Herramientas de minería de textos e inteligencia artificial aplicadas a la gestión de la información científico técnica
94
0
0
Texto completo
(2) Dedicatoria. A mi familia.
(3) Agradecimientos. Agradezco a todas las personas que han contribuido al desarrollo de este trabajo: A mi familia por todo el apoyo que me han brindado durante todos estos años. A la Dra. Lecicia Arco García por su paciencia, dedicación y guía. Al grupo de Ingienería de Software de CEI-UCLV en especial a: Dra. Gheisa Fereira por su visión y guía. Ing. Lianny Ofarrill Fernandez y Msc. Juliet Suarez Ferreira por sus sugerencias. A todos mis colegas por ayudarme, especialmente a los colegas y amigos del grupo de Inteligencia Artificial del CEI-UCLV. A los colegas del Joven Club de Esperanza, en especial al Lic. Jaylo Escariz Llanes.. A todos mis amigos….
(4) Resumen. Resumen La cantidad de información está continuamente creciendo; pero la información en sí misma tiene pocas ventajas, su sistematización, incorporación y utilización son los elementos que aportan su valor añadido: el conocimiento. En el laboratorio de Inteligencia Artificial del CEIUCLV se han desarrollado los sistemas SATEX y GARLucene que si bien permiten gestionar información siguiendo el esquema de indexado, recuperación, agrupamiento y valoración de los grupos textuales obtenidos, no brindan un entorno de trabajo amigable que permita la introducción y generalización de los mismos, ya que no garantizan una interacción efectiva entre usuarios y grandes repositorios de información. Por otro lado, en el CEI-UCLV existe un gran número de artículos científicos y documentos relacionados con diversos temas de investigación, y se hace tedioso para los investigadores descubrir conocimiento que requieren para encausar una investigación a partir de estos grandes volúmenes textuales. De ahí que el objetivo de esta investigación consiste en desarrollar una aplicación que permita gestionar de forma efectiva la información científico-técnica disponible en grandes repositorios de información. Los principales resultados alcanzados son: un conjunto de herramientas que permiten la gestión y recuperación de información científico-técnica, el preprocesamiento y representación de los corpus, y el agrupamiento y valoración de los grupos textuales, y una aplicación web que utiliza el conjunto de herramientas desarrolladas y permita el indexado, recuperación y agrupamiento de documentos científicos, así como etiquetar y evaluar los grupos obtenidos, garantizando una adecuada conexión con los repositorios de información científico-técnica del CEI-UCLV..
(5) Abstract. Abstract The amount of information is continually growing, but the information itself has few advantages, its systematization, incorporation and usage are the elements that bring its added value: knowledge. The Artificial Intelligence Laboratory from the CEI-UCLV has developed the systems GARLucene and SATEX, which allow to manage the information following the scheme of indexing, retrieval, clustering and textual assessment of the obtained groups, but these systems do not provide a friendly environment for the introduction and generalization of the mentioned groups, because they do not guarantee an effective interaction between users and large data repositories. On the other hand, the CEI-UCLV has a huge number of scientific papers and documents related to different research topics, and it becomes tedious for the researchers to discover the knowledge they need from this high-volume text. Hence, the objective of this research is to develop an application that can effectively manage the scientific and technical information available in large repositories of information. The main results obtained are: a set of tools that enable the management and retrieval of scientific and technical information, the preprocessing and representation of the corpus, as well as the grouping and evaluation of textual groups, and a web application which uses the set of developed tools allowing the indexing, retrieval and grouping of scientific papers, together with the labeling and evaluation of the obtained groups, ensuring a proper connection with the repositories of scientific and technical information from the CEI-UCLV..
(6) Tabla de contenidos. Tabla de contenidos INTRODUCCIÓN .................................................................................................................................................. 1 1. Acerca de la gestión de documentos ............................................................................................................ 8 1.1. Generalidades de la gestión de documentos ......................................................................................... 8. 1.1.1 Indexado y recuperación de información .................................................................................... 11 1.1.2 Agrupamiento .............................................................................................................................. 11 1.1.3 Validación ................................................................................................................................... 15 1.1.4 Etiquetamiento ............................................................................................................................ 16 1.2. Herramientas que permiten el desarrollo de sistemas gestores de documentos .................................. 18. 1.2.1 Lucene ......................................................................................................................................... 19 1.2.2 Tika .............................................................................................................................................. 20 1.2.3 Jung ............................................................................................................................................. 20 1.3. Sistemas gestores de documentos desarrollados en la UCLV ............................................................ 21. 1.3.1 Sistema para el Agrupamiento, etiquetamiento y evaluación de colecciones TEXtuales (SATEX)23 1.3.2 Sistema para la Gestión de Artículos científicos Recuperados usando Lucene (GARLucene) ... 25 1.4 2. Consideraciones finales del capítulo .................................................................................................. 26. Herramientas que permiten el desarrollo de sistemas gestores de documentos .................................... 28 2.1. Indexado y recuperación de la información ........................................................................................ 32. 2.1.1 Herramienta para extraer contenido........................................................................................... 32 2.1.2 Herramienta para indexar contenido .......................................................................................... 35 2.1.3 Herramienta para recuperar información .................................................................................. 36 2.2. Representación del corpus textual ...................................................................................................... 39. 2.2.1 Herramienta para transformar información ............................................................................... 39 2.2.2 Herramienta para estructurar información ................................................................................ 42 2.3. Agrupamiento de documentos ............................................................................................................ 45. 2.3.1 Herramienta para crear matriz de similitud ............................................................................... 45 2.3.2 Herramienta para agrupar documentos ...................................................................................... 47 2.4. Valoración del agrupamiento.............................................................................................................. 51. 2.4.1 Herramienta para validar y etiquetar los grupos........................................................................ 51 2.5 3. Conclusiones parciales ....................................................................................................................... 54. Aplicación web que permite la gestión de información científica ........................................................... 55 3.1. Descripción del dominio ..................................................................................................................... 56. 3.2. Requisitos del sistema ........................................................................................................................ 56. 3.2.1 Requisitos funcionales ................................................................................................................. 57 3.2.2 Requisitos no funcionales ............................................................................................................ 57 3.3. Casos de usos...................................................................................................................................... 57. 3.3.1 Diagramas de casos de usos........................................................................................................ 58.
(7) Tabla de contenidos. 3.3.2 Especificaciones de los casos de usos ......................................................................................... 59 3.4. Diseño general del sistema ................................................................................................................. 65. 3.4.1 Marco de trabajo utilizado para realizar la aplicación .............................................................. 65 3.4.2 Diseño de la estructura de la aplicación ..................................................................................... 66 3.4.3 Principales clases del sistema ..................................................................................................... 67 3.5. Configuraciones de la aplicación web en las fases de gestión de la información científico-técnica. aplicando técnicas de minería de textos e inteligencia artificial .................................................................. 69 3.5.1 Módulo de recuperación de la información ................................................................................ 69 3.5.1.1. Indexado de la información contenida en los documentos ..................................................................... 69. 3.5.1.2. Recuperación de la información indexada en las bases de índices ....................................................... 69. 3.5.2 Módulo del procesamiento de la información recopilada ........................................................... 70 3.5.2.1. Transformación del contenido de los documentos recuperados ............................................................ 70. 3.5.2.2. Estructuración de la información transformada de los documentos ....................................................... 70. 3.5.3 Módulo para el agrupamiento de los documentos ...................................................................... 70 3.5.3.1. Matriz de Similitud ................................................................................................................................. 70. 3.5.3.2. Agrupamiento........................................................................................................................................70. 3.5.4 Módulo para la validación del agrupamiento ............................................................................. 71 3.6. Mapa de navegación ........................................................................................................................... 71. 3.7. Valoración preliminar de las herramientas y aplicación web ............................................................. 71. 3.8. Conclusiones parciales ....................................................................................................................... 72. CONCLUSIONES Y RECOMENDACIONES .................................................................................................. 73 Referencias bibliográficas .................................................................................................................................... 75 Anexos .................................................................................................................................................................... 79 Anexo 1.. Distancias, similitudes y disimilitudes más usadas para comparar objetos ............................ 79. Anexo 2.. Algunas medidas internas para la validación del agrupamiento ............................................. 81. Anexo 3.. Esquema general de la aplicación ........................................................................................... 83. Anexo 4.. Descripción general de la interfaz de usuario de SATEX ...................................................... 84. Anexo 5.. Descripción general de la interfaz de usuarios de GARLucene .............................................. 85. Anexo 6.. Descripción de las variables a medir para evaluar la aplicación ............................................. 87.
