) Los Algoritmos Geneticos usan informaci6n (de una funci6n objetiva), no derivativas u otros conocimientos auxiliares.
4) Los Algoritmos Geneticos usan reglas de transici6n probabilisticas, no reglas deterministicas.
Los Algoritmos Geneticos requieren de un conjunto natural de parAmetros del problema de
optimizaci6n y que son codificados en una cadena de longitud finita sobre algún alfabeto finito. ejemplo para estos son:
1) El problema de optimizaci6n de la funci6n f(x) =
x2
sobre el intervalo de enteros [0,3], con el parametro x seleccionamos los verticales mientras alcanzamos el valor mas alto de la funci6n objetiva, con algoritmos geneticos el primer paso sería codificar el parametro X, como una cadena de longitud finita.Algoritmos Geneticos
1000
I
IO
X31
figura que muestra la funci6n de optimización, f(x)
=
x2 sobre el intervalo entero [0,31].2)
El
problema de la caja negra de interruptores, en el cual intervienen una caja negra con un banco de cincos entradas de interruptor y los cinco interruptores los cuales son senales de salida"f", matematicamente f=f(s) donde S es el número particular de interruptores. el objetivo del
problema es que con el conjunto de interrupotres se obtenga el valor maxim0 de "f', este problema con los metodos tradicionales se podría resolver intercambiando cada uno de
los
interruptores uno con otro, usando reglas de transici6n de acuerdo al metodo particular usado. Con algoritmos geneticos primero codificamoslos
interruptores como una cadena de longitud finita, un c6digo simple podría ser la cadena de cinco (1)unos y(O)
ceros donde cualquiera delos
cinco interruptores representado por un (1) esta encendido y un(O) si
esta apagado as¡ la cadena"1 11 10" codifica el conjunto dende los primeros cuatro interruptores estan encendidos y el quinto esta apagado.
Otra tkcnica para resolver este problema es colocar un conjunto de interruptores y por medio de reglas de transici6n generar un nuevo conjunto de interruptores. Con algoritmos genéticos se coloca una poblaci6n sucesiva de cadenas generando una poblaci6n sucesiva de cadenas es decir
O 1 1 0 1
1 1 O 0 0
o 1 O 0 0
1 0 0 1 1
Los algoritmos geneticos tienden a mejorar las búsquedas efectivas y requieren de valores como cadenas individuales, estas características hacen que el algoritmo genético sea un metodo can6nico donde se tienen muchos esquemas.
Muchos metodos usan algoritmos genéticos para reglas de transici6n probabilisticas. Estos Wian la búsqueda a cosas familiares con metodos determinísticos pero usan la probabilidad sujeta a
10s
metodos de búsqueda aleatoria en regiones del espacio de búsqueda con la misma improvisaci6n.Algoritmos Geneticos
ALGORITMO GENÉTICO SIMPLE
Los mecanismos de un algoritmo genetic0 simple son sorprendentemente simples que envuelven notas mhs complejas que copian e intercambian cadenas parciales.
La simplicidad de la operaci6n y su poder para efectuar son las dos mayores atracciones de los algorimtos geneticos.
Si retomamos el ejemplo de la caja negra y la poblaci6n inicial que teníamos.
o 1 1 0 1 1 1 O 0 0 0 1 0 0 0 1 0 0 1 1
Si esta poblaci6n fue escogida aleatoriamente de 20 sucesiones de creacidn imparcial ahora tendremos que definir un conjuto simple de operaciones con el que escogeremos esta poblaci6n inicial y generaremos una poblaci6n sucesiva que mejore su tiempo.
Un algoritmo genetic0 que produce buenos resultados en problemas prhcticos se compone de tres operadores.
1) Reproducci6n
2)
Crossover 3) Mutaci6nREPRODUCCI~N
La Reproducci6n es un proceso donde las cadenas individuales se copian de acuerdo a los valores de una funci6n objetiva f ( Los bidlogos llaman a esta funci6n, la funci6n de Conveniencia), con la cual se maximizan valores convenientes para encadenarlos teniendo una alta probabilidad de contribuci6n de uno o mhs descendientes en la pr6xima generaci6n.
Los operadores son una versi6n artificial de la selecci6n natural. En una pobiaci6n natural la supervivencia se determina con una cadena hhbil que trata de sobrevivir de depredadores, pestilencias, y otros obsthculos, en nuestro conjunto artificial la funci6n objetiva es el que decide que la cadena viva o muera.
CROSSOVER
Despues de la reproduci6n un crossover es simple, ya que este se procesa en dos pasos.
Primero
:
Los miembros de una nueva cadena se reproducen de forma aleatoria.Segundo : Cualquier par de cadenas tienen un crossover, se selecciona una posici6n entera k a lo
largo de la cadena, de 1 a la longitud menor de la cadena, despues dos nuevas cadenas son creadas por intercambio de los caracteres entre las posici6nes k+1 y "I". observe el siguiente ejemplo:
sean: Ao =
O
1 1 OI
1 A i = l l O O l OAlgoritmos Geneticos
Supongase en escoger un número aleatorio entre 1 y 4, si obtenemos un k
=
4 ( indicado por el separadorI).
Los resultados del crossover producen dos nuevas cadenas donde las cadenas(7
intermedias son parte de la nueva generaci6n.
Ao'= O 1 1 O0 Ai' = 1 1 0 0 1
Los mecanismos de reproducci6n y crossover son admirablemente simples envolviendo una generacibn de números aleatorios, copias de cadenas y alguna parte de la cadena intercambiada. La Reproduci6n y Crossover combinan las mejores ideas.
El 6nfasis de reproduci6n y la informaci6n intercambiada de crossover dA a los algoritmos geneticos mucho de su poder. En un principio parecen sorpresivos pues ,j Como pueden dos
simples resultados no usados, permitir sdlo un rdpido y robusto mecanismo de búsqueda ?
Ademas ,j No es poco extrano que pueda desempenar un rol fundamental en un proceso de búsqueda directo ?. Examinemos parte de la respuesta de estas dos preguntas.
No puede haber un cambio puro, por el contrario debe haber una combinaci6n de ideas ya que Hadmard dice que las mejores soluciones se forman mediante la mezcla de todas las
soluciones encontradas.
MUTACIÓN
:
La mutaci6n se hace necesaria debido a que aun a traves de la reproducci6n y crossover se buscan y recombinan nociones existentes pero llegan a ser celosos por lo que pierden potenciabilidad en el material genbtico.
En los algoritmos geneticos la mutaci6n es una alteraci6n aleatoria del valor de la posici6n de una cadena.
Para observar la diferencia entre Reproducci6n, Crossover y Mutaci6n podemos tomar el ejemplo de la caja negra.
En la reproducci6n seleccionamos la siguiente generaci6n dando vueltas a una ruleta cuatro veces. Esta simulaci6n del proceso se hace agitando falsamente las cadenas.
