Introducción a R y Estadística Descriptiva
Lenguaje de Programación R
R es un lenguaje de programación estadística desarrollado por Ihaka y Gentelmen en 1997. Toma como base las características del software comercial SPLUS.
R es de código abierto y de distribución gratuita.
Podemos encontrar la página web de R en la dirección http://cran.rproject.org
Existe mucha documentación en la red acerca de R:
R Para principiantes Introducción a R
Estadística Básica con R y R Commander
El Lenguaje R
R es un lenguaje de programación orientado a objetos, a los cuales se les asigna una serie de características.
R tiene reglas sintácticas:
Distingue entre mayúsculas y minúsculas
El símbolo > aparece antes de recibir cualquier instrucción. Si lo que se muestra es un resultado, no aparece. La tecla Enter, cambia de línea y nos muestra los resultados de la línea anterior.
El símbolo # comenta lo que se escriba a continuación.
Si un comando es correcto sintácticamente, pero falta algo para terminarlo, aparece un símbolo + en la siguiente línea. Para escribir varias instrucciones en la misma línea se separan con ;.
La asignación se realiza con los símbolos < ó =, la igualdad también se usa con otros objetivos, luego es recomendable usar el símbolo <.
Para agrupar un conjunto de instrucciones usaremos {}.
La flecha hacia arriba del teclado nos permite acceder al historial de instrucciones. El tabulador completa la instrucción.
R Como calculadora
5 + 9
## [1] 14
7 * 2
## [1] 14
2^2
## [1] 4
sqrt(144)
## [1] 12
log(1)
## [1] 0
Primeros objetos en R
# Cálculo del valor de x x <- 5 + 2
x
# Variable X X
## Error: object 'X' not found
y <- x * (1 + 6 + 12) x + y
## [1] 140
Los objetos son los elementos básicos del lenguaje R. Los objetos se crean al ser asignados < y se almacenan junto con sus propiedades en la memoria de R. La memoria, salvo que se guarde, se borra al terminar la sesión de R.
Los nombres de los objetos pueden contener letras mayúsculas o minúsculas, números y algunos símbolos que no tengan significado para R.
Para obtener la lista de objetos guardados en R:
ls()
## [1] "x" "y"
Los objetos pueden eliminarse de la memoria,
rm(x) ls()
## [1] "y"
Para eliminar todos los objetos almacenados:
rm(list = ls())
Un objeto posee las siguientes propiedades, clase, modo y estructura. Estas propiedades se pueden obtener con las instrucciones:
class(objeto) mode(objeto) str(objeto)
Class puede tomar valores: logical, integer, complex, character, data.frame, etc.
El modo se refiere a la forma del objeto cuando se almacena en memoria: logical, integer, complex, character, list, expression, name, etc. La estructura representa diversos atributos pertenecientes al objeto en forma de resumen.
Vectores y Matrices
Crearemos ahora un vector de datos:
vector1 <- c(4, 6, 2, 8, 10) class(vector1)
## [1] "numeric"
mode(vector1)
## [1] "numeric"
str(vector1)
## num [1:5] 4 6 2 8 10
A continuación crearemos un vector, de caracteres:
vector2 <- c("a", "b", "c", "d", "e") class(vector2)
## [1] "character"
## [1] "character"
str(vector2)
## chr [1:5] "a" "b" "c" "d" "e"
Podemos concatenar los vectores creados, uno tras otro, uníendolos como dos filas o uniéndolos como dos columnas:
vector3 <- c(vector1, vector2) vector3
## [1] "4" "6" "2" "8" "10" "a" "b" "c" "d" "e"
matriz1 <- rbind(vector1, vector2) matriz1
## [,1] [,2] [,3] [,4] [,5] ## vector1 "4" "6" "2" "8" "10" ## vector2 "a" "b" "c" "d" "e"
matriz2 <- cbind(vector1, vector2) matriz2
## vector1 vector2 ## [1,] "4" "a" ## [2,] "6" "b" ## [3,] "2" "c" ## [4,] "8" "d" ## [5,] "10" "e"
class(matriz2)
## [1] "matrix"
mode(matriz2)
## [1] "character"
str(matriz2)
## chr [1:5, 1:2] "4" "6" "2" "8" "10" "a" "b" "c" "d" ... ## - attr(*, "dimnames")=List of 2
## ..$ : NULL
## ..$ : chr [1:2] "vector1" "vector2"
Para acceder a las componentes de los vectores o matrices:
vector1[3]
## [1] 2
vector1[2:4]
## [1] 6 2 8
matriz1[1, 1]
## vector1 ## "4"
matriz1[2, 3]
## vector2 ## "c"
## [1] "b" "c" "d"
ls()
## [1] "matriz1" "matriz2" "vector1" "vector2" "vector3"
Un primer análisis estadístico
Vamos a almacenar información relacionada con el número de casos atendidos en un servicio de urgencias de un hospital durante la última semana:
urgencias <- c(67, 56, 87, 59, 98, 75, 43)
Si queremos calcular el número medio de urgencias atendidas, sumaremos los siete valores y dividiremos entre 7: \[ \bar{x}=\frac 1 n\sum x_i \]
sum(urgencias)
## [1] 485
sum(urgencias)/7
## [1] 69.29
sum(urgencias)/length(urgencias)
## [1] 69.29
También podemos construir nuestra propia función que nos permita obtener la media de un vector:
media <- function(x) { y <- sum(x)/length(x) return(y)
}
Esta función está lista para usarse sobre cualquier vector:
media(urgencias)
## [1] 69.29
R dispone de un gran número de funciones ya implementadas, como por ejemplo la función mean:
mean(urgencias)
## [1] 69.29
Podemos obtener ayuda e información adicional acerca de cualquier función con:
?mean help(mean) example(mean)
Una vez que tenemos los casos atendidos en el servicio de urgencias del hospital, podemos representar gráficamente este dato:
Si queremos que cada día de la semana tenga su código identificativo, podemos asignar nombres a cada elemento del vector urgencias:
semana <- c("L", "M", "X", "J", "V", "S", "D") names(urgencias) <- semana
barplot(urgencias)
Una vez transcurrida otra semana, podemos añadir los datos a nuestro vector:
urgencias <- c(urgencias, 46, 87, 53, 23, 45, 76, 49) names(urgencias) <- c(semana, semana)
Pudiendo representarlos gráficamente, de forma equivalente:
Para más datos, el diagrama de barras comienza a ser poco apropiado, sería mejor representar los datos de la serie temporal como un diagrama de dispersión:
plot(urgencias)
Si los datos del número de urgencias atendidas se han recogido durante las dos primeras semanas de septiembre, el período de tiempo irá del 3 al 9 de septiembre para la primera semana y del 10 al 16 para la segunda:
dias <- seq(3, 16) dias
## [1] 3 4 5 6 7 8 9 10 11 12 13 14 15 16
De todas las urgencias atendidas, se han contabilizado el número de traumatismos, y se han almacenado en la variable traumatismos:
traumatismos <- c(12, 15, 19, 16, 25, 14, 11, 8, 16, 13, 14, 12, 17, 13)
Podemos calcular ahora por ejemplo el porcentaje de urgencias diarias que son atendidas como traumatismos:
(traumatismos/urgencias) * 100
## L M X J V S D L M X J V ## 17.91 26.79 21.84 27.12 25.51 18.67 25.58 17.39 18.39 24.53 60.87 26.67 ## S D
## 22.37 26.53
También podemos obtener el número de urgencias que no son traumatismos y representarlos gráficamente:
notrauma <- urgencias - traumatismos notrauma
## L M X J V S D L M X J V S D ## 55 41 68 43 73 61 32 38 71 40 9 33 59 36
plot(dias, urgencias, type = "b")
points(dias, notrauma, type = "b", col = "red")
Data Frame en R
Creamos un data.frame con las variables que hemnos venido utilizando:
Serv.Urg <- data.frame(dias, c(semana, semana), urgencias, traumatismos) Serv.Urg
## dias c.semana..semana. urgencias traumatismos
## 1 3 L 67 12
## 2 4 M 56 15
## 3 5 X 87 19
## 4 6 J 59 16
## 5 7 V 98 25
## 6 8 S 75 14
## 7 9 D 43 11
## 8 10 L 46 8
## 9 11 M 87 16
## 10 12 X 53 13
## 11 13 J 23 14
## 12 14 V 45 12
## 13 15 S 76 17
## 14 16 D 49 13
class(Serv.Urg) ## [1] "data.frame" mode(Serv.Urg) ## [1] "list" str(Serv.Urg) ## 'data.frame': 14 obs. of 4 variables: ## $ dias : int 3 4 5 6 7 8 9 10 11 12 ... ## $ c.semana..semana.: Factor w/ 7 levels "D","J","L","M",..: 3 4 7 2 6 5 1 3 4 7 ... ## $ urgencias : num 67 56 87 59 98 75 43 46 87 53 ... ## $ traumatismos : num 12 15 19 16 25 14 11 8 16 13 ... ls() ## [1] "dias" "matriz1" "matriz2" "media" ## [5] "notrauma" "semana" "Serv.Urg" "traumatismos" ## [9] "urgencias" "vector1" "vector2" "vector3" Para renombrar los nombres de las variables que forman nuestro cuadro de datos, accedemos a los nombres: names(Serv.Urg) <- c("Fecha", "Día de la Semana", "Urgencias", "Traumatismos") head(Serv.Urg) ## Fecha Día de la Semana Urgencias Traumatismos ## 1 3 L 67 12
## 2 4 M 56 15
## 3 5 X 87 19
## 4 6 J 59 16
## 5 7 V 98 25
## 6 8 S 75 14
tail(Serv.Urg) ## Fecha Día de la Semana Urgencias Traumatismos ## 9 11 M 87 16
## 10 12 X 53 13
## 11 13 J 23 14
## 12 14 V 45 12
## 13 15 S 76 17
## 14 16 D 49 13
summary(Serv.Urg)
dim(Serv.Urg)
