Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey
Lic. Arturo Azuara Flores:
Director de Asesoría Legal del Sistema
Por medio de la presente hago constar que soy autor y titular de la obra titulada"
_ ", en los sucesivo LA OBRA, en virtud de lo cual autorizo a el Instituto Tecnológico y de Estudios Superiores de Monterrey (EL INSTITUTO) para que efectúe la divulgación, publicación, comunicación pública, distribución y reproducción, así como la digitalización de la misma, con fines académicos o propios al objeto de EL INSTITUTO.
El Instituto se compromete a respetar en todo momento mi autoría y a otorgarme el crédito correspondiente en todas las actividades mencionadas anteriormente de la obra.
De la misma manera, desligo de toda responsabilidad a EL INSTITUTO por cualquier violación a los derechos de autor y propiedad intelectual que cometa el suscrito frente a terceros.
Nombre y Firma AUTOR (A)
Diseño de una Arquitectura Computacional Específica para la
Compresión de Señales Electroencefalográficas
Title Diseño de una Arquitectura Computacional Específica para la Compresión de Señales Electroencefalográficas
Authors Santoyo Rincón, Rolando Affiliation Itesm
Abstract El monitoreo de señales Electroencefalográficas, necesario para hacer análisis y diagnóstico de trastornos cerebrales tales como la epilepsia, presenta algunas limitantes para el paciente. Entre estas limitantes se encuentra el hecho de que este monitoreo se realiza por periodos de más de 24 horas, ocasionando que los costos de hospitalización se incrementen. También, el espacio en memoria para el almacenamiento de la información generada de monitoreo es demasiado grande. A lo anterior se debe agregar que el tener que portar un conjunto de electrodos y tener que permanecer atado al dispositivo de monitoreo, ocasiona al paciente incomodidad no pudiendo realizar sus actividades diarias. En el desarrollo de esta tesis, se hablará de un sistema de adquisición y procesamiento de señales cerebrales propuesto por el Grupo de Investigación de Microsistemas del Tecnológico de Monterrey. Este sistema involucra el monitoreo ambulatorio y transmisión
inalámbrica de señales Electroencefalográficas. El sistema se basa en un arreglo de micro electrodos conectados a un sistema de procesamiento de señal y a un transmisor inalámbrico. El sistema se encuentra en la etapa de diseño y el trabajo de esta tesis involucrará el diseño de una arquitectura computacional específica para la compresión de las señales adquiridas. Esta compresión permitirá transmitir la información de manera, más eficiente, así como un mayor tiempo de monitoreo, y también
almacenará más información. El método de compresión propuesto, consiste en un algoritmo denominado
compresión por Transformada Coseno Discreto (DCT). Con este método se obtiene una buena aproximación de la señal original, obteniendo hasta un 66% de compresión. Este algoritmo también permite remover automáticamente gran parte del ruido de alta frecuencia inducido sobre la señal EEG. Para la implementación de la DCT se empleó un algoritmo basado en un filtro recursivo. Para poder emplear esta técnica es necesario hacer procesamiento previo de la señal de entrada, en base a un algoritmo propuesto en este esfuerzo. Al diseñar la arquitectura computacional específica para ejecutar el algoritmo de compresión propuesto, se siguieron técnicas de Codiseño para integrar en un mismo diseño módulos de software y módulos de hardware. Para esto se propusieron varios diseños, los cuales fueron evaluados considerando
en tan solo 34 ciclos de reloj. Estos módulos se interconectaron a módulos de software tales como un procesador DLX y módulos de memoria, obteniendo una arquitectura con un consumo de potencia estimado inferior a 30 mW
Discipline Ingeniería y Ciencias Aplicadas / Engineering & Applied Sciences
Item type Tesis
???pdf.cover.sheet .dc.contributor.adv isor???
Alfonso Avila Ortega
???pdf.cover.sheet .thesis.degree.disci pline???
Electrónica, Computación, Información y Comunicaciones
???pdf.cover.sheet .thesis.degree.prog ram???
Campus Monterrey
Rights Open Access
Downloaded 18-Jan-2017 07:35:20
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS
SUPERIORES DE MONTERREY
CAMPUS MONTERREY
PROGRAMA DE GRADUADOS EN ELECTRÓNICA,
COMPUTACIÓN, INFORMACIÓN Y COMUNICACIONES
DISEÑO DE UNA ARQUITECTURA COMPUTACIONAL
ESPECÍFICA PARA LA COMPRESIÓN DE SEÑALES
ELECTRO EN CEFALOGRÁFICAS
TESIS
PRESENTADA COMO REQUISITO PARCIAL PARA OBTENER EL
GRADO ACADÉMICO DE
MAESTRO EN CIENCIAS EN INGENIERÍA ELECTRÓNICA
ESPECIALIDAD EN SISTEMAS ELECTRÓNICOS
ING. ROLANDO SANTOYO RINCÓN
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS
SUPERIORES DE MONTERREY
CAMPUS MONTERREY
PROGRAMA DE GRADUADOS EN ELECTRÓNICA, COMPUTACIÓN, INFORMACIÓN Y COMUNICACIONES
Los miembros del comité de tesis recomendamos que la presente tesis del Ing. Rolando Santoyo Rincón sea aceptada, como requisito parcial para obtener el grado de
Maestro en Ciencias en:
Ingeniería Electrónica
Especialidad en Sistemas Electrónicos
Comité de Tesis
Alfonso Avila Ortega Ph.D. Asesor Principal
Sergio O. Martínez Chapa, Ph.D. Sinodal
Graciano Dieck Assad, Ph.D. Sinodal
David A. Garza Salazar, Ph. D.
Director del Programa de Posgrado en Electrónica, Computación, Información y Comunicaciones
Reconocimientos
A Dios por su generosidad al darme la vida que tengo
A mis Padres por todo su apoyo, cariño y enseñanzas que me han dado durante toda mi vida.
A mis hermanos por su apoyo y palabras de aliento siempre que las necesite.
A mi asesor de Tesis, el Dr. Alfonso Ávila por su ayuda durante el desarrollo de esta tesis y por darme su confianza, apoyo y amistad durante mis estudios de maestría.
A mis profesores tanto del ITESM como de FIMEE por el apoyo que me dieron siempre durante todos mis estudios profesionales.
A todos mis compañeros y amigos por su apoyo y compañía, ya que me ayudaron a que mi estancia en Monterrey fuera más agradable .
ROLANDO SANTOYO RINCÓN
Resumen
El monitoreo de señales electroencefalográficas, necesario para hacer análisis y diagnostico de trastornos cerebrales tales como la epilepsia, presenta algunas limitantes para el paciente. Entre estas limitantes se encuentra el hecho de que este monitoreo se realiza por periodos de más de 24 horas, ocasionando que los costos de hospitalización se incrementen. También, el espacio en memoria para el almacenamiento de la información generada de monitoreo es demasiado grande. A lo anterior se debe agregar que el tener que portar un conjunto de electrodos y tener que permanecer atado al dispositivo de monitoreo, ocasiona al paciente incomodidad no pudiendo realizar sus actividades diarias.
En el desarrollo de esta tesis, se hablará de un sistema de adquisición y proce-samiento de señales cerebrales propuesto por el Grupo de Investigación de Microsis-temas del Tecnológico de Monterrey. Este sistema involucra el monitoreo ambulatorio y transmisión inalámbrica de señales electroencefalográficas. El sistema se basa en un arreglo de micro electrodos conectados a un sistema de procesamiento de señal y a un transmisor inalámbrico. El sistema se encuentra en la etapa de diseño y el trabajo de esta tesis involucrará el diseño de una arquitectura computacional especifica para la compresión de las señales adquiridas. Esta compresión permitirá transmitir la infor-mación de manera, más eficiente, así como un mayor tiempo de monitoreo, y también almacenará más información.
El método de compresión propuesto, consiste en un algoritmo denominado com-presión por Transformada Coseno Discreto (DCT). Con este método se obtiene una buena aproximación de la señal original, obteniendo hasta un 66% de compresión. Este algoritmo también permite remover automáticamente gran parte del ruido de alta fre-cuencia inducido sobre la señal EEG. Para la implementación de la DCT se empleó un algoritmo basado en un filtro recursivo. Para poder emplear esta técnica es necesario hacer procesamiento previo de la señal de entrada, en base a un algoritmo propuesto en este esfuerzo.
