Sistema automatizado de gestión de identidades
86
0
0
Texto completo
(2) Universidad Central “Marta Abreu” de Las Villas Facultad de Ingeniería Eléctrica Departamento de Automática y Sistemas Computacionales. TRABAJO DE DIPLOMA Sistema Automatizado de Gestión de Identidades. Autor: Alién Sorroche Salas [email protected] Tutor: Ing. Diana Laura García Gonzales [email protected]. Santa Clara 2011 "Año 53 de la Revolución".
(3) Hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ingeniería en Automática, autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicados sin autorización de la Universidad.. Firma del Autor Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Autor. Firma del Jefe de Departamento donde se defiende el trabajo. Firma del Responsable de Información Científico-Técnica.
(4) i. PENSAMIENTO. "Sólo el hombre que alberga en su espíritu la fuerza de la nobleza forja el camino de sus mayores logros.". José de Jesús Quintero.
(5) ii. DEDICATORIA. A mami y papi por confiar siempre en mí y dármelo todo sin pedir nada. A mi hermano por aconsejarme siempre y estar junto a mí en las buenas y las malas. A mi familia por su apoyo incondicional..
(6) iii. AGRADECIMIENTOS. No quisiera terminar este trabajo sin mencionar a personas que sobre todas las cosas me han tenido presente y me han demostrado que el cariño y la verdad existen. A Yordy, Payan, Raulito por encaminarme y darme el aliento necesario para continuar en estos 5 años de universidad. A los amigos del cuarto, Okier, Alfredo, Lemus, por estar siempre unidos a pesar de las dificultades y llegar juntos hasta el final. A los compañeros de aula, en especial a Kike por los consejos que siempre me daba cuando los necesitaba. A Yamiris y Lili por ser mis amigas y tenerme siempre presente. A mi tutora Diana por su apoyo, consejos y enseñanzas. A mis profesores por todos los conocimientos impartidos durante todo este periodo. A unas personitas que no porque las haya dejado para el final no significan mucho para mí. A Tay, Yadi, Mayara, que gracias a ustedes este año en la universidad ha sido diferente para mí. A todos los que han contribuido de una forma u otra para la realización de este sueño. A todos Gracias..
(7) iv. RESUMEN. El presente Trabajo de Diploma trata acerca del diseño y desarrollo de una propuesta para un Sistema Automatizado de Gestión de Identidades basado en la generación de una identificación para el personal de la Universidad “Marta Abreu” de Las Villas. Incluye un detallado estudio teórico sobre el tema, el proceso de modelado de la herramienta informática de acuerdo a los requerimientos de la organización, así como los aspectos relacionados con el soporte técnico elegido para la implementación. La herramienta informática desarrollada, con tecnología de software libre, facilita de manera automatizada los procesos de gestión y organización de los datos de los usuarios. Potencia la prestación de servicios de identificación de manera puntual con un amplio empleo de las tecnologías de la información además de resultar una alternativa local para el control de acceso en la Universidad..
(8) v. TABLA DE CONTENIDOS. PENSAMIENTO ....................................................................................................................i DEDICATORIA .................................................................................................................... ii AGRADECIMIENTOS ....................................................................................................... iii RESUMEN ...........................................................................................................................iv INTRODUCCIÓN ................................................................................................................. 1 Organización del informe ................................................................................................ 3 CAPÍTULO 1. 1.1. Que entendemos por gestión de información y gestión de contenidos ........ 4. 1.1.1 1.2. REVISIÓN BIBLIOGRÁFICA ................................................................ 4. La gestión de identidades como parte de la gestión de información ..... 6. Utilización de las tecnologías web para la creación de un Sistema. Automatizado de Gestión de Identidades .................................................................... 7 1.2.1. Arquitectura cliente-servidor......................................................................... 7. 1.2.2. Sitios dinámicos.............................................................................................. 8. 1.2.3. Sistema de Gestión de Contenidos (CMS) ................................................ 8. 1.2.4. Ejemplos de CMS ........................................................................................ 12. 1.3. El lenguaje PHP................................................................................................... 13. 1.3.1 1.4. Ventajas de PHP .......................................................................................... 14. Gestor de bases de datos MySQL ................................................................... 15. 1.4.1. Ventajas más significativas de MySQL ................................................... 15.
(9) vi 1.5. Generalidades de los sistemas de identificación automática ....................... 16. 1.5.1. Tipos de Sistemas de Identificación electrónicos ................................... 17. 1.5.2. Evolución histórica de los códigos de barras .......................................... 19. 1.5.3. Definición y principio de funcionamiento .................................................. 20. 1.5.4. Tipos de códigos .......................................................................................... 21. 1.5.5. Características de un código de barras .................................................... 23. 1.5.6. Código de barras como sistemas de identificación automática ........... 24. 1.6. Conclusiones del capítulo .................................................................................. 25. CAPÍTULO 2.. MATERIALES Y MÉTODOS ............................................................... 26. 2.1. Análisis del problema .......................................................................................... 26. 2.2. Método de solución ............................................................................................. 27. 2.2.1. Diseño del carnet características físicas ................................................. 30. 2.3. Metodología de diseño del sistema .................................................................. 31. 2.4. Selección del Drupal ........................................................................................... 33. 2.5. Principales componentes de Drupal................................................................. 36. 2.6. Módulos de Drupal .............................................................................................. 43. 2.6.1. Módulos nativos de Drupal ......................................................................... 44. 2.7. Utilización de módulos contribuidos ................................................................. 45. 2.8. Clase PHP para generar documentos en formato PDF ................................ 48. 2.9. Consideraciones del capítulo ............................................................................ 50. CAPÍTULO 3.. SISTEMA DE CARNET UCLV............................................................ 51. 3.1. Instalación de Drupal .......................................................................................... 51. 3.2. Sistema de Carnet UCLV ................................................................................... 52. 3.2.1. Configuración e implementación del sistema .......................................... 53.
(10) vii 3.2.1.1. Instalación de módulos ............................................................................ 53. 3.2.1.2. Configurando direcciones limpias .......................................................... 58. 3.2.1.3. Servicio de autentificación ...................................................................... 59. 3.2.1.4. Gestión de roles........................................................................................ 60. 3.2.1.5. Servicio de administración ...................................................................... 61. 3.2.1.6. Gestión de tipos de contenido ................................................................ 64. 3.2.1.7. Gestión de bloques .................................................................................. 65. 3.2.2. Generación del formato PDF, módulo propio. ......................................... 66. 3.3. Aplicabilidad, Impacto Social y Valor Económico. ......................................... 66. 3.4. Conclusiones del capítulo. ................................................................................. 68. CONCLUSIONES Y RECOMENDACIONES ................................................................ 69 Conclusiones .................................................................................................................. 69 Recomendaciones ......................................................................................................... 70 REFERENCIAS BIBLIOGRÁFICAS................................................................................ 71 ANEXOS .............................................................................................................................. 74 Anexo I. Configuración principal de la instalación de Drupal................................ 74. Anexo II. Carnet generado con el sistema sin exportar a PDF.......................... 76.