## [1] 14 4
Para acceder a cada variable de nuestro marco de datos, accedemos al nombre del marco $ nombre de la variable:
Serv.Urg$Urgencias
## [1] 67 56 87 59 98 75 43 46 87 53 23 45 76 49
mean(Serv.Urg$Urgencias)
## [1] 61.71
sum((Serv.Urg$Urgencias - mean(Serv.Urg$Urgencias))^2)/dim(Serv.Urg)[1]
## [1] 404.1
La varianza es una medida de la dispersión media respecto a la media: \[ s^2=\frac 1 n\sum (x_i\bar{x})^2 \]
var(Serv.Urg$Urgencias)
## [1] 435.1
var(Serv.Urg$Urgencias) * (dim(Serv.Urg)[1] - 1)/dim(Serv.Urg)[1]
## [1] 404.1
Copia local de un Data Frame
Puede hacerse tedioso aaceder a cada variable del data frame, usando el nombre completo del data frame seguido del nombre de la variable. Existe la opción de crear una copia local del data frame con la función attach:
ls()
## [1] "dias" "matriz1" "matriz2" "media" ## [5] "notrauma" "semana" "Serv.Urg" "traumatismos" ## [9] "urgencias" "vector1" "vector2" "vector3"
Urgencias
## Error: object 'Urgencias' not found
attach(Serv.Urg) ls()
## [1] "dias" "matriz1" "matriz2" "media" ## [5] "notrauma" "semana" "Serv.Urg" "traumatismos" ## [9] "urgencias" "vector1" "vector2" "vector3"
Urgencias
## [1] 67 56 87 59 98 75 43 46 87 53 23 45 76 49
Esta es una copia local, qué significa esto. Si sustituyo la variable Traumatismos por el porcentaje de traumatismos:
Traumatismos <- Traumatismos/Urgencias * 100 Traumatismos
## [1] 17.91 26.79 21.84 27.12 25.51 18.67 25.58 17.39 18.39 24.53 60.87 ## [12] 26.67 22.37 26.53
## [1] 12 15 19 16 25 14 11 8 16 13 14 12 17 13
El data frame original no se ve afectado por los cambios que realicemos sobre la copia local.
Para eliminar la copia local y recuperar los datos origninales, basta con realizar un detach:
detach(Serv.Urg)
Traumatismos
## [1] 17.91 26.79 21.84 27.12 25.51 18.67 25.58 17.39 18.39 24.53 60.87 ## [12] 26.67 22.37 26.53
Urgencias
## Error: object 'Urgencias' not found
ls()
## [1] "dias" "matriz1" "matriz2" "media" ## [5] "notrauma" "semana" "Serv.Urg" "traumatismos" ## [9] "Traumatismos" "urgencias" "vector1" "vector2" ## [13] "vector3"
Directorio de Trabajo
R utiliza un directorio de nuestro ordenador como directorio de trabajo para poder leer datos de él así como para almacenarlos:
getwd()
## [1] "D:/Licesio/Curso R Hospital"
Podemos cambiar el directorio de trabajo y fijarlo en cualquier directorio que deseemos:
setwd("D:/R") getwd()
## [1] "D:/R"
En este directorio podemos guardar el marco de datos que hemos generado:
save(Serv.Urg, file = "ServUrg.Rdata") write.csv(Serv.Urg, file = "ServUrg.csv") rm(list = ls())
ls()
## character(0)
Para cargar los ficheros guardados podemos bien leer del fichero Rdata:
load("ServUrg.Rdata") ls()
## [1] "Serv.Urg"
rm(list = ls()) ls()
## character(0)
O bien del fichero csv:
Serv.Urg <- read.csv("ServUrg.csv") ls()
## [1] "Serv.Urg"
valores<-scan()
Otras Medias de Posición, Dispersión y Forma
Además de la media, podemos determinar la tendencia central de un conjunto de valores con otras medidas de posición como la mediana:
ls()
## [1] "Serv.Urg"
attach(Serv.Urg) median(Urgencias)
## [1] 57.5
quantile(Urgencias, 0.5)
## 50% ## 57.5
mean(Urgencias)
## [1] 61.71
Tanto la media como la mediana son medias de tendencia central, pero que representan conceptos diferentes:
hist(Urgencias)
Además de la tendencia central, los cuantiles nos permiten determinar posiciones intermedias:
quantile(Urgencias, c(0.1, 0.25, 0.5, 0.75, 0.9))
## 10% 25% 50% 75% 90% ## 43.60 46.75 57.50 75.75 87.00
Igualmente las medias de dispersión más clásicas son el máximo y el mínimo, y su diferencia, el rango:
max(Urgencias)
## [1] 98
min(Urgencias)
range(Urgencias)
## [1] 23 98
IQR(Urgencias)
## [1] 29
Todos estos elementos se resumen en los gráficos BoxPlot:
boxplot(Urgencias, main = "Urgencias 3-16 septiembre 2013")
Otras medidas clásicas de dispersión son la varianza y su raiz cuadrada, la desviación típica:
var(Urgencias)
## [1] 435.1
sd(Urgencias)
## [1] 20.86
Un resumen de esta información se puede encontrar mediante la función resumen:
summary(Urgencias)
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 23.0 46.8 57.5 61.7 75.8 98.0
Otras medidas de forma son la Asimetría y la Kurtosis o Apuntamiento.