índice general
Reconocimientos IX
índice de figuras VII
índice de tablas XI
Capítulo 1. Introducción 1
1.1. Justificación 1 1.2. Definición del problema 3 1.3. Objetivo . . . 3 1.4. Contribución y Alcance 3 1.5. Organización de la tesis 4
Capítulo 2. Antecedentes 5
2.1. Ingeniería Biomédica : 5 2.2. Las señales EEG y su medición 5 2.3. Sistemas actuales de monitoreo portátil de señales EEG 6 2.4. El sistema de transmisión inalámbrica de señales EEG propuesto . . . . 7 2.5. Compresión de señales 8 2.6. Compresión por transformación 9 2.7. La compresión de señales por medio de la Transformada Coseno Discreto
2.10. El procesador DLX 21
Capítulo 3. El algoritmo de compresión propuesto 25
3.1. Representación de datos en sistemas digitales 25 3.1.1. Aritmética de punto flotante 25 3.1.2. Aritmética de punto fijo 26 3.2. Algoritmos para la realización de la Transformada Coseno Discreto (DCT) 32 3.3. Algoritmo recursivo para la implementación de la DCT 33 3.3.1. Modelo matemático del algoritmo recursivo para la DCT . . . . 34 3.3.2. Modelo matemático del algoritmo recursivo para la DCT inversa
(IDCT) 36 3.4. Aplicación de la técnica de compresión de señales DCT a las señales EEG 37 3.5. Características del algoritmo propuesto para la compresión y
reconstruc-ción de señales EEG 37 3.6. El algoritmo propuesto para la compresión de señales EEG mediante la
DCT 41 3.6.1. Adquisición 42 3.6.2. Cálculo del VCD de la señal 43 3.6.3. Conversión complemento a 2 en el formato Q1.7 43 3.6.4. Cálculo del valor absoluto máximo entre las muestras adquiridas 44 3.6.5. Eliminación de la componente de CD de la señal EEG 45 3.6.6. Escalamiento inicial de las muestras 46 3.6.7. Nuevo escalamiento de las muestras para incremento de la
res-olución y cálculo del factor de escalamiento 46 3.6.8. Implementación del algoritmo recursivo de la DCT 48 3.6.9. Cuantificación de los coeficientes mediante un escalamiento final
y actualización del factor de escalamiento 50 3.7. Selección del número de muestras tomadas para el algoritmo de
compre-sión de señales mediante DCT 52 3.8. El algoritmo propuesto para la reconstrucción de señales EEG mediante
Capítulo 4. Metodología e Implementación 61
4.1. Implementación SW/SW del algoritmo de compresión de señales EEG utilizando BASCOM 62 4.1.1. Descripción de las funciones que conforman el algoritmo de
com-presión propuesto •. 63 4.2. Implementación del algoritmo de compresión utilizando el multiplicador
en Hardware de la arquitectura AVR 69 4.3. Implementación en Hardware de un multiplicador de 16 bits en formato
Q1.15 70 4.3.1. Descripción de los módulos que conforman la arquitectura del
multiplicador 72 4.4. Implementación SW/SW del algoritmo del algoritmo de compresión de
señales EEG haciendo uso de Seamless 78 4.4.1. El módulo de memoria. 78 4.4.2. Ensamblado del modelo implementado 80 4.4.3. El software implementado 84 4.5. Particionamiento del sistema basado en la DGT 85 4.6. Descripción de un módulo en hardware propuesto para la implementación
completa de la DCT 87 4.6.1. Descripción de los bloques que conforman la arquitectura del
módulo para la implementación completa de la DCT 90 4.7. Implementación HW/SW del algoritmo de compresión de señales EEG,
utilizando el módulo en HW para el calculo completo de la DCT . . . . 98 4.7.1. Ensamblado del SW y HW para la ejecución del algoritmo de
compresión de señales para esta implementación 98 4.8. Descripción de un nuevo módulo de HW para la implementación parcial
de la DCT 101 4.8.1. Diferencias entre los módulos de HW para la implementación de
la DCT de forma parcial y completa 103 4.9. Implementación HW/SW del algoritmo de compresión de señales EEG,
utilizando el módulo en HW para el calculo parcial de la DCT 105
Capítulo 5. Resultados 107
5.1. Resultados obtenidos de la implementación en software (SW/SW) del algoritmo recursivo de la DCT 107 5.2. Resultados de la implementación del algoritmo de compresión utilizando
el multiplicador en Hardware de la arquitectura AVR 110 5.2.1. Resultados de la implementación en hardware del multiplicador
5.3. Resultados obtenidos de la implementación SW/SW del algoritmo de compresión haciendo uso de Seamless 117 5.4. Resultados obtenidos de la implementación del módulo en hardware
propuesto para el calculo completo de la DCT 120 5.5. Resultados obtenidos de la implementación conjunta HW/SW utilizando
el módulo en hardware propuesto para el calculo completo de la DCT . 123 5.6. Resultados de la implementación del módulo de HW para el cálculo
parcial de la DCT 126 5.7. Resultados obtenidos de la implementación conjunta HW/SW utilizando
el módulo en hardware propuesto para el calculo parcial de la DCT . . 127 5.8. Aspectos relevantes para la evaluación de los diseños 130 5.9. La función de evaluación 132 5.10. Evaluación de los diseños 134
Capítulo 6. Conclusiones y trabajo futuro 145
6.1. Conclusiones 145 6.2. Trabajo futuro 146
Apéndice A. Código de la implementación en SW del algoritmo de com presión de señales EEG 149
A.l. Implementación del algoritmo en Matlab 149 A.2. Implementación del algoritmo de compresión de señales en C 153 A.3. Implementación del algoritmo de compresión de señales en BASCOM . 164
Apéndice B. Código de los multiplicadores empleados para la imple mentación HW/SW 187
B.l. Código del multiplicador en la implementación inicial HW/SW utilizan-do la arquitectura AVR 187 B.2. Código del multiplicador en HW implementado en SystemC 189 B.3. Código del multiplicador en HW implementado en VHDL 200 B.3.1. Listado utilizado para la simulación del multiplicador en Modelsim209
Apéndice C. Código para el procesador DLX en la implementación en SW del algoritmo de compresión de señales 211 Apéndice D. Código escrito para la implementación HW/SW en Seamless
usando el módulo de calculo completo de la DCT 223
D.1.3. Latch 228 D.1.4. Registro 229 D.1.5. Coeficiente 230 D.1.6. Listado que se usó para probar el módulo DCT completo . . . . 240 D.2. Módulos que conforman el resto de la arquitectura 244 D.2.1. Programa principal e interfaz 244 D.2.2. Módulo de memoria 251 D.2.3. Generador de reset 253 D.2.4. Generador de señal de reloj 255 D.2.5. Decodificador para el uso del Monitor del Bus 256 D.3. Código escrito para el procesador DLX para esta implementación . . . 257
Apéndice E. Código escrito para la implementación HW/SW en Seamless usando el módulo de calculo parcial de la DCT 265
E.l. Código en VHDL para el módulo que implementa la DCT de forma parcial265 E.1.1. Código principal 265 E.l.2. El controlador 267 E. 1.3. Listado que se usó para probar el módulo que calcula la DCT de
forma parcial 269 E.2. Módulos que conforman el resto de la arquitectura 272 E.3. Código escrito para el procesador DLX para esta implementación . . . 273 E.4. Interfaz propuesta para el diseño final de la arquitectura especifica para
la compresión de señales EEG 281
Bibliografía 285
Índice de figuras
2.1. Ejemplos de señales EEG 6 2.2. El sistema internacional 10 - 20. Vista lateral y superior 7 2.3. Sistema de adquisición y transmisión de señales EEG propuesto 8 2.4. Comparación en el uso de un microelectrodo (izquierda) y un electrodo
con-vencional. En el convencional se requiere un gel electrolítico para medir los biopotenciales (disminuye las características aislantes del Stratum Corneum). En el microelectrodo, las agujas penetran en la capa conductora Stratum Germinativum para sensar los biopotenciales 8 2.5. Tipos de procesadores orientados a su aplicación, a) Procesador de uso general.
