Sistema de Base de Datos para la Gestión del Trabajo Científico en el grupo CAMD BIR
109
0
0
Texto completo
(2) Dictamen. Hago constar que el presente trabajo fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. _____________________ Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. _____________________. _____________________. Firma del tutor. Firma del jefe del Jefe del Laboratorio.
(3) Resumen. El grupo de investigación CAMD-BIR ubicado en la UCLV tiene la necesidad de gestionar sus trabajos científicos para contribuir a mejor la visibilidad de sus investigaciones. Para resolver la problemática anterior se decidió implementar una Sistema de Base de Datos con interfaz web. Uno de los aspectos fundamentales que tiene que cumplir un buen diseño de base de datos son las restricciones de integridad (RI) asociadas a los datos, porque su objetivo principal es mantener la integridad de la información lo cual depende de la validez y la completitud de los mismos . Al ser las RI una parte fundamental de cualquier aplicación de bases de datos, se decidió realizar un trabajo independiente con las RI tanto en el diseño como en la implementación del sistema. Se implementa una aplicación que gestiona los datos científicos, los exporta a diferentes formatos digitales, genera el “currículo Vitae” de los miembros del grupo de forma automática y dinámica, además mantiene la integridad, tanto en la interfaz (con PHP y JavaScript) como en la Base de Datos (a través de los recursos estándares de SQL), siendo en esta última donde se encuentran implementadas la mayoría de las RI. Este proyecto ha sido probado por los usuarios finales, para corregir cualquier imperfección.. Palabras Claves: base de datos, restricciones de integridad, trabajo científico..
(4) Abstract. The research group CAMD-BIR, located in the UCLV, has the need to manage their scientific work to contribute to better visibility of their research. To solve the previous problem it was decided to implement a database system with web interface. One of the key issues that has to meet a good database design are the integrity constraints (IC) associated with the data, because its main purpose is to maintain the integrity of the information which depends on the concepts validity and completeness of thereof. As it the IC a fundamental part of any application database, it was decided to realize an independent job with IC for design and implementation of the system. It implements a n application that manages the scientific data, the export to different digital formats, generates the "Curriculum Vitae" of the group members automatically and dynamically, and maintains the integrity, of both the interface (PHP and JavaScript) and Database (SQL standard resources), being in the latter which are implemented most IC. This project has been tested by the end users, to correct any imperfections.. Keywords: data base, integrity constraint, scientific work..
(5) Contenidos. Introducción. ..................................................................................................................1 1.. Consideraciones Generales. ...............................................................................5 1.1. Grupo CAMD-BIR ......................................................................................6. 1.2. Concepto de Restricción de Integridad (RI) ..........................................7. 1.3. Clasificación de las Restricciones de Integridad ..................................8. 1.3.1. Fuente ..................................................................................................8. 1.3.2. Alcance.................................................................................................9. 1.3.3. Causa de Violación ......................................................................... 10. 1.4. Niveles de Expresión ............................................................................. 11. 1.5. Lenguajes de Especificación ................................................................ 11. 1.5.1. OCL.................................................................................................... 12. 1.5.2. Alloy ................................................................................................... 14. 1.5.3. Comparación entre OCL y Alloy.................................................... 16. 1.6. Restricciones de Integridad en el Modelo Entidad/Relación ........... 17. 1.6.1. Atributo llave..................................................................................... 17. 1.6.2. Restricciones en los Tipos de Relaciones ................................... 18. 1.6.3. Restricciones en Generalización/ Especificación....................... 19. 1.6.4. Restricciones en jerarquías y mallas............................................ 21. 1.7. Restricciones de Integridad en el Modelo Relacional....................... 21. 1.7.1. Tipo o Dominio ................................................................................. 22. 1.7.2. Atributo .............................................................................................. 23. 1.7.3. Entidad .............................................................................................. 23. 1.7.4. Base de Datos.................................................................................. 24. 1.7.5. Transición ......................................................................................... 24. 1.7.6. Integridad de la Entidad.................................................................. 25. 1.7.7. Integridad Referencial..................................................................... 25. 1.8. Implementación de las Restricciones.................................................. 26. 1.9. Recursos de Bases de Datos ............................................................... 27. 1.10. Gestores de bases de datos relacionales. ......................................... 30.
(6) Contenidos. 2.. 1.11. Facilidades de los entornos Web ......................................................... 31. 1.12. Conclusiones del Capítulo .................................................................... 32. Análisis y Diseño del Sistema......................................................................... 33 2.1. Proceso de Análisis y Diseño del Sistema ......................................... 34. 2.2. Análisis de los Requisitos. .................................................................... 35. 2.2.1 2.3. Esquema Entidad Relación (E/R) ........................................................ 37. 2.3.1. Herramienta de diseño ERECASE. .............................................. 38. 2.3.2. Esquema E/R asociado al Sistema. ............................................. 39. 2.3.3. Representación de las RI obtenidas en el Esquema E/R ......... 41. 2.4. Esquema Relacional .............................................................................. 42. 2.4.1. 3.. RI en lenguaje Natural .................................................................... 36. Implementación de las RI obtenidas en MySQL. ....................... 42. 2.5. Actores y Casos de Uso ........................................................................ 46. 2.6. Diagramas de Transición de Estado. .................................................. 51. 2.7. Conclusiones del Capítulo. ................................................................... 56. Interfaz de Usuario. ........................................................................................... 57 3.1. Tecnología Utilizada............................................................................... 58. 3.1.1. HTML ................................................................................................. 59. 3.1.2. Java Script ........................................................................................ 59. 3.1.3. CSS.................................................................................................... 60. 3.1.4. JQuery ............................................................................................... 61. 3.1.5. PHP.................................................................................................... 62. 3.2. Componentes y Módulos del Sistema. ............................................... 62. 3.3. Interfaz Web ............................................................................................ 64. 3.3.1. Sitio de información pública. .......................................................... 64. 3.3.2. Sitio de Gestión de Datos. ............................................................. 68. 3.4. Manejo de las RI ..................................................................................... 77. 3.5. Requerimientos del Software. .............................................................. 80. 3.6. Pasos de Instalación. ............................................................................. 80. 3.7. Conclusiones del Capítulo .................................................................... 81. Conclusiones.............................................................................................................. 82.
(7) Contenidos Recomendaciones..................................................................................................... 84 Referencias Bibliográficas. ...................................................................................... 86 Anexos. ....................................................................................................................... 89 Anexo 1: Requisitos del sistema. ..................................................................... 90 Anexo 2:Restricciones de Integridad en Lenguaje Natural. ........................ 93 Anexo 3: Esquema Entidad /Relación............................................................. 95 Anexo 3.1: Sub-esquema de Personas ..................................................... 95 Anexo 3.2: Sub-esquema de Publicaciones.............................................. 95 Anexo 3.3: Sub-esquema de Cursos.......................................................... 96 Anexo 3.4: Sub-esquema de Eventos ........................................................ 96 Anexo 3.5: Sub-esquema de Tesis............................................................. 97 Anexo 3.6: Sub-esquema de Ficheros para Descargas.......................... 97 Anexo 4: Script SQL para implementar las RI complejas en MySQL. ....... 98.