Crossover se hace en dos pasos:
1) Las cadenas son formadas aleatoriamente, usando mivimientos falsos para juntar parejas. 2) Las parejas formadas usan movimientos para seleccionar los lugares intercambiados.
La Mutaci6n se realiza en base bit a bit, la probabilidad de mutaci6n en este test es 0.001.
Siguiendo la reproduci6n ,Crossover y Mutaci6n la nueva poblaci6n esta lista para ser probada.
Algoritmos Geneticos
ESQUEMAS SIMILARES
Un esquema es una descripci6n similar a un subconjunto de cadenas con similitudes tales como cierta posici6n dentro de la cadena. Para discutir esto tomemos algún límite de el alfabeto binario { 0,l
}.
Motivemos un esquema fdcilmente por adici6n de simbolos a este alfabeto, siadicionamos el o algún otro simbolo, nuestro alfabeto podrd crear cadenas sobre el alfabeto temario { 0,1,* }.
Dispositivo patr6n : Un esquema creado es una cadena particular si en toda localizaci6n en el esquema un 1 apareja un 1 en la cadena, un O apareja un O o un apareja cualquiera, ejemplos:
1) Considere la cadena y esquema de longitud 5 los esquemas *O0000 aparejan dos cadenas {10000.00000}
2)
El esquema *111* describe un subconjunto con cuatro miembros:
{01110,01111,11110,11111}.
3) Los esquemas O*?" aparejan alguna de las ocho cadenas de longitud 5 que comienzan con un O y tienen un 1 en la tercera posici6n.
Como puede observarse un esquema da una poderosa y compacta forma de hablar sobre todo
lo bien definido entre cadenas de longitud finita sobre un alfabeto bien definido recalcamos que es s610 un metabolismo sobre otros simbolos que procesa todas las similitudes posibles entre cadenas de una longitud particular del alfabeto.
Si se contara el número total de posibles esquemas del ejemplo anterior con I = 5 nos daría
(3)(3)(3)(3)(3)= 243
formas de similitudes ya que cualquiera de las 5 posici6nes puede ser 0,l o*.
En general para alfabetos de cardinalidad (número de caracteres del alfabeto) k, seran (k+l) esquemas creados, la búsqueda aqui sera mas difícil.
Para un alfabeto con k elementos seran k' diferentes cadenas de longitud I, la raz6n es considerar los (k+l)' esquemas y alargar el espacio de compaiiia.
TERMINOLOGIA
Necesitamos una terminología maestra usada para rebúsquedas para quienes trabajan algoritmos geneticos. Los algoritmos geneticos son basados en la genetica natural y la ciencia de las computadoras.
La terminología usada en la literatura de algoritmos geneticos es una mezcla de la genetica natural y artificial, hasta ahora se ha enfocado en el lado artificial de los algoritmos geneticos como cadenas, alfabetos, posiciones en la cadena etc. Ahora veremos la correspondencia ente estos terminos, sus contrapartes o conectivos.
Las cadenas de los sistemas geneticos artificiales son andlogos a los Cromosomas en sistemas naturales, uno o mAs cromosomas combinan el total de prescripci6n genetica para la construcci6n y operaci6n de algún organismo.
En sistema natural el paquete genetic0 total es llamado genotipo en sistema artificial, el paquete de cadenas es llamado estructura.
En sistemas naturales los organismos formados por la interacci6n del paquete genetic0 con ambiente es llamado el fenotipo, en sistema artificial, las estructuras decodificadas auna forma particular o parhmetro particular son una solución o punto alternativo.
En Algoritmos gen6ticos se tienen una variedad de alternativas para decodificaci6n de parhmetros num6ricos y no num6ricos.
En terminología natural nosotros vemos que los cromosomas son compuestos de genes, podemos tomar sobre algún número de valores llamados alelos en genetics, la posici6n de un gene es identificado separadamente de la función genes. Podemos hablar de un gene particular
por
ejemplo de animales, gene de color de ojos lo cual pone en posici6n 10 y este es el valor de alelo para ojos azules. En la genética artificial buscamos ver que cadenas son compuestas de "detectores" o facciones por el cual tomamos sobre diferentes valores, rasgos para ser localizados en posici6nes diferentes sobre la cadena.La correspondencia entre terminología natural y artificial se puede resumir como sigue:
N A T U R A L
Cromosoma Gene Alelo Locus Genotipo Phenotipo Epistasis
ALGORITMO GENÉTICO
Cadena
Facciones, Caracter o detector. Valor de Facci6n
Posición de la cadena Estructura
Parhmetros, Sol. alternativa una estructura decodificada No hay.
FUNDAMENTOS MATEMATICOS DE LOS ALGORITMOS GENETICOS
A continuaci6n haremos algunas observaciones de forma mhs rigurosa, pero antes, contaremos el esquema representado dentro de una poblaci6n de cadenas y consideramos cual crece y cual decrece durante cualquier generaci6n dada. Para hacer esto, consideramos el efecto de reproducci611, crossover y mutaci6n en un esquema particular. Este anhlisis nos guía hacia el teorema fundamental de los algoritmos genéticos que cuantifican este crecimiento y decaimiento de manera precisa.
Consideramos una importante pregunta. iC6mO sabemos que combinando la construcci6n de bloques nos guía a una buena realizaci6n en problemas arbitarios ?.
La pregunta nos hace reflexionar sobre nuestra consideraci6n de algunas herramientas relativamente nuevas del análisis de los algoritmos genéticos: transformaciones del esquema y mínimo problema engaiioso.
Algoritmos Geneticos
4 QUIEN VlVlRA Y QUIEN MORIRA 7 EL TEOREMA FUNDAMENTAL
Comenzamos con una poblaci6n aleatoria de n cadenas, copia cadenas con inclinacibn hacia lo mejor, parcialmente cambia subcadenas, muta el valor de un bit para una buena medida.
De los últimos resultados se dice que hay 3 esquemas o similaridades definidas sobre una cadena binaria de tamafio
I
En general para alfabetos de cardinalidad k hay (k + 1) esquemas. Ademhs dijimos que en una poblaci6n con 7 miembros hay a lo mhs n.2 esquemas contenidos en una poblaci6n, porque cada cadena es ella misma una representaci6n de dos esquemas.Para entender realmente la importancia de construcci6n de bloques de soluciones futuras necesitamos distinguir entre los diferentes tipos de esquemas.
No todos los esquemas son creados igual. Algunos son m6s específicos que otros. Las propiedades de los esquemas son: orden y longitud definida.
El orden de un esquema H, denotado por o (H) es simplemente el número de posici6nes fijas presentes en el modelo.
La longitud definida de un esquema H, denotado por (H), es la distancia entre la primera y la última posici6n de una cadena específica.