b) Procesador de uso semiespecífico c) Procesador de uso específico 13 2.6. Circuitos integrados y su orientación de aplicación 14 2.7. Fases fundamentales del codiseño Hardware-Software 16 2.8. Arquitectura de Seamless 19 2.9. Arquitectura del procesador DLX soportada por Seamless 22 2.10. Diagrama esquemático del procesador DLX 22
3.1. Ejemplo que muestra el truncamiento de un número en formato Complemento a 2 28 3.2. Ejemplo de un número en formato Q3.5 28 3.3. Ejemplo de una suma de número en formato Qn.m 30 3.4. Ejemplo de una multiplicación de 2 números sin signo . 30 3.5. Ejemplo de una multiplicación de un número con signo por un número sin
signo 31 3.6. Ejemplo de una multiplicación de 2 números con signo, multiplicador positivo 31 3.7. Ejemplo de una multiplicación de 2 números con signo, multiplicador negativo 31 3.8. Estructura del filtro recursivo para calcular la DCT 35 3.9. Estructura del filtro recursivo para calcular la DCT inversa 37 3.10. Espectro de la señal obtenido al aplicar la DCT a un set de 256 muestras con
fs=128Hz 38 3.11. Señal EEG original en punto flotante comparada con la misma señal con una
3.12. Diagrama de flujo del algoritmo propuesto para la compresión de señales EEG 42 3.13. Representación de una muestra adquirida de la señal EEG 43 3.14. Diagrama del cálculo del VCD 44 3.15. Conversión de un dato sin signo a un dato con signo en complemento a 2 . . 45 3.16. Representación de un dato en el formato Complemento a 2 Q1.7 45 3.17. Diagrama que muestra el escalamiento inicial de las muestras para evitar el
desbordamiento de los registros 46 3.18. Diagrama que muestra un ejemplo del desplazamiento a la izquierda del valor
absoluto máximo para obtener la mejor resolución 47 3.19. Diagrama que muestra el corrimiento a la izquierda aplicado a las muestras
para obtener una máxima resolución 48 3.20. Diagrama de flujo que muestra el cálculo del factor de escalamiento hasta este
punto del algoritmo 50 3.21. Diagrama que muestra el corrimiento final que se le aplica a las muestras para
transmitir o almacenar los coeficientes en menos bits 51 3.22. Resultados obtenidos al procesar 16 muestras al mismo tiempo por el
algorit-mo DCT 54 3.23. Resultados obtenidos al procesar 32 muestras al mismo tiempo por el
algorit-mo DCT 55 3.24. Resultados obtenidos al procesar 64 muestras al mismo tiempo por el
algorit-mo DCT 56 3.25. Resultados obtenidos al procesar 128 muestras al mismo tiempo por el
algo-ritmo DCT 57 3.26. Resultados obtenidos al procesar 256 muestras al mismo tiempo por el
algo-ritmo DCT 58 3.27. Diagrama de flujo que muestra el algoritmo de reconstrucción de la señal EEG. 59
4.1. Ejemplo obtenido de la implementación del algoritmo propuesto en Matlab 62 4.2. Diagrama de flujo para el algoritmo de la multiplicación de 2 números de 16
bits en el formato Q1.15 66 4.3. Diagrama a bloques del algoritmo recursivo para el calculo de la DCT
in-cluyendo el escalamiento inicial de las muestras 67 4.4. Diagrama a bloques del sistema propuesto para implementar el algoritmo de
compresión con un multiplicador por hardware 69 4.5. Diagrama a bloques de la arquitectura del multiplicador implementado ... 71 4.6. Máquina de estados que conforma el controlador del multiplicador 73 4.7. Diagrama a bloques del sistema mínimo a utilizar para la implementación en
SW 78
4.9. Diagrama de interconexión de los sub-bloques que conforman el módulo de memoria y sus terminales 80 4.10. Diagrama con las terminales de los módulos generadores de la señal de reloj
y reset 81 4.11. Diagrama con las terminales de la terminal visual incluida en Seamless. ... 81 4.12. Diagrama con las terminales del monitor de bus incluido en Seamless 82 4.13. Máquina de estados que conforma la interfaz del diseño para la
imple-mentación en software 83 4.14. Diagrama a bloques del particionamiento'final del sistema 86 4.15. Arquitectura del módulo propuesto para implementar la DCT 88 4.16. Diagrama de estados que describe el funcionamiento del controlador A. ... 91 4.17. Arquitectura interna del módulo Coefx, con una mayor utilización de recursos
de HW 92 4.18. Arquitectura interna del módulo Coefx, con una menor utilización de recursos
de HW 95 4.19. Diagrama de estados que describe el funcionamiento del controlador B y el
multiplexor 97 4.20. Comparación agregada al estado EnableMem de la Figura 4.13 para generar
la señal dct_clk 99 4.21. Diagrama de estados del controlador para generar la señal de inicio
dct_start_p 99 4.22. Interconexión del hardware utilizado en el modelo propuesto 100 4.23. Arquitectura del módulo propuesto para el calculo de cada uno de los
coefi-cientes 102 4.24. Máquina de estados que conforma el controlador del nuevo módulo de HW
para le cálculo parcial de la DCT 104
5.1. Demostración del resultado de la simulación de la implementación en la ar-quitectura AVR utilizando el programa BASCOM-AVR 108 5.2. Simulación del multiplicador implementado en VHDL 112 5.3. Diagrama del modelo para la simulación del multiplicador implementado en
SystemC 113 5.4. Simulación del multiplicador implementado en SystemC 115 5.5. Ventana del simulador lógico donde se muestran los resultados de la simulación
de la implementación en SW 118 5.6. Operaciones de lectura/escritura del DLX 119 5.7. Resultados obtenidos con el Performance Profiler de Seamless 120 5.8. Resultado de la simulación del módulo en HW implementado en VHDL . . 122 5.9. Resultado de la simulación del módulo en HW implementado en
5.10. Ventana obtenida del simulador lógico de Seamless para esta implementación HW/SW 126 5.11. Algunas de las ventanas obtenidas del Performance Profiler de Seamless para
esta implementación HW/SW 127 5.12. Resultado de la simulación del módulo en HW que calcula parcialmente la
DCT implementado en VHDL 128 5.13. Ventana obtenida del simulador lógico de Seamless para esta implementación
HW/SW del nuevo diseño 129 5.14. Algunas de las ventanas obtenidas del Performance Profiler de Seamless para
la nueva implementación HW/SW 130 5.15. Modelo de la arquitectura final propuesta para la compresión de señales EEG 138 5.16. Diagrama Interno del módulo de memoria utilizado en la arquitectura final
índice de tablas
2.1. Modelo de pines de la interfaz del DLX 23
3.1. Valores de codificación del factor de escalamiento 49 3.2. Resultados obtenidos de la simulación del algoritmo de la DCT para diferente
número de muestras procesadas 53
4.1. Valores de los cosenos utilizados en la función DCTRec 68 4.2. Tabla de verdad del módulo multiplexor 74 4.3. Tabla de verdad del módulo sumador 75 4.4. Tabla de verdad del módulo que calcula el bit especial 76 4.5. Tabla de verdad del registro de desplazamiento 77
5.1. Muestras de entrada al algoritmo para su prueba funcional 109 5.2. Resultados funcionales obtenidos en la implementación en SW con diversas
herramientas con los datos de entrada de la tabla 5.1 110 5.3. Resultados de las implementaciones basadas en la arquitectura de los
micro-controladores AVR 116 5.4. Funciones involucradas por la DCT y su porcentaje de tiempo de ejecución. 121 5.5. Datos procesados y resultados obtenidos de la implementación en software del
algoritmo recursivo de la DCT 123 5.6. Resultados obtenidos de la síntesis del módulo para el calculo completo de la
DCT 125 5.7. Resultados obtenidos de la síntesis del módulo para el calculo completo de la
DCT (Continuación) 125 5.8. Métricas importantes obtenidas para cada uno de los diseños basados en su
Capítulo 1
Introducción
1.1. Justificación
El área de la medicina, es un campo en el que los avances en la tecnología se ven reflejados de manera notoria. Los sistemas electrónicos para el monitoreo y registro de las señales biomédicas utilizados actualmente, son por lo general dispositivos complejos, robustos, con muy poca portabilidad además de ser caros. La principal razón por la cual dichos dispositivos son complejos, es que el procesamiento de las señales biomédicas adquiridas requiere de varias etapas de acondicionamiento. Esto debido a que las señales se encuentran inmersas en ruido e incluso se ven afectadas por otras señales biomédicas sobreimpuestas a la señal de interés.