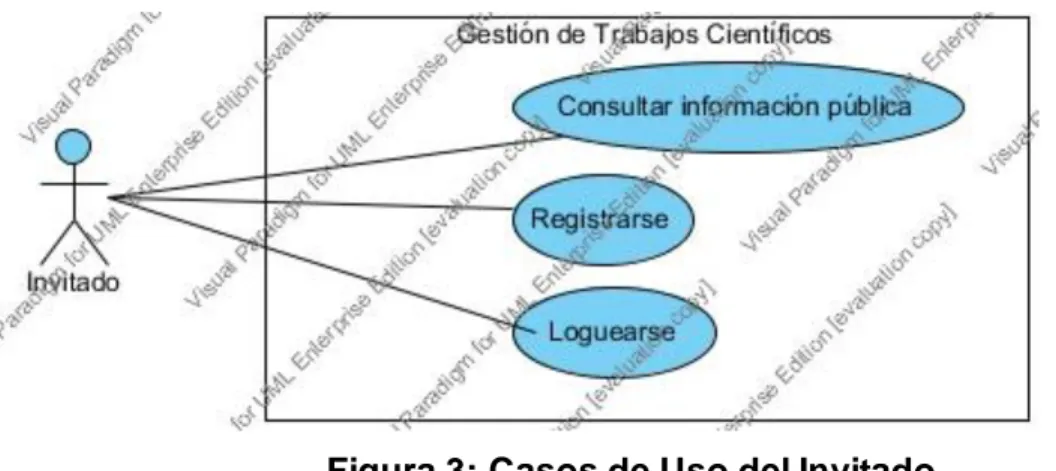
(8) Figuras. Figura 1: Proceso de Análisis y Diseño. ...................................................................35 Figura 2: Proceso de Integridad.................................................................................43 Figura 3: Casos de Uso del Invitado. ........................................................................47 Figura 4: Casos de Uso del Actor tipo Usuario. ......................................................47 Figura 5: Casos de Uso del Administrador de Usuarios. .......................................48 Figura 6: Casos de Uso del Administrador de datos de la Aplicación. ................49 Figura 7: Casos de Uso del Administrador de los datos Científicos. ...................50 Figura 8: Casos de Uso del Usuario Especial, Miembro Activo. ..........................51 Figura 9: Diagrama de Transición de Estados para Registrar un Usuario. ........52 Figura 10: Diagrama de Transición de Estados para Loquearse un Invitado. ...53 Figura 11: Diagrama de Transición de Estados para Insertar una Publicación. 54 Figura 12: Diagrama de Transición de Estados para Exportar Publicaciones. ..55 Figura 13: Componentes y Módulos del Sistema. ..................................................63 Figura 14: Página principal del Sistema. ..................................................................65 Figura 15: Página pública de Publicaciones. ...........................................................66 Figura 16: Página específica de Publicación. ..........................................................67 Figura 17: Página específica de Documento. ..........................................................67 Figura 18: Mensaje de descarga denegada. ...........................................................68 Figura 19: Menús Generales de Administración. ....................................................68 Figura 20: Menú de Administración con todos los privilegios. ..............................68 Figura 21: Menú Adicional para el Administrador de Usuarios.............................69 Figura 22: Menús Adicionales para el Administrador de la Aplicación. ...............69 Figura 23: Menús Adicionales para el Administrador de datos Científicos.........70 Figura 24: Menús Adicionales para el Usuario Especial........................................70 Figura 25: Página de Gestión de Publicaciones. ....................................................71 Figura 26: Formulario de Insertar/Actualizar Publicación. .....................................72 Figura 27: Error sobre que no hay datos seleccionados. ......................................72 Figura 28: Confirmación para Eliminar .....................................................................73 Figura 29: Formulario de Exportar tabla. ..................................................................73.
(9) Figuras Figura 30: Ventana de acción para descargas. .......................................................74 Figura 31: Formulario de búsqueda de Publicaciones. ..........................................74 Figura 32: Configuración General del Currículo Vitae............................................76 Figura 33: Configuración de los Aspectos de los Artículos (Publicaciones). ......76 Figura 34: Error de campo requerido. .......................................................................77 Figura 35: Error al subir un documento. ...................................................................78 Figura 36: Error de dependencias. ............................................................................79 Figura 37: Error al insertar una Publicación.............................................................79 Figura 38: Error de nombre de usuario incorrecto. .................................................79 Figura 39: Error de nombre de usuario ya existente. .............................................79.
(10) Introducción.. ~1~.
(11) Introducción El grupo de investigación: “Unit of Computer-Aided Molecular “Biosilico” Discovery and Bio-Informatic Research”, por sus ciclas CAMD-BIR, fue fundado por el Prof. Dr. Yovani Marrero Ponce como centro de investigación del Departamento de Farmacia (Facultad de Química y Farmacia) de la Universidad Central de Las Villas (UCLV). Las investigaciones que realizan están dedicadas al desarrollo de nuevos métodos computacionales, a la manipulación de la información química, a la minería de bases de datos para la búsqueda de compuestos líderes, a la generación de modelos de farmacólogos para el diseño de nuevos compuestos bioactivos. El grupo de investigación ofrece sus productos y servicios a varios equipos de investigación, departamentos y empresas del mundo. El objetivo principal del CAMD-BIR es el desarrollo y aplicación de métodos de quimio-bio-informáticas integrales para apoyar este ciclo húmedo-seco, y combinaciones de métodos bio-informáticos y quimio-informáticos para apoyar el descubrimiento de fármacos modernos. Este grupo de investigación necesita divulgar sus avances científicos, tanto teóricos como prácticos con el objetivo de mejorar la visibilidad de sus investigaciones. Por ello se define el siguiente problema científico: ¿Cómo contribuir con el grupo CAMD-BIR a la mejora de la visibilidad de las investigaciones, el almacenamiento y distribución de los datos científico– técnicos de sus investigadores, la obtención de los “currículos Vitae” y la distribución de los softwares que han producido? Para darle solución al problema científico se plantea la siguiente hipótesis de Investigación: El diseño e implementación de una aplicación informática que tenga en cuenta las restricciones de integridad, como solución para la Gestión del Trabajo Científico, le permitirá al grupo mejorar la visibilidad de las investigaciones, la gestión de los datos científicos-técnicos de sus investigadores, la obtención de los “currículos Vitae” y la distribución de los softwares que han producido.. ~2~.
(12) Introducción En correspondencia con la hipótesis planteada y para darle solución al problema científico formulado, esta investigación tiene como objetivo general: Desarrollar una aplicación informática para la gestión del trabajo científico desarrollado a partir del año 2007en el grupo CAMD-BIR de la UCLV, teniendo en cuenta las restricciones de integridad (RI) en cada fase del proceso, para facilitar su visibilidad consecuente a nivel nacional e internacional. Para cumplir con el objetivo general se definen los objetivos específicos: . Captar las RI asociadas a los datos de los trabajos científicos.. . Diseñar e implementar una BD para la gestión del trabajo científico que incorpore las RI en cada fase del proceso.. . Implementar una interfaz cliente vía web que sea amigable, sencilla y tenga en cuenta las RI para el manejo y visualización de la información.. Para resolver los objetivos generales y específicos se plantean las siguientes preguntas científicas: . ¿Qué RI están asociadas a los datos de los trabajos científicos?. . ¿Cómo diseñar e implementar una BD para la gestión del trabajo científico que incorpore las RI?. . ¿Cómo implementar una interfaz cliente vía web que sea amigable, sencilla y maneje las RI tanto en la visualización como gestión de los datos?. Como justificación del proyecto tenemos que: Al grupo CAMD-BIRl e es necesario la creación de este proyecto para mejorar la visibilidad de las investigaciones, la comunicación con especialistas y personas interesadas sobre los temas que investigan, el almacenamiento y distribución de los datos científicos – técnicos de sus investigadores, la obtención de los “currículos Vitae” y la distribución de los softwares que han producido. El proyecto tiene un aporte práctico-social porque al almacenar los datos de los trabajos científicos se podrá obtener el “currículo Vitae” de los miembros del grupo y estos datos se mostrarán en la web de forma actualizada.. ~3~.
(13) Introducción Aunque este proyecto está pensado para el grupo de i nvestigación CAMD-BIR tiene una utilidad futura y generalizadora porque se puede utilizar en los distintos grupos de investigación para llevar el control de los trabajos científicos siendo estos de vital importancia para los grupos investigativos y sus miembros. Como viabilidad de la investigación tenemos que: El grupo de investigación apoya el trabajo y está dispuesto a cooperar y participar en la investigación, pues está consciente de que se puede mejorar la visibilidad de las investigaciones, además de obtener el “currículo Vitae” si se diseña una aplicación informática que gestione los trabajos científicos. La estructura de la tesis es la siguiente: En el Capítulo 1, llamado Consideraciones Generales, se describe el grupo de investigación que presenta la necesidad a dar solución, se abordan aspectos de las RI en las bases de datos y de la tecnología web. El Capítulo 2, llamado Análisis y Diseño del Sistema, recoge todo el proceso de análisis y diseño, pasando por: la especificación de los requisitos, el modelado de la base de datos (Modelo E/R y Modelo Relacional) a la par del proceso de RI, muestra los casos de uso y algunos diagramas de transición de estados, además describe la implementación que se utilizará para las RI en el gestor de bases de datos. El Capítulo 3, llamado Interfaz de Usuario, recoge los aspectos relevantes de la aplicación web y los requerimientos de software e instalación.. ~4~.