Los esquemas y sus propiedades proveen lo que se dice bdsico para analizar el efecto neto de reproducci6n y operadores gentiticos en la construcci6n de bloques contenidos dentro de la poblaci6n. Consideramos el efecto individual y combinado de reproducci6n, crossover y mutaci6n en un esquema contenido dentro de una poblaci6n de cadenas.
El efecto de reproducci6n en el número esperado de cadenas en la poblaci6n es particularmente fhcil de determinar. Supongan que nos dan un tiempo t. hay m ejemplos de un esquema particular H contenido dentro de la poblaci6n A(t), donde escribimos m
=
m(H,t) (Hay posiblemente diferentes cantidades de diferentes esquemas H en diferentes tiempos t. Durante la reproducci6n una cadena es copiada de acuerdo a sus propiedades o m6s precisamente una cadena A es seleccionada con probabilidad.Despues tomamos una poblaci6n de tamaño n con reposici6n de la poblaci6n A(t), esperamos tener m(H,t+l) representativos del esquema H en la poblaci6n al tiempo t + l que da por ecuaci6n
m(Ht+l)=m(H,t).n.f(H)/fr donde f(H) es el promedio de las propiedades de la cadena representando el esquema H en el tiempo t.
En palabras un esquema crece como el radio de la proporci6n promedio del esquema a la proporci6n promedio de la poblaci6n. Por otro lado, el esquema con proporci6n de valores sobre el promedio de la poblaci6n recibirh un incremento de número de muestras en la siguiente generaci6n mientras los esquemas con valores proporcionales debajo del promedio de la poblaci6n recibird un decremento en número de muestras. Es interesante observar que este comportamiento esperado es portado fuera con cada esquema H contenido en una poblacidn
particular A en paralelo. En otras palabras todos los esquemas en una poblaci6n crecen o
decrecen de acuerdo a su promedio de esquema sobre la operaci6n de reproducci6n sola.
Geneticos
El efecto de reproducci6n sobre el número de esquemas es cuantitativamente claro arriba del promedio el esquema crece y abajo decrece. Podemos aprender algo mhs sobre la forma matemhtica de este crecimiento de la ecuaci6n del esquema de diferencia. Supongase que asumimos que un esquema particular H queda sobre una cantidad aproximada cf con una constante c.
La reproducci6n no hace nada para promover la exploraci6n de nuevas regiones del espacio de investigaci6n desde que no hay nuevos puntos investigados. El crossover es un cambio estructurado de informaci6n entre cadenas, crea nuevas estructuras con un mínimo de rompimiento a la estrategia dictada por la reproducci6n, esto resulta en incrementar (o
decrementar) proporciones de esquema en una poblaci6n sobre muchos de los esquemas contenidos en la poblaci6n. Para ver que esquemas son afectados por el crossover y cuales no, consideramos una cadena particular de longitud 1=7 y dos esquemas representativos dentro de esa cadena.
A = 0 1 1 1 O 0 0
H = * l * * * *
O
H = * * * l O * *
Claramente los dos esquemas H y H estan representados en la cadena A para ver el efecto del crossover en el esquema. Primero renombraremos ese simple crossover con la selecci6n aleatoria de una pareja, la selecci6n aleatoria de un crossover y el cambio de subcadenas desde el principio de la cadena al crossover puesto que inclusive con la subcadena correspondiente de la cadena elegida. Supongase que cada A ha sido elegida para pareja y crossover. En la cadena de longitud 7 supongase que rotamos para escoger el sitio cruzado. Ademhs supongamos que qued6 en la 3, quiere decir que la posici6n de corte estare en las posici6nes 3 y 4 el efecto de este cruzamiento en nuestros dos esquemas H y H puede verse facilmente en el siguiente ejemplo, donde el sitio del cruzamiento ha sido marcado con el simbolo separador
I:
A = 0 1 1 l l 0 0 0 H = * l
* I *
O
H z * * * I 1
o *
A menos que sean iguales a la A en las posici6nes fijas del esquema, el esquema H sera destruido porque el 1 de la posici6n 2 y el
O
de la posici6n 7, seran puestos en otro lugar en la cadena descendiente. Es igualmente claro que con el mismo punto de corte, el esquema H sobrevivirh porque el 1 en la posici6n 4 y elO
en la posici6n 5 seren llevados intactos en la siguiente cadena.Vemos que la probabilidad de subsistencia en crossover de limite mes bajo puede ser calculada por cualquier esquema. Porque un esquema sobrevive cuando el sitio de cruzamiento cae fuera de la longitud definida.
El efecto combinado de reproducci6n y crossover puede ser considerado como cuando consideramos s610 la reproducci6n, estamos interesados en calcular el número de un esquema particular H esperado en la siguiente generaci6n.
Algoritmos Gen6ticos
El efecto combinado de crossover y reproducci6n es obtenida por multiplicar el número esperado de esquemas para la reproducci6n sola, por la probabilidad de subsistencia sobre el crossover. El esquema H crece o decrece dependiendo del factor de multiplicaci6n. Con ambos crossover y reproduccibn el factor depende de dos cosas, que el esquema est6 sobre o debajo del promedio de la poblaci6n y que el esquema tenga relativamente corta o larga la longitud definida. Claramente estos esquemas sobre el promedio de la realizaci6n observada y una longitud definida corta tienden a ser muestras que crecen exponencialmente.
El último operador a considerar es la mutaci6n. Mutaci6n es la alteraci6n aleatoria de una sola posici6n con probabilidad Pm. En orden a que el esquema H sobreviva, todas las posici6nes específicas deben sobrevivir ellas mismas. De aqui desde la supervivencia de un alelo con probabilidad (l-pm) y desde que cada mutaci6n es estAticamente independiente, un esquema
particular sobrevive multiplicando la probabilidad de supervivencia (I-Pm) por o(H) veces obtenemos la probabilidad de sobrevivencia de mutaci6n (I-pm). Corto, orden bajo sobre el promedio del esquema reciben soluciones que crecen exponencialmente en las siguientes generaciones. A esta conclusi6n le damos el nombre de: TEOREMA DEL ESQUEMA, O EL
TEOREMA FUNDAMENTAL DE LOS ALGORITMOS GENeTlCOS.
El efecto de reproducci6n, crossover y mutaci6n son ahora cuantitativa y cualitativamente claros. El esquema de la longitud definida corta, orden bajo y promedio de proporci6n recibe respuestas que incrementan exponencialmente en generaciones futuras.
la
la0
1bUFig. Muestra la funcion exponencial del tamaAo 6ptimo de experimentaci6n.
L
SON PROCESOS UTlLES LOS ESQUEMAS?Un algoritmo genetic0 procesa un poco del mismo modo n esquemas. Este resultado es muy importante, Holland tiene un nombre especial "paralelismo impllcito".