(8) Introducción. INTRODUCCIÓN La cantidad de información está continuamente creciendo; sin embargo, la habilidad de los humanos para procesarla y asimilarla permanece constante [1, 2]. Además, la información en sí misma tiene pocas ventajas, su sistematización, incorporación y utilización son los elementos que aportan su valor añadido: el conocimiento 1. Es necesario crear sistemas que generen conocimiento, para asegurar el uso productivo de la información y guiar una toma de decisiones óptima, contribuyendo de esta forma a la Gestión del Conocimiento (GC) [3-6]. Aproximadamente un 80% de la información se almacena en forma textual no estructurada [7], de ésta una cantidad significativa está dada por el crecimiento de las publicaciones científicas en diferentes campos. Por ejemplo, Medline 2 ya tiene más de 10 millones de publicaciones, con un incremento semanal entre 7000 y 8000 resúmenes científicos. Gestionar el conocimiento a partir de la información encontrada es fundamental en el trabajo científico [8]. Sin embargo, la gestión de información científica se vuelve cada vez más compleja y desafiante, sobre todo porque las colecciones textuales generalmente son heterogéneas, grandes, diversas y dinámicas. Superar estos desafíos es esencial para proporcionar a los científicos mejores condiciones de administrar el tiempo necesario para procesar la información científica, lo cual constituye la motivación principal de este trabajo. Hoy día, tanto las comunidades científicas, organizaciones y gobiernos, invierten en función del desarrollo de la gestión de la información y el conocimiento, a través de proyectos, congresos, postgrados y desarrollo de sistemas con este fin. Algunos ejemplos son: las políticas trazadas por la Unión Europea para incrementar la competitividad de una economía basada en el conocimiento 3, las acciones realizadas por la OPS/OMS en países en desarrollo4 y las facilidades brindadas por la UNESCO para desarrollar software para el procesamiento de la información 5. Universidades e institutos científicos desarrollan esta línea de investigación, como el grupo de investigación en la gestión del conocimiento y minería de textos de la Universidad de West Bohemia 6, el grupo de investigación en descubrimiento de conocimiento. 1. Considerado un recurso estratégico para el desarrollo económico, científico y social contemporáneo. Base de datos de 11 millones de citas y resúmenes de revistas de medicina y otras fuentes. http://medline.cos.com 3 Comunicación de la comisión de comunidades europeas al parlamento europeo “Información científica en la era digital”. Bruselas. 2007. http://ec.europa.eu/research/science-society/document_library/pdf_06/communication-022007_en.pdf 4 Newsletter BVS 056. 10 de agosto de 2006. http://newsletter.bireme.br/new/index.php?lang=pt&newsletter=20060810 5 CDS/ISIS de UNESCO http://hrueda-isis.blogspot.com/2007_11_01_archive.html 6 http://textmining.zcu.cz 2. 1.
(9) Introducción. a partir de datos no estructurados de la Universidad de Texas 7, el centro nacional del Reino Unido para la minería de textos (The Nacional Centre for Text Mining; NaCTeM) 8, el centro europeo para la computación blanda (European Centre for Soft Computing) 9, el grupo de recuperación de información de la Universidad de Magdeburgo Otto-von-Guericke 10 y el Instituto Kaieteur para la gestión del conocimiento (Kaieteur Institute for Knowledge Management 11). Cuba no está exenta del desarrollo de investigaciones que contribuyan a la gestión de la información y el conocimiento. Ejemplos de ello lo constituyen los trabajos realizados en el Centro de Aplicaciones de Tecnologías de Avanzada (CENATAV) de la Ciudad de La Habana y en el Centro de Reconocimiento de Patrones y Minería de Datos de la Universidad de Oriente en Santiago de Cuba; así como la labor desarrollada por la Asociación Cubana de Reconocimiento de Patrones (ACRP) 12. El conocimiento se puede gestionar de diversas formas y hacerlo requiere de la integración de varias áreas del saber: el descubrimiento de conocimiento en bases de datos, la minería de datos y de textos. Esta última integra la recuperación y extracción de información, el análisis de textos, el resumen, la categorización, la clasificación, el agrupamiento, la visualización, la tecnología de bases de datos, el aprendizaje automático y la minería de datos [1, 9]. En la actualidad los usuarios se enfrentan a grandes colecciones de información o a grandes cantidades de enlaces web recuperados por un buscador y tienen que ser muy pacientes para navegar a través de los enlaces y analizar la información que verdaderamente necesitan. La categorización, clasificación y agrupamiento se pueden utilizar para refinar resultados de la recuperación y extracción de información, y así contribuir al descubrimiento de conocimiento. Especialmente el agrupamiento y los procesos post-agrupamiento permiten organizar la información, determinar información relevante y crear nuevo conocimiento a partir de la información disponible en una colección especificada o resultante de un proceso de recuperación de información. Las organizaciones requieren utilizar la información no sólo para darle significado en su entorno, sino para crear nuevo conocimiento, compartirlo y tomar decisiones [10]. Sus principales incentivos para la gestión del conocimiento son [11, 12]: buscar, aportar,. 7. http://www.cs.utexas.edu/~ml/publication/text-mining.html http://www.cs.manchester.ac.uk/research/groups/infosystems/textmining/ 9 http://www.softcomputing.es 10 http://irgroup.cs.uni-magdeburg.de 11 http://www.kikm.org/ 12 http://acrp.cenatav.co.cu 8. 2.
(10) Introducción. contribuir, diseminar, explotar y evaluar el conocimiento. Se necesita transformar información en conocimiento: estructuración de datos e información y la acción humana sobre éstos [10]. Las organizaciones deben considerar servicios de conocimiento para lograr la integración de fuentes locales (por ejemplo, intranet local, servidores de ficheros, sitios públicos), intra-redes y extra-redes [11]. Pero esto no es suficiente, es necesario utilizar adecuadamente las tecnologías de la información para desarrollar gestores de conocimiento. Los sistemas de gestión de documentos 13 han tomado un gran auge en la actualidad [14]. Docyoument, Text Miner 14 , Worldox 15, Autonomy 16 , Knexa 17 y otros 18 que fueron identificados por el Instituto Kaieteur 19constituyen algunos ejemplos. La gran mayoría son sistemas más dirigidos al comercio del conocimiento en Internet y no la gestión del conocimiento en las organizaciones. Los sistemas dirigidos a las organizaciones tienen un alto precio en el mercado internacional, debido esencialmente a los beneficios que les reportan. Por eso a las instituciones cubanas les resulta casi imposible adquirir este tipo de sistema. Las universidades no están exentas de esta limitante y son de las organizaciones en el país que más requieren manipular grandes cantidades de documentos científicos por la actividad académica y científica que desarrollan [13]. Debido a esta limitante se hace necesario el desarrollo de nuevos sistemas gestores de información y conocimiento en función de tareas específicas para cubrir las necesidades de automatización en las universidades cubanas. Automatizar la gestión de información y el conocimiento conlleva al desarrollo de sistemas que ayuden a los usuarios al enfrentarse a grandes colecciones textuales, mediante la organización y extracción de conocimiento de las mismas. La entrada a estos sistemas debe provenir del resultado de un proceso de recuperación de información de un servidor o colección personal de información textual; y las salidas deben ser los grupos homogéneos de documentos afines, los términos relevantes y los documentos más representativos de cada grupo, así como los que se relacionan con ellos y la calidad con que fueron obtenidos los grupos; garantizando el control para la evaluación de los resultados del agrupamiento [13]. En [13] se presenta un esquema general que describe cómo procesar colecciones textuales de. 13. Sistemas de almacenamiento, sistemas de soporte de búsquedas, modelos de categorización y análisis de contenidos, ontologías y servicios de control de acceso y coordinadores de trabajo colaborativo. 14 http://www.sas.com/technologies/analytics/datamining/textminer 15 http://www.worldox.com/ 16 http://www.autonomy.com 17 http://www.knexa.com 18 Knowinc.com, Keen.com, Yet2.com, iExchange.com, Saba.com, cordis.lu, IQ4Hire.com, petrocore.com y eBrainx.com 19 Instituto para la gestión del conocimiento (Kaieteur Institute for Knowledge Management http://www.kikm.org). 3.