(11) INTRODUCCIÓN. 1. INTRODUCCIÓN. En los últimos años el acceso a la información ha cobrado una importancia inusitada en nuestra sociedad, el tráfico de información nos ha llevado a generar soluciones que automatizan el acceso, siendo más asequible, ágil e importante. Hablar de gestión de la información no resulta ser trivial. Son muchos los caminos y rutas por los que podemos ir en este terreno, pero el principal es el camino hacia el control de acceso. El control por el que se determina que usuarios pueden acceder a determinados datos, además del dónde, cómo y cuándo. Actualmente las empresas comparten información no ya solo entre los empleados de todas las categorías, sino entre sus proveedores y los clientes. La buena marcha de la organización dependerá en gran medida del flujo de información y de la disponibilidad de los datos en el momento adecuado, pero también de la confidencialidad de los mismos, de la seguridad de las transacciones de la información y de la posibilidad de acceso desde cualquier punto, etc. En definitiva, se plantea un marco donde fluye constantemente la información, pero guiado por las relaciones entre los agentes que intervienen. Dentro de este marco se requiere una automatización que lo haga viable, y ésta a su vez demanda orden para garantizar el flujo de la información entre los agentes correctos. Esto cobra mayor importancia si se sitúa en el plano virtual, es decir, en Internet. Es precisamente en la red donde se escenifica con mayor claridad el panorama descrito anteriormente. Garantizar el acceso a los datos de forma automática y con toda confianza es lo más importante para el buen funcionamiento de cualquier organización. La automatización del acceso a la información se tercia finalmente como el baluarte.
(12) INTRODUCCIÓN. 2. del crecimiento y el desarrollo en muchos aspectos de la vida, desde el orden económico hasta la educación o la industria (Microsoft TechNet, 2009). Cualquier organización necesita proteger la identidad de sus datos, como cuánta gente hay, qué derechos y qué recursos tiene cada persona. Es vital por tanto que la organización posea una estrategia de gestión de identidades, para ello se desarrollan los Sistemas de Gestión de Identidades. Nuestro país no está exento del uso de este tipo de sistemas, aunque es usado por pocos centros, mayoritariamente las empresas lo usan para el control de acceso y la protección de las identidades y privilegios del personal de la organización ya que está basado en la generación de un carnet con código de barras. Los Sistemas de Gestión de Identidades almacenan y mantienen accesibles los datos de los usuarios, poseen una gran funcionalidad al ser aplicables en diferentes organizaciones que requieran de este servicio ya que los mismos permiten obtener información rápida y oportuna sobre productos, servicios o localizaciones de dicha organización, además de proporcionar identificación única para cada usuario. Para la implementación de un servicio de este tipo en la universidad se desarrolló una herramienta denominada Sistema de Carnet UCLV especialmente utilizando software libre, el cual procesa los datos de los usuarios para luego exportar el carnet con dichos datos y su correspondiente código de barras, empleado como método de identificación en este caso, el cual permite el ingreso de información eliminando la posibilidad de error en la captura ya que es uno de los métodos de identificación codificada más sencillos y económicos de implementar en la práctica. Para cumplir con la labor investigativa de este trabajo se perfiló el siguiente objetivo general: . Diseñar e implementar un Sistema Automatizado de Gestión de Identidades sobre plataforma web que proporcione una identificación para los usuarios de la UCLV..
(13) INTRODUCCIÓN. 3. Para dar cumplimiento al objetivo general se plantean los siguientes objetivos específicos: . Realizar una revisión bibliográfica en la literatura disponible sobre sistemas de gestión de identidades así como sus aplicaciones, específicamente en sistemas basados en la generación de la identificación con código de barras.. . Evaluar y determinar las prestaciones a incluir en el software a desarrollar.. . Describir el proceso de diseño del sistema a desarrollar.. . Implementar un sistema gestor de identidades,. multiusuario con uso de. software libre. Organización del informe El informe queda estructurado de la siguiente forma, seguido de esta introducción, se cuenta con: tres capítulos, conclusiones, recomendaciones, referencias bibliográficas y anexos. En resumen los capítulos muestran lo siguiente: Capítulo 1 En el primer capítulo se abordará temáticas relacionadas con los sistemas de información, así como los principales métodos de identificación existentes en la actualidad, además se dará un esbozo de la tecnología que se utilizará en el sistema de gestión de identidades. Capítulo 2 En el capítulo 2 se describe la metodología para la construcción y el diseño de un Sistema Automatizado de Gestión de Identidades, se enfatizan las etapas para la selección del CMS indicado para el desarrollo de dicho sistema y por último se describen los principales componentes del CMS a emplear. Capítulo 3 En el capítulo 3 se hace una descripción del Sistema de Carnet UCLV en cuanto al proceso de desarrollo y un análisis del mismo..
(14) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 4. CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. En este capítulo se abordarán temas relacionados con los sistemas de gestión de información y contenido, los sistemas de identificación automática, así como las especificaciones y características de algunos de estos sistemas. Se presenta un análisis cronológico acerca del desarrollo del código de barras como sistema de identificación a lo largo de la historia. Además se describen los sistemas de identificación automática, su principio de funcionamiento y definición, se da una introducción a la tecnología que se utilizará para la creación del sistema de gestión y se caracterizará el código de barras, sistema de identificación el cual juega un papel importante en el desarrollo de esta investigación. Para finalizar se exponen las consideraciones finales del capítulo. 1.1 Que entendemos por gestión de información y gestión de contenidos Los servicios de información y documentación accesibles a través de Internet, más concretamente mediante servidores web, están aumentando de una forma exponencial en la actualidad. La lógica evolución de la web desde hace más de 10 años ha ido produciendo la sustitución de páginas y documentos estáticos por documentos generados dinámicamente, merced a la interacción del usuario con la lógica de procesos y flujos de trabajo definida por los creadores del servicio y a la disponibilidad de cada vez mayores repositorios de información. Evidentemente, se ha ido pasando progresivamente de un concepto de publicación de páginas web, bastante simple en su origen, a esquemas más complejos y diferenciados, fundamentados en procedimientos y técnicas basados en la gestión de información. La cada vez mayor complejidad de los servicios y de los sistemas que.
(15) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 5. los soportan, ha hecho necesaria la formulación de un corpus teórico y práctico en el que se combinen las técnicas clásicas de gestión de información en las organizaciones con las características propias del medioambiente digital. Esta evolución, que se ha acelerado durante la primera mitad de la década del 2000, ha tenido un impacto no sólo en los métodos y técnicas de gestión de información, sino también en la propia tecnología para la gestión de información y, en consecuencia, en el mercado de productos y servicios. Si bien en la segunda mitad de la década de los 90 se podía diferenciar entre productos para gestión documental, para recuperación de información, etc., desde el año 2000 se ha producido una convergencia entre todas las plataformas, de forma que en la actualidad se pueden encontrar soluciones que pretenden ser globales y ofrecer soporte a todo el proceso de gestión de información en una organización. Las herramientas para este trabajo han recibido la denominación de sistemas de gestión de contenidos (o Content Management Systems, CMS), y se han integrado con los sistemas de gestión documental y con los de recuperación de información. A ello hay que unir que, en la concepción actual de la gestión de información, el control de los procesos es un elemento nuclear, por lo que se acompañan de sistemas de workflow, o de flujos de trabajo. Con todo ello se puede delinear un paisaje en el cual las herramientas de gestión documental han ido incorporando a sus prestaciones las capacidades necesarias para gestionar los procesos que crean, almacenan, tratan y presentan información, en el entorno digital. Sin embargo, no por ello cabe afirmar que existe una igualdad directa entre los sistemas de gestión de contenidos y los sistemas de gestión documental. Se pueden encontrar en el mercado sistemas de gestión de contenidos que no ofrecen las prestaciones documentales que serían deseables, y viceversa. De la misma forma, no es posible igualar mediante una ecuación gestión de contenidos y gestión documental o records management, íntimamente relacionadas entre sí, pero iguales no. Sólo el estudio y la evaluación de las características y prestaciones presentes en las herramientas disponibles pueden determinar la adecuación de una solución en un contexto o problema dado. A ello cabe añadir.