(14) 1. Consideraciones Generales.. ~5~.
(15) Capítulo 1: Consideraciones Generales El presente capítulo aborda los temas relacionados con el grupo de investigación que presentó la necesidad a solucionar, las restricciones de integridad como componente esencial de una aplicación de bases de datos, los recursos de bases de datos para implementar las RI y las facilidades que brindan los entornos web como interfaz para aplicaciones informáticas. En la revisión bibliográfica asociada a las restricciones de integridad (RI) se obtuvo el concepto de RI, las clasificaciones por diferentes autores y los lenguajes de especificación para restricciones y recursos estándares del SQL. La importancia de este capítulo radica en tomar las decisiones para el análisis, diseño e implementación del sistema en cuestión. 1.1. Grupo CAMD-BIR. El grupo de investigación: “Unit of Computer-Aided Molecular “Biosilico” Discovery and Bio-Informatic Research”, por sus ciclas CAMD-BIR, fue fundado en el 2007 por el Prof. Dr. Yovani Marrero Ponce como centro de investigación del Departamento de Farmacia (Facultad de Química y Farmacia) de la Universidad Central “Marta Abreu” de Las Villas (UCLV). Ofrece una infraestructura informática a las investigaciones químicas, biotecnológicas y farmacéuticas. La colección de aplicaciones quimio-bio-informáticas del grupo de investigación cubre muchas áreas diferentes, que utilizan métodos modernos de diseño molecular (de fármacos). Las investigaciones que realiza están dedicadas al desarrollo de nuevos métodos computacionales, a la manipulación de la información química, a la minería de bases de datos para la búsqueda de compuestos líderes, a la generación de modelos de farmacólogos para el diseño de nuevos compuestos bioactivos. Algunos software que han realizado atienden a las necesidades de las disciplinas de investigación de hoy en día, incluyendo los estudios de QSAR / QSPR, modelación de proteínas, el diseño de estructuras basado en ligandos, el modelado molecular y simulaciones, cribado virtual de moléculas. En la actualidad, una de las mayores fortalezas del CAMD-BIR radica en la definición de nuevos descriptores moleculares y macromoleculares y el. ~6~.
(16) Capítulo 1: Consideraciones Generales descubrimiento biosílico de nuevas entidades químicas (NCE, según sus siglas en el inglés), así como estudios farmacocinéticas preliminares, la predicción de propiedades fisicoquímicas y toxicológicas. Además, CAMD-BIR aprovecha el conocimiento y tecnología propia para ampliar sus actividades de investigación en el área de docking y scoring functions (principalmente los nuevos enfoques de diseño de fármacos basados en la estructura), la homología de proteínas, las interacciones proteína-proteína, diseño y síntesis asistido por computadoras, la planificación de las reacciones orgánicas, la síntesis impulsado por el diseño y la predicción de la accesibilidad sintética de compuestos en la biblioteca combinatoria. El grupo de investigación ofrece sus productos y servicios a varios equipos de investigación, departamentos y empresas del mundo. El objetivo principal del CAMD-BIR es el desarrollo y aplicación de métodos de quimio-bio-informáticas integrales para apoyar este ciclo húmedo-seco, y combinaciones de métodos bio-informáticos y quimio-informáticos para apoyar el descubrimiento de fármacos modernos. 1.2. Concepto de Restricción de Integridad (RI). Una base de información contiene una representación del conocimiento que un sistema de información tiene sobre el estado de un dominio. El sistema de información obtiene este conocimiento de mensajes recibidos a través de una interfaz de la entrada. En un mundo perfecto, la base de información sería una representación exacta del dominio. Los mensajes de la entrada siempre serían correctos, y el sistema recibiría todos los mensajes importantes. En este mundo perfecto, la base de información contendría siempre sólo hechos verdaderos (sería válido) y todos los hechos importantes (estaría completo). La validez y completitud son los dos componentes de la integridad de una base de información. Una base de información mantiene la integridad cuando los hechos que contiene son válidos y contiene todos los hechos relevantes. Normalmente la falta de integridad tiene consecuencias negativas que en algunos casos pueden ser serios (Olivé, 2007).. ~7~.
(17) Capítulo 1: Consideraciones Generales En la mayoría de los sistemas, la integridad puede ser lograda sólo por la intervención humana. Para asegurar la integridad, se debe verificar los hechos sistemáticamente en la base de información contra el dominio. Es posible construir mecanismos en un sistema de información que garantice automáticamente algún nivel de integridad. Se definen las condiciones en la base de información para lograr algún nivel de confianza en la integridad de la base de información. Estas condiciones se definen en el modelo conceptual. Una restricción de integridad es una condición que no podría satisfacerse en algunos estados de la base de información o por algunos eventos, pero se entiende que el sistema de información incluirá los mecanismos para garantizar su satisfacción en cualquier momento (Olivé, 2007).. 1.3. Clasificación de las Restricciones de Integridad. Un modelo conceptual incluye las RI, las cuales se clasifican atendiendo a: . La razón por la que debe sostenerse (la fuente);. . Los hechos involucrados (el alcance);. . La causa de la violación.. 1.3.1 Fuente Según Olivé las restricciones atendiendo a la fuente se clasifican en analítico, el deóntico y empírico (Olivé, 2007). . Una restricción es analítica si su verdad sigue de la definición o significando de los hechos involucraron en él. Las violaciones de restricciones analíticas son debidas a los errores en la representación de hechos. Por ejemplo: Una puerta no puede ser abierta y cerrada al mismo tiempo.. . Una restricción es deóntica si expresa una condición que contiene el dominio debido a la imposición por algún agente autorizado. Este agente es la fuente de la restricción. Las violaciones de restricciones deónticas pueden ser causadas por los errores en la representación de hechos o. ~8~.
(18) Capítulo 1: Consideraciones Generales porque la conducta del dominio se desvía de la condición declarada. Por ejemplo: El salario de un empleado no puede disminuir. . Una restricción es empírica si expresa una condición que contiene el dominio empíricamente. Nadie ha declarado que la condición debe satisfacerse, pero el dominio se comporta y en cierto modo eso lo satisface. Las violaciones de restricciones empíricas pueden ser causadas por los errores en la representación de hechos o porque alguna excepción se ha levantado en el dominio. Por ejemplo: Un cliente no compra más de 999 unidades de cualquier artículo.. 1.3.2 Alcance Las restricciones son condiciones que deben satisfacerse por la base de información y los eventos. Normalmente, una restricción involucra sólo un juego limitado de hechos en la base de información y/o un juego limitado de eventos, esto permite clasificarlo según los hechos que involucra o el alcance de los mismos. Olivé (Olivé, 2007) distingue seis tipos los cuales son: . Una restricción estática involucra los hechos de un solo estado de la base de información, y debe satisfacerse en cada estado. Todos los lenguajes de modelado conceptual permiten definir las restricciones estáticas. Por ejemplo: Todos los empleados siempre se asignan a algún proyecto.. . Una restricción de transición involucra los hechos de dos o más estados de la base de información. Normalmente, una restricción involucra hechos de sólo dos estados consecutivos, reprimiendo la transición entre ellos, pero en general la restricción puede referirse a cualquier número de estados. Por la extensión, se usa también el término de "restricciones de la transición" para esas restricciones que sólo deben satisfacerse en algunos estados de la base de información. Por ejemplo: Un empleado no puede asignarse el mismo proyecto por más de un año.. ~9~.
