DESARROLLO DE SISTEMA MULTIPLATAFORMA (WEB Y MÓVIL) PARA LA GESTIÓN DEL NOVENO CONGRESO INTERNACIONAL DE COMPUTACIÓN -
CICOM 2019
JOHAN ARMANDO VILLAMIL MORENO 20171678024
JUAN JOSÉ MEDINA SARMIENTO 20171678050
UNIVERSIDAD DISTRITAL FRANCISCO JOSÉ DE CALDAS FACULTAD TECNOLÓGICA
INGENIERÍA TELEMÁTICA BOGOTÁ
DESARROLLO DE SISTEMA MULTIPLATAFORMA (WEB Y MÓVIL) PARA LA GESTIÓN DEL NOVENO CONGRESO INTERNACIONAL DE COMPUTACIÓN -
CICOM 2019
JOHAN ARMANDO VILLAMIL MORENO 20171678024
JUAN JOSÉ MEDINA SARMIENTO 20171678050
PROYECTO PRESENTADO COMO REQUISITO PARA OPTAR POR EL TÍTULO DE INGENIERO EN TELEMÁTICA
TUTOR
MIGUEL ANGEL LEGUIZAMON PAEZ INGENIERO DE SISTEMAS
UNIVERSIDAD DISTRITAL FRANCISCO JOSÉ DE CALDAS FACULTAD TECNOLÓGICA
INGENIERÍA TELEMÁTICA BOGOTÁ
____________________________________
Ingeniero Miguel Angel Leguizamon Paez Docente Universidad Distrital
Director de Proyecto
____________________________________
Ingeniero Luis Felipe Wanumen Silva Docente Universidad Distrital
TABLA DE CONTENIDO
INTRODUCCIÓN 8
1. FASE DE ORGANIZACIÓN, DEFINICIÓN Y ANÁLISIS 9
1.1. PLANTEAMIENTO DEL PROBLEMA 9
1.1.1. PLANTEAMIENTO DE LA SOLUCIÓN 9
1.1.2. SOLUCIÓN TECNOLÓGICA 10
1.2. OBJETIVOS 10
1.2.1. OBJETIVO GENERAL 10
1.2.2. OBJETIVOS ESPECÍFICOS 11
1.3. ALCANCE Y LIMITACIONES 11
1.3.1. ALCANCE 11
1.3.2. LIMITACIONES 11
1.4. JUSTIFICACIÓN 12
1.5. MARCO DE REFERENCIA 13
1.5.1 MARCO TEÓRICO 13
1.5.1.1 REST 13
1.5.1.2. CÓDIGOS QR 15
1.5.1.3. APLICACIONES HÍBRIDAS 17
1.5.1.4 DOCKER 20
1.5.1.6. RUBY ON RAILS 24
1.5.1.7. CICOM 26
1.5.1.8 HASH 27
1.5.2. MARCO METODOLÓGICO 29
1.5.3. FACTIBILIDAD 34
1.5.3.1. FACTIBILIDAD TÉCNICA 34
1.5.3.2. FACTIBILIDAD ECONÓMICA 34
2. DESARROLLO E IMPLEMENTACIÓN 36
2.1. DEFINICIÓN DE ROLES 36
2.2. DEFINICIÓN E IMPLEMENTACIÓN DE HISTORIAS DE USUARIO 38
2.3.1 MULTI TENANCY 55
2.3.1 DIAGRAMA ENTIDAD RELACIÓN 62
3. CONCLUSIONES 63
4. BIBLIOGRAFÍA 65
LISTA DE ILUSTRACIONES
Ilustración 1.Respuesta API REST(JSON)
Ilustración 2. Datos y nivel de corrección de errores/ versión en código QR Ilustración 3. Ejecución aplicación híbrida/Nativa
Ilustración 4. Funcionamiento Máquinas virtuales vs Contenedores con Docker Ilustración 5. Principales servicios de la cloud
Ilustración 6. Login app Ilustración 7. Login web
Ilustración 8. Programación del evento
Ilustración 9. Editar Programación del evento Ilustración 10. Detalle del evento (App)
Ilustración 11.Edición / Creación del Evento (App) Ilustración 12.Edición / Creación del Evento (App) II Ilustración 13. Certificado de Asistencia
Ilustración 14.Diploma
Ilustración 15. Adquisición del ticket (App) Ilustración 16. Adquisición del ticket (App) II Ilustración 17. Escarapela de Entrada (App)
Ilustración 18. Escanear Código QR de Escarapela Ilustración 19. Postular Ponencia
Ilustración 20. Landing Page Ilustración 21. Listado usuarios
LISTA DE TABLAS
Tabla 1. Factibilidad Económica Recursos Humanos Tabla 2. Factibilidad Económica Recursos Técnicos Tabla 3. Factibilidad Económica Costo Total
RESUMEN
Con el tiempo el Congreso Internacional de Computación CICOM ha crecido en popularidad y la necesidad de digitalizar sus procesos ha ido aumentando.
El siguiente documento presenta el desarrollo de un sistema conformado por una aplicación móvil y una aplicación web que tiene como objeto mejorar, optimizar y agilizar los procesos relacionados con la organización del CICOM. Dichas aplicaciones fueron llevadas a cabo usando tecnologías como Ruby y Ruby on Rails para el backend, Javascript y React para el frontend, Postgresql y Docker, entre otras. Por otro lado se hizo uso de la metodología ágil Scrum para la planeación y ejecución del proyecto, siguiendo el principio de iteración constante y continua.
El sistema hace uso de códigos QR como la herramienta principal para facilitar los procesos de organización del evento. Dicho códigos soportan algunas de las funcionalidades principales del sistema tales como la generación, consulta y verificación de certificados de asistencia, diplomas y escarapelas de ingreso al congreso.
Otra de las funcionalidades del sistema es la de posibilitar por medio del mismo la gestión de las ponencias, la cual incluye poder enviar una ponencia por parte de un expositor o speaker y la verificación y posterior aceptación por parte de los jurados.
INTRODUCCIÓN
Es bien conocido que la tecnología ha ido avanzando exponencialmente en los últimos años. Términos como realidad aumentada, autos autónomos e inteligencia artificial son cada vez más y más comunes en la sociedad. Parte fundamental de dichos avances tecnológicos se debe a la colaboración e intercambio de información entre personas con intereses en común que buscan crear nuevas formas de impactar positivamente el mundo. Es por ello que es sumamente importante generar espacios donde estas personas con gustos e intereses en común compartan e intercambien sus conocimientos y se promueva la generación de nuevas ideas dentro de un ambiente respeto y compañerismo.
El Congreso Internacional de Computación CICOM, es un espacio donde estudiantes, profesores, profesionales e investigadores; durante varios años han analizado la realidad tecnológica que los rodea y discutido temas relacionados a la computación y el avance tecnológico mediante conferencias, charlas, talleres y debates. El desarrollo de estas actividades junto con el intercambio de conocimientos ha dado lugar a que los participantes adquieran perspectivas distintas y generen nuevas ideas que impacten positivamente su entorno.
Si bien el CICOM ha aportado durante varios años al desarrollo e intercambio de conocimientos entre distintos actores de la comunidad tecnológica, con el tiempo también ha empezado a experimentar ciertos inconvenientes relacionados a la organización del evento. El desaprovechamiento de recurso y la descentralización de la información son solo algunos de los inconvenientes que dificultan que el evento siga cumpliento con sus objetivos misionales.
1. FASE DE ORGANIZACIÓN, DEFINICIÓN Y ANÁLISIS
1.1. PLANTEAMIENTO DEL PROBLEMA
El Congreso Internacional de computación CICOM, es un un espacio compartido de comunicación científica, debate y aprendizaje que intenta analizar, interdisciplinariamente, los últimos avances y perspectivas en el ámbito computacional desde la perspectiva del desarrollo científico, humano, educativo, tecnológico y educación de la mano de científicos, académicos y profesionales relevantes que permitirán reflexionar sobre los temas más innovadores y controvertidos de las tecnologías emergentes en la cultura digital a través de conferencias, ponencias, talleres, paneles de expertos, debates y comunicaciones orales.