(16) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 6. las diferencias existentes entre la gestión de contenidos para web y la gestión de contenidos para empresas, y que pueden encontrarse en los informes o documentos especializados que publican las propias compañías del sector. Si a esto se suma la complejidad creciente de muchos portales, tanto internos como externos, de las organizaciones, que son soportados por sistemas de gestión de contenidos, y a los procesos de publicación digital necesarios para su producción, los sistemas de gestión de contenidos se configuran como aplicaciones de varias escalas, que pueden llegar a alcanzar una alta complejidad. En la parte humana, las herramientas para gestión de contenidos sólo se pueden entender en un entorno de trabajo en colaboración y distribuido, ya que es en este tipo de ambientes donde se puede aprovechar todo su potencial. De la lectura de los párrafos anteriores se deduce que, frente a enfoques tradicionales de tratamiento documental pasivos, las herramientas actuales han llevado más allá los límites del tratamiento documental, ya que se han extendido hasta el proceso de creación, por su parte inicial, y al proceso de nueva publicación y de personalización, por su parte final. Esto configura ahora un esquema circular e iterativo para el tratamiento documental, a lo que se debe unir, entonces, la necesaria reflexión sobre el concepto y características de los documentos digitales. El ciclo de vida de los documentos digitales muestra significativos cambios sobre el ciclo de vida tradicional, al igual que el concepto de documento. Evidentemente, las actividades informativo-documentales deben reformularse para hacer frente al nuevo medioambiente digital (Glez, 2007). 1.1.1 La gestión de identidades como parte de la gestión de información Se podría definir la gestión de identidades como un tipo de gestión de información que permite a su vez sincronizar datos; cuentas de usuario, grupos, objetos etc. entre diferentes repositorios de naturaleza distinta. Un ejemplo seria poder sincronizar cuentas entre Microsoft Active Directory y una base de datos Oracle, logrando que cuando se diera de alta un usuario en Active Directory este mismo se replicará en la base de datos permitiéndose el acceso a.
(17) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 7. ambos sistemas con la misma cuenta, obviamente no queda limitado a la conexión de dos sistemas si no que se puede conectar tantos sistemas como se requiera. Esta funcionalidad se puede lograr mediante programas a medida o mediante soluciones de gestión de identidades, en el mercado hay varios fabricantes que han lanzado diferentes soluciones, algunas de estas son (Wordpress, 2009):. Oracle Identity Management Sun Identity Manager Microsoft Identity Lifecycle Management Novell Identity Manager 1.2 Utilización de las tecnologías web para la creación de un Sistema Automatizado de Gestión de Identidades En la actualidad, podríamos llegar a diferenciar los distintos tipos de aplicaciones en dos grandes grupos: las de escritorio y las web. Aunque este límite sea cada día más difuso; una aplicación de escritorio puede llegar a tener una interfaz web y, a través de un mismo lenguaje, se puede desarrollar una aplicación y luego definir si va a ser accesible por medio de un navegador o si se va a instalar en el equipo personal del usuario. Las aplicaciones web son aquellas que son accesibles, en general, a través de un navegador web. El usuario ingresa la dirección de ubicación conocida como URL, y comienza a interactuar con ella, tal cual como si se tratara de una aplicación de escritorio. 1.2.1 Arquitectura cliente-servidor Este concepto manejado en muchos tipos de aplicaciones y particularmente en las de interfaz web, podría ser definido como un juego de peticiones y respuestas. Un cliente requiere determinada acción, por ejemplo, a través de un enlace y el servidor deberá, por medio de un procesamiento resolver la demanda y devolver.
(18) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 8. una respuesta. En general, podríamos decir que la aplicación cliente por excelencia es el navegador web. En el lado del servidor pueden darse una serie de alternativas que desembocarán finalmente en construir una respuesta que sea claramente comprensible para el cliente. Entre estas alternativas podemos incluir el tratamiento de esta respuesta a través de un lenguaje de programación, por ejemplo, la extracción de información desde una base de datos, entre muchas otras posibles (Curso de Programación PHP). 1.2.2 Sitios dinámicos Ya dentro de las aplicaciones web, otra distinción posible podría ser aquella que está dada entre lo que serían sitios dinámicos y sitios estáticos. Un lenguaje de programación como el PHP, nos daría la posibilidad de modificar, en tiempo real, la respuesta enviada al cliente sin tener que variar el código de la página, pongamos por ejemplo un sitio que incluye un catálogo de productos, si utilizáramos páginas estáticas deberíamos crear un archivo diferente por cada producto. Con la utilización de lenguajes de programación y con la obtención de la información particular de cada ítem desde una fuente determinada por ejemplo, una base de datos, sólo necesitaríamos contar con un archivo cuyo contenido dinámico (nombre del producto, foto, descripción, etc.) sería modificado tomando como referencia a la petición del usuario (Curso de Programación PHP). 1.2.3. Sistema de Gestión de Contenidos (CMS). Un sistema de gestión de contenidos (en inglés Content Management System, abreviado CMS) es un programa que permite crear una estructura de soporte para la creación y administración de contenidos, principalmente en páginas Web, por parte de los participantes. Un CMS consiste en una interfaz que controla una o varias bases de datos, que guardan el contenido del sitio. Una de las principales ventajas es que separa contenido y el diseño, por lo que es posible manejar el contenido y darle en cualquier momento un diseño distinto al sitio sin tener alterar el contenido de.
(19) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 9. nuevo. Además permite la fácil y controlada publicación en el sitio por parte de varios editores (Cruañes, Rey, & Sala, 2007). Los CMS son aplicaciones prefabricadas altamente configurables que brindan la posibilidad de manipular contenidos de propósito general, aunque se pueden personalizar todo lo que se quiera. El principal objetivo de los CMS es proveer al desarrollador de una herramienta para la construcción de aplicaciones web que manipulen contenidos de forma dinámica minimizando la necesidad de conocimientos técnicos en cuanto a programación se refiere. Por otra parte los CMS brindan a los programadores expertos una plataforma altamente flexible para montar sus aplicaciones a través del desarrollo de plugins que se integran con el sistema, de esta forma el desarrollador puede hacer uso provechoso de las funcionalidades que brinda la plataforma. Según (Álvarez, 2008) en su artículo “Qué es un CMS” define CMS como: una herramienta que permite a un editor crear, clasificar y publicar cualquier tipo de información en una página Web. Generalmente los CMS trabajan contra una base de datos, de modo que el editor simplemente actualiza una base de datos, incluyendo nueva información o editando la existente. El gestor de contenidos facilita el acceso a la publicación de contenidos a un rango mayor de usuarios. Permite que sin conocimientos de programación ni maquetación cualquier usuario pueda indexar contenido en el portal. Además permite la gestión dinámica de usuarios y permisos, la colaboración de varios usuarios en el mismo trabajo, la interacción mediante herramientas de comunicación. También simplifica la actualización, respaldo y reestructuración del portal. La funcionalidad de los sistemas de gestión de contenidos se divide en cuatro categorías: creación de contenido, gestión de contenido, publicación y presentación. Creación de contenido Un CMS aporta herramientas para que los creadores sin conocimientos técnicos en páginas web puedan concentrarse en el contenido. Lo más habitual es.