(19) Capítulo 1: Consideraciones Generales . Una restricción de evento involucra sólo un evento. Por ejemplo: El depósito inicial de una nueva cuenta bancaria debe ser por lo menos de 50 pesos cubanos.. . Una restricción de historia de evento involucra dos o más eventos que ocurren en los mismos o diferentes momentos. Las restricciones de este tipo son a menudo usadas para definir las clasificaciones temporales permitidas de ocurrencias de evento. Por ejemplo: Un cliente no puede abrir dos cuentas en el mismo día.. . Una restricción global involucra los hechos de uno o más estados de la base de información y uno o más eventos. Por ejemplo: Un cliente no puede abrir una nueva cuenta si es un poseedor de alguna cuenta que se ha sobregirado para más de 30 días durante el último año.. . Una restricción de condición previa de evento (es un tipo particular de restricción global), involucra sólo un evento y el estado de la base de información cuando el evento ocurre. Hay muchas restricciones de condición previa de evento, y los lenguajes de modelado más conceptuales permiten su definición. Por ejemplo: Un miembro de la biblioteca no puede reservar un libro para un período de préstamo futuro si él ya tiene ese libro en un préstamo.. 1.3.3 Causa de Violación Una restricción puede violarse por la llegada de un mensaje de la entrada o por la ausencia de mensajes durante un intervalo de tiempo (Olivé, 2007). En el primer caso, se dice que la causa de la violación es el evento informado por el mensaje, y que la restricción es evento – violable. Por ejemplo: El sueldo de un empleado no puede disminuir. En el segundo caso, se dice que la causa de la violación es el paso de tiempo, y entonces la restricción es tiempo – violable. Por ejemplo: Todos los empleados deben reportar sus labores por lo menos una vez al mes.. ~ 10 ~.
(20) Capítulo 1: Consideraciones Generales 1.4. Niveles de Expresión. Las restricciones pueden expresarse de diversas formas, principalmente, según su depuración a lo largo del sistema o incluso en la manera en que se introduzcan a este. Es necesario señalar que existen varios modos a considerar, pero fundamentalmente, se definen tres niveles (Morgan, 2002): . Informal: este nivel proporciona una sentencia en lenguaje natural, sin un rango limitado de parámetros. Por ejemplo: Un cliente de cuenta de crédito debe tener por lo menos 18 años.. . Técnico: este. nivel combina. referencias a datos. estructurados,. operadores y restricciones con el lenguaje natural. Por ejemplo: CreditAccountself.customer.age >= 18 . Formal: este nivel proporciona sentencias conforme a una sintaxis definida, más cercana a propiedades matemáticas específicas. Por ejemplo: {X,. Y,. (cliente. X). (cuenta_de_credito. Y). (poseedor. X. Y)}. ==>(ed (edad X) 18) 1.5. Lenguajes de Especificación. Los lenguajes de programación, son lenguajes interpretables o traducibles por una computadora hacia una representación ejecutable. A diferencia de estos lenguajes, los lenguajes de especificación por lo general no son utilizados para implementar el sistema, sino para especificarlo, conceptualizarlo o incluso validarlo. Algunos lenguajes de especificación: . OCL es un lenguaje para la descripción formal de expresiones en los modelos UML.. . Alloy, lenguaje de especificaciones que utiliza la lógica de primer orden y se basa en el uso de relaciones.. . Autómatas es un formalismo utilizado para modelar sistemas discretos en general.. ~ 11 ~.
(21) Capítulo 1: Consideraciones Generales . B, lenguaje de descripción formal basado en la lógica de predicados.. . Redes de Petri formalismo equivalente a los autómatas, utilizado para la especificación de sistemas discretos paralelos o distribuidos.. . VHDL,. lenguaje. de. descripción. (e. implantación). de. circuitos. electrónicos. . Z, lenguaje de descripción formal basada en la prueba automática de teoremas usando la lógica.. . Z.120, estándar semiformal de la ITU-T para diagramas de flujo.. Vale la pena aclarar que OCL y Alloy son los más utilizados para especificar las RI en los modelos conceptuales, ya que estos modelos se brindan entidades y relaciones, las cuales son aprovechadas por estos lenguajes para referirse a los datos e imponer las restricciones.. 1.5.1 OCL OCL (Object Constraint Language, lenguaje de restricciones de objetos) es un lenguaje notacional, subconjunto del UML estándar industrial, que permite a los desarrolladores de software escribir restricciones sobre modelos de objetos (pre y postcondiciones, guardas, invariantes, valores derivados, restricciones sobre operaciones, etc.). Estas restricciones son particularmente útiles, en la medida en que permiten a los desarrolladores crear un amplio conjunto de reglas que rigen el aspecto de un objeto individual (Cuevas and Fernández, 2000). OCL ha sido parte de UML desde la versión 1.3 de UML. Como parte del proceso de estandarización de UML 2.0, la versión revisada 1.6 de OCL 2.0 fue aceptado por el Grupo de Dirección de Objeto (OMG) en marzo del 2003 y ha sido disponible al público (Yujing He, 2006). OCL tiene las características de un lenguaje de expresiones, un lenguaje de modelos y un lenguaje formal: . OCL es un lenguaje de expresiones puro. Esto significa que un estado del sistema nunca cambiará debido a una expresión OCL, incluso una expresión OCL podría usarse pa ra describir tal cambio de estado (por. ~ 12 ~.
(22) Capítulo 1: Consideraciones Generales ejemplo en una post-condición). Todos los valores de todos los objetos, incluidos los enlaces, no cambiarán. En cualquier momento en que se evalúa una expresión OCL, simplemente devuelve un valor. . OCL es un lenguaje de modelos y no un lenguaje de programación. No se puede escribir un programa lógico o un flujo de control en OCL. Especialmente, no se puede invocar procesos o activar operaciones no de consulta en OCL. Debido a que OCL es en primer lugar un lenguaje de modelos, no se puede asegurar que todo sea directamente ejecutable. Como lenguaje de modelos, todos los aspectos de implementación están fuera de alcance y no pueden expresarse en OCL. Cada expresión OCL es conceptualmente atómica. El estado de los objetos e n el sistema no puede cambiar durante la evaluación.. . OCL es un lenguaje técnico donde todos los constructores tienen un significado formal definido. La especificación de OCL es parte de la especificación de UML. OCL no tiene la intención de reemplazar los lenguajes formales existentes. Los lenguajes formales tradicionales se usaban por personas con conocimientos matemáticos, pero dificulta su uso para la mitad de empresas y modeladores de sistemas. OCL ha sido desarrollado para llenar este hueco.. Puesto que en un proyecto hay muchas personas involucradas (usuario, expertos, encargados del mantenimiento, etc.) los modelos deben ser entendidos por una amplia y variada audiencia. OCL es fácil de aprender y usar por los desarrolladores sin amplios conocimientos matemáticos. OCL tiene ciertas características que permiten a los desarrolladores adoptarlo a su ritmo y sólo donde lo necesiten. Hace accesibles las especificaciones formales con un trasfondo matemático limitado. Otro aspecto importante es que OCL no es un lenguaje completo en sí mismo. Muchos lenguajes formales mandan (o al menos se supone) que la especificación completa se escriba en el mismo lenguaje. Con OCL, no se necesita, incluso se tiene la posibilidad de escribir las especificaciones. ~ 13 ~.