Considere una poblaci6n de n cadenas binarias de longitud I, consideramos
s610
esquemas que sobrevivan con una mayor probabilidad que una constante Ps.Con un esquema de longitud particular, nosotros podemos estimar un salto corto sobre el número de únicos esquemas procesados por una poblaci6n inicial aleatoria de cadenas.
Algoritmos Geneticos
Primero contamos el número de esquemas de longitud "Is" o menor, nosotros entonces multiplicamos estos por una poblaci6n de tamaAo apropiado, escogemos sobre promedio no mas que uno de cualquier esquema de longitud ld2. Suponer que deseamos contar los esquemas de
longitud Is en la siguiente cadena de longitud I=1 O
101 1100010
Para hacer esto, calculamos el número de esquemas en las primeras 5 celdas. Fijamos el último bit de la celda, esto es, nosotros buscamos todos los esquemas de la forma:
%%%%1 *m* donde los
*
no son símbolos de cuidado y los signos de % toman sobre cualquierade los valores fijos ( el 1 en esa posici6n) o uno sin cuidado.
Claramente estos son 2 de estos esquemas porque los ls-1=4 posici6nes pueden ser fijados o tomados sobre los que no son de cuidado. Para contar el número total de estos, nosotros simplemente deslizamos la mascara de 5 a lo largo de un espacio de tiempo.
1 O1110 O010
Ejecutamos esta suerte un total de I-ls+l veces y estimamos el número total de esquemas de longitud Is o menores como 2 .(I-ls+l). Esta cuenta es el número de esquemas semejantes en esta cadena particular.
Para sobreestimar el número de esquemas semejantes en la poblaci6n entera, pudimos simplemente multiplicar por el tamaAo n de la poblaci6n y obtener la cuenta n.2 .(I-ls+l).
IMPLEMENTACION DE ALGORITMO GENETIC0 EN COMPUTADORA
Anteriormente hemos visto como los Algoritmos Geneticos son mecanicamente muy simples, envolviendo nada m& que generaci6n de números aleatorios, copias de cadena y cambios en
cadenas parciales. Por un lado para muchos usuarios de negocios, científicos e ingenieros y
programadores, esta rígida simplicidad es parte del problema estos individuos son familiares con usar y programar c6digos de computadora de alto nivel, envolviendo matemhticas complejas, bases de datos entrelazadas y cxllculos enredados. Mas aun, esta misma audiencia es mas confortable con reasegurar la reproducci6n de programas de computadora.
La manipulaci6n directa de cadenas de bit, la construcci6n de c6digos y aun la aleatoriedad de operadores GA pueden presentar una secuencia de alta dificultad que previene aplicaci6n efectiva.
En este secci6n brincamos estos obsthculos por construir primero las estructuras de datos y
algoritmos necesarios para implementar el simple algoritmo genetic0 descrito antes. Escribiremos un &digo Pascal de computadora llamado el Algoritmo Genético Simple (AGS), el cual contiene poblaciones de cadena no traslapadas, reproducci6n crossover y mutacidn aplicada a la optimizaci6n de una simple funci6n de una variable codificada como un número binario. Tambien examinamos alguna implementaci6n tal como discretizaci6n de pardmetros, codificaci6n de cadenas, refuerzo de coacciones y formaci6n de aptitudes que surgen al aplicar AGS como problemas particulares.
Los Algoritmos Geneticos procesan poblaci6nes de cadenas. Para el AGS construimos una poblaci6n como una formaci6n de individuos donde cada uno contiene el fenotipo (pardmetro o
Algoritmos Geneticos
parametros decodificados), el genotipo (cromosoma artificial o cadena bit) y la aptitud (funci6n objetiva) valuada con otra informaci6n auxiliar. Una esquemhtica de una poblaci6n es mostrada en la siguiente figura. El cbdigo de la posterior a esta declara un tipo de poblaci6n corespondiente a este modelo.
Fig. EsquemMica de una poblaci6n de cadena en un algoritmo genbtico.
NOMERO
I N D I V I D U O S
INDIVIDUAL
CADENA X F(X) OTROS
1 O1111 15 225
2 o1001 e 81
3
n 00111 7 40
Fig. Un simple algoritmo genbtico, declaraciones del tipo de datos en Pascal.
COW
a
x
*
-
100; (ramano maximo de poblacl6n) admax-
30; (Longitud maxima de cadena)type aklo
-
Boolean; ( allalo-
poslcl6n bnJcrrrmoeonu
-
ArrayIl..cadmax] of aielo; ( Cadena de bits)individuo
-
recordcrom : cromosoma; (genotipo cadena blt) x : r e a l ; (fenotipo número sinrlgno) fltna : real;(valor de funcl6n objetivo) pariente 1. pariente 2, xslte : número; end;
poblacYn
-
Arrayfl ..pobmax] of individuo;En el SGA aplicamos operadores geneticos a una poblaci6n entera de cada generacibn, como se muestra a continuaci6n. Para implementar esta operaci6n limpiamente, utilizamos dos poblaciones no solapadas, con lo cual simplificar el nacimiento de un hijo y el reemplazo de los padres. Las declaraciones de las dos poblaciones pobvie y pobnue son mostradas tambikn con la declaracibn de un número de otras variables de programa global.
Algoritmos Geneticos
Fig
.
Esquema de poblaciones no traslapadas usadas en el AGSGENERACION
T
GENEMCION
Ttl'E
2
\Crossover
y
\
utacion
/
Fig. SGA declaraciones de variables globales.
pobvk, pabnw : poblaci6n; (Dos poblaciones no baslapadas) hmpob,lcronr,gen,magen :Integer. (Varlables de tipo entero) pcmss.pmutaci6n.sumfltnes :real; (Varlables globales r e a l e s )
nmutaci6n.ncroos :Integer. (Estadisticas de número)
prom,max.mln :real; (Estadísticas reales)
REPRODUCCIóN, CROSSOVER Y MUTACIóN.
En el c6digo de segmentos que sigue suponemos la existencia de 3 rutinas de elecci6n aleatoria:
random : regresa un número seudoaleatorio entre O y 1 (una variable aleatoria uniforme en el intervalo real [O,l]).
flip : regresa un valor boleano cierto con probabilidad especificada (una variable aleatoria Bernoulli).
r n d : regresa un valor de número entre limites inferiores y superiores especificados (una variable aleatoria uniforme sobre una subposici6n de
números adyacentes).
La reproducci6n es implementada en la funci6n seleccionar como una búsqueda leal a traves de la rueda de ruleta con canales medidos en proprci6n a valores de cadena. En el c6digo mostrado en la Figura siguiente que la función seleccionar regresa al valor indice de poblaci6n correspondiente al individuo seleccihado.