(20) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 10. proporcionar un editor de texto WYSIWYG, en el que el usuario ve el resultado final mientras escribe, al estilo de los editores comerciales, pero con un rango de formatos de texto limitado. Esta limitación tiene sentido, ya que el objetivo es que el creador pueda poner énfasis en algunos puntos, pero sin modificar mucho el estilo general del sitio web. Hay otras herramientas como la edición de los documentos en XML, utilización de aplicaciones ofimáticas con las que se integra el CMS, importación de documentos existentes y editores que permiten añadir marcas, habitualmente HTML, para indicar el formato y estructura de un documento. Un CMS puede incorporar una o varias de estas herramientas, pero siempre tendría que proporcionar un editor WYSIWYG por su facilidad de uso y la comodidad de acceso desde cualquier ordenador con un navegador y acceso a Internet. Para la creación del sitio propiamente dicho, los CMS aportan herramientas para definir la estructura, el formato de las páginas, el aspecto visual, uso de patrones, y un sistema modular que permite incluir funciones no previstas originalmente. Gestión de contenido Los documentos creados se depositan en una base de datos central donde también se guardan el resto de datos de la web, cómo son los datos relativos a los documentos (versiones hechas, autor, fecha de publicación y caducidad, etc.), datos y preferencias de los usuarios, la estructura de la web, etc. La estructura de la web se puede configurar con una herramienta que, habitualmente, presenta una visión jerárquica del sitio y permite modificaciones. Mediante esta estructura se puede asignar un grupo a cada área, con responsables, editores, autores y usuarios con diferentes permisos. Eso es imprescindible para facilitar el ciclo de trabajo workflow con un circuito de edición que va desde el autor hasta el responsable final de la publicación. El CMS permite la comunicación entre los miembros del grupo y hace un seguimiento del estado de cada paso del ciclo de trabajo..
(21) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 11. Publicación Una página aprobada se publica automáticamente cuando llega la fecha de publicación, y cuando caduca se archiva para futuras referencias. En su publicación se aplica el patrón definido para toda la web o para la sección concreta donde está situada, de forma que el resultado final es un sitio web con un aspecto consistente en todas sus páginas. Esta separación entre contenido y forma permite que se pueda modificar el aspecto visual de un sitio web sin afectar a los documentos ya creados y libera a los autores de preocuparse por el diseño final de sus páginas. Presentación Un CMS puede gestionar automáticamente la accesibilidad de la web, con soporte de normas internacionales de accesibilidad como WAI (Web Accessibility Initiative), y adaptarse a las preferencias o necesidades de cada usuario. También puede proporcionar compatibilidad con los diferentes navegadores disponibles en todas las plataformas (Windows, Linux, Mac, Palm, etc.) y su capacidad de internacionalización lo permite adaptarse al idioma, sistema de medidas y cultura del visitante. El sistema se encarga de gestionar muchos otros aspectos como son los menús de navegación o la jerarquía de la página actual dentro del web, añadiendo enlaces de forma automática. También gestiona todos los módulos, internos o externos, que incorpore al sistema. Así por ejemplo, con un módulo de noticias se presentarían las novedades aparecidas en otra web, con un módulo de publicidad se mostraría un anuncio o mensaje animado, y con un módulo de foro se podría mostrar, en la página principal, el título de los últimos mensajes recibidos. Todo eso con los enlaces correspondientes y, evidentemente, siguiendo el patrón que los diseñadores hayan creado (Cruañes, Rey, & Sala, 2007). Debido a las prestaciones que poseen los CMS expuestas anteriormente se puede enunciar algunas de las ventajas más significativas de los mismos. Las ventajas de los CMS suelen ser:.
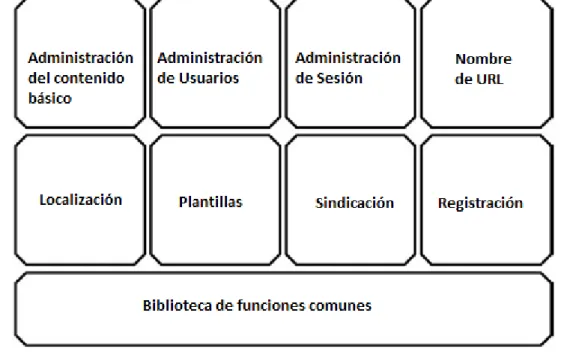
(22) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 12. Mantenimiento descentralizado, normalmente desde un navegador corriente. Edita desde cualquier sitio, en cualquier momento. Diseñado sin editores de contenido técnicos. Normalmente suelen incorporar editores WYSIWYG (What You See Is What You Get) que permiten editar sin conocimientos de HTML. Cooperación y restricciones de uso configurables. Se asigna roles y permisos que evitan modificar contenido si no se tiene permiso para ello. Se preserva la consistencia del diseño. El contenido de todos los autores se presenta con el mismo diseño, ya que el contenido se almacena de forma independiente al diseño. La navegación se suele generar automáticamente. Los menús se suelen generar de forma automática conforme a la creación de los contenidos, con lo que raramente un enlace apuntará a una página inexistente. La información se almacena en una base de datos. Esto permite utilizar el mismo contenido en diferentes páginas del sitio web. Contenido dinámico. Normalmente se puede incluir en las web extensiones que añaden funcionalidad (foros, encuestas, comercio electrónico, etc.). Un buen CMS además debería permitir instalar módulos realizados por el propio usuario (Hernández, 2009). Por lo tanto, gracias a la potente funcionalidad que brinda un CMS, se puede construir multitud de sitios web como webs corporativas o portales, comercio electrónico, pequeños sitios de negocios, webs de organizaciones, aplicaciones gubernamentales, intranets y extranets corporativas, webs de escuelas o agrupaciones, páginas personales o familiares, portales de comunidades, revistas, etc. 1.2.4. Ejemplos de CMS. Drupal: Es un CMS modular multipropósito y muy configurable que permite publicar artículos, imágenes, u otros archivos y servicios añadidos como foros, encuestas, votaciones, blogs, administración de usuarios y permisos. Es un sistema dinámico, el contenido textual de las páginas y otras configuraciones son.
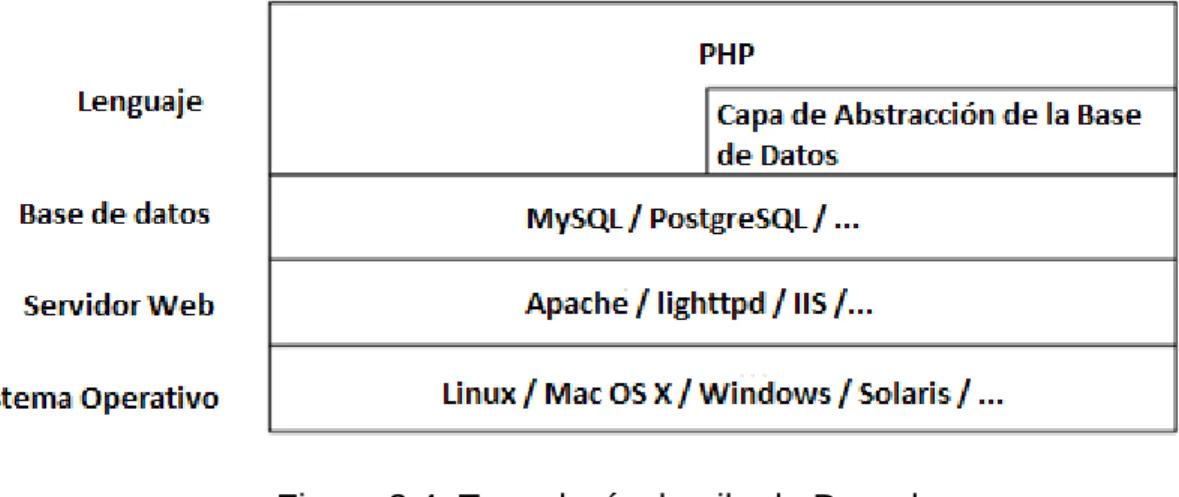
(23) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 13. almacenados en una base de datos y se editan utilizando un entorno Web. Es un programa libre, con licencia GNU/GPL, escrito en PHP, desarrollado y mantenido por una activa comunidad de usuarios. Destacado por la calidad de su código y de las páginas generadas, el respeto de los estándares de la Web, y un énfasis especial en la usabilidad y consistencia de todo el sistema. Joomla!: Es una aplicación de código abierto programada mayoritariamente en PHP bajo una licencia GPL. Este gestor de contenidos puede trabajar en Internet o intranets y requiere de una base de datos MySQL, así como, preferiblemente, de un servidor HTTP Apache. En Joomla! se incluyen características como: mejorar el rendimiento Web, versiones imprimibles de páginas, flash con noticias, blogs, foros,. polls. (encuestas),. calendarios,. búsqueda. en. el. sitio. Web. e. internacionalización del lenguaje. Entre sus principales virtudes está la de permitir editar el contenido de un sitio Web de manera sencilla. Wordpress: Es un CMS enfocado a la creación de blogs (sitios Web periódicamente actualizados). Desarrollado en PHP y MySQL, bajo licencia GPL y código modificable, tiene como fundador a Matt Mullenweg. Las causas de su enorme crecimiento son, entre otras, su licencia, su facilidad de uso y sus características como gestor de contenidos. Tiene una enorme comunidad de desarrolladores y diseñadores, que se encargan de desarrollarlo en general o crear plugins y temas para la comunidad. Cómo se mencionó anteriormente Drupal está programado en PHP y usa una base de datos MySql, a continuación se mustran algunos conceptos referentes a dichas tecnologías. 1.3 El lenguaje PHP Los autores Luke Welling y Laura Thomson en su libro Desarrollo Web con PHP y MySQL ofrecen una definición clara de PHP: PHP fue concebido en 1994 y es fruto del trabajo de un hombre, Rasmus Lerdorf. Es un lenguaje de secuencia de comandos de servidor diseñado específicamente.