El ruido inducido sobre las señales biomédicas es generado en los mismos dis-positivos de medida y registro, o también puede ser transmitido al sistema desde una. fuente externa. Mucha de la interferencia externa se produce en los mismos electrodos utilizados para el sensado de señales. Ya que el gel que se les aplica para mejorar la conductividad de la piel también pueden producir voltajes de DG que pueden saturar los amplificadores de señal o incluso pueden causar cierta corrosión en los mismos elec-trodos. Esta corrosión puede detectar señales RF, permitiendo que se produzca cierta modulación de la señal al llegar al dispositivo de medición.
Además, con los avances de la telemedicina, se vuelve imperativo contar con dis-positivos que no solo sean capaces de monitorear y registrar señales biomédicas, si no que también puedan transmitir la información adquirida de una manera eficiente de modo que pueda ser analizada por expertos de una forma confiable en un lugar distinto de donde se genero la señal.
En un futuro no muy lejano, las señales biológicas tales como electrocardiogra-mas(ECG), electroencefalogramas(EEG) y presión sanguínea no solo serán monitore-adas en ambulancias o lugares remotos, si no que deberán de ser transmitidas sobre canales de capacidades bajas a hospitales cercanos para su interpretación. Además, deben de ser transmitidas de una forma que el ruido no las afecte demasiado y que al ser recibidas puedan ser interpretadas con seguridad por los especialistas. Además, algunas veces las señales biológicas deben ser almacenadas de una forma que ocupen la menor memoria posible. Para esto se requiere que las señales transmitidas sean com-pactadas tanto para su mejor transmisión como para su almacenamiento[18].
En estos días, el monitoreo ambulatorio de las señales EEG se vuelve una her-ramienta valiosa para la caracterización de posibles ataques de epilepsia. Este moni-toreo tiene una clara ventaja sobre el monimoni-toreo ordinario de señales EEG, puesto que permite hasta 72 horas de registro. Este monitoreo puede realizarse desde cualquier lugar y no necesariamente en un hospital donde los costos de admisión son muy altos [22]. El monitoreo ambulatorio implica que el sistema de medición se vuelve de carac-terísticas portátil requiriendo que tenga un consumo de potencia reducido para lograr un mayor tiempo de monitoreo.
1.2. Definición del problema
El monitoreo ambulatorio de señales EEG se ve afectado por gran cantidad de ruido inducido sobre las señales adquiridas. Este monitoreo requiere almacenar gran cantidad de información y transmitirla de manera eficiente. El equipo para el monitoreo ambulatorio es de características portátiles, y por tanto requiere tener un consumo bajo de potencia. Por tanto, en esta tesis se propone diseñar una arquitectura computacional específica para la compresión de señales EEG. Esta arquitectura debe ser específica para, que el consumo de potencia sea mínimo y la compresión se da para poder realizar un monitoreo por mayor tiempo al almacenar menos información, además de facilitar la transmisión.
1.3. Objetivo
Se pretende diseñar una arquitectura computacional específica para la compresión de señales de origen cerebral. La compresión de la señal tiene como objetivo el facilitar su transmisión libre de ruido, así como facilitar el registro de la información permitiendo un monitoreo por mayor tiempo. La arquitectura deberá de ser capaz de procesar al menos 32 canales EEG con una frecuencia de muestreo de 200 Hz[22]. La arquitectura deberá de ser especifica, pues se busca que esta opere con un bajo consumo de potencia utilizando los menores recursos posibles.
1.4. Contribución y Alcance
Actualmente se han desarrollado micro electrodos para el monitoreo inalámbrico de señales EEG, los cuales requieren de circuitería compacta para darles la característica de portabilidad. Esta circuitería debe de contener los elementos específicos para que su costo de fabricación y consumo de potencia sean mínimos y estos sistemas puedan ser competitivos en el mercado. Estos sistemas requieren además de transmitir las señales adquiridas de una manera eficiente para poder ser analizadas o almacenadas posteriormente. Para poder transmitir esta información de una manera eficiente una técnica empleada es la compresión de señales.
tales como velocidad, recursos utilizados y consumo de potencia. La mejor arquitec-tura será la que logre un mejor equilibro entre estas métricas y las necesidades de esta aplicación.
Para la elaboración de la tesis se usaran diversas herramientas tales como Matlab, C y Bascorn para la simulación del algoritmo de compresión en Software. También se manejaran herramientas de descripción, simulación y síntesis de hardware tales como ModelSim y Leonardo Spectrum de Mentor Graphics y herramientas de codisñeo (Hardware/Software) tales como SystemC y Seamless de Mentor Graphics.
1.5. Organización de la tesis
Capítulo 2
Antecedentes
2.1. Ingeniería Biomédica
La ingeniería biomédica. es una disciplina enfocada a aplicaciones en medicina. El estudio de esta área se orienta la restitución o sustitución de funciones y estructuras dañadas del cuerpo humano, y así construir instrumentos con fines terapéuticos y de diagnóstico. La rama de la ingeniería biomédica verifica más directamente el impacto entre la medicina y la ingeniería. La creciente complejidad de los instrumentos, de los métodos de medición e incluso de la interpretación de los datos obtenidos, hacen que los hospitales necesiten de los bioingenieros, con frecuencia jugando papeles comple-mentarios a los del médico en los equipos clínicos[ll].
2.2. Las señales EEG y su medición
Grabaciones eléctricas de la superficie expuesta del cerebro o de la superficie de la cabeza demuestran una actividad eléctrica oscilatoria continua, La intensidad y los patrones de esta actividad eléctrica son determinadas por una gran excitación del cere-bro resultado de las funciones en el RAS (Sistema de Activación Reticular). Las on-dulaciones en los potenciales eléctricos grabados son llamadas ondas cerebrales y la grabación completa se llama electroencefalograma (EEG).
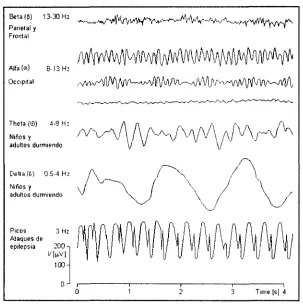
Las intensidades de las ondas cerebrales en la superficie del cerebro pueden ser tan grandes como 10 mV, mientras que esas grabaciones del cuero cabelludo tienen una pequeña amplitud de aproximadamente 100 f.iV. Las frecuencias en las ondas cerebrales tienen un rango de 0.5 - 100 Hz y su carácter es altamente dependiente del grado de actividad en la corteza cerebral. Las ondas cambian marcadamente entre los estados de alerta y sueño[6]. Los distintos tipos de señales EEG se muestran en la Figura 2.1,
Beta(W 1330H: Parietal y
Frontal
Alfa (a) 8I3H2 Occipital
Thetaf®) 48 Hi Niños y
adultos durmiendo
Delta (6) 0.54 Hz Niños y
adultos durmiendo
Picos 3 Hz Alaques de epilepsia 200,
V[uVj
100
0J i
[image:28.613.151.454.75.380.2]0 3 Time [s] 4
Figura 2.1: Ejemplos de señales EEG
total, son colocados 19 electrodos en el cuero cabelludo y 2 en los lóbulos del oído. Estos 2 últimos son utilizados como los electrodos de referencia. Se llama sistema 10 - 20, debido a que los electrodos están localizados con un espaciamiento entre el 10 y 20% de la distancia entre nasión e inión[6]. Esto se muestra en la Figura 2.2.
2.3. Sistemas actuales de monitoreo portátil de
señales EEG
20%
20% 20%
Inion
Figura 2.2: El sistema internacional 10 - 20. Vista lateral y superior.
obtenida con el registro por lapsos esta sujeto a errores de muestreo y los pacientes no serán capaces de activar de forma confiable el modo de registro por medio del botón. Conectando el dispositivo a una computadora con programas de detección de picos y ataques (anormalidades presentes en las señales EEG), se puede detectar instantánea-mente algún problema, pero se sacrifica, la portabilidad.
La integración de la tecnología de la computadora a los sistemas de monitoreo EEG en los 90's fue el parte aguas que permitió la expansión del número de canales de registro y así mejorando el análisis de datos. Actualmente se disponen dispositivos de hasta 32 canales, con tazas de muestreo de 200 Hz y resolución de 16 a 22 bits. Los electrodos están unidos de la cabeza del paciente a la unidad de registro, la cual es usada en la cintura del paciente. Este modelo pesa alrededor de 1.5kg, incluyendo el disco duro y una batería. Las dimensiones de este dispositivo son de aproximadamente 450 - 550 cm3, similar a un reproductor de CDs.