Aqui la suma de la poblaci6n (calculada en el procedimiento estadística) es multiplicado por el número seudoaleatorio normalizado generado por random. Finalmente la construcci6n repetir
hasta busca a traves de la rueda de la ruleta medida hasta la suma parcial es mayor que o igual
Algoritmos Geneticos
al punto de parada rand. La funci6n regresa con el valor actual de indice de poblaci6n j asignado a
seleccionar.
Algoritmos Geneticos
Fig. Funci6n seleccionar, implementa selecci6n de rueda de ruleta.
FUNCTION Seleccionar (tampob:ln er;oumfftneso:real;var pob : poblacidn : integer; *p
(Wecclonar un salo Individuo vla ul.ccl6n de NI&)
VAR rand.partsum:nsl; (Punta aleatorio de la rueda, suma parcial)
j:lnteger, (Indlce de poblaci6n) BEOlN
partsum := 0.0; ]:-O: (Cm contador y acumulador)
rand :I random wmditness; (punta de calculo de la rueda usa número aleatorio p.11). REPEAT (encontrar el canal de la rueda)
j:=]+l;
partsum:=partsum + pobm.fftnese;
UNTIL (partsum >= rand) o (j = tampob); (regresa el número lndlv.) dmcclonar := j;
TERMINA;
La rutina crossover toma dos cadenas parientes llamadas pariente 7 y pariente
2
y genera dos cadenas hijas llamadas nit707 y nit702. Las probabilidades de crossover y mutacibn, pcross y pmutacidn son pasadas a crossover con la longitud de la cadena Icrom, un acumulador de cuenta crossover ncross y un acumulador de cuenta de mutaci6n nmutacibn.Especificamente tiramos una moneda que cae hacia arriba (cierto) con probabilidad pcross. La moneda tirada esta simulada en la funci6n boleana flip, donde flip llama la rutina aleatoria del número seudoaleatorio. Si un cross es llamado, una posici6n de cruzamiento es seleccionada entre 1 y la ultima posici6n cross. La posici6n de cruzamiento es seleccionada en la funci6n md, el cual se vuelve un número seudoaleatorio entre los límites especificados inferiores y superiores (entre 1 y Icrom-1). Si ningún cruce va a ser realizado. la posici6n de cross es seleccionada como
Icrom (la longitud total de la cadena l), as¡ una mutacidn bit por bit tomara lugar no obstante la ausencia de un cross. Finalmente el cambio parcial de crossover es llevado en las dos construcciones for-do al final del c6digo. El primer for-do maneja la tranferencia parcial de bits entre pariente 7 y nit707 y entre pariente 2 y nMo2. El segundo for-do maneja la transfencia y
cambio parcial de material entre pariente 7 y nMo2 y entre pariente
2
y niAo1. En todos los casos una mutaci6n bit por bit es llevada por la funci6n de mutaci6n boleana.La mutaci6n en un punto es llevada por la mutaci6n como se muestra en la figura de mutacibn. Esta funci6n usa la funci6n tirar (la moneda tirada) para determinar si o no cambiar un cierto a un falso (un 1 a un
O)
o viceversa.Por
supuesto la funci6n tirar solamente caera (cierto) porciento de pmutaci6n del tiempo como resultado de la llamada al generador aleatorio de número seudoaleatorio dentro del mismo tirar. La funci6n tambi6n mantiene tabuladores sobre el número de mutaci6nes por incrementar la variable nmutacibn.Algoritmos Geneticos
Fig. El procedimiento crossover implementa crossover simple (punto unico)
pmcdure crossover (var pariente1 .pariente2,nlnol .nino2:cromosoma;
var Ichmm.ncms,nmutacl6nJcroas:entero; var pcmss.pmutacI6n:real); var j:intoger;
BEQlN
IF nlp(pcmss) THEN BEQIN
j c m n :-md(1 Jcrom-I): (cross entre 1 y 1-1)
ncrou:-ncmss + 1; (Incrementa contador crossover)
END
ELSE
j c m n :- Icrom: (otra manera de poner c m 8 para reforzar mutación) ( p r l m r c a m M o 1 a l y 2 a 2 )
FOR 1:-1 TO @ron W BEQlN
nl~ol~:-mutaclón(parientel~.pmutación,nmutac1ón); nilo2~:-mutaclón(pa~ent.2~,pmutaclón,nmutaclón);
TERMINA;
(segundo cambio. 2 a 1 y 1 a 2)
IF jcrof. <> krom THEN FOR j:ycmn+l TO lchrom DO
BEGIN
nilolm:- mutaclón(parient.2~,pmutaclón,nmutaclón);
nlAo2m:- mutaclón(parient.l~,pmutacl6n,nmutaclón)
TERMINA;
TERMINA;
Fig. La funci6n mutaci6n implementa un punto de mutacibn, un solo bit.
FUNCTION mutacl6n(valalelo:alalo;pmutacl6n:real;var nmutacl6n:integer):alelo:
(mutar un alelo Cl pmutacl6n, contar número de mutaciones)
VAR mutacboolean;
BEQlN
mutacltirsr(pmutacl6); (tirar la moneda)
IF mutar THEN
BEGIN
nmutaclón :- nmutaclón + 1;
mugcMn :- no valalelo: (cambiar valor de blt)
END
ELSE
mutaclón :- valalelo:
END
Con los tres grandes diseilados y construidos, crear una nueva poblaci6n de una vieja,
no
es gran asunto. La secuencia propia se muestra en el procedimiento generaci6n. Empezando en un indice individual j=
1 y continuando hasta que el tamailo de la poblacibn, tampob, ha sido excedido, hacemos2
parejas, pareja1 y pareja2, usando llamadas sucesivas para seleccionar. Nosotros cruzamos y mutamos los cromosomas usando crossover (el cual contiene las invocaciones necesarias de mutaci6n). En una agitaci6n final de actividad desesperada nosotros decodificamos el par de cromosomas, evaluar el objetivo (aptitud) valores de la funci6n, e incrementar el indice de poblaci6n j por2.
Gendticos
Para algún problema debemos crear un procedimiento que decodifique la cadena para crear un parhmetro o posici6n de parhmetros apropiados para ese problema. Debemos tambikn crear un procedimiento que reciba el parhmetro o posici6n de paremetros asi decodificados y evaluar la figura de merito o valor de funci6n objetiva asociada con la posici6n de parhmetro dada. Estas rutinas, las cuales llamamos decodificary funobi, son los 2 lugares donde el rubro GA encuentra el camino de aplicaciones.
SGA usa la rutina de decodificaci6n mostrada en la fig. de, la funci6n decodificar. En esta funci61-1, un solo cromosoma es decodificado empezando en el bit de orden bajo (posici6n 1) y
formado de derecha a izquierda por acumular el poder actual de 2 almacenado en la variable poweroftwo cuando el bit apropiado es puesto (valor cierto). El valor acumulado, almacenado en la
variable accum, es finalmente regresado por la función decodificar.