(11) Introducción. forma tal que se extraiga la información organizada y se señalen los elementos relevantes de cada grupo de documentos afines. Este esquema está compuesto por cuatro módulos: recuperación de la información o especificación del corpus textual a procesar, representación del corpus textual obtenido o fijado por el usuario, agrupamiento de los documentos y valoración (validación y etiquetamiento) de los grupos textuales obtenidos. En el Centro de Estudios de Informática (CEI) de la Universidad Central “Marta Abreu” de las Villas (UCLV) se han desarrollado los sistemas para la gestión de la información y el conocimiento (SATEX y GARLucene) que siguen el esquema propuesto en [13] para la confección de sistemas gestores de información en dominios textuales. Estos sistemas brindan amplias ventajas para la gestión de la información y del conocimiento. Sin embargo, el diseño de estos sistemas no permite la utilización de algunos de sus módulos en otras aplicaciones, o la incorporación de otras formas de representación textual, u otros métodos de indexado y recuperación de la información. Por otra parte, estas aplicaciones son de escritorio, limitándose significativamente los procesos de indexado y recuperación de la información, los usuarios necesitan especificar valores a parámetros que desconocen y los términos que se utilizan no son familiares a los usuarios. Aunque los sistemas realizan procesamientos de calidad y logran agrupar correctamente los documentos, así como extraer la información relevante de cada grupo, las desventajas antes mencionadas impiden la introducción y generalización de los mismos, y conllevan a que los usuarios finales no aprecien las ventajas de los mismos al utilizarlos para el procesamiento de grandes volúmenes de información. A pesar de que existe un esquema general correctamente diseñado para indexar, recuperar y agrupar documentos, así como etiquetar y evaluar los grupos obtenidos, y sistemas que implementan este esquema general, aun persisten insuficiencias al llevar a la práctica la introducción de estos resultados en el procesamiento de grandes volúmenes de datos, y en la manipulación de los sistemas por diversos tipos de usuarios. Todo ello constituye una problemática a la cual aún no se le ha dado respuestas definitivas, lo cual justifica el planteamiento del problema de investigación siguiente: Por un lado, existen los sistemas CorpusMiner, SATEX y GARLucene que si bien permiten gestionar información siguiendo el esquema de indexado, recuperación, agrupamiento y valoración de los grupos textuales obtenidos, no brindan un entorno de trabajo amigable que permita la introducción y generalización de los mismos, ya que no garantizan una interacción efectiva entre usuarios y grandes repositorios de información. Por otro lado, en el CEI-UCLV. 4.
(12) Introducción. existe un gran número de artículos científicos y documentos relacionados con diversos temas de investigación, y se hace tedioso para los investigadores descubrir conocimiento que requieren para encausar una investigación a partir de estos grandes volúmenes textuales. El objetivo general de la investigación consiste en desarrollar una aplicación que permita gestionar de forma efectiva la información científico-técnica disponible en grandes repositorios de información. Este se desglosa en los siguientes objetivos específicos: 1.. Desarrollar herramientas que permitan la gestión y recuperación de información científico-técnica que faciliten el intercambio de información con otras etapas de la gestión de información.. 2.. Desarrollar herramientas que permitan el preprocesamiento y representación de corpus textuales.. 3.. Desarrollar herramientas que permitan el agrupamiento y valoración de los grupos textuales obtenidos, contribuyendo al desarrollo de sistemas gestores de información en dominios textuales.. 4.. Desarrollar una aplicación web que utilice el conjunto de herramientas desarrolladas y permita el indexado, recuperación y agrupamiento de documentos científicos, así como etiquetar y evaluar los grupos obtenidos, garantizando una adecuada conexión con los repositorios de información científico-técnica del CEI-UCLV.. Las preguntas de investigación planteadas son: ¿Cómo diseñar las herramientas de forma tal que sean extensibles y que el intercambio de información entre ellas pueda ser utilizado por aplicaciones externas? ¿Qué tecnología utilizar para el desarrollo de la aplicación web y las herramientas que faciliten una buena integración entre las mismas? Después de haber realizado el marco teórico se formuló la siguiente hipótesis de investigación como presunta respuesta a las preguntas de investigación: H1: El desarrollo de herramientas asociadas a los módulos del esquema general para el procesamiento de información textual a través de la definición de interfaces en Java, definiendo el intercambio de información mediante ficheros XML y desarrollando la aplicación web utilizando Java Server Faces, garantiza la extensibilidad, el intercambio de las herramientas con aplicaciones externas y facilita la integración entre las herramientas y la 5.
(13) Introducción. aplicación web. Para lograr los objetivos trazados y demostrar la hipótesis establecida se acometieron las tareas de investigación siguientes: • Análisis de las principales técnicas y sistemas que existen para realizar gestión documental, tales como Lucene, LIUS, Tika y Jung. • Estudio del esquema general para el procesamiento textual a partir del indexado, recuperación y agrupamiento de documentos textuales, así como valoración de los grupos textuales obtenidos. • Diseño e implementación de herramientas que trabajen de forma independiente, sean extensibles y faciliten el intercambio de información, con el objetivo de auxiliar el desarrollo de sistemas gestores de información en dominios textuales. • Diseño de una aplicación web que permita el indexado, recuperación y agrupamiento de documentos científicos, así como etiquetar y evaluar los grupos obtenidos. • Implementación de la aplicación web utilizando Java Server Faces. • Análisis del desempeño de la aplicación web en la conexión con los repositorios de información científico-técnica del CEI-UCLV y la adecuada gestión de la información. El valor práctico del trabajo está dado por: •. Las herramientas desarrolladas para la gestión de la información son independientes entre sí, extensibles, reutilizables por sistemas externos, y se comunican mediante ficheros XML, permitiendo indexar, recuperar, representar colecciones textuales, agrupar documentos, validar resultados de agrupamientos, y seleccionar documentos más representativos de cada grupo, tareas muy demandadas por aplicaciones de minería de textos.. •. La concepción del conjunto de herramientas facilita el desarrollo de servicios web que permitan utilizar de manera remota cada una de las tareas de la minería de textos implementadas en las herramientas.. •. La aplicación web desarrollada permite el indexado, recuperación y agrupamiento de documentos científicos, así como etiquetar y evaluar los grupos obtenidos, garantizando una adecuada conexión con los repositorios de información científico-técnica del CEIUCLV, facilitándole a los investigadores y docentes comenzar una revisión del estado del arte, organizar por temáticas los artículos que le han llegado al comité científico del 6.