Estos sistemas utilizan una batería grande y un disco duro debido a que el registro se realiza en el mismo dispositivo de adquisición de señal. Además el disco duro es tam-bién grande para almacenar todo la información, ya que no se encuentra comprimida, Esto limita el tiempo de almacenamiento de la unidad [22].
2.4. El sistema de transmisión inalámbrica de
señales EEG propuesto
llegan a una etapa de multiplexado para que el procesamiento de las señales sea real-izado por un solo bloque. La señal que sale del multiplexor es acondicionada por medio de una etapa analógica y pasa a un bloque de procesamiento de señal donde la señal es comprimida y librada de interferencias. En este módulo, la señal se deja lista para que sea transmitida inalámbricamente. La Figura 2.3 muestra el modelo del sistema propuesto.
Sistema de Hicroelect rodos
•- —... . .
Acondiciona-miento de señal analog.
Procesamiento
de señal
Transmisor Inalámbrico
Figura 2.3: Sistema de adquisición y transmisión de señales EEG propuesto
Los micro electrodos utilizados son del tipo semi-invasivos ya que estos consisten de un arreglo de agujas puntiagudas diseñadas para la penetración de la piel humana con las cuales se libran los problemas relacionados con las altas impedancias de las capas superficiales de la piel. La mayor ventaja de estos electrodos incluye un procedimiento de aplicación rápido y fácil, una baja impedancia entre el electrodo y la piel (menor que la de los electrodos tradicionales) y un uso mas cómodo para el paciente que los porta[9].
La Figura 2.4 muestra físicamente la comparación entre un electrodo convencional y un micro electrodo.
MicroElectrodo en
seco Electrodo convencionalen húmedo
gel no electrolítico agujas
gel electrolítico
Figura 2.4: Comparación en el uso de un microelectrodo (izquierda) y un electrodo con-vencional. En el convencional se requiere un gel electrolítico para medir los biopotenciales (disminuye las características aislantes del Stratum Corneum). En el microelectrodo, las agu-jas penetran en la capa conductora Stratum Germinativum para sensar los biopotenciales.
2.5. Compresión de señales
la cual requiere menos bits. La compresión permite que las señales sean transmitidas de forma mas rápida, económica, en mayor número y en tiempo real.
Algunas técnicas de compresión son sin perdidas ("lossless"), lo cual significa que la señal puede ser reconstruida exactamente de los datos codificados. Las técnicas de codificación con pérdidas ("lossy"), solo permiten recuperar aproximadamente la señal original de los datos originales, pero son por lo general más eficientes que las técnicas sin perdidas. Pequeños errores pueden ser tolerados en la mayoría de las aplicaciones, de manera que las técnicas sin perdidas se han convertido en las más ampliamente usadas y aceptadas. La compresión de datos con perdidas es esencial en la transmisión digital y almacenamiento de las siguientes señales[18]:
• Señales fisiológicas
• Música
• Imágenes médicas
• Imágenes de satélites
• Vídeo digital
2.6. Compresión por transformación
Una señal puede ser considerada como una-secuencia de N muestras. Esta
secuen-cia puede ser representada por X. Una representación más eficiente de X puede ser
obtenida aplicando una transformación ortogonal Y = TX, donde Y denota el vector
transformado y T denota la matriz de transformación.
El objetivo de la compresión es seleccionar una sub-secuencia de Y conteniendo
M componentes, donde M es substancialmente menor que N. Es decir, son descartados
M — N componentes.
Es posible mostrar que la transformación Karhunen-Loeve (KLT) es la óptima para la representación de señales con respecto al criterio del error cuadrático medio. La mayor
desventaja de usar KLT es el substancial tiempo de computación.
2.7. La compresión de señales por medio de la
Transformada Coseno Discreto (DCT)
Como en todas las técnicas de compresión de señales por medio de transforma-ciones, la DCT involucra el procesamiento de la señal por medio de la descomposición de componentes ortogonales, lo cual causa que no exista perdida de información, si no que solo se produce una rotación del sistema de coordenadas. La compresión entonces se logra por medio de la eliminación de las componentes menos representativas de la señal transformada, y codificando las componentes restantes con menor número de bits. Esto causa definitivamente que exista perdida de la información.
La señal transformada es obtenida por medio de la matriz de rotación DCT:
, DCT
2 COS ^
I ros -^ • • • rosn \.\J!j O / U ^-WO
COS
donde N es el número de muestras de la señal EEG.
Una característica de la DCT es que su matriz de rotación o transformación es independiente de la señal EEG. Además esta matriz tiene coeficientes constantes, tal como se ve en la ecuación 2.1. Esto asegura que la complejidad en software u hardware sea menor, ya que esta matriz puede ser almacenada en una memoria, siempre y cuando el número de muestras permanezca constante.
De esta manera, la señal transformada puede ser obtenida por una simple multi-plicación de matrices:
EEG?rans = (v^CT}tEEGN (2.2)
Donde EEGN es la señal EEG original y EEG^rans es la transformación de la
señal EEG.
Esto también puede ser expresado de la siguiente manera:
EEGtrans[k] = a £ EEGorg{n] cos — (2n + 1) (2.3)
n=0 ¿i
Donde
fc = 0, 1 , - - - , N I
[ 0 , 5 Sifc = 0 ,0 ,.
Ahora, la simple transformación mostrada en la ecuación 2.2 no provee una com-presión de la señal por si misma, ya que se obtiene el mismo numero de coeficientes que el número de muestras en la señal original. Es por eso cine son requeridas técnicas adi-cionales para eliminar la redundancia de datos, mientras que se preserve la información de importancia.
Los coeficientes obtenidos por la DCT son una representación especial de la am-plitud de las componentes espectrales de la señal original. Esto quiere decir que las proyecciones de la señal original sobre los vectores base de la DCT corresponden a las amplitudes de las señales coseno con frecuencias específicas, cuya suma reconstruirá la señal 'original. Estas frecuencias son dependientes de la frecuencia, de muestreo y el número de muestras de la señal original[3|.
El proceso de compresión de señales basado en la DCT consta de los siguientes pasos:
1. Transformar la señal original por medio de la matriz de rotación DCT
2. Eliminar las componentes de frecuencia, que proporcionen menor información.
3. Codificar las componentes restantes con menor cantidad de bits.
Teóricamente, este método de compresión puede dar una razón de compresión aproximadamente de hasta 7:1, dependiendo de las propiedades de la señal a comprimir.
Los coeficientes resultantes de aplicar la DCT se usarán posteriormente para la reconstrucción de la señal EEG. Para esta reconstrucción se utilizará la Transformada Inversa Coseno Discreto (IDCT), para esto se requiere contar con el mismo número de coeficientes que las muestras de entrada al algoritmo de la DCT.
La representación matemática general que describe la IDCT se muestra en la ecuación 2.5.
Í12N~1 Trk
EEGrecons\i] = \/T7 E EEGTrans(k] eos —(2i + 1) (2.5)
' jv fc=o Z7V
Para
i =
o , i , - - - , ; v - i
2.8. Arquitectura de procesadores de acuerdo a su
aplicación.
2.8.1. Arquitectura computacional y sus elementos
Una arquitectura se define como la estructura que permite el funcionamiento de un sistema capaz de desarrollar una serie de procedimientos que satisfacen condiciones de operación deseadas. [1].
Los elementos que componen una arquitectura son: procesador, elementos de memoria, registros, instrucciones, interrupciones, elementos de control, estructuras de entrada/salida y funciones.
Procesadores y la orientación de su aplicación.
Un procesador es un diseño digital capaz de ejecutar un algoritmo y típicamente consta de un controlado!' y una ruta de datos. La ruta de datos incluye componentes digitales básicos tales como registros de almacenamiento de datos, unidad de transfor-mación de datos, multiplexores y buses para mover datos. La unidad del controlador consta de registros, compuertas lógicas que configuran la ruta de datos para hacer transformaciones y almacenamiento de datos. Muchos procesadores son programables y algunos no lo son.