(23) Capítulo 1: Consideraciones Generales completas en OCL. La intención de OCL es la de utilizarlo en combinación con los modelos visuales UML. Muchos aspectos de modelaje pueden expresarse mucho mejor usando diagramas visuales y OCL no intenta reemplazarlos por sus propios mecanismos. Por el contrario, toma la información expresada en los modelos visuales y permite al desarrollador acceder a esta información en las expresiones OCL. OCL es un lenguaje tipado, por lo que cada expresión OCL tiene un tipo. Para ser bien formada, una expresión debe concordar con los tipos de las reglas del lenguaje. Por ejemplo, no puede comparar un dato de tipo Integer con uno String. Cada clasificador definido en un modelo UML representa un tipo distinto en OCL. Además, OCL incluye un conjunto de tipos adicionales predefinidos (Cuevas and Fernández, 2000). OCL usa operaciones para describir las restricciones, estas despiertan algunos problemas en OCL. Por ejemplo, una operación puede entrar en un ciclo infinito o puede ser indefinido, y esto hace a OCL menos preciso. Otro problema es que las operaciones aplicadas a varias clases que tienen la relación de herencia, y entonces las operaciones pueden ser redefinidas por los objetos de esas clases. Por consiguiente, el significado de la expresión que contiene las operaciones puede ser ambiguo para decidir (Yujing He, 2006). 1.5.2 Alloy Alloy es un lenguaje del modelado estructural basado en la lógica de primer orden, por expresar complejas estructuras de restricciones y funcionamiento. El analizador de Alloy es un solucionador de restricciones que proporciona la simulación totalmente automática y chequeo. Alloy se ha desarrollado por el Grupo de Diseño de Software en MIT. El primer prototipo de Alloy salió en 1997, y era un lenguaje de modelado de objeto bastante limitado. Al contrario de un lenguaje de la programación, un modelo Alloy es declarativo: puede describir el efecto de un funcionamiento sin dar su mecanismo. Es similar en el espíritu a los lenguajes de la especificación formales como Z, VDM, Larch,. ~ 14 ~.
(24) Capítulo 1: Consideraciones Generales B, OBJ, etc., pero, al contrario de todos éstos, es dócil al análisis totalmente automático en el estilo de chequeo de un modelo. El lenguaje Z fue una influencia grande sobre Alloy. Muy aproximadamente, Alloy puede verse como un subconjunto de Z. A diferencia de Z, Alloy es de primer orden, que lo hace analizable (pero también menos expresivo). Los mecanismos de la composición de Alloy se diseñan para tener la flexibilidad del esquema de cálculo de Z, pero es basado en los diferentes lenguajes: la extensión por la suma de campos, similar a la herencia en un lenguaje orientado a objeto, y reutilizado de fórmulas por la parametrización explícita, similar a las funciones en un lenguaje de la programación funcional. Alloy es una pura anotación de ASCII (Jackson, 2011). Una meta del lenguaje Alloy es ser extraordinariamente pequeña y simple; tiene menos conceptos que los otros lenguajes (OCL, Z, VDM), y está en algunos respetos más flexible. Estos beneficios no son sin algún costo. Allo y es menos expresiva que los otros lenguajes. Considerando que las estructuras de Alloy son estrictamente de primero orden, B, VDM y Z todas las estructuras son de orden superior y tienen cuantificaciones de apoyo. El análisis del analizador de Alloy es totalmente automático, y cuando una afirmación se encuentra para ser falsa, el analizador Alloy genera un contraejemplo. Es un "refutador" en lugar de un "probador". Cuando un probador de teorema falla al demostrar un teorema, puede ser difícil decir lo que se ha salido mal: si el teorema es no válido, o si la estrategia de la prueba falló. Si el analizador de Alloy no encuentra ningún contraejemplo, la afirmación todavía puede ser no válida (Michael et al., 2011). La estructura de modelos de Alloy sólo se construirá de los átomos y relaciones. Se usan las relaciones para relacionar los átomos. Una relación puede ser vacía, unaria, binaria, ternaria, etc. Alloy sólo considera las relaciones finitas. Los conjuntos son representados con las relaciones unarias. Los escalares son representados con las relaciones de unarias de semifallo. Cada expresión denota una relación. Esto le permite al modelo de Alloy ser más sucinto.. ~ 15 ~.
(25) Capítulo 1: Consideraciones Generales Una función es simplemente una relación binaria que mapea los átomos en el lado izquierdo a lo sumo con un artículo en el lado derecho. Las expresiones en Alloy son construidas anidando operadores a la variable. Todas las expresiones son relaciones, y cada operador toma a uno o más operadores y devuelve también una relación. Para los operadores de conjuntos (por ejemplo la unión, la intersección, la diferencia), el orden de los elementos dentro de la estructura de tupla de una relación no es importante. Para operadores que indican relaciones (por ejemplo transponer, reflexivo, etc.),el orden de los elementos importa (Yujing He, 2006). 1.5.3 Comparación entre OCL y Alloy Alloy y OCL pueden usarse para especificar los requerimientos de diseño los sistemas de software complejos. Ellos pueden describir los estados de un sistema y las transiciones entre los estados. La sintaxis de Alloy es principalmente compatible con OCL, y los dos Alloy y OCL tienen sintaxis formal y semántica. OCL puede especificar las invariantes, condiciones previas, postcondiciones, y transiciones de estados en modelos de UML. Alloy es similar a OCL. La sintaxis y semántica de Alloy son más simples. Alloy es totalmente declaratorio, mientras OCL es declaratorio y operacional. La descripción en OCL se más orientada a objetos, y su sistema de tipo también está cerca al lenguaje orientado a objetos. El estilo de las expresio nes de Alloy es más declaratorio, para que pueda especificar el cálculo en términos de los datos de entrada sin una secuencia paso a paso de comandos. Aunque las notaciones de OCL son similares a las de Alloy, es más complicado para ser usado porque es aplicado en el contexto que incluye subclases, polimorfismo paramétrico, operadores de sobrecarga, herencia múltiple, etc. La sintaxis, semántica y gramática de OCL hace la descripción en OCL más verboso que la de Alloy. Alloy es un lenguaje modelado más simple comparado con OCL. Es más preciso, y es más dócil qué permite el análisis automático. Puede describir un sistema más precisamente que OCL. El analizador de Alloy puede verificar la. ~ 16 ~.
(26) Capítulo 1: Consideraciones Generales consistencia en el modelo. OCL es generalmente más expresivo que Alloy. Tiene más tipos de datos que Alloy. OCL tiene mucho más maneras de describir la arquitectura del sistema, sin embargo, las expresiones para especificar la relación son bastante poderosas en Alloy (Yujing He, 2006). Al comparar los rasgos y las diferencias entre los lenguajes de especificación OCL y Alloy se concluye que: OCL es más complicado, mientras que Alloy es más concisa. OCL es más ambiguo, mientras que Alloy es más exacta. OCL es más expresivo, mientras que Alloy es más abstracta. 1.6. Restricciones de Integridad en el Modelo Entidad/Relación. Elmasri y Navathe definen para el modelo Entidad/Relación los siguientes tipos de restricciones: . Atributo llave (o clave): obtener un atributo identificador de cada objeto de la entidad.. . Restricciones en los tipos de relaciones que pueden ser de cardinalidad y de participación (o cardinalidad mínima): para determinar la cantidad mínima y máxima de objetos de las entidades que intervienen en la relación.. . Restricciones en generalización/especialización que pueden ser de disjunción (disjunto o solapada) y de completitud (total o parcial): para determinar el tipo de generalización/especialización según a la relación entre las subclases.. . Restricciones en jerarquías y mallas: para definir el tipo de estructura.. 1.6.1 Atributo llave Una restricción importante en las entidades de un tipo de la entidad es la llave o restricción de unicidad en los atributos. Un tipo de la entidad normalmente tiene un atributo cuyos valores son distintos para cada entidad individual en el conjunto de la entidad. Tal atributo se llama un atributo llave, y sus valores pueden usarse para identificar cada entidad de forma única.. ~ 17 ~.