(24) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 14. para la Web. Dentro de una página Web se puede incrustar código PHP que se ejecutará cada vez que se visite una página. El código PHP es interpretado en el servidor Web el cual genera un código HTML y otro contenido que el visitante verá. PHP es un producto de código abierto, lo que quiere decir que se puede acceder a su código, puede utilizarlo, modificarlo y redistribuirlo sin coste alguno. Las siglas PHP equivalían inicialmente a Personal Home Page (Página de inicio personal) pero se modificaron de acuerdo con la convención de designación de GNU y ahora equivale a PHP Hipertext Preprocessor (Preprocesador de hipertexto PHP) (Welling & Thomson, 2007). 1.3.1 Ventajas de PHP Entre las ventajas más significativas de PHP se encuentran: Es un lenguaje multiplataforma. Completamente orientado al desarrollo de aplicaciones Web dinámicas con acceso a información almacenada en una base de datos. El código fuente escrito en PHP es invisible al navegador y al cliente ya que es el servidor el que se encarga de ejecutar el código y enviar su resultado HTML al navegador. Esto hace que la programación en PHP sea segura y confiable. Capacidad de conexión con la mayoría de los motores de base de datos que se utilizan en la actualidad, destaca su conectividad con MySQL y PostgreSQL. Capacidad de expandir su potencial utilizando la enorme cantidad de módulos llamados ext's o extensiones. Posee una amplia documentación en su página oficial, entre la cual se destaca que todas las funciones del sistema están explicadas y ejemplificadas en un único archivo de ayuda. Es libre, por lo que se presenta como una alternativa de fácil acceso para todos. . Permite aplicar técnicas de programación orientada a objetos.. . Biblioteca nativa de funciones sumamente amplia e incluida..
(25) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. . 15. No requiere definición de tipos de variables aunque sus variables se pueden evaluar también por el tipo que estén manejando en tiempo de ejecución.. . Tiene manejo de excepciones desde PHP5.. 1.4 Gestor de bases de datos MySQL MySQL es un sistema de gestión de base de datos relacional, multihilo y multiusuario con más de seis millones de instalaciones. MySQL AB (desde enero de 2008 una subsidiaria de Sun Microsystems y esta a su vez de Oracle Corporation desde abril de 2009) desarrolla MySQL como software libre en un esquema de licenciamiento dual. El gestor de bases de datos MySQL se basa en el sistema de bases de datos relacionales, conocido por las siglas RDBMS (Relational Database Management System). Para poder establecer su gestión, el servidor MySQL utiliza un lenguaje propio interno basado en estructuras de consultas. Este lenguaje es conocido con el nombre de SQL (Structured Query Language) o lenguaje de consultas estructuradas. El estándar SQL adopta el modelo ANSI, basado en una normalización norteamericana (Curso de MySQL y PHP, 2008). Este gestor de bases de datos es, uno de los más usados en el mundo del software libre, debido a su gran rapidez y facilidad de uso. Esta gran aceptación es debida, en parte, a que existen infinidad de librerías y otras herramientas que permiten su uso a través de gran cantidad de lenguajes de programación, además de su fácil instalación y configuración. 1.4.1 Ventajas más significativas de MySQL MySQL cuenta con muchas ventajas, entre las que se encuentran las siguientes: Su implementación multihilo le permite aprovechar la potencialidad de sistemas multiprocesador. Alto rendimiento: MySQL es muy rápido. Bajo coste: está disponible de manera gratuita, bajo una licencia de código abierto..
(26) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 16. Facilidad de configuración y aprendizaje: MySQL resulta sencillo de configurar. Portabilidad: MySQL se puede utilizar en una gran cantidad de sistemas Unix diferentes así como bajo Microsoft Windows. Accesibilidad a código fuente: Como en el caso de PHP, puede obtener y modificar el código fuente de MySQL (Curso de MySQL y PHP, 2008). 1.5 Generalidades de los sistemas de identificación automática Desde los principios de la civilización el hombre ha intentado usar medios de identificación, el lenguaje, la vestimenta, los dibujos, los tatuajes fueron los primeros medios de identificación utilizados por el hombre. La escritura y los documentos evidenciaron la rápida evolución de estos medios de identificación ya que eran los caudales necesarios para llevar a cabo la identificación. Con el vertiginoso desarrollo de la sociedad y con la aparición de la fotografía los documentos tomaban un carácter más auténtico al estar complementado con la foto y la huella digital de cada individuo. Los sistemas de identificación se emplean para el manejo de información relativa a las personas y a los objetos. Para tal efecto se utilizan formas de registro magnético, óptico, sonoro e impreso. Generalmente, estos sistemas requieren de dos componentes fundamentales: un elemento codificado que contiene la información (datos procesados siguiendo alguna norma o patrón preestablecido) y un elemento con capacidad de reconocer la información. Posteriormente, el equipo lector se comunica con una computadora donde se realizan diversos procesos; en primer lugar, los datos son decodificados donde se transforman en información entendible para la computadora. A continuación, la información es verificada, comparada y aceptada para luego realizar alguna decisión lógica. De manera cotidiana los sistemas de identificación de personas pueden ser diversos para el acceso a una cuenta en un banco, a un área restringida, a una computadora, a una línea telefónica, a una empresa, a su casa, a los controles remotos, a las tarjetas de crédito, entre otros. Gracias a que los sistemas.
(27) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 17. modernos son automáticos, los procesos se agilizan, se cometen menos errores y en consecuencia se incrementa la confiabilidad y la eficiencia. Estos sistemas también son empleados para la identificación de objetos sobre todo cuando se destinan a usos comerciales. Cuanto mayor es la diversificación, esto es, cuando el número de artículos rebasa la capacidad de clasificación humana, más necesaria es la identificación exacta del producto. De tal manera que el industrial, el comerciante, distribuidor y cliente conocidos en el argot mercadológico como los elementos integradores de los canales de distribución puedan reconocer algunas características del producto como su lugar de origen, ubicación y destino, costo y precio de venta, verificación y control, contabilidad y administración, estadísticas e inventarios (Salgado, 2006). 1.5.1 Tipos de Sistemas de Identificación electrónicos Nos referimos a sistemas de identificación electrónicos, a los que de alguna manera puede acceder un diseñador de equipos electrónicos en aplicaciones típicas de identificación. Se pueden ver de una manera evolutiva en el tiempo y como se podrá comprobar ninguno de ellos hace desaparecer, por ahora, a los demás. Cada uno de ellos permite una aplicación en particular (Mayné, 2009). A continuación se enumerarán algunos de estos sistemas, especificando sus características principales. Identificación Biométrica Sistema que usa la identificación biológica que identifica como factor las características individuales de los organismos. Diferentes sistemas se han desarrollado de esta forma para la identificación de huellas dactilares, ADN, y patrones de retina. Generalmente estos equipos cuentan con cámaras de vídeo y/o conjuntos de células fotoeléctricas o mecánicas que están enlazadas con una computadora que contiene un programa que le permite reconocer forma, imágenes y productos, para control de calidad, posicionamiento, sistemas de inspección y seguridad (Aguirre, 2003)..