(14) Introducción. programa de un evento, así como tener una idea de las asociaciones que existen entre los documentos recuperados. La tesis está estructurada en tres capítulos. En el Capítulo 1 se abordan los elementos generales de la gestión de documentos, enfatizando en el indexado y recuperación de información, el agrupamiento, y la validación y etiquetamiento de los grupos textuales obtenidos; así como los principales sistemas y herramientas que permiten la gestión de documentos, particularmente los sistemas SATEX y GARLucene. En el capítulo 2 se describen las herramientas desarrolladas que permiten el desarrollo de sistemas gestores de documentos. Estas herramientas siguen el esquema de indexado, recuperación, agrupamiento y valoración, y facilitan el intercambio de información entre ellas y con sistemas externos. En el capítulo 3 se presenta la aplicación web que utiliza el conjunto de herramientas desarrolladas y a partir de una adecuada conexión con los repositorios de información científico-técnica del CEI-UCLV, permite gestionar información científico-técnica. Se presentan elementos del análisis y requisitos del sistema, diagramas de casos de uso, los usuarios y privilegios, así como el resto de los elementos que permitieron arribar a un correcto diseño de la aplicación. Se muestra una valoración de las potencialidades que tiene la aplicación, a partir de la evaluación de algunos indicadores de calidad de sistemas de este tipo. Este documento culmina con las conclusiones, recomendaciones, referencias bibliográficas y los anexos.. 7.
(15) Capítulo 1. Acerca de la gestión de documentos. 1 Acerca de la gestión de documentos En este capítulo se abordan los elementos generales de la gestión de documentos, enfatizando en el indexado y recuperación de información, el agrupamiento, y la validación y etiquetamiento de los grupos textuales obtenidos; así como los principales sistemas y herramientas que permiten la gestión de documentos, tomando como punto de partida los sistemas SATEX y GARLucene. 1.1. Generalidades de la gestión de documentos. La información y el conocimiento surgen de acciones humanas que interconectan señales, signos y artefactos en diversos medios. El espacio de información está dado por su codificación, abstracción y difusión [10]. Las dos primeras se refieren a la creación de categorías que faciliten la clasificación de fenómenos y la minimización del número de categorías necesarias, mientras que la tercera combina las dos primeras. Las organizaciones requieren utilizar la información no sólo para darle significado en su entorno, sino para crear nuevo conocimiento, compartirlo y tomar decisiones [10]. Sus principales incentivos para la gestión del conocimiento son [11, 12]: buscar, aportar, contribuir, diseminar, explotar y evaluar el conocimiento. Se necesita transformar información en conocimiento: estructuración de datos e información y la acción humana sobre éstos [10]. La manipulación de documentos trabaja con conocimiento objetivo, formalizado acorde a algún esquema de codificación; por ejemplo, patente, reporte, artículo, norma. Este conocimiento se clasifica como explícito. Otras dos clasificaciones son: tácito, cuando es personal, en un contexto específico y es difícil formalizarlo, e implícito, cuando es subjetivo [10, 15]. El conocimiento explícito tiene gran importancia porque codifica aprendizaje pasado, habilita la coordinación de actividades y funciones y reduce el procesamiento de información mediante la estipulación de premisas, criterios y opiniones [10, 15]. Además, se comunica fácilmente, aunque transferirlo requiere conocimiento colateral del receptor para entenderlo y aplicarlo. Conocimiento colateral que tiene naturaleza tácita porque los expertos interpretan el significado de la nueva información y surgen incógnitas cuando tratan de usarlo. Las organizaciones deben considerar servicios de conocimiento para lograr la integración de fuentes locales (por ejemplo, intranet local, servidores de ficheros, sitios públicos), intra-redes. 8.
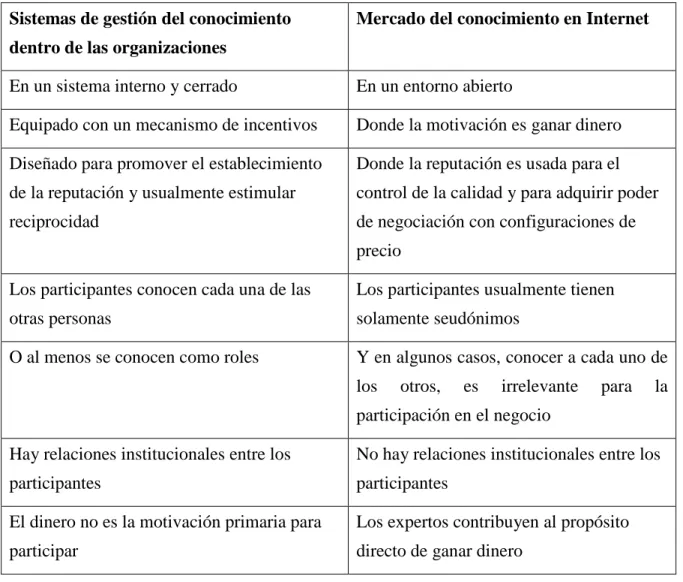
(16) Capítulo 1. Acerca de la gestión de documentos. y extra-redes [11]. Pero sólo esto no es suficiente, es necesario utilizar adecuadamente las componentes de las tecnologías de la información para desarrollar gestores de conocimiento. Los sistemas de gestión de documentos 20 han tomado un gran auge en la actualidad [14]. Docyoument, creado por Media-style 21, encuentra y lista información relevante en varias fuentes a partir de tópicos y preguntas definidas por los usuarios, genera reportes y resúmenes de los documentos, y descubre relaciones entre contenidos. El grupo de herramientas Text Miner 22 descubre y extrae conocimiento desde textos. Otro ejemplo lo constituye Worldox 23, que permite la seguridad de los documentos, el control del acceso, búsquedas a texto completo, visualizadores de documentos en diversos formatos, archivar y guardar la historia de un documento. Autonomy24 permite un servicio de búsqueda inteligente en Internet a partir de fuentes en 65 lenguajes, deriva el significado de las palabras en el contexto dado y genera los perfiles de los usuarios. Knexa 25 es un ejemplo de plaza de mercado electrónico para conocimiento documentado y el Instituto Kaieteur 26 identificó otros ejemplos 27. Estos sistemas y herramientas han sido desarrollados en su inmensa mayoría por importantes compañías 28 que han invertido gran capital en la manipulación de documentos para contribuir a la gestión de información y el conocimiento. La mayoría de los sistemas mencionados están más dirigidos al comercio del conocimiento en Internet que a la gestión del conocimiento en las organizaciones; las diferencias se muestran en Tabla 1.1. Aquellos dirigidos a las organizaciones tienen un alto precio en el mercado internacional, debido esencialmente a los beneficios que les reportan. Esto provoca que para las instituciones cubanas sea muy difícil adquirir este tipo de sistemas. Las universidades no están exentas de esta limitante y son entre las organizaciones del país las que más requieren manipular grandes cantidades de documentos científicos debido a la actividad académica y científica que desarrollan.. 20. Sistemas de almacenamiento, sistemas de soporte de búsquedas, modelos de categorización y análisis de contenidos, ontologías y servicios de control de acceso y coordinadores de trabajo colaborativo. 21 Creación, publicación, gestión, organización, descubrimiento y análisis de contenidos. http://www.media-style.com 22 http://www.sas.com/technologies/analytics/datamining/textminer 23 http://www.worldox.com/ 24 http://www.autonomy.com 25 http://www.knexa.com 26 Instituto para la gestión del conocimiento (Kaieteur Institute for Knowledge Management http://www.kikm.org) 27 Knowinc.com, Keen.com, Yet2.com, iExchange.com, Saba.com, cordis.lu, IQ4Hire.com, petrocore.com y eBrainx.com 28 Autonomy http://www.autonomy.com, ClearForest http://www.clearforest.com, IBM Intelligent Miner for Text http://www-306.ibm.com/software, LexiQuest http://www.lexiquest.com, Teragram http://www.teregram.com y SAS http://www.sas.com. 9.