(27) Capítulo 1: Consideraciones Generales Especificando que un atributo es la llave de un tipo de entidad significa que la propiedad de singularidad precedente debe sostenerse para cada conjunto de entidad de un tipo de entidad. De ahí que, es una restricción que prohíbe a cualquiera de dos entidades tener el mismo valor al mismo tiempo en el atributo llave (Elmasri and Navathe, 2007). Por ejemplo: Un departamento se identifica unívocamente con un ID_Departamento. Otras consideraciones: . Algunos tipos de la entidad tienen más de un atributo llave.. . Un tipo de la entidad también puede no tener ningún atributo llave en ese caso se llama entidad débil.. 1.6.2 Restricciones en los Tipos de Relaciones Los tipos de relación normalmente tienen ciertas restricciones que limitan las posibles. combinaciones. de. entidades. que. pueden. participar. en. el. correspondiente conjunto de relaciones. Se pueden distinguir dos tipos principales de restricciones de relación: proporción de cardinalidad y participación. La restricción de proporción de cardinalidad para una relación binaria especifica el número máximo de casos de la relación en que una entidad puede participar. Las posibles proporciones de cardinalidad para los tipos de la relación binarios son 1:1, 1: N, N: 1, y M: N. La restricción de participación especifica si la existencia de una entidad depende de estar relacionado a otra entidad a través del tipo de la relación. Esta restricción especifica el número mínimo de relación de casos en que cada entidad puede participar, y a veces se llama restricción de cardinalidad mínima. Hay dos tipos de restricción de participación: total y parcial. La participación total también se llama la dependencia de existencia. Por ejemplo: Todo empleado trabaja para un departamento.. ~ 18 ~.
(28) Capítulo 1: Consideraciones Generales La participación es parcial, cuando alguno de los casos de una entidad se relaciona con alguno de los casos de otra entidad, lo que significa que la relación no es necesariamente con todos los casos. Por ejemplo: Uno de los empleados es el director de un departamento. (No significa que todos los empleados sean directores) En los diagramas de ER, la participación total (o dependencia de existencia) se despliega como una línea doble que conecta el tipo de la entidad participando a la relación, considerando que la participación parcial se representa por una sola línea (Elmasri and Navathe, 2007). 1.6.3 Restricciones en Generalización/ Especificación En general, se puede tener una o varias especializaciones definidas en el mismo tipo de entidad (o superclase). En algunas especializaciones se puede determinar las entidades que se volverán exactamente los miembros de cada subclase poniendo una condición en el valor de algún atributo de la superclase. Se llaman a tales subclases atributo-definido o condición-definida. Por ejemplo: Superclase: empleado Subclases: secretario, técnico, ingeniero Responden la condición: tipo de trabajo Este tipo de condición es una restricción que específica para qué atributo de la superclase (en el ejemplo: tipo de trabajo) se obtienen las subclases. La restricción de disjunción especifica que las subclases de la especialización deben ser disjuntas. Esto significa que una entidad puede ser un miembro a lo sumo de una las subclases de la especialización. Una especialización de atributo-definido implica que la restricción es de disjunción. Por ejemplo: Superclase: estudiante Subclases: externo y becado Un estudiante puede ser externo o becado, pero no de los dos tipos.. ~ 19 ~.
(29) Capítulo 1: Consideraciones Generales Si las subclases no se restringen para ser disjuntas, sus conjunto de entidades se pueden solapar; es decir, la entidad puede ser miembro de más de una de las subclases de la especialización. Por ejemplo: Superclase: estudiante Subclases: artista y atleta Un estudiante puede ser artista y también atleta. La restricción de completitud en la especialización, puede ser total o parcial. Un restricción de especialización total especifica que cada entidad de la superclase debe ser un miembro de por lo menos una subclase , en la especialización. Por ejemplo: Superclase: trabajador_de_escuela Subclases: docente y no_docente Los trabajadores docentes unidos con los no docentes forman todos los trabajadores de una escuela. Una restricción de especialización parcial permite que la entidad superclase pueda no pertenecer a cualquiera de las subclases. Por ejemplo: Superclase: empleado Subclases: gerente Hay algunos empleados que son gerentes. Las restricciones de disjunción y completitud son independientes. De ahí se obtienen las siguientes cuatro posibles restricciones en la especialización: . Disjunción total. . Solapamiento total. . Disjunción parcial. . Solapamiento parcial. Las reglas de inserción y eliminación que se aplican a la especialización y generalización. son. consecuencia. de. las. restricciones. especificadas. anteriormente. Según Elmasri y Navarthe (Elmasri and Navathe, 2007) algunas de estas reglas son como sigue: . Eliminar una entidad de una superclase implica que se elimina automáticamente de todas las subclases a la que pertenece.. ~ 20 ~.
(30) Capítulo 1: Consideraciones Generales . Insertar una entidad en una superclase implica que si la superclase es atributo-definido se inserta obligatoriamente en las subclases para que la entidad satisfaga el predicado definiendo.. . Insertar una entidad en una superclase de una especialización total implica que la entidad se inserta obligatoriamente en por lo menos una de las subclases de la especialización.. 1.6.4 Restricciones en jerarquías y mallas Una jerarquía de especialización tiene la restricción que cada subclase participa como una subclase en sólo una relación de clase/subclase; es decir, cada subclase tiene sólo un padre, es decir, produce una estructura del árbol. Por ejemplo: Superclase: Empleado Subclase1_empleado: secretario, técnico e ingeniero Subclase2_empleado: gerente Un empleado tiene un tipo de trabajo, pero además puede ser gerente. Para una malla de especialización, una subclase puede ser una subclase en más de una relación clase/subclase (Elmasri and Navathe, 2007). 1.7. Restricciones de Integridad en el Modelo Relacional. Según Date (Date, 2001) las restricciones de integridad que se clasifican para el Modelo Relacional son de tres tipos: de estado, de transición y metarestricciones. Las de estado se clasifican en cuatro grandes categorías: de tipo (dominio), de atributo, de entidad y de base de datos. Las meta-restricciones, son inherentes al modelo, se clasifican en integridad referencial y en integridad de la entidad. En esencia: . Una restricción de tipo especifica los valores válidos para un tipo dado. Por supuesto, los tipos de relación también están sujetos a las restricciones de tipo, pero dichas restricciones son básicamente solo una. ~ 21 ~.
(31) Capítulo 1: Consideraciones Generales consecuencia lógica de las restricciones de tipo que se aplican a los tipos escalares en términos de los cuales esos tipos de relación están (en última instancia) definidos. . Una restricción de atributo especifica el valor correcto de un atributo dado.. . Una restricción de entidad especifica los valores válidos de una entidad determinada.. . Una restricción de base de datos especifica el valor válido de una base de datos dada.. . Una restricción de transición son transiciones válidas de un estado correcto a otro.. . La integridad referencial promueve que la base de datos no contenga un valor de clave externa (foránea) sin correspondencia.. . La integridad de la entidad no permite que ningún componente de la clave primaria de cualquier entidad base acepte nulos.. 1.7.1 Tipo o Dominio Una restricción de tipo es una sola enumeración de los valores válidos del tipo, aunque algunas veces se expresan con rangos de valores, expresiones regulares o tipos de datos. Por ejemplo el peso de un objeto tiene que ser un valor positivo: TYPE PESO POSSREP ( RATIONAL) CONSTRAINT THE_PESO( PESO) > 0.0 ; Siempre se puede pensar, por lo menos conceptualmente, que las restricciones de tipo son verificadas durante la ejecución de alguna invocación al selector. Como consecuencia, se dice que las restricciones de tipo son verificadas de inmediato y por lo tanto, que ninguna entidad puede adquirir nunca un valor para ningún atributo de cualquier tupla si este no es del tipo apropiado (por supuesto, en un sistema que maneja las restricciones de tipo) (Date, 2001).. ~ 22 ~.
(32) Capítulo 1: Consideraciones Generales 1.7.2 Atributo Una restricción de atributo es básicamente solo una declaración para que un atributo especificado sea de un tipo en particular. Por ejemplo, considere la definición de la entidad de proveedores: VAR V BASE RELATION{ V# V#, PROVEEDOR NOMBRE, STATUS INTEGER, CIUDAD CHAR } En esta entidad, los valores de los atributos V#, PROVEEDOR, STATUS y CIUDAD están restringidos a los tipos V#, NOMBRE, INTEGER y CHAR, respectivamente. En otras palabras, las restricciones de atributo son parte de la definición del atributo en cuestión y pueden ser identificadas por medio del nombre de atributo correspondiente. De aquí que una restricción de atributo solo pueda ser eliminada mediante la eliminación del propio atributo (lo cual, en la práctica significa generalmente eliminar la entidad que lo contiene). En principio, cualquier intento de introducir un valor de atributo que no sea un valor del tipo relevante dentro de la base de datos, será simplemente rechazado. Sin embargo, en la práctica esta situación nunca deberá presentarse en tanto el sistema haga cumplir las restricciones de tipo (Date, 2001). 1.7.3 Entidad Una restricción de entidad es la que es impuesta a una entidad individual (esta se expresa solamente en términos de la entidad en cuestión, aunque en otros aspectos puede ser compleja). Por ejemplo, los proveedores en Londres deben tener un status de 20: CONSTRAINT R5V IS-EMPTY( V WHERE CIUDAD = 'Londres' AND STATUS = 20) ; Las restricciones de entidades siempre son verificadas de inmediato (en realidad, como parte de la ejecución de cualquier instrucción que pudiera ocasionar que fueran violadas). Por lo tanto, cualquier instrucción que intente. ~ 23 ~.