La funcidn objetiva usada en SGA es una simple funci6n de poder, similar a la funci6n usada anteriormente. Es SGA evaluamos la funci6n f(x)=(x/coeff)
.
El valor actual de coeff es elegido para normalizar el parhmetro x cuando una cadena bit de longitud lcrom=
30 es elegida. Asi coeff=
2
-
1=
1073741823.0. Desde que el valor x ha sido normalizado, el valor mhximo de la funci6n serA f(x)=
1 .O cuando x=
2
-
1 para el caso cuando lcrom=
30. Una implernentacion recta de la funci6n de poder es presentada en la fig. 3.10 como la funci6n funobj.Fig. Procedimiento generacion, genera una nueva poblaci6n de la poblaci6n previa.
PROCEDURE generaclon;
(crear una nueva genmclon a t r a v b de seleccionar. crossover y mutacl6n)
(notar: generacl6n asume un tampob aun numerado) VAR ],panjal,panja2jcro%.:intager;
BEOlN
j:=1 ;
REPEAT (wlecclonar,cros.over y mutacl6n hasta que pobnue HI llenado)
pareja1 := wleccionar(tampob.sumRtness,pobvie); pareja2 := wlsccionar(tampob.sumRtness,pobvie);
(crossover y mutacih, mutaci6n encajada dentro de crossover)
c ~ v . r ( p o b v l e [ p a r e j a 1 ] . c h ~ m , p o b v l e ( p . c h r o m ;
pobnue[ j ].chrom.pobnueD + 1 ].chrom;
krom.ncroos,nmutacl¿njcro%.,~ross,pmutci¿n);
(decodlfkar cadena, evaluar aptitud y registrar fecha de parentesco
en ambos nlnos)
WITH pobnuem DO
BEOlN
x:ldewdiRcar(chrorn,lcrom);
aptitud:=objfunc(x);
parlente1:=parejal;
parlente?:=pamja2;
uits:-jcroos;
END;
W I T H pobnue0+1] DO
BEDIN
x:= decodlRcar(chrom.lcrom); aptltud:-funobj(x);
parientsl:=pamja1;
parientaZ:=pareja2:
xsit.:-jcross;
Algoritmos Gen6ticos
END;
(indke de incremento de población) j:9+2;
UNTIL ptampob; END;
Algoritmos Geneticos
Fig. La funci6n decodificar decodifica una cadena binaria como un
solo
númerosin
signo.FUNCTION d.codlRcar(chrom:cromoooma;lbno:.nt.ro):real; (dumd#lwr cadena como número blnario sin signo ciertoll, talpolo) VAR J:entoro;
. c c u m , m : n a l ;
BEQlN
accum:= 0.0; power012 := 1 : FOR j:'1 TO lbits DO
BEQIN
IF chromm THEN
accum :- accum + poweron;
pomroR:- poweror2 2; END;
d.cobincar :- =cum; END
Fig. La funci6n funobj calcula
la
funci6n aptitud f(x)=
cx del parhmetro decodificado x.FUNCTION funobj(x:real):raal; (funcl6n aptitud. qx)
-
x"n)CONST c o d = 1073741823.0; {coeficiente para normalizar dominio) n
-
Io; (poder de x)BEQIN
funobj := poder( Xlcoef, n); END;
PROGRAMA PRINCIPAL.
En la Fig. siguiente vemos el programa principal de SGA. AI inicio del cddigo, empezamos inocentemente por poner el contador de generacidn en O, gen:=O. Construimos corriente conforme leemos los datos del programa, inicializamos una poblaci6n aleatoria, calculamos las estadisticas de poblaci6n inicial.
En sucesidn rApida incrementamos el contador de generacidn, generamos una nueva generacidn en Generacidn, calculamos nuestras estadísticas de generaci6n en Estadística,
imprimimos el reporte de generacidn en reporte y avanzamos la poblaci6n en un arrebato:
pobvie
:=
pobnue;Todo esto continua, paso tras paso, hasta que el contador de generaci6n excede el mhximo, con lo cual forzar la mequinaria a un trabajo pesado.
Estadística calcula los valores de aptitud aproximados, mAximos y mínimos: tambi6n calcula la sumfitness requerida para la rueda de la ruleta.
Algoritmos Gendticos
Fig. Programa principal para un simple algoritmo genetico. SGA.
BEQIN (Programa PrinClpal)
gen :- o;
Inlclallzar;
REPEAT (ob1 principal frecuentatlvo)
gen :- gen + 1; genuaclon;
E.tadl.tlca(tampob.max,avg,min,sumfltness,pobnue):
n p o r q g w
pobvk :- pobnue; (avance la generaclon) UNTIL p.n >- maxgen;
END:
El procedimiento reporte presenta el reporte total de poblaci6n, incluyendo cadenas, aptitudes y valores de pardmetro.
Fig. El procedimiento estadistica calcula importantes estadisticas de poblaci6n.
PROCEDURE Estadistica (tampob:entem;var max,avg.mln.sumfitneOs:~a~
var poppoblaclln);
(Calcular .stadisUcas de poblacl6n) VAR j:.nt.m;
BEQlN
(Inlclallzar)
sumfitness :- pop[l].fltness; mln :- pop[l].fitness;
llux :- pop[l].fltness;
(Asegurar para max.min,sumfitness)
FOR J :- 2 TO tampob DO WITH popm DO
BEQlN
sumfitness :- sumfitness + fitness; (acumular suma fltness)
IF fitness > max THEN max :- fitness; (nuevo max) IF > mln THEN
mln :- fitnaoo; (nuevo mln) END;
(Cakuhr pmcnodlo)
avg :- sumlltnesshmpob; END;
L
Como trabajar bien 3En el estudio de De Jong (1975) de algoritmos geneticos en optimizaci6n de funci6n, una serie de estudios parametricos a traves de 5 funcidnes de problemas sugirieron que la buena realizaci6n GA requiere la elecci6n de una gran probabilidad de crossover, una probabilidad baja de mutaci6n (inversamente proporci6nal al tamaño de poblaci6n) y un tamafio de poblaci6n
Gendticos
moderado. Siguiendo estas sugerencias, adoptamos los siguientes parhmetros para nuestras primeras simulaciones computarizadas.
pmutaci6n
=
0.0333 {Probabilidad de mutaci6n) pcross=
0.6 {Probabilidad de crossover} tampob=
30 vamano de poblaci6n, n)o
Xsobre el intervalo unitario
Fig. Comparaci6n de las unciones
x*
y x10Empezamos el simple algoritmo genético y lo dejamos correr
por
7 generaciones. El reporteestadístico de la carrera es mostrado posteriormente. La poblaci6n inicial empieza con una poblaci6n aproximada de 0.0347. La aptitud aproximada de la funci6n en el intervalo especificado puede ser calculado para ser 0.0909. En algun sentido, hemos estado sin suerte (pero no
irrealmente) en nuestra elecci6n aleatoria de una poblaci6n. Adicionalmente mirando nuestro
mejor miembro en la poblaci6n inicial, f
=
0.2824, deberíamos esperar tener 30(1-
0.2824 )=
3.56 o aproximadamente 4 cadenas en una poblaci6n aleatoria de 30 con aptitud mayor de 0.2824. No hemos estado solamente sin suerte en lo aproximado, hemos estado sin suerte desdeel principio.