La asimetría:
\[ \gamma_1=\frac{\frac 1 n \sum (x\bar{x})^3}{s^3} \]
Puede tomar valores positivos, para el caso de colas a la derecha o valores negativos para colas a la izquierda.
library(e1071)
## Warning: package 'e1071' was built under R version 2.15.1
## Loading required package: class
skewness(Urgencias, type = 1)
Mientras que el apuntamiento o kurtosis:
\[ \gamma_2=\frac{\frac 1 n \sum (x\bar{x})^4}{s^4}3 \]
kurtosis(Urgencias, type = 1)
## [1] -0.74
hist(Urgencias, breaks = seq(20, 100, 10))
hist(Urgencias, breaks = seq(20, 100, 20))
Fichero osteoporosis.csv
Antes de empezar a trabajar con el fichero osteoporosis.csv, eliminaremos todos los objetos de nuestro workspace, comprobaremos nuestro directorio de trabajo y comprobaremos que el fichero esta en el directorio de trabajo:
rm(list = ls()) getwd()
## [1] "D:/Licesio/Curso R Hospital"
dir(getwd())
## [1] "figure" "osteoporosis.csv" "ServUrg.csv" ## [4] "ServUrg.Rdata" "Sesion1.html" "Sesion1.md" ## [7] "Sesion1.Rmd"
Importaremos a continuación el fichero y lo guardaremos en el data frame osteoporosis.
osteoporosis <- read.csv("osteoporosis.csv") ls()
## [1] "osteoporosis"
Haremos una exploración del fichero, accediento a sus dimensiones, estructura, parte inicial y final, nombres de las variables, etc.
dim(osteoporosis)
## [1] 1000 40
class(osteoporosis)
## [1] "data.frame"
## 'data.frame': 1000 obs. of 40 variables: ## $ registro : int 3 4 10 11 12 15 16 17 18 20 ... ## $ area : int 10 10 10 10 10 10 10 10 10 10 ...
## $ f_nac : Factor w/ 923 levels "1/1/1931","1/1/1937",..: 542 802 415 56 519 37 313 479 613 179 ... ## $ edad : int 57 46 45 53 46 45 48 50 51 57 ...
## $ grupedad : Factor w/ 5 levels "45 - 49","50 - 54",..: 3 1 1 2 1 1 1 2 2 3 ... ## $ peso : num 70 53 64 78 56 63.5 86 61.5 60.5 64 ...
## $ talla : num 168 152 158 161 157 170 161 164 158 149 ... ## $ bua : int 69 73 81 58 89 76 87 74 58 61 ...
## $ imc : num 24.8 22.9 25.6 30.1 22.7 ...
## $ clasific : Factor w/ 3 levels "NORMAL","OSTEOPENIA",..: 2 2 1 2 1 1 1 1 2 2 ... ## $ menarqui : int 12 13 14 10 13 14 11 10 14 13 ...
## $ edad_men : Factor w/ 36 levels "24","27","28",..: 36 36 36 25 36 36 36 36 36 25 ... ## $ menop : Factor w/ 2 levels "NO","SI": 1 1 1 2 1 1 1 1 1 2 ...
## $ tipo_men : Factor w/ 5 levels "AMBAS","HISTERECTOMIA",..: 4 4 4 3 4 4 4 4 4 1 ... ## $ t_menop : int 0 0 0 3 0 0 0 0 0 7 ...
## $ ant_mate : Factor w/ 2 levels "NO","SI": 2 1 1 1 1 1 1 1 1 1 ... ## $ activ_la : Factor w/ 2 levels "NO","SI": 2 2 2 2 2 2 2 1 1 1 ... ## $ activ_pr : Factor w/ 2 levels "NO","SI": 2 2 2 2 2 2 2 1 1 1 ... ## $ edad_act : int 16 16 14 16 27 15 12 99 99 99 ...
## $ tipo_act : Factor w/ 200 levels " ","ADMINISTRATIVA",..: 1 2 182 155 148 77 157 1 1 1 ... ## $ mens_est : Factor w/ 2 levels "NO","SI": 2 2 2 2 2 2 2 2 2 2 ...
## $ mens_cic : Factor w/ 33 levels "15","150","16",..: 14 14 14 14 14 16 12 11 14 15 ... ## $ mens_reg : Factor w/ 14 levels " ","1","8","9",..: 1 1 1 1 14 1 1 1 1 1 ...