(28) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 18. Las Bandas Magnéticas Este es quizás uno de los sistemas de identificación más difundidos en la actualidad, principalmente por el uso de las tarjetas de crédito, tarjetas de identificación, tarjetas para el pago y control de servicios. La información se graba sobre segmentos de cinta magnética similar a la empleada en la elaboración de casetes musicales, pero es segmentada y adherida a alguna superficie que permita su manejo y lectura por los equipos destinados para este fin. Por ejemplo, en las tarjetas de crédito, el recubrimiento magnético es aplicado directamente sobre la tarjeta portadora. Cuando la cinta magnética pasa por el lector, la información es interpretada y procesada -esto es lo que ocurre cuando se paga en algún establecimiento con una tarjeta de crédito y de forma inmediata- se imprime el recibo correspondiente a la transacción comercial realizada (Salgado, 2006). Sistema de identificación por radiofrecuencia (RFID) El RFID es una tecnología que usa ondas de radio para identificar productos de forma automática, involucrando etiquetas o TAGS que emiten señales de radio a unos dispositivos llamados lectores, encargados de recoger las señales. Por su parte, (Brewer, Button, & Hensher, 2001) lo definen como una tecnología que permite administrar, identificar y realizar trazabilidad a productos y objetos a través del uso de etiquetas. En tanto, según (Er, Lian, & Lian, 2008), el RFID puede ser utilizado para identificar y seguir una variedad de objetos por medio de aplicaciones estáticas o dinámicas, tales como el control de activos y la trazabilidad logística, respectivamente. Los sistemas de identificación automática utilizando radio frecuencia (RF), pueden leer datos de etiquetas que incluso no son ópticamente visibles al sistema. Una señal de radio se transmite a través de una etiqueta y ésta responde con una señal de radio que es modulada con información ordenada en la etiqueta. Las etiquetas se pueden programar con datos, o pueden permitir que los datos sean cambiados en respuesta a comandos modulados en la señal de radio interrogante. La identificación a través de RF utiliza dos rangos de frecuencia diferentes: muy bajas (por debajo de los 300 KHz) o ultra alta (por encima de 1 GHz). Los.
(29) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 19. sistemas de alta frecuencia permiten rangos más altos, pero los costos también son más elevados. Los sistemas de baja frecuencia permiten una orientación de etiqueta más casual (Aguirre, 2003). Los códigos de barras Según (Myerson, 2006) el código de barras es una etiqueta electrónica leíble, pegada a los productos o contenedores, que proporciona información tal como origen, destino, tipo de producto, información de la factura, entre otros aspectos claves en la identificación del producto. Por su parte, (Espinal, López, & Motoya, 2010) lo define como una herramienta que sirve para capturar información relacionada con los números de identificación de artículos comerciales, unidades logísticas y localizaciones de manera automática e inequívoca en cualquier punto de la red de valor. Además, puede ser utilizado en la identificación y control de documentos, personas u objetos en procesos de intercambio de información y productos, tomando igual importancia tanto para quien entrega como para quien recibe, incluyendo el mejoramiento de la trazabilidad. Este tipo de sistema de identificación automática es el sistema más difundido que se tiene disponible, aplicado exitosamente a nivel mundial desde hace 20 años aproximadamente. 1.5.2 Evolución histórica de los códigos de barras La primera patente de código de barras fue registrada en octubre de 1952 (US Patent #2, 612,994) por los inventores Joseph Woodland, Jordin Johanson y Bernard Silver en Estados Unidos. La implementación fue posible gracias al trabajo de los ingenieros Raymond Alexander y Frank Stietz. El resultado de su trabajo fue un método para identificar los vagones del ferrocarril utilizando un sistema automático. Sin embargo, no fue hasta 1966 que el código de barras comenzó a utilizarse comercialmente. Para 1967 la Asociación de Ferrocarriles de Norteamérica (EE.UU) aplica códigos de barras para control de tránsito de embarques. El proyecto no duró mucho por falta de adecuado mantenimiento de las etiquetas conteniendo los códigos. A fines de los años 60 y comienzos de los 70 aparecieron las primeras aplicaciones industriales pero solo para manejo de.
(30) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 20. información. En 1969, Rust-Oleum fue el primero en interactuar un lector de códigos con un ordenador, el programa ejecutaba funciones de mantenimiento de inventarios e impresión de reportes de embarque. En el año 1973 se anuncia el código U.P.C. (Universal Product Code) que se convertiría en el estándar de identificación de productos. De esta forma la actualización automática de inventarios permitía una mejor y más oportuna compra y reabastecimiento de bienes. En 1975 pocos años después de la invención del transistor se presenta una ponencia en la Cámara de Comercio de los Estados Unidos que visualiza para 1975 una computadora automática que asignaría el precio de todos los artículos conforme fuesen pasando bajo "un ojo electrónico". A finales de la década de los sesentas un número de compañías e individuos empiezan a desarrollar en forma seria sistemas de identificación automáticos para supermercados con enfoques más prácticos. La tecnología de CCD (Dispositivo de Carga Acoplada) es aplicada en un escáner, 1981. En la actualidad este tipo de tecnología tiene bastante difusión en el mercado asiático, mientras que el láser domina en el mundo occidental. En ese año también aparece el código 128, de tipo alfanumérico. En 1990 se publica la especificación ANS X3.182, que regula la calidad de impresión de códigos de barras lineales. En ese mismo año, Symbol Technologies presenta el código bidimensional PDF417 (Cardona, 2001). 1.5.3 Definición y principio de funcionamiento Un código de barra puede ser descrito como un “Código Morse Óptico”. Es una serie de barras negras y espacios en blanco de diferentes anchos impresos en etiquetas para identificar ítems en forma única. Las etiquetas de código de barra se leen con un escáner que mide la luz reflejada e interpreta el código en números y letras que se transmiten a una computadora (Parets, 2009). Las etiquetas de código de barra se leen con un escáner que decodifica el código de barras a través de la digitalización proveniente de una fuente de luz que cruza el código y mide la intensidad de la luz reflejada por los espacios blancos. El patrón de la luz reflejada se detecta a través de un fotodiodo el cual produce una señal eléctrica que coincide exactamente con el patrón impreso del código de.