Los procesadores de propósito general son programables, ya que están diseñados para ejecutar casi cualquier aplicación. La ruta de datos de estos, contiene grandes registros y unidades aritmética-lógica flexibles. Sus controladores no incorporan infor-mación acerca de la aplicación que el procesador esta corriendo, pues solo ejecuta las instrucciones guardadas en memoria que representan la aplicación. Para ajustar una aplicación a un procesador de propósito general se requiere compiladores rápidos y más herramientas.
Así mismo, los diseñadores pueden usar procesadores específicos para ejecutar la aplicación. Estos pueden establecer exactamente el número, el tamaño y las interconex-iones entre los registros y unidades funcionales para que se ajuste mejor a'la aplicación y cumpla con las necesidades de consumo de potencia, y desempeño. Los procesadores específicos pueden incluir grandes "pipelines" o numerosas unidades funcionales de ru-tas de datos para lograr paralelismo. Estos procesadores de uso específico también son referidos a veces como cooprocesadores, aceleradores o periféricos.
mejor rendimiento y bajo consumo de energía de los procesadores específicos y los costos reducidos de los procesadores programables que son producidos en grandes cantidades. La mayoría de las veces los diseñadores deben dividir sus aplicaciones para encontrar un balance entre soluciones generales y especificas.
Actualmente existen dispositivos que caen dentro de los extremos de la división, estos son los DSPs y los microcontroladores. Algunas computadoras embebidas digi-talizan señales analógicas (tales como audio o vídeo), las transforman y devuelven una señal nueva. Esto se requiere hacer en tiempos reducidos. Es por eso que los DSPs incluyen instrucciones especiales y estructuras de hardware para manejar tales señales. Por ejemplo un DSP típico puede contener instrucciones para una lectura y escritura rápida de arreglos grandes de datos, multiplicación y acumulación en un un solo ciclo y aritmética de punto flotante rápida. Los microcontroladores requieren de operaciones, un eficiente manejo de puertos de entrada/salida, y un menor consumo de potencia. Las arquitecturas de los microcontroladores generalmente tienen rutas de datos angostas de (16 ó 8 bits), unidades funcionales sencillas, registros directamente conectados a puertos externos y un uso extensivo de instrucciones a nivel de bits. También incluyen temporizadores, comunicación serial, convertidores analógico digital y algunas otras funciones de control.
Los DSP y microcontroladores representan las 2 formas de arquitecturas o proce-sadores semi-específicos, también conocidos como proceproce-sadores con instrucciones para aplicaciones específicas. Estos tienen grandes aplicaciones en procesamiento digital de imágenes, ruteo en redes y comunicaciones móviles[20].
Memoria de Instrucción
Dr Inst. PC
Controlador
control
Controlado:
Unidad de control
A
i
H
1 Hult-Acum
uta de datos
a) b)
2.8.2. Circuitos integrados y la orientación de su aplicación.
Un circuito integrado (CI) es una interconexión de transistores siguiendo uno de varios posibles estilos de fabricación. También existen CI 's de uso general programadles y de uso específico. Un fabricante de CI's puede diseñar un circuito de aplicación especi-fica usando únicamente los elementos necesarios (transistores) para esto. El resultado de esto es un chip compacto, rápido y de bajo consumo de potencia.
Los CI's de uso general, son construidos por un conjunto de módulos interconec-tados y se programa cada uno de ellos para implementar diferentes componentes. Un módulo debe de ser pequeño, memoria de 16 palabras. Almacenado los bits apropiados en la memoria, se puede implementar la función combinacional deseada. Debido a que los componentes digitales consisten de una lógica combinacional y almacenamiento, en estos se puede mapear cualquier función. Se pueden crear varios módulos dentro del mis-mo CI's e interconectarlos para, crear un sistema completo. Este sistema trabaja bien, aunque se consume más potencia que los CI's de uso especifico y la implementación es menos eficiente. El mas popular de estos dispositivos es el FPGA (Field Programmable Gate Array), el cual consiste de módulos lógicos programables y módulos de almace-namiento interconectados.
CI Programable CI de uso semiespecífico CIde usoespecífico
2.9.
Figura 2.6: Circuitos integrados y su orientación de aplicación
Codiseño HardwareSoftware de sistemas em
bebidos
de control, aeronáutica, sistemas de comunicación y recles, impresoras, dispositivos electrónicos, etc.
La presión comercial de producir sistemas complejos en tiempo cada vez mas corto, ha llevado a los diseñadores a usar nuevas metodologías más formales para el desarrollo de estos sistemas embebidos[2]. Tradicionalmente cuando se desarrollaban sistemas em-bebidos, los diseñadores particionaban el hardware y software al principio del proceso. De esta forma, los ingenieros de software y hardware diseñaban respectivamente sus componentes sin tener alguna comunicación entre estos dos grupos. Esto en muchas ocasiones, provocaba que hubiera que repetir varias veces el proceso por errores de planeación causando elevados costos de diseño y ciclos de desarrollo muy largos.
Como resultado de esto, surgió el llamado Codiseño Hardware - Software (HSG), el cual ha ganado una gran aceptación en la industria y en las universidades la última década. El codiseño integra los principios del diseño de hardware y software y provee métodos estructurados y herramientas para la simulación y verificación conjunta del sistema. Esto conlleva a ciclos de desarrollo mas cortos, costos menores, reuso de com-ponentes y la maximización de la potencia de procesamiento.
Una sola metodología HSC rio puede ayudar al diseño exitoso de todas las aplica-ciones. Existen distintas técnicas o metodologías usadas de acuerdo al tipo de diseño a implantar, aunque existen fases fundamentales que se deben seguir. Estas fases se muestran en la Figura 2.7 y se describen a continuación[10].
2.9.1. Especificación formal
En esta fase, los diseñadores crean un documento con las especificaciones del sis-tema. Estas especificaciones documentan los requerimientos del sistema, su funcional-idad, comportamiento y su interfase. La interfase define el mecanismo por el cual se comunica con el medio externo. En esta fase, también son considerados otros algunos otros criterios como tamaño, consumo de potencia, según sea considerado importante por los diseñadores.
2.9.2. Modelado
Figura 2.7: Fases fundamentales del codiseño Hardware-Software
tal como el SystemC el cual se usa para el modelado estructural. También pueden ser usados lenguajes de descripción de hardware tales como VHDL o Verilog.
2.9.3. Simulación y verificación
Para iniciar la simulación del modelo, los diseñadores primero particionan el sis-tema y seleccionan un procesador. El particionamiento se refiere a la manera en que los diseñadores asignan ciertas funciones de un sistema a ser desarrolladas por hardware y otras por software. Usando simuladores, los diseñadores prueban eventos. Tales eventos contienen un set de condiciones iniciales para controlar el proceso.
general-mente menos costoso, debido a la flexibilidad del software. Aunque recientegeneral-mente con los avances en la tecnología los FPGAs, el hardware ofrece una flexibilidad comparable al software, con la ventaja de que se obtiene un mejor desempeño y un consumo de potencia mucho menor.
Una herramienta utilizada comúnmente para verificar el desempeño y eficiencia
del diseño es la llamada Función de evaluación. Esta consiste simplemente en una
ecuación que tiene como variables los parámetros de rendimiento del sistema tales como velocidad, costo y consumo de energía. Cada diseño implementado se evalúa mediante esta función y se obtiene un valor el cual se busca maximizar.
Al modelo en este punto se le pueden hacer modificaciones y es vuelto a sim-ular hasta que se alcance la funcionalidad deseada del sistema, así como obtener un valor máximo de la función de evaluación. Para realizar estas modificaciones, se re-quiere reparticionar de nuevo el sistema. Consecuentemente, se pasa la mayor parte del desarrollo del sistema en la verificación, pero es la parte más importante del diseño.
2.9.4. Mapeo del modelo
(síntesis)
En esta fase el diseñador transfiere el modelo al hardware especifico,componentes de software o interfases. La especificación del modelo es traducida a código en C (para los componentes de software) y a código en VHDL/Verilog (componentes de hardware). En este punto, el modelo ha sido verificado para cumplir con todos los requerimientos y restricciones y el sistema esta listo para ser implementado.
2.9.5. Implementación y desarrollo del prototipo
Los diseñadores generalmente seleccionan primero la arquitectura de hardware cuando el prototipo es construido. El hardware puede ser alguno de una gran variedad de microcontroladores comerciales y FPGAs disponibles. Además los sistemas en Chip (SOCs)son una alternativa muy popular hoy en día.