CICOM se ha convertido a través de los años en un importante espacio para la colaboración y la investigación académica entre universidades promoviendo la participación de distintos actores; estudiantes de pregrado, profesionales especializados, investigadores y docentes. Con el tiempo, la popularidad del congreso ha crecido notablemente y su impacto es cada vez mayor. Hasta el momento, la organización y logística del evento han sido llevadas a cabo de manera manual por sus organizadores y por algunos voluntarios de las universidades donde ha tenido lugar, pero ha medida que el impacto y popularidad del congreso crecen también lo hacen los requerimientos en cuanto a organización.
Se identifica que existen varias desventajas al llevar a cabo la organización y logística del congreso de manera manual, desde el desaprovechamiento de recursos hasta la descentralización y falta de integridad en la información; además se identifica la necesidad de mejorar los procesos que se relacionan con el desarrollo de las actividades propias de un congreso académico.
1.1.1. PLANTEAMIENTO DE LA SOLUCIÓN
1.1.2. SOLUCIÓN TECNOLÓGICA
Para el desarrollo de la solución se implementó un sistema telemático compuesto de una aplicación móvil que brinda una interfaz gráfica y permite a los usuarios interactuar con las funcionalidades desarrolladas, una arquitectura backend que es la encargada de recepcionar las interacciones de los usuarios y procesar la información recibida; y por último un canal que permite la comunicación segura entre estos dos elementos. Se creó un API Rest en el servidor, el cual es el middleware de comunicación único para el sistema web y el sistema móvil, siendo transparente la implementación de cualquier cliente, y permitiendo una única forma de comunicación para la plataforma.
Se hizo uso de tecnologías actuales y buenas prácticas de desarrollo que dieron como resultado una solución moderna que satisface las necesidades expuestas. Se utilizó para el desarrollo móvil React Native la cual es una tecnología que permite crear una única fuente de código para diferentes plataforma (IOS, android), en cuanto al sistema web se hizo uso de React, el cual brinda una base de código muy similar al antes mencionado React Native pero con un mayor performance para la web, así el sistema se podrá visualizar con igual fluidez en diferentes browsers (Chrome, Mozilla, etc). Se utilizó Ruby on Rails para el backend debido a que permite un desarrollo ágil en corto tiempo, PostgreSQL para la base de datos ya que es una solución open source robusta que ofrece un enfoque objeto-relacional y Docker porque facilita a los programadores definir entornos de desarrollo replicables y a su vez simplifica el despliegue y la integración continua.
1.2. OBJETIVOS
1.2.1. OBJETIVO GENERAL
1.2.2. OBJETIVOS ESPECÍFICOS
➢ Realizar el levantamiento de información que permita crear los módulos del sistema.
➢ Desarrollar un sistema móvil que permita la gestión de los diferentes participantes del evento.
➢ Desarrollar un sistema web para administrar procesos realizados en el evento.
➢ Desplegar el sistema para el uso en el evento CICOM 2019.
1.3. ALCANCE Y LIMITACIONES
1.3.1. ALCANCE
El proyecto consistirá en un sistema telemático compuesto por 3 subsistemas: una aplicación móvil que permitirá a los asistentes registrarse, consultar la programación, visualizar los detalles del congreso y presentar ponencias, así como la consulta de certificados de asistencia, diplomas y escarapelas de ingreso al congreso.
Una aplicación web que será la encargada de proveer las funcionalidades de administración de la plataforma donde se podrá visualizar el listado de asistentes y ponentes, revisar y aceptar ponencias, ver y modificar los detalles del evento y crear nuevos eventos para ediciones posteriores.
Y por último un servidor backend será el encargado de proveer los APIs para nutrir las aplicaciones web y móvil.
El proyecto finaliza con el desarrollo de los 3 subsistemas anteriormente descritos y su puesta en marcha en servidores alquilados temporalmente por los ejecutores del mismo con el fin de demostrar su correcto funcionamiento.
1.3.2. LIMITACIONES
1.4. JUSTIFICACIÓN
El Congreso Internacional de Computación CICOM es un evento de talla mundial que atrae a estudiantes, profesionales, docentes e investigadores de varias partes del mundo y que genera un importante espacio para el debate, la colaboración, la investigación académica y la generación de nuevas e innovadoras ideas que giran en torno a la tecnología.
Por mucho tiempo los procesos organizativos de este evento han sido llevados a cabo de manera manual y poco práctica lo cual a conllevado a problemas como el desaprovechamiento de recursos, la descentralización y falta de integridad en la información y una demora innecesaria en todos sus procesos.
1.5. MARCO DE REFERENCIA
1.5.1 MARCO TEÓRICO 1.5.1.1 REST 1
REST es cualquier interfaz entre sistemas que use HTTP para obtener datos o generar operaciones sobre esos datos en todos los formatos posibles, como XML y JSON. Es una alternativa en auge a otros protocolos estándar de intercambio de datos como SOAP (Simple Object Access Protocol), que disponen de una gran capacidad pero también mucha complejidad. A veces es preferible una solución más sencilla de manipulación de datos como REST.
Características de REST 2
➢ Protocolo cliente/servidor sin estado: cada petición HTTP contiene toda la información necesaria para ejecutarla, lo que permite que ni cliente ni servidor necesiten recordar ningún estado previo para satisfacerla. Aunque esto es así, algunas aplicaciones HTTP incorporan memoria caché. Se configura lo que se conoce como protocolo cliente-caché-servidor sin estado: existe la posibilidad de definir algunas respuestas a peticiones HTTP concretas como cacheables, con el objetivo de que el cliente pueda ejecutar en un futuro la misma respuesta para peticiones idénticas.
➢ Interfaz uniforme: para la transferencia de datos en un sistema REST, este aplica acciones concretas (POST, GET, PUT y DELETE) sobre los recursos, siempre y cuando estén identificados con una URI. Esto facilita la existencia de una interfaz uniforme que sistematiza el proceso con la información.
➢ Sistema de capas: arquitectura jerárquica entre los componentes. Cada una de estas capas lleva a cabo una funcionalidad dentro del sistema REST.
➢ Los objetos en REST siempre se manipulan a partir de la URI . Es la URI y ningún otro elemento el identificador único de cada recurso de ese
1(Json Api, 2019) A specification for building apis in json, recuperado de https://jsonapi.org/
2(BBVA Open, 2016) API REST: qué es y cuáles son sus ventajas en el desarrollo de proyectos,
recuperado de
sistema REST. La URI nos facilita acceder a la información para su modificación o borrado, o, por ejemplo, para compartir su ubicación exacta con terceros.
➢ Uso de hipermedios: hipermedia es un término acuñado por Ted Nelson en 1965 y que es una extensión del concepto de hipertexto. Ese concepto llevado al desarrollo de páginas web es lo que permite que el usuario puede navegar por el conjunto de objetos a través de enlaces HTML. En el caso de una API REST, el concepto de hipermedia explica la capacidad de una interfaz de desarrollo de aplicaciones de proporcionar al cliente y al usuario los enlaces adecuados para ejecutar acciones concretas sobre los datos.
Ilustración 1.Respuesta API REST(JSON)
Ventajas que ofrece REST para el desarrollo 3
➢ Separación entre el cliente y el servidor: el protocolo REST separa totalmente la interfaz de usuario del servidor y el almacenamiento de datos. Eso tiene algunas ventajas cuando se hacen desarrollos. Por ejemplo, mejora la portabilidad de la interfaz a otro tipo de plataformas, aumenta la escalabilidad de los proyectos y permite que los distintos componentes de los desarrollos se puedan evolucionar de forma independiente.