(31) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 21. barras. Luego esta señal es decodificada de regreso de acuerdo con la información original por circuitos electrónicos de bajo costo. Debido a que el diseño de muchas simbologías de código de barras no marca diferencia alguna, se puede digitalizar el código de barras de derecha a izquierda o viceversa (Cardona, 2001). 1.5.4 Tipos de códigos Los códigos de barras son establecidos por la Asociación Internacional de Numeración de Artículos (EAN) en común acuerdo con las asociaciones nacionales. La EAN proporciona un número de identificación conocido como FLAG, de dos o tres dígitos, para el país de origen del producto. Los códigos de barras se dividen en dos grandes grupos: los códigos de barras lineales y los códigos de barras de dos dimensiones. Existen dos simbologías privadas: . UPC (Universal Product Code) utilizado en Estados Unidos y Canadá.. . EAN (European Article Number) utilizado en el resto del mundo.. Códigos de Barras Lineales. Código 39 Código 39 (o Código 3 de 9) es el código de barras más utilizado para aplicaciones personalizadas. Es popular porque soporta tanto texto como números. (A–Z, 0–9, +, -, y <espacio>), y puede ser leído por casi todos los lectores de barras en su configuración por defecto, y es uno de los códigos de barras más antiguos. El Código 39 es un código binario o un código de 2 barras de ancho, y puede soportar cualquier número de caracteres que el lector pueda escanear. El Código 39 se utiliza específicamente a nivel militar y gubernamental. Se auto chequean y no son propensos a errores. No requiere de un checksum, pero se recomienda tenerlo (Parets, 2009). Código 93 El Código 93 es una versión comprimida del Código 39, y Código 39 Extendido. Esta simbología soporta los mismos caracteres que la del Código 39, pero en un.
(32) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 22. ancho menor de carácter. Es muy fácil de leer y muy seguro, pero muchos lectores no lo leen. El Código 93 tiene checksums automáticos. Código 128 Esta simbología es un código de barras muy compacto para todas las aplicaciones numéricas y alfanuméricas. El conjunto total de caracteres ASCII (128 caracteres) puede ser codificado en esta simbología sin los caracteres dobles que se encuentran en el Código 39. Si el código de barras tiene 4 o más números consecutivos (0-9), los números están codificados en modo de doble densidad (donde dos caracteres están codificados en una sola posición). El Código 128 también cuenta con 5 datos espaciales que no son caracteres de datos. Estos son usados para establecer los parámetros del lector o los parámetros de retorno. Actualmente, el Código 128 tiene tres diferentes subconjuntos de codificación. Tiene dos formas de comprobar los errores, por lo que es un código de barras muy estable. Necesita de checksums (Parets, 2009). UPC (Universal Product Code) UPC es el código de barras estándar para los artículos de venta al público. Es el código que se ve en los productos de los supermercados. UPC-A es una longitud fija y es solo numérica. Tradicionalmente la UPC contiene 1 dígito para el Sistema Numérico de Caracteres, 5 dígitos para el número de fabricante, 5 dígitos para el numero de producto, que combinados constituye el prefijo de la empresa designado por la UCC y la EAN.EL código de barras UPC puede ser impreso en dos formatos: uno completo de 12 dígitos (UPC-A) y uno comprimido de 8 (UPCE) Ambas formas exigen código de comprobación (Parets, 2009). EAN/JAN El EAN/JAN-13 y el EAN/JAN-8 son códigos similares a los códigos UPC y son asignados por la EAN para ser utilizados internacionalmente. La iniciativa Sunrise 2005 de la UCC exige a todas las empresas de América del Norte a actualizar sus sistemas para leer los códigos EAN/JAN como así también los códigos UPC. Estos códigos contienen un número variable de dígitos como código de país, un.
(33) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 23. prefijo de la compañía, una identificación del producto y un checksum (Parets, 2009). Códigos de barras bi-dimensionales PDF417 Es un código multifilas, continuo, de longitud variable, que tiene alta capacidad de almacenamiento de datos. El código consiste en un patrón de marcas (17,4), los subjuegos están definidos en términos de valores particulares de una función discriminadora, cada subjuego incluye 929 codewords (925 para datos, 1 para los descriptores de longitud y por lo menos 2 para la corrección de error) disponibles y tiene un método de dos pasos para decodificar los datos escaneados. Es un archivo portátil de datos (Portable Data File), tiene una capacidad de hasta 1800 caracteres numéricos, alfanuméricos y especiales. El código contiene toda la información, no se requiere consultar a un archivo. Cuenta con mecanismos de detección y corrección de errores: 9 niveles de seguridad lo que permite la lectura y decodificación exitosa aun cuando el daño del código llegue hasta un 40% (Parets, 2009). 1.5.5 Características de un código de barras Un símbolo de código de barras puede tener, a su vez, varias características, entre las cuales podemos nombrar: Densidad: Es la anchura del elemento (barra o espacio) más angosto dentro del símbolo de código de barras. Está dado en miles (milésimas de pulgada). Un código de barras no se mide por su longitud física sino por su densidad. WNR: (Wide to Narrow Ratio) Es la razón del grosor del elemento más angosto contra el más ancho. Usualmente es 1:3 o 1:2. Quiet Zone: Es el área blanca al principio y al final de un símbolo de código de barras. Esta área es necesaria para una lectura conveniente del símbolo..
(34) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 24. Figura 1.1. Características del código de barras.. 1.5.6 Código de barras como sistemas de identificación automática De los sistemas de identificación automática el más común en la actualidad por su versatilidad es el código de barras; más del 60% de los procesos industriales y comerciales son realizados con este tipo de método. El código de barras es un código de tipo binario con información, números, letras y símbolos codificados en un patrón impreso de barras y espacios de diferente grosor. Básicamente, los códigos de barras son leídos por el barrido de un pequeño punto de emisión luminosa a través de las barras. La fuente luminosa puede ser un simple lápiz óptico con un diodo emisor de luz o un complejo scanner de tipo láser manual o fijo, con puntos de luz en movimiento mecánica o electrónicamente. La información leída del código de barra se convierte en el computador para su manejo (Aguirre, 2003). La identificación automática o “Auto ID”, comprende el reconocimiento automático, decodificación, procesamiento, transmisión y grabación de datos a través de la impresión y lectura de la información codificada en los códigos de barras. Los códigos de barras permiten la lectura rápida, sencilla y precisa de los datos de los artículos que necesitan ser controlados o administrados. La aparición de sistemas de identificación automática, incluyendo los códigos de barras, impresoras correspondientes, escáneres, software, ha aumentado sustancialmente la velocidad, eficiencia y exactitud de la recopilación y entrada de datos. Las.
(35) CAPÍTULO 1. REVISIÓN BIBLIOGRÁFICA. 25. primeras aplicaciones de código de barras que incluían puntos de venta, seguimiento de ítems y control de inventario, se han ampliado para incluir aplicaciones más avanzadas como tiempo y asistencia, proceso de trabajo, control de calidad, selección, ingreso de pedidos, seguimiento de documentos por la vinculación de la producción, almacenamiento, distribución, ventas y servicios, a los sistemas de información de gestión en forma batch o en tiempo real (Parets, 2009). 1.6 Conclusiones del capítulo A partir de la revisión bibliográfica realizada se puede concluir que los sistemas de gestión de identidades son una alternativa que está tomando auge a nivel mundial por parte de las organizaciones que abogan por una mayor seguridad. Debido a esto, resulta factible el empleo de métodos de identificación que puedan dar cierta seguridad a la información manejada por estos sistemas, al permitir una mejor adquisición de los datos de forma automatizada. La implementación de sistemas de gestión de identidades sobre plataforma web puede brindar facilidades de uso para instituciones con grandes áreas de trabajo ya que es posible la creación de controles de acceso en diferentes puntos de dicha institución..
(36) CAPÍTULO 2. MATERIALES Y MÉTODOS. 26. CAPÍTULO 2. MATERIALES Y MÉTODOS. Aprovechar las potencialidades que las tecnologías web brindan en el desarrollo de servicios y sistemas de información, es una alternativa que las organizaciones dedicadas al manejo de información han de apropiarse para lograr automatizar parte de las prestaciones que las mismas ofrecen. La administración de grandes volúmenes de información, la posibilidad de que el acceso a los datos sea de forma automatizada, las potencialidades de poder obtener los datos desde una base de datos central, son algunas de las ventajas que traen consigo las aplicaciones tecnológicas en este sector. En este sentido aparece el Sistema de Carnet UCLV, servicio que provee del registro y almacenamiento de los datos de los usuarios para un posterior acceso de forma automatizada. En este capítulo se describirán una serie de decisiones tomadas durante la fase de diseño para poder lograr el producto final y que influyen en este, de forma crucial. En cada caso se discute el problema, las posibles alternativas de solución, la decisión tomada y el porqué de esta. Además se abordarán aspectos relacionados con el diseño, elección de tecnologías, implementación y puesta a punto de la aplicación desarrollada. 2.1 Análisis del problema El uso de un sistema manual para la generación de identidades así como el control de los datos de estudiantes y profesores en la UCLV, en la actualidad resulta un proceso engorroso, lento y con carencia de seguridad en el manejo de los datos, la implementación de un Sistema de Carnet UCLV que controle el.