Para permitir la comunicación de los componentes del sistema, es necesario sin-tetizar interfaces. Existen 3 tipos de interfases: hardware con hardware, software con software y hardware con software. Esta comunicación entre los componentes es crucial, debido a que esto asegura la ejecución correcta del programa, y sincroniza, los procesos. Algunos tipos de comunicación son las memorias mapeadas (Entrada/salida), manejo de interrupciones, esperas en el bus y saludo(handshaking).
ser construidos usando herramientas de síntesis.
2.9.6. Herramientas utilizadas para Codiseño
Existen varias herramientas empleadas para conjuntar el software y el hardware en un diseño digital. Dos de los programas que se están comenzando a utilizar ampliamente son el SystemC y el Seamless. Estos se describen de forma breve a continuación.
2.9.6.1. SystemC
SystemC es un lenguaje utilizado para describir hardware y software con múlti-ples niveles de abstracción. Este lenguaje fue creado por la necesidad de conjuntar en un mismo lenguaje el software y el hardware de un diseño. La creación de este lenguaje fue patrocinado por un grupo de empresas que mostraban un fuerte interés en el Co-diseño por las ventajas que este les brindaría. Entre las empresas precursoras del SystemC se encuentran Syriopsys, CoWare, Cadenee, AR.M, Ericsson, Infineon, Lucent, NEC, Fujitsu, Sony, STMicroelectronics, Motorola y Texas Instruments[5].
Básicamente SystemC constituye una librería adicional del lenguaje C++, con la cual se pueden modelar y simular sistemas. Con esta nueva librería, se pueden crear procesos concurrentes, temporizaciones, diversos tipos de datos en distintos formatos, interrupciones así modelar procesos con jerarquía tales como módulos, puertos o señales. Algunas versiones de SystemC permiten visualizar las simulaciones mediante el de-splegado de señales tal como lo hacen los simuladores convencionales de VHDL.
2.9.6.2. Seamless
La Co-verificación o codiseño pueden disminuir el tiempo de diseño de un sistema, debido a la integración temprana del software y hardware mediante el uso de simu-ladores muy veloces, pues la simulación de la ejecución de instrucciones de un micro-procesador modelado en software es más lenta que la ejecución en un micromicro-procesador real.
Seamless es una herramienta para detección de errores (debugging) interactiva entre hardware y software que acelera el proceso de co-verificación permitiendo que cierto software pueda ser ejecutado o simulado en hardware. Este programa fue creado por la empresa Mentor Graphics y la forma en que Seamless acelera el proceso de co-verificación se basa en dos aspectos:
• Separa la función del procesador de su interfaz.
Seamless incluye algunas librerías para soportar algunos procesadores. Estas
li-brerías se denominan PSPs (Processor Support Packages). Estas proveen modelos a
procesadores que aceleran la co-verificación. Los 2 principales componentes de un PSP son el modelo del conjunto de instrucciones (ISM) y el modelo de la interfaz del bus.
El modelo de la interfaz del bus simula el comportamiento de los pines de entrada y salida del microprocesador para la sección de hardware de la co-verificación. El software
ISM executa por separado y mucho más rápido las instrucciones programadas. Esto
lo hace en un simulador de software. Durante la co-verificación, la mayoría de las operaciones del procesador son tareas de rutina tales como la lectura de instrucciones (fetching), o el escribir y leer datos del Stack. En Seamless normalmente el simulador
lógico ejecuta los ciclos para el acceso del bus. Una ventaja de Seamless es que este
puede suprimir estos ciclos de rutina permitiendo que la simulación corra mas rápida[8].
Los principales componentes de Seamless para la co-verificación se muestran en
la Figura 2.8 y se describen a continuación.
Código ejecutable
Petición de acceso de dalos
Temporizactón de instrucción
"\
• Simulador de Software. Este ejecuta la porción de software de la sesión de co-verificación. Este ejecuta el código de máquina, que el usuario produce cuando se compila un código para un procesador específico. La interfaz del simulador de software controla la ejecución del ISM y ejecuta operaciones tales como correr el programa paso a paso, inspección de memoria y funciones típicas de un simulador de software.
• Kernel de coverificación. Este controla la comunicación entre la porción de software y la lógica durante la co-verificación. Este permite al usuario configurar varios aspectos durante la co-verificación por medio de la ventana de sesión de
Seamless. Entre estos aspectos están algunas optimizaciones de acceso a memo-ria,
• El simulador lógico y el kernel de simulación lógica. Estos implementan la porción de hardware de la sesión de co-verificación. Se pueden manejar uno o mas modelos de interfases de bus de microprocesadores y algunos modelos de memoria en el diseño de hardware, el cual generalmente es expresado en un lenguaje de
descripción de hardware (HDL). El simulador lógico controla la ejecución de un
diseño. Entonces el kernel de simulación lógica executa la co-verificación HDL
del diseño.
Otra de las ventajas de este programa consiste en una aplicación denominada Per
formance Profiler. Esta aplicación permite registrar algunas métricas de desempeño del diseño. Entre estas métricas se cuenta, con:
• Code Profile, con el cual se puede analizar el porcentaje del tiempo total que el programa, permanence en alguna función o procedimiento.
• Bus load, con el cual se analiza el porcentaje de utilización del bus de los mi-croprocesadores del diseño.
• Arbitration Delay, el cual permite analizar las esperas para poder ocupar el bus principal por cada uno de los microprocesadores.
• SW Gant Chart, el cual muestra el periodo de tiempo en el cual se ejecuta cada una de las funciones o procedimientos del programa. Esto se despliega como una gráfica de Gant.
Estas métricas ayudan a los diseñadores a decidir nuevas mejoras en el sistema tales como un nuevo particionamiento, incremento de memoria, optimización de código, etc. La forma en que seamless puede obtener estas métricas es simplemente que existe
un módulo de hardware denominado bus monitor, el cual se cuelga de la interfaz y
monitorea en cada momento el estado del bus. De esta forma se obtienen las estadísticas mencionadas.
El sistema mínimo para poder implementar un diseño de hardware-software con-siste de un microprocesador, una unidad de memoria, una interfaz y una señal de reloj. Con lo anterior es posible ejecutar algún software en el microprocesador. A partir de es-ta estructura básica, es posible agregar módulos adicionales de hardware y adicionarlos al diseño. '
2.10. El procesador DLX
Este procesador es bastante conocido y estudiado por su arquitectura ya que esta es la base de la que se derivan muchos de los diseños de mícroprocesadores comerciales, entre ellos se tienen AMD 29K, DECstation 3100, HP850, IBM 801, Intel Í860, MIPS M/1000, Motorola 88K, RISG I, SGI 4D/60, SPARCstation-1 Sun-4/260.
La arquitectura DLX es una arquitectura simple de carga/almacenamiento
(load/store) surgida de una mezcla de otras arquitecturas load/store similares (RISC) y más sofisticadas. Esta arquitectura es de 32 bits y esta basada en las instrucciones más comúnmente utilizadas. Las instrucciones que son menos utilizadas son consideradas menos criticas en términos de desempeño y por lo tanto no se encuentran
implemen-tadas directamente en el DLX.
Existen 4 conceptos importantes en esta arquitectura:
1. La simplicidad del conjunto de instrucciones load/store
2. La importancia de la capacidad de pipelining (capacidad de ejecutar varias fun-ciones al mismo tiempo).
3. Los beneficios de un conjunto de instrucciones fácil de codificar.
4. La compilación de programas de alto nivel en código de máquina eficiente.
El DLX tiene 32 registros de propósito general y 32 registros para operaciones
de punto flotante de precisión sencilla, así como un número de registros misceláneos usados para el manejo de interrupciones y excepciones de punto flotante. La longitud
de palabra (word) del DLX es de 32 bits, mientras la memoria es direccionable por
Por lo ampliamente utilizado este procesador, el programa Seamless incluye un
PSP para este procesador. Este PSP no soporta algunas de las instrucciones del
proce-sador, entre estas las relacionadas con punto flotante. Este PSP tampoco soporta el snooping, que esta relacionado con la memoria cache.
La Figura 2.9 muestra la arquitectura del procesador DLX que es soportada por
Seamless.