➢ Visibilidad, fiabilidad y escalabilidad. La separación entre cliente y servidor tiene una ventaja evidente y es que cualquier equipo de desarrollo puede escalar el producto sin excesivos problemas. Se puede migrar a otros servidores o realizar todo tipo de cambios en la base de datos, siempre y
3 (Chakray, 2017) ¿Cuáles son las ventajas de una api rest?, recuperado de
cuando los datos de cada una de las peticiones se envíen de forma correcta. Esta separación facilita tener en servidores distintos el front y el back y eso convierte a las aplicaciones en productos más flexibles a la hora de trabajar.
➢ La API REST siempre es independiente del tipo de plataformas o lenguajes: la API REST siempre se adapta al tipo de sintaxis o plataformas con las que se estén trabajando, lo que ofrece una gran libertad a la hora de cambiar o probar nuevos entornos dentro del desarrollo. Con una API REST se pueden tener servidores PHP, Java, Python o Node.js. Lo único que es indispensable es que las respuestas a las peticiones se hagan siempre en el lenguaje de intercambio de información usado, normalmente XML o JSON.
1.5.1.2. CÓDIGOS QR
Un código QR (Quick Response Barcode) es un sistema para almacenar información en una matriz de puntos o un código de barras bidimensional creado por la compańía japonesa Denso-Wave en 1994; se caracterizan por los tres cuadrados que se encuentran en las esquinas y que permiten detectar la posición del código al lector. La sigla “QR” se derivó de la frase inglesa “Quick Response” pues el creador aspiraba a que el código permitiera que su contenido se leyera a alta velocidad.
Características 4
➢ Existen versiones desde la 1 a la 40. Por ejemplo, la versión 1 consta de una matriz de 21x21. Al incrementarse una versión, se le añaden cuatro módulos.
➢ Información del formato. Describe el nivel de corrección de errores, patrón de máscara y capacidad de almacenamiento.
➢ Corrección de errores y datos. Se incluye en esta región los datos en sí que se desean almacenar incluyendo la información referente al control y corrección de errores.
➢ Patrones requeridos (4). Se dividen en los patrones de posición (4.1) qué sirven para ayudar a la detección del código QR por parte del lector, los patrones de alineamiento (4.2) usados para la corrección de errores por parte del lector y los patrones de sincronismo (4.3) que sirven para determinar la coordenada del símbolo que se esté decodificando dentro de la matriz de datos.
Almacenamiento.
La cantidad de datos que podemos almacenar depende de tres factores: el tipo de
datos (numérico, alfanumérico…), la versión (indica la densidad del código QR)
el nivel de corrección de errores (a mayor corrección de errores, menos capacidad).
Versión o Densidad
La versión del QR está directamente relacionada con su densidad y por tanto, de la cantidad de datos que puede almacenar. Hay 40 versiones, desde la versión 1 de tamaño de (21×21) hasta la versión 40 que tiene un tamaño de (177 × 177). A mayor densidad, mayor dificultad de lectura a distancia. Veamos un ejemplo de las distintas densidades.
Corrección de errores
La corrección de errores se usa para que aún estando el código QR dañado o poco visible, pueda ser leído por el lector. A mayor nivel (mayor redundancia de datos y mayor cantidad de datos restaurables) menos capacidad de almacenamiento.
Estos son los niveles que se utilizan para categorizar el nivel de datos recuperables.
➢ Nivel L 7% de palabras de código se puede restaurar.
➢ Nivel M 15% de palabras de código se puede restaurar.
➢ Nivel Q 25% de palabras de código se puede restaurar.
➢
Nivel H 30% de palabras de código se puede restaurar.
Estructura QR. 5
Finder pattern: No es más que un patrón que ocupa 3 de las 4 esquinas para
conocer la orientación exacta del código y la forma de interpretar las cadena de bits.
Format information: Formato en que va la información, si es una URL, si es sólo
texto,
Timing pattern: Cadena de 0’s y 1’s para poder seguir la alineación de los Finder
pattern.
Data: Evidentemente son los datos en crudo.
Alignment pattern: Otro identificador extra para conocer la orientación del QR.
Versión: Versión que estamos utilizando, en ella se indica la densidad del código
QR.
1.5.1.3. APLICACIONES HÍBRIDAS 6
Lo primero que tienes que saber es que las aplicaciones móviles multiplataforma son aplicaciones que están desarrolladas en estándares web como HTML5, CSS3 y JAVA. Esto significa que realmente lo que estamos viendo y que está procesando nuestro dispositivo móvil es una aplicación web con forma de aplicación móvil nativa. Esto se consigue gracias a works cómo Ionic o PhoneGap
5 (Sozpic, S.L, 2018) Todo sobre los códigos QR, recuperado de
https://www.sozpic.com/lo-que-tienes-que-saber-sobre-los-codigos-qr/
6 (Ticon, 2018) Aplicaciones Móviles híbridas, recuperado de
que se encargan de ofrecer a los desarrolladores la funcionalidades nativas de los dispositivos como puedan ser las cámaras, los sensores etc. Por otro lado, las aplicaciones nativas son aquellas que se desarrollan en el lenguaje nativo de cada sistema operativo móvil, por ejemplo para programar en Android se usa el lenguaje JAVA, sin embargo para desarrollar aplicaciones para iOS en 2018 se utiliza el lenguaje Swift.
Una de las mayores confusiones que existen al momento para desarrollar en móvil, es pensar que si no usamos Swift o Java ( los lenguajes oficiales de iOS y Android) se trata de un desarrollo híbrido, pero no es así. La mayor diferencia entre un aplicación nativa y una híbrida no es como se programan, si no cómo se ejecutan para el usuario final.
Si requiere algo adicional para ejecutarse como un navegador o un contenedor, son híbridas. Es el caso de Apache Cordova, Ionic y Unity. Si se se ejecutan directamente en el OS, son nativas, tal como lo hace ReactNative, NativeScript y Xamarin.
Hablar de la experiencia que vamos a entregar a los usuarios contra la forma en que vamos a desarrollar el producto es el único factor que debería importar.
Creo que aún se tiene miedo y se piensa que algo que facilita el desarrollo en móviles por defecto es malo. Sin embargo, el desarrollo multiplataforma tiene algo que el nativo no tiene: el poder compartir aprendizajes entre plataformas.
Quizás, hay casos en los que no hay otra opción que usar el desarrollo nativo y los lenguajes oficiales, ya que es la única forma de acceder a cosas a muy bajo nivel y a las últimas APIs del sistema operativo. Pero a nivel de rendimiento o de la percepción de usuarios que estarán usando tu aplicación notarán muy poca diferencia contra algo nativo o creado usando algún otro lenguaje. Si no es tu caso, dale la oportunidad a otras opciones.
Facebook, Instagram, Airbnb, Uber Eats, son sólo algunas de las aplicaciones que usan millones de usuarios día con día y fueron creadas usando JavaScript como lenguaje y React Native cómo librería.
Los juegos que amas jugar en tu teléfono surgieron gracias a la facilidad que tiene Unity por usar una sola base de código y entregarla en casi cualquier OS y te aseguro que no te molesta que sea híbrido.
Al final, las limitantes de usar una opción u otra dependerá bastante de que tantos usuarios y funcionalidades va ganando tu aplicación.
Ventajas de las aplicaciones híbridas 7
➢ Gran parte del desarrollo es compartido con todas las plataformas, Android, iOS, Windows Phone etc.
➢ Menor coste de desarrollo y diseño.
➢ Mantenimiento y actualizaciones más fáciles de desarrollar. ➢ Basadas en estándares web populares.
➢ Prototipado más rápido.
Inconvenientes de las aplicaciones híbridas
➢ En ocasiones no se puede acceder a las funcionalidades del hardware del dispositivo.
➢ El diseño de la aplicación será simulado para parecer una aplicación nativa. ➢ Dependiendo de la complejidad de la app la velocidad y fluidez puede verse
perjudicada.
7 (Northware, 2017) Desarrollo de aplicaciones móviles híbridas, recuperado de
1.5.1.4 DOCKER
La palabra "DOCKER" se refiere a varias cosas. Esto incluye un proyecto de la comunidad open source; las herramientas del proyecto open source; Docker Inc., la empresa que es la principal promotora de ese proyecto; y las herramientas que la empresa admite formalmente. El hecho de que las tecnologías y la empresa compartan el mismo nombre puede ser confuso.