(17) Capítulo 1. Acerca de la gestión de documentos. Tabla 1.1 Gestión del conocimiento en organizaciones vs el mercado del conocimiento en Internet.. Sistemas de gestión del conocimiento. Mercado del conocimiento en Internet. dentro de las organizaciones En un sistema interno y cerrado. En un entorno abierto. Equipado con un mecanismo de incentivos. Donde la motivación es ganar dinero. Diseñado para promover el establecimiento. Donde la reputación es usada para el. de la reputación y usualmente estimular. control de la calidad y para adquirir poder. reciprocidad. de negociación con configuraciones de precio. Los participantes conocen cada una de las. Los participantes usualmente tienen. otras personas. solamente seudónimos. O al menos se conocen como roles. Y en algunos casos, conocer a cada uno de los. otros,. es. irrelevante. para. la. participación en el negocio Hay relaciones institucionales entre los. No hay relaciones institucionales entre los. participantes. participantes. El dinero no es la motivación primaria para. Los expertos contribuyen al propósito. participar. directo de ganar dinero. El conocimiento se puede gestionar de diversas formas y hacerlo requiere de la integración de varias áreas del saber: el descubrimiento de conocimiento en bases de datos, la minería de datos y de textos. Esta última integra la recuperación y extracción de información, el análisis de textos, el resumen, la categorización, la clasificación, el agrupamiento, la visualización, la tecnología de bases de datos, el aprendizaje automático y la minería de datos [1, 9]. En la actualidad los usuarios se enfrentan a grandes colecciones de información o a grandes cantidades de enlaces web recuperados por un buscador y tienen que ser muy pacientes para navegar a través de los enlaces y analizar la información que verdaderamente necesitan. La categorización, clasificación y agrupamiento se pueden utilizar para refinar resultados de la recuperación y extracción de información, y así contribuir al descubrimiento de conocimiento.. 10.
(18) Capítulo 1. Acerca de la gestión de documentos. Especialmente el agrupamiento y los procesos post-agrupamiento permiten organizar la información, determinar información relevante y crear nuevo conocimiento a partir de la información disponible en una colección especificada o resultante de un proceso de recuperación de información. 1.1.1. Indexado y recuperación de información. Recuperación de información (Information Retrieval; IR) puede ser definida como una aplicación de las tecnologías de la computación para la adquisición, organización, almacenamiento, recuperación, y distribución de información. IR está estrechamente relacionada con elementos prácticos y teóricos sobre la mejora de la tecnología de los motores de búsqueda, incluyendo la construcción y mantenimiento de grandes repositorios de información. En años recientes, los investigadores han incrementado y expandido su preocupación acerca de la bibliografía y búsqueda a texto completo en repositorios en la Web, tanto en datos de hipertextos pertenecientes a bases de datos como en multimedia. La recuperación de información es una actividad, y como la mayoría de las actividades tiene sus propósitos. Un usuario de un motor de búsqueda comienza con la información que él necesita, para lo cual realiza una consulta con el objetivo de encontrar documentos relevantes. Esta consulta puede que no sea la mejor conexión que él necesita para encontrar lo que desea. Ésta puede contener errores ortográficos, desaprovechar palabras o haber realizado una selección pobre de las palabras. Sin embargo, esta es la única pista que tiene el motor de búsqueda respecto al objetivo de los usuarios. Generalmente se dice que los documentos resultantes de la búsqueda pueden ser más o menos relevantes respecto a la consulta, pero, estrictamente hablando, esta expresión es errada. Los usuarios juzgan la relevancia respecto a la información que necesitan, no respecto a la consulta. Si se retornan documentos irrelevantes, los usuarios pueden o no darse cuenta de cuáles son los irrelevantes, y pueden o no encontrar la forma de mejorar la consulta. 1.1.2. Agrupamiento. El análisis de grupos es descrito como una herramienta para el descubrimiento porque tiene la potencialidad de revelar relaciones no detectadas previamente, basadas en datos complejos. Los algoritmos de agrupamiento son usados para encontrar una estructura de grupos que se ajuste al conjunto de datos, logrando homogeneidad dentro de los grupos y heterogeneidad entre ellos [16].. 11.
(19) Capítulo 1. Acerca de la gestión de documentos. Debe existir un alto grado de asociación entre los objetos de un mismo grupo y un bajo grado entre los miembros de grupos diferentes [16]. Cuando el agrupamiento se basa en la similitud de los objetos, se desea que los objetos que pertenecen al mismo grupo sean tan similares como se pueda y los objetos que pertenecen a grupos diferentes sean tan diferentes como sea posible [17, 18]. En otras palabras, seguir el principio de maximizar la similitud dentro del grupo y minimizar la similitud entre los grupos. El concepto de “similitud” tiene que ser especificado acorde a los datos. En la mayoría de los casos los datos son vectores de valores reales, entonces se requieren algunas medidas (distancias, similitudes, o disimilitudes) para cuantificar el grado de asociación entre ellos. Las medidas más usadas para comparar objetos se muestran en el Anexo 1. Por otra parte, un reto para la minería de datos es descubrir grupos en datos que al relacionarse forman una estructura interesante para el análisis. Este tipo de datos tiene una mejor descripción cuando se representa como una colección de objetos interrelacionados y enlazados [19]. El enlace entre objetos es un conocimiento que puede explotarse en el agrupamiento, ya que rasgos de objetos enlazados están correlacionados, y es probable la existencia de enlaces entre objetos que tienen elementos comunes. Así, varios métodos parten de representar los objetos y sus relaciones en un grafo y explotan su topología para descubrir los grupos. Estas propuestas ven el conjunto de datos desde la perspectiva de las conexiones entre los objetos más que los objetos en sí mismos [20]. Los conjuntos de datos pueden intrínsecamente formar un grafo o se pueden obtener grafos de similitud a partir de la matriz de similitud entre los objetos. En la actualidad se presupone que el conocimiento de la estructura de los datos es tan importante como los objetos en sí. Ese conocimiento puede ayudar a descubrir grupos que se ocultan en las comunicaciones entre los objetos [19, 21, 22]. Propiedades de los grafos, sobre todo cuando éstos representan redes complejas, pueden ser indicadores importantes para el agrupamiento. Los métodos de agrupamiento se clasifican siguiendo varios criterios: tipo de los datos de entrada del algoritmo, criterios para definir la similitud entre los objetos, conceptos en los cuales se basa el análisis y forma de representación de los datos, entre otros [23]. Una clasificación general distingue dos tipos: aquellos basados en una función objetivo y los jerárquicos [24, 25].. 12.
(20) Capítulo 1. Acerca de la gestión de documentos. Esta primera categoría más general se refiere a la construcción de particiones (grupos) del conjunto de datos sobre la base del perfeccionamiento de algún índice, conocido también como función objetivo. En esencia, dividir n objetos en un número positivo k de grupos, generalmente especificado a priori. El objetivo de estos métodos es encontrar la mejor división de los datos en k grupos basada en una medida de similitud dada y conservar el espacio de particiones posibles en k subconjuntos solamente. La mayoría de los algoritmos que siguen esta técnica son esencialmente basados en prototipos, comienzan con una partición inicial, usualmente aleatoria, y proceden con su refinamiento [18]. Los algoritmos jerárquicos, por su parte, hacen una descomposición jerárquica de los objetos. Dentro de ellos, los aglomerativos (bottom-up), consideran que cada objeto constituye un grupo, por tanto, inicialmente existen tantos grupos como objetos tiene la colección, y sucesivamente los unen, hasta que todos los objetos formen un único grupo. Mientras que los divisivos (top-down) consideran inicialmente que existe un único grupo al cual pertenecen todos los objetos y sucesivamente dividen los grupos en grupos más pequeños, hasta que cada grupo contenga un único objeto. La construcción de la jerarquía se puede detener por criterios automáticos o del usuario. Muchas veces combinar o dividir grupos es comprometido, y no puede ser deshecho o refinado. En [26, 27] se presenta una nueva metodología que combina la estrategia divisiva y la aglomerativa. Otros tipos de métodos han emergido para el análisis de grupos, principalmente motivados en problemas específicos de minería de datos [24]. El agrupamiento basado en densidad (densitybased clustering) agrupa objetos vecinos de un conjunto de datos basándose en condiciones de densidad. Existe una clasificación que divide el agrupamiento en conceptual y estadístico [28]. Por otra parte, aquellos algoritmos que utilizan métodos geométricos y técnicas de proyección se clasifican en agrupamiento incompleto o heurístico [17]. Otra clasificación, no mutuamente excluyente a las ya presentadas, considera la forma de manipular la incertidumbre en términos del solapamiento de los grupos: agrupamiento duro y borroso [17]. Las técnicas duras pueden ser deterministas o con solapamiento. Las deterministas crean una partición, donde los grupos son mutuamente excluyentes y exhaustivos del universo de objetos. Los algoritmos con solapamiento crean un cubrimiento, donde un objeto puede pertenecer a más de un grupo. Las técnicas borrosas se subdividen en probabilísticas y posibilísticas [18].. 13.