(33) Capítulo 1: Consideraciones Generales asignar un valor a una entidad dada que viole cualquier restricción para esa entidad, será en efecto rechazada (Date, 2001). 1.7.4 Base de Datos Una restricción de base de datos es aquella que relaciona dos o más entidades distintas. Por ejemplo, ningún proveedor con status menor que 20 puede suministrar parte alguna en una cantidad superior a 500: CONSTRAINRT1 BD IS-EMPTY((V JOIN VP)WHERE STATUS<20 ANDCANT> CANT(500)) La verificación de restricciones de base de datos no puede hacerse de inmediato, sino que debe diferirse hasta el final de la transacción; es decir, al momento del COMMIT. Si se viola una restricción de base de datos al momento del COMMIT, la transacción será deshecha (Date, 2001). 1.7.5 Transición Las restricciones de transición sobre transiciones válidas de un estado correcto a otro. Por ejemplo, en una base de datos que hiciera referencia a personas, podría haber una serie de restricciones de transición para los cambios en el estado civil. Por ejemplo las siguientes transiciones son válidas (Date, 2001): . De soltero a casado. . De casado a viudo. . De casado a divorciado. . De viudo a casado. (etcétera), en tanto que las siguientes no lo son: . De soltero a viudo. . De soltero a divorciado. . De viudo a divorciado. . De divorciado a viudo. La verificación es diferida al momento del COMMIT. ~ 24 ~.
(34) Capítulo 1: Consideraciones Generales 1.7.6 Integridad de la Entidad El modelo relacional ha requerido históricamente que (al menos en el caso de las entidades base) se elija una sola clave candidata como clave primaria para la entidad en cuestión. Se dice entonces que las claves candidatas restantes, en caso de haberlas, son claves alternas, y luego, junto con el concepto de clave primaria, el modelo ha incluido la siguiente "meta-restricción" o regla: No está permitido que ningún componente de la clave primaria de cualquier entidad base acepte nulos. Según Date (Date, 2001) las razones para esta regla son las siguientes: . Las tuplas en las relaciones base representan entidades en la realidad;. . Las entidades en la realidad son identificables por definición;. . Por lo tanto, sus contrapartes en la base de datos también deben ser identificables;. . Los valores de la clave primaria sirven como esos identificadores en la base de datos;. . Por lo tanto, los valores de clave primaria no pueden estar "faltantes".. 1.7.7 Integridad Referencial La integridad referencial es una propiedad deseable en las bases de datos. Gracias a la integridad referencial se garantiza que una entidad (fila o registro) siempre se relaciona con otras entidades válidas, es decir, que existen en la base de datos. Implica que en todo momento dichos datos sean correctos, sin repeticiones innecesarias, datos perdidos y relaciones mal resueltas. La integridad referencial se define como: La base de datos no debe contener ningún valor de clave externa que no concuerde. Queda claro que la regla de integridad referencial necesita cierto refinamiento, ya que las claves externas deben, en apariencia, permitir nulos y obviamente los valores nulos de la clave externa violan la regla tal como se establece. De hecho, se puede mantener la regla como está establecida, siempre y cuando se. ~ 25 ~.
(35) Capítulo 1: Consideraciones Generales entienda adecuadamente la definición del término "valor de clave externa que no concuerde". Para ser específicos, se define un "valor de clave externa que no concuerde" como un "valor de clave externa no nulo", en alguna entidad referente, para la cual no exista un valor que concuerde en la clave candidata relevante en la entidad relevante a la que se hace referencia (Date, 2001). 1.8 Implementación de las Restricciones. Las restricciones se pueden representar formalmente de disímiles maneras e incluso. pueden existir diferentes. técnicas. para. una. misma.. Morgan. (Morgan, 2002) plantea que fundamentalmente es posible implementar las RI a través de: los lenguajes de programación, los script y en la base de datos, tal que en un sistema se pueden utilizar algunos o todos de ellos. Lenguajes de Programación: Las restricciones incorporadas en el código del programa, probablemente, son la vía de aplicación más común. Es posible utilizar sentencias normales de un lenguaje de programación para implementar una restricción. El requisito mínimo es tener una forma de seleccionar, entre las ramas del código, una alternativa basada en una condición dada. Esto es bastante fácil de satisfacer en cualquier lenguaje de programación, aunque los detalles pueden variar de uno a otro. Scripts: La principal ventaja de los scripts es que al encontrarse en la aplicación cliente son muy veloces, aunque tienen algunos puntos negativos. De estos el fundamental es la dificultad en su manejo y modificación. Bases de Datos: Es probable que las restricciones encajen más naturalmente dentro de la base de datos, donde pueden tener un contacto más directo con los datos según aclara Morgan (Morgan, 2002). Lo más habitual es utilizar las restricciones respecto a palabras funcionales que estén alrededor de lo básico (CREATE, READ, UPDATE y DELETE). Estos mecanismos son comunes a todos los servicios de datos.. ~ 26 ~.
(36) Capítulo 1: Consideraciones Generales 1.9 Recursos de Bases de Datos El lenguaje estructurado de consultas (Structured Query Language, SQL) estándar en sus múltiples revisiones ofrece varios recursos de manejo de datos que se analizan en este epígrafe para seleccionar a la postre los más convenientes en la implementación de las RI. Restricciones (Constraints) CHECK: Las restricciones CHECK exigen la integridad del dominio mediante la limitación de los valores que puede aceptar una columna. Se puede crear una restricción CHECK con cualquier expresión lógica (booleana) que devuelva verdadero o falso basándose en operadores lógicos (Oppel and Sheldon, 2008). Es posible aplicar varias restricciones CHECK a una sola columna y a varias columnas si se crea a nivel de la tabla. Así se pueden comprobar varias condiciones en un mismo sitio. Una restricción CHECK devuelve TRUE cuando la condición que está comprobando no es FALSE para ninguna fila de la tabla. Si una tabla recién creada no tiene filas, cualquier restricción CHECK en esta tabla se considerará. válida. Esta situación puede generar resultados. inesperados al igual que en las instrucciones DELETE dado que las restricciones CHECK no se validan en ellas (MSDN, 2008). Desencadenadores (Triggers): Los desencadenadores son una clase especial definida para la ejecución automática al emitirse una instrucción UPDATE, INSERT o DELETE en una tabla o una vista. Son una herramienta eficaz que pueden utilizar los sitios para exigir automáticamente las reglas comerciales cuando se modifican los datos. Amplían la lógica de comprobación de integridad, valores predeterminados y reglas del estándar SQL, aunque se deben utilizar las restricciones y los valores predeterminados siempre que estos aporten toda la funcionalidad necesaria (Melton and Simon, 2002). Los desencadenadores pueden consultar otras tablas e incluir instrucciones SQL complejas. Son especialmente útiles para exigir reglas o requisitos complejos. También son útiles para exigir la integridad referencial, que conserva las relaciones definidas entre tablas.. ~ 27 ~.