A continuación, le presentamos una breve explicación:
➢ "Docker", el software de TI, es una tecnología de creación de contenedores que permite la creación y el uso de contenedores de Linux.
➢ La comunidad open source Docker trabaja para mejorar estas tecnologías a fin de beneficiar a todos los usuarios de forma gratuita.
➢ La empresa, Docker Inc., desarrolla el trabajo de la comunidad Docker, lo hace más seguro y comparte estos avances con el resto de la comunidad. También respalda las tecnologías mejoradas y reforzadas para los clientes empresariales.
¿Cómo funciona Docker? 8
La tecnología Docker usa el kernel de Linux y las funciones de este, como
Cgroups y namespaces, para segregar los procesos, de modo que puedan
ejecutarse de manera independiente. El propósito de los contenedores es esta independencia: la capacidad de ejecutar varios procesos y aplicaciones por separado para hacer un mejor uso de su infraestructura y, al mismo tiempo, conservar la seguridad que tendría con sistemas separados.
Las herramientas del contenedor, como Docker, ofrecen un modelo de implementación basado en imágenes. Esto permite compartir una aplicación, o un conjunto de servicios, con todas sus dependencias en varios entornos. Docker también automatiza la implementación de la aplicación (o conjuntos combinados de procesos que constituyen una aplicación) en este entorno de contenedores.
Estas herramientas desarrolladas a partir de los contenedores de Linux, lo que hace a Docker fácil de usar y único, otorgan a los usuarios un acceso sin precedentes a las aplicaciones, la capacidad de implementar rápidamente y control sobre las versiones y su distribución.
8 (Red Hat Corporate Communications, 2018), What is docker, recuperado de
Ilustración 4. Funcionamiento Máquinas virtuales vs Contenedores con Docker
Ventajas de los contenedores Docker 9 Modularidad
El enfoque Docker para la creación de contenedores se centra en la capacidad de tomar una parte de una aplicación, para actualizarla o repararla, sin necesidad de tomar la aplicación completa. Además de este enfoque basado en los microservicios, puede compartir procesos entre varias aplicaciones de la misma forma que funciona la arquitectura orientada al servicio (SOA).
Control de versiones de imágenes y capas
Cada archivo de imagen de Docker se compone de una serie de capas. Estas capas se combinan en una sola imagen. Una capa se crea cuando la imagen cambia. Cada vez que un usuario especifica un comando, comoejecutar ocopiar, se crea una nueva capa.
Docker reutiliza estas capas para construir nuevos contenedores, lo cual hace mucho más rápido el proceso de construcción. Los cambios intermedios se comparten entre imágenes, mejorando aún más la velocidad, el tamaño y la eficiencia. El control de versiones es inherente a la creación de capas. Cada vez que se produce un cambio nuevo, básicamente, usted tiene un registro de cambios incorporado: control completo de sus imágenes de contenedor.
Restauración
Probablemente la mejor parte de la creación de capas es la capacidad de restaurar. Toda imagen tiene capas. ¿No le gusta la iteración actual de una imagen? Restáurela a la versión anterior. Esto es compatible con un enfoque de
9 (Villacampa, Óscar, 2017) Qué es docker y para qué sirve, recuperado de
desarrollo ágil y permite hacer realidad la integración e implementación continuas (CI/CD) desde una perspectiva de las herramientas.
Implementación rápida
Solía demorar días desarrollar un nuevo hardware, ejecutarlo, proveer y facilitar. Y el nivel de esfuerzo y sobrecarga era extenuante. Los contenedores basados en Docker pueden reducir el tiempo de implementación a segundos. Al crear un contenedor para cada proceso, puede compartir rápidamente los procesos similares con nuevas aplicaciones. Y, debido a que un SO no necesita iniciarse para agregar o mover un contenedor, los tiempos de implementación son sustancialmente inferiores. Además, con la velocidad de implementación, puede crear y destruir la información creada por sus contenedores sin preocupación, de forma fácil y rentable.
Por lo tanto, la tecnología Docker es un enfoque más granular y controlable, basado en microservicios, que prioriza la eficiencia.
1.5.1.5 CLOUD COMPUTING
Ilustración 5. Principales servicios de la cloud
la nube) que se coordinan mediante un software de gestión y automatización, para que los usuarios puedan acceder a ellos según lo soliciten, a través de los portales de autoservicio a los que dan soporte el escalado automático y la asignación dinámica de recursos. El cloud computing permite que los departamentos de TI no pierdan tiempo ampliando las implementaciones personalizadas al darle a las unidades empresariales el poder para solicitar e implementar sus propios recursos.
Infraestructura como servicio (IaaS) 10
La infraestructura como servicio(IaaS) es la base de todas las implementaciones de nube, e incorpora el hardware y el software, elementos básicos y básicos necesarios para implementar una nube: la red, el almacenamiento, los servidores y la virtualización. La información sobre la infraestructura de los entornos de la computación en nube (es decir, "Infraestructura como servicio"). Cada uno de estos servicios se puede escalar, aprovisionar y medir de forma automática, mientras que los usuarios de la nube deben ser todos los demás elementos del conjunto de TI (desde el sistema operativo hasta las aplicaciones).
La plataforma como servicio (PaaS)
La plataforma como servicio (PaaS) es una plataforma basada en la nube en la que se puede desarrollar e implementar software; Esto nos permite proporcionar todo el hardware y el software que el sistema operativo, el software intermedio y el entorno de tiempo de ejecución. Las plataformas de los contenedores (como las que tienen Red Hat OpenShift) son las plataformas de los contenedores y las redes de los datos. integran de forma perfecta.
Software como servicio (SaaS)
Las aplicaciones con base en la nube, o software como un servicio, se ejecutan en computadoras distantes "en la nube" que son propiedad de otros y operadas por otros, y se conectan a las computadoras de los usuarios por medio de Internet y, por lo general, un navegador web.
Las ventajas de SaaS
10 (RedHat, Openshift, 2019) Understanding Linux containers, recuperado de
➢ Puede registrarse y empezar a utilizar rápidamente las innovadoras aplicaciones de negocio
➢ Las aplicaciones y los datos se encuentran disponibles desde cualquier computadora conectada.
➢ Ningún dato se pierde si su computadora deja de funcionar, ya que los datos están en la nube
➢ Este servicio es capaz de escalar dinámicamente en función de las necesidades de uso
1.5.1.6. RUBY ON RAILS
Ruby on Rails, también conocido como RoR o Rails, es un framework de
aplicaciones web de código abierto escrito en el lenguaje de programación Ruby, siguiendo el paradigma del patrón Modelo Vista Controlador (MVC). Trata de combinar la simplicidad con la posibilidad de desarrollar aplicaciones del mundo real escribiendo menos código que con otros frameworks y con un mínimo de configuración. El lenguaje de programación Ruby permite la metaprogramación, de la cual Rails hace uso, lo que resulta en una sintaxis que muchos de sus usuarios encuentran muy legible. Rails se distribuye a través de RubyGems, que es el formato oficial de paquete y canal de distribución de bibliotecas y aplicaciones Ruby.
Los principios fundamentales de Ruby on Rails incluyen No te repitas (del inglés Don't repeat yourself, DRY) y Convención sobre Configuración.
Modelo Vista Controlador 11
Ruby on Rails es un marco de referencia popular, abierto y orientado al objeto usado por muchos programadores y proveedores de aplicaciones. También es basado en una aproximación de controlador de vista de modelo (MVC).
Los mapas de modelos a las bases de datos y funcionalidad para un objeto en la aplicación, tales como los usuarios. Rails provee una convención estándar para el nombramiento y las estructuras del directorio de archivos, lo que simplifica la programación para también provee soluciones automatizadas para construir la funcionalidad, llamado el andamiaje. También asegura un ambiente común para desarrolladores en el que trabajar juntos y beneficiarse de los esfuerzos del otro.