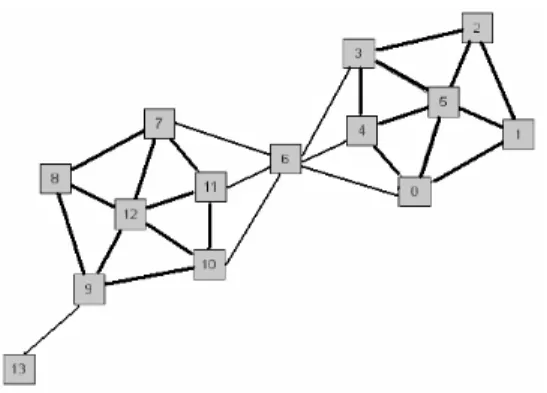
(21) Capítulo 1. Acerca de la gestión de documentos. La teoría de grafos constituye una herramienta valiosa para desarrollar modelos de abstracción para el agrupamiento, proporcionando el formalismo matemático requerido. Sus conceptos básicos han sido utilizados para el desarrollo de algoritmos de agrupamiento y de índices de validación. Los grafos proveen modelos estructurales para el análisis de grupos. Generalmente este tipo de algoritmos no requieren que se especifique el número de grupos a obtener, descubren grupos de formas arbitrarias, no uniformes y de densidades diversas, y son menos sensibles a la presencia de ruido. Las técnicas de agrupamiento tienen ventajas y desventajas en dependencia del tipo de problema al cual son aplicadas. El conocimiento del dominio puede, en muchos casos, ayudar a determinar qué tipo de grupo se va a formar y qué tipo de agrupamiento se va utilizar con el objetivo de obtener los mejores resultados. Se han desarrollado muchos algoritmos para el agrupamiento de documentos, pero muy pocas propuestas toman en consideración las ventajas de las estructuras inherentes en el lenguaje. Cuando se representa una colección textual como un grafo de similitud coseno entre los documentos, sucede que, como se muestra en la Figura 1.1, algunos documentos tienen alta pertenencia a los grupos, otros pertenecen a puentes entre grupos y algunos tienen una pertenencia débil a los grupos; por tanto, es fundamental explotar las propiedades topológicas del grafo y el flujo de información entre los nodos para detectar las estructuras ocultas en él [29]. En algunos casos dos documentos pueden tratar temas diferentes y tener alta similitud coseno. Estos documentos no necesariamente son tan similares a sus vecinos respectivos, y sólo el uso de la similitud no logra identificarlos en grupos diferentes, se requiere analizar los enlaces entre ellos.. Figura 1.1. Grafo donde se han representado dos grupos, el nodo 6 es puente entre los grupos y el nodo 13 tiene muy baja pertenencia a los grupos. Fuente: [29].. Se considera de gran utilidad explotar las propiedades topológicas de los lenguajes y corpus textuales, de ahí que resulta útil aplicar métodos de análisis de redes complejas para abordar 14.
(22) Capítulo 1. Acerca de la gestión de documentos. problemas de la minería de textos. Por tanto, en este trabajo se sigue el enfoque de las técnicas de agrupamiento que trabajan sobre una representación de los objetos en un grafo y que explotan la estructura de las interrelaciones de los objetos en el proceso de agrupamiento. 1.1.3. Validación. “El agrupamiento es un proceso subjetivo; el mismo conjunto de datos usualmente necesita ser agrupado de formas diferentes dependiendo de las aplicaciones” [30]. Esta subjetividad hace el agrupamiento difícil, y aún más su validación. Una forma de evaluación del agrupamiento muy sencilla puede ser, por ejemplo, mediante la visualización del conjunto de datos cuando éste es pequeño y los datos son bidimensionales. Sin embargo, esta forma de evaluación puede ser difícil al intentar una visualización efectiva de un conjunto de datos de alta dimensionalidad [31], aunque técnicas bien establecidas para la reducción de dimensionalidad, como el análisis de componentes principales (Principal Component Analysis; PCA) [32] y el análisis de componentes principales categórico (Categorical Principal Component Analysis; CATPCA), pueden contribuir a la evaluación de este tipo de conjuntos de datos mediante la visualización. Por otra parte, muchos algoritmos de agrupamiento varían sus resultados dependiendo de las características de los datos, por ejemplo, geometría y densidad de distribución [28]. Otros dependen fuertemente de los valores asignados a los parámetros. Por ejemplo, si hay un parámetro que controle la resolución a la cual son vistos los datos, el algoritmo produce un dendrograma en función de ese parámetro. En este caso es necesario decidir cuál nivel del dendrograma refleja mejor los grupos según las propiedades que se desea que el agrupamiento satisfaga. Algunos algoritmos necesitan que se especifique inicialmente el número de grupos a obtener, otros requieren que se especifique el número de vecinos de cada punto como un parámetro externo. Así, los resultados producidos son en función de los parámetros fijados y se hace necesario verificar cuáles se ajustan a los datos [33]. Variaciones a partir de características de los datos, diferentes técnicas de análisis de grupos y definición de parámetros para el algoritmo a aplicar, indican que una evaluación de los resultados es necesaria para medir la calidad del agrupamiento. Una práctica común, en tal sentido, es aplicar medidas de validación de grupos [34]. El procedimiento de evaluar los resultados de algoritmos de agrupamiento se conoce por validación del agrupamiento [35, 36]. Se llama medida de validación de grupos a una función. 15.
(23) Capítulo 1. Acerca de la gestión de documentos. que hace corresponder un número real a un agrupamiento, indicando en qué grado el agrupamiento es correcto o no [17]. Estas medidas en su mayoría son heurísticas por naturaleza para conservar una complejidad computacional plausible. Las medidas de evaluación del agrupamiento se clasifican en: globales y locales, subjetivas y objetivas; internas, externas y relativas; y supervisadas y no supervisadas [17, 37, 38]. Las medidas globales describen la calidad del resultado completo de un agrupamiento usando un único valor real, mientras que las locales evalúan cada grupo obtenido [17]. Las medidas objetivas miden propiedades estructurales de los resultados de los agrupamientos, por ejemplo, la separación entre los grupos y la compactación o densidad de los mismos [28]. La presencia de tales propiedades no garantiza que los resultados sean interesantes para el usuario, estas medidas carecen de enlace con los usuarios, aunque su principal atractivo es que son independientes del dominio. Las medidas subjetivas evalúan considerando la usabilidad de los grupos [34]. Las investigaciones en medidas subjetivas han sido menos intensas que las realizadas en las objetivas [39]. Una clasificación muy usada divide la validación del agrupamiento en: medidas internas, externas y relativas [35, 38]. Otra división consiste en medidas supervisadas y no supervisadas, refiriéndose a externas e internas, respectivamente. Las medidas externas se basan en un criterio externo que es impuesto sobre los datos, por ejemplo, una estructura previamente especificada que refleje la intuición que se tenga del agrupamiento de los datos. No se puede aplicar estas medidas a situaciones del mundo real donde usualmente no está disponible una clasificación de referencia. Las medidas internas evalúan considerando solamente los resultados del agrupamiento en términos de cantidades que involucran los vectores de datos. Las medidas relativas se basan en la comparación del agrupamiento a evaluar con otros esquemas de agrupamiento o con resultados del mismo algoritmo con diferentes valores en los parámetros. 1.1.4. Etiquetamiento. Un creciente número de herramientas soporta la creación y diseminación de la información provocando su proliferación arrolladora. Con esta cantidad de información cada vez más grande, es difícil para un investigador encontrar fácilmente los artículos que responden a sus necesidades y además resulta imposible que pueda leerla y comprenderla toda. Estas son razones por las cuales los problemas de la minería de textos requieren el agrupamiento de documentos y después recuperar las etiquetas de los grupos de las grandes colecciones 16.