No
obstante la desafortunada depresi6n inicial de la poblaci6n, una vez que elalgoritmo genbtico empez6, rapidamente encuentra buena realizaci6n, como nosotros podemos ver vividamente despues de la primera vuelta de reproducci6n, crossover y mutaci6n. En la primera generacih, una cadena muy buena es encontrada con aptitud 0.8715. Como la carrera continúa, se encuentra mayor mejoramiento en ambos, poblaci6n mhxima y aproximada. En la generacion 7, si buscamos arriba y abajo las cadenas bit notamos que hay una cantidad de convenio en la mayoria de la posici6n bit. Esto ha ocurrido aunque no hemos alcanzado el mejor punto en el espacio, hemos estado cerca, como sea. En la generacidn 6 un individuo ha aparecido con aptitud f
=
0.9807. Esto es lo 6ptimo cercano pero no lo 6ptimo (este punto est3 en 0.19% de los puntos en el espacio). El proceder convergente sin garantia de optimalidad molesta a mucha gente que se aproxima a los algoritmos geneticos desde otros, antecedentes de optimizaci6n mhs tradicionales. Hay formas de retardar esta convergencia prematura, como ha sido llamada, y debemos buscar algunos de estos metodos, como sea, el hecho del problema es que los algoritmos geneticos no tienen garantías de convergencia en problemas arbitrarios. Ellos sortean areas interesantes de espacio rApidamente, pero son un metodo dbbil, sin las garantias de mhs procedimientos convergentes. Esto no reduce su utilidad.Fig. Reporte inicial de una carrera de SGA, simple algoritmo genbtico.
Algoritmos Geneticos
PARÁMETROS SGA
TanuLo d. poblscl6n (tampob) I30
Longltud de cromosoma (krom) -30 Número h l m o de genersclb (maxgen) = 10
Pmbabllklad de c m s o v w (pcms)
-
6.0000000000E01 PmbaMlidad do mutrcl6n (pmutaclb) = 3.3300000000EMESTADISTICAS DE GENERACION INICIAL
Aptitud mhima de poblaci6n lnlclal = 2.8241322532E01
ApUtud aproxlmsds de pobiacl6n Inicial = 3.4715832788102 &mud minima de poblacl6n lnlclal = 1.1406151375E-10
suma d. aptitud da pobiacl6n Inicial = 1.0414749897E30
CODIFICACIONES.
Hemos examinado solamente un número muy limitado de alternativas de codificaci6n de cadena para formar una cadena de longitud finita a los parhmetros de un problema de optimizaci6n. Hemos introducido una simple codificaci6n binaria en respuesta a un simple
problema de conexi6n binaria. En esta codificaci6n hemos concatenado una cadena de
codificaci6n de O y 1, donde la i-esima O (o 1) ha significado que la conexi6n i-esima esta fuera (o dentro).
Tambien Remos decodificado una cadena binaria como un número entero sin signo donde la cadena A
=
a a a...
a a ha decodificado al valor del parhmetro x=
a.2
.
Codificar un problema para búsqueda genetica no es problema porque el programador de algoritmo genetic0 esta grandemente limitado por su imaginaci6n. Los algoritmos geneticos estan perdonando porque son robustos, y en ese sentido no hay usualmente necesidad de agonizar
sobre decisiones de codificaci6n. Adicionalmente, ofrecemos 2 principios bdsicos de elecci6n de codificaci6n GA, el principio de bloques de construcci6n significantes y el principio de alfabetos mínimos.
El principio de bloques de construcci6n significantes es simplemente esto:
El usuario debe seleccionar una codificaci6n de esquema corte de orden bajo que sea relevante al problema subrayado y relativamente no relacionado al esquema sobre otras posici4nes madas.
El principio de alfabetos mínimos, esta simplemente fijado:
Geneticos
tienen un solo parametro de control sino mejor una funci6n de control que puede ser especificada en cada punto en una continua-funci6nal. Para aplicar algoritmos geneticos a estos problemas,
primero deben ser reducidos a forma de parhmetro finito antes de que tome lugar la codificaci6n de parAmetro.
FORCE
F
fO f1
5
f 3 f 4 '5TIEMPO
Fig. Fuerza de control discretizada.
REPRESIONES.
Las represiones son usualmente clasificadas como relaciones de igualdad o desigualdad. Desde que las represiones de igualdad deben ser incluidas en un modelo de sistema realmente solo nos interesamos en las represiones de desigualdad. En primera, parecería que las
represiones de desigualdad deben poseer ningún problema particular. Un algoritmo genetic0 genera una secuencia de par6metros a ser examinados usando el modelo de sistema, funci6n objetiva y las represiones.
ORIGENES
Y APLICACIONES DE LOS ALGORITMOS GENÉTICOS
La meta de Holland, fue desarrollar la teoría y procedimientos necesarios para la creación de programas generales y mauinas con capacidad ilimitada para adaptar en ambientes arbitrarios. Al mismo tiempo Holland reconoci6 el papel fundamental de selecci6n no natural una supervivencia artificial del ataque en cualquier programa y mequinas que uno debe disefiar.
AfUcAClONES DE ALGORITMO GENtETICO DE INTERES HISTORICO. BAGLEY Y EL PROGRAMA ADAPTATNO DE JUGAR EL JUEGO.
En el tiempo había un gran asunto de interes en programas de jugar un juego, y en ese espiritu, Bagley ¡de6 un examen controlable de tareas modeladas de jugar el juego de 6 peones. El juego de 6 peones es jugado en una tabla de ajedrez cortada de 3x3 cuadros Cada oponente empieza con 3 peones y trata de llegar al otro lado. Ajustando el calibre del oponente, Bagley fue capaz de controlar la no linealidad de la tarea (el llamo esto "tarea profunda").
Algoritmos Geneticos
Bagley encontr6 que los algoritmos de correlaci6n requieren una buena emparejada entre la no linealidad del juego y la no linealidad del algoritmo de correlaci6n. Por otro lado el algoritmo genetico de Bagley fue insensitivo para jugar no linealidad y realiz6 bien sobre un rango de ambientes (tareas profundas).
El construy6 operadores de reproducci6n, crossover y mutaci6n similares a los descritos anteriormente; en adicidn, el uso cadena diploide de representaciones, dominio e inversi6n. Adicionalmente Bagley us6 alfabetos no binarios en codificar cadenas. Como sabemos de nuestro estudio previo de esquema, hay una buena raz6n para usar alfabetos mínimos. Bagley no tuvo acceso a la teoría de Holland del esquema y como resultado, su trabajo no pudo ser guiado por ella.