La Optimización para la felicidad del programador con la Costumbre sobre la Configuración es la manera en la que nos manejamos.
El Controlador maneja las peticiones primariamente entre el usuario y el servidor, recolectando datos de modelos y retornando al usuario a través de archivos de Vista.
Las Vistas son archivos HTML esencialmente programáticos que se despliegan en la página con los datos dinámicos.
La guía de convenciones de Rails en la que los desarrolladores de apoyan en enrutamiento RESTful. Las acciones del control son generalmente; nuevo, crear, editar, actualizar, destruir, mostrar, índex, etc. Estos son los que permiten que los usuarios y el sistema interactúen con varias características.
Colectivamente, las características MVC de Rails son llamadas el Paquete de Acción, i.e ActionController, ActionView, y ActiveRecord, el último para interactuar con la base de datos.
11 (Reifman, Jeff, 2017) MVC Ruby on Rails, recuperado de
1.5.1.7. CICOM
El Noveno Congreso Internacional de Computación CICOM 2019 tiene como tema central: Inteligencia Artificial como herramienta de evolución tecnológica del siglo XXI
Inteligencia Artificial. (IA)
Cuando se habla de inteligencia artificial, surgen tres preguntas básicas, según la fundación AQUAE : Que es? Que hace? y Como lo hace?.
Existen un número muy grande definiciones, se puede decir que cada autor desarrolla la suya propia.
De una forma muy simple se puede decir que la Inteligencia Artificial es la capacidad que tienen las máquinas para realizar procesos que requieren inteligencia.
Que hace? A esta pregunta la Inteligencia Artificial es la rama de la ciencia que se encarga de crear programas para máquinas que imitan el comportamiento y la comprensión humana. Y que son capaces de aprender, reconocer y pensar por sí mismas.
Como lo hace? Construyendo algoritmos que imitan el comportamiento y el razonamiento humano.
Técnicas utilizadas en la inteligencia Artificial: Dentro de las técnicas utilizadas por la IA, existen:
1. Sistemas Basados en el conocimiento 2. Visión por computador
3. Procesamiento de Voz y lenguaje natural 4. Lógica difusa
5. Redes neuronales Artificiales 6. Computación evolutiva
9. Aprendizaje Automático
10. Resolución de problemas mediante heurísticas 11. Algoritmos de enjambres.
1.5.1.8 HASH 12
Una función hash es método para generar claves o llaves que representen de manera unívoca a un documento o conjunto de datos. Es una operación matemática que se realiza sobre este conjunto de datos de cualquier longitud, y su salida es una huella digital, de tamaño fijo e independiente de la dimensión del documento original. El contenido es ilegible.
Es posible que existan huellas digitales iguales para objetos diferentes, porque una función hash tiene un número de bits definido. En el caso del SHA-1, tiene 160 bits, y los posibles objetos a resumir no tienen un tamaño límite. A partir de un hash o huella digital, no podemos recuperar el conjunto de datos originales. Los más conocidos son el MD5 y el SHA-1, aunque actualmente no son seguros utilizarlos ya que se han encontrado colisiones. Cifrar una huella digital se conoce como firma digital.
Requisitos que deben cumplir las funciones hash:
➢ Imposibilidad de obtener el texto original a partir de la huella digital.
➢ Imposibilidad de encontrar un conjunto de datos diferentes que tengan la misma huella digital (aunque como hemos visto anteriormente es posible que este requisito no se cumpla).
➢ Poder transformar un texto de longitud variable en una huella de tamaño fijo (como el SHA-1 que es de 160 bits).
➢ Facilidad de empleo e implementación.
12 (De luz, Sergio, 2010) Criptografía: Algoritmos de autenticación (hash), recuperado de
Algoritmos de encriptación 13
MD5
Es una función hash de 128 bits. Como todas las funciones hash, toma unos determinados tamaños a la entrada, y salen con una longitud fija (128bits). El algoritmo MD5 no sirve para cifrar un mensaje. La información original no se puede recuperar, ya que está específicamente diseñado para que a partir de una huella hash no se pueda recuperar la información. Actualmente esta función hash no es segura utilizarla, nunca se debe usar.
SHA-1
Es parecido al famoso MD5, pero tiene un bloque de 160 bits en lugar de los 128bits del MD5. La función de compresión es más compleja que la función de MD5, por tanto, SHA-1 es más lento que MD5 porque el número de pasos son de 80 (64 en MD5) y porque tiene mayor longitud que MD5 (160bits contra 128bits). SHA-1 es más robusto y seguro que MD5, pero ya se han encontrado colisiones, por tanto, actualmente esta función hash no es segura utilizarla, nunca se debe usar.
SHA-2
Las principales diferencias con SHA1 radica en en su diseño y que los rangos de salida han sido incrementados. Dentro de SHA-2 encontramos varios tipos, el SHA-224, SHA-256, SHA-384 y SHA-512. El más seguro, es el que mayor salida de bits tiene, el SHA-512, que tiene 80 rondas (pasos), como el SHA-1 pero se diferencia de éste en:
➢ Tamaño de salida 512 por los 160 de SHA-1.
➢ Tamaño del bloque, tamaño de la palabra y tamaño interno que es el doble que SHA-1.
Como ocurre con todos los cifrados y hash, cuanto más seguro, más lento su procesamiento y uso, debemos encontrar un equilibrio entre seguridad y velocidad.
1.5.2. MARCO METODOLÓGICO
Para desarrollar este proyecto se hará uso de una metodología de desarrollo agile denominada SCRUM, la cual permite entregas constantes y de forma iterable, permitiendo una mejora constante del producto, a su vez constantemente realiza retroalimentación del producto para a medida que se avanza en la construcción del dar entregas de mayor calidad y siempre priorizando las historias de usuario que son las funcionalidades que dan valor a nuestra aplicación. 14
Qué es SCRUM?
Scrum es un proceso en el que se aplican de manera regular un conjunto de buenas prácticas para trabajar colaborativamente, en equipo, y obtener el mejor resultado posible de un proyecto. Estas prácticas se apoyan unas a otras y su selección tiene origen en un estudio de la manera de trabajar de equipos altamente productivos.
En Scrum se realizan entregas parciales y regulares del producto final, priorizadas por el beneficio que aportan al receptor del proyecto. Por ello, Scrum está especialmente indicado para proyectos en entornos complejos, donde se necesita obtener resultados pronto, donde los requisitos son cambiantes o poco definidos, donde la innovación, la competitividad, la flexibilidad y la productividad son fundamentales. 15
Fundamentos de SCRUM 16
➢ El desarrollo incremental de los requisitos del proyecto en bloques temporales cortos y fijos ( iteraciones de un mes natural y hasta de dos semanas, si así se necesita).
➢ La priorización de los requisitos por valor para el cliente y coste de desarrollo en cada iteración.
14 (Proyectos Agiles, 2018) Qué es scrum, recuperado de https://proyectosagiles.org/que-es-scrum/
15 (Francia, Joel, 2017) Qué es scrum, recuperado de
https://www.scrum.org/resources/blog/que-es-scrum
16 (Palacios, Jeronimo, 2019) Guía fundamental de Scrum, recuperado de
➢ El control empírico del proyecto. Por un lado, al final de cada iteración se demuestra al cliente el resultado real obtenido, de manera que pueda tomar las decisiones necesarias en función de lo que observa y del contexto del proyecto en ese momento. Por otro lado, el equipo se sincroniza diariamente y realiza las adaptaciones necesarias.
➢ La potenciación del equipo, que se compromete a entregar unos requisitos y para ello se le otorga la autoridad necesaria para organizar su trabajo. ➢ La sistematización de la colaboración y la comunicación tanto entre el
equipo y como con el cliente.
➢ El timeboxing de las actividades del proyecto, para ayudar a la toma de decisiones y conseguir resultados.