## $ nivel_ed : Factor w/ 5 levels "PRIMARIOS","PRIMARIOS SIN FINALIZAR",..: 3 3 1 1 1 3 1 1 3 1 ... ## $ paridad : Factor w/ 2 levels "CON HIJOS","SIN HIJOS": 1 1 1 1 1 1 1 1 1 1 ...
## $ hijo1 : int 23 24 24 23 24 17 26 22 22 25 ... ## $ hijo2 : int 26 31 29 25 27 20 27 27 27 29 ... ## $ hijo3 : int 0 36 0 27 0 25 32 0 0 0 ... ## $ hijo4 : int 0 0 0 35 0 0 0 0 0 0 ... ## $ hijo5 : int 0 0 0 0 0 0 0 0 0 0 ... ## $ aborto1 : int 0 0 0 24 0 0 0 0 27 0 ... ## $ aborto2 : int 0 0 0 0 0 0 0 0 0 0 ... ## $ aborto3 : int 0 0 0 0 0 0 0 0 0 0 ... ## $ aborto4 : int 0 0 0 0 0 0 0 0 0 0 ... ## $ t_hijo : logi NA NA NA NA NA NA ... ## $ aborto5 : int 0 0 0 0 0 0 0 0 0 0 ...
## $ X._exposi: int 91 96 107 81 118 99 117 101 80 87 ... ## $ zu : num -0.38 -0.18 0.3 -0.83 0.82 ... ## $ tu : num -1.27 -1.03 -0.52 -1.92 -0.03 ...
## $ filter_. : Factor w/ 2 levels "No seleccionado",..: 1 1 1 2 1 1 1 1 1 2 ...
head(osteoporosis)
## registro area f_nac edad grupedad peso talla bua imc clasific ## 1 3 10 4/4/1952 57 55 - 59 70.0 168 69 24.80 OSTEOPENIA ## 2 4 10 8/24/1952 46 45 - 49 53.0 152 73 22.94 OSTEOPENIA ## 3 10 10 3/18/1954 45 45 - 49 64.0 158 81 25.64 NORMAL ## 4 11 10 1/29/1946 53 50 - 54 78.0 161 58 30.09 OSTEOPENIA ## 5 12 10 4/2/1953 46 45 - 49 56.0 157 89 22.72 NORMAL ## 6 15 10 1/19/1954 45 45 - 49 63.5 170 76 21.97 NORMAL ## menarqui edad_men menop tipo_men t_menop ## 1 12 NO MENOPAUSIA/NO CONSTA NO NO MENOPAUSIA/NO CONSTA 0 ## 2 13 NO MENOPAUSIA/NO CONSTA NO NO MENOPAUSIA/NO CONSTA 0 ## 3 14 NO MENOPAUSIA/NO CONSTA NO NO MENOPAUSIA/NO CONSTA 0 ## 4 10 50 SI NATURAL 3 ## 5 13 NO MENOPAUSIA/NO CONSTA NO NO MENOPAUSIA/NO CONSTA 0 ## 6 14 NO MENOPAUSIA/NO CONSTA NO NO MENOPAUSIA/NO CONSTA 0 ## ant_mate activ_la activ_pr edad_act tipo_act mens_est ## 1 SI SI SI 16 SI ## 2 NO SI SI 16 ADMINISTRATIVA SI ## 3 NO SI SI 14 SERVICIO DOMESTICO SI ## 4 NO SI SI 16 PANADERIA SI ## 5 NO SI SI 27 MODISTA SI ## 6 NO SI SI 15 COOPERATIVA DE CITRICOS SI ## mens_cic mens_reg nivel_ed paridad hijo1 hijo2 hijo3 hijo4 hijo5 ## 1 28 SECUNDARIOS CON HIJOS 23 26 0 0 0 ## 2 28 SECUNDARIOS CON HIJOS 24 31 36 0 0 ## 3 28 PRIMARIOS CON HIJOS 24 29 0 0 0 ## 4 28 PRIMARIOS CON HIJOS 23 25 27 35 0 ## 5 28 ULTROGESTAN PRIMARIOS CON HIJOS 24 27 0 0 0 ## 6 30 SECUNDARIOS CON HIJOS 17 20 25 0 0 ## aborto1 aborto2 aborto3 aborto4 t_hijo aborto5 X._exposi zu
## 1 0 0 0 0 NA 0 91 -0.37999 ## 2 0 0 0 0 NA 0 96 -0.18000 ## 3 0 0 0 0 NA 0 107 0.30000 ## 4 24 0 0 0 NA 0 81 -0.82999 ## 5 0 0 0 0 NA 0 118 0.81999 ## 6 0 0 0 0 NA 0 99 -0.01999 ## tu filter_.