(24) Capítulo 1. Acerca de la gestión de documentos. textuales. Algunos trabajos han sido desarrollados en esta área; sin embargo, etiquetar es usualmente ignorado por los investigadores en agrupamiento y se le ha prestado menos atención a crear buenos descriptores de grupos, debido a que el problema del agrupamiento no ha sido aún resuelto. Emergen más y más algoritmos de agrupamiento efectivos y que típicamente no tienen una complejidad lineal, entonces la etapa de etiquetamiento se hace crítica para grandes conjuntos de datos, especialmente cuando los puntos en las regiones fronteras de los grupos son significativos para las aplicaciones [40]. Por lo tanto, se requiere del desarrollo y aplicación de un conjunto de procedimientos, instrumentos y métodos que permitan obtener eficientemente el etiquetamiento de grupos de documentos. Las etiquetas a obtener deben ser únicas, sintetizadoras, expresivas, tener poder discriminante, contiguas, poseer consistencia jerárquica, y no ser redundantes [34]. Es deseado que el proceso de etiquetamiento sea no supervisado, de forma tal que se puedan producir etiquetas rápidamente sin el alto costo de la intervención humana en la anotación de conjuntos de entrenamiento [41]. Una forma de etiquetar es representando adecuadamente los grupos [40]. Las representaciones de los grupos pueden ser basadas en centros, puntos representativos, árboles de clasificación y reglas. El uso de centroides es el esquema más popular, el mismo funciona bien cuando los grupos son compactos. Sin embargo, cuando los grupos son alargados, este esquema falla, en este caso, el uso de una colección de puntos soluciona el problema, además funciona mejor ya que describe los grupos con más detalles [30]. Una nueva interrogante surge: ¿cómo definir los puntos más representativos? Hacerlo desde grupos con formas arbitrarias es una tarea tan difícil como el propio problema del agrupamiento. A continuación se presentarán algunas técnicas existentes en la literatura científica para etiquetar grupos, enfatizando en aquellas que etiquetan basadas en los puntos más representativos. Un enfoque muy sencillo puede ser etiquetar los grupos con las palabras de mayor frecuencia de aparición en estos , pero estas etiquetas son muy generales y generalmente no son buenos descriptores discriminantes.. Otras propuestas han tenido en cuenta para etiquetar la. distribución de las palabras en una jerarquía. Popescul y Glover proponen un método estadístico para la selección de los descriptores de un grupo, basados en el contexto de grupos circundantes (grupos “padres y hermanos”) [41].. 17.
(25) Capítulo 1. Acerca de la gestión de documentos. Popescul propone el uso del estadísticoχ2 para detectar diferencias en la distribución de las palabras a través de la jerarquía. Glover muestra cómo un simple modelo que sólo se basa en la frecuencia de los términos en cada documento se puede utilizar para seleccionar los descriptores de los grupos (nodos) padre, hijo y del propio grupo, especialmente para páginas Web. Las etiquetas candidatas son extraídas desde el contenido de la página Web, incluyendo los hipervínculos. Las etiquetas son seleccionadas y ordenadas usando su frecuencia en los documentos teniendo en cuenta límites predefinidos [41]. Pucktada y Jaime presentan un algoritmo para etiquetar grupos resultantes de un agrupamiento jerárquico, para esto utilizan la frecuencia del documento y del término con respecto al grupo. Un proceso de etiquetamiento basado en la visualización de los datos es propuesto en [40]. Su desventaja es que requiere involucrar parcialmente la influencia humana en el proceso, y sus ventajas son que etiqueta y adapta las regiones límites preservando la calidad del agrupamiento y que tiene bajo costo computacional, al menos si se compara con algoritmos para el etiquetamiento basados en la comparación de distancias. Las etiquetas con puntos más representativos logran describir los grupos con más detalles. Entre los trabajos reportados en la literatura para etiquetar con puntos más representativos se encuentra el de Pedersen y Kulkarni donde tratan cada grupo como un corpus y así encuentran las etiquetas que serían un número n de bi –gramas [41]. Los algoritmos de etiquetamiento de grupos de documentos pueden escoger los documentos cercanos a los centroides de cada grupo, como una forma de etiquetamiento. Un ejemplo de algoritmo que usa esta representación es Scatter/Gather, el cual representa un grupo con una lista de documentos cercanos al centroide del grupo y una lista de tópicos. La lista de tópicos son los términos con mayor peso en el centroide del grupo. Este enfoque sólo es posible para etiquetar resultados de agrupamientos que forman particiones y cubrimientos. Requerir centros de grupos es una de las desventajas de esta propuesta [41]. 1.2. Herramientas que permiten el desarrollo de sistemas gestores de documentos. La explosión de Internet y el surgimiento de repositorios de datos electrónicos han provocado que grandes cantidades de información se encuentren disponibles al alcance de la sociedad. Precisamente, el volumen de toda esa información hace prácticamente imposible la gestión de la información mediante la aplicación de métodos tradicionales[42].. 18.
(26) Capítulo 1. Acerca de la gestión de documentos. La necesidad de localizar en un tiempo prudencial información específica, no desde un ordenador personal que contiene la información localizada en sus discos, ni tan siquiera en uno que esté dentro de la misma compañía o subred, sino desde casi cualquier rincón del planeta utilizando medios tan diversos como un teléfono celular, una agenda electrónica, una computadora portátil, etc. Por tanto, esta abundancia de información que constituye un tesoro de la humanidad hay que lograr gestionarla adecuadamente, de forma rápida y eficiente, permitiendo encontrar exactamente lo que se está buscando con el menor esfuerzo posible. Entonces, la creación, desarrollo y mantenimiento y uso de herramientas informáticas que permitan gestionar la información constituye una necesidad de la humanidad en la “era de la Información”. 1.2.1. Lucene. La indexación y la búsqueda de información son pasos claves para una correcta gestión de la información. Lucene es una potente biblioteca de búsqueda e indexación basada en Java y de código abierto, que fácilmente permite la integración con cualquier aplicación. En los últimos años Lucene se ha convertido en una popular biblioteca de recuperación de información que ha sido integrada a las funciones de búsquedas de muchas aplicaciones web y de escritorio. Aunque originalmente fue escrito en java debido a su popularidad ya ha sido implementado en otros lenguajes de programación como (C / C + +, C #, Ruby, Perl, Python, PHP, etc.). Uno de los factores clave detrás de la popularidad de Lucene es su aparente simplicidad, pues realmente cuenta con algoritmos que implementan técnicas de recuperación de la información de última generación. Además, para utilizarla no es necesario un conocimiento profundo acerca de cómo Lucene indexa y recupera información. Resumiendo: Lucene constituye una novedosa herramienta para la gestión de la información. Creada bajo una metodología orientada a objetos e implementada completamente en Java, no se trata de una aplicación que pueda ser descargada, instalada y ejecutada sino de una interfaz de programación de aplicaciones (Application Program Interfaces; API) flexible, muy potente y realmente fácil de utilizar, a través de la cual se pueden añadir, con pocos esfuerzos de programación, capacidades de indexación y búsqueda a cualquier sistema para la gestión de la información. Además, Lucene presenta características importantísimas en una API como: su alto rendimiento entre sus métodos, es escalable y su diseño es compacto y simple.. 19.