Fases de SCRUM
El proceso
En Scrum un proyecto se ejecuta en bloques temporales cortos y fijos (iteraciones que normalmente son de 2 semanas, aunque en algunos equipos son de 3 y hasta 4 semanas, límite máximo de feedback y reflexión). Cada iteración tiene que proporcionar un resultado completo, un incremento de producto final que sea susceptible de ser entregado con el mínimo esfuerzo al cliente cuando lo solicite.
El proceso parte de la lista de objetivos/requisitos priorizada del producto, que actúa como plan del proyecto. En esta lista el cliente prioriza los objetivos balanceando el valor que le aportan respecto a su coste y quedan repartidos en iteraciones y entregas.
Las actividades que se llevan a cabo en Scrum son las siguientes:
Planificación de la iteración 17
El primer día de la iteración se realiza la reunión de planificación de la iteración. Tiene dos partes:
17 (SOFTENG, 2017) Metodología Scrum para desarrollo de software aplicaciones complejas,
recuperado de
➢ Selección de requisitos (4 horas máximo). El cliente presenta al equipo la lista de requisitos priorizada del producto o proyecto. El equipo pregunta al cliente las dudas que surgen y selecciona los requisitos más prioritarios que se compromete a completar en la iteración, de manera que puedan ser entregados si el cliente lo solicita.
➢ Planificación de la iteración (4 horas máximo). El equipo elabora la lista de tareas de la iteración necesarias para desarrollar los requisitos a que se ha comprometido. La estimación de esfuerzo se hace de manera conjunta y los miembros del equipo se auto asignan las tareas.
Ejecución de la iteración
Cada día el equipo realiza una reunión de sincronización (15 minutos máximos). Cada miembro del equipo inspecciona el trabajo que el resto está realizando (dependencias entre tareas, progreso hacia el objetivo de la iteración, obstáculos que pueden impedir este objetivo) para poder hacer las adaptaciones necesarias que permitan cumplir con el compromiso adquirido.
En la reunión cada miembro del equipo responde a tres preguntas:
➢ ¿Qué he hecho desde la última reunión de sincronización? ➢ ¿Qué voy a hacer a partir de este momento?
➢ ¿Qué impedimentos tengo o voy a tener?
Durante la iteración el Facilitador (Scrum Master) se encarga de que el equipo pueda cumplir con su compromiso y de que no se merme su productividad.
➢ Elimina los obstáculos que el equipo no puede resolver por sí mismo.
➢ Protege al equipo de interrupciones externas que puedan afectar su compromiso o su productividad.
Fuente:Ilustración fases de desarrollo de scrum [Imagen] Tomado de https://static.platzi.com/blog/uploads/2015/07/scrum4.jpg
Inspección y adaptación 18
El último día de la iteración se realiza la reunión de revisión de la iteración. Tiene dos partes:
➢ Demostración (1,5 horas máximo). El equipo presenta al cliente los requisitos completados en la iteración, en forma de incremento de producto preparado para ser entregado con el mínimo esfuerzo. En función de los resultados mostrados y de los cambios que haya habido en el contexto del proyecto, el cliente realiza las adaptaciones necesarias de manera objetiva, ya desde la primera iteración, re planificando el proyecto.
➢ Retrospectiva (1,5 horas máximo). El equipo analiza cómo ha sido su manera de trabajar y cuáles son los problemas que podrían impedirle
18 (Esan, 2018) Las etapas del scrum: ¿cómo aplicar este método?, recuperado de
progresar adecuadamente, mejorando de manera continua su productividad. El Facilitador se encargará de ir eliminando los obstáculos identificados.
Roles 19
En Scrum, el equipo se focaliza en construir software de calidad. La gestión de un proyecto Scrum se centra en definir cuáles son las características que debe tener el producto a construir (qué construir, qué no y en qué orden) y en vencer cualquier obstáculo que pudiera entorpecer la tarea del equipo de desarrollo.
El equipo Scrum está formado por los siguientes roles:
➢ Scrum master: Persona que lidera al equipo guiándolo para que cumpla las reglas y procesos de la metodología. Gestiona la reducción de impedimentos del proyecto y trabaja con el Product Owner para maximizar el ROI.
➢ Product owner (PO): Representante de los accionistas y clientes que usan el software. Se focaliza en la parte de negocio y él es responsable del ROI del proyecto (entregar un valor superior al dinero invertido). Traslada la visión del proyecto al equipo, formaliza las prestaciones en historias a incorporar en el Product Backlog y las prioriza de forma regular.
➢ Team: Grupo de profesionales con los conocimientos técnicos necesarios y que desarrollan el proyecto de manera conjunta llevando a cabo las historias a las que se comprometen al inicio de cada sprint.
19 (Softeng, 2017) Proceso y Roles de Scrum, recuperado de
1.5.3. FACTIBILIDAD
1.5.3.1. FACTIBILIDAD TÉCNICA
El backend del sistema será alojado en un servidor provisto por Digital Ocean con sistema operativo Ubuntu 18.04 LTS, dicho servidor permite instalar docker y docker-compose que son herramientas obligatorias para llevar a cabo el correcto despliegue de los servicios. Se implementará una base de datos Postgresql tambien provista por Digital Ocean. La aplicación será desarrollada utilizando Visual Studio Code y posteriormente será alojada en la respectiva tienda de aplicaciones. Para el desarrollo del sistema se utilizarán dos laptop MacBook pro: una con sistema operativo MacOs Mojave, procesador Intel Core i5 de 2.7 GHz, disco duro sólido de 256 GB y memoria RAM de 8Gb; la otra con sistema operativo MacOs High Sierra, procesador Intel Core i7 de 2.8 GHz, disco duro sólido de 254 GB y memoria RAM de 8 GB.
1.5.3.2. FACTIBILIDAD ECONÓMICA
En las tablas que se presentarán a continuación se describe la factibilidad económica, identificando los costos de hardware, software, servidores y recursos humanos necesarios para la realización del proyecto.
Tipo Descripción Valor-Hora Cantidad Total
Tutor
Asesorías para la realización del proyecto,
referente a la metodología.
$ 40.000 50 $ 2.000.000
Desarrolladores
Dos programadores que realicen la
implementación de la solución. $ 25.000 8 horas semanale s $ 6.400.000
Total Recursos Humanos $ 8.400.000
Recurso Descripción Valor Unitario
Cantidad Total
Computadores
Equipos usados para el desarrollo del
sistema.
$ 2.700.000 2 $ 5.400.000
Servidores
Uso de servidores para implementar la
solución (2 Producción y 2
Staging)
$ 230.000 5 meses 4 x $ 4.600.000
Publicación App Store
Licencia para
publicación $ 180.000 1 $ 180.000
Licencia Android Studio
Licencia para utilización y publicación
$ 75.000 1 $ 75.000
Total Recursos Técnicos $ 10.255.000
Tabla 2. Factibilidad Económica Recursos Técnicos
Recurso Valor
Total Recursos Humanos $ 8.400.000
Total Recursos Técnicos $ 10.255.000
Total Otros recursos $ 200.000
Costos imprevistos (10%) $ 1.865.500
TOTAL COSTO $20.520.500
2. DESARROLLO E IMPLEMENTACIÓN
2.1. DEFINICIÓN DE ROLES
Con el fin de que la solución brinde un experiencia personalizada y eficiente se desarrolló un sistema de roles de usuario conformado por 5 roles cuyas características son las siguientes:
DEFINICIÓN DE ROLES DE USUARIO
ROL DEFINICIÓN ACCIONES
assistant Cualquier persona que vaya al evento se considera un assistant (asistente).
● Crear cuenta ● Iniciar Sesión
● Visualizar detalles de evento
● Consultar la programación
● Consultar certificado de asistencia
● Consultar diploma ● Consultar escarapela de
ingreso speaker Son los participantes que
presentan una ponencia.
● Crear cuenta ● Iniciar Sesión
● Visualizar detalles de evento
● Consultar la programación
● Consultar certificado de asistencia
● Consultar diploma ● Consultar escarapela de
ingreso
● Presentar ponencia judge Personas encargadas de
evaluar las ponencias presentadas y decidir si las aceptan o no.