Fig. Sketch de el juego adaptativo
Bagley estuvo profundamente enterado de la necesidad de cifras de selecci6n apropiada al inicio y al final de las carreras de algoritmos genéticos. El introdujo un mecanismo de aptiitud de escala para hacer dos cosas: reducir la selecci6n temprana en una carrera, para prevenir el dominio de una poblaci6n por un solo super individuo, e incrementar la seleccidn posterior en una carrera, para mantener competencia apropiada entre altos ajustes y convergencia de cadenas
similares cercanas a la poblaci6n. Procedimientos similares han sido adoptados por investigadores actuales.
Bagley tambien introdujo la primera noci6n de algoritmos genéticos de autoregulaci6n en lo
que el llamo controles autocontenidos. El sugiri6 codificar el crossover y las probabilidades de mutaci6n dentro de los cromosomas en si; el no presento simulaci6n computarizada de resultados de experimentos con este mecanismo.
ROSENBERG Y LA SIMULACIÓN DE CELDA BIOLOGICA.
Rosenberg (1967) tambien investig6 algoritmos genéticos en su temprana disertaci6n doctoral. Porque el enfatiz6 los aspectos de simulaci6n bioldgica de su trabajo; sus contribuciones al arte de algoritmos son algunas veces dominadas. En su estudio Rosenberg simul6 una poblaci6n, organismos de una celda con una simple bioquímica rigurosa; una membrana
permeable y estructura genetica clAsica. El trabajo de Rosenberg fue importante al desarrollo subsecuente de algoritmos geneticos en aplicaciones artificiales por su semejanza a la optimizaci6n y al encuentro de la raíz.
Rosenberg defini6 una cadena de longitud finita con un par de cromosomas. En sus estudios la longitud de la cadena fue limitada a 20 genes, con un maxim0 de 16 alelos permitidos por gene. El defini6 las concentraciones químicas X y dese6 las concentraciones químicas X
.
El tambien defini6 una posici6n de concentraciones químicas deseadas como una propiedad. El casamiento yselecci6n fueron entonces realizados de acuerdo a la funci6n de anti-aptitud (por la propiedad i-
esima):
Donde la suma es tomada sobre todos los químicos en la propiedad i-esima. Rosenberg dlculo las cantidades inversas de f y realiz6 casamiento y reproducci6n subsecuente de acuerdo a esta anti-aptitud inversa. En todas sus simulaciones, el actualmente s610 consider6 una sola propiedad (i
=
l), y como resultado, paso la oportunidad de realizar el primer algoritmo genetic0 multiobjetivo, una tarea posterior tomada por Schaffer (1 984). Sus simulaciones fueron, como sea, la primera aplicaci6n de algoritmos geneticos a una tarea de encuentro de raiz; donde vistapropiamente, la búsqueda de celdas que minimizan la funci6n de anti-aptitud es equivalente a resolver la ecuaci6n altamente no lineal representada por el cromosoma y celda bioquímica para obtener una propiedad particular.
Rosenberg para mantener el proceso de selecci6n apropiadamente competitivo, adopt6 lo
que llamo la funci6n de generaci6n de hijos (OGF). El defini6 una cantidad "S" que fue relacionada a la anti-aptitud normalizada de los padres de los hijos, f/f. Usando esta cantidad "S", el reprodujo el número de hijos de acuerdo al OGF.
r'c
Rosenberg (1967).
Fig. Funci6n generaci6n (OGF). Despues
Algoritmos Geneticos
CAVlCCHlO Y RECONOCIMIENTO DEL MODELO.
En su estudio
1970
"Búsqueda Adaptativa Usando Evoluci6n Simulada", Cavicchio aplic6 algoritmos gen6ticos a2
problemas de búsqueda artificial: un problema de selecci6n de subrutina y un problema de reconocimiento de modelo.Actualmente Cavicchio no atac6 el problema de reconocimiento de modelo directamente. Mejor, el aplic6 un algoritmo genetic0 al diseilo de una posici6n de detectores para una maquina conocedora del modelo de arquitectura conocida. Para entender lo que signific6 el "Diseilo de juego de Detectores" necesitamos tener una mejor visi6n de la maquina conocedora del modelo que el uso.
Cavicchio adopt6 el esquema de reconocimiento de modelo de Bledzoe y Browning
(1959).
En este esquema una imagen es digitada sobre una reja de
25x25,
formando un cuadro de625
elementos donde cada pixel es un pixel binario, solamente capaz de distinguir entre
2
sombras, claro y obscuro. La buena operaci6n del invento de Bledzoe y Browning es reducida al problema de encontrar un buen juego de detectores. Cavicchio aplic6 su algoritmo genetic0 para el problema de diseilar precisamente este detector.Para hacer esto, Cavicchio permiti6 un aproximado de 11 O detectores por invento (un diseilo particular), entre
2
y 6 pixeles por detector. Los cromosomas (cadenas) fueron codificados como grupos alternantes de números integros positivos y negativos.Cavicchio permitid la reproducci6n y crossover tanto como nosotros las usamos ahora. El trat6 varios operadores de selecci6n (reproducci6n) y finalmente se establecid en una que premi6 altamente la proporci6n de los individuos sin permitirles pasar un alto porcentaje de la poblaci6n aprovechable. Su simple operador crossover es similar a uno descrito en capitulos anteriores excepto que las posici6nes del cruce son permitidas para fallar s610 entre limites de detector (entre grupos alternantes de números positivos y negativos). Por la estructura de genes variables y por el alfabeto de alta cardinalidad, Cavicchio fue forzado a inventar 3 operadores de mutaci6n:
Mutaci6n I cambia un solo pixel dentro de un detector. Mutación 2 cambia todos los pixeles dentro de un detector.
Mutacih 3 cambia asociaci6n de pixeles entre detectores adyacentes.
El permiti6 tambi6n inversi6n crossover en
2
puntos y duplicaci6n de intracromosomas pero mas se ha dicho acerca de estos operadores avanzados en el sig. capitulo.Un mecanismo nuevo adoptado en este estudio fue llamado esquema de preselecci6n. Aqui un buen hijo reemplaz6 uno de sus padres en el deseo de mantener diversidad de poblacibn. Mantenimiento de diversidad fue un problema porque de las pequeilas poblaciones Cavicchio fue forzado a usar (usualmente entre
![figura que muestra la funci6n de optimización, f(x) = x2 sobre el intervalo entero [0,31]](https://thumb-us.123doks.com/thumbv2/123dok_es/5592762.126459/8.912.116.645.135.435/figura-muestra-funci-n-optimización-f-intervalo-entero.webp)