## 1 -1.27000 No seleccionado ## 2 -1.03000 No seleccionado ## 3 -0.51999 No seleccionado ## 4 -1.92000 Seleccionado ## 5 -0.02999 No seleccionado ## 6 -0.83999 No seleccionado
## registro area f_nac edad grupedad peso talla bua imc clasific ## 995 1028 11 5/22/1937 63 60 - 64 71 161 57 27.39 OSTEOPENIA ## 996 1029 11 6/16/1940 60 60 - 64 64 158 69 25.64 OSTEOPENIA ## 997 1030 11 6/19/1933 67 65 - 69 68 157 75 27.59 NORMAL ## 998 1031 11 7/11/1940 59 55 - 59 72 153 67 30.76 OSTEOPENIA ## 999 1032 11 9/17/1935 64 60 - 64 80 152 55 34.63 OSTEOPENIA ## 1000 1033 11 2/12/1938 62 60 - 64 67 161 65 25.85 OSTEOPENIA ## menarqui edad_men menop tipo_men t_menop ant_mate activ_la activ_pr ## 995 14 48 SI NATURAL 15 NO SI SI ## 996 10 40 SI AMBAS 20 NO SI NO ## 997 11 55 SI NATURAL 12 NO NO SI ## 998 12 56 SI NATURAL 3 NO NO SI ## 999 14 50 SI NATURAL 14 NO NO NO ## 1000 13 54 SI NATURAL 8 NO NO NO ## edad_act tipo_act mens_est mens_cic mens_reg
## 995 25 COMERCIO SI 28 ## 996 20 ATS SI NO CONSTA ## 997 14 BAR SI 28 ## 998 18 ALMACEN NARANJA SI 28 ## 999 99 SI 30 ## 1000 99 SI 28
## nivel_ed paridad hijo1 hijo2 hijo3 hijo4 hijo5 ## 995 PRIMARIOS SIN HIJOS 0 0 0 0 0 ## 996 SUPERIORES CON HIJOS 23 25 0 0 0 ## 997 PRIMARIOS SIN FINALIZAR SIN HIJOS 0 0 0 0 0 ## 998 PRIMARIOS CON HIJOS 21 25 0 0 0 ## 999 PRIMARIOS CON HIJOS 23 26 0 0 0 ## 1000 SECUNDARIOS CON HIJOS 24 27 0 0 0 ## aborto1 aborto2 aborto3 aborto4 t_hijo aborto5 X._exposi zu tu ## 995 25 0 0 0 NA 0 87 -0.53 -1.94 ## 996 0 0 0 0 NA 0 102 0.09 -1.23 ## 997 0 0 0 0 NA 0 117 0.66 -0.88 ## 998 0 0 0 0 NA 0 98 -0.09 -1.37 ## 999 25 0 0 0 NA 0 83 -0.67 -2.11 ## 1000 0 0 0 0 NA 0 98 -0.09 -1.47 ## filter_.
## 995 Seleccionado ## 996 Seleccionado ## 997 Seleccionado ## 998 Seleccionado ## 999 Seleccionado ## 1000 Seleccionado
names(osteoporosis)
## [1] "registro" "area" "f_nac" "edad" "grupedad" ## [6] "peso" "talla" "bua" "imc" "clasific" ## [11] "menarqui" "edad_men" "menop" "tipo_men" "t_menop" ## [16] "ant_mate" "activ_la" "activ_pr" "edad_act" "tipo_act" ## [21] "mens_est" "mens_cic" "mens_reg" "nivel_ed" "paridad" ## [26] "hijo1" "hijo2" "hijo3" "hijo4" "hijo5" ## [31] "aborto1" "aborto2" "aborto3" "aborto4" "t_hijo" ## [36] "aborto5" "X._exposi" "zu" "tu" "filter_."
Existen diferentes tipo de variables en nuestro conjunto de datos, por ejemplo la edad, una variable numérica que podemos considerar contínua y para la que podemos calcular un resumen:
summary(osteoporosis$edad)
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 45.0 48.0 52.0 53.4 58.0 69.0
E incluso representar la variable gráficamente:
hist(osteoporosis$edad)
Por otro lado tenemos varaibles como grupedad, que son categóricas:
summary(osteoporosis$grupedad)
## 45 - 49 50 - 54 55 - 59 60 - 64 65 - 69 ## 378 233 176 129 84
El resultado obtenido es una tabla de frecuencias absolutas de cada categoría de la variable, además de la tabla de frecuencias absolutas podemos obtener una tabla de frecuencias relativas, porcentajes, acumuladas, etc.