ALU
Entera
Pipeline de 5 etapas
J
\ \
Banco de Registros
V J
Simulación de software
f >.
Interfaz del bus
V J
Simulación de hardware
Figura 2.9: Arquitectura del procesador DLX soportada por Seamless
La Figura 2.10 muestra un diagrama esquemático del procesador DLX. Así mismo,
la Tabla 2.1 muestra el modelo de la interfaz en Seamless del procesador DLX. También
se da una breve descripción de ellas[7].
I
^\DLX Processor
• BreqP | BusyP • AddrP(32)
• DataP(32) inout • ValidP • RdP_WrN • BurstReqP • ByteEnP(4)
^/
Tabla 2.1: Modelo de pines de la interfaz del DLX Pin del modelo ClkP ResetP BreqP BgntP BusyP AddrP DataP RD_PWrN ByteEnP ValidP AckP BurstReqP BurstGntP SnoopAddrP SnoopEnP Descripción
Entrada de reloj
Señal de reset. Debe mantenerse activa por lo menos 10 ciclos de reloj
Señal de petición del bus por parte del microprocesador Señal de indicación que el bus ha sido asignado al microprocesador
Señal de indicación que el procesador esta utilizando el bus. El procesador mantiene activa esta señal siempre que este usando el bus.
Bus de direcciones de memoria Bus de datos
Señal de selección escritura/lectura. Alto para lectura bajo para escritura
Señal de habilitación del número de bytes a leer o escribir Señal del DLX que indica que la dirección de memoria es valida
Indica que un dato de entra es valido o alguna lectura se completo
Señal de petición a acceso de una ráfaga (burst) a memoria.
Señal que indica que una transferencia en ráfaga puede ser ejecutada.
Usada para mantener coherencia en el cache
Señal activa cuando una dirección valida esta en SnoopAddrp. La configuración más simple es unir (Not RdP.WrN) a esta señal.
Capítulo 3
El algoritmo de compresión propuesto
Antes de comenzar a describir los algoritmo de compresión y reconstrucción de señales EEG propuestos, es necesario comprender algunos conceptos con respecto a la aritmética, que se utilizó en ellos así como una descripción mas detallada, del modelo de compresión manejado para su implementación . En las siguientes secciones se dará una breve descripción de tales puntos, lo cual permitirá comprender de forma mas sencilla, los algoritmos propuestos.
3.1. Representación de datos en sistemas digitales
La mayoría de los sistemas digitales comerciales para el procesamiento de señales se caracterizan por incluir procesadores de punto fijo o punto flotante. Existe algunas diferencias para la implementación de algoritmos en cada uno de estos formatos, tales como el escalamiento que se debe de implementar en los procesos en punto fijo para evitar sobreflujo. En general, los procesadores de punto flotante son mas caros, y gen-eralmente al menos el 50 % de ellos son más lentos que los procesadores de punto fijo. De esta forma, cuando la velocidad y costo del sistema es un criterio importante de diseño, se debe usar un procesador de punto-fijo. Los procesadores de punto fijo se han usado exitosamente en muchas aplicaciones y continúan manteniendo la promesa de proveer soluciones efectivas con respecto a la métrica costo-eficiencia. Pero para seleccionar el tipo de procesador a utilizar, es necesario conocer las diferencias entre ambos formatos aritméticos y conocer las limitaciones de cada uno de ellós[16].
3.1.1. Aritmética de punto flotante
Un número en punto flotante X esta compuesto de una mantiza M ( X ) y un
exponente E(X] de forma tal que:
X = M ( X ) • 2E(X) (3.1)
manejar esto por una unidad computacional es algo complicado y requiere de mayor longitud en sus registros para procesar este tipo de datos. Supongamos que se tienen 2 números en punto flotante X y Y, y se desean multiplicar. El producto de estos números esta dado por la ecuación 3.2
X = M(X}M(Y] • 2£W+E(y) (3.2)
Para este calculo, el hardware de punto flotante que lo implementará deberá con-tener un multiplicador para las matizas y un sumador para los exponentes. La mayor ventaja de usar procesadores de punto flotantes es que proveen un alto rango dinámico que hace que se produzca un sobreflujo se muy poco probable.
Por otro lado, un procesador de punto flotante, requiere de unidades multiplicado-ras y acumuladores más complejas y más grandes que los procesadores de punto fijo. Esto ocasiona que los costos sean más grandes, así como que el consumo de potencia es mayor. Aunque desde luego, con los avances de la tecnología submicron VLSI CMOS, se pueden diseñar procesadores de punto flotante atractivos para las soluciones DSP en términos de costo y velocidad.
3.1.2. Aritmética de punto fijo
Un número en punto fijo a = djv-i , (iN2, • • • , Q-o puede ser tratado como un número con signo o sin signo. Cuando se maneja un formato sin signo, todos los N bits expre-saran la magnitud del número, mientras que en un formato con signo, existirá un bit que definirá el signo del número.
3.1.2.1. Representación en complemento a 2
En un número con signo el bit más significativo (MSB) es usado para representar el signo del número. La representación en complemento a 2 de un número de N bits a = ajv-i, a;v_2, • • • , «o dependerá del bit de signo. Si el bit a^v-i = O, el número
será positivo, y los demás bits representaran la magnitud del número, esto se muestra en la ecuación 3.3.
N2
a = £ «,2' (3.3)
!=0
para a > O
representación O es considerado como un número positivo y el rango de números que pueden ser representados en N bits va de O a 2N~l — 1.
Cuando el bit MSB es 1, a/v_i = 1, entonces tenemos un número negativo y este bit tendrá un peso negativo, mientras que el resto de los números tendrán un peso positivo. La ecuación 3.4 ilustra esto.
a = -(2/v-1)+¿a!21 (3.4)
i=0
para a < O
Combinando las ecuaciones 3.3 y 3.4 tenemos una expresión general: a--(2y v-1)a
w_1+¿aí2l (3.5)
¿=o
3.1.2.2. Extensión y truncamiento de números en formato Complemento a 2
De la ecuación 3.5 se puede ver que el MSB juega un papel fundamental en la representación complemento a 2 de números negativos. En muchos diseños digitales, a menudo se requiere de extender o truncar un número de N bits para formar uno de AI
bits, donde M > N en el caso de extensión y M < N en el caso de truncamiento. • Extensión. En el caso de un número positivo, M — N bits de extensión se llenan
con Os y el número en representación sin signo permanece igual. En el caso de un número negativo, la nueva representación es equivalente a:
2M — | a |, donde | a \ corresponde al valor absoluto de a.
La extensión de u número a complemento a 2 es obtenida moviendo el bit de signo a la nueva MSB posición y llenando los huecos con una copia del bit de signo. Por ejemplo —2 en 4 bits sería 1110, extendiendo esto a 8 bits se convierte en 11111110.
es conveniente utilizar un redondeo antes de eliminar los bits LSBs, esto se hace verificando el bit MSB a ser eliminado, si este es 1, entonces al valor truncado se le deberá sumar un 1. Esto se puede ver en la Figura 3.1, en donde se tiene el número —38 representado en 8 bits se truncará a 4 bits. Si el bit MSB a ser eliminado es O, no se le suma valor alguno para su redondeo.
1 1 011 1 O 1 O
Es 'V, por lo tanto se redondea
Valor truncado a 4
Figura 3.1: Ejemplo que muestra el truncamiento de un número en formato Complemento a 2
3.1.2.3. Formato Qn.m
La mayoría de los sistemas de comunicaciones y procesamiento de señal son sim-ulados con herramientas aritméticas de punto flotante tales como Matlab. Desde el punto de vista de implementación, los dispositivos y hardware de punto flotante, son más caros que los implementaclos en punto fijo.
El formato Qn.m es un sistema numérico establecido para representar números en
punto flotante. Qn.m simplemente significa que un número binario de N bits tiene n
bits a la izquierda, del punto binario y m bits a la derecha. En el caso de números con signo el MSB es usado para el signo. Los bits a la derecha del punto binario tendrán un exponente negativo correspondiente a su posición, mientras que los números a la izquierda del punto binario tendrán un exponente positivo. Esto se muestra con un ejemplo en la Figura 3.2.
2' 2'2' 21 2'
Bit de
signo punto binario Formato Q3.5
para un número
Figura 3.2: Ejemplo de un número en formato Q3.5
Es importante mencionar que para números con signo en formato Qn.m, estos se