● Iniciar Sesión ● Listar ponencias ● Revisar y aceptar
admin El la persona encargada de administrar el sistema. Debe hacer parte del equipo organizador del CICOM.
● Iniciar Sesión
● Visualizar listado de asistentes y ponentes ● Revisar y aceptar
ponencias
● Ver y modificar detalles del evento
● Crear nuevas ediciones del evento
staff Equipo organizador del CICOM que se hace cargo de las operaciones del evento.
● Iniciar Sesión
● Verificar escarapelas de ingreso de los
asistentes
2.2. DEFINICIÓN E IMPLEMENTACIÓN DE HISTORIAS DE USUARIO
A continuación se listan las historias de usuario necesarias para llevar a cabo el sistema. Para su definición se siguió la metodología SCRUM y para la estimación se hizo uso de la técnica de de poker con la variante de sucesión de Fibonacci.20
HISTORIA DE USUARIO No. 1
Prioridad Media Nombre
Estimación 8
Como asistente / speaker quiero registrarme Rol assistant/
speaker
Criterios de aceptación
● Dado que el usuario ingrese datos válidos para su registro, se creará una cuenta nueva
Tabla 5. Historia de usuario No. 1
Ilustración 6. Login app
20 (Scrummanager, 2019). Estimación de póquer - Scrum Manager BoK, recuperado de
HISTORIA DE USUARIO No. 2
Prioridad Media Nombre
Estimación 13
Como asistente / speaker / judge / staff / admin quiero poder iniciar sesión en la plataforma Rol assistant/
speaker/ judge/ admin/
staff
Criterios de aceptación
● Dado que el usuario ingrese datos válidos para su registro, se creará una cuenta nueva
● Cuando el usuario digite su email y contraseña correctamente, podrá iniciar sesión
Tabla 6. Historia de usuario No. 2
HISTORIA DE USUARIO No 3
Prioridad Media Nombre
Estimación 8
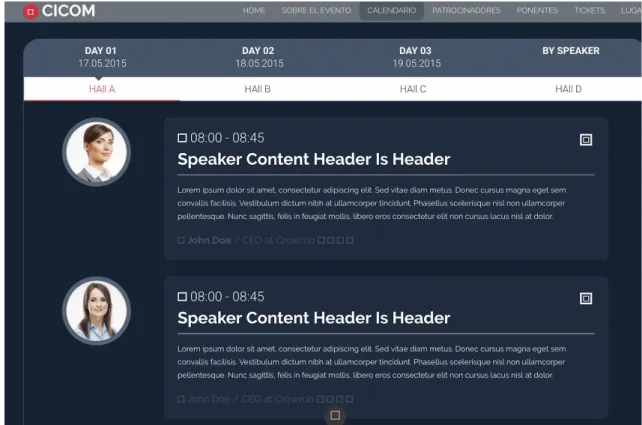
Como asistente / speaker quiero poder ver la programación del evento
Rol assistant/ speaker
Criterios de aceptación
● Dado que el usuario ingrese a la página principal podrá ver la
programación del evento. (Conferencias, conferencistas, fecha y hora, título de las conferencias)
Tabla 7. Historia de usuario No. 3
HISTORIA DE USUARIO No 4
Prioridad Media Nombre
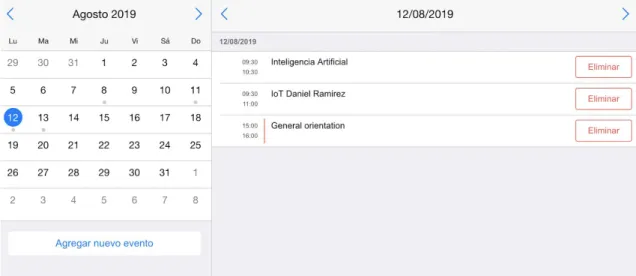
Estimación 5 Cómo admin quiero poder editar la programación del evento
Rol admin
Criterios de aceptación
● Dado que exista un evento activo el admin debe ser capaz de poder actualizar la programación
Tabla 8. Historia de usuario No. 4
HISTORIA DE USUARIO No 5
Prioridad Media Nombre
Estimación 5
Como asistente/speaker quiero visualizar detalles del evento
Rol assistant/ speaker
Criterios de aceptación
● Dado que exista un evento activo los asistentes y speakers podrán ver los detalles del evento (Fecha, lugar, descripción, organizadores)
Tabla 9. Historia de usuario No. 5
HISTORIA DE USUARIO No 6
Prioridad Media Nombre
Estimación 5 Cómo admin quiero poder editar detalles del evento
Rol admin
Criterios de aceptación
● Dado que el usuario administrador haya iniciado sesión podrá editar los detalles del evento.
Tabla 10. Historia de usuario No. 6
HISTORIA DE USUARIO No 7
Prioridad Media Nombre
Estimación 13 Cómo asistente quiero consultar mi certificado de asistencia luego del evento
Rol asistente
Criterios de aceptación
● Dado el usuario asistió al evento y que el evento ya finalizó, podrá consultar su certificado de asistencia mediante la aplicación web
Tabla 11. Historia de usuario No. 7
HISTORIA DE USUARIO No 8
Prioridad Media Nombre
Estimación 13 Cómo speaker quiero consultar mi diploma luego del evento
Rol speaker
Criterios de aceptación
● Dado el usuario es speaker, presentó una ponencia que fue aceptada y que el evento ya finalizó, podrá consultar su diploma mediante la aplicación web
Tabla 12. Historia de usuario No. 8
HISTORIA DE USUARIO No 9
Prioridad Media Nombre
Estimación 13
Como asistente/speaker quiero adquirir la entrada al evento
Rol asistente / speaker
Criterios de aceptación
● Dado que el usuario ya se registró e inició sesión, podrá adquirir la entrada al evento y se generará una escarapela con un código QR
Tabla 13. Historia de usuario No. 9
HISTORIA DE USUARIO No 10
Prioridad Media Nombre
Estimación 13
Como asistente/speaker quiero visualizar la escarapela QR despues de comprar la entrada Rol asistente /
speaker
Criterios de aceptación
● Dado que el usuario ya inició sesión y adquirió la entrada al evento, podrá visualizarla en un submenú de la aplicación móvil.
Tabla 14. Historia de usuario No. 10
HISTORIA DE USUARIO No 11
Prioridad Media Nombre
Estimación 13 Como staff quiero poder escanear escarapelas QR
Rol staff
Criterios de aceptación
● Dado que el usuario inició sesión en la aplicación móvil y tiene rol de staff, podrá escanear las escarapelas con códigos QR para constatar su validez y dar entrada a los asistentes.
Tabla 15. Historia de usuario No. 11
HISTORIA DE USUARIO No 12
Prioridad Media Nombre
Estimación 8 Como speaker quiero poder postular una ponencia para el evento
Rol speaker
Criterios de aceptación
● Dado que el usuario inició sesión en la aplicación móvil y podrá diligenciar un formulario para presentar una ponencia.
Tabla 16. Historia de usuario No. 12
Ilustración 20. Landing Page
HISTORIA DE USUARIO No 13
Prioridad Media Nombre
Estimación 8
Como jurado/admin quiero poder revisar y actualizar el estado de la ponencia Rol judge /
admin
Criterios de aceptación
● Dado que el usuario inició sesión en la aplicación web y tiene rol judge o admin, podrá revisar las ponencias presentadas, aceptarlas o rechazarlas y agregar comentarios.
HISTORIA DE USUARIO No 14
Prioridad Media Nombre
Estimación 5 Cómo admin quiero poder ver los asistentes y speakers que participaron en un evento
Rol admin
Criterios de aceptación
● Dado que el usuario inició sesión en la aplicación web y tiene rol admin, podrá ver un listado con todos los asistentes y speakers que participaron en el evento.