n <- dim(osteoporosis)[1] attach(osteoporosis) table(grupedad)
## grupedad
## 45 - 49 50 - 54 55 - 59 60 - 64 65 - 69 ## 378 233 176 129 84
table(grupedad)/n
## grupedad
## 45 - 49 50 - 54 55 - 59 60 - 64 65 - 69 ## 0.378 0.233 0.176 0.129 0.084
[image:17.595.73.300.70.223.2] [image:17.595.58.549.615.781.2]## grupedad
## 45 - 49 50 - 54 55 - 59 60 - 64 65 - 69 ## 37.8 23.3 17.6 12.9 8.4
cumsum(table(grupedad))
## 45 - 49 50 - 54 55 - 59 60 - 64 65 - 69 ## 378 611 787 916 1000
cumsum(table(grupedad)/n)
## 45 - 49 50 - 54 55 - 59 60 - 64 65 - 69 ## 0.378 0.611 0.787 0.916 1.000
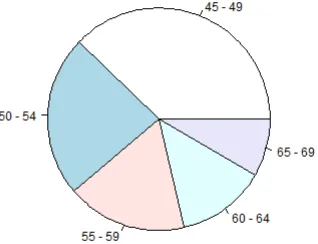
Estas tablas de frecuencias, podemos representarlas gráficamente mediante diagramas de barras o diagramas de sectores:
barplot(table(grupedad))
barplot(table(grupedad)/n)
Relaciones entre dos variables
Para determinar si existen relaciones entre dos variables, las herramientas a utilizar son diferentes si se tratan de variables cuantitativas o cualitativas, continuas o discretas.
Queremos determinar si existe relación entre dos variables cualitativas, como el grupo de edad y la clasificación asignada según la OMS, podemos construir una tabla de contingencia de ambas variables:
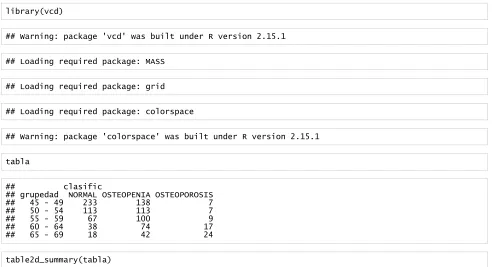
table(grupedad, clasific)
## clasific
## grupedad NORMAL OSTEOPENIA OSTEOPOROSIS
## 45 - 49 233 138 7
## 50 - 54 113 113 7
## 55 - 59 67 100 9
## 60 - 64 38 74 17
## 65 - 69 18 42 24
addmargins(table(grupedad, clasific)) ## clasific ## grupedad NORMAL OSTEOPENIA OSTEOPOROSIS Sum ## 45 - 49 233 138 7 378 ## 50 - 54 113 113 7 233 ## 55 - 59 67 100 9 176 ## 60 - 64 38 74 17 129 ## 65 - 69 18 42 24 84 ## Sum 469 467 64 1000 Esta tabla de contingencia se puede almacenar en una variable y de ella obtener las frecuencias marginales y las frecuencias condicionadas: tabla <- table(grupedad, clasific) margin.table(tabla, 1) ## grupedad ## 45 - 49 50 - 54 55 - 59 60 - 64 65 - 69 ## 378 233 176 129 84
margin.table(tabla, 2) ## clasific ## NORMAL OSTEOPENIA OSTEOPOROSIS ## 469 467 64
[image:19.595.114.273.87.209.2]## clasific
## grupedad NORMAL OSTEOPENIA OSTEOPOROSIS ## 45 - 49 0.61640 0.36508 0.01852 ## 50 - 54 0.48498 0.48498 0.03004 ## 55 - 59 0.38068 0.56818 0.05114 ## 60 - 64 0.29457 0.57364 0.13178 ## 65 - 69 0.21429 0.50000 0.28571
prop.table(tabla, 2)
## clasific
## grupedad NORMAL OSTEOPENIA OSTEOPOROSIS ## 45 - 49 0.49680 0.29550 0.10938 ## 50 - 54 0.24094 0.24197 0.10938 ## 55 - 59 0.14286 0.21413 0.14062 ## 60 - 64 0.08102 0.15846 0.26562 ## 65 - 69 0.03838 0.08994 0.37500
Pudiéndose obtener resúmenes gráficos de estas tablas:
plot(tabla)
barplot(tabla, legend = TRUE)
barplot(t(tabla), legend = TRUE, beside = TRUE)
barplot(t(tabla), legend = TRUE, beside = TRUE, col = c("blue", "red", "green"))
Para el caso de dos variables cuantitativas o continuas, podemos calcular la covarianza o el coeficiente de coorelación: \[ s_{x,y}=\frac 1 n \sum (x_i\bar{x})\cdot(y_i\bar{y}) \]
cov(peso, talla)
## [1] 16.4
cor(peso, talla)