(37) Capítulo 1: Consideraciones Generales CREATE TRIGGER debe ser la primera instrucción en el proceso por lotes y solo se puede aplicar a una tabla. Un desencadenador se crea solamente en la base de datos actual; sin embargo, un desencadenador puede hacer referencia a objetos que están fuera de la base de datos actual (MSDN, 2008). Vistas (Views): Una vista es una tabla virtual cuyo contenido está definido por una consulta. Al igual que una tabla real, una vista consta de un conjunto de columnas y filas de datos con un nombre. Suelen utilizarse para centrar, simplificar y personalizar la percepción de la base de datos para cada usuario (Melton and Simon, 2002). Las vistas se pueden utilizar para realizar particiones de datos y para mejorar el rendimiento cuando estos se copian. Además, permiten a los usuarios centrarse en datos de su interés y en tareas específicas de las que son responsables. Los datos innecesarios pueden quedar fuera de la vista; de ese modo, también es mayor su seguridad, dado que los usuarios solo pueden ver los definidos en la vista y no los que hay en la tabla subyacente (MSDN, 2008). Funciones definidas por el usuario (Functions): Al igual que las funciones en los lenguajes de programación, las funciones definidas por el usuario (MSDN, 2008) son rutinas que aceptan parámetros, realizan una acción, como un cálculo complejo, y devuelven el resultado de esa acción como un valor. Son múltiples las ventajas de las funciones definidas por el usuario entre las cuales se tienen: . Permiten una programación modular.. . Permiten una ejecución más rápida.. . Pueden reducir el tráfico de red.. Procedimientos Almacenados (Stored Procedure): Los procedimientos almacenados pueden facilitar en gran medida la administración de la base de datos y la visualización de información sobre esta y sus usuarios. Son una colección pre -compilada de instrucciones SQL e instrucciones de control de flujo opcionales, almacenadas bajo un solo nombre. ~ 28 ~.
(38) Capítulo 1: Consideraciones Generales y procesadas como una unidad. Estos se guardan en una base de datos, permitiendo ser ejecutados desde una aplicación. Los procedimientos almacenados pueden contener flujo de programas, lógica y consultas a la base de datos; aceptar parámetros y proporcionar sus resultados, devolver conjuntos individuales o múltiples y retornar valores. Se pueden utilizar procedimientos almacenados para cualquier finalidad que requiera la utilización de instrucciones SQL, con estas ventajas (MSDN, 2008): . Ejecución de. una serie de instrucciones SQL. en. un único. procedimiento almacenado. . Referenciar a otros procedimientos almacenados desde el propio procedimiento almacenado, con lo que se puede simplificar una serie de instrucciones complejas.. . El procedimiento almacenado se compila en el servidor cuando se crea, por tanto, se ejecuta con mayor rapidez que las instrucciones SQL individuales.. Aserciones (Assertions): Las aserciones son un tipo de restricción especial que se puede especificar en SQL sin que deba estar asociada a una tabla en particular, como es el caso de las restricciones (Mota, 2005). Generalmente son utilizados para describir restricciones que afectan a más de una tabla. Como las restricciones solo pueden establecerse sobre tuplas de una tabla, las aserciones son útiles cuando es necesario especificar una condición general de la base de datos que no se puede asociar a una tabla específica. Por esta característica de poder especificar una aserción para toda la base de datos y no para una tabla en particular, se le llama restricción autónoma. Esto tiene grandes ventajas a nivel conceptual, pero las hace difíciles de implementar. Transacciones (Transactions): Una transacción es una unidad única de trabajo. Si una transacción tiene éxito, todas las modificaciones de los datos realizadas durante la transacción se confirman y se convierten en una parte permanente de la base de datos. Si una. ~ 29 ~.
(39) Capítulo 1: Consideraciones Generales transacción encuentra errores y debe cancelarse o revertirse, se borran todas las modificaciones de los datos (Gennick, 2006). Cuando finaliza, una transacción debe dejar todos los datos en un estado coherente. En una base de datos relacional, se deben aplicar todas las reglas a las modificaciones de la transacción para mantener la integridad de todos los datos. Las modificaciones realizadas por transacciones simultáneas se deben aislar unas de otras. Una transacción reconoce los datos en el estado en que estaban antes de que otra transacción simultánea los modificara o después de que la segunda transacción haya concluido, pero no reconoce un estado intermedio. Esto se conoce como seriabilidad, ya que deriva en la capacidad de volver a cargar los datos iniciales y reproducir una serie de transacciones para finalizar con los datos en el mismo estado en que estaban después de realizar las transacciones originales (MSDN, 2008). Una vez concluida una transacción, sus efectos son permanentes en el sistema. Las modificaciones persisten aún en el caso de producirse un error del sistema.. 1.10 Gestores de bases de datos relacionales. Los sistemas de gestión de bases de datos (en inglés database management system, abreviado DBMS) son un tipo de software muy específico, dedicado a servir de interfaz entre la base de datos, el usuario y las aplicaciones que la utilizan. El objetivo principal de los SGBD es el de manejar de manera clara, sencilla y ordenada un conjunto de datos que posteriormente se convertirán en información relevante para una organización. Algunas de las ventajas de los SGBD son: Proveen facilidades para la manipulación de grandes volúmenes de datos: o Simplifican la programación de equipos de consistencia. o Manejando las políticas de respaldo adecuadas, garantizan que los cambios de la base serán siempre consistentes sin importar si hay errores correctamente, etc.. ~ 30 ~.
(40) Capítulo 1: Consideraciones Generales o Organizan los datos con un impacto mínimo en el código de los programas. o Bajan drásticamente los tiempos de desarrollo y aumentan la calidad del. sistema. desarrollado. si. son. bien. explotados. por. los. desarrolladores. Usualmente, proveen interfaces y lenguajes de consulta que simplifican la recuperación de los datos. Algunos de los SGBD que existen son: . Oracle. . SQL Server. . Posgre. . MySql. De los gestores anteriormente mencionados uno de los más populares es el Mysql ya que es multihilo y multiusuario con más de seis millones de instalaciones. MySQL AB, desde enero de 2008 una subsidiaria de Sun Microsystems y ésta a su vez de Oracle Corporation desde abril de 2009, desarrolla MySQL como software libre en un esquema de licenciamiento dual. MySQL es software de fuente abierta. Fuente abierta significa que es posible para cualquier persona usarlo y modificarlo. Cualquier persona puede bajar el código fuente de MySQL y usarlo sin pagar. Cualquier interesado puede estudiar el código fuente y ajustarlo a sus necesidades. MySQL usa el GPL (GNU General Public License) para definir qué puede hacer y que no puede hacer con el software en diferentes situaciones (Axmark and Widenius, 2009). 1.11. Facilidades de los entornos Web. Los entornos Web ofrecen muchas facilidades para la implementación de un sistema (Keeker, 2006): . Almacenamiento: Un entorno Web brinda posibilidades ilimitadas de almacenamiento y no depende de un lugar específico para guardar los datos y la información pues esta se almacena de forma electrónica.. ~ 31 ~.
Figure



+7





Documento similar
En el caso del Perú, el Grupo de Trabajo ha tratado los siguientes temas: situación de los derechos humanos en el país o en regiones específicas; empresas de seguridad
CAPÍTULO I MARCO TEÓRICO Y REFERENCIAL 1.1 Introducción 1.2 Logística definiciones 1.3 Aspectos generales sobre el inventario 1.3.1 Clasificación de los inventarios 1.3.2 Método ABC
Durante el capítulo realizamos varias tareas desde todo el proceso de negocio del control del transporte en el Grupo de la Electrónica del MIC donde definimos actores,
En este capítulo, para lograr una mejor comprensión de la necesidad de este trabajo se aborda de los Sistemas de Gestión de Información de forma general, de los procesos de
Este capítulo aborda lo referente al estado del arte relacionado con la gestión y control de los eventos y sucesos de la red en un centro de datos; así como los
Una vez puntualizado cada uno de los elementos de normalización y buenas prácticas de diseño, así como un grupo de soluciones necesarias para el buen desempeño del diseño de base
La necesidad de preparar y hacer más eficiente y científico el trabajo de los maestros en los temas relacionados con el proceso de tránsito. El análisis teórico realizado
Esta investigación tiene como eje central el proceso enseñanza aprendizaje de la Matemática por tanto, este acápite aborda temas de reflexiones generales sobre la