Tabla 18. Historia de usuario No. 14
2.3. MODELADO DE LA BASE DE DATOS
El presente proyecto tiene como objetivo brindar una solución que permita ser utilizada no solo en el Noveno Congreso Internacional de Computación CICOM 2019, si no que también sirva en versiones posteriores del evento. Para ello se desarrolló el modelado relacional de manera clásica pero adicionalmente se implementó un enfoque multitenant 21 adecuandolo a las necesidades del proyecto.
2.3.1 MULTI TENANCY
Se refiere a un principio de arquitectura de software, donde un sistema comparte varios clientes, es decir que trabaja sobre una misma instancia de software, la cual se ejecuta desde un servidor, a este tipo de arquitectura se la llama arquitectura multi propietario o multiusuario.
Otra forma de conceptualizar Multi– Tenancy se refiere a la habilidad para ubicar varios clientes dentro de una única instancia del software que se ejecuta en un servidor. En un entorno Multi-Tenant, todos los clientes y sus usuarios consumen el servicio desde la misma plataforma tecnológica, desde el modelo de datos, servidores y las capas de base de datos.
Con una arquitectura Multi-Tenancy, una aplicación de software está diseñada para particionar sus datos y la configuración de manera que cada cliente trabaje con una instancia de la aplicación virtual personalizada.
Multi-Tenancy hace referencia al modo de operación del software en varias instancias independientes de uno o múltiples aplicaciones las cuales están operando en un entorno compartido. Los casos (Tenancy) están aislados lógicamente, pero físicamente integradas. 22
A continuación se puede apreciar las diferencias entre una arquitectura clásica (tenant simple) y una multi tenant:
21 (Gartner,2018) Multitenancy, recuperado de https://www.gartner.com/it-glossary/multitenancy 22 (División Consultoría de EvaluandoCloud, 2017) Qué es Multi-Tenancy, recuperado de
Ilustración 22. Arquitectura Tenant Simple vs Multi Tenant
En el caso de la solución implementada para el CICOM, se definió un modelado de base de datos para todos los eventos y cada versión del evento que se haga, será tomando como un nuevo “usuario” de la arquitectura. De esta manera se puede ofrecer la posibilidad de soportar la organización de próximos eventos con un mismo sistema y sin la necesidad de configuraciones adicionales. A partir de ahora al hablar de múltiples usuarios en la arquitectura multi tenant se referirá a una versiones distintas del CICOM.
Existen varias opciones para brindar soluciones multi tenancy, todo depende de las necesidades del proyecto y de las herramientas y tecnologías que se deseen utilizar. 23 24
23 (Mantzios, Achilleas, 2018) Multitenancy Options for PostgreSQL, recuperado de
https://severalnines.com/blog/multitenancy-options-postgresql
24 (Bigg, Ryan, 2018) Multitenancy with Rails - 2nd edition, recuperado de
A nivel de base de datos postgres brinda la posibilidad de crear una solución multi tenancy de 3 enfoques o maneras distintas : 25
● Bases De Datos Por Separado
En esta arquitectura los datos de cada cliente se almacenan en bases de datos separadas. Las bases de datos pueden estar en el mismo servidor o pueden ser divididas a través de servidores de bases de datos múltiples. Este enfoque proporciona aislamiento máximo de datos de clientes.
Recursos informáticos y código de aplicación generalmente son compartidos entre todos los Clientes en un servidor, pero cada Cliente tiene su propio conjunto de datos que sigue siendo lógicamente aislada a partir de datos que pertenece a todos los otros Clientes. Metadatos asociados a cada base de datos con el cliente correcto, y la seguridad de base de datos impide cualquier cliente de forma accidental o malintencionada acceder a los datos a otros Clientes.
Dar a cada Cliente su propia base de datos hace que sea fácil de extender la aplicación del modelo de datos para satisfacer las necesidades de los clientes individuales, y la restauración de datos de un cliente de copias de seguridad en caso de un fracaso es un procedimiento relativamente simple. Por desgracia, este enfoque tiende a conducir a mayores costos de mantenimiento del equipo y realizar copias de seguridad de clientes. Los costos de hardware son también más altos ya que están bajo distintos criterios, como el número de clientes que pueden ser alojados en un servidor de base de datos.
Al hacer uso de este enfoque se deben tener en cuenta las siguientes consideraciones:
- El tiempo de desarrollo: El modelo de servidor independiente requiere más tiempo de desarrollo mínimo en comparación con una solución de arquitectura estándar.
- Costos de hardware: Esta es la arquitectura más cara, ya que cada cliente requiere su propio servidor de hardware. Además, cualquier prueba de ejecución a lo largo se sumará al costo.
25 (Macias, Nora, 2016) Arquitecturas Multi-Tenant, recuperado de
- Aplicación y el rendimiento de base de datos: Esta arquitectura tiene el rendimiento más predecible, porque el rendimiento de un cliente no se ve afectada por cualquier otro cliente.
- Seguridad: Debido al total aislamiento de otros clientes, los datos de cada cliente pueden ser muy bien resguardados
- Requisitos de personalización: Cada cliente tiene su propia base de datos, por lo que es más fácil de personalizar.
- El número de clientes: Este enfoque hace que sea mucho más difícil de manejar un gran número de clientes.
Fuente: Z. Artem, Single Database for Single Tenant [Imagen]. Recuperado de
https://rubygarage.org/blog/three-database-architectures-for-a-multi-tenant-rails-based-saas-app
● Bases De Datos Compartidas, Esquemas Separados
Consideraciones del enfoque:
- Aplicación y el rendimiento de base de datos: El rendimiento de un cliente puede verse afectada por las actividades de los clientes que comparten el servidor.
- Seguridad: El DBMS debe asegurar que su estructura de permisos es tal que cada cliente de datos sólo está disponible para usuarios autorizados. Además, la aplicación debe hacer uso de cualquiera de los comandos para seleccionar o restringir el esquema que se accede por un usuario.
- Requisitos de personalización: Cada cliente tiene su propio esquema, así que es fácil de personalizar para las diferentes necesidades de cada cliente.
- El número de clientes: Este modelo es capaz de manejar más clientes que los modelos de bases de datos separadas, pero todavía requieren una cierta cantidad de la administración. La migración de los clientes a una base de datos independiente puede ser un desafío en función de las utilidades que se ofrecen por el DBMS.
Fuente: Z. Artem, Separate Schema for Each Tenant [Imagen]. Recuperado de
https://rubygarage.org/blog/three-database-architectures-for-a-multi-tenant-rails-based-saas-app
Aquí sólo existe una única base de datos y un esquema único. Cada Tabla debe de referirse a un id de cliente.
En este enfoque, todos los clientes comparten el mismo conjunto de tablas, y un ID de cada cliente asociados con los registros de su propiedad
De los tres enfoques que se explican el enfoque del esquema compartido, tiene los más bajos costos de hardware y de copia de seguridad, ya que le permite servir al mayor número de clientes por base de datos del servidor. Sin embargo, debido a múltiples clientes comparten la misma base de datos las tablas, este enfoque puede incurrir en esfuerzo de desarrollo adicional en el ámbito de la seguridad, para garantizar que los clientes no pueden acceder a los datos de otros clientes, incluso en caso de errores inesperados o ataques.
El procedimiento para restaurar los datos de un cliente es similar a la del enfoque común de esquema, con la complicación adicional de que las filas individuales en la base de datos de producción se debe eliminar y luego reinsertados de la base de datos temporal. Si hay un número muy grande de filas en las tablas afectadas, esto puede afectar el rendimiento notablemente para todos los clientes que utilizan la base de datos.
El enfoque de esquema compartido es apropiado cuando es importante que la solicitud sea capaz de servir a un gran número de clientes con un pequeño número de servidores y clientes potenciales están dispuestos a entregar los datos de aislamiento a cambio de los costos más bajos que este enfoque permite.
Consideraciones:
- Aplicación y rendimiento de la base de datos: El rendimiento de un cliente puede verse afectada por las actividades de los otros clientes. El rendimiento de las consultas tendrán que ser examinados cuidadosamente para garantizar los índices adecuados existen.