## [1] 0.2311
plot(peso, talla)
Medidas de Asociación de Variables Cuantitativas
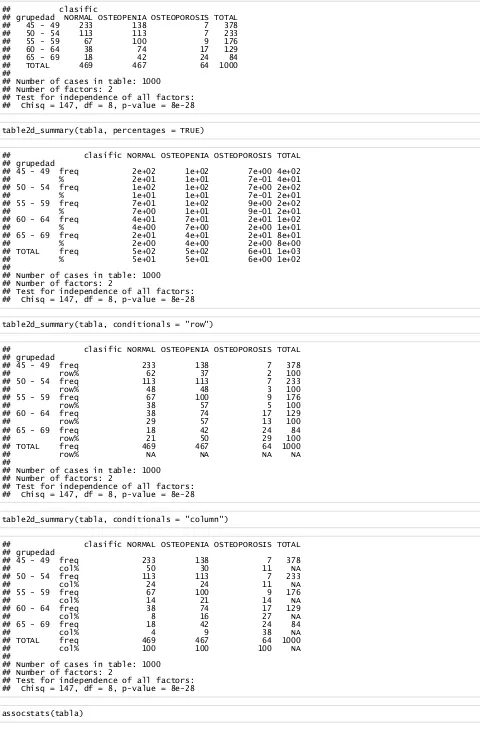
library(vcd)
## Warning: package 'vcd' was built under R version 2.15.1
## Loading required package: MASS
## Loading required package: grid
## Loading required package: colorspace
## Warning: package 'colorspace' was built under R version 2.15.1
tabla
## clasific
## grupedad NORMAL OSTEOPENIA OSTEOPOROSIS
## 45 - 49 233 138 7
## 50 - 54 113 113 7
## 55 - 59 67 100 9
## 60 - 64 38 74 17
[image:22.595.31.524.422.689.2]## 65 - 69 18 42 24
## clasific
## grupedad NORMAL OSTEOPENIA OSTEOPOROSIS TOTAL ## 45 - 49 233 138 7 378 ## 50 - 54 113 113 7 233 ## 55 - 59 67 100 9 176 ## 60 - 64 38 74 17 129 ## 65 - 69 18 42 24 84 ## TOTAL 469 467 64 1000 ##
## Number of cases in table: 1000 ## Number of factors: 2
[image:23.595.63.543.42.783.2]## Test for independence of all factors: ## Chisq = 147, df = 8, p-value = 8e-28
table2d_summary(tabla, percentages = TRUE)
## clasific NORMAL OSTEOPENIA OSTEOPOROSIS TOTAL ## grupedad ## 45 - 49 freq 2e+02 1e+02 7e+00 4e+02 ## % 2e+01 1e+01 7e-01 4e+01 ## 50 - 54 freq 1e+02 1e+02 7e+00 2e+02 ## % 1e+01 1e+01 7e-01 2e+01 ## 55 - 59 freq 7e+01 1e+02 9e+00 2e+02 ## % 7e+00 1e+01 9e-01 2e+01 ## 60 - 64 freq 4e+01 7e+01 2e+01 1e+02 ## % 4e+00 7e+00 2e+00 1e+01 ## 65 - 69 freq 2e+01 4e+01 2e+01 8e+01 ## % 2e+00 4e+00 2e+00 8e+00 ## TOTAL freq 5e+02 5e+02 6e+01 1e+03 ## % 5e+01 5e+01 6e+00 1e+02 ##
## Number of cases in table: 1000 ## Number of factors: 2
## Test for independence of all factors: ## Chisq = 147, df = 8, p-value = 8e-28
table2d_summary(tabla, conditionals = "row")
## clasific NORMAL OSTEOPENIA OSTEOPOROSIS TOTAL ## grupedad ## 45 - 49 freq 233 138 7 378 ## row% 62 37 2 100 ## 50 - 54 freq 113 113 7 233 ## row% 48 48 3 100 ## 55 - 59 freq 67 100 9 176 ## row% 38 57 5 100 ## 60 - 64 freq 38 74 17 129 ## row% 29 57 13 100 ## 65 - 69 freq 18 42 24 84 ## row% 21 50 29 100 ## TOTAL freq 469 467 64 1000 ## row% NA NA NA NA ##
## Number of cases in table: 1000 ## Number of factors: 2
## Test for independence of all factors: ## Chisq = 147, df = 8, p-value = 8e-28
table2d_summary(tabla, conditionals = "column")
## clasific NORMAL OSTEOPENIA OSTEOPOROSIS TOTAL ## grupedad ## 45 - 49 freq 233 138 7 378 ## col% 50 30 11 NA ## 50 - 54 freq 113 113 7 233 ## col% 24 24 11 NA ## 55 - 59 freq 67 100 9 176 ## col% 14 21 14 NA ## 60 - 64 freq 38 74 17 129 ## col% 8 16 27 NA ## 65 - 69 freq 18 42 24 84 ## col% 4 9 38 NA ## TOTAL freq 469 467 64 1000 ## col% 100 100 100 NA ##
## Number of cases in table: 1000 ## Number of factors: 2
## Test for independence of all factors: ## Chisq = 147, df = 8, p-value = 8e-28
## X^2 df P(> X^2) ## Likelihood Ratio 123.79 8 0 ## Pearson 146.97 8 0 ##
## Phi-Coefficient : 0.383 ## Contingency Coeff.: 0.358 ## Cramer's V : 0.271

![Grado en Comunicación Audiovisual [Cuarto Curso] Grado en Periodismo y Grado en Comunicación Audiovisual [Quinto Curso]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)