(37) CAPÍTULO 2. MATERIALES Y MÉTODOS. 27. proceso de almacenamiento y acceso a los mismos es de primordial importancia, así como la generación de una ID que provea la información más significativa de cada usuario, de manera automática, lo cual simplificaría el trabajo de su elaboración así como el acondicionamiento de una herramienta útil para el control de acceso a diversas áreas de la UCLV, mediante la gestión de identidades. 2.2 Método de solución Teniendo en cuenta el problema que se plantea se hizo necesario el análisis de algunos factores que podrían influir en la posterior implementación del sistema. Para el diseño del carnet se utilizó el código de barras como método de identificación, el cual brinda la información fundamental de cada usuario como lo es el número de carnet de ID y número de trabajador o estudiante, además este método es uno de los más utilizados a nivel mundial y para su implementación no se necesitan muchos recursos. Para un mejor acceso desde cualquier lugar de la UCLV se tomó la plataforma web como vía de desarrollo. La implementación del sistema se realizó con DRUPAL, que es uno de los CMS más utilizados en la actualidad. El mismo ofrece características importantes para la programación ágil, como son módulos, gestión de usuarios, gestión de contenidos entre otras, pero la más importante en nuestro caso es que DRUPAL está libremente disponible bajo los términos de software libre y nos permite un montaje más sencillo y optimizado, además responde a las políticas de estandarización de la UCLV en la actualidad del uso de sistemas de gestión de contenidos sobre PHP y MySQL. El Drupal posee algunas ventajas con respecto a la gestión de usuarios, permite tanto la autentificación como el registro de los usuarios integrándolo con el servidor LDAP de la UCLV para la adquisición automática de los datos básicos, que ya se pueden encontrar en las bases de datos de secretaría, todo esto, mediante un módulo desarrollado y soportado actualmente en la comunidad, ”LDAP integration” con acceso libre y licencia “creative commons ”, lo que.
(38) CAPÍTULO 2. MATERIALES Y MÉTODOS. 28. significa, que posee un rango flexible y abierto para su modificación y utilización de manera gratuita y libre. Este sistema además debe permitir al usuario realizar varios tipos de búsquedas acerca de sus datos personales y brindar al usuario registrado, la posibilidad de rellenar un formulario en caso de algún error en sus datos o la actualización de ellos, puede también sugerir recursos que crea importante incluirlos en la base de datos del sistema, así como valorar y emitir comentarios acerca de los recursos del mismo. Los usuarios con mayores privilegios deben contar con interfaces para mantener actualizada la base de datos que sirve de soporte al sistema, deben también poder revisar y actualizar los datos de los usuarios entre otras. El Sistema de Carnet UCLV debe contar con tres usuarios, cada uno con roles diferentes al interactuar con el sistema, ellos son Usuario básico, Usuario de Recursos Humanos y Administrador. Cada uno de ellos debe estar asociado a diferentes tareas dentro del mismo.. Figura 2.1. Roles de los usuarios dentro del sistema. Usuario básico El sistema debe brindarle la posibilidad de poder utilizar el servicio de búsqueda para verificar sus datos. En caso de algún problema o error, debe proveérsele la.
(39) CAPÍTULO 2. MATERIALES Y MÉTODOS. 29. opción de llenar un formulario que será enviado a través del sitio al usuario encargado para corregir dicho problema. Usuario de Recursos Humanos De carácter más avanzado que el usuario básico, debe poseer privilegios para acceder a los directorios personales de los usuarios, revisar y poder cambiar los datos de los usuarios en caso de que sea necesario, así como la generación de la identidad para su posterior impresión. Administrador Usuario más avanzado que los anteriores, tiene la posibilidad de administrar la base de datos del sistema, editar/eliminar usuarios, configurar las propiedades de la aplicación, así como el mantenimiento del sitio. La siguiente imagen muestra una forma general de cómo debe quedar la estructura básica de interfaz del sistema.. Figura 2.2. Interfaz genérica que tendrá el sistema..
(40) CAPÍTULO 2. MATERIALES Y MÉTODOS. 30. 2.2.1 Diseño del carnet características físicas En la implementación del sistema se utilizará la librería TCPDF del lenguaje de programación PHP para habilitar la posibilidad de exportar a PDF el carnet generado por el sistema con cada uno de los campos correspondientes. Se utiliza el formato PDF debido a la disponibilidad de los recursos en la universidad, ya que este formato puede ser impreso en cualquier impresora con bajos recursos, es decir en una impresora de cinta, empleando cualquier tipo de papel, además este formato permite una gran movilidad al ser portable. Estos son algunos de los campos fundamentales que tendrá presente el carnet: . Nombre: aquí se escribirá el nombre del estudiante o profesor.. . Apellidos: en este campo se pondrán lo apellidos correspondientes al estudiante o profesor.. . Área: se pondrá el área de trabajo o facultad en caso de ser estudiante o trabajador.. . Ocupación: en este apartado se dirá la labor que desempeña en la universidad.. . No.Expediente: este acápite dirá el número de expediente del trabajador o estudiante.. Además de todos estos campos necesarios que debe poseer el carnet en su parte delantera, el mismo debe contar también con el logotipo de la UCLV lo que lo hace típico de nuestra entidad y una foto en la parte derecha del estudiante o del trabajador. Al reverso tendrá adjunto un mensaje que dirá lo siguiente: Este carnet es personal e intransferible. Es obligatorio su presentación a las autoridades universitarias que lo soliciten. Cuando culmine su relación laboral es obligatoria su entrega para recibir la baja. También posee un apartado donde firmará el estudiante o trabajador y en la parte inferior estará impreso el código de barras correspondiente que identificará a cada trabajador o estudiante. La siguiente figura muestra un típico carnet con código de barras el cual proporciona algunos datos de la persona que lo porta y el código de barras en su esquina inferior derecha..
Figure




+7




Documento similar
Se trata de la implementación en el aula de un proyecto de aprendizaje orientado a desarrollar competencias informacionales, utilizando una herramienta denominada “WebQuest”,
La implementación de la plataforma de software libre resulta viable, ya que permite a la organización ahorrar costos en renovación de licencias de software y su mantenimiento, lo
En este capítulo se ha realizado el desarrollo de la migración a software libre del módulo de matrícula de Akademos, utilizando la tecnología, el servidor Web y el gestor de base
Diseñar e implementar un sistema automatizado utilizando software libre para dispositivos Android con conexión inalámbrica y computadores, para la supervisión, control y adquisición
La implementación de la herramienta web para la gestión de pruebas de productos de software disminuirá el privilegio no supervisado sobre la ejecución de
Investigaciones recientes plantean que con la implementación de sistemas SCADA para la ges- tión de mantenimiento, se puede llevar el control del equipamiento pertenecientes
La presente investigación propone entre otras actividades el análisis, diseño e implementación de un software de apoyo al SGC para una cátedra, utilizando como metodología
-Se desarrolló una solución para automatizar la Gestión de la Información en los Centros de Rehabilitación de la salud, que da soporte a los procesos relacionados con el flujo