(27) Capítulo 1. Acerca de la gestión de documentos. 1.2.2. Tika. Uno de los más difíciles pero vitales pasos en la construcción de aplicaciones de gestión de la información es la extracción del contenido de las múltiples fuentes de información para su posterior indexación. Las fuentes de información pueden ser muy diversas que varían desde grandes repositorios de información con archivos en diferentes formatos electrónicos, aplicaciones o sitios web, bases de datos, etc. Ante la ausencia de homogeneidad de formato de los archivos los desarrolladores de aplicaciones para la gestión de la información debían buscar los diferentes filtros propios de cada formato de archivo e interactuar con sus APIs, simplemente con el fin de extraer el texto que se necesitaba de los documentos. Tika es un marco de trabajo desarrollado en Java y de código abierto que aloja plugins analizadores para cada tipo de documento admitido. Además, presenta una API de aplicación con la cual los desarrolladores de aplicaciones pueden interactuar para realizar la extracción de texto y los metadatos de un documento, independientemente del tipo de formato de los documentos[42]. La extracción de metadatos y contenido de documentos está soportada para múltiples formatos de documentos, entre los cuales están los documentos de: Microsoft Office (Excel, Word, PowerPoint, Visio, Outlook), Adobe Portable Document Format (PDF), Rich Text Format (RTF), Texto Plano HTML, XML, ZIP, TAR, GZIP, BZIP2. 1.2.3. Jung. JUNG 29 [43] (Java Universal Network/Graph framework) es una biblioteca de software de código abierto y escrita en Java que proporciona un lenguaje común y extensible para el modelado, análisis y visualización de datos que pueden ser representados como grafos o redes. Entre sus principales características se encuentran: •. Soporte para la representación de una variedad de entidades y sus relaciones, incluyendo grafos dirigidos o no dirigidos, grafos multi modales (grafos que contienen más de un tipo de vértice o arista), grafos con aristas paralelas (también conocidos como multigrafos), e hipergrafos (los que contienen hiperaristas, cada una de las cuales puede conectar cualquier número de vértices).. •. Mecanismos para la anotación de grafos, entidades y relaciones con metadatos. Los cuales, facilitan la creación de herramientas analíticas para conjuntos de datos. 29. Disponible en http://jung.sourceforge.net. 20.
(28) Capítulo 1. Acerca de la gestión de documentos. complejos que pueden examinar las relaciones entre entidades, así como los metadatos adjuntos a cada entidad y relación. •. Implementación de un número de algoritmos de la teoría de grafos, el análisis exploratorio de datos, análisis de redes sociales y aprendizaje de máquina. Estos incluyen: rutinas para el agrupamiento, la descomposición, optimización, la generación aleatoria de grafos, análisis estadístico y cálculos de las distancias en las redes, flujos, y medidas de ranking (centralidad, rango de página, HITS, etc.). 1.3. Sistemas gestores de documentos desarrollados en la UCLV. La gestión del conocimiento juega un rol importante en las universidades e institutos de investigación porque sus procesos son estables, generan y preservan valiosa información proveniente de diversos procesos, tienen acceso a importantes fuentes de información externa, poseen capital humano bien capacitado y buen desarrollo de las tecnologías de la información. En estas organizaciones se requiere el desarrollo de sistemas gestores de información y conocimiento en función de tareas específicas que tienen que asumir y en dependencia de las características y recursos de las mismas. Algunas de estas tareas son: recomendar a investigadores y docentes cómo enfrentarse a grandes volúmenes de artículos científicos al comenzar la revisión del marco teórico de un tema de investigación (toda nueva investigación comienza con una amplia revisión bibliográfica sobre el tema en cuestión), organizar materiales por equipos de estudiantes para la docencia, organizar por temáticas los artículos que le han llegado al comité científico de un evento, o tener una idea de las asociaciones que existen entre los documentos recuperados y así organizarlos. Estas tareas son ejemplos de necesidades de automatización sobre todo en las universidades cubanas, donde existen grandes depósitos centrales de información que se comparten y publican libremente. Por otra parte, el gran contenido de trabajo de los profesores e investigadores hace que el tiempo sea limitado y mucho mas si hay que enfrentarse a revisiones bibliográficas. Además, las tareas mencionadas, en su mayoría, tributan a la producción científica que se lleva a cabo en las universidades, actividad relevante que se refleja en un gran número de los indicadores para la medición del capital intelectual en estas organizaciones [44]. Debido a la gran necesidad que tiene principalmente las universidades de tener sistemas gestores de información, es que en [13] se propone un esquema general de aplicación que contribuye a una forma de transformación de la información en conocimiento, porque. 21.
(29) Capítulo 1. Acerca de la gestión de documentos. manipula documentos mediante el agrupamiento y post-agrupamiento, revelando el orden de los datos e imponiendo patrones en los grupos descubiertos. Este esquema general incorpora el agrupamiento y el post-agrupamiento para recomendar a los usuarios cómo enfrentarse a grandes colecciones textuales, mediante la organización y extracción de conocimiento de las mismas, contribuyendo a la gestión de información y conocimiento. La entrada a este proviene del resultado de un proceso de recuperación de información [45], de un servidor o colección personal de información textual. Las salidas son los grupos homogéneos de documentos afines, los términos relevantes y los documentos más representativos de cada grupo, así como los que se relacionan con ellos y la calidad con que fueron obtenidos los grupos; garantizando el control para la evaluación de los resultados del agrupamiento. En el Anexo 3 se muestran los cuatro módulos que conforman el esquema propuesto: Módulo 1. Recuperación de la información o especificación del corpus textual a procesar. Módulo 2. Representación del corpus textual obtenido o fijado por el usuario. Módulo 3. Agrupamiento de los documentos. Módulo 4. Valoración (validación y etiquetamiento) de los grupos textuales obtenidos. Una de las formas de creación de conocimiento se alcanza moviéndolo desde el nivel de individuos hasta el de grupos, durante cuatro etapas del ciclo de conversión del mismo: socialización, exteriorización, combinación e internalización [46]. Este esquema de aplicación contribuye a la manipulación del conocimiento partiendo del conocimiento codificado (explícito, repositorio de conocimiento compartido) y tributa a las dos últimas etapas del ciclo. Por un lado, se crea conocimiento explícito mediante el agrupamiento y valoración de los grupos textuales a partir de la recopilación del conocimiento explícito de múltiples fuentes. Así, se pone en práctica una de las formas de llevar a cabo la combinación: producir nuevo conocimiento explícito mediante la combinación (agrupamiento y organización) del conocimiento explícito acumulado [10]. Por otro lado, se recomienda a los usuarios cómo enfrentarse a la colección textual, y por tanto, tienen más elementos para personificar el conocimiento explícito y aumentar sus experiencias en el tácito. La estrategia de informatización del Centro de Estudios de Informática (CEI) de la Universidad Central “Marta Abreu” de Las Villas (UCLV), consta de cuatro componentes principales: el portal del centro, los servicios de apoyo a la docencia de pregrado y postgrado, los servicios de apoyo a la gestión administrativa y el módulo de información científicotécnica. Este último está formado por dos componentes principales: el repositorio de 22.
Figure

+7

Documento similar
dente: algunas decían que doña Leonor, "con muy grand rescelo e miedo que avía del rey don Pedro que nueva- mente regnaba, e de la reyna doña María, su madre del dicho rey,
Y tendiendo ellos la vista vieron cuanto en el mundo había y dieron las gracias al Criador diciendo: Repetidas gracias os damos porque nos habéis criado hombres, nos
Entre nosotros anda un escritor de cosas de filología, paisano de Costa, que no deja de tener ingenio y garbo; pero cuyas obras tienen de todo menos de ciencia, y aun
Fuente de emisión secundaria que afecta a la estación: Combustión en sector residencial y comercial Distancia a la primera vía de tráfico: 3 metros (15 m de ancho)..
La campaña ha consistido en la revisión del etiquetado e instrucciones de uso de todos los ter- mómetros digitales comunicados, así como de la documentación técnica adicional de
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
This section provides guidance with examples on encoding medicinal product packaging information, together with the relationship between Pack Size, Package Item (container)
95 Los derechos de la personalidad siempre han estado en la mesa de debate, por la naturaleza de éstos. A este respecto se dice que “el hecho de ser catalogados como bienes de
